
Abstract
Segregation of granular materials is a critical challenge in many industries, often aimed at being controlled or minimised. The discrete element method (DEM) offers valuable insights into this phenomenon. However, calibrating DEM models is a crucial, albeit time-consuming, step. Recently, using machine learning (ML)-based surrogate models (SMs) in the calibration process has emerged as a promising solution. Nevertheless, developing such SMs is challenging due to the high number of DEM simulations required for training. Additionally, choosing a suitable ML model is not trivial. This study aims to develop SMs that effectively link particle-particle and particle-wall DEM interaction parameters to segregation of a multi-component mixture. We evaluate several ML models, ranging from artificial neural networks to ensemble learning, that are trained on a very cost-effective dataset, employing Bayesian optimisation with cross-validation to tune their hyperparameters. Next, we introduce a novel transfer learning (TL)-based approach that leverages knowledge from a few scenarios to handle new “unseen” ones. This method enables the construction of adaptive SMs for unseen scenarios, such as a new initial configuration (IC) of granular mixtures, without the need for a full-sized dataset. Our findings indicate that Gaussian process regression (GPR) efficiently builds accurate SMs on a very small dataset. We also demonstrate that only a few samples are required to build an accurate SM for the unseen IC, which significantly reduces the data preparation burden. By incorporating one and five samples from unseen scenarios to update the TL-GPR-based surrogate model, the SM’s performance (based on \(\:{R}^{2}\)) on unseen scenarios improves by 17 and 47%, respectively. The insights and methodology presented in this study will facilitate and accelerate the development of accurate SMs for DEM calibration, assisting in developing reliable DEM models in a shorter timeframe.
Similar content being viewed by others

Introduction
Granular segregation is an occurrence in which flowing particles with similar properties (such as size, density, or shape) accumulate in specific areas. Segregation is regarded unfavourable in the majority of applications because it might reduce the homogeneity of the granular mixtures and, consequently, is aimed at being controlled/minimised1. To achieve this goal, a thorough understanding of segregation and the factors influencing it is required.
Numerous experimental studies have aimed to unravel the segregation phenomenon since the 1970s2,3,4,5. While these studies provided useful insights into segregation, the experimental approaches to studying segregation generally suffer from several limitations6. These include the difficulty in collecting the required samples for segregation measurements, limitations in obtaining particle-scale data, as well as being expensive and time-consuming.
Recent advancements in computational power have led to widespread usage of the discrete element method (DEM), initially introduced by Cundall and Strack7, as a useful alternative to experiments for studying granular materials. Especially for segregation, DEM has major advantages over experiments, as it allows for the modelling of granular mixtures with any combinations of size, density, and shape while providing comprehensive particle-level information that is difficult or impossible to obtain in physical experiments6. While DEM is widely used, achieving a balance between model accuracy and computational efficiency remains a challenge8. The accuracy of the DEM model heavily depends on the proper determination of its parameters through a process called calibration. However, the calibration process can be time-consuming, particularly for multi-component mixtures, where the number of DEM parameters significantly increases.
Trial and error is still extensively employed for calibrating DEM models9,10,11,12,13. However, it is not only inefficient but also depends on the user’s expertise and barely results in an optimal parameter set14. To systematically calibrate the DEM model, several approaches have been proposed. Typically, these approaches use optimisation techniques to update the parameters and determine the calibrated parameter set. Examples include using advanced design of experiments (DoE) in combination with simple optimisation algorithms15, particle swarm optimisation16, and genetic algorithms17,18. However, these methods are still not computationally efficient due to the high number of simulations required14.
Richter et al.14 conducted a thorough literature review on various optimisation techniques, concluding that surrogate-based optimisation is the most suitable approach for DEM calibration. A surrogate model (SM) is an approximation of a more complex and computationally expensive model (such as DEM) aimed at mapping the relationship between the model’s input(s) and output(s)19. They can be built using advanced mathematics or machine learning (ML). Surrogate-based optimisation is effective at finding a global optimum, is computationally efficient, and can handle parameter limitations and multi-objective problems14. Additionally, ML-based surrogates can take advantage of the rapid progress in the field of machine learning in other fields13,20. Several studies have used surrogate-based optimisation for DEM calibration. This includes using Gaussian process regression (GPR) and Kriging14,21,22,23,24, multi-objective reinforcement learning25, Bayesian filtering26,27, multi-variate regression analysis28, neural networks29,30,31, and random forest (RF)13.
Despite the advancement of surrogate-based DEM calibration, several challenges remain to be addressed. Firstly, the vast array of available algorithms can make it challenging to choose the most suitable approach, often leading to subjective decision-making. Secondly, while using the SM reduces the computational cost of the DEM calibration, training the SMs themselves, especially when employing sampling techniques such as Latin Hypercube Sampling (LHS), requires a substantial number of simulations. Thirdly, most of the studies consider only a limited number of DEM parameters to construct the SM, potentially overlooking significant DEM parameters. Lastly, most studies aim at single granular materials, and to the best of the authors’ knowledge, no study has yet explored surrogate modelling for multi-component granular mixtures. This study attempts to address these challenges by developing SMs that effectively link particle-particle and particle-wall DEM interaction parameters to segregation. We demonstrate this on the basis of a case study for reliable estimation of radial segregation of multi-component mixture in a heap.
The objective of this paper is twofold:
-
1.
We evaluate several ML models to develop surrogate models for DEM simulations involving a two-component mixture (i.e., pellet-sinter) that flows from a hopper through a chute into a receiving bin. Our goal is to develop SMs that capture the relationship between all particle-particle and particle-wall DEM interaction parameters to radial segregation in the heap. To investigate the effect of the initial configuration (IC) of the mixture within the hopper on heap segregation, we vary the mixing degree, pellet-to-sinter mass ratio, and layering order within the hopper. For each individual IC, we use the definitive screening design (DSD), a cost-effective three-level DoE technique, to efficiently create our dataset. To construct effective SMs, we encode ICs, which consist of a combination of categorical and numerical variables, to prepare them as input features for the SMs.
-
2.
Following the identification of the most effective SMs, we innovatively implement a transfer learning (TL) approach to transform the surrogate into an adaptive SM tailored for new, unseen ICs, named the ‘transfer learning-based surrogate model (TL-SM)’, thereby addressing our second objective. In pursuit of this, we systematically exclude one IC from the training-validation dataset, designated as the ‘unseen IC’, which serves as the target domain for TL. Subsequently, we train and cross-validate the SM coupled with Bayesian optimisation (BO) using the remaining dataset as the source domain for TL. Utilising the TL methodology, we deploy the pre-trained ML model as the surrogate for the unseen target IC. We then update and retrain the SM by integrating new data points from the unseen IC while monitoring performance enhancements. The effectiveness of the proposed data-driven SM is assessed through nested cross-validation (NCV), which involves iteratively excluding each IC. Additionally, the stability of the TL-SM is evaluated using distinct random seed numbers for weight and bias initialisation.
Achieving these two objectives will pave the way for efficiently building generalised SMs for various scenarios. These SMs, in turn, will facilitate and speed up the DEM calibration process, contributing to the development of more robust and reliable DEM models in a significantly shorter time.
Simulation method and established dataset
Discrete element method
We used the Hertz-Mindlin (no-slip)32 contact model with an elastic-plastic spring-dashpot rolling friction model (referred to as “type C” in33) in our DEM model. This contact model has been successfully employed in past studies on pellets and sinter34,35. Detailed equations and more information on the contact model are addressed in the relevant literature32,33,34,36. We developed the DEM model using the commercial software EDEM version 2022.3, where all of the simulations were performed on the DelftBlue high-performance cluster37.
We simulated the mixture of sinter and iron ore pellets, as an example of a multi-component mixture used in blast furnace. The intrinsic material properties as fixed and varied interaction parameters were employed, which are listed in Tables 1 and 2, respectively.
System and geometry
A system of geometries composed of a hopper, a chute and a receiving bin was used, as shown in (Fig. 1a). The sequence of the simulations’ steps is as follows: First, a mixture of pellets and sinter was generated in the hopper. Next, the outlet of the hopper was opened, allowing the materials to discharge from the hopper under the influence of gravity. Finally, the materials were accumulated in the receiving bin after a chute flow (see Fig. 1b).

(a) The geometry employed in the simulations and their dimensions, (b) the flow of the mixture of pellets and sinter from the hopper to the receiving bin through the chute.
Since the IC of the mixture within the hopper significantly influences the final segregation in the heap, we used various initialisations in the hopper, as illustrated in Fig. 2.

Various initial configurations (ICs) of pellets and sinter in the simulations (copper and black particles represent pellets and sinter, respectively).
Quantifying segregation in heap
At the end of the simulations, a heap of the mixture of pellets and sinter was formed, as illustrated in Fig. 3a. Segregation in the heap can be measured in different directions, namely radial, vertical, and circumferential. This study specifically targets radial segregation. To measure the radial segregation, the heap was first divided into a number (\(\:m\)) of radial bins (see Fig. 3b). Next, the mass ratio of one component such as pellets within each bin (\(\:{C}_{{p}_{m}}\)) was determined. Then, the segregation was quantified using the relative standard deviation (RSD):
where \(\:\sigma\:\) and \(\:\mu\:\) are the standard deviation and the mean of \(\:{C}_{{p}_{m}}\)s, respectively.

(a) Side view of the heap formed within the receiving bin, (b) radial bins used to quantify radial segregation.
Established dataset and feature engineering
Because there is a high number of DEM parameters (15, as listed in Table 2) to vary, we aimed to use a sampling strategy that minimises the number of DEM simulations required. To achieve this, we employed the definitive screening design (DSD), a unique three-level design that was first presented by Nachtsheim and Jones48. The power of DSD is that, in addition to the main effects, it can identify two-factor and quadratic terms. For an odd number of \(\:k\) variables (as in this study), \(\:2k+3\) runs are needed. Furthermore, to increase the DSD design’s power, Jones and Nachtsheim49 suggested adding four extra runs. Therefore, only 37 simulations were required to establish a DSD design for 15 DEM interaction parameters. The DSD design is presented in Table A.1 in the Appendix.
As we conducted the DSD for five different ICs in the hopper (see Fig. 2), the generated dataset comprised a total of 185 simulation samples. To effectively distinguish between these ICs, it was essential to perform feature engineering to create additional features that describe these configurations. This feature engineering could potentially enhance the performance of ML models50. We specifically selected three features: segregation index, pellets mass ratio, and layering mode, which can distinguish between the five ICs used. Since the layering mode is a categorical variable, we employed the label encoding technique, which is known for its computational simplicity, to convert it into a numerical format51. Table 3 presents these three features along with their values for all ICs.
Data-driven surrogate models
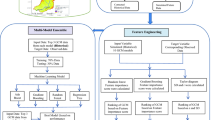
The overall proposed framework for designing data-driven SMs is illustrated in Fig. 4. The dataset underwent nested cross-validation (NCV), one of the most rigorous validation approaches, which involves two other cross-validation (CV) steps. In this section, the ML models employed in this study to build surrogates for DEM are briefly described. These models include linear regression, support vector machine (SVM), regression tree, ensemble learning, Gaussian process regression (GPR), and artificial neural network (ANN). Subsequent sections elaborate on NCV and hyperparameter optimisation for the aforementioned ML models.

The overall proposed framework to design data-driven SM leveraged by TL.
Linear regression
Linear regression is a widely used statistical tool for modelling the linear relationship between independent (inputs) and dependent (output) variables. In the case of only one independent variable, it is called a “simple linear regression model”, and when there is more than one independent variable, it is referred to as a “multiple linear regression model”52, which is the case in the current work. Considering the original dataset composed of n data points as \(\:D=\:\left\{\left({x}_{i},\:{y}_{i}\right),i=1,\:2,\:\dots\:,\:n\right\}\), the linear regression model is expressed as:
where \(\:y\) is the vector of dependent variables (i.e., observed response), \(\:\beta\:\) is the coefficients vector, \(\:{\beta\:}_{0}\) is the intercept (or bias in machine learning), and \(\:{\epsilon\:}_{i}\) is the random error term. The objective in the linear regression is to minimise the sum of squared errors (SSE) between the predicted (\(\:{\widehat{y}}_{i}\)) and actual (\(\:{y}_{i}\)) values, which are calculated using the following equation:
There are several techniques to improve the interpretation of linear regression models, including linear regression with interactions, robust linear regression, and stepwise regression. Linear regression with interactions takes the interactions between the independent variables into account, allowing for modelling of complex relationships among them. Robust linear regression helps mitigate the impacts of outliers, leading to more reliable estimates53. Stepwise regression aids in refining the model by iteratively adding or removing them based on statistical criteria, ensuring that the most significant variables are included in the model. All these techniques contribute to the development of more accurate linear regression models across various scenarios54.
Support vector machine (SVM)
Support vector machines (SVMs) are efficient statistical learning models for classification and regression tasks55. SVMs are known for finding the optimal decision boundary, known as the maximum-margin, which can effectively separate various classes in the data. Because of this feature, SVMs are very effective at handling complicated datasets.
In training data, where \(\:{x}_{i}\) is the multivariate set of \(\:n\) observations, the goal in support vector regression is to determine the estimating function \(\:f\left(x\right)\), which takes the form56:
where \(\:w\) is the weight vector, \(\:b\) denotes the bias term and \(\:G\left(x\right)\) is a set of linear or non-linear kernel functions (e.g., quadratic, cubic, etc.). To determine \(\:w\) and \(\:b\), the following objective function is to minimise57:
subject to:
where \(\:C\) is the box constraint, \(\:{x}_{i}\) and \(\:{y}_{i}\) are the input and output vectors, respectively, and \(\:{\xi\:}_{i}\) and \(\:{\xi\:}_{i}^{*}\) are positive slack variables. SVMs utilise kernel functions (\(\:k\left(x,{x}^{{\prime\:}}\right)\), where \(\:x\) and \(\:{x}^{{\prime\:}}\) are two data points) to handle non-linear relationships between the input and output vectors. Even if the original input space is not linearly separable, kernel functions enable SVMs to implicitly transfer input vectors into a higher-dimensional space where the data may be more separable. In this case, the decision function (Eq. (4)) takes the form:
where \(\:{\alpha\:}_{i}\) and \(\:{\alpha\:}_{i}^{\text{*}}\) are Lagrange multipliers. For example, the decision function for the radial basis function (RBF) kernel is as follows:
where \(\:\gamma\:\) is a parameter for the RBF kernel.
Regression tree
Decision trees are predictive models that partition the feature space to predict the label associated with an instance by traversing from the tree’s root to a leaf58. Regression trees are a specific type of decision trees designed for predicting numerical values. They recursively divide the input space (\(\:{x}_{i}\)) into \(\:J\) number of disjoint regions (\(\:{R}_{1},\:{R}_{2},\:\dots\:,\:{R}_{J}\)) using splitting rules. Regression tree splitting rules are derived from the minimisation of the sum of squared errors inside each division:
where \(\:j\) and \(\:s\) are the index and the threshold value of the feature used for splitting, respectively. \(\:{c}_{m}\) and \(\:{c}_{m}^{{\prime\:}}\) are the constant predictions for regions \(\:{R}_{m}\) and \(\:{R}_{m}^{{\prime\:}}\). The main parameter in regression trees is the minimum leaf size, which represents the minimum number of samples required to create a terminal node (leaf) in the process of building the tree.
Ensemble learning
While regression trees are easy to interpret and fast for fitting and prediction, like other weak learners, they are susceptible to overfitting and have sensitivity to training data. Integrating several weak learners makes the model more resilient and less prone to overfitting, as each learner depends on a different set of data points. Ensemble learning in ML is the process of combining several weak learners. Given regression trees, one way to overcome this issue is to construct a weighted collection of multiple regression trees to build models called ensembles of trees. Combining many regression trees generally improves the prediction capability and accuracy. Several ensemble learning methods exist, including bagging and boosting.
Bagging (bootstrap aggregation) involves training many weak (base) learners (parallelly) simultaneously and integrating them using averaging techniques59. Considering the original data set as \(\:D=\:\left\{\left({x}_{1},\:{y}_{1}\right),\left({x}_{2},\:{y}_{2}\right),\:\dots\:,\:\left({x}_{n},\:{y}_{n}\right)\right\}\), first, a number of bootstrap samples \(\:{(D}_{i},\:i=1,\:2,\:.,\:B)\:\) is created by randomly choosing \(\:n\) samples from \(\:D\) with replacement. Then, a base learner \(\:{f}_{i}\) is trained based on \(\:{D}_{i}\) to minimise the error between \(\:y\) and \(\:{f}_{i}\left(x\right)\). Finally, the aggregated prediction model \(\:f\left(x\right)\) is obtained by averaging the predictions:
By training each learner with the output of the preceding learner, the boosting approach progressively boosts the model’s overall performance. One boosting technique used for building regression ensembles is least-squares boosting (LSBoost)60. This technique successively fits a set of weak learners (e.g., decision trees), with each new learner trained to reduce residual errors from the ensemble’s total predictions. The approach iteratively improves the ensemble’s predictions by including fresh weak learners. First, the ensemble prediction is initialised as the mean of the target values (\(\:{y}_{i},\:i=1,\:2,\:\dots\:,\:n\)):
Then, for iteration \(\:m\:(m=1,\:2,\:\dots\:,\:M)\), the residuals between the target values and the accumulated prediction (\(\:{f}_{m-1}\left({x}_{i}\right)\)) for each observation is calculated as:
Next, a new weak learner (\(\:{h}_{m}\)) is trained by fitting it to the residuals:
Finally, the ensemble model is updated:
where \(\:\eta\:\) is the learning rate (the shrinkage parameter), which controls the contribution of each weak learner and ranges from 0 to 1.
Gaussian process regression (GPR)
Gaussian process regression (GPR) is a probabilistic and non-parametric kernel-based machine learning regression model61 rooted in Bayesian principles. Due to its simplicity of use and flexibility in obtaining hyperparameters, GPR is well-suited to handle small-sized datasets and nonlinear problems62. A Gaussian process (GP) is a collection of random variables having Gaussian distribution and is fully defined by its mean function \(\:\mu\:\left(x\right)\) and covariance kernel function \(\:k\left(x,{x}^{{\prime\:}}\right)\).
Considering \(\:{x}_{i}\) and \(\:{y}_{i}\) as the input and corresponding output vectors, respectively, the GPR model with Gaussian noise is formulated as:
where \(\:{\epsilon\:}_{i}\) denotes a constant additive noise term assumed to follow a Gaussian distribution with a mean of 0 and a standard deviation of \(\:\sigma\:\) (i.e., \(\:{\epsilon\:}_{i}\mathcal{\:}\sim\mathcal{\:}\mathcal{N}(0,{\sigma\:}^{2})\)). The objective of GPR is to infer the function \(\:f\) in a non-parametric and Bayesian approach, utilizing the provided training dataset \(\:\{\left({{x}_{i},y}_{i}\right);\:i=1,\:2,\:\dots\:,\:n\}\). A prior distribution on \(\:f\) needs to be established in order to learn this function. Typically, this prior is utilized to encapsulate qualitative attributes of the function such as continuity, differentiability, or periodicity. In GPR, the prior distribution for \(\:f\) as the regression function is represented by:
In this formulation, while the mean function \(\:\mu\:\left(x\right)\) is often set constant, the covariance kernel \(\:k\left(x,{x}^{{\prime\:}}\right)\) varies. When the values of the function \(\:f\left({x}_{i}\right)\) have a joint Gaussian distribution defined by \(\:\mu\:\left(x\right)\) and \(\:k\left(x,{x}^{{\prime\:}}\right)\) for every finite set of inputs \(\:{x}_{i}\), then the function \(\:f\left(x\right)\) is a GP, implying:
which using the notation below:
the equations can be simplified. In the process of learning functions through GPR, the implications of expanding Eq. (17) by including a new data point \(\:{x}_{*}\), separate from the training data, are being considered. The objective is to predict the value of the function at this particular location, i.e., \(\:f\left({x}_{*}\right)\). To do so, given the already observed values \(\:\mathcal{Y}={[{y}_{1}\dots\:{y}_{n}]}^{T}\), the relationship can be expressed by incorporating Eqs. (15)–(18):
Here, \(\:{\mathbf{I}}_{n}\) is the N×N identity matrix. Conditioning on the new data based on observations, the posterior probability distribution for \(\:f\left({x}_{*}\right)\) can be estimated as:
where:
The posterior probability distribution is Gaussian once more, allowing for Bayesian reasoning on the function \(\:f\). One noteworthy aspect of these formulations is that the function’s posterior expected value, \(\:\mathbb{E}\left(f\left({x}_{*}\right)|\mathcal{Y}\right)\), could be stated using a weighted sum of kernel functions:
where:
To delve into the GPR model, the weighted sum in Eq. (24) is advantageous as it facilitates computations that would otherwise be challenging.
The details on the kernel functions used in this study are presented in Table B.1 in the Appendix. It is possible to use either isotropic or non-isotropic kernel functions with GPR. In contrast to isotropic kernels, non-isotropic ones give each predictor variable a distinct correlation length scale. This results in an improved accuracy at the cost of slowing down the fitting process.
Artificial neural network (ANN)
An artificial neural network (ANN) is an ML model inspired by neuronal organisation in animal brains. ANN is composed of interconnected nodes which are arranged into several layers. These layers are typically organised into three groups: the input layer, hidden layers, and the output layer. Each node (or neuron) conducts a basic computation, and the connections between nodes transport weighted signals from one layer to the next63,64.
The output of the NN is computed through feedforward propagation65. Considering the input vector as \(\:x\), the activation of each neuron in layer \(\:l\) as \(\:{a}^{\left(l\right)}\), the weight matrix linking layer \(\:l\) to layer \(\:l+1\) as \(\:{W}^{\left(l\right)}\), and the bias term for layer \(\:l\) as \(\:{b}^{\left(l\right)}\), the feedforward computation is as follows:
where \(\:{z}^{(l+1)}\) is the input to layer \(\:l+1\) and \(\:g\left(z\right)\) is the activation function which is applied element-wise to the input. In this study, we used the rectified linear unit (ReLU), Tanh, and sigmoid activation functions, whose formulas are provided in Table B.2 in the Appendix.
Hyperparameters optimisation and model validation
Overfitting is a common challenge in ML models, requiring the use of cross-validation (CV) methods to validate the effectiveness of the model. As illustrated in Fig. 5, we employed nested cross-validation (NCV), which consists of two CV steps:
-
I.
An external loop conducts CV on the dataset based on the number of ICs, excluding one IC at each iteration to create a distinct test set of “unseen ICs”.
-
II.
An internal loop performs CV on the remaining dataset after the execution of the external loop to tune hyperparameters and mitigate overfitting.
This NCV technique properly estimates model performance by combining 5-fold outer loops based on the number of ICs with 10-fold inner loops. In the outer loop, model performance assessment occurs through the partitioning of the dataset into a training-validation set (comprising four ICs) and a distinct test set (comprising one IC). The outer loop is also referred to as leave-one-out cross-validation (LOOCV)66 on ICs. The training-validation set undergoes further subdivision into diverse folds using a 10-fold CV to estimate the generalisation error and fine-tune hyperparameters. To this end, Bayesian Optimisation (BO) algorithms67 were employed to adjust hyperparameters. To determine the minimum or maximum of a function, BO combines Bayesian inference with optimisation techniques. BO constructs a prior distribution over parameters, updates it with data, and selects promising parameters using an acquisition function. This iterative process efficiently explores the function space until it converges on the optimal parameters. Compared to exhaustive search techniques such as grid search or random search, this method effectively explores the hyperparameter space and frequently requires fewer trials.

The process of nested cross-validation (NCV), given LOOCV in the outer loop and 10 folds in the inner loop.
Transfer learning (TL) for unseen ICs
In this section, we explore the application of transfer learning (TL) to enhance the performance of the SM when confronting a new, previously unseen IC. TL is a powerful technique that leverages knowledge gained from related tasks or domains to improve performance on a target task68,69,70. TL is specifically advantageous when providing a sufficient number of training samples is costly.
In the context of granular material segregation, the IC is crucial as it can significantly influence segregation outcomes6. Consequently, if the IC changes, the DEM model must be recalibrated, which is very time-consuming. To address this challenge, we can leverage prior knowledge gained from previously encountered ICs as the source domain to pretrain the SMs. Subsequently, we can transfer the pretrained SMs as base learners for new, unseen ICs, treating them as the target domain in TL. In the next stage, the pretrained SMs are updated by incorporating a small number of samples from the target domain through model retraining while retaining the prior information from the source domain. This approach allows TL to expedite the learning process, as the SMs require fewer samples from the unseen ICs to achieve effective learning. Additionally, it eliminates the need for full retraining and cross-validation, coupled with BO, using data from both the source and target domains, thereby reducing computational demands.
Considering \(\:{x}_{i}\) and \(\:{y}_{i}\) representing the input and output vectors, TL involves extracting knowledge from the source domain (\(\:{\mathcal{D}}_{s}={\left\{\left({x}_{i}^{s},{y}_{i}^{s}\right)\right\}}_{i=1}^{{N}_{s}}\), ), and use it to pretrain the model for the target domain (\(\:{\mathcal{D}}_{t}={\left\{\left({x}_{i}^{t},{y}_{i}^{t}\right)\right\}}_{i=1}^{{N}_{t}}\)). Here, we investigate the effectiveness of TL in updating the model by varying the number of samples from the newly unseen IC. This includes the following steps:
-
Initial model training: Initially, the SM model is trained using cross-validation on data from four out of the five ICs, yielding a baseline model \(\:{f}_{s}\). This baseline model provides a starting point for the TL approach.
For example, the training of the source model for GPR can be expressed as:
where the initial learnable parameters are denoted as \(\:{\varvec{w}}_{0}\) and the trained learnable parameters are denoted as \(\:{\varvec{w}}_{\varvec{s}}\). If we denote initial hyperparameters of \(\:f\left(x\right)\) with \(\:{\varvec{\theta\:}}_{0}\), the BO algorithm – given \(\:x\in\:{\mathcal{D}}_{s}\) – is applied to tune hyperparameters of \(\:{f}_{s}\left(x\right)\), after which they can be denoted by \(\:{\varvec{\theta\:}}_{s}\).
-
Testing the unseen IC: Subsequently, the performance of the pretrained baseline model is evaluated on the data from the new unseen IC.
However, the results indicated suboptimal performance, highlighting the need for further model refinement.
-
TL with limited samples: To address the limitations in performance, the transferred model is updated using limited samples from the target domain \(\:{\mathcal{D}}_{t}={\left\{\left({x}_{i}^{t},{y}_{i}^{t}\right)\right\}}_{i=1}^{{N}_{t}}\) alongside the source domain data \(\:{\mathcal{D}}_{s}\). For example, the updating of the source model for GPR can be expressed as:
Specifically, we experimented with \(\:{N}_{t}\) values of 1, 5, 10, and 20 samples available from the new unseen IC to investigate the impact of varying sample sizes of the target domain on model improvement.
Evaluation metrics
We used several metrics to compare the performance of the trained ML models. These metrics can be categorised into two groups: metrics that evaluate the accuracy of the models and those that assess the speed of the training and prediction processes. Regarding the first group, we used root-mean-square error (RMSE), coefficient of determination (R-squared or \(\:{R}^{2}\)), and mean-absolute-error (MAE), with the following equations:
where n is the number of data points, \(\:y\) is the actual value vector, \(\:\widehat{y}\) is the predicted value vector, and \(\:\stackrel{-}{y}\) is the mean of actual values.
In addition to the metrics used to assess accuracy, we also employed two additional metrics: training time and prediction speed. The former indicates the time required for the model to be trained (in seconds), while the latter represents the number of predictions the model can make per second. Therefore, models with low training times and high prediction speeds are preferred.
Results and discussion
In this section, the performance of various ML models (mentioned in Section 3), considered as the SM, is first compared in the subsection “surrogate model selection”. The influence of including or excluding initial configurations (ICs) as complementary input features through label encoding is investigated to select the best models and determine the optimal approach for shaping the feature input. This step is crucial for further evaluations and subsequent steps toward nested cross-validation (NCV) on unseen ICs and updating the SM using TL, as will be discussed in the subsection “Transfer Learning (TL) for Unseen ICs”. We used MATLAB 2022a on a laptop with an Intel Core i7-8665U CPU and 16 GB of RAM to train and evaluate ML models.
Surrogate model selection
We trained various ML models to compare and select those showing the best performance for the next steps. The models were trained under two distinct scenarios with respect to ML inputs: (1) using only DEM interaction parameters, and (2) considering extra inputs to characterise the ICs of the mixture within the hopper (see Fig. 2). Figure 6 illustrates an example of the regression tree model’s performance for both scenarios. Obviously, the model’s performance is significantly enhanced in the case of the extra inputs related to ICs. This improvement is anticipated as the segregation (or degree of mixing) of multiple materials heavily depends on their ICs6. The results for the first scenario (i.e., excluding ICs as ML inputs) are given in Table B.3 of the Appendix, where it is evident that the model’s performance is unsatisfactory even with optimised hyperparameters. As a result, we proceed with the second scenario to train the models.

Comparison of the impact of input features with (w/) and without (w/o) initial configurations (ICs) on fine-tuned regression tree outcomes using Bayesian optimisation (BO), assessed via 5-fold cross-validation.
The training results of various ML models are presented in Table 4, where ICs were included as complementary features. The training was performed with 5-fold cross-validation on 185 samples and 18 features. Optimisable models were fine-tuned using the Bayesian optimisation (BO) algorithm with 50 iterations. Notably, the performance of the models significantly improved when the hyperparameters were optimised using BO, underscoring the importance of fine-tuning hyperparameters in the ML training process. It is also worth mentioning that despite increasing the number of hidden layers and neurons, the performance of ANN did not improve, possibly due to overfitting or vanishing gradient problems71.
Based on the evaluation metrics employed in this study, the optimal model is characterised by minimal error (i.e., RMSE and MAE), maximal \(\:{R}^{2}\), low training time, and high prediction speed. According to Table 4, we identify two models that fulfil the majority of these criteria simultaneously: Gaussian process regression (GPR) and ensemble of trees, with GPR being superior across all metrics.
Transfer learning (TL) for unseen ICs
In this section, we present the outcomes of the TL method and updating process utilised in this study, as explained in Section 5. Results for TL-based ensemble learning (TL-Ensemble) and GPR (TL-GPR) are given in Tables 5 and 6, respectively. To ensure stability and repeatability, we used five different random seed numbers to initialise the ML model’s parameters during training. This strategy ensures a reliable assessment of the model’s performance. The results in Tables 5 and 6 are reported as (mean ± standard deviation) resulting from these five repetitions. All training procedures were performed with 10-fold cross-validation and 18 features. Additionally, hyperparameters were fine-tuned using the BO algorithm. The hyperparameters of these models together with their search space are provided in Table B.4 and Table B.5 in the Appendix.
Initially, we cross-validated the models (i.e., Ensemble learning and GPR) using all 185 available samples given ten folds to establish a benchmark for comparison. The results are displayed in the first row of Tables 5 and 6, labelled as “All ICs were seen”. Then, we iteratively applied the transfer learning approach across all ICs. For each iteration, one IC was excluded, and the model was pretrained on the remaining four ICs (i.e., on 4 × 37 = 148 samples) via a 10-fold cross-validation coupled with BO fine-tuning of hyperparameters. The results of the validation phase are presented under “Validation”, excluding the training phase’s results. Next, we tested the model’s performance on the “unseen IC” as the target domain of TL that was previously excluded. We ran tests where the pretrained model was retrained with 0, 1, 5, 10, and 20 samples from the unseen IC, monitoring its performance each time. These test results are shown under “Unseen IC”. For an overall assessment of the model’s performance across all unseen ICs, we calculated the average of the TL-based outcomes across all unseen ICs for retraining with different available samples of 0, 1, 5, 10, and 20 from the target domain. These averages are displayed at the bottom of Tables 5 and 6, indicated as “Mean”.
To visually illustrate the impact of the updating process on the pretrained TL-SMs, Fig. 7 shows predicted versus true responses for two different unseen initial configurations, IC1 and IC3, where they were updated with 0 (no update), 1, and 5 samples from the target domain. The models’ predictions were initialised using the first random seed number in this figure. As illustrated, providing even a few samples from the unseen IC—the target domain—for updating leads to a significant improvement. Comprehensive results for various unseen ICs, random seed numbers, and the model updated with different numbers of samples (0, 1, 5, 10, 20) from the unseen IC under test are provided in two videos in the supplementary material for both TL-Ensemble and TL-GPR. These videos allow easy tracking of the updating process and the effect on targeting different unseen ICs.

Predicted and true responses for unseen initial configurations IC1 and IC3 with TL-Ensemble and TL-GPR, updated with varying numbers of samples: (a) 0 (no update), (b) 1, and (c) 5 from the unseen IC.
Figure 8 illustrates a comparison between the “mean” performance of TL-Ensemble and TL-GPR across different numbers of available samples from the unseen IC. As shown, TL-GPR consistently outperforms Ensemble-TL across all available sample sizes, highlighting the superiority of TL-GPR over TL-Ensemble. Consequently, we focus our attention on TL-GPR for further analysis of the results.

Comparison between the mean performances of TL-Ensemble and TL-GPR during validation and test phases for different numbers of available samples from unseen IC to update in terms of (a) RMSE, (b) \(\:{R}^{2}\), and (c) MAE.
Figure 9 illustrates the reduction in RMSE in percentage for different sample sizes used to update the TL-GPR model. The reduction was calculated as \(\:\left(\left|{RMSE}_{ICi}-{RMSE}_{IC0}\right|/{RMSE}_{IC0}\right)\times\:100\), where \(\:(i=1,\:5,\:10,\:20)\) corresponds to different numbers of samples to retrain SM, and IC0 denotes the case where no update happens to the pretrained model. The bar graph demonstrates that updating the TL-GPR model with just one sample from the unseen IC results in a significant reduction (~ 50%) in the RMSE. Figure 8a also shows that by updating the model with only a few new samples (e.g. 5 samples) from the unseen IC, its accuracy for the new IC can approach that of the validation set. This finding underscores the efficiency of updating the SM with a minimal number of new DEM simulations to achieve improved accuracy of the SM for unseen IC.

Reduction in RMSE of TL-GPR model following updating with different numbers of samples from unseen ICs.
It is important to note that the results and analyses discussed above are based on the average performance of the TL-based model across all ICs. However, according to Table 6, the model’s performance varies depending on which IC is considered as unseen. To facilitate a clearer comparison, Fig. 10 presents the RMSE and \(\:{R}^{2}\) of TL-GPR across all ICs and for different numbers of samples used to update the pretrained model. It reveals that, when the model is not updated (i.e., 0 sample), the TL-GPR model exhibits the poorest performance for IC3 and IC2, characterised by the highest RMSE and lowest \(\:{R}^{2}\).
The observed performance for IC3, where materials within the hopper are fully-mixed (see Fig. 2), was anticipated. This is because there is no comparable data in the training dataset; the other four initial configurations (IC1, IC2, IC4, and IC5) have fully segregated initial configurations, leading to a far different data distribution for IC3. Similarly, the relatively less optimal performance of the model for IC2 can be attributed to its unique feature, i.e., having a reversed layering order, opposite to IC1, IC4, and IC5. Nevertheless, in both IC2 and IC3 cases, after updating the model with only a few data points, a significant improvement in performance is observed. For instance, in IC3, updating the model with only 1 and 5 samples results in a remarkable reduction in RMSE by 68% and 85%, respectively.

Accuracy of TL-GPR across various unseen ICs and for different numbers of samples to update the model in terms of (a) RMSE and (b) R-squared.
Conclusion
In this study, we successfully demonstrated a framework for developing surrogate models (SMs) that effectively link particle-particle and particle-wall DEM interaction parameters to the segregation of a multi-component mixture. We first examined various ML models to develop SMs capable of estimating radial segregation in the heap based on DEM parameters and the initial configuration (IC) of the mixture. We found that developing accurate SMs requires consideration of features describing IC through feature engineering. Moreover, we emphasise that fine-tuning hyperparameters is crucial to obtaining the optimal performance of ML-based SMs. Among the six ML models tested, Ensemble learning and Gaussian process regression (GPR) demonstrated the best performance.
Next, we developed an adaptive SM leveraging a transfer learning (TL)-based approach using Ensemble learning and GPR. Cross-validation, coupled with Bayesian optimisation for fine-tuning the SM’s hyperparameters, was conducted using four ICs as the pretraining phase of TL, while predictions and a retraining phase made for a fifth “unseen IC”. Model performance was monitored after updating and retraining the TL-SMs with access to different numbers of samples from the unseen IC. We observed that TL-GPR consistently outperformed TL-Ensemble.
Our findings indicate that the performance of TL-SMs varied depending on the specific unseen IC. When testing the pretrained TL-SMs with new ICs possessing specifications not included in the source dataset, their performance appears to be relatively lower. For instance, IC3 is the only configuration out of five in which the materials are fully-mixed, and the TL-SMs’ performance for IC3 was inferior compared to other ICs. However, the performance significantly improved after updating the model with a few samples from the “unseen IC”. For instance, the RMSE of TL-GPR was reduced by an average of 50% by retraining the model with just one additional sample, highlighting the adaptability and effectiveness of our proposed adaptive TL approach.
To overcome the challenge encountered by the TL model for IC3 (i.e., fully-mixed configuration), additional intermediate initial configurations between fully-segregated and fully-mixed ones can be incorporated. Additionally, our surrogate model is currently constrained to predicting segregation for pellets and sinter with specified material properties and certain geometrical properties of the system. To improve the generalisability of the model, it is essential to vary and include these material- and geometry-related properties in the training phase. Furthermore, our surrogate model is developed for only one response variable. However, in DEM model calibration problems, multiple responses are typically considered simultaneously. Future research endeavours could focus on addressing these challenges, including incorporating multiple response variables and exploring a broader range of material and geometric properties to improve model performance and applicability.
The authors would like to acknowledge dr.ir. Jan van der Stel and ir. Allert Adema from Tata Steel Ijmuiden for the insightful discussions in the context of blast furnace.
Data availability
The data presented in this study is available upon request from the corresponding author.
Change history
04 December 2024
A Correction to this paper has been published: https://doi.org/10.1038/s41598-024-80211-w
References
Rosato, A. D., Blackmore, D. L., Zhang, N. & Lan, Y. A perspective on vibration-induced size segregation of granular materials. Chem. Eng. Sci. 57, 265–275 (2002).
Gray, J. M. N. T. Particle segregation in dense granular flows. 50, 407–433. (2018).
Shinohara, K. & Miyata, S. I. Mechanism of density segregation of particles in filling vessels. Industrial Eng. Chem. Process. Des. Dev. 23, 423–428 (1984).
Jain, N., Ottino, J. M. & Lueptow, R. M. Regimes of segregation and mixing in combined size and density granular systems: an experimental study. Granul. Matter. 7, 69–81 (2005).
Duffy, S. P. & Puri, V. M. Primary segregation shear cell for size-segregation analysis of binary mixtures. Kona Powder Part. J. 20, 196–207 (2002).
Hadi, A., Roeplal, R., Pang, Y. & Schott, D. L. DEM modelling of segregation in Granular materials: a review. Kona Powder Part. J. https://doi.org/10.14356/kona.2024017 (2023).
Cundall, P. A. & Strack, O. D. L. A discrete numerical model for granular assemblies. Geotechnique 29, 47–65 (1979).
Roeplal, R., Pang, Y., Adema, A., van der Stel, J. & Schott, D. Modelling of phenomena affecting blast furnace burden permeability using the discrete element method (DEM)—A review. Powder Technol. 415 https://doi.org/10.1016/j.powtec.2022.118161 (2023).
Lee, S. J., Hashash, Y. M. A. & Nezami, E. G. Simulation of triaxial compression tests with polyhedral discrete elements. Comput. Geotech. 43, 92–100 (2012).
Huang, H. & Tutumluer, E. Discrete element modeling for fouled railroad ballast. Constr. Build. Mater. 25, 3306–3312 (2011).
Obermayr, M., Dressler, K., Vrettos, C. & Eberhard, P. Prediction of draft forces in cohesionless soil with the discrete element Method. J. Terrramech. 48, 347–358 (2011).
Roessler, T., Richter, C., Katterfeld, A. & Will, F. Development of a standard calibration procedure for the DEM parameters of cohesionless bulk materials–part I: solving the problem of ambiguous parameter combinations. Powder Technol. 343, 803–812 (2019).
Irazábal, J., Salazar, F. & Vicente, D. J. A methodology for calibrating parameters in discrete element models based on machine learning surrogates. Comput. Part. Mech. 10, 1031–1047 (2023).
Richter, C., Rößler, T., Kunze, G., Katterfeld, A. & Will, F. Development of a standard calibration procedure for the DEM parameters of cohesionless bulk materials – part II: efficient optimization-based calibration. Powder Technol. 360, 967–976 (2020).
Yoon, J. Application of experimental design and optimization to PFC model calibration in uniaxial compression simulation. Int. J. Rock Mech. Min. Sci. 44, 871–889 (2007).
Heß, G., Richter, C. & Katterfeld, A. Simulation of the dynamic interaction between bulk material and heavy equipment: Calibration and validation. In ICBMH –12th International Conference on Bulk Materials Storage, Handling and Transportation, Proceedings 427–436. (2016).
Mohajeri, M. J., Do, H. Q. & Schott, D. L. DEM calibration of cohesive material in the ring shear test by applying a genetic algorithm framework. Adv. Powder Technol. 31, 1838–1850 (2020).
Do, H. Q., Aragón, A. M. & Schott, D. L. A calibration framework for discrete element model parameters using genetic algorithms. Adv. Powder Technol. 29, 1393–1403 (2018).
Fransen, M. P., Langelaar, M. & Schott, D. L. Application of DEM-based metamodels in bulk handling equipment design: Methodology and DEM case study. Powder Technol. 393, 205–218 (2021).
Chinesta, F., Cueto, E. & Klusemann, B. Empowering materials processing and performance from data and AI. Materials 14 https://doi.org/10.3390/ma14164409 (2021).
Rackl, M. & Hanley, K. J. A methodical calibration procedure for discrete element models. Powder Technol. 307, 73–83 (2017).
Grobbel, J., Brendelberger, S., Henninger, M., Sattler, C. & Pitz-Paal, R. Calibration of parameters for DEM simulations of solar particle receivers by bulk experiments and surrogate functions. Powder Technol. 364, 831–844 (2020).
De Pue, J., Di Emidio, G., Flores, V., Bezuijen, R. D. & Cornelis, W. M. A. Calibration of DEM material parameters to simulate stress-strain behaviour of unsaturated soils during uniaxial compression. Soil Tillage. Res. 194, (2019).
Fransen, M. P., Langelaar, M. & Schott, D. L. Including stochastics in metamodel-based DEM model calibration. Powder Technol. 406, (2022).
Westbrink, F., Elbel, A., Schwung, A. & Ding, S. X. Optimization of DEM parameters using multi-objective reinforcement learning. Powder Technol. 379, 602–616 (2021).
Cheng, H. et al. An iterative bayesian filtering framework for fast and automated calibration of DEM models. Comput. Methods Appl. Mech. Eng. 350, 268–294 (2019).
Hartmann, P., Cheng, H. & Thoeni, K. Performance study of iterative bayesian filtering to develop an efficient calibration framework for DEM. Comput. Geotech. 141, (2022).
El-Kassem, B., Salloum, N., Brinz, T., Heider, Y. & Markert, B. A multivariate regression parametric study on DEM input parameters of free-flowing and cohesive powders with experimental data-based validation. Comput. Part. Mech. 8, 87–111 (2021).
Benvenuti, L., Kloss, C. & Pirker, S. Identification of DEM simulation parameters by Artificial neural networks and bulk experiments. Powder Technol. 291, 456–465 (2016).
Zhou, H., Hu, Z., Chen, J., Lv, X. & Xie, N. Calibration of DEM models for irregular particles based on experimental design method and bulk experiments. Powder Technol. 332, 210–223 (2018).
Ye, F. et al. Calibration and verification of DEM parameters for dynamic particle flow conditions using a backpropagation neural network. Adv. Powder Technol. 30, 292–301 (2019).
Zhu, H. P., Zhou, Z. Y., Yang, R. Y. & Yu, A. B. Discrete particle simulation of particulate systems: theoretical developments. Chem. Eng. Sci. 62, 3378–3396 (2007).
Ai, J., Chen, J. F., Rotter, J. M. & Ooi, J. Y. Assessment of rolling resistance models in discrete element simulations. Powder Technol. 206, 269–282 (2011).
Tripathi, A. et al. Quantitative DEM simulation of pellet and sinter particles using rolling friction estimated from image analysis. Powder Technol. 380, 288–302 (2021).
Chakrabarty, A., Biswas, R., Basu, S. & Nag, S. Characterisation of binary mixtures of pellets and sinter for DEM simulations. Adv. Powder Technol. 33, (2022).
Wensrich, C. M. & Katterfeld, A. Rolling friction as a technique for modelling particle shape in DEM. Powder Technol. 217, 409–417 (2012).
Viera Valencia, L. F. & Garcia Giraldo, D. Angewandte Chemie International Edition, 6(11), 951–952. 2 https://www.tudelft.nl/dhpc/ark:/44463/DelftBluePhase1 (2019).
Wei, H. et al. Measurement and simulation validation of DEM parameters of pellet, sinter and coke particles. Powder Technol. 364, 593–603 (2020).
Yu, Y. & Saxén, H. Particle flow and behavior at bell-less charging of the blast furnace. Steel Res. Int. 84, 1018–1033 (2013).
Mitra, T. Modeling of burden distribution in the blast furnace. (2016).
Yu, Y. & Saxén, H. Flow of pellet and coke particles in and from a fixed chute. Ind. Eng. Chem. Res. 51, 7383–7397 (2012).
Lu, Y., Jiang, Z., Zhang, X., Wang, J. & Zhang, X. Vertical section observation of the solid flow in a blast furnace with a cutting method. Metals 9, (2019).
Yu, Y. & Saxén, H. Experimental and DEM study of segregation of ternary size particles in a blast furnace top bunker model. Chem. Eng. Sci. 65, 5237–5250 (2010).
Mio, H. et al. Validation of particle size segregation of sintered ore during flowing through laboratory-scale chute by discrete element method. ISIJ Int. 48, 1696–1703 (2008).
Basu, S. et al. Modeling and simulation of mechanical degradation of iron ore sinter in a complex transfer chute system using the discrete element model and a particle breakage model. Powder Technol. 417, (2023).
Barrios, G. K. P., de Carvalho, R. M., Kwade, A. & Tavares, L. M. Contact parameter estimation for DEM simulation of iron ore pellet handling. Powder Technol. 248, 84–93 (2013).
Izard, E., Moreau, M. & Ravier, P. Discrete element method simulation of segregation pattern in a sinter cooler charging chute system. Particuology 59, 34–42 (2021).
Jones, B. & Nachtsheim, C. J. A class of three-level designs for definitive screening in the presence of second-order effects. J. Qual. Technol. 43, 1–15 (2011).
Jones, B. & Nachtsheim, C. J. Effective design-based model selection for definitive screening designs. Technometrics 59, 319–329 (2017).
Zheng, A. & Casari, A. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists (‘O’Reilly Media, Inc.’, 2018).
Hancock, J. T. & Khoshgoftaar, T. M. Survey on categorical data for neural networks. J. Big Data 7, (2020).
Freedman, D. A. Statistical models: theory and practice. Stat. Models Theory Pract. https://doi.org/10.1017/CBO9780511815867 (2009).
Welsch, R. E. Robust regression using iteratively reweighted least-squares. Commun. Stat. Theory Methods 6, 813–827 (1977).
Neter, J., Kutner, M. H., Nachtsheim, C. J. & Wasserman, W. Applied linear statistical models. (1996).
Hearst, M. A., Scholkopf, B., Dumais, S., Osuna, E. & Platt, J. Supprot vector machines. IEEE Intell. Syst. Their Appl. 13, 18–28 (1998).
Vapnik, V. N. The Nature of Statistical Learning Theory. Nat. Stat. Learn. Theory. https://doi.org/10.1007/978-1-4757-2440-0 (1995).
Smola, A. J. & Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 14 199–222. https://doi.org/10.1023/B:STCO.0000035301.49549.88 (2004).
Witten, I. H., Frank, E. & Geller, J. Data mining: Practical machine learning tools and techniques with Java implementations. SIGMOD Record. 31, 76–77 (2002).
Breiman, L. Bagging predictors. Mach. Learn. 24, 123–140 (1996).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Rasmussen, C. E. Gaussian processes in machine learning. In Summer school on machine learning 63–71 (Springer, 2003).
Wu, Z. et al. Machine learning approach to predicting the macro-mechanical properties of rock from the meso-mechanical parameters. Comput. Geotech. 166, 105933. (2024).
Shalev-Shwartz, S. & Ben-David, S. Understanding Machine Learning: From Theory to Algorithms. Understanding Machine Learning: From Theory to Algorithms 9781107057 (2013).
Bishop, C. M. Pattern recognition and machine learning. Springer Google Schola 2, 5–43 (2006).
Haykin, S. Neural Networks and Learning Machines, 3/E. (Pearson Education India, 2009).
Arlot, S. & Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 4, 40–79 (2010).
Snoek, J., Larochelle, H. & Adams, R. P. Practical bayesian optimization of machine learning algorithms. Adv. Neural. Inf. Process. Syst. 4, 2951–2959 (2012).
Weiss, K., Khoshgoftaar, T. M. & Wang, D. D. A survey of transfer learning. J. Big Data 3, (2016).
Pan, S. J. & Yang, Q. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering 22 1345–1359. https://doi.org/10.1109/TKDE.2009.191 (2010).
Iman, M., Arabnia, H. R. & Rasheed, K. A Review of deep transfer learning and recent advancements. Technologies 11 https://doi.org/10.3390/technologies11020040 (2023).
Sheela, K. G. & Deepa, S. N. Review on methods to fix number of hidden neurons in neural networks. Math. Problems Eng. (2013).
Acknowledgements
This research was carried out under project number T18019 in the framework of the Research Program of the Materials innovation institute (M2i) (www.m2i.nl) supported by the Dutch government. The authors would like to acknowledge ir. Jan van der Stel and dr.ir. Allert Adema from Tata Steel Ijmuiden for the insightful discussions in the context of blast furnace.
Author information
Authors and Affiliations
Contributions
Conceptualisation, A.H., and M.M.; methodology, A.H., and M.M.; software, A.H., and M.M.; validation, A.H., M.M., Y.P., and D.S.; formal analysis, A.H., M.M.; investigation, A.H., M.M.; writing—original draft preparation, A.H., M.M.; writing—review and editing, A.H., M.M., Y.P., and D.S.; visualization, A.H., and M.M.; supervision, Y.P., and D.S.; All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: The original version of this Article contained typographical errors in Equations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary Material 2
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hadi, A., Moradi, M., Pang, Y. et al. Adaptive AI-based surrogate modelling via transfer learning for DEM simulation of multi-component segregation. Sci Rep 14, 27003 (2024). https://doi.org/10.1038/s41598-024-78455-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-78455-7
Keywords
This article is cited by
-
Machine learning for extracellular vesicles enables diagnostic and therapeutic nanobiotechnology
Journal of Nanobiotechnology (2026)
