
Abstract
As a fine-grained sentiment analysis subtask in the natural language processing (NLP) community, aspect-based sentiment analysis (ABSA) aims to predict the sentiment polarity of the aspect terms according to the given sentence. In previous research, external affective knowledge has been utilized to enhance the representation of the sentiment information contained in the text, which has achieved impressive progress in ABSA task. However, it is worth noting that the external knowledge employed is usually leveraged from the single-dimensional perspective, which lacks diversified and multiple-dimensional exploration and leads to insufficient comprehension of the complex sentiment information. Thus, this paper proposes a novel ABSA network to fully exploit the sentiment features from triple dimensions, namely the psychology knowledge assisted graph attention networks (VADGAT). Preliminarily, to obtain the task-relevant semantic representation, an aspect-oriented template is devised firstly to guide the fine-tuning of the pre-trained language model. Besides, to fully leverage the triple-dimensional sentiment, they are injected into the normal dependency graph to construct three mutually independent adjacent matrices, which are implemented by graph attention networks (GAT) to extract the relations among graph nodes, progressively. Meanwhile, to be treated as the fourth dimension of human beings’ sentiment, SenticNet is also leveraged to enhance the sentiment intensity of the words in the text, which are expected to highlight implicit information and support the final sentiment inference. Moreover, an intentional shadow network is devised and leveraged to reinforce the screening ability of sentiment information, which is integrated with the mainstream representation proportionally. Furthermore, to improve the effectiveness of this innovative strategy, this paper utilizes the Jensen–Shannon divergence to evaluate the similarity between the mainstream and the shadow modules and optimizes the designed VADGAT eventually. To validate the effectiveness of the proposed approach, this paper conducted extensive experiments on five publicly available datasets, and the results show that the approach outperforms the state-of-the-art methods.
Similar content being viewed by others

Introduction
With the rapid development of online platforms, numerous comments including multiple aspects are published by users conveniently, which consist of diverse opinion terms simultaneously1,2,3. Designing proper approaches to mine the potential sentiment information contained in the published text, is a significant work to improve the recognition of publishers’ emotional and psychological states4,5. As a challenging but attractive subtask in the realm of Natural Language Processing (NLP), sentiment analysis aims to mine and understand the sentiment information expressed in the corresponding texts by users. Unlike the coarse-grained document-level and sentence-level sentiment analysis, Aspect-based Sentiment Analysis (ABSA) aims to analyze each aspect term’s sentiment polarity according to the given text, which provides a more fine-grained sentiment investigation for the published reviews6,7,8.
In recent studies, with the benefit of developed NLP technology, ABSA has achieved visible progress in extracting the sentiment information from the reviews9,10. Through Pre-trained Language Model (PLM) to acquire the general semantic feature to handle ABSA, is a popular method in the current study of ABSA. However, the gap between this semantic feature and the downstream’s requirement exists obviously11,12. Prompt learning is proposed to minimize this existing gap by designing a task-oriented template to guide the fine-tuning of PLM, which can instruct the PLM to generate the desired contextual feature representation. Nevertheless, designing a task-related prompt template is the core difficulty while leveraging the paradigm of prompt learning. Besides, injecting external knowledge into syntactic information, encourages researchers to explore the thorough comprehension of textual sentiment from another perspective13, which is usually implemented by Graph Attention Networks (GAT)14 subsequently. Despite the notable progress that has been achieved in previous work15,16, the application of additional knowledge still remains in a single-dimensional state, and the exploitation of utilizing multi-dimensional knowledge in ABSA still needs to be conducted urgently
To address the above mentioned problems, this paper proposed a novel network to promote the further exploration of ABSA task, namely the Psychology Knowledge assisted Graph Attention networks (VADGAT). Preliminarily, to bridge the gap between the general representation and the task’s requirement, VADGAT leverages the designed prompt template to reconstruct the input text. Besides, inspired by the prior works15, this work also inserts external affective knowledge to enrich the sentiment information of the obtained dependency graph. Dissimilarly, it is notable that the valuable knowledge introduced is extracted from the triplet-dimensional psychology knowledge volunteered by Mohammad et al.17. Detailedly, to strengthen the sentiment elements progressively, VADGAT takes the mechanism that absorbs Valence, Arousal, and Dominance through the combination with the dependency graph, sequentially. Moreover, GAT is employed to complete the aggregation process of textual features contained in the neighboring nodes. Specifically, to avoid the mis-extraction of the sentiment information, a twin network depending on the above multi-layers GAT, is devised to assist the learning process of VADGAT. Furthermore, this work leverages Jensen–Shannon Divergence (JS) to evaluate the similarity between the main module and its twin module, which is expected to optimize the learning process of VADGAT ultimately. Besides, the mechanism of cross-attention is referenced to further enhance the joint of semantic and syntactic features at the top of VADGAT. Eventually, the corresponding experimental results show the effectiveness of the proposed model VADGAT, in dealing with the ABSA task.
Conclusively, the main contributions of this paper can be summarized as follows:
-
This paper proposes a novel model VADGAT to solve the problem of the insufficient utilization of external affective knowledge in ABSA task, which progressively introduces Valence, Arousal, and Dominance to enhance the syntactic dependency graph.
-
In VADGAT, to achieve the assembled feature map, GAT is leveraged to integrate the semantic features with the psychology knowledge enhanced syntactic graphs successively.
-
To ensure the full success of VADGAT, this paper devises a twin mechanism consisting of the main and the assisted modules, which is implemented with JS divergence to assist the feature extraction of the proposed model.
-
Various experiments are conducted on five benchmarks, and the results prove the effectiveness of the proposed approach in dealing ABSA tasks.
The remainder of this work is organized as follows. Section “Related work” is arranged to review the related work briefly. The detailed architecture of VADGAT is introduced in Section “Methodology”. Section “Experiments and results” describes the experimental results and analysis carefully. The conclusion is summarized in Section “Conclusion”.
Related work
In this section, a brief review about ABSA is provided first, and the composition of sentiment is summarily introduced later.
Graph attention networks in ABSA
Normally, as a challenging and attractive task in the realm of NLP, ABSA is usually divided into several more fine-grained subtasks: Aspect-based Sentiment Classification (ASC), Aspect-Based Sentiment Triplet Extraction (ASTE), Aspect-Based Sentiment Quadruple Extraction(ASQE), and dimensional aspect-based sentiment analysis (dimABSA), and so on. For convenience, researchers usually use ABSA to denote the aspect-aware sentiment polarity prediction, which is also leveraged by this work spontaneously18,19. Generally, given the extensive background knowledge, PLM can be fine-tuned to generate a comprehensive textual semantic representation for the downstream tasks efficiently, and it has been utilized in the ABSA tasks universally, which has also achieved great improvement in the specific task. Additionally, syntactic features also play a critical role in describing the language organization rule20. Thus, probing the regulation contained in syntactic features would benefit the understanding of the sentence. GCN is effective in extracting the sentiment relations among the graph nodes15,21,22. As the innovative version of GCN, GAT proposes to introduce the attention mechanism into the process of information extraction, which is expected to collect the weighted neighbor nodes. In previous works23,24, GAT has been universally used to capture the aspect-specific features from structured graphs, and remarkable advancement has undoubtedly been achieved. To fully exploit syntactic information in a dependency graph, Want et al.25 proposed the model R-GAT to define a unified aspect-oriented dependency tree structure by reshaping and pruning an ordinary dependency parse tree, and leveraged GAT to extract the necessary sentiment relations. To compensate for the lack of relation about word-pairs in R-GAT, Huo et al.26 proposed to employ a weighted relational head to weigh the dependency relations through the word-pairs information, which refines the sentiment information in ABSA tasks. Furthermore, Wu et al.27 aggregated directed dependency edges and phrase information into the dependency relations, which provided more abundant sentiment information for the inference of sentiment polarity. Not only that, but there are many other studies that are also conducted on the network GAT, and they all promote the advancement of ABSA tasks eventually28,29. Therefore, from the above investigation, GAT is thought to be an effective network to handle dependency relations to enhance the sentiment comprehension of ABSA methods, which also benefits the performance of VADGAT.
Sentiment composition: valence, arousal, and dominance
Since sentiment is a complex conscious phenomenon, many researchers work very hard to study the composition of human sentiment assiduously30,31. Through decades of endeavor, sentiment is usually depicted as the expression of the emotional state in a short term32, being consistent with the sentiment information expressed in the short text. Different from the 2D description of sentiment, researchers usually describe the sentiment from three dimensions recently: Valence, Arousal, and Dominance33,34. Unlike the conventional 2D sentiment composition, 3D sentiment composition is preferred and accurate in describing the sentiment state (Fig. 1). Specifically, Dominance refers to feelings and perceptions of being in control of situations versus being influenced by external factors, which is thought as the factor that makes it possible to distinguish the angry from the anxious.

The comparison of 2D and 3D sentiment composition.
Currently, many efforts of researchers have contributed to constructing the corpus of Valence, Arousal, and Dominance (V&A &D) for the corresponding languages. For instance, Imbir et al.35 extended to the previous introduction of the ANPW dataset, which provides well-established research materials for sentiment analysis of Polish-speaking samples. Besides, on the basis of ANEW norms36, Warriner et al.37 extended the corpus to nearly 14,000 English lemmas, providing researchers with a much richer source of information, which promotes the development of sentiment analysis largely. Moreover, Yu et al.38 and Moors et al.39 also established the related V&A &D corpus for Chinese and Dutch, respectively.
Due to its excellent description of emotional state, V&A &D has already been applied in emotion recognition, which enhances the advancement of affective computing significantly. Notably, the current situation draws our attention that the work about ABSA is seldom reported, which leverages V&A &D to enrich the features map. Therefore, depending on the above investigation of the previous studies, this paper proposes a novel ABSA approach, exploring the application of V&A &D to enhance the performance of ABSA.
Methodology
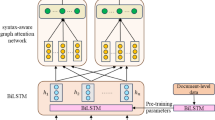
In this section, the key components of the proposed model VADGAT are introduced progressively. Before that, the definition of ABSA tasks is given, which presents the goal of this work. Then, as shown in Fig. 2, this work illustrates the generation of the task-oriented semantic features representation, which is precisely processed by the Biaffine Attention module immediately. Besides, VADGAT leverages the toolkit SpaCy to obtain the syntactic dependency relation, which aims to describe the contextual features from the aspect of syntax. Significantly, to highlight the sentiment elements, the external knowledge SenticNet and V&A &D are injected into the normal dependency graph. Moreover, due to its effectiveness in assembling the relations among nodes, GAT is utilized to integrate the semantic features with the external knowledge-enhanced dependency graphs. To better understand human sentiment, this paper utilized GAT via a progressive strategy to absorb sentiment composition sequentially, which would enhance the proposed model to achieve the eventual contextual representation gradually. Additionally, this work designs an assisted learning module to avoid information loss during extraction and reinforce the learning process ultimately, and this procedure is tackled through the effective utilization of JS Divergence directly. Finally, the loss function used in training is introduced briefly.

The overall architecture of the proposed AKABL.
Task definition
In ABSA, given the sentence \(\mathcal {S}=\{s_1, s_2, ..., \mathcal {A}, ..., s_{n-1}, s_n \}\), where n denotes the length of the input text. \(\mathcal {A}=\{ a_1, a_2,..., a_m\}\) is the aspect terms contained in \(\mathcal {S}\), and m is the length of \(\mathcal {A}\), which is \(1<m<n\). According to the goal of the task, VADGAT aims to predict the sentiment polarity of \(\mathcal {A}\) depending on the absolute comprehension of \(\mathcal {S}\), which is mainly built based on exploring the sentiment cues related to aspect terms in the sentence.
Textual semantic representation
Unlike the approach of querying the pre-trained word vectors, PLMs load the parameters of the pre-trained best checkpoint to improve the performance of the downstream tasks. To minimize the difference between the generated semantic representation and the requirement of ABSA, according to prompt learning, VADGAT designs the task-specific template \(\mathcal {T}= 'The\; aspect\; is\; \mathcal {A}\;.\; What\; is\; the\; sentiment\; polarity\; of\; it\; ?'\) based on the task’s target, and its length is denoted as k. Therefore, the input sentence can be denoted as
Subsequently, the semantic representation can be generated by PLM RoBERTa40 directly, which can be written as
where \(\widehat{\mathcal {H}} = \{ \hat{h}_1, \hat{h}_2, ..., \hat{h}_{n+k-1},\hat{h}_{n+k}\} \in R^{(n+k)\times d}\), and d is the dimension of the hidden layer. For convenience, VADGAT reserves the original text representation through the proper pruning strategy, and the obtained feature map is denoted as \(\widetilde{\mathcal {H}}= \{\hat{h}_1, \hat{h}_2, ..., \hat{h}_{n-1},\hat{h}_n\} \in R^{n\times d}\).
Biaffine attention has been proven effective in improving the quality of textual representation in ABSA tasks41. Therefore, VADGAT applies it to highlight the relationship between aspect terms and contextual features. In this work, the process of biaffine attention is formulated as
where \(W_{\mathcal {B}}\) is the learned weights, \(\mathcal {B}\) is the achieved semantic representations, \(\top\) means the operation of transposition. Hereto, the initial semantic features are mapped into the designed hidden space, which is the cornerstone of further sentiment information extraction.
V, A, D, and SenticNet enhanced syntax graph
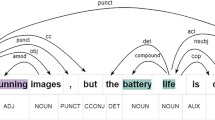
Through investigating previous works42,43, it is clear that the introduction of external knowledge can enhance sentiment information, which is beneficial to the inference of sentiment obviously. Normally, the prior work utilizes the sentiment intensity to strengthen the expression of sentiment information directly. Specifically, SenticNet contributes a lot to enrich the textual feature maps, and it has already been applied in various studies44,45. However, the single dimension of enriching knowledge would lead to distinct bias in the expression of contextual sentiment, which lacks complementarity from multiple perspectives. Valence, Arousal, and Dominance (V&A &D) are proposed to describe human sentiment from triple distinguish dimensions. Inspired by their professionally evaluated mechanism, this work argues that V&A &D can provide abundant external knowledge to the original text. Thus, in this subsection, VADGAT leverages V&A &D to enrich the sentiment information of the dependency graph from triple perspectives. For convenience and to avoid redundancy, this work only presents the injection process of Valence (V), and the process can be formulated as follows. Initially, the toolkit SpaCy is utilized to obtain the adjacent matrix \(\mathfrak {A}_{\mathbb {O}}\) of the original dependency graph,
where \(w_{i}\) and \(w_{j}\) are the i-th and j-th words in the input sentence. Then, this work introduces the external knowledge SenticNet and V&A &D into the adjacent matrix \(\mathfrak {A}_{\mathbb {O}}\). Taking the injection of V as an example, the process can be denoted as,
where \(\mathfrak {A}_\mathbb {V}\) is the achieved Valence-enhanced adjacent matrix. In this process, \(\mathfrak {P}\) is designed to represent the relation between the words \(w_{i}\) and \(w_{j}\), which queries the values from the Valence corpus directly. Besides, \(\mathfrak {D}\) is designed to highlight the significance of the aspect terms. Similarly, VADGAT can gain the other three distinct adjacent matrices \(\mathfrak {A}_{\mathbb {A}}\), \(\mathfrak {A}_{\mathbb {D}}\), and \(\mathfrak {A}_{\mathbb {S}}\), which are constructed on Arousal, Dominance, and SenticNet, respectively. Hereto, this work has achieved the affective knowledge-enhanced dependency graphs, and they would reinforce the contextual comprehension of VADGAT later.
Progressive graph attention networks
Inspired by the previous works46, extracting dependency relations in ABSA would promote the understanding of the input sentence. In this work, GAT is employed to handle the affective knowledge-enhanced syntactic features and the semantic features simultaneously. Moreover, as the agent of human beings in tackling ABSA tasks, it is obliged to teach the networks V&A &D in the order of discovery. Thus, to comprehensively utilize SenticNet and V&A &D, this work injects external knowledge into the contextual representation through GAT progressively. The process can be formulated as
where \(\mathfrak {A}_{\mathbb {X}}\in \{ \mathfrak {A}_{\mathbb {S}}, \mathfrak {A}_{\mathbb {V}}, \mathfrak {A}_{\mathbb {A}}, \mathfrak {A}_{\mathbb {D}} \}\) is the symbol of affective knowledge-enhanced graph, \(\varphi _{i,j}\) is the relation weight between the i-th node and the j-th node, \(\mathfrak {W}_{\mathbb {X}} \in \{ \mathfrak {W}_{\mathbb {S}}, \mathfrak {W}_{\mathbb {V}}, \mathfrak {W}_{\mathbb {A}}, \mathfrak {W}_{\mathbb {D}}\}\) is the final achieved weighted contextual representation. Additionally, it is noted that the element \(\mathcal {B}_{j}\) is replaced by the former output \(\mathfrak {W}_{\mathbb {X}}\in \{ \mathfrak {W}_{\mathbb {S}}, \mathfrak {W}_{\mathbb {V}}, \mathfrak {W}_{\mathbb {A}} \}\) of GAT layer. Thus, the output of the fourth GAT layer can be denoted as \(\mathfrak {W_D}\). Hereto, VADGAT has fused the semantic features with external knowledge-enhanced syntactic features successfully, which provides a refined contextual representation for the prediction of sentiment polarity.
To further highlight the importance of the relationship between semantic and syntactic features, VADGAT also utilizes cross-attention to further extract the sentiment information from these two perspectives, which can be denoted as
where \(\mathcal {F}\) is the achieved contextual representation eventually, \({\top }\) means the operation of matrix transposition, \(W_{D}\) is the learned weight martix, \(d_{D}\) is the scale parameter.
Assisted learning
In the process of fine-tuning a pre-trained contextual word embedding model, even with the same hyperparameters, the consequences would be different in the circumstance of distinct random seeds47. To mitigate this influence on VADGAT, this paper designs an Assisted Learning module to achieve fair contextual representation. According to the design, this paper can obtain similar feature maps \(\widetilde{\mathcal {F}}\), which originates from the twin procedure. Thus, this work can gain the contextual feature representation from dual perspectives simultaneously. And, the process can be formulated as,
where \(\alpha\) and \(\beta\) are the hyperparameters to control the participation of different branches, \(\mathfrak {F}\) is the feature map utilized in further training.
Inference and training
To validate the capability of VADGAT, this work optimizes the proposed model via minimizing the loss function constructed on the basis of cross-entropy. Besides, to further construct the relation between \(\mathcal {F}\) and \(\widetilde{\mathcal {F}}\), this work devises a assisted twin loss based on JS divergence, which is injected into the loss function and can be denoted as
where C is the batch size, T is the category of the sentiment polarity. \(\hat{y}_{c,t}\) and \(y_{c,t}\) are the predicted and the ground truth sentiment label of the t-th polarity, respectively. And, \(\mu\) is the coefficient of \(L_{2}\) regularization \(\Theta\), \(\gamma\) is the hyper-parameter to control the participation of JS in training process. Hereto, the whole architecture of VADGAT is introduced through the description of the transformation of the feature information. To further explain the working mechanism of the proposed VADGAT, the corresponding algorithm is provided in the Algorithm 1.

The proposed ABSA model VADGAT.
Experiments and results
In this section, this work presents the benchmarks utilized to validate the effectiveness of the proposed VADGAT firstly. Then, the experimental settings of the proposed approach will be introduced later. Moreover, this work selects and lists the recent state-of-the-art (SOTA) baselines for further comparison. Furthermore, this work proves its effectiveness by analyzing the main results, ablation study, and each component in VADGAT. Besides, the impacts of the significant hyperparameters are also studied in the later subsections detailedly.
Datasets
For the convenience of comparison, this work conducts experiments on five widely used benchmarks, which are Restaurant14 (Rest14), Restaurant15 (Rest15), Restaurant16 (Rest16), Twitter, and Laptop14 (Lap14). Detailedly, Lap14 and Rest14 are extracted from SemEval 201448, Rest15 and Rest16 are taken from SemEval 201549 and SemEval 201650, and Twitter is collected from the popular social media platform Twitter by Dong et al.51. Besides, the statistics of the sentiment labels in these five datasets are shown in Table 1.
Experimental settings
To conduct the experiments successfully, this work conducts the related experiments on the Pytorch platform and runs them on a 12GB RTX 3080Ti GPU. Moreover, this work employs SpaCy to obtain the original dependency matrix of the sentence. Additionally, the training epoch is set to 30 on the mentioned datasets. Besides, to conveniently compare the results to the baselines, the indicators Accuracy and F1 scores are leveraged to evaluate the model’s performance in the current ABSA task, and the detailed formulation can be referred to this work52.
Baselines
To validate the effectiveness of VADGAT, this work selects several current SOTA baselines for valuable comparison, which mainly focus on LSTM-, BERT-, and RoBERTa-based. Concretely, the selected approaches are introduced briefly as follows,
-
R-GAT25 is the network that encodes the new tree extracted from the original dependency tree, which is constructed through the relational graph attention network.
-
DGEDT53 jointly utilizes the flat representations and graph-based representations simultaneously, which are obtained from the Transformers and the corresponding dependency graph, respectively.
-
DualGCN54 aims to fuse the syntactic complementarity and the correlations of semantic through the proposed dual GCN networks.
-
Hete-GNNs55 encodes opinion dictionary, word relations, and dependency tree through a unified framework at the same time.
-
R-GAT+BERT25 leverages the PLM BERT to enhance R-GAT without the LSTM.
-
APSCL56 captures the potential relationship among different aspects through contrastive learning, which enhances the representation of aspect features.
-
BERT4GCN57 employs the utilization of the intermediate layers of BERT and GCN to achieve the final textual representation.
-
KE-IGCN58 aims to select the highly relevant subgraphs, and proposes an interaction strategy to evaluate the interaction between external knowledge and the input text.
-
RSSG+BERT59 leverages the interaction between aspect-to-context attention scores and the syntactic distances, which is completed through the designed discrete latent opinion tree model.
-
EK-GCN-BERT60 employs the external knowledge and the part of speech to construct the relationship between the aspect and the contextual words.
-
HRLN-BERT61 also leverages the relationship between the aspect and the key contextual sentiment representation to enhance the performance of ABSA tasks.
-
RGAT-RoBERTa62 leverages the PLM RoBERTa to enhance R-GAT without the LSTM.
-
HRLN-RoBERTa61 leverages the PLM RoBERTa to enhance HRLN without the LSTM.
-
RoBERTa4GCN57 leverages the PLM RoBERTa to replace BERT in BERT4GCN.
-
RoBERTa-MLP57 utilizes the multi-layer perceptron to deal with the feature information obtained by RoBERTa.
-
DGEDT-RoBERTa61 leverages the PLM RoBERTa to replace LSTM in DGEDT.
-
PRCL-GCN22 is proposed to distinguish the difference between the original and knowledge-enhanced dependency graph via contrastive learning, which is also prompted by the designed task-specific templates.
Main results
To validate the effectiveness of the proposed VADGAT, this work conducts relevant experiments on five public and available datasets. In order to facilitate comparison, the corresponding results are reported in Table 2, being compared with the selected baselines directly.
From the table, this work can achieve four precise findings, apparently. Firstly, it is obvious that the proposed VADGAT outperforms the chosen baselines in the majority of indicators on five benchmarks. For example, on Lap14, VADGAT achieves 83.07% and 80.10% for Acc and F1, which reach the optimal state on the prediction of sentiment polarity. Moreover, VADGAT also does an excellent job on Rest16, and achieves 93.99% and 82.59% for Acc and F1, respectively, which outperforms the sub-optimal approach RSSG+BERT with the improvements of 0.19% and 0.99%. Additionally, on Twitter and Rest15, VADGAT also achieves quite competitive results on both evaluations. Concretely, on Twitter, the sub-optimal results are obtained by VADGAT, and they are only slightly lower than the results obtained by HRLN+BERT. And, a similar situation can be observed on Rest15. Whereas, the performance on Rest14 achieved by VADGAT is not satisfactory. This finding indicates that the current approach of affective knowledge injection can assist the ABSA model in recognizing the sentiment features largely, but it still has space to improve in the generalization of various fields.
Secondly, it can be observed easily that the methods constructed on the basis of LSTM achieve the worst results in the mentioned three groups. This finding proves again the powerful contextual modeling ability of PLMs.
Thirdly, the methods based on BERT also achieve excellent results on Twitter, Rest14, and Rest16, respectively, and their performances are only a bit lower than the baseline PRCL-GCN and VADGAT.
Fourthly, it is noted that the comparison between PRCL-GCN and VADGAT is interesting. As described above, the semantic features are represented by RoBERTa based on the designed prompt template, which is similar to the strategy used in the PRCL-GCN and differs in the context of the template. In the group of RoBERTa, these two approaches outperform the other baselines, apparently. This finding suggests that the proper prompt template can improve the performance of ABSA model generally, which is also an attractive research topic in the NLP community.
Conclusively, by injecting the external affective knowledge into the syntactic graphs, VADGAT can highlight the implicit features and capture them to enhance the model’s capability in extracting aspect-specific sentiment information.
Ablation study of V, A, and D
In this subsection, the ablation study is conducted to probe the effect of the triple sentiment dimensions (V, A, and D). Specifically, this work explores the optimal portfolio among V, A, and D through extensive experiments on the mentioned five benchmarks, and the corresponding results are collected in Table 3 detailedly.
By carefully observing the results, three observations can be made. Firstly, from the general perspective, the triple sentiment dimensions V, A, and D all contribute a lot to the sentiment inference. Specifically, the results shown by the last row in Table 3, are lower than the other rows, obviously, which can be found in the majority of VADGAT’s performances.
Secondly, the F1 scores of Rest15 and Rest16 without V, A, and D, are higher than the results based on the knowledge-enhanced graphs. Through careful analysis, this work attributes this situation to the size of datasets, which is not enough to provide abundant affective words to encourage the learning ability of PLM.
Thirdly, while inspecting the results achieved based on affective knowledge, this work finds that the optimal results are distributed across different combinations of sentiment dimensions, even on the same dataset. For instance, on Lap14, the combination V&A achieves the best performance in the shown results. However, on Twitter, while only A is utilized to strengthen the graph, VADGAT achieves optimal performance in the current ABSA task. Besides, this phenomenon is also found in the consequences of Rest14, which means the triple sentiment dimensions can inject affective knowledge into the graph from different views and activate different terms’ sentiment recognition.
Conclusively, the above findings imply that V&A &D can bring fresh thoughts to the devised ABSA networks, and the selection of the combination of them and how to utilize them effectively are the critical components while designing the ABSA model.
Robust analysis
Furthermore, to investigate the generalization of the proposed approach VADGAT, this work conducts the corresponding experiments with different contextual representations obtained by different PLMs, which are RoBERTa, BERT, GPT, and BART, respectively. For convenient comparison, the related experimental results are reported in Table 4. From the table, it is obvious that RoBERTa can encourage VADGAT’s capability to recognize the sentence’s sentiment polarity, which is embodied in the five mentioned benchmarks clearly. And, the experimental results based on BERT, GPT, and BART are lower than the ones achieved on RoBERTa. On the other perspective, the generalization of VADGAT is still limited to the special PLM, which denotes the robustness of this work should be studied further in the future. Additionally, this work believes that the manually designed prompt template also limits the generalization of VADGAT in fact. Conclusively, this analysis shows that VADGAT based on RoBERTa can understand the contextual sentiment information comprehensively and capture the key features in predicting the sentiment polarity.
The impact of \(\alpha\) and \(\beta\)
To investigate the importance of the proper ratios in Eq. (13) (\(\alpha\) and \(\beta\)) to VADGAT’s performance, the relevant experiments are conducted to explore the best admirable participation of the original features \(\mathcal {F}\) and its twin \(\widetilde{\mathcal {F}}\). Besides, the corresponding results are collected in Table 5. From the listed results, this work can gain two achievements evidently. Firstly, on different datasets, VADGAT should extract different rate features from the dual feature sources to complement the sentiment information space, which is beneficial to comprehending textual knowledge. For instance, VADGAT selects 0.1 and 0.9 for \(\alpha\) and \(\beta\) as the seed player to fine-tune the designed model, which enhances the performance of ABSA on Lap14. Moreover, 0.7 and 0.3 are chosen to assist the training process of VADGAT according to their advantages on the datasets Twitter and Rest16. Secondly, while \(\alpha > 0.5\) and \(\beta < 0.5\), VADGAT can achieve better performance on the related task. Concretely, the more participation in the mainstream feature, the consequence is better. This phenomenon can be observed from the five lower rows in Table 5, apparently, which denotes that a proper supplement of the twin feature can reinforce the features generated from the original framework. Thus, motivated by the above results, the work selects different but proper \(\alpha\) and \(\beta\) values to conduct the experiments for different datasets.
The impact of JS rate \(\gamma\)
Designing proper loss functions can improve the training efficiency while learning deep learning models. To explore the optimal JS rate \(\gamma\) in the current ABSA task, this work analyzes different performances caused by various \(\gamma\) in Eq. (14), and the results are reported in Table 6. Depending on careful observation, two points can be summarized certainly. Firstly, on different datasets, VADGAT needs different \(\gamma\) to learn the optimal textual features. For example, on Twitter, VADGAT obtains the highest results while \(\gamma\) is set to 0.55. Secondly, it is apparent that the optimal results are distributed across different indicators even on the same dataset. For instance, on Lap14, VADGAT achieves the best Acc with \(\gamma =0.10\), but achieves the best F1 score with 0.01. This situation also happens on the other three datasets (Rest14, Rest15, and Rest16). conclusively, in the validated experiments, this work selects different \(\gamma\) for each dataset, which enhances the proposed approach’s ability to model the contextual representation.
The impact of batch size
Batch size means the granularity of the input data to train the deep learning model, which impacts the learning consequence largely. In this subsection, this work discusses the influence caused by batch size on the performance of VADGAT in ABSA. For intuitive observation, the related results are depicted in Fig. 3. From the figure, it can be learned that this work mainly conducts the relevant experiments with three groups of batch size, which are 2, 4, and 8, respectively. In the scope of investigation, while the batch size is set to 8, VADGAT could learn abundant sentiment information from the input textual materials, and this is the reason that batch size is set to 8 for further validation study in this work.

The impact of batch size.
The impact of optimizer
Through investigating the previous works64, it is clear that the selection of the optimizer impacts the model’s performance significantly. Thus, in this subsection, the experiments based on 7 different optimizers are conducted to motivate the learning capability of VADGAT. Besides, the corresponding experimental results are collected in Table 7. From the table, this work can get the finding that Adam can encourage VADGAT to achieve optimal results obviously, except for the F1 score on Rest15. Besides, Adadelta, Adagrad, Asgd, and SGD all fail in optimizing the designed VADGAT to its best state in the current experiment settings. Summarily, selecting a proper optimizer for fine-tuning the devised model is significant in the ABSA task.
The impact of learning rate
The appropriate learning rate is the key hyper-parameter to learning a successful ABSA model, which has been proven significant in fine-tuning the PLM for downstream tasks. In this subsection, this work also provides a relevant study to attempt to explain the significance of the learning rate to the proposed VADGAT. Figure 4 is depicted to show the experimental results achieved via six learning rates ({1e-5, 2e-5, 3e-5, 4e-5, 5e-5, 6e-5}). From the figure, it is obvious that VADGAT achieves the optimal results on the five mentioned benchmarks simultaneously, while the learning rate is set to \(1e-5\). Besides, the larger the learning rate is, the lower the result is achieved. This finding indicates that VADGAT can be fine-tuned to the optimal state for extracting the sentiment features, which implies the fine-grained features can optimize the restored parameters in the PLM.

The impact of learning rate.
The impact of dropout
Initially, the dropout is devised to mitigate the pressure caused by over-fitting while learning the material, which can reduce the co-adaptability between neurons and increase the generalization ability of the model. In this work, this subsection is organized to analyze the influence caused by the dropout in the fine-tuning of VADGAT, and the results are shown in Fig. 5. In the figure, this phenomenon is apparent that each dataset should be learned with different dropout values in the training process of VADGAT. Concretely, while the dropout is set to 0.4, VADGAT achieves the optimal result on Lap14. Additionally, it is noted that the performances of the other four datasets (Rest14, Rest15, Rest16, and Twitter) are improved largely with the dropout 0.1 in the current state, which suggests that discarding the appropriate proportion of the textual information can promote the robustness of VADGAT effectively.

The impact of dropout.
Case study
To probe the working mechanism of the proposed VADGAT, this subsection is arranged to present the inference of sentiment polarity by analyzing the randomly selected examples from the mentioned datasets (Table 8). Concretely, 12 examples are chosen to show the prediction capability of VADGAT, which consists of 4 samples with Neutral, 4 samples with Negative, and 4 samples with Positive ground truth labels. From the table, two conclusions can be summarized briefly. First, the samples with Negative and Positive labels are all predicted precisely, no matter which sentiment dimension is leveraged. This finding suggests that the introduced sentiment knowledge can enhance the information representation expressed by the text indeed, and the knowledge strengthens the intensity of the sentiment words directly, which provides distinct contextual information for the model’s learning. Second, while predicting the 4 samples with Neutral labels, it can be learned that only half samples are given the correct sentiment polarity prediction. Probing the hidden principle, it is believed that the introduction of external knowledge would exacerbate the phenomenon of over-inference while in the testing process of VADGAT.
Error analysis
For further exploring the prediction error in dealing with the samples with Neutral labels, this subsection is arranged to present the visualization of the hidden weights of case 10 and case 12. The exact heat map is shown in Fig. 6. Through analyzing the distributed attention weights of case 10 in Fig. 6, due to the injection mechanism of external knowledge, VADGAT pays more attention to the aspect term “menu” obviously. Besides, in the modes of A, D, VA, and AD, the model focus on the words “patio area has”, which means that the strong relation between these words and the aspect term is constructed by the proposed model. However, these words only present a neutral feeling in the context, but they are thought of as dangerous places in many real news reports, which leads to over-inference eventually. Furthermore, a similar phenomenon can be found in the attention visualization of case 12, too. From the Table 8, it can be learned that the modes of V and VAD give the correct sentiment polarity prediction to case 12, and these two modes distribute their attention on the contextual words in a nearly balanced state, which guides the model to make a neutral assessment on case 12 finally. On the other side, VADGAT with other modes is confused by the random word in the text, which may be the root of the wrong prediction.

Error analysis.
Discussion and limitations
In the above subsections, the characteristics of VADGAT have been shown through the collected and reported experimental results. On the basis of those, this subsection is arranged to give a brief discussion and show the limitations of the proposed model.
Discussion
Generally, ABSA is a challenging task in the NLP community, struggling to extract the sentiment information and reasoning its polarity. In VADGAT, to highlight the aspect-aware textual features, this work mainly completes the task in three ways, and the proposed strategies all contribute to the improvement of ABSA. Firstly, the gap between PLM and the downstream task is an obstacle to its universal application. VADGAT leverages the manually designed prompt template to merge this fissure effectively (Shown in Eqs. (1) and (2)). Secondly, to avoid the model falling into the special trap under the specific training data, this work attempts to teach the model from the perspective of psychology. Concretely, the knowledge of Valence, Arousal, Dominance, and SenticNet is employed to enrich the model’s cognitive state and improve the performance of ABSA subsequently (Shown in Table 3). Thirdly, the innovation of the assisted module enhances the model’s capability of extracting the key features, reducing the omission of critical sentiment information (Shown in Table 5). From the above discussion, the significant innovations show their effective influence on improving the current ABSA task.
Limitations
However, despite the improvements on the benchmarks being apparent, there are still several limitations of the proposed VADGAT in dealing with ABSA task. Upon the proposed model VADGAT, this work concludes that two limitations still exist in our study. Firstly, while utilizing the prompt template to invoke the PLM’s potential ability, this work is still limited by a single artificial prompt template, not evaluating VADGAT’s capability with more templates, and this should be solved in our future work. Secondly, the progressive injections of four views of external sentiment knowledge into the contextual representation, are not suitable for the learning process of VADGAT, where the latter knowledge would eliminate the former trace, resulting in incomplete and unsystematic learning, and the unified external knowledge utilization mechanism should be exploited further.
Conclusion
To exploit the utilization of psychology knowledge in ABSA task, this paper proposes a novel approach VADGAT to inject the triple-dimensional affective knowledge into the syntactic graph, and integrates the knowledge-enhanced graph with the semantic representation through the powerful GAT progressively. Detailedly, to model the contextual representation precisely, the aspect-specific prompt template is designed to motivate the backbone RoBERTa to capture the aspect-related sentiment information. Moreover, inspired by the effectiveness of external knowledge in strengthening the sentiment representation, this work employs the psychology knowledge to reconstruct the syntactic graphs, which highlight the sentiment relationships among the dependency nodes. Furthermore, to utilize the semantic and syntactic features simultaneously, GAT is leveraged to integrate these two representations effectively. Additionally, to increase the generalization of the proposed approach, this work designs an architecture namely the twin networks to assist the learning of textual materials, and this design provides extreme reliance for the proposed approach’s performance in the extensive experiments. Eventually, the extensive experiments conducted on the five public datasets validated the effectiveness of the proposed VADGAT in ABSA task, which also proved that psychology knowledge can strengthen the sentiment relation among various feature nodes.
In the future, we plan to design more prompt templates to validate the effectiveness of the proposed method. Besides, the auto-generated template will be studied to be applied in our approach. Furthermore, we aim to devise a novel strategy of injecting the psychology knowledge to improve the performance of ABSA task.
Data availability
The datasets generated and/or analyzed during this study can be accessed in the SSEGCN-ABSA repository at https://github.com/zhangzheng1997/SSEGCN-ABSA. Besides, the codes can be available from https://github.com/sxfmch/VADGAT_U.
References
Kang, X., Shi, X., Wu, Y. & Ren, F. Active learning with complementary sampling for instructing class-biased multi-label text emotion classification. IEEE Trans. Affect. Comput. 14(1), 523–536 (2020).
Zhou, Y., Kang, X. & Ren, F. Prompt consistency for multi-label textual emotion detection. IEEE Trans. Affect. Comput. 15(1), 121–129 (2023).
Petrescu, A., Truică, C.-O., Apostol, E.-S. & Paschke, A. Edsa-ensemble: An event detection sentiment analysis ensemble architecture. IEEE Trans. Affect. Comput. 16(2), 555–572 (2025).
Deng, J. & Ren, F. A survey of textual emotion recognition and its challenges. IEEE Trans. Affect. Comput. 14(1), 49–67 (2021).
Apostol, E.-S., Pisică, A.-G. & Truică, C.-O. Atesa-b \(\{\backslash\)AE\(\}\) rt: A heterogeneous ensemble learning model for aspect-based sentiment analysis. Preprint at arXiv:2307.15920 (2023).
Petrescu, A., Truică, C.-O. & Apostol, E.-S. Sentiment analysis of events in social media. In 2019 IEEE 15th International Conference on Intelligent Computer Communication and Processing (ICCP), 143–149 (2019).
Zheng, Y., Li, X. & Nie, J.-Y. Store, share and transfer: Learning and updating sentiment knowledge for aspect-based sentiment analysis. Inf. Sci. 635, 151–168 (2023).
Mitroi, M., Truică, C.-O., Apostol, E.-S. & Florea, A.M. Sentiment analysis using topic-document embeddings. In 2020 IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), 75–82 (2020).
Truică, C.-O., Apostol, E.-S., Şerban, M.-L. & Paschke, A. Topic-based document-level sentiment analysis using contextual cues. Mathematics 9(21), 2722 (2021).
Wang, J., Yu, L.-C. & Zhang, X. Softmcl: Soft momentum contrastive learning for fine-grained sentiment-aware pre-training. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 15012–15023 (2024).
Liu, P. et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 55(9), 1–35 (2023).
Zheng, G., Wang, J., Yu, L.-C. & Zhang, X. Instruction tuning with retrieval-based examples ranking for aspect-based sentiment analysis. In Findings of the Association for Computational Linguistics ACL 2024, 4777–4788 (2024).
Zou, W., Zhang, W., Tian, Z. & Wu, W. A syntactic features and interactive learning model for aspect-based sentiment analysis. Complex Intell. Syst. 10, 1–19 (2024).
Veličković, P. et al. Graph attention networks. Preprint at arXiv:1710.10903 (2017)
Zhu, Z. et al. Knowledge-guided multi-granularity GCN for ABSA. Inf. Process. Manag. 60(2), 103223 (2023).
Bao, Y. et al. PKET-GCN: Prior knowledge enhanced time-varying graph convolution network for traffic flow prediction. Inf. Sci. 634, 359–381 (2023).
Mohammad, S. Obtaining reliable human ratings of valence, arousal, and dominance for 20,000 english words. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (volume 1: Long Papers), 174–184 (2018).
Zhang, W., Li, X., Deng, Y., Bing, L. & Lam, W. A survey on aspect-based sentiment analysis: Tasks, methods, and challenges. IEEE Trans. Knowl. Data Eng. 35(11), 11019–11038 (2022).
Wankhade, M., Kulkarni, C. & Rao, A. C. S. A survey on aspect base sentiment analysis methods and challenges. Appl. Soft Comput. 167, 112249 (2024).
Yuan, L., Wang, J., Yu, L.-C. & Zhang, X. Syntactic graph attention network for aspect-level sentiment analysis. IEEE Trans. Artif. Intell. 5(1), 140–153 (2022).
Wang, J., Li, X. & An, X. Modeling multiple latent information graph structures via graph convolutional network for aspect-based sentiment analysis. Complex Intell. Syst. 9(4), 4003–4014 (2023).
Shi, X., Hu, M., Ren, F. & Shi, P. Prompted representation joint contrastive learning for aspect-based sentiment analysis. Knowl.-Based Syst. 285, 111345 (2024).
Gao, X. et al. Dual-channel relative position guided attention networks for aspect-based sentiment analysis. Expert Syst. Appl. 253, 124271 (2024).
Jiang, J., Wang, A. & Aizawa, A. Attention-based relational graph convolutional network for target-oriented opinion words extraction. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 1986–1997 (2021).
Wang, K., Shen, W., Yang, Y., Quan, X. & Wang, R. Relational graph attention network for aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 3229–3238 (2020).
Huo, Y., Jiang, D. & Sahli, H. Aspect-based sentiment analysis with weighted relational graph attention network. In Companion Publication of the 2021 International Conference on Multimodal Interaction, 63–70 (2021).
Wu, H., Zhang, Z., Shi, S., Wu, Q. & Song, H. Phrase dependency relational graph attention network for aspect-based sentiment analysis. Knowl.-Based Syst. 236, 107736 (2022).
Liang, S., Wei, W., Mao, X.-L., Wang, F. & He, Z. Bisyn-gat+: Bi-syntax aware graph attention network for aspect-based sentiment analysis. In Findings of the Association for Computational Linguistics: ACL 2022, 1835–1848 (2022).
Wu, H., Huang, C. & Deng, S. Improving aspect-based sentiment analysis with knowledge-aware dependency graph network. Inf. Fusion 92, 289–299 (2023).
Das, R. & Singh, T. D. Multimodal sentiment analysis: A survey of methods, trends, and challenges. ACM Comput. Surv. 55(13s), 1–38 (2023).
Zhu, X., Kuang, Z. & Zhang, L. A prompt model with combined semantic refinement for aspect sentiment analysis. Inf. Process. Manag. 60(5), 103462 (2023).
Mneimne, M., Wellington, R., Walton, K. E. & Powers, A. S. Beyond arousal: Valence, dominance, and motivation in the lateralization of affective memory. Motiv. Emot. 39, 282–292 (2015).
Kuppens, P., Tuerlinckx, F., Russell, J. A. & Barrett, L. F. The relation between valence and arousal in subjective experience. Psychol. Bull. 139(4), 917 (2013).
Mäntylä, M., Adams, B., Destefanis, G., Graziotin, D. & Ortu, M. Mining valence, arousal, and dominance: Possibilities for detecting burnout and productivity? In Proceedings of the 13th International Conference on Mining Software Repositories, 247–258 (2016).
Imbir, K. K. Affective norms for 4900 polish words reload (anpw_r): Assessments for valence, arousal, dominance, origin, significance, concreteness, imageability and age of acquisition. Front. Psychol. 7, 1081 (2016).
Altarriba, J., Bauer, L. M. & Benvenuto, C. Concreteness, context availability, and imageability ratings and word associations for abstract, concrete, and emotion words. Behav. Res. Methods Instrum. Comput. 31, 578–602 (1999).
Warriner, A. B., Kuperman, V. & Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 45, 1191–1207 (2013).
Yu, L.-C. et al. Building Chinese affective resources in valence-arousal dimensions. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 540–545 (2016).
Moors, A. et al. Norms of valence, arousal, dominance, and age of acquisition for 4,300 Dutch words. Behav. Res. Methods 45, 169–177 (2013).
Liu, Y. Roberta: A robustly optimized bert pretraining approach. Preprint at arXiv:1907.11692364 (2019).
Chen, H., Zhai, Z., Feng, F., Li, R. & Wang, X. Enhanced multi-channel graph convolutional network for aspect sentiment triplet extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2974–2985 (2022).
Jin, W., Zhao, B., Zhang, L., Liu, C. & Yu, H. Back to common sense: Oxford dictionary descriptive knowledge augmentation for aspect-based sentiment analysis. Inf. Process. Manag. 60(3), 103260 (2023).
Shi, X., Hu, M., Ren, F., Shi, P. & Nakagawa, S. Aspect based sentiment analysis with instruction tuning and external knowledge enhanced dependency graph. Appl. Intell. 54, 1–18 (2024).
Cambria, E., Li, Y., Xing, F. Z., Poria, S. & Kwok, K. Senticnet 6: Ensemble application of symbolic and subsymbolic ai for sentiment analysis. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, 105–114 (2020).
D’Aniello, G., Gaeta, M. & La Rocca, I. KnowMIS-ABSA: An overview and a reference model for applications of sentiment analysis and aspect-based sentiment analysis. Artif. Intell. Rev. 55(7), 5543–5574 (2022).
Zhong, Q. et al. Knowledge graph augmented network towards multiview representation learning for aspect-based sentiment analysis. IEEE Trans. Knowl. Data Eng. 35(10), 10098–10111 (2023).
Dodge, J. et al. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. Preprint at arXiv:2002.06305 (2020).
Pontiki, M. et al. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), 27–35 (Association for Computational Linguistics, 2014).
Pontiki, M., Galanis, D., Papageorgiou, H., Manandhar, S. & Androutsopoulos, I. Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), 486–495 (2015).
Pontiki, M. et al. Semeval-2016 task 5: Aspect based sentiment analysis. In International Workshop on Semantic Evaluation, 19–30 (2016).
Dong, L. et al. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (volume 2: Short Papers), 49–54 (2014).
Truica, C.-O. & Leordeanu, C. A. Classification of an imbalanced data set using decision tree algorithms. Univ. Politech. Bucharest Sci. Bull. Ser. C Electr. Eng. Comput. Sci 79, 69–84 (2017).
Tang, H., Ji, D., Li, C. & Zhou, Q. Dependency graph enhanced dual-transformer structure for aspect-based sentiment classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 6578–6588 (2020).
Li, R. et al. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 6319–6329 (2021).
Lu, G., Li, J. & Wei, J. Aspect sentiment analysis with heterogeneous graph neural networks. Inf. Process. Manag. 59(4), 102953 (2022).
Li, P., Li, P. & Xiao, X. Aspect-pair supervised contrastive learning for aspect-based sentiment analysis. Knowl.-Based Syst. 274, 110648 (2023).
Xiao, Z., Wu, J., Chen, Q. & Deng, C. Bert4gcn: Using bert intermediate layers to augment GCN for aspect-based sentiment classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 9193–9200 (2021).
Wan, Y., Chen, Y., Shi, L. & Liu, L. A knowledge-enhanced interactive graph convolutional network for aspect-based sentiment analysis. J. Intell. Inf. Syst. 1–23 (2022).
Zhang, R., Chen, Q., Zheng, Y., Mensah, S. & Mao, Y. Aspect-level sentiment analysis via a syntax-based neural network. IEEE/ACM Trans. Audio Speech Lang. Process. 30, 2568–2583 (2022).
Gu, T., Zhao, H., He, Z., Li, M. & Ying, D. Integrating external knowledge into aspect-based sentiment analysis using graph neural network. Knowl.-Based Syst. 259, 110025 (2023).
Cao, Y. et al. Heterogeneous reinforcement learning network for aspect-based sentiment classification with external knowledge. IEEE Trans. Affect. Comput. https://doi.org/10.1109/TAFFC.2022.3233020 (2023).
Dai, J., Yan, H., Sun, T., Liu, P. & Qiu, X. Does syntax matter? A strong baseline for aspect-based sentiment analysis with Roberta. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1816–1829 (2021).
Mei, X. et al. A disentangled linguistic graph model for explainable aspect-based sentiment analysis. Knowl.-Based Syst. 260, 110150 (2023).
Daoud, M. S. et al. Gradient-based optimizer (GBO): A review, theory, variants, and applications. Arch. Comput. Methods Eng. 30(4), 2431–2449 (2023).
Acknowledgements
This work was supported in part by the Joint Fund of the National Natural Science Foundation of China and the Civil Aviation of China under Grant U2433216, the Natural Science Foundation of Jiangsu Province under Grant BK20231337, the National Natural Science Foundation of China under Grant 62176084.
Funding
Partial financial support was received from Joint Fund of the National Natural Science Foundation of China and the Civil Aviation of China under Grant U2433216. Partial financial support was received from Natural Science Foundation of Jiangsu Province under Grant BK20231337. Partial financial support was received from National Natural Science Foundation of China under Grant 62176084.
Author information
Authors and Affiliations
Contributions
Xuefeng Shi and Weiping Ding prepared the whole plan and conducted the related experiments. Xuefeng Shi, Fuji Ren, and Min Hu wrote the main manuscript text, and Xuefeng Shi and Xin Kang prepared figures, and Xuefeng Shi and Weiping Ding prepared tables. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical and informed consent for data used
Not applicable.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Shi, X., Ding, W., Hu, M. et al. Triple dimensional psychology knowledge encouraging graph attention networks to exploit aspect-based sentiment analysis. Sci Rep 15, 27109 (2025). https://doi.org/10.1038/s41598-025-08914-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-08914-2
