
Abstract
Antibody escape mutations pose a significant challenge to the effectiveness of vaccines and antibody-based therapies. The ability to predict these escape mutations with computer simulations would allow us to detect threats early and develop effective countermeasures, but a lack of large-scale experimental data has hampered the validation of these calculations. In this study, we evaluate the ability of the MD+FoldX molecular modeling method to predict escape mutations by leveraging a large deep mutational scanning dataset, focusing on the SARS-CoV-2 receptor binding domain. Our results show a positive correlation between predicted and experimental data, indicating that mutations with reduced predicted binding affinity correlate moderately with higher experimental escape fractions. We also demonstrate that higher precision can be achieved using affinity cutoffs tailored to distinct SARS-CoV-2 antibodies from four different classes rather than a one-size-fits-all approach. Further, we suggest that the quartile values of optimized cutoffs reported for each class in this study can serve as a valuable guide for future work on escape mutation predictions. We find that 70% of the systems surpass the 50% precision mark, and demonstrate success in identifying mutations present in significant variants of concern and variants of interest. Despite promising results for some systems, our study highlights the challenges in comparing predicted and experimental values. It also emphasizes the need for new binding affinity methods with improved accuracy that are fast enough to estimate hundreds to thousands of antibody-antigen binding affinities.
Similar content being viewed by others


Introduction
The global impact caused by the Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2), the virus responsible for COVID-19, serves as a stark reminder of the need for robust preparedness and research to effectively combat present and future infectious threats. One crucial area of focus is the study of neutralizing antibodies (nAbs) to combat viral diseases1,2,3,4. These nAbs render viruses noninfectious by binding to functional molecules, blocking viral entry, and ultimately preventing host cell invasion5. By May 2022, the pivotal role of nAbs took center stage as 11 monoclonal nAb treatments received emergency use authorization for COVID-19, marking a crucial advancement in managing the pandemic6. Additionally, the exploration of numerous nAbs in preclinical or clinical trials underscores their potential as both preventive and therapeutic options against SARS-CoV-27.
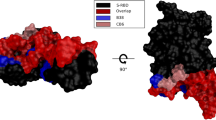
Despite the success of Ab-based therapies, the rapid evolution of viruses allows them to develop escape mutations to nAbs, effectively evading the immune system’s ability to recognize and neutralize the threat (Fig. 1a)8,9,10. Experimental work has been done to map mutations in the SARS-CoV-2 spike protein that show antibody escape, with a focus on the spike receptor binding domain (RBD). The RBD is of particular interest as it serves as the primary binding region for Abs, with RBD targeting Abs categorized into four classes based on their targeted structural epitopes: Class 1 antibodies target the ACE2 binding site specifically when the RBD is in the “up” conformation, Class 2 antibodies also target the ACE2 binding site but can bind in both the “up” or the “down” conformations, Class 3 antibodies bind to regions outside the ACE2 binding site and can attach in either conformation and Class 4 antibodies bind to a cryptic region accessible only when two RBDs are in the “up” conformation (Fig. 1b)1,11,12. Notably, Starr et al. conducted an experimental mapping of all single amino acid mutations within the RBD to determine the impact of each on biophysical properties like Ab binding13,14,15. Their large-scale studies identified mutations and sites associated with Ab-escape using a yeast-displayed deep mutational scanning (DMS) technique. The identification and understanding of Ab-escape mutations, particularly within the RBD, is essential for developing effective strategies against viral resistance and for preparing for future pandemics.

SARS-CoV-2 mutations could lead to Ab escape. (a) A wild-type viral antigen (Ag) can mutate into a variant that may either retain Ab-neutralization hence preventing infection, or lead to Ab-escape hence maintaining infection. (b) RBD-directed neutralizing Abs can be divided into four main classes based on the epitopes they target11. Abs tested in this study are listed according to their class. For each class, one representative Ab bound to the RBD is shown: Class 1, REGN10933; Class 2, LY-CoV555; Class 3, REGN10987; Class 4, S2X259. Protein images on the left were generated with Protein Imager software16.
Computational methods for predicting Ab-escape mutation can significantly reduce the time and financial cost compared to experiments, however, they come with notable challenges. First, validation is difficult due to the limited availability of large datasets. Second, the parameters associated with these methods may lack universal applicability. Third, while some methods provide fast results, their accuracy may be compromised, and more accurate methods may be computationally intensive and time-consuming. Current methods range from sequence-based17,18 to structure-based19,20,21,22, including hybrid models23. Structure-based approaches are particularly important since protein structure profoundly influences their biophysical properties. In these methods, force fields are employed to assess the change in the protein binding affinity due to the mutation, aiming to identify destabilizing mutations (i.e., mutations that disrupt binding) that could lead to Ab-escape24,25,26. These force fields can be based on molecular mechanics, semi-empirical, or statistical potentials27. Semi-empirical and statistical potential methods are fast and tend to rely heavily on the accuracy of the input 3D structure. Molecular mechanics-based potentials such as those used in molecular dynamics (MD) are computationally expensive, and tend to be less reliant on input structures. Computational work has been done to map mutations in the SARS-CoV-2 RBD that show antibody escape by using a structure-based approach and different force fields. For example, Keng-Chang et al. conducted a computational DMS using multiple semi-empirical/statistical potential-based methods to identify immune-escaping hotspots in the SARS-CoV-2 RBD in complex with five different Abs20. Huang et al. proposed a hybrid structure/sequence-based model to predict similar high-risk immune-escaping hotspots on the RBD averaging results from 145 non-specified Abs19. Barnes et al. used MD simulations in combination with FoldX to develop a watchlist for pandemic surveillance for the SARS-CoV-2 RBD in complex with Abs B38 and CB621. These studies offer valuable insights, however, there are some reasons to expand on this body of work. First, some of these studies predominantly concentrate on site-level immune-escaping hotspots19,20. Second, some do not employ conformational sampling of the experimental structures for their predictions19,20. Third, some are limited in their focus on a few specific systems21,22. Finally, some present average effects rather than antibody-specific data; this is important since Abs targeting structurally similar epitopes may elicit different responses to the same mutation19.
Among the array of possible computational approaches, the MD+FoldX method stands out as a promising avenue for predicting Ab-escape mutations, as evidenced by our previous comparison of eight methods across various protein-protein systems27. The MD+FoldX approach was developed by our lab in 2016 and has since been applied to various studies21,27,28,29,30. It is a 3-D structure-based approach that integrates MD simulations with FoldX estimations. For this method, a set of snapshots of the proteins are generated from atomistic MD simulations, FoldX31 is used to estimate binding affinities for each snapshot which are then averaged to generate a single binding affinity estimate per variant, where each variant differs in a single point mutation. These binding affinities can then be used to identify mutations that disrupt binding, typically indicated by high positive values, hence determining possible Ab-escape mutations. This approach holds significant potential as it offers detailed immune-escaping insights at the mutation level, explores diverse protein conformations beyond single experimental structures, and demonstrates versatility in its applicability to a wide range of Abs.
In this study, we capitalize on the wealth of data generated during the COVID-19 pandemic by focusing on the SARS-CoV-2 RBD to tackle significant challenges associated with the MD+FoldX approach. We investigate the validity of using MD+FoldX to predict Ab-escape by comparing to experimental DMS and we examine the generalizability of the energy cutoff that is crucial for identifying escape mutations. Initially, we establish the correlation between MD+FoldX predictions and DMS escape fraction data. Subsequently, we refine the binding affinity cutoff to classify escape mutations and assess the method’s accuracy in identifying escape mutations. Finally, we present the potential escape mutation list generated by our method and propose avenues for future research. Central to our findings are the class-specific cutoffs (Q1, median and Q3) derived from our system-specific results, that are able to tailor predictions to different scenarios, ensuring practical relevance in identifying clinically significant escape mutations for future research.
Methods
In this study, we assessed the predictive capability of the MD+FoldX method for identifying SARS-CoV-2 Ab-escape mutations and examined their transferability across diverse systems using DMS-derived escape fraction data. Our strategy involved selecting SARS-CoV-2 RBD-targeting Abs from four different classes, guided by the availability of experimentally determined complex structures and DMS-derived escape fraction data (Fig. 2a). Binding affinity predictions were conducted through the MD + FoldX approach (Fig. 2b). Binding affinity predictions were correlated with experimental escape fraction data from DMS experiments (Fig. 2c). Subsequently, we refined the affinity cutoff, crucial for selecting predicted escape mutations, tailored individually for each system. The use of such system-specific optimized cutoffs provided precision of the method and Ab-escape lists.

The methodology pipeline of the study is structured as follows: (a) systems are selected based on the availability of data; (b) binding affinity predictions are generated for each system using the MD+FoldX approach; and (c) predictions are compared with experimental escape fraction data, leading to the optimization of the energy cutoff and the precision evaluation, followed by the creation of an Ab-escape mutation list using the optimized cutoff.
Data curation
We selected 19 SARS-CoV-2 RBD-targeting antibodies that have experimentally determined Ab/Ag structures and escape fractions from DMS experiments available (Fig. 1b, Table 1). Experimental structures had resolution ranges of 1.83–3.0 Å from X-ray crystallography and 3.4–3.95 Å from cryo-EM. We named each Ab/Ag pair after the Ab, given the antigen’s consistency across all pairs. For example, the S2H14 Ab/S-RBD complex is referred to as the S2H14 system. The experimentally determined structures of the Ab/Ag complexes were retrieved from the Protein Databank (PDB) and their corresponding PDB identifiers (IDs) are listed in Table 1. DMS data comes from the yeast-display DMS approach, developed by the Bloom lab13 (Refer to Table 1 for DMS data citations). Briefly, it involves creating libraries of all possible monomeric S-RBD single amino acid mutants (Wuhan-Hu-1, Genbank accession number MN908947, residues N331-T531) and filtering out the mutants with significantly reduced ACE2 affinity (bind to ACE2 with \(< 1\%\) the affinity of the unmutated RBD) or folding efficiency. In other words, from the full set of possibilities (201 sites x 19 amino acids = 3819), only a subset of the possible amino acid mutations of the RBD met these criteria and were reported in the experimental data (e.g., 1950 mutations were reported for AZD8895, 1951 for S2E12, 1951 for S2H14, and 1943 for REGN10933). The resulting library is expressed on yeast surfaces and the effect of each mutation on Ab binding is quantified by fluorescence-activated cell sorting and deep sequencing. The escape fraction resulting from each RBD mutation signifies the ratio of cells with that mutation found in the corresponding Ab-escape cell sorting bin. These fractions can range from 0 (indicating no cells with this mutation were found in the Ab-escape bin) to 1.0 (indicating that all cells with that mutation were found in the Ab-escape bin).
In-silico predictions
System preparation
For simulations, we strived to match the S-RBD region used in DMS experiments (N331-T531). For the S2H13 system, only a shorter RBD segment (S443-N501) was available. For systems C144 and C121, the Ab interacted with more than one S-RBD monomer in the crystal structure. To avoid potential loss of important interaction contributions, we included the complete spike trimer for these systems. For system C121, the structure contained two Abs interacting with S-RBD in two different conformations, hence we duplicated that system for both states and included the spike trimer: “up” state (1 RBD “up” and 1 RBD “down” in contact with the Ab) and “down” state (2 RBDs “down” in contact with the Ab). Considering one duplicated system, our analysis uncovered a total of 20 systems. System C002 required the reorientation of the CYS480 sidechain to properly form the disulfide bond with CYS488 in the RBD. Missing residues were added with the OpenMM-based PDBFixer38 application.
MD simulations
Each Ab/Ag complex was placed separately in a water box with physiological ion concentration and then energy minimization, equilibration, and 150 ns-long MD production were performed using GROMACS 2022.5 software39,40. Topologies were created using the parameters from the CHARMM36 force field41. Each system was placed in a dodecahedron simulation box such that all Ab/Ag atoms were at least 1.2 nm from the box edges and the box was then filled with TIP3P42 water molecules. Each box was neutralized by adding the appropriate number of Cl\(^{-}\) and Na\(^{+}\) counter-ions at a physiological concentration of 0.15 M. Systems were subsequently energy minimized under periodic boundary conditions using the steepest decent algorithm43. An initial equilibration phase of 1 ns was conducted under NVT conditions to facilitate the equilibration of water molecules around the proteins. The equilibration phase began at 100 K, with a linear temperature increase, concluding at 310 K. Subsequently, a second equilibration phase was performed by switching on pressure coupling, and then simulated under NPT conditions for 1 ns at a reference pressure of 1 bar, using Parrinello-Rahman coupling. Position restraints with a force constant of 1000 kJ mol\(^{-1}\) nm\(^{-2}\) were imposed during equilibration phases on all heavy atoms. Finally, production simulations were carried out under the NPT ensemble at 310 K and 1 bar each lasting 150 ns with a 2 fs timestep. For all simulation stages, periodic boundary conditions were applied and the LINCS44 algorithm constrained hydrogen bonds to their ideal lengths. Temperature control utilized the V-rescale45 option. Electrostatic interactions were computed using Particle Mesh Ewald with a real-space cutoff of 1 nm. Van der Waals interactions were computed using a cutoff of 1 nm. For systems where the S-RBD was taken into account, 100 conformers were extracted from the last 100 ns simulations every 1 ns. In systems requiring the inclusion of a complete S-trimer, we selected 10 representative structures from MD simulations through conformational clustering using the Gromos algorithm in order to reduce the computational load46.
FoldX calculation
Snapshots from MD simulations were used as input structures for binding affinity (\(\Delta G_{\text {bind}}\)) calculations by first optimizing their geometry with the FoldX 5.047 force field and six repeated energy minimizations using the RepairPDB command. The binding affinity between the wild-type (wt) Ab and Ag (\(\Delta G_{\text {wt}}\)) was determined using the AnalyseComplex command. Next, we introduced point mutations to generate different variants using the BuildModel subroutine. We then computed the binding affinity of the mutated complex (\(\Delta G_{\text {mut}}\)) with AnalyseComplex and calculated \(\Delta \Delta G_{\text {bind}}\) = \(\Delta G_{\text {mut}}\) − \(\Delta G_{\text {wt}}\). In the results section, we report the averages of \(\Delta \Delta G_{\text {bind}}\) or \(\Delta G_{\text {bind}}\), calculated from either 100 individual snapshots or, in the case of trimers, 10 snapshots. The scanning region (Fig. 3) of interacting surface residues for point mutations was the same among Abs from the same class whenever possible. It includes residues on the RBD within 10 Å of any Abs chains in each crystal structure, however, as theses sites can vary from antibody to antibody even though they target similar structural epitopes (Abs within same class), we included the union set, i.e., all residues targeted by at least one antibody in the same class were included in the mutation list for that class. Thus, 1615 mutations were performed for all antibodies in class 1 (85 sites \(\times\) 19 amino acids), 1729 for class 2 (91 \(\times\) 19), 1539 for class 3 (81 \(\times\) 19), and 2679 for class 4 (141 \(\times\) 19).

Binding interface mutation for Ab within a specific class. Interface residues highlighted in red represent the union set of RBD residues located within 10 Å of any antibody chains in this class. A total of 85 sites were mutated in Class 1, 91 in Class 2, 81 in Class 3, and 141 in Class 4. Mutations are mapped onto the 3D structure of one representative Ab/Ag complex per class: Class 1 (AZD8895), Class 2 (LY-CoV555), Class 3 (REGN10987), and Class 4 (S2X259).
Comparing experimental data and predictions
The escape fraction (f) is not a direct measure of the binding affinity (\(\Delta G_{\text {bind}}\)), however, a mutation with a large \(\Delta G_{\text {bind}}\) value (i.e., low affinity) has a higher chance to escape26. Assuming that the experiment is performed under equilibrium conditions, the binding affinity is related to the experimental escape fraction through the Hill relation48,49 as follows:
where f is the experimental escape fraction, R is the gas constant, T is the temperature in Kelvin, and l is the free Ab. As shown \(\mathcal {F}(f)\) is proportional to \(\Delta G\) and is defined as a function of the escape fraction as follows:
In our study, we compared predicted binding affinities and experimental escape fractions by determining the correlation between predicted \(\Delta\)G\(_{\text {bind}}\) and \(\mathcal {F}(f)\) (Eq. (2)). Although FoldX (and hence our method) predicts \(\Delta \Delta\)G\(_{\text {bind}}\), we used \(\Delta\)G\(_{\text {bind}}\) in scatterplots due to its mathematical relationship to escape fraction shown in Eq. (1). We note, however, that our performance and cutoff analysis remain unaffected since the values are consistent whether using either \(\Delta \Delta\)G\(_{\text {bind}}\) or \(\Delta\)G\(_{\text {bind}}\). To assess the degree of correlation we employed two widely used statistical measures: the Pearson and Spearman correlation coefficients. These coefficients provide insights into the linear (Pearson) and monotonic (Spearman) relationships between the predicted and experimental values. Hence, a strong Pearson correlation would suggest our \(\Delta G_{\text {bind}}\) calculations are accurately predicting \(\mathcal {F}(f)\). A strong Spearman correlation would suggest that the rank order of calculated values aligns with the rank order of experimental values.
It’s important to note that yeast-displayed DMS experiments encompassed a comprehensive scan of all RBD sites, including sites that are distant from the interacting region, and mutants with significantly reduced ACE2 binding or expression rates were removed from the experiments. By contrast, our approach focused on sites located within a 10 Å proximity to any Ab chain, and we conducted site saturation mutagenesis only on these selected sites. Finally, we focused in this study on mutations for each antibody that had both predictions and experimental data. This is, 888 for AZD8895, 888 for S2E12, 888 for S2H14, 886 for REGN10933 and 888 for C105, etc.
Optimization of the affinity cutoff
To enhance predictive accuracy, we fine-tuned the “affinity cutoff”, that distinguishes between mutations likely to cause escape due to binding disruption from those less likely to do so. In general, a binary classifier requires a cutoff to separate positive from negative outcomes. For actual outcomes versus predicted outcomes two cutoffs are employed, a vertical and a horizontal, respectively (refer to Fig. 2c). The vertical cutoff classifies the experimental data, and the horizontal cutoff classifies the predictions. These cutoffs segment the diagram into four quadrants in a confusion matrix: the top right quadrant is for True Positives (TP), where both predicted and actual outcomes are positive (i.e., both simulation and experiment agree that it is an escape mutation); the bottom right quadrant is for False Negatives (FN), where the actual outcome is positive, but the prediction is negative (i.e., the simulation predicts it is not an escape mutation, but it actually is); the top left quadrant is for False Positives (FP), where the prediction is positive but the actual outcome is negative (i.e., the simulation predicts escape mutation, but it is actually not); and the bottom left quadrant is for True Negatives (TN), where both predicted and actual outcomes are negative (i.e., both simulation and experiment agree that it is not an escape mutation).
In this study, TP values are a key measure to test the ability to detect affinity-related escape mutations; FP is also important since it reflects the inaccuracies of our method. To assess the ability of MD+FoldX to correctly identify affinity-related escape mutations, we define the performance of the method as precision, i.e., the proportion of correctly identified escape mutations among all positive predictions:
Our method is based on Ab/Ag binding affinity, thus we can reasonably seek to predict escape driven by disruptive binding free energy changes (high actual \(\Delta G_{\text {bind}}\)), but we cannot expect to reliably predict the absence of escape driven by non-disruptive binding energy changes. This is because, theoretically, antibody escape may occur for reasons other than binding affinity disruption. For example, a mutation may have a low actual \(\Delta G_{\text {bind}}\), but still result in actual escape (high escape fraction) due to factors such as changes in binding kinetics or ACE2 out-competition50,51,52,53,54. In this study, FN could be due to either inaccuracy of the methods47 (errors in the calculation) or other non-affinity-based escape mechanisms mentioned above. As we have no way to determine which one is occurring in this study, we have not considered metrics that include negative cases (TN and FN) with low \(\Delta G_{\text {bind}}\), an important measure of success i.e., they are less informative of the method’s performance for our study.
We also investigated the importance of the binding affinity cutoff in the performance of MD+FoldX. We fixed the vertical cutoff at 0.5 consistent with previous studies11,14 (that is, 50% of cells were found in the Ab-escape bin), and on fine-tuned the horizontal cutoff that classifies our MD+FoldX predictions as escape mutations or not. We will refer to this horizontal cutoff as the “affinity cutoff” or simply the “cutoff”. This cutoff differentiates between mutations that are more likely to lead to escape due to binding disruption (above the cutoff) and those that are less likely to cause escape (below the cutoff). To optimize the cutoff, we aimed to maximize the precision (Eq. (3)), while also maintaining a reasonable number of positive predictions. An algorithm that solely focuses on optimizing precision runs the risk of selecting a few points with very high precision but potentially missing broader relevant data. Here, we optimized the cutoff by maximizing the \(\text {F-Score}\), a weighted average of the precision and recall55.
where \(\beta\) represents the weight of recall compared to precision. For our study, \(\beta =0.5\) was chosen meaning that precision is considered twice as important as recall (note that typical values of \(\beta\) are 0.5, 1.0, or 2.0). Precision and \(\text {F-Score}\) metrics are typically recommended for analyzing performance in unbalanced datasets, such as in our study55. For each system, we implemented an algorithm that iteratively tested a range of cutoffs, from the highest \(\Delta G\) value down to \(\Delta G_{\text {wt}}\), incrementing by 0.1 kcal/mol. The cutoff that yielded the highest \(\text {F-Score}\) was selected as the optimal value for each system. Note that we are not considering cutoffs below \(\Delta G_{\text {wt}}\) since we seek mutations that disrupt binding compared to wild-type. For the remainder of the manuscript, we will refer to the “classic cutoff” as a value of 2.0 kcal/mol from our prior studies21,29,56,57, and the “optimized cutoff” as determined by maximizing the \(\text {F-Score}\).
Results
The purpose of this study was to evaluate the ability of the MD+FoldX method to predict antibody escape mutations using large-scale data from DMS experiments. We selected a diverse set of 19 Ab/Ag complexes targeting the SARS-CoV-2 RBD, each with structural and escape fraction data from DMS experiments. Binding affinities (\(\Delta G_{\text {bind}}\)) were predicted for each system using MD+FoldX, and Pearson and Spearman correlations to experimental escape (\(\mathcal {F}(f)\), Eq. (2)) were determined. We then optimized a system-specific binding affinity cutoff based on the experimental DMS data. Subsequently, we evaluated the accuracy of the method by assessing whether the predicted escape mutations were correctly identified according to the experimental DMS data. Finally, we illustrate how the MD+FoldX method identifies escape mutations in a given system and present the list of potential escape mutations generated by our method.
Data curation
The 19 Ab/Ag complexes used in our study are categorized into four distinct classes11 (Fig. 1b, Table 1), plus an additional duplicated system for C121. Our dataset features antibodies ranging in size from 230 to 459 residues with an antigen of approximately 250 residues. When utilized, trimers consisted of over 3300 residues. The simulation dataset contained 33,763 single amino acid mutations, 4443 of which were reported. The reported mutations are the ones reported in the DMS experimental data, hence they are considered to be functional in the experiments13. The distribution of experimental escape fraction values for all Ab/Ag complexes is depicted in Fig. S1 of the Supplemental Material. The majority of experimental escape fraction values cluster around 0.0, with a secondary smaller cluster near 1.0. On average, the escape fraction value for all systems is 0.07, with at least 80% of the values falling below 0.12. The distribution of predicted \(\Delta \Delta G_{\text {bind}}\) values for all Ab/Ag complexes is as follows (Fig. S2 of Supplemental Material): on average, the \(\Delta \Delta G_{\text {bind}}\) value for all systems is 0.23 kcal/mol, with 30\(\%\) of the data points less than 0 kcal/mol, 60% between 0 and 1.4 kcal/mol and 10% of the data above 1.4 kcal/mol. Figure S3 of Supplemental Material shows that the distribution of amino acid residue frequency and type of mutation frequency for the whole dataset used in this work. While not perfectly uniform, the distribution shows a relatively balanced representation of amino acids and mutation types.
In-silico predictions
First, we measured the root mean square deviation (RMSD) of the C\(\alpha\) atoms in the epitope and found that it remained relatively stable for all MD simulations performed in this study (see Figs. S4, S12 in the Supplemental Material), then we proceeded with our affinity estimates. As an example of how escape mutations are identified by the MD+FoldX approach with the optimized cutoff, consider system LY-CoV555. This Ab classified as Class 2 Ab, has been granted an emergency use authorization for the treatment of COVID-1935. Figure 4 shows the predicted \(\Delta \Delta G_{bind}\) for each point mutation within this system. The darker squares on the heatmap indicate a higher positive \(\Delta \Delta G_{bind}\), signifying mutations that significantly weaken the binding affinity between the Ag and Ab, hence increasing the likelihood of escape. A detailed enumeration of escape mutations about all the systems under study is available in Tables S1–S4 of the Supplemental Material.

Heat map of predicted \(\Delta \Delta G_{bind}\) values using MD+FoldX for mutations in the RBD when in complex with LY-CoV555 Class 2 Ab. The horizontal axis displays the amino acid positions in the RBD along with the corresponding native amino acids. The vertical axis represents the mutation of amino acids colored according to physicochemical properties: small non-polar, hydrophobic, polar, negatively charged and positively charged. White squares represent the amino acids of the wild-type. For clarity in visualization, sites where all mutations led to changes in binding free energy of less than 0.5 kcal/mol were omitted from the heat map.
Comparing experimental data and predictions
Figure 5 shows the Pearson and Spearman correlation coefficients between predicted \(\Delta G_{\text {bind}}\) values and \(\mathcal {F}(f)\) (Eq. (2)). Overall, we observe positive Pearson and Spearman correlation between both variables, implying that weaker binding (more positive \(\Delta G_{\text {bind}}\)) is associated with higher experimental \(\mathcal {F}(f)\). Specifically, the Pearson correlation predominantly displayed moderate to strong correlations across most systems, with a mean Pearson correlation of 0.52. This is a considerable increase compared to using only a first-minimized structure, that showed a mean Person correlation of 0.40 (Figs. S5–S8 in the Supplementary Material). Among the systems, 25% exhibited strong correlations (Pearson \(>0.6\)), 55\(\%\) displayed moderate correlations (\(0.6>\) Pearson \(>0.4\)), and the remaining 20% indicated weak correlations (\(0.4>\) Pearson \(>0.2\)). Conversely, the Spearman correlation generally showed weaker associations, with a mean Spearman correlation coefficient of 0.25. This is a slight increase compared to using only a first-minimized structure, that showed a mean Spearman correlation of 0.23 (Figs. S5–S8 in the Supplementary Material). Of the systems, 10% exhibited moderate correlations (\(0.6>\) Spearman \(>0.4\)), while 55% displayed weak correlations (\(0.4>\) Spearman \(>0.2\)), and the remaining 35% indicated very weak correlations (Spearman \(< 0.2\)). Notably, in our study, the LY-CoV555 system demonstrated the strongest correlation coefficient across all systems, with Pearson’s \(r=0.68\) and Spearman’s \(s=0.41\). Conversely, the S2H13 system displayed the lowest Spearman correlation, while the C105 system exhibited the lowest Pearson correlation coefficient. Notably, the S2H14 and C121up systems showed closer correlation coefficients between Pearson and Spearman.

Pearson and Spearman correlation coefficients between predicted \(\Delta G_{\text {bind}}\) values and experimental escape fractions (f), represented by \(\mathcal {F}(f)\) as defined in Eq. (2). We show all the Ab/Ag complexes spanning the 4 Ab classes: Class 1 (purple), Class 2 (blue), Class 3 (green), and Class 4 (yellow).
Optimization of the affinity cutoff
In the MD+FoldX approach, the selection of affinity-driven escape mutations relies on the chosen affinity cutoff. In our previous studies, a lack of large-scale data impeded the verification of this cutoff, compelling us to adopt a cutoff of \(\Delta \Delta G_{\text {bind}}\) = 2.0 kcal/mol, here referred to as the “classic cutoff”. This approach yielded promising results in our prior studies of CB6 and B38 Abs, enabling the identification of mutations previously observed in clinically emerging variants11. Now equipped with extensive data, we are able to test our classic cutoff across a broad variety of systems. As part of this test, we optimized the cutoff to balance the precision and recall by maximizing the F-Score metric (5); a reasonable approach for handling imbalanced datasets55. Figure 6 illustrates our optimization process using the S2H14 system as an example. Figure 6a portrays the precision, recall, and F-Score values obtained across a range of cutoffs. The optimal cutoff of − 14.0 kcal/mol was chosen to maximize the F-Score. At this cutoff value, the corresponding precision is 0.55, recall is 0.59, and the F-Score reaches 0.56. Figure 6b shows the predicted \(\Delta G_{\text {bind}}\) values against experimental \(\mathcal {F}(f)\) values for this illustrative system. Similar correlation plots for all systems are provided in Figs. S5–S8 of the Supplemental Material. A comparison between the classic cutoff (represented by the orange dashed line) and the optimized cutoff (indicated by the green dashed line) reveals that the optimized cutoff is smaller than the classic one in this case, encompassing more data points above the cutoff. Detailed results for class 1 systems using either the classic or optimized cutoff are summarized in Table 2 and Tables S5–S7 of the Supplemental Material for classes 2–4. The mean overall systems using the classic cutoff were precision = 0.59, recall = 0.34 and F-Score = 0.43. The mean overall systems using the optimized cutoff were precision = 0.66, recall = 0.46 and F-Score = 0.55. Overall, a better balance between precision and recall is observed across all cases, as demonstrated by the increased F-Score when employing an optimized cutoff, compared to the classic cutoff. Systems S2H14, C105, C002, and C135 experienced significant performance increases using the optimized cutoff, capturing more data points as true positives and mitigating false negatives.

Example of a cutoff optimization using the S2H14 Class 1 system. (a) Precision, recall, and F-Score values across a range of cutoffs. (b) Scatter of predicted \(\Delta G_{\text {bind}}\) values against \(\mathcal {F}(f)\); the green dashed line represents the optimized cutoff, the orange dashed line indicates the classic cutoff, the grey dashed line represents the escape fraction value at which the 50% of the cells expressing a specific variant escape Ab binding, and the solid grey line indicates the value of the \(\Delta G_{\text {bind}}\) for the wild-type Ag.
Table 3 shows that the median optimized cutoff for all the systems is 1.8 kcal/mol, with an interquartile range (IQR) of 1.8, indicating variability in the cutoff values across the Ab classes. Table 3 illustrates that each Ab class presents a distinct range of cutoff values. Class 4 has the highest median cutoff at 2.9 kcal/mol, while Class 3 has the lowest at 0.8 kcal/mol. The IQR of 1.0 for Class 4 and 0.8 for Class 3 indicates a relatively narrow spread of values. Figure 7 illustrates the cutoff values derived from the optimization process for the complete set of systems. Among the systems, 14 exhibit cutoffs within the range of 1.0 kcal/mol to 3.0 kcal/mol, 5 systems have values below 1.0 kcal/mol, and 1 system is above 3.0 kcal/mol.

Optimized cutoff\(_{\Delta \Delta G}\) for each system. The orange dashed line represents the classic cutoff and the grey dashed line is the median optimized cutoff\(_{\Delta \Delta G}\). Asterisks indicate each system within the cases discussed in the “Discussion” section: Case 1 (*), Case 2 (**), and Case 3 (***).

Precision (expressed in %) comparison across systems as defined by Eq. (3) using optimized cutoffs for each system. Asterisks indicate each system within the cases discussed in the Discussion section: Case 1 (*), Case 2 (**), and Case 3 (***).
Figure 8 illustrates the precision in percentage achieved when utilizing the optimized cutoffs. The mean overall systems was 66%. It can be observed that 70% of the systems exhibit a precision above 50%. Notably, the systems S2X35 and S2D106 demonstrate the highest precision, while C135 and S2H97 display the lowest precision. In contrast, the mean precision achieved when utilizing the classic cutoff was 59%.
Discussion
In this study, we evaluated the ability of the MD+FoldX method to predict SARS-CoV-2 RBD escape mutations using a comprehensive deep mutational scanning dataset. We focused on 19 Ab/Ag systems with structural information of the complexes and escape fractions from the yeast-based DMS technique. Our analysis revealed a positive correlation between predicted affinity and experimental escape fraction. We found that fine-tuning predicted affinity cutoffs using empirical data allowed for more accurate escape mutation identification, underscoring the importance of tailoring cutoffs to specific Ab/Ag interactions rather than adopting a one-size-fits-all approach. Our results demonstrate the potential of MD+FoldX to identify significant affinity-driven escape mutations, some of them already present in variants of concern and interest, and also highlight the need for the development of more accurate methods.
This study includes 19 Ab/Ag systems across four distinct Ab classes, all directed against the SARS-CoV-2 S-RBD. This dataset covers Abs targeting similar epitopes, i.e. Abs within the same class, as well as those targeting different structural epitopes, i.e. Abs from different classes. Analysis of the escape fraction data for all the systems showed that only a small proportion of mutations exhibit escape (high escape fractions), consistent with the prevailing understanding that the majority of mutations have negligible effects on antigenicity58. In addition, our analysis of binding affinity predictions for all systems showed that the majority of the values were destabilizing (\(\Delta \Delta G\) > 0 kcal/mol); this is consistent with previous studies in a series of globular proteins using the FoldX algorithm where approximately 70% of mutations were destabilizing59 and with experiments where random mutations tend to be destabilizing60. Notably, our investigation encompasses a substantial dataset comprising 4443 single amino acid mutations across the 19 antibody-antigen systems, each accompanied by experimental escape fraction data. In comparison, related studies have examined significantly fewer mutations: Tandiana et al. validated 27 mutations in different antibody/hen egg white Lysozyme complexes with experimental data61, Gonzalez et al. validated 253 mutations in Ab/Ag complexes27, Miller et al. validated 114 mutations in 27 Ab/Ag systems29, Beach et al. validated 8 mutation in Ab/Ag systems30, and Sharma et al. validated 22 mutations in Ab/Ag systems54. Validating in silico predictions of affinity-driven antibody escape mutations remains challenging due to the scarcity of large-scale experimental data given that obtaining binding affinity data for a large number of mutations is costly and time-consuming. However, our research shows that the extensive escape fraction data from Bloom’s large-scale studies34,35,36 provides a promising alternative for validating this type of prediction.
In general, our method was able to identify significant variants of concern and interest such as R346K, L452R, E484K/A/Q, F486F/V, K417N/T, and N501Y. Specifically, the escape mutations E484K/A/Q, identified using the MD+FoldX methodology for LY-CoV555 system, were documented across multiple SARS-CoV-2 variants of concern, including the Alpha (B.1.1.7), Beta (B.1.351), Eta (B.1.525), Mu (B.1.621), and Omicron BA.1 and BA.2 (B.1.1.529) lineages, as well as the Kappa (B.1.627.1) lineages16. Similarly, the mutation F486P was observed in the Omicron (XBB.1.5) subvariant62. E484K that substitutes a positively charged residue with a negatively charged one was demonstrated to escape LY-CoV555 Ab reducing neutralization35. Interestingly, S2X259, a broad sarbecovirus neutralizer, exhibits an escape profile confined to a single mutation, G504D, as revealed by DMS and in vitro escape selection experiments37. The fact that we were able to predict these mutations suggests that our approach has the potential to uncover key escape mechanisms that could undermine current antibody-based treatments and vaccines. This insight provides valuable data for ongoing SARS-CoV-2 research, particularly in developing effective therapeutic antibodies and improving future vaccine formulations. Moreover, understanding these mutation patterns helps researchers monitor viral evolution, ultimately contributing to global efforts in preventing and managing COVID-19 and similar infectious diseases.
One primary obstacle we faced was devising a suitable approach to accurately link binding affinity with escape fractions. Here, we assume that the experiment was performed under equilibrium conditions and hence the binding affinity is related to the experimental escape fraction through the Hill relation48,49. We found that the Pearson and Spearman correlation coefficients were consistently positive via the Hill relation. Our mean Pearson correlation coefficient of 0.52 is comparable to the accuracy observed in previous MD+FoldX studies, where a correlation coefficient of 0.39 was reported for predicted versus experimental \(\Delta \Delta G_{\text {bind}}\) in Ab/Ag systems27. In contrast, our mean Spearman correlation coefficient was 0.25, also consistent with the limited performance of other similar methods studying Ab/Ag systems, where Spearman correlation coefficients rarely exceed 0.2827,63. We also confirmed that using a multi-frame approach (MD+FoldX) improves correlation coefficients compared to relying on a single structure (FoldX), as observed in our previous studies27 but with a larger and systematic set of data from DMS experiments. We attribute this improvement to the relaxation of the initial structure, especially if it lacks high resolution, and to the incorporation of variability in the initial structure that is used for mutant construction by FoldX (Figs. S9, S10 of the Supplemental Material).
While \(\Delta G_{\text {bind}}\) serves as a valuable metric for assessing binding strength, its correlation with the escape fraction may be influenced by a multitude of complex factors inherent to the binding process: (1) \(\Delta G_{\text {bind}}\) provides a thermodynamic view of affinity, but escape fractions also include kinetic factors such as binding and unbinding rates. Thus, while high \(\Delta G_{\text {bind}}\) coupled with low kinetic barriers could result in high escape fractions (indicating a strong correlation), the presence of high kinetic barriers alongside high \(\Delta G_{\text {bind}}\) can obscure this relationship due to impeded escape despite weak binding53,64. (2) Protein folding variations can significantly affect epitope accessibility and stability. Altered epitopes due to folding changes can reduce antibody affinity, thereby affecting the likelihood of escape. In particular, the yeast-DMS approach excludes mutants with significant misfolding33. Conversely, predictive models often do not calculate antigen folding stability; when they do, their accuracy can be variable, posing additional challenges to accurately predicting escape mutations19,20,21,22,23. (3) The presence of multimeric structures, such as trimers in spike proteins, could introduce cooperative binding effects that could affect binding strength and escape. In yeast-DMS experiments, antibodies bind to monomeric yeast-expressed RBDs, and therefore cannot fully capture mutational effects on spike-trimer conformation or effects on antibodies that bind quaternary epitopes33. (4) Differences in the glycosylation patterns of yeasts compared to human cells may influence antibody recognition of glycan-rich epitopes. In particular, N-linked glycans on yeast-expressed proteins are more mannose-rich than those on mammalian-expressed proteins33. In this study, our simulations do not include glycans and hence our prediction accuracy would suffer for such an epitope. (5) Finally, variations in the structural dynamics of the Ab/Ag complexes, the influence of solvent effects like bridging water molecules, and the presence of allosteric effects or cooperative binding events, are potentially significant factors that are very challenging to account for in simulations. Indeed, all of the factors listed above underscore the challenges of directly correlating binding energies with escape fractions and highlight the intricate interplay between structural, kinetic, and biological phenomena in antibody-antigen interactions.
Given the factors listed in the previous paragraph that could impact the correlation between predictions and escape fraction data, we will consider three distinct cases. Case 1: Antibodies bind to monomeric non-glycan epitopes. Here, \(\Delta G_{\text {bind}}\) is expected to correlate with f via the Hill relation (Eq. (1)), meaning that significantly larger \(\Delta G_{\text {bind}}\) in mutants compared to wildtype lead to higher likelihood of escape. Case 2: Antibodies bind glycan-free epitopes that span several monomeric units. In this case, the correlation between \(\Delta G_{\text {bind}}\) and escape fractions f may not be strong since the experimental setup includes only monomeric spike protein leading to larger escape fractions (\(f>0.5\)). Case 3: Antibodies bind glycan-rich epitopes. In this case, \(\Delta G_{\text {bind}}\) may not correlate well with escape fractions f since yeast cells produce different glycans. In our study, systems are predominantly consistent with Case 1, including AZD8895, S2E12, S2H14, REGN10933, C105, LY-CoV555, S2D106, S2H13, REGN10987, LY-CoV1404, CoV2-2130, S2H97, S2X259, C002, and S2X35. Here, \(\Delta G_{\text {bind}}\) could be expected to correlate with f via the Hill relation. Positive high Pearson correlation coefficients associated with these systems (Pearson = \(0.28{-}0.68\)) indicate that larger \(\Delta G_{\text {bind}}\) are associated with high escape fractions. By contrast, C121 is consistent with Case 2, Abs targeting glycan-free quaternary epitopes11. In this system the spike trimer structure has 2 Abs bound, the first one (C121up) interacts primarily with 1 RBD in the “down” conformation but also has minor contact with 1 RBD in the “up” conformation. A second Ab (C121down) interacts primarily with 1 RBD in the “down” conformation and has minor contact with a second RBD in the “down” conformation. Although the correlation between \(\Delta G_{\text {bind}}\) and escape fractions f are not expected to be consistent, \(\Delta G_{\text {bind}}\) values could still serve as useful indicators of potential escape events. Systems C110 and C135 are consistent with Case 3, both featuring a glycosylated epitope containing an N343 glycan11. Finally, the C144 system is a hybrid between cases 2 and 3; its epitope spans multiple monomers and includes a glycosylated site (N434). However, its primary interaction is with one of the RBDs that is not glycosylated, and may explain the reasonable correlation found for this system.
In this study, we found that adjusting predicted affinity cutoffs based on empirical data was crucial for accurately identifying escape mutations. Overall, there was significant variability in the optimized cutoff values across different systems and classes. This suggests that the optimal cutoff for predicting escape mutations varies depending on the specific Ab/Ag system, indicating that a one-size-fits-all approach may not be suitable for all systems and highlighting the complexity and specificity of Ab/Ag interactions. The challenge of selecting an appropriate cutoff value is further emphasized by the varied approaches used in different studies to pinpoint SARS-CoV-2 immune hot spots. Chang et al.20 used a \(\Delta \Delta G = 0\) kcal/mol cutoff to classify binding stability, with negative values indicating stabilization and positive ones indicating destabilization. Huang et al.19 developed an immune-escaping score by merging binding free energy measurements with variant frequency, using variants of concern and interest to determine mutation frequency cutoffs. Mauria et al.22 refined binding affinity and escape fraction cutoffs using receiver operating characteristic curve analysis, setting \(\Delta \Delta G = - 0.7\) kcal/mol and an escape fraction of 0.001753. In this study, we fixed the escape fraction cutoff and concentrated on fine-tuning the \(\Delta G_{\text {bind}}\) horizontal affinity cutoff. As observed in our results, significant variability among the systems was found, however, the distribution of optimized cutoffs tends to center around our classic cutoff of 2.0 kcal/mol showing that it could serve as a reasonable starting point for initial predictions. It may be particularly applicable in the absence of system-specific data to guide the optimization of the cutoff value.
The data reveals Class 3 Abs possess a minimal tolerance for energy changes, corresponding to lower escape cutoffs, whereas Class 4 Abs exhibit a higher tolerance, apparently requiring more substantial energy changes to allow mutations to escape. We can consider several factors that contribute to the difference in the optimized cutoff for these extreme cases. Firstly, the distribution of the experimental escape fractions differs between Class 3 and Class 4 (Figs. S1, S5–S8 in the supplemental material). In class 4, most values are clustered near zero, with a few near 1. In contrast, class 3 values are less clustered at the extremes and have more (uniformly distributed) points in between. Secondly, FP and FN are on average higher for class 3 than for class 4 (33 compared to 8 FP and 28 compared to 13 FN). Thirdly, the distribution of predicted values is flattened towards zero in class 3 compared to class 4 (Figs. S2, S5–S8 in the Supplemental Material). In summary, we can expect that in a scatter plot where FP and FN are lower, extreme clusters are more easily distinguished from each other, and have a higher rate of change of affinity along the escape fraction, resulting in a higher optimized energy cutoff. On the other hand, DMS revealed that higher binding affinity reduces the total number of viral escape mutations65. One hypothesis could be related to the affinity of antibodies in different classes, which could result in different levels of response and consequently different cutoff values. In class 4, where fewer mutations are distributed near 1, this indicates that fewer mutations interfere with binding. For example, S2X35 from class 4 has a binding affinity for SARS-CoV-2 RBD of 0.2 nM34, whereas REGN10987 from class 3 has an affinity of 45 nM66. Experimentally, 42 mutations are considered escape (f > 0.5) for S2X35 compared to 103 for REGN10987. Predicted escape mutations are 16 for S2X35 and 36 for REGN10987. This suggests that fewer mutations lead to escape for class 4, and tighter binding requires higher energy to disrupt binding, thus requiring higher optimized energy cutoffs for escape prediction.
It is crucial to weigh the clinical implications of the cutoff selection carefully: an overly stringent cutoff may overlook potential escape mutations, whereas too lenient a cutoff might overpredict escape, potentially triggering unnecessary concern or interventions. Hence, the optimized cutoff must ensure that predictions are both accurate and practically useful for guiding therapeutic strategies and vaccine design. Aiming for the ambitious goal of predicting escape mutations solely through \(\Delta G\) values, adopting a proposed stepwise approach could prove instrumental. We propose the use of system-dependant optimized cutoff whenever possible. If data for optimizations of the particular system is lacking, we can formulate three distinct lists per class based on varying cutoff values to cater to different scenarios. For an optimistic approach, a cutoff based on Q1 in Table 3 is recommended. This threshold may encompass some non-escape mutations but is aimed at generating a concise list suitable for preliminary investigations. The second approach adopts a cutoff based on the median, designed to offer balanced results, making it appropriate for a wide range of cases. Lastly, a more stringent cutoff based on Q3 in Table 3 is suggested for scenarios prioritizing the identification of highly probable escape mutations. While this may not capture all potential escape mutations, it is particularly valuable in therapeutic antibody development, where the focus is on mutations with significant implications for treatment efficacy. In scenarios where systems diverge from those evaluated in this study and lack tailored data for cutoff optimization, the established classic cutoff of 2.0 kcal/mol may provide a practical baseline for initial predictions.
In our analysis, we emphasized positive results, since accurate prediction of escape cases is crucial. To evaluate the ability of the method to correctly identify positive cases (mutations that are more likely to be escape mutations due to binding disruption) while considering possible errors in the method (false positives), we compute the precision. This is the proportion of correctly identified escape mutations out of all positive predictions. For Case 1 systems, high precision is possible, provided that the \(\Delta G_{\text {bind}}\) predictions are accurate, as this is the case where Abs binding glycan-free monomeric epitope as in the experiments. In Case 2 systems, \(\Delta G_{\text {bind}}\) values could still serve as useful indicators of potential escape and high precision is possible, assuming accurate \(\Delta G_{\text {bind}}\) predictions. In Case 3 systems, however, \(\Delta G_{\text {bind}}\) is likely to be inaccurate, resulting in low escape prediction precision. Overall, precision varied across the systems: seven exhibited high precision (Precision \(>80\%\)), 14 showed moderate precision (Precision \(>50\%\)), and six had low precision (Precision \(<50\%\)). This highlights the method’s effectiveness in predicting escape mutations but also emphasizes the need for more accurate and efficient binding-free energy estimation methods. Systems classified under Case 1 showed precision ranging from 23 to 100%. Case 2 systems had a precision range of 45% to 90%. As expected, Case 3 systems displayed relatively low precision in predicting escape mutations, ranging from 25 to 43%. However, we also analyzed a more global metric of performance (Fig. S11 of the Supplemental Material). It showed a good classification ability of the model, with the area under the receiver operating characteristic curve (AUROC) values ranging from 0.75 to 0.91 for class 1 systems. This indicates that the model performs well in distinguishing between true positives and true negatives across different thresholds. However, while the ROC curve and AUCROC are useful metrics, they can provide an overly optimistic view of model performance, especially in the context of an unbalanced dataset. The ROC curve considers both true positive rates (TPR) and false positive rates (FPR) at different thresholds. In an unbalanced dataset where the majority of samples are negative, the FPR can be very low due to the high number of true negatives, making the ROC curve appear better than it actually is.
Future studies should explore how interactions between mutations, known as epistatic effects, could cause non-additive impacts on binding affinity and immune escape. This research would be crucial for understanding the emergence of antibody escape mutations in clinical variants that contain multiple mutations. While our pipeline could be adapted for multiple mutations, the goal of this study was to evaluate its performance using empirical escape fraction data. The bulk of this data is single mutations, a case where MD+FoldX has been proven to excel at prediction for antibody-antigen systems compared to similar methods but not explored in depth. To our current knowledge, there has not been extensive benchmarking done on fast methods like FoldX to predict the effects of higher-order mutations and their ability to capture epistatic effects. Nor is there currently a large corpus of empirical data on systematic higher-order mutations. Additionally, the FoldX scoring function was primarily trained and tested on single mutations47. In addition, our study suggests that there is a need for methods to more accurately estimate binding free energy changes upon mutation at a reasonable computational speed. Furthermore, the impact of antibody structural variability and flexibility on computational predictions warrants further investigation, especially given the challenges posed by lower-resolution structures. Although FoldX provides more accurate free energies for high-resolution crystal structures (less than 2.6 Å)31, its effectiveness with cryo-EM-derived and low-resolution crystal structures requires thorough evaluation. While affinity plays a key role in antibody escape, it does not encompass all aspects of escape potential. Machine learning methods could significantly enhance the detection of escape mutations. These models trained using escape fractions from DMS experiments, could incorporate additional relevant features beyond mere binding affinity.
Conclusions
In this study, we demonstrated the potential of the MD+FoldX method for predicting antibody escape mutations by leveraging deep mutational scanning data from various antibody-antigen complexes targeting the SARS-CoV-2 RBD. The insights gained here were only possible due to the extensive data generated by DMS in several studies14,32,33,34,35,36,37, emphasizing the crucial role of ongoing data collection and analysis in advancing infectious disease research. Our study showed a positive correlation between predicted binding affinity changes and experimental escape fractions, suggesting that MD+FoldX can predict escape mutations in some cases. The strength of the correlation was system-dependent. It is important to acknowledge that even with perfect calculations, \(\Delta G\) will not perfectly correlate to escape fractions due to other factors such as binding rates, protein folding, multimeric epitopes, and glycosylation differences. Yet, it is also the case that a sufficiently large change in \(\Delta G\) will invariably result in escape. Our results emphasize that the ideal cutoff for predicting escape mutations should be tailored to the specific Ab/Ag interaction, challenging the efficacy of a universal standard and highlighting the complexity of Ab/Ag interactions. We recommend a stepwise decision-making approach using the cutoffs found in this work as a reference for similar systems. Overall, our study shows that MD+FoldX can streamline the prioritization of mutations for in-depth analysis, and ultimately facilitate detection of potential escape mutations. However, it also underscores that there is still a need for more accurate methods for estimating binding free energy changes upon mutation at a reasonable computational speed.
Data availability
Code, inputs, and raw data to reproduce plots for this work are available on GitHub at https://github.com/YtrebergLab/SARS-CoV-2_Ab-escape.
References
Boggiano, C. et al. Update on and future directions for use of anti-sars-cov-2 antibodies: National institutes of health summit on treatment and prevention of covid-19. Ann. Intern. Med. 175, 119–126 (2022).
Salazar, G., Zhang, N., Fu, T.-M. & An, Z. Antibody therapies for the prevention and treatment of viral infections. npj Vaccines 2, 19 (2017).
Tam, E. H., Peng, Y., Cheah, M. X. Y., Yan, C. & Xiao, T. Neutralizing antibodies to block viral entry and for identification of entry inhibitors. Antiviral Res. 1, 105834 (2024).
Ahangarzadeh, S. et al. An update on antiviral antibody-based biopharmaceuticals. Int. Immunopharmacol. 86, 106760 (2020).
Burton, D. R. Antiviral neutralizing antibodies: From in vitro to in vivo activity. Nat. Rev. Immunol 23, 720–734 (2023).
Huang, Q., Han, X. & Yan, J. Structure-based neutralizing mechanisms for sars-cov-2 antibodies. Emerg. Microbes Infect. 11, 2412–2422 (2022).
Wagner, T. R. et al. Neutrobodyplex-monitoring sars-cov-2 neutralizing immune responses using nanobodies. EMBO Rep. 22, e52325 (2021).
Alcami, A. & Koszinowski, U. H. Viral mechanisms of immune evasion. Immunol. Today 21, 447–455 (2000).
Carabelli, A. M. et al. Sars-cov-2 variant biology: Immune escape, transmission and fitness. Nat. Rev. Microbiol. 21, 162–177 (2023).
Vossen, M. T., Westerhout, E. M., Söderberg-Nauclér, C. & Wiertz, E. J. Viral immune evasion: A masterpiece of evolution. Immunogenetics 54, 527–542 (2002).
Barnes, C. O. et al. Sars-cov-2 neutralizing antibody structures inform therapeutic strategies. Nature 588, 682–687 (2020).
Chen, Y. et al. Broadly neutralizing antibodies to sars-cov-2 and other human coronaviruses. Nat. Rev. Immunol. 23, 189–199 (2023).
Greaney, A. J. et al. Complete mapping of mutations to the sars-cov-2 spike receptor-binding domain that escape antibody recognition. Cell Host Microbe 29, 44–57 (2021).
Dong, J. et al. Genetic and structural basis for sars-cov-2 variant neutralization by a two-antibody cocktail. Nat. Microbiol. 6, 1233–1244 (2021).
Francino-Urdaniz, I. M. et al. One-shot identification of sars-cov-2 s rbd escape mutants using yeast screening. Cell Rep. 36, 1 (2021).
Tomasello, G., Armenia, I. & Molla, G. The protein imager: A full-featured online molecular viewer interface with server-side hq-rendering capabilities. Bioinformatics 36, 2909–2911 (2020).
Fong, W. et al. Sabres: In silico detection of drug resistance conferring mutations in subpopulations of sars-cov-2 genomes. BMC Infect. Dis. 23, 303 (2023).
Saha, G. et al. Priest-predicting viral mutations with immune escape capability of sars-cov-2 using temporal evolutionary information. BioRxiv 1, 1 (2023).
Huang, S.-H. et al. In silico prediction of immune-escaping hot spots for future covid-19 vaccine design. Sci. Rep. 13, 13468 (2023).
Tsai, K.-C., Lee, Y.-C. & Tseng, T.-S. Comprehensive deep mutational scanning reveals the immune-escaping hotspots of sars-cov-2 receptor-binding domain targeting neutralizing antibodies. Front. Microbiol. 12, 698365 (2021).
Barnes, J. E., Lund-Andersen, P. K., Patel, J. S. & Ytreberg, F. M. The effect of mutations on binding interactions between the sars-cov-2 receptor binding domain and neutralizing antibodies b38 and cb6. Sci. Rep. 12, 18819 (2022).
Maurya, S., Kumar, S. & Padhi, A. K. Interface-guided computational protein design reveals bebtelovimab-resistance mutations in sars-cov-2 rbd: Correlation with global viral genomes and bebtelovimab-escape mutations. ChemistrySelect 8, e202302906 (2023).
Thadani, N. N. et al. Learning from prepandemic data to forecast viral escape. Nature 1, 1–8 (2023).
Kostolansky, F. et al. The strong positive correlation between effective affinity and infectivity neutralization of highly cross-reactive monoclonal antibody iib4, which recognizes antigenic site b on influenza a virus haemagglutinin. J. Gen. Virol. 81, 1727–1735 (2000).
Burton, D. R., Williamson, R. A. & Parren, P. W. Antibody and virus: Binding and neutralization. Virology 270, 1–3 (2000).
He, Q. et al. An updated atlas of antibody evasion by sars-cov-2 omicron sub-variants including bq. 1.1 and xbb. Cell Rep. 4, 1 (2023).
Gonzalez, T. R., Martin, K. P., Barnes, J. E., Patel, J. S. & Ytreberg, F. M. Assessment of software methods for estimating protein-protein relative binding affinities. PLoS ONE 15, e0240573 (2020).
Sapozhnikov, Y., Patel, J. S., Ytreberg, F. M. & Miller, C. R. Statistical modeling to quantify the uncertainty of foldx-predicted protein folding and binding stability. BMC Bioinform. 24, 1–18 (2023).
Miller, C. R. et al. Initiating a watch list for ebola virus antibody escape mutations. PeerJ 4, e1674 (2016).
Beach, S. S., Hull, M. A., Ytreberg, F. M., Patel, J. S. & Miura, T. A. Molecular modeling predicts novel antibody escape mutations in the respiratory syncytial virus fusion glycoprotein. Virol. J. 96, e00353-22 (2022).
Schymkowitz, J. et al. The foldx web server: An online force field. Nucleic Acids Res. 33, W382–W388 (2005).
Starr, T. N. et al. Prospective mapping of viral mutations that escape antibodies used to treat covid-19. Science 371, 850–854 (2021).
Greaney, A. J. et al. Mapping mutations to the sars-cov-2 rbd that escape binding by different classes of antibodies. Nat. Commun. 12, 4196 (2021).
Starr, T. N. et al. Sars-cov-2 rbd antibodies that maximize breadth and resistance to escape. Nature 597, 97–102 (2021).
Starr, T. N., Greaney, A. J., Dingens, A. S. & Bloom, J. D. Complete map of sars-cov-2 rbd mutations that escape the monoclonal antibody ly-cov555 and its cocktail with ly-cov016. Cell Rep. 2, 1 (2021).
Starr, T. N. et al. Deep mutational scans for ace2 binding, rbd expression, and antibody escape in the sars-cov-2 omicron ba. 1 and ba. 2 receptor-binding domains. PLoS Pathog. 18, e1010951 (2022).
Tortorici, M. A. et al. Broad sarbecovirus neutralization by a human monoclonal antibody. Nature 597, 103–108 (2021).
Eastman, P. et al. Openmm 7: Rapid development of high performance algorithms for molecular dynamics. PLoS Comput. Biol. 13, e1005659 (2017).
Van Der Spoel, D. et al. Gromacs: Fast, flexible, and free. J. Comput. Chem. 26, 1701–1718 (2005).
Bauer, P., Hess, B. & Lindahl, E. Gromacs 2022.5 Source Code. https://doi.org/10.5281/zenodo.7586780 (2023).
Huang, J. & MacKerell, A. D. Jr. Charmm36 all-atom additive protein force field: Validation based on comparison to nmr data. J. Comput. Chem. 34, 2135–2145 (2013).
Price, D. J. & Brooks, C. L. III. A modified tip3p water potential for simulation with ewald summation. Chem. Phys. 121, 10096–10103 (2004).
Cauchy, A. et al. Méthode générale pour la résolution des systemes d’équations simultanées. Comp. Rend. Sci. Paris 25, 536–538 (1847).
Hess, B., Bekker, H., Berendsen, H. J. & Fraaije, J. G. Lincs: A linear constraint solver for molecular simulations. J. Comput. Chem. 18, 1463–1472 (1997).
Bussi, G., Donadio, D. & Parrinello, M. Canonical sampling through velocity rescaling. J. Chem. Phys. 126, 1 (2007).
Daura, X. et al. Peptide folding: When simulation meets experiment. Angew. Chem. Int. Ed. 38, 236–240 (1999).
Guerois, R., Nielsen, J. E. & Serrano, L. Predicting changes in the stability of proteins and protein complexes: A study of more than 1000 mutations. J. Mol. Biol. 320, 369–387 (2002).
Goutelle, S. et al. The hill equation: A review of its capabilities in pharmacological modelling. Fundam. Clin. Pharmacol. 22, 633–648 (2008).
Gesztelyi, R. et al. The hill equation and the origin of quantitative pharmacology. Arch. Hist. Exact Sci. 66, 427–438 (2012).
Bachmann, M. F., Mohsen, M. O. & Speiser, D. E. Increased receptor affinity of sars-cov-2: A new immune escape mechanism. NPJ Vaccines 7, 56 (2022).
Reverberi, R. & Reverberi, L. Factors affecting the antigen-antibody reaction. Blood Transf. 5, 227 (2007).
Sela-Culang, I., Kunik, V. & Ofran, Y. The structural basis of antibody-antigen recognition. Front. Immunol. 4, 302 (2013).
Hoare, S. R., Fleck, B. A., Williams, J. P. & Grigoriadis, D. E. The importance of target binding kinetics for measuring target binding affinity in drug discovery: A case study from a crf1 receptor antagonist program. Drug Discov. Today 25, 7–14 (2020).
Sharma, D., Rawat, P., Greiff, V., Janakiraman, V. & Gromiha, M. M. Predicting the immune escape of sars-cov-2 neutralizing antibodies upon mutation. Biochim. Biophys. Acta 1870, 166959 (2024).
Saito, T. & Rehmsmeier, M. The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 10, e0118432 (2015).
Miller, C. R., Lee, K. H., Wichman, H. A. & Ytreberg, F. M. Changing folding and binding stability in a viral coat protein: A comparison between substitutions accessible through mutation and those fixed by natural selection. PLoS ONE 9, e112988 (2014).
Petrosino, M. et al. Analysis and interpretation of the impact of missense variants in cancer. Int. J. Mol. Sci. 22, 5416 (2021).
Harvey, W. T. et al. Sars-cov-2 variants, spike mutations and immune escape. Nat. Rev. Microbiol. 19, 409–424 (2021).
Christensen, N. J. & Kepp, K. P. Accurate stabilities of laccase mutants predicted with a modified foldx protocol. J. Chem. Inf. Model. 52, 3028–3042 (2012).
Bloom, J. D. & Glassman, M. J. Inferring stabilizing mutations from protein phylogenies: Application to influenza hemagglutinin. PLoS Comput. Biol. 5, e1000349 (2009).
Tandiana, R., Barletta, G. P., Soler, M. A., Fortuna, S. & Rocchia, W. Computational mutagenesis of antibody fragments: Disentangling side chains from \(\delta\) g predictions. JCTC 20, 2630–2642 (2024).
Parums, D. V. The xbb. 1.5 (‘kraken’) subvariant of omicron sars-cov-2 and its rapid global spread. Med. Sci. Monit. 29, e939580 (2023).
Wang, E. Prediction of antibody binding to sars-cov-2 rbds. Bioinform. Adv. 3, 103 (2023).
Decherchi, S. & Cavalli, A. Thermodynamics and kinetics of drug-target binding by molecular simulation. Chem. Rev. 120, 12788–12833 (2020).
Zhao, F. et al. Engineering sars-cov-2 neutralizing antibodies for increased potency and reduced viral escape pathways. Iscience 25, 1 (2022).
Nguyen, H., Lan, P. D., Nissley, D. A., O’Brien, E. P. & Li, M. S. Cocktail of regn antibodies binds more strongly to sars-cov-2 than its components, but the omicron variant reduces its neutralizing ability. J. Phys. Chem. B 126, 2812–2823 (2022).
Idaho C3+3 Collaboration. Falcon: High Performance Supercomputer (University of Idaho, 2022).
Acknowledgements
This project is supported by the P3-R1 Grant Matching Program at the University of Idaho (UI). NIH Grant P20GM104420 supported this research; views expressed are solely those of the authors. Computational resources were provided in part by Research Computing and Data Services in the Institute for Interdisciplinary Data Science at University of Idaho. We acknowledge the use of the Falcon supercomputer resources67. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
LAC, JSP and FMY conceived and conceptualized the project. FMY and JSP supervised the project. LAC and JEB conducted the simulations. The results were analyzed by FMY, JSP, LAC, and JEB. The initial draft of the manuscript was prepared by LAC and JEB, and all authors contributed to reviewing and editing the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declares no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chi, L.A., Barnes, J.E., Patel, J.S. et al. Exploring the ability of the MD+FoldX method to predict SARS-CoV-2 antibody escape mutations using large-scale data. Sci Rep 14, 23122 (2024). https://doi.org/10.1038/s41598-024-72491-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-72491-z
