
Abstract
Teacher behavior analysis is essential for enhancing teaching quality and advancing educational development. However, publicly available datasets specifically focused on teacher behavior are scarce, hindering research in this domain. Existing datasets often rely on open course videos from the Internet, which lack the complexity and authenticity of real-world classroom environments and fail to capture teachers’ behavioral patterns accurately. Here, we present MM-TBA, a comprehensive multi-modal dataset designed for analyzing teacher behavior in offline classroom settings. Specifically, we recorded 4,839 teaching videos and manually filtered approximately 32,000 seconds of footage, encompassing the instructional activities of over 300 trainee teachers. Based on these videos, we developed a teaching action detection sub-dataset for detecting teachers’ temporal actions and an evaluation report sub-dataset for teacher lectures. Additionally, we constructed an instructional design sub-dataset. MM-TBA aims to fill existing gaps and promote scientific research on teacher behavior and cognitive science. We hope that MM-TBA will provide a new research tool for educational science, enabling interdisciplinary applications by combining artificial intelligence with educational technology.
Similar content being viewed by others


Background & Summary
Teaching behavior analysis is a vital area of educational research and practice, involving systematic observation, evaluation, and analysis of teachers’ behaviors and instructional methods1. Teachers’ actions, gestures, and instructional language in the classroom play a pivotal role in shaping the learning experience. For instance, teaching actions and gestures can effectively guide learners’ attention allocation and supplement semantic information, thereby promoting cognitive processing. Moreover, language serves as the primary medium of communication in teaching activities, accounting for approximately 80% of all teaching behaviors2.
Traditional methods of analyzing teacher behavior rely on manual observation and evaluation, leading to subjectivity and bias3. Advances in educational technology, particularly the application of artificial intelligence in education, have enabled data-driven tools for behavior analysis, but a comprehensive understanding of instructional behaviors requires extensive data support. Existing studies often focus on student-oriented videos4,5,6, while gathering teacher-focused footage is challenging due to privacy issues. Moreover, most teaching videos originate from online open courses, which fail to represent actual classroom environments accurately. Most of the existing datasets on teachers’ instructional behavior are limited in scope, focusing solely on identifying actions and teacher-student dialogues7,8,9.
For teaching action detection, detecting the actions of characters in videos is a challenging research area within computer vision. Recently, numerous action detection datasets have been introduced, such as AVA10, Kinetics-40011, and Something-Something12. However, existing action recognition works are challenging to transplant to teacher behavior recognition due to the specific educational semantics involved13. Most existing teacher behavior datasets classify teaching actions on video clips7,13, requiring manual extraction of single-action segments, which is both time-consuming and prone to subjectivity.
Teacher lecture evaluation currently relies on empirical descriptions from classroom observations14, which have limitations such as expert dependence, inefficiency, and poor scalability15. With the increasing adoption of artificial intelligence in education, a data-driven research paradigm is emerging. Intelligent technology enables real-time analysis and visual evaluation, transforming teaching evaluation into a powerful tool for instructors to regulate their behaviors and enhance teaching quality. For instance, a previous study14 developed an application framework for evaluating teachers’ classroom teaching behaviors based on three dimensions: emotion, posture, and position preferences.
As for instructional design, we have not yet identified any publicly available datasets. To address the challenges in teacher behavior analysis, we propose MM-TBA, a comprehensive multi-modal dataset for analyzing teacher behavior in offline classrooms. Our MM-TBA consists of annotated teaching actions, teacher lecture transcriptions, lecture evaluation reports, and instructional design annotations (see Table 1). We collected 4,839 teaching videos from approximately 300 trainee teachers, yielding 32,000 seconds of high-quality classroom performance footage. The MM-TBA’s teaching action detection sub-dataset focuses on teachers’ temporal action detection, adopting a fine-grained second-by-second annotation approach inspired by the AVA10 dataset format. Additionally, we fine-tune large language models with the manually verified lecture audio to generate evaluation reports, resulting in a lecture evaluation sub-dataset. We assess the teacher’s lecture across four dimensions. In MM-TBA’s instructional design sub-dataset, we annotated instructional designs using a multivariate analysis method. We conducted extensive data annotation work in constructing MM-TBA. These comprehensive data annotation efforts have produced a multi-dimensional resource that captures various aspects of teaching.
The MM-TBA dataset has numerous practical application scenarios in real-world teaching. Leveraging detailed annotations and multi-modal data, educators and researchers can develop innovative solutions to enhance teaching practices and outcomes. We outline five key application scenarios: teaching practices improvement, teaching quality assessment, intelligent educational aids, teacher professional development, and curriculum personalization (Fig. 1). Detailed explanations of these scenarios are provided in the Usage Notes section. We aspire for the practical application of MM-TBA to advance scientific research on teacher behaviors and support the professional development of educators, thereby contributing to the progress of the educational sector. It is worth mentioning that the current version of MM-TBA only includes teaching data from two disciplines: Mathematics and Information Technology. To enhance the generalizability of MM-TBA across diverse educational disciplines, we are actively collecting teaching data from nine additional disciplines. In future work, we plan to process the teaching data from these different disciplines, thereby enriching and expanding the MM-TBA dataset.

The application scenarios of the MM-TBA.
We place significant emphasis on data privacy, sensitivity, and ethical considerations. During data collection, informed consent and authorization were obtained from all participants. The visual information of trainee teachers was carefully anonymized by encoding it into feature representations, and multiple filters were applied to instructional content to eliminate potential personal information. We ensure that the dataset remains openly accessible and reusable while adhering to privacy standards. Detailed procedures for data privacy management are provided in the Methods section.
Methods
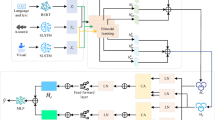
In this section, we present the three sub-datasets that form the MM-TBA dataset. The teaching action detection sub-dataset focuses on identifying teacher actions within teaching videos. The teacher lecture evaluation sub-dataset provides a comprehensive, multi-dimensional assessment of lecture content. The instructional design sub-dataset employs multivariate analysis methods to annotate instructional designs. Figure 2 illustrates the overall framework for constructing the MM-TBA dataset.

The overall framework of constructing the MM-TBA dataset.
Teaching Action Detection Sub-Dataset
The teaching action detection sub-dataset focuses specifically on the hand movements of teachers, categorizing these actions for every second of the teaching videos. Specifically, we defined six action categories: “pointing”, “beat gesture”, “descriptive gesture”, “writing”, “interacting”, and “neutral”. Given the complexity of developing this sub-dataset, we detail the process through three key aspects: data collection, data preprocessing, and data annotation.
Data Collection
We captured films of the trainee teachers instructing in micro-classrooms in 2018-2021. The shooting angles include 0∘ and 30∘ directions facing the teacher’s blackboard. We obtained the instructors’ informed consent prior to filming and informed them that the recordings would be used for future teaching and research purposes, and others. Additionally, we have anonymized the data contained in the dataset, all in an effort to preserve their privacy and the security of their information. We ultimately produced a total of 4,839 teaching videos.
The trainee teachers involved in this study are pre-service graduates from teacher education programs. Prior to their internships, they completed comprehensive coursework in educational theory and pedagogical methods, supplemented by school-based training. Under the guidance and supervision of experienced mentors, they applied these theories and methods in practical settings. Consequently, these teachers acquired practical teaching experience, contributing to the authenticity and representativeness of the collected teaching data.
Data collected at the beginning or end of the semester may not fully represent instructional practices throughout the entire term, and teaching styles can differ significantly by subject and instructor. To minimize these biases, we ensured data diversity by selecting courses from different points within the academic term and across multiple subjects, including Mathematics and Information Technology, spanning middle and high school levels. The gender distribution of teachers is approximately 2:3. This approach ensures that our dataset is reflective of typical classroom environments, thereby enhancing the generalizability of the findings. We present the attributes distribution of the collected data in Fig. 3, and have uploaded the metadata file to the data repository.

The attributes distribution of the MM-TBA.
Data Preprocessing
Given the unique teaching style of each teacher16, we meticulously screened all the videos to ensure quality and relevance. Videos were excluded if they contained excessive repetitive movements, which we defined as a teacher repeating the same gesture or action more than six times within a 10-second window. We also removed segments showing irregular teaching behaviors, such as the teacher facing away from students for over 10 seconds or leaving the podium more than twice per minute. Similarly, segments with no teaching-related actions for over 10 consecutive seconds were discarded. To keep the focus on the teacher, we excluded segments where non-teacher individuals (e.g., students or assistants) blocked the teacher’s view for more than 20% of the duration. These criteria ensured the dataset contained meaningful instructional content.
As a result, 354 videos of approximately 300 trainee teachers with rich movements and standardized teaching behaviors were retained. We removed the opening and closing minutes of each teaching video based on considerations of their irrelevance to the classroom content. Subsequently, we used FFmpeg17 (video editing tool) to crop all the videos into approximately 10-second video clips and performed a second round of filtering. We ultimately obtained 3,173 video clips with a total duration of approximately 32,000 seconds. To safeguard participants’ personal information and privacy, and to mitigate data sensitivity, visual feature extraction was performed on the data, which was subsequently stored as pkl files. The data was then divided into training, test sets in an 8:2 ratio.
Data Annotation
Initially, we utilized FFmpeg to extract frames from all video clips at 30 frames per second, sampling one frame per second. Building on the success of the YOLO series in object detection, we employed the YOLO18 to identify bounding boxes around teachers in the videos. Bounding boxes are utilized to locate the spatial position of the teacher within the video, represented by two pairs of (x, y) coordinates. For annotating teaching actions, we used the VIA tool (version 3.0.11)19,20, configured with a timeline precision of 1 frame per second to enable accurate temporal segmentation. Trained annotators classified the teacher’s actions within these bounding boxes into six predefined categories. This two-step workflow—automated bounding box detection followed by manual action classification—ensured both efficiency and accuracy in the annotation process.
In the field of education, teachers’ gestures in the classroom are typically categorized into three types: pointing, beat, and descriptive gesture21,22. Pointing gestures refer to the intentional physical movements made by teachers to point to specific objects during instruction, thereby capturing students’ attention and highlighting the significance of visual information. Beat gestures involve repetitive hand movements between the waist and chin, which help teachers control the cadence and pace of their speech while emphasizing key points. Descriptive gestures refer to depicting various aspects of the semantic content of speech through hand shapes or hand movement trajectories, evoking learners’ psychological schema of this semantic content visually or metaphorically23. Our work expands on these categories by introducing three additional actions: “writing”, “interacting”, and “neutral”13,24. The action of “writing” refers to the act of a teacher writing on a blackboard or electronic screen. The action of “interacting” signifies the teacher’s invitation for students to answer questions, thereby fostering classroom engagement. The action termed “neutral” describes the teacher’s ordinary movements, such as hands resting naturally at their sides. Figure 4 presents examples of six types of teaching actions.

Examples of teaching action.
Four undergraduate students with computer science and education backgrounds, along with basic knowledge of deep learning, conducted the data annotation. Their multidisciplinary background allowed them to grasp the nuances of teaching actions and the importance of high-quality data for model training. Before officially starting the annotation work, the annotators underwent specialized training. The training content included the following: use of annotation tools, annotation criteria and guidelines, and practical exercises. We regularly reviewed annotation results and provided feedback based on initial model training outcomes, ensuring annotators consistently improved their work. This rigorous training enabled them to efficiently and accurately complete tasks while understanding the critical role of these annotations in deep learning model training, providing a strong foundation for effective training. To ensure quality and minimize subjectivity, each data record was annotated by at least two independent annotators. The final temporal label was established through an additional verification and refinement process, based on the two initial annotations. Additionally, we employed DeepSort25 for tracking and locating teachers, ultimately generating annotation files in the AVA10 dataset format. Figure 5 shows the specific sample counts for each category within the teaching action detection sub-dataset. Our dataset format is compatible with a wide range of video action recognition models.

The specific sample counts for each action category within the teaching action detection sub-dataset.
Teacher Lecture Evaluation Sub-Dataset
The teacher lecture evaluation sub-dataset aims to provide a comprehensive, multi-dimensional assessment of teacher lectures. This sub-dataset allows for the more fine-grained and adaptable evaluation of teaching quality using advanced natural language processing techniques. Specifically, we employed MoviePy26 (a Python library for video editing) to extract audio from the teaching videos, which underwent speech-to-text processing to transcribe the teachers’ lectures. The generated text was then manually verified and corrected, with each transcript averaging approximately 2,220 words. Furthermore, multiple filters were applied to remove sensitive information contained within the lecture content. In recent years, large language models have demonstrated remarkable performance in text generation capabilities. To assess teachers’ lectures, we designed a set of teacher lecture evaluation criteria and prompt templates tailored to the specific characteristics of pedagogy27,28. Figure 6 shows the template for generating fine-tuning data, while Fig. 7 displays the template for creating the final evaluation report. Using these templates, we generated evaluation reports on teachers’ lectures by calling the GPT-3.5 API29. These reports served as training data to fine-tune the Baichuan230 model. In the field of artificial intelligence, fine-tuning refers to the process of adapting a pre-trained model by making incremental adjustments to its parameters to tailor it to a specific task or dataset. This method utilizes the general knowledge acquired during pre-training, allowing the model to efficiently adapt and achieve optimal performance on a new, often smaller, target dataset31.

Prompt template for generating fine-tuning data.

Prompt template for generating final evaluation report.
LoRA (Low-Rank Adaptation)32 is a fine-tuning technique that reduces the number of trainable parameters by introducing low-rank matrices, thereby making the process more efficient while retaining model performance. Inspired by LoRA, we utilized it to enhance the fine-tuning efficiency of large language models. During the fine-tuning process, we utilized the Adam optimizer with specific hyperparameters to enhance the optimization process. We set the “beta1” parameter to 0.9 and the “beta2” parameter to 0.98. Additionally, we configured the epsilon parameter to 1e-8. We optimize the model with a learning rate of 2e-5 and set the training epochs to 10. Upon completing the fine-tuning of the large language model, we obtain a newly optimized weight file.
Subsequently, we proposed a method that synergizes a large language model and subject-specific knowledge graphs to generate more accurate teacher lecture evaluation reports. To enhance lecture evaluation, we constructed knowledge graphs representing subject-specific concepts and their relationships using school mathematics and IT textbooks aligned with national curriculum standards. In these graphs, nodes represent key knowledge points (e.g., “quadratic functions”), while edges denote relationships such as “contains” (e.g., “quadratic functions” includes “parabolas”) or “prerequisite” (e.g., “linear equations” precedes “systems of equations”). We populated the graph by manually extracting concepts from textbooks and linking them based on pedagogical dependencies. During evaluation, we processed lecture transcripts using named entity recognition to identify mentioned knowledge points, mapping them to the graph to assess coverage and coherence. This structured representation enabled us to extract relevant knowledge points from the teacher’s lecture and incorporate them into an automatically generated evaluation report (as shown in Fig. 2(b)). The automatically generated evaluation report assesses the teacher’s lecture across four dimensions: teaching phases33,34, teaching objectives and content35, teaching process and methods36, and teacher-student interaction37. Table 2 presents examples of the teacher lecture evaluation criteria across two dimensions. In addition to detailed descriptions and associated scores for each dimension, the report includes an overall evaluation and recommendations for improving instruction. Using the fine-tuned large language model, we generate a more fine-grained and adaptable teacher lecture evaluation report by following the specified prompt template.
Instructional Design Sub-Dataset
The instructional design sub-dataset aims to systematically annotate and analyze the instructional designs created by teachers. During the practicum of trainee teachers, we also gathered instructional designs that matched the course material from trainee teachers. Instructional design is a systematic activity guided by educational theory, involving the organization of instructional content and resources, the design of learning activities and environments based on learner characteristics, and ultimately supporting learners in achieving their learning objectives effectively38. In our work, we manually screened all collected instructional designs, retaining only those with complete teaching processes. Drawing on experience with multivariate analysis methods that combine instructional events and time sampling15, we introduced a comprehensive approach incorporating instructional designs, teaching videos, and teacher lecture transcripts to annotate the teaching processes within the instructional designs(as shown in Fig. 2(c)). Each annotated instance represents a specific teaching process within the instructional design, corresponding to a particular segment of the teaching video and the associated lecture transcript. Annotating instructional designs enables teachers to pinpoint issues and shortcomings within their teaching methods and activity designs, allowing them to optimize their teaching schedules and place greater emphasis on key instructional points. This process enhances the scientific rigor and effectiveness of instructional design while providing teachers with essential insights for improving their teaching practices.
Data Privacy and Consent
During the construction of the MM-TBA dataset, we adhered strictly to ethical guidelines to ensure the legality of the research data and the full protection of participants’ rights. Prior to data collection, informed consent and authorization were obtained from participants via a public education platform, explicitly agreeing to the recording and use of their teaching videos. Participants fully understood and accepted the platform’s terms before uploading their data, acknowledging that their data would be used for teaching analysis and scientific research. Additionally, we ensured that all other individuals featured in the videos were informed and had consented to their inclusion. In accordance with ethical review procedures, our research and data sharing have received ethical approval from the affiliated institution. The IRB number is ZSRT2025141.
All collected data is processed in accordance with applicable data protection regulations to ensure the security of participants’ personal information and privacy. To maintain data privacy and security, we masked faces in the teaching videos for action detection purposes. We do not directly provide videos and images of classroom instruction. The teaching actions of the trainee teachers were visually encoded and saved as feature files to anonymize the participants’ information. Faces in the images included in the paper were also obscured to safeguard privacy. For the lecture content and instructional design data, we employed a multi-round filtering process involving multiple reviewers to carefully screen and anonymize potentially sensitive information, ensuring that individual identities cannot be tracked. These anonymization steps do not compromise the usability of the dataset. We ensure that the dataset remains publicly accessible and reusable while adhering to privacy standards.
Data Records
The MM-TBA dataset is available at Figshare39. It is organized into three primary folders—Teacher_Action_Detection, Teacher_Instructional_Design, and Teacher_Lecture_Evaluation—each corresponding to a specific sub-dataset. Additionally, the dataset includes a set of supplementary materials. Among them, the README.md file offers detailed usage instructions, encompassing setup of the computational environment and script execution procedures. This documentation serves as a comprehensive guide for data users.
The folder associated with the teacher action detection sub-dataset contains three subfolders: my_mmaction, yolo, and dataset. The my_mmaction subfolder includes all code files utilized for training and validating the model. The yolo subfolder contains code for teacher object detection and associated visual feature files. The dataset subfolder is further divided into train and val, housing annotation files for the training and validation sets, respectively, alongside intermediate processing files and code. The primary annotation files feature fields, listed from left to right, as follows: video name, frame number, X1, Y1, X2, Y2, action label, and person ID. The bounding box coordinates indicate the spatial location of the teacher, the action label categorizes the teacher’s actions, and the person ID is used for tracking the teacher.
The folder corresponding to the teacher lecture evaluation sub-dataset includes several subfolders: baichuan2, finetune_data, gpt_report, llm_report, and teacher_lecture_texts, along with a requirements.txt file. The baichuan2 subfolder contains the project code for the Baichuan2 large language model. The finetune_data subfolder holds evaluation report data used for fine-tuning the large language model. The gpt_report subfolder stores evaluation reports generated via the GPT API, while the llm_report subfolder contains reports produced by various fine-tuned large language models. The teacher lecture evaluation report assesses and scores the lecture content across four dimensions, and provides an overall evaluation along with suggestions for improvement. The teacher_lecture_texts subfolder includes the lecture texts of teachers. The requirements.txt file lists the dependency packages necessary for the teacher lecture evaluation model.
The folder for the teacher instructional design sub-dataset encompasses multiple subfolders, each corresponding to the instructional design data of individual teachers. Within each subfolder, document files represent the original instructional design files created by the teachers. Additionally, two table files are included: one contains classroom dialogue texts from the teachers’ lectures, and the other is an annotation file. In the annotation file, the Range column denotes the time period of the teaching process, the Teaching_Process column describes the teaching process, and the Speech_Text column provides the corresponding indices of classroom dialogues within that time period.
Technical Validation
Constructing MM-TBA was a highly challenging task that involved extensive work across three sub-datasets, including data collection, filtering, preprocessing, annotation, and final analysis. Unlike existing datasets, MM-TBA’s data is sourced from authentic and recent classroom environments, ensuring both timeliness and practicality. Its diversity, complexity, and richness of annotations cover a wide range of teaching activities and behaviors often overlooked in other datasets. By offering a substantial volume of comprehensive and trainable data, MM-TBA serves as a unique resource for identifying and analyzing teacher behaviors, particularly in researching multi-modal data fusion in teaching analysis. This depth and breadth in annotations and data types make MM-TBA an indispensable tool for advancing educational research and facilitating continuous improvement in teaching methods and overall quality.
We conduct extensive experiments with representative methods combined with educational theories to validate our dataset’s quality and utility. We utilized state-of-the-art video action detection models to carry out benchmark experiments on the teaching action detection sub-dataset, confirming the dataset’s high consistency and reliability. Additionally, we performed text analysis experiments on the teacher lecture evaluation sub-dataset to verify the readability and reference value of the evaluation reports. Our experiments were implemented with an NVIDIA RTX A6000 GPU with 48 GB of memory and two NVIDIA RTX 3090 GPUs with 24 GB of memory each.
Teaching Action Detection
Video action recognition at the frame-by-frame level is a difficult undertaking. The field of video action detection has seen the emergence of numerous state-of-the-art models in recent years. We evaluated our teaching action detection dataset using a variety of baseline models, including VideoMAE40, SlowFast41, SlowOnly, and ACRN42. The backbone networks for these models include ResNet5043 and ResNet101. Pre-training was conducted on the Kinetics dataset11 (a large-scale video action recognition dataset). Pre-training is the process of training a model on a large-scale dataset to learn general features and representations before fine-tuning it on a specific downstream task. We employ two frame sampling strategies: 16 × 4 × 1 (sampling 16 frames with a temporal interval of 4 between each frame, performed once) and 8 × 8 × 1. We also employed data augmentation techniques such as random rescaling and random cropping. For frame mAP, the IoU threshold is set at 0.5. The mean Average Precision (mAP) is computed as the mean of the Average Precision (AP) values across all classes, which represents the area under the Precision-Recall curve. The formula for mAP is:
where N is the number of classes and APi is the Average Precision for class i. The IoU measures the overlap between the predicted bounding box and the ground truth bounding box, and is calculated by:
where Bpred is the predicted bounding box, Bgt is the ground truth bounding box, ∣Bpred ∩ Bgt∣ represents the area of overlap between the predicted and ground truth bounding boxes, and ∣Bpred ∪ Bgt∣ is the total area covered by both bounding boxes. We present the detection results of different models under different training strategies in Table 3. The experimental results indicate that MM-TBA’s teaching action sub-dataset achieved comparable accuracy to the AVA10 dataset on baseline models, demonstrating the reliability of our dataset.
In addition to quantitative metrics, we performed an error analysis to gain deeper insights into the model’s behavior. We utilized different models (ACRN42, Slowfast41, Slowonly, VideoMAE40) to generate confusion matrices (Fig. 8) for the test set predictions, providing a visual representation of the classification performance across all categories. The misclassifications across categories were predominantly concentrated in the Neutral category, likely due to the relatively large sample size of Neutral, which led the model to favor predicting static states. The absence of correct predictions for Descriptive and Interactive categories indicates that the model failed to recognize their unique features, potentially due to insufficient samples or overlapping characteristics with other actions. This suggests that future data sampling efforts should focus on increasing the sample sizes for Descriptive and Interactive categories, employing data augmentation techniques (such as rotation and flipping) to generate more training data and ensure a balanced category distribution. Additionally, the confusion between Pointing and Writing, possibly attributable to similarities in hand movements, indicates the need for finer-grained features in future model designs.

A comparative analysis of the confusion matrices of the prediction results of different models (ACRN, Slowfast, Slowonly, VideoMAE) for the sub-dataset of teacher action detection. P: Pointing. B: Beat gesture. D: Descriptive gesture. W: Writing. I: Interacting. N: Neutral.
Teacher Lecture Evaluation Report
We fine-tuned the Baichuan2 large language model to generate teacher lecture evaluation reports. In the task of generating teacher lecture evaluation reports, it is imperative to conduct a comprehensive analysis of the lecture content and provide corresponding evaluations. Our focus lies particularly on ensuring the readability and comprehensibility of the evaluation reports, enabling teachers to effectively identify the strengths and weaknesses of their lectures and make informed adjustments based on the feedback provided. Additionally, it is also crucial to evaluate the differences between the text generated by the fine-tuned model and the original labels.
We employed three metrics to assess text readability and compared the generated evaluation reports with the training labels to obtain the average similarity parameter in our experiment (Table 4). Text readability can be used to measure the complexity of text. We used the cntext44 (a highly-rated text analysis Python library) to calculate the readability of the evaluation reports. In its methodology, “Readability1” represents the average number of characters per clause, while “Readability2” indicates the proportion of adverbs and conjunctions in each sentence. A lower proportion suggests that the sentence is easier to read. “Readability3” is the average of these two metrics. We reported the similarities calculated using two different algorithms: cosine similarity and Jaccard similarity, as shown below:
We split the teacher lecture data into an 8:2 ratio for the training and validation sets and conducted experimental evaluations on the separate validation sets. We compared two other currently popular and highly performant large language models: Qwen45 and LLaMA46. The results show that Baichuan2’s evaluation reports have better readability and highlight its unique strengths in the Chinese education domain. Based on the experimental data, it can be observed that our evaluation report dataset exhibits good readability. The content of evaluation reports accurately and truthfully reflects the actual teaching circumstances of teachers, possessing strong reference value. We conducted a manual inspection of the generated lecture evaluation reports to perform an error analysis. The error analysis revealed that, due to the limited coverage of dialogues in the transcripts, approximately 20% of the reports underestimated the “Teacher-Student Interaction” scores. This finding inspires future research to integrate multimodal cues (e.g., video-based interaction detection) to improve accuracy.
Instructional design
We developed a comprehensive methodology that integrates instructional designs, teaching videos, and teacher lecture transcripts to meticulously annotate the teaching processes encapsulated within the instructional designs. To validate the effectiveness and utility of the instructional design sub-dataset, we performed experiments to evaluate multiple dimensions of instructional designs based on the characteristics of pedagogy47,48. The evaluation criteria encompass preliminary analysis, the clarity of teaching objectives, the design of the teaching process, and adherence to documentation standards. These criteria ensure a precise analysis of the knowledge structure and the accuracy of the instructional content. Additionally, the evaluation scrutinizes the presentation methods, the integration of new curriculum concepts, and the employed learning methods, along with the formatting and layout49. We present the experimental results of the instructional design sub-dataset in Table 5.
Usage Notes
We provide a detailed data usage guide to facilitate data reuse and related research. In the teacher action detection sub-dataset, we use the mmaction250 framework for training and testing. The modified mmaction2 code and pre-trained weights have been uploaded. Users can reuse and reproduce the experiments using the provided script commands. Data users can utilize the provided script commands to reuse and reproduce the experiments, and they can leverage the teacher detection sub-dataset to train and test their own detection models. Additionally, a demo script is provided for visualization of action detection. Data users can obtain target and action detection results for each second of a teacher’s lecture video by uploading the video. For the teacher lecture evaluation sub-dataset, we provide the Baichuan2 large language model code and fine-tuning data. Users can reproduce the fine-tuning process using the provided fine-tuning script and generate evaluation reports by invoking the fine-tuned model with the provided generation script. Users can also leverage LLaMA-Factory51 (a framework for efficient training and fine-tuning of large language models) to experiment with other large language models. Data users can also directly input teacher lecture text and customize prompt words for large language models to generate personalized teacher lecture evaluation reports. In our study, we used a GPU A6000 with 48GB of memory for data processing and model training. The computational requirements of different benchmark models vary depending on their size, with fine-tuning large language models needing higher memory. The computational resource requirements and the environment needed for the code are detailed in the dataset usage instructions.
Application scenarios
Teaching Practices Improvement
We categorized six common teaching actions in the teaching action detection sub-dataset. For instance, using beat gestures can better improve learner engagement and emphasize key points. Descriptive gestures have the power to enhance learners’ understanding of important material and pique their curiosity. These detailed teaching action data can support research in teaching behavior detection. By identifying and analyzing teaching behaviors, these data offer educators insightful visual feedback on their instructional practices. This feedback motivates educators to incorporate a diverse repertoire of teaching actions, emphasize critical content, and foster greater interaction with students.
Teaching Quality Assessment
Integrating the teaching action sub-dataset with the teacher lecture evaluation sub-dataset allows for comprehensive assessments of teaching effectiveness and quality. This holistic approach evaluates both the teaching process and lecture content, providing specific recommendations on lecture structure, pacing, and interaction strategies. By thoroughly analyzing classroom situations, educators receive feedback on teaching outcomes, refining their processes and strategies to enhance overall teaching quality.
Intelligent Educational Aids
The analysis of instructional design annotations enables teachers to identify specific issues in their teaching methods and activity designs, optimizing teaching schedules and emphasizing key instructional points. Based on the instructional design sub-dataset, intelligent educational aids such as smart teaching assistants and intelligent instructional design platforms can be developed. These tools can help teachers design and implement instruction more effectively, supporting better educational outcomes.
Teacher Professional Development
The MM-TBA can serve as a valuable resource for teacher professional development programs. Through comprehensive analysis, teachers can pinpoint common areas requiring further training or support. For instance, insights from the dataset can inform the creation of training modules aimed at enhancing teachers’ use of effective gestures or improving lecture delivery. Furthermore, professional development programs can leverage the dataset to simulate classroom scenarios, enabling teachers to practice and refine their skills in a controlled environment.
Curriculum Personalization
The MM-TBA dataset can be instrumental in developing personalized curriculum resources. By analyzing the annotated teaching actions and lecture evaluations, curriculum developers can identify which instructional strategies are most effective for different types of content and diverse student groups. This allows for the creation of adaptive learning modules that cater to varying learning styles and paces. Educators can use these insights to tailor their curriculum, ensuring that it meets the specific needs of their students.
Code availability
The code for MM-TBA dataset is accessible on the figshare repository39. The software and code used, as well as the data and annotation files, along with a detailed data usage guide and supporting documentation, are all included. Due to the complexity of the code operations, we provide detailed installation instructions and usage examples in the README.md file. The code environment is based on Python version 3.10.13. Key dependency versions include PyTorch 2.2.0, NumPy 1.26.4, Transformers 4.38.2, and MMCV 2.2.0.
References
Alibali, M. W. et al. Teachers’ gestures and speech in mathematics lessons: Forging common ground by resolving trouble spots. ZDM 45, 425–440, https://doi.org/10.1007/s11858-012-0476-0 (2013).
Yang, J., Zhu, F., Jiang, Y. & Pi, Z. Do adults and children learn differently from video lectures with an instructor’s deictic gestures? Educ. Inf. Technol. 28, 8377–8400, https://doi.org/10.1007/s10639-022-11523-5 (2023).
Libao, W., Yanan, C. & Yiming, C. Reform and practical paths of classroom teaching evaluation under artificial intelligence. China Educ. Technol. 5, 94–101 (2021).
Zhou, H., Jiang, F., Si, J., Xiong, L. & Lu, H. Stuart: Individualized classroom observation of students with automatic behavior recognition and tracking. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5, https://doi.org/10.1109/ICASSP49357.2023.10094982 (2023).
Zheng, R., Jiang, F. & Shen, R. Intelligent student behavior analysis system for real classrooms. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 9244–9248, https://doi.org/10.1109/ICASSP40776.2020.9053457 (2020).
Fu, R. et al. Learning behavior analysis in classroom based on deep learning. In 2019 Tenth International Conference on Intelligent Control and Information Processing (ICICIP), 206–212, https://doi.org/10.1109/ICICIP47338.2019.9012177 (2019).
Sharma, V., Gupta, M., Kumar, A. & Mishra, D. Edunet: a new video dataset for understanding human activity in the classroom environment. Sensors 21, 5699, https://doi.org/10.3390/s21175699 (2021).
Wu, D. et al. The recognition of teacher behavior based on multimodal information fusion. Math. Probl. Eng 2020, 1–8, https://doi.org/10.1155/2020/8269683 (2020).
Chen, J., Huang, S., Liu, Z. & Luo, W. Dialogid: A dialogic instruction dataset for improving teaching effectiveness in online environments. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, 3853–3857, https://doi.org/10.1145/3511808.3557580 (2022).
Gu, C. et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 5638-5647, https://doi.org/10.1109/CVPR.2018.00633 (IEEE, 2018).
Kay, W. et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017).
Goyal, R. et al. The “something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE international conference on computer vision, 5842–5850, https://doi.org/10.1109/ICCV.2017.622 (2017).
Gang, Z. et al. A simple teacher behavior recognition method for massive teaching videos based on teacher set. Appl. Intell. 51, 8828–8849, https://doi.org/10.1007/s10489-021-02329-y (2021).
Yuanyuan, L., Zengzhao, C., Rong, C., Yawen, S. & Qiuyu, Z. Research on the application framework of intelligent technologies to promote teachers’ classroom teaching behavior evaluation. Front. Educ. China 18, https://doi.org/10.3868/s110-008-023-0012-8 (2023).
Zhong, S., Kaiyue, L., ChenMeiling, L. L., Lin, X. & Zhiping, S. Classroom teaching analysis based on artificial intelligence. China Educ. Technol. 9 (2020).
Khandaghi, M. A. & Farasat, M. The effect of teacher’s teaching style on students’ adjustment. Procedia-Social Behav. Sci. 15, 1391–1394, https://doi.org/10.1016/j.sbspro.2011.03.299 (2011).
Bellard, F. Ffmpeg. http://ffmpeg.mplayerhq.hu (2001).
Jocher, G. et al. ultralytics/yolov5: v3. 0. Zenodo, https://doi.org/10.5281/zenodo.3983579 (2020).
Dutta, A. & Zisserman, A. The VIA annotation software for images, audio and video. In Proceedings of the 27th ACM International Conference on Multimedia, https://doi.org/10.1145/3343031.3350535 (2019).
Yang, F. A multi-person video dataset annotation method of spatio-temporally actions. arXiv preprint arXiv:2204.10160, https://doi.org/10.48550/arXiv.2204.10160 (2022).
Pi, Z., Zhang, Y., Yang, J., Hu, W. & Yang, H. H. All roads lead to rome: Instructors’ pointing and depictive gestures in video lectures promote learning through different patterns of attention allocation. J. Nonverbal Behav. 43, 549–559, https://doi.org/10.1007/s10919-019-00310-5 (2019).
Alibali, M. W. et al. How teachers link ideas in mathematics instruction using speech and gesture: A corpus analysis. Cogn. instruction 32, 65–100, https://doi.org/10.1080/07370008.2013.858161 (2014).
Pi, Z., Zhang, Y. & Yang, J. The influence of instructor’s gestures on video learning and its cognitive neural mechanism. China Educ. Technol. 4, 103–110 (2019).
Fang, M. et al. Which is the better teacher action? a new ranking model and dataset. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7695–7699, https://doi.org/10.1109/ICASSP48485.2024.10448158 (2024).
Wojke, N., Bewley, A. & Paulus, D. Simple online and realtime tracking with a deep association metric. In 2017 IEEE international conference on image processing (ICIP), 3645-3649, https://doi.org/10.1109/ICIP.2017.8296962 (2017).
Zulko, A. Moviepy - video editing with python. https://zulko.github.io/moviepy (2023).
Cohen, J. & Goldhaber, D. Building a more complete understanding of teacher evaluation using classroom observations. Educ. Res. 45, 378–387, https://doi.org/10.3102/0013189X16659442 (2016).
Xu, Y. & Brown, G. T. Teacher assessment literacy in practice: A reconceptualization. Teach. teacher education 58, 149–162, https://doi.org/10.1016/j.tate.2016.05.010 (2016).
Achiam, J. et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023).
Yang, A. et al. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305 (2023).
Xuhong, L., Grandvalet, Y. & Davoine, F. Explicit inductive bias for transfer learning with convolutional networks. In International conference on machine learning, 2825-2834, (2018).
Hu, E. J. et al. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, arXiv.2106.09685 (2022).
Delvaux, E. et al. How may teacher evaluation have an impact on professional development? a multilevel analysis. Teach. teacher education 36, 1–11, https://doi.org/10.1016/j.tate.2013.06.011 (2013).
Tuytens, M., Devos, G. & Vanblaere, B. An integral perspective on teacher evaluation: A review of empirical studies. Educ. Assessment, Eval. Accountability 32, 153–183, https://doi.org/10.1007/s11092-020-09321-z (2020).
Fan, X. Teachers’ perspectives on the evaluation of teacher effectiveness: A focus on student learning objectives. Teach. Teach. Educ. 110, 103604, https://doi.org/10.1016/j.tate.2021.103604 (2022).
Chen, J. & Lu, H. Evaluation method of classroom teaching effect under intelligent teaching mode. Mob. Networks Appl. 27, 1262–1270, https://doi.org/10.1007/s11036-022-01946-2 (2022).
Howe, C., Hennessy, S., Mercer, N., Vrikki, M. & Wheatley, L. Teacher-student dialogue during classroom teaching: Does it really impact on student outcomes? J. learning sciences 28, 462–512, https://doi.org/10.1080/10508406.2019.1573730 (2019).
Zhong, X., Song, S. & Jiao, L. Instructional design based on the idea of the flipped classroom in ict environment. Open Educ. Res. 19, 58–64 (2013).
Huang, C. et al. A Multi-Modal Dataset for Teacher Behavior Analysis in Offline Classrooms, figshare, https://doi.org/10.6084/m9.figshare.28942487 (2025).
Tong, Z., Song, Y., Wang, J. & Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. Advances In Neural Information Processing Systems 35, 10078–10093 (2022).
Feichtenhofer, C., Fan, H., Malik, J. & He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision, 6202–6211, https://doi.org/10.1109/ICCV.2019.00630 (2019).
Sun, C. et al. Actor-centric relation network. In Proceedings of the European Conference on Computer Vision (ECCV), 318–334, https://doi.org/10.1007/978-3-030-01252-6_20 (2018).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778, arXiv.1512.03385 (2016).
Deng, X. & Nan, P. cntext: a python tool for text mining. Zenodo, https://doi.org/10.5281/zenodo.7063523 (2022).
Yang, A. et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2024).
Touvron, H. et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023).
Großmann, L. & Krüger, D. Assessing the quality of science teachers’ lesson plans: Evaluation and application of a novel instrument. Sci. Educ. 108, 153–189, https://doi.org/10.1002/sce.21832 (2024).
Jacobs, C. L., Martin, S. N. & Otieno, T. C. A science lesson plan analysis instrument for formative and summative program evaluation of a teacher education program. Sci. education 92, 1096–1126, https://doi.org/10.1002/sce.20277 (2008).
Wang, Q. et al. Dual trustworthy mechanism for illness classification with multi-modality data. In 2023 IEEE International Conference on Data Mining Workshops (ICDMW), 356–362, https://doi.org/10.1109/ICDMW60847.2023.00051 (2023).
MMAction2 Contributors. OpenMMLab’s Next Generation Video Understanding Toolbox and Benchmark, https://github.com/open-mmlab/mmaction2 (2020).
Zheng, Y. et al. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), arXiv.2403.13372 (2024).
Acknowledgements
This work was supported by the National Key R&D Program of China under Grant (2022YFC3303600), the Natural Science Foundation of Zhejiang Province under Grants (LY23F020010, QN25F020030), and the Zhejiang Provincial Philosophy and Social Sciences Planning Project (24NDJC191YB).
Author information
Authors and Affiliations
Contributions
C.L.H. and J.Z. designed and conceived the study. Y.L.J and Z.Z.C. collected the data. J.X.L. and Z.Z.C. performed full data anonymization. H.H.G. and Z.L.L. processed and analyzed the data. W.S.J. and H.C. conceived the experiments, and C.L.H. and H.H.G. conducted the experiments. C.L.H. performed the data analyses and wrote the original draft. M.Y. and P.D.M. revised the manuscript. J.Z. supervised the entire study. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Huang, C., Zhu, J., Ji, Y. et al. A Multi-Modal Dataset for Teacher Behavior Analysis in Offline Classrooms. Sci Data 12, 1115 (2025). https://doi.org/10.1038/s41597-025-05426-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05426-6
