
Abstract
In the domain of Prognostics and Health Management (PHM) technologies, the focus of Remaining Useful Life (RUL) prediction is on the forecasting of the time to failure by uncovering the complex correlations between equipment degradation features and RUL labels, thereby enabling effective support for predictive maintenance strategies. However, extant research primarily emphasizes single-scale and single-dimensional feature extraction, which fails to adequately capture both long- and short-term dependencies as well as the interrelationships among sensor feature dimensions. This limitation has a detrimental effect on the accuracy and robustness of RUL prediction. To address the aforementioned issues, this paper proposes an Adaptive Dilated Temporal Convolutional Network (AD-TCN) approach, incorporating a Multi-Scale Cross-Dimension Interaction Module (MSCDIM) to enhance feature extraction and interaction. First, a dynamic adaptive dilation factor is incorporated into the TCN, thereby enabling the model to adjust its receptive field dynamically, which facilitates the capture of long- and short-term dependencies across different scales, allowing a more comprehensive representation of equipment degradation patterns. Second, the MSCDIM module has been designed to perform multi-scale feature extraction, interaction, and fusion across temporal and sensor dimensions, dynamically adjusting feature weights in order to suppress redundant information and enhance the representation of critical features. Finally, contrastive and ablation experiments are conducted on the widely used C-MAPSS dataset and N-CMAPSS dataset. And the experimental results demonstrate that the proposed method achieves high performance, with the MSCDIM module exhibiting strong adaptability and significant potential for broad applications.
Similar content being viewed by others

Introduction
In the context of the rapid advancements witnessed within the modern manufacturing and aerospace industries, there has been a discernible increase in the demand for enhanced reliability in complex systems.The advent of large-scaMe data storage, pervasive adoption of sensor technologies, and substantial advancements in high-performance equipment have collectively fostered a robust technological foundation for Prognostics and Health Management (PHM) technology, thereby facilitating its extensive application and ongoing development.
The PHM technology facilitates predictive maintenance through continuous monitoring and analysis of the operational status of critical components within complex systems in real time. Utilising these evaluations, maintenance schedules are optimised to effectively prevent potential failures. A particularly critical aspect of PHM is the prediction of Remaining Useful Life (RUL), which plays a central role in PHM. By accurately assessing the present degradation state of equipment, RUL prediction enables the early identification of fault indicators and facilitates the dynamic adjustment of maintenance strategies. The implementation of these measures has been shown to have a significant impact on the mitigation of potential failures, as well as a substantial enhancement of system reliability and operational efficiency1.
In the task of predicting the RUL of equipment, it is crucial to capture both the long-term and short-term dependencies inherent in the degradation process. Long-term dependencies involve gradual changes that follow a persistent trend, such as progressive wear or ongoing performance decline in mechanical components. In contrast, short-term dependencies manifest as rapid fluctuations, often spurred by sudden failures or abrupt environmental changes, that can substantially alter the degradation trajectory. A model that focuses on only one type of dependency may overlook critical features needed for accurately assessing degradation trends. Consequently, achieving precise RUL predictions requires that models capture both long-term and short-term dependencies simultaneously, thereby offering a comprehensive depiction of the equipment’s degradation state2.
The techniques for predicting RUL can be categorized into three distinct groupings: failure mechanism-based methods, data-driven methods, and hybrid approaches. Among them, failure mechanism-based prediction methods primarily leverage domain-specific prior knowledge to develop mathematical models that reflect or simulate the degradation processes of equipment. This enables the prediction of its remaining useful life. For instance, Xue et al. combined the discrete-variable degradation model of equipment with continuous-variable boundary and initial conditions in order to dynamically describe the degradation mechanism of critical components and the validity of their approach was validated through simulations using fault data from the bearings of a nuclear circulating water pump test bench3. However, failure mechanism-based RUL prediction methods are primarily suitable for mechanical components with well-defined degradation characteristics and mechanisms that can be accurately modeled. And as equipment complexity increases, developing precise failure mechanism models becomes significantly more challenging in practical applications.
Furthermore, research on hybrid methods aims to enhance the accuracy of RUL prediction by integrating the strengths of failure mechanism models and data-driven models. For instance, Ma et al. developed a physics-based degradation model for lithium-ion batteries, leveraging domain expertise and deriving key parameters, which were then integrated with a deep neural network to predict RUL of the batteries based on a single charging curve4.Nevertheless, the effective integration of degradation mechanism models with deep learning remains a significant technical challenge.
In recent years, with the development of digital industry, a large number of key links deployed in various types of sensors have accumulated a large amount of industrial data, through the extraction of effective information from these multi-sensor data can be mined in-depth relationship between equipment degradation and industrial data, equipment degradation diagnosis and prediction of the state of provide a strong support. For example, Kai et al. proposed an advantageous discriminant analysis-aided collaborative alignment network (DA-CAN) that leverages multi-sensor data to enhance inter-sensor correlations, thereby enabling fault diagnosis across devices.5. Fu et al. proposed a novel shareability-exclusivity collaborative representation (SECR) method, which partitions multi-sensor data into multiple blocks and leverages the synergistic interplay between shared information and distinctive features to extract both common and exclusive characteristics from each block, thereby significantly enhancing the diagnostic capabilities of multi-sensor systems in complex industrial processes6.
Data-driven methods can be further categorized into statistical learning-based methods and machine learning-based methods.Among them, statistical learning-based methods analyze equipment degradation data to extract statistical features and construct degradation models for RUL prediction. For example, Xin et al. employed a joint estimation method combining domain adaptation (DA) and unscented Kalman filtering (UKF), achieving high-precision joint estimation of the state of charge (SOC) and state of energy (SOE) for lithium-ion batteries under varying temperature conditions7. However, in real industrial environments, the diversity and uncertainty of critical factors such as equipment conditions and operating environments render the construction of degradation models using statistical learning methods highly complex, thereby limiting their practicality to a certain extent.Conversely, machine learning-based methods employ the utilisation of collected equipment degradation data to facilitate a profound exploration of multidimensional features and establish RUL prediction models by associating these features with the remaining useful life. These methods have been shown to excel in the handling of nonlinear and high-dimensional complex data, to be less affected by environmental factors, and to eliminate the need for extensive domain knowledge or the construction of complex degradation mechanism models. The high predictive accuracy of these methods has led to their extensive use in industrial practice.
Based on the complexity of machine learning models, they can be further divided into shallow machine learning and deep learning approaches. Specifically, shallow machine learning methods, such as support vector machines (SVM), extreme learning machines (ELM), and random forests (RF), are widely adopted traditional approaches. These methods typically involve manual feature engineering to extract key information from data and build regression models for predicting the remaining useful life of equipment. For instance, Li et al. employed Gaussian process regression (GPR) and Kalman filtering to estimate the state of health (SOH) and state of charge (SOC), combining these with least squares support vector machines (LS-SVM) to predict the RUL of lithium-ion batteries8. Patel et al. proposed a milling cutter RUL prediction approach based on Shannon entropy feature selection and squared exponential Gaussian process regression (SE-GPR). The method computes the Shannon entropy of features derived from vibration and force sensors to identify those that encapsulate the most state information, and subsequently employs the SE-GPR model for prediction, thereby significantly enhancing accuracy while reducing feature dimensionality9. However, due to the simple structure of shallow machine learning models, they heavily rely on feature engineering and domain expertise, with prediction accuracy largely dependent on the quality of manually extracted features. Conversely, deep learning methods excel in feature learning, automatically extracting deep abstract features from data without requiring manual intervention. They are particularly effective in addressing nonlinear and high-dimensional problems, leading to a growing number of studies focusing on deep learning approaches.
In the complex multivariate time series regression task of RUL prediction, traditional deep learning architectures such as RNN and CNN have been widely used to efficiently extract deep key features from time series data to capture long- and short-term dependencies. Boujamaza et al. proposed a dilated recurrent neural network (D-RNN) that embeds dilated convolutions within the RNN framework and employs random grid search for parameter optimization, ultimately achieving precise predictions of turbofan engine RUL10. However, when RNN and its variants (e.g., LSTM, GRU, etc.) networks to process time-series data, due to the model’s inherent sequential dependence, the input of each time step is contingent on the output of the previous time step. Such an architecture is susceptible to issues such as gradient disappearance and gradient explosion when performing long time-series data training to explore the long-term dependence of equipment degradation data, This complicates the effective transfer of key information to the current moment state, which hinders the model’s ability to capture effective long-term dependencies in the face of extensive device degradation processes, and greatly affects the efficiency and prediction accuracy of the device RUL prediction task11. To alleviate this problem, Li et al. proposed a rolling bearing RUL prediction method based on recursive exponential slow feature analyses (RESFA) and bi-directional LSTM (Bi-LSTM), which utilises an autoencoder to extract the features and effectively captures the long-term degradation trend of the system through RESFA, thus significantly improving the stability and accuracy of the prediction while coping with the noise disturbances12. Moreover, since RNN-based models and their variants inherently depend on outputs from preceding time steps when computing the current step, they cannot efficiently process time series data in parallel, resulting in slow training, especially when capturing long-term dependencies during device degradation or handling large-scale datasets. To reduce the adverse impact of rapidly increasing time-series data on model training efficiency, Sun et al. developed a 1D CNN-GRU prediction model that leverages the update and reset gate mechanisms of GRU to mitigate the gradient vanishing problem in long-sequence prediction, integrates and selects multisensor monitoring data to enhance training efficiency, and more accurately captures long-term dependencies inherent in equipment degradation processes13.
In comparison to RNNs and their variants, CNNs have the capacity to process time series data in parallel by means of a sliding window approach. Utilising convolution operations, CNNs effectively capture the relationships between each time window and RUL labels. This approach circumvents the information loss and gradient vanishing issues that arise from conventional step-by-step processing of time series data. For instance, Guo et al. have proposed a sandglass-shaped multi-scale feature extractor (HME) based on a 1D-CNN and integrated it with a Transformer network to achieve accurate RUL prediction14. Chen et al. proposed a hybrid model that integrates a multi-scale deep convolutional neural network with a LSTM network for the extraction of features under complex and multi-fault operating conditions, thereby enabling accurate prediction of RUL for aircraft engines15. Zhang et al. proposed a parallel hybrid neural network composed of a 1D-CNN and a bidirectional gated recurrent unit (BiGRU) for predicting the RUL of aircraft engines16.
However, although CNN effectively extract short-term dependencies in time series data via convolutional operations, they are limited by a fixed receptive field when extended to capture long-term dependencies17. This limitation is particularly pronounced when processing degradation time series data under complex operational conditions across multiple time scales. In such cases, conventional CNNs cannot flexibly adjust their receptive fields to accommodate features specific to different time scales, thereby failing to fully capture the interplay between short and long term dependencies. To address this limitation, temporal convolutional networks (TCNs), a variant of convolutional neural networks, utilize causal convolutions to ensure that each time step depends solely on inputs from the current and preceding time steps. And the integration of dilated causal convolutions, which serves to expand the model’s receptive field, and the employment of residual connections, which are employed to maintain stability, result in TCNs effectively alleviating the vanishing gradient issue while preserving the causality and continuity of time-series processing. Consequently, they demonstrate an enhanced capacity to capture long-term dependencies in tasks involving the analysis of equipment degradation time-series data. For instance, Zhang et al. incorporated an enhanced self-attention mechanism and a squeeze-and-excitation mechanism into TCN to capture feature correlations across different time steps and channels, thereby enabling accurate RUL prediction18. Lin et al. proposed a dual-attention framework called Channel and Temporal Attention Temporal Convolutional Network (CATA-TCN), which enhances features and extracts critical degradation characteristics to improve the accuracy of RUL prediction19. Jiang et al. integrated a multi-head self-attention (MSA) mechanism with a TCN model to capture critical features during the degradation process of rolling bearings, enabling accurate residual RUL prediction for such components20.Tang et al. proposed a novel method for predicting RUL of rolling bearings, integrating health indicators and combining time-domain, frequency-domain, and time-frequency domain features through a parallel combination of TCN and Transformer, significantly improving RUL prediction accuracy by leveraging both local and global features21.
Although conventional TCNs have demonstrated outstanding performance in time-series forecasting, particularly in their marked ability to capture long-term dependencies, they still encounter certain challenges in practical applications. Firstly, many existing approaches to time-series analysis primarily focus on extracting and mining features along a single temporal dimension while neglecting the inter-variable correlations among data collected from multiple sensors and the coupling between features across different dimensions during the equipment degradation process, which ultimately undermines the accuracy of RUL predictions for equipment operating under complex degradation patterns. Furthermore, in the realm of temporal feature extraction, most existing approaches rely on a single time scale for feature learning, failing to fully account for the mutual influence between long-term trends and short-term fluctuations. In practice, equipment degradation typically occurs concurrently across multiple time scales, encompassing both gradual trend changes and rapid fluctuations, and neglecting the interrelationships among these scales can compromise the accuracy of RUL predictions.
In order to address the aforementioned issues, We introduce a spatiotemporal convolutional network (AD-TCN) that leverages a multi-scale cross-dimension interaction module (MSCDIM). Specifically, the AD-TCN expands the receptive field of the spatiotemporal convolutional model by introducing a dynamic, adaptive dilation factor, thereby enabling flexible adjustment according to the temporal scale of the data and effectively addressing the challenge of capturing both long-term trends and short-term fluctuations in diverse equipment degradation processes. In addition, a serial TCN architecture is employed to independently capture temporal dependencies from both the time and sensor dimensions, thereby effectively extracting multi-dimensional feature information in the equipment degradation process and further enhancing the model’s representational capacity. And the proposed MSCDIM module focuses on multi-scale feature extraction along both the temporal and sensor dimensions while enabling cross-dimensional information interaction; by adjusting the weighting parameters for each scale and dimension, the model is dynamically guided to attend to key features relevant to equipment degradation and suppress redundant information that could otherwise impede RUL prediction accuracy. Furthermore, by applying nonlinear transformations and related techniques, the extracted key degradation features are associated with RUL labels, thereby facilitating accurate predictions of remaining useful life.
The contributions of this paper are as follows:
-
1.
A dynamic adaptive dilation factor has been designed within the TCN framework, thus enabling the convolutional receptive field to be adaptively adjusted across different time steps by learning dynamically generated dilation factors. This approach effectively captures long-, medium-, and short-term dependencies in time series data while setting a dilation factor threshold to prevent the introduction of noise.
-
2.
The MSCDIM has been developed for the purpose of filtering information across different dimensions and scales. This module employs attention weights to adaptively focus on critical information within the features while suppressing redundant information. Furthermore, the employment of nonlinear transformations and associated operations facilitates the effective integration of diverse features, thereby enhancing the model’s robustness.
-
3.
A series of comparative and ablation experiments were conducted on the C-MAPSS dataset and the N-CMAPSS dataset in order to systematically validate the effectiveness of the proposed method.
The remainder of this paper is organized as follows. Section Methodology provides a detailed exposition of the proposed methodology. The subsequent section, Sect. Experimental validation, provides a comprehensive description of the data preprocesing procedures and the experimental configurations. Section Conclusion presents a comprehensive comparison and analysis of the results. Finally, Section 5 concludes the paper and offers perspectives on future work.
Methodology
Problem formulation
The RUL of a system is defined as the time interval \(t_{current}\) from the current time point to the point where system performance degrades to the failure threshold \(t_{failure}\), expressed as follows:
The core task of RUL prediction is to estimate the remaining time from the current point to the failure point based on degradation information collected during the system’s operational phase. This process involves the analysis and extraction of deep degradation features from current data, combined with historical data, to provide an accurate estimate of the system’s remaining useful life. Specifically, the system degradation state is represented as follows:
where the \(x_t\) represents a set of data collected at time \(t\) , and \(x_i(t_j)\) denotes the observation value of the \(i\)-th sensor at time \(t_j\) .
The primary objective of RUL prediction is to establish a mapping function \(g(\cdot )\) that relates the input \(x(t)\), which encapsulates the system’s current degradation state and historical data, to the RUL label. The relationship between these variables can be expressed mathematically as follows:
Leveraging this mapping capability enables the accurate prediction of the system’s remaining useful life, thereby providing valuable insights for maintenance and operational planning purposes22. And a typical equipment RUL degradation process is illustrated in Fig. 1.

Diagram of equipment RUL degradation.
Nevertheless, the challenge lies in the highly nonlinear and uncertain nature of the degradation process. The degradation trajectory of a system is often subject to variation due to operational conditions, environmental factors, and individual differences. Consequently, the primary research focus is on developing methodologies to comprehensively extract critical features from degradation data, integrate them with historical data, and construct a mapping function corresponding to the RUL label to enable accurate prediction of the system’s future state.
Structure of the AD-TCN-MSCDIM method
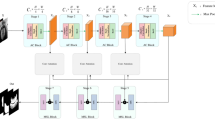
This paper proposes a novel method for RUL prediction, integrating an adaptive dilated TCN with a multi-scale fusion module to enhance the accuracy of remaining useful life estimation.The proposed model’s overall framework is illustrated in Fig. 2. For the complex task of RUL prediction, the process commences with data preprocessing, which incorporates data normalisation, time windowing, and RUL label construction on the C-MAPSS dataset. Subsequently, the preprocessed data is fed into the model for training, generating RUL prediction results. Finally, the model’s performance is evaluated by comparing the predicted RUL with actual RUL data.

The general architecture of the proposed model.
The model is composed of two primary components: the Adaptive Dilated Temporal Convolutional Network (AD-TCN) architecture and the Multi-Scale Cross-Dimension Interaction Module (MSCDIM). Among them, The AD-TCN architecture, consisting of two serially connected TCNs with adaptive dilation factors, integrates multi-layer temporal convolutions and residual connections to effectively address long-term temporal dependencies and enhance the model’s ability to represent complex nonlinear degradation paths.The MSCDIM employs dynamic adjustment of feature weights through the utilisation of channel and temporal attention mechanisms, integrating multi-scale features across temporal and sensor dimensions, suppressing redundant information and enhancing the representation capabilities of features.
Adaptive dilated temporal convolutional network architecture
The TCN represents a refinement of the CNN, with a specific focus on the extraction of features from time series data. Its architecture comprises three primary components: causal convolutions, dilated causal convolutions, and residual connections.
Causal convolution
The fundamental objective of causal convolution is to construct a model that is constrained in time, thereby ensuring that the output at each time step depends solely on the current and past input data, without utilizing future information, thereby preserving true temporal causality is preserved in the model.
For a given one-dimensional input sequence \(x = [x_0 , x_1,\dots ,x_{t-1}, x_t, x_{t+1},\dots ]\), traditional standard convolution can be expressed as a sliding operation of a convolution kernel over the sequence. Typically, zero-padding is applied at the sequence boundaries to ensure that the output length matches the input length.The convolution operation can be represented as follows:
where \(y_t\) is the output at time step \(t\), \(w\) = \([w_0, w_1,\dots ,w_{k-1}]\) is the convolution kernel of length \(k\) , and \(x_{t-i}\) represents the input value at time step \(t-i\). Besides, Zero-padding is applied when \(t -i < 0\) or \(t-i \ge T\) (where \(T\) is the length of the input sequence) to handle cases where the index falls outside the input sequence.
However, in the standard convolution mode, the receptive field of the convolution kernel includes both past and future data, which may contravene the causality requirement in time series prediction. As demonstrated in Fig. 3a and b, causal convolution differs from standard convolution in the following way: when computing the output\(y_t\) , it only considers data from the current and past time steps, such as \({\dots ,x_{t-1},x_t}\), while excluding future information, such as \({x_{t+1}, x_{t+2},\dots }\).

Schematic of different types of convolution.
In order to ensure the strict enforcement of causality in time-series prediction, it is imperative that the convolutional kernel exclusively accesses current and past inputs. Consequently, when adopting a left-to-right time indexing (\(t=0\) as the earliest point), zero-padding is applied to the left of the input sequence (i.e., for \(t-i < 0\)), ensuring no reference is made to future values \(x_{t+1}\), \(x_{t+2}\), etc. This approach prevents any information leakage from future time steps, thereby preserving strict causality during both training and inference.
Dilated causal convolution
In the context of time series prediction, causal convolution is employed with zero-padding on the left side of the input sequence to ensure that the prediction results depend solely on the current and past data. However, when attempting to capture long-term dependencies, a significant increase in the number of parameters is observed with the increase in the convolution kernel length. As shown in Fig. 3c, In order to address this issue, a dilation factor \(d\) is introduced into causal convolution, thus enabling the receptive field to be expanded without a significant increase in the number of parameters. This facilitates the capture of long-term dependencies while preserving the fundamental principles of causality.
The term ’receptive field’ (RF) is employed to denote the range of input data that corresponds to a specific output position, representing the area of influence within the input data that contributes to the output at a given location. For a standard convolution with a kernel length of \(k\), no dilation \((d = 1)\), and a stride of 1, the receptive field is equal to \(k\). And in a single-layer causal convolution, although left padding ensures that the output depends only on the current and past time steps, the receptive field remains unchanged at \(k\). In order to capture long-term dependencies without a significant increase in the number of parameters, a dilation factor, \(d\), is introduced into causal convolution, resulting in Dilated Causal Convolution. The output at time step t can be defined as:
where \(y(t)\) represents the output at time step \(t\) ; denotes the \(i\)-th weight of the convolution kernel of length \(k\); \(x_{t-d\cdot i}\)is the input value at time step \(t-d\cdot i\); and \(d\) is the dilation factor, which determines the sampling interval of the convolution kernel along the time axis.
At this point, unlike standard convolution, each kernel element in dilated convolution no longer samples input data continuously. Instead, each kernel element samples input data at intervals of \(d\) points along the time axis. The receptive field for this operation is given by:
where the \(K\) denotes the length of the kernel, and \(d\) denotes the dilation factor.
Although conventional TCN can extend their receptive fields to capture long-term dependencies by increasing the dilation factor \(d\), this factor is typically fixed, inhibiting flexible adjustments based on the multi-scale requirements of time-series data. While increasing \(d\) expands the receptive field to capture extended temporal dependencies, an excessively large, fixed dilation factor is liable to introduce unnecessary parameters when the long-term dependencies in equipment degradation data are not pronounced. In such cases, short-term feature extraction may also be hampered, making it difficult to strike a balance between capturing long- and short-term dependencies. Consequently, overall model efficiency is reduced, and the accuracy of RUL predictions can be adversely affected.
Adaptive dilation factor
To overcome the limitations of conventional TCNs in capturing both long- and short-term dependencies in equipment degradation time-series data, an adaptive dilation factor \(d_\theta\) is introduced. Unlike the fixed dilation factor \(d\) used in traditional TCN, \(d_\theta\) can be dynamically adjusted to accommodate various input characteristics. Furthermore, by expanding or contracting the model’s receptive field according to the requirements of different time steps, this adaptive factor offers greater flexibility, thereby more effectively modeling dependencies across multiple temporal scales. At this point, the convolution operation output is expressed as:
In this formulation, \(d_\theta\) serves as a dynamically trainable parameter that can be adjusted according to the characteristics of the input time-series data and is updated via backpropagation during training. Consequently, the receptive field can be automatically expanded when capturing long-term dependencies and contracted for short-term dependencies, mitigating the limitations posed by a fixed receptive field in conventional TCN. This approach also delivers enhanced flexibility in handling multi-scale time-series data under complex operating conditions.
At this point, the RF is given by: \(RF = 1 + (K-1) \cdot d_\theta\), As the value of \(d_\theta\) increases, the receptive field of the convolution layer undergoes an expansion. However, \(d_\theta\) is an adaptive learning parameter, excessively large values can result in an overly expansive receptive field, leading to a significant increase in the number of parameters and potentially causing over-smoothing. Conversely, overly small values of \(d_\theta\) may fail to effectively expand the receptive field. Therefore, it is crucial to set a threshold for \(d_\theta\) based on practical requirements to ensure that the receptive field of a single convolution layer is both effective and appropriately scaled.
In the context of \(d_{min}\), it is imperative to ensure that the minimum receptive field of a single convolution layer is of a specified length and effective. This is to avoid the inclusion of distant historical data that may introduce noise. Consequently, \(d_{min}\) is set to 1 to ensure sufficient capability in capturing short-term dependency features from the data. For \(d_{max}\) , maximizing its value is essential for capturing long-term dependency features, as it allows the receptive field of a single convolution layer to cover a broader time span. Nevertheless, it is imperative to note that unduly large values have the potential to substantially augment computational expenses and engender instability during the training process. A review of studies related to RUL prediction on the C-MAPSS dataset reveals that the time window \(W\) is typically set within the range of 20–6023.
Thus, when the convolution kernel length is set to \(k = 3\), to ensure coverage of a maximum time step of 60, the following condition must be satisfied:
And through calculation, when \(d_{max} = 30\), the receptive field becomes:
which can cover a time step of 60. Therefore, \(d_{max}\) is set to 30. Moreover, during the processes of model initialization and training, the quantity \(d_\theta\) is initialized to \((d_{min} + d_{max})/2\). Thereafter, a learnable parameter \(\phi\) and a sigmoid activation function are utilised to map \(d_\theta\) within the range of \(d_{min}\) and \(d_{max}\). This methodological approach permits the model to determine the optimal receptive field in an adaptive manner, based on the prevailing dependency requirements during the training process.
where the parameter \(\phi\) is learnable and dynamically optimized during network training. and the \(\delta (\cdot )\) represents the sigmoid activation function, which maps \(\phi\) to the range [0, 1]. The value of is constrained within the range [\(d_{min}\), \(d_{max}\)] and adaptively adjusts the receptive field size during training. This ensures a balance between capturing short-term local dependency features and representing long-term global dependency features during the modeling process.
Although setting thresholds for \(d_\theta\) helps prevent the receptive field from becoming too large or too small, to ensure that the input length \(T_{in}\) matches the output length \(T_{out}\), appropriate padding and trimming operations need to be applied to the output data in conjunction with the adaptive dilation factor \(d_\theta\). The output length is calculated as follows:
where \(T_{in}\) represents the input sequence length, \(T_{out}\) denotes the output sequence length, \(k\) is the convolution kernel size, and \(p\) refers to the amount of padding applied, \(s\) is the stride. And when the stride \(s\) is set to 1, the formula \(T_{out}\) can be further simplified as:
And when \(T_{out}\) = \(T_{in}\) , the amount of padding \(p\) can be calculated as:
And in this case, the input and output sequence lengths are consistent. However, to ensure causality, a right-padding strategy is required. In this case, the padding p is set to:
To ensure that the output at each time step depends only on past and current input values, without incorporating future information. When substituting the formula(14) into the formula, we have:
This results in each output sequence being \(d_{\theta }(k-1)\) time steps longer than the input sequence, which causes a mismatch in lengths. To address this, the Chomp1d operation in TCN is used to trim the extra \(d_{\theta }(k-1)\) time steps from each output sequence, ensuring the output length matches the input length. The adjusted output length is expressed as:
Thus, by applying right-side padding and trimming, causality is ensured for each time step, while maintaining consistency between the lengths of the output \(T_{out}^{\prime }\) and input \(T_{in}\) sequences at every time step.
Residual block
The utilization of residual connections facilitates the integration of the features extracted by TCN with the input information, thereby effectively mitigating the gradient vanishing problem that arises as network depth increases during back propagation.
As shown in Fig. 4, each residual block in the AD-TCN module is composed of Adaptive Dilation Factor convolution, activation function, Weight normalization, dropout layer, and a residual connection. The mathematical formulation is as follows:
where, the \(x_t\) represents the input vector at time \(t\), \(y_t\) represents the output feature vector corresponding to time \(t\), and \(F(x_t)\) denotes the output generated by processing \(x_t\) through the Adaptive Dilation Factor convolution, activation function, and other layers.

Structure of AD-TCN.
As illustrated in Fig. 4, to fully explore the dynamic relationships among various features within time-series data during equipment degradation, this study proposes a feature extraction framework composed of two serial AD-TCN modules. Firstly, the initial AD-TCN module processes the raw time-series data, leveraging multi-layer adaptive dilated causal convolutions and residual connections along the time dimension (W) to extract deep temporal dependency features that effectively capture both short- and long-term dependencies. In addition, a clipping strategy and fully connected layers are utilized for channel mapping to ensure consistency between input and output shapes, thereby enhancing the model’s overall efficiency. Besides, a second AD-TCN module takes the output from the initial stage as its input, further extracting temporal correlations from the sensor feature dimension (H). This approach delves into the intricate sequential relationships between sensor data features and temporal characteristics, thereby capturing both short-term fluctuations and long-term trends.
By designing a serial architecture with two AD-TCN modules, the model independently performs temporal modeling on distinct features along both the time and sensor dimensions in equipment degradation time-series datasets, thereby effectively capturing the long- and short-term dependencies within each dimension. Besides, this architecture enhances the model ability to flexibly handle complex temporal correlations spanning both the time and sensor dimensions, while simultaneously providing high-quality feature representations for subsequent multi-scale feature extraction. As a result, it improves the accuracy and robustness of RUL predictions in equipment degradation scenarios.
Multi-scale cross-dimension interaction module
Although the dual-module AD-TCN framework initially extracts key temporal features from both time and sensor dimensions by modeling time dependencies and feature correlations in sequence data, it still faces certain limitations in deeper multi-scale feature extraction and cross-dimensional feature interaction. Specifically, the proposed AD-TCN architecture primarily focuses on extracting dependencies at a single temporal scale by introducing an adaptive dilation factor and feature-dimension transformations to dynamically expand the model’s receptive field along the temporal dimension, thereby effectively capturing both short- and long-term dependencies in the data, yet it does not comprehensively model the complex multi-scale patterns arising during the degradation process, restricting the model’s capacity for cross-multi-scale feature extraction. Besides, although the serial AD-TCN architecture independently captures critical features along the time and sensor dimensions, it does not sufficiently resolve cross-dimensional interactions or address the redundancy introduced by feature coupling, thereby hindering the effective integration of complex dependencies across multiple time scales and sensor dimensions and making it challenging to achieve feature fusion and interaction in degradation time-series data.
To address these limitations in the serial AD-TCN architecture, we propose the MSCDIM module. By employing parallel multi-scale convolutional branches, the module achieves more comprehensive and in-depth multi-scale feature extraction across both the temporal and sensor dimensions, thereby avoiding the feature stacking issues caused by information redundancy and limited dimensional interaction in serial architectures, while effectively capturing the complex interactions among features at different time scales and across various dimensions, ultimately enabling the efficient fusion of critical features. Beside, to address cross-dimensional information fusion between the temporal dimension and the sensor feature dimension, we design operations such as max pooling, average pooling, and nonlinear transformations to compute distinct attention weights for each dimension-enabling the model to adaptively emphasize pivotal feature information while suppressing redundant data-and further employ concatenation and segmentation strategies to ensure the effective integration of key features across diverse dimensions and time scales, thereby enhancing model robustness and its capacity to capture crucial patterns in complex degradation scenarios.
Therefore, by employing parallel multi-scale feature extraction and cross-dimensional information fusion, the MSCDIM module heightens the model’s capacity to interpret pivotal information from both the temporal and sensor feature dimensions, providing richer and more precise feature representations for equipment degradation RUL prediction.

Structure of MSCDIM.
As shown in Fig. 5, the input data \(X\) (\(X\in R^{B\times W\times H}\))undergoes an unsqueeze operation to add a channel dimension, adjusting the shape of the input data to meet the requirements for subsequent convolution operations, resulting in the new data tensor \(X^{'}\)(\(X^{'} \in R^{B\times 1\times W\times H}\)).
By applying Conv2d operations at three distinct scales, the model provides multiple receptive fields that capture localized spatial information at varying scales within the \(W\times H\) space. And by performing convolution operations at multiple scales to extract spatial features of varying levels, the model conducts local modeling on the input data across diverse ranges, capturing everything from fine details to global structures, thereby enhancing its capacity to represent multi-level spatial patterns and providing a comprehensive feature representation that facilitates subsequent feature fusion.
Subsequently, a squeeze operation is applied to revert the data shape to its original dimensions, ensuring consistency between output and input shapes and preventing shape mismatches introduced by multi-scale convolution operations. Moreover, feature information from different scales is compressed and fused into a single output \(Y\), thereby achieving a more comprehensive and enriched feature representation, which serves as a sufficient input for subsequent feature processing and integration.
Next, the corresponding features of the fused feature representation \(Y\) are aggregated and mined along the \(W\) and \(H\) dimensions. The features in each dimension are aggregated and linearly transformed, while pooling operations are applied to compress the features from different dimensions, reducing dimensional redundancy while preserving key global statistical features.
In this process, pooling operations are performed along the \(W\) dimension, thereby aggregating the \(H\)-values in each column. The application of both average pooling and max pooling serves to reduce the spatial dimensions of the feature map, while ensuring the retention of the most significant features and global information at each position. Furthermore, a fully connected layer is employed to facilitate the mapping of features, thereby enhancing the model’s capacity to represent spatial information.
Specifically, \(Avgpool_H\) applies average pooling along the \(H\)-dimension to extract overall trends and global features, thereby capturing common information at every position. And the \(Maxpool_H\) performs max pooling along the H-dimension, highlighting extreme values within the features and enabling the model to focus on critical local information at each position. Subsequently, the \(FC_W\) (a fully connected layer) processes and transforms the pooled features along the \(W\)-dimension, learning intricate relationships among the input features and strengthening the representation capacity of \(W\)-dimensional information. Finally, the final output \(Y_W\) encapsulates the \(W\)-dimensional feature representation after pooling and processing with the fully connected layer.
In a similar manner, performing pooling along the \(H\)-dimension yields the feature representation \(Y_H\). Next, a concatenation operation combines the key features from both the \(W\)-dimension and the \(H\)-dimension into a unified, high-dimensional representation \(Y_{cat}\) that thoroughly captures the complex correlations present in degradation data.
By means of this concatenation operation, features from the time and sensor dimensions are effectively fused, enabling cross-dimensional information integration while preserving each dimension’s structural characteristics, ultimately offering a more comprehensive feature representation for subsequent integration and model training. Subsequently, the fused features undergo additional refinement through fully connected layers, nonlinear activation functions, and normalization, ensuring deeper feature representation and numerical stability; consequently, the model is better equipped to handle complex multi-dimensional features and multi-scale dependencies in equipment degradation RUL prediction tasks, while also improving its robustness and generalization capabilities.
Where the \(FC_1\), \(FC_2\) and \(FC_H\) are fully connected layers, the \(Avgpool_W\) and \(Maxpool_W\) operations are applied along the \(W\)-dimension to aggregate features across the spatial dimension, the \(Relu\) is the activation function, the \(Cat\) is the concatenation operation, and the \(LayerNorm\) is the layer normalization operation.
Finally, to further emphasize the salient features of the time and sensor dimensions, the MSCDIM module employs a \(Split\) operation to isolate these dimensional representations, then applies a \(\sigma (\cdot )\) function for nonlinear mapping to derive attention weights corresponding to each dimension, thereby adaptively focusing on the key features across different dimensions. And the generated attention weights \(Q_W\) and \(Q_H\) are multiplied element-wise with the original input X to achieve cross-dimensional information fusion. By adaptively accentuating key features in both the temporal and sensor dimensions while suppressing redundant or irrelevant features, the model is able to more effectively capture deep and complex features as well as long- and short-term dependencies, ultimately producing the final output \(Z_{out}\).
Where, the \(Split\) denotes the feature splitting operation, and \(\sigma (\cdot )\) represents the application of the Sigmoid activation function, which performs a nonlinear transformation on the features, compressing the output values to the range (0, 1).
Experimental validation
In this section, the effectiveness of the proposed method is validated through experiments conducted using the widely adopted C-MAPSS and N-CMAPSS datasets, with the results then being compared with those of state-of-the-art methods in the field. The structure of this chapter is organized as follows: Sect. Dataset description introduces the fundamental information and salient features of the C-MAPSS and N-CMAPSS datasets. Section The data preprocessing delineates the fundamental steps involved in the process of data preprocessing. Section The hyperparameter experiments presents hyperparameter simulation experiments and their analysis. Section The comparison experiments involves the execution of comparative experiments with other state-of-the-art methods, with the aim of validating the effectiveness of the proposed model. Section The ablation experiment performs ablation experiments to further verify the effectiveness of individual modules.
Furthermore, all experiments in this study were conducted on an experimental platform configured with PyTorch 2.2.2, Python 3.9.19, and an NVIDIA GeForce RTX 4080. To reduce the impact of randomness, all experiments were repeated multiple times, and hyperparameter settings were optimized using the grid search method to identify the best configuration.
Dataset description
The C-MAPSS (Commercial Modular Aero-Propulsion System Simulation) dataset, provided by the NASA Ames Research Center, is a baseline dataset generated using commercial modular aero-propulsion system simulation software to simulate the full lifecycle of turbofan engines. And It is employed extensively for the validation of RUL prediction models for aircraft engines.

Schematic diagram of the engine in C-MAPSS.
As demonstrated in Fig. 6, the aircraft engine is composed of components such as the fan and low-pressure compressor, with the detailed structure presented in Table 1. Furthermore, 21 distinct sensor types are installed at various locations on the engine to collect parameters throughout its lifecycle, with the specific sensor configurations listed in Table 2.
As shown in Table 3, the C-MAPSS dataset is comprised of four subsets: FD001, FD002, FD003, and FD004. Each subset is designed to simulate distinct operating conditions and failure modes, incorporating both training and testing sets. The training sets contain multi-sensor data collected throughout the entire lifecycle of the engines, while the testing sets include operational state data collected before failure points, along with the corresponding RUL labels. FD004 is regarded as the most complex subset due to its incorporation of the most variability in operating conditions and failure modes.
The N-CMAPSS is an updated iteration of the C-MAPSS dataset, capturing the full operational trajectories of multiple engines from normal function to failure. As shown in Table 4, it is divided into eight subsets (DS01 through DS08), featuring additional engine units, longer run cycles, and more complex fault modes, while also providing richer sensor data and more diverse operating conditions.
Furthermore, in order to accurately evaluate the performance of the proposed model, the Root Mean Square Error (RMSE) and Score metrics are adopted, which are widely used in such evaluations. The RMSE is utilised to quantify the discrepancy between the predicted and actual RUL values, and its definition is as follows:
Where \(\hat{y}_i\)represents the actual RUL of the \(i\)-th current sample, \(y_i\) represents the \(i\)-th predicted RUL, and \(N\) is the total number of samples. Additionally,, in the Score metric, a penalty mechanism is introduced in order to account for discrepancies between predictions and actual values. In instances where the predicted value deviates from the actual value, a penalty is applied, with greater penalties imposed when the predicted RUL exceeds the actual RUL. The metric is defined as follows:
Where \(\hat{y}_i\)represents the actual RUL of the \(i\)-th current sample, \(y_i\) represents the \(i\)-th predicted RUL, and \(N\) is the total number of samples. Additionally, as demonstrated in Fig. 7, when the predicted RUL corresponds to the actual RUL, both RMSE and Score are equivalent to zero. However, as the prediction error increases, the RMSE grows linearly, while the Score exhibits exponential growth. Consequently, although both RMSE and Score are related to prediction errors, Score is more sensitive, tolerating smaller errors well but amplifying larger errors significantly24.

The relationship between RMSE and Score.
The data preprocessing
Data selection and normalization
The C-MAPSS dataset comprises measurement data collated by 21 sensors. However, the correlation between the degradation data from different sensors and the RUL labels varies significantly. To address this, a correlation analysis is conducted using visualisation techniques to identify and exclude sensors with weak correlations to RUL. The specific correlations are illustrated in Fig. 8. And it can be observed that sensors S1, S5, S6, S10, S16, S18, and S19 maintain constant values throughout the engine lifecycle. In order to provide further validation of this hypothesis, the Pearson correlation coefficients between the sensor data and the RUL labels are computed. The outcomes, illustrated in Fig. 9, substantiate that the aforementioned sensors bear no correlation to the engine RUL labels. Consequently, the sensors identified as S2, S3, S4, S7, S8, S9, S11, S12, S13, S14, S15, S17, S20, and S21 are selected as inputs to the model25.

The sensor value trends across the aircraft engine lifecycle.

Pearson coefficients between sensor readings and RUL.
To provide further validation of the model performance, we supplement our analysis with the N-CMAPSS dataset, which offers comprehensive coverage of fault modes, extended run cycles, and richer sensor data26. Among its eight subsets, DS02 has been widely employed in numerous studies; accordingly, this research selects DS02 for additional verification. Specifically, DS02 comprises six training sets (Units 2, 5, 10, 16, 18, and 20) and three test sets (Units 11, 14, and 15). These three test sets are merged into a single combined test set, referred to as the WT test set, to facilitate a more robust evaluation. The specific parameters of this dataset are presented in Table 5, where Unit Num denotes the subset unit index, Sample Size refers to the number of samples (in millions), and Failure Mode indicates the type of degradation, categorized as either HPT (High Pressure Turbine Degradation) or LPT (Low Pressure Turbine Degradation). In addition, the 20 sensor parameters listed in Table 6 are selected as inputs to the model.
Besides, the discussion in this section is based on the C-MAPSS dataset, which includes fewer parameters than the N-CMAPSS dataset and is thus more suitable for detailed analysis and illustration. Despite the difference in scale, the two datasets exhibit a high degree of similarity in terms of data structure, degradation patterns, and sensor configuration, allowing insights derived from C-MAPSS to be transferable and representative for the more complex scenarios encountered in N-CMAPSS27.
Furthermore, as shown in Fig. 10, in order to mitigate the impact of differences in magnitude and unit inconsistencies among sensors, a min-max normalization strategy is applied. This method involves mapping the data collected by each sensor to a unified range of [0, 1], thereby eliminating proportional differences between sensors28. The efficacy of this normalization is twofold: it accelerates the model convergence process and improves training efficiency. The formula employed is as follows:

The normalization of C-MAPSS.
where \(X_{norm}\) represents the normalized data, \(X\) is the original data, \(X_{max}\) and \(X_{min}\) represent the maximum and minimum values in the data.
The slide window
In the context of RUL prediction tasks, multi-time-step data of equivalent duration has been shown to contain a greater quantity of information than single-time-step data. Consequently, As shown in Fig. 11, when processing time-series data, the utilisation of a sliding time window method along the time axis is a prevailing practice for the segmentation of time-series data into multiple samples of equal length. These samples are then matched with their corresponding RUL labels29. This methodological approach facilitates the capture of more detailed degradation trends in the data, thereby enhancing the model’s predictive performance.

The process of the slide window.
Thus, to achieve this objective, a range of time window sizes \(W\) have been configured in this study. The purpose of this configuration is to determine the optimal time window size for the proposed model, with the objective of achieving the best possible performance. Further details can be found in the hyperparameter experiment section.
The RUL label reconstruction
During the operation of the equipment, the RUL label is set to 0 at the time of failure and calculated backwards as the remaining useful life for each time point relative to the failure time. However, within the context of the equipment’s lifecycle, it is generally assumed that the initial operation phase represents a healthy state. And as the equipment operates, the ageing process accelerates, leading to a reduction in the equipment’s remaining lifespan. As shown in Fig. 12 In order to address this issue, a piecewise linear model is employed, with the RUL label threshold set at 125 during the healthy state phase23. This methodological approach facilitates the model’s capacity to prioritise degradation characteristics in subsequent phases of operation, enhancing its resilience and prediction precision.

Segmented linear function of RUL.
The hyperparameter experiments
In this section, the investigation focuses on two key hyperparameters in the model: the window_size (\(W\)) and the hidden_dim (\(H\)). By this way to provide preliminary validation of the model’s effectiveness, and explore the impact of hyperparameter variations under a range of complex operating conditions.
In order to ascertain the impact of differing window_size (\(W\)) on the RUL prediction task within the confines of the experimental setup, reference was made to analyses conducted in related studies that experimented with varying window sizes (e.g.1,10,20,30,40,50,60 ) on the dataset30. Consequently, we set the range of \(w\) to 10,20,30,40,50,60. Moreover, analogous research investigated the impact of the hyperparameter hidden_dim (\(H\)) , evaluating values of \(H\) = 16, 32, 64, 12831. Consequently, the range of \(H\) was set to 16, 32, 64, 128. Thus, we conducted experiments within the parameter ranges of \(w = [10, 20, 30, 40, 50, 60]\) and \(H = [16, 32, 64, 128]\) to determine the optimal hyperparameter configuration for our model.
The size of the window is the primary factor in determining the length of historical data that the model is able to observe along the temporal dimension, enabling it to capture the dynamic evolution characteristics of the time series. And the hidden_dim primarily maps the 14 original sensor features from their raw space, which may contain redundancy and noise, to a more expressive latent representation space. Because the direct input of raw sensor feature data into the model not only makes it challenging to accurately capture the complex nonlinear relationships between features but also limits the model’s ability to represent complex equipment degradation patterns due to fixed low-dimensional feature representations. This has the potential to compromise learning efficiency and adversely affect prediction performance.
The introduction of a fully connected layer facilitates the mapping of the 14-dimensional raw sensor features into a new \(H\)-dimensional space, thereby enabling the effective extraction of more expressive high-dimensional features. Besides, the model is able to adaptively adjust the weight coefficients through backpropagation, thereby ensuring the comprehensive capture of relevant information for the prediction task whilst enhancing the model’s representational capacity without a significant increase in computational overhead. Therefore, by tuning the window size and hidden dimension hyperparameters, the model can achieve improved key information capture and enhanced representational capacity across both the temporal and sensor feature dimensions.

The RMSE with different hyperparameters on the four datasets.
As demonstrated in Fig. 13, across the four subsets of the C-MAPSS dataset, the model attains optimal overall performance when \(W\)=40, with the lowest RMSE values. Furthermore, the selection of the hyperparameter \(H\) is contingent upon the complexity of the dataset. In FD001 and FD003, where the operation conditions are set to 1 and the data is relatively simple, a smaller feature space \((H=32)\) suffices to capture the relevant features. Conversely, in FD002 and FD004, with six operation conditions and more complex sensor data, a higher-dimensional feature space \((H=64)\) is required to capture richer feature distributions and engine degradation patterns.
Therefore, all the hyperparameter settings adopted in the experiments of this paper are shown in Table 7.
The comparison experiments
In this chapter, we compare our method with related state-of-the-art approaches in the field using the C-MAPSS dataset and N-CMAPSS dataset to validate the effectiveness of the proposed model.
-
MSIDSN32: A multi-scale integrated deep self-attention network (MSIDSN) is proposed for RUL prediction, leveraging multi-scale feature extraction, enhanced recurrent modules, and efficient loss functions to process aero-engine degradation data and deliver accurate predictions.
-
AGATT33: An RUL prediction model integrating attention mechanisms, graph attention networks (GATs), and transformers, employs spatial and temporal channels to extract and fuse dependencies across sensors and time steps for accurate predictions.
-
Res-HSA34:A residual hybrid network with a self-attention mechanism for RUL prediction, enhancing feature extraction and mitigating abnormal health fluctuations for improved accuracy in rotating machinery maintenance.
-
IMDSSN23:An integrated multi-head dual sparse self-attention network that combines ProbSparse and LogSparse mechanisms for efficient and accurate remaining useful life prediction, addressing computational complexity and enhancing feature extraction from temporal data.
-
ABGRU35:A model integrating an attention mechanism with a Gate Recurrent Unit (GRU) network to predict RUL, improving feature weighting and enhancing prediction accuracy on the NASA C-MAPSS dataset.
-
MSDCNN15:A hybrid approach combining a multi-scale deep convolutional neural network with Long Short-Term Memory (LSTM) to predict the RUL of aircraft engines.
-
PHNN16:A novel method combining a 1-D Convolutional Neural Network (1-DCNN) and Bidirectional Gated Recurrent Unit (BiGRU) for predicting the RUL, effectively handling spatial and temporal features.
-
SA-MSTCN-GFA36:An Attention-based Multi-Scale Temporal Convolutional Network (MSTCN) integrating Self-Attention and Global Fusion Attention mechanisms.
-
ATCN18:An attention-based temporal convolutional network (ATCN) leveraging an improved self-attention mechanism and squeeze-and-excitation mechanism for aero-engine RUL prediction.
-
MHT14:A multiscale Hourglass-Transformer (MHT) incorporating hourglass-shaped multiscale feature extraction and pyramid self-attention mechanisms for aero-engine RUL prediction.
-
CATA-TCN19:A dual attention framework, CATA-TCN, integrating channel attention and temporal attention within a temporal convolutional network to enhance feature extraction.
-
Transformer-RW37:A transformer-based RUL estimation method combined with an Adaptive RUL-wise Reweighting (ARR) technique to address data imbalance.
-
DL-PRP38:A deep learning-based probabilistic RUL prediction model that optimizes prior distribution parameters to enhance prediction accuracy and robustness.
-
DVGTformer39:A dual-view graph Transformer (DVGTformer) model for RUL prediction that integrates temporal and spatial information from multi-sensor signals to enhance prediction accuracy and robustness.
-
MAGCN15:A multi-scale adaptive graph neural network that captures scale-specific temporal and inter-variable dependencies for improved multivariate time series forecasting.
-
LOGO40:A local-global correlation fusion framework that integrates dynamic and stable sensor relationships using graph neural networks to jointly model spatial and temporal dependencies for accurate RUL prediction.
-
PI-STHNN27:A physics-informed spatio-temporal hybrid neural network that integrates prior physical knowledge and parallel spatio-temporal feature extraction to enhance RUL prediction of aircraft engines.
As demonstrated in Table 8, the proposed method attains RMSE values of 11.39, 13.41, 10.17, and 15.28 across the four subsets of the C-MAPSS dataset, with an average RMSE of 12.56. The corresponding Score values are 170.52, 563.03, 134.87, and 877.44, with an average Score of 436.47. And in order to further evaluate the performance differences between our model and state-of-the-art methods, the average values of the metrics were calculated and a comparative analysis conducted. The findings indicate that, in comparison to the second-best method, our model attains RMSE enhancements of 0.74%, 3.78%, and 1.16% in FD002, FD003, and FD004, correspondingly. Furthermore, in FD002 and FD004, Score enhances by 24.53% and 20.77%, respectively, while maintaining a consistently high level of performance in other cases. Overall, compared to the second-best method, the proposed model has been shown to achieve an average RMSE improvement of 3.83% and an average Score improvement of 25.36%. These results demonstrate the strong competitiveness of the proposed method in RUL prediction tasks, particularly in the more complex FD002 and FD004 datasets. The superior performance of the proposed model can be attributed to its ability to map raw sensor features from their original space into a more expressive \(H\)-dimensional space. This facilitates the model’s capture of complex linear relationships among sensor features, thereby enhancing its predictive performance.
Table 9 shows that our method achieves RMSE values of 4.98, 8.33, 4.24, and 5.76 for Units 11, 14, 15, and the WT test set on the N-CMAPSS dataset, with corresponding Score values of 3545.67, 1281.17, 1381.75, and 6687.09. Compared with the second-best method, our model improves the RMSE metric by 2.68%, 1.39%, and 1.69% on Units 11, 15, and WT, respectively, and achieves Score improvements of 17.25%, 24.06%, 24.39%, and 22.64% on Units 11, 14, 15, and WT, respectively. These results suggest that our method offers a consistent performance advantage across multiple test scenarios. The improvements in both RMSE and Score demonstrate the model’s effectiveness in learning degradation trends and capturing key temporal-spatial features relevant to RUL prediction.
To visually demonstrate the predictive capability of the proposed method on the C-MAPSS dataset, we compared the actual RUL and predicted RUL of selected engines through visualization (as shown in Fig. 14),and further a typical engine prediction result is selected in each dataset for further demonstration (as shown in Fig. 15) . It is evident that, with the exception of minor deviations at specific time points, the predicted curves demonstrate a high degree of alignment with the actual RUL curves in the majority of cases. This finding suggests that the proposed method demonstrates a high degree of accuracy and stability in engine RUL prediction tasks.

Remaining useful life prediction on the C-MAPSS dataset.

Partial engine prediction results in four subsets of C-mapss.
In addition, due to the large number of samples in the N-CMAPSS test datasets, we randomly selected 150 samples from unit11, 14 ,15 and WT for visualization to assess the effectiveness of the proposed model in the RUL prediction task. As illustrated in Fig. 16), the predicted RUL values closely follow the ground truth across most time steps, indicating that the model is capable of accurately capturing the degradation trend.

Partial engine prediction results in four subsets of N-Cmapss.
The ablation experiment
In this section, the effectiveness of the proposed method is validated and the generalizability of the MSCDIM module within other typical approaches is further evaluated through the design of four sets of ablation experiments as follows:
-
Baseline TCN Model: A standard TCN model is used as the baseline for comparison.
-
AD-TCN: A TCN model incorporating the dynamic adaptive dilation factor, designed to evaluate the effectiveness of the adaptive factor in temporal modeling tasks.
-
TCN-M: A model that integrates the MSCDIM module into the baseline TCN model to validate the effectiveness of the module in feature extraction and fusion.
-
AD-TCN-M: A model that integrates the MSCDIM module into the AD-TCN model, representing the complete architecture of the proposed method.
As demonstrated in Table 10, the incorporation of the dynamic adaptive dilation factor into the baseline TCN model resulted in a reduction of RMSE by 4.54%, 12.75%, 11.85%, and 12.53% across the four subsets, with an average improvement of 10.42%. A similar enhancement was observed in the Score metric, which demonstrated improvements of 10.64%, 38.22%, 23.05%, and 48.05%, with an average improvement of 29.99%. These results suggest that incorporating the dynamic adaptive dilation factor enables the model to adjust its focus on different time steps adaptively, effectively capturing both long-term and short-term dependencies in the data. Furthermore, the incorporation of the MSCDIM module into the baseline TCN model resulted in RMSE improvements of 2.37%, 10.37%, 8.88%, and 15.46% across the four subsets, with an average improvement of 9.27%. For the Score metric, the improvements were 13.83%, 45.78%, 17.89%, and 46.64%, with an average improvement of 29.99%. And the incorporation of the MSCDIM module into the AD-TCN model resulted in an enhancement of RMSE by 4.86%, 7.02%, 7.26%, and 23.68% across the subsets, with an average improvement of 10.70%. A similar trend was observed in the Score metric, which exhibited enhancements of 16.23%, 18.29%, 23.02%, and 65.44%, yielding an average improvement of 30.74%. These results demonstrate that the MSCDIM module effectively suppresses redundant information and integrates features in multi-scale cross-dimensional interactions. In addition, the module demonstrated superior performance on the more complex FD002 and FD004 datasets, indicating its strong applicability to complex time-series data modelling tasks.
Besides, the Table 11 reports the ablation study results on the N-CMAPSS dataset. When the baseline TCN is enhanced with an adaptive dilation factor ,the RMSE improvements of 7.36%, 2.61%, 10.86%, and 5.62% are observed for Units 11, 14, 15, and the WT test set, respectively, along with Score improvements of 10.65%, 5.06%, 17.83%, and 10.03% . Further integrating the MSCDIM module into the TCN yields additional RMSE improvements of 10.13%, 30.15%, 14.10%, and 20.44% and Score enhancements of 13.29%, 49.66%, 16.15%, and 27.38%. Overall, our complete method surpasses the baseline TCN by achieving RMSE improvements of 12.16%, 45.69%, 26.79%, and 24.12% and Score enhancements of 18.72%, 66.38%, 33.87%, and 34.83% on Units 11, 14, 15, and WT, respectively. These results suggest that both the adaptive dilation factor and the MSCDIM module contribute to improved performance, demonstrating the generality and effectiveness of our approach for RUL prediction.
To further explore the generalizability of the proposed MSCDIM module, we integrated it into widely used models in the field and conducted experimental validation. The results are as follows:
-
CNN-GRU16: A multi-dimensional feature fusion network that combines Convolutional Neural Networks and Gated Recurrent Units.
-
DAMCNN41:A Deep Attention Mechanism Convolutional Neural Network designed to capture long-term dependencies in time series data.
-
IMDSSN23:An Integrated Multi-head Dual Sparse Self-Attention Network (IMDSSN) based on an improved Transformer.
-
MLP42:A deep network architecture for multidimensional feature extraction that can be used for time series data.
-
Dual-Mixer31:A dual-path feature extraction network that leverages the MLP-Mixer framework for parallel temporal and feature dimension interaction and extraction.
Where, \(-M\) is the model after adding the MSCDIM module. And \(Improvement\) is the model enhancement after adding the MSCDIM module.
As shown in Table 12, the implementation of the MSCDIM module in five widely utilised models within the field resulted in an average enhancement of 9.97% in RMSE and 23.85% in Score. And a subsequent analysis of the performance on the four subsets reveals that the RMSE improved by an average of 7.39%, 20.47%, 5.63%, and 6.39%, while the Score improved by 10.27%, 33.70%, 22.13%, and 29.29%, respectively. These improvement results indicate that the MSCDIM module enhances the ability to capture multi-dimensional feature information and perform dynamic feature fusion. Particularly in scenarios with higher data complexity, the significant improvement in the Score metric further demonstrates the module’s advantages in suppressing redundant information and enhancing the expression of key features through its multi-scale and cross-dimensional interaction mechanism. Consequently, the MSCDIM module demonstrates considerable applicability and potential for RUL prediction tasks based on the C-MAPSS dataset.
Conclusion
In this paper, a Multi-Scale Cross-Dimension Interaction Approach with Adaptive Dilated TCN (AD-TCN-MSCDIM) for RUL prediction is proposed. The integration of a dynamic adaptive dilation factor into the traditional TCN architecture, in conjunction with the construction of a serial AD-TCN framework, facilitates the incorporation of the MSCDIM module. This integration enables the model to dynamically adjust its receptive field based on the complex temporal data characteristics, thereby focusing on key features and suppressing the impact of redundant information on the model’s predictive performance. And an extensive series of tests were conducted on the widely utilised C-MAPSS dataset and N-CMPASS dataset in the domain of RUL prediction. The findings demonstrate the efficacy of the proposed method in surpassing advanced approaches in the RUL prediction task. This conclusion was further validated through a series of ablation experiments, which demonstrated the efficacy of the dynamic adaptive dilation factor on TCN. The experiments also confirmed the versatility and effectiveness of the MSCDIM module.
Nevertheless, the model exhibits certain limitations. The current configuration, though effective, incurs relatively high computational costs. Consequently, subsequent endeavours will focus on the optimisation of the model while preserving its predictive accuracy, thereby enhancing its adaptability to varied operational settings. Furthermore, the exploration of the transferability of the algorithm to other industrial domains, such as the prediction of key components in rice milling equipment, is planned. This will enhance the model’s generalizability and expand its potential applications.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Wang, L., Zhu, Z. & Zhao, X. Dynamic predictive maintenance strategy for system remaining useful life prediction via deep learning ensemble method. Reliab. Eng. Syst. Safety 245, 110012 (2024).
Chen, L. et al. Remaining useful life prediction of milling cutters based on long-term data sequence and parallel fully convolutional feature learning. Journal of Intelligent Manufacturing 1–23 (2024).
Liu, X. et al. Optimized online remaining useful life prediction for nuclear circulating water pump considering time-varying degradation mechanism. IEEE Transactions on Industrial Informatics (2024).
Ma, L., Tian, J., Zhang, T., Guo, Q. & Hu, C. Accurate and efficient remaining useful life prediction of batteries enabled by physics-informed machine learning. J. Energy Chem. 91, 512–521 (2024).
Zhong, K. et al. Discriminant analysis-guided alignment network for multi-machine fault collaborative learning and diagnosis. IEEE Transactions on Instrumentation and Measurement (2024).
Fu, Y., Ding, J. & Xu, X. Shareability-exclusivity collaborative representation and its application for distributed process monitoring. IEEE Transactions on Instrumentation and Measurement (2024).
Bao, X. et al. Joint estimation of state-of-charge and state-of-energy of lithium-ion batteries at different ambient temperatures based on domain adaptation and unscented kalman filter. Electric Power Syst. Res. 231, 110284 (2024).
Li, D., Liu, X. & Cheng, Z. The co-estimation of states for lithium-ion batteries based on segment data. J. Energy Storage 62, 106787 (2023).
Patel, N., Rai, R. N. & Sahu, P. K. Effective rul prediction of the milling tool based on shannon entropy feature selection method and squared exponential-gaussian process regression model. Int. J. Adv. Manufact. Technol. 136, 693–715 (2025).
Boujamza, A. & Elhaq, S. L. Optimizing remaining useful life predictions for aircraft engines: A dilated recurrent neural network approach. IFAC-PapersOnLine 58, 811–816 (2024).
Zhang, Z. et al. A novel local enhanced channel self-attention based on transformer for industrial remaining useful life prediction. Eng. Appl. Artif. Intell. 141, 109815 (2025).
Li, X., Zhang, W., Ding, Y., Cai, J. & Yan, X. Rolling bearing degradation stage division and rul prediction based on recursive exponential slow feature analysis and bi-lstm model. Reliab. Eng. Syst. Safety 259, 110923 (2025).
Sun, S., Wang, J., Xiao, Y., Peng, J. & Zhou, X. Few-shot rul prediction for engines based on cnn-gru model. Sci. Rep. 14, 16041 (2024).
Guo, J., Lei, S. & Du, B. Mht: A multiscale hourglass-transformer for remaining useful life prediction of aircraft engine. Eng. Appl. Artif. Intell. 128, 107519 (2024).
Chen, W., Liu, C., Chen, Q. & Wu, P. Multi-scale memory-enhanced method for predicting the remaining useful life of aircraft engines. Neural Comput. Appl. 35, 2225–2241 (2023).
Zhang, J. et al. A parallel hybrid neural network with integration of spatial and temporal features for remaining useful life prediction in prognostics. IEEE Trans. Instrum. Meas. 72, 1–12 (2022).
Liang, P., Yu, Z., Wang, B., Xu, X. & Tian, J. Fault transfer diagnosis of rolling bearings across multiple working conditions via subdomain adaptation and improved vision transformer network. Adv. Eng. Inform. 57, 102075 (2023).
Zhang, Q., Liu, Q. & Ye, Q. An attention-based temporal convolutional network method for predicting remaining useful life of aero-engine. Eng. Appl. Artif. Intell. 127, 107241 (2024).
Lin, L. et al. Channel attention & temporal attention based temporal convolutional network: A dual attention framework for remaining useful life prediction of the aircraft engines. Adv. Eng. Inform. 60, 102372 (2024).
Jiang, G., Duan, Z., Zhao, Q., Li, D. & Luan, Y. Remaining useful life prediction of rolling bearings based on tcn-msa. Meas. Sci. Technol. 35, 025125 (2023).
Tang, Y., Liu, R., Li, C. & Lei, N. Remaining useful life prediction of rolling bearings based on time convolutional network and transformer in parallel. Meas. Sci. Technol. 35, 126102 (2024).
Li, H., Zhang, Z., Li, T. & Si, X. A review on physics-informed data-driven remaining useful life prediction: Challenges and opportunities. Mech. Syst. Signal Process. 209, 111120 (2024).
Zhang, J., Li, X., Tian, J., Luo, H. & Yin, S. An integrated multi-head dual sparse self-attention network for remaining useful life prediction. Reliab. Eng. Syst. Safety 233, 109096 (2023).
Keshun, Y., Guangqi, Q. & Yingkui, G. A 3d attention-enhanced hybrid neural network for turbofan engine remaining life prediction using cnn and bilstm models. IEEE Sensors Journal (2023).
Hu, G. et al. Remaining useful life prediction of mechanical equipment based on time-series auto-correlation decomposition and cnn. Meas. Sci. Technol. 35, 105104 (2024).
Chao, M. A., Kulkarni, C. S., Goebel, K. & Fink, O. Aircraft engine run-to-failure dataset under real flight conditions for prognostics and diagnostics. Data (2021).
Zhou, M., Li, Y., Cao, Y., Ma, X. & Xu, Z. Physics-informed spatio-temporal hybrid neural networks for predicting remaining useful life in aircraft engine. Reliab. Eng. Syst. Safety 256, 110685 (2025).
Zhao, C., Shi, H., Huang, X. & Zhang, Y. A multiple conditions dual inputs attention network remaining useful life prediction method. Eng. Appl. Artif. Intell. 133, 108160 (2024).
Fu, S. et al. Mca-dtcn: A novel dual-task temporal convolutional network with multi-channel attention for first prediction time detection and remaining useful life prediction. Reliab. Eng. Syst. Safety 241, 109696 (2024).
Zhang, Z., Song, W., Li, Q. & Gao, H. Multiscale global and local self-attention-based network for remaining useful life prediction. Meas. Sci. Technol. 34, 125154 (2023).
Fu, E., Hu, Y., Peng, K. & Chu, Y. Supervised contrastive learning based dual-mixer model for remaining useful life prediction. Reliab. Eng. Syst. Safety 251, 110398 (2024).
Zhao, K., Jia, Z., Jia, F. & Shao, H. Multi-scale integrated deep self-attention network for predicting remaining useful life of aero-engine. Eng. Appl. Artif. Intell. 120, 105860 (2023).
Zeng, M., Wu, F. & Cheng, Y. Remaining useful life prediction via spatio-temporal channels and transformer. IEEE Sensors Journal (2023).
Zhu, J., Jiang, Q., Shen, Y., Xu, F. & Zhu, Q. Res-hsa: Residual hybrid network with self-attention mechanism for rul prediction of rotating machinery. Eng. Appl. Artif. Intell. 124, 106491 (2023).
Lin, R., Wang, H., Xiong, M., Hou, Z. & Che, C. Attention-based gate recurrent unit for remaining useful life prediction in prognostics. Appl. Soft Comput. 143, 110419 (2023).
Xu, Z., Zhang, Y. & Miao, Q. An attention-based multi-scale temporal convolutional network for remaining useful life prediction. Reliability Engineering & System Safety 110288 (2024).
Kim, G., Choi, J. G. & Lim, S. Using transformer and a reweighting technique to develop a remaining useful life estimation method for turbofan engines. Eng. Appl. Artif. Intell. 133, 108475 (2024).
Keshun, Y., Guangqi, Q. & Yingkui, G. Optimizing prior distribution parameters for probabilistic prediction of remaining useful life using deep learning. Reliab. Eng. Syst. Safety 242, 109793 (2024).
Wang, L., Cao, H., Ye, Z., Xu, H. & Yan, J. Dvgtformer: A dual-view graph transformer to fuse multi-sensor signals for remaining useful life prediction. Mech. Syst. Signal Process. 207, 110935 (2024).
Wang, Y. et al. Local–global correlation fusion-based graph neural network for remaining useful life prediction. IEEE Transactions on Neural Networks and Learning Systems (2023).
Jiang, F. et al. Dual-attention-based multiscale convolutional neural network with stage division for remaining useful life prediction of rolling bearings. IEEE Trans. Instrum. Meas. 71, 1–10 (2022).
Tolstikhin, I. O. et al. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural. Inf. Process. Syst. 34, 24261–24272 (2021).
Acknowledgements
The authors would like to thank the National Natural Science Foundation of China (No. 32472000) for providing support for this paper.
Author information
Authors and Affiliations
Contributions
Conceptualization, Zhe Lu.; methodology, Zhe Lu.; validation, Changyu Fu, Jiang Bai.; formal analysis, Changye Fu, Junbao Wu.; data curation, Liang Xu.; writing—original draft preparation, Zhe Lu.; writing—review and editing, Siye Jia.; visualization, Li Zelong.; project administration and funding acquisition Bing Li.; All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflicts of Interest
The authors declare no conflicts of interest.
Ethical approval
Not applicable.
institutional review
Not applicable.
Informed consent
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Lu, Z., Li, B., Fu, C. et al. A multi-scale cross-dimension interaction approach with adaptive dilated TCN for RUL prediction. Sci Rep 15, 19229 (2025). https://doi.org/10.1038/s41598-025-00572-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-00572-8
