
Abstract
Current research in deep learning, which is widely used in mineral prospectivity prediction, focuses on obtaining high-performance models to predict mineral resources. However, because the network structure and depth of different algorithms differ, there are some differences in the correlation between the spatial pattern of ore-generating geological big data and the spatial location of discovered ore deposits; this causes instability in the prediction. To solve this problem, this paper proposes the use of ensemble learning to synthesize convolutional neural network algorithms and self-attention mechanism algorithms for mineral prospectivity prediction. In this study, 14 factors related to gold mineralization were selected, 10 types of geochemical exploration data (Au, Ag, As, Cu, Pb, Zn, Hg, Sb, W, and Mo) and 4 geological factors (ductile shear zones, brittle fault zones, mineralization–alteration body zones, and metamorphic quartz sandstone zones). Six classical convolutional neural network models (MobileNet V2, ResNet 50, VGG 16, AlexNet, LeNet, and VIT) were used to extract the features of the metallogenic factors. After training, a network model with an accuracy over 94% was obtained. Then, the mineral prospectivity of an unknown area was predicted. The models were evaluated according to their accuracy. Using these results, ensemble learning was performed, areas with high potential were obtained, and the prospectivity prediction map was drawn. This map provides guidance for gold exploration in the Bawanggou mine area of the northern Hanyin gold orefield, South Qinling, China. This comprehensive method can effectively leverage the advantages of various models, fully extract the internal relationships of deep-level mineralization, and has extremely high extensibility. The calculated results can be made more scientific and stable by adding more mineralization factors and introducing an algorithm with the new structure in the future.
Similar content being viewed by others
Introduction
The prediction and evaluation of mineral resources is the scientific prediction and comprehensive evaluation of the possible output positions and resource potential of mineral resources with economic value. Scientific and reasonable metallogenic prediction is an important task for discovering ore deposits and enlarge the reserves of resources1. Since the 1940s, metallogenic prediction has been developed from qualitative evaluation methods such as “seeking differences” and “similar analogies” to the quantitative positioning evaluation of mathematical models based on comprehensive information mining and fusion2,3. In recent years, with the advent of the era of big data4, modern geoscience based on big data strategies is rapidly expanding, and big data is triggering a profound revolution in geoscience. This represents not only a revolution in scientific research methods but also a revolution in scientific worldview. While big data brings many challenges to geoscience research, it also opens up a broader new approach to the field5,6,7,8.
It worthwhile to use big data methods to analyze geological data and apply the results to metallogenic prediction and geological minerals survey, providing a new method of prospecting9. Deep learning are among the important methods of big data and the core methods of intelligent geology10,11. Deep learning is a subclass of machine learning research that aims to learn more useful features by constructing a machine learning model with many hidden layers and massive amounts training data so as to improve the accuracy of classification or prediction12,13,14,15,16,17,18. The main types of deep learning methods are convolutional neural networks (CNNs), recurrent neural networks, stacked self-coding networks, deep belief networks, and generative adversarial networks. In recent years, deep learning algorithms have been successfully applied to the prediction and evaluation of mineral resources3,19,20,21,22,23,24,25,26,27,28,29. However, deep learning is still in the exploration stage in the analysis and integration of big data of geological minerals survy. A series of problems need to be solved to fully tap the potential of deep learning models in prospecting prediction and to finally form universal theories and methods20,30. For example, previous studies often focused on the learning network with the best performance. After the evaluating the feature extraction performance of a single network model or the comparative evaluation of the performance of multiple models with different structures, a network with relatively good performance was used to predict mineral resources, and the models with other structures were often ignored. It is obvious that the model with the highest accuracy in a biased test is not reliable, and the prediction results may be unstable because of the structural defects of the network itself.
Therefore, to make the best use of the advantages of different model architectures in the internal connections among ore-generating and ore-prospecting information, instability in the results of mineral resources prediction can be reduced by a single model, and prediction accuracy can be improved. This paper proposes using the approach of ensemble learning to carry out the deep extraction and integration of mineral resource prediction information. Taking the Bawanggou gold mine area in the northern Hanyin gold orefield of Ankang, Shaanxi Province, China, as an example, this study combined previous research results, considered geochemical data and geological data, and used inverse distance interpolation and buffer distance density to generate the basic data. A data enhancement method was used to enhance the training performance of the model, and five representative CNNs and the self-attention mechanism (VIT) model were trained to meet the accuracy requirements through continuous adjustment and participation. Then, the multi-model prediction method based on the idea of ensemble learning combined the prediction results of the six models, and obtained the distribution map of ore-forming favorable degree in the Bawanggou gold mine area. This method takes into account the advantages of different network architectures also weakens the influence of low performance models after grading according to precision. With further research, an increasing number of network models will be introduced into the metallogenic prediction. In theory, introducing more models will lead to the extraction of more ore-forming features, increasing the credibility of the ore-forming prediction results.
Regional geological background
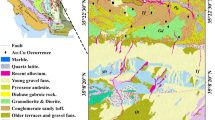
The South Qinling tectonic belt is located in the Qinling orogenic belt at the junction of the South China and North China block, bound by the Shangdan suture zone in the north and the Mianlue suture zone in the south. It is the largest and most complex tectonic unit in the Qinling orogenic belt (Fig. 1a). The northern Hanyin gold orefield in Ankang, Shaanxi Province, is an important gold metallogenic belt in the South Qinling orogenic belt and is located in the Shiquan–Shenhe thrust nappe belt of South Qinling (Fig. 1b). The outcrops in the orefield are mainly early Paleozoic deformed metamorphic rocks, except for the basement of the ancient continental dome. Silurian formations are widely exposed. The basic orefield structure is composed of five large brittle–ductile shear zones near the EW direction. The parallel secondary faults and interlayer fracture zones develop along both sides of the brittle–ductile shear zones31,32,33,34,35,36,37,38. In recent years, with the development of prospecting and exploration, dozens of gold deposits and mineralization sites of different sizes have been found in the orefield. From north to south, the largest deposits are Jindoupo, Bamiaogou, Huanglong, Bawanggou, Changgou, Luming, Shagou, Liukeng, Wujiawan, and Hanjiawan. Most of the gold deposits are bedded, stratoid, or lenticular, mainly altered-rock type, but quartz-vein type are also found. The genetic type of gold deposit in the orefield belongs to hydrothermal type and can be classified as orogenic type. The industrial type of gold deposit can be classified as altered-rock type gold deposit in brittle-ductile shear zone related to orogeny35.
The Bawanggou gold deposit belongs to the Shiquan–Shenhe detachment thrust nappe to the south of the South Qinling tectonic belt. The main outcrops in the area are the Meiziya Formation of the Lower Silurian. The main lithology includes sericite quartz schist, garnet-bearing biotite porphyry sericite quartz schist, carbonaceous sericite quartz schist, meta-quartz sandstone, and a few siliceous zones. The rocks of the Meiziya Formation are characterized by strong deformation, well-developed foliation, typical mylonitization, and generally developed crumple and foliation transposition. The faults in the area are well developed; ductile shear fracture is the main type, and brittle fracture is the second. The scale of the ductile shear fracture is large: it is a NEE-trending shear fracture, its length is more than 10 km, and its width is 100–300 m. It is characterized by a dense-structure schist zone and dense permeable–semi-permeable shear fracture surface. Large fault structures are superimposed near the boundary of ductile shear zone, and interlayer fracture zones and fault zones of different scales are superimposed inside. At present, there are four gold orebodies and nine mineralization bodies delineated in the Bawanggou gold mine area. The orebodies are mainly controlled by DSZ2 (a brittle–ductile shear zone). Most of the output is in the banded form (Fig. 1c).

(a) Simplified structural map showing the location of the South Qinling belt (modified after Hu et al., 2012; Li et al., 2013)39,40. (b) Geological map showing the tectonic location of the northern Hanyin gold orefield (modified after Feng and Yang, 1994)41. (c) Geological map of the Bawanggou gold mine area (modified after Shaanxi Geology and Mining First Geological Team Co. LTD., 2021)42. NCB North China block, NQB North Qinling belt, SQB South Qinling belt, SCB South China block, SDS Shangdan suture zone, MLS mianlue suture zone, NDZ North dabashan zone, SDZ South dabashan zone, HN hannan massif, SNJ shennongjia massif, HL huangling massif, FHS fenghuangshan massif, PL pingli massif, ZGB zigui basin, LLF luonan–luanchuan fault, AKF ankang fault, CKF chengkou fault, ZBF zhenba fault, TWF tiexi–wuxi fault, YPGF yangpingguan fault, ZPHTB ziyang–pingli detachment nappe belt, XZRHTB Xunyang–Zhen’an ductile detachment thrust–nappe belt, SSRHTB Shiquan–Shenhe ductile detachment thrust–nappe belt.
Methods
In the field of mineral resources prediction, many scholars use a single convolutional neural network model for prediction, and some scholars use multiple models for experiment, but most experiments use these models as comparison experiments to highlight the merits of a particular model. But through the knowledge discovery related with big data competition, the single model in the generalization and the forecast aspect effect is not as stable as many models, but in the mineral resources prediction field, the related theory research is quite few, how to apply this knowledge to mineral resources prediction is worthy of further study.
Therefore, in order to reduce the risk of multi-base model’s weak generalization ability, avoid the base model falling into the local minimum, improve the adaptive ability of algorithm, and make the final model learning better, the classic six CNN models are used to test based on the combination strategy of ensemble learning at first.
CNNs. A representative algorithm of deep learning, the CNN is an efficient recognition method developed in recent years. The special structure of local weight sharing has unique advantages in speech recognition and image processing, and its layout is modeled on actual biological neural networks, whereas its weight sharing reduces the complexity of the network. In the field of pattern classification, a multi-dimensional input vector image can be directly input to the network, which avoids complex pre-processing of the image and reduces the complexity of data reconstruction in feature extraction and classification43,44. With the development of deep learning theory and improvements in numerical computing equipment, the CNN has developed rapidly, giving birth to many excellent network structures, from LeNet to VGGNet and from Google’s Inception series to the ResNet series, with each neural network model contributing its own innovation.
MobileNet V2
The MobileNet model is a lightweight deep CNN proposed by Google. Its core idea is depthwise separable convolution, and MobileNet V2 uses the inverted residual block and a linear bottleneck to form the whole network. The model has few parameters, low weight, and high training speed while maintaining depth and accuracy. The inverted residual structure first passes through 1 × 1 dimension increases, then 3 × 3 Depthwise (DW) convolution, and finally 1 × 1 dimension reduction, so that less information is lost when the high-dimensional information passes through the ReLU activation function. The structure of the MobileNetV2 network used in this paper is shown in (Fig. 2a), where t is the factor of dimensionality increases within the bottleneck (Fig. 2b), n is the number of replications of the bottleneck, and s is the stride, where stride = 1 joins the input and output characteristics using an element-wise sum and stride = 2 without a shortcut joins the input and output characteristics45.

(a) Schematic diagram of the MobileNet V2 architecture. (b) Schematic diagram of the bottleneck structure.
ResNet 50
The residual net was proposed by He et al. at Microsoft Research Institute in 201546. Achieving first place in the 2015 ImageNet Image Classification Contest, it is a classic CNN model because of its simplicity and practicality. The main approach of ResNet is to use the idea of a highway network, which is the concrete architecture shown in Fig. 3a, taking a layer of data output near the front layers and skipping the middle layers to introduce the input to the later layers, which means that the content of the later feature layers is partially and linearly affected by the preceding one. The ResNet 50 model has two basic modules, the conv block and the identity block. The structure of the conv block module is shown in (Fig. 3b). It has different input and output dimensions, so it is used only in series to change the network dimensions. The structure of the identity block module is shown in (Fig. 3c). It has the same input and output dimensions and can be used directly in series to deepen the network layers. The specific structure of the model used in this paper is shown in Fig. 3d. We added two fully connected layers to the classic ResNet 50, which can increase classification precision.

(a) Schematic diagram of the ResNet architecture. (b) Schematic diagram of the conv block structure. (c) Schematic diagram of the identity block structure. (d) Diagram of the ResNet 50 architecture.
VGG
VGG is a CNN proposed by Simonyan and Zisserman in 201447,48, which demonstrates that increasing network depth can affect a network’s final performance to some extent. VGG, which finished second in the 2014 ImageNet Image Classification Contest, has demonstrated its superior performance. VGG 16 consists of 16 hidden layers with three different layers, including the convolution layer and maximum pool layer. VGG 16 replaces the larger convolution cores in AlexNet with successive 3 × 3 convolution cores. For a given receptive field, it is better to use a smaller convolution kernel than a larger convolution kernel; thus, the depth of the network is increased while keeping the receptive field fixed, and the effect of the neural network is thereby enhanced. The execution mode of VGG 16 in the paper is shown in (Fig. 4a).
The structure of VGG 8 is very simple, and the network uses the same convolutional core size and maximum pool size. However, as VGG increases in depth, it also increases the volume of the parameter space, resulting in a larger model than networks such as AlexNet and LeNet, and it has a longer training period. For this reason, we refer to the previous VGG 8 network structure with eight hidden layers, as shown in (Fig. 4b).

(a) Schematic diagram of the VGG 16 network architecture. (b) Schematic diagram of VGG 8 network architecture.
AlexNet
AlexNet was proposed by Krizhevsky et al.49. It is a relatively simple network using eight layers of CNNs, with the first five layers being convolution layers and the remaining three layers being fully connected layers, as shown in (Fig. 5). AlexNet can reduce the training time, prevent over-fitting, and increase the mutual information between adjacent data by introducing the ReLU activation function, pooling operation, and dropout operation. AlexNet has a deeper network structure than the original LeNet, which has allowed researchers to realize that the network depth has a large impact on performance, laying the foundation for the emergence of deeper networks in the future.

Schematic diagram of the AlexNet network architecture.
LeNet
LeNet is one of the first CNNs. In 1998, LeCun et al.50 first applied the LeNet CNN to image classification, with great success in handwritten digit recognition tasks. The structure of the LeNet network is shown in (Fig. 6). It has eight layers, namely, three convolution layers, two pooling layers and three fully connected layers. Average pooling was used as the pooling method, the activation function was the commonly used ReLU, and the dropout operation was added in the fully connected layer to prevent overfitting.

Schematic diagram of LeNet network structure.
VIT
The vision Transformer (VIT) was proposed by Dosovitskiy et al.51 to apply the Transformer to image classification tasks. As an attention-based encoder–decoder architecture, the Transformer has revolutionized the field of natural language processing (NLP) and has led to some groundbreaking work in computer vision (CV). The largest difference between the traditional CNN and VIT is the receptive field. Traditional CNNs usually have a small receptive field in the shallow layers, whereas VIT has a larger receptive field. The model structure of the VIT used in this paper is shown in (Fig. 7a). The model consists of three modules (embedding, transformer encoder, and MLP head). The embedding layer performs the preprocessing of the data, using a 16 × 16 convolutional kernel to convert the data into the desired data shape for the VIT. The Transformer encoder layer is essentially a 12-pass stack of the encoder block, as shown in (Fig. 7b), the layer norm is the normalization process for each token, and multi-head attention is the process of segmenting the data into self-attention for each token and then stitching them together. The dropout/droppath uses the dropout layer directly. The structure of the MLP block is shown in (Fig. 7c). It combines linear, GELU, and dropout layers. The MLP head layer converts the shape output from the Transformer encoder into the final classification result.

(a) Schematic diagram of the VIT network architecture. (b) Schematic diagram of the encoder block structure. (c) MLP block schematic diagram.
Ensemble learning
In the supervised learning algorithms of machine learning, the goal is to train a stable and well-integrated model, but in practice, it is only possible to obtain more than one model with a preference (which works better in some respects). Each learning period is called weakly supervised model. Ensemble learning combine several weakly supervised learning models according to a certain rule to obtain a better and more comprehensive strongly supervised model. If a single network model is thought of as a single researcher, the approach of ensemble learning is equivalent to gathering multiple researchers to analyze and make decisions for the same task, thus improving the predictive performance of multiple network models to avoid the instability of the prediction result caused by using a single model. The underlying idea of ensemble learning is that even if one classifier makes a wrong prediction, other classifiers can correct the error and increase the reliability of the prediction.
If the model used in the ensemble process is the same type, then the integration is homogeneous. The most common homogeneous ensemble algorithm is the random forest. If the different models are used, then the integration is heterogeneous. For example, the different CNN model algorithms are integrated. the idea of the ensemble learning algorithm is to learn from data sets using multiple models of homogeneity or heterogeneity, and then use a certain combination strategy to integrate the models, finally, an ensemble model with strong generalization ability is constructed to achieve the goal of “learning from the best”. It is proved by the practice of big data competition that the integration of multiple models can often achieve more stable and better performance than the single model (Fig. 8)52,53,54.

Schematic diagram of the concept of ensemble learning.
How to enhance the performance of weak models is always a hot research topic. Among them, the most classical algorithms in the integration of classification models are the average method and voting method. The average method is mainly divided into the simple average method and the weighted average method. The simple average method is to average the outputs of several weak learners directly to obtain the final predicted outputs. The weighted average method is to assign a weight to each learner, and then to average the outputs of all weak learners, take the values obtained as the final prediction results. There are many kinds of voting methods, including majority voting, plurality voting and weighted voting. The plurality voting method is to count the predicted results on the number of weak learners to the samples, the largest number of prediction categories will be recognized as the final classification category. The majority voting method requires counting the number of categories in the output, on the basis, the final category of output is confirmed not only by the highest number of votes in the category, but also by a majority of votes, or refuse to predict. The weighted voting method multiplies the corresponding weight for the votes of each weak classifier, and then accumulates the weighted votes, the category with the largest number is determined as the final category.
Considering that each heterogeneous ensemble algorithm has some limitations, in order to obtain more realistic prediction results in mineral resources prediction, in this study, 5 kinds of classical heterogeneous integration algorithms are studied in order to get the most practical prediction results by comparison.
Application and experiment
Data and data processing
The gold orebodies in the study area are mainly multi-layered in the lithologic sections of the Meiziya Formation of the Lower Silurian. The original Fe-rich and Au-bearing strata of the Meiziya Formation have been deposited in a reducing environment since the early Late Caledonian. In the Late Caledonian-Hercynian, tectonic movement in South Qinling and magmatic activity in the southern Niushan area resulted in the formation of an extensional detachment structure and dome. A series of large thrust nappe and ductile shear structures were formed under the influence of the Indosinian plate collision orogeny, and the original strata of the Meiziya Formation underwent regional metamorphism. During the Late Indosinian–Early Yanshanian orogeny, a large brittle-ductile shear zone was formed in the study area. At this stage, Au was enriched and mineralized. During the Middle–Late Yanshanian, the gold deposit was reformed by the Continental orogeny37,38,55. The known gold orebodies in the region mainly developed in the brittle-ductile shear zones, which control the spatial distribution of gold deposits, and the secondary fault fracture zone in the belt controls the specific production location of orebodies. According to the results of earlier researchers, the author, and his team, who have researched this area for many years, the gold deposit in this area is mainly controlled by a ductile shear zone, and can be classified as a structural altered rock type gold deposit controlled by a ductile shear zone. Based on the theory of mineral system, considering the information of source, pathway, and trap, combining the systemic study of regional geological background, mine area geological background, metallogenic and mineralized law and index in the Bawanggou mine area, ductile shear zone, brittle fault zone, alteration zone, metamorphic quartz sandstone zone, and 1:25000 geochemical data (Au, Ag, As, Cu, Pb, Zn, Hg, Sb, W, and Mo) were selected as the parameters for training the deep learning model.
To train a deep learning network model, it is necessary to construct a set of standard and objective training sample data. Without enough sample data to reflect the characteristics of the task, a deep neural network algorithm cannot be effectively trained, and it cannot effectively predict. Hence, it will lose its application value. Computers can’t read and understand raw geological data directly. Hence, special data processing is required to convert the collected training factors. Geological data generally contain spatial location information, and hence it is necessary to retain this important information in the data conversion. In reality, metallogenesis is a low-probability singular event, and it is difficult to meet the requirements of deep learning using the limited distribution of gold orebodies in the study area. A deep learning network needs enough positive and negative samples to extract features. Faced with these problems, this study proposes a complete data processing flow that includes drawing the basic data, gridding the data, labelling the positive and negative samples, and data augmentation processing (Fig. 9). ArcGIS software was used to draw the basic data, and the grid processing, labelling the positive and negative samples, and data enhancement processing were implemented in the Python programming language.

Schematic diagram of the data generation process.
Drawing the basic data
We used inverse distance weighted interpolation to convert geochemical element data into continuous concentration maps23,56,57 for input to the CNN for processing. However, for geological prospecting factors such as the fault zone, mineralization alteration body, quartz vein, and metamorphic quartz sandstone zone, if a geological map made directly from the original data reflecting the spatial positions and characteristic forms is input into the CNN, the relationship between geological factors such as the fault zone, mineralization alteration, and orebody cannot be clarified. We need to reflect the distance and influence between the geological factors and the orebodies on the geological map; therefore, the influence of the fault zone, mineralization alteration body, quartz vein, and metamorphic quartz sandstone zone on the orebodies can be quantified. The continuous buffer distance method58,59,60 can effectively preserve the influence of geological structure distance while retaining the location and direction information of the geological structure. In fact, geological factors at different positions do not have an equal influence on the orebody, and the tectonic location has the strongest influence on the formation of an orebody. In view of this, we introduced density information based on the buffer distance. The radiation range and intensity of areas with numerous fault developments or large exposed alteration areas are increased to simulate the impact of structural phenomena on the orebody as much as possible. This method eliminates the loss of development intensity information caused by the discrete buffer distance and simulates the control of the fault zone on the orebody as much as possible. Finally, we plotted a series of 10 geochemical element concentration maps and buffer distance density maps of the geological factors (Figs. 10 and 11).

Soil geochemical element concentration maps.

Buffer distance density maps of the geological factors.
Data gridding processing
To help the deep learning model to fully learn the characteristics of mineralization, grid-based training samples for the deep learning models were produced. In Fig. 9b, we divided the whole study area into 40 parts at 20 m east–west intervals and 16 parts at 23 m south–north intervals. In this study, 14 factors related to gold mineralization were selected, not all of them covered the entire study area, there is a blank area in the lower left corner. In order to ensure the principle of data consistency, we had to eliminate the small study areas that were missing some kind of data. In the end, this generated 568 small, area-based samples for each predictor, each of which is a 606 × 716 × 3 pixel RGB image. Since the RGB image is three-channel data, each small sample is a digital matrix of 606 × 716 × 3. The RGB image data of each small block are combined into a digital matrix 12 × 606 × 716 × 3 in size according to the density maps of the structure buffer zones between ductile shear zones and brittle faults, the density maps of buffer distance between the alteration zone and metamorphic quartz sandstone zone, and the concentrations maps of 10 geochemical elements. A total of 568 basic data were generated.
Labeling positive and negative samples
The establishment of objective and systematic datasets of ore-bearing and non-ore-bearing samples in the study area is very important for the training of the deep learning network and the final prediction results. Hence, the grid cell of an area in the study area where a known gold orebody is located is usually considered to be a positive sample. Previous studies have treated orebody and mineralization factors to divide the training data into positive and negative samples. As a result, too much information about the orebody distribution is lost and the prediction result is inaccurate. According to the known spatial distribution of the four orebodies, the area through which the orebody passes is considered to be a positive sample. To determine negative samples, the grid cell of an area without an orebody cannot be simply considered as a negative sample. It is possible that the target area actually contains ore, but no orebody has yet been found by existing research. The results of comprehensive drilling and trenching verification are used to confirm that an ore-free grid area is a negative sample. The remaining uncertain grid regions are identified as unknown samples. In total, 331 negative samples, 30 positive samples, and 207 unknown samples were obtained.
Data enhancement processing
Because deep learning networks often require a large number of data samples for training, it is clear that the number of our basic data does not meet the model training requirements. Hence, data enhancement is needed to expand our dataset. There are many ways to enhance data, such as flipping, rotating, twisting, scaling, brightness adjustment, contrast adjustment, and Gaussian noise. However, methods such as flipping, rotating, scaling, and distortion may change the spatial location information of geological data, and adjusting the brightness, adjusting the contrast, and increasing Gaussian noise can directly alter real geological information. By contrast, the cropping method only generates data on the basis of the original data and does not change the geological location information and authenticity. Hence, the cropping method was used in this study to expand the dataset. The data in different formats are first grayed out, and the sample blocks of 32 × 32 pixels61 are repeatedly trimmed from each sample of 606 × 716 pixels. Considering the density of the geochemical data and the radiation range of the geological structures, the 32 × 32 pixels area is about 1 m×1 m in size, which basically covers the structure influence area, and ensures that the resulting positive samples are ore-bearing during the data enhancement. The cropping window moves along the X-axis in intervals of a pixel and along the Y-axis in intervals of b pixels. The operation is repeated N times to multiply the original data N times. For positive sample data, N is set to 50 (a is set to 12 and b is set to 24) to obtain 1500 positive samples. For negative sample data, N is set to 10 (a is set to 32 and b is set to 64) to obtain 3310 negative samples. The unknown sample is unified into a standard size of 32 × 32 pixels by central trimming. Finally, 80% of the enhanced positive and negative samples were randomly allocated to a training dataset for model training and the remaining 20% were allocated to a test dataset for model accuracy verification.
Experiment design
We used networks with six different depths and architectures to study the correlation between gold metallogenic areas and selected metallogenic factors and compared the training performance and model accuracy of different networks. We set the batch size to 16, the optimizer to Adam, and the momentum parameter to 0.9 to update the weights and deviance of the networks. The maximum learning rate was set to 0.0001 and the minimum learning rate was set to 0.00001. The learning rate was automatically adjusted using the cos learning rate descent method, and the data were read by eight threads and iterated 50 times. The Colab cloud computing platform, an online workbench provided by Google that allows users to execute Python code directly from the browser, was used. Colab offers GPU computing power for free as well as storage capabilities tied to Google Drive.
Results and discussion
As deep learning network have evolved and improved, we studied the impact of different architectures of neural networks on the prediction of gold orebodies. To use the training samples to extract the intrinsic relationships between the metallogenic indication characteristics of gold orebodies and the known spatial location of gold deposits in the study area, we analyzed the performance of MobileNet V2, ResNet 50, VGG 16, AlexNet, LeNet, and VIT. The network models were trained using 3848 training samples, and the network performance was obtained using 962 test samples. Finally, 207 unknown samples were used to realize the effective prediction of gold orebodies in the study area.
Training of the deep learning network model
We used the loss curve to evaluate whether the deep learning algorithms could extract the relationship between the indication characteristics of gold orebodies and the spatial location of the gold orebodies. If training loss and testing loss are decreasing, then the network is still learning. If training loss is decreasing and testing loss tends to be constant, then the network is overfitting. If training loss and testing loss tend to be constant, then this indicates a learning bottleneck. If training loss and testing loss are increasing, then the network parameters have not been set properly. After training, according to the experimental design, we obtained the loss curve (Fig. 12). The curve features of different network models tend to converge during the training process, and there is no fitting feature. In the training process, each network can quickly converge to a smaller loss value and obtain a smaller reconstruction error. These results indicate that the six models with different architectures and depths can effectively extract the intrinsic relationship between the gold ore-forming indicators and the distribution of gold orebodies.

Loss curves of the training process for the deep learning network models.
Performance analysis of the deep learning network models
The six network models we used can successfully extract the characteristics of the metallogenic factors, and the loss value of the model converges to a very small value. We evaluated the performance of the validation and test models using a confusion matrix and several evaluation indicators (precision, recall, F1-score, accuracy, mean precision, mean recall, and mean F1-score; Table 1; Fig. 13). The result shows that the accuracy of the ResNet 50 model is the highest (96.92%), followed by MobileNet V2 (96.35%). The highest recall in the ore-bearing category is 96.06% for MobileNet V2, and 95.76% for VGG 16. The networks with the highest accuracy are ResNet 50 and MobileNet V2. ResNet 50 had the highest mean precision (97.40%). The network with the highest mean recall is the MobileNet V2. The networks with the highest mean F1-score is MobileNet V2. On the whole, the better the feature extraction performance, the better the deep learning network model prediction performance. However, the prediction performance of the six network architectures after multiple iterations of training and adjustment is not much different, and each network has a good prediction performance. Models with scores over 94% in all evaluation indexes can be used for metallogenic prediction.

Confusion matrix.
Model integration and analysis
According to the above analysis, the six network models can be used to predict mineral resources, and unknown regional samples can be input into the network model in turn to obtain the prediction results of each small block. Then, according to the prediction results, a map of the regions that are favorable for ore forming is made. The redder the color, the higher the ore-forming potential, whereas green represents medium ore-forming potential, and blue represents the no or low ore-forming potential, as shown in (Fig. 14). Six network models predicted large-area ore-forming potential areas in the middle and northwest of the study area, and some narrow ore-forming potential areas are scattered in the east and south of the study area. As a whole, the known orebody positions in the prediction results of each model are almost all contained in the high potential ore-forming areas. In addition, the distribution of the favorable areas is similar, but there are differences in statistical structure and spatial distribution details. Objectively, it is inevitable that the six trained ore-forming prediction models will have different results in the generalization of prediction. It is obviously not advisable to assume the results of a single model are reliable.

Prediction results of the deep learning network models.
From a statistical point of view, because the hypothesis space of a deep learning task is often large, the training set for the Bawanggou gold mine may include several hypotheses that achieve the same performance. Hence, if only a single learning network is used at this time, it may cause poor generalization performance because of misselection, and combining multiple network models will reduce this risk. From a computational point of view, there may be more than one local minima when solving the same problem, and some local minima lead to weak generalization ability. From an output point of view, the ore-forming hypothesis of the learning task for gold prediction may not be in the hypothesis space provided by the current network model. By combining multiple network models, that is, multiple hypothesis spaces, better approximations can be learned with greater probability. This paper adopts the idea of ensemble learning. Using the results of the six well-trained deep learning models for gold mineralization prediction, a heterogeneous ensemble learning method is developed to predict likely ore-forming areas in the Bawanggou gold mine area according to the above-mentioned combined strategies. The prediction results are shown in (Fig. 15).

Prediction results for areas favorable for ore forming obtained by the ensemble learning model.
The known ore deposits in the mineral prospectivity map generated by the ensemble learning method are in good agreement with the high potential ore-forming areas. Moreover, the predicted results are in agreement with each other. According to the statistical results of the ore-bearing samples in the prediction results of Table 2, the ensemble learning method predicted completely correctly the known ore-bearing areas and non-ore-bearing areas. However, the results of a single deep learning ore-forming prediction model are very different, and there are always some cases in which ore-bearing areas are predicted in low ore-forming potential areas.
As far as the number of ore-bearing areas is concerned, it represents the maximum ore-bearing areas predicted by the algorithm in the study area. The standard deviation of the prediction results for six single CNN algorithms is 3.83, and the coefficient of variation is 0.08, after the model integration by ensemble learning, the standard deviation decreases to 2.48, and the coefficient of variation decreases to 0.05, which indicates that ensemble learning further confirms the maximum ore-bearing range predicted by the model. The number of ore-bearing area the unknown area is predicted show that the model further makes the ore-forming prediction for the unknown area based on the study of the known orebody position, this is obviously the most unstable but critical part of the model algorithm. The standard deviation of a single network before integration is 5.89, and the coefficient of variation is 0.28. After the model integration, the standard deviation and the coefficient of variation decrease to 0.28 and 0.14 respectively. The effect is obviously significant, and the ensemble learning obviously enhances the ability of the algorithm to predict the ore-forming of unknown areas. As for the two cases where the actual ore-bearing prediction is also ore-bearing and the actual non-ore-bearing prediction is ore-bearing, we hope that the prediction of the algorithm is as correct and stable as possible. In Table 2, a single algorithm often makes mistakes, but when the model is integrated, even if there are always mistakes, they will be corrected by other predicted correct algorithms. At the same time, compared with the research achievements of the predecessors, it was found that many scholars used a single convolutional neural network model for prediction, and some scholars used multiple models for experiment, but most experiments used these models as comparison experiments to highlight the merits of a particular model. At last, a network with relatively good performance was used to predict mineral resources for the study area, and the models with other structures were often ignored3,19,20,21,22,23,24,25. Therefore, the method of ore-forming prediction based on ensemble learning not only alleviates the problem of unstable prediction results, but also improve the network prediction ability.
Ore-forming potential area prediction
The plurality voting and majority voting methods return the majority prediction results of the six different deep learning models. These results represent the ore-forming areas with the most potential and stability in the Bawanggou gold mine area. The simple average method returns the average of the six models in the ensemble, which represents the largest prediction range of the Bawanggou gold mine area. The weighted average and weighted voting methods take into account the prediction accuracy of different models. These methods not only highlight the local anomalies common to the prediction results of multiple networks, but also retain the specific differences of the prediction results of different models, and the rationality of the forecast result is ensured. On the basis of the mineral prospectivity map, the four most favorable prospecting prediction areas are delineated in the Bawanggou gold mine area (Fig. 16).

Distribution map of prospectivity and target areas predicted by the ensemble learning model.
The results show that the high ore-forming potential areas are mainly distributed in the north and northwest of the study area, which are highly consistent with the known distribution of gold orebodies and are mainly controlled by the brittle faults. The prediction areas I and II are highly consistent with the distribution of the known orebodies and are controlled by several brittle faults. The main outcrops are the second layer of the third lithological section in the Meiziya Formation of the Lower Silurian. There are a lot of quartz veins and limonite mineralization, and there are many mineralization alteration zones, which reflect a great prospecting potential. The prediction areas III and IV are relatively close to the DSZ2 brittle-ductile shear zone, and there are some secondary faults (F3, F4, F5, etc.) superposition. Although no large-scale orebody has been found in the area, there is still a prospecting potential that can’t be ignored.
Conclusions
-
(1)
Considering that metallogenic factors cannot be directly input into the network for feature extraction and learning without a uniform format, we first used the inverse distance weighted interpolation method to transform geochemical elements into continuous concentration maps. The distribution characteristics of fault zones and mineralization alteration bodies were transformed into a buffer distance density map using the continuous buffer density distance method. Then, the study area was partitioned to generate small sample area data, which is convenient for labelling positive and negative samples. To solve the problem that models cannot be trained because of insufficient data, a data enhancement operation was carried out using the cropping method. Finally, the data were fed into six different deep learning networks to extract the deep correlation characteristics between gold deposit locations and the ore-forming factors, and six predictive models with accuracies over 94% were obtained by parameter training.
-
(2)
The unknown areas of the Bawanggou gold field in Northern Hanyin, South Qinling, China, were predicted by the six trained deep learning models. Then, the prediction result of each potential area was determined using ensemble learning. The ensemble learning method predicted completely correctly the known ore-bearing areas and non-ore-bearing areas. However, the results of each deep learning ore-forming prediction model are very different, and there are always some cases in which ore-bearing areas are predicted in areas with low ore-forming potential. Therefore, the method of ore-forming prediction based on ensemble learning not only alleviates the problem of unstable prediction results, but also improves the networks’ prediction ability.
-
(3)
Considering that the deep learning algorithm can extract the intrinsic relationship between the ore-causing factors and ore-forming characteristics, using previous research results, a prediction model based on multiple deep learning was proposed, and ensemble learning was used to obtain the gold deposit prediction areas in this study. This method takes into account that the different architectures and depths of the network models used to learn the relationship between metallogenic factors and metallogenic characteristics lead to different results.
Data availability
All the data generated or analyzed during this study are included in the paper.
References
Zhao, P. D. Quantitative mineral prediction and deep mineral exploration. Earth Sci. Front.14 (5), 1–10 (2007).
Yuan, F. et al. Three dimension prospectivity modelling based on integrated geoinformation for prediction of buried orebodies. Acta Geol. Sin.88 (4), 630–643 (2014).
Liu, Y. P., Zhu, L. X. & Zhou, Y. Z. Experimental research on big data mining and intelligent prediction of prospecting target area-application of convolutional neural network model. Geotecton. Metallog.44 (2), 192–202 (2020).
Mayer-Schönberger, V. & Cukier, K. Big data: A Revolution that will Transform how we live, work, and Think (Houghton Mifflin Harcourt, 2013).
Zhang, Q. & Zhou, Y. Z. Big data will lead to a profound revolution in the field of geological science. Chin. J. Geol.52 (3), 637–648 (2017).
Zhang, Q. & Zhou, Y. Z. Big data helps geology develop rapidly. Acta Petrologica Sinica34 (11), 3167–3172 (2018).
Luo, J. M. & Zhang, Q. Big data pioneers new ways of geoscience research: identifying relevant relationships to enhance research feasibility. Earth Sci. Front.26 (4), 6–12 (2019).
Zuo, R. G. Data science-based theory and method of quantitative prediction of mineral resources. Earth Sci. Front.28 (3), 49–55 (2021).
Wang, D. H., Liu, X. X. & Liu, L. J. Characteristics of big geodata and its application to study of minerogenetic regularity and minerogenetic series. Mineral. Depos.34 (6), 1143–1154 (2015).
Zhou, Y. Z. et al. Advances and prospects of big data and mathematical geoscience. Acta Petrol. Sinica34 (2), 255–263 (2018).
Zhou, Y. Z., Zhang, L. J., Zhang, A. D. & Wang, J. Big Data Mining and Machine Learning in Geoscience (National Sun Yat-sen University, 2018).
Hinton, G. E., Osindero, S. & The, Y. A fast learning algorithm for deep belief nets. Neural Comput.18, 1527–1554 (2006).
Hinton, G. E. et al. The shared views of four research groups. IEEE. Signal. Process. Mag.29 (6), 82–97 (2012).
Brenden, M., Ruslan, S. & Joshua, B. Human-level concept learning through probabilistic program induction. Science350 (6266), 1332–1338 (2015).
LeCun, Y., Bengio, Y. & Hinton, G. E. Deep learning. Nature521 (7553), 436–444 (2015).
Schmidhuber, J. Deep learning in neural networks: an overview. Neural Netw.261, 85–117 (2015).
Bianco, S., Buzzelli, M., Mazzini, D. & Schettini, R. Deep Learn. Logo Recognit. Neurocomput.245, 23–30 (2017).
Zhou, Y. Z. et al. Machine learning, deep learning and python language in field of geology. Acta Petrol. Sinica34 (11), 3173–3178 (2018).
Liu, Y. P., Zhu, L. X. & Zhou, Y. Z. Application of convolutional neural network in prospecting prediction of ore deposits: taking the Zhaojikou Pb-Zn ore deposit in Anhui province as a case. Acta Petrol. Sinica34 (11), 3217–3224 (2018).
Zuo, R. G., Peng, Y., Li, T. & Xiong, Y. H. Challenges of geological prospecting big data mining and integration using deep learning algorithms. Earth Sci.46 (1), 350–358 (2021).
Yang, N., Zhang, Z. K., Yang, J. H., Hong, Z. L. & Shi, J. A convolutional neural network of GoogLeNet applied in mineral prospectivity prediction based on multi-source geoinformation. Nat. Resour. Res.30 (6), 3905–3923 (2021).
Yang, N., Zhang, Z. K., Yang, J. H. & Hong, Z. L. Mineral prospectivity prediction by integration of convolutional autoencoder network and random forest. Nat. Resour. Res.31 (3), 1103–1119 (2022).
Yang, N., Zhang, Z. K., Yang, J. H. & Hong, Z. L. Applications of data augmentation in mineral prospectivity prediction based on convolutional neural networks. Comput. Geosci.161, 1–15 (2022).
Ding, K., Xue, L. F., Ran, X. J., Wang, J. B. & Yan, Q. Siamese network based prospecting prediction method: a case study from the au deposit in the Chongli mineral concentrate area in Zhangjiakou, Hebei province, China. Ore Geol. Rev.148, 1–15 (2022).
Wang, H. J. Mineral Prospectivity Mapping Based on Convolutional auto-encoder Neural Networks: A case Study of Yawan-Daqiao Au-Sb mine Concentration area (Jilin University, 2022).
Chen, J. X. & Chen, Y. L. A high-performance voting-based ensemble model of graph convolutional extreme learning machines for identifying geochemical anomalies related to mineralization. Ore Geol. Rev.162, 1–14 (2023).
Esmaeiloghli, S., Lima, A. & Sadeghi, B. Lithium exploration targeting through robust variable selection and deep anomaly detection: an integrated application of sparse principal component analysis and stacked autoencoders. Geochemistry 1–13 (2024).
Liu, Z. K. et al. C. 3D mineral prospectivity modeling in the Sanshandao goldfield, China using the convolutional neural network with attention mechanism. Ore Geol. Rev.164, 1–15 (2024).
Soltani, Z., Hassani, H. & Esmaeiloghli, S. A deep autoencoder network connected to geographical random forest for spatially aware geochemical anomaly detection. Comput. Geosci.190, 1–14 (2024).
Zuo, R. G. Deep learning-based mining and integration of deep-level mineralization information. Bulletin of mineralogy. Petrol. Geochem.38 (1), 53–59 (2019).
Wu, W. R., Wang, B. Y. & Feng, M. S. Formation and Evolution of the Ductile Shear zone in the Central Qinling Orogenic belt of Shaanxi Province and its Relationship with gold Mineralization (Shaanxi Bureau of Geology and Mineral Resources, 1991).
Yang, X. K. et al. Study Report on Silurian rock gold ore Field Structure and Rapid Evaluation Exploration Methods in Tiefo of Hanyin-Liufang of Hanbin District, Ankang of Shaanxi (Chang’an University, 2012).
Yang, X. K. et al. Special Mapping and Exploration Prospecting in Shiquan-Xunyang gold Deposits Package Exploration area, Shaanxi Province (Chang’an University, 2016).
Yang, X. K. et al. The structural deformation and tectonic evolution of intra-continental progeny in South Qinling orngen: structural deformation analysis of the northern part of Shiquan-Hanyin belt in the late Indosinian-Yanshanian period. Earth Sci. Front.23 (4), 72–80 (2016).
Yang, X. K. et al. Intracontinental orogenic structure-altered lithofacies mapping and prospecting model of the changgou gold deposit in the Hanyin gold orefield, South Qinling. Geol. Bull. Ch.39 (11), 1715–1725 (2020).
He, H. J. et al. Controls on the formation of the changgou gold deposit and implications for exploration within the North Hanyin area, South Qinling Mountains, China. Geol. J.54 (4), 2431–2446 (2019).
Han, K., Yang, X. K., He, H. J., Chao, H. X. & Zhang, W. S. Timing of structural deformation and age of mineralization in the northern Shiquan-Hanyin gold orefield, South Qinling belt, China: constraints from zircon U-Pb and biotite 40Ar-39Ar isotope dating. Ore Geol. Rev.125, 1–16 (2020).
Han, K. et al. Characteristics of ore-controlling brittle-ductile shear zone and ages of deformation and mineralization in the Northern Hanyin gold field, South Qinling, China. Geotecton. Metallog.44 (5), 801–818 (2020).
Hu, J. M. et al. Mesozoic deformations of the Dabashan in the southern Qinling orogen, central China. J. Asian Earth Sci.47, 171–184 (2012).
Li, J. H., Zhang, Y. Q., Dong, S. W. & Shi, W. Structural and geochronological constraints on the mesozoic tectonic evolution of the North Dabashan zone, South Qinling, central China. J. Asian Earth Sci.64, 99–114 (2013).
Feng, M. S. & Yang, J. D. Basic characteristics of ductile nappe structure and its ore-control of gold deposit in North Ankang. Geol. Shaanxi12 (1), 17–26 (1994).
Shaanxi Geology and Mining First Geological Team Co. LTD. General Survey Report of Bawanggou gold Deposit in Hanyin County, Ankang, Shaanxi Province, China (Ankang, 2021).
Wei, X. C. Analytic deep Learning: Convolutional Neural Network Principles and Visual Practice (Publishing House of Electronics Industry, 2018).
Ge, C. et al. Tectonic discrimination based on convolution neural network and big data of volcanic rocks. Earth Sci. Front.26 (4), 22–32 (2019).
Sandler, M., Howard, A., Zhu, M. L., Zhmoginov, A. & Chen, L. C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 4510–4520 (2018).
He, K. M., Zhang, X. Y., Ren, S. Q. & Sun, J. Deep residual learning for image recognition. ImageNet Large Scale Visual Recognit. Chall.2015, 1–12 (2015).
Simonyan, K. & Zisserman, A. Two-stream convolutional networks for action recognition in videos. Proc. NIPS, 1–11 (2014).
Simonyan, K. & Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. International Conference on Learning Representations (ICLR) 2015, 1–14 (2015).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems 25, Neural Information Processing Systems 2012, 1–9 (2012).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE86 (11), 2278–2324 (1998).
Dosovitskiy, A. et al. An image is worth 16x16 words: transformers for image recognition at scale. ICLR2021, 1–21 (2021).
Liu, Y. J. Research on Spam Detection Based on Heterogeneous Ensemble Learning (Yanshan University, 2019).
Gong, W. J. Research and Application of Lithology Identification Based on Ensembling Learning (Northeast Petroleum University, 2022).
Luo, S. Y. Research on Text Sentiment Analysis Based on Neural Network and Ensemble Learning (Wuhan Institute of Technology, 2022).
Gao, Y. N. Study on Regularity and Pattern for Structure-Magma-Metallogenic of Gold Ore-field in Intracontinental Orogeny Phase, North Hanyin, South Qinling (Chang’an University, 2017).
Xiong, Y. H. & Zuo, R. G. Recognition of geochemical anomalies using a deep autoencoder network. Comput. Geosci.86, 75–82 (2016).
Zuo, R. G. & Xiong, Y. H. Big data analytics of identifying geochemical anomalies supported by machine learning methods. Nat. Resour. Res.27 (1), 5–13 (2017).
Xiong, Y. H. & Zuo, R. G. GIS-based rare events logistic regression for mineral prospectivity mapping. Comput. Geosci.111, 18–25 (2018).
Xiong, Y. H., Zuo, R. G. & Carranza, E. J. M. Mapping mineral prospectivity through big data analytics and a deep learning algorithm. Ore Geol. Rev.102, 811–817 (2018).
Sun, T., Chen, F., Zhong, L. X., Liu, W. M. & Wang, Y. GIS-based mineral prospectivity mapping using machine learning methods: a case study from Tongling ore district, eastern China. Ore Geol. Rev.109, 26–49 (2019).
Hengl, T. Finding the right pixel size. Comput. Geosci.32 (9), 1283–1298 (2006).
Acknowledgements
This work was financially supported by the Natural Science Foundation of Shaanxi Province (2023-JC-YB-261 and 2023-JC-YB-276), the Geological Survey Projects of the Geological Survey Bureau of China (12120114014201).
Author information
Authors and Affiliations
Contributions
H.H. conceived and designed the study and wrote the paper. H.Z. analyzed and interpreted the data. X.Y. took part in the field research and interpreted the geological background. W.Z. and J.W. collected and interpreted the data. All authors gave their final approval of the manuscript version to be submitted.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
He, H., Zhu, H., Yang, X. et al. Mineral prospectivity prediction based on convolutional neural network and ensemble learning. Sci Rep 14, 22654 (2024). https://doi.org/10.1038/s41598-024-73357-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-73357-0
Keywords
This article is cited by
-
Unsupervised AI-Driven MPM: Application of K-Means, K-Medoids and Self-Organizing Maps
Journal of the Indian Society of Remote Sensing (2025)
-
Comparative analysis of deep learning architectures for multi-class mineral classification: a study using EfficientNet and ResNet models
Earth Science Informatics (2025)
-
Anomaly Detection-Oriented Positive-Unlabeled Metric Learning for Extracting High-Dimensional Geochemical Anomalies Linked to Mineralization
Natural Resources Research (2025)
-
Machine-learning crystal size distribution for volcanic stratigraphy correlation
Scientific Reports (2024)
