
Abstract
We introduce Kust4K, a UAV-based dataset for RGB-TIR multimodal semantic segmentation. Kust4K dataset is designed to overcome key limitations in existing UAV-based semantic segmentation datasets: low information density, limited data volume, and insufficient robustness discussion under non-ideal environment. Kust4K dataset featuring 4,024 of 640 × 512 pixel-aligned RGB-Thermal Infrared image pairs captured across diverse urban road scenes under variable illumination. Extensive experiments with state-of-the-art models demonstrate Kust4K’s effectiveness, with multimodal training, significantly outperforming unimodal baselines. Additionally, these results highlight that multimodal image information is critical for obtaining more reliable semantic segmentation results. In total, Kust4K dataset advance robust urban traffic scene understanding, offering a valuable resource for intelligent transportation research.
Similar content being viewed by others


Background & Summary
With the accelerating pace of urbanization and the increasing complexity of traffic issues, traditional urban traffic management methods (e.g., fixed surveillance cameras) can no longer meet the demands for efficient, comprehensive, and reliable monitoring. This is particularly in complex and dynamic urban road scenes, where traditional monitoring methods often face limitations such as restricted viewpoints and incomplete information. UAV remote sensing technology1, with its high flexibility, broad coverage, and relatively low cost, has gradually become a key tool to address these issues.
However, despite the immense potential of UAV remote sensing images in many applications2,3,4,5,6,7, a single image modality often struggles to provide comprehensive information in complex environments8,9,10,11. This limitation is particularly evident in low-illumination, complex and dynamically changing urban road scenes12. As shown in Fig. 1, RGB images perform poorly under low-illumination conditions. Although thermal infrared (TIR) images can provide effective thermal radiation information under low-illumination conditions, such as at night, they lack sufficient color and shape detail. Therefore, how to combine information from multiple modalities and leverage the strengths of each modality has become a key issue13,14,15 in enhancing UAV visual perception capabilities.

(a) and (b) Show the heatmap visualization results, (c) illustrates the “artifact” phenomenon in TIR images. (a) In low-illumination environments, thermal radiation information from the TIR modality (e.g., pedestrians on the sidewalk) dominates. (b) In contrast, the color information from the RGB modality (e.g., “white” vehicles) becomes dominant. (c) Due to sunlight exposure and vehicle occlusion, the ground temperature drops below the ambient temperature after the vehicle leaves, causing “artifact”. This “artifact” in the TIR modality is easily misinterpreted as a real vehicle.
To achieve fine-grained scene understanding critical for traffic management, identifying vehicles and pedestrians, semantic segmentation – the pixel-level classification of image, emerges as a fundamental task. In recent years, many semantic segmentation datasets8,16,17,18,19,20 captured from a UAV perspective have been released, significantly advancing the development of data-driven UAV semantic segmentation models, the attribute comparison of existing UAV semantic segmentation datasets and multimodal semantic segmentation datasets is shown in Table 1. However, these datasets face three key challenges that need to be addressed:
-
High scene redundancy. Existing UAV-based semantic segmentation datasets often suffer from information redundancy. Many images in these datasets16,18,19 are collected from the same or highly similar scenes, resulting in minimal inter-frame variation. As evidenced by datasets like Aeroscapes16 (which contains 3,269 images with ~23 captures per scene), consecutive frames often capture identical or highly similar scenes, resulting in negligible inter-frame variation. This redundancy fundamentally limits the effective information gain per annotated sample, consequently constraining the generalization capability and real-world robustness of segmentation models in diverse operational scenarios.
-
Low data volume. Due to the wide spatial coverage of UAV-captured images, which typically contain many diverse object categories and exhibit complex, densely populated scenes, the manual annotation process for semantic segmentation is both time-consuming and labor-intensive. As a result, existing UAV-based semantic segmentation datasets (e.g., UDD17 and UAVid19) generally suffer from limited sample sizes. This shortage of large-scale annotated data hinders the ability to fully meet the demands of data-driven deep learning models, which require substantial amounts of training data to achieve optimal performance.
-
Limited robustness discussion. Existing UAV-based semantic segmentation datasets only include RGB images, which limit their ability to meet the all-time monitoring requirements, particularly in low-illumination environments. Additionally, the stability of imaging sensors is often compromised during UAV flights, especially in high-speed, vibration-prone, or windy conditions. These conditions are commonly encountered in real-world applications and easily affect image quality.
To address the issues of exiting UAV-based semantic segmentation datasets, as depict in Fig. 2, we propose a multimodal UAV semantic segmentation dataset, termed as Kust4K, which covers a wide range of urban road scenes, both RGB and thermal infrared (TIR) images were captured. RGB and TIR modalities exhibit distinct advantages, and neither modality alone can provide reliable visual perception. As shown in Fig. 1(a,b), each modality—RGB and TIR provides unique feature information: RGB images offer color and texture details of contents, while TIR images capture the thermal radiation information of the objects. The complementary information of these two modalities enables more robust multimodal joint perception. Besides, some TIR-exclusive studies10,21 facing reliability limitations under specific operational conditions. As illustrated in Fig. 1(c), vehicle occlusion induces artifacts in TIR images – particularly problematic in UAV perspectives where such artifacts may be misinterpreted as actual vehicles. Consequently, our Kust4K dataset integrates both RGB and TIR modalities to mitigate these constraints. Samples of our Kust4K dataset under different lighting conditions in various urban road scenes, along with their corresponding semantic segmentation annotations, are shown in Fig. 3.

The samples of different open access UAV-based semantic segmentation datasets.

The Kust4K dataset includes samples from diverse scenes and under varying lighting conditions, from a well-lit day to a low-lit night. The first row displays the RGB images, the second row shows the TIR images, and the third row presents the semantic segmentation annotations, where each pixel is labelled with 8 object categories: Road, Building, Motorcycle, Car, Truck, Tree, Person, and Traffic Facilities.
Additionally, considering the potential image quality degradation that may occur during UAV flight15, we manually applied noise to a subset of the images. By introducing noise, we can evaluate the model’s performance under low-quality imaging conditions, further advancing the application and development of UAV semantic segmentation technologies in complex environments. For detailed information on the noise augmentation process, please refer to the Dataset Attributes and Statistics section. Kust4K is a UAV-based RGB-TIR semantic segmentation dataset, specifically designed for robust urban traffic scene understanding under challenging conditions, which serves as a valuable resource to facilitate advances in robust multimodal perception and intelligent transportation systems.
Methods
We utilized a hexacopter drone model HET-3021C equipped with both RGB and thermal infrared (TIR) dual-spectrum cameras as the multimodal image acquisition platform, The HET-3021C is a professional-grade unmanned aerial vehicle specifically designed for long-range, high-precision patrol and surveillance missions. The detailed specifications of the HET-3021C drone are summarized in Table 2. The construction of our Kust4K dataset consists of four main stages: data acquisition, data registration, data annotation, and dataset generation.
Data acquisition
Previous datasets captured from UAV perspectives often consist of consecutive video frames with limited incremental information between frames, which poses challenges for effectively improving downstream semantic segmentation performance. To address this issue, we sampled synchronized RGB and TIR frames every 15 frames from the recorded dual-modal videos. This approach yielded a total of 4,024 paired RGB-TIR images. The RGB images have a resolution of 1920 × 1080, while the TIR images are captured at a resolution of 640 × 512.
Data registration
Due to inherent differences in imaging time and field of view between RGB and TIR sensors, registration of the collected RGB-TIR image pairs is necessary to ensure accurate spatial alignment. This challenge is particularly pronounced in urban road scenes, where the presence of fast-moving vehicles exacerbates misalignment between the two modalities. Proper registration is critical to enable effective multimodal fusion and to maintain the integrity of semantic segmentation labels across modalities. To address this, we first applied the Scale-Invariant Feature Transform (SIFT) algorithm to extract key points from the two modalities and subsequently computed the transformation matrix based on these matched feature points to align the RGB and TIR images. However, since the Kust4K dataset was collected under varying lighting conditions, low-illumination environments posed significant challenges for reliable key point detection. We then employed manual registration. During this process, the RGB-TIR images were cropped and resized to a resolution of 640 × 512 pixels to match the TIR image resolution. The RGB-TIR multimodal image registration process is shown in Fig. 4.

RGB-TIR dual-modal image acquisition and registration workflow. This diagram shows the process of aligning RGB and TIR images captured by a UAV, using SIFT for key point extraction followed by manual registration to ensure accurate spatial alignment between the two modalities.
Data annotation
The Kust4K dataset includes RGB images captured under varying lighting conditions. Relying solely on a single modality, particularly in low-illumination environments, makes it challenging to achieve high-precision, high-quality semantic segmentation annotations. Therefore, it is essential to simultaneously leverage information from both modalities for accurate semantic segmentation labelling. Besides, the semantic segmentation annotation tool Labelme22 integrates the Segment Anything Model (SAM)23, significantly enhancing the efficiency of semantic segmentation labelling. This is particularly valuable for UAV remote sensing images, which often cover large areas and include a wide variety of content categories. Based on this, we have designed a systematic semi-automated annotation workflow for the Kust4K multimodal semantic segmentation dataset. Considering the varying importance and frequency of occurrence of different content in real-world applications, we selected eight categories for annotation: Road, Building, Motorcycle, Car, Truck, Tree, Person, and Traffic Facilities. The annotation workflow for our Kust4K dataset is shown in Fig. 5, which consists of four stages:
-
Multimodal Channel Aggregation. To simultaneously acquire both RGB and TIR information for annotation in Labelme22, we first aggregated the RGB and TIR images. Specifically, we split the TIR image into three channels and calculated the average value of these channels, which was then used as the fourth channel to combine with the RGB image. The color information from the RGB image and the thermal radiation information from the TIR image within a single four-channel image.
-
SAM-based Initial Masking. We use SAM in Labelme22 to generate initial semantic segmentation masks for the multimodal four-channel images. Through interactive prompt points, generating initialization masks for the corresponding contents, as shown in Fig. 5(b).
-
Expert Annotation Refinement. Expert annotators refine the initial labels generated by SAM, referring information such as color and texture from the original RGB image, and temperature and thermal radiation from the TIR image. This process includes boundary refinement, category correction and other optimizations. Particular attention is given to small objects, such as motorcycles and person.
-
Experts Cross Verification. Finally, we adopted a cross-validation approach, where expert annotators validate and correct the semantic segmentation labels created by other annotators. The final review is conducted by a reviewer who was not involved in the previous annotation process. This iterative cycle of validation, correction, and review continues until the reviewer determine that the quality of the semantic segmentation labels meets the required standards. Only then are the validated samples included in the final Kust4K dataset.

Annotation workflow for Kust4K semantic segmentation dataset in urban scenes. (a) Aggregation of multimodal four-channel images. (b) Initial annotations generated using Segment Anything (SAM)23. (c) Expert manual correction of the initial annotations produced by SAM23. (d) Expert cross validation and verification of the annotated information.
Generation of dataset
The semantic segmentation mask annotations exported from Labelme22 in JSON format are then converted into PNG format mask images suitable for semantic segmentation tasks. Specifically, according to JSON file, the corresponding mask annotations (segmentation points and categories) are mapped to the PNG mask image using different pixel values. In this stage, the pixel values corresponding to each category are as follows: “Road” is assigned a pixel value of 1, “Building” as 2, “Motorcycle” as 3, “Car” as 4, “Truck” as 5, “Tree” is assigned 6, “Person” is assigned 7, and “Traffic Facilities” as 8. Any unannotated areas are considered as “unlabeled” and are assigned a pixel value of 0.
Data Records
The Kust4K24 dataset is publicly available at figshare. Kust4K dataset is designed to provide a reliable dataset for the data-driven UAV visual perception, particularly for developing robust multimodal semantic segmentation models. This section introduces the image file naming and dataset splits.
File naming
The image naming format we define is “NNNNNT.png”, where “NNNNN” represents the image’s sequence number, starting from “00001” to ensure that each image has a unique identifier. The “T” denotes the time of image acquisition, with “D” indicating daytime and “N” indicating nighttime. For the same scene, the naming of the RGB and TIR images remains consistent, ensuring a clear correspondence between the RGB and TIR images.
These detailed annotations and statistical analyses, driving the development of UAV-based semantic segmentation technology in intelligent urban traffic management.
Figure 6(a) presents a statistical analysis of the samples under different lighting conditions in Kust4K dataset. Additionally, considering the potential image quality degradation that may occur in real-world, we applied noise processing to a subset of Kust4K dataset to enhance the dataset’s diversity and improve the model’s adaptability to low-quality data. Specifically, as shown in Fig. 6(b), for RGB failure samples, we set all pixel values to 0 to simulate scenes under complete darkness or extremely low light conditions. For TIR failure samples, we introduced Gaussian blur to simulate image blurring caused by focusing failure or vibrations during high-speed UAV flight. For each RGB-TIR image pair, we only applied noise to one modality to ensure that the model could still extract information from the other modality. This design not only simulates potential modality failures in real-world applications but also helps prevent the model from becoming overly reliant on any single modality during multimodal learning. The experimental results related to modality failure can be found in the Technical Validation section.

Kust4K dataset attributes and statistical analysis. (a) statistics of images and RGB-TIR samples under different lighting levels. (b) statistics of modality failure.
Dataset splits
We divided Kust4K dataset into training, testing, and validation subsets with 7:2:1 split ratio. To prevents model bias caused by illumination imbalance, we balanced the samples based on the illumination intensity. The training set contains 2814 RGB-TIR image pairs (1758 taken in day, 1056 taken in night), the testing set contains 807 RGB-TIR image pairs (504 taken in day, 303 taken in night), the validation set contains 403 RGB-TIR image pairs (252 taken in day, 151 taken in night). Besides, the training set contains 528 RGB failure samples and 316 TIR failure samples, the testing set contains 151 RGB failure samples and 91 TIR failure samples, the validation set contains 74 RGB failure samples and 46 TIR failure samples.
Data Overview
Dataset attributes and statistics
Kust4K dataset covers a variety of urban road scenes and is designed to provide reliable UAV-based semantic segmentation data for intelligent urban traffic management. The dataset annotates key categories in urban traffic management, offering comprehensive support for traffic scene analysis. The Kust4K dataset includes 8 object categories: “Road”, “Building”, “Motorcycle”, “Car”, “Truck”, “Tree”, “Person”, and “Traffic Facilities”, with all unlabeled regions designated as the background. Kust4K dataset provides reliable semantic segmentation annotations for researchers in the field. In Fig. 7, we present a statistical visualization of the pixel counts for the annotations of different categories in Kust4K dataset. This allows us to visually observe the distribution of each category within the dataset, helping researchers to better understand the composition of our Kust4K dataset.

Statistics on the number of labelled pixels for different categories in Kust4K dataset.
Technical Validation
Task definition
Semantic segmentation is one of the core tasks in computer vision, with the primary goal of assigning a precise semantic label to each pixel in a scene, representing the object category or region type it belongs to. Kust4K dataset contains 4,024 pairs of RGB-TIR images captured from a UAV perspective, aimed at providing a detailed analysis of complex urban road scenes under varying lighting conditions.
Models and training details
Semantic segmentation models
We selected 8 state-of-the-art semantic segmentation methods25,26,27,28,29,30,31,32 for comparison and evaluation, including 3 CNN-based methods (UNet30, UperNet31 and RTFNet25), Attention-based methods (FEANet26, EAEFNet27, CMNeXt28 and CMX29), and the latest Mamba-based methods (Sigma32). Traditional single-modality semantic segmentation methods (UNet30 and UperNet31) lack modality fusion and interaction modules. To address this, we replicated the original single-modality branches and fused the images by element-wise addition of feature matrices. These 9 different methods cover a range from traditional single-modality methods to multimodal fusion techniques, aiming to thoroughly explore and evaluate the segmentation performance of different algorithms in complex urban road scenes.
Training details
All models were built using the PyTorch framework and experiments were conducted on a single Nvidia GeForce RTX 4090 GPU with 24 GB of VRAM, the resolution of all input RGB and TIR images is 640 × 512. To ensure the fairness and reliability of the experimental results, we strictly adhered to the hyperparameter configurations recommended in the original papers for each method, including optimizer type, learning rate, loss functions, and other relevant training details. In terms of data augmentation, all methods used horizontal flipping with a probability of 0.5 during training. This was the only data augmentation strategy applied to ensure consistency across models. Furthermore, the pre-trained weights for all models were obtained from the official publicly available checkpoints to ensure consistency in the starting point of model training.
Performance evaluation metrics
Same as previous multimodal semantic segmentation works26,27,28, we employ mean intersection over union (mIoU) as evaluation metrics to assess the performance of different semantic segmentation models on Kust4K dataset. mIoU is the average result of summing the percentage overlap between the target or region masks and the predicted outputs for each category. The mathematical definition of mIoU is as follows:
where N represents the number of categories. \(T{P}_{i}={\sum }_{m=1}^{M}{P}_{ii}^{m},F{P}_{i}={\sum }_{m=1}^{M}{\sum }_{j=1,j\ne i}^{N}{P}_{ji}^{k}\) and \(F{N}_{i}={\sum }_{m=1}^{M}{\sum }_{j=1,j\ne i}^{N}{P}_{ij}^{k}\), where M is the number of samples in the test set. For the test sample k, \({P}_{ii}^{m}\) is the number of pixels correctly classified as class i, \({P}_{ji}^{k}\) is the number of pixels misclassified as class i but actually belonging to class j, and \({P}_{ij}^{k}\) is the number of pixels misclassified as class j but actually belonging to class i.
Experimental result analysis
Table 3 and Fig. 8 present the quantitative and qualitative experimental results of different semantic segmentation methods on Kust4K dataset. We use an effective element-wise additional feature fusion module for CNN-based single-modality UNet30 and UperNet31. While UNet30 and UperNet31 perform reasonably well in simple scenes, there remains a significant performance gap when handling complex objects and low-contrast details, compared to the well-designed multimodal fusion modules in multimodal semantic segmentation methods. The CNN-based multimodal semantic segmentation method RTFNet25 shows an improvement in mIoU by 7.3% compared to UNet30 and 4.6% compared to UperNet31. This improvement is attributed to RTFNet’s design of multi-level cross-modal feature fusion, which incorporates multi-scale TIR features into the RGB features, thereby enhancing the overall performance.

Qualitative experiments of different semantic segmentation methods on Kust4K dataset.
Besides, small objects are often challenging to segment accurately, particularly under low-illumination conditions. This phenomenon is particularly evident in our Kust4K dataset, which contains small objects in the scene. These small objects are often difficult to segment accurately, especially under low-illumination conditions. As shown in Table 3, compared to CNN-based methods, Attention-based and Mamba-based methods exhibit better segmentation performance for small objects such as Motorcycle and Traffic Facilities. This improvement is attributed to the long-range feature interaction design in Attention-based (global attention) and Mamba-based (state space recurrence) methods, which allows for a deeper understanding of the advantageous features of both modalities. By fusing the color and shape information from the RGB images with the thermal radiation information from the TIR images, Attention-based and Mamba-based methods effectively complement each other’s weaknesses, thereby enhancing the model’s ability to segment small objects.
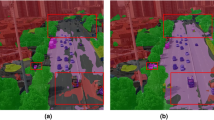
In Fig. 9, we present qualitative comparisons of different methods under single-modality failure scenes. As observed from Fig. 9, UperNet31 demonstrates notably weaker segmentation performance compared to other multimodal semantic segmentation methods in cases of modality failure. For example, UperNet31 exhibits misclassification of vehicles when the TIR modality fails and reduced accuracy in “tree” segmentation when the RGB modality fails. In contrast, the other multimodal semantic segmentation methods27,32, benefiting from their specially designed adaptive feature fusion modules, exhibit stronger robustness against modality failure. This indicates that modality failure negatively impacts semantic segmentation tasks, particularly when the model lacks the ability to adaptively adjust the weights of each modality.

Qualitative comparisons of different methods under single-modality failure scenarios.
Modality robustness analysis
To further analyse the effect of different modal images on model robustness, we carried out experiments comparing unimodal and multimodal inputs, and a discussion for when a particular modal image fails.
Modality-specific analysis
UNet30, CMX29 and Sigma32 was trained and tested using single RGB images, single TIR images, and RGB-TIR image pairs (multimodal input). As shown in Table 4, single-modality inputs generally perform worse, especially RGB images. In contrast, TIR images are less sensitive to lighting conditions and can provide effective target cues by capturing the thermal radiation information of objects, resulting in significantly better performance compared to unimodal RGB images. When using RGB-TIR image pairs as multimodal inputs, the model can simultaneously leverage the color and texture information from RGB images and the thermal radiation data from TIR images, compensating for the limitations of single-modality inputs. As shown in Table 4, when RGB + TIR is used as input, UNet30, CMX29 and Sigma32 achieve optimal performance. Moreover, compared to single-modality methods, the “RGB + TIR” multimodal input shows a more significant improvement in multi-modality model performance. For UNet30, when the input is “RGB + TIR”, the performance improves by 3.6% compared to TIR alone, besides, CMX29 and Sigma32 show improvements of 5.1% and 6.3%, respectively. This indicates that multimodal methods (CMX29 and Sigma32) are better at utilizing information from different modalities, with the performance improvement being more significant when compared to the multimodal input of single-modality method.
Modality-failure analysis
In real-world applications, RGB and TIR imaging sensors may experience modality failure due to adverse weather conditions, hardware malfunctions, or other factors. Therefore, testing the robustness of the model in cases of single-modality failure is crucial. We conducted experiments on UNet30, CMX29 and Sigma32 trained with Kust4K multimodal images, specifically testing it on modality failure samples from the test set (151 RGB failure samples and 91 TIR failure samples), the results are presented in Table 5. The segmentation performance of all three methods decreases in modality failure scenes. Compared to their overall performance, the performance gap between UNet30, CMX29 and Sigma32 narrows when the TIR modality fails, indicating that the TIR modality plays a dominant role in the feature fusion. While multimodal methods effectively leverage the strengths of both modalities, they are more susceptible to the failure of the dominant modality. In Fig. 10, we present the semantic segmentation results of CMX29 using single-modality and multimodality inputs when the RGB or TIR modality fails. The segmentation results indicate that when the failed image is used as a single-modality input, the model is almost unable to perform reliable semantic segmentation. When only the non-failed modality is used for segmentation, the model performs better and can accurately segment the scene.

Qualitative experiments of CMX on modality failure samples.
While RGB + TIR is used as the input for CMX29, the segmentation results are inferior compared normal unimodal input (“Tree” in the RGB failure case; “traffic facilities” in the RGB failure case). However, the multimodal interaction and fusion module in the CMX29 model is still able to extract effective information from the non-failed modality, maintaining relatively stable performance. This result demonstrates that even when one modality image fails, the model can still effectively use the data from the remaining modality, partially compensating for the impact of the failed modality, thus highlighting the important role of multimodal input in enhancing model robustness.
Data availability
The dataset described in this article is now publicly available on figshare24 (https://doi.org/10.6084/m9.figshare.29476610.v3).
Code availability
All the data processing code written in Python is available on the figshare at https://doi.org/10.6084/m9.figshare.29476610.v3. The code includes the following scripts: tools/visual.py: This script is used for visualizing semantic segmentation annotations and includes the color palette corresponding to each category. tools/merge.py: This script aggregates RGB and TIR images to form a four-channel image for annotation purposes. Additionally, the infos folder contains statistical information on modality failure scenes: broke_RGB.txt, broke_TIR.txt, broken_in_test_day_151.txt, broken_in_test_night_91.txt, broken_in_train_day_528.txt, broken_in_train_night_316.txt, broken_in_val_day_74.txt and broken_in_val_night_46.txt.
References
Hawashin, D. et al. Blockchain applications in UAV industry: Review, opportunities, and challenges. Journal of Network and Computer Applications 230, 103932 (2024).
Aibibu, T., Lan, J., Zeng, Y., Hu, J. & Yong, Z. Multiview angle UAV infrared image simulation with segmented model and object detection for traffic surveillance. Sci. Rep. 15, 5254, https://doi.org/10.1038/s41598-025-89585-x (2025).
Ma, W., Chu, Z., Chen, H. & Li, M. Spatio-temporal envolutional graph neural network for traffic flow prediction in UAV-based urban traffic monitoring system. Sci. Rep. 14, 26800, https://doi.org/10.1038/s41598-024-78335-0 (2024).
Huang, Y. et al. Plant species classification of coastal wetlands based on UAV images and object- oriented deep learning. Biodiv Sci 31, 22411, https://www.biodiversity-science.net/CN/abstract/article_93263.shtml (2023).
Li, H., Fu, T., Hao, H. & Yu, Z. MAVSD: A Multi-Angle View Segmentation Dataset for Detection of Solidago Canadensis L. Sci. Data 12, 861, https://doi.org/10.1038/s41597-025-05199-y (2025).
Song, Z. et al. An infrared dataset for partially occluded person detection in complex environment for search and rescue. Sci. Data 12, 300, https://doi.org/10.1038/s41597-025-04600-0 (2025).
Deng, L. et al. Comparison of 2D and 3D vegetation species mapping in three natural scenarios using UAV-LiDAR point clouds and improved deep learning methods. International Journal of Applied Earth Observation and Geoinformation 125, 103588, https://www.sciencedirect.com/science/article/pii/S1569843223004120 (2023).
Cai, W. et al. VDD: Varied Drone Dataset for semantic segmentation. Journal of Visual Communication and Image Representation 109, 104429 https://www.sciencedirect.com/science/article/pii/S1047320325000434 (2025).
Zhu, Q. et al. Unrestricted region and scale: Deep self-supervised building mapping framework across different cities from five continents. ISPRS J Photogramm Remote Sens. 209, 344–367, https://www.sciencedirect.com/science/article/pii/S0924271624000303 (2024).
Suo, J. et al. HIT-UAV: A high-altitude infrared thermal dataset for Unmanned Aerial Vehicle-based object detection. Sci. Data 10, 227, https://doi.org/10.1038/s41597-023-02066-6 (2023).
Zhu, Q., Ran, L., Zhang, Y. & Guan, Q. Integrating geographic knowledge into deep learning for spatiotemporal local climate zone mapping derived thermal environment exploration across Chinese climate zones. ISPRS J Photogramm Remote Sens. 217, 53–75, https://www.sciencedirect.com/science/article/pii/S0924271624003162 (2024).
Wang, Q., Yin, C., Song, H., Shen, T. & Gu, Y. UTFNet: Uncertainty-guided trustworthy fusion network for RGB-thermal semantic segmentation. IEEE Geosci Remote Sens Lett. 20, 1–5 (2023).
Sun, Y., Cao, B., Zhu, P. & Hu, Q. Drone-based RGB-infrared cross-modality vehicle detection via uncertainty-aware learning. IEEE Trans Circuits Syst Video Technol. 32, 6700–6713 (2022).
Wang, Q. et al. Improving rgb-infrared pedestrian detection by reducing cross-modality redundancy. in 2022 IEEE International Conference on Image Processing (ICIP). 526–530 (IEEE).
Ouyang, J., Jin, P. & Wang, Q. Multimodal feature-guided pre-training for RGB-T perception. IEEE J Sel Top Appl Earth Obs Remote Sens. (2024).
Nigam, I., Huang, C. & Ramanan, D. Ensemble knowledge transfer for semantic segmentation. in 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). 1499–1508 (IEEE).
Chen, Y., Wang, Y., Lu, P., Chen, Y. & Wang, G. Large-scale structure from motion with semantic constraints of aerial images. in Pattern Recognition and Computer Vision: First Chinese Conference, PRCV 2018, Guangzhou, China, November 23-26, 2018, Proceedings, Part I 1. 347–359 (Springer).
Anonymous. Icg drone dataset, http://dronedataset.icg.tugraz.at/ (2019).
Lyu, Y., Vosselman, G., Xia, G.-S., Yilmaz, A. & Yang, M. Y. UAVid: A semantic segmentation dataset for UAV imagery. ISPRS J Photogramm Remote Sens. 165, 108–119 (2020).
Rahnemoonfar, M. et al. Floodnet: A high resolution aerial imagery dataset for post flood scene understanding. IEEE Access 9, 89644–89654 (2021).
Liu, F. et al. InfMAE: A Foundation Model in the Infrared Modality. 420–437 (Springer Nature Switzerland, 2025).
wkentaro. Labelme, https://github.com/wkentaro/labelme (2018).
Kirillov, A. et al. Segment anything. in Proceedings of the IEEE/CVF international conference on computer vision. 4015–4026 (2023).
OuYang, J., Wang, Q. & Shen, T. Kust4K: An RGB-TIR Dataset from UAV Platform for Robust Urban Traffic Scenes Semantic Segmentation. figshare https://doi.org/10.6084/m9.figshare.29476610.v3 (2025).
Sun, Y., Zuo, W. & Liu, M. RTFNet: RGB-thermal fusion network for semantic segmentation of urban scenes. IEEE Robot Autom Lett. 4, 2576–2583 (2019).
Deng, F. et al. FEANet: Feature-enhanced attention network for RGB-thermal real-time semantic segmentation. in 2021 IEEE/RSJ international conference on intelligent robots and systems (IROS). 4467–4473 (IEEE, 2021).
Liang, M. et al. Explicit attention-enhanced fusion for RGB-thermal perception tasks. IEEE Robot Autom Lett. 8, 4060–4067 (2023).
Zhang, J. et al. Delivering arbitrary-modal semantic segmentation. in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1136–1147 (2023).
Zhang, J. et al. CMX: Cross-modal fusion for RGB-X semantic segmentation with transformers. IEEE trans Intell Transp Syst. 24, 14679–14694 (2023).
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmentation. in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. 234–241 (Springer).
Xiao, T., Liu, Y., Zhou, B., Jiang, Y. & Sun, J. Unified perceptual parsing for scene understanding. in Proceedings of the European conference on computer vision (ECCV). 418–434.
Wan, Z. et al. Sigma: Siamese mamba network for multi-modal semantic segmentation. in 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). 1734–1744 (IEEE, 2025).
Ha, Q., Watanabe, K., Karasawa, T., Ushiku, Y. & Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 5108–5115 (IEEE).
Shivakumar, S. S. et al. Pst900: Rgb-thermal calibration, dataset and segmentation network. in 2020 IEEE international conference on robotics and automation (ICRA). 9441–9447 (IEEE, 2020).
Acknowledgements
This work is funded in part by the Yunnan Fundamental Research Projects under Grant 202401AW070019 and 202301AV070003, in part by the Youth Project of the National Natural Science Foundation of China under Grant 62201237.
Author information
Authors and Affiliations
Contributions
Junlin Ouyang designed the experiments, organized the data, annotated the images, and wrote the paper. Qingwang Wang supervised the work, reviewed the paper, and provided funding. Yin Shang, Pengcheng Jin and Liman Zhou were responsible for flying the drone and taking RGB-TIR images, annotating the images. Tao Shen reviewed the paper and assisted with the experiments. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ouyang, J., Wang, Q., Shang, Y. et al. An RGB-TIR Dataset from UAV Platform for Robust Urban Traffic Scenes Semantic Segmentation. Sci Data 12, 1701 (2025). https://doi.org/10.1038/s41597-025-05994-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05994-7
