
Abstract
Characterizing the nonclassicality of quantum systems under minimal assumptions is an important challenge for quantum foundations and technology. Here we introduce a theory-independent method of process tomography and perform it on a superconducting qubit. We demonstrate its decoherence without assuming quantum theory or trusting the devices by modelling the system as a general probabilistic theory. We show that the superconducting system is initially well-described as a quantum bit, but that its realized state space contracts over time, which in quantum terminology indicates its loss of coherence. The system is initially nonclassical in the sense of generalized contextuality: it does not admit of a hidden-variable model where statistically indistinguishable preparations are represented by identical hidden-variable distributions. In finite time, the system becomes noncontextual and hence loses its nonclassicality. Moreover, we demonstrate in a theory-independent way that the system undergoes non-Markovian evolution at late times. Our results extend theory-independent tomography to time-evolving systems, and show how important dynamical physical phenomena can be experimentally monitored without assuming quantum theory.
Similar content being viewed by others

Introduction
Demonstrating that some quantum systems have properties that genuinely defy classical explanation is at the forefront of current theoretical and experimental research. The strongest form of nonclassicality, Bell nonlocality1, allows us to refute local hidden-variable models for experiments on spatially separated quantum systems. It is often experimentally more tractable to focus on single systems, avoiding the need for spacelike separation, and the Kochen-Specker theorem2 precludes the existence of noncontextual hidden-variable models for such systems of Hilbert space dimension at least three.
The Kochen-Specker theorem relies, however, on several undesirable assumptions: it assumes the validity of quantum theory, the fact that the performed measurements are noiseless projective measurements, and that the outcomes depend deterministically on the underlying hidden variables. The latter two assumptions in particular are detrimental to the goal of the practical certification of nonclassicality. Spekkens’ notion of generalized noncontextuality overcomes these difficulties3. In a nutshell, it stipulates that statistically indistinguishable operations (measurements, preparations or transformations) should have identical representations on the hidden-variable level. Generalized contextuality admits of robust experimental detection4,5,6, and subsumes a variety of natural notions of nonclassicality (such as Wigner negativity7,8) into a single simple criterion.
Here, we certify the generalized contextuality of a superconducting qubit experimentally, directly from the measurement statistics and without assuming quantum theory. In contrast to earlier experimental detection of Kochen-Specker contextuality in a superconducting platform9, our analysis thus makes significantly weaker assumptions. We analyze how the amount of contextuality changes over time—in particular, the system becomes noncontextual in finite time due to decoherence. In fact, we do more than this: we characterize the system completely, for different evolution times, by generalizing theory-agnostic tomography10,11. That is, by performing many preparation and measurement procedures, we determine its space of states and of effects (measurement outcomes) which, when combined linearly, reproduce the experimental statistics. Such pairs are known as generalized probabilistic theories (GPT)12,13,14,15, with quantum theory and its qubit as a special case. For a quantum bit, the state space is the three-dimensional Bloch ball, but a GPT’s state space can be any convex set of any dimension. Without assuming the validity of quantum theory, we determine directly from the data that our superconducting system’s normalized state space is likely three-dimensional and in shape close to a ball. Observing the contraction of this “bumpy Bloch ball” yields a theory-independent monitoring of the quantum decoherence process, of its loss of contextuality, and of its non-Markovianity16 at late times.
Superconducting qubits17 admit the rapid implementation of a very large number of preparation and measurement procedures, which is necessary for the data-demanding sort of process tomography that we implement here. Our results hence demonstrate the suitability of the superconducting system for this sort of theory-independent analysis.
Results
Experimental setup
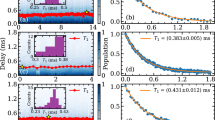
Our experiments are performed on a transmon superconducting qubit18 with frequency ωq = 2π ⋅ 5.05 GHz, hosted inside a three-dimensional readout cavity resonator with frequency ωr = 2π ⋅ 8.56 GHz. Strong dispersive coupling between the two allows us to measure the qubit’s state by performing a transmission measurement on the resonator to probe its qubit-state-dependent resonance frequency, as standard in circuit-QED19. This signal is amplified by both cryogenic and room temperature amplifiers, which give a readout fidelity of 85(1)%. We measure a qubit energy relaxation rate T1 = 21.9 ± 0.4 μs and Ramsey decoherence rate \({T}_{2}^{*}=12.7\pm 0.6\,{\mathrm{\mu s}}\), as well as a resonator frequency shift χ = − 2π ⋅ 1.89 MHz when the qubit is excited. Preparation of the initial state is achieved by applying a 200 ns resonant Rabi pulse with well-defined amplitude and phase to the qubit t = 0 state \(\left|0\right\rangle\). This amplitude and phase are chosen from a list \({{{\mathcal{V}}}}_{m}\) defining the space of m states. In order to have a uniform distribution of m points on the surface of the Bloch sphere, we chose a Fibonacci distribution20. We then wait for a variable time τ, after which a second Rabi pulse is applied in order to specify the measurement basis. Again, amplitude and phase of the pulse are chosen from a list \({{{\mathcal{V}}}}_{n}\), now specifying the space of effects. In our case, m = n = 100, and the two lists of preparations and measurement directions coincide. Finally, the qubit’s state is measured in the computational z-basis \(\{\left|0\right\rangle,\left|1\right\rangle \}\) by the standard circuit-QED readout technique in the strong-dispersive-coupling regime, as mentioned above. For each combination of state preparation and measurement, this sequence is repeated 2000 times in order to average over the qubit projection noise. This gives us the frequencies Fij from which we estimate the probabilities p(0∣Pi, Mj) entering Eq. (3) below.
We describe the experimental setup and the qubit readout characterization procedure in more detail in the Methods’ subsection “Experimental setup and qubit readout characterization”.
Theory-independent analysis
To provide a theory-independent analysis, we view the experimental setup as a prepare-and-measure scenario, see Fig. 1. We have m possible preparation procedures Pi and n measurement procedures Mj, each with outcome a ∈ {0, 1}. Moreover, we have the option to introduce a waiting time τ between preparation and measurement. Without loss of generality, we choose the convention that this evolution for time τ is considered a part of the preparation procedure, yielding effective preparation procedures \({P}_{i}^{\tau }\). Thus, we probe the system (the superconducting qubit) to estimate the conditional probabilities \(p(a| {P}_{i}^{\tau },{M}_{j})\). By normalization, it is sufficient to obtain the statistics for one of the outcomes which we denote by a = 0 – shown in Fig. 2 for τ = 0. Statistics are gathered for all the possible i, j and for τ = {0, 5, 10, 15, 20, 30, 40, 50} μs. For every fixed value of τ, this defines a corresponding operational theory3: a collection of preparation and measurement procedures together with a probability rule that describes the statistical properties of the laboratory system.

We regard the actual state preparation and the subsequent time evolution as a single preparation procedure, which is simply a convenient convention (analogous to the choice of Schrödinger versus Heisenberg picture). As a result, the prepared states will depend on the waiting time τ, but the measurements will not.

Experimentally measured frequency of occurrence of the outcome a = 0 for the m × n table of preparations and measurements, for τ = 0.
Following this operational approach, generalized noncontextuality3,21 requires that procedures which are statistically equivalent at the operational level (i.e., producing identical statistics if all other processes are fixed) must also be identically represented in the underlying hidden-variable model. A hidden-variable model (also known as an ontological model) of an operational theory is defined on a measurable space Λ. To each preparation P in the theory, there corresponds a probability distribution μP(λ) on Λ, and to every outcome a of every measurement M, there corresponds a response function χa∣M(λ), such that ∑aχa∣M(λ) = 1. The assignments are such that the probabilities are reproduced by the laws of classical probability theory,
A hidden-variable model is preparation-noncontextual3,21 if any two operationally equivalent preparations P and \({P}^{{\prime} }\) have \({\mu }_{P}(\lambda )={\mu }_{{P}^{{\prime} }}(\lambda )\). Two preparations P and \({P}^{{\prime} }\) are operationally equivalent if
Similarly, the model is measurement-noncontextual if operationally equivalent measurement outcomes (i.e., ones that have identical probabilities for all preparation procedures) are represented by the same response function.
For our scenario, we may not only consider the actually implemented procedures Mi and Pj, but also statistical mixtures of those, such as the preparation procedure Pmix which results in implementing either preparation P1 or P2 with probability λ or 1 − λ, respectively. We can then represent operationally equivalent preparation procedures P and \({P}^{{\prime} }\) by some state \({{{\boldsymbol{s}}}}_{P}={{{\boldsymbol{s}}}}_{{P}^{{\prime} }}\), an element of some vector space over the real numbers. Statistical mixtures are then represented by convex combinations, such that, for example, \({{{\boldsymbol{s}}}}_{{P}_{{{\rm{mix}}}}}=\lambda {{{\boldsymbol{s}}}}_{{P}_{1}}+(1-\lambda ){{{\boldsymbol{s}}}}_{{P}_{2}}\). Similarly, we can represent operationally equivalent measurement-outcome pairs (a, M) and \(({a}^{{\prime} },{M}^{{\prime} })\) as so-called effects \({{{\boldsymbol{e}}}}_{a,M}={{{\boldsymbol{e}}}}_{{a}^{{\prime} },{M}^{{\prime} }}\), elements of the dual space, such that p(a∣P, M) = 〈ea,M, sP〉. All possible states of a system form a convex set \({{\mathcal{S}}}\), and all possible effects yield another convex set \({{\mathcal{E}}}\). This defines a generalized probabilistic theory (GPT)14,15, sometimes also called a “GPT system”. Please see the “Methods” section for more details, and for how a quantum bit is described in this formalism. In particular, its space of pure states is the famous Bloch sphere, and the full space \({{\mathcal{S}}}\) of all (pure and mixed) states is the Bloch ball.
Quantum and classical systems are examples of GPT systems, but the framework contains many more exotic possibilities, such as theories with superstrong nonlocality12 and higher-order interference22,23. Originally, interest in GPTs originated in the research program to reconstruct the abstract formalism of quantum theory from simple physical principles24,25,26,27. Here, however, we use the GPT formalism as a tool for a theory-independent description of our experimental statistics. In particular, knowing the GPT associated to an operational theory allows us to determine whether it admits of a preparation- and measurement-noncontextual hidden-variable model, using the criterion of simplex embeddability demonstrated in ref. 28. If it does admit of such a model, we say that the physical system is noncontextual. This can be checked with a linear program29,30.
For example, it can be checked that the qubit GPT system is contextual, i.e. cannot be embedded into any classical probability simplex, in contrast to the stabilizer qubit, a GPT system defined by restricting the qubit to convex combinations of its stabilizer states and to stabilizer measurements31, as illustrated in Fig. 3. Hence, the stabilizer qubit is noncontextual (when restricted to preparations and measurements) or “classical” in this sense. This is related to the Gottesman-Knill theorem, establishing the efficient classical simulatability of stabilizer quantum computation32. More generally, generalized contextuality is a resource for a number of information processing tasks33,34,35,36,37,38.

a The state space of the stabilizer qubit (in green) is embedded in the state space of the qubit, given by the gray ball; b the state space of the stabilizer qubit (in green) is embeddable within a tetrahedron (in gray), the state space of a classical four level system; c the embedding of the stabilizer qubit into the tetrahedron pictured here is such that any valid effect on the stabilizer qubit is also a valid effect on the tetrahedron. This requirement prevents, for example, the embeddability of the qubit into the tetrahedron (we know that the qubit is nonembeddable because it is contextual). Here the orange planes represent the effect corresponding to the +1 outcome of the Pauli Z measurement: the upper plane intersects all states giving probability 1 for the outcome +1, the central plane those giving probability \(\frac{1}{2}\) and the lower plane those giving probability 0.
The obstacle to applying this directly to our experiment is that we do not know the probabilities p(a∣P, M), but only experimentally determined approximations, namely the frequencies of occurrence of the outcomes (depicted in Fig. 2). Hence, we cannot directly write down the GPT that describes our superconducting system, but have to estimate the GPT from the experimental data. We do so by modifying and generalizing the method of theory-agnostic tomography10,11, which leads to the following multi-step procedure.
Let us first discuss the procedure for a fixed value of waiting time τ; say, τ = 0. We start by collecting the experimental statistics for a large set of possible preparations Pi and two-outcome measurements Mj, with i ∈ {1, …, m} and j ∈ {1, …, n}. The goal is to estimate the conditional probabilities p(0∣Pi, Mj) for obtaining outcome a = 0, given preparation Pi and measurement Mj. We organize the collection of statistics in the form of an m × n matrix D as:
In an actual experiment, the conditional probabilities p(0∣Pi, Mj) are estimated by running the experiment N times. Thus, when talking about experimental data, instead of the matrix D we will refer to a matrix F containing the observed frequencies Fij = f(0∣Pi, Mj). i.e., F is a frequency table. Given that there are N runs for each pair of preparation and measurement (Pi, Mj), we have \({F}_{ij}=\frac{{N}_{ij}}{N}\), where Nij is the number of outcomes 0 observed for the pair (Pi, Mj). In the case where a large number M of frequency tables \({\{{F}^{q}\}}_{q=1}^{M}\) are obtained, one can directly compute the variance of a frequency table Fq as \({(\Delta {F}_{ij}^{q})}^{2}={({F}_{ij}^{q}-{\bar{F}}_{ij})}^{2}\), where \({\bar{F}}_{ij}=\frac{1}{M}{\sum }_{q=1}^{M}{F}_{ij}^{q}\). In the case where one does not have a large number of frequency tables, we can estimate \({(\Delta {F}_{ij})}^{2}\) by making the following assumptions10. We expect that in the limit of N → ∞, these frequencies converge to the conditional probabilities p(0∣Pi, Mj), under the assumption of ideal repeatability disregarding drift and other imperfections. In this case, the variable Nij is the number of 0 outcomes of N independent events in a sequence of experiments. This can be modeled as a binomial distribution with N events and probability given by the frequency \({F}_{ij}=\frac{{N}_{ij}}{N}\). The variance in Nij is therefore \(\frac{{N}_{ij}(N-{N}_{ij})}{N}\), which implies that the variance in the frequency is therefore \({(\Delta {F}_{ij})}^{2}=\frac{{N}_{ij}(N-{N}_{ij})}{{N}^{3}}=\frac{{F}_{ij}(N-{N}_{ij})}{{N}^{2}}=\frac{{F}_{ij}(1-{F}_{ij})}{N}\).
The matrix D contains all relevant statistical information about the prepare-and-measure experiment. For every GPT, the probabilities p(0∣Pi, Mj) are given by 〈ej, si〉, where the effects ej describe the measurement and its outcome, and the states si describe the preparation procedures. States are elements of some real vector space of unspecified dimension k and effects elements of the dual space, with 〈, 〉 denoting the natural pairing, i.e., the application of the covector ej to the vector si, yielding a real number. The sets of all possible states and effects define the GPT and determine its information-theoretic and physical behavior. Our goal now is to find the GPT state and effect spaces that best fit for D while minimizing the number of parameters. That is, we want to find a fitting GPT model which assigns a k-dimensional state vector si to each preparation Pi and a k-dimensional effect vector ej to each measurement outcome 0 of Mj. Thus, the m × k matrix \(S={({{{\boldsymbol{s}}}}_{1},{{{\boldsymbol{s}}}}_{2},\ldots,{{{\boldsymbol{s}}}}_{m})}^{\top }\) and the k × n matrix E = (e1, e2, …, en) can be used to factorize the data table D = SE, resulting in an m × n matrix of rank k, this time with entries \({D}_{ij}={{{\boldsymbol{s}}}}_{i}^{\top }{{{\boldsymbol{e}}}}_{j}\) corresponding to the probabilities p(0∣Pi, Mj) predicted by the GPT.
To perform theory-agnostic tomography in our experiment, we first have to determine the appropriate rank k. To this end, we fit a rank k matrix D = SE to the experimentally obtained frequency table F for various values of k. The best rank k matrix D is determined via minimization of the weighted \({\chi }_{k}^{2}\) in the following optimization problem10:
In the Methods’ subsection “Solving the weighted low-rank approximation problem of Eq. (4)”, we describe how we solve this nonconvex optimization problem numerically, following the method presented in ref. 10.
The experimental data consists of ten frequency tables \({\{{F}^{\alpha }\}}_{\alpha=1}^{10}\) for the 100 preparations and measurements specified in section “Experimental setup”. For every k ∈ {2, …, 9}, the average optimal \({\chi }_{k}^{2}\) over Fα is plotted in blue in Fig. 4a. It decreases sharply for k < 4 and decreases slowly for k≥4. The large \({\chi }_{k}^{2}\) values for k < 4 indicate that the models Dk have too few parameters to properly account for the regularities in the data; they underfit the data. For k > 4, the \({\chi }_{k}^{2}\) decrease at a slower rate as the extra parameters in the models fit to the statistical fluctuations in the frequency tables. The inflection point at k = 4 indicates that this is likely the rank of the underlying ‘true’ GPT generating the probability table D of Eq. (3).

a Test and train errors for the optimal GPT fits for ranks k ∈ {2, …, 9}. Inset: zoomed in for ranks k ≥ 4. The training error is evaluated on 10 frequency tables \({\{{F}^{\alpha }\}}_{\alpha=1}^{10}\), whilst the test error is evaluated on the 90 pairs of frequency tables (Fα, Fβ) with α ≠ β. The error bars for the training error and test error are given by the statistical uncertainty over the 10 tables and 90 pairs, respectively. b For each pair (Fα, Fβ) with α, β ∈ {1, …, 10}, α ≠ β with Fα serving as the training data and Fβ as the testing data we plot \({\chi }_{k}^{2}({F}^{\beta },{D}_{k}^{\alpha })-{\chi }_{k-1}^{2}({F}^{\beta },{D}_{k-1}^{\alpha })\) which is the change in the test error between the best fit rank k and best fit rank k − 1 models. For k ≤ 4 it is strictly negative, showing that the test error decreases, while for k > 4 it is strictly positive, showing that the test error increases.
Fitting to statistical fluctuations is a signature of overfitting of a model. Following ref. 11, we can detect overfitting of a model by evaluating the optimal rank k fit Dk obtained from a frequency table Fα on a different frequency table Fβ. Fα is known as the training data (since it is used to train the model Dk) and Fβ is known as the test data (since it is used to evaluate the model Dk). Since the statistical fluctuations of Fα and Fβ are independent, the more a model Dk fits the statistical fluctuations in Fα, the worse it will perform when evaluated on Fβ. Given a training data/test data pair \((F,{F}^{{\prime} })\) the test error relative to a model D is
The test error is expected to be high for models which underfit the data (since they have too few parameters to adequately capture the structure of the data), and expected to decrease as k approaches the true underlying rank ktrue. For k > ktrue the test error is expected to increase. As such, the test error is expected to be minimal for the value of k which neither underfits nor overfits the data, which is expected to be k = ktrue.
Figure 4a shows the average test error for each k ∈ {2, …, 9} evaluated for every pair (Fα, Fβ)(α ≠ β), where Fα is the training data and Fβ is the test data. The large statistical variances in the test error in Fig. 4a do not allow us to infer that the test error reaches its minimum at rank 4. In Fig. 4b, we plot the average difference in test error \({\chi }_{k}^{2}({F}^{\beta },{D}_{k}^{\alpha })-{\chi }_{k-1}^{2}({F}^{\beta },{D}_{k-1}^{\alpha })\). The error bars are sufficiently small to allow us to conclude that the change in test error is negative for k ≤ 4 and positive for k > 4, allowing us to conclude that the minimal test error occurs for k = 4, and thus that the rank of the underlying true GPT is likely ktrue = 4.
Dynamical analysis: decoherence
To determine the dimension of the GPT system, we restrict our attention to the τ = 0 data. In Fig. 4a, we have computed the optimal models fitting the experimental data F for different rank k candidates with k ∈ {2, …, 9}. In particular, following Eq. (4), we minimize \({\chi }_{k}^{2}\) for each candidate k obtaining the best-fit GPT models of rank k to the obtained experimental data.
We have seen that solving Eq. (4) provides a model with the best-fit of rank k to the probability matrix D sampling the observed measurement outcomes. Moreover, we have observed that rank k = 4 provides the best estimate of an underlying model describing the experiment. This could correspond to a qubit description as expected: the dimension of the set of normalized states will then be k − 1 = 3, which coincides with the dimension of a qubit’s Bloch ball state space.
Let us now characterize the state and effect spaces for the GPT model of rank k = 4, which generate D. To obtain D, we have split the problem into estimating the realized GPT states \({{\mathcal{S}}}\) and effects \({{\mathcal{E}}}\). The decomposition D = SE is not unique: for every invertible k × k-matrix L, we also have D = (SL)(L−1E), and all possible decompositions are of this form, see Methods’ subsection “Uniqueness of the decomposition D = SE”. Following ref. 10, we choose a parametrization where the first component of a state denotes its normalization, and so the first column of S consists entirely of ones. Furthermore, the first column of E is chosen to be the unit (normalization) effect. All further freedom in choosing L only leads to a different linear reparametrization of the resulting GPT, and this does not change any of its physical properties (see the notion of “equivalent GPTs” in Methods’ subsection “Generalized probabilistic theories”.
Figure 5a shows the resulting state space in blue, and Fig. 5b, c shows projections of the effect space in blue for one specific parametrization (see Methods’ subsection “Generalized probabilistic theories”). As expected, \({{\mathcal{S}}}\) resembles a quantum bit Bloch ball, and \({{\mathcal{E}}}\) resembles the set of Hermitian 2 × 2 operators E with eigenvalues in [0, 1] (which is (k = 4)-dimensional). However, in contrast to a perfect quantum bit, \({{\mathcal{S}}}\) and \({{\mathcal{E}}}\) are polytope and not exact duals of each other since only finitely many preparations and measurements have been implemented. That is, given our realized set of effects \({{\mathcal{E}}}\), we can consider the set \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}\) of all possible vectors s which give valid probabilities for all measurements, i.e., 0≤〈e, s〉≤1 for all effects \(e\in {{\mathcal{E}}}\). Then \({{\mathcal{S}}}\subsetneq {{{\mathcal{S}}}}_{{{\rm{consistent}}}}\). Similarly, given \({{\mathcal{S}}}\), we can consider the set \({{{\mathcal{E}}}}_{{{\rm{consistent}}}}\) of all possible covectors e that give valid probabilities on all states, and \({{\mathcal{E}}}\subsetneq {{{\mathcal{E}}}}_{{{\rm{consistent}}}}\). These sets are shown in green in Fig. 5.

Plots showing the realized (blue) and consistent (green) spaces for the rank k = 4 GPT for τ = 0. a The normalized state spaces are three-dimensional and similar to Bloch balls; b effect space projection onto dimensions 1,2,3; c effect space projection onto dimensions 0,1,2 (or similarly for 0,2,3 and 0,1,3) containing the zero and unit effects 0 and 1.
For the sake of the argument, assume for a moment that the no-restriction hypothesis holds39, as predicted, e.g., by quantum theory: all possible outcome probability rules are implementable effects, and all possible vectors yielding valid probabilities on the possible measurements are implementable states. In the hypothetical (but unrealistic) case that the measurements have been perfectly noiseless and all possible measurements have actually been implemented, this would imply that \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}\) describes the set of all possible states of the system, and \({{\mathcal{S}}}\) being a strict subset of this means that the preparations have been inherently noisy. Realistically, both preparations and measurements are noisy, but a theory-independent analysis cannot tell us whether the error occurred on the level of the former or the latter. All our analysis can tell us is that the no-restriction hypothesis is violated by the experimentally realized GPT system, and the considerations below allow us to quantify how strong the violation is.
Consider the distinguishability of two states s and \({{{\boldsymbol{S}}}}^{{\prime} }\), defined as \({{\mathcal{D}}}({{\boldsymbol{s}}},{{{\boldsymbol{s}}}}^{{\prime} }):=\mathop{\max }\limits_{{{\boldsymbol{e}}}\in {{\mathcal{E}}}}| \langle {{\boldsymbol{e}}},{{\boldsymbol{s}}}\rangle -\langle {{\boldsymbol{e}}},{{{\boldsymbol{s}}}}^{{\prime} }\rangle |\). For ideal quantum systems, this equals the trace distance between the two density matrices that represent the states, \(\frac{1}{2}\parallel {\rho }_{{{\boldsymbol{s}}}}-{\rho }_{{{{\boldsymbol{s}}}}^{{\prime} }}{\parallel }_{1}\). For any given state s, consider the function \(f({{\boldsymbol{s}}}):={\max }_{{{{\boldsymbol{s}}}}^{{\prime} }\in {{\mathcal{S}}}}{{\mathcal{D}}}({{\boldsymbol{s}}},{{{\boldsymbol{s}}}}^{{\prime} })\), then 0≤f(s)≤1, and this equals 1 if and only if s is perfectly distinguishable from some other state. As shown in ref. 40, the no-restriction hypothesis implies that f(s) = 1 for all boundary points s of the state space, the “perfect distinguishability” axiom of ref. 40. In our case, this function takes values in between 0.681 ± 0.003 and 0.691 ± 0.004, whose minimum on the boundary points gives us a theory-independent quantity saying “how restricted” the effective GPT system is. Under the additional assumption that quantum theory holds, and that the superconducting system is fundamentally described by a qubit, this tells us that there must have been states ρs prepared (i.e. \({{\boldsymbol{s}}}\in {{\mathcal{S}}}\)) that are close to pure, in the sense that their largest eigenvalue is \({\lambda }_{\max }({\rho }_{s})\ge 0.846\pm 0.002\) (and, assuming approximate rotational symmetry as apparent in Fig. 5, all prepared states for τ = 0 should have this property approximately); see Methods’ subsection “Lower bound on the purity of the prepared states”. Note that \({\lambda }_{\max }({\rho }_{{{\boldsymbol{s}}}})=\langle \psi | {\rho }_{{{\boldsymbol{s}}}}| \psi \rangle\), i.e., the fidelity between the prepared state ρs and its eigenstate \(\left|\psi \right\rangle\) corresponding to its largest eigenvalue.
Let us now turn to the task of monitoring the time evolution of our superconducting system, via snapshots for different evolution times τ. We modify and extend the method of theory-agnostic tomography as follows. For a finite set of {τ0, τ1, …τT}, we can obtain the frequency tables {Fτ}. Since the measurements for each Fτ are treated to be the same by convention (recall Fig. 1), we can write a total frequency table F, which is a m(T + 1) × n matrix:
The probability table for a rank k-GPT in this set of prepare-and-measure experiments with shared measurements is
with S an m(T + 1) × k matrix and E a k × n matrix.
The problem of finding the best rank-k GPT fit for the sequence of prepare-and-measure scenarios \(\{({{{\mathcal{P}}}}^{{\tau }_{0}},{{\mathcal{M}}}),({{{\mathcal{P}}}}^{{\tau }_{1}},{{\mathcal{M}}}),\ldots,({{{\mathcal{P}}}}^{{\tau }_{T}},{{\mathcal{M}}})\}\) is thus equivalent to the task of finding the best GPT rank-k GPT fit for m(T + 1) preparations and n measurements \(\{{{{\mathcal{P}}}}^{{\prime} },{{\mathcal{M}}}\}\), where \({{{\mathcal{P}}}}^{{\prime} }={\bigcup }_{i}{{{\mathcal{P}}}}^{{\tau }_{i}}\).
The result is shown in Fig. 6. From our knowledge of quantum physics and the experimental platform, we expect two effects to be in place: decoherence and relaxation to the ground state. Both effects are visible in the theory-independent representation. For every GPT, reversible transformations are represented by linear symmetries of the state space. Hence, under reversible time evolution, \({{\mathcal{S}}}\) is preserved. For τ ≤ 20 μs, we see, however, that this is not the case, and that the time evolution is manifestly irreversible, shrinking \({{\mathcal{S}}}\) towards more mixed states. For all times, we see that evolution moves the state space closer to a single distinguished state (potentially a pure state), which describes a relaxation process. Quantum physics intuition tells us that this should correspond to the superconducting qubit’s ground state, but our theory-independent analysis does not allow us to conclude this with certainty.

Plots of the consistent state space \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}\) (green) for all preparations, and realized state spaces \({{{\mathcal{S}}}}^{\tau }\) (blue) for varying wait times τ = [0, 5, 10, 15, 20, 30, 40, 50] μs.
Contextuality and its loss under decoherence
Now that we have a description of the different \({{{\mathcal{S}}}}^{\tau }\) and \({{{\mathcal{E}}}}^{\tau }\), we can check whether the corresponding GPT systems are noncontextual. To do so, we use the linear program of ref. 30 to determine whether the GPT systems are simplex-embeddable. Every system becomes noncontextual if a sufficient amount of noise is added. To quantify this, we use the state μτ, which is the average of all extremal states of \({{{\mathcal{S}}}}^{\tau }\) (think of it as the maximally mixed state in the center of \({{{\mathcal{S}}}}^{\tau }\)), and we consider depolarizing noise that replaces every given state by μτ with probability r. The resulting state space \({{{\mathcal{S}}}}_{r}^{\tau }:=(1-r){{{\mathcal{S}}}}^{\tau }+r{\mu }^{\tau }\) will be noncontextual if r is large enough. In Fig. 7, we show how large r has to be chosen such that \({{{\mathcal{S}}}}_{r}^{\tau }\) is noncontextual. If the answer is r > 0, then the system at time τ is contextual, and otherwise, if r = 0, it is noncontextual. The uncertainties in Fig. 7 (resp. Fig. 8) are given by the standard deviations in the robustness (resp. relative volume) computed from 7 frequency tables \({\{{F}^{\alpha }\}}_{\alpha=1}^{7}\) of the form given in Eq. (6).

Plot showing the robustness coefficient, i.e., the necessary amount of depolarizing noise r that has to be added such that a noncontextual ontological model exists for the GPT system, tested for increasing delay time τ (with 7 runs per value of τ, with the standard deviation then determining error bars). For robustness r = 0, the superconducting system is noncontextual, and otherwise contextual.

Numerically determined relative volumes of the realized to consistent state spaces \({{\rm{Vol}}}({{{\mathcal{S}}}}^{\tau })/{{\rm{Vol}}}({{{\mathcal{S}}}}_{{{\rm{consistent}}}})\) for different waiting times τ, again with the standard deviation determining error bars. The volume always decreases, as required by Markovian time evolution, except between τ4 = 20 μs and τ5 = 30 μs.
We see that the system is initially contextual, but that it looses its contextuality between the times of τ2 = 10 μs and τ3 = 15 μs. In other words, the decoherence process leads to the system becoming effectively classical and remaining so. Note that the error bars around r = 0 are zero, because small perturbations of noncontextual systems are typically noncontextual too. Indeed, we have obtained r = 0 for τ ≥ 15 μs in all repetitions.
It is well-known that the quantum bit is noncontextual in the sense of Kochen and Specker2, and that it admits of simple hidden-variable models, including one that has already been given by Bell41. However, as shown by Spekkens3, all such models must be contextual according to the generalized notion introduced in Results’ subsection “Theory-independent analysis”. As we have demonstrated above, the same is true for the “noisy qubits” that describe the superconducting system for sufficiently small evolution times.
Non-Markovianity at late times
In Fig. 6, it can be seen that the state space shrinks during all time steps, except between τ4 = 20 μs and τ5 = 30 μs, where it appears to expand. This is a signature of non-Markovianity. Let us define what this means for arbitrary GPTs, including but not restricted to quantum theory. We say that a system S has Markovian time evolution from time τ0 to τ1 > τ0 if there is a transformation T, defined on the system S alone, such that sS(τ1) = T sS(τ0), with sS(τ) the state of S at time τ (in QT; this would be a trace-preserving completely positive map). This requirement is automatically fulfilled if we are able to prepare the system at time τ0 in some arbitrary state of \({{\mathcal{S}}}\), uncorrelated with other systems and the environment. Mathematically, the corresponding transformation T will then be a linear map on the set of unnormalized states (a well-known fact for GPTs). Thus, it must act as an affine-linear map on the set of normalized states \({{\mathcal{S}}}\). Since it maps states to valid states, it holds that \(T({{\mathcal{S}}})\subset {{\mathcal{S}}}\), and so it must be volume-non-increasing (see Methods’ subsection “Markovian evolutions do not increase the volume” for details).
On the other hand, if there are initial correlations between the system S and its environment E at time τ0, then initial state sSE and final state \({{{\boldsymbol{s}}}}_{SE}^{{\prime} }\) are related by some transformation of the total system SE, \({{{\boldsymbol{s}}}}_{SE}^{{\prime} }={T}_{SE}{{{\boldsymbol{s}}}}_{SE}\). Thus, there will not, in general, be a transformation (or other linear map) T that relates the possible initial and final marginal states \({{{\boldsymbol{s}}}}_{S}^{{\prime} }\) and sS. In the quantum case, this fact has been pointed out by Schmid et al.42. Intuitively, this sort of non-Markovianity happens if there is some information backflow from the environment to the system.
We have numerically determined the volumes of the state spaces \({{{\mathcal{S}}}}^{\tau }\) (see Fig. 8), and see that the volume increases between times τ4 = 20 μs and τ5 = 30 μs, as is visible in Fig. 6. In particular, for each τ, we calculated the volume of the realized state space \({{\rm{Vol}}}({{{\mathcal{S}}}}^{\tau })\) relative to the volume of the consistent state space \({{\rm{Vol}}}({{{\mathcal{S}}}}_{{{\rm{consistent}}}})\). The observation that the relative volume increases between τ4 and τ5 proves that there is non-Markovian evolution during this time interval. This is physically not unexpected, since the transmon is only approximately a qubit, and higher-lying levels cannot be perfectly ignored. For the experiment we consider, the non-Markovianity may thus be due to the residual off-resonant coupling with an additional degree of freedom, such as another qubit hosted in the same readout cavity resonator. On the other hand, successful state preparation at time τ0 = 0 implies that time evolution from time τ0 = 0 to any other time τ1 = τ must always be Markovian, and so \({{\rm{Vol}}}({{{\mathcal{S}}}}^{0})\ge {{\rm{Vol}}}({{{\mathcal{S}}}}^{\tau })\) for all τ≥0, which is confirmed by our data.
We fit an exponential decay function \(A{e}^{-\frac{\tau }{B}}\) to the relative volumes for different τ (weighted by the uncertainties in the relative volume), obtaining values A = 0.45 ± 0.01 and B = 0.227 ± 0.004 μs−1. This provides a theory-independent estimate of the relaxation rate \(\frac{1}{B}=4.409\,{\mathrm{\mu s}}\).
The two phenomena discussed in this and the previous subsection have very different roles to play: generalized contextuality is a precious resource that is hard to obtain; non-Markovianity, on the other hand, is a frequent statistical phenomenon that is often detrimental rather than desirable. What we claim to be remarkable is not that there is non-Markovianity in the experiment, but that we are able to demonstrate it as a property of the system’s time evolution without assuming the validity of quantum theory.
Discussion
Theory-agnostic tomography for preparations and measurements was introduced in ref. 10, where it was applied to a photonic qubit, and subsequently in ref. 11 to a photonic qutrit. The present work makes use of the methods of refs. 10,11 to construct the state and effect space of the best fit GPT model of the superconducting qubit.
Following ref. 11, we determine the best rank fit as the one which least overfits the data, requiring fewer assumptions than the AIC criterion used in ref. 10. However, unlike ref. 11, the 10 different frequency tables obtained provide us with 90 pairs of training and test data, allowing us to give error bars for the best fit χ2 values for each dimension.
In the present work, we extend theory-agnostic tomography of refs. 10,11 to include a form of process tomography. We use this for theory-independent monitoring of decoherence, and to obtain a theory-independent witness of non-Markovianity. We also monitor the time evolution of generalized contextuality of the superconducting qubit, showing that it is contextual for times τ = 0, 5, 10 μs and non-contextual for times greater than 15 μs.
An experimental demonstration of Kochen-Specker contextuality in a three-level superconducting system was shown in ref. 9. The notion of generalized contextuality used in the present work is weaker than Kochen-Specker contextuality in that it does not require projective measurements (but rather applies to POVMs more generally) nor does it require outcome-determinism. Outcome-determinism is the requirement that outcomes of measurements depend deterministically on the underlying hidden variable λ. As argued in ref. 3, outcome-determinism is not entailed by noncontextuality, and thus should be viewed as an independent assumption in proofs of contextuality.
In addition to the assumption of outcome-determinism/projective measurements, a number of additional assumptions are needed in the demonstration of contextuality of ref. 9, as specified in ref. 9, Supplementary Material. We briefly comment on these assumptions (1.(a), 1.(b), 2. and 3.) and how they relate to the present work. Assumptions 2. and 3. are concerned with sequential measurements and compatibility of measurements, neither of which are needed in present work. Assumption 1.(a) concerns the probability of picking a particular context, which is not needed in this work either. Assumption 1.(b), which states that the probability distribution over the ontic states is the same in every run, is shared with the present work.
As discussed in section “Contextuality of GPTs”, we make the assumption that the preparations and measurements implemented in the experiment are tomographic relative to one another, which is not needed in ref. 9. The tomography loophole for experimentally demonstrating generalized contextuality can be viewed as analogous to the finite precision measurement loophole43 for experimental demonstrations of Kochen-Specker contextuality.
Finally, we briefly contrast the theory-independent approach based on GPTs used here to the device-independent (DI) approach44, which can also used to certify nonclassicality using minimal assumptions. In both the DI approach and GPT tomography, the basic objects are frequencies/probabilities over outputs given some inputs, which together with some well-motivated principles form the basis of the analysis. We note that the DI approach is not necessarily theory-independent, for instance, self-testing protocols verify that a certain quantum state (up to a family of local transformations) has been prepared based solely on the Bell inequality violation of the observed statistics45. The DI approach typically uses assumptions about causal structure (motivated by special relativity), whereas the GPT tomography approach makes both a causal assumption (λ-mediation21) and a tomographic completeness assumption, which are not motivated by appeal to another physical theory.
To summarize, in this work we have monitored the decoherence of a physical system, its evolution of generalized contextuality, and the (non-)Markovianity of its time evolution in a theory-independent way. This means that we have not assumed the validity of quantum theory in any of the data analysis or the conclusions that we have drawn. All that we had to assume was that the experimental setup includes a physical system that is probed in a way such that the implemented preparations and measurements are tomographically complete for each other, which allowed us to use the GPT formalism that does not depend on any specific choice of theory.
Our analysis has shown us that our experimental data is best described by a GPT that has a four-dimensional space of states and effects (consistent with the description as a qubit). We have shown that the state space shrinks over time (decoherence), loses its contextuality (emergence of classicality), and undergoes non-Markovian evolution at late times. Since we do not need to assume quantum theory in the analysis of the experiment, these properties are demonstrated to hold irrespective of the theoretical description of the physical system. That is, even if quantum theory were to be overturned by another theory in the future, our conclusions would still hold, as long as our experiment and its analysis have been correctly performed, and our assumption of tomographic completeness (see Methods’ subsection “Contextuality of GPTs”) is satisfied. This is to some extent similar to experimental demonstrations of the violation of Bell inequalities46,47,48, which show the failure of local realism not only within quantum theory, but as a property of nature that will survive all future revisions of our theoretical description. While we do not claim the same sort of device independence as for Bell experiments (mainly due to the assumption of tomographic completeness), we believe that our results represent a significant step forward towards the goal of a theory-independent reevaluation of experiments under minimal assumptions, which includes subjecting quantum theory to rigorous scrutiny.
It is instructive to be slightly more specific about what the GPT system really is that we have determined. Our experimental choice of 100 preparation and measurement procedures defines an operational theory, to which we have fitted an effective GPT system with state space \({{\mathcal{S}}}\) and effect space \({{\mathcal{E}}}\). As discussed in the Methods’ subsection “Determining the set of consistent states”, the set of all possible preparations and measurements on the superconducting qubit is larger, with state and effect spaces \({{{\mathcal{S}}}}_{{{\rm{phys}}}}\supset {{\mathcal{S}}}\) and \({{{\mathcal{E}}}}_{{{\rm{phys}}}}\supset {{\mathcal{E}}}\). Due to our assumption of tomographic completeness, however, our effective GPT is, in the terminology of ref. 49, a fragment of the physical GPT of the superconducting system. Hence, the proof of generalized contextuality for the former (for times 10 μs or less) applies directly to the latter, and so does the proof of non-Markovianity and the observation that the state space contracts over time.
Our work raises several interesting questions. For example, what can such experiments tell us if we do not make any assumption of tomographic completeness, such as in cases where many-body systems are probed with coarse-grained or collective measurements only50? Some progress has recently been made on this question51, in particular by showing that a notion of relative tomographic completeness is sufficient for demonstrating generalized contextuality, but there are still important open questions on how to apply this to the analysis of concrete experiments. Furthermore, can (standardly performed) measurements of the Wigner function, interpretable as large collections of preparation or measurement procedures, reveal generalized contextuality or other phenomena related to the GPT representation37? We believe that further theoretical analyses and experimental exploration may lead to interesting new insights into the foundations and practical certification of nonclassicality, as well as novel precision tests of quantum theory.
Methods
To complement the methods section, in the repository52 we provide an open-source Python code and the actual data used in this paper.
Generalized probabilistic theories
A GPT system (without transformations) is described by a convex set of (normalized) states \({{\mathcal{S}}}\subset V\) (V ≃ Rd) and a convex set of effects \({{\mathcal{E}}}\subset {V}^{*}\) such that 0≤〈e, s〉≤1 for all states and effects. The set of effects contains the 0 effect: 〈0, s〉 = 0 for all \({{\boldsymbol{s}}}\in {{\mathcal{S}}}\) and the unit effect u: 〈u, s〉 = 1 for all \({{\boldsymbol{s}}}\in {{\mathcal{S}}}\). The number 〈e, s〉 gives the probability that the measurement outcome represented by e occurs when the system is prepared in state s. Given a set of effects {e1, …, en} and a set of states {s1, …, sm}, the associated probability table D is a m × n matrix with entries Dij = 〈ej, si〉. Two GPT systems \(({{\mathcal{S}}},{{\mathcal{E}}})\) and \(({{{\mathcal{S}}}}^{{\prime} },{{{\mathcal{E}}}}^{{\prime} })\) are equivalent if exists an invertible linear map \(L:V\to {V}^{{\prime} }\) such that \(L({{\mathcal{S}}})={{{\mathcal{S}}}}^{{\prime} }\) and \({({L}^{-1})}^{*}({{\mathcal{E}}})={{{\mathcal{E}}}}^{{\prime} }\), where T* denotes to adjoint of a linear map T. Therefore two equivalent systems yield the same probabilities: \(\langle {{{\boldsymbol{e}}}}^{{\prime} },{{{\boldsymbol{s}}}}^{{\prime} }\rangle=\langle {({L}^{-1})}^{*}({{\boldsymbol{e}}}),L({{\boldsymbol{s}}})\rangle=\langle {{\boldsymbol{e}}},{L}^{-1}L({{\boldsymbol{s}}})\rangle=\langle {{\boldsymbol{e}}},{{\boldsymbol{s}}}\rangle\).
As a simple example of a GPT system, consider a qubit in quantum theory. The normalized states of the qubit are the 2 × 2 density operators, which form a convex subset of the real vector space of Hermitian operators on \({\mathbb {C}}^2\). The effects of a qubit are the positive semidefinite operators E such that 0 ≤ E ≤ 1, where 0 is the zero effect and 1 the unit effect. The probability of effect E given state ρ is given by \(\langle E,\rho \rangle={{\rm{Tr}}}(\rho E)\).
The vector representation of a qubit is given by the Bloch representation. The state of a qubit can be written in the form \(\rho=\frac{1}{2}\left({{\bf{1}}}+{\sum }_{i=1}^{3}{a}_{i}{\sigma }_{i}\right)\), where the σi are the Pauli matrices, which together with the identity 1 form a basis for the 4-dimensional real vector space of Hermitian operators on \({\mathbb {C}}^2\). Positive semidefiniteness of is equivalent to \({\sum }_{i}{a}_{i}^{2}\le 1\). Thus, the states of a qubit can be equivalently expressed in Bloch vector form as \({{{\boldsymbol{s}}}}_{\rho }=\frac{1}{2}{(1,{a}_{1},{a}_{2},{a}_{3})}^{\top }\) with ∥a∥≤1. The effects can be expressed in the same basis as a vector \({{{\boldsymbol{e}}}}_{E}={({c}_{0},{c}_{1},{c}_{2},{c}_{3})}^{\top }\), where \({c}_{i}=\frac{1}{2}{{\rm{Tr}}}(E{\sigma }_{j})\). Hence, the outcome probabilities are not w \(p(0| {P}_{i},{M}_{j})={{\rm{Tr}}}({\rho }_{i}{E}_{j})={{{\boldsymbol{s}}}}_{i}^{\top }{{{\boldsymbol{e}}}}_{j}\). The full probability table can now be written as:
Thus, the m × n probability table D for the qubit can be factored into a m × 4 matrix S and a 4 × n matrix E. This implies that D is a rank-4 matrix.
Another canonical example of a GPT system is the d-dimensional classical system Δd. The normalized states of Δd consist of probability distributions over d outcomes, which form a convex subset of \({\mathbb {R}}^d\). The effects are the response functions, namely all linear functionals e which map states to [0, 1]. In the vector representation, the normalized states are d-dimensional vectors with entries in [0, 1] which sum to 1 and the effects are vectors with entries in [0,1]. The 0 effect is the vector (0, …, 0)⊤ and the unit effect is the vector (1, …, 1)⊤. The states form a d-dimensional simplex, whilst the effects form a d-dimensional hypercube.
Uniqueness of the decomposition D = S E
Lemma 1
Suppose that D = SE, where S is a real m × k matrix, E is a real k × n matrix, and k = rank D. If \(D={S}^{{\prime} }{E}^{{\prime} }\) is another decomposition with these properties, then there is an invertible matrix L such that \({S}^{{\prime} }=SL\) and \({E}^{{\prime} }={L}^{-1}E\).
Proof.
If M is some matrix, we denote its Moore-Penrose pseudoinverse53 by M+. Set \(L:=E{({E}^{{\prime} })}^{+}\), then
Now, the k rows of \({E}^{{\prime} }\) are linearly independent, because otherwise, we would have \({{\rm{rank}}}\,D\le {{\rm{rank}}}\,{E}^{{\prime} } < k\). This implies \(E{\prime} {({E}^{{\prime} })}^{+}={{\bf{1}}}\), and hence \(SL={S}^{{\prime} }\). Similarly, the k columns of E are linearly independent, which implies both E+E = 1 and \({(E{({E}^{{\prime} })}^{+})}^{+}={E}^{{\prime} }{E}^{+}\). Thus
It remains to be shown that L is invertible. Using all of above, this follows from
hence L+ = L−1.
Solving the weighted low-rank approximation problem of Eq. (4)
In this section, we outline the methodology introduced in ref. 10 to find a rank-k matrix Drealized, which serves as the best estimate for the ideal probability table D leading to the experimentally observed statistics F. Let us recall that this is achieved by minimizing the weighted \({\chi }_{k}^{2}\) statistics in the following optimization problem (4):
where \(\Delta {F}_{ij}^{2}\) is the statistical variance in Fij. Note that D = SE contains the inner products \({{{\boldsymbol{s}}}}_{i}^{\top }{{{\boldsymbol{e}}}}_{j}\), which makes Eq. (4) a non-convex optimization problem. Moreover, this minimization problem is known to not have an analytical solution54,55. Following ref. 10, we employ an iterative approach that decomposes the optimization into two convex subproblems. Specifically, we alternate between optimizing the states while fixing the effects and optimizing the effects while fixing the states, with each optimization being a convex quadratic program10. This iterative process, known as the see-saw algorithm56,57, continues until the cost function, here the \({\chi }_{k}^{2}\), converges to a desired numerical precision. However, it is important to note that due to the non-convexity of the general problem, this procedure does not guarantee convergence to a global minimum. We refer the reader to ref. 10 [Appendix C] for an explicit description of how the \({\chi }_{k}^{2}\) minimization in Eq. (4) can be translated into a series of alternating convex optimizations.
The output of the optimization algorithm is a rank k matrix D with entries in [0, 1]. In order to obtain the corresponding GPT states and effects, we must factor D into two matrices S and E. Note that this factorization is non-unique. As in ref. 10, we first append a column of 1’s to D, which reflects the probability associated with the unit effect (corresponding to the identity operator in quantum theory), assuming no experimental losses. Then, as described in ref. 10 [Appendix C], we perform a QR decomposition of D to express it as D = SE. This ensures that the first column of S consists of 1’s, thus effectively encoding the normalization of the GPT states (analogous to the trace degree of freedom for quantum states).
Hence the matrices of states and effects have the following forms:
From the optimization problem and choice of factorization, we obtain the unit effect 1 = e0 and n effects e1…en, where \({{{\boldsymbol{s}}}}_{i}^{\top }{{{\boldsymbol{e}}}}_{j}\in [0,1]\) for all i, j by construction. Every measurement Mj has two outcomes 0 and 1 with \(p(0| {P}_{i},{M}_{j})={{{\boldsymbol{s}}}}_{i}^{\top }{{{\boldsymbol{e}}}}_{j}\). Since P(0∣Pi, Mj) + P(1∣Pi, Mj) = 1 it follows that \(p(1| {P}_{i},{M}_{j})=1-{s}_{i}^{\top }{e}_{j}={s}_{i}^{\top }({{\bf{1}}}-{e}_{j})\).
Hence, in order to account for the probabilities p(1∣Pi, Mj), the effect space should include the complement effect (1 − ej) for every ej. We append the (n + 1) × k matrix of complement effects \({E}^{{\prime} }\) with columns (1 − ej) to the matrix E to obtain a 2(n + 1) × k matrix of effects (which we shall label as E hereon for convenience). Augmenting the set of effects in this manner does not change the set of consistent states or effects.
Determining the best fit rank k
When solving Eq. (4), note that as the chosen rank k increases, the error of the fit \({\chi }_{k}^{2}\) naturally decreases. However, note that in general the experimental noise causes F to be a full rank matrix, even when the underlying D it approximates is not. Therefore, increasing k can result in a model that overfits the experimental data, which is to say that it fits the noise in the training set data F. In practice, this can be determined by separating the data into a training set F = Ftrain and a test set \({F}^{{\prime} }={F}^{{{\rm{test}}}}\), where the \({{\chi }_{k}^{2}}^{{{\rm{test}}}}\) is evaluated according to Eq. (5). The \({{\chi }_{k}^{2}}^{{{\rm{train}}}}\) for the training data determines how much the model underfits the data; the higher the \({\chi }_{k}^{2}\) value the worse the fit is. To test for overfitting, the model is applied to the test set Ftest. Models that overfit will have a significantly worse \({{\chi }_{k}^{2}}^{{{\rm{test}}}}\) since they will fit to noise that was present in Ftrain but is not present in Ftrain. There is a value kopt for which the models will transition from underfitting to overfitting. Then, the matrix \({D}_{{k}^{{{\rm{opt}}}}}\) is chosen as the best fit.
In summary, to estimate the rank kopt, we hypothesize several values k for kopt and test each one. Then, for each hypothesized rank, we compute the optimal estimate of the rank-k matrix D and evaluate its fit to the data using the χ2 statistic. Additionally, to decide which k provides the best balance between fitting the experimental data and maintaining simplicity in the model, we split the analysis with a training and a test set to ensure that the model is not overfitting the data. As we have seen in subsection “Generalized probabilistic theories”, if the experiment is described by a qubit quantum model (as we expect, since we have prepared and probed a system that is, from quantum physics and the experimental setup, expected to be a qubit), then the rank is expected to be 4. Indeed, following this method, we have shown in Fig. 4a that this is the case. Nonetheless, recall that we are keeping it general to follow a theory-agnostic approach, where we obtain the best GPT fit without assuming the correctness of quantum theory.
Determining the set of consistent states
The methodology so far estimates one possible set of states and effects compatible with the experimental data, which we denote \({{\mathcal{S}}}\) and \({{\mathcal{E}}}\). However, as in ref. 10, we can further estimate the set of all logically consistent states and effects for the experiment, named respectively \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}\) and \({{{\mathcal{E}}}}_{{{\rm{consistent}}}}\). The former is given by the set of all possible vectors s, normalized such that 〈u, s〉 = 1, which, when acted on by any covector of the realized effect space, give valid probabilities, i.e. all s such that 0≤〈e, s〉≤1 for all \({{\boldsymbol{e}}}\in {{\mathcal{E}}}\). Conversely, the latter is defined by the set of all covectors e that take the vectors of the realized state space to valid probabilities, i.e. all e such that 0≤〈e, s〉≤1 for all \({{\boldsymbol{s}}}\in {{\mathcal{S}}}\). These inequalities tell us that the consistent spaces are the duals of the realized spaces, i.e., \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}={{\rm{dual}}}\left({{\mathcal{E}}}\right)\) and \({{{\mathcal{E}}}}_{{{\rm{consistent}}}}={{\rm{dual}}}({{\mathcal{S}}})\). If the realized state space \({{\mathcal{S}}}\)/effect space \({{\mathcal{E}}}\) is smaller (in particular, if it is a strict subset of the set of states \({{{\mathcal{S}}}}_{{{\rm{phys}}}}\)/effects \({{{\mathcal{E}}}}_{{{\rm{phys}}}}\) that could in principle be implemented on the system, which is always the case in experiments on quantum systems with infinitely many pure states), then its corresponding dual is larger — since there is a larger set of covectors/vectors that combine appropriately to give valid probabilities. Accordingly, we know that \({{{\mathcal{S}}}}_{{{\rm{phys}}}}\) and \({{{\mathcal{E}}}}_{{{\rm{phys}}}}\) must lie somewhere between the realized and consistent state/effect spaces, comprising lower and upper bounds, respectively.
The duals are calculated via the cdd library in Python58, and amounts (in their terminology) to converting from the H-representation of a convex polyhedron P to its V-representation. For a given matrix of points, say that of \({{\mathcal{S}}}\), that must be combined with \({{{\mathcal{E}}}}_{{{\rm{consistent}}}}\) to give valid probabilities, a convex polyhedron of the form P = {x∣Ax≤b} can be defined, where \(A={[-[{{\mathcal{S}}}],[{{\mathcal{S}}}]]}^{\top }\) and \(b={[{[0]}^{m},{[1]}^{m}]}^{\top }\). The H-representation is the matrix [b − A], representing the set of linear inequalities characterizing P. The polyhedron can also be represented by the convex hull of its vertices, i.e., P = conv(v1, …, vn), which is called its V-representation. We can use the get_generators() method of the cdd library to obtain the V-representation [t − V], where \(t={[{[1]}^{n}]}^{\top }\) and \(V=[{{{\mathcal{E}}}}_{{{\rm{consistent}}}}]\).
Reparametrization of the state space
In order to compare the different \({{{\mathcal{S}}}}^{\tau }\) for different decoherence times τ, we are interested in finding an appropriate parametrization for these distinct sets. This is achieved by applying a linear transformation that approximates their respective \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}\) set to a unit sphere. Note that \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}\) is a function of \({{\mathcal{E}}}\), which does by construction not depend of τ. As explained in Subsection “Generalized probabilistic theories”, we can always reparametrize GPT systems linearly without changing any of their relevant properties. The method we present is split in three steps: (1) we make sure that the set of data points we work with are all extremal points; (2) we center the boundary on the origin, and (3) we pose the search for the suitable linear transformation as an optimization problem. After finding an appropriate centering and transformation for the boundary of the consistent state space \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}\), we apply the same to all realized state spaces \({{{\mathcal{S}}}}^{\tau }\), so they can be appropriately compared.
Let us start with a cautionary preliminary step by removing all the interior points of a given set of states \({{\mathcal{S}}}\). This is to guarantee that we are left only with boundary points. We do so by probing whether a given state \({{{\boldsymbol{s}}}}_{i}\in {{\mathcal{S}}}\) can be obtained as a convex combination of all the other points \({{{\boldsymbol{s}}}}_{j}\in {{\mathcal{S}}}\backslash \{{{{\boldsymbol{s}}}}_{i}\}\) for i ≠ j. This can be posed as a feasibility problem using linear programming. If the linear program is feasible, then we know that the state being probed si is a mixture of the other points; i.e., there exists a convex combination ∑j≠iλjsj = si with \({{{\boldsymbol{s}}}}_{j}\in {{\mathcal{S}}}\backslash \{{{{\boldsymbol{s}}}}_{i}\}\), 0≤λj≤1 and ∑j≠iλj = 1. The feasibility linear program is the following:
Therefore, when the linear program is feasible, we discard the state si and update the set of states to \({{{\mathcal{S}}}}^{{\prime} }={{\mathcal{S}}}\backslash \{{{{\boldsymbol{s}}}}_{i}\}\). We iterate this procedure for all i ∈ {1, …, n} until we have tested all states si and we are left only with the ones which cannot be obtained as convex combinations of the rest.
Next, we center the boundary \({{{\mathcal{S}}}}^{{\prime} }\) on the origin by subtracting the columnwise mean; namely \({{{\mathcal{S}}}}_{{{\rm{centered}}}}={{{\mathcal{S}}}}^{{\prime} }-{{\boldsymbol{\mu }}}\), where is a μ is a column vector with entries \({{{\boldsymbol{\mu }}}}_{j}=\frac{1}{n}{\sum }_{i=1}^{n}\,{{{\mathcal{S}}}}_{i,j}\) denoting the mean for column j of \({{{\mathcal{S}}}}^{{\prime} }\).
Finally, let us now provide a method to find a linear transformation that maps \({{{\mathcal{S}}}}_{{{\rm{centered}}}}\) closer to the unit sphere. Consider a state \({{{\boldsymbol{s}}}}_{i}\in {{{\mathcal{S}}}}_{{{\rm{centered}}}}\); the idea is to find a transformation L such that \(\parallel {{{\boldsymbol{s}}}}_{i}^{{\prime} }\parallel \approx 1\,\forall i\) with \({{{\boldsymbol{s}}}}_{i}^{{\prime} }:=L{{{\boldsymbol{s}}}}_{i}\). If we focus in the case where the state space has rank k = 4, then L will be a (k − 1) × (k − 1) = 3 × 3 matrix. By means of the singular value decomposition, L = UΣV⊤, note that we are only interested in finding a diagonal matrix Σ ≔ diag(σ1, σ2, σ3) with \({\sigma }_{i}\in {{\mathbb{R}}}_{\ge 0}\) and a 3 × 3 real orthogonal matrix V. We can neglect U since, by definition, \(\parallel {{{\boldsymbol{s}}}}_{i}^{{\prime} }\parallel=\sqrt{{s}_{i}^{\top }V{\Sigma }^{\top }{U}^{\top }U\Sigma {V}^{\top }{{{\boldsymbol{s}}}}_{i}}=\sqrt{{{{\boldsymbol{s}}}}_{i}^{\top }V{\Sigma }^{2}{V}^{\top }{{{\boldsymbol{s}}}}_{i}}\). Furthermore, we use Euler angles parametrization for V, which guarantees the constraint VV⊤ = 1 while having full coverage of SO(3) with 3 parameters (angles) \(\alpha,\beta,\gamma \in {\mathbb{R}}\):
Therefore, to find the suitable Σ and V, we consider the following constrained minimization problem:
Once we find the suitable translation μ and transformation L = ΣV⊤ for a given \({{{\mathcal{S}}}}_{{{\rm{consistent}}}}\), we apply them in turn to all realized state spaces \(L({{{\mathcal{S}}}}^{\tau }-\mu )\) so that we can properly compare the sets as shown in Fig. 6.
Lower bound on the purity of the prepared states
If we assume that quantum theory holds, then there will be a valid qubit density matrix ρs for every state \({{\boldsymbol{s}}}\in {{\mathcal{S}}}\). Let us assume that \({\lambda }_{\max }({\rho }_{{{\boldsymbol{s}}}})\le c\) for all \({{\boldsymbol{s}}}\in {{\mathcal{S}}}\), where \(\frac{1}{2}\le c\le 1\). Then the Bloch vectors of all ρs are contained in ball of radius 2c − 1 around the origin in the Bloch representation. Since the one-norm distance of quantum states corresponds to the Euclidean distance in the Bloch ball, this means that \({{\mathcal{D}}}({{\boldsymbol{s}}},{{{\boldsymbol{s}}}}^{{\prime} })\le \frac{1}{2}\parallel {\rho }_{{{\boldsymbol{s}}}}-{\rho }_{{{{\boldsymbol{s}}}}^{{\prime} }}{\parallel }_{1}\le 2c-1\) for all \({{\boldsymbol{s}}},{{{\boldsymbol{s}}}}^{{\prime} }\in {{\mathcal{S}}}\). Hence \(c\ge \frac{1}{2}\left(1+{\max }_{{{\boldsymbol{s}}},{{{\boldsymbol{s}}}}^{{\prime} }\in {{\mathcal{S}}}}{{\mathcal{D}}}({{\boldsymbol{s}}},{{{\boldsymbol{s}}}}^{{\prime} })\right)\), and the distinguishability maximum is numerically determined to be at least 0.691 ± 0.004, thus c ≥ 0.846 ± 0.002.
Markovian evolutions do not increase the volume
If T is any transformation on a GPT system, then it acts linearly on the set of unnormalized states in \({{\mathbb{R}}}^{k}\)14,15. In particular, in the parametrization where the first component of a state vector is its normalization, we have \({{{\boldsymbol{s}}}}^{{\prime} }=\left(\begin{array}{c}1\\ {s}^{{\prime} }\end{array}\right)=T\left(\begin{array}{c}1\\ s\end{array}\right)\), and so \({s}^{{\prime} }={T}^{{\prime} }s+t\), with some vector t and linear transformation \({T}^{{\prime} }\) on \({{\mathbb{R}}}^{k-1}\). (To see this explicitly, write \(T={({T}_{ij})}_{i,j=0}^{k-1}\), then \({s}_{j}^{{\prime} }={T}_{j0}+{\sum }_{n=1}^{k-1}{T}_{jn}{s}_{n}=:t+{T}^{{\prime} }s\).) Clearly, transformations map valid states to valid states, so the image of the full state space must satisfy \({T}^{{\prime} }{{\mathcal{S}}}+t\subseteq {{\mathcal{S}}}\), and so
Thus, \(| \det {T}^{{\prime} }| \le 1\), and hence the action of the transformation on the normalized state space cannot increase the volume of any region.
To compute the volumes shown in Fig. 8 for each \({{{\mathcal{S}}}}^{\tau }\), we have used the Delaunay Triangulation59 on their boundary points. This splits the polytope into non-overlapping simplices (tetrahedras in our case), for which the volume formula can be easily calculated. The total volume of \({{{\mathcal{S}}}}^{\tau }\) is then estimated by summing the volumes of these simplices.
Decoherence in GPTs
In the main text, we say that the state of the superconducting system decoheres, even though the notion of “decoherence” is usually only used in QT. Here, we point out that (1) there is a rigorous definition of decoherence for GPTs in the literature which applies to the long-time behavior of the superconducting system; and (2) for finite times, the system evolves irreversibly, and this allows us to draw very similar conclusions to the quantum version of decoherence, justifying the name also beyond QT.
Regarding (1), we will use the definition of ref. 60, which is slightly more general than that of ref. 61 or ref. 62: a complete decoherence map T is a transformation such that T2 = T, i.e., applying the transformation twice is the same as applying it once. In QT, an example is given by the map that removes all off-diagonal elements of a density matrix. Figure 6 indicates that the long-time effect of the time evolution is to map every initial state ω to the same final state ω0 (which we physically expect to be the ground state), T(ω) = ω0. This is clearly a decoherence map according to the previous definition, since T(T(ω)) = T(ω0) = ω0.
To see (2), note that reversible transformations T map pure states of a GPT system to pure states, and they preserve the state space \({{\mathcal{S}}}\), i.e., \(T({{\mathcal{S}}})={{\mathcal{S}}}\). This is clearly not the case in our system’s time evolution: most pure states are mapped to mixed states (in particular, for times τ≤15μs), and the image of \({{\mathcal{S}}}\) is strictly smaller than \({{\mathcal{S}}}\). Hence, we have irreversible time evolution on the superconducting system S that we are probing. However, if we assume that the total evolution of S and its environment E is reversible (in QT, this would be equivalent to global unitarity), then it cannot act on S and on E independently (otherwise, S and E would individually preserve their purity). In other words, it must be the reversible interaction between S and E that makes the initially close to pure state of S mixed. This resembles the phenomenology of decoherence of QT and justifies the use of this term in the more general GPT context.
Contextuality of GPTs
Having shown the image of the GPT state space according to the time delay τ, we want a theory-independent test of their (non-)contextuality. It was shown in ref. 29 that non-contextuality can be established via a linear program which takes as an input a set of states and a set of effects, and determines whether their statistics, via a specified probability rule, can be reproduced by a classical (noncontextual) model. We make use of an open-source version of this program30, which, moreover, in the case that the GPT is contextual, computes the amount of noise that must be added such that a noncontextual model can be fitted. More specifically, the linear program of ref. 30 is a test of simplex embeddability: the property that a GPT’s state space can be embedded into a classical probability simplex, with its effect space as the dual of that simplex. This was shown in refs. 28,49 to be equivalent to the existence of a noncontextual ontological model.
For the nonembeddibility of the GPT to meaningfully imply nonclassicality, we must assume that there is some system that our experiment probes for which our preparations and measurements are relatively tomographically complete51. We note that the system being probed will in general be a subsystem of some larger system, for instance in this case it corresponds to the first two energy levels of an anharmonic oscillator. However, crucially, it must be such that the preparations and measurement of that subsystem are tomographically complete relative to each other, or equivalently, that the subsystem being probed is embeddable within the larger system60. Without assuming so, it is always possible that the statistics derive from some higher-dimensional, noncontextual system, c.f. the Holevo projection63. Tomographic completeness in itself is a theory-independent assumption, but can be strongly motivated here by quantum physics—in particular, by the state space of the qubit being a Bloch ball, for which we have chosen a tomographically highly overcomplete distribution of points to sample (k = 4 linearly independent states and effects would have been sufficient for tomographic completeness, but many more of these procedures are needed to obtain an accurate estimate of the shape of the state and effect spaces as depicted in Figs. 5 and 6).
To use the linear program, one inputs the GPT’s set of states \({{{\mathcal{S}}}}^{\tau }\) and set of effects \({{\mathcal{E}}}\), which were found via the theory-independent analysis of Results’ subsection “Theory-independent analysis”, as well as two row vectors specifying the unit effect u and the average state mτ. The unit effect is given by (1, 0, 0, 0), which is always the first entry of the set of effects, whilst the average state is calculated by taking the columnwise mean of the set of states. The program then outputs a coefficient r, termed the robustness of nonclassicality, as well as a set of epistemic states and response functions (which specify a noncontextual ontological model for the scenario). The important information is encoded in r, which quantifies how much depolarizing noise must be added such that a noncontextual ontological model can be fitted. In particular, the maximally mixed state defines a depolarization map \({D}_{r}^{\tau }({{\boldsymbol{s}}}):=(1-r){{\boldsymbol{s}}}+r{{{\boldsymbol{m}}}}^{\tau }\); the minimum r such that a noncontextual ontological model can be fitted to the scenario thus constitutes an operational measure of nonclassicality. More specifically, a robustness of r = 0 indicates that a noncontextual ontological model can be constructed precisely, without adding noise, whilst r > 0 indicates that some amount of depolarizing noise is necessary for an ontological model—thereby witnessing contextuality.
Experimental setup and qubit readout characterization
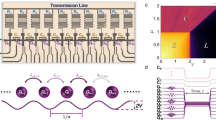
The device used for this work is a superconducting transmon qubit hosted inside a three-dimensional readout cavity resonator. For operation, this device is cooled down at ~ 10 mK temperature by a dilution refrigerator and operated by commercial microwave electronics, see Fig. 9 for an illustration. Qubit rotation and readout pulses are generated at room temperature by an arbitrary waveform generator and then up-converted to gigahertz frequencies. After a room-temperature amplification stage, these pulses are sent to the sample inside the refrigerator through a line of cryogenic attenuators and filters protecting the qubit from undesired electromagnetic radiation. The qubit readout pulse is transmitted through the cavity, amplified by both cryogenic and room-temperature components, down-converted to megahertz frequencies, and finally digitalized by a FPGA before being recorded on a PC.

The superconducting qubit device used in this work is hosted inside a three-dimensional microwave cavity cooled down at cryogenic temperature by a dilution refrigerator. Qubit state preparation and readout are controlled by microwave electronics at room temperature.
Following the standard practice in superconducting qubit experiments, the state of our qubit is measured in the strong dispersive regime of circuit-QED19. To calibrate our readout and characterize its fidelity, we collect 2000 measurement shots for the qubit in its ground state \(\left|0\right\rangle\) and an equal number of shots for the qubit prepared in \(\left|1\right\rangle\). Representative results are shown in Fig. 10 (left), which allow us to identify the decision boundary for the \(\left|0\right\rangle\) vs. \(\left|1\right\rangle\) state. For clarity, we also show a 1D projection of the measurement distributions along the direction connecting their means in Fig. 10 (right).

Left: for each qubit initial state, 2000 measurements are collected for identifying the decision boundary (dashed line) in the IQ-plane. Right: projection of the distributions along the direction connecting their means (solid line).
From the collected statistics, we can identify the conditional probability p(a∣P) of assigning the label \(a\in \{\left|0\right\rangle,\left|1\right\rangle \}\) when state \(P\in \{\left|0\right\rangle,\left|1\right\rangle \}\) was prepared. These are given in Table 1.
The average readout fidelity is then defined as 1 − (p(0∣1) + p(1∣0))/2, which gives 85(1)%. Contributions to the infidelity come from the finite cavity dispersive shift, qubit state decay during the ~ 10 μs long readout pulse, as well as finite thermal population of ~ 10−3 at equilibrium.
Data availability
The data that support the findings of this study are publicly available in the Zenodo repository52.
Code availability
The custom code used to produce the results presented in this paper is publicly available in the Zenodo repository52.
References
Bell, J. S. On the Einstein-Podolsky-Rosen paradox. Physics 1, 195–200 (1964).
Kochen, S. & Specker, E. P. The problem of hidden variables in quantum mechanics. J. Math. Mech. 17, 59–87 (1967).
Spekkens, R. W. Contextuality for preparations, transformations, and unsharp measurements. Phys. Rev. A 71, 052108 (2005).
Mazurek, M. D., Pusey, M. F., Kunjwal, R., Resch, K. J. & Spekkens, R. W. An experimental test of noncontextuality without unphysical idealizations. Nat. Commun. 7, 11780 (2016).
Kunjwal, R. Contextuality beyond the Kochen-Specker Theorem. Ph.D. thesis, Homi Bhabha National Institute (2016).
Krishna, A., Spekkens, R. W. & Wolfe, E. Deriving robust noncontextuality inequalities from algebraic proofs of the Kochen-Specker theorem: the Peres-Mermin square. New J. Phys. 19, 123031 (2017).
Spekkens, R. W. Negativity and contextuality are equivalent notions of nonclassicality. Phys. Rev. Lett. 101, 020401 (2008).
Schmid, D., Selby, J. H., Pusey, M. F. & Spekkens, R. W. A structure theorem for generalized-noncontextual ontological models. Quantum 8, 1283 (2024).
Jerger, M. et al. Contextuality without nonlocality in a superconducting quantum system. Nat. Commun. 7, 12930 (2016).
Mazurek, M. D., Pusey, M. F., Resch, K. J. & Spekkens, R. W. Experimentally bounding deviations from quantum theory in the landscape of generalized probabilistic theories. PRX Quantum 2, 020302 (2021).
Grabowecky, M., Pollack, C., Cameron, A., Spekkens, R. W. & Resch, K. J. Experimentally bounding deviations from quantum theory for a photonic three-level system using theory-agnostic tomography. Phys. Rev. A 105, 032204 (2022).
Barrett, J. Information processing in generalized probabilistic theories. Phys. Rev. A 75, 032304 (2007).
Janotta, P. & Hinrichsen, H. Generalized probability theories: what determines the structure of quantum theory? J. Phys. A Math. Theor. 47, 323001, (2014).
Müller, M. P. Probabilistic theories and reconstructions of quantum theory (Les Houches 2019 lecture notes). SciPost Phys. Lect. Notes 28, 1–41 (2021).
Plávala, M. General probabilistic theories: an introduction. Phys. Rep. 1033, 1–64 (2023).
Li, L., Hall, M. J. & Wiseman, H. M. Concepts of quantum non-Markovianity: a hierarchy. Phys. Rep. 759, 1–51 (2018).
Kjaergaard, M. et al. Superconducting qubits: current state of play. Annu. Rev. Condens. Matter Phys. 11, 369–395 (2020).
Koch, J. et al. Charge-insensitive qubit design derived from the Cooper pair box. Phys. Rev. A 76, 042319 (2007).
Blais, A., Grimsmo, A. L., Girvin, S. M. & Wallraff, A. Circuit quantum electrodynamics. Rev. Mod. Phys. 93, 025005 (2021).
González, Á Measurement of areas on a sphere using Fibonacci and latitude-longitude lattices. Math. Geosci. 42, 49–64 (2010).
Catani, L. & Leifer, M. A mathematical framework for operational fine tunings. Quantum 7, 948 (2023).
Ududec, C., Barnum, H. & Emerson, J. Three slit experiments and the structure of quantum theory. Found. Phys. 41, 396 (2011).
Barnum, H., Müller, M. P. & Ududec, C. Higher-order interference and single-system postulates characterizing quantum theory. New J. Phys. 16, 123029 (2014).
Hardy, L. Quantum theory from five reasonable axioms. arXiv https://doi.org/10.48550/arXiv.quant-ph/0101012 (2001).
Dakić, B. & Brukner, Č. Quantum theory and beyond: is entanglement special? in Deep Beauty: Understanding the Quantum World through Mathematical Innovation (ed. Halvorson, H.) (Cambridge University Press, 2011).
Masanes, L. & Müller, M. P. A derivation of quantum theory from physical requirements. New J. Phys. 13, 063001 (2011).
Chiribella, G., d’Ariano, G. M. & Perinotti, P. Informational derivation of quantum theory. Phys. Rev. A 84, 012311 (2011).
Schmid, D., Selby, J. H., Wolfe, E., Kunjwal, R. & Spekkens, R. W. Characterization of noncontextuality in the framework of generalized probabilistic theories. PRX Quantum, 2, 010331 (2021).
Gitton, V. & Woods, M. P. Solvable criterion for the contextuality of any prepare-and-measure scenario. Quantum 6, 732 (2022).
Selby, J. H., Wolfe, E., Schmid, D., Sainz, A. B. & Rossi, V. P. A linear program for testing nonclassicality and an open-source implementation. Phys. Rev. Lett. 132, 050202 (2024).
Lillystone, P., Wallman, J. J. & Emerson, J. Contextuality and the single-qubit stabilizer subtheory. Phys. Rev. Lett. 122, 140405 (2019).
Gottesman, D. The heisenberg representation of quantum computers. arXiv https://doi.org/10.48550/arXiv.quant-ph/9807006 (1998).
Spekkens, R. W., Buzacott, D. H., Keehn, A. J., Toner, B. & Pryde, G. J. Preparation contextuality powers parity-oblivious multiplexing. Phys. Rev. Lett. 102, 010401 (2009).
Hameedi, A., Tavakoli, A., Marques, B. & Bourennane, M. Communication games reveal preparation contextuality. Phys. Rev. Lett. 119, 220402 (2017).
Saha, D. & Chaturvedi, A. Preparation contextuality as an essential feature underlying quantum communication advantage. Phys. Rev. A 100, 022108, (2019).
Schmid, D. & Spekkens, R. W. Contextual advantage for state discrimination. Phys. Rev. X 8, 011015 (2018).
Schmid, D., Du, H., Selby, J. H. & Pusey, M. F. Uniqueness of noncontextual models for stabilizer subtheories. Phys. Rev. Lett. 129, 120403 (2022).
Catani, L., Galley, T. D. & Gonda, T. Resource-theoretic hierarchy of contextuality for general probabilistic theories. arXiv https://doi.org/10.48550/arXiv.2406.00717 (2024).
Chiribella, D., D’Ariano, G. M. & Perinotti, P. Probabilistic theories with purification. Phys. Rev. A 81, 062348 (2010).
Chiribella, D., D’Ariano, G. M. & Perinotti, P. Informational derivation of quantum theory. Phys. Rev. A 84, 012311 (2011).
Bell, J. S. On the problem of hidden variables in quantum mechanics. Rev. Mod. Phys. 38, 447–452 (1966).
Schmid, D., Ried, K. & Spekkens, R. W. Why initial system-environment correlations do not imply the failure of complete positivity: a causal perspective. Phys. Rev. A 100, 022122 (2019).
Meyer, D. A. Finite precision measurement nullifies the Kochen-Specker theorem. Phys. Rev. Lett. 83, 3751 (1999).
Pironio, S., Scarani, V. & Vidick, T. Focus on device independent quantum information. New J. Phys. 18, 100202 (2016).
Mayers, D. & Yao, A. Quantum cryptography with imperfect apparatus. In Proc. 39th Annual Symposium on Foundations of Computer Science, FOCS, Palo Alto 503–509 (IEEE, 1998).
Hensen, B. et al. Loophole-free Bell inequality violation using electron spins separated by 1.4 kilometres. Nature 526, 682 (2015).
Giustina, M. et al. Significant-loophole-free test of Bell’s theorem with entangled photons. Phys. Rev. Lett. 115, 250401 (2015).
Shalm, L. K. et al. Strong loophole-free test of local realism. Phys. Rev. Let. 115, 250402 (2015).
Selby, J. H. et al. Accessible fragments of generalized probabilistic theories, cone equivalence, and applications to witnessing nonclassicality. Phys. Rev. A 107, 062203 (2023).
Schmied, R. et al. Bell correlations in a Bose-Einstein condensate. Science 352, 6284 (2016).
Schmid, D., Selby, J. H., Rossi, V. P., Baldijão, R. D. & Sainz, A. B. Shadows and subsystems of generalized probabilistic theories: when tomographic incompleteness is not a loophole for contextuality proofs. arXiv https://doi.org/10.48550/arXiv.2409.13024 (2024).
Aloy, A., Fadel, M., Galley, T. D., Jones, C. L. & Müller, M. P. Code and data for “Theory-independent monitoring of the decoherence of a superconducting qubit with generalized contextuality”. Zenodo https://doi.org/10.5281/zenodo.17979407 (2024).
Barata, J. C. A. & Hussein, M. S. The Moore-Penrose pseudoinverse: a tutorial review of the theory. Braz. J. Phys. 42, 146–165 (2012).
Gillis, N. & Glineur, F. Low-rank matrix approximation with weights or missing data is NP-hard. SIAM J. Matrix Anal. Appl. 32, 1149–1165 (2011).
Markovsky, I. Low Rank Approximation: Algorithms, Implementation, Applications 906 (Springer, 2012).
Pál, K. F. & Vértesi, T. Maximal violation of a bipartite three-setting, two-outcome Bell inequality using infinite-dimensional quantum systems. Phys. Rev. A 82, 022116 (2010).
Werner, R. F. & Wolf, M. M. Bell inequalities and entanglement. Quantum Inf. Comput. 1, 1–25 (2001).
Troffaes, M. C. M. Working with polyhedron representations. https://pypi.org/project/pycddlib/ (2025).
Lee, D. T. & Schachter, B. J. Two algorithms for constructing a Delaunay triangulation. Int. J. Comput. Inf. Sci. 9, 219–242 (1980).
Müller, M. P. & Garner, J. P. Testing quantum theory by generalizing noncontextuality. Phys. Rev. X 13, 041001 (2023).
Lee, C. M. & Selby, J. H. A no-go theorem for theories that decohere to quantum mechanics. Proc. R. Soc. A 474, 20170732 (2018).
Richens, J. G., Selby, J. H. & Al-Safi, S. W. Entanglement is necessary for emergent classicality in all physical theories. Phys. Rev. Lett. 119, 080503 (2017).
Holevo, A. Probabilistic and Statistical Aspects of Quantum Theory (North Holland, 1982).
Acknowledgements
T.G. acknowledges helpful discussions with Robert Spekkens and Patrick Daley, and thanks Michael Mazurek for providing him with the data from ref. 10. These contributions helped with writing an initial version of part of the code used in the present paper. This research was funded by the Austrian Science Fund (FWF) 10.55776/PAT2839723; funded by the European Union—NextGenerationEU (AA, TDG, CLJ, MPM). Furthermore, this research was supported in part by Perimeter Institute for Theoretical Physics (MPM). Research at Perimeter Institute is supported by the Government of Canada through the Department of Innovation, Science, and Economic Development, and by the Province of Ontario through the Ministry of Colleges and Universities. M.F. was supported by the Swiss National Science Foundation Ambizione Grant No. 208886, and by The Branco Weiss Fellowship—Society in Science, administered by the ETH Zürich.
Author information
Authors and Affiliations
Contributions
M.F. performed the experiment, A.A., C.J., T.G., and M.M. worked out the theoretical results and wrote the paper, A.A., C.J., and T.G. performed the numerical analysis, and M.M. directed the research.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aloy, A., Fadel, M., Galley, T.D. et al. Theory-independent monitoring of the decoherence of a superconducting qubit with generalized contextuality. Nat Commun 17, 2474 (2026). https://doi.org/10.1038/s41467-026-69030-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-026-69030-x
