
Abstract
Internet of Vehicles (IoV) is a multi-node network which switches data in an open and wireless environment. Numerous interaction activities occur among IoV entities to share significant information, which is essential for network operation. As part of intellectual transportation, IoV is a hot topic for researchers because it faces numerous unresolved challenges, particularly regarding privacy and security. The development of recent malicious software with the expanding use of digital services has increased the likelihood of stealing data, corrupting data, or other cybercrimes by malware threats. Hence, malicious software should be perceived previously. It impacts a vast amount of computers. Researchers have proposed numerous malware detection solutions for the past few years. Machine learning (ML) and deep learning (DL)-based detection models can decrease analysis time and increase malware detection accuracy. This study proposes a novel Malware Detection Model in the Internet of Vehicles Using Deep Learning-Based Explainable Artificial Intelligence (MDMIoV-DLXAI). The main intention of the MDMIoV-DLXAI model is to enhance the malware detection and classification model in IoV by utilizing advanced two-tier optimization models. Initially, the data normalization stage is performed by the min-max normalization to convert input data into a beneficial format. Besides, the proposed MDMIoV-DLXAI model utilizes the reptile search algorithm (RSA) model for feature selection. Furthermore, the hybrid of bidirectional long short-term memory with a multi-head self-attention (BiLSTM-MHSA) model is employed for the malware classification process. The parameter tuning process is performed through the pelican optimization algorithm (POA) to improve the classification performance of the BiLSTM-MHSA classifier. Finally, SHAP is utilized as an XAI technique to enhance malware detection and decision-making processes of AI-driven security systems. The experimental evaluation of the MDMIoV-DLXAI method is examined under the malware dataset. The comparison study of the MDMIoV-DLXAI method demonstrated a superior accuracy value of 97,393% over existing techniques.
Similar content being viewed by others
Introduction
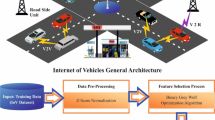
With the faster growth of the Internet of Things (IoT), vehicles have increased because of Intelligent Transportation Systems (ITS), which is the intellectual IoV1. The IoV can provide reasonable and effective interaction service for vehicles to assist in different applications and use sophisticated driving assistance methods. It is a significant model for utilizing ITS to recognize smart cities2. Recently, several networking models, like the 5 G-enabled communication system, have formerly engaged in IoVs to provide a larger variety for consumers. The IoV is an open network for every consumer. However, the consumer might be a probable attacker. Because of the IoV transparency, several viruses generally attack it, such as Trojan horses and worms3. Meanwhile, Distributed Denial of Service (DDoS) attacks are a primary threat for vehicles, whereby the flooded DDoS attacks are termed a brute-force threat that drains the computing source and cache of the vehicle. Thus, intrusion detection models have attained continuous attention in IoVs to safeguard consumers’ security and privacy. The IoV is vital to a vehicular ad-hoc pattern that permits communication utilizing another vehicle over the Internet. Figure 1 represents the structure of IoV. Nevertheless, novel vehicles became progressively connected, and their flaws in cyber threats grew4. Cyber threats impact the stability and performance of IoV and result in car outages or traffic mortalities. Several intruders tricked a jeep automobile by accomplishing hazardous activities at a high velocity, leading to a substantial accident. The cybercriminals and malware computer operators frequently focus on automobiles or self-driving vehicles5. Everybody recognizes that the connected functions of vehicles are only in restricted settings and may only get remote control guidelines from established protective communication networks, namely servers developed by notable manufacturers and software. A limited atmosphere precludes the trouble of malicious or unauthorized guidelines6. Conversely, novel independent vehicles may link to other vehicles, intellectual gadgets, and structures distinct from the vehicle by managing signals and internal information. Motor vehicle security is vital at this moment; consequently, it is essential to examine every threat vector on vehicles with remote and secure cyber-security7. The safety of self-driving vehicle owners is intently associated with the protection of vehicles.

Architecture of IoV.
To resolve cybersecurity cases, ongoing studies generally utilize intrusion detection systems (IDS) to recognize the external traffic of vehicle networks in IoV8. Compared to rule-based IDS, DL and ML-based IDS have a robust ability to identify unknown threats and a multitude of data processing, which have become hotspots in ongoing investigations9. Compared to conventional approaches, such as signature-relevant malware detection, which is based on recognizing particular models of detected malware, DL and ML-related identification can determine former unobservable malware groups and give greater detection efficiency and efficacy10. The utilization of DL and ML models in IoV settings is growing faster, but the security consequences of their incorporation with IoV have received less attention.
This study proposes a novel Malware Detection Model in the Internet of Vehicles Using Deep Learning-Based Explainable Artificial Intelligence (MDMIoV-DLXAI). The main intention of the MDMIoV-DLXAI model is to enhance the malware detection and classification model in IoV by utilizing advanced two-tier optimization models. Initially, the data normalization stage is performed by the min-max normalization to convert input data into a beneficial format. Besides, the proposed MDMIoV-DLXAI model utilizes the reptile search algorithm (RSA) model for feature selection. Furthermore, the hybrid of bidirectional long short-term memory with a multi-head self-attention (BiLSTM-MHSA) model is employed for the malware classification process. The parameter tuning process is performed through the pelican optimization algorithm (POA) to improve the classification performance of the BiLSTM-MHSA classifier. Finally, SHAP is utilized as an XAI technique to enhance malware detection and decision-making processes of AI-driven security systems. The experimental evaluation of the MDMIoV-DLXAI method is examined under the malware dataset. The key contribution of the MDMIoV-DLXAI method is listed below.
-
The MDMIoV-DLXAI technique applies min-max normalization to scale the data, ensuring effective processing and improving the overall accuracy of the classification. This technique transforms features to a consistent range, improving the model’s performance. Standardizing input data across varying scales also assists in mitigating biases during training.
-
The MDMIoV-DLXAI model utilizes the RSA technique to perform efficient feature selection, detecting the most relevant features for malware classification. This ensures that the model concentrates on the most significant data, improving accuracy and computational efficiency. By removing irrelevant features, RSA improves the overall performance of the malware detection system.
-
The MDMIoV-DLXAI approach employs a hybrid BiLSTM-MHSA model for malware classification, capturing sequential dependencies and contextual relationships in the data. This technique improves the model’s capability to comprehend complex patterns in malware behaviour. By integrating BiLSTM with MHSA, the model attains more accurate and robust malware detection.
-
The MDMIoV-DLXAI methodology implements the POA method to fine-tune the model’s hyperparameters, improving its performance in malware detection. By adjusting key parameters, this optimization ensures that the model operates at its highest potential. POA-based tuning enhances the model’s output’s accuracy, efficiency, and robustness.
-
SHAP is incorporated into the model to improve the transparency and interpretability of the decision-making process. By giving insights into how individual features impact the predictions, SHAP enhances the model’s trustworthiness. This technique ensures a clearer understanding of the factors driving malware detection outcomes.
-
The MDMIoV-DLXAI method integrates advanced methods like RSA for feature selection, BiLSTM-MHSA for classification, POA for tuning, and SHAP for explainability, presenting a robust solution for malware detection. Its novelty is in the hybrid approach that integrates sequential and contextual learning while prioritizing feature relevance and model transparency. This comprehensive integration improves both performance and interpretability in AI-driven security systems.
Literature survey
Liu et al.11 proposed a fractional-order IoV (FIOV) to examine malware broadcast designs in Vehicles and Road Side Units (RSU). To precisely consider the actual spread of malware, the actual connectivity, the channel fading, and the traffic density are deliberated in mathematical methods. Subsequently, the model-based optimum quarantine and treatment control approach originated from the optimum control theory. Furthermore, an innovative model-free FIOV multi-agent soft actor-critic (FIOV-MASAC) method is initially projected to overwhelm malware propagation in IoV. The authors12. introduced a secure DL-enabled malware attack detection for IoT-enabled ITS (SDLMA-IITS). The explainable artificial intelligence (XAI) model is employed for effectual malware detection. A deep security analysis of the projected SDLMA-IITS is offered to demonstrate its security against diverse possible threats. The SDLMA-IITS comparative performance analysis is favoured with the other equivalent present methods. Eventually, a practical performance of SDLMA-IITS is offered to assess its effect on the security of the IoT-enabled ITS gadgets and systems. Anargya et al.13 focus on analyzing the performance of Random Under-Sampling to enhance the implementation of classification models in recognizing threats on IoV methods. These models are employed in this work and comprise K-Nearest Neighbors (KNN), Random Forest (RF), and decision tree (DT). Almakayeel14 developed a DL-Based Improved Transformer Method on Android Malware Detection (DLBITM-AMD) approach for IoVs. The major intention of the projected model is to identify Android malware accurately and effectively. The presented model employs the binary grey wolf optimizer (BGWO) method for choosing an optimum subset of features. An enhanced transformer is incorporated into the RNN method and softmax to increase Android malware classification. Eventually, the snake optimizer algorithm (SOA) approach is utilized to choose an optimal parameter for the classification model.
The authors15 developed a specialized BERT-based Feed Forward Neural Network Framework (BEFNet) for IoT backgrounds. For assessing, a new structure with different modules is utilized to analyze eight databases, each demonstrating a diverse kind of malware. BEFSONet has been enhanced using the Spotted Hyena Optimizer (SO), emphasizing its flexibility in handling malware data. In16, an ML-based recognition method utilizing a hybrid analysis-based particle swarm optimizer (PSO) and an adaptive genetic algorithm (AGA) is projected for the recognition of Android malware. During the presented model, feature selection is initially accomplished by utilizing PSO. At another level, the implementation of RF-ML and XGBoost classifiers is enhanced by employing the AGA. Alterazi17 developed an improved Android Malware Detection utilizing the Self-Attention Transformer Model (EAMD-SATM) in IoV. The developed method recognizes and categorizes the Android malware accurately and efficiently. To obtain this, the projected method continues a min-max method employing data pre-processing at the primary phase. Additionally, the presented approach leverages the self-attention-based transformer (SA-T) model for malware detection. To increase the SA-T solution of the model, the projected technique employs the improved mother optimizer (IMO) model for the parameter tuning process. Bangash et al.18 focus on addressing upcoming challenges in recognizing malware and enhancing effective approaches in smart cities. ML models are employed to classify and evaluate the model performance, upgrading computation time and categorical threats. DL methods are endorsed to enhance the efficiency and accuracy of malware recognition in smart cities. Incorporating IoT-based methods and DL allows the recognition of diverse malware in smart cities. Latif, Ma, and Ahmad19 explore advanced neural networks, feature engineering, and privacy-preserving techniques to improve the security of Federated Learning (FL) systems in intrusion detection environments.
Sumathi and Rajesh20 propose a hybrid artificial neural network (ANN)-based GBS IDS model to improve DDoS attack detection in cloud environments, enhance accuracy, mitigate false alarms, and optimize prediction time. Ma et al.21 present a lightweight botnet detection methodology for IoT networks using a cloud–edge–node framework, integrating a two-step feature selection process for efficient real-time detection and reduced computational overhead. Sokkalingam and Ramakrishnan22 introduce a hybrid ML-based IDS model for real-time DDoS detection in cloud computing, utilizing 10-fold cross-validation, feature selection, and hybrid HHO-PSO optimization for enhanced performance and accuracy. Shen et al.23 propose a Bayesian-based privacy preservation optimization approach (BA2C) methodology for defending against malware-induced privacy leakage in EI-enabled IoT systems, utilizing incomplete stochastic games and probability analysis for effective decision-making. Sumathi, Rajesh, and Lim24 develop an efficient IDS for DDoS attacks in cloud computing using a hybrid LSTM-based DL model with Harris Hawks optimization (HHO) and PSO for optimal parameter tuning and feature selection. Chen et al.25 introduce a novel SAE-CNN traffic classification model that improves accuracy and reduces latency, particularly for 5G services. Sumathi, Rajesh, and Karthikeyan26 developed an effectual IDS for detecting DDoS attacks using ML methods like C4.5, SVM, and KNN classifiers. Zha et al.27 propose an adaptive network IDS (A-NIDS) technique. A-NIDS consists of a main task for real-time detection and two bypass tasks: a clustering model for detecting data drift and a generation model to handle old data and mitigate forgetting. Sumathi and Rajesh28 detect and mitigate DDoS attacks in cloud computing using hybrid ANN models, specifically Backpropagation Neural Network (BPN) and Multilayer Perceptron (MLP). The study employs HHO-PSO for feature selection and tuning.
Despite the improvements in IDS and malware detection techniques in IoT and cloud environments, various limitations still exist. Many existing models fail to effectually address challenges such as data drift, real-time detection, and the trade-off between detection accuracy and computational overhead. Moreover, most methods rely on static datasets or overlook dynamic environmental conditions, which mitigates their robustness and adaptability. Furthermore, while some models improve detection accuracy, they often do so at the cost of increased complexity, longer processing times, or higher false positive rates. Research gaps exist in developing lightweight, real-time, and adaptive models capable of efficiently handling diverse and growing threat landscapes while maintaining low computational overhead.
Materials and methods
This paper develops a new MDMIoV-DLXAI model. The proposed model aims to enhance the malware detection and classification model in IoV by utilizing advanced two-tier optimization models. Figure 2 proves the entire flow of the MDMIoV-DLXAI method.

Overall flow of MDMIoV-DLXAI approach.
Min-max normalization
At first, the data normalization stage is executed by the min-max normalization for converting input data into a beneficial format29. This is chosen to scale the data within a specific range, usually between 0 and 1, ensuring that all features contribute equally to the learning process. This technique is specifically effective when dealing with algorithms sensitive to the scale of data, such as neural networks and distance-based methods. NormalizingNormalizing the data assists in faster convergence during training, mitigating bias towards variables with larger magnitudes. Compared to other techniques like Z-score normalization, Min-Max is more appropriate for preserving the relationships and relative differences in data, specifically when the model relies on non-linear transformations. Its simplicity and effectiveness in scaling diverse data types make it an ideal choice for this malware detection system.
Data pre-processing stages are critical to guarantee the data’s reliability and quality before it is connected to the predictive methods. Normalization is then used for scaling the input data to a reliable range, commonly amongst \(\:(0\),1). It enhances the combination of optimizer methods and improves the performance of NNs. Min-max normalization is usually applied, converting all parameters \(\:x\) utilizing the equation:
Dimensionality reduction using RSA
Besides, the proposed MDMIoV-DLXAI model designs RSA for the feature selection procedure30. This model is chosen because it can effectually select the most relevant features from a high-dimensional dataset, improving model performance and computational efficiency. Unlike traditional methods like Principal Component Analysis (PCA), which transforms the entire feature set, RSA directly detects crucial features, retaining the original data structure and improving interpretability. RSA also avoids the data loss that can occur in linear methods, making it specifically appropriate for complex, non-linear problems like malware detection. By mitigating irrelevant or redundant features, RSA assists in reducing the “curse of dimensionality,” ensuring faster training times and better generalization. Moreover, its ability to handle large datasets and avoid overfitting provides a clear advantage in real-world scenarios. Figure 3 illustrates the steps involved in the RSA method.

Steps involved in the RSA methodology.
The RSA is a meta-heuristic model subject to how crocodiles naturally search. Dual stages are essential for the RSA function: the searching and encircling. A similar method guarantees optimum balances amongst exploitation and exploration phases: it separates into four observable stages after drawing, making it either efficient or suitable for challenging each promising optimizer challenges, utilizing related strategies to this applied by tactical crocodile searching. The comprehensive step-wise architecture of the RSA is provided below as Algorithm 1.

Pseudocode of RSA.
Initialization
During the first stage of the RSA, a set of possibility start solutions has been made stochastically using the succeeding Eq. (2):
Whereas \(\:{x}_{jk}=\)initialization matrix, \(\:j=\text{1,2},\dots\:,\:P\). \(\:P\) characterizes the size of the population (the initialization matrix rows), and \(\:n\) represents the sizes (the initialization matrix columns) of the provided optimizer problem. \(\:{U}_{b}\), \(\:{L}_{b},\:\)and \(\:rand\) symbolize the upper and lower bound limits and random values.
Exploration (encircling stage)
In the encircling Stage, densely populated regions are mostly discovered. Higher walking, in addition to belly walking, mainly originated from crocodile motions, is essential in the surrounding period. These motions help find an excellent search space but do not promote catching prey.
\(\:Best\) \(\:\left(\tau\:\right)\) signifies the optimum solution attained at the \(\:k\:th\) location inside the present iteration. \(\:rand\) indicates a stochastic variable demonstrating random numbers, whereas \(\:\tau\:\) characterizes the present iteration amount, with \(\:T\) describing the upper bound. The parameter \(\:\mu\:(j,k)\) summarizes the searching operator value for \(\:the\:j\:th\) solution, particularly at the \(\:k\:th\) location. The succeeding Eqs administer the value computation for (j, k). (5) and (6):
On the other hand, \(\:{r}_{1}\) characterizes randomly selected numbers among \(\:one\) and \(\:N\). Now, \(\:N\) signifies the whole candidate solution counts. The pair \(\:({r}_{1},1)\) specifies an arbitrary location for the \(\:k\:th\) solution. Also, \(\:{r}_{2}\) is another randomly selected number in the interval of (1-\(\:N),\) and \(\:e\) embodies a smaller size. \(\:ES\:(\tau\:\)), or Evolutionary Sense, is a probabilistic ratio calculating the method’s adaptive dynamics. The mathematic expression of the Evolutionary Sense is provided as shown:
The Reptile searching method removes the maximal significant features from a massive feature group. Reptile, a meta-mastering model, enhances function selection by schooling the form on numerous subdivisions of abilities and enhancing its complete performance. This iterative procedure effectively determines and preserves the maximal significant trends and precision. Then, the selected qualities were applied to instruct the last model category.
The fitness function (FF) signifies the classifier’s accuracy and the number of chosen features. It exploits the classifier’s accuracy and diminishes the selected feature’s set dimensions. Then, the FF has been applied to weigh individual solutions, as formulated in Eq. (8).
While \(\:ErrorRate\) designates the classifier rate of error\(\:,\:it\) is projected as the ratio of incorrect, which is considered the number of classifications made between 0 and 1. \(\:\#SF\) represents the number of chosen features. \(\:\#All\_F\) indicates the complete number of features in an original dataset. Here, \(\:\alpha\:\) controls the consequence of sub-set length and classifier excellence. The value of \(\:\alpha\:\) is 0.9.
Hybrid malware classification process
Furthermore, the hybrid BiLSTM-MHSA model is utilized for the malware classification model31. This model is chosen for its capacity to capture both sequential and contextual dependencies in data, making it highly effective for complex tasks like malware detection. BiLSTM can process data in both forward and backward directions, giving a richer understanding of the data’s temporal dynamics. The addition of MHSA improves this by allowing the model to concentrate on diverse parts of the input concurrently, enhancing its ability to recognize patterns across diverse time steps. This hybrid approach is more robust than conventional models like CNN or RNN, which may not effectively capture long-range dependencies or contextual information. Integrating BiLSTM and MHSA gives superior performance in handling sequential data with complex dependencies, making it an ideal choice for malware classification tasks where both temporal and contextual patterns are crucial. Figure 4 portrays the infrastructure of the Bi-LSTM-MHSA technique.

Architecture of Bi-LSTM-MHSA.
LSTM models are specific recurrent neural networks (RNNs) established for capturing long-range dependencies, making them efficient for sequential data analysis. The LSTM method contains the following sections:
-
1.
Cell state: The central part of an LSTM method is the cell state, which is responsible for storing and transferring information. This allows the system to maintain long-range dependencies and comprehend handling sequential data.
-
2.
Forget gate: This gate decides which data is excluded from the cell state. Utilizing the activation function of the sigmoid, it assesses all state of the cell values to determine what amount to maintain, permitting the system to adjust its memory. The operation of the forgetting gate is described by Eq. (5):
Whereas \(\:{f}_{t}\) refers to forgetting gate output, \(\:{w}_{f}\) means oblivion gate’s weighted matrix, \(\:{h}_{t-1}\) represents the hidden layer (HL) of the preceding time-step, \(\:{x}_{t}\) represents input at present, and \(\:{b}_{f}\) denotes oblivion gate’s bias term.
-
3.
Input gate: This gate comprises a sigmoid layer, which chooses values for updating a \(\:\text{t}\text{a}\text{n}\text{h}\) layer, and the cell state, which makes candidate values for addition. These functions are described by Eqs. (10) and (11):
$$\:{i}_{t}=\sigma\:\left({W}_{i}\cdot\:\left[{h}_{t-{1}^{{\prime\:}}}{x}_{t}\right]+{b}_{i}\right)$$(10)$$\:{\stackrel{\sim}{C}}_{t}=tanh\left({W}_{c}\cdot\:\left[{h}_{t-1},{x}_{t}\right]+{b}_{C}\right)$$(11)
Here, \(\:{i}_{t}\) signifies the input gate’s output; \(\:{W}_{i}\) symbolizes the input gate’s weighting matrix; \(\:{\stackrel{\sim}{C}}_{t}\) refers to a novel candidate message; \(\:{W}_{c}\) represents a weighted matrix of the novel candidate message; and \(\:{b}_{i}\) and \(\:{b}_{C}\) denote the input gate’s bias terms and the novel candidate information, correspondingly.
-
4.
Module status upgrade: The updating procedure of the cell state includes multiplying the forget gate’s output through the unique cell state and adding the input gate’s output. This process retains the continuity and validity of the cell state. The equations to update a cell are stated as demonstrated in Eq. (12):
$$\:{C}_{t}={f}_{t}\odot\:{C}_{t-1}+{i}_{t}\odot\:{\stackrel{\sim}{C}}_{t}$$(12)
Whereas \(\:{C}_{t}\) denotes the cell state at the present moment, \(\:{f}_{t}\) signifies oblivion gate output, \(\:\odot\:\) symbolizes the primary multiplication operation, \(\:{C}_{t-1}\) refers to a cell state, \(\:{i}_{t}\) stands for the input gate’s output, and \(\:{\stackrel{\sim}{C}}_{t}\) denotes the candidate cell state.
-
5.
Hidden state: This state is the LSTM unit output, comprising information from the present time step given to the following time step to guarantee the data’s consistency and coherence.
-
6.
Output gate: This gate defines the following hidden state value, which is the real output of the LSTM method. It is fine-tuned so that the network’s output considers the main information of the present time step. The equation for an output gate is stated in Eqs. (13) and (14).
Whereas \(\:{O}_{t}\) represents the output gate’s output, \(\:{W}_{O}\) stands for the weighting matrix of the output gate, \(\:{h}_{t}\) refers to HL of the present time step, and \(\:{b}_{O}\) denotes the output gate’s bias term. LSTM models are mainly efficient at preserving and capturing long-range dependencies in sequential data because of their memory cells and gate mechanisms. Nevertheless, LSTMs carry out one-way propagation that bounds their capability to take dependencies in either direction. To deal with this, Bi-LSTM was established.
Bi-LSTM encompasses the LSTM structure by combining backward or forward propagation, allowing the method to seize dependencies in either direction of sequential data. This bi-directional mechanism improves feature extraction from time-based sequences, creating Bi-LSTM stronger solutions for tasks that need composite, time-sensitive pattern detection. The dual propagation in Bi-LSTM significantly enhances the dependability and precision of model outputs, mainly for applications requiring complete temporal extraction of the features in sequence analysis. The cycle computations in either direction are presented in Eqs. (15) and (16):
Whereas \(\:{x}_{t}\) symbolizes an input vector of the present time-step \(\:\left(t\right){,\:h}_{t-1}\) and \(\:{h}_{t}\) correspondingly represent HLs of the preceding and the present time steps, and \(\:{c}_{t-1}\) and \(\:{c}_{t}\), denote cell states of \(\:t\) and \(\:t-1\) time steps.
The last output HL (\(\:H\)) refers to a splice in either direction:
MHSA is a DL method advanced in the domain of natural language processing (NLP), which permits methods to increase focus on related characteristics and avoids overfitting. Attention is a mechanism that allows a technique for capturing dependencies inside a series by concentrating on various positions. The multi-head self‐attention mechanism imitates the multiple, with all \(\:head\)s learning a diverse input data representation. Lastly, a linear layer connects and controls the output vectors to obtain the last output. The attention layer’s output matrix of (value (\(\:V\)), query (\(\:Q\)), and key (\(\:K\))) is presented in Eq. (18):
Here, \(\:{d}_{k}\) denotes the feature size of all keys applied for weight scaling and standardized within the range of \(\:0\) and \(\:1\) by the softmax fthee MHSA, a function applied to four attention heads, and the computation of every attention head is presented in Eq. (19):
Now, \(\:{{W}_{i}^{V},\:W}_{i}^{Q},\:\text{a}\text{n}\text{d}\) \(\:{W}_{i}^{K}\) signify the weighting matrices of\(\:,\) \(\:Q\), and\(\:\:K\), correspondingly and \(\:hea{d}_{i}\) denotes\(\:\:i\:th\) head.
The method incorporates numerous attention heads, all with its linear transformation matrix. The output is presented in Eq. (20):
Linear characterizes the process of linear mapping, \(\:{W}^{O}\) represents linear mapping weight, and \(\:Concat\) denotes the splicing process. By presenting MHSA, this method can concentrate on several portions of the sequence simultaneously to capture the global dependences, enhancing the insight of complete sequence patterns.
The Bi-LSTM-MHSA hybrid method is mainly efficient after addressing significantly imbalanced datasets, a common issue in malware detection. Bi-LSTM seizures the temporal dependences in sequential data, whereas MHSA improves these representations by concentrating on the best significant features. By focusing on the essential features and utilizing the bi-directional learning abilities, the method realizes improved generalization and decreases false positives and negatives. Using the strengths of both techniques provides a higher-performance architecture that can address the advanced malware threads.
Parameter tuning using POA
The parameter tuning process is performed through POA to improve the classification performance of the BiLSTM-MHSA classifier32. This technique is chosen because it efficiently finds optimal solutions in complex, high-dimensional search spaces. POA replicates the foraging behaviour of pelicans, effectually balancing exploration and exploitation, which makes it appropriate for global optimization tasks. Unlike conventional methods like grid or random search, POA can navigate the parameter space more effectively, ensuring faster convergence to optimal or near-optimal hyperparameters. Additionally, the capability of the POA method to avoid local optima and adapt to dynamic environments makes it more robust compared to other optimization techniques, such as genetic algorithms (GA) or PSO. This ensures better performance and stability in ML models, particularly for tasks like malware detection, where the optimal hyperparameters significantly impact classification accuracy. POA’s adaptability to diverse types of problems additionally improves its value in improving model performance across diverse scenarios. Figure 5 specifies the structure of the POA methodology.

Structure of POA technique.
The POA is a heuristic intelligent optimizer model presented, which is stimulated by the smart and natural searching pelican’s behaviours when capturing fish. This model contains three stages: the population initialization stage, the development stage that mimics the pelican’s behaviours skimming the water’s surface, and the exploration stage that mimics the pelican’s behaviours moving toward prey. The POA is a population-based model mainly described by the faster speed of convergence, higher precision of hunting for best outcomes, smaller configuration parameters, and a wide variety of applications compared with other methods. During the subdivision, the phases of the POA are defined comprehensively.
Initialization stage
Assume that there are \(\:n\) pelicans within the \(\:m\)-dimensionality area, and the location of the \(\:ith\) pelican in the \(\:m\)‐dimensioned area is \(\:{X}_{i}=[{X}_{i1},{\:X}_{i2},\:\dots\:,{\:X}_{in}]\). The mathematical model of the location \(\:{X}_{i}\) of each of the pelicans is stated as a matrix with \(\:m\) columns and\(\:\:n\) rows:
The initialization equation is
Whereas \(\:{x}_{ij}\) refers to the locality of the \(\:ith\) pelican in the \(\:jth\) size; \(\:n\) denotes the pelican’s population size; \(\:m\) represents the solution problem’s dimension; \(\:\alpha\:\) stands for the randomly generated number in (\(\:\text{0,1})\) and \(\:{U}_{j}\) and \(\:{\text{l}}_{j}\) signifies lower and upper limits of the solution problem in the \(\:j\:th\) dimensionality, correspondingly.
Exploration stage
In this initial stage, the pelican identifies the prey position and moves toward the well-known place. By demonstrating this pelican’s tactic, the searching region is scanned, enhancing the POA’s search ability to determine several regions of the searching area. During all iterations, the mathematic representation of the pelican’s new location is characterized in the succeeding Eq. (23):
Whereas \(\:{x}_{ij}^{p1}\) denotes the locality of the \(\:ith\) pelican within the \(\:jth\) size after the initial-phase updates, \(\:\sigma\:\) denotes randomly generated numbers within the interval of (\(\:\text{0,1})\), \(\:I\) denotes randomly formed integer within the interval of (1, 2), \(\:{P}_{j}\) refers to the prey’s location in the \(\:jth\) size, and \(\:{F}_{p}\) denotes the objective function value.
When an objective function value \(\:{F}_{p}\) was enhanced at the \(\:ith\) location, the location was upgraded through the succeeding Eq. (24):
Whereas \(\:{x}_{i}^{p1}\) refers to a new location of the \(\:ith\) pelican, \(\:{x}_{i}\) signifies the original location of the \(\:ith\) pelican; afterwards, the initial phase is updated, and \(\:{F}_{i}^{p1}\) denotes an objective function of an \(\:ith\) pelican.
Development stage
During the next phase, the pelican attains the water surface and extends its wings over its surface to capture the fish out upwards. This attacking tactic results in more fish being captured in the attacking region, and pretending this behaviour lets the POA incorporate into improved points inside the searching region, enhancing the model’s local capability of seeking and application. During all iterations, the mathematic representation of the pelican’s new location is characterized in the next Eq. (25):
Here, \(\:{x}_{ij}^{p2}\) stands for the locality of the \(\:ith\) pelican within the \(\:jth\) size after the second-phase update, \(\:\beta\:\) means randomly generated numbers in (\(\:\text{0,1}),\) \(\:R\) signifies a randomly formed integer of 1 or 2, \(\:t\) symbolizes present iteration counts, and \(\:T\) refers to maximal iteration counts.
When the objective function value \(\:{F}_{p}\) is enhanced at \(\:the\:ith\:\)location, the location was upgraded with the succeeding Eq. (26):
Now, \(\:{x}_{i}^{p2}\) means the original place of the \(\:ith\) pelican; \(\:{x}_{i}\) refers to the original place of the \(\:ith\) pelican after the second phase was updated, and \(\:{F}_{i}^{p2}\) symbolizes an objective function of \(\:an\:ith\) pelican. The POA originates from an FF to attain enhanced classification performance. It is a positive number for suggesting a better outcome for the candidate’s solution. The classifier rate of error reduction is reflected as FF. It is computed below in Eq. (27).
XAI using the SHAP model
At last, SHAP is utilized as an XAI technique to enhance malware detection and decision-making processes of AI-driven security models. As ML methods become more and more multifaceted, understanding their basic details and decision-making methods offers a vital challenge33. The prediction precision established by these methods only is inadequate to guarantee their reliability. Enhancing the interpretability of black‐box methods and figuring out their productive capacities became essential to improving the capability and reliability of ML methods in numerous applications. The SHAP model is derived from the SHAP value from a supportive game concept. It establishes the equal delivery of costs or profits inside coalitions. Once connected to ML methods, each feature is considered a\(\:\:contributor\), and the Shapley value characterizes the equal delivery of the forecast values produced within the prediction instances to all features. The value given to all features, or the contribution degree, impacts the rise or reduction in the last method outcomes. For a provided method \(\:f\) and input instance \(\:x\), the feature’s SHAP value \(\:i\) is computed as presented in Eq. (28). Now, \(\:N\:\)characterizes the collection of each of the features; \(\:S\) refers to features subdivision eliminating feature \(\:i;\left|S\right|\) represents the number of components in set \(\:S;\left|N\right|\) denotes complete feature counts; \(\:{f}_{x}\left(S\cup\:\left\{i\right\}\right)\) and \(\:{f}_{x}\left(S\right)\) represents forecast values of the method with and without feature \(\:i\), correspondingly.
The values of SHAP offer quantitative measures of all features’ participation in the predictions of an ML method. By gaining SHAP values, the transparency and interpretability of the technique are considerably enhanced, resulting in a deep consideration of the relations among features. This value’s computation guarantees that all features’ giving is appropriately measured. The SHAP model examines the influence of all features on the method’s prediction outcomes by computing the amount to which all features participate in the model’s output. This model additionally improves the interpretability of black-box methods or composite ML methods.
Experimental validation
The investigational result of the MDMIoV-DLXAI technique is examined under the malware dataset34. The suggested method is simulated using the Python 3.6.5 tool on PC i5-8600k, 250GB SSD, GeForce 1050Ti 4GB, 16GB RAM, and 1 TB HDD. The parameter settings are provided: learning rate: 0.01, activation: ReLU, epoch count: 50, dropout: 0.5, and batch size: 5. Table 1 describes the dataset. There are 34 features in total, but only 25 features are selected.
Figure 6 established confusion matrices made by the MDMIoV-DLXAI technique on dissimilar epochs. On 500 epochs, the MDMIoV-DLXAI technique has known 24,038 samples to be benign and 24,741 samples to be malware. Besides, on 1500 epochs, the MDMIoV-DLXAI technique recognized 24,128 samples as benign and 24,745 as malware. Followed by, on 2000 epochs, the MDMIoV-DLXAI technique has acknowledged 24,116 samples as benign and 24,814 samples as malware. Furthermore, on 3000 epochs, the MDMIoV-DLXAI approach has 24,204 samples into benign and 24,760 samples into malware.

Confusion matrix of MDMIoV-DLXAI method (a–f) Epochs 500–3000.
Table 2; Fig. 7 inspect the malware detection of the MDMIoV-DLXAI approach below dissimilar epochs. The table values indicate that the MDMIoV-DLXAI approach correctly recognized benign and malware samples. On 500 epochs, the MDMIoV-DLXAI technique provides an average \(\:acc{u}_{y}\) of 97.56%, \(\:pre{c}_{n}\) of 97.60%, \(\:rec{a}_{l}\) of 97.56%, \(\:{F1}_{score}\) of 97.76%, and \(\:AU{C}_{score}\:\)of 97.56%.

Average of MDMIoV-DLXAI method (a–f) Epochs 500–3000.
Moreover, on 1000 epochs, the MDMIoV-DLXAI technique provides an average \(\:acc{u}_{y}\) of 97.61%, \(\:pre{c}_{n}\) of 97.62%, \(\:rec{a}_{l}\) of 97.61%, \(\:{F1}_{score}\) of 97.61%, and \(\:AU{C}_{score}\:\)of 97.61%. Also, on 1500 epochs, the MDMIoV-DLXAI method provides an average \(\:acc{u}_{y}\) of 97.75%, \(\:pre{c}_{n}\) of 97.78%, \(\:rec{a}_{l}\)of 97.75%, \(\:{F1}_{score}\) of 97.75%, and \(\:AU{C}_{score}\:\)of 97.75%. Simultaneously, on 2000 epochs, the MDMIoV-DLXAI method provides an average \(\:acc{u}_{y}\) of 97.86%, \(\:pre{c}_{n}\) of 97.90%, \(\:rec{a}_{l}\) of 97.86%, \(\:{F1}_{score}\) of 97.86%, and \(\:AU{C}_{score}\:\)of 97.86%. Besides, on 2500 epochs, the MDMIoV-DLXAI method provides an average \(\:acc{u}_{y}\) of 97.76%, \(\:pre{c}_{n}\) of 97.76%, \(\:rec{a}_{l}\) of 97.76%, \(\:{F1}_{score}\) of 97.76%, and \(\:AU{C}_{score}\:\)of 97.76%. Eventually, on 3000 epochs, the MDMIoV-DLXAI method provides an average \(\:acc{u}_{y}\) of 97.93%, \(\:pre{c}_{n}\) of 97.95%, \(\:rec{a}_{l}\) of 97.93, \(\:{F1}_{score}\) of 97.93%, and \(\:AU{C}_{score}\:\)of 97.93%.
Figure 8 illustrates the training (TRA) \(\:acc{u}_{y}\) and validation (VAL) \(\:acc{u}_{y}\) analysis of the MDMIoV-DLXAI technique below epoch 3000. The \(\:acc{u}_{y}\:\)analysis is calculated within the range of 0-3000 epochs. The figure highlights that TRA and VAL \(\:acc{u}_{y}\) analysis exhibitions an amplifying tendency that learned MDMIoV-DLXAI methodology’s capacity with superior outcomes across multiple iterations. Simultaneously, the TRA and VAL \(\:acc{u}_{y}\) leftovers closer across the epochs, which leads to inferior overfitting and exhibitions maximum performance of MDMIoV-DLXAI methodology, ensuring dependable prediction on hidden samples.

\(\:Acc{u}_{y}\) curve of MDMIoV-DLXAI model on Epoch 3000
Figure 9 shows the MDMIoV-DLXAI approach’s TRA loss (TRALOS) and VAL loss (VALLOS) curves under epoch 3000. The loss values are computed across the range of 0-3000 epochs. The TRALOS and VALLOS analysis exemplify a diminishing trend, informing the MDMIoV-DLXAI approach’s ability to balance a trade-off. The continuous reduction guarantees the MDMIoV-DLXAI methodology’s high performance and tunes the prediction results.

Loss analysis of MDMIoV-DLXAI methodology on Epoch 3000.
In Fig. 10, the precision-recall \(\:\left(PR\right)\) graph outcome of the MDMIoV-DLXAI methodology below epoch 3000 clarifies its outcomes by plotting Precision alongside Recall for every class. The figure demonstrates that the MDMIoV-DLXAI method continually achieves superior PR analysis over distinct classes, signifying its capacity to keep up a significant section of true positive predictions amongst all positive predictions \(\:\left(precision\right)\) where besides picking up an excellent ratio of actual positives (\(\:recall\)). The balanced rise in PR results among each class represents the efficiency of the MDMIoV-DLXAI method in the classification procedure.
Figure 11 examines the ROC analysis of the MDMIoV-DLXAI methodology below epoch 3000. The outcome suggests that the MDMIoV-DLXAI methodology achieves better ROC results over each class, indicating its essential capacity for discerning class labels. This trustworthy tendency of maximum ROC analysis across multiple classes shows the capable outcomes of the MDMIoV-DLXAI technique on forecasting class labels.

PR graph of MDMIoV-DLXAI methodology on Epoch 3000.

ROC curve of MDMIoV-DLXAI method on Epoch 3000.
Table 3; Fig. 12 compare the MDMIoV-DLXAI methodology with existing techniques35,36,37,38. The results stated that the MDMIoV-DLXAI methodology outperformed more excellent performances. For \(\:acc{u}_{y}\), the MDMIoV-DLXAI methodology attained a higher \(\:acc{u}_{y}\) of 97.93%. At the same time, the Manual Deep Semantic, SVM, LightGBM, k-mean SMO, DexRay, DeepMalDet, MalDetGCN, and GBDT models have obtained lesser \(\:acc{u}_{y}\) of 96.48%, 94.55%, 96.19%, 95.06%, 97.23%, 96.92%, 97.04%, and 96.88%, respectively. Moreover, concerning \(\:Pre{c}_{n}\), the MDMIoV-DLXAI technique attained maximal \(\:Pre{c}_{n}\) of 97.95% where the Manual Deep Semantic, SVM, LightGBM, k-mean SMO, DexRay, DeepMalDet, MalDetGCN, and GBDT models attained lower \(\:Pre{c}_{n}\) of 91.90%, 92.92%, 91.81%, 90.54%, 91.71%, 93.00%, 94.31%, and 95.22%, respectively. Regarding \(\:Rec{a}_{l}\), the MDMIoV-DLXAI technique attained a better \(\:Rec{a}_{l}\) of 97.93%. In contrast, the Manual Deep Semantic, SVM, LightGBM, k-mean SMO, DexRay, DeepMalDet, MalDetGCN, and GBDT techniques attained worst \(\:Rec{a}_{l}\) of 92.83%, 91.28%, 90.88%, 91.42%, 90.22%, 91.16%, 92.87%, and 94.08%, respectively. Eventually, based on \(\:{F1}_{score}\), the MDMIoV-DLXAI technique attained a superior \(\:{F1}_{score}\) of 97.93%. In contrast, the Manual Deep Semantic, SVM, LightGBM, k-mean SMO, DexRay, DeepMalDet, MalDetGCN, and GBDT techniques attained minimal \(\:{F1}_{score}\) of 96.93%, 96.22%, 90.90%, 95.04%, 93.28%, 91.26%, 92.76%, and 95.39%, correspondingly.

Comparative outcomes of MDMIoV-DLXAI methodology with existing models.
Table 4; Fig. 13 show the execution time (ET) result of the MDMIoV-DLXAI methodology with existing models. Based on ET, the MDMIoV-DLXAI technique delivers a minimum ET of 08.64 s. In contrast, the Manual Deep Semantic, SVM, LightGBM, k-mean SMO, DexRay, DeepMalDet, MalDetGCN, and GBDT models achieve better ET of 21.97 s, 19.74 s, 11.74 s, 20.55 s, 17.94 s, 21.94 s, 14.27 s, and 16.22, correspondingly.

ET outcome of MDMIoV-DLXAI technique with existing methods.
Conclusion
In this paper, a new MDMIoV-DLXAI approach is developed. The main aim of the proposed MDMIoV-DLXAI approach is to enhance the malware detection and classification model in IoV by utilizing advanced two-tier optimization models. At first, the data normalization stage is executed by the min-max normalization to convert input data into a beneficial format. Besides, the proposed MDMIoV-DLXAI model designs RSA for the feature selection procedure. Furthermore, the hybrid BiLSTM-MHSA model has been deployed for the malware classification model. The parameter tuning process is performed through POA to improve the classification performance of the BiLSTM-MHSA classifier. At last, SHAP is utilized as an XAI technique to enhance malware detection and decision-making processes of AI-driven security models. The experimental evaluation of the MDMIoV-DLXAI method is examined under the malware dataset. The comparison study of the MDMIoV-DLXAI method demonstrated a superior accuracy value of 97,393% over existing techniques.
Data availability
The data supporting this study’s findings are openly available in the Kaggle repository at https://www.kaggle.com/datasets/blackarcher/malware-dataset, reference number34.
References
Taslimasa, H. et al. Security issues in the Internet of Vehicles (IoV): A comprehensive survey. Internet of Things 22, 100809 (2023).
Halabi, T., Wahab, O. A., Mallah, A., Zulkernine, M. & R. and Protecting the internet of vehicles against advanced persistent threats: A bayesian Stackelberg game. IEEE Trans. Reliab. 70 (3), 970–985 (2021).
Sharma, S. & Kaushik, B. A survey on internet of vehicles: Applications, security issues & solutions. Veh. Commun. 20, 100182 (2019).
Li, X., Hu, Z., Xu, M., Wang, Y. & Ma, J. Transfer learning-based intrusion detection scheme for the internet of vehicles. Inf. Sci. 547, 119–135 (2021).
Kumar, R., Kumar, P., Tripathi, R., Gupta, G. P. & Kumar, N. P2SF-IoV: A privacy-preservation-based secured framework for internet of vehicles. IEEE Trans. Intell. Transp. Syst. 23(11), 22571–22582 (2021).
Nie, L. et al. Data-driven intrusion detection for intelligent internet of vehicles: A deep convolutional neural network-based method. IEEE Trans. Netw. Sci. Eng. 7(4), 2219–2230 (2020).
Banafshehvaragh, S. T. & Rahmani, A. M. Intrusion, anomaly, and attack detection in smart vehicles. Microprocess. Microsyst. 96, 104726 (2023).
Rani, P. & Sharma, R. Intelligent transportation system for internet of vehicles based vehicular networks for smart cities. Comput. Electr. Eng. 105, 108543 (2023).
Abualkishik, A. Z., Almajed, R. & Thompson, W. Multi-attribute decision-making method for prioritizing autonomous vehicles in real-time traffic management: towards active sustainable transport. Int. J. Wirel. Ad Hoc Commun. 3, 91–101 (2021).
BP, D. S. V. Incremental research on cyber security metrics in android applications by implementing the ML algorithms in malware classification and detection. J. Cybersecur. Inform. Manage. (JCIM) Vol. 3(1), 14–20 (2020).
Liu, G. et al. Fractional-Order optimal control and FIOV-MASAC reinforcement learning for combating malware spread in internet of vehicles. IEEE Trans. Autom. Sci. Eng. (2025).
Wazid, M. et al. Explainable deep Learning-Enabled malware attack detection for IoT-Enabled intelligent transportation systems. IEEE Trans. Intell. Transp. Syst. (2025).
Anargya, M. A. N., Ghozi, W. & Rafrastara, F. A. Random under sampling for performance improvement in attack detection on internet of vehicles using machine learning. Jurnal Informatika: Jurnal Pengembangan IT. 10(1), 11–19 (2025).
Almakayeel, N. Deep learning-based improved transformer model on android malware detection and classification in the internet of vehicles. Sci. Rep. 14(1), 25175 (2024).
Almazroi, A. A. & Ayub, N. Deep learning hybridization for improved malware detection in smart Internet of Things. Sci. Rep. 14(1), 7838 (2024).
Hammood, L., Doğru, İ. A. & Kılıç, K. Machine learning-based adaptive genetic algorithm for android malware detection in auto-driving vehicles. Appl. Sci. 13(9), 5403 (2023).
Alterazi, H. A. Enhancing Android Malware Detection in Internet of Vehicles using Self-Attention Transformer Model (2024).
Bangash, S. H. et al. Integrating machine learning and deep learning approaches for efficient malware detection in IoT-Based smart cities. J. Comput. Biomedical Inf. 5 (02), 280–299 (2023).
Latif, N., Ma, W. & Ahmad, H. B. Advancements in securing federated learning with IDS: a comprehensive review of neural networks and feature engineering techniques for malicious client detection. Artifi. Intell. Rev. 58(3), 91 (2025).
Sumathi, S. & Rajesh, R. HybGBS: A hybrid neural network and grey Wolf optimizer for intrusion detection in a cloud computing environment. Concurrency Computation: Pract. Experience. 36 (24), e8264 (2024).
Ma, W., Wang, X., Dong, J., Hu, M. & Zhou, Q. A lightweight method for botnet detection in internet of things environment. IEEE Trans. Netw. Sci. Eng. (2025).
Sokkalingam, S. & Ramakrishnan, R. An intelligent intrusion detection system for distributed denial of service attacks: A support vector machine with hybrid optimization algorithm based approach. Concurrency Computation: Pract. Experience 34 (27), e7334 (2022).
Shen, Y., Shepherd, C., Ahmed, C. M., Shen, S. & Yu, S. Privacy preservation strategies for malware-infected edge intelligence systems: A Bayesian Stochastic Game-Based Approach. IEEE Trans. Mobile Comput. (2025).
Sumathi, S., Rajesh, R. & Lim, S. Recurrent and deep learning neural network models for DDoS attack detection. J. Sens. 2022(1), 8530312 (2022).
Chen, C. et al. A deep Learning-Based traffic classification method for 5G aerial computing networks. IEEE Internet Things J. (2025).
Sumathi, S., Rajesh, R. & Karthikeyan, N. DDoS attack detection using hybrid machine learning based IDS models. (2022).
Zha, C. et al. A-NIDS: adaptive network intrusion detection system based on clustering and stacked CTGAN. IEEE Trans. Inf. Forensics Secur. (2025).
Sumathi, S. & Rajesh, R. A dynamic BPN-MLP neural network DDoS detection model using hybrid swarm intelligent framework. Indian J. Sci. Technol. 16 (43), 3890–3904 (2023).
Sundararajan, S. C. M. et al. IoT-based prediction model for aquaponic fish pond water quality using multiscale feature fusion with convolutional autoencoder and GRU networks. Sci. Rep. 15(1), 1925 (2025).
Bansal, J., Gangwar, G., Aljaidi, M., Alkoradees, A. & Singh, G. EEG-Based ADHD classification using autoencoder feature extraction and resnet with double augmented attention mechanism. Brain Sci. 15(1), 95 (2025).
Yang, Z. et al. Hybrid CNN-BiLSTM-MHSA model for accurate fault diagnosis of rotor motor bearings. Mathematics 13(3), 334 (2025).
Zou, H. et al. Optimal scheduling of multi-energy complementary systems based on an improved pelican algorithm. Energies 18(2), 365 (2025).
Yuan, H. et al. Assessment of peak particle velocity of blast vibration using hybrid soft computing approaches. J. Comput. Des. Eng., qwaf007 (2025).
Guo, W. et al. MalHAPGNN: An enhanced call graph-based malware detection framework using hierarchical attention pooling graph neural network. Sensors 25(2), 374 (2025).
Mohanraj, A. & Sivasankari, K. Android traffic malware analysis and detection using ensemble classifier. Ain Shams Engineering Journal, 15(12), 103134 (2024).
Minh, M. V. & Xuan, C. D. A novel approach for android malware detection based on intelligent computing. Computers Mater. Continua, 81(3) (2024).
Ma, K. P., Ryu, D. J. & Lee, S. J. Reverse analysis method and process for improving malware detection based on XAI model. Computers Mater. Continua 81(3) (2024).
Acknowledgments
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project under grant number RGP2/43/45. Princess Nourah bint AbdulrahmanUniversity Researchers Supporting Project number (PNURSP2025R330), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. Researchers Supporting Project number (RSP2025R459), King Saud University, Riyadh, Saudi Arabia. The authors extend their appreciation to the Deanship of Scientific Research at Northern Border University, Arar, KSA for funding this research work through the project number “NBU-FFR-2025- 2847-05. The authors are thankful to the Deanship of Graduate Studies and Scientific Research at University of Bisha for supporting this work through the Fast-Track Research Support Program.
Author information
Authors and Affiliations
Contributions
Manal Abdullah Alohali: Conceptualization, methodology development, experiment, formal analysis, investigation, writing. Sultan Alahmari: Formal analysis, investigation, validation, visualization, writing. Mohammed Aljebreen: Formal analysis, review and editing. Mashael M Asiri : Methodology, investigation. Sami Saad Albouq: Review and editing.Othman Alrusaini: Discussion, review and editing. Ali Alqazzaz: Discussion, review and editing. Achraf Ben Miled: Conceptualization, methodology development, investigation, supervision, review and editing.All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Alohali, M.A., Alahmari, S., Aljebreen, M. et al. Two stage malware detection model in internet of vehicles (IoV) using deep learning-based explainable artificial intelligence with optimization algorithms. Sci Rep 15, 20615 (2025). https://doi.org/10.1038/s41598-025-00269-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-00269-y
