
Abstract
Aiming to apply automatic arousal detection to support sleep laboratories, we evaluated an optimized, state-of-the-art approach using data from daily work in our university hospital sleep laboratory. Therefore, a machine learning algorithm was trained and evaluated on 3423 polysomnograms of people with various sleep disorders. The model architecture is a U-net that accepts 50 Hz signals as input. We compared this algorithm with models trained on publicly available datasets, and evaluated these models using our clinical dataset, particularly with regard to the effects of different sleep disorders. In an effort to evaluate clinical relevance, we designed a metric based on the error of the predicted arousal index. Our models achieve an area under the precision recall curve (AUPRC) of up to 0.83 and F1 scores of up to 0.81. The model trained on our data showed no age or gender bias and no significant negative effect regarding sleep disorders on model performance compared to healthy sleep. In contrast, models trained on public datasets showed a small to moderate negative effect (calculated using Cohen's d) of sleep disorders on model performance. Therefore, we conclude that state-of-the-art arousal detection on our clinical data is possible with our model architecture. Thus, our results support the general recommendation to use a clinical dataset for training if the model is to be applied to clinical data.
Similar content being viewed by others

Introduction
Sleep and arousal
Good quality and quantity of sleep have major impact on health and overall quality of life1. One substantial measure of sleep quality are sleep arousals, as they provide deep insights into the pathophysiology of sleep disorders and sleep quality2. In general, arousals are short transient wakening reactions that can lead to a more fractured sleep3, but they are also an important part of the normal sleep process2.
Scoring of arousals is part of the standard diagnostic procedure for sleep analysis. The American Academy of Sleep Medicine4 has defined the standard process for annotating arousals. Arousals are detected visually by an expert. This is done using the electroencephalogram (EEG) and electromyogram (EMG), which are part of polysomnography (PSG). According to the American Academy of Sleep Medicine (AASM), an arousal is an abrupt shift in the frequency of the EEG that lasts at least three seconds and requires ten seconds of preceding sleep4. In practice, this results in a maximum length of 15 s, otherwise the epoch would be scored as a wake epoch. During the stage of rapid eye movement sleep (stage R sleep), scoring an arousal also requires a simultaneous increase in the submental EMG4. Arousals are spontaneous or may occur in response to sleep-disrupting events such as apneas, hypopneas, respiratory effort-related arousals (RERAs), and periodic leg movements. Arousal detection is a time-consuming process and requires a trained expert. Scoring is also influenced by individual raters, resulting in lower inter-rater and intra-rater reliability5, and may be biased by the knowledge of the specific diagnosis. In conclusion, manual scoring has two disadvantages: (1) it is tedious and time-consuming, even for experts, and (2) the results might be subjective.
Challenges in automation and machine learning
Automated arousal detection is therefore of great interest. It promises to be fast, objective and reliable. However, the complexity of the underlying pathophysiological processes and how they affect the biosignal has made automatic arousal detection a challenge. According to Qian et al.6, there are several approaches that try to solve this problem using signal processing, traditional machine learning with feature extraction and deep neural networks. The latter has shown the most promising results on large datasets in recent years6. However, there are three major limitations with current approaches to arousal detection:
-
lack of patients or patient diversity in the test sets
-
there is no medical evaluation of how well the models would perform in different patient groups
-
the metrics used do not provide information on relevant clinical parameters
The first two limitations are straightforward: a good test set should represent the range of patients who visit a sleep laboratory. Therefore, it should include patients of different ages, genders and sleep disorders. The lack of such diversity in current publicly available datasets limits the real-world applicability of automated arousal detection models. Additionally, a certain number of patients in the test set is required for statistical purposes. Furthermore, medical evaluation requires medical information such as sleep disorder diagnosis.
In contrast, the third problem is more specific to the setting of an automated detection. Machine learning requires segmentation of a signal to predict events, and these segments can then be evaluated with metrics against the ground truth. However, because they are applied to segments of fixed size, these metrics do not provide information about the actual arousal events. According to the AASM, the number of arousals and the arousal index (ArI: number of arousals during one hour of sleep) are the only parameters to be reported for PSG that are solely influenced by arousal detection4. A common evaluation strategy might be to consider only 30 s sleep epochs7,8 and compare whether there is any arousal at all in that epoch. However, these strategies may not translate well into clinical parameters. Other approaches use a very small segment size of 5 milliseconds9,10, which consequently requires a strategy to merge the segments into events.
Related work
Attempts to automate arousal detection date back to 199811, where a feed-forward network was used to analyse the EEG, EMG and EOG signal of eight subjects to determine sleep stages and the k-mean method to determine sleep arousals. In a following study12, two EEG and one EMG signal were used from eleven patients with sleep disorders to automatically detect arousals by using wavelet transformation. Both experiments showed promising results for automating arousal detection and laid the foundation for further research. Interest accelerated in the following years with the publication of the importance of arousals during sleep in 20042. In 2005 Cho et al.13 used time–frequency analysis and a support vector machine classifier on a single EEG from nine patients to detect arousals. The EMG and two EEGs of 20 patients were used by Alvarez-Estévez and Moret-Bonillo14 to detect arousals using different signal processing steps.
Research reached a peak with the public availability of large (n > 1000) datasets15,16,17 and the PhysioNet challenge in 201818. The PhysioNet challenge presented a dataset of patients monitored in a sleep laboratory to diagnose sleep disorders. The approaches from Howe-Patterson, Pourbabaee, and Benard9 and Li and Guan10 achieved the best results in the challenge using machine learning. Using the test set of 989 patients, they were able to make better assumptions about the generalisability of their models. The approach of Li and Guan10 even showed the portability of their model architecture to the SHHS dataset. Unfortunately, the PhysioNet challenge did not provide information about the patients’ medical conditions and diagnoses, so medical evaluation was still not possible, and the approaches only used the PhysioNet challenge scoring for comparison, which does not include information about the number of arousals.
In Olesen et al.19 applied machine learning to detect arousals and leg movements during sleep using a test set of 1000 male participants. They improved this approach in 202020 by using different setups for their EEG channels, and achieved similar results on the test set with only a third of the training data. This approach was later extended by Zahid et al.21 by combining arousal detection with leg movement and sleep-disordered breathing, presumably using the same test set of 1000 male participants. They also included the correlation between the calculated ArI and the manually scored ArI in their evaluation.
The approach of Alvarez-Estevez and Fernández-Varela7 uses a more diverse dataset with a test set of 2296 participants from the SHHS study combined with 472 patients from their clinical sleep laboratory. This is also one of the few attempts to include the effect on ArI.
A comparison of the different metrics used in more recent approaches can be found in Table 1.
Our approach
We addressed the current limitations using a large dataset from our clinical sleep laboratory, at the University Hospital Carl Gustav Carus in Dresden. The dataset includes records from over twelve years of daily work. This allowed us to evaluate our algorithm on a wide variety of patients and to assess the influence of different sleep disorders, age groups and sex on the performance of our model. We also used an event-based evaluation to determine the quality of arousal detection and calculated the ArI for each record to determine the impact on diagnosis. We also validated the portability of our approach to different datasets and how a model trained on these datasets would perform in our sleep laboratory. Our aim was to achieve state-of-the-art results with a machine learning algorithm trained on clinical data from the daily work of a sleep laboratory and to investigate the impact of sleep disorders on publicly trained models. To the best of our knowledge, there is no published approach using a dataset of this size from day-to-day work in a sleep laboratory, nor an evaluation of the effect of different sleep disorders on an automated sleep arousal detector.
Methods
Datasets
A successful deep learning approach requires a heterogeneous dataset with a large diversity of patients and enough labels to learn from. For model development and optimization, we used our own clinical Dresden Sleep Dataset (abbreviated as “DSDS” in the following text), which allows us to evaluate over additional clinical data. For reasons of reproducibility and to investigate the portability of our approach, we used equally large datasets that have been made publicly available on the National Sleep Research Resource (NSRR)22. An overview of the datasets can be found in Table 2.
DSDS
The DSDS dataset was recorded in the sleep laboratory of the Department for Neurology at the University Hospital Carl Gustav Carus in Dresden. This interdisciplinary sleep laboratory examines and treats patients from the entire spectrum of sleep medicine. The focus is on the diagnosis and treatment of neurological sleep disorders: parasomnia, hypersomnia (narcolepsy) and restless legs syndrome. Patients were referred to the sleep laboratory by their general practitioner or specialist. Therefore, they all they all had specific sleep disorders or self-reported sleep problems. The dataset was collected retrospectively during the European Regional Development Fund project “Tele-Schlaf-Medizin”. It contains 7677 PSGs for 3125 patients from 2008 to 2020. The use of the data and methods for this research was done in accordance with relevant guidelines and regulations, and approved by the ethics committee of TUD Dresden University of Technology (BO-EK-92032020), which allowed the retrospective use of the pseudonymized data without informed consent.
PSGs were recorded using the Philips Alice 5 diagnostic system. Most PSGs were recorded in a standard setup according to AASM criteria, including.
-
six-channel EEG (F3:A2, F4:A1, C3:A2, C4:A1, O1:A2, O2:A1, A1:A2)
-
two-channel electrooculogram (EOG),
-
two-channel chin EMG,
-
leg EMGs,
-
nasal pressure and (in later recordings) thermistor signal as airflow signals,
-
chest and abdomen belts as respiratory effort signals,
-
oxygen saturation by finger oximetry,
-
body position sensor,
-
electrocardiogram,
-
additional snoring microphone,
-
synchronized PSG video.
The signals, including all annotations, were stored electronically in a proprietary data format. Export to machine-readable formats was performed using the Alice 6 PSG diagnostic system.
To separate the dataset by patient, we excluded records that could not be associated with a patient, resulting in 7657 records from 3125 patients. As we wanted to detect sleep arousals, we only included overnight PSG recordings with a minimum record duration of 5 h. This resulted in 3115 patients with a total of 6309 PSG recordings. We excluded recordings with an EEG sampling rate of less than 200 Hz, as recommended by the AASM and as necessary to reproduce state of the art results, e.g. by Li et al.10. The final dataset contains 1703 patients with a total of 3423 PSG recordings, recorded from 02/2008 to 11/2020. The record selection procedure is shown in Fig. 1.

Procedure on selecting relevant recordings for the DSDS.
The dataset has a heterogeneous patient population ranging in age from 18 to 92 years and 40% are women. The average ArI is 27/h and the average Apnea–hypopnea index (AHI) is 16/h. The average sleep duration is 369 min. Most of the patients spent two consecutive nights in the sleep laboratory. In the majority of the cases one diagnostic night and one night with therapy were recorded, but two consecutive diagnostic nights were common as well. The dataset includes information on whether a patient was treated for sleep apnea, which accounts for a total of 40% of nights.
Recordings were scored by trained and experienced PSG technologists and somnologists according to AASM guidelines. Sleep disorder diagnoses were based on the International Classification of Sleep Disorders23 and were obtained from medical reports. It is possible for a record to have more than one of these diagnoses, as they are not mutually exclusive. The most common diagnosis is sleep-related breathing disorders (SRBD), which were diagnosed in 73% of all diagnostic nights, including obstructive sleep apnea (OSA), central sleep apnea, complex OSA and hypoventilation. Insomnia disorders were diagnosed in 16% of the cases and sleep-related movement disorders (SRMD) in 17%, including restless legs syndrome, periodic leg movement disorder (PLMND) and other SRMD. Parasomnia disorders were diagnosed in 13%, including rapid eye movement sleep behavior disorder (RBD) and non rapid eye movement parasomnias. Hypersomnia disorders were diagnosed in 5% of the cases including narcolepsy type 1 and narcolepsy type 2, Kleine-Levin syndrome and idiopathic hypersomnia. Normal findings, including no evidence of sleep disturbance or only mild SRBD (AHI < 15/h), were diagnosed in 8% of cases.
Sleep heart health study (SHHS) dataset
The Sleep Heart Health Study (SHHS)15 was a multicentre cohort study designed to investigate the association between sleep-disordered breathing and cardiovascular disease. The study consisted of two visits at which a PSG was obtained. Visit one (SHHS1) included 6441 participants between 1959 and 1998, and visit two (SHHS2) consisted of 3295 participants between 2001 and 2003. The study includes 5793 (SHHS1) and 2651 (SHHS2) full overnight PSGs performed at home.
Multi-ethnic study of atherosclerosis (MESA) dataset
The Multi-Ethnic Study of Atherosclerosis17 was investigating the factors associated with the development of subclinical cardiovascular disease and its progression to clinical disease in different ethnic groups. Of the 6814 participants, 2237 also underwent a sleep study including a full night of unattended PSG that took place between 2010 and 2012.
MrOS sleep study (MrOS) dataset
The MrOS Sleep Study16 aimed to investigate the relationship between sleep disorders and health outcomes such as falls, fractures and vascular disease in men aged 65 years and older. As part of the larger Osteoporotic Fractures in Men Study, which enrolled 5994 men, the Sleep Study subset included 3135 participants who underwent complete unattended polysomnography.
Preprocessing
Like Olesen et al.19, we used three signals from the PSG for the arousal detection: the EEG to detect frequency shifts, the EOG as an indicator of R sleep and the chin EMG for the requirement of increased submental EMG in R sleep. During training, one channel was randomly selected for each signal to create a three-channel input.
We tested three different preprocessing steps from the literature10, using different sampling rates (50 Hz, 128 Hz and 200 Hz) and preprocessing steps. The method by Howe-Patterson et al.9 achieved the highest area under the precision-recall curve (AUPRC) on the MrOS validation set. We therefore kept this hyperparameter at 50 Hz during further optimization. An antialiasing finite impulse response (FIR) filter was applied to all signals before they were downsampled to 50 Hz. The signals are then normalised by removing the mean and root mean square over an 18 min moving window.
Based on the method used in the PhysioNet challenge 201818, manual labelling was extended to include autonomous responses two seconds before the start and 10 s after the end of an arousal. The arousal labels were interpolated into a label signal so that the sampling rate matched the input signals and a sample wise evaluation is possible.
Model architecture
We used a state-of-the-art model architecture described in the approach of Li and Guan10. We used an extensive grid search to optimize the architecture (number of layers, filter sizes, kernel size), choosing the best setting by best AUPRC on the DSDS validation set.
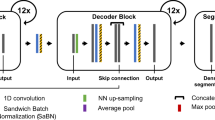
The final architecture is shown in Fig. 2 and uses fewer layers and a higher kernel size (k = 21) than the original model. Our final model takes the three-channel PSG signal with a sampling rate of 50 Hz as input. It produces a 50 Hz signal containing the probability of an arousal at any given time.

Final U-net architecture with eight layers of double convolution, where each convolution (Conv) uses a padding to preserve the length of the input, a number of filters (f) and a kernel size (k).
Training
Prior to training, we performed a participant-wise train-test split of all datasets. We randomly selected participants for our holdout test sets, which resulted in 1202, 1698, 616 and 815 recordings for the DSDS, SHHS, MESA and MrOS datasets, respectively. The remaining data was divided into training (80% of participants) and validation (20% of participants) sets for each dataset.
We used the binary cross entropy as the a loss function and the Adam optimizer24 to update the weights of our model. To determine the learning rate (LR), we used an LR range test25. We cycled the LR between 0.003 and 0.00075 every four epochs. For regularisation, we randomly selected one of the available channels (e.g. right or left EOG) per signal type for each iteration. We also applied normalisation and added random noise with a factor between 0.8 and 1.3. If the validation metric (AUPRC) does not improve for 15 epochs, the training run stopped.
Evaluation
For evaluation, we used metrics that are commonly used in the literature to compare our results at a sample and an event-based level. The most common metric for sample-based evaluation is the area under the precision-recall curve (AUPRC). For event and segment based evaluation the harmonic mean of precision and recall is used (F1 score).
To convert the predicted probabilities to events, we averaged our samples to a one second segment and used an approach from Brink-Kjaer et al.27. Where a threshold is used to determine positive samples, all consecutive positive samples are combined with a patience of ten seconds. Any arousal event under three seconds is discarded, as required by the AASM. We changed the minimum arousal length to 15 s to be consistent with our label manipulation and the patience to three seconds to be more precise. We optimized the threshold using the F1 score of the calculated events from the validation set. Each overlapping manual and automated scored event is marked as a true positive. The special case of two automated events overlapping a single manual event will result in one true positive and one false negative. Similarly, the case of two manual events overlapping an automated event will result in two true positives and one false positive. The final F1 score is calculated from the sum of the record-wise confusion matrices for the entire test set (micro F1 score).
To see how well our pre-trained model performed on data from other studies and scored by different experts, we also evaluated the model on different datasets using their specific test sets. We also wanted to see if a publicly available dataset would be suitable for scoring our clinical data. Therefore, we trained a model on each dataset-specific training set (e.g. DSDStest trained on DSDS) and evaluated it on each hold-out test set (e.g. SHHS1test: scored on test data from SHHS1). None of the training or validation data was used for testing.
To understand the medical implications, we use the absolute difference between the predicted ArI and the ArI from the manual annotations on a per record basis and refer this as the ArI error. We tested whether our DSDS model had a bias in the ArI error for different patient age groups and sexes. We performed a Shapiro–Wilk test on the different groups, to see if the ArI error is normally distributed. Since the ArI error was not normally distributed between age groups and sexes, we proceeded by performing a Kruskal–Wallis test to investigate if there were significant differences between the groups. We performed a post-hoc Dunn test with Bonferroni correction to see which groups differ significantly.
We used the DSDS test set to assess the ability of public trained non-clinical data to detect sleep arousals in clinical data. We therefore grouped our test set into six different non-exclusive categories (without recordings using any SRBD related treatment) (see Table 3). We added 480 recordings to an exclusive category where SRBD was treated (including positive air presure therapy, positional therapy and mandibular advancement device therapy). This can provide insight into the model’s performance on recordings with therapy devices, which are generally excluded from public datasets15,16,17. We used Cohens D26 to calculate the effect size of the ArI error by comparing each category with the exclusive category normal findings. We tested each model to see if the effect size (ranging from none (0–0.2), small (0.2–0.5), moderate (0.5–0.8) and large (0.8–1) effect size) was different for each group.
Ethics declarations
The use of the data for this research was approved by the local medical ethics committee (BO-EK-92032020) and allowed the retrospective use of the anonymous data without informed consent.
Results
Based on ArI error the best results were achieved on the SHHS1 dataset with an AUPRC of 0.83, an F1 score of 0.80, an ArI correlation of 0.88 and an ArI error median of 1.71 (0.75–3.27), achieving state of the art results as shown in Table 1. The model trained and tested on our DSDS achieved an AUPRC of 0.71, an event-based F1 score of 0.74 and a Pearson correlation of 0.78 for arousal index prediction and an ArI error of 4.37 (1.88–7.72). The models trained on public datasets performed better than the model trained on our clinical DSDS, which may be due to the more heterogeneous test set.
Evaluation across datasets
Evaluation across different datasets shows that each model performs best on its own test set for the technical metrics. This is shown for the F1 score in Table 4 and for the AUPRC in Table 5. The results seem to vary widely between datasets.
Medical implication
The AUPRC and F1 Score metrics do not give a direct indication of ArI. Therefore, the ArI error was used to investigate the medical implications. It was found that the ArI error has a low, significant correlation (r = 0.28, p = 0.004) with the arousal index within the normal finding group, as shown in Fig. 3. This indicates that the number of prediction errors increases with the severity of the pathological changes (sleep fragmentation), regardless of the sleep disorder.

Correlation between Absolute difference in the arousal index (ArI error) and arousal index for the normal finding group in the Dresden Sleep Dataset (DSDS) using the model trained on DSDS.
Figure 4 shows the influence of age on the quality of the DSDS model using the ArI error. The Kruskal–Wallis test showed a significant difference in the age distribution, but the series of post-hoc Dunn tests revealed no significant differences between individual pairs of age groups at the 0.05 significance level. The Kruskal–Wallis test showed no significant difference in the ArI error for male or female patients, shown in Fig. 5.

Influence of age on ArI error in the DSDS using the model trained on DSDS.

Influence of sex on ArI error in the DSDS using the model trained on DSDS.
The Fig. 6 shows slightly non-significant higher predicted ArI values for the SRBD and SRMD groups. Further details are provided in the next section, which shows the impact of the different training datasets.

Influence of diagnosis on ArI error in the DSDS. The red dotted line indicates the median of the ArI error for the normal findings group.
Medical implications of publicly trained models
The Table 6 shows that the ArI error showed similar variation between the datasets as the technical metrics (shown in Tables 4 and 5). Each model performs best on its own test set. The model trained on the SHHS1 dataset performed best on our clinical dataset, with only a slightly higher ArI error of 4.43 (2.00–8.91) compared to 4.37 (1.88–7.72) for the DSDS model.
Finally, the performance of all models were evaluated on the DSDS test set. Clinical groups were grouped and compared to the normal findings group (as shown in Table 7). The model trained on the DSDS showed a small negative effect (Cohens D of 0.22 and 0.21) for the SRMD and SRBD groups and a small positive effect (Cohens D of − 0.3) for the hypersomnia disorder group. This positive effect was not observed in other models, with the model trained on the MESA dataset even showing a moderate negative effect (Cohens D of 0.72). Besides the hypersomnia disorder group, all public datasets showed a small to moderate negative effect on the other sleep disorders groups (Cohens D ranging from 0.2 to 0.73).
Discussion
For the technical metrics F1 score and AUPRC, our models trained on publicly available datasets outperformed other approaches found in the literature (see Table 1). The model trained on the clinical DSDS still achieved state-of-the-art results, but was significantly lower than the other models. This may be due to the heterogeneous test set and the fact that we used data directly from the daily work of the sleep laboratory, without any re-evaluation or filtering for PSG quality. The technical metrics are well suited for comparing models at a low level of granularity, but may not be well suited for evaluating the actual task of detecting arousal events. Implementation details such as segment length, patience for combining events, and label manipulation as used in this work can affect these scores, making them difficult to compare with other approaches. Metrics based on the medical parameters of arousal index or arousal count give a direct insight into the impact of the algorithm when generating a sleep report. They are not influenced by implementation details. However, they negate false positives and negatives within recordings and may not be the best metrics to use during development.
In addition to the technical metrics, we chose to use the absolute difference in ArI for our evaluation because this metric is easy to interpret as it shows the expected difference in ArI during the night. A difference in the ArI, which can also be negative (as used in7), would negate the overestimation and underestimation of arousal events at the dataset level. It is therefore not suitable for comparing different clinical groups. A relative difference in the ArI or the F1 score would also be appropriate metrics. However, our model produces a negative correlation with these metrics and the ArI index within the normal findings group. This would lead to a bias in favour of healthy patients, as sleep disorders tend to have a higher ArI. The metric we used has a positive correlation with the ArI, which is also not ideal. However, this could explain the small negative effect on the SRBD and SRMD groups in our DSDS model, as these are the groups with the highest ArI.
Compared to other sleep-related scores, arousal scoring appears to have lower inter-rater agreement5,28,29. There is also a lack of large studies on inter-rater agreement in arousal detection. Other areas of sleep are better studied, such as respiratory events30. This makes it impossible to assess the quality of the current state of the art. The lower inter-rater agreement between experts also explains the lower results when transferring our model to another dataset.
With our model trained on the comprehensive clinical dataset, we have achieved state-of-the-art results with the model architecture and preprocessing we have optimized. Our model shows no age or sex bias and shows only small negative effects on some sleep disorders compared to healthy sleep. However, we also see some limitations in our DSDS. It is not known which record was scored by which expert. Due to the size of the dataset, we did not re-evaluate the records by another expert and used the data directly as a “real-World”-Dataset from the daily work of the sleep laboratory. Information on the ethnicity of our patients is also missing. The fact that we have multiple diagnoses for a single night may distort the evaluation of the clinical groups. In a larger test set, the evaluation could be done only on patients with an exclusive diagnosis.
The model, trained on a single dataset and tested on other datasets, shows a large shift in performance independent of sleep disorders. Approaches such as Brink-Kjaer et al.27, mix different datasets, which could have a positive impact31 on the diversity of experts and under-represented ethnicities. However, our aim was to demonstrate and compare current approaches using a dataset from a practising sleep laboratory. Therefore, we did not mix the datasets to show whether models with different data bases have a bias towards specific sleep disorders or SRBD therapy. However, mixing datasets may be an important approach for future work, especially when multiple clinical datasets are available.
The preprocessing by Howe-Patterson et al.9 gave the best results. By downsampling the signal to 50 Hz, only information up to 25 Hz is included, which is below the 35 Hz recommended by AASM. Although this may help to reduce the complexity for the model, it may also remove sleep-related information. A sampling rate of 70 Hz should be additionally investigated in the future.
Furthermore, we would like to point out that the transition from sample-wise to arousal event is taken from the literature27 and is not well investigated in our approach or in the literature in general. This could be a key factor in the performance evaluation of the models and should be further investigated.
Conclusion
We have shown that it is possible to achieve state-of-the-art results on a large clinical dataset from the day-to-day work of a sleep laboratory. The performance of our model architecture trained and validated on one dataset varies when tested on different datasets. This needs to be considered when implementing automatic arousal detection for a sleep laboratory. In particular, when used to detect arousals in patients with sleep disorders. We propose that more approaches use additional metrics like the ArI error to evaluate their models, as they have medical relevance and show the expected error when used in practice.
Concluding from these results, a universally applicable model for automated arousal detection would require several clinical datasets from different centres and annotated sleep disorders. These should be mixed to reduce individual scorer bias. Other studies have shown that combining different micro-events during sleep improves results21. Therefore, we aim to further improve the results by adding other micro-events during sleep and sleep staging.
Data availability
The datasets SHHS, MESA and MrOS datasets are available from the National Sleep Research Resource website https://sleepdata.org/datasets. The DSDS data set used for the medical evaluation is available on reasonable request from the corresponding authors. The DSDS dataset is not publicly available because they contain information that could compromise the consent and privacy of research participants.
Code availability
The complete implementation for the arousal detector was done using Python and Pytorch. The code and pretrained models are available on GitLab https://gitlab.com/sleep-is-all-you-need/arousaldetector under the GNU General Public License.
References
Mukherjee, S. et al. An official american thoracic society statement: The importance of healthy sleep. Recommendations and future priorities. Am. J. Respir. Crit. Care Med. 191, 1450–1458 (2015).
Halász, P., Terzano, M., Parrino, L. & Bódizs, R. The nature of arousal in sleep. J. Sleep Res. 13, 1–23 (2004).
Scoring, E. EEG arousals: Scoring rules and examples: A preliminary report from the sleep disorders atlas task force of the American sleep disorders association. Sleep 15, 174–184 (1992).
Berry, R. B. et al. The AASM manual for the scoring of sleep and associated events. Rules Terminol. Tech. Specif. Darien Ill. Am. Acad. Sleep Med. 176, 2012 (2012).
Ruehland, W. R. et al. The 2007 AASM recommendations for EEG electrode placement in polysomnography: Impact on sleep and cortical arousal scoring. Sleep 34, 73–81 (2011).
Qian, X. et al. A review of methods for sleep arousal detection using polysomnographic signals. Brain Sci. 11, 1274 (2021).
Alvarez-Estevez, D. & Fernández-Varela, I. Large-scale validation of an automatic EEG arousal detection algorithm using different heterogeneous databases. Sleep Med. 57, 6–14 (2019).
Chien, Y.-R., Wu, C.-H. & Tsao, H.-W. Automatic sleep-arousal detection with single-lead EEG using stacking ensemble learning. Sensors 21, 6049 (2021).
Howe-Patterson, M., Pourbabaee, B. & Benard, F. Automated detection of sleep arousals from polysomnography data using a dense convolutional neural network. In 2018 Computing in Cardiology Conference (CinC) vol. 45 1–4 (IEEE, 2018).
Li, H. & Guan, Y. DeepSleep convolutional neural network allows accurate and fast detection of sleep arousal. Commun. Biol. 4, 1–11 (2021).
Pacheco, O. R. & Vaz, F. Integrated system for analysis and automatic classification of sleep EEG. in Proceedings of the 20th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Vol. 20 Biomedical Engineering Towards the year 2000 and Beyond (cat. No. 98CH36286) vol. 4 2062–2065 (IEEE, 1998).
De Carli, F., Nobili, L., Gelcich, P. & Ferrillo, F. A method for the automatic detection of arousals during sleep. Sleep 22, 561–572 (1999).
Cho, S., Lee, J., Park, H. & Lee, K. Detection of arousals in patients with respiratory sleep disorders using a single channel EEG. In Conference Proceedings :Annual International Conference of the IEEE Engineering in Medicine and Biology Society. IEEE Engineering in Medicine and Biology Society. Annual Conference vol. 2005, 2733–2735 (2005).
Alvarez-Estévez, D. & Moret-Bonillo, V. Identification of electroencephalographic arousals in multichannel sleep recordings. IEEE Trans. Bio-Med. Eng. 58, 54–63 (2011).
Quan, S. F. et al. The sleep heart health study: Design, rationale, and methods. Sleep 20, 1077–1085 (1997).
Blackwell, T. et al. Associations between sleep architecture and sleep-disordered breathing and cognition in older community-dwelling men: The osteoporotic fractures in men sleep study. J. Am. Geriatrics Soc. 59, 2217–2225 (2011).
Chen, X. et al. Racial/ethnic differences in sleep disturbances: The multi-ethnic study of atherosclerosis (MESA). Sleep 38, 877–888 (2015).
Ghassemi, M. M. et al. You snooze, you win: The physionet/computing in cardiology challenge 2018. In 2018 Computing in Cardiology Conference (CinC) vol. 45 1–4 (IEEE, 2018).
Olesen, A. N. et al. Towards a flexible deep learning method for automatic detection of clinically relevant multi-modal events in the polysomnogram. In 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) 556–561 (2019). https://doi.org/10.1109/EMBC.2019.8856570.
Olesen, A. N., Jennum, P., Mignot, E. & Sorensen, H. B. Deep transfer learning for improving single-EEG arousal detection. In 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) 99–103 (IEEE, 2020).
Zahid, A. N., Jennum, P., Mignot, E. & Sorensen, H. B. MSED: A multi-modal sleep event detection model for clinical sleep analysis. IEEE Trans. Biomed. Eng. 70, 2508–2518 (2023).
Zhang, G.-Q. et al. The national sleep research resource: Towards a sleep data commons. J. Am. Med. Inform. Assoc. 25, 1351–1358 (2018).
Sateia, M. J. International classification of sleep disorders. Chest 146, 1387–1394 (2014).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. (2014).
Smith, L. N. Cyclical learning rates for training neural networks. In 2017 IEEE winter conference on applications of computer vision (WACV) 464–472 (2017). https://doi.org/10.1109/WACV.2017.58.
Cohen, J. Statistical Power Analysis for the Behavioral Sciences (Academic press, 2013).
Brink-Kjaer, A. et al. Automatic detection of cortical arousals in sleep and their contribution to daytime sleepiness. Clin. Neurophysiol. 131, 1187–1203 (2020).
Magalang, U. J. et al. Agreement in the scoring of respiratory events and sleep among international sleep centers. Sleep 36, 591–596 (2013).
Pitkänen, H. et al. Multi-centre arousal scoring agreement in the sleep revolution. J. Sleep Res. https://doi.org/10.1111/jsr.14127 (2023).
Rosenberg, R. S. & Van Hout, S. The american academy of sleep medicine inter-scorer reliability program: Respiratory events. J. Clin. Sleep Med. 10, 447–454 (2014).
Fiorillo, L. et al. U-sleep: Resilient to AASM guidelines. arXiv:2209.11173 (2022).
Acknowledgements
This research was partly funded by the European Regional Development Fund with the project 100346021 Tele-Schlaf-Medizin and by the the Federal Ministry of Education and Research under the funding code 01ZZ2324F.  The Sleep Heart Health Study (SHHS) was supported by National Heart, Lung, and Blood Institute cooperative agreements U01HL53916 (University of California, Davis), U01HL53931 (New York University), U01HL53934 (University of Minnesota), U01HL53937 and U01HL64360 (Johns Hopkins University), U01HL53938 (University of Arizona), U01HL53940 (University of Washington), U01HL53941 (Boston University), and U01HL63463 (Case Western Reserve University). The National Heart, Lung, and Blood Institute provided funding for the ancillary MrOS Sleep Study, “Outcomes of Sleep Disorders in Older Men,” under the following grant numbers: R01 HL071194, R01 HL070848, R01 HL070847, R01 HL070842, R01 HL070841, R01 HL070837, R01 HL070838, and R01 HL070839.The Multi-Ethnic Study of Atherosclerosis (MESA) Sleep Ancillary study was funded by NIH-NHLBI Association of Sleep Disorders with Cardiovascular Health Across Ethnic Groups (RO1 HL098433). MESA is supported by NHLBI funded contracts HHSN268201500003I, N01-HC-95159, N01-HC-95160, N01-HC-95161, N01-HC-95162, N01-HC-95163, N01-HC-95164, N01-HC-95165, N01-HC-95166, N01-HC-95167, N01-HC-95168 and N01-HC-95169 from the National Heart, Lung, and Blood Institute, and by cooperative agreements UL1-TR-000040, UL1-TR-001079, and UL1-TR-001420 funded by NCATS. The National Sleep Research Resource was supported by the National Heart, Lung, and Blood Institute (R24 HL114473, 75N92019R002).
The Sleep Heart Health Study (SHHS) was supported by National Heart, Lung, and Blood Institute cooperative agreements U01HL53916 (University of California, Davis), U01HL53931 (New York University), U01HL53934 (University of Minnesota), U01HL53937 and U01HL64360 (Johns Hopkins University), U01HL53938 (University of Arizona), U01HL53940 (University of Washington), U01HL53941 (Boston University), and U01HL63463 (Case Western Reserve University). The National Heart, Lung, and Blood Institute provided funding for the ancillary MrOS Sleep Study, “Outcomes of Sleep Disorders in Older Men,” under the following grant numbers: R01 HL071194, R01 HL070848, R01 HL070847, R01 HL070842, R01 HL070841, R01 HL070837, R01 HL070838, and R01 HL070839.The Multi-Ethnic Study of Atherosclerosis (MESA) Sleep Ancillary study was funded by NIH-NHLBI Association of Sleep Disorders with Cardiovascular Health Across Ethnic Groups (RO1 HL098433). MESA is supported by NHLBI funded contracts HHSN268201500003I, N01-HC-95159, N01-HC-95160, N01-HC-95161, N01-HC-95162, N01-HC-95163, N01-HC-95164, N01-HC-95165, N01-HC-95166, N01-HC-95167, N01-HC-95168 and N01-HC-95169 from the National Heart, Lung, and Blood Institute, and by cooperative agreements UL1-TR-000040, UL1-TR-001079, and UL1-TR-001420 funded by NCATS. The National Sleep Research Resource was supported by the National Heart, Lung, and Blood Institute (R24 HL114473, 75N92019R002).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
F.E. and M.G. designed the experiments; T.S. and M.B. supervised the data collection and provided medical feedback; F.E. developed and optimized the algorithm, implemented the pipline and conducted the experiments; F.E., T.S., M.G., M.Sc. and M.B. analyzed the results; M.G. M.Sc, M.B., H.M. and M.Se provided supervision; H.M., M.Se and M.B. provided resources; F.E. drafted the manuscript with feedback from M.G., T.S., M.B, M.Sc, M.Se. And H. M.; All authors reviewed and approved the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ehrlich, F., Sehr, T., Brandt, M. et al. State-of-the-art sleep arousal detection evaluated on a comprehensive clinical dataset. Sci Rep 14, 16239 (2024). https://doi.org/10.1038/s41598-024-67022-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-67022-9
