
Abstract
The aim of this paper is to develop more effective methods for estimating population means in sample surveys using auxiliary attributes. To achieve this goal, we introduce a modified version of the estimators proposed by Koyuncu (2013b) and Shahzad et al. (2019), as well as a new class of estimators. We derive expressions for the bias and mean squared error of these new estimators up to the first degree of approximation. Our results show that the suggested classes of estimators perform better than other existing methods, with the lowest mean squared error under optimal conditions. We also conduct an empirical investigation to support our findings.
Similar content being viewed by others

Introduction
The use of auxiliary attribute is a well-known method for improving the efficiency of an estimator in estimating population parameters. Auxiliary attributes (say \(\phi\)), which are highly correlated with the study variable (y), are commonly encountered in practice. Examples include a person's height (y), the amount of milk produced by a cow (y), and the yield of a particular variety of wheat (y), which may respectively depend on factors such as gender, breed of the cow, and type of wheat. For more examples, see Kendale and Stuart1, Shabbir and Gupta2, and Sharma and Singh3, among others. The estimation of the population mean of the study variable (y) using an auxiliary attribute \(\left( \phi \right)\) under simple random sampling without replacement has been extensively studied. See, for instance, Naik and Gupta4, Jhajj et al.5, Solanki and Singh6, Singh et al.7, Gupta and Tailor8, and other relevant literature.
The simple random sampling scheme is commonly used when the population units are homogeneous. However, in many practical situations, the population units are heterogeneous, and to obtain a better estimate of the population parameters, we use stratified random sampling. Therefore, our objective is to estimate the population mean of the study variable (y) using information on an auxiliary attribute \(\left( \phi \right)\) under stratified random sampling. Various authors, including Sharma and Singh3, Koyuncu9,10, Shahzad et al.11, Zaman12,13, Hussain et al.14,15, Zaman et al.16,17, and Ahmad et al.18,19, have discussed the problem of estimating the population mean of the study variable using an auxiliary attribute under stratified random sampling.
Shahzad et al.20,21 used a calibration approach in stratified random sampling. They also proposed an estimator to estimate the coefficient of variation using calibrated estimators in stratified random sampling Shahzad et al.22.
Notations
Consider a population size N unit, is divided into L strata units hth stratum containing Nh units, where h = 1, 2,…, L such that \({\sum }_{h=1}^{L}{N}_{h}=N\). A simple random sample of size nh is drawn without replacement the hth stratum such that \({\sum }_{h=1}^{L}{n}_{h}=n\). Let \(\left({y}_{hi},{\phi }_{hi}\right)\) be observed value of study variable y and the auxiliary attribute \(\phi\) on the ith unit of the hth stratum, respectively, where \(i=\mathrm{1,2},...,{N}_{h}\) and \(h=\mathrm{1,2},...,L\).
Further, let \({\overline{y}}_{h}={\sum }_{h=1}^{{n}_{h}}\frac{{y}_{hi}}{{n}_{h}}\) and \({\overline{y}}_{st}={\sum }_{h=1}^{L}{W}_{h}{\overline{y}}_{h}\) be unbiased estimators of population means \({\overline{Y}}_{h}={\sum }_{i=1}^{{N}_{h}}\frac{{y}_{hi}}{{N}_{h}}\) and \(\overline{Y}={\sum }_{h=1}^{L}{W}_{h}{\overline{Y}}_{h}\), where \({W}_{h}=\frac{{N}_{h}}{N}\) is the stratum weight.
We also assume that
Let \({s}_{yh}^{2}={\sum }_{i=1}^{{n}_{h}}\frac{{\left({y}_{hi}-{\overline{y}}_{h}\right)}^{2}}{\left({n}_{h}-1\right)}\) and \({s}_{\phi h}^{2}={\sum }_{i=1}^{{n}_{h}}\frac{{\left({\phi }_{hi}-{p}_{h}\right)}^{2}}{\left({n}_{h}-1\right)}\) be the hth sample variances and \({S}_{yh}^{2}={\sum }_{i=1}^{{N}_{h}}\frac{{\left({y}_{hi}-{\overline{Y}}_{h}\right)}^{2}}{\left({N}_{h}-1\right)}\) and \({S}_{\phi h}^{2}={\sum }_{i=1}^{{N}_{h}}\frac{{\left({\phi }_{hi}-{P}_{h}\right)}^{2}}{\left({N}_{h}-1\right)}\) be the hth population variances of the study variable y and the auxiliary attribute \(\phi\), respectively.
Further, \({s}_{y\phi h}={\sum }_{i=1}^{{n}_{h}}\frac{\left({y}_{hi}-{\overline{y}}_{h}\right)\left({\phi }_{hi}-{p}_{h}\right)}{\left({n}_{h}-1\right)}\) and \({\widehat{\rho }}_{y\phi h}=\frac{{s}_{y\phi h}}{{s}_{yh}{s}_{\phi h}}\) are the hth sample covariance and point bi-serial correlation and \({S}_{y\phi h}={\sum }_{i=1}^{{N}_{h}}\frac{\left({y}_{hi}-{\overline{Y}}_{h}\right)\left({\phi }_{hi}-{P}_{h}\right)}{\left({N}_{h}-1\right)}\) and \({\widehat{\rho }}_{y\phi h}=\frac{{S}_{y\phi h}}{{S}_{yh}{S}_{\phi h}}\) are population covariance and point bi-serial correlation between the study variable y and the auxiliary attribute \(\phi\), respectively.
To derive the bias and mean squared error (MSE) of the estimators, we write
such that \(E\left( {e_{o} } \right) = E\left( {e_{1} } \right) = 0\) and
where \({p}_{st}={\sum }_{h=1}^{L}{W}_{h}{p}_{h}\) such that \(E\left({p}_{st}\right)=P={\sum }_{h=1}^{L}{W}_{h}{P}_{h}\) and \({\gamma }_{h}=\frac{{N}_{h}-{n}_{h}}{{n}_{h}{N}_{h}}\).
Reviewing some existing estimators
The conventional unbiased estimators for population mean \(\overline{Y}\) of the study variable y under stratified random sampling is given by
The variance/MSE of the estimator \(t_{0}\) is given by
The ratio estimator for population mean \(\overline{Y}\) using auxiliary attribute \(\phi\) in stratified random sampling due to Naik and Gupta4 is given by
The MSE of the estimator \(t_{1}\) up to the first degree of approximation (fda), is given by
where \(C=\frac{{A}_{y\phi }}{{A}_{\phi }}\).
The stratified version of ordinary product estimator for population mean \(\overline{Y}\) is defined by
The MSE of \(t_{2}\) to the fda, is given by
The usual regression estimator for \(\overline{Y}\) is given by
where \(b_{st}\) is the sample regression coefficient of y on \(\phi\).
To the fda the MSE of \(t_{3}\) is given by
where \({\rho }_{y\phi }=\frac{{A}_{y\phi }}{\sqrt{{A}_{y}{A}_{\phi }}}\).
Koyuncu9 suggested a class of estimators for \(\overline{Y}\) is given by
where \(\left({w}_{1},{w}_{2}\right)\) are suitable constants, \({a}_{st}\left(\ne 0\right)\) and \({b}_{st}\) are either real numbers or the functions of the known parameters for the hth stratum of the auxiliary attribute \(\phi\), such as standard deviation \({S}_{\phi \left(st\right)}={\sum }_{h=1}^{L}{W}_{h}{\sigma }_{\phi h}\), coefficient of variation \({C}_{\phi \left(st\right)}={\sum }_{h=1}^{L}{W}_{h}{C}_{\phi h}\) with \({C}_{\phi h}=\frac{{S}_{\phi h}}{{P}_{h}}\),skewness \({\beta }_{1\left(\phi \right)st}={\sum }_{h=1}^{L}{W}_{h}{\beta }_{1h}\left(\phi \right)\) and kurtosis \({\beta }_{2\left(\phi \right)st}={\sum }_{h=1}^{L}{W}_{h}{\beta }_{2h}\left(\phi \right)\) and correlation coefficient \({\rho }_{\left(y\phi \right)st}={\sum }_{h=1}^{L}{W}_{h}{\rho }_{y\phi {h}}\) where \({\beta }_{1h\left(\phi \right)}=\frac{{\mu }_{3h}^{2}\left(\phi \right)}{{\mu }_{2h}^{3}\left(\phi \right)}\), \({\beta }_{2h\left(\phi \right)}=\frac{{\mu }_{4h}\left(\phi \right)}{{\mu }_{2h}^{2}\left(\phi \right)}\), \({\sigma }_{\phi h}^{2}={\mu }_{2h}\left(\phi \right)=\frac{1}{{N}_{h}}{\sum }_{i=1}^{{N}_{h}}{\left({\phi }_{hi}-{P}_{h}\right)}^{2}\), \({\mu }_{3h}\left(\phi \right)=\frac{1}{{N}_{h}}{\sum }_{i=1}^{{N}_{h}}{\left({\phi }_{hi}-{P}_{h}\right)}^{3}\) and \({\mu }_{4h}\left(\phi \right)=\frac{1}{{N}_{h}}{\sum }_{i=1}^{{N}_{h}}{\left({\phi }_{hi}-{P}_{h}\right)}^{4}\).
The MSE of the estimator t4 to the fda is given by
where \({B}_{1}=\left[1+{A}_{y}+{\upsilon }_{st}{A}_{\phi }\left(3{\upsilon }_{st}-4C\right)\right]\), \({B}_{2}=\frac{{A}_{\phi }}{{R}^{2}},\) \({B}_{3}=\left(\frac{{A}_{\phi }}{R}\right)\left(2{\upsilon }_{st}-C\right),\) \({B}_{4}=\left[1+{\upsilon }_{st}{A}_{\phi }\left({\upsilon }_{st}-C\right)\right],\) \({B}_{5}=\left(\frac{{A}_{\phi }}{R}\right){\upsilon }_{st}\),\(R=\frac{\overline{Y}}{P}\) and \({\upsilon }_{st}=\frac{{a}_{st}P}{\left({a}_{st}P+{b}_{st}\right)}\).
The MSE t4 at (10) is minimized for
Therefore, the resulting minimum MSE of t4 is given by
Using information on auxiliary attribute \(\phi\), Sharma and Singh3 proposed the following exponential type estimators for \(\overline{Y}\) as
where \(\alpha\) being a suitable chosen constant.
To the fda the MSEs of the estimators \(t_{1e,} t_{2e}\) and \(t_{\alpha e,}\) are respectively given by
The \(MSE\left({t}_{\alpha e}\right)\) is minimum when
This yields the minimum MSE of \({t}_{\alpha e}\) is given by
Sharma and Singh3 proposed the following class of estimators for population mean \(\overline{Y}\) as
where \(\left({a}_{st},{b}_{st}\right)\) are same as defined for the class of estimators \({t}_{4}\) at (9) and \(\left({w}_{1},{w}_{2}\right)\) are suitable chosen constants to be determined such that MSE of \({t}_{5}\) is minimum.
If we set \({a}_{st}=1\) and \({b}_{st}=NP\) in (21), then the class of estimators \({t}_{5}\) reduces to the Shahzad et al.11 class of estimators for \(\overline{Y}\) as
We note that the expressions of bias and MSE of the class of estimators \({t}_{5}\) derived by Sharma and Singh3 [Eqs. (4.6) and (4.7), p. 1789] are not correct. The correct expressions of bias and MSE of the estimator \({t}_{5}\) to the fda are respectively given by
and
where \({A}_{1}=\left[1+{A}_{y}+{\upsilon }_{st}{A}_{\phi }\left({\upsilon }_{st}-2C\right)\right]\), \({A}_{2}=\frac{{A}_{\phi }}{{R}^{2}}\), \({A}_{3}=\left(\frac{1}{R}\right){A}_{\phi }\left({\upsilon }_{st}-C\right)\), \({A}_{4}=\left[1+\frac{{\upsilon }_{st}{A}_{\phi }}{8}\left(3{\upsilon }_{st}-4C\right)\right]\), \({A}_{5}=\frac{{\upsilon }_{st}{A}_{\phi }}{2R}\).
The MSE t5 at (24) is minimized for
Therefore, the minimum MSE of t5 is given by
Putting \({a}_{st}=1\) and \({b}_{st}=NP\) in (24), we get the MSE of \(t_{6}\) to the fda is given by
where \({A}_{1\left(1\right)}=\left[1+{A}_{y}+{\upsilon }_{st\left(1\right)}{A}_{\phi }\left({\upsilon }_{st\left(1\right)}-2C\right)\right]\), \({A}_{2\left(1\right)}=\frac{{A}_{\phi }}{{R}^{2}}\), \({A}_{3\left(1\right)}=\left(\frac{1}{R}\right){A}_{\phi }\left({\upsilon }_{st\left(1\right)}-C\right)\), \({A}_{4\left(1\right)}=\left[1+\frac{{\upsilon }_{st\left(1\right)}{A}_{\phi }}{8}\left(3{\upsilon }_{st\left(1\right)}-4C\right)\right]\), \({A}_{5\left(1\right)}=\frac{{\upsilon }_{st\left(1\right)}{A}_{\phi }}{2R}\),\({\upsilon }_{st\left(1\right)}=\frac{1}{\left(N+1\right)}\).
The MSE t6 at (27) is minimum when
Therefore, the minimum MSE of t6 is given by
Koyuncu10 and Shahzad et al.11 proposed the following class of estimators for \(\overline{Y}\) as
where \(\left({w}_{1},{w}_{2},\gamma \right)\) are suitable chosen constants and \(\left({a}_{st},{b}_{st}\right)\) are same as defined earlier.
To the fda, the MSE of t7 is given by
where \({C}_{1}=\left[1+{A}_{y}+{\upsilon }_{st}{A}_{\phi }\left({\upsilon }_{st}-2C\right)\right]\), \({C}_{2}=\frac{1}{{P}^{2}{R}^{2}}\left[1+{A}_{\phi }\left\{{\gamma }^{2}+{\upsilon }_{st}^{2}-2\gamma {\upsilon }_{st}+\gamma \left(\gamma -1\right)\right\}\right]\), \({C}_{3}=\left(\frac{1}{PR}\right)\left[1+{A}_{\phi }\left\{\left({\upsilon }_{st}^{2}+\frac{\gamma \left(\gamma -1\right)}{2}-{\upsilon }_{st}\gamma \right)+\left(\gamma -{\upsilon }_{st}\right)C\right\}\right]\), \({C}_{4}=\left[1+\frac{{\upsilon }_{st}{A}_{\phi }}{8}\left(3{\upsilon }_{st}-4C\right)\right]\), \({C}_{5}=\frac{1}{PR}\left[1+\left\{\frac{\gamma \left(\gamma -1\right)}{2}-\frac{\gamma {\upsilon }_{st}}{2}+\frac{3}{8}{\upsilon }_{st}^{2}\right\}{A}_{\phi }\right]\).
\(MSE\left({t}_{7}\right)\) at (31) is minimized for
Therefore, the minimum MSE of t7 is given by
In this paper we have suggested a class of estimators for population mean \(\overline{Y}\) of the study variable y using auxiliary attribute \(\phi\). Expressions of bias and MSE of the proposed class of estimators are obtained up to terms of order 0 (n−1).
We have obtained the optimum condition under which the MSE of the proposed class of estimators is minimum. We have derived the conditions under which the suggested class of estimators is more efficient than the conventional estimator and the estimators due to Naik and Gupta4, Koyuncu9, Sharma and Singh3 and Shahzad et al.11. Numerical illustration is given in support of the proposed study.
Suggested class of estimators
We note that the exponent part of (30) is obtained on using the transformation \(\left({a}_{st}{p}_{st}+{b}_{st}\right)\) such that \(E\left\{{a}_{st}{p}_{st}+{b}_{st}\right\}=\left({a}_{st}P+{b}_{st}\right)\), in the first bracket coefficient of \({w}_{2}\) is \({\left(\frac{{p}_{st}}{P}\right)}^{\gamma }\) which does not use the transformation \(\left({a}_{st}{p}_{st}+{b}_{st}\right)\). Thus, authors are in opinion that coefficient of \({w}_{2}\) should be \({\left(\frac{{a}_{st}{p}_{st}+{b}_{st}}{{a}_{st}P+{b}_{st}}\right)}^{\gamma }\). Hence the modified suggested class of estimators for \(\overline{Y}\) is given by
where \(\left( {w_{1} ,w_{2} } \right)\) are suitably chosen constants to be determined such that MSE of \(t_{7\left( m \right)}\) is minimum; and \(\left( {a_{st} ,b_{st} ,\gamma } \right)\) are same as defined earlier.
To the fda, the bias and MSE of \(t_{7\left( m \right)}\) are respectively given by
and
where \(D_{1} = \left[ {1 + A_{y} + \upsilon_{st} A_{\phi } \left( {\upsilon_{st} - 2C} \right)} \right]\), \(D_{2} = \,\frac{1}{{R^{2} P^{2} }}\left[ {1 + \upsilon_{st}^{2} \theta \left( {2\theta - 1} \right)A_{\phi } } \right]\), \(D_{3} = \left( \frac{1}{RP} \right)\left[ {1 + \frac{{\upsilon_{st}^{{}} \left( {2\theta - 1} \right)}}{8}A_{\phi } \left( {2\theta + 4C - 3} \right)} \right]\), \(D_{4} = \left[ {1 + \frac{{\upsilon_{st}^{{}} }}{8}A_{\phi } \left( {3\upsilon_{st}^{{}} - 4C} \right)} \right]\), \(D_{5} = \frac{1}{RP}\left[ {1 + \frac{{\upsilon_{st}^{2} \theta \left( {\theta - 1} \right)}}{2}A_{\phi } } \right]\), \(\theta = \frac{{\left( {2\gamma - 1} \right)}}{2}\).
The \(MSE\left( {t_{7\left( m \right)} } \right)\) at (36) is minimized for
Therefore, the minimum MSE of \(t_{7\left( m \right)}\) is given by
Now we can conclude this as a theorem given below.
Theorem 2.1
The MSE of \(t_{7\left( m \right)}\) is greater than or equal to the minimum MSE of \(t_{7\left( m \right)}\).
An alternative class of estimators
We propose another class of estimators for population mean as \(\overline{Y}\) as
where \(\left( {w_{1} ,w_{2} ,a_{st} ,b_{st} } \right)\) are same as defined earlier and \(\left( {\delta ,\eta } \right)\) are constants which take real numbers like (− 1,0,1).
To the fda, the bias and MSE of \(t_{8}\) are respectively given by
and
where \(E_{1} = \left[ {1 + A_{y} - 4\eta \upsilon_{st} A_{y\phi } + \eta \left( {2\eta + 1} \right)\upsilon_{st}^{2} A_{\phi } } \right]\), \(E_{2} = \,\frac{1}{{R^{2} P^{2} }}\left[ {1 + \theta \left( {2\theta + 1} \right)\upsilon_{st}^{2} A_{\phi } } \right]\), \(E_{3} = \left( \frac{1}{RP} \right)\left[ {1 + \frac{{\left( {\eta + \theta } \right)\left( {\eta + \theta + 1} \right)}}{2}\upsilon_{st}^{2} A_{\phi } - \left( {\eta + \theta } \right)\upsilon_{st}^{{}} A_{y\phi } } \right]\), \(E_{4} = \left[ {1 + \frac{{\eta \upsilon_{st}^{{}} }}{2}\left\{ {\frac{{\left( {\eta + 1} \right)}}{2}\upsilon_{st}^{{}} A_{\phi } - 2A_{y\phi } } \right\}} \right]\), \(E_{5} = \frac{1}{RP}\left[ {1 + \frac{{\theta \left( {\theta + 1} \right)}}{2}\upsilon_{st}^{2} A_{\phi } } \right]\).
The \(MSE\left( {t_{8} } \right)\) at (41) is minimized for
Substitution of (42) in (41) provides the minimum MSE of \(t_{8}\) is given by
Now we have the following theorem.
Theorem 3.1
The MSE of \(t_{8}\) is greater than or equal to the minimum MSE of \(t_{8}\).
Efficiency comparison
From (2), (4), (6), (8), (16) and (17) we have
It follows from (44) to (46) that the regression estimator t3 is more efficient than \(\overline{y}_{st} ,t_{1,} t_{2} ,t_{1e} \,{\text{and}}\,t_{2e}\).
From (8), (12), (22), (26), (29), (33), (38) and (43) we have
It follows from (49) to (54) that the classes of estimators \(t_{4,} t_{5} ,t_{6} ,\,t_{7} ,t_{7\left( m \right)} \,{\text{and }}t_{8}\) are more efficient than the regression estimator \(\,t_{3}\).
Further from (12), (26), (29), (33), (38) and (43) we have
where \(M_{1} = \frac{{\left( {E_{2} E_{4}^{2} - 2E_{3} E_{4} E_{5} + E_{1} E_{5}^{2} } \right)}}{{\left( {E_{1} E_{2} - E_{3}^{2} } \right)}}\), \(\,M_{2} = \frac{{\left( {A_{y} - \upsilon_{st}^{2} A_{\phi } A_{y\phi }^{2} - \upsilon_{st}^{2} A_{\phi }^{2} + \upsilon_{st}^{2} A_{\phi }^{2} A_{y}^{{}} } \right)}}{{\left( {A_{\phi } + A_{y} A_{\phi } - \upsilon_{st}^{2} A_{\phi }^{2} - A_{y\phi }^{2} } \right)}}\), \(\,M_{3} = \frac{{\left( {A_{2} A_{4}^{2} - 2A_{3} A_{4} A_{5} + A_{1} A_{5}^{2} } \right)}}{{\left( {A_{1} A_{2} - A_{3}^{2} } \right)}}\), \(\,M_{4} = \frac{{\left( {A_{2\left( 1 \right)} A_{4\left( 1 \right)}^{2} - 2A_{3\left( 1 \right)} A_{4\left( 1 \right)} A_{5\left( 1 \right)} + A_{1\left( 1 \right)} A_{5\left( 1 \right)}^{2} } \right)}}{{\left( {A_{1\left( 1 \right)} A_{2\left( 1 \right)} - A_{3\left( 1 \right)}^{2} } \right)}}\), \(\,M_{5} = \frac{{\left( {C_{2} C_{4}^{2} - 2C_{3} C_{4} C_{5} + C_{1} C_{5}^{2} } \right)}}{{\left( {C_{1} C_{2} - C_{3}^{2} } \right)}}\), \(M_{6} = \frac{{\left( {D_{2} D_{4}^{2} - 2D_{3} D_{4} D_{5} + D_{1} D_{5}^{2} } \right)}}{{\left( {D_{1} D_{2} - D_{3}^{2} } \right)}}\).
Therefore we can say that the proposed class of estimators \(t_{8}\) is more efficient than the estimators \(t_{4,} t_{5} ,t_{6} ,t_{7}\) and \(t_{7\left( m \right)}\) as long as the conditions (55), (56), (57), (58), and (59) respectively are satisfied.
Numerical illustration
To judge the merits of the suggested class of estimators \(t_{8}\) over other existing estimators, we have computed the percent relative efficiency (PRE) of different estimators with respect to usual unbiased estimator \({\overline{\text{y}}}_{{{\text{st}}}}\) by using the following formulae:
To demonstrate the effectiveness of the proposed class of estimators \(t_{8}\), we utilise data on the number of teachers as the study variable (y), and the number of students classified as more or less than 750 in both primary and secondary schools as the auxiliary attribute \(\phi\) for 923 districts across six regions (as 1: Marmara, 2: Agean, 3: Mediterranean, 4: Central Anatolia, 5: Black Sea, 6: East and Southest Anatolia) in Turkey in 2007 (Source: The Turkish Republic Ministry of Education).
The summary statistics of the data are given in Table 1. We applied Neyman23 allocation for allocating the samples to various strata24. Source: Koyuncu9.
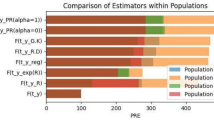
It is observed from Table 2 that the estimators \({t}_{1}\text{ and }{t}_{1e}\) are more efficient than the usual unbiased estimator \(\overline{y}\) (which does not utilize the auxiliary attribute). The product estimator \({t}_{2}\) and product-type exponential estimator \({t}_{2\left(e\right)}\) perform poor than \(\overline{y}\) (due to positive correlation between y and φ). The \({t}_{3}\) is more efficient than \({t}_{1},{t}_{1e},{t}_{2}\text{ and }{t}_{2e}\). The performance of the estimators \(\left({t}_{4},{t}_{5},{t}_{6}\right)\) are almost same but marginally better than estimators \({t}_{1},{t}_{1e},{t}_{2},{t}_{2e } \; \text{and } \; {t}_{3}\).
Table 2 also demonstrates that the proposed estimator \(t_{8}\) with \(\left(\delta =-1,\eta =1,{a}_{st}={C}_{\phi \left(st\right)},{b}_{st}=NP\right)\) has the largest PRE(= 1.49E+11) followed by \({t}_{7\left(m\right)}\) with \(\left(\lambda =-1,{a}_{st}={C}_{\phi \left(st\right)},{b}_{st}=NP\right)\). It is further observed that the proposed classes of estimators \(t_{7\left( m \right)}\) and \(t_{8}\) are always better than the classes of estimators \(t_{1}\)4, \({t}_{1e},{t}_{2}\text{ and }{t}_{2e}\), \({t}_{3}\) (difference estimator), \(t_{4}\)9, \({t}_{5}\)3, \({t}_{6}\)11, \({t}_{7}\)10 for all choices of \(\left({a}_{st},{b}_{st}\right)\). The proposed class of estimators \(t_{8}\) is the best among the estimators closed in Table 2.
Thus, our recommendation is to use the suggested class of estimators \({t}_{7\left(m\right)}\) and \({t}_{8}\) in practice.
Conclusion
In this article, we propose two classes of estimators for estimating the population mean \(\overline{Y}\) of the study variable y using information on an auxiliary attribute \(\left( \phi \right)\). The suggested classes of estimators are wide-ranging. The biases and mean squared errors of the proposed classes of estimators \(t_{7\left( m \right)}\) and \(t_{8}\) are derived up to the first degree of approximation. The optimum estimators in the classes of estimators \(t_{7\left( m \right)}\) and \(t_{8}\) are investigated using the minimum mean squared error formulae. An empirical study is conducted to evaluate the efficiency of the proposed classes of estimators \(t_{7\left( m \right)}\) and \(t_{8}\) and the findings are presented in Table 2. The results of Table 2 demonstrate that the suggested classes of estimators \(t_{7\left( m \right)}\) and \(t_{8}\) are more efficient than the recently developed classes of estimators \(t_{4} ,t_{5} {,}t_{6} ,t_{7} \;{\text{and}}\;t_{3} \,\) by Koyuncu9, Sharma and Singh3, Shahzad et al.11, Koyuncu10, and the difference estimator, with a considerable gain in efficiency. Therefore, we conclude that the proposed classes of estimators and are justified and can be used in practice.
One potential direction for future research is the application of advanced statistical techniques, such as machine learning and artificial intelligence, can be explored to improve the accuracy and efficiency of the estimators. These techniques can also help in identifying relevant auxiliary variables for improving the estimation process. The impact of various sampling designs on the estimation process can be investigated. For example, the effect of unequal sample sizes in different strata, non-response rates, and measurement errors on the accuracy and efficiency of the estimators can be studied. Finally, the extension of the current research to other types of population parameters, such as variance and quantiles, can also be explored. This can lead to the development of new classes of estimators and further improve the accuracy and efficiency of the estimation process.
Data availability
All the necessary data generated and/or analysed during the current study are included in this published article.
References
Kendall, M. G. & Stuart, A. The Advanced Theory of Statistics 2nd edn. (Charles Griffin and Company Limited, 1967).
Shabbir, J. & Gupta, S. On estimating the finite population mean with known population proportion of an auxiliary variable. Pak. J. Stat. 23(1), 1–9 (2007).
Sharma, P. & Singh, R. Efficient estimator of population mean in stratified random sampling using auxiliary attribute. World Appl. Sci. J. 27(12), 1786–1791 (2013).
Naik, V. D. & Gupta, P. C. A note on estimation of mean with known population proportion of an auxiliary character. J. Indian Soc. Agric. Stat. 48(2), 151–158 (1996).
Jhajj, H. S., Sharma, M. K. & Grover, L. K. A family of estimators of population mean using information on auxiliary attribute. Pak. J. Stat. 22(1), 43–50 (2006).
Solanki, R. S. & Singh, H. P. Improved estimation of population mean using population proportion of an auxiliary character. Chilean J. Stat. 4(1), 3–17 (2013).
Singh, H. P., Gupta, A. & Tailor, R. Estimation of population mean using a difference-type exponential imputation method. J. Stat. Theory Pract. 15, 1–43 (2021).
Gupta, A. & Tailor, R. Ratio in ratio type exponential strategy for the estimation of population mean. J. Reliability Stat. Stud. 551–564 (2021).
Koyuncu, N. Improved estimation of population mean in stratified random sampling using information on auxiliary attribute. In Proceeding of 59th ISI World Statistics Congress, Hong Kong, China, 25–30 (2013).
Koyuncu, N. Efficient combined estimators of population mean using auxiliary attribute under stratified random sampling. In Proceeding of 11th International Conference of Numerical Analysis and Applied Mathematics, vol. 1558, 1466–1469 (2013).
Shahzad, U., Hanif, M., Koyuncu, N. & Garcia, A. V. A family of ratio estimators in stratified random sampling utilizing auxiliary attribute alongside the nonresponse. J. Stat. Theory Appl. 18(1), 12–25 (2019).
Zaman, T. Efficient estimators of population mean using auxiliary attribute in stratified random sampling. Adv. Appl. Stat. 56(2), 153–171 (2019).
Zaman, T. An efficient exponential estimator of the mean under stratified random sampling. Math. Popul. Stud. 28(2), 104–121 (2021).
Hussain, S., Ahmad, S., Saleem, M. & Akhtar, S. Finite population distribution function estimation with dual use of auxiliary information under simple and stratified random sampling. PLoS ONE 15(9), e0239098 (2020).
Hussain, S., Akhtar, S. & El-Morshedy, M. Modified estimators of finite population distribution function based on dual use of auxiliary information under stratified random sampling. Sci. Prog. 105(3), 00368504221128486 (2022).
Zaman, T. & Bulut, H. An efficient family of robust-type estimators for the population variance in simple and stratified random sampling. Commun. Stat.-Theory Methods (2021).
Zaman, T. & Kadilar, C. Exponential ratio and product type estimators of the mean in stratified two-phase sampling. AIMS Math. 6(5), 4265–4279 (2021).
Ahmad, S. et al. Dual use of auxiliary information for estimating the finite population mean under the stratified random sampling scheme. J. Math. 1–12 (2021).
Ahmad, S. et al. Improved estimation of finite population variance using dual supplementary information under stratified random sampling. Math. Probl. Eng. 2022 12. https://doi.org/10.1155/2022/3813952 (2022).
Shahzad, U., Ahmad, I., Almanjahie, I. M., Al-Noor, N. H., & Hanif, M. A novel family of variance estimators based on L-moments and calibration approach under stratified random sampling. Commun. Stat.-Simul. Comput. 1–14. https://doi.org/10.1080/03610918.2021.1945629 (2021).
Shahzad, U., Ahmad, I., Almanjahie, I. & Al-Noor, N. H. L-Moments based calibrated variance estimators using double stratified sampling. Comput. Mater. Continua 68(3), 3411–3430 (2021).
Shahzad, U., Ahmad, I., García-Luengo, A. V., Zaman, T. & Al-Noor, N. H. Kumar, A estimation of coefficient of variation using calibrated estimators in double stratified random sampling. Mathematics 11, 252 (2023).
Neyman, J. On the two different aspects of the representative method: The method of stratified sampling and the method of purposive selecting. J. R. Stat. Soc. 97, 558–606 (1934).
Cochran, W. G. Sampling Techniques 3rd edn. (Wiley, 1977).
Acknowledgements
We would like to express our sincere gratitude to the anonymous reviewers and the editor for their valuable comments, feedback, and suggestions, which greatly improved the quality and impact of this manuscript. Their thoughtful and constructive criticisms and insights have been immensely helpful in shaping the final version of this paper. We appreciate their time, effort, and expertise in reviewing and editing this work. I also acknowledged to Dhanashree Bhure, Editorial Support at Scientific Reports for assisting and guiding us for the proper submission of the manuscript.
Author information
Authors and Affiliations
Contributions
Idea of the estimator generation is of H.P.S. Theoretical study and comparison have been carried out by R.T. A.G. has carried out the empirical study of the estimator and drafted the whole research paper in article form. All authors read and approved the final study manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Singh, H.P., Gupta, A. & Tailor, R. Efficient class of estimators for finite population mean using auxiliary attribute in stratified random sampling. Sci Rep 13, 10253 (2023). https://doi.org/10.1038/s41598-023-34603-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-023-34603-z
This article is cited by
-
Evaluating the performance of logarithmic type estimators using auxiliary attribute
Life Cycle Reliability and Safety Engineering (2023)
