
Abstract
This study aims to predict individual Acceleration-Velocity profiles (A-V) from Global Navigation Satellite System (GNSS) measurements in real-world situations. Data were collected from professional players in the Superleague division during a 1.5 season period (2019–2021). A baseline modeling performance was provided by time-series forecasting methods and compared with two multivariate modeling approaches using ridge regularisation and long short term memory neural networks. The multivariate models considered commercial features and new features extracted from GNSS raw data as predictor variables. A control condition in which profiles were predicted from predictors of the same session outlined the predictability of A-V profiles. Multivariate models were fitted either per player or over the group of players. Predictor variables were pooled according to the mean or an exponential weighting function. As expected, the control condition provided lower error rates than other models on average (p = 0.001). Reference and multivariate models did not show significant differences in error rates (p = 0.124), regardless of the nature of predictors (commercial features or extracted from signal processing methods) or the pooling method used. In addition, models built over a larger population did not provide significantly more accurate predictions. In conclusion, GNSS features seemed to be of limited relevance for predicting individual A-V profiles. However, new signal processing features open up new perspectives in athletic performance or injury occurrence modeling, mainly if higher sampling rate tracking systems are considered.
Similar content being viewed by others

Introduction
Global Navigation Satellite System (GNSS) is one of the gold standard systems in position measurements in field sports. Widely used for athlete monitoring purposes1,2,3,4,5,6,7,8,9,10,11, GNSS permits discriminating the physical demand at exercise through objective mechanical parameters, computed from GNSS and Inertial Measurement Units (IMU) signals12. Data collected from these wearable devices provide useful insights for understanding a player’s activity and its relationship with performance outcomes or injury occurrences during practice6,13,14,15,16.
In most cases, the information provided by wearable GNSS devices are summarised features over a session or a period (e.g. distance covered at different speed intervals, averaged pace for a given interval, acceleration, and deceleration counts). Beyond a standard set of simple and easily comprehensible features, extra information of mechanical and energetic nature that is derived from the players’ position may be available for customers under the manufacturer’s policy17,18,19. However, the validity of GNSS sport receivers should be considered regarding their technical properties, such as sampling frequency. Despite a lack of accuracy for quantifying exercise demand over short distances covered at high speed, including sharp turns, GNSS suffers from error rates according to a relatively low GNSS sampling frequency20,21. The signal quality of receivers also depends on the spatial configuration of satellites locked for recording (i.e. the number of satellites and their geometrical distribution in the sky)22. Nonetheless, GNSS with embedded IMU stands of interest and remains prone to further technological improvements. Beyond technological aspects, practitioners mostly use summarised GNSS statistics or metrics, whereas raw data are seldom considered for player analysis. The usual data fed back from the GNSS units might be elementary, while new features extracted from raw data could be more insightful for monitoring the physical demand of exercise and the related athlete’s response.
Using GNSS data for predicting athletic performance in team sports remains challenging. First, it implies defining an athletic performance in which interactions with opponents and the environment are sufficiently lowered. Usually, assessing athletic performances requires specific testing sessions performed in controlled conditions. It comes with challenging issues due to time and investigation costs, injury exposure, psychological state disruptions, and adjustments to training plans. Nevertheless, Morin et al.23 recently proposed a timely method for assessing a player’s athletic performance while practicing football without performing any specific tests. In brief, the method determines individual acceleration-velocity profiles (A-V) from continuous GNSS measurements for in-game and post hoc analysis. Such profiles come with practical meanings, notably for monitoring changes in athletic properties (by analogy to force-velocity profiles). They could be used for optimising training plans or proceeding to in-game tactical adjustments in case of significant profile impairments. However, determining in situ A-V profiles for monitoring athletic performances remains at a proof-of-concept stage23. It should be further validated for athletic performance modeling and injury explanation purposes.
On this basis and according to the literature, the present study considers three research issues:
-
1.
The predictability of A-V profiles using only related GNSS features
-
2.
The value of common metrics (summarised statistics) and aggregated features that are delivered by GNSS sensors manufacturers for predictive applications
-
3.
The use of raw GNSS data for extracting new features for prediction purposes
In order to investigate these issues, we attempted to predict A-V profiles using data from an elite football team through different modeling approaches. A baseline approach that only considers A-V profiles and dismisses any potential predictors other than historical profiles was carried out. Then, we compared it with two distinct tasks that used commercial GNSS features and features extracted from raw GNSS data.
The rest of the manuscript is organized as follows. We introduce the data set that highlights the predictor and outcome variables. Next, we introduce the proposed models and their variants. Accordingly, we present the obtained results followed by exhaustive discussions of these results before concluding our study in the last section.
Methods
This section introduced a descriptive analysis of the data set used in our experiments. We defined the predictors and outcome variables besides the considered problem formulations before elaborating the proposed models. For clarification, we provided a pseudo-code of the modeling methodology through Algorithms 1, 2 and 3.
Data set
Population studied
Data from the FC Lucerne football club were collected over a 1.5 season period (2019–2021). The team evolves in the Superleague division, the highest division in Swiss professional football. A total of 196 training sessions and 74 games were stored in a cloud-hosted multi-model database (ArangoDB, CA, USA). For each session, raw GNSS data (Fieldwiz V1, CH, with concurrent reception of Global positioning system, Galileo, GLONASS, and BeiDou systems) and summarised features (see Appendix A for details) of each player were stored in a database as json files. A total of 42 players were initially recorded, including regular professional players and young hopes. Participants were fully informed about data collection, and their written consent were obtained. The study was performed in agreement with the standards set by the declaration of Helsinki (2013) involving human subjects. The protocol was reviewed and approved by the local research Ethics Committee (EuroMov, University of Montpellier, France). The present retrospective study relied on the collected data without causing any changes in the training plans of football players.
Predictor variables
Predictors are summarised in Appendix 1, Table A1. Let \(\mathcal {X} \subset \mathbb {R}^d\) with \(d \in \mathbb {N}\) be the domain of definition of the random variable \(X = \{x_1, \ldots , x_d\} \). The variable X is thus defined as a vector of d dimensions, composed of aggregations of the summarised features given by the GNSS software (Fieldwiz, ASI, CH). Aggregated features can take two forms:
-
1.
The average of summarised features \(\bar{X}= \{\bar{x_1}, \ldots , \bar{x_d}\}\), such that:
$$\begin{aligned} \bar{X}_{i} = \frac{1}{N} \sum _{j=1}^{N} X_{i,j} \, \quad , 1 \le i \le d \end{aligned}$$(1) -
2.
An exponential weight according to a softmax function (see Eq. 2), such that:
$$\begin{aligned} X_d = \sum _j w_j X_{d, j} \quad \text {where} \quad w_j = \sigma (\varvec{t})_j^{\beta } = \frac{e^{-\beta t_j}}{\sum _{k=1}^{K} e^{- \beta t_j}} \quad \forall j \in \{1, \ldots , K \} \, . \end{aligned}$$(2)
In Eq. 2, \(X_d\) denotes an aggregated feature weighted by a scaling factor \(w_j\). \(w_j\) is determined by a softmax function \(\sigma (\varvec{t})_j^{\beta }\) in which \(\varvec{t}\) is a time vector describing the distance of events to the game of interest and \(\beta \) denotes a scale parameter that sets the sensibility of the exponential decay weighting function.
For both aggregation methods, we arbitrarily set a window L of size \(L = 5\). It refers to the summarised predictor sets given by the GNSS software that are pooled according to the last L sessions (either training or game) preceding the game of interest. Since the frequencies of sessions are heterogeneous, the number of days preceding the game to be predicted may differ over the weeks.
Outcome variables
In order to investigate the effect of training on athletic performances, we relied on A-V profiles such as provided by23 but in a slightly different way. Individual A-V profiles were modeled for each games. From the raw velocity \(\mathbf {V}\) and a sampling frequency \(\omega \), we derived an acceleration A such that
Here, we consider a signal \(x(t) \rightarrow x \left[ n \right] \) with \(x \left[ n \right] = x (nT)\) being the discrete formulation of x(t).
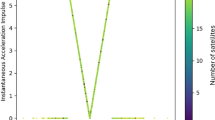
Then, a first-order Butterworth filter was applied to the acceleration signal with a cut-off frequency of 1 Hz. Velocity observations were binned into \(0.1 \, \text {m}.\text {s}^{-1}\) width bins in which the maximal acceleration values were retained. Hence, we modeled A-V profiles over velocities superior to \(3 \, \text {m}.\text {s}^{-1}\) using a linear regression between acceleration and velocity (see Fig. 1). A total of 1032 profiles were modeled, for an average of \(25.80 \pm 20.37\) per player. The large standard deviation is related to occasional players (e.g. young players) who only played a few games through the season.

Example of A-V profile modeled for a given player and a randomly selected game. Only plain dots (velocities above 3 m s−1) were used for fitting the linear regression.
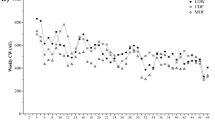
The performance definition is given by \(\big \{ Y^a, Y^b \big \} \in \mathcal {Y}\) such that \(Y^a\) and \(Y^b\) refer to the corresponding slope and the intercept of individual A-V profiles, respectively. Therefore, each observation in the ensemble \(\big \{ y^{a}_{j,t}, y^{b}_{j,t} \big \} \in \big \{ Y^{a}, Y^{b} \big \}\) is related to both an athlete j and the day of realisation t. A sample of fitted coefficients is presented in Figure 2. To formalize, letting \(X \times Y \sim f\) with a density function f, the built data set is a sample \(S = \Bigg \{ \left( x_j, y^{p}_{j} \right) \Bigg \}_{j \le n} \sim f^{n}\) .

Evolution of A-V profiles fitted intercept and slopes over the 1.5 season period. Three players are randomly selected.
A descriptive analysis of A-V coefficients reported mean values and standard deviation as a noise estimate. Accordingly, we have \(\mu _a = -0.533 \pm 0.078\) and \(\mu _b = 4.721 \pm 0.483\) for \(Y^a\) and \(Y^b\), respectively.
Definition of models and multivariate approaches
Time-series forecasting
Time-series forecasting problems are dominant in sports, applied to game outcomes24,25,26,27 generally intended to tipsters or bookmakers, sports popularity28, or performance monitoring29. In our study, we first consider that the auto-regressive component of the target variable may be influential in the prediction of individual athletic performances. Therefore, we started the modeling by defining baseline prediction performances from time-series forecasting, only using games observations (excluding training sessions).
In time-series forecasting, models without covariates use a restricted data set in which predictors are merely time information. The forecasting is deduced from the information in trend and seasonality components. In order to find the most performing models for time-series forecasting, we proceeded with a model selection using a simple holdout procedure, according to a split ratio of 0.8 between the training and testing data set. We can righteously expect a linear relationship between changes in theoretical maximal acceleration and maximal running velocity. Consequently, the ensemble \(\{ Y_a, Y_b \}\) was predicted in two different ways: sequentially (uni-modal forecasting) and concurrently (multi-modal forecasting).
Afterwards, we benefited from the selected forecasting models by combining them into a weighted average ensemble for better performances than a randomly selected single model on average.
Ridge regularisation
Then, we addressed the problem of predicting the acceleration-velocity profile from GNSS summarised features. Changes in A-V fitted parameters were investigated using a predictive regression approach. For this, a linear model (a ridge regularisation) used features pooled according to the two aforementioned aggregation methods (see Eqs. 1 and 2) and were compared to a Long Short Term Memory (LSTM) neural network, a particular case of recurrent neural networks (RNN).
Using a ridge regularisation was motivated by the high dimensional context that may lead to unsteady multivariate linear models, excessively sensitive to an expanded space of solutions. Accordingly, ridge regularisation reduces the space of solutions while solving collinearity problems, which remains common in sports30,31,32. It thus prevents biased estimates through penalising estimates of correlated features33,34. According to the two aggregation methods, the multivariate linear models \(m^{ridge} : X_p \rightarrow Y\) and \(m^{ridge^{*}} : X_{p^{*}} \rightarrow Y\) take the general formulation
where \(\varvec{x} \in X_{p}\) denotes the pooled predictors according to the mean function (see Eq. 1) and \(\varvec{x} \in X_{p^{*}}\) refers to the pooled predictors according to the exponential weighting function (see Eq. 2) for \(m^{ridge}\) and \(m^{ridge^{*}}\), respectively. Also, \(\beta \in \mathbb R^{d}\) denotes the parameters of the model and \(\epsilon _t\) the random error term.
In addition, we defined a control task in which we attempted to predict \(\big \{ y^a_{j,t}, Y^b_{j,t} \big \}\) from \(\varvec{X}_{j,t}\). Using commercial features of the day of A-V profile realisation should be, in theory, the simplest regression task and provide the lowest error rates in prediction.
Long short term memory neural network
Recurrent neural network is the class of neural networks that considers past information to be used as inputs while preserving the hidden states. Let us consider a multidimensional vector \(\varvec{X}\) of fixed length l and dimension d, which includes unpooled summarised features as the model’s input. Basically and from a \(l \times d\) matrix, a recurrent unit successively combines the current values of \(\varvec{X}_t\) of size d with the predicted value at time \(t-1\) to return an output \(\varvec{h}_t\), defined by a function \(f(\varvec{X}_t, \varvec{h}_{t-1})\) (see Fig. 3a). This procedure is repeated as many times as the number of training sessions preceding a game in a multi-layered structure. However, RNN suffers from short-term memory due to a vanishing gradient problem. Nevertheless, used for updating neural network weights, a gradient that shrinks as it back propagates through time stops the learning of layers. These layers may thus cause a loss of past information, particularly with long sequences.
Introduced by Hochreiter et al.35, LSTM neural networks are designed to conserve long-term information through extended internal mechanisms. LSTM architecture benefits from a cell state and various gates that regulate the flow of information. As shown in Fig. 3b the cell state maps the previous cell state \(\varvec{C}_{t-1}\) to a new cell state \(\varvec{C}_{t}\) in which all the relevant information is carried throughout the sequence and where gates add or remove information to/from it. More details about LSTM dynamics in handling recurrent sequences are available in the original reference35. In sports, the use of LSTM remains quite recent with applications among action and activity recognition36,37,38,39,40, game outcomes41 and sports related concussion42.

Simplified diagram of (a) a RNN cell and (b) a LSTM cell.
Multivariate modeling approaches
Using commercial features
In order to investigate the effect of training sessions on changes in athletic performances, a multivariate analysis that includes data from training sessions is required.
We aimed at predicting \(\{ Y_a, Y_b \}\) using two sets of aggregated predictors \(X_p\) and \(X_{p^{*}}\) from the original features displayed in Appendix A, Table A1. Since models rely on several predictors, we consider the multivariate modeling approach.
For multivariate models, we performed a feature selection based on F-statistics and p-values converted from the cross-correlation between each feature of interest and the target through univariate sequential linear regression tests. Accordingly, we held the ten most meaningful features for making further predictions.
Extracting new features from raw global navigation satellite system data
In the previous formulation, the player position was recorded by GNSS at a sampling frequency of 10 Hz. Timestamp, player position (i.e. latitude, longitude), and velocity were available. Since commercial features were computed from the raw velocity vector \(\mathbf {V}\) and its derivative \(\mathbf {A}\), we proposed to extract new features directly from \(\mathbf {V}\).
First, we consider \(\mathbf {V}\) being a stationary time-series \((X_t)_{t \in \mathbb {R}}\). Formally, a time series is stationary if the law \(\mathcal {L}\) of a generated vector \((X_{t_{1}}, \ldots , {t_{n}})\) is time translation invariant. That is, we consider a law \(\mathcal {L}\) such as \(\mathcal {L} (X_{t_{1}}, \ldots , {t_{n}}) = \mathcal {L} (X_{t_{1}+h}, \ldots , X_{t_{n}+h}), \quad \forall (t_1, \ldots , t_n) \in \mathbb {R}^n \quad and \quad h \in \mathbb {R}\) with t being a time value and \(\mathbb {R}\) being a set of real numbers43. The stationary of time-series was checked using a Dickey-Fuller test44.
Several features were extracted from the time series in both time and frequency domains through Discrete Fourier Transform. For this purpose, we used the tsfresh Python module45. The feature extraction from both domains provided categorized 779 features46. A feature selection like performed during the previous tasks let us retain only the ten most relevant features, according to their significance level (F statistic and p value).
In summary, pseudo-code of the algorithms used in the methods is provided in Appendix 1, Section A.3.
Statistical analysis
In prediction, model performances were characterised by the mean absolute percentage error (%, MAPE) computed on test data sets. Repeated measures analysis of variance (ANOVA) and post-hoc analysis highlighted the significance of differences in MAPE distribution between models. Depending on a reference model for comparison, Tukey’s or Dunnett’s p value adjustment was used. The marginal mean difference \(\beta _{diff}\) was reported along with 95 % confidence intervals. Partial \(\eta ^{2}\) (or \(\eta ^{2}\) for one-way ANOVA) values were reported as a measure of effect size in ANOVAs. The significance level was set at p = 0.05 and consistently reported within the analysis.
Results
Predicting A-V profiles from games: reference models
The first baseline prediction was described by error rates observed in the control task. Using a set of predictors to predict A-V coefficients of the same session using a ridge regularisation returned an average MAPE of 0.066% and 0.102% for intercept and slope, respectively.
As shown in Fig. 4, we observed likely different MAPE values between intercept and slope predictions of A-V profiles. For this reason, we considered linearly re-scaled coefficients due to range and variance differences (averaged range = 0.325 and range = 3.98; \(\sigma ^{2} = 0.006\) and \(\sigma ^{2} = 0.246\) for the slope and the intercept, respectively). Accordingly, a two-way repeated measure ANOVA showed a slight trend in favour of an easier prediction task on A-V intercept (\(\beta _{diff} = -0.011 \, \in \, [-0.07, 0.003] \, 95 \, \% \, CI, p = 0.122\)).

Distributions of MAPE regarding multi-modal and uni-modal ensemble forecasting models.
Average ensembles were built following a model selection of a large set of time-series forecasting models \(\mathcal {M}_{ts}\). In the uni-modal approach, the forecasting models which provided the lowest MAPE in prediction were Prophet47, Theta, FourTheta48, and Fast Fourier Transform based. As expected, the combination of these models into an averaged ensemble provided the best performances (see Fig. 5 for examples). In the multi-modal approach, the retained forecasting models were VARIMA49, RNN-LSTM, and auto-regressive encoder-decoder Transformer50. In this case, RNN-LSTM and the averaged ensemble provided the best performances for predicting A-V slopes and intercepts, respectively. However, multi-modal averaged ensembles provided only a slight trend for a greater accuracy and were not significantly more accurate than univariate ensembles models on average (\(\beta _{diff} = -0.004 \, \in \, [-0.012, 0.020] \, 95 \, \% \, CI, p = 0.541\)). Overall synthesis of the selected forecasting models and their performances are presented in Table 1.
In comparison to the simplest scenario in which A-V profiles coefficients are predicted from a set of commercial features from the day of A-V realisation (\(\big \{ y^a_{j,t}, Y^b_{j,t} \big \}\), the control task), averaged ensembles forecasting models tended to be less accurate (\(\beta _{diff} = 0.013 \, \in \, [-0.002, 0.028] \, 95 \, \% \, CI, p = 0.095\)).

Example A-V profiles slopes forecasting using the uni-modal averaged ensemble. (a) represents the best prediction, (b) is the median prediction. Note that the red line represents the prediction made on the testing data set.
Time series forecasting models are considered as a reference for further performance predictions and model comparisons.
A multivariate modeling using data from past training sessions and games
Analysis of re-scaled MAPE a lower error rate when predicting the intercept coefficients (\(\beta _{diff} = -0.013 \, \in \, [-0.021, -0.005] \, 95 \, \% \, CI, p = 0.002, \, \text {partial} \, \eta ^{2} = 0.06 \, \in \, [0.01, 0.15] \, 95 \, \% \, CI\)). Post-hoc comparisons showed that multivariate LSTM and ridge regression that used data from past training and games sessions provided a higher error rate than the ridge regression of the control scenario. However, no significant differences in MAPE were observed between multivariate time-series forecasting models and regularised regression (LSTM and ridge regularisation). On average, individually fitted models did not provide lower prediction errors than those fitted on the group (p = 0.381). Except for univariate time-series forecasting models which only considered data from games and multivariate LSTM, there was no advantage of using the exponentially weighted aggregation (refer to Eq. 2 for details) over a simple aggregation according to the mean (\(\beta _{diff} = 0.001 \, \in \, [-0.010, 0.012] \, 95 \, \% \, CI, p = 0.844\)).
No significant difference was reported between averaged intercept and slope predictions in models that used features extracted from raw data. Only a slight trend for a lower MAPE was imputed to intercept predictions (\(\beta _{diff} = -0.012 \, \in \, [-0.027, 0.002] \, 95 \, \% \, CI, p = 0.09\)). In addition, individual and group computed LSTM provided similar performances in terms of accuracy (p = 0.775). That discarded any advantage of building models per player for predictions.
An overview of model performances showed that in average, the control task (the prediction of A-V profiles from commercial features of the same game) provided a lower error rate than any modeling task using past data (\(\beta _{diff} = -0.019 \, \in \, [-0.031, -0.008] \, 95 \, \% \, CI, p = 0.001, \, \eta ^{2} = 0.03 \, \in \, [0.01, 0.08] \, 95 \, \% \, CI\)). In addition, neither models that used commercial features, nor models that considered new features extracted from raw data outperformed the time-series forecasting ensembles (p = 0.124, see Fig. 6). No significant differences in error rate distribution were found between the source of features (p = 0.453).

Distributions of models’ MAPE.
Discussion
This study compared two multivariate modeling approaches that use commercial features and features extracted from GNSS raw data to a time-series forecasting approach. We considered the last as reference models that account for past events for predicting the A-V profiles of the next game. Beforehand, predictions made using predictors of the game of A-V profile realisation (i.e. control models) informed their predictability in ecological conditions.
Concerning the reference models, performing multi-modal forecasting might provide better results, but it also requires a larger sample size than uni-modal forecasting methods to estimate model parameters correctly. Accordingly, we filtered out players who performed less than 40 games for computing multi-modal forecasting models. Only nine players (out of 42) were retained for prediction, whereas the uni-modal task included data from a larger population (19 players). Therefore, the sample size heterogeneity should be considered when interpreting the forecasting results since a larger sample size might reasonably provide different, if not better, forecasting performances.
A practical limitation of univariate forecasting models is that we only consider game data for prediction. Hence, interpretations drawn from each forecast are restricted to the effect of preceding games on the next game, and the contribution of training sessions preceding a performance remains unclear. Accordingly, technical and medical staff around players should exploit multivariate models for detecting key performance indicators (KPIs) of A-V changes, or any other outcome51.
Being based on commercial summarised statistics (i.e. returned by the manufacturer, see Appendix 1, Table A1) or features extracted from the velocity vector, it was likely easier for the model to predict A-V profiles’ intercepts than the slopes. A greater variance allocated to this parameter may reasonably explain that finding, easing the estimation of the coefficient regarding a random error. In practice, a small change in the A-V profile may result in a substantial modification of the theoretical normalised force output (i.e. the acceleration) at the onset of maximal locomotor activities.
When comparing multivariate to reference forecasting models (uni-modal and multi-modal), no significant differences in error rates suggest that features describing past sessions were not informative enough to improve predictions. Accordingly, time stands as a significant predictor variable of subsequent events.
In addition, ridge regularisation used pooled features according to a simple aggregation by the mean or exponential smoothing. However, changing one pooling method to another did not lower prediction error rates. At first glance, that indicates either a limited relevance of the explanatory features used in the model or a lack of A-V profile predictability. However, the low error rates of predictions provided by control models allow us to support a reasonable A-V profile predictability.
In a small sample context, using a larger population may lead to more robust estimates of parameter coefficients. One possible way could be to build models over a group of players instead of a model per player32. Our results did not confirm such benefits since there is no benefit to using player-specific models for predicting A-V profiles with the current data.
An overall analysis and model comparison highlight that despite slight differences between top and bottom model ranking (see Table 2), no significant differences in prediction errors were reported. Accordingly, neither commercial, new features extracted from time and frequency domain analysis nor the pooling methods and model framework (time-series forecasting or multivariate regressions) led to significantly better prediction of A-V parameters. Once again, it questions the relevancy of GNSS-based features for modeling physiological adaptations to training52 or their value for explaining outcomes under a substantial opponent influence. It is essential to point out the lack of information for the GNSS signal quality. As mentioned in the introduction, GNSS signal accuracy relies on time/frequency and spatial parameters. The receiver manufacturer used in our study (Fieldwiz V1, CH) did not store any spatial accuracy factor such as horizontal dilution of precision. Therefore, we recommend the manufacturer to report signal quality details for practical use and research purposes53,54. Nevertheless, using features not based on expert hypotheses but fully extracted from signal processing methods appeared to be as valuable as the commercial ones. It leverages information that could be drawn from GNSS data and opens the way to future works on data mining and knowledge discovery in the sports field. However, this perspective comes with feature interpretability issues, particularly those related to the frequency domain.
Features retained for regression after the feature selection procedure reveal KPIs of A-V profile changes. Based on a top ten representation (see Appendix 1, Table A2), we could state that the distance covered at high intensity is not necessarily the highest value when regarding other variables, such as the number of accelerations and decelerations for specific intensity bands. Such KPIs should help guide field and resistance training regarding individual objectives. However, since multivariate models suffered from explanatory power regarding reference models (i.e. univariate forecasting models), interpretation of the selected features for practical application should be made with caution.
Finally, when considering re-scaled MAPE, prediction errors varied between 7% and 10%. We believe this is an acceptable accuracy since the A-V profile depends on unmeasured and uncontrolled factors, namely the opponent activity, then any psychological, environmental, or nutritional aspects. Therefore, GNSS wearable sensors could stand of value, though limited, for prediction purposes and more generally included in athlete monitoring systems while estimating external training loads9. Regardless, in light of the above limits, monitoring processes should be carried out under a more data-informed than the data-driven approach in which external training indicators are monitored along with internal markers, and environmental factors55.
In our study, we provided a simple estimation of the A-V predictability through the control task, which benefits from the relationship between the commercial features and the modelled profiles of a given game. However, a deeper analysis of the A-V estimator noise and heteroscedasticity of the outcome variables should be carried out in a future study.
Beyond predictive applications, A-V profiles provide relevant insights regarding the theoretical maximal isometric force of hip extensors (i.e. through the profile intercept) and the capacity to produce a significant level of horizontal force at high velocities (i.e. according to the slope of A-V relationship). These mechanical factors may be key determinants of soft-tissue injury occurrence56, short sprint performances57 and could guide individual training prescription.
The technological rise provides higher sampling frequency systems (e.g. IMU and motion capture systems) as compared to GNSS devices, intended for discriminating exercise and its demand in ecological conditions. A physiological representation of the responses to exercise may be therefore extracted. Besides, going through raw data recorded by these systems may contribute to solving the enigma of injury occurrence, which remains a hot research area in sports science with major economic repercussions58,59.
Conclusion
In this study, we aimed at modeling coefficients of individual A-V profiles. For this purpose, we first considered time-series forecasting models, which used data from games only as the baseline of models’ performances. Then, multivariate modeling approaches were compared to these baseline models with a regression task using a regularised linear regression (ridge) and a neural network architecture (RNN-LSTM). Two distinct functions were employed to aggregate training sessions predictors; a mean and an exponential weighting function (both of them are defined in Eqs. 1 and 2). Finally, we extracted new signal processing features from the GNSS raw data and assessed their contribution to the modeling process. We recall that except for time-series forecasting, models were fitted either per player or over the group of players. Overall, no method showed significant better performances in prediction than the time-series forecasting. Global navigation satellite system features seemed to be of limited relevance for predicting individual in-situ A-V profiles. However, time-domain and frequency-domain features extracted from the raw data outlined the potential of signal processing methods for extracting new information. That opens up new perspectives in athletic performance or injury occurrence modeling, using IMU and movement tracking systems concurrently.
Key points
-
Global navigation satellite systems are valuable for modeling in-situ A-V profiles. However, its predictability using GNSS-derived features from training sessions remains limited.
-
Multivariate modeling highlights key performance indicators of A-V changes among commercial, training-related features. Alternatively, signal processing methods pave the way to new modeling perspectives of performance and injury modeling, mainly if applied to measurement systems with higher sampling rates (e.g. IMUs).
-
A-V time-derived features are likely as relevant as GNSS-based features for explaining changes in A-V profiles. It emphasizes the necessity for multidimensional modeling while considering the opponent’s activity, psychological and environmental factors.
Data availability
The data sets generated during and/or analysed during the current study are not publicly available due to property of FC Lucerne but are available from the corresponding author on reasonable request.
References
Jennings, D., Cormack, S., Coutts, A. J., Boyd, L. & Aughey, R. J. The validity and reliability of gps units for measuring distance in team sport specific running patterns. Int. J. Sports Pysiol. Perform. 5, 328–341 (2010).
Buchheit, M. et al. Monitoring accelerations with gps in football: Time to slow down? Int. J. Sports Physiol. Perform. 9, 442–445 (2014).
Akenhead, R. & Nassis, G. P. Training load and player monitoring in high-level football: Current practice and perceptions. Int. J. Sports Physiol. Perform. 11, 587–593 (2016).
Bourdon, P. C. et al. Monitoring athlete training loads: Consensus statement. Int. J. Sports Physiol. Perform. 12, S2-161 (2017).
Cardinale, M. & Varley, M. C. Wearable training-monitoring technology: Applications, challenges, and opportunities. Ind. J. Sports Physiol. Perform. 12, S2-55 (2017).
Malone, J. J., Lovell, R., Varley, M. C. & Coutts, A. J. Unpacking the black box: Applications and considerations for using gps devices in sport. Int. J. Sports Physiol. Perform. 12, S2-18 (2017).
Coppalle, S. et al. Relationship of pre-season training load with in-season biochemical markers, injuries and performance in professional soccer players. Front. Physiol. 10, 409 (2019).
Kupperman, N. & Hertel, J. Global positioning system-derived workload metrics and injury risk in team-based field sports: A systematic review. J. Athl. Train. 55, 931–943 (2020).
Ravé, G., Granacher, U., Boullosa, D., Hackney, A. C. & Zouhal, H. How to use global positioning systems (gps) data to monitor training load in the “real world” of elite soccer. Front. Physiol. 11 (2020).
Ryan, S., Kempton, T. & Coutts, A. J. Data reduction approaches to athlete monitoring in professional australian football. Int. J. Sports Physiol. Perform. 1, 1–7 (2020).
Theodoropoulos, J. S., Bettle, J. & Kosy, J. D. The use of gps and inertial devices for player monitoring in team sports: A review of current and future applications. Orthop. Rev. 12 (2020).
Gómez-Carmona, C. D., Bastida-Castillo, A., Ibáñez, S. J. & Pino-Ortega, J. Accelerometry as a method for external workload monitoring in invasion team sports. a systematic review. PloS ONE 15, e0236643 (2020).
Rossi, A. et al. Effective injury forecasting in soccer with gps training data and machine learning. PloS ONE 13, e0201264 (2018).
Claudino, J. G. et al. Current approaches to the use of artificial intelligence for injury risk assessment and performance prediction in team sports: A systematic review. Sports Med. Open 5, 1–12 (2019).
Maupin, D., Schram, B., Canetti, E. & Orr, R. The relationship between acute: Chronic workload ratios and injury risk in sports: A systematic review. J. Sports Med. 11, 51 (2020).
Vallance, E., Sutton-Charani, N., Imoussaten, A., Montmain, J. & Perrey, S. Combining internal-and external-training-loads to predict non-contact injuries in soccer. Appl. Sci. 10, 5261 (2020).
Osgnach, C., Poser, S., Bernardini, R., Rinaldo, R. & Di Prampero, P. E. Energy cost and metabolic power in elite soccer: A new match analysis approach. Med. Sci. Sports Exerc. 42, 170–178 (2010).
Barrett, S., Midgley, A. & Lovell, R. PlayerloadTM: reliability, convergent validity, and influence of unit position during treadmill running. Int. J. Sports Physiol. Perform. 9, 945–952 (2014).
Di Prampero, P. E., Botter, A. & Osgnach, C. The energy cost of sprint running and the role of metabolic power in setting top performances. Eur. J. Appl. Physiol. 115, 451–469 (2015).
Scott, M. T., Scott, T. J. & Kelly, V. G. The validity and reliability of global positioning systems in team sport: A brief review. J. Strength Cond. Res. 30, 1470–1490 (2016).
Crang, Z. L. et al. The validity and reliability of wearable microtechnology for intermittent team sports: A systematic review. Sports Med. 1–17 (2020).
Zhang, Q., Chen, Z., Rong, F. & Cui, Y. Preliminary availability assessment of multi-gnss: A global scale analysis. IEEE Access 7, 146813–146820 (2019).
Morin, J.-B. et al. Individual acceleration-speed profile in-situ: A proof of concept in professional football players. J. Biomech. 123, 110524 (2021).
Forrest, D. & Simmons, R. Forecasting sport: The behaviour and performance of football tipsters. Int. J. Forecast. 16, 317–331 (2000).
Koopman, S. J. & Lit, R. Forecasting football match results in national league competitions using score-driven time series models. Int. J. Forecast. 35, 797–809 (2019).
Do, H. D. et al. Time series forecasting with data transform and its application in sport. In RICE, 29–32 (2021).
Hsu, Y.-C. Using convolutional neural network and candlestick representation to predict sports match outcomes. Appl. Sci. 11, 6594 (2021).
Miller, R., Schwarz, H. & Talke, I. S. Forecasting sports popularity: Application of time series analysis. Acad. J. Interdiscip. Stud. 6, 75 (2017).
Sands, W. A., Kavanaugh, A. A., Murray, S. R., McNeal, J. R. & Jemni, M. Modern techniques and technologies applied to training and performance monitoring. Int. J. Sports Physiol. Perform. 12, S2-63 (2017).
Macdonald, B. Adjusted plus-minus for nhl players using ridge regression with goals, shots, fenwick, and corsi. J. Quant. Anal. Sports 8 (2012).
Kostrzewa, M. et al. Significant predictors of sports performance in elite men judo athletes based on multidimensional regression models. Int. J. Environ. Res. Public Health 17, 8192 (2020).
Imbach, F., Perrey, S., Chailan, R., Meline, T. & Candau, R. Training load responses modelling and model generalisation in elite sports. Sci. Rep. 12, 1–14 (2022).
Hoerl, A. E. & Kennard, R. W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 12, 55–67 (1970).
Marquardt, D. W. & Snee, R. D. Ridge regression in practice. Am. Stat. 29, 3–20 (1975).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
Tsunoda, T., Komori, Y., Matsugu, M. & Harada, T. Football action recognition using hierarchical lstm. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 99–107 (2017).
Chen, J., Samuel, R. D. J. & Poovendran, P. Lstm with bio inspired algorithm for action recognition in sports videos. Image Vis. Comput. 112, 104214 (2021).
Guo, J., Liu, H., Li, X., Xu, D. & Zhang, Y. An attention enhanced spatial-temporal graph convolutional lstm network for action recognition in karate. Appl. Sci. 11, 8641 (2021).
Uddin, M. Z. & Soylu, A. Human activity recognition using wearable sensors, discriminant analysis, and long short-term memory-based neural structured learning. Sci. Rep. 11, 1–15 (2021).
Ullah, M. et al. Attention-based lstm network for action recognition in sports. Electron. Imag. 2021, 302–1 (2021).
Zhang, Q. et al. Sports match prediction model for training and exercise using attention-based lstm network. Digit. Commun. Netw. (2021).
Thanjavur, K. et al. Recurrent neural network-based acute concussion classifier using raw resting state eeg data. Sci. Rep. 11, 1–19 (2021).
Cox, D. R. & Miller, H. D. The Theory of Stochastic Processes (Routledge, 2017).
Fuller, W. A. Introduction to Statistical Time Series, vol. 428 (Wiley, 2009).
Christ, M., Braun, N., Neuffer, J. & Kempa-Liehr, A. W. Time series feature extraction on basis of scalable hypothesis tests (tsfresh-a python package). Neurocomputing 307, 72–77 (2018).
Christ, M., Braun, N. & Neuffer, J. Overview on time series feature extraction (tsfresh–a python package).
Taylor, S. J. & Letham, B. Forecasting at scale. Am. Stat. 72, 37–45 (2018).
Assimakopoulos, V. & Nikolopoulos, K. The theta model: A decomposition approach to forecasting. Int. J. Forecast. 16, 521–530 (2000).
Tiao, G. C. & Box, G. E. Modeling multiple time series with applications. J. Am. Stat. Assoc. 76, 802–816 (1981).
Vaswani, A. et al. Attention is all you need. In Advances in neural information processing systems, 5998–6008 (2017).
Schelling, X. & Robertson, S. A development framework for decision support systems in high-performance sport. Int. J. Comput. Sci. Sport 19, 1–23 (2020).
Hader, K. et al. Monitoring the athlete match response: Can external load variables predict post-match acute and residual fatigue in soccer? a systematic review with meta-analysis. Sports Med.-Open 5, 1–19 (2019).
Principe, V. A., Vale, R. G. d. S. & Nunes, R. d. A. M. A systematic review of load control in football using a global navigation satellite system (gnss). Motriz: Revista de Educacão Fisica 26 (2020).
Rico-González, M., Los Arcos, A., Clemente, F. M., Rojas-Valverde, D. & Pino-Ortega, J. Accuracy and reliability of local positioning systems for measuring sport movement patterns in stadium-scale: A systematic review. Appl. Sci. 10, 5994 (2020).
Montull, L., Slapšinskaitė-Dackevičienė, A., Kiely, J., Hristovski, R. & Balagué, N. Integrative proposals of sports monitoring: Subjective outperforms objective monitoring. Sports Med. Open 8, 1–10 (2022).
Clark, R. A. Hamstring injuries: Risk assessment and injury prevention. Ann. Acad. Med. Singap. 37, 341 (2008).
Buchheit, M. et al. Mechanical determinants of acceleration and maximal sprinting speed in highly trained young soccer players. J. Sports Sci. 32, 1906–1913 (2014).
McMahon, B. Report estimates the cost of injuries to premier league players at \$267m (2019).
Eliakim, E., Morgulev, E., Lidor, R. & Meckel, Y. Estimation of injury costs: Financial damage of english premier league teams’ underachievement due to injuries. BMJ Open Sport Exerc. Med. 6, e000675 (2020).
Acknowledgements
We are grateful to Christian Schmidt for collaboration and sharing data sets.
Funding
This research was funded by the Association Nationale de la Recherche et de la Technologie (ANRT) Grant number 2018/0653.
Author information
Authors and Affiliations
Contributions
Conceptualisation, F.I., W.R., V.L., R.C. (Romain Chailan); methodology and investigation, F.I., W.R., V.L., R.C. (Romain Chailan); recruitment, S.P.; formal analysis and data curation F.I., W.R., V.L., R.C. (Romain Chailan); resources S.P.; writing original draft preparation, F.I.; writing-review and editing, F.I., W.R., V.L., R.C. (Robin Candau), S.P.; visualisation, F.I.; supervision, W.R., S.P.; project administration, S.P., R.C. (Robin Candau); funding acquisition, F.I. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interest
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Imbach, F., Ragheb, W., Leveau, V. et al. Using global navigation satellite systems for modeling athletic performances in elite football players. Sci Rep 12, 15229 (2022). https://doi.org/10.1038/s41598-022-19484-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-022-19484-y
This article is cited by
-
A holistic approach to performance prediction in collegiate athletics: player, team, and conference perspectives
Scientific Reports (2024)
-
Global navigation satellite systems’ receivers in mountain running: the elevation problem
Sports Engineering (2024)
