
Abstract
Hydropower is a crucial renewable source that depends heavily on water availability. Analyzing drought and climate change impacts on hydropower potential requires detailed data on both hydropower plant attributes (e.g. plant type and head) and reservoir characteristics (e.g. area, depth and volume). However, existing open-source datasets are poorly integrated: hydropower plant datasets often lack reservoir information, while reservoir datasets commonly miss hydropower plant information. This paper addresses this gap by introducing GloHydroRes, a global dataset that combines existing open-source hydropower plant and reservoir datasets. GloHydroRes includes attributes like plant location, head, plant type as well as reservoir details such as dam and reservoir location, dam height, reservoir depth, area, and volume for 7,775 plants in 128 countries. GloHydroRes covers nearly 79% and 81% of the global installed capacity when compared with installed hydropower data as reported by the EIA(2022) and IRENA (2023), respectively. The open-source GloHydroRes dataset provides crucial data to improve hydropower generation modelling at plant level and can support energy security and planning at continent to global scale.
Similar content being viewed by others
Background & Summary
Hydropower is considered an important source of renewable energy due to its flexibility and storage capabilities, accounting for nearly 14% of all electricity generation in 20231. Furthermore, to decarbonize the power sector and achieve the Paris Agreement targets, hydropower capacity needs to be expanded2. This is particularly true in developing countries where growing population and economic development increase energy demand3,4. These countries also coincidentally tend to have high exploitable hydropower potential5. Hydropower potential mainly depends on water availability. Therefore, climate change and hydroclimatic extremes such as droughts can have major impacts on their operations. It is thus important to study the linkage between climate, streamflow, and hydropower generation especially for hydro-dependent power systems in the world. These studies are of major value for effective energy policy making at the water-energy nexus, benefiting both short-term energy supply security and long-term energy transition strategies6. These studies require detailed data on hydropower plant and reservoir characteristics, while currently a global dataset with consistent reporting of the information is lacking6.
Hydropower plants can be categorized into three main types based on their storage capacity and function: storage (STO), pumped storage (PS), and run-of-river (ROR). ROR is a type of hydropower plant that utilizes the natural flow of rivers and elevation decrease to generate electricity with little or no water storage7. Hydropower facilities located on man-made canals or aqueducts are commonly referred to as canal plants. In contrast, storage (STO) hydropower uses large reservoirs that allow them to generate electricity during periods of dry conditions and high energy demand8,9. Pumped storage (PS) plants function as energy batteries, with two reservoirs at different elevations. During periods of low energy demand, water is pumped from the lower reservoir to the upper reservoir and then released back to the lower reservoir during high energy demand. The multi-purpose nature of reservoirs and competition for water amongst different sectors and functions (e.g. drinking supply, irrigation, navigation, flood control, and recreation)10,11 also impact the outflow from reservoirs and thereby influencing hydropower generation12,13. Moreover, the growing demand for water in water-stressed areas–driven by factors such as increased irrigation needs, climate change, industrial usage, and hydropower generation has led to the development of Inter-Basin Transfer (IBT) projects14. These projects move water from one basin or river to another, thus not only impact the hydropower generation capacity of donor basin but also that of the receiving basin by altering streamflow patterns15. To effectively simulate hydropower generation, especially for large reservoirs and at sub-annual scale, detailed data is required beyond just streamflow. This includes information on reservoir elevation and tailwater elevation (with their difference, commonly known as plant head), exact reservoir location (latitude, longitude), reservoir operation rules and reservoir characteristics such as the area for evaporation losses16,17. Furthermore, to effectively simulate hydropower generation in IBT projects, where water transfer is managed manually, it is essential to have data on the project’s water transfer volume capacity, sectoral water demands, and the water allocation strategy15.
Previous studies that analysed drought and climate change impacts on existing hydropower highly differ in their levels of detail. Hydropower usable capacity were analysed for 24,515 hydropower plants globally18,19, but the head dynamics were disregarded due to lack of detailed data on reservoir characteristics. Turner et al.16 applied detailed modelling with time-varying head information and evaporation losses from reservoir, but only 1,593 hydropower plants globally were examined due to data limitations. Other studies which used detailed modelling techniques focused either on single river basin20 or specific regions such as the United States21,22 and Europe23.
The primary barrier to detailed global-scale modelling is the lack of a comprehensive, open-access dataset that integrates both hydropower plant characteristics (e.g., installed capacity, hydraulic head, plant type) and reservoir data (dam height, surface area, and volume). Existing hydropower plant datasets differ in their coverage and level of details. For instance, the global power plant dataset from the World Resource Institute (WRI)24 provides information on nearly 7,000 existing hydropower plants, including installed capacity, generation, and commissioning year. However, this WRI global hydropower plant datasets lacks reservoir attributes. Regional datasets often offer more details. For example, the recently published Renewable Power Plant database for Africa (RePP)25 includes information on both existing and planned hydropower plants in Africa. Together with plant attributes, it provides plant type (ROR, STO and PS), dam height, and reservoir volume for some of the hydropower plants. Similarly, the JRC hydropower database26, developed as part of the Water-Energy-Food-Ecosystem-Nexus project provides certain reservoir information such as dam height and reservoir volume. Regardless, both regional datasets lack information on reservoir location, and none of the two datasets provide the actual head of hydropower plants. Based on a comprehensive literature review, the most complete database linking hydropower with reservoirs is, to our knowledge, only publicly available for the United States. The linking of Existing Hydropower Assets (EHA)27 dataset with Hydropower Infrastructure - LAkes, Reservoirs, and RIvers (HILARRI)28 dataset, both provided by OAK RIDGE National Laboratory, using common id (eha_id), provides not only reservoir characteristics but also reports actual head of each hydropower plant. On the other hand, various reservoir datasets exist, but they usually lack information on hydropower plant characteristics (e.g. plant type, head). The Global Reservoir and Dam (GranD)29 database, the most comprehensive reservoir dataset, offers more than 50 attributes on dams and reservoirs. Yet, due to its level of detail, this dataset is limited to 7,320 dams. The recently developed Georeferenced global Dams and Reservoir (GeoDAR)30 and GlObal geOreferenced Database of Dams (GOODD)31 provide the locations of over 20,000 and 38,000 dams and reservoirs, respectively. However, they do not include additional attributes such dam height and reservoir volume.
In this paper, we present a new comprehensive global dataset of existing hydropower plants by combining open-source hydropower and reservoir datasets. This new dataset, GloHydroRes32, provides not only plant attributes such as location, installed capacity but also reservoir attributes such as dam and reservoir location, dam height, reservoir depth, area and volume. GloHydroRes32 is created to support a wide range of applications, from academic research to industrial operation and policy design, by offering a rich and reliable data source. It can be used for hydropower planning, water resource management, water-energy nexus and climate impact and adaptation assessment.
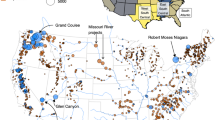
GlohydroRes32 provides data for 7,775 hydropower plants with a total installed capacity of 1,096.3 GW across 128 countries. This contributes to 79% and 81% of the global installed capacity when compared with installed hydropower data as reported by the U.S. Energy Information Agency (EIA) for 202233 and the International Renewable Energy Agency (IRENA) for 202334 respectively. In Europe, data is available for 2,888 plants, followed by North America and Asia with 1,880 and 1,823 plants respectively. However, in terms of installed capacity, Asia leads with 474.1 GW being represented, followed by Europe with 205.3 GW and North America with 199.44 GW. This is not only due to the presence of large hydropower plants in Asia, such as the Three Georges Dam (22,500 MW) (Fig. 1), but also because data for smaller hydropower plants are more readily available in Europe and North America compared to Asia (e.g. Figure 2). Out of these 7,775 plants, 3,237 (41.6%) are ROR plants and 2,658 (34.2%) are STO (e.g. Table 1). Only 4.3% classified as PS (Table 1) and most of these are located in Asia, Europe, and North America (Fig. 2). Regarding data availability, attributes such as head, reservoir area and volume of large hydropower plants (i.e. installed capacity > 500 MW) are typically more easily accessible across all continents. Data for smaller hydropower plants (i.e. installed capacity < 5 MW) are generally less well represented, but their total contribution to the overall installed capacity is small (0.3%) (Fig. 2). Furthermore, 170 hydropower plant have been identified as being impacted by IBT projects. These plants are located either on the IBT projects themselves or upstream and downstream of them.

Global spatial distribution of hydropower plants, with color representing the hydropower plant type, i.e. run-of-river (ROR), storage (STO), pumped storage, (PS), Canal or not available (NA). The bubble size indicates the installed capacity of the hydropower plant. The figure also consists of four subplots, each showing a zoomed-in view of regions with a high concentration of hydropower plants, highlighted by red boxes in the global plot.The label inside the each red boxes is corresponds to the respective subplot.

Total installed capacity (first column), along with percentage of data available for head (second column), reservoir volume (third column), and reservoir area (fourth column) in GloHydroRes for different plant types, presented across different continents and, categorized by plant size (<5 MW, 5–500 MW and >500 MW). Reservoir area and volume data are often unavailable for ROR and Canal types, which are grouped together due to their minimal reservoir requirements (first row). Results for storage (STO; second row) and pumped storage (PS; third row) are presented separately. The numbers above the bars in the first column indicate the number of hydropower plants.
Methods
An overview of the datasets used and steps followed to develop the GloHydroRes32 dataset is provided in the flowchart in Fig. 3. Details about the attributes collected are presented in Table 2 and are further explained in the following subsections.

Flow chart illustrating the main steps taken in developing the GloHydroRes dataset. The hydropower datasets used include the World Resource Institute v1.3 (WRI), the Renewable Power Plant database (RePP), the Joint Research Commission (JRC), the Existing Hydropower Assets (EHA), as well as other sources such as research articles and the Open Infrastructure Map. Reservoir datasets utilized are the Global Reservoir and Dam v1.3 (GranD), the Georeferenced global Dams and Reservoir v1.1 (GeoDAR) and HydroLAKES v1.0.
Data collection
The GloHydroRes32 dataset was built by compiling publicly available datasets on existing hydropower plants and reservoirs with creative common license. The following procedure was used to create the GloHydroRes dataset. First, data on hydropower plants were compiled from the WRI24, EHA27, RePP25 and JRC26 datasets. While datasets like RePP25 also include information on planned hydropower projects, this data was not incorporated due to the lack of detailed information about their plant and reservoir characteristics. During compilation process, duplicate entries were encountered because hydropower plants in the global WRI dataset were also present in the regional RePP and JRC datasets. These duplicates were removed by manually comparing the locations and installed capacities of the hydropower plants, retaining entries from the regional datasets (RePP, JRC, and EHA) as they provide more detailed information compared to the global WRI dataset. In the second step, reservoirs were linked to their corresponding hydropower plants using the GranD29, GeoDAR30 and HydroLAKES35 datasets. These datasets were chosen due to greater accuracy of reservoir shapes, compared to other datasets which often use simplified rectangular representations. GDAT36 data was also used to fill in the reservoir attribute missing in GeoDAR and HydroLAKES datasets. It is important note that the HILARRI dataset developed for the United States already links hydropower with reservoir data from GranD and the National Inventory of Dams (2021)28. However, to reduce number of sources of reservoir information, we retained the hydropower plants linked with GranD and connected the remaining plants with either GeoDAR or HydroLAKES. Furthermore, reported head and hydropower type (ROR, STO, Canal, and PS) were manually collected from various sources, including turbine supplier companies, power utility companies, research articles, energy agencies, Clean Development Mechanism (CDM) documents from United Nations Framework Conventions on Climate Change (UNFCCC)37 and websites such as power technology38 and Wikipedia39. It is important to note that the hydropower plant types in the GloHydroRes32 dataset is derived from original hydropower data sources such as RePP for Africa25 and JRC for Europe26, following the decision tree (Fig. 3). For the United States, plant type information is obtained from the Hydropower Reform Coalition40. Similarly, data for South America, Asia and Oceania continent are compiled from diverse sources such as Clean Development Mechanism (CDM)37, websites like power technology38. We prioritize using the categorization provided by the original sources rather than using arbitrary thresholds to identify hydropower plant types, which might be subject to the assumptions and choices of the thresholds. While collecting head attribute, we encountered significant discrepancies in how head values are reported by different sources with a range of terminologies, including gross, net, nominal, hydraulic, effective, rated, maximum, minimum, and average head. The gross head represents the difference between headwater and tailwater elevations, while the net head also accounts for friction losses in the penstock and losses in the conveyance system41. Previous studies have highlighted the importance of using net head to simulate hydropower generation accurately41,42,43. Rated and nominal head are often provided by turbine manufactures to represent the optimal operating condition for their turbines. To ensure consistency, we prioritize using net head followed by rated, nominal and gross head. When head values are reported as maximum, minimum or average, we gave priority to the average head, followed by maximum and then minimum head. For the United States, the EHA reports the rated head of all hydropower plants27. Therefore, these head values were directly incorporated into GloHydroRes32. During the Google search for information on head and hydropower type attributes, existing or new hydropower plants were found that were not present in any existing datasets. These hydropower plants were incorporated into GloHydroRes32, geolocated using either Google Earth Engine or Open Street Map, and linked to the corresponding reservoir. Hydropower projects located on IBT projects were identified based on shared basins between the hydropower projects and the IBT projects. For this purpose, two IBT datasets were used: Siddik et al.44 (for the United States and Canada) and Lammers et al.45 (global coverage). The HydroBasin46 dataset was utilized for basin information. Attributes related to IBT projects–such as project name, start year, status, water flow direction, minimum, maximum, and mean discharge flow for project, as well as project length (Table 3)–are provided in separate file. This file can be linked with GloHydroRes dataset using the common identifier glohydrores_id corresponding to the ID in GloHydroRes32.
Data processing
We used two conditions to assign a hydropower plant to its nearest reservoir (1) distance between the hydropower plant and dam must be less than 10 kilometres (proximity criteria) and (2) elevation of the hydropower plant must be lower than elevation of dam (elevation difference criteria). The global digital elevation model (15 arc-seconds resolution) from Hydrosheds47 was used to obtain elevation estimates for both hydropower plants and dams. If multiple dams met both the proximity and elevation difference criteria in a single reservoir dataset, then nearest dam was assigned to that hydropower plant. First hydropower plants were matched with GranD dataset and if no reservoir matches both conditions, then GeoDAR dataset was used. GranD was given priority over GeoDAR because it provides a higher level of detail. Since GeoDAR provides only the geolocation of dams and reservoirs without attributes such as dam height, river name, reservoir area and volume, this information was supplemented from other sources. These sources include reservoir datasets HydroLAKES, GDAT or were manually incorporated from e.g. research articles (Fig. 3). Furthermore, if neither of the reservoir datasets (i.e. GranD and GeoDAR) contained a reservoir following both conditions, then HydroLAKES data was used. It is important to note that although HydroLAKES provides information on 1.43 million waterbodies, it was given priority after GranD and GeoDAR. This decision was made because HydroLAKES is a dataset of lakes rather than reservoirs. Using HydroLAKES can introduce uncertainties, as there is an increased probability that a small nearby lake rather than a large, purpose-built reservoir is being unintendedly assigned to a hydropower plant. If none of the three sources contained reservoir information, a manual search was conducted to identify the hydropower plant reservoir. The dam’s longitude and latitude were then manually obtained from scientific literature or Google Earth Engine search, and this information is displayed in the man_dam_lat and man_dam_lon columns (Table 2). For PS hydropower, only the attributes of the upper reservoir are provided. After all hydropower plants were linked to their nearest reservoirs, a through manual verification process was undertaken. This involved cross-referencing research articles, hydropower utility companies, Google Earth Engine or OpenStreetMap to ensure that all hydropower plants were correctly linked to their respective reservoirs. To ensure traceability between GloHydroRes and the source datasets of hydropower plants and reservoirs, we included the unique ID from the source datasets along with the dataset name32. These are shown in the attributes plant_source_id and plant_source for hydropower plants, and res_dam_source_id and res_dam_source for reservoirs in Table 2. For example, if the reservoir of a hydropower plant matched with one of the GranD dataset reservoirs, then we provided the corresponding “grand_id” in the res_dam_source_id column and “GranD” value in the res_dam_source column (Table 2). This will allow future users to link to the original datasets to update and add relevant new information which is not available in the GloHydroRes32 but provided by the original dataset. Similarly, IBT attributes include ibt_id and ibt_source to capture additional attributes provided by the original source (Table 3).
Data Records
GloHydroRes32 is available in Excel (.xlsx) and Comma-Separated Values (.csv) formats and can be accessed through the open-source platform Zenodo at https://doi.org/10.5281/zenodo.14526360 under the names GloHydroRes_vs1.xlsx and GloHydroRes_vs1.csv. The excel file contains four worksheets: “Summary”, “Acronyms”, “Field Description” and “Data”. The “Summary” worksheet offers brief overview of GloHydroRes, while “Acronyms” explains the abbreviation used in dataset. The “Field Description” contains details about collected attributes and the “Data” worksheet contains the actual data32. The CSV format includes only the core dataset from the “Data” worksheet along with a README file for guidance. A total of 29 attributes were collected (Table 2) covering both plant and reservoir characteristics from various aspects. Plant attributes include plant name, installed capacity, plant geolocation, and type. Reservoir attributes include dam height, dam geolocation, river name, reservoir depth, area, and volume. Similarly, the file IBT_GloHydroRes_Hydropower_Combined.xlsx and IBT_GloHydroRes_Hydropower_Combined.csv contains information about GloHydroRes hydropower projects located on inter-basin transfer projects. Overall, the file includes 15 attributes related to inter-basin transfer and can be linked to GloHydroRes using the glohydrores_id column in the IBT_GloHydroRes_Hydropower_Combined.xlsx file and ID column in the GloHydroRes_vs1.xlsx file32. All geolocations are provided in the World Geodetic System (WGS) 84 coordinate system. GloHydroRes32 is an open-source dataset developed by combining other open-source hydropower and reservoir datasets. The code used to generate the GloHydroRes dataset (see the “Code Availability” section} is also open accessible to everyone. Consequently, anyone can contribute to updating and enhancing the dataset in the future when new hydropower plant and reservoir data will become available.
Technical Validation
Data availability review
GloHydroRes32 expands regional datasets, such as HILARRI28, and provides the first comprehensive global dataset that covers both hydropower plant attributes and reservoir characteristics. In total, 4,552 hydropower reservoirs were identified from sources like GranD, GeoDAR or HydroLAKES (Table 4). Additionally, 2,407 hydropower reservoirs were identified through manual research, with 537 in China (Table 4 & Fig. 4). Moreover, 5,353 hydropower head data were provided, compared to just 971 offered by Wan et al.48 or those found only in regional datasets such as EHA27. To ensure the quality of the dataset, all the attributes of dataset were verified. ArcGIS Pro49 was used for manual verification to ensure the data accuracy in linking hydropower with reservoirs.

Global spatial distribution of hydropower plants, with colour representing the source of the reservoir dataset and bubble size indicating the hydropower plant head. Zoomed-in view of four regions are provided, highlighted by red boxes in the global plot, with labels inside the boxes corresponding to their respective regional plots.
To evaluate completeness of GloHydroRes32, country-level aggregated installed capacity is compared with data provided by international intergovernmental organisation, the International Renewable Energy Agency (IRENA)50 and the International Energy Agency (IEA)51 and the U.S. Energy Information Administration (EIA)52. These agencies collect data through partnerships with governmental organizations in each country, and therefore can be considered to cover nearly all installed hydropower capacity within a country.
GloHydroRes32 installed capacity was compared with IRENA data of 202334 and EIA data of 202233. IEA data was not used for comparison as it is not a freely available dataset and requires a paid subscription53. In comparison that follow, data from IRENA is presented without bracket, while data from the EIA is shown in brackets. European countries are well-represented in GloHydroRes, with half of the countries in these continents having more than 96% (90%) of their installed capacity covered, compared to reported estimates of IRENA (EIA) data (Fig. 5). Similarly, African countries have 98% of their installed capacity covered, compared to both the IRENA and EIA data. African countries, such as Angola, Cameroon, Egypt and South Africa, the installed capacity even exceeds the figures reported by IRENA and EIA (Fig. 5). Similarly, in European countries like Austria, Croatia, France, Spain, and Switzerland, installed capacities surpass those reported by IRENA, while in Lithuania and United Kingdom, they exceed EIA estimates. This discrepancy can be attributed to the use of not only the global WRI dataset but also the detailed regional datasets provided by JRC for Europe and RePP for Africa. These additional datasets ensure that smaller hydropower plants, which may be missing from the IRENA and EIA data, are well represented. In contrast, the representation of several North American countries such as Costa Rica, Honduras, and Panama is low with only 55% (55%), 56% (60%) and 57% (59%) of installed capacity covered in GloHydroRes, respectively, compared to IRENA (EIA). This is because the hydropower plant data for these countries come solely from the WRI dataset, and no regional or country-specific dataset is available. The WRI dataset typically includes information on hydropower plants installed before 2019, thus missing information on recent installations. However, other North American countries, like the United States and Canada, benefit from extensive data availability, leading to a more comprehensive picture in GloHydroRes. South American countries exhibit wide variability with Bolivia, Colombia and Peru having below 65% (60%) representation, while Brazil, Paraguay, Uruguay, and Venezuela have more than 95% (95%) representation in terms of installed capacity when compared to IRENA (EIA) data. Asian countries have a moderate level of representation, with a median coverage of 77% (77%). Interestingly, in some countries, EIA estimates of installed capacity for 2022 are higher than the IRENA estimates for 2023 (Fig. 5). This may be due to difference in the data sources used by each agency within individual countries and variations in their data collection methodologies. Overall countries or continents with dedicated hydropower datasets (e.g. JRC for Europe, RePP for Africa, and EHA for the United States) tend to have better representation in GloHydroRes compared to other regions.

The total installed capacity in GloHydroRes is compared at country level with IRENA data for 2023 and EIA data for 2022. The left panel shows the spatial distribution of the percentage contribution in installed capacity at country level covered by GloHydroRes compared to IRENA and EIA. The right panel presents boxplots representing the distribution of the proportion of installed capacity covered for countries in each continent, comparing GloHydroRes with IRENA and EIA.
It is important to note that GloHydroRes32 has information on 7,775 hydropower plants, compared to the 24,515 hydropower plants included in the study by Van Vliet et al.18, which evaluated the impact of climate change and droughts on hydropower. Due to limited resources and the extensive time required, it is not feasible to obtain information on all hydropower plants in a country, particularly smaller plants (less than < 5 MW), as covered by the Platts dataset54 used by Van Vliet et al.18, which is provided by S& P Global, an organization with significant resources. However, a key advantage of GloHydroRes54 is that it is freely accessible, unlike the Platts54 dataset, which requires a license. Additionally, GloHydroRes provides more detailed attributes, such as reservoir characteristics, compared to Platts18.
Validating hydropower generation
Hydropower production at a turbine is usually simulated using the following equation.
where Pt is hydropower generated (kW), ⍴ is density of water (1000 kg m−3), g is gravitational acceleration (9.81 m s−2), h is head (m), q is streamflow (m3 s−1) and η is turbine efficiency. Due to the lack of actual or reported head data, previous studies often use proxies such as the elevation difference between reservoir and turbine location55, dam height18 or reservoir level16. However, these methods can overestimate generation if the turbine is not located at the dam toe or underestimate if the turbine is located underground. We validate this by simulating monthly hydropower generation for four hydropower plants: Crystal dam (31.5 MW) on the Gunnison River, Wanapum Dam (1,098 MW) on the Columbia River in the United States, Estreito (1,087 MW) on Tocantins River and Jupiá (1,551 MW) on the Parana River in Brazil. We selected these plants because they are of the ROR type and do not have large reservoirs, thus eliminating the need to simulate reservoir operations which can impacts the monthly hydropower generation56. Additionally, these hydropower plant sites were selected due to the availability of observed streamflow data close to these hydropower stations. Here we used dam height and reported head data from GloHydroRes32 as the head parameter in the above mentioned equation to calculate the monthly hydropower generation and compared the results with actual generation data obtained from Turner et al.56 for the United States and Operdor Nacional do Sistema Eletrico (ONS)57 for Brazil. Monthly observed streamflow data were obtained from Global Runoff Data Center (GRDC)58 for the United States and Catchment Attributes and Meteorology for Large-sample Studies (CAMELS) dataset for Brazil59. Note that, since information regarding turbine efficiency (η) is generally unavailable, a default value of 1 is assumed.
The results show that simulated generation using reported head follows actual generation more closely compared to the simulation using dam height (Fig. 6). This finding underscores the potential for enhancing hydropower generation simulations at individual plant sites by considering the detailed head information provided in the GloHydroRes dataset. Despite the improvement gained from using actual head data, simulated hydropower generation does not precisely match actual generation, particularly at the Wanapum and Jupiá sites (Fig. 6). This discrepancy can be attributed to water spill from hydropower plants, which occurs in both controllable and uncontrollable forms. Controllable spill usually occurs in STO plants, which are often mandated by environmental regulations. These regulations require the release of a certain amount of water to maintain downstream water levels for purposes such as fishing, water quality maintenance, ecosystem preservation and accommodation of other downstream uses6,56,60. In contrast, ROR plants, are more susceptible to uncontrollable spill, especially during period of high streamflow. In these scenarios, excess water flow exceeds the plant generation capacity, leading to spillover that cannot be harnessed for energy production61. This spill is commonly referred to as “non-power spill”. However, site-specific data on spill is generally not available. Notably, it is recognized that ROR plants have typically experience greater non-power spill compared to STO plants61. Since the GloHydroRes32 dataset provides information on plant types, future studies can leverage this data to estimate non-powered spill based on plant type, enabling more accurate simulations of hydropower generation. Overall, this new open-source dataset can provide crucial information to improve hydropower generation modelling and can support informed decision-making in energy security and planning at the plant level in regions worldwide.

The monthly generation of four hydropower plants is simulated using head as (1) dam height and (2) reported head from the GloHydroRes dataset, applying the physical based equation: \({{\rm{P}}}_{{\rm{t}}}={\rm{\rho }}\ast {\rm{g}}\ast {\rm{h}}\ast {{\rm{q}}}_{{\rm{t}}}\ast {\rm{\eta }}\) where Pt is hydropower generation, \({\rm{\rho }}\) is density of water (1000 kg m−3), g is gravitational acceleration (9.81 m s−2), h is head (m), q is streamflow (m3 s−1) and η is turbine efficiency. The simulated generation is compared with actual monthly generation data. The actual generation data is obtained from Turner et al.56 for the United States and Operdor Nacional do Sistema Eletrico (ONS)57 for Brazil.
Code availability
The Python code used to link hydropower plants to their corresponding reservoirs and to plot figures is available on GitHub (https://github.com/SustainableWaterSystems/GloHydroRes/tree/main).
References
IEA. Renewables 2023. https://www.iea.org/reports/renewables-2023 (2023).
IHA. Hydropower 2050: Identifying the next 850+ GW towards Net Zero. https://www.hydropower.org/publications/hydropower-2050-identifying-the-next-850-gw-towards-2050.
De Cian, E. & Sue Wing, I. Global Energy Consumption in a Warming Climate. Environ. Resour. Econ. 72, 365–410 (2019).
van Ruijven, B. J., De Cian, E. & Sue Wing, I. Amplification of future energy demand growth due to climate change. Nat. Commun. 10, 1–12 (2019).
Gernaat, D. E. H. J., Bogaart, P. W., Vuuren, D. P. V., Biemans, H. & Niessink, R. High-resolution assessment of global technical and economic hydropower potential. Nat. Energy 2, 821–828 (2017).
Turner, S. W. D. & Voisin, N. Simulation of hydropower at subcontinental to global scales: A state-of-the-art review. Environ. Res. Lett. 17 (2022).
Galletti, A., Avesani, D., Bellin, A. & Majone, B. Detailed simulation of storage hydropower systems in large Alpine watersheds. J. Hydrol. 603, 127125 (2021).
Hunt, J. D., Byers, E., Riahi, K. & Langan, S. Comparison between seasonal pumped-storage and conventional reservoir dams from the water, energy and land nexus perspective. Energy Convers. Manag. 166, 385–401 (2018).
Hunt, J. D. et al. Global resource potential of seasonal pumped hydropower storage for energy and water storage. Nat. Commun. 11, 1–8 (2020).
Grill, G. et al. Mapping the world’s free-flowing rivers. Nature 569, 215–221 (2019).
Biemans, H. et al. Impact of reservoirs on river discharge and irrigation water supply during the 20th century. Water Resour. Res. 47 (2011).
Arunkumar, R. & Jothiprakash, V. Optimal Reservoir Operation for Hydropower Generation using Non-linear Programming Model. J. Inst. Eng. Ser. A 93, 111–120 (2012).
Neachell, E. Book Review - Environmental flows: Saving rivers in the thrid millennium. River Res. Appl. 30, 132–133 (2014).
Rollason, E., Sinha, P. & Bracken, L. J. Interbasin water transfer in a changing world: A new conceptual model. Prog. Phys. Geogr. 46, 371–397 (2022).
Zhou, Y., Guo, S., Hong, X. & Chang, F. J. Systematic impact assessment on inter-basin water transfer projects of the Hanjiang River Basin in China. J. Hydrol. 553, 584–595 (2017).
Turner, S. W. D., Ng, J. Y. & Galelli, S. Examining global electricity supply vulnerability to climate change using a high-fidelity hydropower dam model. Sci. Total Environ. 590–591, 663–675 (2017).
Zahedi, R. et al. Development of a New Simulation Model for the Reservoir Hydropower Generation. Water Resour. Manag. 36, 2241–2256 (2022).
van Vliet, M. T. H., Sheffield, J., Wiberg, D. & Wood, E. F. Impacts of recent drought and warm years on water resources and electricity supply worldwide. Environ. Res. Lett. 11, 124021 (2016).
Van Vliet, M. T. H., Wiberg, D., Leduc, S. & Riahi, K. Power-generation system vulnerability and adaptation to changes in climate and water resources. Nat. Clim. Chang. 6, 375–380 (2016).
Qin, P. et al. Assessing concurrent effects of climate change on hydropower supply, electricity demand, and greenhouse gas emissions in the Upper Yangtze River Basin of China. Appl. Energy 279, 115694 (2020).
Zhou, T., Voisin, N. & Fu, T. Non-stationary hydropower generation projections constrained by environmental and electricity grid operations over the western United States. Environ. Res. Lett. 13 (2018).
Voisin, N. et al. Vulnerability of the US western electric grid to hydro-climatological conditions: How bad can it get? Energy 115, 1–12 (2016).
Gøtske, E. K. & Victoria, M. Future operation of hydropower in Europe under high renewable penetration and climate change. iScience 24, 102999 (2021).
Byers, L. et al. A Global Database of Power Plants. World Resour. Inst. 1–18 (2021).
Peters, R., Berlekamp, J., Tockner, K. & Zarfl, C. RePP Africa – a georeferenced and curated database on existing and proposed wind, solar, and hydropower plants. Sci. Data 10, 1–14 (2023).
Felice, M.D. Peronato, G. & K. K. energy-modelling-toolkit/hydro-power-database: JRC Hydro-power database - release 10 (Version v10). https://doi.org/10.5281/zenodo.5215920 (2021).
Johnson, M. M., Shih-Chieh, K. & Martinez, R. U. Existing Hydropower Assets (EHA) Plant Database, 2022. HydroSource. Oak Ridge National Laboratory, Oak Ridge, Tennessee, USA. https://doi.org/10.21951/EHA_FY2022/1865282 (2022).
Hansen, C. H. & Matson, P. G. Hydropower Infrastructure - LAkes, Reservoirs, and RIvers (HILARRI), Version 2. HydroSource. Oak Ridge National Laboratory, Oak Ridge, Tennessee, USA. https://doi.org/10.21951/HILARRI/1960141 (2023).
Lehner, B. et al. Global Reservoir and Dam (GRanD) database. Tech. Doc. 3, 12 (2011).
Wang, J. et al. GeoDAR: georeferenced global dams and reservoirs dataset for bridging attributes and geolocations. Earth Syst. Sci. Data 14, 1869–1899 (2022).
Mulligan, M., van Soesbergen, A. & Sáenz, L. GOODD, a global dataset of more than 38,000 georeferenced dams. Sci. Data 7, 1–8 (2020).
Shah, J., Hu, J., Edelenbosch, O. & van Vliet, M. T. H. GloHydroRes - a global dataset combining open-source hydropower plant and reservoir data. https://doi.org/10.5281/zenodo.14526360 (2024).
EIA. https://www.eia.gov/international/data/world (2022).
IRENA. https://www.irena.org/Data/Downloads/IRENASTAT (2023).
Messager, M. L., Lehner, B., Grill, G., Nedeva, I. & Schmitt, O. Estimating the volume and age of water stored in global lakes using a geo-statistical approach. Nat. Commun. 7, 1–11 (2016).
Zhang, A. T. & Gu, V. X. Global Dam Tracker: A database of more than 35,000 dams with location, catchment, and attribute information. Sci. Data 10, 1–19 (2023).
Clean Development Mechanism (CDM). https://cdm.unfccc.int/ (2023).
Power Technology. https://www.power-technology.com/ (2023).
Wikipedia. https://www.wikipedia.org/ (2023).
Hydropower Reform Coalition. https://hydroreform.org/about-hrc/ (2023).
Yildiz, V. & Vrugt, J. A. Environmental Modelling & Software A toolbox for the optimal design of run-of-river hydropower plants. Environ. Model. Softw. 111, 134–152 (2019).
Hidalgo, I. G. et al. Efficiency Curves for Hydroelectric Generating Units. 86–92 https://doi.org/10.1061/(ASCE)WR.1943-5452 (2014).
Pérez, J. I., Wilhelmi, J. R. & Maroto, L. Adjustable speed operation of a hydropower plant associated to an irrigation reservoir. Energy Convers. Manag. 49, 2973–2978 (2008).
Siddik, M. A. B., Dickson, K. E., Rising, J., Ruddell, B. L. & Marston, L. T. Interbasin water transfers in the United States and Canada. Sci. Data 10, 1–9 (2023).
Lammers, R. B. Global Inter-Basin Hydrological Transfer Database. MSD LIVE https://doi.org/10.57931/1905995 (2022).
Lehner, B. G. Global river hydrography and network routing: baseline data and new approaches to study the world’s large river systems. Hydrological Processes 27(15), 2171–2186, https://doi.org/10.1002/hyp.9740 (2013).
Lehner, B., Verdin, K. & Jarvis, A. New global hydrography derived from spaceborne elevation data. Eos (Washington. DC). 89, 93–94 (2008).
Wan, W., Zhao, J., Popat, E., Herbert, C. & Döll, P. Analyzing the Impact of Streamflow Drought on Hydroelectricity Production: A Global-Scale Study. Water Resour. Res. 57 (2021).
ESRI. ArcGIS Pro. https://www.esri.com/en-us/arcgis/products/arcgis-pro/overview (2023).
IRENA. https://www.irena.org/ (2023).
IEA. https://www.iea.org/ (2023).
U.S. Energy Information Administration. https://www.eia.gov/ (2023).
IEA. https://www.iea.org/data-and-statistics/data-product/electricity-information (2023).
Platts Market Data - Electric Power. https://www.spglobal.com/commodityinsights/en/products-services/electric-power/market-data-power (2023).
Bartos, M. D. & Chester, M. V. Impacts of climate change on electric power supply in the Western United States. 5, 1–5 (2015).
Turner, S. W. D., Voisin, N. & Nelson, K. Revised monthly energy generation estimates for 1,500 hydroelectric power plants in the United States. Sci. Data 9, 1–11 (2022).
Operador Nacional do Sistema Eletrico. https://dados.ons.org.br/dataset/geracao-usina-2/resource/b56e215c-074e-418f-83c7-3d7a6d1292ff (2023).
Global Runoff Data Center. https://grdc.bafg.de/GRDC/EN/02_srvcs/21_tmsrs/211_ctlgs/catalogues_node.html (2023).
Chagas, V. B. P. et al. CAMELS-BR: Hydrometeorological time series and landscape attributes for 897 catchments in Brazil. Earth Syst. Sci. Data 12, 2075–2096 (2020).
Renöfält, B. M., Jansson, R. & Nilsson, C. Effects of hydropower generation and opportunities for environmental flow management in Swedish riverine ecosystems. Freshw. Biol. 55, 49–67 (2010).
Turner, S. W. D., Ghimire, G. R., Hansen, C., Singh, D. & Kao, S. C. Hydropower capacity factors trending down in the United States. Nat. Commun. 15, 1–14 (2024).
Acknowledgements
This research was funded by the European Research Council (ERC) under the European Union’s Horizon Europe research and innovation programme (B-WEX project, grant agreement no. 101039426) awarded to MTHvV.
Author information
Authors and Affiliations
Contributions
J.S. and M.T.H.v.V. designed the study with input of J.H. and O.E. J.S. collected all data, performed the data analysis and drafted the manuscript. M.T.H.v.V., J.H. and O.E. supervised the project and contributed to the writing. All authors contributed to the editing of whole manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shah, J., Hu, J., Edelenbosch, O.Y. et al. Global dataset combining open-source hydropower plant and reservoir data. Sci Data 12, 646 (2025). https://doi.org/10.1038/s41597-025-04975-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-04975-0
This article is cited by
-
Spatiotemporal variations in dissolved organic carbon in China’s major river basins and their associations with climate change and human activities
Carbon Balance and Management (2025)
-
Forty-year hydropower generation reanalysis for Conterminous United States
Scientific Data (2025)
-
Global dataset of sand dam features and geographical distribution across drylands
Scientific Data (2025)
