
Abstract
In the maritime industry, accurately detecting a ship’s draft line is crucial for ensuring transaction fairness and navigational safety. Existing deep learning-based methods for draft line detection primarily use segmentation techniques to segment the entire body of water before determining the waterline. These approaches incur high computational costs and often face challenges under varying environmental conditions, such as lighting changes and different hull colors. To address these issues, we propose multi-scale feature fusion keypoint detection network (MFFKD) for precise and efficient ship draft line detection. Our network integrates four stages of Dilated Residual-Channel Recalibration Module (DR-CRM) blocks to extract multi-scale features. Meanwhile, the Feature Enhancement Extraction Modules (FEEM) are employed to enhance these extracted features, and the Multi-scale Feature Weighted Integration (MFWI) module efficiently fuses the enhanced multi-scale features. Furthermore, a task head for keypoint prediction is designed to ensure accurate localization of keypoints. By integrating the predicted keypoint data with mark information detected by the character recognition head through a mathematical model, we achieve precise predictions of waterline readings. To enhance the model’s adaptability to various environmental conditions, we adopt a dual-phase training strategy: an initial pre-training phase for learning general ship features and waterline characteristics, followed by a fine-tuning phase using data from diverse scenes. Extensive experimental results show that our method surpasses the baseline models in waterline detection accuracy. In terms of model execution speed, our method exceeds the advanced segmentation-based approaches. These demonstrate the effectiveness of integrating keypoint detection with dual-phase training in ship waterline detection.
Similar content being viewed by others


Introduction
In maritime operations, the draft line or waterline, represents the vertical distance between the waterline and the bottom of the hull, critically affecting the ship’s buoyancy, stability, and cargo capacity. In 2023, the global trade volume for dry bulk shipping reached 5.508 billion metric tons. Given that ships carry thousands or even tens of thousands of tons of cargo, even minor discrepancies in waterline measurements can lead to substantial financial losses. This underscores the urgent need for improved measurement techniques1.

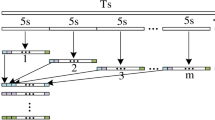
Comparison between MFFKD and traditional segmentation methods..
In recent decades, there has been a progressive evolution in waterline measurement technology. The traditional method of waterline reading predominantly relies on manual labor, with port workers physically inspecting ship drafts. This approach is time-consuming, labor-intensive, and subject to visual errors and safety risks, especially in adverse weather conditions such as wind, waves, rain and fog2,3. Subsequently, sensor-based methods for detecting ship waterlines were proposed4. Shen et al.5 utilized radar liquid level measuring instruments to measure the draft line of ships. Chen et al.6 used laser radar to measure the distance between the sensor and the water surface. However, sensor-based methods are typically expensive and susceptible to noise and measurement errors, which can lead to decreased measurement accuracy. To address the limitations of manual waterline observation and sensor-based methods, a solution employing image processing techniques for automatic waterline reading has been proposed7. This method involves capturing images of a ship’s draft with cameras and applying image processing algorithms to automatically detect and calculate the waterline. Due to its cost-effectiveness and simplicity, this approach is considered more practical for real-world applications. Tsujii et al.8 used morphological operations to identify draft markers and the Canny edge detection method to locate the waterline. Similarly, Ran et al.9 applied the Canny edge detection algorithm to extract waterline contours from images, followed by the Hough transformation for further detection. While effective, these methods face challenges in adapting to diverse and complex scenarios, and their accuracy often does not meet the requirements for practical applications. The aforementioned challenge has been mitigated in automated draft reading by integrating deep learning-based image processing techniques. Wang et al.10 proposed a hybrid approach that combined traditional computer vision methods with deep learning. They used traditional methods to annotate draft lines, while deep learning facilitated character recognition. Wang et al.11 employed Mask R-CNN to segment draft marks and water bodies in images, subsequently employing UNet to refine draft line detection. Ship draft readings were then computed based on the extracted visual information. Similarly, Li et al.12 introduced a novel U2-NetP neural network modified with Coordinate attention for water bodies segmentation. However, current deep learning-based approaches for ship draft reading primarily utilize segmentation methods, which present several drawbacks13. First, the computational cost depends on the spatial resolution; higher image resolutions lead to increased computational expenses, while reducing resolution sacrifices spatial information. Second, these methods typically focus on segmenting the water surface rather than directly identifying the waterline, often requiring full segmentation before determining the waterline’s position, which increases computational and time overhead. Third, the accuracy of waterline detection with segmentation methods can be affected by varying lighting conditions and complex weather scenarios.
In recent years, deep learning-based keypoint detection has yielded remarkable results in areas such as facial recognition and human pose estimation14,15, where keypoints represent critical nodes of the human body and the connecting lines delineate various body parts16,17. This technique has expanded beyond human-centric applications. For example, Wang et al.18 successfully applied keypoint detection to monitor material surfaces in blast furnace, and Wong et al.19 applied 3D object keypoint detection for robotic arm grasping. Inspired by these developments14,15,16,17,18,19, we propose a multi-scale feature fusion keypoint detection network (MFFKD) for precise and efficient ship draft line detection. We think that the waterline can be accurately represented by detecting and connecting a few keypoints along it. Our keypoint detection network focuses only on the waterline, rather than the entire body of water, which reduces computational overhead and improves detection speed, as illustrated in Fig. 1. Additionally, we implement a dual-phase training strategy to enable the model to adapt to diverse challenging scenarios. Our main contributions are summarized as follows:
-
1.
Innovative Methodology: We design a keypoint detection network specifically for ship draft reading. This network incorporates four stages of Dilated Residual-Channel Recalibration Module (DR-CRM) blocks to extract multi-scale features, with the Feature Enhancement Extraction Module (FEEM) further enhancing these extracted features. The Multi-scale Feature Weighted Integration (MFWI) module then efficiently fuses the enhanced multi-scale features, and a dual-branch task head accurately determines the coordinates of keypoints along the waterline.
-
2.
Dual-Phase Training Model: We utilize a dual-phase training model for waterline detection, starting with pre-training on daylight images for basic feature learning, followed by fine-tuning with nighttime, colored ship and daylight datasets. It significantly enhances the model’s performance in challenging conditions.
-
3.
Comprehensive Evaluation: Our approach surpasses other backbone models in accuracy and adaptability across various conditions and ship colors, achieving an error as low as 0.008 meters. Additionally, the inference time for each image sized at 1080\(\times\)1920 is only 5 milliseconds when performing on an NVIDIA RTX 2080Ti GPU, which is 1.8 times faster than existing segmentation methods.

The overall architecture of our proposed method. Initially, our model utilizes two convolutional blocks to extract fundamental features from the input data. The processed data is then fed into four FFEMs. The features produced by FFEMs will undergo multi-scale feature fusion via FWMs. Ultimately, the integrated feature maps are directed into a task-specific head designed for keypoint detection, which predicts the waterline keypoints. These keypoints, combined with character recognition results, are used to compute the final waterline prediction value through a mathematical model.
Proposed method
Overall architecture
Our model, built on a Convolutional Neural Network (CNN) framework, is specifically designed for the keypoint detection task. As illustrated in Fig. 2, it comprises several modules that progressively extract and combine spatial structures relevant to the visual characteristics of the waterline. Initially, our model utilizes two convolutional blocks to extract fundamental features from the input data. The processed data is then fed into four stages of DR-CRM blocks. The features produced at each stage by the DR-CRM blocks will be refined and enhanced using the FEEMs. The outputs of FEEMs will undergo multi-scale feature fusion via MFWI. Ultimately, the integrated feature maps are directed into a task-specific head designed for keypoint detection, which predicts the waterline keypoints. These keypoints, combined with character recognition results, are used to compute the final waterline prediction value through a mathematical model.
Backbone network design

The architecture of DR-CRM block. Dilated convolution increases the receptive field of the convolution kernel without adding parameters and enhances the network’s contextual understanding of the input data. The CRM accentuates significant features and suppresses less relevant ones, ensuring that subsequent convolution layers process a more refined representation of the input.

Comparison between dilated convolution and standard convolution. Dilated convolution has a larger receptive field.
DR-CRM block
The DR-CRM (Dilated Residual-Channel Recalibration Module) enhances the traditional ResNet module by substituting standard convolutions with dilated convolutions and incorporating a Channel Recalibration Module (CRM) into each residual block. The backbone consists of four stages of DR-CRM blocks, with 3, 4, 6, and 3 blocks in stages one through four, respectively. In each block, all convolutions employ a 3\(\times\)3 kernel by default; downsampling is performed via a stride of 2 in the first convolution of stages two, three, and four, while all remaining convolutions use a stride of 1. The structure of the DR-CRM is depicted in Fig. 3. Dilated convolution increases the receptive field of the convolution kernel without adding parameters and enhances the network’s contextual understanding of the input data, as illustrated in Fig. 4. The CRM accentuates significant features and suppresses less relevant ones, ensuring that subsequent convolution layers process a more refined representation of the input.
Specifically, after two dilated convolutions, the features are fed into both an adaptive average pooling layer and an adaptive standard deviation pooling layer. These pooling operations reduce the spatial dimensions of the input data, condensing each channel into a single representative value. The average pooling layer captures the overall information of the channel features, whereas the standard deviation pooling layer highlights the variability among the channel features. This adaptive process ensures that the global context is preserved regardless of input size, maintaining the essential global features. The outputs of these two pooling layers are passed through a convolution layer and a sigmoid activation function to obtain a set of scores. The sigmoid function is chosen for its output range between 0 and 1, making it ideal for generating attention scores. These attention scores represent the significance of each channel feature. These scores are then multiplied by the inputs of the CRM, and finally concatenated. The combined outputs of these two pooling layers are then passed through a fully connected layer that transforms the pooled features into a higher-level representation. This linear transformation is crucial because it allows for dense recombination of channel statistics, creating a more expressive set of features to better guide the attention mechanism. The transformed features then undergo processing by a sigmoid activation function. Finally, the output of the sigmoid function is element-wise multiplied with the features after two dilated convolutions. This operation scales each channel according to its importance, modulating the input based on the attention it receives. The entire process of CRM is shown in Eq. (1) as follows:
where \(\textbf{Y}\) represents the input feature of the CRM, \(H\) and \(W\) denote its height and width. \(\textbf{Y}_{\text {avg}}\) is the average value of \(\textbf{Y}\) over its spatial dimensions, and \(\textbf{Y}_{\text {std}}\) is the standard deviation of \(\textbf{Y}\) over the same dimensions. \(\text {Conv}\) refers to a convolution operation, \(\sigma\) is the sigmoid function, \(\odot\) represents element-wise multiplication, \(\text {Concat}\) denotes the concatenation operation, and \(\text {FC}\) is a fully connected layer. \(\textbf{Y}_{\text {final}}\) represents the final output of CRM after the recalibration process.

The architecture of FEEM. The input feature map is divided into three groups along the channel dimension, enabling each group to be processed independently and efficiently.
FEEM
The Feature Enhancement Extraction Module (FEEM) is designed to enhance feature extraction by integrating multi-scale convolutions with channel attention mechanisms, as shown in Fig. 5. In this module, the input feature map is initially divided into three groups along the channel dimension, enabling each group to be processed independently and efficiently. The module consists of three parallel branches that apply convolutions with different kernel sizes: a 1\(\times\)1 convolution, a 3\(\times\)3 depthwise separable convolution, and a 5\(\times\)5 depthwise separable convolution. The stride for all convolutions is set to 1. The 1\(\times\)1 convolution aggregates information across channels, while the 3\(\times\)3 and 5\(\times\)5 convolutions capture local and global context, respectively. After these convolutional operations, each branch processes its output through a fully connected (linear) layer, followed by a sigmoid activation function. This produces attention weights for each feature map, which are then applied via element-wise multiplication to recalibrate the feature maps and focus on the most relevant spatial and channel-wise information. The re-weighted feature maps from the three branches are concatenated along the channel dimension, and a final 1\(\times\)1 convolution fuses them into a unified, enhanced feature representation. This design effectively captures diverse and complementary features while significantly reducing computational cost through the use of depthwise separable convolutions.

The architecture of MFWI. The six feature maps of different sizes generated by the FEEMs are progressively integrated.
MFWI
Our backbone network is specifically designed to fully exploit multi-scale feature information. MFWI is tailored for the fusion of these multi-scale features. The beginning of the backbone includes two blocks, each comprising convolution, batch normalization, and ReLU activation, to extract fundamental features from the input data. The processed data is then fed into four-stage DR-CRM blocks. Each stage of the DR-CRM blocks generates feature maps at different scales, which are then processed through the MFWI. Figure 6 illustrates the structure of the MFWI. In the MFWI module, every convolution employs a 3\(\times\)3 kernel with a stride of 2. The six feature maps of different sizes generated by the FEEMs are progressively integrated into the convolutional stream, starting from the largest and moving to the smallest. The final output of the convolutional stream is the result of the combined contribution of feature information across these six scales. Simultaneously, the information at each scale passes through individual downsampling layers to generate independent feature maps. The final output from the convolution, together with the independent feature maps from each scale, is fused through a weighted fusion process, producing the final combined output, which serves as the backbone’s ultimate output, as detailed in Eq. (2).
where \(\textbf{X} = [x_1, x_2, \dots , x_m, x_o]\) and \(\textbf{W} = [w_1, w_2, \dots , w_m, w_o]\). m is the number of FEEMs. \([x_1, x_2, \dots , x_m]\) represents the downsampled output features from the m FEEMs. \(x_0\) is the output of the convolutional stream. \(\textbf{W}\) represents the weight parameters corresponding to the output features. This architectural design enables the model to fully leverage multi-scale feature information.
Task head design
Detection head
The detection head in our architecture employs an ingeniously dual-branch design, tailored for the keypoint detection task, as shown in Fig. 7. This dual-path approach processes spatial information along two separate paths, one for the X-axis and another for the Y-axis, and then combines their outputs to accurately predict keypoint coordinates. In each branch of our architecture, the input feature map first undergoes a compression mechanism that efficiently reduces dimensionality while preserving the essential data necessary for accurate keypoint localization. Following this, the compressed features are upsampled using deconvolution layers tailored to their respective axes. This step is critical for restoring the spatial resolution that is reduced during compression and for refining localization along each axis. The upsampled features then pass through a series of convolution layers, ensuring that intricate details pertinent to keypoint locations are clearly delineated across the X and Y dimensions. After this convolution processing, each branch directs its feature map to a dedicated fully connected layer, which serves as a regressor for the specific axis, transforming high-level features into coordinate vectors that represent keypoint locations along the X and Y axes. In the final integration phase, the outputs from the X and Y branches are merged via a concatenation operation. This fusion creates a unified 2D representation of keypoint locations, enabling the final prediction of keypoint coordinates as (X, Y) pairs. This approach captures the spatial essence of the input data, ensuring that the predicted keypoints are accurately aligned with the context of the original image.

The structure diagram of the detection head for keypoint detection. This dual-path approach processes spatial information along two separate paths, one for the X-axis and another for the Y-axis, then combines their outputs to accurately predict keypoint coordinates.
Loss function
The loss function used for training the keypoint detection model is the Mean Squared Error (MSE)18 loss according to Eq. (3). MSE is a widely-used statistical measure that quantifies the average squared difference between the predicted values produced by a model and the ground truth. It is particularly suitable for regression tasks where the continuity and sensitivity of the predictions are of essence, as is the case with water level measurements.
where \(N\) is the total number of training samples. \(n\) represents the number of keypoints in each image. \(x^{P}_{i,j}\) and \(y^{P}_{i,j}\) are the predicted x and y coordinates of the \(i\)-th keypoint in the \(j\)-th image. \(x^{L}_{i,j}\) and \(y^{L}_{i,j}\) are the label x and y coordinates of the \(i\)-th keypoint in the \(j\)-th image.
Character recognition head (CR Head)
We annotated various classes of numbers and characters in our dataset using LabelImg, including challenging rusted characters and those with reduced visibility in low-light conditions. Subsequently, we utilized the YOLOv5 model with pre-trained YOLOv5s weights to recognize scale numbers and characters on ships. The recognition results are shown in Fig. 8. YOLOv5 is built upon PyTorch, a widely adopted deep learning framework known for its flexibility and ease of use20. This allows us to easily integrate YOLOv5 into our existing workflow and leverage its extensive ecosystem for model training and deployment. Moreover, YOLOv5s, the smallest variant in the YOLOv5 series, trained on the diverse COCO dataset21, significantly enhance the model’s ability to adapt and improve accuracy in specialized tasks22 such as recognizing alphanumeric characters on ships by leveraging its robust foundational knowledge of varied visual features. Additionally, the compact size of YOLOv5s (approximately 14 MB) ensures low computational overhead, making it ideal for deployment on edge devices with constrained resources, such as onboard systems in marine environments.

Mark recognition results in different scenes. (a) Characters with rust corrosion. (b) Daytime scene. (c) Nighttime scene. (d) Colored ship scene.
Mathematical modeling
Our method utilizes a mathematical model to convert the observed data into a quantifiable water level measurement. As depicted in Fig. 9, \(v_2\) represents the water level we aim to calculate. The coordinates of \(v_2\) in the image are determined by a point on the line connecting the keypoints, and the point is positioned directly below the bottom mark. \(v_0\) refers to the large-scale mark in meters above the waterline, which provides a major calibration point. \(v_1\) is the value of the smaller scale mark just above the waterline, with a distance of 0.2 meters between the small scale marks, providing a reference point for finer accuracy.
The distances \(d_0\), \(d_1\), and \(d_2\) correspond to specific physical measurements in the scene:
-
\(d_0\) is the distance between the second and third marks above the waterline.
-
\(d_1\) is the distance between the first and second marks above the waterline.
-
\(d_2\) is the distance between the waterline and the nearest mark above it.
Due to the possibility of the vessel not being flat or the camera having a certain angle relative to the vessel during photography, the pixel distances of \(d_0\) and \(d_1\) in the image may differ. This discrepancy leads to perspective distortion. To mitigate the impact of perspective distortion, we define the ratio \(r = \frac{d_1}{d_0}\) to represent the trend of distance variation between adjacent marks around the waterline. The final water level \(v_2\) is then calculated by correcting \(v_0\) with the information from \(v_1\) and the ratio r, as follows:

The schematic diagram of waterline readings.
Two-phase training approach
Phase 1 general feature acquisition
In the first phase of training, we concentrate on leveraging a dataset consisting of daylight images. The primary goal at this stage is to enable the model to recognize and comprehend the fundamental characteristics of draft lines. By implementing a higher learning rate, we accelerate the learning process, enabling the model to rapidly assimilate the essential contours and placements of draft lines. This phase is essential for establishing a baseline of general visual features upon which the model can build in subsequent phases.
Phase 2 specialized refinement
The second phase of training involves a targeted fine-tuning process across three distinct streams to enhance robustness in varied operational scenarios. The first stream, Nighttime Images, focuses on low-light conditions to improve the model’s sensitivity to draft lines when visibility is compromised, addressing a common nighttime challenge. The second stream, Colored Ships, deals with variability in ship colors, which can significantly impact the perception of draft lines. Training the model on ships with different colors ensures better generalization across a wider range of vessels. The third stream, Daytime Images, revisits daylight conditions, aiming to refine the model’s detection capabilities in scenarios with similar but slightly varied lighting, such as different times of the day or under varied weather conditions. In this phase, a lower learning rate is employed to make precise adjustments to the model’s parameters, allowing it to fine-tune its ability to detect draft lines under these challenging and diverse conditions. This careful calibration aims to enhance the model’s precision without sacrificing the broader contextual understanding developed in the first phase, ensuring adaptability and accuracy across all conditions.
Experiment and analysis
Experimental setup

The examples from different scenarios. (a) Daytime scene. (b) Nighttime scene. (c) Colored ship scene.
Dataset
In our study, we utilize a waterline dataset collected in 2019 at Huanghua Port, which is operated by the China Coal Research Institute Corporation. The dataset comprises 500 high-resolution RGB images from 56 cargo vessels, each with a resolution of 1080\(\times\)1920, categorized and annotated as follows: 300 daylight images with clear visibility of the draft line, 160 nighttime images, where visibility is naturally reduced, 40 images of ships with various hull colors, including low-contrast scenarios against the water. The weather conditions during image collection were all clear. Figure 10 shows examples of images from these different scenarios. Annotations were provided by port workers, indicating the waterline readings on each image. Moreover, to facilitate model training and performance validation, we divided the dataset for each of the three scenarios into training and testing subsets, adhering to an 8:2 ratio.
Implementation details
All experiments were conducted on a platform with the Ubuntu 20.04 operating system, an NVIDA RTX 2080Ti GPU with 11GB RAM, and Intel Core i5-13600k CPU with 32GB RAM. The software platform is Pytorch 1.12.1, based on the Python 3.8.0. We compared our proposed model with seven advanced backbones, MobileNetV323, InceptionV324, ResNet25, SENet26, DRN27, ConvNeXt28 and TransNeXt29, by replacing the network before the task head to validate the effectiveness of our method.
Evaluation metrics
To assess the performance of our waterline reading system, we select the Average MSE (AMSE) as our primary evaluation metric, which calculates the AMSE value of predicted key points in each sample according to Eq. (5):
where \(N_t\) is the total number of the test samples. A lower AMSE value indicates a higher accuracy of the model’s predictions, as it implies a smaller average squared deviation from the actual values.
Additionally, we conduct comparisons between the model’s predicted readings and manual readings to evaluate the model’s performance in completing the final waterline reading task. Each image’s manual reading is derived from evaluations by four workers, with the average of these readings serving as the manual reading value. For different environmental conditions, we calculate the discrepancy between predicted and manual readings for each image. Subsequently, the average of all discrepancies is computed as the model’s predicted waterline reading error. We also use the percentage of readings with an error less than 0.03m (PRE@0.03) as an additional metric to assess the model’s accuracy in predicting the waterline.
Train strategy
To avoid bias from varying training strategies, a unified model training strategy was adopted in the experiment. The Adam optimizer30 was chosen, with an initial learning rate of 0.0003, and a LambdaLR31 scheduler was used, with the learning rate decay formula shown in Eq. (6). In each of the three diverse scenes, fine-tuning32 sessions were trained for only 50 epochs.
During the training of our model, due to the presence of learnable weight parameters involved in the fusion of multiple features, we specifically set the learning rate for these parameters to 0.1 and incorporated them into the Adam optimizer.
Comparative experiments
Detection accuracy
The experiments demonstrate that our model surpasses seven baseline models in accuracy and efficiency for waterline detection across all three scenarios. Under daytime, nighttime, and diverse colored ship conditions, the AMSE is only 62.34%, 66.23%, and 50.22% of the best-performing baseline model, TransNeXt, respectively, as shown in Table 1. The average reading error is 44.0%, 40.63%, and 38.10% of the baseline model under the same corresponding conditions, as shown in Table 2. PRE@0.03 achieves 91.67%, 93.75%, and 100.00% under the three scenarios, significantly surpassing other backbones, as shown in Table 3. The visualization of predicted readings is shown in Figs. 11, 12 and 13, where (a), (b), (c), (d), (e) and (f) respectively depict the waterline reading predictions using MobileNetV3, InceptionV3, ResNet, SENet, DRN and our MFFKD as backbones.



Detection speed
To evaluate the efficiency of our method for waterline detection, we conduct comparative tests against six established segmentation models: UPerNet33, DeepLabv3Plus34, PSANet35, PSPNet36, DANet37 and YOLOv5 segmentation38 model. To ensure equitable comparisons, we select versions of UPerNet, DeepLabv3+, PSANet, PSPNet and DANet that are based on the ResNet3425 backbone, similar to our own model. Additionally, we choose a YOLOv5 segmentation model whose number of parameters is comparable to or less than that of our model.
We test the detection on 10 images with a resolution of 1080x1920, focusing exclusively on detection and excluding character recognition and reading computation. The average inference time for these images is used as the benchmark for per-image processing time. As shown in Table 4, our model achieves inference speeds 2.8 times faster than the UPerNet model with the ResNet34 backbone, and 1.8 times faster than the YOLOv5 segmentation model. These results demonstrate the superior detection efficiency of our method than other segmentation-based approaches.
Ablation study

Comparison of AMSE and average reading error accross all test samples between one-stage and two-stage training in three scenarios.

Ablation analysis of DR-CRM.

Ablation analysis of MFWI.
Advantages of two-stage training
The experimental results in Fig. 14 demonstrate that two-stage training outperforms the one-stage training in performance. This approach enables our model to adapt more effectively to different environments.
Impact of DR-CRM
Figure 15 presents the ablation study of the DR-CRM. In our experiments within MFFKD, we replace the DR-CRM block with standard convolution and dilated convolution for comparative analysis. The experimental results demonstrate that the DR-CRM block outperforms both standard and dilated convolutions, underscoring the effectiveness of the DR-CRM block. Additionally, we compared the performance of the DR-CRM block with 3 stages to that of the standard 4-stage version. Table 5 demonstrates the effectiveness of the 4-stage configuration.
Impact of FEEM
Our FEEM includes convolutions with three different kernel sizes. We compare this with a setup that only retains the 3x3 convolution. The results in Table 6 demonstrate the effectiveness of our FEEM.
Impact of MFWI
Figure 16 presents a comparison of the AMSE between the scenarios where the model utilizes MFWI for feature fusion and where it does not. It is evident that the model employing MFWI outperforms those using direct feature addition or feature concatenation across all three scenes, demonstrating the effectiveness of incorporating MFWI.
Impact of backbone size
We investigate the impact of different pre-trained weights on detection accuracy by utilizing DRN 18, DRN 34, and DRN 50. The parameter variations in these pre-trained weights typically affect the complexity of the model and its ability to handle complex detection tasks. To conduct an effective comparative analysis, we evaluate the performance of our models against the best-performing DRN model among the comparison models. Our investigation demonstrates that regardless of the parameter count, the AMSE of all our models is lower than the best-performing DRN model. The experimental results, presented in Table 7, indicate that our MFFKD significantly improves detection accuracy, superior performance in challenging conditions such as nighttime and colored ship detection.
Discussion
Our model has fewer parameters compared to most segmentation methods, and directly detects the waterline instead of segmenting the water body. This design leads to faster inference speed, highlighting the model’s potential for real-time deployment in resource-constrained environments, such as onboard ships. Our mathematical model assumes that the water surface in the photo is horizontal, which is an idealized scenario and places certain requirements on the image capture. In cases where the water surface is not horizontal, some errors may be introduced. In the future, we plan to consider curve fitting techniques to more accurately determine the waterline position. In addition, our model employs a two-stage training process. In the first stage, the model learns general visual features related to waterline detection, while in the second stage, it adapts to various challenging conditions. This approach ensures that the model performs effectively across different environmental scenarios. However, the non-end-to-end nature of the training process introduces added complexity to the model’s training pipeline. Our future research aims to explore the development of an end-to-end training framework that remains adaptable to diverse challenges, which could streamline the training process and potentially improve both training efficiency and deployment flexibility.
Conclusions
In this work, we apply keypoint detection method to the task of ship draft detection for the first time. We employ a two-stage training strategy that enables the model to adapt effectively to different scenarios. Our model possesses strong feature extraction capability and is able to effectively utilize multi-scale features. On our self-constructed waterline dataset, we achieve an error as low as 0.008 meters in specific scenarios, demonstrating higher waterline detection accuracy than other backbones. Besides, with an NVIDIA RTX 2080Ti GPU, our model achieves an impressive inference time of 5 milliseconds for each image sized at 1080 \(\times\) 1920, which is 1.8 times faster than existing segmentation methods. In the future, we plan to deploy our model on edge devices to further evaluate its performance and capabilities in practical applications. Additionally, we will also investigate the application of the keypoint detection network in other maritime sectors.
Data availability
Data underlying the results presented in this paper may be obtained from the corresponding author upon reasonable request.
References
Wu, J. & Cai, R. Problem in Vessl’s draft survey and countmeature to increase its precision. J. Insp. Quar. 20, 79–80 (2010).
Jiang, X., Mao, H. & Zhang, H. Simultaneous optimization of the liner shipping route and ship schedule designs with time windows. Math. Probl. Eng. 2020, 1–11 (2020).
Zhang, X. et al. Self-powered distributed water level sensors based on liquid-solid triboelectric nanogenerators for ship draft detecting. Adv. Funct. Mater. 29, 1900327 (2019).
Rodriguez, D. R., Peavey, R. W., Beech, W. E. & Beatty, J. M. Portable draft measurement device and method of use therefor (2002). US Patent 6,347,461.
Yijun, S., Bo, L. & Penghao, W. Application of ranging technique of radar level meter for draft survey. Chin. J. Ship Res. 12, 134–140 (2017).
Wenwei, C., Ji, Y. U., Jie, X. U., Canhong, J. & Lian, C. A new measurement system of ship draft. Shipbuilding of China (2013).
Kirilenko, Y. & Epifantsev, I. Automatic recognition of draft marks on a ship’s board using deep learning system. In International School on Neural Networks, Initiated by IIASS and EMFCSC, 1393–1401 (Springer, 2022).
Tsujii, T., Yoshida, H. & Iiguni, Y. Automatic draft reading based on image processing. Opt. Eng. 55, 104104–104104 (2016).
Ran, X., Shi, C., Chen, J., Ying, S. & Guan, K. Draft line detection based on image processing for ship draft survey. In 2011 2nd International Congress on Computer Applications and Computational Science: Volume 2, 39–44 (Springer, 2012).
Wang, Z., Shi, P. & Wu, C. A ship draft line detection method based on image processing and deep learning. In Journal of Physics: Conference Series, vol. 1575, 012230 (IOP Publishing, 2020).
Wang, B., Liu, Z. & Wang, H. Computer vision with deep learning for ship draft reading. Opt. Eng. 60, 024105–024105 (2021).
Li, W. et al. Research and application of u 2-NetP network incorporating coordinate attention for ship draft reading in complex situations. J. Signal Process. Syst. 95, 177–195 (2023).
Lateef, F. & Ruichek, Y. Survey on semantic segmentation using deep learning techniques. Neurocomputing 338, 321–348 (2019).
Newell, A., Yang, K. & Deng, J. Stacked hourglass networks for human pose estimation. In Computer Vision–ECCV 2016: 14th European Conference, 483–499 (Springer, 2016).
Cao, Z., Hidalgo, G., Simon, T., Wei, S.-E. & Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 43, 172–186 (2021).
Law, H. & Deng, J. CornerNet: Detecting objects as paired keypoints. In European Conference on Computer Vision (ECCV), 734–750 (2018).
Fisch, M. & Clark, R. Orientation keypoints for 6d human pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 44, 10145–10158 (2021).
Wang, H., Li, W., Zhang, T., Li, J. & Chen, X. Learning-based key points estimation method for burden surface profile detection in blast furnace. IEEE Sens. J. 22, 9589–9597 (2022).
Wong, C.-C., Yeh, L.-Y., Liu, C.-C., Tsai, C.-Y. & Aoyama, H. Manipulation planning for object re-orientation based on semantic segmentation keypoint detection. Sensors 21, 2280 (2021).
Jiang, P., Ergu, D., Liu, F., Cai, Y. & Ma, B. A review of yolo algorithm developments. Procedia Comput. Sci. 199, 1066–1073 (2022).
Ge, Z., Liu, S., Wang, F., Li, Z. & Sun, J. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021).
Ying, Z., Lin, Z., Wu, Z., Liang, K. & Hu, X. A modified-yolov5s model for detection of wire braided hose defects. Measurement 190, 110683 (2022).
Wadekar, S. N. & Chaurasia, A. Mobilevitv3: Mobile-friendly vision transformer with simple and effective fusion of local, global and input features. arXiv preprint arXiv:2209.15159 (2022).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. & Wojna, Z. Rethinking the inception architecture for computer vision. In IEEE Conference on Computer Vision and Pattern Recognition, 2818–2826 (2016).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In the IEEE Conference on Computer Vision and Pattern Recognition, 7132–7141 (2018).
Yu, F., Koltun, V. & Funkhouser, T. Dilated residual networks. In IEEE Conference on Computer Vision and Pattern Recognition, 472–480 (2017).
Liu, Z. et al. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11976–11986 (2022).
Shi, D. Transnext: Robust foveal visual perception for vision transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 17773–17783 (2024).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Johnson, T. S. et al. Lambda: Label ambiguous domain adaptation dataset integration reduces batch effects and improves subtype detection. Bioinformatics 35, 4696–4706 (2019).
Friederich, S. Fine-tuning. The Stanford encyclopedia of philosophy (2017).
Xiao, T., Liu, Y., Zhou, B., Jiang, Y. & Sun, J. Unified perceptual parsing for scene understanding. In European Conference on Computer Vision (ECCV), 418–434 (2018).
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F. & Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In European conference on computer vision (ECCV), 801–818 (2018).
Zhao, H. et al. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), 267–283 (2018).
Zhao, H., Shi, J., Qi, X., Wang, X. & Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2881–2890 (2017).
Fu, J. et al. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3146–3154 (2019).
Yang, G. et al. Face mask recognition system with yolov5 based on image recognition. In 2020 IEEE 6th International Conference on Computer and Communications (ICCC), 1398–1404 (IEEE, 2020).
Acknowledgements
This work was supported by New Product and New Process Development Funding Project of China Coal Research Institute Corporation (2023CG-MJ-05).
Author information
Authors and Affiliations
Contributions
Conceptualization, B.Z., Y.Y., and K.M.; methodology, B.Z., Y.Y., K.M. and H.W.; software, B.Z., Y.Y., and K.M.; validation, B.Z., and H.W.; formal analysis, H.W.; investigation, B.Z., and Y.Y.; resources, B.Z.; data curation, K.M.; writing–original draft preparation, B.Z., Y.Y., K.M.; writing–review and editing, B.Z., Y.Y., K.M., and H.W.; visualization, K.M.; supervision, B.Z., and H.W.; project administration, H.W.; funding acquisition, H.W., and B.Z. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, B., Yin, Y., Ma, K. et al. Multi-scale feature fusion keypoint detection network for ship draft line localization. Sci Rep 15, 26397 (2025). https://doi.org/10.1038/s41598-025-10594-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-10594-x
