
Abstract
Little is known about tissue-specific changes that occur with aging in humans. Using the description of 33 million histological samples we extract thousands of age- and mortality-associated features from text narratives that we call The Human Pathome (pathoage.com). Notably, we can broadly determine when post-development aging starts at the organism and tissue level, indicating a sexual dimorphism with females aging earlier but slower and males aging later but faster. We employ unsupervised topic-modeling to identify terms and themes that predict age and mortality. As a proof of principle, we cross-reference these terms in PubMed to identify nintedanib as a potential aging intervention and show that nintedanib reduces markers of cellular senescence, reduces pro-fibrotic gene pathways in senescent cells and extends the lifespan of fruit flies. Our findings pave the way for expanded exploitation of population text datasets towards discovery of novel aging interventions.
Similar content being viewed by others


Introduction
Aging is a complex, multifactorial process1,2 that leads to declining physiology and a susceptibility to disease3. Yet, little is known about tissue-specific changes that occur with aging in humans. Clinical text constitutes the most abundant data type in electronic healthcare records which are implemented in most countries4. Specifically, pathology records are rich in descriptions of cellular and histological samples of healthy and diseased human tissue and therefore represent a considerable opportunity to systematically characterize tissue-specific changes that occur in aging. Nonetheless, electronic healthcare records are a vastly underused data resource due to their limited availability to researchers5. Furthermore, unstructured text data are not directly amenable to computational analysis and clinical text is highly heterogeneous. Importantly, using natural language processing and machine learning, phenotypes can be extracted from clinical text and used to discover correlations and stratify patient cohorts6,7.
Aging research has traditionally focused on experimental studies in model organisms. However, translating these findings to humans remains a major challenge due to species-specific differences and the complexity of human aging biology. Making use of large-scale, real-world clinical data offers a unique opportunity to uncover human-specific aging patterns. By systematically analyzing pathology records, we sought to provide a comprehensive view of the aging process across tissues and uncover actionable insights for potential therapeutic interventions.
To get an unbiased description of organismal- and tissue-specific aging, we analyzed The Danish National Pathology Register containing the clinical description of over 33 million samples collected since 19708 from over 4.9 million individuals some born as early as 1876 (Fig. 1a). Using natural language processing we extracted thousands of clinical features from unstructured pathology narrative texts. We combine this with vital statistics to identify age- and mortality-associated features. Using supervised and unsupervised machine-learning we identify population-based patterns of aging and surprisingly discover that patterns of aging-related changes appear to start almost immediately after development in the late teens for females. For males, patterns of aging-related changes start later (~ 40 years) but progress faster. Conversely, tissue-specific patterns of aging show that some tissues age linearly and others age along developmental and post-developmental trajectories. To further investigate the meaning of clinical features we employ topic-modeling9 and reveal specific age- and mortality-associated themes. As a proof of principle, we deploy this in lung pathology records and find that the predictive power of topic modeling themes is stronger than individual features. We further cross-reference the age-associated terms from the pathology datasets within all published PubMed abstracts and identify compounds enriched in aging terms. Among them, we identify nintedanib, a tyrosine kinase inhibitor10, as a potential pharmacological intervention in aging. Indeed, nintedanib, an antifibrotic agent, reduces markers of cellular senescence, reduces pro-fibrotic gene pathways in senescent cells and extends the lifespan of Drosophila melanogaster.

a The Human Aging Pathome and aging intervention discovery concept and workflow. b PCA of age-aggregated pathology records (n = 20,316,270) from the entire pathology register. Normalized Euclidean distance between age-adjacent PCA coordinates. c, d PC1, PC2 coordinates vs. age. e PCA of age-aggregated of pathology records (n = 14,492,989) from females in the entire pathology register. Normalized Euclidean distance between age adjacent PCA coordinates. f, g PC1, PC2 coordinates vs. age. h PCA of age-aggregated pathology records (n = 5,823,281) from males in the entire pathology register. Normalized Euclidean distance between age-adjacent PCA coordinates. i, j PC1, PC2 coordinates vs. age. k t-SNE of clinical features in age-aggregated pathology records in the entire pathology register. l UMAP of clinical features in pathology records in the entire pathology register. m–o Positive morphology-specific enrichment: Inflammation, Adenocarcinoma and Adenoma. p–r Positive enrichment of clinical terms in tissue-specific pathology records: Lung, Skeletal system and Bone marrow.
Results
Aging patterns emerge post-development for females and at mid-life for males
To assess how well the occurrence of terms in the pathology register reflects real-world age-dependent changes in tissue, we examined the age-dependent frequency of phenotypes known to increase or decrease with age. We observed age-associated increases in mentions of terms, such as atrophy11, fibrosis12, fat13, apoptosis14, amyloid15, and inflammation16 (Supplementary Fig. 1a). Conversely, we found an age-dependent decrease in mentions of hair and melanocytes corresponding with the known age-related decline of these features17,18. To better understand the drivers of variance in pathology records, we calculated the average term frequency for each age group (0–100 years). This also served to normalize the over- and under-representation of certain age groups in the pathology register (Supplementary Fig. 1b for age distribution). We conducted principal component analysis (PCA) on the age-aggregated term vectors. Strikingly, the two main principal components, PC1 (35.5%) and PC2 (26.52%), were strongly correlated with age, suggesting that variance in pathology records could be largely explained by age (Fig. 1b). We observed that developmental ages (0-18) varied predominantly along PC1 (Fig. 1c), whereas post-developmental ages (19 and over) varied primarily along PC2 (Fig. 1d). The observation that developmental and post-developmental ages associated strongly with variance along PC1 and PC2, respectively, could suggest that PC1 represents variance related to developmental processes (e.g. tissue maturation, cell differentiation), while PC2 reflects age-associated changes associated with post-developmental aging (e.g. accumulation of damage, decline in repair mechanisms). To assess the rate of aging-associated changes, we calculated the Euclidean distance between adjacent age groups in PCA space, revealing peaks around the end of development, at mid-life and late life, perhaps suggesting three waves of aging, similar to findings in the plasma proteome19. Since we observed increased variance around mid-life, we speculated that sex-dependent differences in aging might emerge post-development, particularly around menopause. To assess sex-dependent differences in aging post-development, we analyzed males and females separately and found that both males and females exhibited these waves of aging. However, female-specific age-associated changes appeared immediately after development (Fig. 1e–g) while male-specific aging changes began around age 40 and accelerated over time (Fig. 1h–j). Notably, while aging-associated changes in females appear to occur earlier, they contribute less to overall variance (PC2 in females accounts for 25.8% of variance, compared to 64.5% for PC1 in males). To visualize the full landscape of term frequencies, we applied t-distributed stochastic neighbor embedding (t-SNE) and Uniform Manifold Approximation and Projection (UMAP) to the average term frequencies for each age group, overlaid with the mean incidence age of each feature in the pathology register (Fig. 1k; Supplementary Fig. 2a for UMAP). Interestingly, the t-SNE plot shows that terms associated with younger age groups coalesce in the center, while those associated with older age groups project outwards, reflecting an apparent age-dependent progression from order to disorder.
Patterns of tissue-specific vocabulary identified in pathology records
We sought to better understand the co-occurrence patterns of clinical terms in the entire pathology register. To visualize these patterns, we used UMAP to generate a low-dimensional embedding of the dataset, where frequently co-occurring terms are represented by nearby points. In the UMAP visualization, we observed a tendency for terms with similar mean incidence age to cluster together (Fig. 1l; Supplementary Fig. 2b for t-SNE, Supplementary Fig. 2c, d for sex-specific t-SNEs, Supplementary Fig. 2e, f for sex-specific UMAPs). Pathology records are annotated with structured SNOMED codes indicating association with specific tissues and morphologies (Fig. 1m–r; Supplementary Fig. 2g for additional tissues). We observed that records annotated with the morphology code for ‘inflammation’ were enriched with terms spanning broad clusters across the feature landscape (Fig. 1m). Moreover, records associated with specific tissues, such as the lung, skeletal system, and bone marrow, exhibited enrichment of clinical terms in more narrowly defined regions of the feature landscape (Fig. 1p–r). Notably, terms enriched in lung tissue overlapped significantly with inflammation-related terms, supporting the idea that inflammation is particularly pervasive in lung tissue20. Additionally, we found a tendency for terms enriched in tissue-specific records to form distinct, non-overlapping clusters, suggesting the existence of distinct tissue-specific vocabularies. However, a cluster of terms enriched in skeletal system records (Fig. 1q) was found in close proximity to those enriched in bone marrow records (Fig. 1r), indicating a shared vocabulary used to describe related tissues. Altogether, these findings suggest that tissue-specific patterns of aging can be identified in the dataset.
Tissues age along specific trajectories
We investigated whether tissue-specific aging patterns could be identified in pathology records. To that end, we repeated the above analyses for every tissue in the body. We noted a similarly strong correlation between the two main principal components, PC1 and PC2, and age in multiple tissues (Fig. 2a). Furthermore, we analyzed males and females separately and observed different sex-specific aging trajectories in specific tissues. (Fig.2b, c, Supplementary Fig. 2h–j). The sex-specific PCAs reveal that in some tissues, the aging trajectory differs significantly between males and females, suggesting that the underlying biological processes of aging could be influenced by sex. Moreover, in the liver, we observe an overall linear aging trajectory in both males and females, however, age appears to explain a smaller proportion of aging changes in males (PC1 + PC2 = 44.4%) when compared to females (PC1 + PC2 = 55.3%). To understand whether the mean incidence age of terms (Fig. 2d) and the mortality (defined as time to death from examination) associated with terms are correlated, we linked the mortality data of over 1.3 million individuals with their pathology records (Fig. 2e). Incidentally, the hazard of death is associated with the length (word count) of clinical text narratives and with birth cohort (Supplementary Fig. 2k, l) (Supplementary Fig. 3a–c for additional tissues). Indeed, we observed that age and mortality appear broadly correlated in all tissues. Interestingly, in several tissues (lung, kidney, bladder, nervous system) we observe that age-related changes appear to be biphasic (Fig. 2f) perhaps suggesting a phase associated with aging during development and one associated with aging post-development. For other tissues, aging appears more linear (liver, gallbladder, skeletal system). Notably, there are also differences in when aging appears to start depending on the tissue. When investigating a single tissue, such as lung, clinical features enriched in categories, such as inflammation and benign tumors (Fig. 2g, h), appear to be mostly non-overlapping, while adenoma and adenocarcinoma morphologies (Fig. 2i, j) appear to coincide. In sum, tissue-specific trajectories define different patterns of aging indicating that different tissues age in different ways. To allow exploration of these phenomena, we have created a browsable database of The Human Pathome, publicly available at pathoage.com.

a PCA of age-aggregated tissue-specific pathology records. b,c PCA of age-aggregated pathology records from males and females, respectively, in the tissue-specific records in the pathology register. d UMAP of clinical features of tissue-specific pathology records (mean incidence age). e UMAP of clinical features of tissue-specific pathology records (Cox regression coefficient).Tissues shown are: Lung (n = 177,795), Liver (n = 156,057), Heart (n = 27,055), Kidney (n = 85,244), Nervous system (n = 183,729), Bladder (n = 250,532), Skeletal system (n = 242,282) and Gallbladder (n = 182,261). f Normalized Euclidean distance between age-adjacent PCA coordinates of lung, liver, heart, kidney, nervous system, bladder, skeletal system, and gallbladder tissue. g–j Positive enrichment of clinical terms in morphology-specific lung records: g Inflammation. h Benign tumor. i Adenoma. j Adenocarcinoma.
Clinical features in pathology text predict age
To better understand the relationship between mentions of clinical terms and tissue-specific aging, we employed supervised machine learning to predict age using clinical text features from lung pathology records. Initially, we used an Ordinary Least Squares (OLS) regression model to predict age from clinical text features. The model yielded a Median Absolute Error (MedAE) of 7.66 years, Mean Absolute Error (MAE) of 9.43 years, and an R-squared (R2) of 0.26, indicating moderate predictive power (Supplementary Fig. 4a). To better model the effect of non-linear relationships between clinical text features on age prediction, we fit a supervised deep neural network Multilayer Perceptron (MLP) regression. This model showed a slight improvement in predictive power over the OLS model, yielding a Median Absolute Error (MedAE) of 7.61 years, a Mean Absolute Error (MAE) of 9.28 years, and an R-squared (R2) of 0.29 (Fig. 3a, Supplementary Fig. 4b). To further understand the contribution of individual terms, we performed a permutation feature importance (PFI) analysis on the MLP model (Fig. 3b). We identified terms like ‘carcinoma’, ‘anthracnose’, ‘planocellular’ and ‘sarcoidosis’ among the most predictive of lung aging. However, each term’s contribution to the model’s accuracy was relatively small (ΔR2 < 0.021). Given the model’s limited predictive power (R2 = 0.29), we investigated whether a collection of associated terms would enhance predictive accuracy. To explore how clinical features semantically relate to one another, we applied a Latent Dirichlet Allocation (LDA) topic model9 to tissue-specific pathology records, enabling us to identify clusters of co-occurring terms. We fitted an LDA topic model to 177,795 lung pathology records and employed a model perplexity minimization strategy to determine that the clinical feature space is optimally decomposed into sixty topics (Supplementary Fig. 4c). A t-SNE visualization of clinical feature distributions in topics demonstrates the topic model’s ability to segregate associated features into clusters (Fig. 3c, d). This approach also enabled us to stratify individual pathology records by topic (Fig. 3e). Interestingly, the topic model appears to identify collections of features with closely associated age and mortality (Fig. 3f, g; Supplementary Fig. 4d, e) suggesting that these semantic structures might represent clinically significant themes. Furthermore, records grouped by these topics showed a strong association with age at examination (Fig. 3h) further strengthening the notion that the topics we identified may characterize cohorts of similar individuals.

a MLP age-prediction from clinical features in lung pathology records. b Permutation feature importance (PFI). c UMAP of clinical features in lung records (LDA topic). d t-SNE of clinical feature LDA distributions in topics (LDA topics). e t-SNE of LDA record distributions in topics (LDA topics). f t-SNE of clinical feature LDA distributions in topics (mean incidence age). g t-SNE of clinical feature LDA distributions in topics (mortality: Cox regression coefficient). h t-SNE of LDA record distributions in topics (age). i Topic-associated age-prediction linear regression. j Topic-associated permutation feature importance (PFI). k Topic-associated age-prediction regression slope. l Terms describing Obstetric Gynecologic Pulmonary Complications (OGPC). m Terms describing pulmonary aging (PA). n Bivariate kernel density estimation (KDE) and histograms of chronological age vs. predicted age, records closely associated with PF and OGPC.
Enhanced predictive accuracy with topics over individual features
To assess the predictive power of collections of associated terms, we performed linear regression on the chronological age and predicted age of records closely associated with each topic (Fig. 3i; Supplementary Fig. 4f). Furthermore, we assessed the importance of the collected terms that make up each topic (Fig. 3j; Supplementary Fig. 4g). Notably, the maximum contribution of a collection of terms to model accuracy (ΔR2 < 0.039) was nearly two fold greater than that of the most influential individual feature (ΔR2 < 0.021). To identify topics that are highly correlated with aging, we inspected topics with a steep age-prediction regression slope, potentially yielding collections of terms that together are modified with or elicit alterations in aging. (Fig. 3k; Supplementary Fig. 4h). Among these topics (full list in Supplementary Data 1), we uncovered clinical themes involving lung pathologies. Among the topics (Supplementary Data 1 for full list), we identified clinical themes consisting of terms broadly describing cases of lung pathologies. One topic appeared to describe the Human Immunodeficiency Virus (HIV) with terms, such as ‘fungi’, ‘pneumocystis’, ‘carinii’, ‘pneumocystis carinii’, ‘alveolar’, ‘inflammation’, and ‘fibrosis’ (Supplementary Fig. 4i) and another appeared associated with obstetric gynecologic pulmonary complications (OGPC) consisting of terms, such as ‘development’, ‘intrauterine’, ‘placenta’, and ‘malformations’ (Fig. 3l). Interestingly, a topic appeared to describe pulmonary aging (PA) with terms, such as ‘interstitial’, ‘fibrosis’, ‘non-specific’, ‘pneumonia’, ‘interstitial fibrosis’, ‘pneumonitis’ and ‘fibroelastosis’ (Fig. 3m). To assess the potential impact that negated forms of clinical terms might have on the semantic interpretation of topics, we investigated the prevalence of negated forms of clinical terms in the lung aging topic and found that for most terms the prevalence of negated forms of the term does not exceed 5% (Supplementary Fig. 4j). Further illustrating the relationship between the age and predicted age of records are kernel density estimation plots corresponding to each of the topic-specific regressions (Fig. 3n; Supplementary Fig. 4k). Notably, the pulmonary aging topic regression shows strong chronological age dependency. In sum, our approach effectively leads us to identify a collection of potential aging modifiers.
Cross-validation with PubMed identifies age-modifying drugs
Since we identified age-associated terms in the pathology register, we could identify any other terms (clinical concepts, genes, drugs, etc.) in other text-based databases (e.g. PubMed, OMIM.org, etc.) that co-occur with these age-associated pathology terms. Focusing on molecules co-mentioned with clinical terms linked to lung aging (Fig. 4a), we investigated approximately 35 million molecules in PubChem that are co-mentioned in over 31.8 million PubMed abstracts with clinical terms from our identified lung-aging topic, assigning each molecule a proximity score (Fig. 4b). Among the top-scoring molecules (Supplementary Data 3 for list of 3938 molecules) we observed the presence of drugs used in the treatment of non-small-cell lung carcinomas. However, cancer drugs are generally not ideal candidates for aging interventions due to their high toxicity. We also identified drugs used in the treatment of cystic fibrosis, a disease unrelated to aging, leading us to speculate that such drugs may have limited relevance for aging therapies. Moreover, we noted the presence of several antibiotics, which are impractical as an aging intervention due to the risk of developing antibiotic resistance. Among the top-scoring drugs, we identified nintedanib (ranked #34), a tyrosine kinase inhibitor, as a potential pharmacological aging intervention. Nintedanib is an antifibrotic drug used in the treatment of the idiopathic pulmonary fibrosis21, an aging-related disease, consistent with the tissue phenotypes described by clinical terms in the lung-aging topic. Alongside nintedanib, we tested axitinib, another tyrosine kinase inhibitor with potential anti-fibrotic effects22 as a control for potential off-target effects in nintedanib. In comparison, axitinib (ranked #1050) ranked considerably lower than nintedanib.

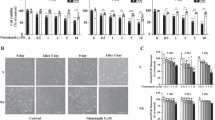
a Lung aging terms from the pathology register combined with molecules in PubMed abstracts. b Proximity scoring of candidate compounds. c p21 intensity. d Representative micrographs; scale bar: 25 μm; IR, ionizing radiation; [drug], nintedanib. e 53BP1 and γH2AX foci per nucelus. f Predicted (deep neural network) probability of senescence in ionizing radiation (IR) and non-IR plates (n = 3, mean ± SEM). g RNA-seq volcano plots of respective enrichment analyses (n = 3). h Venn diagram showing common significantly enriched pathways (GSEA) at FDR < 0.05 confidence between each case and the respective control DMSO. i Enrichment Map showing clusters of significantly enriched pathways (GSEA). j Drosophila melanogaster survival curves (n = 90).
Nintedanib reduces cellular senescence and extends the lifespan of fruit flies
To investigate the potential anti-aging effects of nintedanib, we examined its impact on cellular senescence, a cellular model of aging that has been implicated in lung fibrosis23. Senescence was induced in human dermal fibroblasts through ionizing radiation (IR) exposure and markers of DNA damage (53BP1 and γH2AX) and senescence p21 were assessed (Fig. 4c–e and Supplementary Fig. 5a–e). To assess senescence, we employed a convolutional neural network trained to predict senescence based on nuclear morphology24. Remarkably, a 10 µM dose of nintedanib reduced DNA damage markers, p21 levels, and predicted senescence in IR-induced senescent fibroblasts (Fig. 4f and Supplementary Fig. 5f, g). However, a 10 µM dose of nintedanib also induced a cytotoxic effect in both IR and non-IR exposed cells manifested in a significant decrease in the relative cell count (Supplementary Fig. 5h).
To further understand the effect of nintedanib on senescent cells, we explored changes in global gene expression using RNA sequencing (Fig. 4g). Exposure of human dermal fibroblasts (HDFs) to ionizing radiation induced a senescence phenotype, evidenced by upregulation of the cell-cycle inhibitor CDKN1A/p21 (1.64 log2 fold change, Supplementary Fig. 6a, Supplementary Data 5 for full gene list) and marked repression of proliferative markers MKI67 (–5.13 log2 fold change, Supplementary Fig. 6a) and PCNA (–0.98 log2 fold change, Supplementary Fig. 6a)25, together with significant enrichment of the SenMayo SASP gene set (DMSO: IR vs NonIR, NES = 1.92, Supplementary Fig. 6b)26. Treatment with nintedanib 1 µM largely preserved cell-cycle arrest (MKI67 –2.37 log2 fold change vs IR, Supplementary Fig. 6a) while suppressing the SenMayo gene set (nintedanib 1 µM: vs IR, NES = –0.51, Supplementary Fig. 6b). CDKN2A/p16 and CDKN1A/p21 showed no significant difference (Supplementary Fig. 6a). In contrast, nintedanib 10 µM also appeared to maintain cell-cycle arrest (MKI67 –3.69 log2 fold change, Supplementary Fig. 6a) but showed no significant enrichment or suppression of the SenMayo gene set (Supplementary Fig. 6b), CDKN2A/p16 or CDKN1A/p21 (Supplementary Fig. 6a). Combined, this suggests that nintedanib may function as a senomorphic modulator of ionizing radiation-induced senescence at low concentrations as reported previously27. Since nintedanib and axitinib share common molecular targets28, we isolated pathways (Fig. 4h, Supplementary Data 2) altered only in senescent cells treated with 10 µM nintedanib. Notably, nintedanib downregulated collagen metabolic processes and wound healing gene pathways (Fig. 4i) both of which are implicated in lung fibrosis and aging29,30.
To assess nintedanib’s impact on aging in vivo, we tested its effect on the lifespan and healthspan of Drosophila melanogaster (w1118 fly strain), a common aging model organism. Flies fed a diet supplemented with 100 µM nintedanib showed a significant increase in maximum lifespan compared with the dimethyl sulfoxide (DMSO) vehicle as a control (Fig. 4j). The lifespan extension is most evident in late life. Overall, this highlights nintedanib as a potential drug influencing the aging process.
Discussion
In this study, we introduce The Human Aging Pathome (pathoage.com), a compendium of tissue-specific, age- and mortality-associated clinical features derived from the clinical text narratives of The Danish National Pathology Register. Our analysis reveals a strong age-related variance across two distinct trajectories corresponding to developmental31 and post-development stages. Notably, we observed sex-specific differences in the onset and rate of aging-related changes. In males, these changes typically emerge around forty years of age, while in females, aging trajectories appear almost immediately following the development phase. Interestingly, females exhibit slower cellular and molecular aging compared to males, consistent with our finding that aging contributes less to overall variance in pathology data in females32. Notably, while we also observe sex-specific differences in the onset and rate of aging-related changes in tissue-specific analyses, not all tissues exhibit sex-specific differences. The observation that age appears to explain a smaller proportion of aging changes in male live may align with previous findings that estrogen has a protective effect on liver tissue and that these effects decline post-menopause33. Nevertheless, disparities in healthcare-seeking behavior between males and females34 could contribute to bias in our results. Conversely, females tend to exhibit greater frailty and perform worse than males in physical functioning throughout life32. Furthermore, evidence showing higher incidence of cardiovascular disease (CVD) in females earlier in life, and a reversal of this trend later in life3, may also point to sexual dimorphism in the onset and rate of aging. If reflective of true aging processes, our findings could be considered as evidence towards the decades-old contentious hypothesis35 that aging may be a selected trait in evolution, since it occurs in females prior to peak fertility. Although speculative, these results could suggest that evolution may have allowed successful males to age later perhaps allowing greater reproduction. Interestingly, the patterns of aging in males occur around the time of the mean life-expectancy of ancient humans36.
We also assessed whether age could be predicted from clinical text features in lung pathology records and found relatively poor predictive power using individual terms. This is not entirely surprising given the abstract nature of language. Nonetheless, even relatively poor predictive power can reveal useful patterns with the terms ‘carcinoma’37 and ‘sarcoidosis’38 emerging as important contributors to prediction accuracy. To enhance predictive accuracy, we explored whether the use of broader topics, or collections of associated terms, could contribute to greater predictive power. Indeed, the predictive power of topics was approximately twofold greater than that of any individual term. Moreover, pathology records closely associated with the lung aging topic showed strong predictive power.
As an example of the utility of The Human Pathome, we mined PubMed abstracts for molecules frequently co-occurring with aging lung terms from the pathology register, identifying nintedanib as a potential drug affecting aging. Our analysis of global gene changes showed that nintedanib downregulates collagen metabolism and wound healing pathways in senescent human dermal fibroblasts, consistent with evidence that idiopathic pulmonary fibrosis is characterized by the accumulation of collagen30 and an altered wound healing in response to persistent lung injury39. Furthermore, nintedanib reduced markers of senescence and extends the lifespan of fruit flies, suggesting that nintedanib could induce a senomorphic or a senolytic effect in senescent cells27. While previous studies have implicated nintedanib as a potential senolytic, its potential role as a broader aging intervention has not been extensively explored. It is important to highlight that the approach we used to identify nintedanib can be used to identify any term associated with aging, such as the discovery of new genetic components of aging. The method can also be applied to identify concepts associated with any pathology described in the database. For instance, drugs that may impact liver fibrosis, neurodegeneration, or any other defined pathology can be explored. However, an inherent characteristic of this discovery approach is that the identification of targets for intervention may be influenced by existing research in the scientific literature which the method relies on. Traditional literature-based discovery relies heavily on prior knowledge and specific hypotheses. In contrast, our methodology, which combines the comprehensive nature of the pathology register, provides a more systematic and less biased way to uncover potential interventions.
While outside the scope of this work, Large Language Models (LLMs) could be used to enhance aspects of biomedical text mining in future investigations of The Danish Pathology Register and PubMed. LLMs may, for example, improve identification of clinical entities, such as genes, drugs, and diseases, and more accurately identify negations and relationships between entities.
In sum, our investigation reveals population-level patterns of aging that are connected with aging during development and post-development ages. This allows us to identify modifiers of aging that can be translated into new aging interventions. Lastly, we present The Human Pathome, a unique compendium of thousands of tissue-specific aging and mortality associated features.
Methods
The Danish National Pathology Register
The Danish National Pathology Register stores pathology records from tissue and cell sample examinations conducted on the Danish population since 1970. These records predominantly consist of clinical text narratives describing biological tissue samples. The register encompasses data from 4,349,996 individuals, of whom 1,818,363 are male and 2,531,633 are female. Over the 48-year period from 1970 to 2018 inclusive, a total of 20,316,270 samples were collected, with 5,823,281 from male patients and 14,492,989 from female patients. We calculated the distribution of patient age at the time of examination for all samples, as well as for males and females separately. Samples in the register originate from all pathoanatomical investigations performed at Danish hospitals, including those related to disease indications, routine screenings, and diagnostic tests. The distribution of samples across different tissue types is detailed in Supplementary Data 4.
Danish dictionary of clinical terms
To facilitate the identification of clinical features in the pathology register we, constructed a dictionary of clinical terms in Danish, derived from the patoSnoMed ontology (www.patobank.dk/snomed) and the Danish version of the Systematized Nomenclature of Medicine — Clinical Terms (SNOMED CT)40 ontology (https://sundhedsdatastyrelsen.dk/snomedct). Terms in these ontologies may consist of multiple words (e.g., “severe inflammation”). In addition to incorporating multi-word terms, we expanded our dictionary by including individual components of these terms (e.g., “severe” and “inflammation”).
Clinical term extraction
We identified a total of 2,665,283 unique terms from 32,961,459 pathology text records in The Danish National Pathology Register consisting of 178,226 unigrams (single words) and 2,487,957 bigrams (two consecutive words). This produced a binary matrix of 32,961,459 samples and 2,665,283 features. We filtered this dataset keeping only terms present in our dictionary of Danish clinical terms, reducing the dataset to 20,316,270 records and 16,237 terms. To improve the quality and relevance of the data, and to reduce noise and dimensionality of the document-term matrix, we retained terms that appeared at least 50 times in the pathology register and records with five or more features. This filtering step seeks to facilitate better analysis by allowing models to more effectively identify meaningful patterns in the data. Next, we created tissue-specific records by identifying records associated with specific tissues using the topology (T) code assigned to each record in the register. For example, to construct a dataset of skeletal system tissues (T10000) we collected all records with a topology code starting with “T1”, which also includes bone tissue (T11000). The same filtering strategy was applied to all tissue-specific datasets. For skeletal tissue (T1000), we extracted 242,284 records and 4684 terms. Similarly, for lung (T28000), we extracted 177,795 records and 4275 terms, and for liver tissue (T56000), we extracted 156,057 records and 4048 terms, among other tissues.
Term normalization
We normalized the clinical term matrix to a term frequency–inverse document frequency (tf-idf) representation41. The tf-idf representation for a term t in a document d within a document set of n documents is defined as : tf-idf(t,d)=tf(t,d)*idf(t), where tf(t,d) is the frequency of a term t in document d, and and idf(t) is given by: idf(t)=log[n/df(t)]+1. In this equation, df(t) represents the frequency of term t across all documents in the document set. To identify the average term frequency within each age group, we calculated the mean value of all record vectors corresponding to each age group. This yielded one term vector per age group.
Clinical term mean incidence age
We calculated the mean incidence age of clinical terms in the entire register and in each of the tissue-specific datasets by calculating the mean age of all records where each term occurs.
Topic modeling with Latent Dirichlet allocation (LDA)
We employed the scikit-learn implementation of Latent Dirichlet Allocation (LDA)9 to identify latent semantic structures within the entire corpus of records in the tissue-specific datasets. LDA was run using the batch variational Bayes method. To determine the optimal number of topics yielding the best fit for the model, we utilized a perplexity minimization approach42. This involved repeatedly fitting an LDA model to a dataset while varying the number of topics from 2 to 140. The optimal number of topics was identified as that associated with the smallest perplexity score. The topic model produces topic-word distributions, signifying the number of times each word is assigned to a topic. Similarly, the topic model also generates document-topic distributions, representing the degree to which each topic is associated with a document.
Age prediction
We employed a deep neural network (DNN) multilayer perceptron (MLP)43 regression model to predict age from clinical text features represented in the one-hot encoding of the clinical term matrix. The dataset was randomly split into training and test subsets using the scikit-learn train_test_split function, with the test set size comprising of 25% of the entire dataset. The MLP neural network was constructed using the scikit-learn MLPRegressor. The network consists of an input layer with one neuron per input feature, followed by a hidden layer containing 100 neurons. Each hidden neuron computes a weighted linear summation of all the input neurons, transforming the outcome using a rectified linear unit (ReLU) activation function. The output layer consists of a single neuron representing the weighted linear summation of the outputs from all neurons in the hidden layer. We trained the model on the training subset using backpropagation with an Adam solver, a stochastic gradient-based optimizer. The loss function employed was the squared error. Finally, we calculated the model’s coefficient of determination score (R2), the median absolute error (MedAE) and the mean absolute error (MAE) on the test subset.
Clinical term negation prevalence analysis
For a given clinical term (e.g., “inflammation”), we identified pathology records containing all instances of the clinical term as well as all its negated forms (e.g., “no inflammation” or “no sign of inflammation”). For each term, we searched for seven forms of negation in Danish: “ikke <term > ”, “ingen <term > ”, “intet <term > ”, “uden <term > ”, “ingen tegn på <term > ”, “intet tegn på <term > ” and “<term> er ikke”. Among these, the two most common negation forms were: ikke “<term > ” and “ingen <term > ”44. To identify non-negated instances of the clinical term within specific pathology records, we identified occurrences of the clinical term in records that did not also contain any of the negated forms of the clinical term. For each clinical term, we calculated the ratio of negated forms to non-negated forms.
Topic-specific age regression slope
We used ordinary least squares (OLS) linear regression to analyze the relationship between predicted age and chronological age across records. This approach allowed us to calculate corresponding topic-specific regression slopes.
Permutation feature importance
We utilized the scikit-learn implementation of permutation feature importance45 to inspect the MLP age-prediction model and assess the impact of individual features on the model’s accuracy, as measured by the coefficient of determination score (R2).
Permutation topic importance
To assess the impact of a collection of associated terms (i.e., a topic) on the model’s age-prediction accuracy, we shuffled the collected term vectors within each topic and calculated the resulting change in the model coefficient of determination score (R2). Topics that exhibited a greater change in the R2 score were deemed more important to age prediction.
Principal component analysis (PCA)
We used principal component analysis (PCA)46 to visualize and identify population-level patterns of aging in pathology record text, both across the entire pathology register and in collections of tissue-specific pathology records. PCA is a linear dimensionality reduction technique for transforming high-dimensional data into a new coordinate system, where the greatest variance in the data is captured in as few dimensions as possible. This enhances the visualization and interpretability of the data’s variance in one or two dimensions. We utilized the scikit-learn implementation of PCA on age-aggregated tf-idf term matrices.
t-distributed stochastic neighbor embedding (t-SNE)
We used t-distributed Stochastic Neighbor Embedding (t-SNE)47 to visualize clusters of clinical terms within Latent Dirichlet Allocation (LDA) topic-word distributions, as well as clusters of pathology records within LDA document-topic distributions. t-SNE is a non-linear dimensionality reduction method that projects high-dimensional data into lower-dimensional space while attempting to preserve the local structure of the data. We used the scikit-learn implementation of t-SNE with default parameters.
Uniform manifold approximation and projection (UMAP)
We used Uniform Manifold Approximation and Projection (UMAP)48 to visualize and identify clinical term co-occurrence patterns in pathology record text, both across the entire pathology register and in tissue-specific collections. UMAP is a non-linear dimensionality reduction method that projects high-dimensional data into a low-dimensional space while aiming to preserve the structure of the data, facilitating visualization and interpretation of latent patterns. We applied the umap-learn implementation of UMAP with default parameters to tf-idf-normalized document term matrices.
Term enrichment in tissue and morphology-specific records
Term enrichment in tissue or morphology-specific records was calculated as log((B + 1)/(A-B + 1)) where B is the frequency of a term in the tissue or morphology-specific records, and A represents the frequency of the term in the entire dataset. This measure helps identify terms that are more prevalent in specific tissue or morphology contexts compared to their overall occurrence.
PubMed term proximity score
We extracted a total of 175,555 unique terms from 31,850,051 PubMed abstracts (downloaded on 12 December 2020) to calculate a PubMed term proximity score. Given a binary feature matrix M and a set A of terms within matrix M, we computed a proximity score for each term in a separate set B. We first applied a tf-idf transformation to feature matrix M and calculated the cosine distances between individual terms in set A to individual terms in set B, resulting in a distance matrix AxB. The term proximity score for each term in set B to all terms in set A that are co-mentioned with term b at least once. For Matrix M we selected PubMed abstracts years 2000 onwards to identify potential compounds due to more recent discoveries. Moreover, many abstracts from old literature are missing and abstracts prior to 2000 represents a relatively small number of the total abstract pool. Furthermore, the PubChem database (Set B above) with which we combine PubMed abstracts (Matrix M) was introduced in 2004.
-
Matrix M: PubMed abstracts years 2000 onwards.
-
Set A: Pulmonary aging terms + the term ‘lung’ (patoSnoMed:T28000:lung) associated with all lung pathology records.
-
Set B: All PubChem (downloaded on 5 July 2021) compounds that occur in PubMed abstracts ten times or more.
Term and topic associated mortality
We used the R survival package to perform Cox proportional hazards regression for both term- and topic-associated mortality. For each clinical term, we calculated a Cox regression coefficient reflecting the hazard associated with the presence of the term in pathology records, adjusted for word count and birth cohort (year of birth). For topic-associated mortality, we grouped patient pathology records according to identified topics. A Boolean variable was created for each topic, indicating whether a pathology record was associated with that particular topic. This yielded a matrix of records and topics. We then performed Cox survival regression to model time to death from date of examination, with the Cox regression coefficient for each topic reflecting the hazard associated with its occurrence in the pathology records.
Cell culture
Human primary fibroblast cell lines AG08498 (AG), GM22159 (159) and GM22222 (222) (Coriell, NJ, USA) were cultured in 4.5 g/L-enriched Dulbecco’s Modified Eagle’s Medium (DMEM)/ Ham’s F-12 Nutrient Mix (F12) in a 1:1 solution supplemented with 10% fetal bovine serum (FBS) and 1% penicillin/streptomycin. Cells were maintained at 37 °C in a 5% CO2 atmosphere conditions and passaged every 2–3 days. For senescence assays, cells at 70–80% confluency and below 20 passages were seeded in 96-well plates (Corning, 3340) at a density of 3000 cells/well and incubated overnight at 37 °C and 5% CO2. Control plates were seeded at 3000 cells/well or 1500 cells/well. One day after seeding, plates were irradiated using a YXLON Smart Maxi Shot. Cells were exposed with emission of 0.85 Gy/min. for 12 min for a total exposure of 10 Gy. After IR exposure, cells were incubated for 6 days with medium changed every 48 h. Control plates were seeded on day 6. On day 7 cells were treated with compounds or vehicle for 48 h after which the cells were either harvested for RNA or fixed with 4% paraformaldehyde for 10 min, washed in PBS and stained with DAPI. Cells were subsequently imaged using an IN Cell analyzer 2200 high content microscopy at 20x magnification, 12 fields per well.
RNA sequencing
RNA was extracted using Trizol (phenol-chloroform-based extraction) following the manufacturer’s protocol (Thermo-Fischer). RNA integrity was confirmed using 260/280 and 260/230 ratios. DNBSEQ Eukaryotic Long Non-Coding RNA sequencing was performed by BGI Denmark, available in the GEO repository, accession GSE245045. Mapping-based quantification of the GRCh38 transcriptome from RNA sequencing paired-end reads was performed using salmon49 with a pre-computed transcriptome index obtained from refgenie50. Differential expression analysis was performed using DESeq2 (version 1.38.2)51 on genes mapped from transcripts with, using the Gencode annotation of the Ensembl gene set downloaded from refgenie. Genes with fewer than ten reads across all samples were filtered out prior to all downstream analyses. Gene set enrichment analysis (GSEA) was performed using GSEA (version 4.3.2)52. An expression dataset file (.gct) was prepared using DESeq2-normalized counts for all samples, and phenotype labels files (.cls) were created for each group comparison. GSEA was performed with the gene set database MsigDB c5.go.bp.v2022.1.Hs.symbols.gmt53, using the gene_set permutation type parameter. For downstream analyses, only gene sets significantly enriched (upregulated) at FDR < 0.05 in each phenotype were considered. Significantly enriched pathways identified from GSEA52 were visualized in Cytoscape54 using the EnrichmentMap, AutoAnnotate, WordCloud and clusterMaker2 applications.
Fruit fly maintenance
All diets were made on a standard diet (SD) base consisting of 47.5 g cornflour, 41.6 g dextrose, 19.3 g Brewer’s Yeast, 6.55 g Low Melting Agar (Calbiochem), and 2.46% Nipagin (Merck, Germany) per litre. All ingredients except Nipagin were mixed and heated to 80°C. When the mixture had cooled to 40 °C, Nipagin was added. The mix was distributed in falcon tubes and compounds added in various concentrations to make the treatment diets. Diets with equivalent amounts of DMSO were used as controls. Stock flies were housed in vials of 30 flies to avoid overcrowding and kept on the standard diet. Both stock and treatment flies were kept at a constant temperature of 25 °C, a relative humidity of 60%, and a 12:12 h light:dark cycle. The w1118 fly strain (Bloomington Drosophila Stock Center) was used for all longevity assays. Before assays, 5–10 crosses with a ratio of 15:9 female to male flies were set and kept under standard rearing conditions in polypropylene vials on standard diet.
Fruit fly lifespan assay
Flies were transferred to new vials containing a standard diet every three days for 9–12 days after hatching. Hatchlings were collected at birth and placed into new vials under the specified compound condition. For each condition, three vials were prepared with ten male flies per vial. Vials were placed in front of cameras connected to the Tracked.bio fly tracking system (http://tracked.bio). For the longevity assay, flies were transferred to fresh food vials once per week. Each vial contained ten male flies, selected from newly hatched flies of specific crosses. Only male flies without visible wing damage were chosen.
During each transfer (“flipping”), flies were counted, and the data recorded in a spreadsheet. Behavioral metrics were tracked using the Tracked.bio system. We used the lifelines55 Python package to fit a Kaplan-Meier estimator for survival function analysis of fruit fly lifespan and performed a log-rank test to assess statistically significant differences in lifespan. Fruit fly vial initiation was staggered over several days as newly hatched flies were collected. Since not all vials were initiated on the same day and live fly counts were recorded weekly during transfers, we converted weekly counts into daily counts prior to conducting the survival analysis.
Statistical analysis
A two-sample t-test was used to evaluate differences in p21 intensity, 53BP1 and γH2AX foci per nucleus and probability of senescence. The results are reported as mean ± standard deviation, with a significance threshold set at p < 0.05. Differences in Kaplan-Meier estimator survival curves of fruit fly lifespans were assessed using a log-rank test. Multiple testing correction was applied using the Benjamini-Hochberg procedure to both RNA-seq differentially expressed genes and enriched GSEA pathways to adjust for false discovery rate (FDR).
Sample size for fruit fly lifespan experiments was determined by an a priori power analysis in Python using the statsmodels package. With an effect size f = 0.40 (moderate), α = 0.05, power = 0.80 and three groups, the analysis returned a total N ≈ 63 ( ≈ 21 per group, rounded up to 22). To buffer against vial-to-vial variability and occasional handling losses, we implemented three biological replicates (independent cohorts on separate days), each comprising three technical replicates per treatment with 10 flies per vial. This yields 30 flies per treatment per biological replicate (90 flies per treatment overall; 270 flies total), well above the minimum suggested by the power analysis.
All statistical calculations were performed using R or Python.
Ethics statement
This study was conducted in accordance with the Declaration of Helsinki. Approval for the use of registry-based pathology data was obtained from the Research Service at Statistics Denmark and the Danish Health Data Authority. Data were extracted from the Danish National Pathology Register (Landsregisteret for Patologi) and were fully anonymized prior to analysis. According to Danish law, the use of anonymized registry data for research purposes does not require informed consent from individuals. Therefore, the requirement for informed consent was waived.
Data availability
The register-based data that support the findings of this study are available from The Danish Health Data Agency but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. All other data are available from the authors upon reasonable request. The browsable biomarker dataset of The Human Pathome is available at pathoage.com. RNA-seq data is available in the NCBI Gene Expression Omnibus (GEO) under accession number GSE245045.
Code availability
Source code is available on https://github.com/scheibye-knudsen-lab/human_pathome.
References
López-Otín, C., Blasco, M. A., Partridge, L., Serrano, M. & Kroemer, G. Hallmarks of aging: an expanding universe. Cell 186, 243–278 (2023).
Andreassen, S. N., Ben Ezra, M. & Scheibye-Knudsen, M. A defined human aging phenome. Aging 11, 5786–5806 (2019).
Niccoli, T. & Partridge, L. Ageing as a risk factor for disease. Curr. Biol. CB 22, R741–R752 (2012).
Névéol, A., Dalianis, H., Velupillai, S., Savova, G. & Zweigenbaum, P. Clinical natural language processing in languages other than english: opportunities and challenges. J. Biomed. Semant. 9, 12 (2018).
Jensen, P. B., Jensen, L. J. & Brunak, S. Mining electronic health records: towards better research applications and clinical care. Nat. Rev. Genet. 13, 395–405 (2012).
Denny, J. C. et al. Systematic comparison of phenome-wide association study of electronic medical record data and genome-wide association study data. Nat. Biotechnol. 31, 1102–1110 (2013).
Roque, F. S. et al. Using electronic patient records to discover disease correlations and stratify patient cohorts. PLoS Comput. Biol. 7, e1002141 (2011).
Erichsen, R. et al. Existing data sources for clinical epidemiology: the Danish National Pathology Registry and Data Bank. Clin. Epidemiol. 2, 51–56 (2010).
Blei, D. M., Ng, A. Y. & Jordan, M. I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 3, 993–1022 (2003).
Wollin, L., Maillet, I., Quesniaux, V., Holweg, A. & Ryffel, B. Antifibrotic and anti-inflammatory activity of the tyrosine kinase inhibitor nintedanib in experimental models of lung fibrosis. J. Pharmacol. Exp. Ther. 349, 209–220 (2014).
Naruse, M., Trappe, S. & Trappe, T. A. Human skeletal muscle-specific atrophy with aging: a comprehensive review. J. Appl. Physiol. Bethesda Md 1985 134, 900–914 (2023).
Mohammed, S. et al. Necroptosis contributes to chronic inflammation and fibrosis in aging liver. Aging Cell 20, e13512 (2021).
JafariNasabian, P., Inglis, J. E., Reilly, W., Kelly, O. J. & Ilich, J. Z. Aging human body: changes in bone, muscle and body fat with consequent changes in nutrient intake. J. Endocrinol. 234, R37–R51 (2017).
Tower, J. Programmed cell death in aging. Ageing Res. Rev. 23, 90–100 (2015).
Fjell, A. M. et al. What is normal in normal aging? Effects of aging, amyloid and Alzheimer’s disease on the cerebral cortex and the hippocampus. Prog. Neurobiol. 117, 20–40 (2014).
El Assar, M., Angulo, J. & Rodríguez-Mañas, L. Oxidative stress and vascular inflammation in aging. Free Radic. Biol. Med. 65, 380–401 (2013).
Rauch, S. D., Velazquez-Villaseñor, L., Dimitri, P. S. & Merchant, S. N. Decreasing hair cell counts in aging humans. Ann. N. Y. Acad. Sci. 942, 220–227 (2001).
Sarin, K. Y. & Artandi, S. E. Aging, graying and loss of melanocyte stem cells. Stem Cell Rev. 3, 212–217 (2007).
Lehallier, B. et al. Undulating changes in human plasma proteome profiles across the lifespan. Nat. Med. 25, 1843–1850 (2019).
Rogers, L. K. & Cismowski, M. J. Oxidative Stress in the Lung - The Essential Paradox. Curr. Opin. Toxicol. 7, 37–43 (2018).
Richeldi, L. et al. Efficacy and safety of nintedanib in idiopathic pulmonary fibrosis. N. Engl. J. Med. 370, 2071–2082 (2014).
Richeldi, L. et al. Efficacy of a tyrosine kinase inhibitor in idiopathic pulmonary fibrosis. N. Engl. J. Med. 365, 1079–1087 (2011).
Schafer, M. J. et al. Cellular senescence mediates fibrotic pulmonary disease. Nat. Commun. 8, 14532 (2017).
Heckenbach, I. et al. Nuclear morphology is a deep learning biomarker of cellular senescence. Nat. Aging 2, 742–755 (2022).
Juríková, M., Danihel, Ľ, Polák, Š & Varga, I. Ki67, PCNA, and MCM proteins: Markers of proliferation in the diagnosis of breast cancer. Acta Histochem 118, 544–552 (2016).
Saul, D. et al. A new gene set identifies senescent cells and predicts senescence-associated pathways across tissues. Nat. Commun. 13, 4827 (2022).
Cho, H.-J. et al. Nintedanib induces senolytic effect via STAT3 inhibition. Cell Death Dis. 13, 760 (2022).
Slobbe, P. et al. Two anti-angiogenic TKI-PET tracers, [(11)C]axitinib and [(11)C]nintedanib: radiosynthesis, in vivo metabolism and initial biodistribution studies in rodents. Nucl. Med. Biol. 43, 612–624 (2016).
Maher, T. M., Wells, A. U. & Laurent, G. J. Idiopathic pulmonary fibrosis: multiple causes and multiple mechanisms? Eur. Respir. J. 30, 835–839 (2007).
Jessen, H. et al. Turnover of type I and III collagen predicts progression of idiopathic pulmonary fibrosis. Respir. Res. 22, 205 (2021).
Coleman, L. & Coleman, J. The measurement of puberty: a review. J. Adolesc. 25, 535–550 (2002).
Hägg, S. & Jylhävä, J. Sex differences in biological aging with a focus on human studies. eLife 10, e63425 (2021).
Burra, P., De Martin, E., Gitto, S. & Villa, E. Influence of age and gender before and after liver transplantation. Liver Transplant. Publ. Am. Assoc. Study Liver Dis. Int. Liver Transplant. Soc. 19, 122–134 (2013).
Larrazabal, A. J., Nieto, N., Peterson, V., Milone, D. H. & Ferrante, E. Gender imbalance in medical imaging datasets produces biased classifiers for computer-aided diagnosis. Proc. Natl. Acad. Sci. USA 117, 12592–12594 (2020).
Kirkwood, T. B. L. & Melov, S. On the programmed/non-programmed nature of ageing within the life history. Curr. Biol. 21, R701–R707 (2011).
Eshed, V., Gopher, A., Gage, T. B. & Hershkovitz, I. Has the transition to agriculture reshaped the demographic structure of prehistoric populations? New evidence from the Levant. Am. J. Phys. Anthropol. 124, 315–329 (2004).
Torre, L. A., Siegel, R. L. & Jemal, A. Lung cancer statistics. Adv. Exp. Med. Biol. 893, 1–19 (2016).
Varron, L., Cottin, V., Schott, A.-M., Broussolle, C. & Sève, P. Late-onset sarcoidosis: a comparative study. Medicine 91, 137–143 (2012).
Zhang, L. et al. Macrophages: friend or foe in idiopathic pulmonary fibrosis? Respir. Res. 19, 170 (2018).
Lee, D., de Keizer, N., Lau, F. & Cornet, R. Literature review of SNOMED CT use. J. Am. Med. Inform. Assoc. JAMIA 21, e11–e19 (2014).
Rajaraman, A. & Ullman, J. D. Mining of Massive Datasets. (Cambridge University Press, 2011). https://doi.org/10.1017/CBO9781139058452.
Zhao, W. et al. A heuristic approach to determine an appropriate number of topics in topic modeling. BMC Bioinforma. 16, S8 (2015).
Hinton, G. E. Connectionist learning procedures. Artif. Intell. 40, 185–234 (1989).
Engel Thomas, C., Bjødstrup Jensen, P., Werge, T. & Brunak, S. Negation scope and spelling variation for text-mining of Danish electronic patient records. in Proceedings of the 5th International Workshop on Health Text Mining and Information Analysis (Louhi) 64–68 (Association for Computational Linguistics, Gothenburg, Sweden, 2014). https://doi.org/10.3115/v1/W14-1109.
Breiman, L. [No title found]. Mach. Learn. 45, 5–32 (2001).
Abdi, H. & Williams, L. J. Principal component analysis: principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2, 433–459 (2010).
Van der Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008).
McInnes, L., Healy, J. & Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. (2018) https://doi.org/10.48550/ARXIV.1802.03426.
Patro, R., Duggal, G., Love, M. I., Irizarry, R. A. & Kingsford, C. Salmon provides fast and bias-aware quantification of transcript expression. Nat. Methods 14, 417–419 (2017).
Stolarczyk, M., Reuter, V. P., Smith, J. P., Magee, N. E. & Sheffield, N. C. Refgenie: a reference genome resource manager. GigaScience 9, giz149 (2020).
Love, M. I., Huber, W. & Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 15, 550 (2014).
Subramanian, A. et al. Gene set enrichment analysis: A knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl. Acad. Sci. USA 102, 15545–15550 (2005).
Liberzon, A. et al. The Molecular Signatures Database (MSigDB) hallmark gene set collection. Cell Syst. 1, 417–425 (2015).
Shannon, P. et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 13, 2498–2504 (2003).
Davidson-Pilon, C. lifelines: survival analysis in Python. J. Open Source Softw. 4, 1317 (2019).
Acknowledgements
This research was supported by the Novo Nordisk Foundation (#NNF17OC0027812, #NNF0089176), the Nordea Foundation (#02-2017-1749), the Danish Cancer Society (#R368-A21521), the Neye Foundation, the Lundbeck Foundation (#R324-2019-1492), the Ministry of Higher Education and Science (#0238-00003B) and Insilico Medicine. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript. Some figures were created using BioRender.com.
Author information
Authors and Affiliations
Contributions
The initial conception of the project was devised by M.S.K. M.B.E. led the project, including the development of methodology, data analysis, and interpretation. RNA-seq data analysis was carried out by M.B.E. Fruit fly survival assays were carried out by M.B.E., J.B.G., N.R., and M.A.P. Senescence prediction was carried out by I.J.H. Cell experiments were carried out by J.B.G., N.R., M.C.M., and D.B. L.M. contributed to statistical modeling and provided expertise in survival analysis. All authors contributed to the manuscript's preparation, provided critical feedback, and approved the final version of the paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ben Ezra, M., Garbrecht, J.B., Rasmussen, N. et al. The human pathome shows sex and tissue specific aging patterns. npj Aging 12, 23 (2026). https://doi.org/10.1038/s41514-025-00307-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41514-025-00307-z
