
Abstract
Conventional image formats have limited information conveyance, while Hyperspectral Imaging (HSI) offers a broader representation through continuous spectral bands, capturing hundreds of spectral features. However, this abundance leads to redundant information, posing a computational challenge for deep learning models. Thus, models must effectively extract indicative features. HSI’s non-linear nature, influenced by environmental factors, necessitates both linear and non-linear modeling techniques for feature extraction. While PCA and ICA, being linear methods, may overlook complex patterns, Autoencoders (AE) can capture and represent non-linear features. Yet, AEs can be biased by unbalanced datasets, emphasizing majority class features and neglecting minority class characteristics, highlighting the need for careful dataset preparation. To address this, the Dual-Path AE (D-Path-AE) model has been proposed, which enhances non-linear feature acquisition through concurrent encoding pathways. This model also employs a down-sampling strategy to reduce bias towards majority classes. The study compared the efficacy of dimensionality reduction using the Naïve Autoencoder (Naïve AE) and D-Path-AE. Classification capabilities were assessed using Decision Tree, Support Vector Machine, and K-Nearest Neighbors (KNN) classifiers on datasets from Pavia Center, Salinas, and Kennedy Space Center. Results demonstrate that the D-Path-AE outperforms both linear dimensionality reduction models and Naïve AE, achieving an Overall Accuracy of up to 98.31% on the Pavia Center dataset using the KNN classifier, indicating superior classification capabilities.
Similar content being viewed by others

Introduction
Hyperspectral Imaging (HSI) is widely used in remote sensing and medical images. These are the images that measure continuous spectral bands. They contain dozens to hundreds of spectral bands. A single pixel of the image contains a vector of values varying from dozen to hundreds compared to conventional RGB images where only three channel values are stored to represent a single pixel. HSI images thus contain rich features and have better discriminative ability.
HSI is a powerful remote sensing technique that captures detailed spectral information across a wide range of wavelengths. This rich spectral data enables precise analysis and identification of materials, making HSI valuable across various domains. Feng et al.1 introduces a bidirectional cross-attention transformer architecture to address domain shifts in few-shot hyperspectral target detection, leveraging spectral-spatial feature alignment to improve cross-domain adaptability. Duan et al.2 proposes a multiexposure fusion approach that integrates spatial-spectral information to effectively remove shadows while preserving image details in hyperspectral remote sensing data.3 presents a hybrid model that integrates convolutional neural networks with vision transformers to effectively capture both spatial and spectral features, achieving efficient and accurate hyperspectral change detection.4 introduces a novel deep learning architecture that leverages the Kolmogorov-Arnold representation theorem to efficiently capture both spatial and spectral features in hyperspectral data, enabling accurate change detection with significantly fewer parameters, reduced computational load, and lower memory requirements compared to traditional deep learning models. Xi et al.5 propose a hybrid architecture combining CNNs and transformers to efficiently extract local and global spectral-spatial features for Mars HSI classification, enhanced by graph contrastive learning to improve inter-class discrimination.
Land-cover classification is a key application of HSI, enabling a detailed analysis of surface materials based on their spectral signatures. By capturing rich spectral information, HSI can differentiate between vegetation, soil, water bodies, and urban structures. When combined with LiDAR, which provides elevation and structural data, the accuracy of land-cover mapping improves significantly. However, integrating these two modalities remains complex due to their different data properties. Recent methods like IamCSC6 and \({\text{HI}}^{2}\, {\text{D}}^{2}\)FNet7 enhance the HSI-LiDAR fusion, improving feature extraction and classification performance for more precise land-cover identification. On the other hand, hyperspectral images have high dimensionality and are hard to process using deep learning models. Furthermore, HSI often contain redundant information because their spectral bands are continuous, meaning that adjacent bands capture highly similar data. This redundancy arises because the spectral reflectance of materials changes gradually rather than abruptly, leading to overlapping information across neighboring bands. Keeping in view these two problems, applying deep models directly may not be a good choice for HSI data. The dimensionality reduction models are normally applied to these HSI before processing using deep learning models. These models can learn a subset of input features that best describe the original data. Specifically in HSI, the reduced features are the subset of original spectral bands that best describe their parent HSI data that is high in dimensions. Machine learning techniques have better generalization for unseen data. Learning effective features using a machine learning model is a challenging task. Machine learning models have the ability to learn features automatically. In machine learning based approaches, deep learning based models have proven accuracy for different image analysis problems. Deep learning models have the ability to learn complex features from training data. These models usually return better accuracy for image analysis as compared to typical machine learning models. Conventionally linear dimension reduction techniques were applied for this purpose. Principal Component Analysis (PCA) proposed by Maćkiewicz et al.8 is one of the most famous and easy methods for reducing dimensionality. Wadstromer et al.9 used PCA for reducing the dimensionality of remote sensing HSI scenes. Linear models are not a good choice for HSI as the spectral response of a material may not always be linear as the response contains different other factors like light, moist, and other atmospheric factors. Therefore the spectral responses of these objects will not be a linear sequence of values. In other words, the wavelength will not be in linear form. Therefore linear models can not capture these underlying non-linear patterns thus non-linear models should be applied for processing HSI.
With autoencoders, we use neural networks to automate the process of representation learning in unsupervised learning scenarios. AE is a neural network architecture that places a bottleneck on the network and generates a compressed knowledge representation of the original input. If the input features were independent of each other, it would be very difficult to compress and then reconstruct them. If there is a bottleneck in the network, the input can be forced through it by learning a structure in the data, such as correlations between input attributes. The typical AE model is composed of the encoder, latent space, and decoder elements. Using the original data as a starting point, the encoder module learns the compressed information as a latent space module. Using the input from latent space, the decoder module reconstructs the original input data. In this instance, the encoder module uses the spectral responses of the objects as input, the latent space holds the compressed low-dimension features, and the decoder module reconstructs the compressed features using the latent space as input. This paper mainly focuses on unsupervised, nonlinear dimensionality reduction for HSI using Autoencoder (AE).
In the literature, both spectral and spatial features are used, but our proposed work particularly focuses on spectral features due to their simplicity. Most of the studies have focused on reconstruction error but the main focus should be the classification ability. The use of AE with imbalance class problems is not well studied, despite its critical importance. Following these research gaps, our main contributions are :
-
1.
Using Dual-Path Dense Model to HSI to help enhance the feature learning capability of AE
-
2.
Using balanced HSI data to train AE thus making AE learn different classes equally.
Section “Literature survey” of the paper presents a brief overview of the literature. Section “Methodology” gives the details about methodology, and Section “Dataset” provides a detailed overview of three datasets used in experiments. Section “Results and experiments” presents some analysis of the experiment and evaluation using different parameters. Section “Conclusion” concludes the paper and presents future work.
Literature survey
In literature, dimensionality reduction has been carried out using different approaches. These models can be categorized as linear or non-linear transformations. PCA, Independent Component Analysis (ICA)10, and Linear Discriminant Analysis (LDA)11 are a few common dimensionality reduction models. PCA extracts components by computing the covariance matrix and then finds the direction with maximum variation. PCA tries to minimize the reconstruction error and maximize the variance. ICA reduces dimensions by eliminating noise features and only considering mutually independent features. The features are both linearly and non-linearly independent. LDA is a supervised classification model, used for dimensionality reduction as well. LDA maximizes the distance between means of different classes and minimizes the spread between each class. Linear transformation fails when complex non-linear transformation is required. Dimensionality reduction is not always limited to linear transformations; in many cases, the relationships within the data are highly non-linear. As a result, models that incorporate non-linear transformations become essential for effectively capturing complex structures and preserving meaningful patterns in the reduced representation. t-distributed Stochastic Neighbor Embedding (t-SNE)12, Locally Linear Embedding (LLE)13, and AE14 are some common non-linear transformation based models used for dimensionality reduction.
Particularly for HSI, Yand Zhang15 uses PCA and Nonparametric Feature Extraction (NWFE) for dimensionality reduction of HSI. Evgeny Myasnikov16 used Auto Associative Neural Network (AANN). In this paper, PCA is first applied to extract principal components, which are used to pretrain the encoder and decoder separately, and then the entire Autoassociative Neural Network (AANN) is fine-tuned using the original hyperspectral data to enhance reconstruction and classification performance.
AE is a type of neural network that is leveraged for representation learning. AE, similar to Locally Linear Embedding and t-SNE, utilize non-linear transformations to project high-dimensional data into a lower-dimensional space, capturing complex patterns and relationships that linear methods might miss. These models are trained using two modules encoder and a decoder. Between these two modules, a bottleneck layer, called latent space or code is used to force a compressed knowledge representation. The encoder is used as a dimensionality reduction model while the decoder is used as a generative model. Once the model is trained, only the encoder is used, and the decoder is trashed. The network is trained to minimize reconstruction error using optimization. AE has a vast application to HSI domain, specifically for feature learning and dimensionality reduction. Hanachi et al.17 proposed a graph-based AE model that preserves both spatial and spectral features. A deep AE model that learns the latent features is constructed. Zhang et al.18 used dual graph-based AE that learns discriminative features by measuring pixel pair and band pair similarity and constructing geometric connectivity. Hassanzadeh et al.19 used a contractive AE based model to learn multi-manifold structure. Wang et al.20 used a latent representation-based feature selection and implemented AE for this purpose. Cao et al.21 used transformer based masked AE for HSI classification. Ranjan et al.22 used 3D-Convolutional AE for HSI classification that used an embedded Siamese network. Ashley Babjac23 compared AE with PCA, Lasso, and t-SNE using the random forest as a classifier for RGB or Grayscale images. They concluded that AE outperforms other methods.
Particularly for dimensionality reduction, Huang et al.24 used Denoising AE (DAE)25 for image reconstruction and reduced the image to a bottleneck with reduced dimensionality. They validated their results on multiple face recognition datasets. KL divergence is used as a sparsity constraint on hidden layers when the number of hidden neurons is large. KL divergence helps learn only meaningful features. Manakov et al.26 used Convolutional AE (CAE)25 to learn the bottleneck features. They used CAE for the reconstruction of the Pokemon image dataset. They explored how the bottleneck layer’s dimensions affected generalization.
Wadstromer et al.27 used SAE to reduce the dimensionality of HSI. They used mean square error. They performed their analysis on natural scene images. Stephen et al.28 used Variational Autoencoder (VAE) to the galaxy spectra and reduce the dimensionality. They compared their results with PCA and found that spectra were well with only six latent parameters, outperforming PCA with the same number of components. Pandey et al.29 used attention-based convolutional AE that focuses more on important wavelengths. Pandey et al.30 used Spectral Spatial features of HSI and used a Residual blocks-based AE and used SVM as a classifier. Pandey et al.31 used a bi-directional RNN model that helps tackle the vanishing gradient problem in the Naïve RNN model. Pandey et al.32 proposed a feedback-based self-updating model that is based on 1D convolutional AE. Haut33 used Extreme Learning Machine based Neural networks to reduce the dimensionality of HSI. Patel34 used an AE with the CNN model that reduces the similarity and does classification. Kulkarni et al.35 used AE for dimensionality reduction and then applied a K-Means clustering algorithm to group similar spectra from the agriculture domain. Fejjari et al.36 compared well-known linear and non-linear dimensionality reduction techniques and concluded that non-linear methods outperform both in terms of accuracy and speed output. Swain et al.37 used a hybrid CNN model for classification. They used three well-known linear models PCA, Kernal PCA, and fast ICA for reducing dimensionality.
There are some other applications of AE to HSI that leverage the feature learning capability of AE and improve classification without simply reducing the dimensionality. Wang et al.38 propose an AE based model for few-shot learning that project visual and semantic features of the HSI. Zerrouki et al.39 propose VAE based model to identify desertification regions from remote sensing scenes. Li et al.40 use sparse AE to learn mid-level features and classify remote sensing scenes. Zhang et al.41 uses stacked denoising AE while Lv et al.42 uses extreme learning machines for classification. Bai et al.43 used two-stage convolutional AE to classify HSI dataset. A summary of some key research related to our proposed model is given in Table 1
Based on the literature reviewed above, we conclude that there is vast research on the application of AE and its variation for feature learning in the HSI domain. Moreover, a lot of studies use any variation of Naïve AE that is incapable of picking up complex features. The issue of class inequality is not addressed in any of the research. By employing a Dual-Path neural network, we hope to improve AE model feature learning. We also conduct in-depth experiments where we compare and evaluate the classification accuracy of linear and non-linear dimensionality reduction methods. Our goal is to address the issue of class imbalance to improve accuracy overall.
Methodology
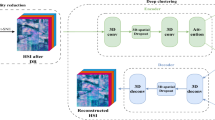
Our proposed model is based on parallel dual path AE that is used to reduce the dimensionality of the HSI spectral features. The encoder part of the AE is the addition of two different encoder paths that help better learn the complex features. The reduced spectral features are then evaluated for their classification ability. The abstract view of the model is shown in Fig. 1.

The abstract view of the proposed architecture.
The image illustrates an abstract representation of the proposed workflow for hyperspectral image classification. It begins with a 3D HSI cube, where spectral features are extracted to capture the detailed spectral information of each pixel. In the next step, downsampling is applied to balance the dataset by reducing redundancy and addressing class imbalances. The processed data is then fed into a dual-path AE model, which performs dimensionality reduction while retaining essential spectral characteristics. Finally, the reduced spectral features are used for classification, enabling efficient and accurate identification of different objects in the hyperspectral scene. The diagram visually encapsulates the systematic progression from raw hyperspectral data to refined classification results.
As a preprocessing step, we have used min-max normalization to transform all the feature values to the same scale. We use the standard min-max equation as given below:
We train a deep neural network in a non-linear fashion which is more suitable for the analysis of remote sensing scenes. We explicitly trained an AE model to learn the features of HSI. Apart from normalization layers, the AE we used has two layers, encoder and decoder. The encoder block comprises the concatenation of two different dense layers followed by batch normalization layers networks. Both encoder and decoder modules comprise one dense layer with ReLU activation and one batch normalization layer. Given an n-dimensional input \({\mathbf{x}}\), where \({\mathbf{x}} = (x_1, \dots , x_n)\), the weighted sum of each dimension of the \(x_i\) and its corresponding weights \(w_i\) is calculated as:
The ReLU function is applied to learn complex non-linear features of the spectra. The ReLU function is defined as:
ReLU function involves a very basic mathematics computation that is easily computed. ReLU is a sparse activation function when the negative inputs. The more the inputs are negative, the more it is sparse. ReLU non-linearity function has improved efficiency due to its simplistic and sparse nature. It further helps the vanishing gradient problem to an extent because negative weights are changed into 0. Logistic Activation also known as sigmoid activation is straightforward and the base of many AE equations. The sigmoid is a differentiable monotonically increasing function that takes any real-valued number and maps it to [0, 1]. For large negative numbers, it asymptotes to 0 while for large positive numbers, it asymptotes to 1. It is defined as
The sigmoid function is perhaps the most widely used non-linearity function for neural networks due to its monotonic nature and accordingly, the firing rate of neurons given its potential. When the potential is low, it fires the neuron with less probability and vice versa. Another property is that its derivative is very fast to the computer once solved analytically. An optimization algorithm can use this data to iteratively adjust the weights in order to reduce the error.
Training a model without adding normalization layers can give unexpected results. We take the weights randomly and then the weights are updated, sometimes the output from one or more layers may be exceptionally large, which will lead to an exploding gradient problem and the model will not learn anything useful. Furthermore, the input features will not be at the same scale, resulting in a slow convergence time. Batch normalization is a technique that helps the model learn useful information without being overly cautious about initialization and regularization techniques. Generally, in Normalization for a given input x over a minibatch of size m, each sample \(x_i\) contains m elements, i.e. the length of flatten \(x_i\) is m, by applying transformation of your inputs using some learned parameters \(\beta\) and \(\gamma\), the outputs could be expressed as:
In a multilayer neural network, each \(k-1\)th layer works as input to \(k\)th layer. If this input changes drastically, the network will again run into a problem. We pass every output of a layer into a non-linear activation function that again can give such type of output. We compel the output to have a zero mean and unit variance to limit the output of a layer. In batch normalization, each feature across the minibatch is transformed by subtracting their respective mean and then dividing by standard deviation.
For the given AE model, after the input of \({\mathbf{x}}\), i.e., the spectral feature of our dataset, returns a vector value \(\hat{{\mathbf{x}}}\). Where \(\hat{{\mathbf{x}}}\) is the reconstructed \({\mathbf{x}}\). Given the correct output \({\mathbf{x}}\) the error, or cost, or the MSE is computed as :
For the optimization of the model, the input and error must be taken into account while modifying the network’s weights (\(E = \hat{{\mathbf{x}}} - x\) in the Perceptron). To reduce some inaccuracies, the learning technique modifies the weights as follows:
where \(\eta\) is referred to as the learning rate that is a scaling factor and scales the steps of the optimizer. For optimization, an optimizer function is needed that iteratively reduces the error and learns the weights correctly. For this purpose we used Adam optimizer.
Undersampling majority classes
The motivation behind solving the class imbalance problem in deep learning stems from the need to address the skewed distribution of classes within a dataset, which can significantly impact the performance and reliability of machine learning models. In scenarios where one class significantly outnumbers the other, the model may become biased towards the majority class, leading to poor generalization and inaccurate predictions for the minority class. By tackling class imbalance, researchers aim to improve the model’s ability to learn from all classes equally, enhance its predictive accuracy, and prevent it from being dominated by the majority class.
In the context of the AE applied to HSI, addressing the class imbalance problem is crucial because imbalance classes will make the AE learn only the specific distribution of spectra and ignore the other ones. To ensure fair representation of all classes in the dataset, enhance model performance, and enable accurate predictions across all classes, class balancing is unavoidable. We use a down-sampling technique to carry out this process. In down-sampling, we first find the smallest class with a lesser number of spectra say \({{C}}_{\text {small}}\), then we down-sample the rest of the class, i.e., majority classes by selecting only \({{C}}_{\text {small}}\) number of samples. The resultant dataset has an equal number of samples for each class. We used this balanced dataset for training the AE model and then predicting the overall scene using the trained AE. Thus training on reduced and balanced dataset is not only effective but also efficient because the new dataset is enormously small in size as compared to the original dataset. This procedure is shown in Fig. 2.

Down-sampling of the original dataset.
Dual-path encoding
In our proposed model, we use a parallel Dual-Path encoder that uses two sub-encoders and concatenates their result. In this model, the features are learned by routing inputs through two parallel paths within layers. The motivation behind this strategy is to enhance the learning capability of AE model by learning features from the data using two different models. After dense and batch layers, a concatenate layer is used that performs point-wise concatenation as under:
Where \(s_i\) and \(h_j\) are the output vectors of learned encoders modules and have the same number of dimensions. This process is illustrated in Fig. 3

Structure of AE with Dual Path Encoding.
The layer detail of D-Path-AE model is given in Table 2 and the overall architecture of the proposed model is given in Fig. 4 and the overall procedure is given in Algorithm 1.

The architecture of the D-Path-AE model: Spectral features are extracted from the HSI cube and the dataset is converted to a balanced dataset through down-sampling. The model is divided into two parts, Encoder and Decoder. The encoder model takes input and compresses the input to reduced dimensions where the user specifies the number of dimensions. The final layer of the encoder is given as latent space or encoding dimension. The input from the encoding dimension is passed to the decoder module that takes compressed spectra and learns to regenerate the original spectra by reducing Mean Squared Error as the loss function. In each layer, a dense layer along with a Normalization and a ReLU non-linearity function is used.

D-Path-AE
Dataset
HSI data is three-dimensional data containing spatial and spectral features and is stored in a 3-D data cube (x,y,z), where x,y represents the spatial coordinates while z represents the spectral details. z is a vector that measures the spectral bands at a specific pixel x,y. We have used three publicly available datasets discussed as under:
Pavia center dataset
The dataset covers the urban area of Pavia, Italy. The scene is captured by the ROSIS-03 (Reflective Optics System Imaging Spectrometer) sensor during a flight campaign over Pavia, Northern Italy. The dataset typically includes images with about 102 spectral bands. spectral range covers from approximately 430 nm to 860 nm. The spatial resolution of the dataset is approximately 1.3 meters per pixel. Table 3 shows the details of the samples and classes in this dataset. The ground truth and RGB scene of the dataset are shown in Fig. 8
Kennedy Space Center (KSC) dataset
The KSC dataset covers the Kennedy Space Center in Florida, USA. The scene in the KSC dataset is captured Airborne Visible/Infrared Imaging Spectrometer (AVIRIS). The dataset we use for our experiments consists of 176 spectral bands. Table 4 shows the information on the number of classes and the samples for each class of interest. The ground truth and RGB scene of the dataset are shown in Fig. 10
Salinas dataset
Salinas scene was captured by an Airborn Visible over Salinas Valley of California. The dataset consists of 512 \(\times\) 217 spatial pixels, 204 spectral bands, and a resolution of 3.7 m a. The first 20 bands are due to the water absorption and are removed from the dataset. Table 5 shows the details of the number of samples for different classes of interest. The RGB scene and the ground truth of the scene consist of 16 classes that are shown in Fig. 9
Results and experiments
For evaluation, the dataset is converted to the balanced dataset and then the new dataset is divided into train and test sets. For the training set, we have used 90% of the total samples while 10% of the samples are used for the testing set. To measure the quality of the trained model, MSE is used as a loss function. MSE is a measure that computes the reconstruction loss, i.e., the error of original and reconstructed spectra. For optimization, the Adam optimizer is used. We have trained the model for 1000 epochs and checked the results for different encoding dimensions. After training the model, the encoder part is used to reduce the dimensionality of the original HSI scenes. We performed our experiments by reducing the dimensions up to roughly 25% of the original dimensions and for a fair comparison, we applied the same dimensions to PCA, ICA, Naïve AE, 3D ResAE30, and Dual-Path AE. We reduced the dimensions of Pavia Center dataset to 25 from 104, KSC 40 from 167, and Salinas 50 from 204.
We have used different machine learning classifiers to check the classification ability of the reduced data samples. In our study, we use three classifiers, Decision Tree, SVM, and K-Nearest Neighbours. To carry out a fair comparison, we have checked the classification ability of three types of spectral features; the original features, features with reduced dimensions through linear models, i.e., PCA and ICA, and lastly features with reduced dimensions through deep learning based AE. For deep learning based AE, we have used a Naïve AE, 3D ResAE, and then AE with routing of features over a parallel dual path encoder. We have used Cohen’s Kappa (\(\kappa\)) measure that computes the score by comparing actual and predicted classes and measuring the observed agreement. It is best used for imbalance class problems, as the datasets involved possess an imbalance nature, the (\(\kappa\)) is one of the good choices and is commonly used for HSI classification in literature. \(\kappa\) is calculated using the formula:
where \(p_o\) is the relative observed agreement ratio, \(p_e\) is the hypothetical probability of chance agreement. The value of \(\kappa\) indicates the level of agreement. \(\kappa = 1\) shows perfect agreement , \(\kappa = 0\), No agreement and \(\kappa < 0\), Less agreement than expected by chance. Another accuracy measure that we use in our experiments is Overall Accuracy (OA). The OA accuracy is the standard measure used in literature that computed the percentage of making correct decisions. The OA is calculated using the formula: The Overall Accuracy (OA) is calculated using the formula:
where \(N\) is the total number of classes, \(TP_i\) is the number of true positives for class \(i\) and the Total Number of Predictions is the sum of all true positives across all classes. The OA is expressed as a percentage and represents the proportion of correctly classified instances in the dataset.
Another accuracy measure we use in our experiments is Average Accuracy (AA) which computes the average of the per-class accuracy. Here the accuracy for each class is the ratio of true positives to the sum of true positives and false negatives for that class. The AA is calculated using the formula:
where \(N\) is the total number of classes, \(TP_i\) is the number of true positives for class \(i\). \(FN_i\) is the number of false negatives for class \(i\).
The results for three datasets are shown in Tables 6, 7 and 8.
Table 6 shows the classification results of Pavia Center dataset with different reduction models and the data with actual dimensions. We applied three classifiers, DT, SVM, and KNN as discussed earlier. From the table, it is shown that for Pavia Center dataset, AE based model outperforms linear models, PCA, and ICA, and even performs better than the data with actual dimensions. In AE particularly, D-Path-AE outperforms all the rest of the models in terms of (\(\kappa\)) and OA. In a balanced dataset, a high OA suggests that the model’s performance is consistently good across all classes, which is desirable. The AA is not highest for D-Path-AE but is high for ICA. This is because AA is too sensitive to classwise accuracy and is affected by individual class accuracy. Table 7 shows the classification results of the KSC dataset with models and classifiers as in Table 6. From the table, it is shown that again, D-Path-AE outperforms both linear models and the data with actual dimensions. Again, ICA returns good AA as Pavia Center in Table 6 discussed earlier. Table 8 shows the results of Salinas dataset in the same pattern. It is seen from the table that D-Path-AE has slightly low (\(\kappa\)) and OA accuracy as compared to actual data and linear models but returns the best AA among the rest of the models. This decline in (\(\kappa\)) and OA is due to the misclassification of the samples from classes 8 and 15 for all three classifiers. We can see this low accuracy score in Table 5 where the classwise score of each class is shown separately. It is further depicted in Fig. 5 where samples of class 8 are misclassified as class 15 and samples of class 15 are misclassified as class 8. This might be because of the higher similarity between the two classes. In other words, this is because of the insufficient representativeness of training data for classes 8 and 15 or due to the inherent difficulty in distinguishing these two classes. Table 5 further shows that 14 out of 16 classes have accuracy higher than 90% which is the reason why AA for the Salinas dataset is better than Pavia Center and KSC.
We further computed the class-wise scores for each dataset. Tables 9, 10, and 11 show the classification results for individual classes with the Kappa, OA, and AA measures for each dataset.
Run time analysis of D-Path-AE
We performed a computational efficiency analysis to compare the execution time of different feature extraction models. Table 12 shows the execution time for the four models, PCA, ICA, Naïve-AE, and D-Path-AE. All the training times are measured in seconds. From the table, we can say that linear models, especially PCA are quite faster than AE. We further see that PCA is efficient as compared to ICA. In AE models, we can see that our proposed model is faster than Naïve AE and also returns improved classification accuracy.
Sensitivity of D-Path-AE to noise
A sensitivity analysis was conducted to assess the robustness of the D-Path-AE model against noisy training conditions. In this analysis, Gaussian noise was deliberately added to the input features during the training phase, while testing was performed on clean, noise-free data. The classification accuracies obtained across different datasets are summarized in Table 13. The results illustrate the model’s ability to learn meaningful and robust latent representations, effectively filtering out irrelevant noise during the learning process. Despite being exposed to noisy data during training, the D-Path-AE maintains strong generalization capability and consistently achieves high classification accuracy across various datasets.
Layer wise performance analysis of D-Path-AE
A layer-wise performance analysis was carried out to investigate the influence of specific architectural components on the classification accuracy of the proposed model. The analysis focused on systematically adding or removing layers from the encoder and decoder modules to assess their individual and collective contributions. The results, summarized in Table 14, demonstrate that the optimal performance is achieved when the encoder comprises two parallel layers followed by a batch normalization layer, and the decoder includes a single layer. This configuration ensures an effective balance between feature extraction and reconstruction, leading to improved classification accuracy while preserving computational efficiency.
Visualizations
We further expand our results by adding confusion matrices for all three datasets that show the accuracy of decisions performed by classifiers on the reduction through D-Path-AE model. Figures 5, 6 and 7 shows the confusion matrix for all three datasets.

Confusion Matrix of the Validation Set after reducing dimensionality, classified with SVM classifier.

Confusion Matrix of the Validation Set after reducing dimensionality, classified with KNN classifier.

Confusion Matrix of the Validation Set after reducing dimensionality, classified with DT classifier.
For better illustrative presentation, the RGB scene, the ground truth, and the classification map generated by reduced spectral features and classified through the decision tree are shown in Figs. 8, 9 and 10.

PC Scene: (a) Shows the RGB image of PC using bands (80, 40, 20). (b) Shows the ground truth of the dataset. (c) Shows the classification map generated through the SVM classifier using D-Path-AE model. (d) Shows the classification map generated through the KNN classifier using D-Path-AE model. (e) Shows the classification map generated through the DT classifier using D-Path-AE model.

KSC Scene: (a) Shows the RGB image of KSC using bands (40, 20, 10). (b) Shows the ground truth of the dataset. (c) Shows the classification map generated through the SVM classifier using D-Path-AE model. (d) Shows the classification map generated through the KNN classifier using D-Path-AE model. (e) Shows the classification map generated through the DT classifier using D-Path-AE model.

Salinas Scene: (a) Shows the RGB image of Salinas using bands (29, 19, 9). (b) Shows the ground truth of the dataset. (c) Shows the classification map generated through the SVM classifier using D-Path-AE model. (d) Shows the classification map generated through the KNN classifier using D-Path-AE model. (e) Shows the classification map generated through the DT classifier using D-Path-AE model.
t-SNE visualization of the balanced training set
We further evaluated the effectiveness of the model using t-SNE visualization. The features of the datasets were first learned using the AE, and subsequently, both the original and encoded features were visualized to analyze the feature distribution and structure. Figure 11 shows the tSNE of the balanced trained set before and after encoding for all the datasets. For PC and SA, the t-SNE visualizations of the original features and the encoded features appear almost identical, which indicates the effectiveness of the feature encoding process. This similarity suggests that the AE has successfully learned the essential and meaningful structure of the data while reducing its dimensionality. The preserved cluster patterns and local neighborhood relationships in both t-SNE plots demonstrate that the AE has retained the discriminative information required for classification, despite compressing the feature space. Additionally, this behavior implies that the AE has effectively filtered out noise and redundant information without compromising the underlying data distribution. As a result, the reduced features offer a compact, noise-free, and informative representation of the data, which is beneficial for improving model efficiency, reducing computational complexity, and enhancing generalization in subsequent classification tasks.

t-SNE visualization of the balanced training set before and after feature encoding: The visualizations illustrate that the distribution and clustering patterns of the original and reduced features are nearly identical, indicating that the AE effectively preserves the essential data structure while reducing dimensionality. This reflects the AE’s ability to retain meaningful information and remove redundancy without compromising the class-separating characteristics of the data.
Computational cost
Training the AE model requires significant computational resources due to the complexity of capturing meaningful representations in high-dimensional feature space. The high training time can be attributed to the model architecture and the depth of feature extraction required. In contrast, the proposed D-Path model is lightweight, efficient, and capable of learning complex features effectively with lower computational overhead. All experiments were conducted on an NVIDIA Tesla T4 GPU with 12 GB VRAM and 16 GB of system RAM. The AE model required approximately 10 ms per epoch. This reduction in training time is primarily due to the down-sampling of the input data, as training was performed on a lightweight, balanced dataset comprising only the requisite number of samples per class. Classifier training based on the learned latent features took up to 120 s, depending on the dimensionality of the encoded space. Additionally, the use of the Adam optimizer contributed to faster convergence and computational efficiency.
Conclusion
HSI is widely used in remote sensing, capturing dozens to hundreds of continuous spectral bands per pixel, compared to the three channels in conventional RGB images. This results in better discriminative ability, but also leads to high dimensionality. To address this, dimensionality reduction techniques are applied before deep learning to select the most representative spectral bands. Deep learning models, especially AE, excel in learning complex features and providing accurate image analysis. AEs consist of an encoder, latent space, and decoder. The encoder compresses the spectral data into a lower-dimensional latent space, which the decoder then uses to reconstruct the original data, capturing essential patterns and correlations. In this work, we reduced the dimensionality of HSI using the AE model, which helps effectively preserve important information compared to linear models. In AE, a parallel dual path encoder is used to learn the features using two different paths. From the results, it is clear that the proposed model learns enhanced features and results in good classification ability. It is concluded that linear models, PCA, and ICA are efficient as compared to AE but AE despite taking greater training time, returns better accuracy. In scenarios with significant class imbalance, models may become biased towards the majority class, leading to poor generalization and inaccurate predictions for the minority class. Addressing this imbalance is crucial, especially in AEs applied to HSI, to ensure fair representation and improve model performance. We use down-sampling to balance classes, enhancing predictive accuracy across all classes. Experiments on three datasets confirmed this approach’s effectiveness, using MSE as the loss function and the Adam optimizer. We compared the classification ability of dimensionality-reduced data using PCA, ICA, Naïve AE, and Dual-Path AE, tested with Decision Tree, SVM, and K-Nearest Neighbours classifiers. Evaluation metrics included Kappa, The best overall accuracy of 98.31% was achieved on the Pavia Center dataset using the KNN classifier, which is approximately 2% higher than that of PCA. While the proposed model outperforms the Naïve AE in classification, a drawback is that AE and classifier models are not integrated. Future work aims to embed the AE model inside the classifier for more efficient and effective training.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Feng, S. et al. Transformer-based cross-domain few-shot learning for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 63, 1–16 (2025).
Duan, P., Hu, S., Kang, X. & Li, S. Shadow removal of hyperspectral remote sensing images with multiexposure fusion. IEEE Trans. Geosci. Remote Sens. 60, 1–11 (2022).
Shafique, A., Seydi, S. T., Alipour-Fard, T., Cao, G. & Yang, D. SSViT-HCD: A spatial-spectral convolutional vision transformer for hyperspectral change detection. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 16, 6487–6504 (2023).
Teymoor Seydi, S., Sadegh, M. & Chanussot, J. Kolmogorov–Arnold network for hyperspectral change detection. IEEE Trans. Geosci. Remote Sens. 63, 1–15 (2025).
Xi, B. et al. MCTGCL: Mixed CNN-transformer for mars hyperspectral image classification with graph contrastive learning. IEEE Trans. Geosci. Remote Sens. 63, 1–14 (2025).
Yu, W. et al. IamCSC: Intuitive assimilation modality driven crossmodal subspace clustering for land-cover identification and hyperspectral-LiDAR fusion. IEEE Trans. Geosci. Remote Sens. 63, 1–13 (2025).
Yu, W., Gao, L., Huang, H., Shen, Y. & Shen, G. HI2D2FNet: hyperspectral intrinsic image decomposition guided data fusion network for hyperspectral and LiDAR classification. IEEE Trans. Geosci. Remote Sens. 61, 1–15 (2023).
Maćkiewicz, A. & Ratajczak, W. Principal components analysis (PCA). Comput. Geosci. 19, 303–342 (1993).
Zhu, L., Chen, Y., Ghamisi, P. & Benediktsson, J. A. Generative adversarial networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 56, 5046–5063 (2018).
Stone, J. V. Independent component analysis: An introduction. Trends Cogn. Sci. 6, 59–64 (2002).
Tharwat, A., Gaber, T., Ibrahim, A. & Hassanien, A. E. Linear discriminant analysis: A detailed tutorial. AIC 30, 169–190 (2017).
Rogovschi, N., Kitazono, J., Grozavu, N., Omori, T. & Ozawa, S. t-Distributed stochastic neighbor embedding spectral clustering. In 2017 International Joint Conference on Neural Networks (IJCNN), pp. 1628–1632 (2017). https://doi.org/10.1109/IJCNN.2017.7966046.
Chen, J. & Liu, Y. Locally linear embedding: A survey. Artif. Intell. Rev. 36, 29–48 (2011).
Wang, Y., Yao, H. & Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 184, 232–242 (2016).
Zhang, Y., Sun, M., Hung, C.-C. & Jung, E. An empirical study on the effectiveness of hyperspectral image classification algorithms with dimensionality reduction. In: Proceedings of the 2011 ACM Symposium on Research in Applied Computation 187–191 (Association for Computing Machinery, 2011). https://doi.org/10.1145/2103380.2103419.
Myasnikov, E. Dimensionality reduction of hyperspectral images using autoassociative neural networks. In 2019 International Multi-Conference on Engineering, Computer and Information Sciences (SIBIRCON) 0591-0595 (2019). https://doi.org/10.1109/SIBIRCON48586.2019.8958408.
Hanachi, R., Sellami, A., Farah, I. R. & Mura, M. D. Semi-supervised classification of hyperspectral image through deep encoder-decoder and graph neural networks. In 2021 International Congress of Advanced Technology and Engineering (ICOTEN) 1–8 (2021). https://doi.org/10.1109/ICOTEN52080.2021.9493562.
Zhang, Y., Wang, Y., Chen, X., Jiang, X. & Zhou, Y. Spectral-spatial feature extraction with dual graph autoencoder for hyperspectral image clustering. IEEE Trans. Circuits Syst. Video Technol. 32, 8500–8511 (2022).
Hassanzadeh, A., Kaarna, A. & Kauranne, T. Unsupervised multi-manifold classification of hyperspectral remote sensing images with contractive autoencoder. In: Image Analysis (eds. Sharma, P. & Bianchi, F. M.) 169–180 (Springer International Publishing, 2017). https://doi.org/10.1007/978-3-319-59129-2_15.
Wang, X., Wang, Z., Zhang, Y., Jiang, X. & Cai, Z. Latent representation learning based autoencoder for unsupervised feature selection in hyperspectral imagery. Multimedia Tools Appl. 81, 12061–12075 (2022).
Cao, X., Lin, H., Guo, S., Xiong, T. & Jiao, L. Transformer-based masked autoencoder with contrastive loss for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 61, 1–12 (2023).
Ranjan, P., Kumar, R. & Girdhar, A. A 3D-convolutional-autoencoder embedded Siamese-attention-network for classification of hyperspectral images. Neural Comput. Appl. 36, 8335–8354. https://doi.org/10.1007/s00521-024-09527-y (2024).
Babjac, A., Royalty, T., Steen, A. D. & Emrich, S. J. A comparison of dimensionality reduction methods for large biological data. In Proceedings of the 13th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics 1–7 (ACM, 2022). https://doi.org/10.1145/3535508.3545536.
Huang, R., Liu, C., Li, G. & Zhou, J. Adaptive deep supervised autoencoder based image reconstruction for face recognition. Math. Probl. Eng. 2016, 6795352 (2016).
Vincent, P., Larochelle, H., Bengio, Y. & Manzagol, P.-A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine Learning 1096–1103 (Association for Computing Machinery, 2008). https://doi.org/10.1145/1390156.1390294.
Manakov, I., Rohm, M. & Tresp, V. Walking the Tightrope: An Investigation of the Convolutional Autoencoder Bottleneck. ArXiv (2019).
Niclas, N. & Gustafsson, D. Non-Linear Hyperspectral Subspace Mapping using Stacked Auto-Encoder (2016).
Portillo, S. K. N., Parejko, J. K., Vergara, J. R. & Connolly, A. J. Dimensionality reduction of SDSS spectra with variational autoencoders. AJ 160, 45 (2020).
Pande, S. & Banerjee, B. Attention based convolution autoencoder for dimensionality reduction in hyperspectral images. In 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS 2727–2730 (2021). https://doi.org/10.1109/IGARSS47720.2021.9553019.
Pande, S. & Banerjee, B. Dimensionality reduction using 3D residual autoencoder for hyperspectral image classification. In IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium 2029–2032 (2020). https://doi.org/10.1109/IGARSS39084.2020.9323359.
Pande, S. & Banerjee, B. Bidirectional GRU based autoencoder for dimensionality reduction in hyperspectral images. In 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS 2731–2734 (2021). https://doi.org/10.1109/IGARSS47720.2021.9555048.
Pande, S. & Banerjee, B. Feedback convolution based autoencoder for dimensionality reduction in hyperspectral images. In IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium 147–150 (2022). https://doi.org/10.1109/IGARSS46834.2022.9883594.
Haut, J. M., Paoletti, M. E., Plaza, J. & Plaza, A. Fast dimensionality reduction and classification of hyperspectral images with extreme learning machines. J. Real-Time Image Proc. 15, 439–462 (2018).
Patel, H. & Upla, K. P. A shallow network for hyperspectral image classification using an autoencoder with convolutional neural network. Multimedia Tools Appl. 81, 695–714 (2022).
Kulkarni, P. et al. Agricultural field analysis using satellite hyperspectral data and autoencoder. In Recent Trends in Image Processing and Pattern Recognition (eds. Santosh, K., Hegadi, R. & Pal, U.) 363–375 (Springer International Publishing, 2022). https://doi.org/10.1007/978-3-031-07005-1_31.
Fejjari, A., Saheb Ettabaa, K. & Korbaa, O. Feature extraction techniques for hyperspectral images classification. In Soft Computing Applications (eds. Balas, V. E., Jain, L. C., Balas, M. M. & Shahbazova, S. N.) 174-188 (Springer International Publishing, 2021). https://doi.org/10.1007/978-3-030-52190-5_12.
Swain, S. & Banerjee, A. Evaluation of dimensionality reduction techniques on hybrid CNN-based HSI classification. Arab. J. Geosci. 14, 2806 (2021).
Wang, C., Peng, G. & De Baets, B. A distance-constrained semantic autoencoder for zero-shot remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 14, 12545–12556 (2021).
Zerrouki, Y., Harrou, F., Zerrouki, N., Dairi, A. & Sun, Y. Desertification detection using an improved variational autoencoder-based approach through ETM-landsat satellite data. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 14, 202–213 (2021).
Li, E., Du, P., Samat, A., Meng, Y. & Che, M. Mid-level feature representation via sparse autoencoder for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 10, 1068–1081 (2017).
Zhang, X., Chen, G., Wang, W., Wang, Q. & Dai, F. Object-based land-cover supervised classification for very-high-resolution UAV images using stacked denoising autoencoders. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 10, 3373–3385 (2017).
Lv, F., Han, M. & Qiu, T. Remote sensing image classification based on ensemble extreme learning machine with stacked autoencoder. IEEE Access 5, 9021–9031 (2017).
Bai, Y., Sun, X., Ji, Y., Fu, W. & Zhang, J. Two-stage multi-dimensional convolutional stacked autoencoder network model for hyperspectral images classification. Multimed Tools Appl. 83, 23489–23508 (2024).
Acknowledgements
The authors would like to thank MIST Research Center and SISAu Research Group for the support in this work. The results of this work are part of the project “Tecnologías de la Industria 4.0 en Educación, Salud, Empresa e Industria” developed by Universidad Tecnológica Indoamérica. The authors express sincere gratitude to Hosei University, Japan, for providing research facilities and technical support under Grant HU23K17736, which greatly supported this research.
Funding
Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2025R300), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
Conceptualization, B.N.A. and S.M.M.; Data curation, H.S.M.B.; Formal analysis, F.K.K.; Funding acquisition, F.K.K and S.M.M.; Investigation, J.V.A.; Methodology, M.I.U. and S.M.M.; Resources, M.I.U.; Software, B.N.A.; Validation, J.V.A.; Visualization, S.M.M.; Writing—original draft, S.M.M. and M.I.U.; Writing—review and editing, J.V.A., M.I.U. and S.M.M.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Noor Asmat, B., Syed Muhammad Bilal, H., Uddin, M.I. et al. Enhancing feature learning of hyperspectral imaging using shallow autoencoder by adding parallel paths encoding. Sci Rep 15, 17363 (2025). https://doi.org/10.1038/s41598-025-01758-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-01758-w
