
Abstract
An effective algorithm for detecting cracks in bare concrete structures in building construction, capable of identifying small targets, is essential for safeguarding buildings. Unfortunately, detecting and precisely locating cracks in buildings is challenging due to variations in crack size, material texture, and inconsistent data quality. This study proposes a YOLO-based model for bare concrete crack detection, designated as BCCD-YOLO. Firstly, this model optimizes the Path Aggregation Network (PAN) by introducing lateral skips and weighted feature fusion mechanisms, improving the multi-scale fusion capability of bare concrete crack features. Secondly, a newly designed EC2f module is introduced into the neck network, adopting a channel-wise attention weighting mechanism to enhance feature fusion while maintaining computational efficiency. To further improve feature extraction, this study proposes an innovative SAC2f mechanism, which effectively integrates spatial and channel attention mechanisms for improved feature interaction. Empirical findings demonstrate that the refined model achieves a 3.3% increase in precision for detecting cracks in bare concrete structures within the gathered dataset. This contributes to the accurate and timely identification of structural cracks, thereby enhancing maintenance efficiency and preventing potential failures in building construction.
Similar content being viewed by others

Introduction
A comprehensive detection system is essential for the safety evaluation of building construction. Timely identification and subsequent maintenance of building structures are critical to preventing potential structural failures, ensuring long-term durability, and reducing economic losses1. Advanced technologies are utilized to facilitate effective damage assessment, ensuring the integrity of building infrastructure while minimizing financial losses and safety risks2. This constitutes a significant domain for contemporary study, as conventional manual visual inspection techniques employed to evaluate the structural integrity of building exhibit several limitations3.
Dependable, rapid, and effective crack detection techniques are essential for assessing the integrity of structures, as they influence their safety and longevity4. The outcomes of conventional (manual) crack detection techniques are significantly influenced by the proficiency and methodologies employed by the investigators. Manual inspection involves analyzing cracks, namely their location and widths, resulting in subjective outcomes that depend on the inspector’s expertise5. These constraints result in inadequate damage evaluation of vital infrastructure6. Consequently, there is a pressing necessity for automated ways to effectively identify cracks in building construction, thereby surmounting the constraints of manual methods.
Various computer vision methodologies have been employed to overcome the challenges of image segmentation and crack detection6. Many crack detection algorithms utilize diverse edge detection techniques, including fast Haar transform, fast Fourier transform, and the Sobel and Canny operators7. The efficacy of fundamental edge detection techniques is significantly influenced by image contrast and background uniformity8. Consequently, hybrid algorithms have been employed to enhance the automatic detection of cracks in images of bare concrete.9.
An effective method for automated damage identification is image processing. Image processing approaches facilitate the identification of cracks from the crack picture dataset and allow for essential metrics, including direction and breadth10,11. A considerable body of research has employed image processing techniques to detect damage in bare concrete structures, including cracks and fractures12,13, as well as defects in other structural materials14. The image processing algorithms are often adequate and efficient for identifying fractures in certain photos. Nonetheless, its resilience is compromised by the presence of many objects, including light, shadows, rough surfaces, and other disturbances encountered in real-world scenarios15. In practical applications, building construction crack images exhibit significant variations in size and scale, complicating the development of robust detection models. Moreover, in exposed concrete building structures, cracks may be partially or completely obscured due to coverings such as walls, columns, pipes, and decorative materials. Additionally, variations in lighting conditions, dust accumulation, and background complexity can further interfere with the accuracy and reliability of crack detection. These challenges arise because, unlike cracks in bridges, which are usually visible on exposed surfaces, structural members of buildings often hide cracks behind multiple layers of decorative materials. In many cases, these cracks can be completely hidden, making detection more difficult. In addition, changing lighting conditions can reduce the contrast between cracks and their surroundings, while rough surfaces and cluttered backgrounds can obscure finer crack details. These occlusion factors, coupled with environmental disturbances, necessitate the development of more advanced inspection strategies that are able to cope with these practical challenges. As a result, automated detection systems must be able to address issues of occlusion, scale variation, and environmental complexity in order to reliably identify cracks in real-world built environments.
Generally, different methods, including computer vision and image processing techniques, have been applied for damage detection but they have their limitations that can be overcome by using various hybrid approaches based on artificial intelligence and machine learning techniques16,17,18. Therefore, to enhance the performance of image processing methods for crack detection, the current research utilizes artificial intelligence and machine learning techniques19. The machine learning approaches use image processing techniques for feature extraction to identify cracks or other damages20. Various methods, including artificial neural networks (ANNs) and support vector machines (SVM), have been employed to detect cracks in bare concrete structures. However, their performance is highly dependent on the quality of extracted crack features. In contrast, deep learning can autonomously extract deep features from raw data itself while no longer need manual feature extraction, possessing more powerful representation learning capabilities.
As a branch of machine learning, deep learning aimed at mimicking the neural networks of human’s brain in terms of structure and functioning. In the realm of deep learning, object detection algorithms fall into two main categories: two-step detection algorithms and one-step detection algorithms. Two-stage detection algorithms, which is also called region proposal-based target detection methods, generate candidate boxes containing potential targets firstly, and then refine them precisely through region classifiers. CNN3, RCNN21, Fast-RCNN22, and Mask- RCNN23 are included in the two-step target detection models. Swarna et al.24 proposed method fuses features from bare concrete surface images through a ResNet-50 convolutional neural network (CNN) and curvelet transform handcrafted (HC) method that enhances crack detection accuracy and interpretability. Deng et al.25 applied a new type of region-based CNN (R-CNN) crack detector with deformable modules. Li et al.26 proposes an improved Faster R-CNN crack recognition model that incorporates attention mechanisms. Two-stage detection algorithms comprise two distinct models: one for generating candidate regions and the other for target classification/regression. This dual-model setup introduces significant complexity, exacerbated by the large number of parameters involved. Therefore, careful attention must be paid to file size constraints when transmitting and storing these parameters, particularly in environments with restricted network bandwidth or limited storage resources. Compared with two-stage detection models, one-step detection models, alternatively termed regression-based target detection algorithms, can combine target classification and localization in one step, achieving faster detection speed while maintaining excellent accuracy.
The representative one-step models mainly are SSD (Single Shot Multibox Detector)27 and the YOLO series28. Different from SSD, YOLO has faster inference speed and better utilization of global information, while reducing parameters and complexity, achieving a good balance between timely performance and accuracy, making YOLO superior to SSD29,30,31. Liao et al.32 used an improved YOLOv3 network with K-Means clustering to address the inadequacy of anchor sizes in crack detection. Cai et al.33 developed a lightweight detection network by integrating YOLOv3 with depthwise separable convolutions and attention mechanisms for real-time surface crack identification. Yu et al.34 combined YOLOv5 with the UNet3 + algorithm to enhance intelligent crack detection. Tan et al.35 incorporated YOLOF and ResNet modules into the DeepLabv3 + model, significantly improving accuracy. Liu et al.36 improved YOLOv5 for crack detection in bare concrete structures, optimizing memory usage for real-time applications on mobile devices and UAVs. Known as the newest version of Ultralytics’ YOLO, new changes and developments are proposed in YOLOv8 based on the successful foundation of previous versions to enhance flexibility, capability, and effectiveness37.
YOLOv8 accommodates a comprehensive array of visual AI works, such as image detection, image recognition, image segmentation, semantic segmentation, keypoint detection, scene understanding, optical character recognition (OCR) etc. Excellent adaptability makes it easier to address a variety of applications and domain requirements using YOLOv8’s capabilities. Despite the improvements in many aspects, YOLOv8 still has some limitations. For example, its ability to detect targets of different scales in complex backgrounds needs to be improved, while further optimization is necessary for the feature extraction and fusion performance in algorithms.
Therefore, in this work, we propose a building construction crack detection model, named as BCCD-YOLO, which adopts the most lightweight version, yolov8n, of YOLOv8 as the baseline, meeting the requirements for lightweight while demonstrating excellent performance in accuracy. Firstly, we employ a weighted bidirectional feature fusion mechanism (BiFPN) to address the multiscale feature fusion problem in building construction crack detection. Next, we replace C2f in the neck with EC2f to effectively capture the correlation between channel features, thereby reducing complexity and enhancing the model’s performance in feature fusion. Additionally, inspired by the self-attention mechanism (SA), we introduce SA-C2f at the backbone layer to not only enhance cross-channel integration but also capture relationships between local features. By combining spatial and channel attention, it can better integrate local features and enhance their representation capabilities. To sum up, compared to the baseline model, the model refined in this study demonstrates superior performance, characterized by a notable improvement in recognition accuracy and a substantial acceleration in speed.
Methods
YOLOv8n model
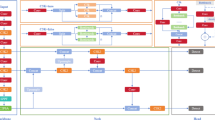
YOLOv838 represents the newest addition to the YOLO series of detection algorithms, which covers five architectures: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x, each optimized for datasets of varying scales. To satisfy the requirement for instantaneous performance, YOLOv8n is selected as the baseline model. This model achieves better performance while maintaining fast speed and optimizing speed to the extreme. It mainly contains four parts: input, backbone, neck, and head, as shown in Fig. 1.

Structure of YOLOv8n.
Input: This component handles tasks such as changing the inputs to the required size and performing data pre-processing and augmentation operations. The former one involves normalizing and resizing images to ensure uniform input dimensions and pixel ranges. For data augmentation, methods like resizing, hue modification, mosaic enhancement, as well as casual alterations such as trimming, spinning, and mirroring are used. Additionally, the model utilizes an anchor-free approach to directly estimate object centers, thereby simplifying complication and minimizing reliance on predetermined anchor point dimensions and configurations.
Backbone: The backbone comprises Conv, C2f, and SPPF modules to enhance its feature extraction capabilities. The innovative C2f design leverages residual information for learning, enhancing gradient flow data. Meanwhile, SPPF (spatial pyramid pooling fusion) converts characteristic representation of varying dimensions into consistent-size feature vectors.
Neck: This part follows feature pyramid network (FPN)39 and path aggregation network (PAN)40, remarkably integrating information flow from hierarchical and foundational pathways within the network, improving effectiveness.
Head: The head part applies feature maps of various sizes to access details on the classification and locations of objects at different scales. By utilizing the distribution focal loss (DFL)41, the parameter counts and computation complexity is greatly reduced. YOLOv8n achieves big progress in timely detection and shows substantial improvements in precision.
Improved YOLOV8n network structure
BiFPN
In real circumstances, the size and scale of building construction cracks images often vary. In addition, unlike bridges, where cracks are usually clearly visible on open surfaces, in bare concrete building structures, cracks may appear partially or completely obscured by the covering of walls, columns, pipelines and decorative materials. In addition, variations in lighting conditions, dust accumulation and the complexity of the background environment may also interfere with the accuracy and reliability of crack detection. Additionally, some cracks are frequently obscured, causing certain features to be omitted. Enhancing the integration of multi-scale features is crucial for improving the feature extraction capability for forest building construction cracks detection across varied scales and efficiently reducing the impact of irrelevant features in intricate environments. The original YOLOv8 algorithm utilized FPN and PAN in the feature fusion process. Nevertheless, up sampling and down sampling can result in the omission of superficial details within feature maps, resulting in a relatively low reuse rate. Furthermore, the requirement for feature fusion and transmission across multiple scales in this architecture leads to an increase in computational cost40. In the YOLO algorithm, the PAN-FPN structure directly uses the outputs from the Backbone’s C3, C4, and C5 layers during feature fusion. This approach overlooks the semantic differences among various feature layers, leading to suboptimal fusion outcomes for non-adjacent layer features42. To overcome the constraints, the weighted bidirectional feature pyramid network (BiFPN)43, which incorporates bidirectional connections, is proposed to enhance transmission capabilities and improve the handling of objects of various sizes. Additionally, a weighted feature integration mechanism is utilized to enhance the precision and generalization capabilities through repeated fusion processes. These enhancements significantly boost object detection performance.
Firstly, this network removes one-way input units. These nodes exhibit minimal involvement in cross-level feature integration and exert negligible influence on overall network performance, thereby facilitating simplification of the network structure. Next, it connects the initial nodes within their respective layers. This allows the characteristic maps within that layer to be preserved and applied when it is in the feature fusion step. As a result, the capability for information flow and integration within features of the same layer maps are enhanced, improving target perception and recognition. This process is then repeated for a specified number of times, improving the ability to progressively integrate features that span different tiers. Ultimately, a more through, exhaustive and conclusive feature representation is produced.
BiFPN employs weighted feature fusion as opposed to the conventional methods that involve the basic stacking or addition of feature maps. Given that features probably exhibit diverse semantic content and resolutions, their fusion requires the utilization of varied weights to guarantee coherent and precise feature representations. And because of the complicated correlation pattern, a precise processing method requires formulation. YOLO-ESC configures adjustable arguments and training weights to optimize the branches using the BiFPN_Concat2 module, applying the Concat operation across output tensor in both dual-branch and triple-branch setups. The structures are shown in Fig. 2, respectively. This structural design facilitates the transfer of information between feature maps in diverse sizes, thereby boosting the detection capabilities for targets of various scales.

The improvement of the network structure. (a) Structure of PAN-FPN. (b) Structure of BiFPN.
With a weighted feature fusion strategy, BiFPN effectively integrates input features of different resolutions. In this strategy, each feature is assigned a relevance weight, which is normalized for feature fusion. After normalizing, the weight values range between 0 and 1 and the weights are calculated as follows:
where \(O\) means the output features, \(w\) means the node weights and \({I}_{i}\) means the input features. Notably, to ensure stable output generation, the learning rate \(\upvarepsilon\) is fixed at 0.0001.
EC2f
To improve the utilization of output features at various scales, YOLOv8 modifies the C3 structure from YOLOv5 by incorporating the C2f module, which enhances gradient flow. Additionally, it modifies the number of channels for models at varying scales. However, the C2f module does not adequately consider the correlation between channel features, which may impact the model’s precision in locating target objects. Furthermore, the architecture employs multiple convolution and pooling layers, leading to higher computational complexity and increased resource demands. Consequently, this study integrates the newly designed mechanism, EC2f, into the model to tackle the challenges. The schematic of EC2f is demonstrated in Fig. 3.

Structure of the EC2f. (a) Structure of C2f. (b) Structure of EC2f.
In the ECA module, fully connected layers are substituted with one-dimensional convolutions, where the channels count \(C\) determines the kernel size. Without reducing dimensionality, the one-dimensional convolutional kernel (denoted as \(k\)) computes the global average value for each channel. This kernel size \(k\) captures local cross-channel interactions between each channel and its neighboring ones. The size of the convolutional kernel signifies the number of adjacent channels involved in channel attention prediction, thus indicating the scope of local cross-channel interaction coverage. To effectively integrate interactions among channels, the size of \(k\) adjusts according to the number of channels.
In particular, following global average pooling, the ECA module utilizes rapid one-dimensional convolution to capture the interaction among each channel and its neighboring channels. The convolutional kernel size is directly proportional to channels count. Relationship can be described as follows:
where b is assigned a value of 1 and \(\upgamma\) is set to 2. The term \({|t|}_{odd}\) refers to the nearest odd integer \(|t|\). All channels share weights in order to optimize parameter efficiency. In this context, the \({w}_{k}\) array, consisting of \(k*C\) parameters, is employed for attention learning. The weight \({w}_{i}\) of channel \({y}_{i}\) is computed solely by how it interacts with \({y}_{i}\) and the \(k\) neighboring channels. The specific expression is as follows:
Here, \(\Omega_{i}^{k}\) denotes the set of \(k\) neighboring channels of channel \({y}_{i}\), and \(\upsigma\) represents the sigmoid activation function. After information interaction, weight sharing is performed as follows:
The entire computation process relies on fast one-dimensional convolution within the ECA structure, utilizing adaptive convolution kernels, represented as follows:
\(C1D\) indicates fast one-dimensional convolution. This cross-channel information interaction attention mechanism significantly enhances the efficiency of the attention mechanism without increasing computational load. The structure is shown in Fig. 4.

The architecture of ECA.
SA-C2f
In complex forest scenes, images often contain substantial background information, complicating the effective detection of building construction cracks targets. To extracting the key information better, attention mechanisms have been widely adopted in researches because these mechanisms are generally classified into two types: channel attention and spatial attention mechanisms. The former is concerned with content. It captures dependencies between channels, whereas spatial attention targets task-relevant areas by capturing pixel-level spatial relationships. However, channel attention typically concentrates on features within a single channel, potentially neglecting correlations and interactions among other channels. Similarly, spatial attention calculations can be problematic; when attention allocation is uneven or inaccurate, detailed or local structural information may be lost.
Although the C2f structure introduced by YOLOv8n integrates multi-level information through cross-stage feature fusion, it may lack flexibility in facilitating cross-local feature interactions. Additionally, C2f comprises multiple bottleneck layers, each containing various convolution kernels (\(1\times 1\), \(3\times 3\), and \(1\times 1\)), leading to a large parameter amount and increases complexity. As for these limitations, we introduce the innovative SAC2f mechanism, which combines the advantages of the SA mechanism and C2f The proposed structure is showed in the following Fig. 5.

The architecture of SAC2f module.
The shuffle attention (SA) mechanism is a more efficient and lightweight approach within deep convolutional neural networks. It effectively combines spatial attention mechanisms and channel attention mechanisms, thus capturing the relationships between features more comprehensively. By utilizing a shuffling operation, the shuffle attention mechanism enables more flexible and efficient exchange and fusion of features. The architecture of shuffle attention is shown Fig. 5, where the input features are first divided into multiple sub-feature groups, which helps to better learn feature representations and reduce the convergence difficulty in deep network training. Specifically, for the input feature map \(X\), which has dimensions of \(C\times H\times W\), shuffle attention (SA) initially divides \(X\) into g groups along the channel dimension, forming grouped feature map \(X= [{X}_{1}, \cdot \cdot \cdot , {X}_{k}, \cdot \cdot \cdot , {X}_{g}]\), where \(k \in [1, g]\). Each subgroup \({X}_{k}\) acquires specific semantic information progressively through the SA module and corresponding weight coefficients. These sub-feature groups initiate two branches, \({X}_{k1}\) and \({X}_{k2}\), at the outset of the attention module.
For each sub-feature group, a random unit is applied to simultaneously construct channel and spatial attention, thereby suppressing potential noise and emphasizing regions with correct semantic features, generating correlation coefficients for the sub-features. SA employs a straightforward \({F}_{c}\) linear transformation module and sigmoid function activation to generate a concise feature for adaptive selection and precision guidance. The following is the output formula for channel attention.
where \({W}_{1}\) and \({b}_{1}\) (\({R}^{C/2G\times 1\times 1}\) and \({R}^{C/2G\times 1\times 1} )\) denote the weight vector and the bias vector of the linear transformation layer, used for scaling and shifting. \(\sigma (\cdot )\) signifies applying the sigmoid activation function to each element of the input vector. Spatial attention serves as a complementary mechanism by emphasizing positional information. For the branch denoted as \({X}_{k2}\), we begin by applying the group normalization (GN) function to derive spatial statistical information. This is followed by a linear transformation and a function computation, generating the eventual outcome. And it is given by:
where \({W}_{2}\) represents the weight vector and \({b}_{2}\) denotes the bias vector of the linear transformation layer, both formatted as \({R}^{C/2G\times 1\times 1}\). The two branches are subsequently combined to align with the input channels.
Subsequently, the shuffle attention unit rearranges the sub-feature groups using channel shuffling operations and integrates the information within each feature group. Meanwhile, the Channel Shuffle operation facilitates information exchange between different sub-feature groups, thereby enhancing the overall feature representation capability.
The branches \({X}_{k1}\) and \({X}_{k2}\) are then merged to align with the input channel count. Following this, channel shuffling is introduced to enhance inter-group information flow and effectively integrate all sub-features while preserving inter-group dynamics. The combined attention weights, denoted as \({X{\prime}}_{k1}\) for channel attention and \({X{\prime}}_{k2}\) for spatial attention, are aggregated to form a grouped dimension of \(CG\times H\times W\). These grouped blocks are then recombined to restore the initial dimension of \(C\times H\times W\). Upon finishing learning the attention mechanism and feature recalibration, the two branches are concatenated and merging. Finally, after aggregating all sub-features, a channel grouping operation is executed.
Experiments and results
Data collection
In order to evaluate the effectiveness of the proposed model, a dataset of 800 crack images was constructed, all of which were from exposed concrete structures, including walls, slabs and columns in building construction. The dataset was acquired using a combination of high-resolution cameras and Unmanned Aerial Vehicle (UAV) systems to ensure that high-quality crack images were captured under different lighting conditions and to enhance the diversity and applicability of the data.
The data collection in this study was carried out mainly in medium- and high-rise buildings (five floors and above) in Hohhot, combining an open-source crack image database and field collection data to ensure the representativeness and authenticity of the data. The UAV employed for data collection was a DJI M200 quadcopter, which was equipped with a Global Navigation Satellite System (GNSS) receiver, barometer, Inertial Measurement Unit (IMU), and Vertical Take-off and Landing (VTOL) capability. The employment of the UAV serves to minimise disruption to building construction and daily operations, while providing an efficient, flexible and cost-effective means of acquiring crack data. Photographs of cracks collected at several building sites in Hohhot are presented in Fig. 6.

Cracks included in the dataset.
To ensure measurement accuracy, all images were taken at a fixed resolution of 1920 × 1080 pixels. Crack dimensions were labeled manually using image processing software calibrated with a standard reference scale. The cracks were categorized based on width, length, and propagation characteristics, as summarized in Table 1. The measurement accuracy for crack width was ± 0.1 mm, verified through manual validation using a crack gauge.
The dataset was randomly divided into training and validation sets in an 8:2 ratio to meet experimental requirements. It focused on a single category and was annotated using a labeling tool. Annotations for the training set included category labels, central coordinates (x, y) of bounding boxes, as well as width and height measurements, as shown in the Fig. 7.

Label data volume and label distribution.
Experimental environment and assessment indicators
In the Linux environment, experiments utilized an Intel Xeon CPU E5-2680 v3 and NVIDIA GeForce RTX 2080 Ti GPU with 11 GB VRAM. The framework employed was PyTorch version 1.7.0, and Python version 3.8 was used. The experiment was configured with the following hyperparameters: an initial learning rate of 0.01, 150 training epochs, momentum set to 0.937, weight decay coefficient of 0.0005, and a batch size of 32.
To accurately assess object detection performance, four fundamental metrics were utilized: Precision (P), Recall (R), F1-score (F1), and Mean Average Precision (mAP)44,45. The specific formulas are provided below:
In the aforementioned equation, ‘TP’ (True Positive) signifies that the model accurately identifies cracks that are present, and that the detected crack widths and lengths correspond to the actual measurements taken during manual inspection. Conversely, ‘FP’ (False Positive) denotes the model incorrectly identifying non-existent cracks or incorrectly categorising cracks. ‘FN’ (False Negative) denotes a situation where the model fails to detect an existing crack, i.e. the crack is present in the image but not detected by the model, whilst ‘TN’ (True Negative) refers to a situation where cracks are not present in the image and the model correctly identifies the absence of cracks. The area under the Precision-Recall (PR) curve for each crack category is denoted as Average Precision (AP). It can be interpreted that the larger the AP, the better the model performs in identifying that particular category of cracks. Mean Accuracy (mAP) is the average accuracy value across all crack categories in the dataset, providing an overall assessment of the model’s detection performance across all categories, giving a single value to assess its overall effectiveness.
Data augmentation strategies
To improve model robustness and generalization capability, several data augmentation techniques were applied to the training dataset. These techniques simulate real-world variations in crack images, enhancing the model’s adaptability to diverse conditions.
Applied data augmentation methods
Table 2 provides an overview of the primary data augmentation techniques used in this study.
Quantitative evaluation of data augmentation
To assess the impact of data augmentation on model performance, an ablation study was conducted. We trained three versions of the BCCD-YOLO model. Baseline (No Augmentation), Basic Augmentation (Geometric + Color Transformations), Full Augmentation (All Techniques Applied). Table 3 summarizes the results of these experiments.
These results indicate that full augmentation improves mAP by 4.7% compared to the baseline, demonstrating the effectiveness of noise injection and data synthesis techniques in reducing false negatives.
Visual representation of augmented data
To further illustrate the effectiveness of these augmentation techniques, Fig. 8 presents sample images before and after augmentation.


Comparison of results with different data enhancements (10 images as an example).
The visual comparisons highlight how data augmentation enhances image diversity while preserving key crack features.
Hyperparameter tuning
Hyperparameter tuning plays a crucial role in improving the performance and generalization of the BCCD-YOLO model. This study employed grid search (Grid Search) and Bayesian optimization (Bayesian Optimization) to optimize key hyperparameters, including learning rate, batch size, momentum, and weight decay. The tuning process involved the following steps.
-
Learning rate (LR): The learning rate was tested in the range [0.001, 0.005, 0.01, 0.02], and experiments demonstrated that 0.01 achieved the best balance between convergence speed and stability.
-
Batch size: The batch size was varied among 16, 32, and 64, and a batch size of 32 was selected as it provided an optimal trade-off between memory efficiency and training stability.
-
Momentum and weight decay: Bayesian optimization was used to fine-tune these parameters, enabling better generalization and reducing overfitting.
The optimized hyperparameters contributed to a more stable training process, improved detection accuracy, and reduced training oscillations. Table 4 presents the impact of hyperparameter tuning on model performance.
The results indicate that hyperparameter optimization led to an improvement of 2.7% in precision, 3.0% in recall, and 3.0% in F1-score, confirming the effectiveness of the applied tuning strategies.
Comparison of model performance with manual inspection
In order to assess the effectiveness of the BCCD-YOLO model for building crack detection, an experiment was designed in this study to compare the results of the model’s crack detection with those of a manual detection method.
Firstly, the manual inspection was carried out by a trained inspector following standard procedures for the assessment of cracks in building construction. The inspector visually located and assessed cracks at a distance of approximately 1 m from the structural component. Cracks were categorised according to location, width and length and crack dimensions were measured using a ruler and crack gauge.
In order to assess the accuracy of the BCCD-YOLO model, the results of the model’s inspection were compared with those of manual inspection in this study. The main metrics analysed were the detection accuracy of crack location, width and length, which were evaluated using precision, recall and mean absolute error (MAE), as shown in Table 5.
As shown in Table 5, the BCCD-YOLO model exhibited a 3.7% improvement in detection accuracy compared to the baseline model, with a mean absolute error (MAE) of 0.3 mm for crack width and length measurements. This result confirms that the model’s measurements closely match the manual inspection outcomes.
Crack images were acquired from a fixed 90° angle under controlled illumination conditions (200–1000 lx) to minimize the impact of lighting variations and ensure consistent data. The crack characteristics, including classification, are detailed in Table 1. During manual inspection, cracks were marked by the inspector on the structural components, and their width and length were measured using a calibration tool. These manual measurements were then compared with the results from the BCCD-YOLO model.
The model demonstrated a high recall rate of 96.1% for detecting penetration cracks, indicating its effectiveness in identifying critical cracks that affect the structural integrity of the building. For smaller hairline cracks, the recall was 92.8%, suggesting room for future improvements. These findings collectively highlight the BCCD-YOLO model’s accuracy, reliability, and potential for further optimization in building crack detection applications.
In the proposed model, the precision was determined by comparing the results of the BCCD-YOLO model to manual crack measurements, which were considered as the ground truth. The precision of the model is not simply based on manual inspection but is instead an improvement over previous crack detection models. Empirical results demonstrate a 3.3% increase in precision when compared to earlier versions, thereby showcasing the effectiveness of the BCCD-YOLO model in detecting cracks in bare concrete structures. This increase in precision highlights the advancements made in the model’s ability to more accurately locate and classify cracks, particularly through the enhanced feature fusion and attention mechanisms, which were not present in earlier models.
Results before and after optimization
By utilizing identical training environments and datasets, a comparative analysis was conducted when comparing the YOLOv8 model and the initial YOLOv8n model to showcase the performance improvement of the updated model. The specific results can be found in Table 6. In order to evaluate the efficacy of the model across a range of crack types, an analysis was conducted to assess the detection performance of BCCD-YOLO for different categories of crack. The results of this analysis are presented in Fig. 9, which illustrates the detection outcomes for various crack types. Additionally, Table 7 provides a comprehensive overview of the precision, recall, and F1-score for each category.

PR diagram of YOLOv8n and BCCD-YOLO.
Table 6 illustrates that the BCCD-YOLO model shows notable enhancements which is proposed in this study compared to YOLOv8n. Precision, recall, F1, and mAP are included in the metrics, with increases of 3.3%, 3.7%, 3.5%, and 3.1%. The improvement is mainly due to the adoption of the weighted bidirectional connection in the neck section, effectively addressing the issue of multi-scale feature fusion in building construction cracks detection. Substituting C2f with EC2f in the neck section enables more efficient capture in feature correlating process. Thus, the model’s performance in feature fusion is greatly enhanced while simplifying its complexity. Additionally, the introduction of SAC2f promotes more effective information exchange and integration among features, leading to clearer feature extraction in dynamic scenarios such as building construction cracks and significantly enhancing the network’s accuracy.
The results in Table 7 indicate that the BCCD-YOLO model maintains high detection accuracy across various crack types, with particularly strong performance in detecting through cracks due to their well-defined structural characteristics. However, hairline cracks exhibited a slightly lower recall, suggesting potential improvements in fine-scale detection. Overall, the model demonstrates a 3.7% to 5.6% improvement in detection performance compared to the baseline YOLOv8n, validating the effectiveness of multi-scale feature fusion (BiFPN), channel-wise attention (EC2f), and spatial-channel attention mechanisms (SAC2f) in enhancing detection robustness and accuracy.
To comprehensively evaluate and compare model optimization in landslide detection before and after, we plotted PR curves at an IOU of 0.5 during testing. Results demonstrate significantly improved recognition accuracy compared to the baseline model, as depicted in Fig. 9.
In summary, in comparison to the baseline models, the BCCD-YOLO model introduced above has achieved advancements in feature extraction and fusion, demonstrating exceptional performance in recognition accuracy and processing speed.
Ablation experiments
For evaluating that every innovative improvement component is necessary, we conducted additional ablation experiments. The trained building construction cracks detection model was evaluated under the same situation to obtain specific relevant performance metrics, which were subsequently analyzed. The concrete results are illustrated in Fig. 10, Fig. 11 and Table 8.

Comparison of the mAP with different models.

Comparison of the precision with different mAPs.
As illustrated in Table 8, the improvement of the model after the BiFPN enhancement led to a 0.9% increase in mAP. This performance boost can be attributed to the structural optimization achieved by BiFPN compared to traditional FPN. By removing unnecessary nodes and introducing lateral connections, BiFPN reduces parameters and computational complexity while allowing for information flow in both forward and backward directions, allowing the efficient utilization of feature information across various tiers. The weighted feature fusion employed by the network helps mitigate the impact of redundant feature maps and places greater emphasis on the more important feature maps for object detection tasks. Additionally, BiFPN performs multiple feature fusions across different levels, effectively integrating feature information from various depths, thereby elevating the model’s generalization ability. Meanwhile, it significantly improves the detection performance for objects at different scales.
The introduction of the newly designed EC2f component in the Neck layer contribute to a 0.7% growth in the model’s mAP value. This performance improvement can be attributed to the characteristics of EC2f. The EC2f module adopts average pooling for obtaining global information, while applying channel attention mechanisms to weigh the features of each channel, thus facilitating comprehensive integration of global information. Moreover, through cross-stage partial feature fusion, EC2f integrates feature information from different depths, enhancing the network’s capability to fully fuse features and improving its perceptual ability and generalization performance.
Upon the integration of the SAC2f mechanism, a notable 1.5% increase in the model’s mean Average Precision (mAP) value was observed. This enhancement can be attributed to the feature interaction facilitated by the novel SAC2f mechanism, leveraging shuffling operations in conjunction with spatial and channel attention mechanisms. This approach not only facilitates the cross-interaction and amalgamation of feature channels but also captures interrelationships among local features. Additionally, tailored attention masks are devised for individual position within each attention module, effectively mitigating noise while reinforcing semantic information. Consequently, these optimizations culminate in improved performance without imposing additional computational costs.
The cracks shown in the figure are directly related to structural components of the building (e.g., walls or columns), and the locations and classifications of the cracks have been clearly labelled to ensure that cracks in critical structural components are shown. To demonstrate the detection capability of the model, several building construction crack scenarios have been evaluated and the results are shown in Fig. 12. In the figure, the crack detection results are labelled by rectangular boxes, each containing a crack category label and a confidence value. The BCCD-YOLO model demonstrates excellent performance in crack identification, accurately and efficiently identifying cracks, demonstrating its high reliability and robustness in building construction crack management and monitoring.

Test result on the dataset: (a) YOLOv8n; (b) BCCD-YOLO; (c) YOLOv8n; (d) BCCD-YOLO.
Discussion
Crack identification is a complex and labor-intensive task. Manual inspection is often subjective and inconsistent, which can be mitigated by implementing automated techniques. In this paper, a pioneering model named BCCD-YOLO is proposed, demonstrating exceptional proficiency in extracting and integrating target features across multiple scales, leading to more accurate detection in complex building construction environments.
While YOLOv8 is a leading single-step model known for its outstanding feature extraction and detection capabilities, its high computational demands limit its practical application for real-world crack detection. To address this, the lightweight YOLOv8n is enhanced with three key innovations: (1) a weighted bidirectional feature fusion mechanism to improve multi-scale feature integration, (2) the EC2f module in the Neck layer to enhance channel-wise feature fusion, and (3) the SAC2f mechanism in the Backbone layer, which leverages spatial and channel attention with random shuffle operations to improve crack detection accuracy and robustness. These modifications significantly boost the model’s sensitivity and reliability in detecting construction cracks, making it well-suited for early warning and maintenance applications. Furthermore, analyzing crack dimensions and propagation trends provides additional insights into the structural integrity of materials. The incorporation of high-resolution image preprocessing and improved feature extraction techniques could further enhance detection performance, particularly for hairline cracks. Additionally, experimental results demonstrate that the BCCD-YOLO model effectively identifies various crack types, including hairline cracks, through cracks, and branched cracks, with a notable improvement in precision and recall compared to traditional detection methods. The model’s ability to adapt to different crack widths and propagation patterns confirms its robustness in real-world applications.
A more comprehensive examination of the materials in which cracks propagate is also essential for assessing the model’s versatility. Different materials, such as steel and concrete, exhibit distinct crack propagation behaviours due to their varying mechanical properties. Concrete, being a brittle material, tends to develop micro-cracks that coalesce over time, leading to sudden fracture. In contrast, steel experiences more ductile failure, where cracks propagate gradually under tensile stress and may undergo plastic deformation before complete fracture. It is imperative to comprehend these variations in order to adapt the BCCD-YOLO model to different material types.
In order to enhance the model’s generalizability, further investigation will be conducted into the influence of different materials on detection performance, with feature extraction strategies and detection thresholds being adjusted accordingly. Subsequent studies will also incorporate additional datasets containing steel and other material-based crack images, with the aim of fine-tuning the model and ensuring its robustness in diverse structural conditions. Expanding the dataset to include materials such as composites and asphalt surfaces will provide broader applicability for infrastructure health monitoring.
Contribution to structural health monitoring
The results of this study have important implications for health monitoring practices in civil engineering. The BCD-YOLO model realizes the real-time detection and identification of building cracks, which provides an efficient and automated solution for infrastructure maintenance, bridge inspection and tunnel monitoring. Compared with the traditional manual inspection methods, the proposed method performs better in detection accuracy, adaptability to complex environments and scalability for large-scale applications, thereby improving the overall efficiency of structural health assessment.
In addition, BGD-YOLO can be integrated into a long-term monitoring system to track the evolution process of cracks and facilitate the implementation of predictive maintenance strategies. By taking full advantage of the detection capabilities of the model, engineers can analyze the evolution trend of cracks and implement targeted repair and reinforcement measures, thereby extending the service life of critical infrastructure.
In addition to the evaluation of a single structure, BGD-YOLO has the potential to be used in large-scale infrastructure monitoring networks to support automated Unmanned Aerial Vehicle (UAV) and Internet of Things (IoT) detection systems. When combined with UAV-based monitoring solutions, the model can autonomously inspect a wide range of infrastructure, reducing manual labor and improving inspection efficiency. Combined with iot sensor data, real-time image-based crack analysis can be integrated into a decision support system (DSS) for proactive maintenance planning.
In addition, combining the machine learning-based damage prediction model with the crack detection results of BGD-YOLO can further improve the structural health prediction. By analyzing historical crack data and correlating them with environmental stresses such as temperature fluctuations, traffic loads, and material aging, predictive models can help identify critical maintenance periods before structural integrity may be compromised.
Future work will focus on improving the interpretability of the model, employing techniques such as saliency mapping and time series analysis to improve the transparency of the decision-making process and provide more operational insights for field engineers.
Application to beach mark analysis
Beach marks serve as essential indicators in fatigue crack propagation analysis, providing critical information about structural safety. Given the ability of BCCD-YOLO to extract and integrate multi-scale features effectively, its application can be extended to the detection and analysis of beach marks on structural surfaces. The BiFPN-based multi-scale feature fusion and EC2f/SAC2f attention mechanisms make the model well-suited for capturing the periodicity and spatial distribution of beach marks, which are crucial for assessing fatigue damage.
In future studies, BCCD-YOLO will be adapted to analyze beach mark patterns, enabling automated recognition of fatigue crack growth curves. The integration of frequency-domain feature extraction methods and adaptive filtering techniques within the model could further enhance its ability to differentiate between crack initiation zones and propagation phases. Additionally, leveraging deep learning-based pattern recognition could refine the identification of subtle beach mark variations, improving the accuracy of structural fatigue assessments.
BiFPN for crack growth modeling in steel materials
While this study primarily focuses on crack detection in building construction materials, the proposed BCCD-YOLO model possesses the potential for adaptation to steel material crack detection. In steel structures, crack propagation is influenced by material thickness, geometric constraints, and external stress conditions. The BiFPN-based multi-scale feature fusion mechanism is particularly advantageous in handling varied crack sizes and propagation patterns across different structural materials.
BiFPN enables bidirectional information flow and adaptive feature weighting, ensuring that fine-scale cracks in thin steel plates and large-scale fatigue cracks in thick steel components are effectively captured. The weighted feature fusion process allows the model to prioritize critical crack features, thereby enhancing detection accuracy across diverse material thicknesses and geometric conditions. Additionally, the integration of EC2f and SAC2f modules improves the model’s ability to distinguish between microstructural surface variations and actual crack formations.
Future research will explore the application of BCCD-YOLO in steel material crack detection by incorporating additional datasets that encompass steel-specific failure modes, such as fatigue cracks, stress corrosion cracks, and weld joint defects. Furthermore, integrating fracture mechanics principles (e.g., Paris’ Law for fatigue crack growth modeling) with deep learning methodologies could enable more accurate predictions of crack progression in steel structures. This research direction will further enhance the generalization capability of BCCD-YOLO, making it a more comprehensive tool for structural health monitoring across different material domains.
Enhancing interpretability of BCCD-YOLO
In engineering applications, model interpretability is crucial for ensuring the reliability and transparency of automated detection systems, particularly in structural health monitoring and civil engineering inspections. While deep learning models such as BCCD-YOLO demonstrate high detection accuracy, their black-box nature limits their direct usability in engineering decision-making. To address this challenge, several interpretability strategies are proposed to enhance the transparency of BCCD-YOLO’s predictions and facilitate its integration into real-world infrastructure monitoring.
Interpretability in machine learning is categorized into post-hoc interpretation and intrinsic model transparency. Post-hoc methods, such as Grad-CAM and SHAP, provide insights into the decision-making process of complex neural networks, whereas intrinsic interpretability is often achieved through simpler, rule-based models. In the context of crack detection, explainability is essential to ensure. Regulatory compliance, Structural inspection standards require models to provide interpretable results for safety assessment. Trust and adoption in engineering practice, Engineers need to understand why a model classifies a region as a crack. Bias identification, Identifying systematic errors or biases due to variations in lighting conditions, textures, or material properties. To enhance the interpretability of BCCD-YOLO’s predictions, several post-hoc interpretability techniques are considered.
-
1.
Visual analysis using Grad-CAM and feature heatmaps
Grad-CAM (Gradient-weighted Class Activation Mapping) highlights the most influential regions of an input image that contribute to crack classification. This technique enables real-time visualization of model attention, allowing engineers to verify whether the model is detecting meaningful crack features or being misled by background textures.
-
2.
SHAP (shapley additive explanations) for feature importance quantification
SHAP analysis provides a quantitative understanding of how different factors (e.g., crack width, material type, texture, and illumination) influence the final detection results. This analysis is particularly useful for identifying bias in low-contrast or hairline cracks, where the model may rely excessively on non-crack-related features.
-
3.
Misclassification and false detection analysis
Systematic evaluation of false positives (e.g., shadows mistaken for cracks) and false negatives (e.g., missed micro-cracks) can reveal deficiencies in the model. This process aids in fine-tuning data augmentation strategies and optimizing feature extraction layers.
-
4.
Uncertainty estimation using bayesian deep learning
Implementing Monte Carlo Dropout allows for quantification of the model’s uncertainty, which is critical in applications where false negatives (missed cracks) could lead to structural failures. Engineers can use uncertainty estimates to prioritize high-risk areas for further inspection.
While deep learning enhances detection accuracy, it lacks physical interpretability, which is crucial in civil engineering applications. To bridge this gap, future research will integrate physics-based crack propagation models with BCCD-YOLO.
Hybrid Data-Driven and Physics-Based Models, Combining deep learning detection outputs with Paris’ Law and fracture mechanics principles to predict crack growth behavior over time. Time-Series Analysis for Structural Health Monitoring, Leveraging interpretability techniques to analyze crack progression under different stress conditions.
The enhanced interpretability of BCCD-YOLO enables its direct deployment in engineering decision-making. Automated Crack Inspection Reports: Generating explainable detection summaries for infrastructure maintenance. Real-Time UAV Crack Detection: Deploying Grad-CAM-enhanced visualization in UAV-based inspections. Regulatory Compliance and Engineering Trust: Enabling engineers to justify AI-driven assessments to regulatory bodies.
Future research will focus on. Expanding interpretability frameworks for multi-material crack detection (e.g., steel vs. concrete). Developing a human-in-the-loop system where engineers can interactively refine AI-generated crack detection results. Investigating explainable AI (XAI) models that inherently integrate domain knowledge into the network architecture.
By integrating these techniques, BCCD-YOLO evolves from a black-box detection model to an interpretable, engineering-ready tool, capable of improving real-world structural integrity assessment.
Limitations and future work
Despite its effectiveness, the proposed model has certain limitations. The dataset does not encompass all real-world scenarios, such as extreme weather conditions, varied detection angles, and nighttime settings, which will be addressed in future studies. Limited data diversity constrains feature learning, necessitating improvements in data augmentation strategies. Additionally, deep feature map processing demands substantial computational resources, and BiFPN’s reliance on empirical tuning increases model storage requirements, training time, and potential risks of overfitting.
Balancing performance advantages with these limitations is crucial. While the ECA module enhances feature extraction, its effectiveness depends on the distribution of input features and may not generalize across all conditions. Similarly, the SA mechanism, while beneficial for capturing local dependencies, may overly rely on localized information, increasing the likelihood of missed detections or false alarms, particularly in scenarios requiring long-range context understanding.
By addressing these challenges, the BCCD-YOLO model can further enhance its applicability and reliability in real-world structural health monitoring, reinforcing its value in civil engineering applications.
Conclusions
This study introduced a building construction crack detection model designated as BCCD-YOLO to meet the command of the rapid and precise identification of construction crack. This methodology is predicated on the lightweight Yolov8n model, integrating the Weighted Bi-directional Feature Pyramid Network (Bi-FPN) as the feature fusion network in the neck to augment multi-scale feature fusion capability. Additionally, the introduction of novel EC2f and SAC2f structures serves to enhance the network’s feature fusion capability in complex backgrounds with a minimal increase in model parameters. This advancement improves the model’s ability to perceive local areas while facilitating the acquisition of broader contextual information, thereby significantly enhancing the network’s feature extraction capability. Future research endeavors will concentrate on employing more lightweight models while maintaining detection speed and accuracy, thereby broadening the model’s applicability and practical value.
Data availability
The data used in this study can be obtained from the corresponding authors.
References
Abdel-Qader, I., Abudayyeh, O. & Kelly, M. E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 17(4), 255–263 (2003).
Liu, J. et al. Automated pavement crack detection and segmentation based on two-step convolutional neural network. Comput.-Aided Civil Infrastruct. Eng. 35(11), 1291–1305 (2020).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. Commun. ACM 60(6), 84–90 (2017).
Nishikawa, T., Yoshida, J., Sugiyama, T. & Fujino, Y. Concrete crack detection by multiple sequential image filtering. Comput.-Aided Civil Infrastruct. Eng. 27(1), 29–47 (2012).
Brownjohn, J. M. Structural health monitoring of civil infrastructure. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 365(1851), 589–622 (2007).
Ullah, F., Sepasgozar, S. M., Thaheem, M. J. & Al-Turjman, F. Barriers to the digitalisation and innovation of Australian Smart Real Estate: A managerial perspective on the technology non-adoption. Environ. Technol. Innov. 22, 101527 (2021).
Cha, Y. J., Choi, W. & Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civil Infrastruct. Eng. 32(5), 361–378 (2017).
Liu, S. W., Huang, J. H., Sung, J. C. & Lee, C. C. Detection of cracks using neural networks and computational mechanics. Comput. Methods Appl. Mech. Eng. 191(25–26), 2831–2845 (2002).
Cheng, H. D., Chen, J. R., Glazier, C. & Hu, Y. G. Novel approach to pavement cracking detection based on fuzzy set theory. J. Comput. Civ. Eng. 13(4), 270–280 (1999).
El Adoui, M., Mahmoudi, S. A., Larhmam, M. A. & Benjelloun, M. MRI breast tumor segmentation using different encoder and decoder CNN architectures. Computers 8(3), 52 (2019).
Fan, Z. et al. Ensemble of deep convolutional neural networks for automatic pavement crack detection and measurement. Coatings 10(2), 152 (2020).
Ham, Y. & Kamari, M. Automated content-based filtering for enhanced vision-based documentation in construction toward exploiting big visual data from drones. Autom. Constr. 105, 102831 (2019).
Li, S. & Zhao, X. Image-based concrete crack detection using convolutional neural network and exhaustive search technique. Adv. Civil Eng. 2019(1), 6520620 (2019).
Fujita, Y. & Hamamoto, Y. A robust automatic crack detection method from noisy concrete surfaces. Mach. Vis. Appl. 22, 245–254 (2011).
Han, L., Liang, H., Chen, H., Zhang, W. & Ge, Y. Convective precipitation nowcasting using U-Net model. IEEE Trans. Geosci. Remote Sens. 60, 1–8 (2021).
Ullah, F., Sepasgozar, S. M., Shirowzhan, S. & Davis, S. Modelling users’ perception of the online real estate platforms in a digitally disruptive environment: An integrated KANO-SISQual approach. Telematics Inform. 63, 101660 (2021).
Koch, C., Georgieva, K., Kasireddy, V., Akinci, B. & Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 29(2), 196–210 (2015).
Ullah, F. & Al-Turjman, F. A conceptual framework for blockchain smart contract adoption to manage real estate deals in smart cities. Neural Comput. Appl. 35(7), 5033–5054 (2023).
Dinh, T. H., Ha, Q. P. & La, H. M. Computer vision-based method for concrete crack detection. In 2016 14th International Conference on Control, Automation, Robotics and Vision (ICARCV), 1–6 (IEEE, 2016).
Hoang, N. D. Image processing-based pitting corrosion detection using metaheuristic optimized multilevel image thresholding and machine-learning approaches. Math. Probl. Eng. 2020(1), 6765274 (2020).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 580–587 (2014).
Ren, S., He, K., Girshick, R. & Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2016).
He, H. et al. Mask R-CNN based automated identification and extraction of oil well sites. Int. J. Appl. Earth Obs. Geoinf. 112, 102875 (2022).
Swarna, R. A., Hossain, M. M., Khatun, M., Rahman, M. M. & Munir, A. Concrete crack detection and segregation: a feature fusion, crack isolation, and explainable AI-based approach. J. Imaging 10(9), 215 (2024).
Deng, L., Chu, H. H., Shi, P., Wang, W. & Kong, X. Region-based CNN method with deformable modules for visually classifying concrete cracks. Appl. Sci. 10(7), 2528 (2020).
Li, Q., Xu, X., Guan, J. & Yang, H. The improvement of Faster-RCNN crack recognition model and parameters based on attention mechanism. Symmetry 16(8), 1027 (2024).
Jiang, P., Ergu, D., Liu, F., Cai, Y. & Ma, B. A review of Yolo algorithm developments. Procedia Comput. Sci. 199, 1066–1073 (2022).
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y. & Berg, A. C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, 21–37 (Springer International Publishing, 2016).
Shamsoshoara, A. et al. Aerial imagery pile burn detection using deep learning: The FLAME dataset. Comput. Netw. 193, 108001 (2021).
Wang, Q., Wu, B., Zhu, P., Li, P., Zuo, W. & Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11534–11542 (2020).
Wang, C. Y., Bochkovskiy, A. & Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7464–7475 (2023).
Liao, Y. N. & Li, W. Bridge crack detection method based on convolution neural network. Comput. Eng. Des. 42, 2366–2372 (2021).
Cai, F. H., Zhang, Y. X. & Huang, J. A bridge surface crack detection algorithm based on YOLOv3 and attention mechanism. Pattern Recogn. Artif. Intell. 33(10), 926–933 (2020).
Yu, J., Liu, B., Yin, D., Gao, W. & Xie, Y. Bridge crack intelligent recognition and measurement based on YOLOv5 and UNet3+. J. Hunan Univ. 50, 65–73 (2023).
Tan, G. J., Ou, J., Ai, Y. M. & Yang, R. C. Bridge crack image segmentation method based on improved DeepLabv3+ model. J. Jilin. Univ 52, 1–7 (2022).
Liu, Y. et al. Rotating target detection method of concrete bridge crack based on YOLO v5. Appl. Sci. 13(20), 11118 (2023).
Dong, X., Liu, Y. & Dai, J. Concrete surface crack detection algorithm based on improved YOLOv8. Sensors 24(16), 5252 (2024).
Saydirasulovich, S. N., Mukhiddinov, M., Djuraev, O., Abdusalomov, A. & Cho, Y. I. An improved wildfire smoke detection based on YOLOv8 and UAV images. Sensors 23(20), 8374 (2023).
Lin, T. Y., Dollár, P., Girshick, R., He, K., Hariharan, B. & Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2117–2125 (2017).
Liu, S., Qi, L., Qin, H., Shi, J. & Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 8759–8768 (2018).
Qian, Q., Chen, L., Li, H. & Jin, R. Dr loss: Improving object detection by distributional ranking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12164–12172 (2020).
Lin, Z., Wang, Y., Zhang, J. & Chu, X. Dynamicdet: A unified dynamic architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6282–6291 (2023).
Chiley, V. et al. RevBiFPN: the fully reversible bidirectional feature pyramid network. Proc. Mach. Learn. Syst. 5, 625–645 (2023).
Liu, W., Quijano, K. & Crawford, M. M. YOLOv5-Tassel: Detecting tassels in RGB UAV imagery with improved YOLOv5 based on transfer learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 15, 8085–8094 (2022).
Wang, C. et al. A low-altitude remote sensing inspection method on rural living environments based on a modified YOLOv5s-ViT. Remote Sens. 14(19), 4784 (2022).
Abou-Zeid, M., Fowler, D. W., Nawy, E. G. & Allen, J. H. Control of Cracking in Concrete Structures (ACI Report 224R-01) (American Concrete Institute, 2001).
Lee, J. S., Hwang, S. H. & Choi, I. Y. Estimation of crack width based on shape-sensitive kernels and semantic segmentation. Struct. Control. Health Monit. 27(2), e2504 (2020).
Gilbert, I. Shrinkage, cracking and deflection—the serviceability of concrete structures. Electron. J. Struct. Eng. 1, 1–12 (2001).
Yamaguchi, T. & Hashimoto, S. Practical image measurement of crack width for real concrete structures. Electron. Commun. 93(8), 1016–1024 (2009).
Acknowledgements
The authors would like to thank the editors and anonymous reviewers for their helpful suggestions.
Funding
This work is supported by the Research Program for Science and Technology of Inner Mongolia Autonomous Region in University (NJZY22388) and the Basic Research Program for Directly Affiliated Universities in Inner Mongolia Autonomous Region (JY20230007).
Author information
Authors and Affiliations
Contributions
Conceptualization, Z.Z.; formal analysis, W.R.; methodology, W.R. and Z.Z.; software, W.R.; validation, Z.Z.; writing—original draft, W.R.; writing—review and editing, Z.Z.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ren, W., Zhong, Z. Building construction crack detection with BCCD YOLO enhanced feature fusion and attention mechanisms. Sci Rep 15, 23167 (2025). https://doi.org/10.1038/s41598-025-05665-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-05665-y
Keywords
This article is cited by
-
A lightweight YOLO11n seg framework for real time surface crack detection with segmentation
Scientific Reports (2026)
-
A lightweight crack segmentation network based on the importance-enhanced Mamba model
Scientific Reports (2025)
