
Abstract
Accurate land cover data was fundamental for formulating sound land planning and sustainable development strategies. This study focused on the Tibetan Plateau (TP), a globally sensitive ecological area, and developed a locally tailored annual 30 m resolution land cover dataset from 1990 to 2023 (TPLCD). Leveraging the Google Earth Engine (GEE) platform for Landsat data processing, LandTrendr was employed to generate robust, high-precision training samples. Subsequently, random forest classification and spatiotemporal smoothing strategies were applied to precisely map the land cover dynamics of the TP. Rigorous validation through visual interpretation, authoritative third-party datasets (Geo-Wiki and GLCVSS), and thematic dataset cross-comparisons, revealed an overall accuracy of 84.8%, and a Kappa coefficient of 0.78, fully affirming the dataset’s high reliability. This dataset provided invaluable empirical evidence for understanding the vulnerability and adaptability of the TP’s ecosystem.
Similar content being viewed by others

Background & Summary
Land cover, as a pivotal indicator for climate regulation and biodiversity conservation1,2, highlighted the intricate and persistent interplay between global ecosystem changes and human activities3. Since the 1950s, global agricultural expansion4, urban sprawl5,6 and other activities related to Land Use/Cover Change (LUCC) have increasingly influenced Earth system processes, including the surface energy balance7,8, carbon cycle9,10, hydrological dynamics11,12, and biodiversity patterns13,14,15. These changes have not only emerged as a primary driver of global ecological issues, but have also engendered significant uncertainties for regional ecosystems16,17,18. Obtaining continuous and accurate land cover products at fine spatial scales is essential for formulating effective ecological restoration strategies19 and supporting the implementation of climate change adaptation measures20,21,22. Remote sensing plays a central role in this field, enabling precise mapping of land cover dynamics23,24.
Over the past several decades, a wide range of remote sensing sensors, including MODIS, SPOT, Landsat, and Sentinel-2, have been extensively applied. Among these, Landsat has been particularly prominent in the detection and analysis of LUCC25 due to its long-term, freely accessible and continuous data record26, providing critical evidence for revealing historical trends in Earth’s surface dynamics27,28. Notable examples include FROM-GLC29, GlobeLand3030, and GLC_FCS3031. Concurrently, remote sensing data processing technology has undergone a profound paradigm shift from traditional workstations to cloud-based platforms. Google Earth Engine (GEE) epitomizes this trend32, offering users instant access to petabytes of satellite imagery and a diverse range of geospatial datasets, thereby enabling the generation of accurate annual land cover products on a global scale33.
Traditional national or regional land cover maps were typically updated annually, consuming considerable time and resources while posing challenges for the high-frequency collection of large-scale remote sensing imagery34. In light of these, some research has proposed classification expansion or generalization techniques to enable land cover classification without the need for annually updated training samples35,36. For instance, Gong et al. utilized metrics such as spectral distance to measure the similarity of sample data between different years, allowing for the selection of unchanged samples in inter-annual transfer tasks, thus demonstrating the feasibility of stable classification with limited samples for global land cover mapping37,38. Furthermore, continuous change detection schemes, such as Continuous Change Detection and Classification (CCDC)39, Time-Series Classification approach based on Change Detection (TSCCD)40, and Landsat-based detection of Trends in Disturbance and Recovery (LandTrendr)41 have been proposed. While CCDC algorithm can be executed on GEE, it was not well-suited for detecting more gradual land cover transitions unrelated to distinct disturbance events, such as vegetation regeneration42,43. Similarly, the TSCCD method, which integrates Prophet and Dynamic Time Warping, demanded significantly higher computational resources40. In contrast, LandTrendr, which can also run on the GEE platform, is more easily scaled to broad-area analyses44, and effectively applied to time-series change detection in medium-resolution satellite imagery, primarily Landsat. Moreover, LandTrendr demonstrates the ability to efficiently and accurately track LUCC at large scales, adeptly handling extensive time-series datasets while detecting and identifying changes in land cover types. It maintains high classification accuracy and exhibits strong resistance to disturbances41,45,46, showing robust performance in the presence of noise. Considering factors such as data storage requirements, computational efficiency, and scalability, LandTrendr offers a practical and reliable solution for mapping dynamic land cover changes with limited training samples.
The Tibetan Plateau (TP), renowned as the “Roof of the World” and the “Third Pole on Earth”47, serves not only as a pivotal ecological security barrier for Asia but also as one of the highest and most environmentally challenging regions globally, with human activities dating back 40,000 to 160,000 years48,49. In recent years, the dual impacts of climate change and human activities have triggered severe ecological issues, including grassland degradation and habitats fragmentation50,51, particularly affecting ecosystems dominated by alpine meadows and alpine steppes52,53. Nevertheless, existing datasets have not sufficiently delineated grassland systems in accordance with the unique ecological characteristics of the TP. Most studies have been confined to localized or typical areas54,55, lacking a systematic understanding of LUCC across the entire plateau, thereby highlighting limitations in research perspectives.
The Second Comprehensive Scientific Expedition to the Tibetan Plateau has defined a more precise geographic boundary based on plateau elevation and mountain integrity, encompassing not only southwestern China but also extending into neighboring countries, ensuring geographic continuity of the plateau’s margin56. Although the annual China Land Cover Dataset (CLCD)57 provided long-term, annually updated land cover data, its coverage does not fully align with the entire geographical boundary of the TP. While global land cover datasets, such as GlobeLand3030, offer basic land cover information for the region, their limitations in temporal resolution hinder in-depth analyses of long-term land cover dynamics. Furthermore, these datasets fail to adequately characterise the grassland-dominated ecosystem, impeding a deeper understanding of grassland ecological functions, degradation status, and restoration potential. Given the distinctive ecological characteristics of the TP and their vital role in global biodiversity conservation, it is imperative to develop a land cover classification system that distinguishes between different grassland types and provides precise, long-term monitoring of land cover dynamics across this integral geographical unit.
The study addressed the gap in high-resolution, long-term land cover monitoring of the TP. By leveraging the LandTrendr algorithm, a representative training dataset was developed. Utilizing GEE to process Landsat data, a series of spectral feature indices were derived, and a Random Forest (RF) classification model was employed to generate the Tibetan Plateau Land Cover Dataset (TPLCD), which provides annua land cover data for the TP from 1990 to 2023. The study pursued two main objectives: (1) to accurately monitor land cover dynamics on the TP over a long time series from 1990 to 2023 by applying a continuous change detection algorithm to construct representative training samples; and (2) to precisely assess the accuracy of the derived TPLCD using multi-source validation datasets. The findings provided highly credible data to analyse the current status of land cover on the TP, aiding policymakers to make informed, science-based decisions.
Methods
Study area
The TP, located between 25°59′-40°1′N and 67°40′-104°40′E, spans across nine countries, including China, India, and Nepal, with a total area of 3.08 million km2. Approximately 2.58 million km2 (accounting for 83.7% of the total area) lies within Chinese borders56. The TP has an average elevation of around 4,320 m and exhibits a diversity of climates, with temperature and precipitation generally decreasing from the southeast to the northwest. The southeastern region enjoys a warm and humid climate, while the northwest is colder and drier, with an annual average temperature ranging from −6 °C to 20 °C and an annual average precipitation varying from 20 mm to 4,500 mm. In recent decades, the TP has faced a series of ecological crises such as grassland degradation and habitat loss58, it is particularly urgent to conduct continuous and precise land cover monitoring, which is essential for capturing subtle ecological changes, providing timely warnings of potential risks (Fig. 1).

The study area of the research. (a) the elevation of the Tibetan Plateau, (b) geographical distribution of Landsat scenes used on the Tibetan Plateau, (c) number of Landsat scenes used on the Tibetan Plateau for each year from 1990 to 2023.
Overview
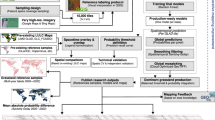
The workflow included training sample generation, feature variable input, RF classification, accuracy assessment, and dataset comparison (Fig. 2). This process primarily relied on the GEE platform. Initially, annual available Landsat images were collected, and key spectral indices were calculated. The LandTrendr algorithm was used to identify spectrally stable pixels, thereby gathering accurate and robust training samples. Subsequently, the RF algorithm was employed for annual classification, with the classification results smoothed and corrected using a spatiotemporal optimization strategy. Finally, the classification accuracy was evaluated by validation sets to produce a continuous and high-precision land cover maps for the TP from 1990 to 2023.

Research workflow for generating land cover products on the TP.
Landsat data processing
Landsat satellite imagery provided the longest time series of surface observations, with atmospheric corrections applied and cloud and shadow interference effectively removed using the CFMask technique59. This study utilized Surface Reflectance data from Landsat 5 (L5), Landsat 7 (L7), and Landsat 8 (L8) spanning from 1990 to 2023, totaling 93,520 scenes, specifically 27,694 scenes from L5, 43,394 scenes from L7, and 22,432 scenes from L8 (Fig. 1). To construct annual composite images, a 12-month temporal window was employed, implementing a pixel-level median compositing strategy. This approach effectively eliminated extreme values caused by clouds and shadows, while also mitigating edge effects at the junctions of different Landsat scenes, ensuring high fidelity and accuracy in the annual composite images60.
Classification system
The TP is predominantly covered by alpine grasslands, with alpine meadows and alpine steppes serving as typical components of this ecosystem61. Considering the unique regional attributes of the TP, the study developed a classification system comprising ten key land cover types: cropland, forest, shrubland, alpine steppe, alpine meadow, water bodies, bare land, impervious surfaces, wetlands, and snow/ice. This system not only subdivided the alpine grasslands ecosystem but also ensured compatibility and seamless conversion with international standardized systems, such as International Geosphere-Biosphere Programme (IGBP) (Table S1).
Feature variables input
In land cover mapping practices, integrating auxiliary environmental parameters and spectral indices can enhance classification accuracy60,62. This study calculated eight spectral indices to optimize classification performance, including the Modified Normalized Difference Water Index (MNDWI), Enhanced Vegetation Index (EVI), Bare Soil Index (BSI), Soil Adjusted Vegetation Index (SAVI), and the Normalized Difference Built-up and Bare Index (NDBBI), Normalized Difference Water Index (NDWI), 95th percentiles of NDVI (maxNDVI) and 5th percentiles of NDVI (minNDVI). Furthermore, Shuttle Radar Topography Mission Version 3 elevation data provided by NASA-JPL was incorporated to accurately represent topographic features. By combining six basic spectral bands, eight spectral indices, and three topographic variables (DEM, slope, and topographic diversity), a total of 17 feature variables were constructed (Table S2). This comprehensive strategy not only maintained the integrity of the time series, but also effectively reduced data dimensionality and significantly minimized the interference of external factors.
Training samples generation
In large-scale land cover mapping tasks, the study adopted an innovative strategy to collect high-quality training samples by leveraging the advanced change detection technique—the LandTrendr algorithm—to construct training samples with both spatiotemporally robust and reliable. LandTrendr, a trajectory and spectral time series segmentation algorithm, has demonstrated strong effectiveness in detecting and analysing subtle land cover changes over time, making it highly efficient for distinguishing stable areas from changing ones41,46. We applied LandTrendr to analyse three spectral indices sensitive to vegetation, water bodies, and non-vegetated hard surfaces: EVI, NDWI, and NDBBI. Specifically, the NDBBI was a crucial indicator for analysis of urban changes, excelling in highlighting the distribution of built-up areas and was highly sensitive for monitoring urban sprawl and assessing LUCC63. Parameter configurations for the LandTrendr algorithm are detailed in Table S3.
By applying linear regression to the spectral indices of each pixel, deviations potentially caused by land cover changes were identified (Fig. 3), enabling the selection of regions that have remained stable over the long term, which formed the ideal source of our training samples. This method was efficiently implemented on the GEE platform, providing robust computational support for large-scale analysis. Based on these, LandTrendr was employed to precisely locate pixels with high temporal and spatial consistency, forming the foundation of the classification model. Within these preselected stable regions, polygon samples were uniformly extracted to balance the accuracy and representativeness of the training samples while maintaining computational efficiency. Pixel values derived from these samples were then used for classification training (Table S4).

Schematic representation of four typical spectral changes detected using the LandTrendr algorithm. (a) no abrupt change, (b) single change, and (c) two changes.
Classification and spatial–temporal consistency
Although spatiotemporally stable areas significantly enhanced the reliability of samples, they were not entirely error-free. Previous studies have confirmed the RF models exhibit high robustness to training samples31,64, effectively supporting the use of samples derived from spatiotemporally stable regions for land cover classification. Consequently, we adopted the RF algorithm for land cover classification.
RF, proposed by Breiman, is a machine learning method that improves overall classification performance by constructing multiple decision trees and aggregating their outputs. Each tree is built using a random subset of the training data to reduce the risk of overfitting65. Considering the memory limitations of the GEE platform, after several iterations of experiments, we determined that setting the number of trees to 200 satisfied the classification accuracy requirements while avoiding resource overload.
To enhance the robustness of the land use classification, the study adopted an annual repeated classification strategy, conducting 10 classifications per year. These results were subsequently mode-synthesised at the raster scale to produce the final map, thereby reducing the variability inherent in single classifications. Additionally, to improve the temporal consistency of the classification series, a sliding window technique was employed to process multi-year data, which updated the land use types of the central year based on time series patterns within the sliding window. By comparing the confusion matrices of the smoothed results with window lengths of 3 and 5 years, we chose the 5-year window that more effectively reduced noise and improved classification accuracy (Fig. S1).
Accuracy assessment
In the field of land cover classification, accuracy assessment is crucial for ensuring the reliability of classification results. This study employed two validation strategies to assess the reliability of the classification results: (1) Visual Interpretation of Google Earth Images: Using the same strategy as for obtaining training samples, we applied spatially uniform sampling to randomly select 7,000 samples for visual interpretation, aiming to evaluate the data quality from 1990 to 2023 (Fig. 4). (2) Use of Authoritative Third-Party Datasets: Geo-Wiki66 and Global Land Cover Validation Sample Set (GLCVSS)67, for additional accuracy verification. Geo-Wiki is a crowdsourced validation resource providing samples covering ten major global land cover types with imagery spanning from 2000 to 2012. Considering data reliability, we selected 1,667 samples located in the TP and marked as “sure”. GLCVSS was designed based on random sampling principles to ensure global spatial representativeness and uniformity, making it suitable for use across many years and large spatial scales. From this dataset, we selected 1,005 samples. This study utilized confusion matrices based on Geo-Wiki and GLCVSS to evaluate the classification accuracy of TPLCD for the periods 2000–2012 and post-2013, quantifying key metrics such as Producer’s Accuracy (PA), User’s Accuracy (UA), Overall Accuracy (OA), Kappa coefficient, and F1 score. Besides, using these three datasets, we conducted cross-comparison analyses of existing land cover products including GLC_FCS30D68, CLCD57, MODIS Land Cover product (MCD12Q1)69, European Space Agency’s Global Land Cover product (ESA’s GLC)70,71, and ESRI’ Global Land Cover data (ESRI’s GLC)72. To ensure the comparability of different datasets, all were mapped to a common classification system following the IGBP classification scheme (Table S5).

Spatial distribution of the validation samples in TP. (a) Samples from visual interpretation referring to Google earth images; (b) Samples from Geo-wiki and GLVSS, and the number of samples for land use type on the two platforms was indicated in the photos.
Datasets inter-comparison
In addition to existing annual land cover products, this study enhances the comprehensiveness of quality assessment by conducting detailed comparisons with multiple specialized datasets. Specifically, TPLCD was meticulously compared with the Global Surface Water dataset (GSW)73, the Global Forest Change dataset (GFC)74,75, and global impervious surface datasets (GISA 2.076 and GAIA77). The GSW dataset (JRC Yearly Water Classification History, v1.4), covering the period from 1984 to 2021, features low error rates (omission error < 5%, commission error < 1%), ensuring high accuracy in water body identification. The GFC datasets included Hansen Global Forest Change v1.11 (2000–2023), focusing on areas with cover greater than 10%, and EC JRC global map of forest cover 2020, v1. These two datasets were used to validate the forest cover in TPLCD for the years 2000 and 2020, respectively. GISA 2.0 offered improved accuracy and stability compared to GISA 1.0; GAIA, for the first time, provided a 30 m resolution representation of dynamic artificial impervious surfaces from 1985 to 2018, with an average overall accuracy exceeding 90%. Based on these datasets, we integrated data on a spatial grid of 0.05° × 0.05° to create dot distribution maps showing the area covered by different datasets, and assessed the consistency and accuracy of TPLCD using linear regression and the coefficient of determination (R²)78.
Data Records
TPLCD provides an annually updated land cover dataset for the TP from 1990 to 2023, with a spatial resolution of 30 m, using the WGS-84 as the spatial reference, and publicly available in GeoTIFF format on Zenodo79. The pixel values range from 1 to 10, corresponding to the following land use types: 1 for cropland, 2 for forest, 3 for shrubland, 4 for alpine steppe, 5 for alpine meadow, 6 for water body, 7 for bare land, 8 for impervious surfaces, 9 for wetlands, and 10 for snow/ice.
Technical Validation
Accuracy assessment of TPLCD
Based on all available Landsat data on GEE, we generated the annually updated TPLCD from 1990 to 2023. To validate the accuracy of TPLCD, we first compared it with samples visually interpreted based on Google Earth imagery. The dataset demonstrated stable reliability, with OA ranging from 72.04% to 90.11% and an average OA of 79.07%. Additionally, the Kappa coefficient varied between 0.68 and 0.88, with an average value of 0.76. Forests exhibited the highest average F1 score (87.76%), followed by water bodies (86.54%), impervious areas (85.59%), and wetlands (83.24%) (Table 1).
To further validate the accuracy of TPLCD, we utilized Geo-Wiki to conduct a detailed comparison between TPLCD, GLC_FCS30D, CLCD, and MCD12Q1 from 2000 to 2012. The statistics indicated that TPLCD consistently exhibited higher classification accuracy, with OA ranging from 84.95% to 89.62% and Kappa coefficients between 0.74 and 0.82. The average OA and Kappa values were 86.31% and 0.77, respectively, significantly outperforming MCD12Q1 (average OA = 71.98%, Kappa = 0.49), GLC_FCS30D (average OA = 76.34%, Kappa = 0.57), and CLCD (average OA = 81.98%, Kappa = 0.66) (Table 2). Among the various land cover types, grasslands had the highest F1 score at 91.61%, followed by forests (90.07%), water bodies (81.79%), barren lands (75.96%), and impervious surfaces (75.38%). Furthermore, using GLCVSS, we evaluated the performance of TPLCD relative to GLC_FCS30D, CLCD, ESA’s GLC, ESRI’s GLC, and MCD12Q1 after 2015. During this period, TPLCD maintained the highest accuracy, with average OA and Kappa coefficients of 88.44% and 0.81, respectively (Table 3). Among the other datasets, ESA’s GLC performed second best with an average OA of 87.9% and a Kappa of 0.81, followed by GLC_FCS30D with an average OA of 86.66% and a Kappa of 0.74.
In summary, through visual interpretation verification and comparisons with third-party datasets, TPLCD has demonstrated superior OA compared to MCD12Q1, ESA’s GLC, CLCD, GLC_FCS30D, and ESRI’s GLC. TPLCD achieved an average OA of 84.8% and an average Kappa coefficient of 0.78. Notably, TPLCD offers a continuous time series spanning 34 years (1990–2023), providing more extensive temporal coverage compared to ESRI’s GLC (2017 to 2022), ESA’s GLC (2020 to 2021), and MCD12Q1 (2001 to 2022).
Comparison with other products
Through thematic comparison with GFC datasets, TPLCD-forest demonstrated a high degree of consistency with both Hansen-forest and JRC-forest. Specifically, the R² between TPLCD-forest and Hansen-forest was 0.88, while the R² with JRC-forest was as high as 0.96. These high values strongly validate the reliability and accuracy of TPLCD in forest classification (Fig. 5). The spatial distribution of TPLCD-forest also showed significant similarity to that of the two GFC datasets, visually confirming the quality of the TPLCD-forest and further highlighting its potential and application value in global-scale forest monitoring (Fig. 6).

Scatterplots of forest areas between the TPLCD and GFC in the TP in 2000 and 2020.

Forest map examples for TPLCD and GFC in 2000 and 2020.
This study also analysed the R² between TPLCD and GSW dataset concerning water body area at the grid scale from 1990 to 2021 to validate the accuracy of TPLCD. The results showed the R2 between the two datasets fluctuated between 0.61 and 0.9 during 1990–1999, with the R² of 0.73 in 1990. Since 2000, the R² has shown a steady increase, reaching 0.98 in 2021 (Fig. 7), indicating a significant improvement in the consistency between the datasets. To further assess the accuracy of water bodies in TPLCD, we selected three representative lakes—Qinghai Lake, Namtso, and Zhari Namco—and analyzed their distribution maps for the four periods of 1990, 2000, 2010, and 2023. The findings indicated an expansion trend in the lakes on the TP (Figs. S2–4), which aligns with numerous existing studies80,81,82. Moreover, further exploration in the spatial dimension confirmed the high consistency between TPLCD and GSW in depicting water distribution patterns, while also demonstrating the finesse of the GSW dataset in capturing the dynamic changes of seasonal and permanent water surfaces (Fig. 8).

Scatterplots of water body areas between the TPLCD and GSW during 2000 and 2020.

Examples of water body morphology for TPLCD and GSW in 1990 and 2021.
In recent years, with the acceleration of urbanization, the impervious surface area (ISA) on the TP has shown a significant growth trend. The study conducted a comparative analysis with existing 30 m resolution ISA products (GAIA and GISA 2.0) and used a linear regression model to evaluate the consistency between these datasets. The results indicated strong consistency between TPLCD-ISA and GAIA, with R² values ranging from 0.55 to 0.76 (Figs. S5, S6), while TPLCD-ISA showed a high spatial fit with both GAIA and GISA 2.0 in the urban areas of Xining and Srinagar, but GISA 2.0 failed to capture the dynamics of the city in Lhasa (Fig. 9). Notably, the average slope of TPLCD-ISA was higher compared to GAIA (0.57) and GISA 2.0 (0.3), suggesting that existing ISA data might be underestimating ISA changes. TPLCD-ISA provided a more accurate and detailed depiction of ISA changes, particularly in identifying the expansion of rural settlements in the complex terrain of the TP, showcasing its unique advantages. This is attributed to the limitations of GAIA and GISA 2.0 at a global scale, which do not fully capture the unique ISA dynamics of the region. Although the TP is not a mainstream region for global urbanization, its urbanization strategies hold a unique position due to their special mission of safeguarding national security and maintaining ecological security.

Comparative examples of development dynamics from the cities of Xining, Lhasa and Srinagar in TPLCD, GAIA and GISA 2.0 respectively.
Limitations and prospects
The study developed the TPLCD from 1990 to 2023 using Landsat data on the GEE platform, achieving an OA of 84.8%. Despite this, the dataset still had some limitations, primarily due to issues with the data sources. The L5 and L7 data suffered from uneven spatial and temporal coverage, early data acquisition limitations, and technical faults that affected data integrity, significantly impacting the accuracy and precision of the TPLCD. The research found that the misclassification rates of land cover types and the number of masked pixels before 2000 were significantly higher than those after 2000. Classification accuracy improved significantly after 2000, and the stability of the dataset strengthened since 2012. L5 had lost relay capability since 1992, making its data transmission dependent on receiving station28,83, while L7, although technologically upgraded, suffered from a Scan Line Corrector failure in 2003, resulting in data stripe loss60, severely impacting data acquisition and continuity analysis of the TP. Besides, the high altitude and variable weather conditions of the TP often resulted in cloud cover84, and the wide field-of-view design of L5 and L7 further complicated data acquisition, affecting the coherence of the time series.
Indeed, while the LandTrendr algorithm has shown unique advantages in environmental monitoring and tracking land use changes, it also faces certain limitations. The 16-day revisit cycle of Landsat satellites results in a discontinuous observational data sequence85, making LandTrendr potentially blind when detecting short-term events such as sudden forest disturbances. Cloud cover is another factor impacting the performance of LandTrendr, frequent cloud coverage can lead to gaps in the time series or anomalies in phenological characteristics due to a lack of valid data45. Without access to complete and continuous data, LandTrendr may struggle to accurately capture trends within a region. Additionally, while LandTrendr effectively identifies the year in which a change occurs, its capability to detect changes at finer temporal scales, such as intra-seasonal variations, remains limited, which restricts its effectiveness in specific application scenarios.
Despite these inherent limitations of the data, TPLCD incorporated a locally tailored land cover classification system, enabling precise evaluation of grassland degradation and restoration dynamics. It successfully filled the gap in long-term, high-precision land cover data for the TP, a comprehensive natural geographic unit. Future research aims to address the limitations of long-term land cover change monitoring on the TP by optimizing monitoring efficiency and data quality from multiple dimensions. Multi-source satellite data, such as Sentinel imagery, will be integrated to compensate for the spatial resolution and specific period data gaps of the Landsat series. Moreover, advanced cloud detection algorithms and sub-cloud surface feature restoration techniques will be explored using deep learning technology to accurately process cloud-obscured areas and enhance data validity and purity. Furthermore, integrating ground truth data, meteorological variables, and socio-economic indicators will strengthen the accuracy of tracking and forecasting land cover dynamics.
Usage Notes
This study developed an annual land cover dataset, TPLCD, covering yearly updated land cover products from 1990 to 2023 at a 30 m resolution, including 10 land use types. Through multi-dimensional validation, TPLCD demonstrated high classification accuracy, with an OA of 84.8% and a Kappa coefficient of 0.78, and an average F1 score surpassing those of similar products. As the first land cover monitoring product for the TP covering a 34-year period and tailored to local characteristics, TPLCD deepened the understanding of the states and functional differences within grassland ecosystems through detailed differentiation of alpine grasslands, and successfully filled the gap in long-term, high-precision land cover data for this unique natural geographic unit. Not only does TPLCD provide invaluable resources for researchers studying ecological security issues on the TP and globally, but it also lays a solid foundation for formulating effective conservation strategies.
Code availability
The TPLCD mapping algorithms were implemented in GEE. The map processing codes and produced TPLCD were available on zenodo79.
References
Bojinski, S. et al. The Concept of Essential Climate Variables in Support of Climate Research, Applications, and Policy. Bulletin of the American Meteorological Society 95, 1431–1443 (2014).
Pettorelli, N. et al. Framing the concept of satellite remote sensing essential biodiversity variables: challenges and future directions. Remote Sensing in Ecology and Conservation 2, 122–131 (2016).
Feng, S. et al. Land Use/Land Cover Mapping Based on GEE for the Monitoring of Changes in Ecosystem Types in the Upper Yellow River Basin over the Tibetan Plateau. Remote Sensing 14, 5361 (2022).
Macedo, M. N. et al. Decoupling of deforestation and soy production in the southern Amazon during the late 2000s. Proc. Natl. Acad. Sci. U.S.A. 109, 1341–1346 (2012).
Darvishi, A., Yousefi, M. & Marull, J. Modelling landscape ecological assessments of land use and cover change scenarios. Application to the Bojnourd Metropolitan Area (NE Iran). Land Use Policy 99, 105098 (2020).
Xiong, H., Ma, C., Li, M., Tan, J. & Wang, Y. Landslide susceptibility prediction considering land use change and human activity: A case study under rapid urban expansion and afforestation in China. Science of The Total Environment 866, 161430 (2023).
Adeyeri, O. E. et al. Land use and land cover dynamics: Implications for thermal stress and energy demands. Renewable and Sustainable Energy Reviews 179, 113274 (2023).
Ghodichore, N., Dhanya, C. T. & Hendricks Franssen, H.-J. Isolating the effects of land use land cover change and inter-decadal climate variations on the water and energy cycles over India, 1981–2010. Journal of Hydrology 612, 128267 (2022).
Hou, H. et al. Future Land Use/Land Cover Change Has Nontrivial and Potentially Dominant Impact on Global Gross Primary Productivity. Earth’s Future 10, e2021EF002628 (2022).
Tang, X., Woodcock, C. E., Olofsson, P. & Hutyra, L. R. Spatiotemporal assessment of land use/land cover change and associated carbon emissions and uptake in the Mekong River Basin. Remote Sensing of Environment 256, 112336 (2021).
Liu, Z., Rong, L. & Wei, W. Impacts of land use/cover change on water balance by using the SWAT model in a typical loess hilly watershed of China. Geography and Sustainability 4, 19–28 (2023).
Yilmaz, Y. A., Sen, O. L. & Turuncoglu, U. U. Modeling the hydroclimatic effects of local land use and land cover changes on the water budget in the upper Euphrates – Tigris basin. Journal of Hydrology 576, 596–609 (2019).
Desta, H. & Fetene, A. Land-use and land-cover change in Lake Ziway watershed of the Ethiopian Central Rift Valley Region and its environmental impacts. Land Use Policy 96, 104682 (2020).
Luiza Petroni, M., Siqueira-Gay, J. & Lucia Casteli Figueiredo Gallardo, A. Understanding land use change impacts on ecosystem services within urban protected areas. Landscape and Urban Planning 223, 104404 (2022).
Prestele, R. et al. Hotspots of uncertainty in land-use and land-cover change projections: a global-scale model comparison. Global Change Biology 22, 3967–3983 (2016).
Jones, K. R. et al. One-third of global protected land is under intense human pressure. Science 360, 788–791 (2018).
Shrestha, N., Xu, X., Meng, J. & Wang, Z. Vulnerabilities of protected lands in the face of climate and human footprint changes. Nat Commun 12, 1632 (2021).
Xu, P., Herold, M., Tsendbazar, N.-E. & Clevers, J. G. P. W. Towards a comprehensive and consistent global aquatic land cover characterization framework addressing multiple user needs. Remote Sensing of Environment 250, 112034 (2020).
Chen, X. et al. Distribution of ecological restoration projects associated with land use and land cover change in China and their ecological impacts. Science of The Total Environment 825, 153938 (2022).
Cui, F. et al. Climate change versus land-use change—What affects the ecosystem services more in the forest-steppe ecotone? Science of the Total Environment 759, 143525 (2021).
Lekka, C., Petropoulos, G. P. & Detsikas, S. E. Appraisal of EnMAP hyperspectral imagery use in LULC mapping when combined with machine learning pixel-based classifiers. Environmental Modelling & Software 173, 105956 (2024).
Li, X. et al. Untangling the effects of climate change and land use/cover change on spatiotemporal variation of evapotranspiration over China. Journal of Hydrology 612, 128189 (2022).
Wang, Y. et al. A review of regional and Global scale Land Use/Land Cover (LULC) mapping products generated from satellite remote sensing. ISPRS Journal of Photogrammetry and Remote Sensing 206, 311–334 (2023).
Zakeri, F. & Mariethoz, G. A review of geostatistical simulation models applied to satellite remote sensing: Methods and applications. Remote Sensing of Environment 259, 112381 (2021).
Tassi, A. & Vizzari, M. Object-Oriented LULC Classification in Google Earth Engine Combining SNIC, GLCM, and Machine Learning Algorithms. Remote Sensing 12, 3776 (2020).
Potapov, P. et al. Landsat Analysis Ready Data for Global Land Cover and Land Cover Change Mapping. Remote Sensing 12, 426 (2020).
Hemati, M., Hasanlou, M., Mahdianpari, M. & Mohammadimanesh, F. A Systematic Review of Landsat Data for Change Detection Applications: 50 Years of Monitoring the Earth. Remote Sensing 13, 2869 (2021).
Wulder, M. A. et al. The global Landsat archive: Status, consolidation, and direction. Remote Sensing of Environment 185, 271–283 (2016).
Gong, P. et al. Finer resolution observation and monitoring of global land cover: first mapping results with Landsat TM and ETM+ data. International Journal of Remote Sensing 34, 2607–2654 (2013).
Chen, J. et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS Journal of Photogrammetry and Remote Sensing 103, 7–27 (2015).
Zhang, X. et al. GLC_FCS30: global land-cover product with fine classification system at 30m using time-series Landsat imagery. Earth System Science Data 13, 2753–2776 (2021).
Gorelick, N. et al. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sensing of Environment 202, 18–27 (2017).
Xu, H. et al. Monitoring three-decade dynamics of citrus planting in Southeastern China using dense Landsat records. International Journal of Applied Earth Observation and Geoinformation 103, 102518 (2021).
Peña-Barragán, J. M., Ngugi, M. K., Plant, R. E. & Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sensing of Environment 115, 1301–1316 (2011).
Hestir, E. L., Greenberg, J. A. & Ustin, S. L. Classification trees for aquatic vegetation community prediction from imaging spectroscopy. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 5, 1572–1584 (2012).
Zhong, L., Hawkins, T., Biging, G. & Gong, P. A phenology-based approach to map crop types in the San Joaquin Valley, California. International Journal of Remote Sensing 32, 7777–7804 (2011).
Gong, P., Wang, J. & Huang, H. Stable classification with limited samples in global land cover mapping: Theory and experiments. Science Bulletin https://doi.org/10.1016/j.scib.2024.03.040 (2024).
Huang, H. et al. The migration of training samples towards dynamic global land cover mapping. ISPRS Journal of Photogrammetry and Remote Sensing 161, 27–36 (2020).
Zhu, Z. & Woodcock, C. E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sensing of Environment 144, 152–171 (2014).
Yan, J. et al. A time-series classification approach based on change detection for rapid land cover mapping. ISPRS Journal of Photogrammetry and Remote Sensing 158, 249–262 (2019).
Cohen, W. B., Yang, Z., Healey, S. P., Kennedy, R. E. & Gorelick, N. A LandTrendr multispectral ensemble for forest disturbance detection. Remote Sensing of Environment 205, 131–140 (2018).
Zhu, Z. et al. Continuous monitoring of land disturbance based on Landsat time series. Remote Sensing of Environment 238, 111116 (2020).
Cohen, W. B. et al. How Similar Are Forest Disturbance Maps Derived from Different Landsat Time Series Algorithms? Forests 8, 98 (2017).
Pasquarella, V. J. et al. Demystifying LandTrendr and CCDC temporal segmentation. International Journal of Applied Earth Observation and Geoinformation 110, 102806 (2022).
Mugiraneza, T., Nascetti, A. & Ban, Y. Continuous Monitoring of Urban Land Cover Change Trajectories with Landsat Time Series and LandTrendr-Google Earth Engine Cloud Computing. Remote Sensing 12, 2883 (2020).
Shimizu, K., Murakami, W., Furuichi, T. & Estoque, R. C. Mapping Land Use/Land Cover Changes and Forest Disturbances in Vietnam Using a Landsat Temporal Segmentation Algorithm. Remote Sensing 15, 851 (2023).
Yao, T. et al. Third Pole Environment (TPE). Environmental Development 3, 52–64 (2012).
Chen, F. et al. A late Middle Pleistocene Denisovan mandible from the Tibetan Plateau. Nature 569, 409–412 (2019).
Zhang, D., Xia, H. & Chen, F. Early human occupation of the Tibetan Plateau. Science Bulletin 63, 1598–1600 (2018).
Han, W. et al. Anthropogenic activities altering the ecosystem in Lake Yamzhog Yumco, southern Qinghai-Tibetan Plateau. Science of The Total Environment 904, 166715 (2023).
Wang, Q., Wang, R., Yang, X., Anderson, N. J. & Kong, L. Interactive effects of climate-atmospheric cycling on aquatic communities and ecosystem shifts in mountain lakes of southeastern Tibetan Plateau. Science of The Total Environment 914, 169825 (2024).
Hua, T., Zhao, W., Cherubini, F., Hu, X. & Pereira, P. Continuous growth of human footprint risks compromising the benefits of protected areas on the Qinghai-Tibet Plateau. Global Ecology and Conservation 34, e02053 (2022).
Wang, Z., Li, J. & Liang, L. Ecological risk in the Tibetan Plateau and influencing urbanization factors. Environmental Challenges 6, 100445 (2022).
Li, P. et al. Dynamic changes of land use/cover and landscape pattern in a typical alpine river basin of the Qinghai‐Tibet Plateau, China. Land Degrad Dev 32, 4327–4339 (2021).
Wang, Z. & Huang, L. Spatial variations and influencing factors of soil organic carbon under different land use types in the alpine region of Qinghai-Tibet Plateau. Catena 220, 106706 (2023).
Zhang, Y., Li, B., Liu, L. & Zheng, D. Redetermine the region and boundaries of Tibetan Plateau(in chinese). Geographical Research 40, 1543–1553 (2021).
Yang, J. & Huang, X. The 30m annual land cover dataset and its dynamics in China from 1990 to 2019. Earth System Science Data 13, 3907–3925 (2021).
Wang, S. et al. Assessment of multiple factors and interactions affecting grassland degradation on the Tibetan Plateau. Ecological Indicators 154, 110509 (2023).
Foga, S. et al. Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sensing of Environment 194, 379–390 (2017).
Ji, Q. et al. Mapping land use/cover dynamics of the yellow river basin from 1986 to 2018 supported by google earth engine. Remote Sensing 13, (2021).
Xia, J. et al. Estimates of grassland biomass and turnover time on the Tibetan Plateau. Environ. Res. Lett. 13, 014020 (2018).
Polykretis, C., Grillakis, M. G. & Alexakis, D. D. Exploring the impact of various spectral indices on land cover change detection using change vector analysis: A case study of Crete Island, Greece. Remote Sensing 12, 319 (2020).
Samat, A. et al. Mapping blue and red color-coated steel sheet roof buildings over china using sentinel-2a/b msil2a images. Remote Sensing 14, 230 (2022).
Pelletier, C., Valero, S., Inglada, J., Champion, N. & Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sensing of Environment 187, 156–168 (2016).
Breiman, L. Random forests. Machine Learning 45, 5–32 (2001).
Fritz, S. et al. A global dataset of crowdsourced land cover and land use reference data. Sci Data 4, 170075 (2017).
Zhao, Y. et al. Towards a common validation sample set for global land-cover mapping. International Journal of Remote Sensing 35, 4795–4814 (2014).
Zhang, X. et al. GLC_FCS30D: the first global 30m land-cover dynamics monitoring product with a fine classification system for the period from 1985 to 2022 generated using dense-time-series Landsat imagery and the continuous change-detection method. Earth System Science Data 16, 1353–1381 (2024).
Sulla-Menashe, D., Gray, J. M., Abercrombie, S. P. & Friedl, M. A. Hierarchical mapping of annual global land cover 2001 to present: The MODIS Collection 6 Land Cover product. Remote Sensing of Environment 222, 183–194 (2019).
Zanaga, D. et al. ESA WorldCover 10 m 2020 v100. Zenodo https://doi.org/10.5281/zenodo.5571936 (2021).
Zanaga, D. et al. ESA WorldCover 10 m 2021 v200. Zenodo https://doi.org/10.5281/zenodo.7254221 (2022).
Karra, K. et al. Global land use/land cover with Sentinel 2 and deep learning. in 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS 4704–4707, https://doi.org/10.1109/IGARSS47720.2021.9553499 (2021).
Pekel, J.-F., Cottam, A., Gorelick, N. & Belward, A. S. High-resolution mapping of global surface water and its long-term changes. Nature 540, 418–422 (2016).
Clement, B. et al. Mapping Global Forest Cover of the Year 2020 to Support the EU Regulation on Deforestation-free Supply Chains (2024).
Hansen, M. C. et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 342, 850–853 (2013).
Huang, X. et al. Toward accurate mapping of 30-m time-series global impervious surface area (GISA). International Journal of Applied Earth Observation and Geoinformation 109, 102787 (2022).
Gong, P. et al. Annual maps of global artificial impervious area (GAIA) between 1985 and 2018. Remote Sensing of Environment 236, 111510 (2020).
Zhang, X. et al. Development of a global 30m impervious surface map using multisource and multitemporal remote sensing datasets with the Google Earth Engine platform. Earth System Science Data 12, 1625–1648 (2020).
Li, S. et al. Annual 30 m land cover dataset on the Tibetan Plateau from 1990 to 2023. Zenodo https://doi.org/10.5281/zenodo.13989241 (2024).
Zhang, G., Luo, W., Chen, W. & Zheng, G. A robust but variable lake expansion on the Tibetan Plateau. Sci. Bull 64, 1306–1309 (2019).
Song, C., Huang, B., Richards, K., Ke, L. & Hien Phan, V. Accelerated lake expansion on the Tibetan Plateau in the 2000s: Induced by glacial melting or other processes? Water Resources Research 50, 3170–3186 (2014).
Xu, F. et al. Widespread societal and ecological impacts from projected Tibetan Plateau lake expansion. Nat. Geosci. 17, 516–523 (2024).
Loveland, T. R. & Dwyer, J. L. Landsat: Building a strong future. Remote Sensing of Environment 122, 22–29 (2012).
Xie, S., Liu, L., Zhang, X. & Chen, X. Annual land-cover mapping based on multi-temporal cloud-contaminated landsat images. International Journal of Remote Sensing 40, 3855–3877 (2019).
Gao, F. et al. Fusing Landsat and MODIS Data for Vegetation Monitoring. IEEE Geoscience and Remote Sensing Magazine 3, 47–60 (2015).
Acknowledgements
This study was supported by the Special Project of the Chinese Academy of Sciences.
Author information
Authors and Affiliations
Contributions
Siya Li: Methodology, Software, Data curation, Visualization, Writing – original draft. Quansheng Ge: Conceptualization, Project administration, Supervision. Fubao Sun: Conceptualization, Supervision Methodology, Project administration. Qiulei Ji: Methodology, Software, Writing – review & editing. Wenbin Liu: Supervision, Writing – review & editing. Ronggao Liu: Software, Visualization. Duanyang Xu: Visualization, Writing – review & editing. Zexing Tao: Supervision, Methodology.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, S., Ge, Q., Sun, F. et al. Annual 30 m land cover dataset on the Tibetan Plateau from 1990 to 2023. Sci Data 12, 510 (2025). https://doi.org/10.1038/s41597-025-04759-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-04759-6
