
Abstract
The circulation of prohibited and restricted goods in online transactions seriously violates consumer rights and threatens public safety. However, the lack of a dataset for prohibited and restricted goods makes it difficult to regulate such illegal online transactions. Therefore, a multimodal dataset for prohibited and restricted goods is proposed, including 38,513 images and 77,026 texts. Nevertheless, because of the diversity and potential adversarial modifications of prohibited and restricted goods, intelligent recognition of such items still faces significant challenges. Thus, an image editing framework for prohibited and restricted goods in online transactions is proposed. This framework integrates three novel components: (1) a PR-adapter that optimizes image prompts through image augmentation and compression representation techniques; (2) a text description generator combining the CLIP model and a multimodal large language model (MobileVLM) to generate more precise textual descriptions of images; and (3) an image generator, including a new loss function designed to fine-tune the stable diffusion model, enabling a better understanding of text semantics and generating images that more closely align with the textual descriptions. Experimental results show that this framework can generate diverse and accurate images of prohibited and restricted goods, effectively enhancing the development of intelligent supervision for online transactions.
Similar content being viewed by others

Introduction
With the rapid development of e-commerce, online platforms have significantly facilitated the swift circulation and trading of goods, making online transactions a vital component of modern commerce1,2,3. However, the anonymity and convenience of online platforms also create opportunities for illegal transactions, particularly those involving prohibited and restricted products. These products include, but are not limited to, controlled knives, firearms, and protected animals. The illicit trade of such goods not only infringes on consumer rights but also poses a severe threat to public safety and social order4. Although deep learning-based image recognition techniques have shown promising performance in general object classification tasks, a lack of data on prohibited and restricted products greatly hinders research on identification technology, making intelligent recognition difficult and regulatory enforcement a significant challenge5,6,7.
To effectively regulate illegal online transactions, Nali et al.8 introduced a keyword detection method to identify online sales of tobacco and cannabis. Yao et al.9 proposed an N-type encoding structure that broadens the network’s receptive field, enhancing detection across seven categories of prohibited products. Xu et al.10 combined machine learning with supplementary analysis to detect keywords associated with ivory and pangolins, incorporating known euphemisms. An automated system was developed to detect illegal ivory products sold on eBay11. Further, numerous deep learning-based methods have been proposed for identifying illicit goods in online transactions12,13,14. However, these methods primarily rely on image- or text-based detection techniques to independently monitor the illegal trade of prohibited and restricted products on e-commerce platforms15,16,17,18. In addition, these methods are limited by the size and category coverage of existing datasets. Currently, no comprehensive dataset fully encompasses all prohibited and restricted product categories, hindering the widespread application and advanced research of these technologies. To this end, this paper proposes a large-scale multimodal dataset for the prohibited and restricted goods in online transactions. The dataset contains 10 major categories and 115 subcategories of prohibited and restricted products, totaling 38,513 images and 77,026 texts. However, since the prohibited and restricted goods in online transactions are of many types and diverse styles and are hidden deeply, it is difficult to achieve intelligent identification and effective supervision relying solely on this dataset.
Therefore, a multimodal image editing framework for prohibited and restricted goods in online transactions is proposed. The framework consists of the PR-adapter, a text description generator, and an image generator. The proposed PR-adapter comprises image augmentation and image compression representation modules, which enhance the input images through Grayscale, Gaussian blur, Gaussian noise addition, and elastic transformation while also compressing image representations1. The proposed text generator integrates the CLIP model19 and a multimodal large language model (MobileVLM)20. Using the text generator, accurate and detailed textual descriptions can be generated for prohibited and restricted product images21. Compared to previous image description methods22,23,24,25,26,27,28,29,30, the proposed text generator leverages the text generation capabilities of multimodal large language models and the cross-modal capabilities of CLIP, enabling more accurate recognition of the categories of prohibited and restricted goods images and the generation of precise textual descriptions. The image prompts obtained via the PR-adapter, combined with the text prompts, improve the quality of prompts fed into the image generator, producing more accurate and diverse images of prohibited and restricted products. In addition, to better comprehend text semantics and generate more accurate images aligned with textual descriptions, a new loss function has been proposed for training the stable diffusion model (SDM)31 in the image generator. The framework utilizes the text prompts and the PR-adapter to edit input images, increasing the diversity of images of prohibited or restricted goods in online transactions. The experimental results demonstrate that the proposed framework can generate diversified images of prohibited and restricted products that are consistent with textual descriptions yet distinct from the original images, further enriching the dataset. We believe that the proposed image generation framework and multimodal dataset can promote intelligent identification and effective regulation of online trading of prohibited and restricted products.
To sum up, the main contributions of this article are as follows:
-
A large-scale multimodal dataset for prohibited and restricted products of illegal online transactions is constructed.
-
An image editing framework is proposed for prohibited and restricted products in online trading. This framework includes the PR-adapter, a text description generator, and an image generator. In addition, a novel loss is proposed to fine-tune SDM to better understand text information and generate more accurate images.
-
A series of experiments have been conducted on the proposed dataset. The experimental results demonstrate the effectiveness and superiority of the proposed image editing framework. Furthermore, a benchmark has been constructed on the proposed dataset for identifying prohibited and restricted goods in online transactions.
Related work
Overview of online transaction product dataset
Multimodal datasets for online transactions have gained increasing importance in recent years. They integrate different types of media data to provide richer and more comprehensive information in fields like e-commerce, online advertising, and social media analysis. To advance the development of e-commerce and online transactions, the Product1M dataset32 was created as one of the largest multimodal cosmetics datasets for real-world instance-level retrieval. To improve food classification, the FoodX-251 dataset33 was proposed. This dataset contains 158,000 images of 251 fine-grained food categories collected from the web. For cross-domain retrieval of products and micro-videos, the PKU Real20M dataset34 was developed as a large-scale e-commerce dataset specifically designed for cross-domain retrieval. To capture complementary semantic information from different modalities of products in online transactions, the large-scale M5Product multimodal pre-training dataset35 was proposed. Additionally, many other multimodal datasets for online transactions36,37,38,39,40 have been introduced for product classification, matching, detection, and personalized recommendations to help researchers and companies better understand user consumption habits, emotional responses, and product preferences. These datasets (as shown in Table 1) have significantly promoted research and application of multimodal machine learning and deep learning in online transactions.
However, most of them focus on compliant and legal online transactions, and no large-scale multimodal dataset is currently available to address the illicit transactions occurring on these platforms. Therefore, this paper proposes the first multimodal dataset for prohibited and restricted products in online transactions. It is believed that this dataset will facilitate intelligent identification and effective regulation of illegal online trading practices.
Image generation methods
In recent years, image generation technology based on diffusion models has developed rapidly and has demonstrated significant progress in various fields41,42,43,44. Diffusion models can generate very high-quality images that closely resemble real ones in both detail and overall structure, demonstrating remarkable results22,45,46,47,48. Since probabilistic diffusion models were introduced to image generation, many excellent methods have emerged. Ho et al.49 proposed the Denoising Diffusion Probabilistic Model (DDPM), based on probabilistic diffusion models, which introduced new parameterization and sampling strategies, showcasing competitive performance against Generative Adversarial Networks (GANs). Nichol and Dhariwal50 advanced this work with the Denoising Diffusion Implicit Model (DDIM), significantly reducing sampling steps and solidifying diffusion models as a robust alternative to GANs. Rombach et al.31 proposed Latent Diffusion Models, which improved computational efficiency by operating in low-dimensional latent space, enhancing applicability to tasks like text-to-image generation. Dhariwal et al.51 also introduced a conditional diffusion model based on text descriptions, providing a powerful tool for creative applications. Furthermore, Kim et al.52 applied pseudo-labeling and deep-domain diffusion prior techniques during the sampling phase, allowing generated images to self-regulate and align with the estimated depth map. To produce more accurate images, Vahdat et al.53 proposed Latent Score-based Generative Model (LSGM). Du et al.54 proposed a flexible diffusion model, which is a universal framework for parameterized diffusion models. The comparison of these methods is illustrated in Table 2. Furthermore, a series of methods55,56,57,59,60 were proposed to combine multiple models and improved sampling algorithms to enhance image generation quality. However, these methods still face significant challenges in terms of image accuracy. Additionally, they have not fully utilized prompts (including images and text) for new image generation. Therefore, this paper proposes a new image generation framework, PRIG.
Methodology
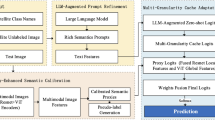
The structure of the proposed framework PRIG for generating images of prohibited and restricted goods in online transactions is shown in Fig. 1. It consists primarily of three components: the PR-adapter, the text generator, and the image generator.

The structure of the proposed framework PRIG.
PR-adapter
To better construct image prompts for generating images of prohibited and restricted goods, the PR-adapter is proposed. The design of the PR-adapter is motivated by the need to address two core challenges in generating images of prohibited and restricted goods: limited diversity in existing image datasets and the risk of overfitting to superficial features. Traditional image augmentation alone may increase diversity but cannot address the semantic compression issue. However, relying only on feature extractors such as CLIP may cause a loss of local visual cues. Therefore, we combined both strategies: augmentation to enrich diversity and compression to enhance abstract representation. This dual approach allows the generator to focus on high-level features while maintaining generalization capabilities. In addition, several alternative approaches were considered. For example, one option was to use only the CLIP image encoder to generate prompts directly from the raw image without the augmentation and compression modules. However, such prompts were overly biased toward dominant image features, resulting in repetitive outputs. Another option was to apply traditional augmentation techniques and concatenate the features directly. However, this method often led to redundant representations and did not effectively improve the diversity or semantic quality of generated images. Our PR-adapter overcomes these limitations by jointly optimizing augmented and compressed embeddings, thereby enabling the generation module to produce more realistic and semantically accurate images. The structure of PR-adapter is shown in Fig. 2. It consists primarily of an image augmentation module and an image compression representation module. The image augmentation module is primarily used to augment the original input images, increasing the diversity of prohibited and restricted product images. To prevent the model from simply memorizing the superficial features of the images, the image compression representation module is designed. This module compresses both the original and augmented input images to enable a deeper understanding of the images61. The image compression representation module not only significantly reduces the amount of data processed by the model but also allows it to extract and utilize more abstract, high-level features from the prohibited and restricted images, ultimately enhancing the diversity of the generated images. The calculation of the images in the PR-adapter is shown as follows:
where \(I_{img}\) is the input original prohibited and restricted product image; \(Aug( \cdot )\) is the calculation of the image augmentation methods; \(N\) is the image obtained using the image augmentation methods; \(CLIP( \cdot )\) is the calculation of the enhanced image by the CLIP image encoder; \(E_{N}\) is the embedding of the enhanced image obtained by the CLIP image encoder; \(E_{in}\) is the embedding of the original input image obtained through the CLIP image encoder; \(\alpha\) and \(\beta\) are the weights of the original input image embedding and the enhanced image embedding, respectively; \(E_{img}\) is the sum of the original input image embedding and the enhanced image embedding; \(mlp( \cdot )\) is the calculation of the Linear layer and Layer Normalization layer in the image compression representation module; and \(E_{f}\) is the image embedding output by the image compression representation module.

The structure of the proposed PR-adapter.
Image augmentation
To increase the diversity of generated images, image augmentation is performed in the PR-adapter on each collected image of prohibited and restricted goods. Image augmentation includes four methods: Grayscale, Gaussian blur, adding Gaussian noise, and Elastic transformation. The explanation of these image augmentation methods is as follows:
Grayscale. Remove color information from color images of prohibited and restricted products, leaving only brightness information. This allows focusing on the structural and shape information of the image. Its calculation is as follows:
where \(R\), \(G\), and \(B\) represent the values of the red, green, and blue channels, respectively; \(\lambda_{1}\), \(\lambda_{2}\), and \(\lambda_{3}\) represent the weight of different colors, respectively; and \(Y\) is the calculated gray value.
Gaussian blur. The image is smoothed by applying a Gaussian function as a weight kernel. Gaussian blur can effectively reduce image noise and details, and its calculation is as follows:
where \(x\) and \(y\) represent the horizontal and vertical distances from the pixel point \((i,j)\), respectively; and \(\sigma\) controls the size of the Gaussian kernel and the degree of its smoothing effect.
Adding Gaussian noise. By adding randomly generated Gaussian distributed values to the pixel values of the image, the robustness of the image can be increased. The calculation for Adding Gaussian noise is as follows:
For an image pixel \(p\), the pixel value \(p^{\prime}\) after adding noise can be expressed as:
where \(p\) is the image pixel and \(z\) is a random sample drawn from the Gaussian distribution \(N(0,\sigma^{2} )\).
Elastic transformation. It increases the diversity of the image by simulating local distortion of the image, and is calculated as follows:
where \((x,y)\) represents the pixel coordinates in the original image; \(dx\) and \(dy\) represent randomly generated random fields used to describe the pixel displacement in the \(x\) and \(y\) directions, respectively; \(\sigma\) is the standard deviation used for the Gaussian filter; \(\alpha\) is a coefficient that controls the intensity of deformation; \(G(dx,\sigma )\) and \(G(dy,\sigma )\) represent the smooth displacement field obtained after applying Gaussian filtering; and \((x^{\prime},y^{\prime})\) represents the new pixel position after deformation.
Image compressed representation
To minimize the irrelevant information of non-prohibited and restricted products in images while preserving the critical and semantic content of prohibited and restricted products as much as possible, we employ a pre-trained CLIP image encoder19 to compress the representations of input images. However, this high-compression method often overlooks some details of the prohibited and restricted products, leading to the loss of semantic information. To address this, we employ image enhancement techniques to retain as many details of prohibited and restricted products as possible. Furthermore, we compress both the original input images and the enhanced images together to obtain a shared representation vector. Specifically, during the image compression representation process, all enhanced images of size 416 × 416 × 3 and the original input are first resized to a uniform 224 × 224 × 3. Then, using the pre-trained CLIP image encoder, these 224 × 224 × 3 images are compressed into 1024-dimensional vectors. A weighted sum of these vectors is then computed to form the image prompts that are input to the image generator.
Text description generator
When generating textual descriptions for prohibited and restricted product images, directly using a multimodal large language model is a good approach. However, multimodal large language models exhibit low accuracy in recognizing prohibited and restricted product images. Thus, this work introduces a textual description generator combining CLIP and the multimodal large language model. Its structure is shown in Fig. 3. The textual description generator mainly consists of the CLIP model and the multimodal language model MobileVLM20. The CLIP model and predefined textual category prompt templates are utilized to match the prohibited and restricted product categories, generating a simple textual description of the item’s category. This basic description is then employed as a prompt for the MobileVLM model to obtain a more accurate and detailed textual description of the prohibited and restricted goods.

The structure for text description generator of the proposed PRIG.
Category image-text matching
To improve the accuracy of the multimodal large language model MobileVLM in recognizing prohibited and restricted product categories and generating more accurate and detailed descriptions, predefined textual prompt templates and the CLIP model are introduced. Leveraging the zero-shot capability of CLIP and a predefined list of prohibited and restricted product categories, we perform image-to-text category matching21. The CLIP image encoder and text encoder map both the prohibited and restricted product images and category texts into the same multidimensional space, where images and texts of the same category are placed close to each other. The resulting category text that is closest to the input image, combined with a predefined textual prompt template, forms a simple textual prompt. The matching between prohibited and restricted product images and category texts via CLIP is computed as follows:
where \(I_{img}\) is the input image; \(CLIP_{i} ( \cdot )\) is the calculation of CLIP image encoder; \(v\) is the image embedding output by the image encoder; \(T_{i}\) is the \(i\)-th prohibited and restricted product category; \(CLIP_{t} ( \cdot )\) is the calculation of CLIP text encoder; \(t_{i}\) is the text embedding output by the encoder; \(S_{i}\) is the the cosine similarity for \(v \,\) and \(t_{i}\); and \(C_{img}\) is the predicted prohibited and restricted product category with the highest probability.
Text description generation
In the proposed PRIG framework, MobileVLM, a multimodal large language model MobileVLM20, is selected for precise textual description of images. However, the recognition accuracy of MobileVLM for prohibited and restricted product categories is low and prone to recognition errors. Therefore, the simple text description of prohibited and restricted product categories obtained from CLIP19 is utilized as a prompt to improve the recognition accuracy of multimodal large language models. The structure of MobileVLM is illustrated in Fig. 4. MobileVLM comprises a visual encoder, a lightweight large language model named MobileLLaMa, and an efficient projector known as the Lightweight Downsample Projector (LDP) for aligning visual and textual spaces. The calculation for generating accurate and detailed textual descriptions by inputting simple category texts and images of prohibited and restricted products into MobileVLM is as follows:

The structure of the MobileVLM is shown in the left and the right is the structure of the LDP.
Image encoding:
where \(X_{img}\) represents the input image of prohibited and restricted goods; \(VE( \cdot )\) represents the calculation of the visual encoder; and \(E_{V}\) represents the image embedding obtained through the visual encoder.
Text encoding:
where \(X_{text}\) represents a simple text prompt entered into MobileVLM regarding prohibited and restricted product categories; \(TK( \cdot )\) represents the calculation of tokenizer; and \(E_{T}\) represents the text embedding obtained through Tokenizer.
Visual representation compression and projection: LDP implements linear transformation, nonlinear transformation, and spatial downsampling of visual features through point-by-point convolution, GELU activation function, and depth-wise convolution (with strides of 1 and 2), thereby effectively compressing visual tokens and aligning them to the format required by the language model. The calculation of LDP is as follows:
where \(PW( \cdot )\) is the calculation of the pointwise convolution; \(GELU( \cdot )\) is the calculation of the activation function; \(E_{{V_{0} }}\) is the output visual representation for the first block of LDP; \(DW( \cdot )\) is the calculation of the depthwise convolution; \(DW( \cdot )\) is the calculation of layer normalization; \(E_{{V_{1} }}\) is the visual representation obtained by residual calculation; \(LN( \cdot )\) is the calculation of layer normalization; and \(E_{{V^{\prime}}}\) is the visual representation of the final output of the LDP.
where \(p(D|E_{{V^{\prime}}} ,E_{T} )\) is the conditional probability of generating the image description \(D\); \(L\) is the length of the generated image description \(D\); \(d_{i}\) is the \(i\)-th generated token in the image description; and \(d_{ < i}\) is all the tokens generated before the \(i\)-th token in the image description, which is used to guide the generation of the next token.
Image generator
The structure of the image generator for prohibited and restricted goods is mainly based on the SDM. The SDM based image generator is a complex generative model that includes two processes: diffusion and denoising. During the diffusion process, noise is gradually added to the data using Markov chains to convert a clear image into noise. During this process, no image prompts or text prompts will be used. The calculation of this process is as follows:
Initialize image: Assuming the original input image is \(X_{0}\), which is usually a clean and noise free image.
Gradually add noise: Between time steps \(t = 1\) to \(T\), the model gradually adds Gaussian noise to the image. The addition of noise at each time step can be viewed as a Markov process, where the image \(X_{t}\) at a later time step only depends on the image \(X_{t - 1}\) at the previous time step. The process is calculated as follows:
where \(\beta_{t}\) is a time step-dependent hyperparameter, which controls the amount of noise added at each step; \(I\) is the identity matrix; after \(T\) steps, the image \(X_{t}\) is almost completely occupied by noise, and the forward process is completed; \(q(X_{t} |X_{t - 1} )\) represents the transition probability density function from time step \(t - 1\) to time step \(t\); and \({\mathcal{N}}\) represents the multivariate normal distribution.
Denoising is the inverse process of diffusion, and its goal is to restore the original, meaningful image from the noise state. At this stage, text cues and image cues are used as conditions to guide the generation of images, which are calculated as follows:
where \(\varepsilon_{\theta } (x_{t} ,t,c)\) is the noise predicted by the neural network; \(x_{t}\) is the current noise image state; \(t\) is the current time step; \(c\) is the embedding vector generated using text prompts and image prompts as conditional input; and \(\alpha_{t}\) is the control Noise level parameters.
To generate more accurate images that allow the image generator to fully understand the semantics of the prompt text, a new loss function \(L_{PRIG}\) is utilized when training the restricted product generator and PR-adapter together. This loss function enables the model to understand text semantics better and retain each textual concept information as much as possible while reducing the semantic overlap of multiple text concepts in the detailed description text of prohibited and restricted product images generated by MobileVLM. It is proposed due to the loss of semantics of textual concepts. By using this loss function, the controllability of text input to the generator can be enhanced to generate better images of prohibited and restricted products that are more in line with text prompts. The total loss function \(L_{PRIG}\) of the image generator is calculated as follows:
where \(\varepsilon\) is the actual noise, \(\varepsilon_{\theta }\) is the noise predicted by the model, \(x_{t}\) is the noise image of the current step, \(t\) is the time step, \(c\) is the condition information (such as text embedding); and \(L_{1}\) is the Loss of SDM.
where \(t\) is the time step; \(K\) is all the text concepts in the text description of the prohibited and restricted image, \(F_{t}^{x}\) and \(F_{t}^{y}\) are a pair of cross attention maps at the time step \(t\), \(x,y \in K\); \([F_{t}^{x} ]_{ij}\) is the pixel value at position \((i,j)\); and \(L_{2}\) is the text concept overlap loss.
where \(G_{t}^{x}\) represents the real value; \(F_{t - 1}^{x}\) represents the attention map of the next time step; and \(L_{3}\) is the text concept retention loss.
where \(L_{PRIG}\) is the Loss of the image generator; \(\alpha\), \(\beta\), and \(\gamma\) are the weight parameters of \(L_{1}\), \(L_{2}\), and \(L_{3}\), respectively.
PRIG
The proposed image generation framework for prohibited and restricted goods, PRIG (as shown in Fig. 1), consists of a PR-adapter, a text description generator, and an image generator. This PR-adapter consists of an image augmentation module and an image compression representation module. The image augmentation module can increase the diversity of images of prohibited and restricted products. The image compression representation module can reduce the irrelevant information of prohibited and restricted products in the image, and preserve the semantic information of prohibited and restricted products as much as possible. The text description generator consists of the CLIP and the multimodal large language model MobileVLM. To solve the problem of low accuracy in recognizing images of prohibited and restricted goods in online transactions using multimodal large language models, a simple text prompt template and the powerful zero sample ability of the CLIP are utilized to obtain a simple text description of the categories of prohibited and restricted goods. Then the simple category text description is input as a prompt into the multimodal large language model MobileVLM, so that MobileVLM can provide extremely accurate detailed descriptions of prohibited and restricted product images. This text description, along with the image prompts obtained through PR-adapter, can be input into the image generator to obtain more accurate and more diverse images of prohibited and restricted products. The calculation of the entire process of the proposed framework PRIG is as follows:
where \(I_{img}\) is the input prohibited and restricted product image; \(Augs( \cdot )\) represents the calculation of image augmentation methods; \(N_{img}\) represents the enhanced images; \(CR( \cdot )\) represents the calculation of the image compression representation module; \(E_{image}\) represents the output image prompt of the image compression representation module; \(\lambda\) and \(\gamma\) represent the weight parameters of the input image and the enhanced images, respectively; \(C_{class}\) is the categories of prohibited and restricted goods; \(CLIP( \cdot )\) represents the calculation of CLIP; \(D{(} \cdot )\) represents the predefined prompt template; \(T_{1}\) is a simple text prompt about the prohibited and restricted categories obtained by CLIP and the predefined text prompt template; \(MVLM( \cdot )\) is the calculation of MobileVLM; \(T_{2}\) is the more accurate text description of prohibited and restricted products obtained through MobileVLM; \(IG( \cdot )\) represents the calculation of the prohibited and restricted product image generator;and \(I_{new}\) represents the new generated image.
Dataset
Data collection
To address the issue of missing datasets for prohibited and restricted goods for online transactions, a category list of prohibited and restricted goods was constructed based on the laws and regulations formulated by relevant departments, as well as the clear categories of prohibited and restricted goods on multiple e-commerce platforms. The category list (as shown in Table 3) consists of 10 major categories and 115 subcategories of prohibited and restricted goods (including firearms, controlled knives, bank cards, protected animals, and others). According to this list of prohibited and restricted products, professionals have collected a large number of images on multiple online trading platforms and other information search platforms using manual collection and automated crawler tools. To remove irrelevant images, professionals utilize automated tools combined with manual review methods. Initially, the automated software and scripts are utilized to perform preliminary filtering on the collected images, filtering out those that are repetitive or highly overlapping in content. Subsequently, each image is manually reviewed and the images unrelated to prohibited or restricted product categories are deleted. Finally, all the collected images are resized to a uniform size of 416 × 416 pixels. As a result, a prohibited and restricted product dataset is obtained comprising 38,513 high-quality images, standardized in size and format. Some sample images of prohibited and restricted products from this dataset are shown in Fig. 5.

Some sample images of the proposed of prohibited and restricted goods dataset.
Data annotation
After completing data collection, 30 professionals were assigned to annotate the collected data to construct a multimodal dataset for the identification and regulation of prohibited and restricted goods in online transactions. The 30 professionals were divided into 10 groups, with three members per group. Each group annotated and reviewed the same batch of data to ensure consistency and accuracy in the annotations. In this dataset, each image of prohibited and restricted goods is accompanied by two types of text descriptions: a simple category description and an accurate, detailed description. The first type, the simple category description, was generated using the powerful zero-shot capabilities of the CLIP model combined with predefined descriptive templates. Then, incorrect category descriptions are manually checked and corrected. The second type, the accurate detailed description, was derived by prompting a multimodal large language model (Qwen) with the simple category description. Both types of text descriptions were reviewed by professionals, and any incorrect descriptions were corrected. A portion of the image-text samples from the dataset is shown in Fig. 6. Additionally, to facilitate the training of the prohibited and restricted goods recognition model, the open-source image annotation tool LabelImg was used to label the collected images, specifying the category and location of the prohibited and restricted items within the images. The labels for prohibited and restricted goods and their corresponding images were then formatted in the same way as the Pascal VOC dataset for training detection models. Fleiss’ Kappa was employed to evaluate annotation consistency. The Fleiss’ Kappa value for consistency in the detailed text descriptions was 0.58, and the Fleiss’ Kappa value for image annotations was 0.81.

Some examples of image and text samples in the proposed dataset.
Data statistics
The constructed dataset of prohibited and restricted goods consists of 10 major categories and 115 subcategories. This dataset consists of 38,513 images of prohibited and restricted products and corresponding 77,026 texts. This multimodal dataset also includes annotations for the category and location information of prohibited and restricted products in each image. In this dataset, an image of a prohibited or restricted product corresponds to a simple text description, a detailed text description, and a label used for the detection task of prohibited or restricted products. The quantity of prohibited and restricted goods in different categories in this dataset is shown in Fig. 7. From Fig. 7, it can be observed that the quantity of"hazardous control equipment"in the dataset is relatively high, whereas the quantities of certain other categories of restricted commodities are much smaller compared to this category. This indicates the presence of a class imbalance issue in the dataset.

The quantity of various prohibited and restricted product categories.
Experiments and results
Experimental settings
To effectively evaluate the proposed image generation framework and the dataset for prohibited and restricted goods, we conducted a series of experiments. All experiments were conducted on a server equipped with a GPU. The operating system of this server is Ubuntu 20.04. The graphics card model is NVIDIA A100, and the graphics memory size is 80 GB. All experiments were implemented based on Python and PyTorch. Due to the limitation of computing resources, the manual tuning method was used to select parameters. The image generator adopts a pre-trained stable diffusion model. The proposed PR-adapter and image generator were trained on this server for 100 epochs. The size of the input image is 416 × 416 × 3. The batch size is 8. AdamW is selected as the optimizer. The learning rate is 0.0001. The weight decay is 0.01. For the task of classifying prohibited and restricted goods, the main hyperparameter settings are as follows: The size of all input images is 416 × 416; the number of epochs trained is 500; the optimizer is SGD; the learning rate is 0.01; and the weight decay is 0.0001. For detection tasks, the main hyperparameter settings are as follows: The size of all input images is 416 × 416; the number of epochs trained is 100; the optimizer is Adam; and the learning rate is 0.0001.
Evaluation metrics
To better evaluate the constructed dataset of prohibited and restricted goods and verify its accuracy in identifying prohibited and restricted goods on e-commerce platforms, 14 advanced classification models and 12 object detection algorithms were selected to test the dataset. To accurately test the performance of each classification model in this dataset, Accuracy, Precision, Recall, and F1-score were used as evaluation metrics. To better test the performance of the detection algorithm, Precision, Recall, F1-score, AP, and mAP were selected as evaluation metrics. Furthermore, to accurately evaluate the performance of the proposed text description generator, BLEU (Bilingual Evaluation Understudy) was selected, which measured the performance of the text description generator by calculating the n-gram accuracy between the generated text and the manually annotated text. The calculation of these evaluation metrics is as follows:
where \(TP\) is the number of correctly identified positive samples; \(FP\) is the number of negative samples that are incorrectly identified as positive samples; \(FN\) is the number of positive samples that are incorrectly identified as negative samples; \(TN\) is the number of samples that are correctly identified as negative samples; \(A\) is Accuracy, which is the proportion of samples correctly identified as restricted or prohibited goods in the total sample size; \(P\) is Precision, which represents the proportion of samples correctly identified as positive classes among all samples that are actually positive classes; \(R\) is Recall, which represents the proportion of samples correctly identified as positive classes among all samples that are actually positive classes; \(F\) is F1-score, which is the harmonic mean of Precision and Recall; \(p_{smooth}\) is the Precision-Recall curve after smoothing; \(AP\) is the average precision rate for a single category at all different recall rates; \(n\) represents the number of categories; \(AP_{i}\) is the \(AP\) value for the \(i\)-th category; \(mAP\) is the average \(AP\) value of all categories; \(BLEU\) is the final BLEU score; \(BP\) is the length penalty; \(M\) is the maximum n-gram value, which represents the accuracy of calculating 1-g to 4-g; \(P_{m}\) represents the proportion of \(m\)-grams that match the generated text and the human annotated text; \({\text{len}}(gen)\) is the length of the generated text; \({\text{len}}(ann)\) is the length of the human annotation text; \(\sum\limits_{c \in C} {{\text{count}}_{match} } (c)\) is the number of n-gram matches in the generated text with the human annotated text; \(\sum\limits_{c \in C} {{\text{count}}_{gen} } (c)\) represents the total number of n-grams in the generated text; and C represents all possible n-gram combinations.
Classification results
To validate the effectiveness of the proposed dataset, 14 popular state-of-the-art (SOTA) classification models were selected for testing. The experimental results are shown in Table 4, where ConvNeXt achieved the best performance compared to other classification models, with an Accuracy value of 88.07%. The Precision, Recall, and F1-score values are 85.15%, 82.01%, and 83.05%, respectively, which are higher than other classification models. The performance of AlexNet is the worst, with the lowest Accuracy value of only 77.67%. In addition, the values of Precision, Recall, and F1-score of AlexNet are also the lowest, with values of 70.55%, 69.16%, and 69.20%, respectively. The values of Accuracy for EfficientNet, EfficientNetV2, ResNeXt50, SEResNet50, ShuffleNetV1, ShuffleNetV2, and Swin Transformer are 85.87%, 85.36%, 85.68%, 85.96%, 86.56%, 86.67%, and 85.96%, respectively. These models have an accuracy rate of over 85.00% and have achieved good recognition performance on the proposed dataset for identifying prohibited and restricted goods images. The values of Accuracy for VGG, ResNet50, and Vision Transformer are relatively low, at 82.07%, 80.19%, and 79.03%, respectively. The experimental results of classification have demonstrated the availability and effectiveness of the constructed image dataset of prohibited and restricted goods.
Detection results
To better evaluate the proposed dataset of prohibited and restricted products, 12 popular SOTA detectors are selected and tested on this dataset, and the experimental results are presented in Table 5. Among these models, SSD achieved the highest mAP value on this dataset, with a value of 91.48%. YOLOv7 performed closely to SSD, with an mAP value of 90.97%. Following closely were EfficientDet-D0, Faster R-CNN, RetinaNet, YOLOv3, YOLOv5-X, and YOLOv8-N, with mAP values of 87.87%, 89.82%, 87.10%, 87.77%, 88.17%, and 88.96%, respectively. All the detectors achieved mAP values above 85.00%, slightly below SSD and YOLOv7. CenterNet, YOLOv4, YOLOv7-tiny, and YOLOX-N obtained mAP values of 82.67%, 82.18%, 81.82%, and 82.53%, respectively, with their mAP values all below 85.00%. YOLOv7-tiny achieved the lowest mAP value at 81.82%. On this dataset, both SSD and YOLOv7 achieved mAP values exceeding 90.00%, with their parameter sizes being relatively close, at 38.85 MB and 37.81 MB, respectively. Although SSD has 1.04 MB more parameters than YOLOv7, its computational complexity is 34.96 GFLOPs lower than YOLOv7. This indicates that SSD has the best overall performance on the proposed dataset and is highly suitable for detecting prohibited and restricted products in online transactions. In situations with limited computational resources, EfficientDet-D0 and YOLOX-N are more suitable, with computational complexities of 5.45 GFLOPs and 2.67 GFLOPs, respectively. These models are more suitable for detecting prohibited and restricted product images on mobile devices and lightweight devices.
Results of text description generator
To evaluate the performance of the designed text generator, experiments were conducted on the proposed dataset. The experimental results are shown in Table 6. In general, leveraging large multimodal language models’ powerful image description capabilities is a promising approach. However, this solution is relatively simplistic. Without any data fine-tuning, MobileVLM achieved an accuracy of only 7.50% in identifying prohibited and restricted items. The experimental results indicate that relying solely on MobileVLM’s zero-shot capabilities is insufficient for recognizing prohibited and restricted items. This is due to the complexity and diversity of prohibited and restricted item categories, which are not commonly represented. One idea was to fine-tune the multimodal language model using simple descriptions to improve its accuracy in identifying prohibited and restricted items. However, this method also yielded unsatisfactory results—after fine-tuning, MobileVLM’s accuracy increased to only 16.69%. Although fine-tuning with simple text descriptions improved MobileVLM’s performance to some extent, the recognition accuracy remained relatively low. Therefore, a text generator was designed. This generator uses CLIP to match images of prohibited and restricted items with category texts to determine the item categories. Using category texts matched via CLIP to prompt the fine-tuned MobileVLM increased the recognition accuracy to 78.38%.
Furthermore, to evaluate the quality of the text description generator, the BLEU score was employed for testing. As shown in Table 6, the BLEU score of the unfine-tuned MobileVLM is 9.75%, which improves to 16.18% after finetuning, indicating that finetuning enhances the accuracy of text generation. When the fine-tuned MobileVLM is combined with the CLIP model, the BLEU score of the proposed text description generator further increases to 36.65%, demonstrating that the integration of CLIP and multimodal models significantly enhances the alignment between the generated text and human-annotated reference text, thereby validating the effectiveness of fine-tuning and multimodal integration in improving the accuracy and quality of text generation.
Quantitative results of image generation
To evaluate the performance of the proposed image generation framework PRIG on images of prohibited and restricted items, we utilized the proposed dataset and fine-tuned PRIG with the proposed new loss function to generate newly generated images of prohibited and restricted items. In addition, we also compared the proposed PRIG framework with other SOTA models, and the images generated by them are shown in Fig. 8. It can be observed that the images of prohibited and restricted items generated by PRIG are better and more accurate than other image-generation models. Although SDM and other image generation models can generate images with prohibited and restricted features, there are significant differences in details and shapes compared to real prohibited and restricted items. The images generated by PRIG not only have greater diversity but are also very close to real prohibited and restricted items in terms of details and categories. This indicates that the proposed PRIG can generate highly realistic images of prohibited and restricted items that are different from the original images.

The generated prohibited and restricted product images of PRIG.
To accurately evaluate the performance of the proposed PRIG, we employed CLIP score, Fréchet Inception Distance (FID), and Inception score, with the specific results shown in Table 7. The experimental results demonstrate that PRIG outperforms other comparison models on all evaluation metrics. Specifically, PRIG achieves better performance on FID, indicating that the distribution difference between the generated images and real images is smaller, thus ensuring the high quality of the generated images. Additionally, PRIG scores significantly higher than other methods on the CLIP score, indicating stronger semantic consistency between the generated images and textual descriptions and better capturing of the relationship between images and text. Finally, PRIG also surpasses all comparison models on the Inception Score, highlighting its superior performance in terms of image clarity and diversity, further validating its generative capability. In conclusion, the outstanding performance of PRIG across various metrics confirms its effectiveness as an image-generation method, demonstrating the significant advantages of the proposed approach in generating prohibited and restricted item images.
User study
Furthermore, to more accurately compare the quality of prohibited and restricted product images generated by PRIG and SDM, an evaluation team of 20 professionals was assembled to assess the 12 sets of generated images. The professionals evaluated the images generated by PRIG and SDM based on consistency, accuracy, and detail. Each criterion had a maximum score of 10, for a total possible score of 30 across the three metrics. This scoring method allowed for a precise assessment of the performance of the proposed image-generation framework. The scores obtained according to these three standards are shown in Table 8. The scores of PRIG for the three metrics are 8.94, 9.03, and 8.69, respectively. The scores of SDM for the same metrics are 7.41, 7.64, and 7.06, respectively. The overall average scores for PRIG and SDM were 26.66 and 22.10, respectively. The experimental results show that PRIG’s total score significantly exceeds that of SDM. PRIG-generated images of prohibited and restricted products outperform SDM in terms of consistency, accuracy, and item detail. The experimental results demonstrate that the proposed PRIG is capable of generating diverse and highly realistic images of restricted and prohibited products.
Discussion
Limitation
The proposed dataset for prohibited and restricted goods in online transactions covers multiple categories but faces challenges in image recognition and generation for categories with fewer samples, such as"Flammable, explosive, and corrosive","Illegal tools and equipment","Personal security and privacy", and"Drugs and their paraphernalia". This data imbalance leads to suboptimal performance in image generation and object detection tasks for these underrepresented categories. To address this, the PRIG framework utilizes various data augmentation techniques, such as Gaussian blur, elastic transformations, and contrast enhancement, to increase image prompt diversity and improve model generalization. Furthermore, by utilizing the text descriptions of the text generator, the framework enhances the diversity of generated images, thereby expanding the range of prohibited goods in online transactions. Although PRIG generates high-quality images for most categories, it faces challenges in certain cases. For example,“Boot Knife”suffers from occlusion and small size, while"Cat Eye Reverse Peep"exhibits significant shape variation due to limited samples and varying angles. These difficulties underscore the challenge of generating precise and high-quality images, particularly when dealing with small samples, complex shapes, and high category similarity. Further improvements in model architecture, including advanced image generation algorithms, enhanced adversarial training, and multi-view learning, are needed to address these issues and improve the accuracy and robustness of generated images. Furthermore, the integration of a high-capacity image generator and a multimodal large language model within the framework necessitates considerable computational resources. In future work, we aim to explore model compression, low-rank approximation, and knowledge distillation techniques to reduce the computational footprint while maintaining or improving performance.
Integrability
The PRIG framework is inherently modular, which allows for easy adaptation and integration with other models. For example, the image generator component, which currently uses a fine-tuned SDM, can be replaced with alternative generative models, such as DALLE65 and StyleGAN series66, depending on specific performance requirements or deployment constraints. Similarly, the text description generator can incorporate other multimodal large language models like Bootstrapping language-image pre-training (BLIP)67 or Flamingo68 in place of MobileVLM. The PR-adapter module, responsible for image enhancement and compression, can also leverage different visual backbones, such as Swin Transformer69 and ConvNeXt70, for feature extraction. This flexibility enables the proposed framework to generalize across a variety of applications involving multimodal generation, recognition, or even domain-specific dataset expansion tasks. Future work will explore these extensions in depth.
Privacy, ethics, and dataset management
Given the sensitivity of prohibited and restricted goods, strict ethical and privacy considerations were integrated into the dataset construction and usage framework. All data were sourced exclusively from publicly accessible platforms without involving any personally identifiable information or private content. Images were manually reviewed to exclude scenes that could potentially expose individual identities, locations, or private assets. To further ensure ethical compliance, de-identification techniques were employed where necessary, including blurring, cropping, or removal of sensitive visual elements. Additionally, a comprehensive dataset governance policy has been established. The dataset is intended strictly for non-commercial academic research and public safety applications. Access to the dataset will be granted upon request through a formal application process, during which users must agree to a data usage agreement. This agreement explicitly prohibits redistribution, commercial use, model training for non-regulatory purposes, or any use that may lead to the misuse or abuse of the dataset content. Regular audits, watermarking, and usage logging mechanisms are considered to track and regulate downstream use. By incorporating technical safeguards and administrative controls, the proposed dataset not only supports innovation in AI-driven regulation but also upholds core ethical standards in data handling.
Conclusion
To address the challenge posed by the absence of datasets for prohibited and restricted goods in online transactions, and to achieve intelligent recognition and effective supervision of such goods, this paper proposes a new image generation framework (PRIG) and a multimodal dataset for prohibited and restricted goods in online transactions. The dataset comprises 38,513 images and 77,026 texts across 10 main categories and 115 subcategories of prohibited and restricted goods. This dataset is the first multimodal dataset constructed to address illegal online transactions of prohibited and restricted goods. The proposed framework consists of the PR-adapter, the text description generator, and the image generator. The designed PR-adapter consists of an image augmentation module and an image compression representation module, which can provide better and more diverse image prompts for the image generator. The text description generator consists of CLIP and the multimodal large language model MobileVLM, which can obtain more accurate and detailed descriptions of prohibited and restricted product images. The image generator can use text descriptions and PR-adapter image prompts to obtain accurate and more diverse images of prohibited and restricted products. In addition, to reduce semantic loss in text descriptions, a new loss function is proposed to generate more accurate and consistent images of prohibited and restricted goods. The experimental results demonstrate the effectiveness and superiority of the proposed framework for generating images of prohibited and restricted goods in online transactions. It is believed that this framework and the dataset can promote the development of intelligent identification technology for illegal online transactions, providing new references and assistance for the implementation of intelligent supervision of online transactions.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Li, J. et al. Online portfolio management via deep reinforcement learning with high-frequency data[J]. Inf. Process. Manage. 60(3), 103247 (2023).
Fang Y, Tang Z, Ren K, et al. Learning multi-agent intention-aware communication for optimal multi-order execution in finance[C]//Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4003–4012. (2023).
Skare, M., Gavurova, B. & Rigelsky, M. Innovation activity and the outcomes of B2C, B2B, and B2G E-Commerce in EU countries[J]. J. Bus. Res. 163, 113874 (2023).
Ibrahim, M. A., Ozoh, P. & Ojo, O. A. Fraud detection model for illegal transactions[J]. J. Comput. Soc. Info. 3(1), 8–17 (2024).
Lucas, G. A., Lunardi, G. L. & Dolci, D. B. From e-commerce to m-commerce: An analysis of the user’s experience with different access platforms[J]. Electron. Commer. Res. Appl. 58, 101240 (2023).
Ahmad, A. Y. A. B. et al. E-commerce trend analysis and management for Industry 5.0 using user data analysis[J]. Int. J. Intell. Syst. Appl. Eng. 11, 135–150 (2023).
Maher, J. et al. Weed wide web: Characterising illegal online trade of invasive plants in Australia[J]. NeoBiota 87, 45–72 (2023).
Nali, M. C. et al. Identification and characterization of illegal sales of cannabis and nicotine delivery products on telegram messaging platform[J]. Nicotine Tob. Res. 26, ntad248 (2023).
Yao, S. et al. A prohibited items identification approach based on semantic segmentation[J]. Optoelectron. Lett. 17, 247–251 (2021).
Xu, Q. et al. Use of machine learning to detect wildlife product promotion and sales on Twitter[J]. Front. Big Data 2, 28 (2019).
Hernandez-Castro, J. & Roberts, D. L. Automatic detection of potentially illegal online sales of elephant ivory via data mining[J]. PeerJ. Comput. Sci. 1, e10 (2015).
Xu C, Han N, Li H. A dangerous goods detection approach based on YOLOv3[C]//Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence. 600–603 (2018).
Miao C, Xie L, Wan F, et al. Sixray: A large-scale security inspection x-ray benchmark for prohibited item discovery in overlapping images[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2119–2128 (2019).
Wang H, Li Y, Huang R, et al. Illicit Promotion on Twitter[J]. arXiv preprint arXiv:2404.07797, 2024.
de Azevedo Kanehisa R F, de Almeida Neto A. Firearm Detection using Convolutional Neural Networks[C]//ICAART (2).: 707-714 (2019).
Gandhi S, Kokkula S, Chaudhuri A, et al. Scalable detection of offensive and non-compliant content/logo in product images[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2247–2256 (2020).
Cardoso, A. S. et al. Detecting wildlife trafficking in images from online platforms: A test case using deep learning with pangolin images[J]. Biol. Cons. 279, 109905 (2023).
Toomes, A. et al. A snapshot of online wildlife trade: Australian e-commerce trade of native and non-native pets[J]. Biol. Cons. 282, 110040 (2023).
Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning. PMLR. 8748–8763 (2021).
Chu X, Qiao L, Lin X, et al. Mobilevlm: A fast, reproducible and strong vision language assistant for mobile devices[J]. arXiv preprint arXiv:2312.16886, 2023.
Zhong Y, Yang J, Zhang P, et al. Regionclip: Region-based language-image pretraining[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16793–16803 (2022).
Liu, W. et al. Sound to expression: Using emotional sound to guide facial expression editing[J]. J. King Saud Univ.-Comput. Info. Sci. 36, 101998 (2024).
Sharma, D., Dhiman, C. & Kumar, D. Control With Style: Style embedding-based variational autoencoder for controlled stylized caption generation framework[J]. IEEE Trans. Cogn. Dev. Syst. https://doi.org/10.1109/TCDS.2024.3405573 (2024).
Sharma, D., Dhiman, C. & Kumar, D. Evolution of visual data captioning Methods, Datasets, and evaluation Metrics: A comprehensive survey[J]. Expert Syst. Appl. 221, 119773 (2023).
Liu, W. et al. A semi-supervised mixture model of visual language multitask for vehicle recognition[J]. Appl. Soft Comput. 159, 111619 (2024).
Sharma, D., Dhiman, C. & Kumar, D. XGL-T transformer model for intelligent image captioning[J]. Multimed. Tools Appl. 83(2), 4219–4240 (2024).
Sharma, D., Dhiman, C. & Kumar, D. FDT− Dr2T: A unified dense radiology report generation transformer framework for X-ray images[J]. Mach. Vis. Appl. 35(4), 1–13 (2024).
Sharma D, Dingliwal R, Dhiman C, et al. Lightweight transformer with GRU integrated decoder for image captioning[C]//2022 16th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS). IEEE. 434–438 2022.
Sharma D, Dhiman C, Kumar D. A review of stylized image captioning techniques, evaluation parameters, and datasets[C]//2022 4th International Conference on Artificial Intelligence and Speech Technology (AIST). IEEE. 1–5 2022.
Sharma D, Dhiman C, Kumar D. Automated image caption generation framework using adaptive attention and bi-LSTM[C]//2022 IEEE Delhi Section Conference (DELCON). IEEE. 1–5 2022.
Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695 (2022).
Zhan X, Wu Y, Dong X, et al. Product1m: Towards weakly supervised instance-level product retrieval via cross-modal pretraining[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 11782–11791 (2021).
Kaur P, Sikka K, Wang W, et al. Foodx-251: a dataset for fine-grained food classification[J]. arXiv preprint arXiv:1907.06167, 2019.
Chen Y, Zhong H, He X, et al. Real20M: A Large-scale E-commerce Dataset for Cross-domain Retrieval[C]//Proceedings of the 31st ACM International Conference on Multimedia. 4939–4948 (2023).
Dong X, Zhan X, Wu Y, et al. M5product: Self-harmonized contrastive learning for e-commercial multi-modal pretraining[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21252–21262 (2022).
Liu, F. et al. MEP-3M: A large-scale multi-modal E-commerce product dataset[J]. Pattern Recogn. 140, 109519 (2023).
Zhao, Q., Wang, Z. & Wang, H. Product summarization extraction model with multimodal information fusion[J]. J. Comput. Appl. 44(1), 73 (2024).
Bender, T. et al. Learning to taste: A multimodal wine dataset[J]. Adv. Neural Info. Process. Syst. 36, 7351–7360 (2024).
Das N, Joshi A, Yenigalla P, et al. MAPS: multimodal attention for product similarity[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 3338–3346 (2022).
Zhang, J. et al. PKU-GoodsAD: A supermarket goods dataset for unsupervised anomaly detection and segmentation[J]. IEEE Robot. Auto. Lett. 9, 2008–2015 (2024).
Zhang L, Rao A, Agrawala M. Adding conditional control to text-to-image diffusion models[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 3836–3847 (2023).
Ruiz N, Li Y, Jampani V, et al. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22500–22510 (2023).
Mou C, Wang X, Xie L, et al. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 38 (5) 4296–4304 2024.
Chen X, Huang L, Liu Y, et al. Anydoor: Zero-shot object-level image customization[J]. arXiv preprint arXiv:2307.09481, 2023.
Wang Q, Bai X, Wang H, et al. Instantid: Zero-shot identity-preserving generation in seconds[J]. arXiv preprint arXiv:2401.07519, 2024.
Bai J, Dong Z, Feng A, et al. Integrating view conditions for image synthesis[J]. arXiv preprint arXiv:2310.16002, 2023.
Kim K, Park S, Lee J, et al. Reference-based image composition with sketch via structure-aware diffusion model[J]. arXiv preprint arXiv:2304.09748, 2023.Li Z, Cao M, Wang X, et al. Photomaker: Customizing realistic human photos via stacked id embedding[J]. arXiv preprint arXiv:2312.04461, 2023.
Sohl-Dickstein J, Weiss E, Maheswaranathan N, et al. Deep unsupervised learning using nonequilibrium thermodynamics[C]//International conference on machine learning. PMLR. 2256–2265 (2015).
Ho, J., Jain, A. & Abbeel, P. Denoising diffusion probabilistic models[J]. Adv. Neural. Inf. Process. Syst. 33, 6840–6851 (2020).
Nichol A Q, Dhariwal P. Improved denoising diffusion probabilistic models[C]//International conference on machine learning. PMLR. 8162–8171 (2021).
Dhariwal, P. & Nichol, A. Diffusion models beat gans on image synthesis[J]. Adv. Neural. Inf. Process. Syst. 34, 8780–8794 (2021).
Kim G, Jang W, Lee G, et al. Dag: Depth-aware guidance with denoising diffusion probabilistic models[J]. arXiv preprint arXiv:2212.08861, 2022.
Vahdat, A., Kreis, K. & Kautz, J. Score-based generative modeling in latent space[J]. Adv. Neural. Inf. Process. Syst. 34, 11287–11302 (2021).
Du W, Zhang H, Yang T, et al. A flexible diffusion model[C]//International Conference on Machine Learning. PMLR 8678–8696 2023.
Dockhorn T, Vahdat A, Kreis K. Score-based generative modeling with critically-damped langevin diffusion[J]. arXiv preprint arXiv:2112.07068, 2021.
Ho J, Salimans T. Classifier-free diffusion guidance[J]. arXiv preprint arXiv:2207.12598, 2022.
Zhang, Q. & Chen, Y. Diffusion normalizing flow[J]. Adv. Neural. Inf. Process. Syst. 34, 16280–16291 (2021).
De Bortoli, V. et al. Diffusion schrödinger bridge with applications to score-based generative modeling[J]. Adv. Neural. Inf. Process. Syst. 34, 17695–17709 (2021).
Mardieva, S. et al. Lightweight image super-resolution for IoT devices using deep residual feature distillation network[J]. Knowl.-Based Syst. 285, 111343 (2024).
Liu L, Ren Y, Lin Z, et al. Pseudo numerical methods for diffusion models on manifolds[J]. arXiv preprint arXiv:2202.09778, 2022.
Yang B, Gu S, Zhang B, et al. Paint by example: Exemplar-based image editing with diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18381–18391 (2023).
Chen X, Huang L, Liu Y, et al. Anydoor: Zero-shot object-level image customization[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6593–6602 2024.
Ye H, Zhang J, Liu S, et al. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models[J]. arXiv preprint arXiv:2308.06721, 2023.
Wang A, Ai B, Wen B, et al. Wan: Open and Advanced Large-Scale Video Generative Models[J]. arXiv preprint arXiv:2503.20314, 2025.
Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation[C]//International conference on machine learning. Pmlr. 8821–8831 2021.
Karras T, Aila T, Laine S, et al. Progressive growing of gans for improved quality, stability, and variation[J]. arXiv preprint arXiv:1710.10196, 2017.
Li J, Li D, Xiong C, et al. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation[C]//International conference on machine learning. PMLR 12888–12900 2022.
Alayrac, J. B. et al. Flamingo: A visual language model for few-shot learning[J]. Adv. Neural. Inf. Process. Syst. 35, 23716–23736 (2022).
Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF international conference on computer vision. 10012–10022 2021.
Woo S, Debnath S, Hu R, et al. Convnext v2: Co-designing and scaling convnets with masked autoencoders[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16133–16142 2023.
Acknowledgements
This work was supported in part by the National Key Research and Development Program of China, under Grant 2023YFC3304903.
Funding
National Key Research and Development Program of China, 2023YFC3304903.
Author information
Authors and Affiliations
Contributions
Wenjin Liu: Conceptualization; Data curation; Formal analysis; Funding acquisition; Investigation; Methodology; Project administration; Supervision; Validation; Visualization; Roles/Writing—original draft; and Writing—review & editing. Jingyu Zou: Conceptualization; Data curation; Formal analysis; Funding acquisition; Investigation; Methodology; Project administration; and Writing—review & editing. Shudong Zhang: Conceptualization; Data curation; Formal analysis; Funding acquisition; Investigation; Methodology; and Writing—review & editing. Ning Luo: Conceptualization; Data curation; Formal analysis; Funding acquisition; Investigation; Methodology; Project administration; Resources; Software; Supervision; and Writing—review & editing. Haoming Liu: Conceptualization; Data curation; Formal analysis; Funding acquisition; Investigation; Methodology; Project administration; Resources; Software; Supervision; and Writing—review & editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics statement
We declare that we have no financial and personal relationships with other people or organizations that can inappropriately influence our work, and there is no professional or other personal interest of any nature or kind in any product, service, or company that could be construed as influencing the position presented in, or the review of, the manuscript entitled.
Consent for publication
We confirm that informed consent has been obtained from all participants and/or their legal guardians for the publication of any identifying information and images in this online open-access journal.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
A. Commodity Management Specification documents of online transactions
-
Compliance Guidelines for Prohibited and Restricted Goods on Online Trading Platforms. https://scjgj.beijing.gov.cn/zwxx/2024zcjd/202502/t20250213_4009359.html
-
Regulations on the Management of Prohibited Items for Delivery. https://www.gov.cn/xinwen/2017-01/20/content_5161414.htm
-
Tiktok Global Shopping Commodity Management Specification. https://school.jinritemai.com/doudian/web/article/108057
-
Taobao Global Prohibited Information Management Rules. https://world.taobao.com/wow/oversea/act/weijinxinxirule
-
JD Global Purchase Self operated Supplier Violation Management Rules. https://rule.jd.com/rule/ruleDetailNew.action?ruleId=774891682402537472
-
Prohibited Seller Activities and Conduct. https://sellercentral-japan.amazon.com/help/hub/reference/external/G200386250?ref=efph_200390640_relt_RJBNX5JLCVYBRGS%26locale=zh-CN.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, W., Zou, J., Zhang, S. et al. A customized image editing framework for diverse prohibited and restricted products in illegal online transactions. Sci Rep 15, 21546 (2025). https://doi.org/10.1038/s41598-025-07043-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-07043-0
