
Abstract
Diabetic retinopathy (DR) is a common diabetes complication that presents significant diagnostic challenges due to its reliance on expert assessment and the subtlety of small lesions. Although deep learning has shown promise, its effectiveness is often limited by low-quality data and small sample sizes. To address these issues, we propose a novel deep learning framework for DR that incorporates self-paced progressive learning, introducing training samples from simple to complex, and randomized multi-scale image reconstruction for enhanced data augmentation and feature extraction. Additionally, ensemble learning with Kullback–Leibler (KL) divergence-based collaborative regularization improves classification consistency. The method’s effectiveness is demonstrated through experiments on the integrated APTOS and MESSIDOR-Kaggle dataset, achieving an AUC of 0.9907 in 4-class classification, marking a 2.2% improvement compared to the ResNet-50 baseline. Notably, the framework achieves a recall of 97.65% and precision of 96.54% for the No-DR class, and a recall of 98.55% for the Severe class, with precision exceeding 91% across all categories. Furthermore, superior classification performance on limited data samples, as well as robust localization of subtle lesions via multi-scale progressive learning, has been demonstrated, underscoring the potential of the proposed framework for practical clinical deployment.
Similar content being viewed by others
Introduction
Ocular health in contemporary society faces significant threats from a wide spectrum of diseases, among which diabetic retinopathy (DR) stands out as a principal cause of visual impairment. As a microvascular complication arising from diabetes mellitus, DR has drawn increasing concern in recent years. According to the International Diabetes Federation (IDF), diabetes affected approximately 463 million individuals globally in 2019, corresponding to a prevalence of 9.3%1. As shown in Fig. 1, this number has already climbed to an estimated 537 million by 2021 and is projected to reach 783 million by 2045. Furthermore, the global prevalence of DR has reached a striking 34.6%2.

The figure shows the number of people with diabetes from 2000 to 2021 based on incomplete statistics from the International Diabetes Federation, and the projection that 783 million people worldwide will have diabetes in 2045.
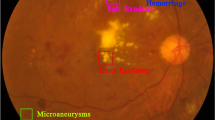
Being a retinal vascular disease, DR is defined by pathological modifications that mainly concern the retinal blood vessels. The accurate diagnosis and grading of DR severity, however, are often impeded by the subtlety of early pathological features—microaneurysms smaller than 125 micrometers, for instance, can be particularly challenging to detect3. Representative fundus images and the associated pathological characteristics of DR are depicted in Fig. 2.

Examples of the fundus images and pathological characteristics of DR. Representative examples of fundus images and associated pathological features of diabetic retinopathy are shown in Fig. 2a and b, respectively, both derived from the Indian Diabetic Retinopathy Image Dataset (IDRiD)4. The microaneurysm masks in Fig. 2b were generated using ground truth annotations provided by IDRiD. To facilitate detailed inspection, a region containing a microaneurysm has been magnified eightfold in the lower right corner; however, even with such magnification, reliable identification of these minute lesions remains challenging without further visual enhancement.
Deep neural networks (DNNs) have rapidly advanced, ushering in a new era of transformation in computer-assisted medical imaging analysis and diagnosis. Notably, convolutional neural networks (CNNs) have attracted significant attention due to their exceptional image-processing capabilities and are now routinely incorporated into image recognition algorithms. In the context of medical imaging, deep CNNs have demonstrated human-level performance across a variety of tasks, including medical image feature extraction5,6, pathological image segmentation3,7,8, lesion detection9,10,11, and disease severity classification12,13,14,15,16,17,18,19,20,21,22,23. Although several approaches have achieved remarkable success in DR diagnosis, there are still several enduring challenges in the field. Chief among these is the limited availability of high-quality, annotated medical images, without which the development of robust models is hindered. In addition, the presence of data noise, subtle morphological distinctions between lesion types, and pronounced sample imbalance within datasets further complicate the analysis. As a result, there remains a pressing need for innovative solutions capable of addressing these multifaceted obstacles.
Recent research into diabetic retinopathy (DR) diagnosis has seen a variety of methodological advancements. The importance of image preprocessing in constructing effective classification networks has been underscored by Lam et al.24, with enhanced image quality frequently leading to improved deep learning model performance. It has been noted that some preprocessing methods, such as adaptive histogram equalization, are not always advantageous for the analysis of multi-class disease images. Improved classification accuracy has been reported in hybrid models that incorporate multi-scale filtering and residual learning concepts, as demonstrated by Gangwar et al.15. There is also evidence that ensemble learning frameworks25, by leveraging the complementary strengths of multiple models, can further boost diagnostic performance. Still, both hybrid and ensemble methods are inclined to complicate models, with ensemble frameworks specifically being linked to high computational costs. Despite these advances, substantial limitations remain, especially when training data are scarce and class distributions are imbalanced. In such scenarios, conventional convolutional neural networks are susceptible to overfitting or underfitting, while ensemble methods impose heavy computational burdens. Thus, future approaches must seek to achieve a balance between model accuracy and complexity.
A new framework has been created for classifying diabetic retinopathy, incorporating self-paced learning with progressive multi-scale image training. This approach enables precise differentiation between closely related stages of retinopathy, even without a significant amount of additional training data. The experimental results suggest that our method is superior in handling imbalanced class distributions and outperforms other models. The principal contributions of this work are outlined as follows: (1) Classification with Limited Data: A medical image classification framework tailored for small datasets is presented, making it particularly advantageous for the analysis of diabetic retinopathy fundus images. (2) Guided Progressive Multi-scale Learning Concept: In a self-paced progressive learning framework, the model first pays attention to features that are simple to recognize. Incorporating randomized multi-scale image reconstruction further boosts this process, enabling a gradual and systematic evolution towards the recognition of more complex discriminative features. This guided learning approach ensures a structured learning process that builds a strong foundational understanding before tackling more subtle pathological indicators. (3) Addressing Class Imbalance: Balanced sampling is used alongside a class-balanced loss function and KL divergence ensemble constraints to achieve precise differentiation among different classes. (4) Superior Performance: Our method demonstrates superior performance, achieving Area Under the Curve (AUC) scores of 0.9907 and 0.9872 for four-class and five-class lesion classifications in Diabetic Retinopathy (DR), respectively.
The structure of the paper is outlined as follows. The proposed methodology is detailed in the Methods section, with particular attention given to the Diabetic Retinopathy Detection Framework, Guided Progressive Multiscale Learning, preprocessing and data augmentation techniques, dataset introduction, and implementation details. The Results section includes experimental findings, featuring detailed assessments of overall performance and ablation studies. The Discussion section offers a balanced evaluation of the proposed approach, addressing both its advantages and inherent limitations, while outlining avenues for future research. In the concluding section, the main contributions are concisely summarized, underscoring the broader significance and potential impact of this study within the field of medical image analysis.
Methods
Diabetic retinopathy detection framework
As depicted in Fig. 3, the Guided Progressive Multi-scale KL-Ensemble Network (GPMKLE-Net) is introduced as an innovative framework specifically tailored for the multi-class classification of diabetic retinopathy severity. GPMKLE-Net seamlessly integrates randomized multi-scale image reconstruction, ensemble learning with KL-divergence-based collaborative regularization, and a guided learning approach, leveraging the meta-learning concept of self-paced progressive learning to optimize performance in few-shot medical image classification tasks. This method enables the model to systematically evolve from recognizing easily identifiable pathological features to mastering more complex and subtle ones, significantly enhancing its efficiency in handling limited training datasets. Our findings highlight the potential of GPMKLE-Net to revolutionize DR severity classification, paving the way for more accurate and efficient medical image analysis.

This figure comprehensively illustrates the architectural design of GPMKLE-Net, a network specifically designed for detecting diabetic retinopathy (DR). It showcases the overall structure, featuring several key components: the Diabetic Retinopathy Attention Residual (DRAR) Block for feature extraction, various stages of the Diabetic Retinopathy Network Backbone (DR-STAGE), the Guided Diabetic Retinopathy Encoder (GDR-Encoder), the multi-scale feature fusion layer, and the ensemble learning classification module with Kullback-Leibler (KL) divergence regularization. The input image passes through the network backbone, where it captures and emphasizes lesion features at multiple scales across different stages. These features are then re-encoded by the GDR-Encoder. Subsequently, through feature fusion and an ensemble learning classification algorithm enhanced with KL divergence regularization, features extracted in previous stages are effectively integrated to determine the DR grade of the input image.
Backbone network
The backbone of GPMKLE-Net employs ResNet-50, a widely used convolutional neural network for feature extraction. In order to effectively leverage multi-stage features, the original ResNet-50 architecture was modified such that feature maps from its final three stages are extracted and subsequently integrated into the feature extraction layer of the Guided Diabetic Retinopathy (GDR) Encoder. This approach maintains the computational flow while enhancing the model’s ability to capture features at different scales.
DRAR block: DR attention residual module
Prior research has demonstrated that shallow neural networks excel at capturing texture, shape, and other fundamental features, thereby preserving essential spatial information. However, as network depth increases, there is a tendency for certain spatial details to be lost, resulting in the extraction of more abstract representations26. To address this limitation and retain the benefits of shallow feature extraction, the backbone block of our neural network has been augmented through the integration of the Squeeze-and-Excitation (SE) attention mechanism27. Within the SE module, global average pooling is first employed to aggregate spatial information across each feature map channel, effectively capturing global contextual information. This is followed by a fully connected–ReLU–fully connected structure, through which the channel-wise dependencies are learned and non-linear interactions are modeled. Ultimately, the resulting channel weights are projected back onto the original feature maps, allowing the network to selectively emphasize or suppress specific channels. By adaptively recalibrating channel-wise feature responses, the SE module enables the network to emphasize informative pathological texture features, as depicted in Fig. 3. Furthermore, the application of multi-scale convolution allows the model to attend more precisely to pathological regions, a strategy that is consistent with the findings reported by Gangwar et al. in the context of diabetic retinopathy analysis15. Through these architectural enhancements, it is anticipated that the network will be better equipped to capture subtle yet clinically significant features within retinal images.
GDRC: guided diabetic retinopathy classifier
A central function of the GDRC structure lies in its ability to integrate information derived from multiple stages of both the backbone network and the DR-Stage. Notably, the features to be fused within the GDRC are extracted by the Guided Diabetic Retinopathy (GDR) Encoder. Within the GDR Encoder, features from each stage are first subjected to a series of operations, wherein two consecutive convolutional block sequences (Convolution-BatchNorm-ReLU sequences, CBRs), each followed by max pooling, are employed. By means of these CBRs, not only is feature extraction substantially enhanced, but normalization of the intermediate representations is also facilitated, thereby ensuring that the data are optimally conditioned for subsequent fusion and processing within the GDRC.
A key aspect of the GDRC is its integration with the concept of Rdrop, which introduces diversity and robustness into the learning process. Within the GDRC, the concatenated feature maps from different stages are fed into a multi-layer perceptron (MLP). This MLP, enhanced with Dropout layers, not only adds regularization but ensures that each stage contributes unique parameters to the final prediction. By incorporating Dropout within the MLP, the GDRC effectively generates diverse sets of parameters from each stage, mimicking the behavior of multiple models. This approach not only enhances the model’s generalization capabilities but also reduces the risk of overfitting, as each “sub-model” within the GDRC contributes its own unique perspective to the final prediction. In essence, the GDRC, through its clever integration of Dropout within the MLP, transforms the concatenated feature maps from various stages into robust and diverse predictions for each DR severity category.
Ensemble classification head
In pursuit of further improvements in classification accuracy, an ensemble learning strategy is adopted. Ensemble learning has proven to be effective in enhancing model performance by combining the predictions of multiple models or, in our case, different stages of the same network.
Within our framework, each stage of the network, along with the concatenated feature stage, is regarded as an independent sub-model. In particular, the three distinct stages derived from the backbone network, together with the concatenated feature stage, collectively function as four approximate sub-models, each contributing to the overall prediction process. For every input, these four sub-models independently generate predictions regarding the severity of diabetic retinopathy. To synthesize these outputs, a voting scheme is employed, whereby the individual predictions are aggregated, resulting in a final classification that is both more robust and accurate than would be achievable by any single sub-model alone. This ensemble strategy leverages the diverse perspectives offered by each stage, thereby mitigating the risk of individual biases or errors.
Guided progressive multi-scale learning
Drawing inspiration from human cognitive mechanisms, the meta-learning paradigm derived from self-paced learning has been integrated into a progressive training methodology for deep learning systems28. This integration led to conceptualizing the Guided Progressive Multi-scale Learning (GPML) approach. The GPML process integrates two fundamental components: randomized multi-scale image reconstruction and guided loss function.
Randomized multi-scale image reconstruction
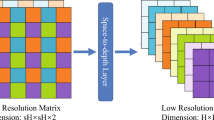
In recent years, supervised representation learning has garnered significant attention, particularly in its application to medical image analysis. Our study aligns with this trend, leveraging the advantages of multi-resolution image processing to enhance neural networks’ sensitivity to fine-grained pathological details, thereby fostering more robust and generalizable image representations. Building upon the insights provided by Du et al.28, a jigsaw generator is utilized to preprocess diabetic retinopathy (DR) fundus images, thereby facilitating the concurrent execution of supervised representation learning and multi-scale feature extraction.
In determining the optimal size and quantity of fundus image patches, careful consideration was given to both the specific requirements of the classification task and the dimensions of the training images. Throughout the training phase, multi-scale image processing was applied to each batch of fundus images, resulting in the generation of uniformly sized image patches. These patches, prior to being recombined to match the pixel dimensions of the original images, were labeled according to their respective source images. At each stage of training, patches of varying sizes were utilized to capture features at different spatial resolutions. For example, during the initial stage (denoted as (l = 1)), 64 patches were produced, each representing one-eighth of the original (224 \(\times\) 224) image, yielding patches of (28 \(\times\) 28) pixels. In the subsequent stage, 16 patches were generated, each corresponding to one-quarter of the original size ((56 \(\times\) 56) pixels). The third stage involved the creation of 4 patches, each measuring half the original dimensions ((112 \(\times\) 112) pixels). Finally, in the concatenation stage ((l = concat)), a single patch encompassing the full (224 \(\times\) 224) pixel image was employed.
The comprehensive framework for diagnosing DR, as illustrated in Fig. 4, is organized into four hierarchical training levels, corresponding to Step 1 through Step 4. Each level is designed to process and train on images of a specific scale, with each step generating its own loss feedback to guide the learning process. Features extracted from the first three steps are passed through their respective Deep-Feature Encoders and subsequently fused in Step 4 via the Multi-level Feature Fusion module. This fusion process integrates the hierarchical features from Steps 1–3, producing a unified representation in Step 4. The framework generates four feature maps: the individual outputs from the deep-feature encoders of Steps 1–3 and the fused output from Step 4.

The Diabetic Retinopathy Detection Framework is divided into four steps, each responsible for learning specific levels of detail in retinal images. Guided learning loss is vital in regularization, ensuring that each stage’s classification models do not favor errors.
Each of these feature maps is then fed into its corresponding Regularized Dropout Multilayer Perceptron (MLP), which produces a classification result for each step, yielding a total of four classification outputs. To ensure consistency across these outputs, Kullback-Leibler (KL) divergence is employed as a regularization mechanism (Regularized Dropout Loss (\(\mathcal {L}_{Rdrop}\))) , encouraging the predictions from each classifier to converge towards greater alignment. This design not only enhances the stability of the model but also promotes consistency and robustness in the classification results.
Guided learning loss function
Our GPMKLE-Net framework is optimized using a composite loss function that integrates three distinct components: cross-entropy loss (\(\mathcal L_{CE}\)), class-balanced loss with focal weighting29 (\(\mathcal L_{CB}^{Focal}\)), and regularized dropout30 loss (\(\mathcal {L}_{Rdrop}\)). Each of these loss functions plays a crucial role in improving the model’s performance and robustness.
Cross-Entropy Loss (\(\mathcal L_{CE}\)). This serves as the primary supervised loss term, guiding the classifier to minimize the discrepancy between predicted and actual class probabilities. It provides a solid foundation for the model’s learning by ensuring that the classifier’s predictions align with the ground truth labels.
Class-Balanced Loss with Focal Weighting (\(\mathcal L_{CB}^{Focal}\)). To address the issue of class imbalance in the diabetic retinopathy dataset, a class-balanced loss function with focal weighting has been used. This loss dynamically adjusts weights based on class frequency, assigning greater significance to underrepresented classes29. Additionally, the focal term emphasizes difficult-to-classify samples, further enhancing the model’s performance across all categories. The \(\mathcal L_{CB}^{Focal}\) loss is defined as follows:
In this equation, C represents the total number of classes, and \(n_y\) represents the total number of samples belonging to the target class. The tunable hyperparameter \(\beta\) balances the proportion of positive and negative examples within the dataset. At the same time, \(p_j^t\) refers to the predicted probability of the j-th class, and t represents the actual class for the given sample. Additionally, \(\gamma\) is a tunable factor used to modulate the misclassification loss. By incorporating the class-balancing term \(\frac{1-\beta }{1-\beta ^{n_y}}\) and the focal weighting factor \((1-p_j^t)^\gamma\), \(\mathcal L_{CB}^{Focal}\) effectively addresses two key challenges in medical image classification: class imbalance and varying degrees of classification difficulty.
Regularized Dropout Loss (\(\mathcal {L}_{Rdrop}\)). To enhance both the robustness and generalization ability of the model, regularized dropout techniques are incorporated into the loss function. Specifically, \(\mathcal {L}_{Rdrop}\) imposes a Kullback-Leibler divergence regularization between the output distributions of two distinct classifiers, encouraging their predictions to be consistent30. This guided constraint not only reduces overfitting but also enhances the model’s stability, particularly during the initial stages of training when the model is most susceptible to deviations. Specifically, the \(\mathcal {L}_{Rdrop}\) regularization is applied as follows:
Where C represents the total number of classes, \(p_j\) and \(q_j\) are the predicted probability distributions for the j-th class from the two classifiers, respectively. This formulation ensures that the predictions from both classifiers are in close agreement, effectively reducing the model’s sensitivity to random dropout patterns and enhancing its overall stability. During training, the \(\mathcal {L}_{Rdrop}\) loss is combined with other loss terms within a composite loss function, weighted by a balancing coefficient \(\lambda _{Rdrop}\).
The overall loss function for GPMKLE-Net is a weighted sum of these three loss components:
By integrating these three loss components through a weighted summation, a comprehensive guided learning loss function is formulated, which serves to systematically direct the model’s learning trajectory. The adjustable hyperparameters (\(\lambda _{CE}\), \(\lambda _{CB}\), and \(\lambda _{Rdrop}\)) allow us to fine-tune the relative importance of each loss term, ensuring that the model is optimized for the specific challenges of DR fundus image classification. A detailed description of the loss function is available in Algorithm 1.

Guided Learning Loss
Preprocessing and data augmentation
Given the dataset’s inherent limitations and imbalances, several preprocessing and data augmentation approaches have been implemented.
Dataset extension
Due to the limited availability of manually labeled fundus images, a multi-dataset fusion approach was used, combining various DR fundus image datasets to fully utilize the diversity across data sources and enhance the training set. Enhancements in the generalizability and accuracy of DR detection were pursued by combining these diverse datasets. To guarantee that the combined datasets upheld high quality and consistency, a range of sophisticated data augmentation and image preprocessing methods was methodically applied during the merging process.
Image segmentation
Emphasizing accurate segmentation of fundus images helps minimize the risk of model errors from non-retinal regions. For this purpose, the Otsu thresholding method31, recognized for its efficiency and widespread adoption, was utilized to delineate the retinal foreground from the background. Optimizing the segmentation threshold to maximize inter-class variance led to better detection of retinal boundaries and greatly reduced the effect of dark patches in the images. This step improved the accuracy and quality of fundus region segmentation, contributing to more reliable model predictions.
Image color standardization
Variations in acquisition protocols and environmental conditions frequently lead to color inconsistencies in fundus images, which can significantly impact model performance. To mitigate such effects, image color standardization was undertaken, whereby the mean and standard deviation of pixel intensities across all RGB channels were computed, and each pixel was subsequently normalized in accordance with these statistics. The standardization of color distributions in the training set not only minimized the impact of different data sources but also quickened the model’s convergence.
Histogram equalization sampling
A strategy was created to solve the persistent problem of class imbalance in diabetic retinopathy fundus image classification by integrating histogram equalization sampling with a class-balanced loss function29. Rather than relying solely on conventional sampling methods, histogram equalization sampling was first employed to assess the distribution of samples across categories, with weights subsequently assigned to ensure a more equitable representation among classes. By coupling this sampling technique with a dynamically rescaled class-balanced loss, a synergistic effect is achieved, whereby both model stability and generalization are markedly enhanced. Balanced sampling ensures that underrepresented classes are not neglected during training, and the class-balanced loss further underscores their significance by adaptively changing each class’s contribution to the overall loss. The simultaneous optimization of model parameters and the loss function, directed by these complementary mechanisms, results in a more robust model that is better equipped to deal with imbalanced data distributions.
Dataset
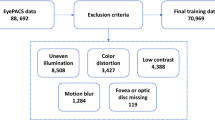
A combination of datasets was employed to ensure both comprehensive analysis and robust model training. The Messidor-1 dataset32, recognized for its high-quality images and precise annotations, served as the primary resource for this study. To address the issue of category imbalance and to enhance data diversity, additional images were selectively incorporated from the Kaggle DR Detection dataset33, with particular attention given to enriching the Mild category.
The Kaggle DR Detection dataset33, originally released in 2015, encompasses a wide range of retinopathy stages—from normal to proliferative retinopathy—captured using various cameras under diverse conditions. While this diversity provides a rich dataset, it also introduces challenges such as noise, overexposure, underexposure, and blurriness due to equipment variations and capture conditions. This dataset’s long-tail distribution of images across categories poses additional complexities in maintaining balanced training sets. Similarly, the APTOS 2019 Blindness Detection dataset34, accessible on Kaggle and divided into five categories, has characteristics akin to the Kaggle DR Detection dataset, such as image noise.
The Messidor-1 dataset32, funded by the French Ministry of Defense’s TECHNO-VISION project, stands out for its precision and quality. Compiled from three ophthalmology facilities, it contains 1200 carefully annotated images. Notably, it is a four-category dataset focusing on diabetic retinopathy. Nevertheless, it was observed that the Mild category is notably underrepresented, a factor that may adversely affect classification accuracy. To mitigate this limitation, 125 high-quality images from the Mild category of the Kaggle DR dataset were strategically selected, thereby enhancing the training set and promoting a more balanced representation of disease stages. The APTOS dataset was further utilized as a validation resource to rigorously assess the effectiveness of the proposed methodological approach. Through this integrated strategy, a comprehensive evaluation of the classification model was achieved, as summarized in Table 1.
Implementation details
In this study, feature extraction was performed using a ResNet-50 backbone35, whose weights had been initialized with ImageNet pre-training36 to mitigate the risk of overfitting, given the limited size of the available dataset. Rather than training a model from scratch, this transfer learning approach was adopted to leverage the generalization capabilities conferred by large-scale pre-training. Training was conducted for 300 epochs. Model optimization was carried out using stochastic gradient descent (SGD) with a batch size of 32, a weight decay of \(5 \times 10^{-4}\), and a fixed momentum of 0.9. The initial learning rate was set to \(8 \times 10^{-3}\) and subsequently annealed according to a cosine schedule, with the minimum learning rate set to \(1 \times 10^{-5}\). Notably, the incorporation of a Guided Loss combination into the loss function represents a methodological innovation unique to this work, whereas all other comparative methods employed the standard cross-entropy loss. To construct the training set, 70% of the dataset was randomly selected, with the remaining 30% reserved for validation and testing. During training, a series of data augmentation techniques were employed to improve generalization, including resizing to 256 pixels, center cropping and random cropping to 224 pixels, random horizontal flipping with a probability of 0.5, random rotations of up to 90 degrees, conversion to tensor format, and normalization using the dataset-specific mean and standard deviation.
All experiments were conducted using the PyTorch framework. Model training and evaluation were performed on an NVIDIA A5000 GPU, ensuring efficient processing of all tasks.
Results
There exists a thorough evaluation of the overall performance of GPMKLE-Net, followed by an in-depth ablation study that examines the efficacy of Randomized Multi-scale Image Reconstruction (RMIR), the influence of Histogram Equalization Sampling (HES), and the advantages of Guided Learning Loss (GLL).
Overall performance
The availability of high-quality fundus images for diabetic retinopathy (DR) is often limited, and larger datasets, when accessible, tend to suffer from suboptimal quality, pronounced category imbalance, the presence of noise, and challenges in distinguishing between categories. Such factors collectively present considerable obstacles for deep neural network training. To demonstrate the efficacy of the proposed model in accurately differentiating between various lesion categories of DR, this part delineates its specific performance. A random sampling strategy was adopted, whereby 70% of the fundus images from each category across the entire dataset were allocated for training purposes. To mitigate the risk of the model overfitting to edge shape characteristics, it was deemed necessary to scale and crop the fundus images prior to the commencement of training, as these images are frequently high-resolution and contain substantial black borders. Various data augmentation methods, such as random 90° rotations, flipping, and cropping, were used to tackle the problem of a small sample size. In addition, color normalization was standardized across all augmented images to further enhance model training efficacy. The final size of each image following augmentation was set to \(224\times 224\) pixels.
A prominent challenge in diabetic retinopathy (DR) classification arises from class imbalance, whereby certain stages of the disease are represented by a disproportionately large number of instances compared to others, thereby complicating the classification process. Thus, focusing only on metrics such as classification accuracy (ACC) may not provide a comprehensive understanding of model performance, particularly in contexts with marked class imbalances. To overcome this limitation, the Area Under the Curve (AUC) metric has been implemented, providing a more thorough evaluation by measuring the model’s ability to distinguish between categories over the entire range of decision thresholds. A rise in AUC signifies improved model performance. Additionally, recall and precision for each lesion category were integrated into the ablation studies, allowing for a more detailed evaluation of the proposed method’s ability to distinguish between various classes.
According to Table 2, GPMKLE-Net achieved a remarkable classification accuracy of 94.47% on the combined MESSIDOR-Kaggle DR dataset, outperforming prior state-of-the-art methods. With an AUC score of 0.9907, the model shows an extraordinary ability to differentiate among stages of diabetic retinopathy, even when there are minor pathological differences. Such findings serve to highlight the efficacy of the proposed randomized multi-scale image reconstruction in conjunction with the self-paced progressive learning strategy, both of which contribute to the extraction of intricate features from datasets that are limited in size and affected by noise. Comparable trends were observed on the APTOS dataset34, where GPMKLE-Net continued to deliver highly competitive results, particularly with respect to AUC, which remained the highest among all evaluated methods. Specifically, an AUC of 0.9872 was achieved, thereby outperforming several widely adopted techniques, including Swin-Transformer37 and ViT38, and maintaining superiority over ConvNeXt39 in this metric. It should be noted, however, that in terms of classification accuracy (ACC), GPMKLE-Net exhibited a marginally lower value than ConvNeXt, suggesting that while the proposed model excels in distinguishing between classes across the entire range of decision thresholds, ConvNeXt may offer slightly higher accuracy when classifying individual samples. Taken together, these results underscore the strong competitiveness of GPMKLE-Net in addressing the inherent challenges of DR classification tasks.
Ablation study
To evaluate the effectiveness of randomized multi-scale image reconstruction (RMIR), histogram equalization sampling (HES), and guided learning loss (GLL) rigorously, comparative experiments were conducted using ResNet-50. Besides assessing classification accuracy, the model’s performance was further evaluated using the Area Under the Curve (AUC) metric for a more complete analysis. Precision and Recall were also added to the analysis to capture the detailed impact of the proposed methods on different lesion grades. The purpose of this comprehensive analysis was to quantitatively demonstrate the enhancements in classification accuracy and overall model performance brought about by our approach.
RMIR efficacy
Given the inherent complexity of diabetic retinopathy (DR) fundus image classification—particularly the subtlety of lesion features and the challenge of distinguishing adjacent severity levels—the introduction of a randomized multi-scale image reconstruction (RMIR) strategy was designed to address these issues by varying patch sizes throughout training. This approach, which emulates the human visual system’s progression from local to global perception, has led to notable improvements in several key performance metrics.
As presented in Table 3, the implementation of RMIR resulted in a clear enhancement of overall classification accuracy, increasing from 92.71 to 93.22%. The AUC also saw a substantial rise from 0.9687 to 0.9801, indicating improved discriminative capability. Particularly noteworthy is the improvement in recall for the No-DR class, which increased from 97.65 to 99.37%. Additionally, the recall for the Severe class improved from 93.3 to 97.24%, suggesting that the model became more adept at detecting severe DR cases. It is also worth highlighting that the precision for both the Mild and Moderate classes increased (from 89.73 to 99.84% for Mild and from 89.07 to 92.4% for Moderate), further demonstrating the model’s enhanced ability to correctly identify these intermediate disease stages.

HeatMap. Shown in this figure are the heatmaps generated at four distinct stages within the architecture of our proposed method, thereby illustrating the progressive extraction of features across multiple levels. Through the visualization of these heatmaps, the hierarchical learning process of the model can be discerned, with increasingly complex patterns being captured at each successive stage. By comparing these stages, valuable insights are provided into how retinal images are interpreted by the model at varying levels of diabetic retinopathy severity, ranging from No-DR to Severe. In addition, a representative classification prediction is presented using Grad-CAM-based heatmaps, by which the regions of greatest relevance to the model’s decision-making process can be clearly identified, thus offering enhanced interpretability regarding the areas of interest for each classification.
Early Stages: Capturing Fine-Grained Details. During the early phases of training, our model employs smaller image patches (e.g., 8 × 8 patches with a resolution of 224/8 pixels) that are randomly shuffled and then reconstructed into a new image for training. This approach facilitates the model’s ability to swiftly identify subtle and otherwise hard-to-distinguish pathological characteristics. In alignment with this observation, HeatMap Analysis (refer to Fig. 5) demonstrates that, in these initial training stages, the network’s attention is widely distributed across various image regions, thereby capturing a broad spectrum of pathological indicators. Progressive Transition: Moving Towards Global Features. As training progresses, the size of the image patches gradually increases (to 4 × 4, 2 × 2, and eventually the full image). This progressive transition enables the model to learn more holistic and abstract features while maintaining its grasp on the fine-grained details acquired in earlier stages. Reflecting this progression, the HeatMap Analysis reveals that the network’s attention shifts from scattered areas to more cohesive regions, particularly diseased areas, as it delves deeper into the network.
Notably, in the moderate DR stage, the model successfully detects the yellow-white hard exudate, a critical pathological feature, demonstrating its refined understanding of disease manifestations. This evolution of attention from local to global features underscores the model’s ability to mimic human cognition in interpreting complex medical imagery.
HES data sampling impact

Confusion Matrix. This confusion matrix describes the classification performance of our method and some of the state-of-the-art classification methods.
In the early stages of diabetic retinopathy (DR), patients often struggle to perceive notable changes in their vision due to the asymptomatic nature of the condition. This poses a significant challenge in the timely detection and documentation of mild DR cases, leading to a prominent class imbalance in DR image classification tasks. While samples for healthy states and severe DR are relatively abundant, those for mild DR are exceedingly scarce. This imbalance hinders model training effectiveness and affects generalization capabilities in practical applications.
To mitigate the challenges posed by class imbalance, a Histogram Equalization Sampling (HES) strategy was introduced, whereby both the weights and the quantities of samples from each category in the training set are adaptively adjusted. Through this targeted sampling approach, the model is afforded the opportunity to learn more balanced and representative features across all classes, rather than being disproportionately influenced by majority categories. The efficacy of HES, when introduced on top of the RMIR strategy, is clearly reflected in the experimental results summarized in Table 3. Building upon the improvements already achieved with RMIR, the integration of HES leads to a further notable increase in overall classification accuracy, which rises from 93.22 to 93.97%. Likewise, the AUC is elevated from 0.9801 to 0.9850, underscoring an enhanced discriminative capability. Beyond these aggregate metrics, additional class-specific gains are observed: for example, the recall for the Moderate class improves from 85.99 to 88.77%, while the recall for the Severe class increases from 97.24 to 98.55%, accompanied by a precision boost from 91.25 to 94.82%. Collectively, these results indicate that, when HES is employed in conjunction with RMIR, the model becomes more proficient at recognizing minority and challenging categories, thereby achieving a more balanced and robust classification performance. More importantly, an in-depth analysis of the confusion matrix (as shown in Fig. 6) reveals that our model has made breakthrough progress in distinguishing between mild and moderate DR. Prior to implementing HES, models without this strategy often struggled to clearly distinguish between mild DR and other categories due to the scarcity of mild DR samples. This resulted in frequent misclassifications, particularly at the boundary between mild DR and adjacent categories. However, by incorporating HES, our model demonstrates a significantly improved ability to accurately capture the distinctive characteristics of mild DR, notably reducing misclassification rates compared to models without HES.
Advantages of guided learning loss
Given the inherent complexity of DR fundus image classification, our tailored loss function strategy significantly optimized the performance of GPMKLE-Net. Remarkable classification accuracy was attained through the seamless integration of self-paced learning principles into a multi-loss optimization framework. Central to our approach is guided learning loss, which leverages the strengths of self-paced progressive learning. This innovative strategy initially exposes the model to easier-to-detect samples, gradually increasing the complexity of the training data. This gradual progression not only accelerated the model’s learning but also facilitated the systematic enhancement of its overall performance. Our composite loss function, comprising cross-entropy loss (\(\mathcal L_{CE}\)), class-balanced loss with focal weighting (\(\mathcal L_{CB}^{Focal}\)), and regularized dropout loss (\(\mathcal {L}_{Rdrop}\)), each played a pivotal role in addressing specific challenges. While \(\mathcal L_{CE}\) provided a solid foundation for classifier training, \(\mathcal L_{CB}^{Focal}\) dynamically adjusted weights to address class imbalance, ensuring balanced performance across all DR severity categories. Furthermore, \(\mathcal {L}_{Rdrop}\) introduced a regularization mechanism that strengthened the model’s robustness and generalization capabilities by encouraging consistency between predictions from different classifiers.
Experiments demonstrate that, by integrating these loss functions, our model not only achieves a classification accuracy of 94.47% but also attains an AUC evaluation metric of 0.9907. This holistic approach effectively balances performance across diverse categories, underscoring the model’s versatility and reliability in handling complex DR fundus image classifications.
Discussion
This study presents GPMKLE-Net, a novel framework for diabetic retinopathy detection from fundus images. The model achieved high accuracy and AUC on the MESSIDOR-Kaggle and APTOS datasets, demonstrating its effectiveness and robustness, particularly under limited data conditions. Despite these promising results, several limitations remain. The model’s generalizability has not been fully established, as the evaluation was limited to self-constructed and a few public datasets. Additionally, distinguishing mild from moderate DR cases remains challenging, and explicit lesion localization was not addressed. In the future, we will focus on expanding and diversifying datasets, improving feature extraction for subtle cases, and integrating lesion localization techniques. The integration of self-supervised and unsupervised learning paradigms with the GPMKLE-Net framework holds promise for further performance gains, especially in settings where labeled data are scarce. Transfer learning from related medical image classification tasks may also provide valuable insights into improving generalization.
Conclusion
In summary, we have proposed a novel framework, the Guided Progressive Multi-scale KL-Ensemble Network (GPMKLE-Net), for diabetic retinopathy detection from fundus images. Our approach, which integrates guided learning and ensemble regularization, achieves state-of-the-art performance on the MESSIDOR-Kaggle dataset, with a classification accuracy of 94.47% and an AUC of 0.9907. These results highlight the potential of our method to address key challenges in medical image analysis, particularly in scenarios with limited data. Beyond technical improvements, our study demonstrates that progressive multi-scale feature learning and self-paced training strategies can substantially enhance model robustness and generalizability. The ensemble regularization via KL divergence further improves predictive stability, suggesting broader applicability to other medical imaging tasks. Overall, our findings provide new insights into the design of robust deep-learning models for medical image analysis, with potential implications for improving automated disease screening and supporting clinical decision-making.
Data availibility
The datasets used in this study are publicly available and can be accessed through the following links. The Kaggle DR Dataset can be accessed free of charge for research and educational purposes at https://www.kaggle.com/competitions/diabetic-retinopathy-detection/data. The APTOS Dataset can be accessed free of charge for research and educational purposes at https://www.kaggle.com/datasets/mariaherrerot/aptos2019/data. The Messidor-1 database can be accessed free of charge for research and educational purposes at https://www.adcis.net/en/third-party/messidor/.
References
Federation, I.D. Idf diabetes atlas, tenth. International Diabetes (2021).
El-Kebbi, I. M., Bidikian, N. H., Hneiny, L. & Nasrallah, M. P. Epidemiology of type 2 diabetes in the middle east and north Africa: Challenges and call for action. World J. Diabetes 12, 1401 (2021).
Tavakoli, M., Jazani, S. & Nazar, M. Automated detection of microaneurysms in color fundus images using deep learning with different preprocessing approaches. In Medical Imaging 2020: Imaging Informatics for Healthcare, Research, and Applications, vol. 11318, 110–120 (SPIE, 2020).
Porwal, P. et al. Indian diabetic retinopathy image dataset (idrid): A database for diabetic retinopathy screening research. Data 3, 25 (2018).
Khojasteh, P. et al. Exudate detection in fundus images using deeply-learnable features. Comput. Biol. Med. 104, 62–69 (2019).
Mateen, M., Wen, J., Nasrullah, N., Sun, S. & Hayat, S. Exudate detection for diabetic retinopathy using pretrained convolutional neural networks. Complexity 2020, 5801870 (2020).
Shankar, K. et al. Automated detection and classification of fundus diabetic retinopathy images using synergic deep learning model. Pattern Recogn. Lett. 133, 210–216 (2020).
Qiao, L., Zhu, Y. & Zhou, H. Diabetic retinopathy detection using prognosis of microaneurysm and early diagnosis system for non-proliferative diabetic retinopathy based on deep learning algorithms. IEEE Access 8, 104292–104302 (2020).
Benzamin, A. & Chakraborty, C. Detection of hard exudates in retinal fundus images using deep learning. In 2018 Joint 7th International Conference on Informatics, Electronics & Vision (ICIEV) and 2018 2nd International Conference on Imaging, Vision & Pattern Recognition (icIVPR), 465–469 (IEEE, 2018).
Hatanaka, Y. Retinopathy analysis based on deep convolution neuralnetwork. In Deep Learning in Medical Image Analysis: Challenges and Applications, 107–120. (Springer, 2020).
Qureshi, I., Ma, J. & Abbas, Q. Diabetic retinopathy detection and stage classification in eye fundus images using active deep learning. Multimed. Tools Appl. 80, 11691–11721 (2021).
Hemanth, D. J., Deperlioglu, O. & Kose, U. An enhanced diabetic retinopathy detection and classification approach using deep convolutional neural network. Neural Comput. Appl. 32, 707–721 (2020).
Shankar, K., Zhang, Y., Liu, Y., Wu, L. & Chen, C.-H. Hyperparameter tuning deep learning for diabetic retinopathy fundus image classification. IEEE Access 8, 118164–118173 (2020).
Oh, K. et al. Early detection of diabetic retinopathy based on deep learning and ultra-wide-field fundus images. Sci. Rep. 11, 1–9 (2021).
Gangwar, AK. & Ravi, V. Diabetic retinopathy detection using transfer learning and deep learning. In Evolution in Computational Intelligence, 679–689 (Springer, 2021).
Atwany, M. Z., Sahyoun, A. H. & Yaqub, M. Deep learning techniques for diabetic retinopathy classification: A survey. IEEE Access 10, 28642–28655 (2022).
Sebastian, A., Elharrouss, O., Al-Maadeed, S. & Almaadeed, N. A survey on deep-learning-based diabetic retinopathy classification. Diagnostics 13, 345 (2023).
Alwakid, G., Gouda, W., Humayun, M. & Jhanjhi, N. Z. Deep learning-enhanced diabetic retinopathy image classification. Digit. Health 9, 20552076231194944 (2023).
Beevi, S. Z. Multi-level severity classification for diabetic retinopathy based on hybrid optimization enabled deep learning. Biomed. Signal Process. Control 84, 104736 (2023).
Parthiban, K. & Kamarasan, M. Diabetic retinopathy detection and grading of retinal fundus images using coyote optimization algorithm with deep learning. Multimed. Tools Appl. 82, 18947–18966 (2023).
Saranya, P., Pranati, R. & Patro, S. S. Detection and classification of red lesions from retinal images for diabetic retinopathy detection using deep learning models. Multimed. Tools Appl. 82, 39327–39347 (2023).
Mohanty, C. et al. Using deep learning architectures for detection and classification of diabetic retinopathy. Sensors 23, 5726 (2023).
Sivapriya, G., Devi, R. M., Keerthika, P. & Praveen, V. Automated diagnostic classification of diabetic retinopathy with microvascular structure of fundus images using deep learning method. Biomed. Signal Process. Control 88, 105616 (2024).
Lam, C., Yi, D., Guo, M. & Lindsey, T. Automated detection of diabetic retinopathy using deep learning. AMIA Summits Trans. Sci. Proc. 2018, 147 (2018).
Qummar, S. et al. A deep learning ensemble approach for diabetic retinopathy detection. IEEE Access 7, 150530–150539 (2019).
Liu, Z., Gao, G., Sun, L. & Fang, L. Ipg-net: Image pyramid guidance network for small object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 1026–1027 (2020).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7132–7141 (2018).
Du, R. et al. Fine-grained visual classification via progressive multi-granularity training of jigsaw patches. In European Conference on Computer Vision, 153–168 (Springer, 2020).
Cui, Y., Jia, M., Lin, T.-Y., Song, Y. & Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9268–9277 (2019).
Wu, L. et al. R-drop: Regularized dropout for neural networks. Adv. Neural. Inf. Process. Syst. 34, 10890–10905 (2021).
Jiao, S., Li, X. & Lu, X. An improved ostu method for image segmentation. In 2006 8th International Conference on Signal Processing, vol. 2 (IEEE, 2006).
Decencière, E. et al. Feedback on a publicly distributed image database: The messidor database. Image Anal. Stereol. 33, 231–234 (2014).
Graham, B. Kaggle diabetic retinopathy detection competition report. University of Warwick 24–26 (2015).
Karthik, S.D., Maggie. Aptos 2019 blindness detection (2019).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Deng, J. et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255 (Ieee, 2009).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10012–10022 (2021).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
Liu, Z. et al. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11976–11986 (2022).
Howard, A. et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 1314–1324 (2019).
Xu, K. et al. Learning in the frequency domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1740–1749 (2020).
Shubin, D. About Explicit Variance Minimization: Training Neural Networks for Medical Imaging with Limited Data Annotations. Ph.D. thesis, University of Toronto (Canada) (2021).
Li, S. et al. Moganet: Multi-order gated aggregation network. In The Twelfth International Conference on Learning Representations (2023).
Sun, K., Xiao, B., Liu, D. & Wang, J. Deep high-resolution representation learning for human pose estimation. In CVPR (2019).
Xiao, B., Wu, H. & Wei, Y. Simple baselines for human pose estimation and tracking. In European Conference on Computer Vision (ECCV) (2018).
Wang, J. et al. Deep high-resolution representation learning for visual recognition. TPAMI (2019).
Zhu, L. et al. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417 (2024).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1251–1258 (2017).
Dai, Z., Liu, H., Le, Q. V. & Tan, M. Coatnet: Marrying convolution and attention for all data sizes. Adv. Neural. Inf. Process. Syst. 34, 3965–3977 (2021).
Zhang, T. et al. Msht: Multi-stage hybrid transformer for the rose image analysis of pancreatic cancer. IEEE J. Biomed. Health Inform. 27, 1946–1957 (2023).
Xie, S., Girshick, R., Dollár, P., Tu, Z. & He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1492–1500 (2017).
Szegedy, C. et al. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1–9 (2015).
Funding
This research is supported by NSFC-FDCT under its Joint Scientific Research Project Fund (Grant No. 0051/2022/AFJ).
Author information
Authors and Affiliations
Contributions
Q.Z. conceived the project; Y.G. directed the project; Q.Z. performed the experiments; Q.Z., Y.F. and Y.L. contributed to the analysis of the code; All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhou, Q., Guo, Y., Liu, W. et al. Enhancing pathological feature discrimination in diabetic retinopathy multi-classification with self-paced progressive multi-scale training. Sci Rep 15, 25705 (2025). https://doi.org/10.1038/s41598-025-07050-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-07050-1
