
Abstract
The utilization of high-risk test cases constitutes an effective approach to enhance the safety testing of autonomous vehicles (AVs) and enhance their efficiency. This research paper presents a derivation of 2052 high-hazard pre-crash scenarios for testing autonomous driving, which were based on 23 high-hazard cut-in accident scenarios from the National Automobile Accident In-Depth Investigation System (NAIS) through combining importance sampling and combined testing methods. Compared to the direct combination of the original distribution after sampling, the proposed method has a 2.92 times higher crash rate of 69.32% for the test case set in this paper. It also has a 5.8 times higher rate of triggering Automatic Emergency Braking (AEB), improving hazardous scenario coverage. Using the proposed method, the generated parameters of the cut-in accident scenario test set were compared with those of the cut-in test scenarios included in existing Chinese autonomous driving test protocols and standards. The velocity of the ego-vehicle obtained using the proposed method matched those in the existing protocols, whereas the velocity, time gap, and time to collision of the target vehicle were significantly lower than those existing protocols indicating scenarios obtained from accident data can enrich the selection of testing scenarios for autonomous driving.
Similar content being viewed by others

Introduction
The emergence of AV technology has the potential to greatly improve road traffic conditions and alleviate driver fatigue. However, in certain situations such as open roads or specific scenarios, the driving environment can be more complex and pose challenges for autonomous driving systems. To ensure the reliability and safety of these systems, thorough testing of the entire system is crucial. Scenario-based virtual simulation testing can improve testing efficiency and reduce costs through parallelism and acceleration, so the method of virtual simulation testing that includes various typical and extreme scenarios is an effective way to test the safety of autonomous driving systems1.
In a variety of complex traffic scenarios faced by self-driving vehicles, cut-in scenarios are particularly prone to traffic accidents. Cut-in scenarios refer to those instances in which vehicles in the surrounding lanes suddenly change lanes to the front of the target vehicle while the target vehicle is in motion, thereby affecting the driving of the target vehicle2. A clustering method based on hierarchical clustering optimization was used to obtain four typical lane changing entry scenarios, which are significantly related to the longitudinal speed, relative longitudinal speed, longitudinal distance, and entry duration of the main vehicle in the dangerous entry scenario3.Reports from the National Highway Traffic Safety Administration analyzed 594,200 accidents in the 2004 General Estimates System (GES) crash database and categorized precrash scenarios into single-vehicle accidents, two-vehicle accidents, and multi-vehicle accidents. Lane change accidents ranked 11th, 4th, and 6th among the most common precrash scenarios for these three categories, respectively. Furthermore, when considering all light vehicle pre-crash scenarios, lane change accidents were the 6th most common scenario type4. In the United States, it is estimated that approximately 24,000–61,000 traffic accidents are caused by inappropriate lane changes each year5. Hu et al.6 used a clustering method to obtain 21 typical pre-crash scenarios, including 2 typical V2V cut-in pre-crash scenarios, after regionally dividing the accident data in the initiative for the global harmonisation of accident data (IGLAD). Consequently, it is of paramount importance to expand the research conducted on self-driving vehicles in cut-in scenarios. This is because it will facilitate the improvement of the safety of the self-driving system and the reduction of the accident rate in lane-changing cut-in scenarios.
When testing the safety of an automated driving system against a cut-in scenario, the scenario data are mainly derived from real data, simulated data and expert experience, where real data sources include natural driving data as well as accident data1. Due to the high safety level of the vehicles when collecting natural driving data, there is a problem of extracting less dangerous segments from the data that cannot meet the test requirements. The accident data, conversely, is widely used to simulate hazard scenarios and test the stress capability of automated driving systems, as mentioned by Xu et al.7, Chen et al.8, and Gambi et al.9. However, as far as most of the current studies conducted by scholars using accident data are concerned, the obtained scenarios are mainly used to supplement the types of AV test scenarios, and the hierarchy is divided into functional or logical scenarios, ignoring the parameter settings of specific scenarios in self-driving test scenarios, as discussed by Tan et al.10, Sui et al.11, Zhang et al.12, and Zhou et al.13. Therefore, the feature parameters extracted from the accident data in this paper provide stronger data support for the generalisation of hazard scenarios and provide a method for parameter selection for standard regulatory test scenarios.
Current research on scenario generation focuses on two types of approaches: mechanism modelling and data-driven approaches. The mechanism modelling approach focuses on creating scenarios based on theory, while the data-driven approach focuses on achieving scenario reproduction and key scenario derivation based on data14,15. Specific scenarios generation algorithms, combined with the current state of the art, can be divided into 6 main categories. The first category is clustering algorithms, i.e. clustering analysis of a large amount of natural driving data or traffic accident data to extract representative typical scene types as standard scenarios for automated driving tests. Liao et al.16 based on the National Vehicle Accident In-depth Investigation System (NAIS) database, used MATLAB software to perform clustering analysis and used hierarchical clustering to obtain four classes of dangerous accident scenarios at ding junctions. However, when the data has a high dimensionality, hierarchical clustering may run into the problem of dimensionality catastrophe, leading to a sharp increase in computational complexity, which may affect the accuracy and efficiency of the clustering results. The second category is devoted to the development of reinforcement generation algorithms, which encompass two principal categories: Monte Carlo Tree Search (MCTS) and deep learning methods. MCTS is based on the parameter space of the scenarios and employs a search strategy to identify the most probable test scenarios under a specific search incentive strategy. Deep learning is based on a large amount of natural driving or accident data. After deep learning, complex feature representations can be automatically learned from the data to generalise to different scenarios. Owais et al.17 and Moussa et al.18 provide a complex technique based on a deep learning paradigm. This technique presents a deep residual neural network (DRNN) structure that employs residual shortcuts. The connections enable the DRNNs to sidestep a few levels of the deep network architecture, evading the regular training with high accuracy issues. The third category is the combination generation algorithm, which is mainly based on the theory of combinatorial testing, after discretising the influencing factors of the scenarios, the corresponding test scenarios are generated by selecting specific parameter values using combinatorial testing tools such as PICT, and the method can effectively reduce the number of combinations of test scenarios. Gao et al.19 proposed an improved combinatorial testing algorithm that increases the complexity of scenario generation while taking into account testing efficiency.The fourth category is the deductive reasoning approach, represented by ontology, which is a philosophical theory that explores the origin or substrate of the world, and has been applied in various application areas, such as ontology for decision making, traffic description and autonomous driving, etc. Chen et al.20 proposed an ontology-based test case generation method for a convergence point scenario on a highway, where three ontologies (highway, weather, and vehicle) are established to conceptualise and describe the test cases.The fifth category is random sampling algorithms, mainly including Monte Carlo and Rapidly-exploring Random Tree (RRT) algorithms, generate specific use cases based on the probability distribution of scenario parameters. Yang et al.21 and Lee22 extracted data segments from real vehicle tests of forward collision warning and adaptive cruise control, and generated test scenarios of the automatic emergency braking system through Monte Carlo simulation. The sixth category is mainly a combination or optimisation of 2 or more of the above 5 methods, e.g. Shu et al.23 combined method 1 and method 4 and proposed a weighted Euclidean distance based K-medoids clustering method to cluster 2234 sets of key test cases obtained by the variable intensity combination strategy, and obtained 9 sets of typical key test cases. In summary, existing mechanism modelling approaches address the issue of reasonableness and coverage of generated test scenarios, but will inevitably generate a large number of meaningless homogeneous redundant scenarios. Data-driven approaches focus on generating scenarios with high complexity and realism, but also suffer from problems such as difficulty in building generative models. Therefore, this paper mainly uses the sixth category of methods that combines combinatorial testing in mechanism modelling with importance sampling in data-driven methods, which solves the problem of data redundancy caused by mechanism modelling class methods, and also retains the advantage of the high percentage of high-hazard cut-in pre-collision scenarios generated by generalisation of data-driven class methods.
This paper presents a method to generate test scenarios for autonomous driving testing based on a small sample of high-risk collision data. The contributions of the paper are as follows:
-
(a)
The paper addresses the issue of infrequent but severe collision incidents caused by cutting-in. By combining combinatorial testing and data-driven importance sampling, the proposed method effectively reduces data redundancy while ensuring a higher proportion of generated high-risk cutting-in collision scenarios. This improves the efficiency of generating dangerous pre-crash scenarios under small data samples.
-
(b)
The paper compares the parameter space of the cutting-in pre-crash scenario generated with the parameters defined in current autonomous driving functional testing standards. Findings show that certain parameter settings in the current standards are overestimated. This result demonstrates that the proposed method can be used to select optimal parameter values for testing scenarios in standard regulations. It also enriches the selection of optimal parameters for specific cutting-in testing scenarios for AVs from an accident data perspective.
-
(c)
The paper proposes a process for generating test scenarios for autonomous driving systems based on accident data. This process can create a large number of testing scenarios and accelerate the iteration and upgrading of autonomous driving systems.
Materials and methods
Data sources and analysis
The data for this study were obtained from the National Automobile Accident In-Depth Investigation System (NAIS), which includes both collection and analysis data. The collection data is gathered by the traffic accident investigator through on-site surveys and related traffic police departments, including photographs of the accident scene, road traces, information of the participants, statements of the parties involved, surveillance video, EDR data, and tachograph video.
Following the screening process, a total of 23 cut-in accidents were identified in which the ego-vehicle maintained its straight trajectory on a linear road segment while the target vehicle entered this lane from the right-hand side. The analysis of three typical intelligent vehicle cut-in accidents caused by the assisted driving system revealed that these accidents were attributed to the failure to accurately recognize the action process of slow cut-ins from vehicles on the right side by the intelligent vehicle assisted driving system. This indicates that there are still limitations in recognizing this specific type of cut-in scenario by current intelligent vehicle driving systems.
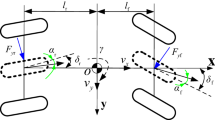
Based on the parameter settings of the cut-in scenario in the current protocol for the AV function test24 and the parameters selected by Zhao et al.25, in their acceleration test study, the lateral cut-in velocity of the target vehicle affects the ego-vehicle’s recognition of the driving intention of the target vehicle26; therefore, the target vehicle’s lane change time (the time from the start to the end of the vehicle’s lane change trajectory) was considered. We selected four parameters to analyze 23 cut-in accidents: the ego-vehicle’s velocity \(V_{s}\), the longitudinal relative distance \(S\) between the ego-vehicle and target vehicle at the initial moment of cut-in, the target vehicle’s lane change time \(t\), and the relative velocity \(\Delta V{ = }V_{s} - V_{t}\) (where \(V_{t}\) denotes the target vehicle’s velocity) between the ego-vehicle and target vehicle. The cut-in scenario and its key parameters are shown in Fig. 1. By using the Shapiro–Wilk test to test the hypothesis of normal distribution for each parameter, we obtained p-values of 0.313, 0.390, and 0.765 for the ego-vehicle velocity, relative distance, and relative velocity, respectively. These values indicate that each key parameter conforms to the hypothesis of the normal distribution with a confidence level of 95%. The mean and standard deviation of each parameter are shown in Fig. 2. Lin et al.27 extracted 560 complete lane-changing trajectories using the open-source HighD dataset and tested that the lane-changing time conforms to the hypothesis of the normal distribution.

Schematic and key parameters of the considered cut-in scenario.

Key parameters and probability distribution of cut-in accident scenarios in the NAIS database.
Research methods
Although the cut-in accident data from the NAIS database exhibits a heightened level of hazard and extreme conditions in comparison to naturalistic driving data, the limited sample size hampers its applicability for simulating autonomous driving systems. In this paper, we utilize a Monte Carlo importance sampling method in conjunction with a cross-entropy (CE) algorithm to adjust the original distribution of cut-in accidents. We then use the Pairwise Independent Combinatorial Testing (PICT) tool to combine the key parameters of the sampled cut-in accident scenarios after adjustment and generalize them to obtain a large amount of data for cut-in accident scenarios.
PICT methods
The idea underlying PICT28 is that for any positive small integer \(t\) of a parameter (usually 2 or 3), all combinations of its possible values are covered by at least one test case. This method is also called \(t\) combinatorial testing, where t indicates the number of parameters considered; For example, the two-parameter combination test, which requires testing all possible combinations of values for two parameters, can significantly reduce both testing time and costs, while also ensuring high test quality.
Monte Carlo importance sampling
The main Monte Carlo variance reduction techniques are importance sampling, conditional Monte Carlo sampling, and stratified sampling. Of these techniques, the importance sampling method has the highest testing efficiency for low-probability events. Importance sampling involves using the concept of variance reduction to change the sample distribution while ensuring its unbiased nature, sampling rare events to improve the probability of rare event collection, and accelerating the testing process. The proposed sampling method, which involved combining importance sampling with the CE algorithm, is illustrated in Fig. 3.

Flowchart of the proposed sampling method.
Importance sampling must be combined with a safety boundary to classify pre-crash scenarios by hazard level and thus offset the original accident distribution toward more hazardous scenarios and increase the probability of a hazardous scenario being extracted. Before the offset iteration is used to obtain the optimal offset value, the safety boundary function must be determined to define the indicator function to judge whether a scenario is dangerous and establish a theoretical optimal distribution model of key parameters.
-
1.
Determination of the safety boundary function
The naturalistic driving data and accident data collected in real driving scenarios often have concentrated or sparse data parameter intervals. Modeling the safety boundary function with the original data can lead to drawbacks such as insufficient sampling, missing sampling, or too high sampling frequency in high-frequency intervals, resulting in insufficient reliability of the obtained safety boundary curve. Therefore, in combination with the parameter selection in the existing test standards29, the parameter intervals of the original data distribution are extended to ensure maximum coverage of the parameter space of the cut-in scenario and to avoid missing test cases that are not covered due to insufficient original data collection. Finally, the extended intervals of each key parameter are determined as follows: the ego-vehicle velocity interval is [20,120] km/h, the relative velocity interval between two vehicles is [0,100] km/h, and the relative distance interval is [0,100] m.
To obtain test cases that are uniformly distributed in the parameter space and to ensure that the simulation test results have obvious distribution boundaries, we set the relative velocity \(\Delta V > 0\) and obtained 60 sampling values through uniform sampling of each parameter. Subsequently, we performed a 2-parameter combination test using the PICT tool, resulting in 2957 test cases after removing those that did not conform to actual conditions. By considering the distribution of the lane change time in German HighD open-source naturalistic driving data for the cut-in condition27, we selected 4.5, 5.5, 6.5, and 7.5 s as the lane change times in this study. We performed automated simulation tests using MATLAB/Simulink and PreScan to obtain simulation results for each cut-in test case. Figures 4 and 5 display the simulation platform structure and the cut-in scenario simulation process.

MATLAB/Sumlink-Prescan simulation platform.

Cut-in scenario simulation process.
In order to combine the actual driving situation of the vehicle and minimize the collision injury, this article considers a control strategy that combines the cruise control (CC), adaptive cruise control (ACC), and automatic emergency braking (AEB) functions of the host vehicle. Under this condition, a simulation test of dangerous scenarios in the cut-in condition is conducted.
In terms of specific control strategy design, three simple states are defined: cruise mode (CC mode), adaptive cruise mode (ACC mode) and emergency collision avoidance mode (AEB mode). CC mode is the default entry state of state machine, and the expected speed in CC mode is the initial speed of the vehicle. The expected speed in ACC mode is the target vehicle speed, which can be used when the vehicle speed is higher than the target vehicle. The main vehicle can automatically adjust the cruise speed of the vehicle according to the speed of the target vehicle in front to play the role of speed following. The desired speed in AEB mode is 0. The minimum collision time (TTC) and relative distance are used to characterize the criticality of the cut-in scenario. The switching logic and risk level settings of the three states are shown in Table 1.
The simulation results were categorized into four groups: the safety scenario (no triggering safety function and no collision), the triggering of the ACC function without collision, the triggering of the AEB function without collision, and collision. The ACC trigger rate, AEB trigger rate, and collision rate under different lane change times are illustrated in Fig. 6.

Comparison of the ego-vehicle status and collision rates under different lane change times.
As illustrated in Fig. 6, in each test scenario, the overall collision rate, AEB trigger rate, and ACC trigger rate decreased gradually with an increase in the lane change time (indicating a smoother lane change process). To obtain the most typical safety boundary curve, the test results with the highest accident rate in the lane change time were selected for analysis, as shown in Fig. 7.

Test results at 4.5 s lane change time.
The test cases obtained based on the assumption of uniform distribution sampling are displayed in Fig. 7a. However, after the simulation platform test, the test cases in which the collision occurs have obvious curvilinear characteristic boundaries in the \(\Delta V - S\) plane, which proves that the safety boundary conditions have an obvious correlation with the parameter settings of relative velocity and relative distance, as shown in Fig. 7b. The ego-vehicle velocity has no obvious boundary characteristics with relative velocity and relative distance, as shown in Fig. 7c and d. In Fig. 7d, the test cases are predominantly concentrated in the lower right corner due to the utilization of PICT for generating test cases that require consideration of relative velocity \(\Delta V > 0\). It can be observed that collision occurrences when determining the ego-vehicle velocity are distributed across various intervals of both relative distance and relative velocity without displaying any discernible distribution patterns. Therefore, this paper takes the curve in the \(\Delta V - S\) plane as the study object of the safety boundary curves and extracts two types of scenario boundary points where AEB triggered no collision and collision occurred. A cubic polynomial curve was used to fit boundary point data to obtain the upper and lower curves of the safety boundary, as expressed in Eq. (1). The fitted safety boundary curve is displayed in Fig. 8.

Fitting diagram of the safety boundary curve.
-
2.
Indicator function
Determining the hazard level of a pre-crash scenario requires the definition of an indicator function. Let the full sample space be denoted \(\Omega\), and let the sample space of rare events (dangerous scenarios) be denoted \(\varepsilon\); thus, the danger space defined by the safety boundary is \(\varepsilon \in \Omega\). An indicator function is then expressed as follows:
-
3.
Theoretical optimal distribution model
The probability distribution of a parameter is associated with an idealized pure accident model, wherein all samples are confined within the sampling space of accident scenarios. Consequently, the likelihood of a sample falling within the range of safety scenarios becomes negligible (approaching zero), ensuring that all sampling outcomes correspond to the desired accident scenario. This is achieved by defining the probability density function as follows:
where \(I_{\varepsilon } (x)\) is the indicator function, the value of 1 denotes an accident scenario and 0 represents a safety scenario. The judgment is based on the safety boundary curve. \(r\) is the accident rate of the ego-vehicle under the actual distribution model test, which is an unknown parameter; \(f(x)\) is the original probability density function of the selected parameters. Based on \(f{*}(x)\) for sampling, all obtained results correspond to accident scenarios, indicating that the indicator function \(I_{\varepsilon } (x)\) remains consistently equal to 1. Since \(r\) is unknown, this probability distribution model exists only at the theoretical level and cannot be solved for specific probability density function values. However, it can serve as a reference for transforming the initial probability density function and provide theoretical support for the CE algorithm in determining the optimal offset λ.
-
4.
CE algorithm for obtaining the optimal offset value
The CE algorithm is widely applied to the probability estimation of rare events for solving optimization problems of probabilistic models due to its advantage of being adaptive30,31. The basic idea is to minimize the Kullback–Leibler (KL) scatter32 between the importance sampling function and the theoretical optimal distribution function as the optimization objective, so that the two probability distribution models are as similar as possible, and then the optimal offset value \(\lambda\) is taken gradually through an iterative process to solve for the unknown new probability distribution model. The K-L scatter is a quantitative measure of the similarity between two probability distribution models, and the K-L scatter of the new probability density function to be found and the pure accident probability density function is calculated in Eq. (4).
When \(g(x) = f*(x)\), the K-L scatter between the two functions is 0. The CE algorithm can reduce the scatter between the new probability density function and the theoretical optimal distribution function.
When the probability density function \(g(x)\) obtained using the offset and Eq. (3) are substituted into Eq. (4), \(f_{KL} \left[ {g(x),f*(x)} \right]\) takes its minimum value, and the iterative formula for \(\lambda\) can be expressed as follows:
where \(i\) is the number of iterations, \(N\) is the cumulative number of samples, and \(L(x)\) is the likelihood ratio function. The likelihood ratio function is expressed as follows:
The functional relationship for \(\lambda\) is as follows:
By taking the derivative of \(\psi (\lambda )\), the following equation is obtained:
During the iterative process, the number of samples \(N\) should be selected such that the relation \(\sum\limits_{{{\text{n}} = 1}}^{N} {I_{\varepsilon } } (x) > 0\) is always valid, which ensures that dangerous scenarios are always present in the sample and that \(L(x) > 0\) constants exist (according to Eq. 6). In this case, the following equation is obtained:
When \(\psi{\prime} (\lambda ) = 0\), \(\lambda\) is expressed as follows:
The following equation is obtained by evaluating the monotony of \(\psi (\lambda )\) at \(\psi{\prime} (\lambda ) = 0\) by using Eqs. (8 and 10):
Equation (11) indicates that the function \(\psi (\lambda )\) reaches its minimum value at \(\lambda\), and this minimum value is the optimal offset value \(\lambda\) with the smallest KL distance. As the mean of \(g(x)\) changes to \(\mu + \lambda\) after \(f(x)\) is transformed into \(g(x)\), the mean of \(g(x)\) always changes with \(\lambda\) in the offset iteration process. Therefore, the iteration equation of \(\lambda\) is as follows:
where \(i\) is the number of iterations. As shown in Fig. 7a, it is equivalent to offsetting both relative velocity and relative distance of the safety boundary curve. Therefore, the relative velocity is selected here for the CE iterative solution, and the specific iterations are shown in Fig. 9. The absolute error converged to within 0.01 km/h at the 59th iteration, and the optimal offset of the relative velocity \(\Delta V\) was − 5.234 km/h, which indicated that the distribution of the relative velocity shifted to a lower-value region because of the decrease in \(\lambda\).

Relative velocity offset iterations and offsets.
After the optimal offset is determined, a new distribution of the relative velocity can be obtained through importance sampling. The probability density function is obtained by substituting the offset data into the following equation:
Results
The sampling method used to extract 60 sample values for each of the three parameters of ego-vehicle velocity \(V_{s}\), relative velocity \(\Delta V\), and relative distance \(S\) was the same as in section “Monte Carlo importance sampling”. These samples were taken from both the original distribution and the distribution after parameter offset, resulting in a total of 2097 and 2957 test cases, respectively, as shown in Fig. 10. Upon comparing the two types of test cases, it was found that the test cases generated through importance sampling were primarily concentrated in the low-value interval of relative velocity, which was denser. Conversely, the test cases generated by directly using the original distribution were more scattered.

Distribution of the test cases generated using two methods.
The test cases generated by the two distributions shown in Fig. 10 were tested in a batch simulation using a simulation platform. The resulting distribution of crash occurrences for each test case is depicted in Fig. 11. Out of the 5054 test cases generated by the two distributions, 2609 resulted in accidents, accounting for 51.62%. Of these accidents, 2052 were crash scenarios generated from test cases using importance distribution sampling, which accounts for 78.65% of all crash cases. Thus, the combination test method based on importance sampling is capable of generating more hazardous scenarios than the combination generation method directly from the original distribution sampling.

Simulation results obtained for the two types of test cases.
The collision rates, AEB trigger rates, and ego-vehicle collision velocities obtained using the two adopted sampling methods were compared to further examine the effect of the adopted sampling method.
-
1.
Collision rate
The collision rate, which represents the percentage of test cases that involve collisions, is the most intuitive indicator of the hazard level in a set of test scenarios. Figure 12 illustrates variations in simulated collision rates and relative collision rate errors with increasing numbers of simulations. After importance sampling was applied, the generated test cases had considerably higher collision rates than the original ones. Additionally, fluctuations in relative collision rate errors were smaller after importance sampling than those observed in original parameter distributions.

Variations in the collision rate and relative collision rate error with the number of simulations.
Table 2 presents a comparison of collision rates and the number of simulation runs required for convergence when using two different case generation methods. The test cases obtained through importance sampling converged significantly faster than those generated directly from the original parameter distributions, resulting in an approximately 2.92 times increase in collision rate and a considerable rise in the percentage of dangerous scenarios. Additionally, importance sampling led to a collision rate convergence that was about 2.52 times faster under the same error limit compared to direct sampling, indicating its potential to enhance simulation testing efficiency by generating more hazardous scenarios within a certain number of tests.
-
2.
AEB trigger rate
The AEB system of an AV is utilized to actively engage the brakes in response to sudden target appearances or when the relative distance to a target vehicle falls below the safe driving threshold, thereby preventing collisions or mitigating collision damage. The triggering of the AEB system in test scenarios can partially reflect the level of danger associated with these scenarios. We analyzed the situations that triggered AEB activation in two sets of test scenarios (Fig. 13). The original parameter distributions resulted in an AEB trigger rate of 8.22%, whereas after applying importance sampling to the test cases, the AEB trigger rate increased significantly to 47.41%, which was approximately 5.8 times higher than that observed with the original parameter distribution. Consequently, importance sampling caused an increase in the percentage of test cases with a high hazard level in the sampled scenarios.

AEB trigger rates before and after importance sampling.
-
3.
3.Ego-vehicle collision velocity
Different collision velocities result in varying energy losses for vehicles, leading to different levels of danger. Therefore, the collision velocities of the ego-vehicle before and after importance sampling were analyzed (Fig. 14). As anticipated, the number of collision scenarios in the original parameter distributions was significantly lower compared to those obtained after importance sampling. The mean collision velocity of the ego-vehicle for the original parameter distribution and that obtained after importance sampling were 42.85 km/h and 48.12 km/h respectively; thus, indicating a higher ego-vehicle collision velocity following importance sampling.

Comparison of the collision velocities of the ego-vehicle before and after importance sampling.
Furthermore, the generation process based on accident data to testing scenarios can be obtained, as shown in Fig. 15. By applying this process, automatic driving testing scenarios can be quickly generated and applied to standard regulatory scenario parameter settings (as discussed in section “Discussion”).

The process and application of accident data to testing scenarios.
Discussion
Combinatorial testing and importance sampling are widely used methods for generating incident scenario generalizations, according to Deng et al.15. The combinatorial testing method has been applied in the field of computer software testing and quality control to prevent an explosion of the number of combinations caused by the full combination of parameters. Researchers have been inspired by this approach and have applied it to the study of automatic scenario generation, as stated by Duan et al.33. Shu et al.34, used the PICT tool to fully combine the possible relative positions and motion directions of an AV and the vehicles surrounding it in traffic. They generated 3019 test cases through MATLAB & Simulink and CarSim simulations and then screened 185 critical test cases in accordance with thresholds for critical scenario evaluation indices; thus, the percentage of critical cases was only 6.13%. Similarly, critical pre-crash scenarios accounted for only 26.56% of the test scenario set generated through combinatorial testing in the present study (Fig. 11). This low proportion is not conducive to large-scale simulation testing.
Zhao35, and Feng et al.36, used importance sampling to achieve accelerated testing for cut-in scenarios. In accelerated testing, a higher number of hazardous scenarios can be tested, enabling improvement of system safety. Xia et al.37, used the kernel density estimation method to calculate the probability distributions of accident parameters based on data collected under natural road conditions. They used the Metropolis–Hastings algorithm to sample parameters in accordance with their probability distributions to filter out key scenarios by safety indicators. The aforementioned authors found that their sampling method accelerated testing while ensuring that the relative errors were small. The parameter distributions obtained in the present study were derived by fitting a normal distribution curve to the collected accident data, and the parameter distributions obtained by offsetting the relative velocity (Fig. 9) caused a considerable increase in the percentage of hazardous scenes compared with the percentage achieved before offsetting the relative velocity.
However, when used individually, importance sampling and combinatorial testing exhibit limitations and demonstrate low efficiency in scenario generation. Therefore, in this study, importance sampling was combined with combinatorial testing, with the parameter distribution being optimized and offset before combinatorial testing was performed. A comparison between Figs. 10 and 11 reveals that the integration of these two methods effectively reduces the generation of noncritical scenarios with invalid parameter ranges while enhancing the efficiency of hazard scenario generation.
For the simulated accident data (Fig. 11), the parameters of the pre-crash scenarios in the test cases generated directly by using the original parameter distribution and generated using importance sampling were mainly distributed in two planes at a certain angle to the \(\Delta V - V_{s}\) plane, with the intervals of the relative velocity and relative distance being [0, 16] km/h and [1, 8] m, respectively. The ego-vehicle’s velocities in the pre-crash scenarios were distributed in the interval [35, 60] km/h (Fig. 16).

Distribution of pre-crash scenarios for the two types of test cases.
The ego-vehicle’s velocity \(V_{s}\), target vehicle’s velocity \(V_{t}\), time gap \(\tau\), and time to collision \(t_{TTC}\) for the dangerous cut-in scenarios extracted using the proposed method were compared with those for the dangerous cut-in scenarios in existing protocols and standards (Table 3). The aforementioned parameters were obtained using the following equations: \(V_{t} = V_{s} - \Delta V\), \(\tau = S/V_{s}\), and \(t_{TTC} = S/\Delta V\).
As shown in Table 3, the velocity range of the ego-vehicle obtained in this study falls within the values specified by regulations and standards. However, compared to these standards, our study found a wider target vehicle velocity range by 14 km/h. Conversely, due to our use of accident data with high danger levels and low-value intervals, we observed smaller time gap and time to collision intervals than those specified by standards. These two parameters are primarily influenced by both ego-vehicle and target vehicle velocities; thus, we compared these velocities between each standard and our present study (Fig. 17).

Comparison of target vehicle velocity-taking values under ego-vehicle velocity determination.
When the ego-vehicle's velocity was set at 30 and 65 km/h, the target vehicle's velocities in the simulated accident data obtained in this study were found to be lower than those specified by relevant standards or regulations. The differences between the simulated data and the standards ranged from a minimum of 14.3 km/h to a maximum of 34.3 km/h for ego-vehicle velocities of 40, 60, or 8 km/h. These findings suggest that the current parameter settings for the cut-in scenario in existing standards38,39 may result in some sampled scenarios being less hazardous than actual accident scenarios, thereby impeding the complete testing of automatic-driving systems. Therefore, optimizing certain velocity values for the ego-vehicle within these standards could enhance system comprehensiveness and safety during testing. For instance, reducing the velocity difference between the ego-vehicle and the target vehicle at speeds of 60 or 80 km/h would be appropriate.
Conclusion
This paper proposes a generalization method involving combinatorial testing and importance sampling. This method can be used to generalize accident data to generate numerous high-risk simulation test scenarios that can be used for autonomous-driving tests. The collision rate in the test scenario set generated by directly sampling the original parameter distributions of the accident data was 26.56%, whereas the collision rate in the test scenario set generated using the proposed method was 69.32%. The AEB trigger rate and ego-vehicle crash velocity were 5.8 times greater and 18.96% higher when using the proposed method than when generating test cases directly using the accident data's original parameter distributions. The crash data obtained in this study indicate that compared with the method involving direct sampling of the original parameter distributions of accident data, the proposed method can effectively increase the percentage of hazardous scenarios in the test scenario set, thereby improving the efficiency of testing.
A comparison of the parameter distributions obtained using the proposed method with the optimal parameter settings of cut-in scenarios in existing standards indicates that the parameter space formed by pre-crash scenarios obtained through the generalization of accident data is smaller than that corresponding to the settings in the standards but is more suitable for thoroughly testing the functions of AVs and ensuring the safety of their functions. Compared with the direct sampling approach, the proposed method can effectively generate a cut-in scenario test set containing a higher proportion of hazardous scenarios. The proposed method can also serve as a standard method for generating numerous generalized test scenarios related to different types of accidents for testing an AVs functions. Moreover, this method can be used to select optimal test parameters when formulating standard test scenarios. In the future, the parameter boundaries of different types of scenarios will be extracted for optimal standardized test parameter selection, which will provide data support for the rapid construction and application of autonomous driving test scenarios.
Data availability
The datasets used and analyzed during the current study available from the corresponding author on reasonable request.
References
Zhu, B. et al. Review of scenario-based virtual validation methods for automated vehicles. China J. Highway Transport. 32(6), 1–19. https://doi.org/10.19721/j.cnki.1001-7372.2019.06.001 (2019).
Song, Y. et al. Research on test and evaluation of ADAS system under lane change cut-in scenario. J. Autom. Eng. 14(03), 363–375 (2024).
Sun, D. X. Study on the construction of a lane change cut scene library based on natural driving data. Jilin Univ. https://doi.org/10.27162/d.cnki.gjlin.2021.006689 (2022).
Najm, W. G., Smith, J. D. & Yanagisawa, M. Pre-crash scenario typology for crash avoidance research (tech. rep. DOT-HS-810 767). In Washington, DC: National Highway Transportation Safety Administration Research (2007).
Hou, Y., Edara, P. & Sun, C. Situation assessment and decision making for lane change assistance using ensemble learning methods. Expert Syst. Appl. 42(8), 3875–3882. https://doi.org/10.1016/j.eswa.2015.01.029 (2015).
Hu, W. H. et al. Mining and comparative analysis of typical pre-crash scenarios from IGLAD. Accid. Anal. Prev. https://doi.org/10.1016/j.aap.2020.105699 (2020).
Xu, X. Y. et al. Review of key technologies for autonomous vehicle test scenario construction. Autom. Eng. 43, 4. https://doi.org/10.19562/j.chinasae.qcgc.2021.04.019 (2021).
Chen, J. Q., Shu, X. X., Lan, F. C. & Wang, J. F. Construction of autonomous vehicles test scenarios with typical dangerous accident characteristics. J. South China Univ. Techol. Nat. Sci. Ed. 49, 5. https://doi.org/10.12141/j.issn.1000-565X.200371 (2021).
Gambi, A., Huynh, T. & Fraser, G. Generating effective test cases for self-driving cars from police reports. In IEEE ACM. Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering 257–267 (ACM, 2019). https://doi.org/10.1145/3338906.3338942.
Tan, Z. P. et al. Research of fatal car-to-pedestrian precrash scenarios for the testing of the active safety system in China. Accid. Anal. Prev. https://doi.org/10.1016/j.aap.2020.105857 (2021).
Sui, B., Lubbe, N. & Bärgman, J. A clustering approach to developing car-to-two-wheeler test scenarios for the assessment of Automated Emergency Braking in China using in-depth Chinese crash data. Accid. Anal. Prev. https://doi.org/10.1016/j.aap.2019.07.018 (2019).
Zhang, S. B. et al. Test scenarios of automatic emergency braking system at intersections based on NAIS. J. Transport Inf. Saf. 39(01), 87–96. https://doi.org/10.3963/j.jssn.1674-4861.2021.01.010 (2021).
Zhou, H. et al. Research on safety of the intended functionality of autom-obile AEB perception system in typical dangerous scenarios of twowheelers. Accid. Anal. Prev. https://doi.org/10.1016/j.aap.2022.106709 (2022).
Riedmaier, S., Ponn, T., Ludwig, D., Schick, B. & Diermeyer, F. Survey on scenario-based safety assessment of automated vehicles. IEEE Access. 8, 87456–87477. https://doi.org/10.1109/ACCESS.2020.2993730 (2020).
Deng, W. W., Li, J. K., Ren, B. T., Wang, W. Q. & Ding, J. A survey on automatic generation methods on simulation scenarios for autonomous driving. China J. Highway Transport. 2021, 1–21 (2021).
Liao, J. Q., Zhang, D. W., Gao, L. & Liao, W. J. A study of dangerous scenarios at dingzhi intersections based on NAIS accident data clustering. J. Automot. Saf. Energy Conserv. 12(03), 336–345 (2021).
Owais, M. et al. Prioritizing rear-end crash explanatory factors for injury severity level using deep learning and global sensitivity analysis. Expert Syst. Appl. 245, 123114. https://doi.org/10.1016/j.eswa.2023.123114 (2024).
Moussa, G. S., Owais, M. & Dabbour, E. Variance-based global sensitivity analysis for rear-end crash investigation using deep learning. Accid. Anal. Prevent. 165, 106514. https://doi.org/10.1016/j.aap (2022).
Gao, F. et al. A test scenario automatic generation strategy for intelligent driving systems. Math. Probl. Eng. 2019, 3737486 (2019).
Chen, W. & Kloul, L. An ontology-based approach to generate the advanced driver assistance use cases of highway traffic. In HAL. 10th International Joint Conference on Knowledge Discovery, Berlin: Knowledge Engineering and Knowledge Management (2018).
Yang, H. H. & Peng, H. Development and evaluation of collision arning/collision avoidance algorithms using an errable driver model. Veh. Syst. Dyn. 48(1), 525–535 (2010).
Lee, K. Longitudinal Driver Model and Collision Warning and Avoidance Algorithms Based on Human Driving Databases (University of Michigan, 2004).
Shu, H. et al. Construction of key scenarios for self-driving cars travelling straight at signalless intersections. China J. Highway 35(07), 328–338 (2022).
CAICV. Intelligent network connection car automatic driving function test procedures (Trial). https:// www.caicv.org.cn/policy/ (2019).
Zhao, D., Peng, H., Lam, H. et al. Accelerated evaluation of automated vehicles in lane change scenarios. In IEEE. Dynamic Systems and Control Conference. American Society of Mechanical Engineers, New York: ASME 57243: V001T17A002 (2015).
Remmen, F., Cara, I., Gelder, E. & Willemsen, D. Cut-in scenario prediction for automated vehicles. In IEEE International Conference on Vehicular Electronics and Safety (ICVES), Madrid, Spain 1–7 (2018). https://doi.org/10.1109/ICVES.2018.8519594.
Lin, L. B., Li, Y. & Zou, Y. J. Factors affecting lane-changing duration based on time-dependent proportional-hazards regression. J. Tongji Univ. (Nat. Sci.) 49(7), 933–940 (2021).
Richard-Kuhn, D., Kacker, R. N. & Lei, Y. Introduction to Combinatorial Testing (Taylor and Francis Group, 2013).
GB/T 41798-2022. Intelligent and connected vehicles-Track testing methods and requirements for automated driving functions. http://c.gb688.cn/bzgk/gb/showGb?type=online&hcno=C3FD7FF23C6D06A9F7459DCD73E68905 (2022).
Kanjilal, O., Papaioannou, I. & Straub, D. Cross entropy-based importance sampling for first-passage probability estimation of randomly excited linear structures with parameter uncertainty. Struct. Saf. 91, 102090. https://doi.org/10.1016/j.strusafe.2021.102090 (2021).
Chaslot, G.M.J.-B., Winands, M. H. M., Szita, I. & Van-Den-Herik, H. J. Cross-entropy for Monte-Carlo tree search. Icga J. 31(3), 145–156. https://doi.org/10.3233/ICG-2008-31303 (2008).
Liese, F. & Vajda, I. On divergences and informations in statistics and information theory. IEEE Trans. Inf. Theory 52(10), 4394–4412. https://doi.org/10.1109/TIT.2006.881731 (2006).
Duan, J. L., Gao, F. & He, Y. Test scenario generation and optimization technology for intelligent driving systems. IEEE Intell. Transport. Syst. Mag. 14(1), 115–127. https://doi.org/10.1109/MITS.2019.2926269 (2022).
Shu, H., Lv, H. R., Liu, K., Yuan, K. & Tang, X. L. Test scenarios construction based on combinatorial testing strategy for automated vehicles. IEEE Access 2021, 9. https://doi.org/10.1109/ACCESS.2021.3103912 (2021).
Zhao, D. et al. Accelerated evaluation of automated vehicles safety in lane change scenarios based on importance sampling techniques. IEEE Trans. Intell. Transport. Syst. 18(3), 595–607. https://doi.org/10.1109/TITS.2016.2582208 (2016).
Feng, S., Yan, X., Sun, H., Feng, Y. H. & Liu, H. X. Intelligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment. Nat. Commun. 12(1), 1–14 (2021).
Xia, Q., Chai, Y., Lv, H. R. & Shu, H. Research on accelerated testing of cut-in condition of electric automated vehicles based on Monte Carlo simulation. Sustainability 13, 22. https://doi.org/10.3390/su132212776 (2021).
I-VISTA SM-ADAS-ICAR-A0-2019, Intelligent Cruising Assist Rating Protocol. China Automotive Technology & Research Center Co. Ltd. https://www.i-vista.org/d/file/p/2022-09-08/33c9fd34aa5d491249b46589cb44aca4.pdf (2020).
CCRT, CCRT (China Car Consumer Research and Testing Programme) Management Regulation. China Automotive Technology & Research Center Co. Ltd. https://www.cpqs.org.cn/Uploads/file/20210630/1625013372_92755.pdf (2021).
Funding
The research was supported by Research on the key technologies of in-depth investigation and accident reconstruction of intelligent vehicle (282023Y-10408/2023MK185) and the NAIS database.
Author information
Authors and Affiliations
Contributions
P.L.: Conceptualization, Methodology, Writing—review & editing, Modification. X. Z.: Writing—review & editing, Methodology, Software. Y.R.:Writing—review & editing, Methodology, Software. Z.T.: Writing—review & editing, Modification. W.H.: Supervision, Resources, Writing—review & editing. Y.Z.: Writing—review & editing, Data curation. C.X.: Writing—review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, P., Zhu, X., Ren, Y. et al. Generalization of cut-in pre-crash scenarios for autonomous vehicles based on accident data. Sci Rep 14, 17664 (2024). https://doi.org/10.1038/s41598-024-68263-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-68263-4
This article is cited by
-
Vehicle game lane-changing mechanism and strategy evolution based on trajectory data
Scientific Reports (2025)
