
Abstract
This work aims to enhance the accuracy and efficiency of corporate strategic decision-making, particularly in rapidly changing and highly competitive market environments. Traditional strategic decision-making methods rely on managers’ experiential judgment and exhibit limitations when handling complex data and high-frequency market fluctuations. To address this issue, this work proposes a hybrid optimization model combining transformer models and reinforcement learning algorithms, designed to optimize corporate strategic decision-making processes and improve competitiveness. First, relevant studies on strategic decision-making and corporate competitiveness are reviewed, clarifying the potential and advantages of artificial intelligence (AI) in decision support. Second, the hybrid model is developed and trained through steps including data collection and preprocessing, algorithm selection and model construction, as well as model training and validation. Finally, real-world data are applied to evaluate model performance across indicators such as training time, convergence speed, and prediction effectiveness. The results demonstrate that the hybrid model successfully converges within 150 iterations and exhibits substantial advantages over traditional algorithms, particularly in prediction accuracy for market share (92%), profit growth rate (91%), and customer satisfaction (89%). Implementing the model leads to notable improvements in corporate market position, brand influence, and technological innovation capabilities. The work shows that the hybrid model enhances the scientific rigor and accuracy of decision-making. Meanwhile, it strengthens corporate competitiveness and market responsiveness, highlighting the substantial potential of AI technologies in strategic management. This work provides enterprises with an efficient and reliable decision-support tool, facilitating the maintenance of competitive advantages in complex and dynamic market environments.
Similar content being viewed by others



Introduction
Strategic management decisions play a crucial role in the operations of modern enterprises1. They involve formulating long-term strategies in a competitive market environment to achieve optimal resource allocation and enhance competitive advantage2. Effective strategic decision-making allows enterprises to adjust their operational direction, respond to market changes, and maintain sustained competitiveness in a dynamic business environment3. Therefore, how to make scientifically sound and reasonable strategic decisions in a complex and ever-changing market has become a major challenge for enterprise managers.
However, traditional strategic decision-making methods have many limitations, such as excessive reliance on the subjective judgment of managers, insufficient data processing capabilities, and limited ability to model complex variable relationships. These methods often seem inadequate when dealing with high-frequency market fluctuations, handling massive data, and cross-dimensional decision-making tasks4,5. Therefore, the introduction of artificial intelligence (AI) technology with the capabilities of data mining, trend identification, and learning is expected to fundamentally enhance the scientificity and forward-looking nature of strategic management.
In recent years, the application of AI in strategic management has become a hot topic. With the progress of big data, machine learning, and deep learning technologies, AI provides powerful data analysis and decision support capabilities6. In strategic management, AI can help enterprises more accurately predict market trends, analyze competitor dynamics, and optimize the decision-making process7. By applying advanced algorithms, enterprises can extract valuable information from vast amounts of data, achieving precise strategic planning and real-time adjustments8. The introduction of these technologies not only enhances the scientific and accurate nature of decisions but also accelerates the decision-making process, enabling enterprises to respond more quickly to market changes.
In traditional strategic management, corporate decision-making primarily relies on managerial experiential judgment and static analytical tools. While these methods have proven relatively effective in the past, they exhibit three significant limitations in today’s rapidly changing, information-intensive business environment. Traditional methods show significant limitations in processing high-dimensional, large-scale, and real-time updated data, including social media sentiment analysis, real-time market dynamics, and competitor behavior monitoring. Lack of dynamic adaptability: Most conventional decision-making models operate statically and cannot update strategies in real-time based on new information, resulting in reactive strategic responses with inherent time lags. Reliance on subjective experience: Human decision-makers are particularly susceptible to cognitive biases (such as overconfidence and path dependence) when confronting uncertainty and complexity, whereas AI systems can effectively learn from historical data to mitigate these biases. Within this context, the integration of AI technologies—particularly machine learning, deep learning, and RL—demonstrates both necessity and distinctive advantages. AI systems can effectively process and analyze both structured and unstructured data, extracting valuable insights from massive information sources to enhance decision-making comprehensiveness. RL algorithms enable continuous strategy learning and optimization, facilitating “dynamic strategy formulation” that adapts to market fluctuations. By integrating predictive modeling with optimization algorithms, AI can simulate multiple scenarios in uncertain environments, supporting enterprises in developing forward-looking, multi-dimensional strategic frameworks.
In strategic management decisions, many scholars have conducted in-depth research on the application of AI technology in recent years9. The balanced scorecard method, although originally used for performance evaluation in strategic management, has gradually attracted attention in its application in the context of AI10. Regarding the application of AI technology, Rana et al.11 explored the application of transformer models in strategic decision-making through empirical research on deep learning models. Their research indicated that the transformer model performed exceptionally well in handling complex data sequences and predicting market trends. Laguir et al.12 adopted a model based on the self-attention mechanism; By comparing it with the traditional recurrent neural network, they found that the transformer model could improve prediction accuracy and computational efficiency.
Kaggwa et al.13 studied the application of reinforcement learning (RL) in strategic decision-making. They verified the effect of RL in dynamic decision optimization by applying Deep Q-Network (DQN) in the simulated environment. Zhao et al.14 also found that RL could optimize the decision-making process and improve the adaptability and efficiency through continuous learning and adjusting strategies. Stollberger et al.15 idscussed the application of Bayesian optimization in the hyperparameter optimization of an AI model. Their research showed that Bayesian optimization could effectively improve the model performance, especially in the case of extensive and complex hyperparameter space. The research results of Balasubramanian et al.16 indicated that Bayesian optimization could provide better model configuration under multiple objective functions, markedly improving the model’s prediction ability and stability.
The comparison of relevant research methods is exhibited in Table 1:
Although the existing research has achieved some results at the specific algorithm level, there are generally the following shortcomings. first, the method is single and lacks multi-model fusion to enhance the robustness of the system; Second, it fails to systematically integrate strategic management theory and AI algorithm framework; Third, most studies focus on short-term forecasting indicators, ignoring the modeling and evaluation of long-term dimensions such as corporate competitiveness.
The motivation of this work is to explore how AI technologies can be effectively integrated into strategic management decisions to address the limitations of traditional decision-making methods. Although existing research has demonstrated the significant advantages of AI in decision support, integrating these technologies with strategic management theories to achieve optimal decisions remains an unresolved issue. Through an in-depth examination of the application of AI in strategic management, this work aims to provide enterprises with more scientific decision-making tools, promote innovation and enhancement in strategic management, and ultimately achieve greater success in a highly competitive market. This work specifically focuses on how strategic management can enhance corporate competitiveness through AI. Corporate competitiveness is reflected in market share and profitability. It also includes brand influence, technological innovation capability, and flexibility in adapting to market changes. By leveraging AI-assisted strategic decision-making, enterprises can better integrate internal resources and dynamically adjust strategies, thereby achieving continuous optimization of competitive advantages. Given the limitations of existing research, this work proposes a hybrid optimization framework combining Transformer models with RL. This framework possesses powerful feature extraction and modeling capabilities while dynamically adapting to complex environments, enabling automatic strategy optimization and feedback adjustment. Unlike approaches relying solely on single AI models, the proposed hybrid model demonstrates superior adaptability and effectiveness in responding to market changes, optimizing corporate strategies, and enhancing comprehensive competitiveness.
Current research has employed algorithms such as support vector machines and neural networks to assist corporate strategic decision-making. However, these methods often suffer from insufficient generalization ability or high dependency on complex data. For instance, Silvestrini and Lavagna17 indicated that deep neural networks exhibited limited learning stability in dynamic strategic contexts. In contrast, the Transformer-RL hybrid model proposed here demonstrates strong feature extraction capability and rapid environmental adaptability. Meanwhile, it enables dynamic strategy optimization, markedly boosting decision-making accuracy and implementation effectiveness.
The primary objective of this work is to explore the application of AI technology in strategic management decisions and to evaluate its impact on enhancing corporate competitiveness. To achieve these goals, the work reviews existing research achievements, provides a detailed description of the AI application framework, and explains its specific implementation in strategic decision-making. It also presents the model’s performance evaluation, practical application effects, and its influence on corporate competitiveness. Finally, the work summarizes its findings, offers improvement suggestions, and outlines future research directions. The research innovation lies in the application of advanced AI technologies, particularly transformer models and RL algorithms, in strategic management decisions.
Research model
Research theoretical foundation
The theoretical foundation of this work lies primarily at the intersection of strategic management and AI technology. First, strategic management theory provides the decision-making framework and guiding principles for this work18. Strategic management involves the processes by which enterprises analyze, formulate, implement, and evaluate strategies to achieve their long-term goals and sustainable development in a competitive environment. Classic strategic management theories include Porter’s Competitive Advantage Theory, the Resource-Based View (RBV), and Dynamic Capabilities Theory. These theories offer a theoretical basis for how enterprises can maintain competitiveness in a complex and ever-changing market environment19,20.
Porter’s Competitive Advantage Theory emphasizes that enterprises should achieve competitive advantage through three basic strategies: cost leadership, differentiation, and focus21,22. The Resource-Based View posits that an enterprise’s unique resources and capabilities are the fundamental sources of its competitive advantage. Dynamic Capabilities Theory further asserts that enterprises must continually adjust and reconfigure their resources and capabilities to adapt to rapidly changing environments23.
Research design and key variable identification
This work encompasses five main aspects: data collection and preprocessing, algorithm selection and model construction, model training and validation, decision support and output, and continuous optimization and updating, as illustrated in Fig. 1.

Overall research design.
Based on the content of Fig. 1, data collection and preprocessing form the foundation of the entire model design. To ensure the comprehensiveness and representativeness of the data, data related to strategic management are collected through various channels, including market data, internal corporate operation data, and competitor information. In terms of algorithm selection and model construction, this work employs Transformer algorithms and RL algorithms. Model training and validation are critical steps in the model design, ensuring the model has good generalization capability. In the decision support and output stage, the trained model can make real-time predictions and analyses on new input data, generating optimal strategic decision recommendations. Finally, in the practical application process, new data are continuously collected, and the model is iteratively optimized and updated to ensure its ongoing adaptability to changing environments.
Table 2 lists the input and output variables.
Construction of the algorithm model
This work employs modern Transformer models and RL algorithms to address complex strategic decision-making problems. The Transformer model, a deep learning architecture that has achieved remarkable success in natural language processing in recent years, is primarily innovative due to its self-attention mechanism. This mechanism efficiently captures long-term dependencies in sequence data24. The Transformer model consists of two parts: the encoder and the decoder. The encoder processes input data through multiple self-attention layers and feedforward neural network layers, while the decoder converts the encoder’s output into the final prediction results25. The self-attention mechanism is calculated using Eq. (1):
\(Q\), \(K\), and \(V\) represent the query, key, and value matrices, respectively, and \({d}_{k}\) is the dimension of the key.
The Gaussian Error Linear Unit (GELU) activation function, defined as Eq. (2), is used:
\(\Phi\) is the cumulative distribution function of the standard normal distribution.
Cross-entropy loss is used to measure the discrepancy between the predictions and the actual labels, defined as Eq. (3):
\({y}_{i}\) is the actual label and \({\widehat{y}}_{i}\) is the predicted probability.
RL is a learning method based on reward and punishment mechanisms, particularly suitable for scenarios requiring dynamic decision-making26,27. The primary algorithm used is the DQN28. The core of the Q-learning algorithm is the Q-function, which evaluates the long-term return of taking a specific action in a given state29,30. The Q-value update is defined by Eq. (4):
\({s}_{t}\) is the current state, \({a}_{t}\) is the action taken, \({r}_{t+1}\) is the reward received, \(\gamma\) is the discount factor, and \(\alpha\) is the learning rate.
To ensure training stability and sample diversity, the experience replay mechanism configures a replay buffer capacity of 100,000 records. During each iteration, 64 samples (mini-batch) are randomly sampled for network training, with a sampling frequency of once per training step. By disrupting temporal correlations, experience replay mitigates high interdependencies among samples, thus enhancing model generalization ability and convergence speed.
A deep neural network is used to approximate the Q-function. The network training employs an experience replay mechanism to enhance training stability31,32. To combine the strengths of Transformer models and RL algorithms, this work proposes a hybrid optimization strategy. The Transformer model is used for feature extraction from input data to capture complex dependencies in sequence data, while the RL algorithm dynamically optimizes decisions based on these extracted features33,34. During the optimization process, the features generated by the Transformer model are used for RL state representation, and the RL algorithm adjusts the decision strategy based on these states35,36.
The model workflow is shown in Fig. 2:
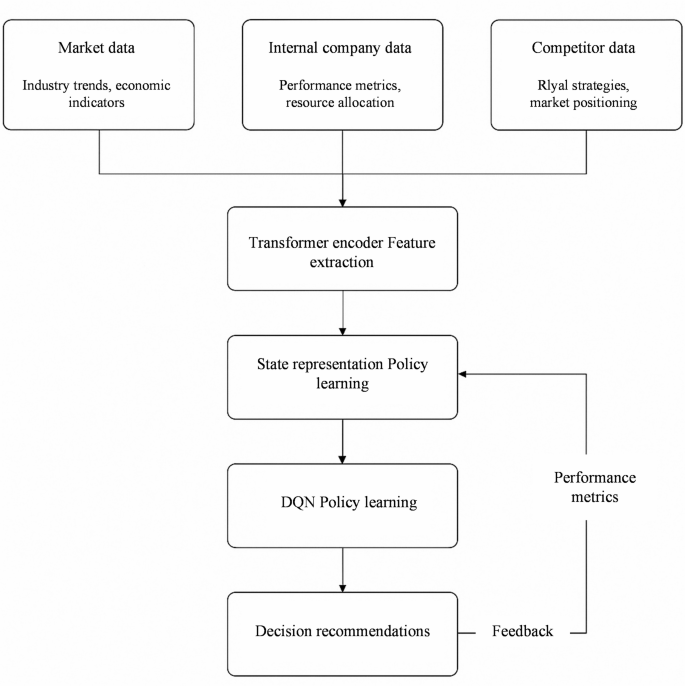
The workflow of the model.
In Fig. 2, the framework forms a complete dynamic learning loop, encompassing data input, feature encoding, policy learning, and output recommendation with feedback updates. The Transformer module extracts long-term dependencies in market trend features. The DQN module performs action selection and policy updates based on the state space, enabling dynamic generation of strategic optimization recommendations.
This work incorporates three categories of strategy-relevant data: market data (e.g., industry growth rate, customer demand shifts, macroeconomic indicators); internal corporate data (e.g., financial statements, employee turnover rate, product gross margins); competitor data (e.g., market share fluctuations, patent counts, public financing events). They are heterogeneous, multi-dimensional raw datasets.
A unified feature engineering process is first adopted to transform the data into structured numerical features for algorithmic modeling. Time-series variables (e.g., monthly sales, quarterly profits) preserve temporal ordering as Transformer model inputs. Categorical variables (e.g., competitive strategy types) are processed via one-hot encoding or embedding vectors. Continuous variables (e.g., market share) are normalized before direct model input. The features are ultimately encoded into high-dimensional dense vectors as input sequences for the Transformer. Through self-attention mechanisms, the Transformer extracts critical dependency relationships and outputs a composite state vector serving as the “environment state” for RL’s DQN.
The DQN selects optimal “actions” (strategies) based on the current state. These actions are designed as concrete strategic recommendations, including increasing budget allocation for specific business lines, adjusting human resource deployment, entering emerging markets next quarter, and engaging in price competition with rivals. The final output actions are mapped into natural language strategic recommendation reports for executive decision-making. This “strategy suggestion” process incorporates actual corporate feedback (e.g., profit changes, customer satisfaction variations) as reward signals for subsequent reinforcement learning iterations.
Algorithm optimization
In the process of algorithm optimization, this work employs several advanced optimization strategies to enhance the performance of the transformer model and RL algorithm. First, adaptive learning rate adjustment is a technique for dynamically adjusting the learning rate. Traditional fixed learning rates can lead to slow or unstable convergence during model training37,38. To address this issue, this work utilizes an adaptive learning rate algorithm. The Adam optimizer combines the momentum method and adaptive learning rate adjustment, adjusting each parameter’s learning rate by computing the first-order and second-order moment estimates of the gradient. The update rules of the Adam optimizer are given by Eqs. (5–9):
\({m}_{t}\) and \({v}_{t}\) are the momentum and variance estimates of the gradient, respectively. \({\beta }_{1}\) and \({\beta }_{2}\) are the momentum decay factors, \(\eta\) is the learning rate, and \(\epsilon\) is a smoothing term to prevent division by zero.
Compared to traditional optimization methods with fixed learning rates (e.g., Stochastic Gradient Descent), the Adam optimizer exhibits superior ability in dynamically adjusting parameter update magnitudes, particularly suitable for high-dimensional complex networks. In practical training, the Adam optimizer allocates adaptive learning rates to individual parameters based on gradient variation scales. Thus, it can accelerate early-stage convergence speed, reduce oscillation phenomena, and enhance final training stability. This approach enables the model to reach optimal ranges more efficiently while effectively decreasing iteration cycles and loss fluctuations.
Next, the hybrid optimization strategy leverages the strengths of both the transformer model and the RL algorithm. To optimize the hyperparameters in the transformer model, this work employs Bayesian Optimization. Bayesian Optimization guides the selection of hyperparameters by establishing a probabilistic model (Gaussian process) of the hyperparameter space39,40. The core of the optimization process lies in using the established probabilistic model to predict the performance of hyperparameter configurations and then selecting the optimal configuration through an exploration–exploitation strategy41. The objective function of Bayesian Optimization is given by Eq. (10):
\(\theta\) represents the hyperparameters, and \({\mathbb{E}}_{\text{model }}[f(\theta )]\) is the expected performance under the hyperparameter configuration.
In contrast to traditional grid search and random search methods, Bayesian optimization introduces prior knowledge and probabilistic prediction models to intelligently evaluate potentially optimal hyperparameter configurations within the search space. During model parameter tuning, Bayesian optimization typically locates near-optimal solutions with fewer trials, thus reducing tuning duration while improving precision. This methodology proves particularly advantageous for high-dimensional parameter spaces and computationally expensive training scenarios, such as selecting the number of attention heads and hidden layer dimensions in Transformer architectures.
Bayesian optimization employs Gaussian processes to model the hyperparameter space. The prior distribution adopts the common Radial Basis Function because it can capture the smooth changes in the input space. This work selects expected improvement as the acquisition function to guide optimization, effectively balancing exploration and exploitation to ensure focused searching in potentially optimal regions. The optimization procedure executes 100 iterations to progressively identify optimal hyperparameter combinations. During each iteration, the model updates based on current prior knowledge and experimental results, ultimately selecting the optimal configuration.
In the optimization of the RL algorithm, a multi-objective optimization (MOO) strategy is adopted, utilizing the Non-dominated Sorting Genetic Algorithm II (NSGA-II) to optimize the multi-objective function of the policy42,43. In this work, NSGA-II incorporates three optimization objectives: profit growth rate enhancement, customer satisfaction maximization, and resource consumption cost minimization. Each strategic action (e.g., market share adjustment or workforce allocation) corresponds to a three-dimensional objective function value.
NSGA-II generates multiple solution sets through population initialization and non-dominated sorting, while maintaining diversity via crowding distance computation. During iterations, the Pareto frontier progressively approaches optimal boundaries, with the solution closest to the ideal point ultimately selected for model policy updates. This methodology achieves balanced resource allocation and strategic recommendations under multiple competing objectives.
NSGA-II ranks different objectives of the policy and selects the optimal policy using the crowding distance44,45. The optimization process is described by Eqs. (11) and (12):
\(\text{Pareto Front}\) represents the Pareto frontier under multiple objectives, and \({\text{Cost}}_{i}\) is the cost of the i-th objective function.
NSGA-II, as a classical MOO method, can generate non-dominated solution sets when handling conflicting objectives in strategy selection (e.g., profit maximization versus cost minimization), from which Pareto-optimal strategies can be selected. During policy training, by incorporating crowding distance and rank sorting mechanisms, the algorithm effectively avoids local optima, thereby achieving a balance between solution diversity and global optimality. Particularly in complex market environments, NSGA-II enables decision-makers to evaluate trade-offs among multiple objectives, providing more robust policy references for RL.
Lastly, for the hybrid optimization of the transformer model and the RL algorithm, ensemble learning methods are introduced to integrate the results of different optimization algorithms46,47. By performing a weighted average of the prediction results from the transformer model and RL algorithm at different stages, the overall performance of the model is further enhanced48. The weighted equation for ensemble learning is given by Eq. (13):
\({\widehat{y}}_{1}\) and \({\widehat{y}}_{2}\) are the prediction results of the transformer model and the RL algorithm, respectively, and \({\alpha }_{1}\) and \({\alpha }_{2}\) are the corresponding weights.
Experimental design and performance evaluation
Datasets collection, experimental environment and parameters setting
To ensure the comprehensiveness and reliability of the data, three public datasets are selected. These datasets cover market data, internal corporate data, and competitor information, providing necessary data support for training and validating the strategic management decision model.
Specifically, Kaggle’s Financial Market Data comprises historical trading data from multiple financial markets, including stock prices, trading volumes, and market indices. Each record contains the following fields: timestamp, stock symbol, opening price, closing price, highest price, lowest price, and trading volume. The data follows a time-series format, with each data point representing trading information for a single business day. All trading data undergo standardization to meet the model’s input requirements. Stock price data are normalized by subtracting the mean and dividing by the standard deviation for each data point, enabling the model to effectively process data with varying measurement scales. The University of California, Irvine (UCI) Online Retail Data originates from the UCI Machine Learning Repository. It contains online retail transaction records, including order Identifier (ID), product information, customer ID, order timestamps, and other fields. The data is formatted in tabular form, comprising order numbers, product descriptions, purchase quantities, unit prices, and customer information. For model input, categorical variables such as product information and customer IDs are encoded into numerical data, while temporal information is converted into continuous time variables representing timestamps for each order. All numerical data undergo processing via the Z-score normalization method. The Crunchbase Data contains detailed information about companies, investments, and financing activities, including fields such as company names, investment amounts, funding rounds, and industry categories. This dataset primarily provides competitor information to facilitate the model’s analysis of market trends and competitive landscapes. Given the presence of multiple categorical fields, all categorical variables are transformed into dummy variables and standardized for analytical purposes. Following preprocessing, these datasets are merged into a unified input dataset, with feature selection and dimensionality reduction applied to ensure data quality and consistency. All data are converted into formats suitable for training both Transformer and RL models, ensuring effective data transmission for model learning and prediction purposes.
Table 3 presents the experimental environment of this work.
Table 4 presents the parameter settings of this work.
In Table 4, this work selects 8 attention heads for the Transformer model, as the multi-head attention mechanism can simultaneously learn diverse feature relationships within input data. The 8-head configuration provides sufficient model complexity while avoiding excessive computational overhead. The hidden layer dimension is set to 512, determined as the optimal value through experimental tuning, which effectively captures long-term dependencies in sequences while maintaining computational efficiency. Smaller dimensions may inadequately model complex features, whereas larger dimensions could lead to computational costs and overfitting. The initial learning rate is set to 0.001, a value determined through preliminary research and experimental results. Experimental observations indicate that excessively low learning rates result in slow model training, while excessively high rates lead to unstable training processes. A dynamic learning rate adjustment strategy is implemented to enhance convergence speed and prevent overfitting. Meanwhile, it incorporates learning rate decay during training, progressively reducing the learning rate as training epochs increase. This strategy ensures the model gradually approaches optimal solutions and achieves stable convergence in later training stages.
Performance evaluation
Model training and validation results
Training time and convergence speed are important indicators for evaluating model efficiency. A shorter training time and faster convergence speed indicate that the model can achieve high performance in a shorter period, saving computational resources and accelerating application speed. Figure 3 compares the training time and number of iterations for different algorithms and the training and validation errors of the hybrid model. The algorithms used for comparison include linear regression, support vector machine (SVM), decision tree model, and neural network.

Comparison of training, convergence performance, and model errors (a Comparison of training time and number of iterations; b Training and validation errors of the model).
Figure 3a suggests that the hybrid model demonstrates a significant advantage in training time compared to other complex algorithms, such as neural networks, without compromising performance. The hybrid model converges within 150 iterations, showing faster convergence speed than complex models like neural networks and SVM. Figure 3b indicates that with the increase in iterations, both training and validation errors gradually decrease and stabilize, suggesting that the hybrid model exhibits good convergence and stability during training.
Figure 4 presents the prediction performance of the hybrid model and other traditional models on the validation set.

Comparison of prediction performance on the validation set for different models.
Figure 4 shows that the hybrid model proposed outperforms other traditional algorithms in terms of prediction accuracy on the validation set, particularly for key indicators such as market share, profit growth rate, and customer satisfaction. The model achieves a prediction accuracy of 92% for market share, 91% for profit growth rate, and 89% for customer satisfaction on the validation set.
Evaluation of practical application effects
The practical applicability and effectiveness of the model are validated by comparing indicators such as market share, profit growth rate, and customer satisfaction of a certain enterprise in 2023. Additionally, the model’s impact on enhancing competitiveness is assessed by comparing the enterprise’s competitiveness indicators across different periods, such as market position, brand influence, and technological innovation capability.
In practical applications, the hybrid model generates strategic decision recommendations by analyzing market data, internal corporate data, and competitor information. To evaluate the effectiveness of these decisions, key indicator changes before and after implementing the model’s recommendations are compared. Figure 5 displays the results.

Comparison of market share, profit growth rate, and customer satisfaction.
Figure 5 reveals that the predicted market share by the model aligns with the actual values. After implementing the strategic recommendations suggested by the hybrid model, the enterprise’s market share significantly increases, indicating the model’s strong predictive and guidance capabilities in terms of market share. The profit growth rate also improves after applying the hybrid model’s suggestions, further validating the model’s effectiveness in practical business decision-making. Customer satisfaction presents a notable rise, reaching a peak of 80% in the fourth quarter, demonstrating the model’s effectiveness in optimizing customer experience.
The enhancement of corporate competitiveness is a crucial indicator for evaluating the practical application effects of the model. The effectiveness of the hybrid model’s application is assessed by comparing the enterprise’s competitiveness indicators, such as market position (ranking), brand influence, and technological innovation capability, across different time periods. Figure 6 presents the results.

Changes in corporate competitiveness enhancement.
Figure 6 shows that after implementing the hybrid model’s recommendations, the enterprise experiences significant improvements in market position, brand influence, and technological innovation capability. The enterprise’s market ranking increases by up to 2 positions, indicating that the model effectively enhances corporate competitiveness.
Discussion
The design of the hybrid model combines the advantages of multiple algorithms, significantly enhancing training efficiency and prediction accuracy through this multimodal fusion approach. Compared to a single algorithm, the hybrid model captures complex patterns in the data more comprehensively, especially when dealing with multivariable problems, demonstrating greater flexibility. It optimizes both training time and convergence speed by integrating the characteristics of different algorithms. The hybrid model’s superior performance on the validation set is closely related to its intrinsic structural design. By weighting and integrating the prediction results of various models, the hybrid model mitigates potential biases inherent in single models, thereby improving prediction accuracy and stability. This approach is particularly suitable for applications involving complex data features and pronounced nonlinear relationships. In terms of practical application effects, the model’s improvements in market share, profit growth rate, and customer satisfaction validate its effectiveness in business decision-making. The hybrid model generates strategic recommendations by comprehensively analyzing market data, internal corporate data, and competitor information. These recommendations have significantly improved the enterprise’s core indicators in practice.
Conclusion
Research contribution
This work combines AI technology with strategic management decisions to propose an innovative hybrid model that optimizes the strategic decision-making process for enterprises. The main contributions of this work are as follows. First, this work systematically integrates deep learning, RL, and Bayesian optimization techniques, applying them innovatively to strategic decision-making, thereby improving the accuracy and real-time performance of decisions. Second, through comparative experiments, the superiority of the hybrid model in key indicators such as market share, profit growth rate, and customer satisfaction is validated, providing enterprises with a practical decision-support tool. Besides, the work deeply analyzes the practical application effects of the model, revealing its role in enhancing corporate competitiveness. This enriches the research content in the field of strategic management and provides a theoretical foundation and practical reference for future related research.
Future works and research limitations
Despite the successful application of the hybrid model in strategic management decisions, there are still some limitations. First, the application scenarios of the model are primarily focused on specific industries and datasets, and its generalizability and cross-industry adaptability need further verification. Moreover, the current model has high requirements for data quality. In practical applications, enterprises may face issues with incomplete data or noise, which could affect the model’s performance and stability. Future research can explore the following areas: first, expand the application scope of the model to verify its performance across more industries and under different data conditions; second, optimize the model’s computational efficiency and develop robust methods to handle data noise and incompleteness; third, incorporate more external factors, such as policy changes and market trends, to enhance the model’s decision support capabilities. These efforts can further improve the model’s practicality and its value for wider application.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author Xingchen Pan on reasonable request via e-mail panxingchen0916@163.com.
References
Wong, L. W., Tan, G. W. H., Ooi, K. B., Lin, B. & Dwivedi, Y. K. Artificial intelligence-driven risk management for enhancing supply chain agility: A deep-learning-based dual-stage PLS-SEM-ANN analysis. Int. J. Prod. Res. 62(15), 5535–5555 (2024).
Chen, M. & Du, W. Dynamic relationship network and international management of enterprise supply chain by particle swarm optimization algorithm under deep learning. Expert Syst., 41(5), e13081. (2024).
Nagy, M., Lăzăroiu, G. & Valaskova, K. Machine intelligence and autonomous robotic technologies in the corporate context of SMEs: Deep learning and virtual simulation algorithms, cyber-physical production networks, and industry 4.0-based manufacturing systems. Appl. Sci. 13(3), 1681 (2023).
Tang, M. & Liao, H. From conventional group decision making to large-scale group decision making: What are the challenges and how to meet them in big data era? A state-of-the-art survey. Omega 100, 102141 (2021).
Rajagopal, N. K. et al. Future of business culture: An artificial intelligence-driven digital framework for organization decision‐making process. Complexity 2022(1), 7796507 (2022).
Cao, Y., Shao, Y. & Zhang, H. Study on early warning of E-commerce enterprise financial risk based on deep learning algorithm. Electron. Commer. Res. 22(1), 21–36 (2022).
Tuboalabo, A., Buinwi, J. A., Buinwi, U., Okatta, C. G. & Johnson, E. Leveraging business analytics for competitive advantage: Predictive models and data-driven decision making. Int. J. Manag. Entrepreneurship Res. 6(6), 1997–2014 (2024).
Kim, K. & Kim, B. Decision-making model for reinforcing digital transformation strategies based on artificial intelligence technology. Information 13(5), 253 (2022).
Schmitt, M. Deep learning in business analytics: A clash of expectations and reality. Int. J. Inform. Manage. Data Insights. 3(1), 100146 (2023).
Kitsios, F. & Kamariotou, M. Artificial intelligence and business strategy towards digital transformation: A research agenda. Sustainability. 13(4), 2025. (2021).
Rana, N. P., Chatterjee, S., Dwivedi, Y. K. & Akter, S. Understanding dark side of artificial intelligence (AI) integrated business analytics: Assessing firm’s operational inefficiency and competitiveness. Eur. J. Inform. Syst. 31 (3), 364–387 (2022).
Laguir, I., Gupta, S., Bose, I., Stekelorum, R. & Laguir, L. Analytics capabilities and organizational competitiveness: Unveiling the impact of management control systems and environmental uncertainty. Decis. Support Syst. 156, 113744 (2022).
Kaggwa, S. et al. AI in decision making: Transforming business strategies. Int. J. Res. Sci. Innov. 10 (12), 423–444 (2024).
Zhao, Y. et al. Development and innovation of enterprise knowledge management strategies using big data neural networks technology. J. Innov. Knowl. 7(4), 100273 (2022).
Stollberger, J., Guillaume, Y. & Van Knippenberg, D. Inspiring, yet tiring: How leader emotional complexity shapes follower creativity. Organ. Sci. 35(3), 1015–1041 (2024).
Balasubramanian, N., Ye, Y. & Xu, M. Substituting human decision-making with machine learning: Implications for organizational learning. Acad. Manag. Rev. 47(3), 448–465 (2022).
Silvestrini, S. & Lavagna, M. Deep learning and artificial neural networks for spacecraft dynamics, navigation and control. Drones 6(10), 270 (2022).
Huo, D. & Chaudhry, H. R. Using machine learning for evaluating global expansion location decisions: An analysis of Chinese manufacturing sector. Technol. Forecast. Soc. Chang. 163, 120436 (2021).
Pap, J., Mako, C., Illessy, M., Kis, N. & Mosavi, A. Modeling organizational performance with machine learning. J. Open. Innov. Technol. Market Complex. 8(4), 177 (2022).
Hallioui, A., Herrou, B., Santos, R. S., Katina, P. F. & Egbue, O. Systems-based approach to contemporary business management: An enabler of business sustainability in a context of industry 4.0, circular economy, competitiveness and diverse stakeholders. J. Clean. Prod. 373, 133819 (2022).
Behl, A. Antecedents to firm performance and competitiveness using the lens of big data analytics: A cross-cultural study. Manag. Decis. 60(2), 368–398 (2022).
Ribeiro, A. M. N., do Carmo, P. R. X., Endo, P. T., Rosati, P. & Lynn, T. Short-and very short-term firm-level load forecasting for warehouses: A comparison of machine learning and deep learning models. Energies 15(3), 750 (2022).
Chatterjee, S., Chaudhuri, R., Gupta, S., Sivarajah, U. & Bag, S. Assessing the impact of big data analytics on decision-making processes, forecasting, and performance of a firm. Technol. Forecast. Soc. Chang. 196, 122824 (2023).
Mahrinasari, M. S. et al. The impact of decision-making models and knowledge management practices on performance. Acad. Strategic Manage. J. 20, 1–13 (2021).
Zhang, H., Zang, Z., Zhu, H., Uddin, M. I. & Amin, M. A. Big data-assisted social media analytics for business model for business decision making system competitive analysis. Inf. Process. Manag. 59(1), 102762 (2022).
Ranjan, J. & Foropon, C. Big data analytics in building the competitive intelligence of organizations. Int. J. Inf. Manag. 56, 102231 (2021).
Bharadiya, J. P. Machine learning and AI in business intelligence: Trends and opportunities. Int. J. Comput. (IJC). 48(1), 123–134 (2023).
Ricardianto, P., Lembang, A., Tatiana, Y., Ruminda, M., Kholdun, A., Kusuma, I. G., Sembiring, H., Sudewo, G., Suryani, D. & Endri, E. Enterprise risk management and business strategy on firm performance: The role of mediating competitive advantage. Uncertain Supply Chain Manag. 11(1), 249–260 (2023).
Shang, Y., Zhou, S., Zhuang, D., Żywiołek, J. & Dincer, H. The impact of artificial intelligence application on enterprise environmental performance: Evidence from microenterprises. Gondwana Res. 131, 181–195 (2024).
Jusman, I. A., Ausat, A. M. A. & Sumarna, A. Application of Chatgpt in business management and strategic decision making. Jurnal Minfo Polgan. 12(2), 1688–1697 (2023).
Bharadiya, J. P. The role of machine learning in transforming business intelligence. Int. J. Comput. Artif. Intell. 4(1), 16–24 (2023).
Grabowska, S. & Saniuk, S. Assessment of the competitiveness and effectiveness of an open business model in the industry 4.0 environment. J. Open. Innov. Technol. Market Complex. 8(1), 57 (2022).
Yan, Y. & Chu, D. Evaluation of enterprise management innovation in manufacturing industry using fuzzy multicriteria decision-making under the background of big data. Math. Probl. Eng. 2021(1), 2439978 (2021).
Niu, Y., Ying, L., Yang, J., Bao, M. & Sivaparthipan, C. B. Organizational business intelligence and decision making using big data analytics. Inf. Process. Manag. 58(6), 102725 (2021).
Taherdoost, H. & Madanchian, M. Artificial intelligence and sentiment analysis: A review in competitive research. Computers 12(2), 37 (2023).
Bahoo, S., Cucculelli, M. & Qamar, D. Artificial intelligence and corporate innovation: A review and research agenda. Technol. Forecast. Soc. Chang. 188, 122264 (2023).
Mishra, S. & Tripathi, A. R. AI business model: An integrative business approach. J. Innov. Entrepreneurship. 10(1), 18 (2021).
Chen, S. & Lin, N. Culture, productivity and competitiveness: Disentangling the concepts. Cross Cult. Strategic Manage. 28(1), 52–75 (2021).
Grant, R. & Phene, A. The knowledge based view and global strategy: Past impact and future potential. Glob. Strategy J. 12(1), 3–30 (2022).
Sestino, A. & De Mauro, A. Leveraging artificial intelligence in business: Implications, applications and methods. Technol. Anal. Strateg. Manag. 34(1), 16–29 (2022).
Hou, H., Tang, K., Liu, X. & Zhou, Y. Application of artificial intelligence technology optimized by deep learning to rural financial development and rural governance. J. Global Inform. Manag. (JGIM). 30(7), 1–23 (2021).
Nassar, N. & Tvaronavičienė, M. A systematic theoretical review on sustainable management for green competitiveness. Insights into Reg. Dev. 3(2), 267–281 (2021).
Terán-Bustamante, A., Martínez-Velasco, A. & Dávila-Aragón, G. Knowledge management for open innovation: Bayesian networks through machine learning. J. Open. Innovation: Technol. Market Complex. 7(1), 40 (2021).
Kamble, S. S., Gunasekaran, A., Kumar, V., Belhadi, A. & Foropon, C. A machine learning based approach for predicting blockchain adoption in supply chain. Technol. Forecast. Soc. Chang. 163, 120465 (2021).
Perifanis, N. A. & Kitsios, F. Investigating the influence of artificial intelligence on business value in the digital era of strategy: A literature review. Information 14(2), 85 (2023).
Ibeh, C. V. et al. Business analytics and decision science: A review of techniques in strategic business decision making. World J. Adv. Res. Reviews. 21(2), 1761–1769 (2024).
Jhurani, J. Revolutionizing enterprise resource planning: The impact of artificial intelligence on efficiency and Decision-making for corporate strategies. Int. J. Comput. Eng. Technol. (IJCET), 13, 156–165 (2022).
Adigwe, C. S. et al. Forecasting the future: The interplay of artificial intelligence, innovation, and competitiveness and its effect on the global economy. Asian J. Econ. Bus. Acc. 24(4), 126–146 (2024).
Funding
This work was sponsored in part by Research on the Mechanism and Path of Collaborative Distribution for Logistics Enterprises in Western China Empowered by New Quality Productivity (Grant No.GZF2024XZX03).
Author information
Authors and Affiliations
Contributions
Yang Pu: Conceptualization, methodology, software, validation, formal analysis, investigation, resources, data curation, writing—original draft preparation Hao Li: software, validation, formal analysis Wenjia Hou: visualization, supervision Xingchen Pan: writing—review and editing, visualization, supervision, project administration, funding acquisition.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors. All methods were performed in accordance with relevant guidelines and regulations.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Pu, Y., Li, H., Hou, W. et al. The analysis of strategic management decisions and corporate competitiveness based on artificial intelligence. Sci Rep 15, 17942 (2025). https://doi.org/10.1038/s41598-025-02842-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-02842-x
