
Abstract
Power Line Communication technology uses power cables to transmit data. Knowing whether a node is working in advance without testing saves time and resources, leading to the proposed model. The model has been trained on three dominant features, which are SNR (Signal to Noise Ratio), RSSI (Received Signal Strength Indicator), and CINR (Carrier to Interference plus Noise Ratio). The dataset consisted of 1000 readings, with 90% in the training set and 10% in the testing set. In addition, 50% of the dataset is for class 1, which indicates whether the node readings are optimum. The model is trained with multi-layer perception, K-Nearest Neighbors, Support Vector Machine with linear and non-linear kernels, Random Forest, and adaptive boosting (ADA) algorithms to compare between statistical, vector-based, regression, decision, and predictive algorithms. ADA boost has achieved the best accuracy, F-score, precision, and recall, which are 87%, 0.86613, 0.9, 0.8646, respectively.
Similar content being viewed by others

Introduction
Power Line Communication (PLC) is a communication technology that uses existing power cables for data transmission. Hence, PLC is an attractive and cost-effective method for transmitting data from all devices plugged into the power plugs, such as sensors and actuators. Therefore, using PLC as a communication technology avoids adding another infrastructure for data exchange by using the power line1,2,3. Power line communication is divided into two categories based on the data rate; narrow band power line and broadband power line communications4,5. Narrow-band PLC is used a lot in the smart grid, by electricity companies, and in-home networks for smart home applications. Moreover, PLC is used in in-vehicle and vehicle-to-infrastructure systems, and next-generation battery management systems6,7. On the other hand, broadband power line communication is used in multimedia communications. Such applications are often characterized by many connected nodes, which are increasing with the Internet of Things (IoT) expansion.
The shared environment nature of the PLC raises many challenges for the communication process, such as the variable media characteristics. One issue concerns impedance matching at both the transmitter (TX) and the receiver (RX) for the PLC front end. The matching impacts the self-interference and the signal-to-self-interference-plus-noise ratio (SSINR). Typical PLC modems use a low impedance Tx path and a higher impedance Rx path in the analogue front-end for efficient harmonic distortion operation5,7,8,9. Much effort has been made for impedance matching for the PLC10. However, there are still challenges in the power line impedance matching due to its variable load nature.
Contemporary PLC network performance deteriorates with increasingly connected nodes. Similarly, the coexistence with neighbouring DSL networks degrades the link quality. Hence, the European Telecommunications Standards Institute (ETSI) recommends using a dynamic spectral adaptation approach11. Broadband PLC modems estimate the DSL-to-PLC channel interference and adapt the PLC’s transmit power spectral density accordingly. Moreover, a considerable effort has been made in PLC focused on the physical layer to deal with issues such as the time-varying behaviour of loads in electric power systems. Hence, there are dynamics and diversity of loads that result in time-frequency varying behaviour and signal attenuation when frequency and/or distance increase. Different impedance matching techniques have been illustrated in10. Furthermore, high power impulsive noise, impedance mismatching, the widespread use of unshielded power cables, and coupling losses impact link quality1,4,6,11,12. In addition, high power impulsive noises yielded by connecting and disconnecting loads, equipment, alternate current/direct current (AC/DC) converters, and electromagnetic interference due to unshielded power lines and coupling problems affect the communication media performance dynamically over time.
Research in the domain of PLC is still running to address these issues. Communities such as PRIME and G3 are developing advanced tools, techniques, methods, and approaches, such as different implementations for the MAC and PHY layers which deals with different challenges5,9,10,11. Moreover, field studies have discussed these issues9,13. Another technique for addressing these issues is using another communication medium, such as RF, in regions where PLC is unstable. For example, using PLC (G3-based ) with RF technology such as 6LowPAN14 or LoRA has been better performance13,15,16. However, using another technology violates the main advantage of using PLC: using existing infrastructure without added cost. Furthermore, another effort has been made to improve communication performance based on artificial intelligence (AI). So, AI is used to determine link quality and communication media quality. AI has been primarily used for RF-based technologies such as 4G/5G, optical networks, and smart cities data analysis17,18,19,20,21. Hence, this work focuses on using AI to predict link quality for a PLC-based network and determining the optimum time slot for communicating with the node via the PLC network. The used data is collected from a field configured to work with a PRIME based PLC network.
This work uses the PRIME standard to build a PLC network in the field. The nodes are implemented using PL360 PLC transceiver from Microchip technology. The network consists of 500 PLC nodes, while the data concentrator unit (DCU) is located at the transformer site. Then, a PLC sniffer located one node after the DCU point. The dataset has been collected consisting of 1000 instances of the time in which a PLC node has optimum readings of the Signal to Noise Ratio (SNR), Received Signal Strength Indicator (RSSI), and Carrier to Interference-plus-Noise (CINR). The dataset trained six models representing Statistical, Vector-based, regression, decision, and predictive algorithms. The trained statistical algorithm is adaptive boosting. The vector-based algorithms are the Support Vector Machine (SVM) linear kernel and the SVM non-linear kernel. Decision algorithms are the random forest and decision trees. Finally, the predictive algorithm is K-Nearest Neighbors.
In the rest of the paper, AI in communications is discussed in Sect. 2, and the algorithms and the dataset details are discussed in Sect. 3. Then, the behaviours of the trained models are shown in Sect. 4, with a discussion of the results in Sect. 5, and the paper is concluded in Sect. 6.
AI in communications
AI is the field that allows computers to be smart and perform tasks that humans only did before. It has been widely developed in previous years and used in different applications. For example, AI is used for predicting some events in the future based on their historical performance, which saves time22.
PLC is recently being used more. It is data transmission using a Power Line Network (PLN). The problem in PLC is that PLN is not designed for this transmission, so PLC faces large noise23,24.
The work in25 has used machine learning to cluster the multi-conductor noise in PLCs to determine whether automatic clustering is helpful in this topic or not. They have used the MIMO NB noise database. They preprocessed the database to create the feature library, a Table consisting of the time segments from 5 to 500 \(\mu s\) and two types of features. The first was to extract the signal, and the other was to find the relation between the two multi-conductor signal traces. The features have been evaluated to determine which are beneficial to consider. The authors have used principal component analysis (PCA) and box plots for feature evaluation. PCA reduces the dataset dimensions and keeps most of the information. A box plot displays the data on a standardized graph depending on six metrics: median, 25th percentile, 75th percentile, outlier, minimum, and maximum. The PCA shows that features 5 (Samples Skewness), 7(Samples Pearson correlation), and 9 (Distance Correlation) are the most informative features, and box-plot also shows features 5 and 7 have a visible data separation25,26. Three methods have been used in clustering: hierarchical clustering, self-organizing map (SOM), and clustering using representatives (CURE). Hierarchical clustering sets for each point of a cluster, calculate the distances between the clusters, combine the nearest two clusters into one cluster and then redo the process till all the clusters are combined into one cluster, forming a dendrogram which is clusters’ tree27. On the other hand, in CURE, a subset of the data representing C clusters is selected. For each cluster, some points far from each other are selected, then they are moved by 20% to the cluster centroid, then the algorithm merges every two clusters having two nearby representative points and then clusters all data points28. Finally, SOM is a network of mapped units that each unit refers to a cluster such that the larger the number of units, the more accurate the separation of data29. The clusters have been labeled according to the probability density functions (PDFs), which led to 35% of the data being normal, 23% being Middleton Class A, 27% being Alpha STable, 13% Generalized Extreme Value, and 2% of unknown classes. It is worth mentioning that more than five conventional noise classes were needed to represent the nature of the noise, especially in a noisy network such as a PLC environment29.
The noise affects the PLC node, affecting data transfer reliability. AI can be used to detect whether a node is working at a specific time or not. This can be done by knowing the readings of the node in the past and training the AI model on these readings, which leads to the prediction of the time intervals where the readings of the PLC nodes are not optimal. This prediction will lead to the early selection of other nodes for the transmission instead of testing each node to determine the functioning nodes30.
Methodology
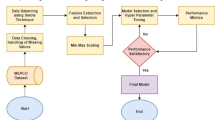
In this section, the trained machine learning algorithms, which are Multi-Layer Perception, K-Nearest Neighbour, Support Vector Machine, Random Forest, and Adaptive Boosting, are discussed along with the key information of the collected data.
Machine learning algorithms
Multi-layer perception (MLP)
Multi-Layer Perception (MLP) is a neural network that is a supervised learning technique. The MLP consists of six layers: the input layer, four hidden layers, and the output layer, as depicted in Fig. 1. All the non-input nodes are neurons that use a nonlinear activation function.

Relation between different layers of the MLP.
K-nearest neighbour (KNN)
K-Nearest Neighbour (KNN) is an algorithm that predicts the input class based on voting for the most similar training data instances to the input. This takes the majority class of the K nearest similar neighbours without a learning process. As shown in Fig. 2, the green circle next to the question mark is the input that is not labelled. The two red triangles and a blue square are next to the input circle because they are similar; in other words, their features are similar to the input’s features. In this example, the value of the K is chosen to be three, so the black circle contains the nearest three instances to the input. After knowing the voting participants, the majority class will be the class of the input, so the prediction of the input class is the red triangle class

K-Nearest Neighbors, which shows the selection of the most similar k points to the input point.
where the blue square is class 1, the red triangle is class 0, and the green circle is the input.
Support vector machine (SVM)
SVM separates the data points into another readily separable dimension using a kernel. For example, as shown in Fig. 3, there are two features, x1 and x2, and two classes, black and white dots. To be able to identify which combination of the feature values would refer to the class, the feature values of each instance have been plotted, and using a non-linear kernel as part (a) and linear kernel as part (b), the parts of the plot indicating each class could be known. The hyperplane is the plane that separates the classes in n-dimensional space. The more it is farther from the data points, the more accurate the classification31,32,33.

Diagram for the Support Vector Machine which shows the classification using the non-linear and linear kernels34.
Random forest
The Random Forest algorithm is a group of decision trees, as shown in Fig. 4. Each of these decision trees is trained on a subset of the dataset. These portions are equally distributed. When an input is given to the random forest algorithm, each tree, based on its training, gives a classification for this input. The class with the majority of predictions is input predicted class35,36.

Adaptive boosting
An ensemble learning algorithm adjusts the weak classifier’s weights by iterating over them to enhance performance and create a more robust classifier. As shown in Fig. 5, the algorithm starts with fitting the model on the dataset and having some results, then adjusts some weights in the weak classifier and tests the model; if it is a weak classifier, it adjusts its weights till it becomes a more robust classifier.

Ada Boost38.

Nodes activity over time.
Figure 6 shows the number of registered nodes in a time instance such that, as part (a) and part (b) show, as the variation in the number of registered nodes increases, the variation of the number of switch nodes in a time instance increase.
Dataset
In this work, data is collected from a test field that consists of 400 PLC modems. The PLC data are based on the PL360 chipset from Microchip, and the protocol used for the communication is PRIME standard. The data is collected using a PLC sniffer from Microchip as the sniffer is placed one node after the Data Concentrator Unit (DCU). Firstly, the data has been analyzed and filtered to be even. Then, the parameters representing the channel quality have been chosen based on the literature5,16.

Dataset most dominant parameters histogram distribution.
The dataset consists of 1000 readings of the most dominant parameters, which are Signal to Noise Ratio (SNR), Received Signal Strength Indicator (RSSI), and Carrier to Interference-plus-Noise (CINR); these are the most dominant parameters as shown in Fig. 7. Table 1 shows a sample for the dataset. 50% readings for label 0 indicate that the channel is not working for these values. On the other hand, for labeled 1, the communication channel is working and suitable for data exchange. The readings helped to determine which timestamp the node was working and which was not, which helped in determining, at a given time, the probability that a node was working or not. The dataset was divided into 90% for training and 10% for testing. Samples of the data for a specific node are displayed in the following figures. For example, Fig. 8 shows the SNR values over time, while Fig. 9, depicts the RSSI of the channel for a specific node in the network. The diagrams show that the change in the parameters is random over the time of sniffing. Moreover, the CINR is illustrated in Fig. 10. The captured data shows that the signal quality is variable over time.

SNR values over the time.

RSSI values over the time.

CINR values over the time.
Data analysis
Analysis was done on our data to identify the relation between features and how these parameters can affect nodes performance. A subset of data was taken for simplicity to visualize all feature over the time creating Figure 11. This plot clearly shows the high correlation between all features, for example when SNR increases at specific time, the Bersoft decreases so a high negative correlation appears between these two features.

All quality features over the time.
Another type of visualization to prove correlation is a correlation matrix which depends on Pearson correlation calculations as in Figure 12. As shown, a very high correlation appears between all quality features. Besides, a high correlation appears in up & down column with Pdutype and level. This can be explained that as a the node tends to be in a high level, lower quality appears resulting in down performance.

Correlation matrix of all quality features.
A histogram of all features can be visualized as well in Figure 13. This shows that the most abundant value in SNR is 4 indicating a bad quality of almost 75% of the data. Moreover, Bersoft and Bersoft max shows the same distribution which proves their high correlation of 1 which appears in the correlation matrix.

A histogram of all quality features.
Results
In this section, six AI models have been used with the collected data in order to predict channel behavior. Hence, the results of these models and their impact on network performance are discussed. Then, a comparison between these results is conducted. Four metrics are used to evaluate the models; accuracy, F1-score, precision, and recall. Furthermore, a confusion matrix has been plotted for each model. The confusion matrix is a 2-d matrix whose rows refer to the true labels, and its columns refer to the predicted labels. The confusion matrix shows how many predicted instances are for each class, indicating the model performance39.
The metrics’ equations are shown in equation 1. The accuracy is evaluated using (1a), the ratio between the summation of all the correct predictions. Which are the truly predicted positive class (TP) and truly predicted negative class (TN) to all the predictions, which are the true predictions of positive class (TP) and negative class (TN) and the falsely predicted positive class (FP) and the falsely predicted negative class (FN). As (1b) shows, the precision is how much truly predicted positive class (TP) is concerning all the predicted positive classes either truly predicted (TP) or falsely predicted (FP). The recall is how much truly predicted positive class for the number of positive class instances in the testing dataset, whether they are truly predicted (TP) or falsely predicted (FN) as shown in (1c). The F1-score is the ratio between double the multiplication of the precision and the recall to their summation as shown in (1d)40. Fig. 14 shows the confusion matrices for the proposed models. The confusion matrix compares the predictions of each model with respect to the actual predictions such that the rows represent the actual class and the columns represent the predicted class such that the diagonal shows the correctly classified instances.
Multi-layer perception (MLP)
MLP has been tested on 100 instances and achieved an accuracy of 84% such that, as Fig. 14 - a shows, 47 of 52 instances were correctly classified as class ’1’, and 37 of 48 were correctly classified as class ’0’. The model resulted in a precision of 0.8456, a recall of 0.8373, and an F1-score of 0.8384.
K-nearest neighbour (KNN)
KNN prediction accuracy differs with different Ks, as explained in Sect. 2. Therefore, the model has been tested to predict the testing set instances with different Ks to determine the value with the best results, such that at K equals 15, the model has the best results. Fig. 14 - b shows the KNN model’s predictions when tested on 100 instances. The model correctly predicts 35 out of 48 for the 0 class and 32 out of 52 for the 1 class, which have an accuracy of 67 %, F1-score equals 0.6697, a precision of 0.6737, and recall equal of 0.6723.
SVM-linear kernal
The model correctly predicted 49 out of 52 instances to be class ’1’ and 36 out of 48 class ’0’ as shown in Fig. 14 - c, with an accuracy of 85%, F1-score equals 0.8465, the precision equals 0.8698, and recall of 0.8454.
SVM-non-linear kernel
The model’s accuracy is 86% which classified 50 out of 52 instances class ’1’, and 36 out of 48 of class ’0’, as shown in Fig. 14 - d, with F1-score equals 0.8572, precision of 0.8769, and recall of 0.8558
Random forest
The Random Forest model has been tested with several estimators ranging from 1 to 100. The number of estimators is the number of trees in a random forest. This has been done to know which number of estimators will have the best results. The number of estimators that has the best accuracy is 34. Fig. 14 - e shows that the model has successfully correctly predicted 50 out of 52 instances to be class 1 and 35 out of 48 instances to be class 0. The model has an accuracy equal to 85%, F1-score of 0.8465, precision equal to 0.8698, and recall of 0.8454.
ADA boost
The model has been tested with several estimators such that the estimators starting from 12 have the best results. Fig. 14 - f shows that the model has successfully correctly predicted 52 out of 52 instances to be class 1 and 35 out of 48 instances to be class 0. The model has an accuracy equal to 87%, F1-score of 0.8661, precision equal to 0.9, and recall of 0.8646. As shown in Table 2, The ADA Boost was the best algorithm with respect to the accuracy, F1-score, precision, and recall to predict at which time, a PLC node is optimum with an accuracy of 87%, while the least accurate model was KNN with 67% accuracy.

Confusion matrices for trained models.
Discussion
Recently, PLC has been used in different IoT applications. However, the PLC environment is vulnerable to noise sources, negatively impacting network quality. Indeed, a considerable effort has been made over the past decade to improve the network, and link quality10,12. For example, some researchers targeted different MAC and PHY layer implementations to improve network reliability. Furthermore, some effort has been made on the level of electronic circuit implementations10. However, despite the previous work on improving the network quality, PLC-based networks still need more stability due to variable conditions over time. Hence, this work uses AI to predict network stability and link quality. Six AI techniques have been used to predict the network quality and the optimum time slot for communications. Table 2 illustrates a comparison between the different techniques. The ADA Boost gave an accuracy of 87% for hitting the optimum communication slot, while KNN gave the worst accuracy of 67%. However, KNN is the fastest execution time (0.0039 sec.) for 21 threads. On the other hand, ADA Boost takes (0.02 sec) for 25 threads during the training time. This means the KNN requires fewer CPU resources than ADA Boost during the training process. This enables the concept of enabling training in a limited resources environment. Furthermore, the SVM-nonlinear kernel gave an accuracy of 86% with a training time of 0.043 sec. for 23 threads. However, SVM linear kernel achieves an accuracy of 85% for a training time of 0.024 sec. The significant advantage of selecting the optimum time slot for communication is increasing the efficiency of the communication link. This also increases the number of nodes the same DCU device can serve. Furthermore, increasing the link efficiency minimizes the number of trials to get the reading for the PLC node. Hence, the system can increase the number of nodes
served by the same DCU.
Conclusion
Predicting the availability of a PLC node earlier enhances the network performance. MLP, KNN, SVM linear and non-linear kernels, Random Forest, and AdaBoost algorithms were trained and tested to predict whether a PLC node was available at a particular time or not. They represent Statistical, Vector-based, regression, decision, and predictive algorithms. Signal to Noise Ratio (SNR), Received Signal Strength Indicator (RSSI), and Carrier to Interference-plus-Noise (CINR) readings were used to determine whether a PLC node was optimum to be used at a specific time using a dataset of 1000 instances was used such that 90% of it was used in training the model. The model has achieved accuracy, F1-score, precision, and recall which are 87%, 0.86613, 0.9, and 0.8646, respectively, for the AdaBoost algorithm, which exceeded the other algorithms.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Mlỳnek, P., Rusz, M., Benešl, L., Sláčik, J. & Musil, P. Possibilities of broadband power line communications for smart home and smart building applications. Sensors 21(1), 240 (2021).
Al-Fuqaha, A., Guizani, M., Mohammadi, M., Aledhari, M. & Ayyash, M. Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Commun. Surv. Tutor. 17(4), 2347–2376 (2015).
González-Ramos, J. et al. Upgrading the power grid functionalities with broadband power line communications: Basis, applications, current trends and challenges. Sensors 22(12), 4348. https://doi.org/10.3390/s22124348 (2022).
Ghasempour, A. Internet of things in smart grid: Architecture, applications, services, key technologies, and challenges. Inventions 4(1), 22 (2019).
Hamamreh, J. M., Furqan, H. M. & Arslan, H. Classifications and applications of physical layer security techniques for confidentiality: A comprehensive survey. IEEE Commun. Surv. Tutor. 21(2), 1773–1828 (2018).
Vincent, T. A., Gulsoy, B., Sansom, J. E. & Marco, J. Development of an in-vehicle power line communication network with in-situ instrumented smart cells. Transp. Eng. 6, 100098 (2021).
Brandl, M. & Kellner, K. Performance evaluation of power-line communication systems for lin-bus based data transmission. Electronics 10(1), 85 (2021).
Prasad, G. & Lampe, L. Full-duplex power line communications: Design and applications from multimedia to smart grid. IEEE Commun. Magaz. 58(2), 106–112 (2019).
Rocha Farias, L., Monteiro, L. F., Leme, M. O. & Stevan, S. L. Jr. Empirical analysis of the communication in industrial environment based on g3-power line communication and influences from electrical grid. Electronics 7(9), 194 (2018).
Wang, B. & Cao, Z. A review of impedance matching techniques in power line communications. Electronics 8(9), 1022 (2019).
Oliveira, R. M., Vieira, A. B., Latchman, H. A. & Ribeiro, M. V. Medium access control protocols for power line communication: A survey. IEEE Commun. Surv. Tutor. 21(1), 920–939 (2018).
Appasani, B. & Mohanta, D. K. A review on synchrophasor communication system: Communication technologies, standards and applications. Protect. Control Mod. Power Syst. 3(1), 1–17 (2018).
Sanz, A., Sancho, D., & Ibar, J.C. Performances of g3 plc-rf hybrid communication systems. In: 2021 IEEE International Symposium on Power Line Communications and Its Applications (ISPLC), pp. 67–72 (2021). IEEE
Deru, L., Dawans, S., Ocaña, M., Quoitin, B. & Bonaventure, O. Redundant border routers for mission-critical 6lowpan networks. In Real-world Wireless Sensor Networks (ed. Dev, T.) 195–203 (Springer, 2014).
Kassab, A.S., Seddik, K.G., Elezabi, A., & Soltan, A. Realistic wireless smart-meter network optimization using composite rpl metric. In: 2020 8th International Conference on Smart Grid (icSmartGrid), pp. 109–114 (2020). IEEE
Stiri, S. et al. Hybrid plc and lorawan smart metering networks: Modeling and optimization. IEEE Trans. Indus. Inf. 18(3), 1572–1582 (2021).
Ullah, Z., Al-Turjman, F., Mostarda, L. & Gagliardi, R. Applications of artificial intelligence and machine learning in smart cities. Comput. Commun. 154, 313–323 (2020).
Mata, J. et al. Artificial intelligence (ai) methods in optical networks: A comprehensive survey. Optic. Swit. Netw. 28, 43–57 (2018).
Fu, Y., Wang, S., Wang, C.-X., Hong, X. & McLaughlin, S. Artificial intelligence to manage network traffic of 5G wireless networks. IEEE Netw. 32(6), 58–64 (2018).
Yang, H. et al. Artificial-intelligence-enabled intelligent 6G networks. IEEE Netw. 34(6), 272–280 (2020).
Shi, Y., Yang, K., Jiang, T., Zhang, J. & Letaief, K. B. Communication-efficient edge AI: Algorithms and systems. IEEE Commun. Surv. Tutor. 22(4), 2167–2191 (2020).
Zhang, C. & Lu, Y. Study on artificial intelligence: The state of the art and future prospects. J. Indus. Inf. Integr. 23, 100224. https://doi.org/10.1016/j.jii.2021.100224 (2021).
Balada, C. et al. Fühler-im-netz: A smart grid and power line communication data set. IET Smart Gridhttps://doi.org/10.1049/stg2.12093 (2022).
R̃ighini, D., Tonello, A.M. Noise determinism in multi-conductor narrow band plc channels. In: 2018 IEEE International Symposium on Power Line Communications and its Applications (ISPLC) (2018) https://doi.org/10.1109/isplc.2018.8360239
Righini, D., Tonello, A.M.: Automatic clustering of noise in multi-conductor narrow band plc channels. In: 2019 IEEE International Symposium on Power Line Communications and its Applications (ISPLC) (2019) https://doi.org/10.1109/isplc.2019.8693272
Reyes, D. M. A., Souza, R. M. C. R. & Oliveira, A. L. I. A three-stage approach for modeling multiple time series applied to symbolic quartile data. Exp. Syst. Appl. 187, 115884. https://doi.org/10.1016/j.eswa.2021.115884 (2022).
Bade, K., & Nurnberger, A. Personalized hierarchical clustering. In: 2006 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2006 Main Conference Proceedings)(WI’06) (2006) https://doi.org/10.1109/wi.2006.131
Leskovec, J., Rajaraman, A. & Ullman, J. D. Mining of Massive Datasets (Cambridge University Press, 2014).
Vesanto, J. & Alhoniemi, E. Clustering of the self-organizing map. IEEE Trans. Neural Netw. 11(3), 586–600. https://doi.org/10.1109/72.846731 (2000).
Dubey, A., Mallik, R. K. & Schober, R. Performance analysis of a multi-hop power line communication system over log-normal fading in presence of impulsive noise. IET Commun. 9(1), 1–9. https://doi.org/10.1049/iet-com.2014.0464 (2015).
Hossam, M., Afify, A.A., Rady, M., Nabil, M., Moussa, K., Yousri, R., & Darweesh, M.S. A comparative study of different face shape classification techniques. In: 2021 International Conference on Electronic Engineering (ICEEM), pp. 1–6 (2021). https://doi.org/10.1109/ICEEM52022.2021.9480638
Prajapati, G.L., & Patle, A. On performing classification using svm with radial basis and polynomial kernel functions. In: 2010 3rd International Conference on Emerging Trends in Engineering and Technology (2010) https://doi.org/10.1109/icetet.2010.134
Almaiah, M. A. et al. Performance investigation of principal component analysis for intrusion detection system using different support vector machine kernels. Electronics 11(21), 3571 (2022).
Verma, A.R., Singh, S.P., Mishra, R.C., & Katta, K. Performance analysis of speaker identification using gaussian mixture model and support vector machine. In: 2019 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE) (2019) https://doi.org/10.1109/wiecon-ece48653.2019.9019970
Khan, M. Y. et al. Automated prediction of good dictionary examples (gdex): A comprehensive experiment with distant supervision, machine learning, and word embedding-based deep learning techniques. Complexityhttps://doi.org/10.1155/2021/2553199 (2021).
Liu, P., Zhang, Y., Wu, H. & Fu, T. Optimization of edge-plc-based fault diagnosis with random forest in industrial internet of things. IEEE Internet Things J. 7(10), 9664–9674. https://doi.org/10.1109/jiot.2020.2994200 (2020).
Bhushan, S. et al. An experimental analysis of various machine learning algorithms for hand gesture recognition. Electronics 11(6), 968. https://doi.org/10.3390/electronics11060968 (2022).
Abirami, S. P., Kousalya, G. & Karthick, R. Varied expression analysis of children with ASD using multimodal deep learning technique. Deep Learn. Parallel Comput. Environ. Bioeng. Syst.https://doi.org/10.1016/b978-0-12-816718-2.00021-x (2019).
Heydarian, M., Doyle, T. E. & Samavi, R. Mlcm: Multi-label confusion matrix. IEEE Access 10, 19083–19095. https://doi.org/10.1109/access.2022.3151048 (2022).
Abdulhammed, R., Musafer, H., Alessa, A., Faezipour, M. & Abuzneid, A. Features dimensionality reduction approaches for machine learning based network intrusion detection. Electronics 8(3), 322. https://doi.org/10.3390/electronics8030322 (2019).
Acknowledgements
This paper is based upon work supported by Information Technology Academia Collaboration (ITAC) of Egypt, under Grant No. CFP 207.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
In this work, we are using AI to predict the link availability for Power Line Communication (PLC) network. we have collected data from the field and we applied different AI algorithms for predicating the link availability over time. The algorithms showed predication accuracy more than 85Author contribution is as follows: Eng. K.M. did the algorithm implementation for optimization and prediction Eng M.M.A. did the figure generation and initial writing Dr. M.S.D. did the initial writing the supervision during the AI algorithm development Dr. L.A. Said did the modeling and for the data analysis Eng A.E.M.E. supported in the data collection and field testing Dr. Ahmed Soltan project PI and initiator of the idea and he did the final writing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Moussa, K., Amin, M.M., Darweesh, M.S. et al. A comparative study of predicting the availability of power line communication nodes using machine learning. Sci Rep 13, 12658 (2023). https://doi.org/10.1038/s41598-023-39120-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-023-39120-7
This article is cited by
-
Smart cities: the data to decisions process
Nature Cities (2025)
-
Predicting the availability of power line communication nodes using semi-supervised learning algorithms
Scientific Reports (2025)
-
Determinants of multimodal fake review generation in China’s E-commerce platforms
Scientific Reports (2024)
