
Abstract
Autism is clinically defined by social communication deficits, suggesting that autistic people may be less effective at sharing information, particularly with one another. However, recent research indicates that neurotype mismatches, rather than autism itself, degrade information sharing. Here, using the diffusion chain method, we examined information transfer in autistic, non-autistic and mixed-neurotype chains (N = 311), replicating and extending a key study. We hypothesized that information transfer would deteriorate faster and rapport would be lower in mixed-neurotype compared with single-neurotype chains. Additionally, we examined whether informing participants of the diagnostic status of their chain and whether information was fictional or factual impacted performance and rapport. We found no difference in information transfer between single-neurotype and mixed-neurotype chains. Non-autistic chains indicated higher rapport, and disclosing diagnosis improved rapport. This result challenges assumptions about autistic communication deficits but contrasts with prior findings. Enhanced participant heterogeneity and methodological differences may explain these unexpected results. Protocol registration The Stage 1 protocol for this Registered Report was accepted in principle on 23 August 2022. The protocol, as accepted by the journal, can be found at https://osf.io/us9c7/.
Similar content being viewed by others

Main
The diagnostic criteria for autism spectrum disorder (henceforth ‘autism’)1 include lifelong impairments in social communication and interaction that contribute to broad social disabilities and poor functional outcomes2. These difficulties are associated with fewer friendships3, less social support4, loneliness5, challenges securing and maintaining employment6,7,8, poorer mental health9,10 and reduced quality of life11.
The majority of research so far has assumed a deficit model of autism, characterizing the differences in autistic sociability and communication as deviations from normality in need of remediation (for a review, see ref. 12). This model, however, ignores the relational nature of social interaction and locates the cause of social interaction difficulties exclusively within the autistic person13. A growing body of research has begun to examine the factors that influence how autistic people interact with non-autistic people and the impact that this has on autistic social experiences14,15. Communication is bidirectional, and social difficulties experienced by autistic people can be exacerbated by the behaviours, social judgements and misunderstandings of non-autistic social partners13,16,17.
Though attitudes about autism are improving18, stigma remains high19,20,21,22. Non-autistic people form rapid negative judgements about autistic people on the basis of on their non-normative social presentations14 that are strongly associated with a greater reluctance to interact with them14,15. Such judgements reduce the social opportunities afforded to autistic people by the non-autistic majority and present barriers to achieving personal and professional goals23,24.
Non-autistic people also misconstrue and misunderstand what autistic people are thinking and feeling25. Countless studies have documented the difficulties of autistic people when accessing and interpreting the mental states and emotion of non-autistic people26,27, yet the reverse occurs as well. Non-autistic people struggle to identify autistic facial expressions28 and understand autistic mental states29, and these misunderstandings are associated with liking them less30. Non-autistic people also overestimate how egocentric autistic people are31 and even report being helpful to autistic people in circumstances when, objectively, no evidence of helpful behaviour is demonstrated32.
Unsurprisingly given this context, autistic people report feeling more comfortable and relaxed in the company of other autistic people33,34,35,36,37. They are more likely to want to spend time with other autistic people16,38, disclose more to autistic interaction partners38 and empathize more with other autistic individuals39. Autistic people also often communicate in a more direct, literal or ‘frank’ manner that is sometimes interpreted as rude by non-autistic people but is welcomed as a preferred communication style by other autistic people14,33. Other recent studies have provided further support for these conclusions. Autistic interactions feature non-normative social behaviours that result in enhanced communication with other autistic people32,36. Autistic people also use common social cues differently when communicating with autistic and non-autistic people40, and the positive rapport produced between autistic pairs extends beyond self-report and can be detected by observers41. These findings challenge assumptions that impaired social communication and connection are inherent to autism and suggest that the social and communication difficulties of autistic people arise, at least in part, from a mismatch between autistic and non-autistic modes of communication and understanding. This is supported by empirical studies of the kinematic dissimilarity hypothesis of social interaction, which suggests that kinematic similarity is important for action predication and social interaction42. There are well-documented kinematic differences between autistic and non-autistic people43, and recent studies have found that autistic observers are more able to accurately predict autistic actions than non-autistic actions44, and conversely that non-autistic observers are more able to accurately predict non-autistic actions than autistic actions42. These data suggest that difficulties in social interactions arise because of objective differences in the way that autistic and non-autistic people communicate, rather than an autistic social deficit.
This literature, however, is still in its infancy and, up to this point, has consisted of single studies using relatively small samples and divergent methodologies. More rigorous examination of autistic-to-autistic communication, using larger samples and standardized methodology across independent sites, is needed. Crompton et al.34 provided the most direct and ecologically valid evidence of intact communication efficacy between autistic partners, with selective breakdowns in communication occurring between autistic and non-autistic people. Using a cultural learning paradigm to capture the transmission of information between autistic–autistic pairs, non-autistic control pairs and mixed (that is, autistic and non-autistic) pairs, Crompton et al.34 found that autistic partnerships facilitate interaction for autistic people. Specifically, (1) autistic people transfer information to and from other autistic people as effectively as non-autistic people do with each other, (2) the quality of information sharing selectively breaks down when one person is autistic and the other is not and (3) interpersonal rapport is higher within than between diagnostic groups and these feelings accompany information-sharing benefits.
Although this study has been impactful and has generated new lines of enquiry, it was generated from a relatively modest sample (N = 72) recruited from a single geographical location. The reproducibility and generalizability of experimental results is an essential part of the scientific process and is particularly important in studies producing results that conflict with prevailing assumptions—and indeed in this case with clinical criteria. The aim of the proposed study is to replicate the work of Crompton et al.34 but with a substantially increased sample size (see Figs. 1 and 2) across three independent sites, two of which are independent of the initial study. This study examines the effect of matched and mismatched neurotype on information transfer and self-reported rapport between autistic and non-autistic people. The procedure for participation is presented in Table 1. We predict a replication of the original finding showing that information transfer degrades most rapidly in chains of mixed (autistic with non-autistic interactions), compared with chains of matched-pair interactions (H1; see Table 2 for full details). We also predict that rapport will follow a similar pattern, with enhanced rapport in matched-neurotype pairs and poorer rapport in mixed pairs (H2; see Table 2 for full details).

A priori power analysis (G*Power)99 on the original data from Crompton et al.34 using a mixed design (chain type–between and position–within) with the number of chains as the sample size unit. F tests from repeat-measures ANOVA, within–between interaction. N groups = 3, N measurements = 6, correlation among repeated measures of 0.4, non-sphericity correction ε = 0.7, α error probability of and effect size f = 0.25.

Simulation results (R package simr83) for the number of chains ranging from 9 to 54 to determine the exact power for the interaction effect ‘chain type–position’ (blue circles) and 90% CIs (error bars). The linear mixed-effect model ‘Story_prop ~ chain type × position + (1|chain)’ was fitted to the original data from Crompton et al.34 with three chain types and six positions. The estimated coefficients were reduced by one-third to make sample size estimation more conservative. The horizontal dashed black and red lines indicate 80% and 95% power, respectively.
The current study also extends beyond ref. 34 in two important ways. First, we explore whether being informed of the diagnostic status of one’s interaction partner affects information transfer. In ref. 34, participants were informed of the diagnostic status of their partner before their interaction. However, in real-world interactions, many autistic adults choose not to disclose their diagnosis to avoid bias and discrimination45, and emerging evidence suggests that awareness of an autism diagnosis influences how autistic people are perceived by non-autistic people, but not by other autistic people16,46. A diagnostic-informing manipulation in the current study offers an opportunity to explore whether such patterns have downstream effects on communication and rapport. We also explored whether the efficacy of information transfer differs as a function of material content. Reference 34 involved participants retelling a fictional story to partners sequentially in a chain, and it is unclear whether the findings would differ between fictional and factual passages matched on length and complexity. Prior research has indicated that autistic people have greater interest in, and facility with, information about factual systems47, but whether this translates to efficacy of communication and rapport is unclear.
Results
Information transfer
Separate analyses of task performance for fictional and factual information transfer were conducted in R48. The following hypotheses were investigated: hypothesis 1a: participants in autistic and non-autistic chains will share significantly more details than in mixed chains (main effect ‘chain type’); hypothesis 1b: information will deteriorate between participants (order ‘1–6’) in each chain (main effect ‘order’); hypothesis 1c: information decay will be steeper in mixed chains compared with autistic and non-autistic chains while autistic and non-autistic chains will perform similarly (interaction between ‘chain type’ and ‘order’).
Multilevel mixed-effect models (MLMs; R package lme4 (ref. 49), all models presented in lme4 syntax) considered dependencies between observations within chains by estimating random intercepts and random slopes for each chain. Covariate order was replaced by log-transformed log(order) to capture nonlinear decay of information within diffusion chains. To assess site differences, models included the control variable site (Dallas, Edinburgh or Nottingham), and to assess any impact of participants being informed of the diagnostic status of their chain, we included diagnostic informing (info for short; informed or uninformed). A third variable first (fictional story first or factual story first) addresses the counterbalanced sequence of tasks. Full details of effects of site, diagnostic informing and task order are detailed in Supplementary Information. Bayes factors (BFs) were established by comparing a simpler model without a predictor and associated interactions against a more complex model with the predictor and associated interactions (generalTestBF function in the R package BayesFactor using default priors and repeated measures for observations in each chain)50,51. The story scores are shown in Fig. 3.

a, The mean fictional story scores (±1 s.e.m.) reported by six successive participants across three chain types: non-autistic, autistic and mixed. b, The mean factual story scores (±1 s.e.m.) for the same chain types. Individual data points (n = 311) represent raw story scores for each participant, with colours corresponding to chain types. To improve clarity, data points are jittered horizontally. Both a and b reveal a general decline in story scores with increasing chain order, with variations in the rate of decline observed across chain types.
Fictional information
A model comparison in terms of the Akaike information criterion (AIC) favoured the model ~chain type × log(order) + site × info × first + (1 + log(order)|number), which also met the criterion for multi-collinearity (variance inflation factor (VIF) <5). Alternative models with more interactions gave similar results but improved model fit only marginally and increased collinearity (VIF >5). This model predicted task performance (range 0–30) with an adjusted (marginal) R2 = 0.55 and adjusted (conditional) R2 = 0.87 (R package MuMIn52). Satterthwaite’s method was used to adjust degrees of freedom in t-tests (R package lmerTest53).
As predicted, the main effect of log(order) was large and statistically significant (b = −5.29, t(51.3) = −9.07, P < 0.001, η2 = 0.17, 95% confidence interval (CI) −6.43 to −4.15; R package r2glmm54). There was no statistically significant difference of task performance for chain type, meaning no significant differences between autistic, non-autistic and mixed chains (BF of 7.91 for the simpler model). A significant but unpredicted interaction between chain type ‘autistic’ and log(order) reduced task performance compared with chain type ‘non-autistic’ (b = −1.73 (s.e.m. of 0.83), t(48.9) = −2.09, P = 0.042, η2 = 0.01, 95% CI −3.37 to −0.11). Keeping participants uninformed about diagnostic status had negligible effects (BF of 0.85 for the simpler model).
Factual information
A model comparison in terms of AIC favoured a full MLM featuring all predictors and interactions but indicated multi-collinearity (VIF >5). Model ~chain type × log(order) + site × info × first + (1 + log(order)|number) was a more parsimonious model in terms of AIC and collinearity (VIF <5). This model predicted performance scores with an adjusted (marginal) R2 = 0.60 and adjusted (conditional) R2 = 0.89. As predicted, the main effect of log(order) was strong and statistically significant (b = −4.57, t(50.9) = −8.29, P < 0.001, η2 = 0.26, 95% CI −5.65 to −3.49). There was no statistically significant difference of task performance for chain type (BF of 125.0 for the simpler model). Keeping participants uninformed about diagnostic status had negligible effects (BF of 0.41 for the simpler model).
Summary
H1a was not confirmed, as no significant effect between autistic, non-autistic and mixed chains emerged. H1b was confirmed, showing a strong effect of (log-transformed) order on information decay. H1c was not confirmed, as there was no interaction between the mixed chain type and (log-transformed) order, as predicted, although an unpredicted significant interaction between autistic chain type and (log) order was observed. As groups significantly differed on intelligence quotient (IQ), gender and ethnicity, these control variables were included in post hoc analyses. The effects were small and did not affect the results described above (Supplementary Information). Additional models using linear and nonlinear approaches confirmed that the findings above were robust (Supplementary Information).
Self-rated rapport
The following hypotheses for self-rated rapport were investigated, with ‘teachers’ (transmitting information in a chain) and ‘learners’ (receiving information in a chain) analysed and reported separately: hypothesis 2a: there will be higher rapport scores in autistic and non-autistic chains compared with mixed chains (main effect of ‘chain type’); hypothesis 2b: the rapport score will increase in the second relative to the first transfer between participants in mixed chains (interaction between ‘chain type’ and ‘first’); hypothesis 2c: participants in the informed condition will have higher rapport scores than participants in the uninformed condition (main effect diagnostic informing or ‘info’ for short). The rapport results are shown in Fig. 4.

The violin plots (shaded transparently) show the distribution of rapport scores across chain types and roles (learner in grey and teacher in orange) (n = 311). The box plots (outlined in black) display the median (centre line), interquartile range (25th to 75th percentiles), and whiskers extending to 1.5 times the interquartile range. The jittered grey points represent individual data values, and diamonds indicate mean scores for each group.
Teacher rapport
MLM with random intercepts for each chain were used, with Satterthwaite’s method to adjust degrees of freedom in t-tests (R package MuMIn52). A model comparison for teacher rapport scores in terms of AIC favoured a model where ~chain type + story type × first + info + site + (1|number) predicted the rapport scores (range 0–500). More complex models with higher-order interactions improved model fits only marginally and increased collinearity (VIF >5). This model predicted the teacher rapport score with an adjusted (marginal) pseudo R2 = 0.07 and adjusted (conditional) pseudo R2 = 0.10 (R package MuMIn52), indicating that random intercepts captured some variability. Teachers in non-autistic chains had significantly higher rapport scores than those in mixed chains (b = −35.8, t(46.9) = −3.45, P = 0.0012 η2 = 0.03, 95% CI −56.2 to −15.4) and in autistic chains (b = −33.3, t(54.3) = −3.21, P = 0.002, η2 = 0.03, 95% CI −53.7 to −12.9). Teachers who were uninformed about the neurotype of the learner had lower rapport score than teachers who were informed but the effect did not reach significance (b = −17.8 (s.e.m. of 8.98), t(47.4) = −1.98, P = 0.054, η2 = 0.01, 95% CI −35.4 to −0.20). The effect of story type (BF of 2.47 for the simpler model) and first (BF of 0.48 for the simpler model) was negligible (η2 < 0.01), but the interaction between story type and first was significant (b = −36.5, t(458.9) = −2.48, P = 0.013, η2 = 0.01, 95% CI −65.3 to −7.69), where rapport was higher for the second (factual) task when the fictional task was first. No other significant effects were noted.
Learner rapport
The same model as above predicted learner rapport score with an adjusted pseudo (marginal) R2 = 0.082 and adjusted (conditional) pseudo R2 = 0.16 (R package MuMIn52). Learners in non-autistic chains had higher rapport than those in mixed chains (b = −22.3, t(47.7) = −2.01, P = 0.04, η2 = 0.01, 95% CI −43.7 to −0.94), but not significantly higher than in autistic chains (b = −20.8, t(47.6) = −1.92, P = 0.06, η2 = 0.01, 95% CI −42.0 to 0.37). Learners who were uninformed about the neurotype of the teacher had a significantly lower rapport score compared with learners who were informed (b = −19.8, t(47.4) = −2.11, P = 0.04, η2 = 0.02, 95% CI −38.2 to −1.43). The main effect of story type (BF of 0.02 for the simpler model) and first (BF of 0.01 for the simpler model) was negligible (η2 < 0.01), but the interaction between story type and first was significant (b = 50.0, t(457.1) = 3.87, P < 0.001, η2 = 0.03, 95% CI 24.7 to 75.3), where rapport was higher for the second (factual) task when the fictional task was first. No other statistically significant effects were observed.
Summary
H2a was partially confirmed: the difference between non-autistic and mixed chains was statistically significant, but the difference between autistic and mixed chains was negligible. H2b was not confirmed: there was no significant difference between rapport scores when participants completed them after the first and second diffusion chain tasks. H2c was partially confirmed because reductions of rapport scores for uninformed compared with informed participants were small, and the effect was significant for the rapport scores for learners but not for teachers. The most robust effects were reduced teacher and learner rapport scores for mixed and autistic chains, as well as the interaction between story type and first. Post hoc analyses that included IQ, gender and ethnicity as control variables did not affect the results described above (Supplementary Information).
Discussion
Universal deficits in social communication, including behaviours used for social interaction, a reduced interest in peers and ‘abnormal social approaches’, are central to the current diagnostic criteria for autism2. It follows that autistic people should demonstrate impairments in sharing information with others. However, previous research has indicated that autistic and non-autistic people are similarly accurate at sharing information with others of the same neurotype, with both selectively experiencing poorer information transfer in mixed-neurotype settings34. The current study rigorously tested the generalizability of these findings in a much larger and more diverse sample.
An important feature in the original study also appeared in this replication: there was no significant difference in information transfer accuracy between autistic and non-autistic chains, indicating that autistic adults are not impaired relative to non-autistic participants in their ability to transfer information accurately within same-neurotype chains. This holds true for different samples and sites, and is inconsistent with the core deficit theory of autism55, current diagnostic criteria2 and a canon of social-cognitive autism research56 that assumes that autistic people should perform more poorly at communicative tasks than non-autistic people, regardless of context. These findings validate the presence of effective communicative skills in autistic people, even if they do not necessarily adhere to non-autistic social norms.
However, mixed-neurotype chains also did not differ from either autistic or non-autistic single-neurotype chains in information transfer. In other words, while autistic interaction pairs showed equal communicative abilities when compared with non-autistic pairs, we did not find the predicted selective breakdown of communication when autistic and non-autistic people were interacting. The pattern occurred in both fictional and factual tasks and strongly favoured a model without chain types.
As previous research indicates that disclosing diagnosis results in more positive impressions of autistic people46, it was hypothesized that participants who were informed of the diagnostic status of their partner would experience higher rapport than uninformed participants (H2c). The results elicited a mixed picture. Across the board, rapport was higher when diagnosis was disclosed, aligning with previous work46. When participants rated rapport as someone sharing information (that is, ‘teacher’), non-autistic chains had higher scores than autistic and mixed chains. Autistic people particularly enjoyed talking to other autistic people. However, when participants rated rapport as someone learning information (that is, ‘learner’), autistic and non-autistic chains did not differ, and both had higher scores than mixed chains. People preferred learning from someone of the same neurotype.
While some findings from the original study generalized, others did not. One likely explanation for results differing between the two studies is the increased heterogeneity of the sample. The participants in the current study encompassed a range of ages, genders and ethnicities. The autistic group specifically had a wide range of IQ scores and included both clinically and self-identified participants who reported a range of ages of (self-)diagnosis. Additionally, participants were drawn from multiple recruitment routes, at three sites across three nations—albeit all Western cultures. The original study had far less diversity in all these respects. While our questions focus on the impact of neurotype on information transfer, other individual differences such as age57 and gender58 also shape human interactions. For example, matching on gender and ethnicity can lead to improved learning59 and rapport57,58,60. In this study, increasing the diversity of the sample may have influenced interactions, overshadowing an effect of neurotype matching. Nonetheless, variability—including variability of IQ—did not influence the autistic sample from sharing information and experiencing rapport with each other. In summary, we infer that it is not simply whether someone is autistic or not that determines the success of their interaction with others, but also the match or mismatch of other characteristics. Disentangling such intersectional effects would require systematically manipulating multiple demographic variables, which was beyond the scope of the current study.
This study has limitations, which could be addressed by future research. First, all participants were drawn from the USA and UK, and thus were aligned with Western cultural and communicative norms. We do not know whether similar findings would arise across participants from different cultural backgrounds. Second, the mean IQ of the participant groups were high, and participants all engaged in verbal communication; it is not known whether a similar pattern of findings would occur with participants with an intellectual disability or with participants communicating using non-speaking channels. Finally, although we examined individual effects of gender and ethnicity on performance, diffusion chains included participants of different and ethnic backgrounds, meaning that we could not examine the effects of matching participants on these other important variables to examine their potential effects on communication, information transfer and rapport.
Although this study was a conceptual replication of ref. 34, it included several methodological differences, yet none should have differentially affected one chain type more than any other. First, we wrote a new fictional story to avoid the risk that participants read the published original before taking part. The original and replication stories were carefully matched on length and reading difficulty. Second, to standardize administration across sites, participants watched a video of a man recounting the fictional story to them, whereas in the original study the fictional story was recounted live by a female researcher. There is no evidence of differences in recall between face-to-face and video instruction in non-autistic populations61. Although no research has examined this for autistic people, this methodological feature is unlikely to explain the pattern of effects already discussed—that is, absence of differences between chain types. Third, in this study, half the participants heard the factual narrative first, whereas the fictional task was the only task in the original study. Again, even if some kind of practice effect arose from hearing a factual story first, there is no discernible reason why this should affect chains differentially. Finally, this study used six-person chains, to avoid collecting data influenced by floor effects at later positions. As effects were detectable after just six positions in the original study, this change is unlikely to have affected the results reported here.
Future research could examine the content of the interactions to investigate whether participants in the three conditions differ in the types of information they share or the way it is conveyed. One could also ask whether these findings replicate across different types of tasks—motor as well as verbal domains, or in open-ended, creative tasks. One further question concerns the extent to which the success of mixed-neurotype interactions depends on pre-existing beliefs about being autistic. An autistic person who is working hard to fit in (often referred to as ‘masking’62) could end up more effectively sharing information with non-autistic partners, and both give and receive higher rapport scores. Extrapolating beyond our experimental scenario, a pattern like this could deliver short-term interactional gains at the expense of long-term mental health63,64. Conversely, it is possible that positive beliefs about being autistic could negatively affect interactions across neurotypes. This might happen if autistic people are working to be their authentic selves, rather than effortfully bridging the communication gap, and/or if they bring an expectation of lack of success to the interaction. In the original study, participants were older than in the current study, and autistic people have reported masking less as they get older65: it may be that the younger participants were more likely to mask, inflating cross-neurotype information transfer and rapport scores. Future work should consider including a scale of masking, such as the Camouflaging Autistic Traits Questionnaire66, to ascertain its potential role.
Conclusions
This well-powered, preregistered study replicated the finding that autistic and non-autistic people share information and establish rapport with similar levels of success within same-neurotype contexts. Additionally, no difference was found in performance in mixed-neurotype chains. A growing body of empirical evidence32,34,35, along with first-person accounts from autistic people13,67,68,69, have shown a preference for same-neurotype interactions, with mixed-neurotype interactions being more challenging to navigate. The experimental context tested here may have failed to capture difficulties experienced in real-world cross-neurotype interactions. This could be due to real-world conversations being more dynamic and interactive than the unidirectional information transfer tasks used here. Research examining the role of multiple intersecting identities is needed, but for now, these data support a growing challenge to the lack of contextual nuance in the diagnostic criteria for autism.
Methods
Ethics
This study was carried out in accordance with the British Psychological Society’s Code on Human Research Ethics and the American Psychological Association’s Ethical Principles of Psychologists and Code of Conduct. Experimental procedures were reviewed and approved by the University of Edinburgh’s Medical Research Ethics Committee, the University of Nottingham School of Psychology Ethics Committee and the University of Texas at Dallas’s Institutional Review Board. All participants provided written informed consent before participating and were remunerated for their time (£30/US$40).
Pilot data
Data demonstrating the feasibility of our approach were collected and published in ref. 34. This pilot study used a diffusion chain paradigm with autistic, non-autistic and mixed chains, and assessed the fidelity of information transfer of a fictional story and between-participant rapport in each condition. Thus, we were confident in the feasibility of the methods and proposed analyses for this study.
In the pilot study, a standard linear regression model including predictor variables of chain type and position (order) showed a steeper decline for the mixed chains of alternating autistic and non-autistic participants (β = −6.04 (s.e.m. of 1.32), P < 0.0001), with chains consisting solely of autistic or non-autistic participants not differing significantly (β = 0.13 (s.e.m. of 1.32), P = 0.93). This conclusion was also supported by additional analyses showing a significant interaction between the chain type and position, indicating a significantly faster deterioration rate of information sharing in the mixed chains (β = 0.57 (s.e.m. of 0.26), P < 0.05). Together, chain type and position accounted for 85% of the variance in the amount of information shared (F(5,66) = 77.05, P < 0.0001, R2 = 0.85). Thus, autistic and non-autistic chain types did not differ in their information-sharing capabilities, and penalties for information transfer selectively occurred in the mixed chains where diagnostic status was mismatched. In the current study, we suggested a revised data analysis for the power calculations (see the ‘Sampling plan’ section).
Design
Experimental design
This study used a mixed experimental design incorporating both between and within-groups factors. Between-groups factors included chain type (autistic, non-autistic or mixed) and diagnostic informing (informed or uninformed), with task type (fictional or factual) as within-group factors.
Participants and recruitment
Three hundred twenty-four adult participants (162 autistic people and 162 non-autistic people) comparable on age, gender and IQ were recruited across three sites (the University of Edinburgh, the University of Nottingham and the University of Texas at Dallas), and 311 (154 autistic people and 157 non-autistic people) attended research days. The autistic group was predominantly female (51.3%) and non-binary (30.52%) with a mean age of 28.68 years (s.d. 11.18 years). The non-autistic group was predominantly female (75.16%) with a mean age of 26.83 years (s.d. 11.26 years). Full details of participant demographic and clinical information are detailed in Supplementary Information. Participants were recruited through databases held at each university (Edinburgh: the Patrick Wild Centre Participant Database; Nottingham: the Autism Research Team Database; and Dallas: The Autism Research Collaborative), partnerships with local autism charities and autistic organizations, and social media. Participants were remunerated (£30/US$40) for their time.
One hundred eight participants were allocated to the uninformed condition, and 216 participants were allocated to the informed condition. This allowed for a direct replication of the original study (where participants were informed about diagnostic status) with a sample size powered to detect smaller effects, while also permitting assessment of the effect of diagnostic information on task performance within the resources available for this study. The distribution of participants to these conditions was because of the funding constraints of this study. Specifically, we applied for funding to a scheme designed solely to fund replications and powered our study on that basis. In response to reviewer comments, the funder offered additional support to allow us to extend the study to include a smaller, uninformed diagnosis condition, and this resulted in the imbalanced groups.
Inclusion criteria
Autistic and non-autistic participants were required to be over 18 years, of any gender, to speak English to a native level and have normal/corrected normal sight and hearing. Consistent with the Crompton et al.34 study, participants were ineligible if they had a diagnosis of social anxiety disorder or uncontrolled epilepsy. The autistic group included participants reporting a clinical diagnosis of autism (n = 144) and those who self-identified as being autistic (n = 40) provided they exceeded a clinical threshold using validated measures (see below). We anticipated that the likelihood of including significant numbers of self-identifying autistic people in this study was low given the availability of databases of people with confirmed diagnoses at each site, but are included here as a possibility if recruitment challenges were encountered. Participants who self-identified as autistic completed the Ritvo Autism and Asperger’s Diagnostic Scale (RAADS)–Revised70 and were included in the study if their score was above 72, as recommended in the literature71. All participants completed the RAADS 14-item screen (RAADS-14)72, and non-autistic participants were excluded from participating if their scores indicated high levels of autistic traits (score >14).
Chain types
This study involved comparing performance on information transfer and rapport scores between three conditions (chain types) to which participants were assigned upon enrolment. The chain types were autistic chains, where all participants were autistic, non-autistic chains, where none of the participants were autistic, and mixed chains, where half the participants were autistic and half of the participants were not. We attempted to ensure that groups were comparable on gender, age, educational level, linguistic ability and IQ. However, as it was not possible to match the groups on gender and ethnicity, these variables were included as additional control variables on post hoc analysis as planned. These variables did not affect the results (Supplementary Information).
Randomization
This study was non-randomized, and participants were assigned to either a non-autistic, autistic or a mixed autistic–non-autistic chain and to the informed or uninformed condition according to gender, age and order of recruitment. Assignment was also affected by participant availability to attend on a particular data collection day.
Revealing diagnostic status
This study examined information transfer in two conditions: (1) the informed condition, where participants were aware of the diagnostic status of the participants in their diffusion chain group, and (2) the uninformed condition, where participants were not informed of the diagnostic status of the other participants in their diffusion type. The researchers were aware of the diagnostic status of all participants, and thus data collection, scoring and analysis was not performed blind to the conditions of the experiment.
Content type
This study examined whether the efficacy of information transfer differs for factual and fictional information. Content type was counterbalanced across the chains, with half of all chains first completing a fictional task and half first completing the factual task.
Timeline
Participants were recruited between August 2022 and October 2023.
Procedure
The experimental diffusion chain tasks
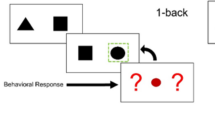
This study used a diffusion chain methodology—a controlled, experimental form of the game ‘Telephone’—which has been effective in probing cultural learning between individuals in a social group73,74. In this method, an experimenter models a complex behaviour to the first person in the chain; in this case, telling the participant a short passage of information. The person then has a chance to replicate the behaviour alone (that is, rehearse retelling the information) before being paired with the next person in the chain and instructed to demonstrate the behaviour to them (that is, retelling the passage). After hearing the passage, the second participant can practise the behaviour and then must pass it on to the next individual, and so on. Before commencing a diffusion chain, we ensured that consecutive participants in the chain did not know one another.
In practice, this meant that the researcher played a video to the first participant (A) in which a non-autistic man read the passage aloud. The researcher then left the room, and a second participant (B) entered. Participant A then recounted the story to participant B. Participant A then left the room, and a third participant (C) entered. Participant B then recounted the story to participant C, and so on, to the sixth participant (F). The sixth participant recounted the story aloud, alone. Participants waited in separate rooms for their turn, to avoid contamination during the information sharing. For mixed chains, half began with an autistic participant and half began with a non-autistic participant before alternating between autistic and non-autistic participants. All diffusion chains were video recorded for scoring purposes.
In each diffusion chain, six participants completed two separate diffusion chain tasks: a fictional and factual task. In each chain, six participants completed one task in full—for instance, passing a fictional story through all six people in the chain—and then the same chain in the same participant order completed the second task (in this case, factual information transfer). The order of fictional and factual task administration (within-group factor) was counterbalanced across chain types so that familiarity effects (from interacting with the same person twice) were distributed evenly between fictional and factual task conditions.
The fictional condition task was a short story that was surreal and difficult to predict. The factual condition task involved a short passage describing facts of an obscure scientific nature. The passages for both tasks feature 30 individual details, allowing the task to be scored out of a maximum of 30 for each participant. Both tasks had comparable Flesch–Kincaid grade level and Flesch reading ease scores, featured a comparable number of words and had comparable word and sentence lengths75,76. Both were designed to be completely novel to participants, difficult to predict and not involve any inherently social features.
A participant’s final score corresponded to the number of details they recalled when recounting the passage to the next person in the chain, out of a maximum of 30. A higher score indicated a greater amount of information shared. Two researchers independently coded 50% of the videos. Additionally, they each second-coded 5% of randomly selected video material assigned to the other researcher, giving a 10% overlap of videos that were double coded. Inter-rater reliability was calculated using a single rating absolute-agreement two-way mixed-effects model as per ref. 77 and was very high for both tasks (factual intraclass correlation coefficient 0.986 (P < 0.0001), 95% CI 0.975 to 0.992; fictional intraclass correlation coefficient 0.978 (P < 0.0001), 95% CI 0.961 to 0.987). Participants within each of the chains were ordered in ascending age to minimize a possible effect of age-related memory decline. Chains were also organized to minimize frequent switches of gender to avoid a possible effect on information transfer and rapport. Participants in the informed condition (n = 216) were told whether they were in an autistic, non-autistic or mixed chain. Participants in the uninformed condition (n = 108) were not informed of chain types. Participants did not meet before the study started and were isolated in separate rooms throughout the study, except when participating in the diffusion chains.
The experimental rapport measure
Participants were asked to rate the rapport they experienced while completing the diffusion chain tasks. Participants completed these rapport measures twice: once for the interaction when they were the ‘listener’ (that is, when they were listening to another participant recount the passage to them) and once for the interaction when they were the ‘speaker’ (that is, when they were recounting the passage to another participant). The first participant in each chain only rated rapport as a speaker, and the last participant in the chain only rated rapport as a listener. The rapport measure used was taken from the original study by Crompton et al.34,40,41 and involved participants answering using a slider on a scale from 0 to 100: (1) how much did you enjoy the interaction? (2) how easy was the interaction? (3) how successful was the interaction? (4) how friendly was the interaction? (5) how awkward was the interaction? (reverse scored). The full measure can be found on the Open Science Framework website alongside the data for this study.
Studies of rapport in dyadic interactions typically use self-rated questionnaires78. While self-rated rapport may be subject to response biases (for example, if autistic people underestimate their rapport owing to negative self-perception of social skills or a history of difficult interactions with others, or if non-autistic people overestimate their rapport40), we consider that it is nevertheless the optimal way to assess each participants’ direct experience of the interaction. Specifically, self-rated rapport was selected over observer-rated rapport, as most methods developed for measuring observer-rated rapport do not accommodate neurodiverse interactional experiences. External rapport measures can be biased by a neuro-normative lens: normative external indicators of rapport are less likely to be observed between autistic pairs40, and this may be undetected or misinterpreted by observers. This means that, even if autistic pairs are experiencing high rapport, external observers are likely to rate them as having low rapport. For example, when independent observers rate videos of autistic people, they rate them as being more awkward and less approachable14, both of which are key factors in building rapport. These biases are robust, are developed very rapidly and do not change with increased exposure14. Importantly, independent autistic observers have a similar tendency to non-autistic judges to evaluate autistic adults less favourably than non-autistic adults in videos16, and so this bias cannot be overcome by simply recruiting both autistic and non-autistic independent judges. Similarly, emotion recognition is subject to strong neuro-normative biases—autistic people have different facial expressions to non-autistic people, and autistic people (and thus, emotion-recognition software based on non-autistic norms) are poor at identifying these emotions28, which is related to their perceiving them unfavourably. Normative biases are also replicated within intelligent learning algorithms79, and thus automated tools based in machine learning are similarly problematic to use in this context. Additionally, since we examined whether rapport varies depending on social context (single or mixed dyad), rather than as a main effect of diagnosis (autistic or non-autistic), any influence of response bias associated with autism was well managed by the study design. For these reasons, self-rated rapport was used in this study.
Standardized tasks
To characterize the IQ of the sample and match across groups, participants completed the Wechsler Abbreviated Scale of Intelligence II (WASI-II) two-subtest version80. Autistic participants had a mean IQ of 118.14 (s.d. 15.50), and non-autistic participants had a mean IQ of 111.46 (s.d. 12.95). A breakdown of group-level IQ scores by the chain condition (autistic, non-autistic and mixed) is available in Supplementary Information. All participants completed the RAADS-14 (ref. 72) to characterize the sample. Autistic participants had a mean score of 33.39 (s.d. 18.59), and non-autistic participants had a mean score of 5.15 (s.d. 4.17). A breakdown of RAADS scores and age of diagnosis by chain conditions that included autistic (autistic or mixed) is available in Supplementary Information. Additionally, participants who self-identified as autistic completed the RAADS-Revised70 to ensure they scored above the threshold of 72, as recommended in the literature72.
Protocol
Participants completed the tasks in the order shown in Table 1.
Sampling plan
Expected effect sizes
There are few scientific comparisons between autistic, non-autistic and mixed social groups. The analysis in the original study gave a partial η2 effect size of 0.45 for chain type, 0.83 for position and 0.08 for the interaction of chain type and position34, though there are insufficient similar studies to know if these are reliable effect sizes. We therefore proposed being conservative in our effect size estimates given the paucity of data, especially in high-powered studies. In the proposed study, we suggested a sample size that is based on a revised data analysis and powered to detect medium effects in the data.
Power analysis
A mixed design for chains with both between and within factors appeared more appropriate than a between-subjects design. This increased the power of the study. We modified the linear model so that each chain (rather than participant) was treated as an independent observation and the proportion of recalled information from a participant in a chain was considered as a repeated measure, allowing for dependencies between participants within a chain. Applying a corresponding linear model with repeated measurements to the original data by Crompton et al.34 suggested larger effect sizes for the main effects and interaction (chain type partial η2 = 0.52, position in chain 0.87 and interaction 0.20). For equivalent analyses of rapport scores, we found a partial η2 of 0.19 for the interaction.
Since the main effects were strong, the smallest meaningful interaction effect between chain type and position would be a medium effect of η2 = 0.06 (partial Cohen’s f = 0.25). To establish a correlation coefficient for the within-factor position, we had to introduce assumptions about the correlation matrix. For compound symmetry, we estimated ρ = 0.502 using a general least square fit (function gls() in R package nlme). Fitting an auto-regressive AR(1) correlation matrix to the data increased the coefficient to ϕ = 0.767, but this fit was not significantly better than the compound symmetry fit. Assuming a statistical significance level of P = 0.05, a medium effect size of η2 = 0.06, a lower correlation of r = 0.4 and a correction for non-sphericity of ε = 0.7 (Greenhouse–Geisser), then a power analysis59 for a within–between interaction in an analysis of variance (ANOVA) with repeated measures 54 chains with 6 positions (participants) suggested a total of 324 participants to reach 95% power (see also Fig. 1).
A priori power analyses for linear mixed-effect models are notoriously difficult to conduct and require simulation studies81,82. The simulation-based power analysis required fitting a linear mixed model to the existing data by Crompton et al.34, with eight participants in each of three chains for each condition (N = 72). Since this dataset has the minimum number of chains per condition, we could only fit a mixed model with random intercepts. If ‘order’ was added as a further random effect, then the model failed to converge and we could no longer run a simulation-based power analysis.
We calculated the exact power for the interaction effect of a mixed-effect linear model with a random intercept for each chain using the R packages lme4 (ref. 49) and simr83. On the basis of the estimated coefficients of the mixed-effect model analysis on the original data (omitting the data for chain positions 7 and 8), Monte Carlo simulations gave power estimates for different numbers of chains. The simulation results were conservative because they are based on the estimated coefficients reduced by one-third. The simulations suggested more than 45 chains to test the fixed effect of interaction chain type by position with 95% power (Fig. 2).
Further details of the power analysis and simulations in R can be found in the R file PowerAnalysis alongside published data and code. The large sample of 324 participants was the maximum feasible under current funding constraints and provided sufficient power (>95%) to test the hypotheses and to explore undirected and two-way interaction effects on post hoc analyses. For the main hypotheses, we also computed BFs for normally distributed differences between means (R package BayesFactor50). Unlike Neyman–Pearson statistical inference, BFs accumulate evidence with increasing sample size and inform about the likelihood of the alternative relative to the null hypothesis given the evidence84,85. We also conducted comprehensive model comparisons using information criteria to establish the most parsimonious (mixed-effect/nonlinear) model86.
Our sample (311 participants in 54 chains) was considerably larger than the original sample (72 participants in 9 chains) in ref. 34. There are several benefits of this. First, we were powered (>95%) to detect and replicate results for reduced effect sizes. Second, this sample size provided us the opportunity to fit the maximal model87 and/or to identify the most parsimonious model87,88—rather than relying on the intercept-only model used in the simulation. Third, it enabled us to examine further undirected effects, namely, comparing across informed and uninformed conditions, sites and content type with effect sizes that are likely to be smaller. Finally, it allowed us to account for potential data loss or outliers. The sample size was therefore substantially larger than the original study34, and far exceeded the sample size of previous studies reporting similar group differences28. The increased sample and therefore number of chains was further justified because variability within chains could be investigated using not only linear, but also nonlinear and dynamic models (see post hoc analyses included in Supplementary Information).
Adjusted significance levels
A standard P < 0.05 threshold was used to determine statistical significance for testing in standard linear analyses. False discovery rate correction89 was used to control for inflated alpha levels due to multiple comparisons, where applicable.
Bayesian analysis
Bayesian testing and modelling were carried out in R (for example, packages bayesfactor50 and brms90). As there were no comparable previous studies to guide the exact specification of priors in these analyses, default priors were used for parameters and hypotheses. Sequential analysis, sensitivity analysis and predictive checks were carried out to ensure that default priors provide robust and accurate results85. Owing to the nature of the diffusion-chain task, observations inside a chain were not only dependent but were likely to follow a nonlinear decay function. On post hoc analyses, it was therefore planned to fit different decay functions and dependencies to further improve model fit. There were various options to establish nonlinear models to test between different chain conditions ranging from generalized linear mixed-effect models (R packages lme4 (ref. 49) and nlme91), social reinforcement learning92,93, auto-regressive models (R package fpp2 (ref. 94)) to stochastic (dyadic) process models (R packages brms90 and rstan76) that can capture the transfer of information from one (autistic or non-autistic) person to the next (autistic or non-autistic) person inside each chain. We explored these analysis options to identify critical parameters and perform appropriate post hoc statistical testing.
Data exclusion
Outliers were identified as values ±2.5 s.d. from the mean in performance and rapport variables. These values were either (1) be left in if the distribution of the data still meets the assumption of the test (for example, adequate normality) or (2) excluded to make data meet the assumption of the test. In addition, (3) videos and notes were checked to see whether there is an explanation for outlying performance, and data were excluded if the underlying observation is non-representative (for example, task interrupted by an external event or a violation of the protocol). This was noted and discussed in reporting.
Using these criteria, no data were excluded from the analysis in the original study, and thus we hoped no data would need to be excluded from this replication. We made every effort to keep outliers in the dataset and select analyses that are robust to this, for example, by using type III sums of squares ANOVA, which are more tolerant to minor violations to assumptions of normality. However, three research days produced data of insufficient quality or quantity. Thus, the data from these days were not included, and the diffusion chains were re-run with new participants. Our reasons for excluding these data were (1) 1 day only had four participants attend, so there were not sufficient data to include, (2) one chain included a participant in position one who recalled a very low level of information, below the outlier threshold of ±2.5 s.d. from the mean outlined in our sampling plan, and (3) we had an unequal balance of missing data from five-person chains across the three conditions (autistic, non-autistic or mixed). To ensure that missing data were balanced across the three conditions, an additional autistic chain was re-run with six participants.
Analysis plan
Data
Our analyses were based on two data sources: participant task performance data and self-rated rapport data. Additionally, demographic data was directly self-reported using a Qualtrics online form and downloaded into a .csv file. Next, we outline the proposed analysis pipeline for participant task performance data and self-rated rapport data, including preprocessing steps and planned analyses.
Participant task performance data
Participant interactions were videotaped, transcribed and then scored according to the number of details out of 30 transferred to the subsequent participant using the task scoring tool. Participant scores were then stored in a .csv data file and imported into R for analysis.
Self-rated rapport data
Participants self-rated their rapport experience out of 100 across five domains by using the rapport tool available alongside published data. These scores were entered into a datafile by a researcher and imported to R for analysis. The internal structure of the rapport construct was assessed using Cronbach’s alpha, and analyses used a singular construct of rapport if the internal consistency was over an acceptable threshold (0.7), as recommended in the literature71. If any item caused the alpha to be below 0.7 it was dropped. From all items with an internal consistency of 0.7 or above, a mean was calculated, referred to as the ‘rapport rating’. If items did not have high internal consistency, they were used in the following analysis individually, with false discovery rate corrections to avoid increased type 1 error risk.
Analyses
Hypotheses 1: (1a) participants in autistic and non-autistic chains will share significantly more details than in mixed chains; (1b) information will deteriorate between participant position (1–6) in each chain; and (1c) this should occur significantly earlier in mixed chains compared with autistic and non-autistic chains. Autistic and non-autistic chains will not differ in their deterioration rate.
We first examined the data, calculating descriptives (for example, mean and s.d.) and visualizations for the dependent variable (performance or rapport score) in each group (autistic, non-autistic or mixed) and checked for outliers. We then checked whether the five assumptions of linear regression are met for this model: (1) that the data were linear (checked by inspecting a residuals versus fitted plot), (2) that residuals variance was homogeneous (checked by examining a spread-location plot), (3) that residuals were normally distributed (checked by examining a QQ plot), (4) that there was independence of residual error terms (checked by examining a scatter plot of residuals versus fits) and (5) collinearity (checked by residual plots and model fits). Next, we performed a linear regression on chains in mixed design, with the dependent variable of participant score and independent variables of chain type (between autistic, non-autistic and mixed) and chain position (within 1–6). This was compared with equivalent analyses on the original dataset. Additional post hoc analyses included nonlinear regression. The decay of information inside chains was unlikely to follow a linear function because loss of information may be larger at the start of the chain and smaller towards the end. Thus, a nonlinear regression model may significantly improve data fit. A nonlinear regression analysis essentially followed the same design as the linear regression: dependent variable of participant score and independent variables of chain condition (autistic, non-autistic and mixed) and position (1–6) in a mixed design.
Hypotheses 2: (2a) we predict significantly higher rapport scores in the autistic and non-autistic chains relative to the mixed chain; (2b) given that contact with autistic people is associated with more favourable impressions, less stigma and more inclusionary attitudes20,71, we hypothesized that rapport will increase in the second relative to the first interaction between partners in mixed chains; and (2c) participants in the informed condition would have higher rapport scores than participants in the uninformed condition46.
This analysis used data from both diffusion chain tasks completed by participants, whether fictional or factual. We examined and visualized the data and check the assumptions of the analysis method as described in hypothesis 1. We first performed a linear regression. This included the dependent variable of individual rapport score and predictor variables of chain type (autistic, non-autistic or mixed), interaction order (first or second) and diagnostic informing (informed or uninformed). We then investigated more complex linear models by adding one predictor at a time. In a comprehensive model comparison using information criteria, we compared the simplest established model with more complex models that include additional variables as well as two-way interactions to determine the most parsimonious linear model and its effects. We only interpreted the results of the most parsimonious model.
Exploratory analyses
Generalizability of findings
In response to the reproducibility crisis95, we addressed problems of generalizability96 in the current project. Among the many recommendations to improve standards, we targeted sample size and power, alongside a more representative or ecologically valid design that addresses sampling of participants (three different sites), two different instructions (diagnostic informing) and stimulus material (content type). It was planned to emphasize variance estimates (instead of point estimates) and to fit alternative and more expansive statistical models (model comparison, mixed-effect models and nonlinear models). If similar effects of chain type and position were replicated under these broadened conditions and for different analyses, then we can rest assured that the effects hold true in the wider population.
Generalizability of hypothesis 1
To check whether there were differences in the data collected across the three sites, we established models that add predictor site (Edinburgh, Nottingham or Dallas), diagnostic information (informed or uninformed) and information content (fictitious or factual) as well as two-way interactions in a forwards selection. We performed model comparisons using information criteria to compare models and to determine the most parsimonious linear model and its effects.
Generalizability of hypothesis 2
To check whether there were differences in the data collected across the three sites, we established models that add predictor site (Edinburgh, Nottingham or Dallas), participant role (whether they were speaking or listening) and information content (fictitious or factual), as well as two-way interactions in a forwards selection. We performed model comparisons using information criteria to compare models and to determine the most parsimonious linear model and its effects.
Exploring potential effects of diagnostic informing and content type
This study extended beyond ref. 34 by examining the potential impact of two manipulations: diagnostic informing (informed or uninformed) and content type (fictional or factual). Previous research has not clearly indicated whether diagnostic disclosure affects communication16,46,97 nor is there sufficient evidence to suggest whether autistic or non-autistic people share fictional or factual information differently. Therefore, these hypotheses are exploratory and undirected. We examined and visualized the data and checked the assumptions of the analysis method, as described in hypotheses 1. We then performed a linear regression analysis using a simple linear model. This included the dependent variable of individual participant score and predictor variables of chain type (autistic, non-autistic or mixed) and chain position (1–6). We then added diagnostic informing (uninformed or informed), content type (fictional or factual) and site (Edinburgh, Dallas or Nottingham) as additional predictors. We created different linear models in a forwards selection by adding one predictor at a time. In a comprehensive model comparison using suitable information criteria, we compared the original model with more complex models that include more predictors and interactions to determine the most parsimonious linear model80. We only interpreted the output and effects of the most parsimonious model.
Additional post hoc analyses included nonlinear regression analyses. The decay of information inside all diffusion chains is unlikely to be linear; thus a nonlinear regression model may provide a better account of information loss across positions. The nonlinear regression followed the same design as the linear regression: dependent variable of individual participant score and predictors including chain type, chain position, diagnostic informing, information content and site. Similarly, testing utilized Bayesian statistics and model comparison to establish whether a nonlinear model outperforms a linear model (for example, package brms90).
Exploring distortions in diffusion chain content
In diffusion chains, the content of an original piece of information generally degrades over repeated social transmissions73. However, it is also possible that information becomes distorted, with participants adding detail not included in the original information (for example, “She turned left at the blue windmill” becomes “She turned left at the blue flowery windmill”) or making an error in information transfer (for example, “She turned left at the blue windmill” becomes “She turned left at the blue castle”), which is then transferred to subsequent participants92. Thus, in addition to counting the number of correct details transmitted, we examined transcripts of interactions to quantify distortions occurring in information transfer. However, we were not able to arrive at a reliable coding scheme for deviations, as it was not possible to reach a moderate level of agreement among coders on what constituted a deviation. We attempted to code whether participants switched content (that is, removing one piece of content and replacing it with another) or introduced new content in addition to the existing content, but there were problems comparing substitutions between participants and defining what constituted a single ‘unit’ of deviation for scoring purposes was very complex. Though various coding schemes were posited, the application of these resulted in agreement consistently below 60%. This rate of agreement is too low to ensure data quality. As we could not meet a minimum threshold for data quality for coding this variable, this variable was not calculated or analysed98.
We planned to examine and visualize the data and check the assumptions of the analysis method as described for hypothesis 1. Our plan had been that, if the assumptions were met, then we would perform a linear regression analysis using a simple linear model and if not, we would apply Bayesian analysis methods. This would include the dependent variable of individual participant distortion score (that is, how many distortions each participant introduced), and predictor variables of chain type (autistic, non-autistic or mixed) and chain position (1–6). Collectively, the analyses could therefore determine both whether information degrades differently across chain types and whether new incorrect information was generated to a greater degree in some chain types (and by some participants) compared with others.
Protocol registration
The Stage 1 protocol for this Registered Report was accepted in principle on 23 August 2022. The protocol, as accepted by the journal, can be found at https://osf.io/us9c7/.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All data and materials are freely and openly available via the Open Science Framework at https://osf.io/us9c7/.
Code availability
All analysis code in R is freely and openly available via the Open Science Framework at https://osf.io/us9c7/.
References
Kenny, L. et al. Which terms should be used to describe autism? Perspectives from the UK autism community. Autism 20, 442–462 (2016).
American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders: DSM-5 Vol. 5 (American Psychiatric Association, 2013).
Mazurek, M. O. Loneliness, friendship, and well-being in adults with autism spectrum disorders. Autism 18, 223–232 (2014).
Billstedt, E., Gillberg, C. & Gillberg, C. Autism after adolescence: population-based 13- to 22-year follow-up study of 120 individuals with autism diagnosed in childhood. J. Autism Dev. Disord. 35, 351–360 (2005).
Bauminger, N. & Kasari, C. Loneliness and friendship in high‐functioning children with autism. Child Dev. 71, 447–456 (2000).
Baldwin, S., Costley, D. & Warren, A. Employment activities and experiences of adults with high-functioning autism and Asperger’s disorder. J. Autism Dev. Disord. 44, 2440–2449 (2014).
Scott, M. et al. Factors impacting employment for people with autism spectrum disorder: a scoping review. Autism 23, 869–901 (2019).
Shattuck, P. T. et al. Postsecondary education and employment among youth with an autism spectrum disorder. Pediatrics 129, 1042–1049 (2012).
Eaves, L. C. & Ho, H. H. Young adult outcome of autism spectrum disorders. J. Autism Dev. Disord. 38, 739–747 (2008).
Cage, E., Di Monaco, J. & Newell, V. Experiences of autism acceptance and mental health in autistic adults. J. Autism Dev. Disord. 48, 473–484 (2018).
Howlin, P., Moss, P., Savage, S. & Rutter, M. Social outcomes in mid- to later adulthood among individuals diagnosed with autism and average nonverbal IQ as children. J. Am. Acad. Child Adolesc. Psychiatry 52, 572–581.e1 (2013).
Kapp, S. How social deficit models exacerbate the medical model: autism as case in point. Autism Policy Pract. 2, 3–28 (2019).
Milton, D. E. M. On the ontological status of autism: the ‘double empathy problem. Disabil. Soc. 27, 883–887 (2012).
Sasson, N. J. et al. Neurotypical peers are less willing to interact with those with autism based on thin slice judgments. Sci. Rep. 7, 40700 (2017).
Morrison, K. E., DeBrabander, K. M., Faso, D. J. & Sasson, N. J. Variability in first impressions of autistic adults made by neurotypical raters is driven more by characteristics of the rater than by characteristics of autistic adults. Autism 23, 1817–1829 (2019).
DeBrabander, K. M. et al. Do first impressions of autistic adults differ between autistic and nonautistic observers? Autism Adulthood 1, 250–257 (2019).
Botha, M. & Frost, D. M. Extending the minority stress model to understand mental health problems experienced by the autistic population. Soc. Ment. Health 10, 20–34 (2020).
White, D., Hillier, A., Frye, A. & Makrez, E. College students’ knowledge and attitudes towards students on the autism spectrum. J. Autism Dev. Disord. 49, 2699–2705 (2019).
Butler, R. C. & Gillis, J. M. The impact of labels and behaviors on the stigmatization of adults with Asperger’s disorder. J. Autism Dev. Disord. 41, 741–749 (2011).
Gillespie-Lynch, K. et al. Factors underlying cross-cultural differences in stigma toward autism among college students in Lebanon and the United States. Autism 23, 1993–2006 (2019).
Hinshaw, S. P. & Stier, A. Stigma as related to mental disorders. Annu. Rev. Clin. Psychol. 4, 367–393 (2008).
Jones, D. R., DeBrabander, K. M. & Sasson, N. J. Effects of autism acceptance training on explicit and implicit biases toward autism. Autism 25, 1246–1261 (2021).
Flower, R. L., Dickens, L. M. & Hedley, D. Barriers to employment: raters’ perceptions of male autistic and non-autistic candidates during a simulated job interview and the impact of diagnostic disclosure. Autism Adulthood 3, 300–309 (2021).
Mitchell, P., Sheppard, E. & Cassidy, S. Autism and the double empathy problem: implications for development and mental health. Br. J. Dev. Psychol. 39, 1–18 (2021).
Davis, R. & Crompton, C. J. What do new findings about social interaction in autistic adults mean for neurodevelopmental research? Perspect. Psychol. Sci. 16, 649–653 (2021).
Kennedy, D. P. & Adolphs, R. The social brain in psychiatric and neurological disorders. Trends Cogn. Sci. 16, 559–572 (2012).
Lozier, L. M., Vanmeter, J. W. & Marsh, A. A. Impairments in facial affect recognition associated with autism spectrum disorders: a meta-analysis. Dev. Psychopathol. 26, 933–945 (2014).
Sheppard, E., Pillai, D., Wong, G. T.-L., Ropar, D. & Mitchell, P. How easy is it to read the minds of people with autism spectrum disorder? J. Autism Dev. Disord. 46, 1247–1254 (2016).
Edey, R. et al. Interaction takes two: typical adults exhibit mind-blindness towards those with autism spectrum disorder. J. Abnorm. Psychol. 125, 879–885 (2016).
Alkhaldi, R. S., Sheppard, E. & Mitchell, P. Is there a link between autistic people being perceived unfavorably and having a mind that is difficult to read? J. Autism Dev. Disord. 49, 3973–3982 (2019).
Heasman, B. & Gillespie, A. Perspective-taking is two-sided: misunderstandings between people with Asperger’s syndrome and their family members. Autism 22, 740–750 (2018).
Heasman, B. & Gillespie, A. Participants over-estimate how helpful they are in a two-player game scenario toward an artificial confederate that discloses a diagnosis of autism. Front. Psychol. 10, 1349 (2019).
Crompton, C. J., Hallett, S., Ropar, D., Flynn, E. & Fletcher-Watson, S. ‘I never realised everybody felt as happy as I do when I am around autistic people’: a thematic analysis of autistic adults’ relationships with autistic and neurotypical friends and family. Autism 24, 1438–1448 (2020).
Crompton, C. J., Ropar, D., Evans-Williams, C. V., Flynn, E. G. & Fletcher-Watson, S. Autistic peer-to-peer information transfer is highly effective. Autism 24, 1704–1712 (2020).
Chen, Y.-L., Senande, L. L., Thorsen, M. & Patten, K. Peer preferences and characteristics of same-group and cross-group social interactions among autistic and non-autistic adolescents. Autism 25, 1885–1900 (2021).
Granieri, J. E., McNair, M. L., Gerber, A. H., Reifler, R. F. & Lerner, M. D. Atypical social communication is associated with positive initial impressions among peers with autism spectrum disorder. Autism 24, 1841–1848 (2020).
Williams, G. L., Wharton, T. & Jagoe, C. Mutual (mis)understanding: reframing autistic pragmatic ‘impairments’ using relevance theory. Front. Psychol. 12, 616664 (2021).
Morrison, K. E. et al. Outcomes of real-world social interaction for autistic adults paired with autistic compared to typically developing partners. Autism 24, 1067–1080 (2020).
Komeda, H., Kosaka, H., Fujioka, T., Jung, M. & Okazawa, H. Do individuals with autism spectrum disorders help other people with autism spectrum disorders? An investigation of empathy and helping motivation in adults with autism spectrum disorder. Front. Psychiatry 10, 376 (2019).
Rifai, O. M., Fletcher-Watson, S., Jiménez-Sánchez, L. & Crompton, C. J. Investigating markers of rapport in autistic and nonautistic interactions. Autism Adulthood 4, 3–11 (2022).
Crompton, C. J. et al. Neurotype-matching, but not being autistic, influences self and observer ratings of interpersonal rapport. Front. Psychol. 11, 586171 (2020).
Cook, J. From movement kinematics to social cognition: the case of autism. Philos. Trans. R. Soc. B 371, 20150372 (2016).
Cook, J. L., Blakemore, S.-J. & Press, C. Atypical basic movement kinematics in autism spectrum conditions. Brain 136, 2816–2824 (2013).
Montobbio, N. et al. Intersecting kinematic encoding and readout of intention in autism. Proc. Natl Acad. Sci. USA 119, e2114648119 (2022).
Jones, S. C., Gordon, C. S., Akram, M., Murphy, N. & Sharkie, F. Inclusion, exclusion and isolation of autistic people: community attitudes and autistic people’s experiences. J. Autism Dev. Disord. 52, 1131–1142 (2022).
Sasson, N. J. & Morrison, K. E. First impressions of adults with autism improve with diagnostic disclosure and increased autism knowledge of peers. Autism 23, 50–59 (2019).
Baron-Cohen, S., Ashwin, E., Ashwin, C., Tavassoli, T. & Chakrabarti, B. Talent in autism: hyper-systemizing, hyper-attention to detail and sensory hypersensitivity. Philos. Trans. R. Soc. B 364, 1377–1383 (2009).
R Core Team. R: A Language and Environment for Statistical Computing (R Foundation for Statistical Computing, 2023).
Bates, D., Mächler, M., Bolker, B. & Walker, S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48 (2015).
Morey, R. D. & Rouder, J. N. BayesFactor: computation of Bayes factors for common designs. R version 0.9.12-4.7 https://doi.org/10.32614/CRAN.package.BayesFactor (2012).
Rouder, J. N. & Morey, R. D. Default Bayes factors for model selection in regression. Multivar. Behav. Res. 47, 877–903 (2012).
Bartoń, K. MuMIn: multi-model inference version 1.48.4 https://cran.r-project.org/web/packages/MuMIn/index.html (2024).
Kuznetsova, A., Brockhoff, P. B. & Christensen, R. H. B. lmerTest package: tests in linear mixed effects models. J. Stat. Softw. 82, 1–26 (2017).
Jaeger, B. r2glmm: computes R squared for mixed (multilevel) models version 0.1.2 https://cran.r-project.org/web/packages/r2glmm/index.html (2017).
Minshew, N. J. & Goldstein, G. Autism as a disorder of complex information processing. Ment. Retard. Dev. Disabili. Res. Rev. 4, 129–136 (1998).
Velikonja, T., Fett, A.-K. & Velthorst, E. Patterns of nonsocial and social cognitive functioning in adults with autism spectrum disorder: a systematic review and meta-analysis. JAMA Psychiatry 76, 135–151 (2019).
Vasquez‐Tokos, J. “If I Can Offer You Some Advice”: rapport and data collection in interviews between adults of different ages. Symb. Interact. 40, 463–482 (2017).
Lammers, W. J. & Byrd, A. A. Student gender and instructor gender as predictors of student–instructor rapport. Teach. Psychol. 46, 127–134 (2019).
Egalite, A. J. & Kisida, B. The effects of teacher match on students’ academic perceptions and attitudes. Educ. Eval. Policy An. 40, 59–81 (2018).
Leitner, J. B., Ayduk, Ö., Boykin, C. M. & Mendoza-Denton, R. Reducing negative affect and increasing rapport improve interracial mentorship outcomes. PLoS ONE 13, e0194123 (2018).
Abdous, M. & Yoshimura, M. Learner outcomes and satisfaction: a comparison of live video-streamed instruction, satellite broadcast instruction, and face-to-face instruction. Comput. Educ. 55, 733–741 (2010).
Pearson, A. & Rose, K. A Conceptual analysis of autistic masking: understanding the narrative of stigma and the illusion of choice. Autism Adulthood 3, 52–60 (2021).
Bradley, L., Shaw, R., Baron-Cohen, S. & Cassidy, S. Autistic adults’ experiences of camouflaging and its perceived impact on mental health. Autism Adulthood 3, 320–329 (2021).
Cassidy, S., Bradley, L., Shaw, R. & Baron-Cohen, S. Risk markers for suicidality in autistic adults. Mol. Autism 9, 42 (2018).
Miller, D., Rees, J. & Pearson, A. “Masking Is Life”: experiences of masking in autistic and nonautistic adults. Autism Adulthood 3, 330–338 (2021).
Hull, L. et al. Development and validation of the Camouflaging Autistic Traits Questionnaire (CAT-Q). J. Autism Dev. Disord. 49, 819–833 (2019).
Watts, G. et al. ‘A certain magic’ – autistic adults’ experiences of interacting with other autistic people and its relation to Quality of Life: a systematic review and thematic meta-synthesis. Autism https://doi.org/10.1177/13623613241255811 (2024).
Black, M. H. et al. “That impending dread sort of feeling”: experiences of social interaction from the perspectives of autistic adults. Res. Autism Spect. Dis. 101, 102090 (2023).
Sinclair, J. Don’t Mourn for Us (Autistic Rights Movement UK, 1999).
Ritvo, R. A. et al. The Ritvo Autism Asperger Diagnostic Scale-Revised (RAADS-R): a scale to assist the diagnosis of autism spectrum disorder in adults: an international validation study. J. Autism Dev. Disord. 41, 1076–1089 (2011).
Andersen, L. M. J. et al. The Swedish Version of the Ritvo Autism and Asperger Diagnostic Scale: Revised (RAADS-R). A validation study of a rating scale for adults. J. Autism Dev. Disord. 41, 1635–1645 (2011).
Eriksson, J. M., Andersen, L. M. & Bejerot, S. RAADS-14 Screen: validity of a screening tool for autism spectrum disorder in an adult psychiatric population. Mol. Autism 4, 49 (2013).
Flynn, E. & Whiten, A. Cultural transmission of tool use in young children: a diffusion chain study. Soc. Dev. 17, 699–718 (2008).
McGuigan, N. & Graham, M. Cultural transmission of irrelevant tool actions in diffusion chains of 3- and 5-year-old children. Eur. J. Dev. Psychol. 7, 561–577 (2010).
Flesch, R. A new readability yardstick. J. Appl. Psychol. 32, 221–233 (1948).
Kincaid, J. P., Fishburne, Jr, Robert, P., Rogers, R. L. & Chissom, B. S. Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel (DTIC, 1975); http://www.dtic.mil/docs/citations/ADA006655
Koo, T. K. & Li, M. Y. A guideline of selecting and reporting intraclass correlation coefficients for reliability research. J. Chiropr. Med. 15, 155–163 (2016).
Frisby, B. N. & Martin, M. M. Instructor–student and student–student rapport in the classroom. Commun. Educ. 59, 146–164 (2010).
Fletcher-Watson, S. et al. Diversity computing. interactions 25, 28–33 (2018).
Wechsler, D. Wechsler Abbreviated Scale of Intelligence—second edition (WASI-II) [database record]. APA PsycTests https://doi.org/10.1037/t15171-000 (2011).
Brysbaert, M. & Stevens, M. Power analysis and effect size in mixed effects models: a tutorial. J. Cogn. 1, 9 (2018).
DeBruine, L. M. & Barr, D. J. Understanding mixed-effects models through data simulation. Adv. Methods Pract. Psychol. Sci. https://doi.org/10.1177/2515245920965119 (2021).
Green, P. & MacLeod, C. J. SIMR: an R package for power analysis of generalized linear mixed models by simulation. Methods Ecol. Evol. 7, 493–498 (2016).
Kruschke, J. K. What to believe: Bayesian methods for data analysis. Trends Cogn. Sci. 14, 293–300 (2010).
Wagenmakers, E.-J. et al. Bayesian inference for psychology. Part I: theoretical advantages and practical ramifications. Psychon. Bull. Rev. 25, 35–57 (2018).
James, G., Witten, D., Hastie, T., Tibshirani, R. & Taylor, J. An Introduction to Statistical Learning: With Applications in Python (Springer, 2023).
James, G., Witten, D., Hastie, T. & Tibshirani, R. An Introduction to Statistical Learning Vol. 112 (Springer, 2013).
Bates, D., Kliegl, R., Vasishth, S. & Baayen, H. Parsimonious mixed models. Preprint at https://arxiv.org/abs/1506.04967 (2018).
Benjamini, Y. & Yekutieli, D. The control of the false discovery rate in multiple testing under dependency. Ann. Stat. 29, 1165–1188 (2001).
Bürkner, P.-C. brms: an R package for Bayesian multilevel models using Stan. J. Stat. Softw. 80, 1–28 (2017).
Pinheiro, J., Bates, D. & R Core Team. nlme: linear and nonlinear mixed effects models. https://cran.r-project.org/web/packages/nlme/index.html (2024).
Moussaïd, M., Brighton, H. & Gaissmaier, W. The amplification of risk in experimental diffusion chains. Proc. Natl Acad. Sci. USA 112, 5631–5636 (2015).
Moussaïd, M., Herzog, S. M., Kämmer, J. E. & Hertwig, R. Reach and speed of judgment propagation in the laboratory. Proc. Natl Acad. Sci. USA 114, 4117–4122 (2017).
Hyndman, R. fpp2: data for ‘Forecasting: Principles and Practice’ (second edition) https://cran.r-project.org/web/packages/fpp2/fpp2.pdf (2023).
Open Science Collaboration. Estimating the reproducibility of psychological science. Science 349, aac4716 (2015).
Yarkoni, T. The generalizability crisis. Behav. Brain Sci. 45, e1 (2022).
Thompson-Hodgetts, S., Labonte, C., Mazumder, R. & Phelan, S. Helpful or harmful? A scoping review of perceptions and outcomes of autism diagnostic disclosure to others. Res. Autism Spectr. Disord. 77, 101598 (2020).
Landis, J. R. & Koch, G. G. The measurement of observer agreement for categorical data. Biometrics 33, 159–174 (1977).
Faul, F., Erdfelder, E., Buchner, A. & Lang, A.-G. Statistical power analyses using G*Power 3.1: tests for correlation and regression analyses. Behav. Res. Methods 41, 1149–1160 (2009).
Acknowledgements
This work was funded by a grant from the Templeton World Charity Foundation (TWCF0442) awarded to C.J.C. (principal investigator), N.J.S., D.R. and S.F.-W. (co-investigators). Following peer review, the foundation offered additional funding to allow us to include a condition in which participants were uninformed about the diagnostic status of their interaction partner, as described in the Methods section. This was in response to recommendations from peer reviewers. Otherwise, the funders had no role in study design, data collection and analysis, decision to publish or preparation of the paper.
Author information
Authors and Affiliations
Contributions
C.J.C.: conceptualization, funding acquisition, methodology, project administration, investigation, methodology, writing—original draft, writing—reviewing and editing, and supervision. S.J.F.: data collection, project administration and writing—reviewing and editing. C.E.H.W.: data collection, project administration, writing—reviewing and editing. M.D.: data collection, project administration and writing—reviewing and editing. T.N.E.: data curation, visualization and writing—reviewing and editing. N.J.S.: conceptualization, funding acquisition, methodology, project administration, investigation, methodology, writing—reviewing and editing, and supervision. D.R.: conceptualization, funding acquisition, methodology, project administration, investigation, methodology, writing—reviewing and editing, and supervision. M.L.: methodology, visualization, formal analysis, writing—original draft and writing—reviewing and editing. S.F.-W.: conceptualization, funding acquisition, methodology, methodology and writing—reviewing and editing
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Human Behaviour thanks Cristina Becchio and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Supplementary information
Supplementary Information (download PDF )
Tables 1.1 and 1.2 and descriptive statistics of the sample; linear and nonlinear models of task performance; post hoc models, which include additional predictor variables; and linear models of rapport.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Crompton, C.J., Foster, S.J., Wilks, C.E.H. et al. Information transfer within and between autistic and non-autistic people. Nat Hum Behav 9, 1488–1500 (2025). https://doi.org/10.1038/s41562-025-02163-z
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41562-025-02163-z
This article is cited by
-
Reduced Habituation: A Key to Understanding Sensory Sensitivity in Autism
Journal of Autism and Developmental Disorders (2026)
-
Deep neural networks and deep deterministic policy gradient for early ASD diagnosis and personalized intervention in children
Scientific Reports (2025)
