
Abstract
Drone aerial imaging has become increasingly important across numerous fields as drone optical sensor technology continues to advance. One critical challenge in this domain is achieving both accurate and efficient multi-object tracking. Traditional deep learning methods often separate object identification from tracking, leading to increased complexity and potential performance degradation. Conventional approaches rely heavily on manual feature engineering and intricate algorithms, which can further limit efficiency. To overcome these limitations, we propose a novel Transformer-based end-to-end multi-object tracking framework. This innovative method leverages self-attention mechanisms to capture complex inter-object relationships, seamlessly integrating object detection and tracking into a unified process. By utilizing end-to-end training, our approach simplifies the tracking pipeline, leading to significant performance improvements. A key innovation in our system is the introduction of a trajectory detection label matching technique. This technique assigns labels based on a comprehensive assessment of object appearance, spatial characteristics, and Gaussian features, ensuring more precise and logical label assignments. Additionally, we incorporate cross-frame self-attention mechanisms to extract long-term object properties, providing robust information for stable and consistent tracking. We further enhance tracking performance through a newly developed self-characteristics module, which extracts semantic features from trajectory information across both current and previous frames. This module ensures that the long-term interaction modules maintain semantic consistency, allowing for more accurate and continuous tracking over time. The refined data and stored trajectories are then used as input for subsequent frame processing, creating a feedback loop that sustains tracking accuracy. Extensive experiments conducted on the VisDrone and UAVDT datasets demonstrate the superior performance of our approach in drone-based multi-object tracking.
Similar content being viewed by others

Introduction
With the rapid advancement of drone remote sensing technology, the application scope of drone aerial imagery has significantly widened, encompassing crucial domains such as environmental monitoring, urban planning, agricultural management, and disaster relief1. In these application scenarios, accurate and efficient tracking of multiple objects in aerial imagery is paramount. Multi-object tracking technology provides real-time information about object positions and movement trajectories, offering vital data support for decision-makers2,3. However, drones face many challenges when performing complex tasks, such as accurately tracking small objects on the ground (such as wildlife, pedestrians, or specific objects). Drones frequently change their perspective and position during mission execution, resulting in rapid changes to the appearance and position of the tracked object in the image. Traditional algorithms struggle to maintain stable tracking in such dynamic environments. When drones fly at high altitudes, they often face more complex and varied backgrounds than on the ground and are easily obstructed by objects such as trees and buildings. This increases the difficulty of object detection and tracking. Drones are constrained by their payload and energy consumption, so the demand for computing resources and communication bandwidth must be as low as possible. Therefore, algorithms need to minimize computational complexity and data transmission while ensuring performance.
Traditional multi-object tracking methods heavily rely on manually designed feature extractors and complex tracking algorithms, often exhibiting subpar performance when dealing with complex backgrounds and occlusion scenarios4. In recent years, deep learning technology has provided new solutions for multi-object tracking. Deep learning models such as convolutional and recurrent neural networks have made significant strides in multi-object tracking5,6,7. However, these methods typically involve separating object detection from tracking into two independent steps, which increases computational complexity and may lead to decreased tracking performance8.
To overcome these challenges, researchers have begun exploring end-to-end multi-object tracking methods, integrating object detection and tracking tasks into a unified model, aiming for one-stop solutions9,10,11. In this context, the Transformer model has made breakthrough progress in various domains, including natural language processing and computer vision, due to its robust feature representation capabilities and self-attention mechanism. The Transformer model can capture global dependency relationships, offering inherent advantages in handling complex backgrounds and inter-object interactions in aerial imagery12.
Hence, we present End-to-End Drone Multiple Object Tracking (ETDMOT), a novel approach utilizing Transformers to efficiently and accurately track multiple objects in drone aerial footage. By integrating object detection and tracking into a unified Transformer framework, our approach leverages self-attention mechanisms to capture complex relationships among objects, significantly enhancing the tracking pipeline. The primary contributions of this work are as follows:
-
(1)
Object Detection and Long-term Tracking Matching (ODLTM) We introduce ODLTM to address the challenges of object matching discrepancies, such as missing objects and non-overlapping matches. By utilizing a Gaussian distribution to model the effective response field of feature points, we calculate the similarity between detections and trajectories using receptive field distance. This comprehensive method enhances both precision and robustness in tracking.
-
(2)
Cross Frame Self-Attention Mechanism (CF-SA) The CF-SA mechanism accurately retrieves rich semantic information from recorded trajectories, capturing both horizontal and vertical details through strip attention. Techniques like linear projection and attention processes combine horizontal and vertical features, yielding a thorough representation of the object’s trajectory for more precise tracking.
-
(3)
Enhanced Self Characteristics (ESC) ESC is designed to achieve semantic alignment by leveraging residual-form multi-head self-attention. This module optimizes individual feature extraction by incorporating information from various points on the feature map. The inclusion of a sine function encoding method addresses the challenge of position discrimination in attention mechanisms, resulting in semantically aligned feature maps and improved tracking performance.
-
(4)
Storage Attention Layer This layer ensures object consistency and stability by extracting long-term characteristics from all previous object states. A long-term memory vector, updated using an exponential decay moving average, facilitates information sharing between objects with different IDs. This process improves feature representation, ensuring accurate and continuous tracking across frames by preserving past state data.
Our approach innovatively combines object detection and tracking into a unified pipeline, streamlining the process and enhancing both accuracy and efficiency. Through the use of self-attention mechanisms, ETDMOT is able to capture complex relationships between objects, making it particularly well-suited for dynamic and cluttered environments typical of drone footage.
Related work
Multiple object tracking
Multi-object tracking (MOT) technology has garnered significant attention due to its wide-ranging applications, sparking considerable interest among scholars13. In the early stages of research, scholars primarily focused on utilizing optimization algorithms to deduce object trajectories. One of the simplest MOT methods is IOUTracker, which relies solely on the intersection over the union of bounding boxes to achieve object tracking14. Over time, researchers gradually introduced motion models and Kalman filters to predict object positions in the next frame. Despite these improvements enhancing speed and performance, MOT algorithms still exhibit unsatisfactory performance in complex occlusion and object loss scenarios15. To overcome these challenges, researchers began incorporating re-identification (ReID) features as appearance models, utilizing visual features of objects across different frames to match objects and improve the correlation accuracy between trajectories and detection results16. Apart from ReID, some studies utilize image segmentation techniques for object identification and tracking to handle occlusion scenarios better17.
Additionally, some researchers have started using recurrent neural networks or attention mechanisms to model the spatiotemporal relationships between objects to enhance tracking accuracy and stability. Recently, attention mechanisms and recurrent neural networks have been used to model spatiotemporal relationships between objects, improving tracking accuracy and stability. However, many of these methods rely on a single matching strategy and fail to consider the diverse attributes of different object types, leading to suboptimal performance. Complex combinations of motion, appearance, and spatiotemporal features further reduce effectiveness, especially in dynamic environments. To address these limitations, we propose ETDMOT framework that unifies detection and tracking within a Transformer-based architecture. This approach leverages self-attention mechanisms to capture intricate relationships between objects, providing a more robust and efficient solution for multi-object tracking in drone-based footage.
Object feature-based multi-object tracking methods
As a result of the rapid development of object detectors, feature-based modeling has become widely used in drone-based multi-object tracking algorithms. It achieves multi-object tracking by capturing unique features of objects, such as color, texture, and optical flow. These extracted features must be distinctive to ensure their effective differentiation in feature space, enabling the identification of the most similar objects in the next frame based on similarity criteria. SCTrack employs a three-stage data association method, integrating object appearance models, spatial distance, and explicit occlusion handling units. The system relies on tracked objects’ motion patterns and takes environmental constraints into account, demonstrating exemplary performance in handling occluded objects18. The OSIM network trains a vast residual network on the VeRi dataset to extract object appearance features. They use the Mahalanobis distance of detected bounding boxes as a motion metric and compute the minimum cosine distance of pixels inside bounding boxes as an appearance similarity metric. By combining and weighting these two metrics and using cascade matching to connect data, we can do strong multi-object tracking19. Appearance, similarity, and consistency are often fused to address the subjective setting of fusion proportions between appearance and motion. We find out how similar two objects look to other objects nearby and use the social LSTM network to guess how they will move. Then, we use the weighted appearance similarity and motion prediction to make connections between this object and the object from the previous frame20.
Despite advancements, existing feature-based multi-object tracking methods face key limitations: high computational costs, making real-time tracking in drone footage challenging; frequent false detections due to dynamic aerial environments; and complex object association, as balancing appearance and motion features can be inconsistent and subjective. These challenges highlight the need for improvement in scalability, accuracy in cluttered environments, and unified feature integration. To address these issues, our approach, ETDMOT, integrates detection and tracking while introducing innovations such as Enhanced Self Characteristics (ESC), which improves semantic alignment by optimizing feature extraction across frames. Combined with CF-SA’s powerful feature extraction and the Storage Attention Layer for long-term consistency, ETDMOT addresses these limitations, optimizing both accuracy and computational efficiency in drone-based environments.
Joint detection and tracking multi-object methods
To enhance the operational speed of the entire drone aerial multi-object tracking system, researchers actively explore methods that combine object detection and feature extraction to achieve greater levels of sharing in computation. JDE is the first work to attempt this approach, innovatively integrating the feature extraction branch into the YOLOv3 single-stage detector21. FairMOT balances the handling between detection and recognition tasks more evenly by reducing anchor ambiguity using the anchor-free detector CenterNet22. In addition to these joint detection and feature embedding methods, other single-stage trackers have emerged. GLOA creates global-local perception blocks that take in input frames and extract scale variance feature information. It then adds identity embedding branches to prediction heads to get more discriminative identity information23. CenterTrack24 and Chained Tracker25 predict bounding boxes in consecutive frames using a multi-frame approach to facilitate efficient short-term correlation, ultimately forming long-term object trajectories. However, these methods often suffer from numerous identity switches due to difficulties in capturing long-term dependency relationships. Moreover, these methods cannot simultaneously consider the multiple features of objects and the differences in features between different categories, making the tracking of small objects prone to loss. SOE-Net26 incorporates long-range context into pointwise local descriptors. The CASSPR method27 takes out and groups low-resolution data through a sparse voxel branch and gets detailed local data through a pointwise branch. Text2Loc28 uses max pooling and hierarchical transformers to find the global locations of things. It does this by keeping the balance between positive and negative samples through text subgraph contrastive learning and capturing the changing relationships between each sample.
Despite advancements, joint detection and tracking methods face key limitations: frequent identity switches due to difficulties in maintaining long-term dependencies, inadequate handling of diverse object features (especially for small or distinct objects), and limited long-term tracking capabilities. These issues undermine tracking performance, particularly in complex drone environments. By leveraging ODLTM’s precise matching and the Storage Attention Layer’s memory-driven tracking, ETDMOT significantly reduces identity switches and enhances long-term tracking accuracy. These contributions, coupled with the self-attention mechanism, enable better tracking of diverse object features, improving overall efficiency and performance in drone-based applications.
Transformer-based multi-object tracking methods
In recent years, Transformer-based models have achieved tremendous success in computer vision, particularly excelling in object detection, spawning several Transformer-based methods in the drone MOT domain. Swin-JDE29, STDFormer30, and MOTR31 are highly regarded, all built upon the DETR32 and its derivative models, becoming representatives of online tracking. The Transformer’s long-range modeling abilities are used by STDFormer to find intent information in time motion and decision information in space interaction. With the help of Transformer, Swin-JDE matches each trajectory and detection information by taking into account the detection confidence, appearance embedding distance, and IoU distance factors. Moreover, MOTR achieves end-to-end object tracking by iteratively updating tracking queries, eliminating the need for complex post-processing steps. MeMOT33, similar to MOTR, is based on attention mechanisms and can be predicted by focusing on object states. Although these methods pave the way for new tracking paradigms, their performance still falls short of state-of-the-art tracking algorithms. Standard self-attention can capture fine-grained interactions between short and long distances. However, when paying attention to high-resolution feature maps, they suffer from high computational costs, leading to explosive growth in time and memory costs. EANTrack34 enhances the model’s discriminative ability by integrating relevant feature information through a complementary structure and functionality. ASTMT35 utilizes a spatial-temporal memory network to store scene information and reduce interference, along with an aligned matching module to alleviate occlusion effects, thereby enhancing tracking accuracy. RPformer36, a novel parallel Transformer-based tracker, integrates the principles of Siamese and Transformer methodologies through its design, which includes two complementary Transformer modules and a feature fusion head.
While Transformer-based approaches introduce innovative tracking paradigms, they face several limitations: high computational costs due to the self-attention mechanism on high-resolution feature maps, challenges in handling occlusions and maintaining trajectory consistency, and difficulty in differentiating diverse object features like size and movement. These issues hinder real-time tracking, increase identity switches, and reduce performance in complex drone environments. Our proposed ETDMOT framework optimizes the self-attention mechanism for greater computational efficiency, improves occlusion handling through ESC, and ensures long-term trajectory consistency using the Storage Attention Layer. These enhancements enable more accurate, efficient, and reliable tracking in complex drone environments.
Methodology
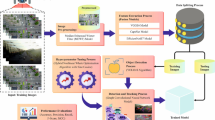
ETDMOT consists of four main modules, as shown in Fig. 1: (1) Object detection and trajectory feature joint extraction module, which detects objects and provides candidate object and trajectory information for each frame of the current time step; the Backbone network efficiently extracts object features from video frames and passes these features to the Transformer Encoder for information aggregation and integration. We choose ResNet-50 as our backbone. Subsequently, the aggregated features and detection and tracking queries serve as inputs to the L-layer decoder for detecting newly appearing objects or continuously tracking labeled objects. (2) In the matching stage, we adopt the ODLTM strategy for label allocation, which comprehensively considers the object’s appearance, space, and Gaussian features to ensure the label allocation’s accuracy and rationality–used to obtain rich contextual information and enhance the expression ability of features. (3) Historical information extraction module SAL (Storage Attention Layer). We have created independent storage for each object to support long-term stable tracking. After fusing the trajectory information of the current frame with the previous frame, the feature, long-term memory vector, and current frame output vector are used as Key, Query, and Value, which are input into the cross-frame long-term interaction module to deeply explore the long-term features of the object, providing strong information support for stable tracking of the object. (4) To ensure the semantic consistency of the input of the cross-frame long-term interaction module, we designed an ESC module (Enhanced Self Characteristics) to extract the semantic features of the trajectory information between the current frame and the previous frame. At the same time, we introduced the Cross Frame Self-Attention mechanism to extract the deep semantic information of stored trajectories accurately. Finally, we combine this processed information with Trajectory Storage as input for the subsequent frame processing to achieve cyclic iteration and ensure the continuity and accuracy of tracking.

The framework of ETDMOT. The ETDMOT framework efficiently extracts object features from video frames using a Backbone network and integrates them with a Transformer Encoder. With ResNet-50 as the backbone, the framework detects new objects and tracks labeled ones using the P-layer decoder. We use the ODLTM strategy for label assignment, considering appearance, spatial, and Gaussian features. Each object has independent storage for long-term, stable tracking. Trajectory information from consecutive frames is fused and used as input to the Cross-frame Long-term Interaction module for extracting long-term features. The ESC module guarantees semantic consistency, whereas the Cross Spatial-SA mechanism extracts deep semantic information. Combined with trajectory storage, continuous and accurate tracking is achieved through cyclic iteration.
Object detection and long-term tracking matching
ODLTM selects appearance, space, and Gaussian features as the basic features for tracking. The appearance features provide unique visual information about the object, which helps to distinguish and recognize it in complex backgrounds. The spatial features describe the object’s motion trajectory and dynamic changes, which helps predict its possible position in the next frame. Gaussian features provide a description of the object’s local or global statistical properties, which helps to address issues of partial occlusion or deformation. These three features each have their own advantages in object tracking and can complement each other, thereby improving tracking accuracy and robustness.Although small objects occupy fewer pixels in the image, their appearance features (such as color, brightness contrast, etc.) are often more prominent and easily distinguishable from other objects. Meanwhile, information such as velocity and acceleration in spatial features is particularly important in small object tracking, as they can more quickly reflect the motion trend and direction of small objects. As for Gaussian features, they also have certain advantages in dealing with slight deformations or partial occlusions of small objects because Gaussian models can tolerate feature changes and noise interference to a certain extent.
The framework of ODLTM is shown in Fig. 2. At moment \(t-1\), there are \(N^{t-1}\) queries categorized into two types: \(N_{Tra}^{t-1}\) tracking queries \(Q_{Tra}\) and \(N_{Det}^{t-1}\) detection queries \(Q_{Det}^{t-1}\), where \(N^{t-1}=N_{Det}^{t-1}+N_{Tra}^{t-1}\). All the queries self-attend each other and then cross-attend the image feature tokens via L decoders, and the output embeddings of the l-th decoder are denoted as \(ET_{Tra}^{l}\) and \(ED_{Det}^{l}\).

The framework of ODLTM. Match the current frame’s detection results with the previous frame’s tracking results through comprehensive matching. High-scoring results in the detection are assigned new IDs, high-scoring tracks in the tracking are retained while low-scoring ones are considered out of sight. Finally, the tracking results of the previous frame are used as Q, and the re-matched trajectories are used as K and V inputs to the Object Feature Cluster, achieving feature clustering. Finally, merge with new trajectories and enter the next iteration.
At moment t, there are \(M_{G}^{t}\) ground truth boxes. Among them, \(M_{Tra}^{t}\) previously tracked objects, denoted as \(\widehat{ET}\), are assigned to \(N_{Tra}^{t-1}\) tracking queries, where \(M_{Tra}^{t} \le N_{Tra}^{t-1}\) as some objects disappear. Formally, the j-th tracking embedding \(e_{j}^{p}\) will be assigned to the same identity with the previous timestamp if still alive at this moment, otherwise zero (disappearing). Besides, \(M_{Det}^{t}\) newborn objects, denoted as \(\widehat{ED}\), are assigned to \(N_{Det}^{t-1}\) detection queries. Specifically, the Hungarian matching algorithm is used to find the optimal pairing between \(F^{i}\) and \(\widehat{F}\) for each decoder by a cost function
That takes into account the class scores and box overlapping. Where \(L_{f}(a)\) represents the focal loss for classification, \(L_{1}(b)\) represents the \(L_{1}\) cost of the bounding box, and \(L_{g}(c)\) represents the Kullback-Leibler divergence distance between the object and trajectory frame Gaussian distribution. Next, we provide a detailed introduction to \(L_{g}(c)\).
Traditional trackers often use IOU as an evaluation criterion. However, it is sensitive to small offsets and incredibly ineffective when there is no overlap, leading to missed detections and matches for small objects. To address this issue, we introduce a method based on Gaussian distribution, where the effective response field of feature points is simulated as a Gaussian distribution, and the similarity between detection and trajectory is measured using receptive field distance. Due to the smooth transition of the Gaussian distribution, the influence range of each feature point covers the entire image, with weights gradually decreasing from the center to the edge but always positive, thus achieving a balanced selection of positive samples for objects of different sizes.
As the exact Effective Receptive Field (ERF) of each feature point accounts for only a fraction of the entire Total Receptive Field (TRF), measuring precise ERFs is challenging37. Both ERF and TRF share the same center point, and the theoretical receptive field TRF of the n-th layer in a standard convolutional neural network is represented as \(tr_{n}\):
where \(tr_{n}\) denotes the TRF for each point on the n-th convolutional layer, \(k_{n}\) and \(s_{n}\) represent the kernel size and stride of the convolution operation on the n-th layer. The half radius of TRF is approximated as the half radius of ERF (\(er_{n}\)). The square of \(er_{n}\) is used as the covariance of the two-dimensional Gaussian distribution for standard square convolutional kernels. The range of ERF is modeled as a two-dimensional Gaussian distribution \(N_{e}(\mu _{e},\Sigma _{e})\):
To better measure the matching degree between ERF and trajectory frame, the trajectory frame \((x_{g},y_{g},w_{g},h_{g})\) is also modeled as a standard two-dimensional Gaussian distribution \(N_{g}(\mu _{g},\Sigma _{g})\). Where the center point of each annotated box is used as the mean vector of the Gaussian, and the square of half the side length is used as the covariance matrix:
The Kullback-Leibler divergence is used to measure the statistical distance between two Gaussian distributions, and the KLD between ERF and trajectory frame is as follows:
The high scores in the detection results are assigned a new ID, while the high scores in the tracking continue to be retained, while the low scores are considered out of sight. Input the tracking result of the previous frame as Q and the rematched trajectory as K and V into the Object Feature Cluster to achieve feature clustering. Finally, merge with the new trajectory and enter the next loop.
Cross frame self attention block
The structure of the Cross Frame Self Attention Block is shown in Fig. 3. In CF-SA, we employ distribution multi-head attention to focus on adjacent distributions within a window of input frames for capturing sequential details. This approach consists of four simultaneous components. Let Y represent the features extracted from a collection of input frames in \(\mathbb {R}^{T \times H \times W \times C}\) , where T, H, W, and C denote the number of frames, height, width, and channels, respectively.

The framework of cross frame self attention block. The storage of each trajectory is first randomly divided into four parts, each without overlap. After segmentation, each feature is sent to a different distribution multi-head attention to extract trajectory information from multiple time instances. Finally, the features of each random block are re-stitched to extract long-term features.
For each frame \(Y_i \in \mathbb {R}^{H \times W \times C}\), \(i \in \{1,2,\ldots , T\}\), we first normalize them with Layer Normalization (LN), we partition \(Y \in \mathbb {R}^{T \times H \times W \times C}\) into \(Y^1\), \(Y^2\), \(Y^3\), and \(Y^4\) that are non-overlapping and situated in the exact location. These partitions serve as the input features for every self-attention block.
These distributions are denoted as \(Y_i^j \in \mathbb {R}^{T \times W \times \frac{C}{2}}\), where \(j \in \{1,2,\ldots ,4\}\) denote the number of SAs. Then, we generate \(Q_{i,m}^j\), \(K_{i,m}^j\), and \(V_{i,m}^j \in \mathbb {R}^{T \times W \times \frac{C}{4M}}\) as queries, keys, and values respectively. These are derived from a linear projection of \(Y_i^j\).
where \(P_m^Q\), \(P_m^K\), and \(P_m^V \in \mathbb {R}^{{C}\times \frac{C}{4M}}\), and \(m \in \{1,2,\ldots , M\}\) respectively denote linear transformation matrices for the queries, keys, and values. \(M=8\) is the number of heads for the multi-head distribution attention. Following that, \(Q_{i,m}^j\),\(K_{i,m}^j\), and \(V_{i,m}^j\) are transformed into tensors within \(\mathbb {R}^{T \times W \times \frac{C}{4M}}\). Subsequently, the attention mechanism operates on a strip-wise basis in the temporal dimension, resulting in attended outputs denoted as \(O_{i,m}^{j} \in \mathbb {R}^{T \times W \times \frac{C}{2M}}\).
Subsequently, \(O_{i,m}^{j}\) undergoes reshaping into \(T \times W \times \frac{C}{4M}\) for all heads, followed by concatenation along the channel dimension, resulting in \(O_i^{j} \in \mathbb {R}^{T \times W \times \frac{C}{4}}\). These H attended outputs, \(O_i^{j}\), are then consolidated into \(O^{j} \in \mathbb {R}^{T \times H \times W \times \frac{C}{4}}\), serving as the reweighted features in the horizontal direction. Following the same procedure, we obtain the final output:
we then generate the final CF-SA output \(O^{CF} \in \mathbb {R}^{T \times H \times W \times C}\). Its total space complexity is \(O((H+W)T^4)\).
Enhanced self characteristics
The structure of ESC is illustrated in Fig. 4. ESC dynamically integrates information from various positions of the feature map using multi-head self-attention in a residual manner. The attention mechanism cannot discern the positional information of the input feature sequence. Therefore, we introduce a spatial positional encoding process to the input \(X \in \mathbb {R}^{d \times N_x}\). We employ a sine function to generate spatial positional encoding. Ultimately, the mechanism of ESC can be summarized as follows:
where \(P_x \in \mathbb {R}^{d \times N_x}\) represents the spatial positional encodings, and \(X_{\text {ESC}} \in \mathbb {R}^{d \times N_x}\) denotes the output of ESC.

The ESC module is based on multi-head self-attention in a residual form.
Storage attention layer
Whenever a new object appears, we create a corresponding long-term memory vector \(S_{i}^{tra}\) using its feature vector. Since the object’s appearance gradually changes over time, it is necessary to update this long-term memory vector continuously. The storage attention layer structure is shown in Fig. 5. Considering that the changes in objects between consecutive frames are typically smooth, we use the exponential moving average method to update this vector, calculating the weighted average of all previous vectors with weights decaying exponentially. The specific expression is as follows:
where \(\alpha \in (0, 1]\). In practice, \(\alpha\) is set to 0.01 to ensure that the long-term memory vector of the same object undergoes only slight changes across consecutive frames. This ensures smooth and stable updates of the memory vector, continuously maintaining the latest feature representation of the object and preserving its stability and continuity in long-term memory. After the computation of one frame is completed, all output vectors \(O_{Tra}^{t}\) corresponding to the tracked objects are input into the subsequent module, and the tracking embedding \(E_{Tra}^{t+1}\) for use by the next frame decoder is updated accordingly.

The framework of storage attention layer.
The current frame’s output vector \(O_{Tra}^{t}\) is dynamically combined with the previous frame’s output vector \(O_{Tra}^{t-1}\) to generate the fused feature \(\widehat{O}_{Tra}^{t}\). This method of enhancement using adjacent frames effectively strengthens the representation of objects in the video and produces more robust features. The Storage-Attention Layer employs a separate layer of self-attention mechanism. The fused feature \(\widehat{O}_{Tra}^{t}\), long-term memory vector \(M_{Tra}^{t},\) and current frame output vector \(O_{Tra}^{t}\) of each object are respectively used as inputs for the query, key, and value of the self-attention mechanism. This allows interaction between objects with different IDs, enabling the learning of more discriminative feature representations beneficial for subsequent frame tracking. We inject the corresponding object’s long-term memory vector for each object vector outputted by the Storage-Attention Layer through simple addition. Since the update of long-term memory is stable and smooth, this step helps to stabilize subsequent tracking embeddings over time, thereby improving tracking performance.
Experiments
Dataset and evaluation metrics
The proposed algorithm underwent comprehensive evaluations on the VisDrone MOT38 and UAVDT39 datasets, which encompass diverse drone-captured scenes, facilitating a thorough assessment of the proposed methods’ practical effectiveness. Extensive evaluations compared the algorithm with other leading multi-object trackers across various scenarios and conditions. Established MOT evaluation metrics were utilized to assess performance comprehensively, aiming to gauge overall effectiveness and pinpoint potential weaknesses in each model. The metrics include:
-
(1)
FP (\(\downarrow\)): Number of false positives in the entire video.
-
(2)
FN (\(\downarrow\)): Number of false negatives in the entire video.
-
(3)
IDSW (\(\downarrow\)): Number of identity switches in the entire video.
-
(4)
FM (\(\downarrow\)): Number of ground truth trajectories interrupted during the tracking process.
-
(5)
IDF1 (\(\uparrow\)): Ratio of correctly identified detections to the computed detections and ground truth.
-
(6)
MOTA (\(\uparrow\)): Combined FP, FN, and IDSW, scored as follows:
$$\begin{aligned} MOTA = 1- \frac{FN+FP+IDSW}{GT} \end{aligned}$$(13)7) MOTP (\(\uparrow\)): Mismatch between ground truth and predicted results calculated as:
$$\begin{aligned} MOTP = 1-\frac{ {\Sigma }_{t,i} d_{t,i}}{{\Sigma }_{t} c_{t}} \end{aligned}$$(14)These metrics contribute to a comprehensive assessment of MOT algorithm performance in various aspects, providing in-depth insights into system effectiveness.
Experimental settings
The detector is initialized with pre-existing weights obtained from training on the COCO dataset. We train the detector using SGD with the following parameters: 150 epochs, a batch size of 16, a learning rate of 0.02, momentum set to 0.9, and decay set to 0.0001. We train the detector on both the VisDrone and UAVDT datasets and perform validation using the same set of verification images. We execute the testing on hardware (NVIDIA RTX 4090 with 24GB of memory) and calculate the average over the top 100 most reliable detection results.
Comparative experiments
The comparison was conducted between DeepSORT40, ByteTrack41, BoT-SORT42, UAVMOT43, DCMOT44, MTTJDT45, SimpleTrack46 and JDE47, as well as Transformer-based methods including TransTrack48, TrackFormer49, TransCenter50, MOTR31, MeMOT33, GTR51, TR-MOT52, STN-Track53, STDFormer30 and GAO-Tracker54. In the datasets, the distribution of object categories is uneven, leading to performance differences in detection models across different classes. Different thresholds were set for different object categories to balance the detection accuracy of each class during evaluation. The threshold for cars was set at 0.3, trucks at 0.1, pedestrians at 0.4, and buses, which are visually more variable, were set at a lower threshold of 0.05 to capture bus objects in various scenes more effectively.
Tables 1 and 2 comprehensively compare ETDMOT with other popular trackers on the VisDrone MOT and UAVDT datasets. Evaluation includes critical metrics such as MOTA, MOTP, IDF1, and IDSW, along with comparisons with other methods. ETDMOT demonstrates outstanding performance by effectively utilizing position and appearance information. In comparison, DeepSORT independently associates each class based solely on position information to extend its framework for handling multiple classes. ByteTrack utilizes low-score detections for similarity tracking and background noise filtering. BoT-SORT introduces camera motion compensation to enhance matching. UAVMOT enhances object feature association through an ID feature update module. SimpleTrack creates a new association matrix by merging object embedding cosine and GIOU distances. TransTrack, based on Transformer, tracks existing objects in the current frame using a Query-Key mechanism while completing new object detection. TrackFormer considers position, occlusion, and object recognition features simultaneously. TransCenter globally and robustly predicts the heatmap of object centers for the association. MOTR models the entire trajectory of a object with a track query. MeMOT encodes information from all previous frames as clues for tracking. GTR expands the window length of matching and fully utilizes interaction information. TR-MOT achieves reliable association using visual temporal features. STDFormer utilizes Transformer’s remote modeling ability to extract intent information in temporal motion and decision information in spatial interaction. However, these methods use a single matching rule for all detections, failing to accurately model various object categories, resulting in inferior tracking performance. MTTJDT improves tracking efficiency by using adjacent frames as shared feature inputs. STN-Track uses the Swin Transformer as the neck of YOLOX for the detection module and the G-Byte data association method for the tracking module.
Figures 6 and 7 illustrate a significant comparison between ETDMOT and other trackers on the VisDrone and UAVDT datasets. Leveraging its outstanding performance, ETDMOT can accurately identify diverse objects from the perspective of drones, covering various objects such as pedestrians and vehicles. It not only accurately separates objects from cluttered backgrounds, but it also delineates precise bounding boxes around these objects. Meanwhile, EDTMOT achieved smooth frame rates of 20.4 FPS and 22.1 FPS on the VisDroneMOT and UAVDT datasets, respectively, meeting real-time processing standards. At the same time, it demonstrates extraordinary computing power with 751 GFLOPs of floating-point operations per second, maintaining a small number of parameters and further highlighting its powerful processing performance. Thanks to the jointly optimized object detection and tracking strategy, ETDMOT maintains stable and efficient tracking performance even in complex scenarios involving object occlusion and high-speed movement. Remarkably, despite facing multiple complex factors, such as frequent changes in drone perspective, fluctuations in lighting conditions, and significant variations in object sizes, the algorithm still demonstrates stable tracking capabilities, ensuring the continuity and accuracy of the tracking.

Comparison of visualization results between ETDMOT and other latest trackers on the VisDrone dataset.

Comparison of visualization results between ETDMOT and other latest trackers on the UAVDT dataset.
Ablation experiments
On the VisDrone and UAVDT datasets designed explicitly for drone aerial scenes, we conducted comprehensive ablation experiments to validate the effectiveness of our proposed Transformer-based end-to-end multi-object tracking method. Specifically, we focused on assessing the performance impact of several key components, including the new trajectory detection label matching strategy, cross-frame self-attention mechanism, Enhanced Self Characteristics module, and Storage Attention Layer.
Impact of ODLTM
To validate the effectiveness of our ODLTM, we compared it with traditional methods, including IOU, Cooperation label assignment, and Tracklet-Aware Label Assignment. Baseline uses IOU matching. Table 3 presents the performance evaluation results of the proposed ETDMOT combined with different matching strategies. In the evaluation results on the UAVDT dataset, the Cooperation label assignment yielded the best performance among the matching strategies, with MOTA, MOTP, and IDF1 metrics reaching 62.1%, 75.4%, and 66.4%, respectively. Additionally, using ODLTM resulted in the lowest IDSW count. However, on the more challenging VisDrone dataset, the performance advantage of ODLTM was more pronounced. It achieved 38.9% MOTA, 76.9% MOTP, and 65.7% IDF1, significantly reducing FP count.
Since VisDrone contains many crowded scenes, the experimental results indicate that ODLTM can effectively improve MOT tracking performance in congested situations. The experimental results demonstrate that our new strategy significantly enhances the accuracy and rationality of label assignment by comprehensively considering object appearance, spatial position, and Gaussian features, thereby improving tracking performance. The architecture of CALA is more suitable for the UAVDT dataset, while the data augmentation method used by ODLTM is not as suitable as CALA for the UAVDT dataset. However, ODLTM performs poorly in MOTA metrics, but overall performance is still acceptable and has better generalization.
Impact of cross spatial self attention block
Self-attention mechanisms excel within a single frame but perform poorly in modeling long-term dependencies. Multi-head attention mechanisms effectively segment attention but have limited capabilities in modeling long-term dependencies. Cross-attention mechanisms handle different information sources effectively but are unsuitable for modeling long-term dependencies. Cross-frame self-attention mechanisms focus on long-term dependency relationships, improving object tracking accuracy by leveraging cross-frame information. Experimental results in Table 4 demonstrate that cross-frame self-attention mechanisms excel in capturing long-term dependencies between objects, providing richer contextual information for the tracking process. This enables our tracking method to maintain high accuracy and stability when facing complex scenarios and long-duration tracking tasks.
Impact of enhanced self characteristics
It was compared with two other methods to gain deeper insights into the role of the Enhanced Self Characteristics (ESC) module in cross-frame long-term interactions. Firstly, we examined the scenario without the ESC module, resulting in a lack of extraction and enhancement of semantic trajectory information when processing cross-frame information, thereby affecting the stability and accuracy of tracking significantly when objects are occluded, deformed, or exhibit complex motion trajectories. Secondly, we compared with attempts to fuse features, which lacked in-depth exploration and specialized processing of trajectory information, resulting in limited effectiveness. Finally, the model with the ESC module could extract semantic features and effectively improve the continuity and accuracy of tracking by combining with Trajectory Storage. This ensures the semantic consistency of input information and enhances the model’s understanding and processing capabilities of trajectory information. As shown in Table 5, the experimental results demonstrate that the ESC module performs excellently in extracting semantic features, effectively enhancing the continuity and accuracy of tracking.
Impact of storage attention layer
The Storage Attention Layer aims to optimize the utilization of stored information, thereby enhancing tracking stability and accuracy. In the absence of the Storage Attention Layer, when the model processes cross-frame information, it fails to effectively integrate historical trajectory information, leading to frequent loss and confusion of tracking information. Particularly in scenarios where objects are occluded, situated in complex backgrounds, or exhibit rapid motion, the model struggles to maintain stable tracking of the objects, resulting in a significant decline in tracking performance. Subsequently, we compared with methods integrating historical trajectory information through weighted averaging. Although this approach considers historical information to some extent, due to the lack of effective filtering and appropriate weight allocation, it cannot fully utilize stored trajectory information nor effectively distinguish the importance of different trajectories. Therefore, this method has limited effectiveness in improving tracking performance. The results are shown in Table 6.
In contrast, the Storage Attention Layer introduces an attention mechanism that adaptively adjusts the weights of different trajectory information, enabling the model to focus more on historical trajectories closely related to the objects in the current frame. Additionally, this layer effectively integrates and updates stored information, ensuring the coherence and consistency of information during the tracking process. Experimental results demonstrate that the Storage Attention Layer’s introduction significantly improves the model’s tracking performance.
Real scenario validation
To test the effectiveness and adaptability of our algorithm in drone object tracking, we selected DJI drone as the data acquisition platform. Flight tests were conducted in multiple real-world scenarios, and video data containing different lighting conditions, background complexity, and object motion states were collected. It covers various environments such as urban streets, parks and green spaces, farmland, and forests, ensuring the breadth and represent ativeness of the experiment. The result is shown in Fig. 8. Algorithms can accurately identify and track objects in videos, ensuring stable tracking even when the object is moving rapidly, changing posture, or partially occluded.

Real scenario validation.
Conclusion
The proposed Transformer-based end-to-end multi-object tracking method in the domain of drone aerial imagery has achieved significant results. Integrating object detection and tracking into a unified model and introducing new modules such as trajectory detection label matching strategy, cross-frame self-attention mechanism, and Enhanced Self Convolution enables accurate and efficient tracking of objects. Experimental results demonstrate that the proposed method performs excellently in multi-object tracking tasks, especially in complex backgrounds and occlusion scenarios. Future research directions include further optimizing model performance, improving tracking robustness and real-time capabilities, and exploring more effective feature extraction and correlation modeling methods to address increasingly complex scenarios and objects and, additionally, combining reinforcement learning and other methods to enhance the intelligence level of tracking algorithms further, enabling them to adapt to changing environments and task requirements, and realizing more intelligent, adaptive multi-object tracking systems.
Algorithms have limitations in terms of computational complexity, parameter tuning, and dependence on data quality. Due to the combination of multiple features in the method, high computational resources are usually required for computation. At the same time, spatial features may also become unreliable when objects move at high speeds or when there is occlusion. When integrating multiple features, it is necessary to carefully adjust the weights and parameters of each feature to ensure that they can work together and achieve the best results, which requires a lot of experimentation and tuning work. In addition, the effectiveness of feature extraction largely depends on the quality of the input data. If the input image quality is poor (such as low resolution, high noise, etc.), the accuracy and reliability of feature extraction will be affected. Meanwhile, given that the current model implementation heavily relies on large GPU resources, we plan to research knowledge distillation techniques with the aim of effectively reducing model size and complexity through this technology, thereby achieving seamless migration and application of models to edge devices.
In future research, efforts will be made to improve the accuracy, robustness, real-time performance, and intelligence level of multi-object tracking. We will focus on more efficient deep learning models and continue to explore and develop more efficient and lightweight deep learning models to reduce computational resource consumption and improve real-time processing capabilities. Research on how to effectively fuse different modalities of data (such as images, videos, text, sound, etc.) to provide more comprehensive information support and improve the accuracy and robustness of multi-object tracking. For example, introducing point cloud processing technology into image tracking to enhance the ability to handle complex occlusion situations55. By combining natural language processing and computer vision technology, natural language descriptions can be used to assist in object tracking.
Data availibility
The datasets used and analysed during the current study available from the corresponding author on reasonable request.
References
Wu, X., Li, W., Hong, D., Tao, R. & Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 10, 91–124 (2021).
Li, Y., Zhang, H., Yang, Y., Liu, H. & Yuan, D. RIStrack: Learning response interference suppression correlation filters for UAV tracking. IEEE Geosci. Remote Sens. Lett. 20, 1–5 (2023).
Qi, H., Feng, C., Cao, Z., Zhao, F. & Xiao, Y. P2b: Point-to-box network for 3d object tracking in point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6329–6338 (2020).
Hendria, W. F., Phan, Q. T., Adzaka, F. & Jeong, C. Combining transformer and cnn for object detection in uav imagery. ICT Express 9, 258–263 (2023).
Xue, Y. et al. Smalltrack: Wavelet pooling and graph enhanced classification for uav small object tracking. IEEE Trans. Geosci. Remote Sens. (2023).
Xue, Y., Jin, G., Shen, T., Tan, L. & Wang, L. Template-guided frequency attention and adaptive cross-entropy loss for UAV visual tracking. Chin. J. Aeronaut. 36, 299–312 (2023).
Xue, Y. et al. Mobiletrack: Siamese efficient mobile network for high-speed uav tracking. IET Image Process. 16, 3300–3313 (2022).
Dai, M., Hu, J., Zhuang, J. & Zheng, E. A transformer-based feature segmentation and region alignment method for UAV-view geo-localization. IEEE Trans. Circuits Syst. Video Technol. 32, 4376–4389 (2021).
Xue, Y. et al. Consistent representation mining for multi-drone single object tracking. IEEE Trans. Circuits Syst. Video Technol. (2024).
Xue, Y. et al. Handling occlusion in uav visual tracking with query-guided redetection. IEEE Trans. Inst. Meas. (2024).
Xia, Y., Wu, Q., Li, W., Chan, A. B. & Stilla, U. A lightweight and detector-free 3d single object tracker on point clouds. IEEE Trans. Intell. Transp. Syst. 24, 5543–5554 (2023).
Yi, S., Liu, X., Li, J. & Chen, L. Uavformer: A composite transformer network for urban scene segmentation of UAV images. Pattern Recogn. 133, 109019 (2023).
Yongqiang, X. et al. Optimal video communication strategy for intelligent video analysis in unmanned aerial vehicle applications. Chinese J. Aeronaut. 33, 2921–2929 (2020).
Bochinski, E., Eiselein, V. & Sikora, T. High-speed tracking-by-detection without using image information. In Proc. 14th IEEE Int. Conf. Adv. Video. Signal Surveill., 1–6 (Lecce, Italy, 2017).
Chen, G. et al. Visdrone-mot2021: The vision meets drone multiple object tracking challenge results. In Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshops, 2839–2846 (Virtual, 2021).
Bisio, I., Garibotto, C., Haleem, H., Lavagetto, F. & Sciarrone, A. Vehicular/non-vehicular multi-class multi-object tracking in drone-based aerial scenes. IEEE Trans. Veh. Technol. 1–17 (2023).
Lin, Y. et al. Multiple object tracking of drone videos by a temporal-association network with separated-tasks structure. Remote Sens. 14, 3862 (2022).
Al-Shakarji, N. M., Bunyak, F., Seetharaman, G. & Palaniappan, K. Multi-object tracking cascade with multi-step data association and occlusion handling. In Proc. 15th IEEE Int. Conf. Adv. Video. Signal Surveill., 1–6 (2018).
Wang, J., Simeonova, S. & Shahbazi, M. Orientation-and scale-invariant multi-vehicle detection and tracking from unmanned aerial videos. Remote Sens. 11, 2155 (2019).
Yu, H., Li, G., Zhang, W., Yao, H. & Huang, Q. Self-balance motion and appearance model for multi-object tracking in uav. In Proc. ACM Multimedia Asia, 1–6 (Beijing,China, 2019).
Wang, Z., Zheng, L., Liu, Y., Li, Y. & Wang, S. Towards real-time multi-object tracking. In Proc. 16th Eur. Conf. Comput. Vis., 107–122 (2020).
Wu, H., Nie, J., He, Z., Zhu, Z. & Gao, M. One-shot multiple object tracking in uav videos using task-specific fine-grained features. Remote Sens. 14, 3853 (2022).
Shi, L., Zhang, Q., Pan, B., Zhang, J. & Su, Y. Global-local and occlusion awareness network for object tracking in UAVs. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 16, 8834–8844 (2023).
Zhou, X., Koltun, V. & Krähenbühl, P. Tracking objects as points. In Proc. 16th Eur. Conf. Comput. Vis., 474–490 (2020).
Peng, J. et al. Chained-tracker: Chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking. In Proc. 16th Eur. Conf. Comput. Vis., 145–161 (Glasgow, UK, 2020).
Xia, Y. et al. Soe-net: A self-attention and orientation encoding network for point cloud based place recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11348–11357 (2021).
Xia, Y. et al. Casspr: Cross attention single scan place recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 8461–8472 (2023).
Xia, Y., Shi, L., Ding, Z., Henriques, J. F. & Cremers, D. Text2loc: 3d point cloud localization from natural language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14958–14967 (2024).
Tsai, C.-Y., Shen, G.-Y. & Nisar, H. Swin-jde: Joint detection and embedding multi-object tracking in crowded scenes based on swin-transformer. Eng. Appl. Artif. Intel. 119, 105770 (2023).
Hu, M. et al. Stdformer: Spatial-temporal motion transformer for multiple object tracking. IEEE Trans. Circuits Syst. Video Technol. 33, 6571–6594 (2023).
Zeng, F. et al. Motr: End-to-end multiple-object tracking with transformer. In Proc. 17th Eur. Conf. Comput. Vis., 659–675 (Tel Aviv, Israel, 2022).
Carion, N. et al. End-to-end object detection with transformers. In Proc. 16th Eur. Conf. Comput. Vis., 213–229 (Glasgow, UK, 2020).
Cai, J. et al. Memot: Multi-object tracking with memory. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 8090–8100 (New Orleans, Louisiana, 2022).
Gu, F., Lu, J., Cai, C., Zhu, Q. & Ju, Z. Eantrack: An efficient attention network for visual tracking. IEEE Trans. Autom. Sci. Eng. (2023).
Yuan, D., Shu, X., Liu, Q. & He, Z. Aligned spatial-temporal memory network for thermal infrared target tracking. IEEE Trans. Circuits Syst. II Express Briefs 70, 1224–1228 (2022).
Gu, F., Lu, J. & Cai, C. RPformer: A robust parallel transformer for visual tracking in complex scenes. IEEE Trans. Inst. Meas. 71, 1–14 (2022).
Xu, C. et al. Rfla: Gaussian receptive field based label assignment for tiny object detection. In European Conference on Computer Vision, 526–543 (Springer, 2022).
Zhu, P. et al. Vision meets drones: Past, present and future. arXiv:2001.06303 (2020).
Du, D. et al. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proc. 15th Eur. Conf. Comput. Vis., 370–386 (Munich, Germany, 2018).
Wojke, N., Bewley, A. & Paulus, D. Simple online and realtime tracking with a deep association metric. In Proc. 2017 IEEE Int. Conf. Image Process., 3645–3649 (Beijing, China, 2017).
Zhang, Y. et al. Bytetrack: Multi-object tracking by associating every detection box. In Proc. 17th Eur. Conf. Comput. Vis., 1–21 (Tel Aviv, Israel, 2022).
Aharon, N., Orfaig, R. & Bobrovsky, B.-Z. Bot-sort: Robust associations multi-pedestrian tracking. arXiv:2206.14651v2 (2022).
Liu, S., Li, X., Lu, H. & He, Y. Multi-object tracking meets moving uav. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 8876–8885 (New Orleans, Louisiana, 2022).
Deng, K. et al. Jointing recurrent across-channel and spatial attention for multi-object tracking with block-erasing data augmentation. IEEE Trans. Circuits Syst. Video Technol. 33, 4054–4069 (2023).
Keawboontan, T. & Thammawichai, M. Toward real-time uav multi-target tracking using joint detection and tracking. IEEE Access 11, 65238–65254 (2023).
Li, J., Ding, Y., Wei, H.-L., Zhang, Y. & Lin, W. Simpletrack: Rethinking and improving the jde approach for multi-object tracking. Sensors 22, 5863 (2022).
Makarov, S. B., Pavlov, V. A., Bezborodov, A. K., Bobrovskiy, A. I. & Ge, D. Multiple object tracking using convolutional neural network on aerial imagery sequences. In in Proc. Int. Youth Conf. Electron. Telecommun. Inf. Technol., 413–420 (Petersburg, Russia, 2020).
Sun, P. et al. Transtrack: Multiple object tracking with transformer. arXiv:2012.15460 (2020).
Meinhardt, T., Kirillov, A., Leal-Taixe, L. & Feichtenhofer, C. Trackformer: Multi-object tracking with transformers. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 8844–8854 (New Orleans, Louisiana, 2022).
Xu, Y. et al. Transcenter: Transformers with dense representations for multiple-object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 45, 7820–7835 (2022).
Zhou, X., Yin, T., Koltun, V. & Krähenbühl, P. Global tracking transformers. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 8771–8780 (New Orleans, Louisiana, 2022).
Chen, M., Liao, Y., Liu, S., Wang, F. & Hwang, J.-N. Tr-mot: Multi-object tracking by reference. arXiv:2203.16621 (2022).
Xu, X. et al. Stn-track: Multiobject tracking of unmanned aerial vehicles by swin transformer neck and new data association method. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 15, 8734–8743 (2022).
Yuan, Y., Wu, Y., Zhao, L., Pang, Y. & Liu, Y. Multiple object tracking in drone aerial videos by a holistic transformer and multiple feature trajectory matching pattern. Drones[SPACE]https://doi.org/10.3390/drones8080349 (2024).
Xia, Y. et al. Asfm-net: Asymmetrical siamese feature matching network for point completion. In Proceedings of the 29th ACM International Conference on Multimedia, 1938–1947 (2021).
Acknowledgements
This work was supported by Funding for Outstanding Doctoral Dissertation in NUAA under Grant BCXJ24-10, Postgraduate Research & Practice Innovation Program of Jiangsu Province under Grant KYCX24_0583, the National Natural Science Foundation of China under Grant 61573183 and the Natural Science Foundation of Shaanxi Province of China under Grant 2024JC-YBQN-0695.
Author information
Authors and Affiliations
Contributions
Conceptualization, Y.Y.; methodology, Y.Y., Y.W. and Y.L.; software, Y.P. and Y.L.; formal analysis, Y.W.; investigation, Y.W.; resources, Y.P.; data curation, L.Z., Y.P. and Y.L.; writing–original draft, Y.Y.; writing–review and editing, Y.W. and L.Z.; visualization, Y.L.; supervision, L.Z.; project administration, Y.P. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yuan, Y., Wu, Y., Zhao, L. et al. End-to-end multiple object tracking in high-resolution optical sensors of drones with transformer models. Sci Rep 14, 25543 (2024). https://doi.org/10.1038/s41598-024-75934-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-75934-9
Keywords
This article is cited by
-
Reynolds rules in swarm fly behavior based on KAN transformer tracking method
Scientific Reports (2025)
-
Real-time multi-object detection and tracking in UAV systems: improved YOLOv11-EFAC and optimized tracking algorithms
Journal of Real-Time Image Processing (2025)
