
Abstract
Schizophrenia is a serious mental disorder with a complex neurobiological background and a well-defined psychopathological picture. Despite many efforts, a definitive disease biomarker has still not been identified. One of the promising candidates for a disease-related biomarker could involve retinal morphology , given that the retina is a part of the central nervous system that is known to be affected in schizophrenia and related to multiple illness features. In this study Optical Coherence Tomography (OCT) data is applied to assess the different layers of the retina. OCT data were applied in the process of automatic differentiation of schizophrenic patients from healthy controls. Numerical experiments involved applying several individual 1D Convolutional Neural Network-based models as well as further using the aggregation of classification results to improve the initial classification results. The main goal of the study was to check how methods based on the aggregation of classification results work in classifying neuroanatomical features of schizophrenia. Among over 300, 000 different variants of tested aggregation operators, a few versions provided satisfactory results.
Similar content being viewed by others
Introduction
Optical Coherence Tomography (OCT) is a non-invasive imaging technique that uses reflected light to generate high-resolution, cross-sectional images of biological tissues. OCT is widely used in many medical fields, such as cardiology, dermatology, and gastroenterology, for imaging staging, and diagnosing multiple conditions1. It’s primary use has been in ophthalmology, for imaging the thickness and volume of retinal neural layers and other structures (e.g., macula, retinal nerve fiber layers (RNFL), ganglion cells, which together with inner and outer nuclear and plexiform layers create the ganglion cells complex (GCC)2, photoreceptor layer and retinal pigment epithelium3). OCT images of the retina are considered to be as high-resolution as histological images. In standard ophthalmological evaluation, clinicians look mainly for structural abnormalities, but when OCT is used in research involving between-group comparisons, the focus is on quantitative measurement of selected retinal layers thickness and volume4.
One such group includes patients with severe psychiatric illnesses. Mental health disorders are a growing challenge for health care and science5. At the same time, psychiatry seems to be the last field of medicine in which diagnostic procedures are still not based on objective biological markers, but on subjective clinical assessment, mainly based on behavioral and self-report data6. Schizophrenia is a mental illness whose basic symptoms have been characterized for over 100 years, but for which no clear biomarkers have yet been developed, e.g. based on neuroimaging outcomes7. Patients with schizophrenia express many psychopathological symptoms, such as auditory and visual hallucinations, paranoid thoughts, cognitive dysfunctions, and substantial problems with social functioning. Schizophrenia is a long-lasting disease with phases of exacerbation and improvement, in which the so-called negative or deficit symptoms, such as lack of initiative, interpersonal and communicational withdrawal, and blunted affect dominate, even when pharmacological treatment is provided8. Although it is generally agreed that schizophrenia is a neurobiological disease9, probably due to its high level of its complexity and heterogeneity, its major neural mechanism is still not unequivocally known .
Since the retina ontologically develops from the neural tube and might be treated as an observable part of the brain, it is assumed that its morphology is sensitive to pathological changes typical of neuropsychiatric disorders . Indeed, much evidence, in multiple neurodegenerative disorders10, and in psychiatry11, indicate that specific retinal variables can serve as disease-related biomarkers12. Previous research confirms the existence of thinner retinal layers in schizophrenia, especially macular thickness, and to a lesser extent retinal nerve fiber layer (RNFL), but many questions still remain about when in the course of illness the retinal changes can be observed, how/whether these progress over time, and which clinical features and outcomes they are most strongly related to13,14,15. In addition, many previous analyzes did not control for the influence of confounding factors such as somatic health14 (e.g., diabetes, smoking, hypertension, other cardiovascular diseases) that can damage the retina and significantly affect the results of OCT assessment16.
The expectation of significant alterations in retinal morphology in schizophrenia has many grounds. First, retinal thinning has long been observed in neurodegenerative diseases due to atrophic changes throughout the central nervous system17. Schizophrenia as a progressive disease was defined as dementia preaecox by Kraepelin already in the early stages of psychiatry development18. In addition to developmental abnormalities, contemporary neuroimaging data also confirm neuroprogressive changes in schizophrenia patients’ brain structure19. Data from cognitive studies have also shown that these patients have disturbances in auditory and, olfactory, but also visual perception, and therefore, the neurobiological basis of these dysfunctions has been sought20. In recent years, retinal alterations have been even more closely linked with the neuronal substrate of schizophrenia and its specific course. Sheehan et al.21, referring to earlier observations by Johnson and Cowey22, suggested that thinning of the retina’s neuronal layers in schizophrenia may result from well-established thalamic abnormalities. Thalamic dysfunctions are a key feature of the cognitive dysmetria hypothesis23 regarding the neuroaetiology of schizophrenia, which emphasize the role of thalamo-centric brain network dysfunctions in this disorder. It has been suggested that, as a result of retrograde transsynaptic degeneration , morphological abnormalities of the thalamus lead to loss of ganglion cell axons projecting from the retina to the thalamus (e.g., the RNFL fibers that constitute the optic nerve), which eventually leads to loss of ganglion cell bodies and the other retinal neurons that project to them (e.g., bipolar cells). It should also be pointed out that individuals with schizophrenia exhibit altered aging trajectories regarding the central nervous system leading to accelerated aging of the neuronal structures, which may also involve the retina, especially considering its high metabolic demands24,25.
So far, retinal measures have been used only a few times to verify computational methods for the automatic differentiation of schizophrenia patients from healthy controls. Although some of the results report progress in this matter26, sometimes it was not possible to achieve discrimination accuracy better than 70\(\%\). Binary classification of schizophrenia spectrum disorder (SSD) patients and healthy controls was also presented in27, where authors used classical classification models, especially logistic regression. The latest Indian research28, which included probably the largest group of patients so far, seems to be promising considering the results of analyzes using a trained convolution neural network (CNN) deep learning algorithm, but this study evaluated retinal vascular abnormalities based on fundus camera images, not OCT data.
Currently, deep neural networks are considered the best classifiers. Therefore, in this paper, we develop this approach to classifying schizophrenia patients from controls based on OCT data. Several 1D CNN-based models were used in the first stage of the calculations . If the quality of the classification (accuracy of the method) is not satisfactory, it is advisable to aggregate classification results. A certain, although minor, disadvantage is the need to use at least two classifiers. On the other hand, this approach usually results in an increase in classification accuracy.
Aggregation techniques have been successfully developed by researchers recently, in particular in the field of fuzzy logic and fuzzy sets. Aggregation methods include various types of averages, t-norms or s-norms29,30,31,32,33, but also more advanced operators such as the Choquet integral34,35, Ordered Weighted Averaging Operators36,37, pre-aggregation functions38,39,40,41,42, generalizations and expansions of the Choquet integral43, modifications of classical operators such as Bonferroni mean44, intuitionistic operators, e.g.,45,46, conditional aggregation operators47, granular models48, order-2 fuzzy sets49. Also, current approaches to aggregating classification results from different methods include procedures to maximize aggregation security (see50), and incorporate fuzzy inference systems51 and geometrical approaches52. Therefore, we include these methods in the current study.
Particularly in medical applications such as disease detection, the ultimate effectiveness of the classification process is more important than the effectiveness of any single method . Because of this, combining deep neural networks and the results they generate using effective aggregation operators has the potential to be an effective solution The aim of this paper was to determine if it is possible to differentiate SSD patients from healthy controls using deep learning models based on OCT data only. One of the main goals of the article is to check how methods based on the aggregation of classification results work in classifying people as having schizophrenia vs healthy donors . Over 300, 000 different variants of aggregation operators have been tested. Unfortunately, only a few versions provided satisfactory results that can be confidently said to improve the classification results significantly. Nevertheless, the results clearly show that new generalizations and extensions of the Choquet integral and its earlier extensions (so-called pre-aggregation functions) can successfully aid in disease classification. A novel aspect of this study is that classical and deep learning classifiers, but also using different variants of aggregation operators to improve the classification results , are applied to OCT data in schizophrenia for the first time.
An outline of the remainder of the paper is as follows. “Methods” describes the research methods including subject ascertainment and methods for obtaining OCT data . In “Classification on a basis of deep neural networks”, individual classifiers (deep neural networks) are discussed. The general aggregation scheme is presented in “Classification based on an aggregation procedure”. “Results” covers numerical experiments and a description of the obtained results. In “Discussion”, we present conclusions and potential directions for future research work.
Methods
Participants
Patients diagnosed with schizophrenia according to ICD10 classification (with code F20.x), hospitalized in the Medical University Psychiatric Clinic in Poland were enrolled in the clinical group. 17.0% of patients’ cases were hospitalized due to the first psychotic episode. The chlorpromazine equivalent was 452.22 mg/day (SD = 128.2), 57% of patients received atypical antipsychotic drugs only, and the remaining patients received a combination of classic and atypical medications. The mean age of patients was 39.52 (SD = 15.38), 55% of patients were male, and the mean duration of illness was 16.83 (SD = 13.72) years. Years of education among patients was 13.05 (SD = 2.37) years. Patients did not differ significantly from controls on age, sex, years of education, or BMI (all p > 0.05). However, a significantly higher percentage of patients were unemployed and unmarried (both p < 0.001), and 43.14% of patients consumed various forms of tobacco products compared to 15.97% from the control group (p = 0.001). Psychiatric diagnosis was established by a certified specialist in the field of psychiatry, typically, the attending psychiatrist. Psychopathology was assessed using the original three-factor scoring solution for the Positive and Negative Syndome Scale (PANSS)53. Mean sydrome scores were: positive symptoms = 18.94 (SD = 6.41), negative symptoms = 24.11 (SD = 7.25), and general symptoms = 46.58 (SD = 9.17). The total PANSS score was 89.63 (SD = 19.45).
Considering the necessity to maintain a high level of OCT measurement validity,we used the following exclusion criteria for patients and controls: previously diagnosed ophthalmological disease (e.g. glaucoma, macular degeneration, diabetic retinopathy), diabetes, untreated arterial hypertension (or, if treated, blood pressure above 140/90 mmHg during the examination), history of trauma to the eye area, ophthalmologic surgery, head injuries with neurological consequences, eye refraction over \(\pm 5\) diopters, glaucoma risk (DDLS scale \(\ge 6\)), history of psychoactive substances addiction (except nicotine), inherited intellectual disability, dementia. The presence of a relevant comorbid psychiatric disorder was also an exclusion criterion for patients, and the presence of any psychiatric disorder was an exclusion criterion for controls. OCT evaluation was conducted during the phase of clinical improvement to maximize patient cooperation . After completing the clinical group, a healthy control sample was collected using the pairwise sampling method, taking into account basic demographic characteristics. This study was approved by the Bioethics Committee at the Medical University (consent nr KE-0253/248/2020 issued on 26 November 2020,) and all participants provided informed consent according to the Declaration of Helsinki. Initial recruitment of study participants began at the beginning of 2021, and the study lasted until the end of 2022.
OCT assessment
OCT data were acquired using an OPTOPOL COPERNICUS REVO®SD-OCT device54. This has a scanning speed of up to 80,000 scans/s, an axial resolution of 2.6 \(\mu\) m, a lateral resolution of 12 \(\mu\) m, and a scanning depth of 2.4 mm. The device uses a superluminescent diode (SLED) with a light wavelength of 830 nm as a signal source. The measurements were generated using OPTOPOL SOCT version 11.0.7. The software enables automatic segmentation of retinal layers, and includes adjustments for potential artifacts . In addition to automatic adjustments that are made during imaging, the quality of each image is automatically rated on a scale of 0-10. Only high-quality images were included in the study (Score \(\ge\) 7). Each patient had 4 photos taken (2 for each eye). The macular image was taken using a protocol of 640 A-scans and 85 B-scans on a 7x7mm square area centered on the macula. The image of the optic disc was taken using a protocol of 512 A-scans and 112 B-scans on a 6x6 mm area centered on the optic disc. Spot measurements were divided into quadrants according to the EDTRS grid55.
Data processing
The processing of the dataset was divided into several steps. All steps were performed using custom programs created in Python using Anaconda distribution and Anaconda Navigator graphical interface. Keras, Scikit-Learn and TensorFlow libraries were the most important libraries applied for this study.
Data processing steps included preprocessing steps such as feature extraction, feature normalization and feature selection. The main processing was related to training and testing classification models as well as applying aggregation of classifiers.
The entire original dataset covered 122 observations, from which 2 observations were discarded due to serious missing data fragments. Among the remaining 120 observations 61 belonged to the control healthy group and 59 were for the patient group.
Observations were defined in terms of a class label and a set of features. The class label defined the observations as belonging to one of the two groups: patients or healthy control. The original set of features consisted of more than 140 features. They were divided into several categories such as demographic and education category, neurological evaluation and symptoms category, hospital treatment, and psychotic symptoms category defined for patient group only. The most important category applied in this research, however, is OCT metrics-related category covering 80 features measured for all participants. The OCT features included macular thickness (MT), retinal macular volume (MV), combined outer nuclear layer and outer plexiform layer (ONL-OPL), macular and peripapillary RNFL thickness and GCC. Measurements for each eye were treated as separate features.
The choice of these OCT measures, subsequently used as features included in the computational experiments, was based on conclusions from previous meta-analyses and reviews of studies on retinal morphology in schizophrenia. For example, according to Prasannakumar et al.56, RNFL structure was OCT variable that most strongly differentiated between psychotic disorder vs. healthy controls status. Shew et al.’s review57 concluded that patients with schizophrenia are characterized by a significantly thinner global peripapillary RNFL layer, thinner average macular layer, and macular ganglion cell-inner plexiform sublayer. Analogous findings regarding MT, pRNFL, and GCL were documented earlier by Komatsu et al.15,58 and Gonzalez-Diaz with co-workers59. Additionally, meta-analysis of Lizano et al.60 and Asanad et al.27 also reached the same concussions: macular thickness, macular and peripapillary RNFL followed by ganglion cell complex are most thinned in schizophrenia patients.
Before the classification, the standard preprocessing procedures of outlier detection and data normalization were performed . The next step in the preprocessing pipeline was feature selection. This procedure was performed using Logistic Regression, a classical classification model that gives easily interpretable results.
Features importance in the form of weight vectors were derived, and the features with the lowest weights, (i.e., 0.01) were removed from the dataset. The feature selection procedure was performed using 5-fold cross-validation on a training dataset and tested on a testing dataset and the whole procedure including train-test split was repeated 1000 times and averaged to achieve stable results. This step enabled the reduction of the dimensionality of the dataset to 20 features. This feature selection procedure enables a balance between the number of features and the number of observations, to avoid the curse of dimensionality problem. What is more, the smaller dimensionality of the dataset helps to avoid overfitting and enable more efficient computations. The number of remaining features (20) represented an optimal tradeoff between the dimensionality of the dataset and the flexibility of the model. To verify this, tests using different number of features were also performed. Results showed that classification performed with more than 20 features did not improve classification results. .
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
Classification on a basis of deep neural networks
The classification task aimed to differentiate between two classes: Schizophrenia patients and healthy control. Classification was performed on a dataset containing 120 observations and 20 OCT-related, numerical features. The dataset was shuffled in random order and split into training and testing sets in the proportion of 80:20. Data from a single participant were used only one time, in the train or test dataset, in order to provide compliance with a subject-independent approach. This approach ensures that the data of participants from the test dataset are unknown for the model. 20% of the input dataset used for testing corresponds to 24 participants. The procedure of shuffling, splitting, and classifying was repeated 1000 times to obtain stable, non-random results.
Before applying CNN models classical supervised machine learning classification models were examined in order to obtain the reference results. Several models were examined including: Support Vector Machine (SVM) with the radial, linear, and polynomial kernel, Multi-layer Perceptron (MLP), K-Nearest Neighbor(KNN), and Logistic Regression. Before the classification, a hyperparameter grid searching procedure was applied to adjust the hyperparameters of classifiers. The procedure of hyperparameter searching, similarly to what was done during feature selection, was done using 5-fold cross validation performed on a training dataset and tested on a testing dataset and the whole procedure including train-test split was repeated 1000 times and averaged. Used hyperparameter values are presented in Table 1 and classification accuracies obtained with these classifiers are presented in Table 2.
Several classification models based on 1D CNN were applied. These types of models were chosen due to the numerical nature of the dataset. Among analysed models were models well-known in the literature, such as different versions of ResNet, SeResNet, Net1D, ACNN, CRNN, DenseNet, VGG and EfficientNet. Calculations were applied using 1D variants of 1D Zoo using Keras and TF.Keras libraries61. Weights were obtained by converting ImageNet weights from corresponding 2D models. The default pooling/stride size for 1D models was set to 4 to match (2, 2) pooling for 2D nets. Parameter settings and weights were adjusted in the process of model tuning. The models chosen for this have a a relatively small number of layers. These uncomplicated models were chosen due to the relatively small sample size available for this deep learning modeling. This choice was also confirmed by the initial preliminary tests. Beyond mentioned architectures, two simple CNN, marked as Model no. 1 and Model no. 2, were also applied. Characteristic of all applied models is presented in Table 3. What is more, details of Model no. 1 and Model no. 2 are presented in Table 4 and Table 5. An Adam optimizer was applied and accuracy was used as a metric. Categorical crossentropy was used as a loss function.
The mentioned CNN-based models were tested in the first part of the classification tests. The test sample was balanced, so accuracy was chosen as the classification quality metric. Table 6 shows the mean values of accuracy obtained for the most effective classifiers achieved for the dataset.
Classification based on an aggregation procedure
This discussion of aggregation techniques will begin with a focus on the Choquet integral approach. Imagine we have several classification algorithms trying to predict an outcome, such as determining whether a person is sick or healthy. Each of these algorithms, known as classifiers, provides its “opinion” in the form of probabilities, but not all opinions are equally important. This is where use of the Choquet integral becomes beneficial: it allows one to intelligently combine these opinions, taking into account their individual importance and how well they work together.
As an example, take the case of having three classifiers: the first analyzes lab results, the second focuses on demographic data, and the third looks at symptoms described by the patient. Each gives its probability estimate, for example: \(80\%\) (sick), \(60\%\) (sick), and \(50\%\) (healthy). A traditional method might simply average these values, yielding a result of \(63.3\%\). However, such an average ignores the fact that the classifiers differ in their precision and reliability, and it also disregards the pairwise agreement between the three of them.
The Choquet integral works differently because it considers not only the individual weight of each classifier but also how well their results align. For instance, if the two classifiers analyzing lab and demographic data indicate a similar outcome, their agreement will be “amplified,” increasing their influence on the final result. Meanwhile, the third classifier, which gives a different result, will have less impact, especially if its predictions are less reliable. As a result, instead of a simple average of \(63.3\%\), the Choquet integral might yield a result of \(75\%\), which better reflects the significance and agreement of the individual classifiers.
In this manner, the Choquet integral is more than just a simple averaging method - it reflects an intelligent system that better utilizes the “votes” of individual classifiers by considering both their individual importance and their collaboration. It is like a team of experts working together, each specializing in a different area, where the final decision is more accurate because it considers not only individual opinions but also how well the experts agree. This ensures that the resulting outcome is more precise and trustworthy. Moreover, the interpretability of the Choquet integral has been treated in depth in the literature, see, for instance62,63,64. Generalizations or extensions of Choquet integral have also been described38,39,40,41,42,43.
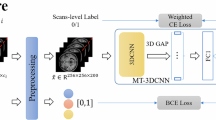
Our approach involved the following sequence. First, a data record describing the patient is used as an input to several different deep neural networks that return the probability values of the selected record belonging to a specific class. These probabilities are aggregated into a single result. To obtain it, the importance (weights) of individual classifiers are also taken into account. These may include, among others, accuracy values obtained in a series of pretests. The final value is yielded with the help of an aggregation operator such as Choquet integral, OWA operator and many others. The general scheme of the procedure is presented in Fig. 1.

General overall scheme of the aggregation procedure.

Accuracy of the Quadrature-Inspired Smooth Generalized Choquet Integral in dependence on the \(\alpha\) parameter value.

Accuracy of the classical pre-aggregation function in dependence on the \(\alpha\) parameter value.

Standard deviations in dependence on the \(\alpha\) parameter values.
As an example, one of the operators65 is a generalized aggregation function of the form
where , n is the number of classifiers, M is any t-norm, C is a quadrature-inspired function, for instance, of a Weddle form
\(h_j, j=1,\ldots ,n\) are the values of belongingness to a specific class obtained with the n classifiers sorted in a non-decreasing manner (with an assumption that \(h_{0}=h_{-1}=\ldots = h_1\) and \(h_{n+1}=h_{n+2}=\ldots =0\)), and \(g\left( A_i\right)\) are some \(\lambda\)-fuzzy measure values, built recursively on a basis of the importance of individual classifiers.
Results
Below, we describe the results obtained by the proposed method and compare them with various results obtained by individual classifiers. They are presented as averages obtained from one hundred iterations of the experiment for various input data. We have tested over 300, 000 versions of classifiers. They are, among others, OWA, Choquet integral, generalized Choquet integrals (so-called pre-aggregation functions), and classical aggregation functions such as averages, weighted averages, or t-norms. It is worth emphasizing that we have implemented a substantial number of aggregation functions and we do not discuss the findings for all of them. Rather, we emphasize those functions and parameters that led to the highest levels of classification accuracy. Finally, it is worth stressing that more detailed results can be made available to interested readers upon request.
The results presented below were obtained using the same 80:20 data partition (training:testing) method as used during the testing of individual deep learning-based classifiers. It is worth noting that aggregation in this study is a process applied to the classification results obtained by individual classifiers, but these classifiers are not trained collectively for the purpose of aggregation; instead, they are trained separately to achieve the best possible results individually. For instance, the authors of a work on pre-aggregation functions66 do not mention a separate validation set. All validation and testing are conducted within the framework of 10-fold cross-validation, which combines the evaluation of the model on training and testing sets. Therefore, it can be stated with certainty that an aggregation operator is good when its application results in a classification accuracy measure that exceeds the accuracy of the best individual classifier. We refer the reader to the classic work explaining the application of Choquet-type operators in aggregation and classification35. Finally, it is worth noting that there are many aggregation or aggregation-like operators used in practice. They can be, for instance, typical average functions such as arithmetic mean. These functions are not trained. Typically, they are just used to aggregate the results not as a part of the trained model. However, they can be.
The best accuracy was obtained by Quadrature-Inspired Smooth Choquet Integral given by formula (1). However, the function presented after the integral sign is of the Newton-Cotes 9-point quadrature form
where \(h_j\) are defined in the previous section. Moreover, the t-norm used in the formula is
and \(\alpha =5.2\).
An interesting finding is that classical pre-aggregation functions of the general form
where M is a t-norm or overlap function, returned an accuracy that was over 2 percentage points lower than the QISCI. The t-norm for which the result was found at this level is (4) for \(\alpha =1.6\). Also, the overlap function given by
produces good results in a combination with \(Ch_M\) pre-aggregation operator.
The next result was obtained by classical Choquet integral
Finally, the other non-Choquet-like functions giving acceptable results (see Table 7) were
i.e., Bonferroni mean67 for \(p=0.01\) and \(q=0.01\), and Ordered Weighted Averaging Tangent
where
It is worth noting that the results using the functions described above significantly outperformed the individual classifiers discussed in Table 6. All the results obtained on the basis of aggregation operators are gathered in Table 7.
Figure 2 shows the dependency of the accuracy value of the function (1) on the value of parameter \(\alpha\) appearing in (4). The best choice of the parameter \(\alpha\) is near the value 5.2. However, smaller values still lead to accurate results. Figure 3 demonstrates a similar dependency, but for another formula (5) with the same t-norm. One can observe that only with values close to the maximal \(\alpha\) can satisfactory results be obtained.
Figure 4 depicts the standard deviation values as a function of the value of the \(\alpha\) parameter. It is interesting that in the neighborhood of the winning \(\alpha\) values for the two methods, the standard deviations are relatively small.
Figure 5 depicts AUC values that show that the Quadrature-Inspired Generalized Choquet Integral method is the best aggregation operator for detecting patients with symptoms of schizophrenia and largely corresponds to the results presented in Table 7. Similarly, when analyzing fragments of the ROC curve, i.e. pROC plot, it can be seen that the values closest to the key point in the upper left corner of the graph (i.e., low FP rate and high TP rate) are the QIGCI values.

ROC curves with the AUC values for the aggregation operators denoted by the formulae numbers.
Discussion
In this paper, we presented a protocol for detecting schizophrenia based on retinal imaging (OCT) data that combined two types of classification methods: deep neural networks and operators aggregating classification results output by these networks. Individual deep neural networks have proven to be effective in classifying individuals with schizophrenia based on retinal layer thickness measures. We found that higher levels of classification accuracy could be obtained by combining the two methods. The combination of deep neural network outputs and the Quadrature-Inspired Smooth Generalized Choquet Integral was particularly effective at performing accurate classification. We compared over 300, 000 aggregation methods. The combination of the results of individual classifiers (deep neural networks) and aggregation methods based on fuzzy techniques gives very good results.
Using the latest, but also classic, aggregation operators, one can easily combine the results of individual classifiers and obtain better accuracy. The method described by formula (1) was associated with almost \(88\%\) accuracy, beating individual classifiers by over 10 percentage points. This shows that with a relatively small amount of data, high levels of classification accuracy can be obtained by combining classifiers and building solutions that allow for the fusion of information (at the data level or at the results level).
It is worth noting that each of the aggregation functions has slightly different characteristics and so the final results can vary slightly depending on the application area, understood as the parameters outcoming from the experimental settings. Therefore, one challenge for future research is to streamline the process of identifying the aggregation operators that are most likely to achieve optimal classification.
Measures of the macular thickness (MT) were the features with the highest weights in the classification models. This outcome is consistent with the results of recent meta-analyses and reviews of OCT data in schizophrenia58. According to Sheehan et al.21, for example, macular volume and thickness values differentiate schizophrenia patients from other groups better than peripapillary (e.g., RNFL) measures, because macular features are more susceptible to neurodegenerative processes68. The OCT scans covering the macular volume includes a greater proportion of ganglion cell bodies and ganglion cell axons and dendrites compared with the region adjacent to the optic disc. The higher level of feature importance regarding macular measures in our groups is also consistent with data showing accelerated aging effects in schizophrenia’ OCT findings24,25. This suggests that computational models using retinal imaging data could generate indices of the retinal age gap (i.e., the difference between chronological age and predicted retinal age relative to a normative sample), similar to recent brain aging modeling in schizophrenia69.
There are some limitations of the study to be addressed. The experimental group was relatively small taking into account the sample size desired in analyses using deep neural networks methods. Using a larger sample would allow for increased reliability in feature extraction and hyperparameter values, and for a separate validation dataset.
Additionally, the clinical group comprised only inpatients diagnosed with schizophrenia, which could introduce confounding factors. This would occur to the extent that the observed classification results were due to variables related to acute exacerbation of symptoms (e.g., increases in anxiety, changes in medication dose, suicidality), as opposed to a diagnosis if schizophrenia per se70. However, according to the recent meta-analysis by Shew et al.57 there is no evidence that OCT outcomes are significantly different in acute and more stable phases of schizophrenia. Another potentially confounding factor was a significantly higher representation of smokers in the schizofrenia group. It is well documented that smoking worsens the retina morphology71,72, however some meta-analyses do not corroborate such influence73. Nevertheless, future studies focused on automatic classification of schizophrenia using CNS biomarkers should at the very least balance the percentage of smokers in the formed groups.
The key difference between schizophrenia patients and the control group in our study is the use of psychotropic drugs, primarily antipsychotics, by the former. Previous findings regarding the potential impact of antipsychotics on OCT imaging data are equivocal, but trend towards indicating neurodegenerative effects14,74,75. These data are consistent with those indicating that long-term neuroleptic use is related to a slight, but noticeable brain tissue volume reduction76,77. Despite these suggestions, the debate about whether antipsychotics have a dominant atrophic or neuroprotective effect is still ongoing78,79. Antipsychotic neuroleptics are primarily antagonists, i.e. they have a blocking effect on brain areas with dopaminergic receptors80. Studies confirm the important role of dopaminergic neurons in the functioning of the retina, which additionally suggests that the previously unspecified range of retinal changes typical of schizophrenia may be related to the effects of dopaminergic antagonists81. However, it should also be pointed out that the mere fact of a correlation between antipsychotic dosage and OCT results in schizophrenia does not undoubtedly prove the effect of these drugs on the retinal morphology. The antipsychotic dosage also implies the magnitude of psychopathological symptoms82. Undoubtedly, the problem of the potential influence of antipsychotic agents on the accuracy of schizophrenia classification based on OCT data requires further research and verification. A potential solution to this problem may be to include a third group in the study (e.g. schizophrenia, bipolar disorder, and control). A second clinical group such as patients with bipolar disorder with a history of psychotic features would allow for matching patient groups on variables such as current and lifetime antipsychotic medication use. This needs to be done because, as recent meta-analyses show, studies of automatic classification of schizophrenia based on various types of neuroimaging and neurophysiological data typically include only a group of schizophrenia patients and healthy controls83,84. Our study also addresses only the schizophrenia classification by distinguishing SSZ patients from controls. Therefore, future studies using OCT data are necessary to test whether retinal measures are sufficient to automatically differentiate schizophrenia and e.g. affective disorders.
As we have already noted, there is a fast-growing body of studies using classical statistical methods demonstrating structural and functional retinal abnormalities in schizophrenia58,59,60. However, so far there have been only a few published ML-based analyses testing whether retinal measures can be efficiently used in computational models to classify schizophrenia, and some of these attempts were not based on OCT results27,28. Our goal was therefore to test whether the use of deep networks and aggregation functions enables such classification. The results indicate that this is indeed possible, but it should be noted that the outcomes were derived from complex, multi-stage computational analyses, which may hinder direct translational use. Still, such translational difficulties regarding implementing ML-dependent outcomes into clinical practice in psychiatry are common regardless of input data type85. According to Ferrara et al’s86 review of the current ML-based biomarker candidates, individual studies of ML or artificial intelligence methods for diagnostic classification show promise, but applications to real-world practice are still in their infancy. Therefore, if further studies confirm the value of OCT data for detection of schizophrenia, it will be necessary to increase the user-friendliness of ML applications, including simplifying the interpretation of results, in order to translate obtained data into clinical practice.
Data availability
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
References
Jung, W. & Boppart, A. Optical coherence tomography for rapid tissue screening and directed histological sectioning. Anal. Cell Pathol. (Amst.) 35(3), 129–430. https://doi.org/10.3233/ACP-2011-0047 (2012).
Vujosevic, S. et al. Optical coherence tomography as retinal imaging biomarker of neuroinflammation/neurodegeneration in systemic disorders in adults and children. Eye (Lond.) 37(2), 203–219. https://doi.org/10.1038/s41433-022-02056-9 (2023).
Shirazi, M. F. et al. Visualizing human photoreceptor and retinal pigment epithelium cell mosaics in a single volume scan over an extended field of view with adaptive optics optical coherence tomography. Biomed. Opt. Exp. 22 (11(8)), 4520–4535. https://doi.org/10.1364/BOE.393906(2020).
Domínguez-Vicent, A., Brautaset, R. & Venkataraman, A. P. Repeatability of quantitative measurements of retinal layers with sd-oct and agreement between vertical and horizontal scan protocols in healthy eyes. PLoS One 22 (14(8)), e0221466. https://doi.org/10.1371/journal.pone.0221466(2019).
van der Velden, P. G. et al. The prevalence of anxiety and depression symptoms (ads), persistent and chronic ads among the adult general population and specific subgroups before and during the covid-19 pandemic until december 2021. J. Affect. Disord. 1(338), 393–401. https://doi.org/10.1016/j.jad.2023.06.042 (2023).
Abi-Dargham, A. et al. Candidate biomarkers in psychiatric disorders: State of the field. World Psychiatry 22(2), 236–262. https://doi.org/10.1002/wps.21078 (2023).
Galińska-Skok, B. & N., W. Markers of schizophrenia—A critical narrative update. J. Clin. Med. 7 (11(14)), 3964. https://doi.org/10.3390/jcm11143964 (2022).
Sarkar, S., Hillner, K. & Velligan, D. I. Conceptualization and treatment of negative symptoms in schizophrenia. World J. Psychiatry 22 (5(4)), 352–361. https://doi.org/10.5498/wjp.v5.i4.352 (2015).
Luvsannyam, E. et al. Neurobiology of schizophrenia: A comprehensive review. Cureus 8 (14(4)), e23959. https://doi.org/10.7759/cureus.23959 (2022).
Silverstein, S. M., Demmin, D. L., Schallek, J. B. & Fradkin, S. I. Measures of retinal structure and function as biomarkers in neurology and psychiatry. Biomark. Neuropsychiatry 2, 100018. https://doi.org/10.1016/j.bionps.2020.100018 (2020).
Tsokolas, G., Tsaousis, K. T., Diakonis, V. F., Matsou, A. & Tyradellis, S. Optical coherence tomography angiography in neurodegenerative diseases: A review. Eye Brain. 12, 73–87. https://doi.org/10.2147/EB.S193026 (2020).
Schwitzer, T., Leboyer, M., Laprévote, V., Louis Dorr, V. & Schwan, R. Using retinal electrophysiology toward precision psychiatry. Eur. Psychiatry 14 (65(1)), e9. 10.1192/j.eurpsy.2022.3 (2022).
Kazakos, C. T. & Karageorgiou, V. Retinal changes in schizophrenia: A systematic review and meta-analysis based on individual participant data. Schizophr. Bull. 4 (46(1)), 27–42. https://doi.org/10.1093/schbul/sbz106 (2020).
Silverstein, S. M., Fradkin, S. I. & Demmin, D. L. Schizophrenia and the retina: Towards a 2020 perspective. Schizophr. Res. 219, 84–94. https://doi.org/10.1016/j.schres.2019.09.016 (2020).
Komatsu, H. e. a. Retina as a potential biomarker in schizophrenia spectrum disorders: A systematic review and meta-analysis of optical coherence tomography and electroretinography. Mol. Psychiatry 29, 64–482. https://doi.org/10.1038/s41380-023-02340-4 (2024).
Dziedziak, J., Zaleska-Żmijewska, A., Szaflik, J. P. & Cudnoch-Jędrzejewska, A. Impact of arterial hypertension on the eye: A review of the pathogenesis, diagnostic methods, and treatment of hypertensive retinopathy. Med. Sci. Monit. 20(28), e935135. https://doi.org/10.12659/MSM.935135 (2022).
Satue, M. et al. Optical coherence tomography as a biomarker for diagnosis, progression, and prognosis of neurodegenerative diseases. J Ophthalmol. 1, 8503859. https://doi.org/10.1155/2016/8503859 (2016).
Kendler, K. S. Kraepelin’s final views on dementia praecox. Schizophr Bull. 47, 635–643. https://doi.org/10.1093/schbul/sbaa177 (2021).
Stone, W. S. et al. Neurodegenerative model of schizophrenia: Growing evidence to support a revisit. Schizophr Res. 243, 154–162. https://doi.org/10.1016/j.schres.2022.03.004 (2022).
Adámek, P., Langová, V. & Horáček, J. Early-stage visual perception impairment in schizophrenia, bottom-up and back again. Schizophrenia (Heidelb) 8, 27. https://doi.org/10.1038/s41537-022-00237-9 (2022).
Sheehan, N., Bannai, D., Silverstein, S. M. & Lizano, P. Neuroretinal alterations in schizophrenia and bipolar disorder: An updated meta-analysis. Schizophr Bull. 50, 1067–1082. https://doi.org/10.1093/schbul/sbae102 (2024).
Johnson, H. & Cowey, A. Transneuronal retrograde degeneration of retinal ganglion cells following restricted lesions of striate cortex in the monkey. Exp Brain Res. 132, 269–275 (2000).
Andreasen, N. C. et al. Schizophrenia and cognitive dysmetria: A positron–emission tomography study of dysfunctional prefrontal-thalamic-cerebellar circuitry. Proc. Natl. Acad. Sci. USA 93, 9985–90. https://doi.org/10.1073/pnas.93.18.9985 (1996).
Domagała, A., Domagała, L., Kopiś-Posiej, N., Harciarek, M. & Krukow, P. Differentiation of the retinal morphology aging trajectories in schizophrenia and their associations with cognitive dysfunctions. Front Psychiatry 14, 1207608. https://doi.org/10.3389/fpsyt.2023.1207608 (2023).
Blose, B. A., Lai, A., Crosta, C., Thompson, J. L. & Silverstein, S. M. Retinal neurodegeneration as a potential biomarker of accelerated aging in schizophrenia spectrum disorders. Schizophr Bull. 49, 1316–1324. https://doi.org/10.1093/schbul/sbad102 (2023).
Joseph, D. et al. Using machine learning to classify schizophrenia based on retinal images. MedRxiv 2021.04.04.21254893. https://doi.org/10.1101/2021.04.04.21254893 (2021).
Asanad, S. et al. Neuroretinal biomarkers for schizophrenia spectrum disorders. Transl. Vis. Sci. Tech. 10(4), 29. https://doi.org/10.12659/MSM.935135 (2021).
Appaji, A. et al. Deep learning model using retinal vascular images for classifying schizophrenia. Schizophr. Res. 241, 238–243. https://doi.org/10.1016/j.schres.2022.01.058 (2022).
Klement, E. P. & Mesiar, R. Logical, Algebraic, Analytic, and Probabilistic Aspects of Triangular Norms (Elsevier, 2005).
Klement, E. P., Mesiar, R. & Pap, E. Triangular Norms (Springer, 2000).
Beliakov, G., Pradera, A. & Calvo, T. Aggregation Functions: A Guide for Practitioners (Springer, 2007).
Alsina, C., Frank, M. J. & Schweizer, B. Associative Functions. Triangular Norms and Copulas (World Scientific, 2006).
Baczyński, M., Bustince, H. & Mesiar, R. Aggregation functions: Theory and applications. Fuzzy Set Syst. 324, 325 (2017).
Choquet, G. Theory of capacities. Ann. l’Instit. Fourier 5, 131–295 (1953).
Grabisch, M. The application of fuzzy integrals in multicriteria decision making. Eur. J. Oper. Res. 89, 445–456 (1996).
Yager, R. R. & Kacprzyk, J. The Ordered Weighted Averaging Operators: Theory and Applications (Springer, 2012).
Jin, L., Mesiar, R. & Yager, R. Ordered weighted averaging aggregation on convex poset. IEEE Trans. Fuzzy Syst. 27, 612–617 (2019).
Bustince, H. et al. Pre-aggregation functions: Definition, properties and construction methods. In 2016 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE). 294–300 (2016).
Lucca, G. et al. The notion of pre-aggregation function. In MDAI 2015, LNAI (Torra, V. Y. N. ed.). Vol. 9321. 33–41 (2015).
Bustince, H. et al. d-Choquet integrals: Choquet integrals based on dissimilarities. Fuzzy Sets Syst. 414, 1–27 (2021).
Karczmarek, P., Pedrycz, W., Kiersztyn, A. & Dolecki, M. A comprehensive experimental comparison of the aggregation techniques for face recognition. Iran. J. Fuzzy Syst. 16, 1–19 (2019).
Karczmarek, P. Selected Problems of Face Recognition and Decision-making Theory (Lublin University of Technology Press, 2018).
Karczmarek, P. et al. Quadrature-inspired generalized Choquet integral in an application to classification problems. IEEE Access 11, 124676–124689 (2023).
Ruan, C., Chen, X., Zeng, S., Ali, S. & Almutairi, B. Fermatean fuzzy power Bonferroni aggregation operators and their applications to multi-attribute decision-making. Soft. Comput. 28, 191–203. https://doi.org/10.1007/s00500-023-09363-7 (2024).
Senapati, T., Chen, G., Mesiar, R. & Yager, R. R. Intuitionistic fuzzy geometric aggregation operators in the framework of Aczel-Alsina triangular norms and their application to multiple attribute decision making. Expert Syst. Appl. 212, 118832 (2023).
Yang, X., Mahmood, T., Ali, Z. & Hayat, K. Identification and classification of multi-attribute decision-making based on complex intuitionistic fuzzy frank aggregation operators. Mathematics 11, 3292 (2023).
Boczek, M., Hutník, O. & Kaluszka, M. Choquet-Sugeno-like operator based on relation and conditional aggregation operators. Inf. Sci. 582, 1–21 (2022).
Zhang, B., Pedrycz, W., Fayek, A. R., Gacek, A. & Dong, Y. Granular aggregation of fuzzy rule-based models in distributed data environment. IEEE Trans. Fuzzy Syst. 29, 1297–1310 (2021).
Pedrycz, W., Gacek, A. & X., W. Aggregation of order-2 fuzzy sets. IEEE Trans. Fuzzy Syst. 29, 3570–3575 (2021).
Zhang, J., Li, X., Gu, K., Liang, W. & K., L. Secure aggregation in heterogeneous federated learning for digital ecosystems. IEEE Trans. Consumer Electr. 70, 1995–2003. 10.1109/TCE.2023.3330501 (2023).
Kerk, Y. W., Teh, C. Y., Tay, K. M. & Lim, C. P. Parametric conditions for a monotone tsk fuzzy inference system to be an n-ary aggregation function. IEEE Trans. Fuzzy Syst. 29, 1864–1873 (2021).
Pérez-Fernández, R. & De Baets, B. Aggregation theory revisited. IEEE Trans. Fuzzy Syst. 29, 797–804 (2021).
Kay, S. R., Fiszbein, A. & Opler, L. A. The positive and negative syndrome scale (PANSS) for schizophrenia. Schizophr. Bull. 13, 261–276. https://doi.org/10.1093/schbul/13.2.261 (1987).
Optopol. Soct Software Version 10.0.1. https://optopol.com/news/soct-software-version-10-0-1/.
Group, E. T. D. R. S. R. Grading diabetic retinopathy from stereoscopic color fundus photographs—An extension of the modified airlie house classification: Etdrs report number 10. Ophthalmology 98, 786–806 (1991).
Prasannakumar, A. et al. A systematic review and meta-analysis of optical coherence tomography studies in schizophrenia, bipolar disorder and major depressive disorder. World J. Biol. Psychiatry 24, 707–720. https://doi.org/10.1080/15622975.2023.2203231 (2023).
Shew, W., Zhang, D. J., Menkes, D. B. & Danesh-Meyer, H. V. Optical coherence tomography in schizophrenia spectrum disorders: A systematic review and meta-analysis. Biol Psychiatry Glob Open Sci. 4, 19–30. https://doi.org/10.1016/j.bpsgos.2023.08.013 (2023).
Komatsu, H. et al. Retinal layers and associated clinical factors in schizophrenia spectrum disorders: A systematic review and meta-analysis. Mol. Psychiatry 27, 3592–3616 (2022).
Gonzalez-Diaz, J. et al. Mapping retinal abnormalities in psychosis: Meta-analytical evidence for focal peripapillary and macular reductions. Schizophr. Bull. 48, 1194–1205. https://doi.org/10.1093/schbul/sbac085 (2022).
Lizano, P. et al. A meta-analysis of retinal cytoarchitectural abnormalities in schizophrenia and bipolar disorder. Schizophr. Bull. 46, 43–53. https://doi.org/10.1093/schbul/sbz029 (2020).
Solovyev, R. Classification models 1d zoo-keras and tf.keras. https://github.com/ZFTurbo/classification_models_1D.
Murray, B. et al. Explainable ai for understanding decisions and data-driven optimization of the Choquet integral. In 2018 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE). 1–8 (2018).
Murray, B. J. et al. Explainable AI for the Choquet integral. IEEE Trans. Emerg. Top. Comput. Intell. 5, 520–529 (2021).
Huang, J. J. Building the hierarchical Choquet integral as an explainable AI classifier via neuroevolution and pruning. Fuzzy Optim. Decis. Mak. 22, 81–102 (2023).
Karczmarek, P. et al. Analysis of smooth and enhanced smooth quadrature-inspired generalized Choquet integral. Fuzzy Sets Syst. 483, 108926 (2024).
Lucca, G. et al. Applying aggregation and pre-aggregation functions in the classification of grape berries. In 2018 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE). 1–6 (2018).
Bonferroni, C. Sulle medie multiple di potenze. Boll. Mat. Ital. 5, 267–270 (1950).
Casciano, F. et al. Retinal alterations predict early prodromal signs of neurodegenerative disease. Int. J. Mol. Sci. 25, 1689 (2024).
Constantinides, C. et al. Brain ageing in schizophrenia: Evidence from 26 international cohorts via the enigma schizophrenia consortium. Mol. Psychiatry 28, 1201–1209. https://doi.org/10.1038/s41380-022-01897-w (2023).
Roick, C. E. A. Factors contributing to frequent use of psychiatric inpatient services by schizophrenia patients. Soc. Psychiatry Psychiatr. Epidemiol. 39, 2744-751. 10.1007/s00127-004-0807-8 (2004).
Işik, M., Akay, F., Akmaz, B., Güven, Y. Z. & Şahin, O. F. Evaluation of subclinical alterations in retinal layers and microvascular structures with oct and octa in healthy young short-term smokers. Photodiagn. Photodyn. Ther. 36, 102482. https://doi.org/10.1016/j.pdpdt.2021.102482 (2021).
Aboud, S. A., Hammouda, L. M., Saif, M. Y. S. & Ahmed, S. S. Effect of smoking on the macula and optic nerve integrity using optical coherence tomography angiography. Eur. J. Ophthalmol. 32, 436–442. https://doi.org/10.1177/1120672121992960 (2022).
Yang, T. K., Huang, X. G. & Yao, J. Y. Effects of cigarette smoking on retinal and choroidal thickness: A systematic review and meta-analysis. J. Ophthalmol. 29, 8079127. https://doi.org/10.1155/2019/8079127 (2019).
Altun, I., Turedi, N., Aras, N. & Atagun, M. I. Psychopharmacological signatures in the retina in schizophrenia and bipolar disorder: An optic coherence tomography study. Psychiatr. Danub. 32, 351–358. https://doi.org/10.24869/psyd.2020.351 (2020).
Boudriot, E. E. A. Optical coherence tomography reveals retinal thinning in schizophrenia spectrum disorders. Eur. Arch. Psychiatry Clin. Neurosci. 273, 575-588. 10.1007/s00406-022-01455-z (2023).
Ho, B. C., Andreasen, N., Ziebell, S., Pierson, R. & Magnotta, V. Long-term antipsychotic treatment and brain volumes: A longitudinal study of first-episode schizophrenia. Arch. Gen. Psychiatry 68, 128–37. https://doi.org/10.1001/archgenpsychiatry.2010.199 (2011).
Fusar-Poli, P. et al. Progressive brain changes in schizophrenia related to antipsychotic treatment? A meta-analysis of longitudinal MRI studies. Neurosci. Biobehav. Rev. 37, 1680–91. https://doi.org/10.1016/j.neubiorev.2013.06.001 (2013).
Hunsberger, J., Austin, D., Henter, I. & Chen, G. The neurotrophic and neuroprotective effects of psychotropic agents. Dial. Clin. Neurosci. 11, 333–48. https://doi.org/10.31887/DCNS.2009.11.3/jhunsberger (2009).
Chen, A. T. & Nasrallah, H. A. Neuroprotective effects of the second generation antipsychotics. Schizophr. Res. 208, 1–7. https://doi.org/10.1016/j.schres.2019.04.009 (2019).
Miller, R. Mechanisms of action of antipsychotic drugs of different classes, refractoriness to therapeutic effects of classical neuroleptics, and individual variation in sensitivity to their actions: Part I. Curr. Neuropharmacol. 7, 302–14. https://doi.org/10.2174/157015909790031229 (2009).
Popova, E. Role of dopamine in distal retina. J. Comp. Physiol. A Neuroethol. Sens. Neural Behav. Physiol. 200, 333–58. https://doi.org/10.1007/s00359-014-0906-2 (2014).
Ringen, P. et al. Predictors for antipsychotic dosage change in the first year of treatment in schizophrenia spectrum and bipolar disorders. Front. Psychiatry 10, 649. https://doi.org/10.3389/fpsyt.2019.00649 (2019).
Di Camillo, F. E. A. Magnetic resonance imaging-based machine learning classification of schizophrenia spectrum disorders: A meta-analysis. Psychiatry Clin. Neurosci. 10.1111/pcn.13736 (2024).
Rahul, J., Sharma, D., Sharma, L. D., Nanda, U. & Sarkar, A. K. A systematic review of EEG based automated schizophrenia classification through machine learning and deep learning. Front. Hum. Neurosci. 18, 1347082. https://doi.org/10.3389/fnhum.2024.1347082 (2024).
Benoit, J., Onyeaka, H., Keshavan, M. & Torous, J. Systematic review of digital phenotyping and machine learning in psychosis spectrum illnesses. Harv. Rev. Psychiatry 28, 296–304. https://doi.org/10.1097/HRP.0000000000000268 (2020).
Ferrara, M. E. A. Machine learning and non-affective psychosis: Identification, differential diagnosis, and treatment. Curr. Psychiatry Rep. 24, 925–936. 10.1007/s11920-022-01399-0 (2022).
Acknowledgements
This research was supported by Polish Ministry of Education and Science, grant no. MEiN/2023/DPI/2194, project title: Lublin Digital Union-Use of Digital Solutions and Artificial Intelligence in Medicine-Research Project.
Author information
Authors and Affiliations
Contributions
P.Kr. and S.M.S. conceived the experiment(s), A.D. and P.Kr. conducted the experiment(s), M.P.W., P.Ka., A.K. and K.J. analysed the results. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Karczmarek, P., Plechawska-Wójcik, M., Kiersztyn, A. et al. On the improvement of schizophrenia detection with optical coherence tomography data using deep neural networks and aggregation functions. Sci Rep 14, 31903 (2024). https://doi.org/10.1038/s41598-024-83375-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-83375-7
