
Abstract
Ensuring proper Personal Protective Equipment (PPE) compliance is crucial for maintaining worker safety and reducing accident risks on construction sites. Previous research has explored various object detection methodologies for automated monitoring of non-PPE compliance; however, achieving higher accuracy and computational efficiency remains critical for practical real-time applications. Addressing this challenge, the current study presents an extensive evaluation of You Only Look Once version 10 (YOLOv10)-based object detection models designed specifically to detect essential PPE items such as helmets, masks, vests, gloves, and shoes. The analysis utilized an extensive dataset gathered from multiple sources, including surveillance cameras, body-worn camera footage, and publicly accessible benchmark datasets, ensuring thorough and realistic evaluation conditions. The analysis was conducted using an extensive dataset compiled from multiple sources, including surveillance cameras, body-worn camera footage, and publicly available benchmark datasets, to ensure a thorough evaluation under realistic conditions. Experimental outcomes revealed that the Swin Transformer-based YOLOv10 model delivered the best overall performance, achieving AP50 scores of 92.4% for non-helmet, 88.17% for non-mask, 87.17% for non-vest, 85.36% for non-glove, and 83.48% for non-shoes, with an overall average AP50 of 87.32%. Additionally, these findings underscored the superior performance of transformer-based architectures compared to traditional detection methods across multiple backbone configurations. The paper concludes by discussing the practical implications, potential limitations, and broader applicability of the YOLOv10-based approach, while also highlighting opportunities and directions for future advancements.
Similar content being viewed by others
Introduction
On construction sites, utilizing Personal Protective Equipment (PPE)—including helmets, safety vests, gloves, masks, and shoes—is critical to preventing workplace injuries. Nonetheless, many construction workers frequently fail to adhere to PPE guidelines, often citing discomfort or insufficient awareness of safety protocols1. Therefore, it is essential to ensure consistent PPE compliance across all site personnel. Conventionally, monitoring PPE usage involves manual site inspections, physical patrols, or reviewing extensive surveillance footage. These traditional methods, however, are inefficient, labor-intensive, and prone to human error, particularly when inspectors experience fatigue from extended monitoring sessions2.
A promising alternative for detecting PPE non-compliance involves leveraging deep learning-based object detection on images sourced from surveillance systems or body-worn cameras. Object detection technology localizes and identifies specific objects within images by using bounding boxes, significantly automating tasks traditionally performed manually. Training such systems on extensive datasets, representing varied lighting conditions and object sizes, enables the deep learning models to generalize robustly and enhance detection reliability3,4. The You Only Look Once (YOLO) framework has become particularly prominent in the construction sector due to its rapid detection capabilities and ongoing enhancements across versions5,6,7.
This research employs YOLOv10 because of its enhanced robustness, accuracy improvements, and versatile adaptability compared to its predecessors. YOLOv10 exhibits superior performance in feature representation, handling diverse object scales, and effectively managing partial occlusions. Its modular architecture enables customization, particularly regarding the backbone network, crucially impacting both detection precision and processing speed by extracting essential features from input images8.
Conventionally, Convolutional Neural Network (CNN)-based backbones have dominated the field owing to their consistent performance9,10. However, recent developments in transformer-based backbones, including Vision Transformer (ViT), Swin Transformer, Pyramid Vision Transformer (PVT), MobileViT, and Axial Attention Transformer, have demonstrated significant potential in improving object detection across various domains11,12. To assess whether these contemporary architectures meet both the accuracy and real-time detection requirements essential for effective helmet compliance monitoring, this study evaluates multiple YOLOv10 configurations employing different transformer-based backbone models. The evaluation specifically focuses on detecting helmets in images captured from both stationary surveillance systems and mobile body-worn cameras. The primary contributions of this study are:
-
1)
Utilizing datasets collected from construction site surveillance systems, body-worn camera footage, and benchmark datasets to comprehensively evaluate PPE non-compliance detection.
-
2)
Proposing and customizing YOLOv10-based detection methods enhanced with advanced transformer architectures tailored specifically for detecting PPE items such as helmets, masks, vests, gloves, and shoes.
-
3)
Assessing and benchmarking the generalizability of the proposed YOLOv10-based approach through comprehensive comparisons with other object detection methods.
Literature review
Existing studies for vision-based non-PPE monitoring
Over recent decades, extensive research has focused on developing automated approaches using deep learning—particularly CNNs—to detect safety helmets in construction environments. Fang et al.13 proposed a helmet detection model using Faster Region-Based Convolutional Neural Networks (Faster R-CNN), achieving accuracy rates ranging from 90.1 to 98.4% across diverse scenarios. However, this model’s processing time was approximately 0.2 s per image, limiting real-time applicability. Gu et al.14 improved upon Faster R-CNN by incorporating multi-scale training and increased anchor strategies, enhancing accuracy by approximately 7%; however, they did not explicitly report processing speed.
Considering the necessity for both high detection accuracy and swift processing, single-stage detectors have gained popularity. Yang et al.15 employed an image pyramid structure combined with YOLOv3 and DarkNet53 to capture multi-scale feature representations, achieving 95.13% accuracy at only 0.017 s per image, surpassing Single Shot Detection (SSD) and Faster R-CNN. Yan and Wang16 modified the YOLOv3 backbone, integrating densely connected convolutional networks to significantly enhance detection speed by 52% and accuracy by 5.7%, without compromising processing time. Shen et al.17 adopted a distinctive two-stage approach, initially using a single-stage face detector based on VGG16, followed by regression-based mapping and DenseNet-based classification for helmets. Nath18 combined YOLOv3 for worker detection with VGG16, ResNet, and Xception classifiers for helmets and vests, achieving an accuracy of 71.23%. Wang et al.19 compared YOLOv5x and YOLOv5s, identifying YOLOv5x as the more accurate option (86.55%) and YOLOv5s as faster (0.019 s per frame). Lee et al.20 introduced a real-time detection framework based on You Only Look At CoefficienTs (YOLACT) with MobileNetV3, achieving 66.4% accuracy for helmets and vests. Nguyen et al.21 improved YOLOv5 models using the Seahorse Optimization algorithm (SHO), achieving 66% average accuracy across multiple PPE categories (helmets, masks, gloves, vests, shoes). Park et al.22 highlighted the advantages of individual augmentation strategies using YOLOv8 with transformer architectures such as Swin Transformer and Axial Transformer to enhance non-PPE detection performance.
The existing literature is summarized in Table 1. These studies collectively highlight the effectiveness of various deep learning techniques for real-time PPE compliance monitoring. However, direct comparisons among these studies remain challenging due to their reliance on diverse, often non-public datasets. Moreover, due to unreported hyperparameter optimizations and omitted architectural details, exact replication of existing methods is challenging; thus, this research implements methods from existing studies as closely as possible to facilitate a fair comparative analysis.
Transformer-based architectures for YOLOv10
In YOLO-based object detection frameworks, the choice of backbone architecture significantly influences the system’s capability to accurately detect and classify objects through effective extraction of meaningful image features6. Recently, transformer-based backbone architectures have garnered considerable attention due to their distinct advantages over traditional CNN-based methods. CNN backbones primarily utilize convolutional layers optimized for capturing localized spatial features, which, although efficient for real-time detection, tend to lack extensive global contextual awareness, limiting their effectiveness in complex scenarios or detecting smaller-scale objects23.
Transformer-based backbones, by contrast, leverage self-attention mechanisms to capture extensive local and global context simultaneously. This enhanced contextual comprehension significantly improves detection accuracy, especially within visually complex environments common on construction sites24. However, previous integrations of transformer architectures, such as combinations of YOLOv8 with Swin or Axial Transformers, often encountered increased computational demands or suboptimal implementations, thus constraining real-time applicability.
The challenge of accurately monitoring multiple PPE items simultaneously within complex images under strict real-time constraints highlights a critical research gap. As summarized in Table 1, existing detection methods exhibit potential limitations compared to the proposed YOLOv10 approach. Specifically, two-stage methods such as Faster R-CNN are inherently slower due to separate region proposal and classification processes, resulting in lower inference speeds. Traditional CNN-based YOLO methods, while faster, often struggle with accurately detecting small or challenging objects due to limited global context awareness. Methods involving additional classifiers after YOLO detection, such as VGG16, ResNet, and Xception, further reduce real-time performance due to multi-step processes. Additionally, instance segmentation methods like Mask R-CNN have inherently higher computational costs, resulting in slower inference25,26. Optimization techniques like SHO on YOLOv5, though effective, provide moderate accuracy improvements but still exhibit limitations in robustness to diverse object scales and complexities.
This study systematically evaluates and compares several advanced transformer-based backbone architectures—ViT, Swin Transformer, and PVT—within the YOLOv10 detection framework, specifically targeting automated non-PPE detection. The primary objective is to achieve an optimal balance between accuracy and real-time efficiency under realistic construction site conditions.
Methods
The following sections present detailed descriptions of the various YOLOv10-based models and their differing architectures, followed by a comprehensive overview of the overall methodology.
YOLOv10 framework
Figure 2 illustrates the workflow of the proposed YOLOv10-based detection approach, consisting of three primary components: a backbone, a neck, and a head. The backbone extracts multi-scale features from the input images, effectively capturing both low-level image details and higher-level semantic content. The neck employs a Path Aggregation Network (PAN), which integrates these extracted features across multiple scales through interconnected pathways27.

Workflow of YOLOv10-based method for detecting non-PPE.
The head incorporates a dual-label assignment strategy: firstly, a one-to-many mechanism generates multiple candidate predictions per object; secondly, a one-to-one mechanism uniquely pairs each prediction to the corresponding ground-truth bounding box. A consistent matching metric combining confidence scores, classification probabilities, and Intersection over Union (IOU) with ground-truth boxes is applied:
In this equation, \(\:s\) represents the prediction confidence, \(\:{p}^{a}\) denotes the classification probability raised to the exponent \(\:a\), \(\:\text{I}\text{O}\text{U}{\left(\widehat{b},\:b\right)}^{\beta\:}\) calculates the overlap between the predicted bounding box \(\:\widehat{b}\) and the actual ground-truth bounding box \(\:b\). The adjustable parameters \(\:a\), and \(\:\beta\:\) regulate the relative contributions of these factors. Employing this matching strategy enhances YOLOv10’s accuracy and consistency in predictions, effectively addressing challenges posed by varying object boundaries across diverse detection scenarios.
Backbone architectures
The sections below summarize key aspects of each architecture. For comprehensive explanations and technical analysis of these architectures, refer to Khan et al.28.
ViT
ViT is a purely transformer-based architecture designed for visual recognition tasks. It operates by segmenting the input images into fixed-size patches, treating each as an independent token (Fig. 2). The principal advantage of ViT is its capability to apply self-attention mechanisms directly to these tokens, allowing it to effectively capture global dependencies within images. However, ViT generally requires large-scale datasets and significant computational resources, as the complexity of its self-attention mechanisms scales quadratically with the number of patches2.

Architecture of ViT for non-PPE detection.
Swin transformer
Swin Transformer employs a hierarchical architecture featuring shifted-window self-attention mechanisms (Fig. 3). Initially, the input image is divided into local windows without overlap, after which these windows are shifted between layers to capture interactions across adjacent regions. This method results in linear complexity regarding attention operations relative to image size. Additionally, its hierarchical structure facilitates multi-scale feature extraction, effectively capturing both detailed local features and broader contextual information29.

Architecture of Swin Transformer for non-PPE detection.
PVT
PVT combines pyramid-based multi-scale feature extraction—traditionally used by CNNs—with a transformer-based framework (Fig. 4). It employs a spatial-reduction attention mechanism that reduces the spatial dimension within attention layers to efficiently generate multi-scale feature representations. This pyramid structure maintains the global contextual advantages associated with transformer architectures while significantly improving computational efficiency, effectively balancing high accuracy with reduced computational demands30.

Architecture of PVT for non-PPE detection.
Optimization process
Transfer learning
Training a deep learning model from scratch allows for greater flexibility and customization but requires significant computational resources and a large dataset. A practical and widely-used alternative is employing a pre-trained model, which has already learned generalizable features from extensive datasets and can transfer this knowledge to new, related tasks efficiently31,32. However, pre-trained models are often trained on datasets within specific contexts, potentially introducing biases or domain mismatches when applied to significantly different domains. This mismatch could lead to reduced performance if the new task’s data substantially differs from the original training set33.
In this study, ImageNet34 was selected for pre-training the feature extraction layers of our chosen model architectures. With over 14 million images covering diverse categories such as vehicles and people, ImageNet provides a robust and generalizable foundation.
Hyperparameter
Training deep learning models for high accuracy typically requires careful optimization of multiple hyperparameters, as model performance can vary significantly based on their configurations35,36. Although no universal hyperparameter set exists that guarantees optimal results across all tasks and datasets, a common and practical strategy involves adopting hyperparameter choices informed by existing literature and empirical evidence37. Hyperparameters proven effective in closely related tasks frequently yield strong results in similar contexts. Consequently, this research selected hyperparameter values guided by successful implementations of YOLO-based methods, such as those used in rebar counting applications on construction sites8.
Evaluation of model performance
AP
In object detection tasks, Average Precision (AP) is widely adopted as a standard evaluation measure to assess model effectiveness38. AP summarizes precision at various recall levels across a range of Intersection over Union (IOU) thresholds. IOU evaluates how accurately the predicted bounding boxes overlap with the ground-truth objects.
In this study, detection accuracy is evaluated using two primary AP metrics: AP50 and AP50:95. Specifically, AP50 denotes the precision calculated at an IOU threshold of 0.5, while AP50:95 represents the averaged precision over multiple IOU thresholds ranging from 0.5 to 0.95, providing insights into model robustness across different localization criteria.
Additionally, the performance of the detection model is analyzed based on the size of non-PPE objects detected. These are categorized according to pixel dimensions as follows:
-
Small objects (AP_S): objects smaller than 32 × 32 pixels.
-
Medium objects (AP_M): objects between 32 × 32 and 96 × 96 pixels.
-
Large objects (AP_L): objects larger than 96 × 96 pixels.
For practical non-PPE monitoring scenarios, the AP50 metric is especially relevant, as operational priorities typically emphasize correctly identifying non-PPE items rather than achieving perfect bounding box alignment.
Detection speed
Detection speed indicates how rapidly the model can process and analyze each image, commonly expressed as frames per second (FPS). Evaluating detection speed is essential to confirm whether the YOLO-based model meets the real-time processing requirements essential for practical non-PPE monitoring applications.
Experiment
Data Preparation
Original dataset construction
In this research, data was gathered from two main sources: on-site data collection and publicly accessible datasets. On-site data collection involved using two camera setups across several construction sites in South Korea. Specifically, seven sites were monitored using 42 strategically placed Bosch FLEXIDOME IP Starlight 8000i surveillance cameras to provide comprehensive visual coverage. Additionally, GoPro HERO9 Black cameras were attached to safety helmets worn by 35 construction workers at five of these sites. Due to financial constraints, body-worn cameras were not implemented at the remaining two sites.
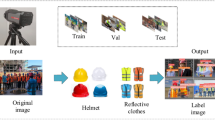
Continuous video footage was captured, from which frames were systematically extracted at regular intervals to authentically represent on-site conditions. Frames obtained from the body-worn cameras and surveillance cameras are illustrated in Fig. 5(a) and (b), respectively. Initially, this extraction produced a large dataset of 85,875 images. To ensure balanced representation between scenarios—workers fully compliant with PPE requirements and those missing PPE—a subset of 2,297 representative images was selected.
To further enrich the dataset, publicly available resources were incorporated, specifically the Safety Helmet Wearing Dataset (SHWD)39 consisting of 530 images and the Safety Helmet Computer Vision Project (SHCVP)40 containing 565 images. These additional images, exemplified in Fig. 5(c), expanded the visual diversity and context coverage for non-PPE detection tasks. In total, 3,392 images were consolidated from these combined sources.

Example images from each source dataset.
Data split
The collected dataset was randomly partitioned into three subsets: training, validation, and testing, using proportions of 60%, 20%, and 20%, respectively. Specifically, from the complete dataset of 3,392 images, 2,036 images were allocated for training, 678 images for validation, and 678 images for testing. The dataset acquired from body-worn cameras was similarly divided according to the same proportional distribution. This method ensures an unbiased and thorough evaluation, thereby facilitating a reliable assessment of the developed detection models.
Image augmentation techniques
Image augmentation parameters significantly affect both image quality and the resulting performance of detection models. Preliminary analyses indicated stricter detection requirements for safety helmets compared to other PPE categories. Consequently, augmentation methods were selectively applied to a targeted subset of 102 images featuring non-safety-helmet scenarios. Eight distinct augmentation techniques were used to artificially enlarge this dataset, resulting in a total of 816 augmented images. These techniques and their parameters were carefully selected through iterative experimentation to produce realistic augmentations, summarized in Table 2, and visually demonstrated in Fig. 6.

Examples of images augmentation techniques.
Annotation
For annotation purposes, each occurrence of missing PPE was identified by placing rectangular bounding boxes around five distinct categories: “Non-helmet,” “Non-mask,” “Non-glove,” “Non-vest,” and “Non-shoes.” All other areas not associated with these categories were labeled as “background.” The annotation process was carried out using LabelImg, generating annotations in the VOC XML format. An illustrative example of this annotation process is provided in Fig. 7.

Examples of annotation process for detecting non-PPE.
Synthesis of final dataset
To evaluate the proposed methodology, datasets from both construction-specific and general contexts were collected and subsequently divided into training, validation, and testing subsets. Before labeling, eight augmentation techniques were selectively applied only to images containing non-safety helmet scenarios, addressing class imbalance caused by their initially limited number. Each image was then labeled according to specific non-PPE categories. Table 3 summarizes the annotated datasets, clearly outlining the distribution of each non-PPE category within the respective subsets.
Experimental settings
All experiments were conducted on a workstation running Windows 10. The system featured a high-performance Intel Core i7-13700 H CPU equipped with 14 cores and 20 threads, along with 128 GB of RAM. Computational tasks were accelerated using a powerful NVIDIA GeForce GTX 4090 Ti GPU.
Results, and discussion
Results of training and validation
Assessment of underfitting, and overfitting
Figure 8 presents the training and validation loss curves for three YOLOv10 transformer-based models, each employing a distinct backbone architecture, evaluated on both raw and augmented datasets at 30,000 iterations. Throughout the training process, all models demonstrated a steady decline in loss for both the training and validation sets, although slight fluctuations occurred across epochs. This steady reduction indicates successful model training and improved generalization on the validation data, ultimately nearing convergence. The continuous decrease in the training loss further confirms the absence of underfitting, whereas the consistent trend and small gap between training and validation losses suggest that overfitting was not problematic. Consequently, none of the evaluated models required exclusion due to concerns related to underfitting or overfitting.

Training and validation loss curves.
Analysis of augmentation techniques effectiveness in overall performance
As shown in Table 4, all three architectures (ViT, Swin Transformer, and PVT) notably benefited from data augmentation. For AP50, ViT demonstrated the highest improvement (+ 3.36%), closely followed by PVT (+ 3.05%) and Swin Transformer (+ 2.97%). For stricter localization (AP50:95), ViT again exhibited the largest gain (+ 5.28%), followed by Swin Transformer (+ 4.74%) and PVT (+ 3.95%).
Improvements in IOU were highest for Swin Transformer (+ 5.41%), suggesting that its hierarchical attention mechanism effectively adapted to augmentation-induced transformations. Gains were particularly pronounced for detecting small objects (AP_S), with Swin Transformer achieving the highest improvement (+ 7.54%), closely followed by ViT (+ 7.14%) and PVT (+ 5.61%). Medium (AP_M) and large (AP_L) objects showed smaller but still meaningful improvements, consistently favoring Swin Transformer.
Analysis of augmented model performance with different architectures by class
The Swin Transformer consistently achieved the highest overall performance, with average AP50 (87.25), AP50:95 (64.52), and IOU (82.56), surpassing both ViT and PVT, as presented in Table 5. Among individual classes, non-helmet detection achieved the highest accuracy (AP50 > 91%), indicating distinctive visual characteristics. Conversely, detection accuracy was lowest for non-glove and non-shoes (approximately 82–85% AP50), likely due to visual ambiguity or occlusion issues. Performance consistently increased with object size (AP_S, AP_M, AP_L), and Swin Transformer notably achieved the best results across these metrics, highlighting its effectiveness in capturing detailed features, especially for smaller or partially occluded items.
Table 6 indicates that PVT achieved the fastest inference speed (36.54 FPS), closely followed by Swin Transformer (35.32 FPS) and ViT (34.26 FPS). All models demonstrated consistent and stable inference times, exhibiting minimal variability across different conditions, as indicated by narrow ranges between minimum and maximum FPS values. Overall, Swin Transformer delivered superior detection accuracy across various classes and object sizes, while PVT provided the highest inference speed, making these architectures suitable for high-precision and real-time applications, respectively, in construction-site environments. Additionally, the detailed Floating Point Operations (FLOPs)—a measure of computational complexity indicating the number of floating-point calculations required—and parameter counts (M) for each method are summarized in Table 7.
Model evaluation in test images
Overall performance
The best-performing Swin Transformer model was evaluated using previously unseen test data, demonstrating excellent consistency with validation results. This consistency indicated minimal overfitting and robust generalizability, as summarized in Fig. 9. Table 8 further details the class-wise performance metrics. Detection performance varied significantly among classes. Categories with visually distinctive features, such as non-helmet, achieved high accuracy (exceeding 92%). In contrast, visually challenging categories, such as non-shoes, had comparatively lower accuracy (~ 83.5%), likely due to practical difficulties such as occlusions and visual ambiguity.

Best model performance on test data (Swin Transformer).
Figure 10 provides visual examples of correctly and incorrectly detected non-PPE objects. The model demonstrated notably better performance in detecting larger objects compared to smaller ones, highlighting the effectiveness of the Swin Transformer’s hierarchical attention mechanism in addressing multi-scale detection challenges. However, there was a noticeable decrease in performance under stricter localization thresholds (AP50:95 approximately 64.5%), emphasizing the inherent difficulties in precisely aligning bounding boxes in complex real-world construction scenarios.

Visual examples of correctly, and incorrectly detected images.
Impact of image conditions
Table 9 summarizes the model’s detection performance (AP50) across various image conditions. The analysis reveals that detection accuracy consistently decreased under more complex scenarios, notably low illumination, far-field views, outdoor environments, overlapping workers, grouped workers, and scenarios involving multiple individuals. Among these factors, illumination and visual range exerted the greatest influence on detection accuracy, with high-illumination conditions and near-field views achieving noticeably higher mean average precision (mAP: approximately 88.2%) compared to low illumination and far-field conditions (mAP around 86.4%).
Additionally, scenarios involving multiple workers or significant overlap considerably reduced accuracy, indicating the model’s sensitivity to visual clutter and partial occlusion. Indoor scenarios generally achieved slightly higher accuracy (mAP: 88.15%) compared to outdoor environments (mAP: 86.49%), likely due to better-controlled visual backgrounds and lighting. These findings underscore practical challenges encountered in real-world construction environments, emphasizing the need for robust solutions tailored to handle varying illumination, object scale, and crowded scenarios.
Comparative analysis
Experiments with benchmark datasets
Data description
As presented in Table 10, four widely used benchmark datasets39,40,41,42 were employed to evaluate the models developed in this research. Most existing benchmark datasets are not exclusively derived from construction sites; instead, they often include images collected from search engines such as Google or Baidu, resulting in scenarios that may not accurately represent real-world construction environments. Additionally, these datasets typically include only non-safety helmet images, accompanied by a limited number of images from other non-PPE classes. Consequently, evaluations conducted using these datasets were restricted to non-helmet tests only. Illustrative examples from these datasets are presented in Fig. 11.

Visual example of each benchmarking dataset.
Comparison results with benchmark datasets
Table 11 presents the performance results of the trained model when evaluated on external benchmark datasets (SHWD, SHCVP, SHD, and HHWD). The highest detection performance was observed on the original dataset (Our dataset), achieving an AP50 of 92.4%, AP50:95 of 68.23%, and notably high IOU of 87.46%. However, when tested on the external datasets, the model exhibited a noticeable reduction in accuracy, with AP50 declining by approximately 4–7% points. Specifically, performance metrics ranged from 85.9% (SHD) to 88.23% (SHCVP) for AP50, and from 60.38% (SHWD) to 62.59% (SHD) for AP50:95.
This performance drop likely reflects domain shifts between the original dataset and external benchmarks, including variations in viewpoints, lighting conditions, object scales, and environmental factors. Smaller objects (AP_S) consistently demonstrated more significant accuracy reductions, highlighting specific challenges related to object scale and perspective variations. These findings emphasize the necessity of incorporating a broader diversity of training examples representing various viewpoints and environmental contexts to enhance the model’s robustness and generalization capabilities in practical, real-world scenarios.
Comparison with other detectors
Selection of other detectors
To demonstrate the superiority of the proposed YOLOv10 model utilizing a Swin Transformer backbone, comparative evaluations were conducted against several widely-used object detection architectures, including Faster R-CNN, SSD500, and Region-based Fully Convolutional Network (R-FCN). These models employed various alternative backbone architectures such as ResNet-101, ResNet-152, and MobileNetv3. Additionally, YOLOv10 with CNN-based backbones (CSPNet, ConvNeXt, EfficientNet), YOLOv5 (CSPDarknet53s, CSPDarknet53x), and YOLOv8 (Swin Transformer, PVT, Axial Transformer) were included to provide a comprehensive comparison.
All experimental setups, including batch sizes and iteration counts, were kept consistent with their original configurations to ensure fairness in comparisons. Due to unreported hyperparameter optimizations and omitted architectural details in existing studies, exact replication was challenging; therefore, this research implemented methods from previous studies as closely as possible to facilitate a fair comparative analysis.
Comparison results with other detectors
Table 12 presents a comprehensive comparative evaluation of the proposed method against other detection models on the test dataset. The proposed YOLOv10 model utilizing a Swin Transformer backbone consistently demonstrated superior performance across key accuracy metrics—AP50 (87.32%), AP50:95 (64.71%), and IOU (82.39%)—compared to other popular detectors and backbone combinations.
Specifically, the proposed method outperformed competing models by approximately 1–3% points in AP50 and about 0.5–1% points in AP50:95. Additionally, it achieved the highest AP across various object scales (small: 61.22%, medium: 84.9%, large: 91.51%), highlighting its robust detection capability irrespective of object size or complexity.
Regarding inference speed, the proposed model attained a competitive FPS (35.32), slightly faster than lighter CNN-based architectures such as SSD500 with ResNet-152 (32.84 FPS) and YOLOv10 with EfficientNet (34.01 FPS), and notably faster than heavier CNN-based architectures like Faster R-CNN with ResNet-101 (20.77 FPS). YOLOv8 with Swin Transformer and YOLOv10 with CSPNet achieved comparable speeds (31.90 FPS and 33.12 FPS, respectively) but exhibited somewhat lower detection accuracy. The detailed FLOPs and parameter counts (in millions) for each method are summarized in Table 7.
Overall, this comparison clearly highlights that the proposed YOLOv10 with a Swin Transformer backbone achieves an optimal balance between detection accuracy and real-time efficiency, making it particularly suitable for high-precision, real-time detection tasks in construction-site environments.
Conclusions
This research conducted an extensive evaluation of YOLOv10-based object detection models tailored specifically for automated detection of non-PPE compliance on construction sites. The focus was placed on identifying critical PPE items, including helmets, masks, vests, gloves, and shoes. The analysis utilized a diverse dataset compiled from construction site surveillance cameras, body-worn camera recordings, and publicly available benchmark sources to rigorously assess PPE compliance scenarios.
Due to initially limited data availability for the non-safety helmet category, image augmentation techniques were selectively applied only to images containing non-safety helmets to enhance dataset balance. In evaluating the effectiveness of these augmentation methods, the ViT-based model demonstrated significant performance gains; however, the best overall results were achieved by the Swin Transformer-based YOLOv10 model. Specifically, the Swin Transformer model recorded AP50 metrics of 92.4% for non-helmet, 88.17% for non-mask, 87.17% for non-vest, 85.36% for non-glove, and 83.48% for non-shoes, with an average AP50 of 87.32%.
Experimental findings also confirmed the superior performance of transformer-based architectures compared to traditional detection frameworks such as Faster R-CNN, SSD, and R-FCN utilizing various backbone architectures. The consistent accuracy, notably high for essential PPE items like helmets, indicates that the Swin Transformer model is highly suitable for real-world safety monitoring, where reliability and accuracy are paramount.
Despite these promising outcomes, certain limitations were identified. One key limitation involves reduced detection accuracy for smaller PPE, as highlighted by relatively lower AP_S scores across datasets. This indicates a particular challenge in identifying helmets appearing small due to distance or lower image resolution—an issue critically relevant in crowded or expansive construction environments. Additionally, the performance decrease observed when models were tested on benchmark datasets indicates challenges related to generalizing effectively across diverse data distributions and unfamiliar conditions.
For future studies, enhancing model generalizability remains crucial. This can be accomplished by expanding training datasets to include greater image diversity, covering various environmental conditions, camera viewpoints, and scenarios beyond typical construction settings. Moreover, considering the challenges identified by the authors regarding small object detection, previous research in different contexts43,44 has addressed similar issues by incorporating additional modules, such as super-resolution techniques, into YOLO. Therefore, further exploration into integrating these hybrid approaches with transformer architectures is warranted.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Chen, S. & Demachi, K. Towards on-site hazards identification of improper use of personal protective equipment using deep learning-based geometric relationships and hierarchical scene graph. Autom. Constr. https://doi.org/10.1016/j.autcon.2021.103619 (2021).
Eum, I., Kim, J., Wang, S. & Kim, J. Heavy equipment detection on construction sites using you only look once (YOLO-Version 10) with transformer architectures. Appl. Sci. 15, 2320. https://doi.org/10.3390/app15052631 (2025).
Cha, Y. J., Choi, W., Suh, G., Mahmoudkhani, S. & Büyüköztürk, O. Autonomous structural visual inspection using Region-Based deep learning for detecting multiple damage types. Comput. Civ. Infrastruct. Eng. https://doi.org/10.1111/mice.12334 (2018).
Wang, S. Evaluation of impact of image augmentation techniques on two tasks: window detection and window States detection. Results Eng. 24, 103571 (2024).
Hu, H., Wang, L., Zhang, M., Ding, Y. & Zhu, Q. Fast and Regularized Reconstruction of Building Fac Ades from Street-View Images Using Binary Integer Programming. in ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences (2020). https://doi.org/10.5194/isprs-annals-V-2-2020-365-2020
Mokayed, H., Alsayed, G., Lodin, F., Hagner, O. & Backe, B. Enhancing Object Detection in Snowy Conditions: Evaluating YOLO v9 Models with Augmentation Techniques. in 2024 11th International Conference on Internet of Things: Systems, Management and Security (IOTSMS) 198–203 (IEEE, 2024).
Han, J., Kim, J., Kim, S. & Wang, S. Effectiveness of image augmentation techniques on detection of Building characteristics from street view images using deep learning. J. Constr. Eng. Manag. 150, 1–18 (2024).
Wang, S., Kim, M., Hae, H., Cao, M. & Kim, J. The development of a Rebar-Counting model for reinforced concrete columns: using an unmanned aerial vehicle and Deep-Learning approach. J. Constr. Eng. Manag. 149, 1–13 (2023).
Wang, S., Moon, S., Eum, I., Hwang, D. & Kim, J. A text dataset of fire door defects for pre-delivery inspections of apartments during the construction stage. Data Br. 60, 111536 (2025).
Wang, S., Park, S., Park, S. & Kim, J. Building façade datasets for analyzing Building characteristics using deep learning. Data Br. 57, 110885 (2024).
Dai, Y., Liu, W., Wang, H., Xie, W. & Long, K. Yolo-former: marrying Yolo and transformer for foreign object detection. IEEE Trans. Instrum. Meas. 71, 1–14 (2022).
Rajput, L., Tyagi, N., Tyagi, S. & Tyagi, D. K. State of the art object detection: A comparative study of YOLO and ViT. in 2024 International Conference on Intelligent Systems for Cybersecurity (ISCS) 1–6 (2024). https://doi.org/10.1109/ISCS61804.2024.10581202
Fang, Q. et al. Detecting non-hardhat-use by a deep learning method from far-field surveillance videos. Autom. Constr. https://doi.org/10.1016/j.autcon.2017.09.018 (2018).
Gu, Y., Xu, S., Wang, Y. & Shi, L. An advanced deep learning approach for safety helmet wearing detection. in Proceedings – 2019 IEEE International Congress on Cybermatics: 12th IEEE International Conference on Internet of Things, 15th IEEE International Conference on Green Computing and Communications, 12th IEEE International Conference on Cyber, Physical and So (2019). https://doi.org/10.1109/iThings/GreenCom/CPSCom/SmartData.2019.00128
Yang, W. et al. Int. J. Innov. Comput. Inf. Control doi:https://doi.org/10.24507/ijicic.18.03.973. (2022).
Yan, D. & Wang, L. Improved YOLOv3 Helmet Detection Algorithm. in 2021 4th International Conference on Robotics, Control and Automation Engineering, RCAE 2021 (2021). https://doi.org/10.1109/RCAE53607.2021.9638803
Shen, J. et al. Detecting safety helmet wearing on construction sites with bounding-box regression and deep transfer learning. Comput. Civ. Infrastruct. Eng. https://doi.org/10.1111/mice.12579 (2021).
Nath, N. D., Behzadan, A. H. & Paal, S. G. Deep learning for site safety: Real-time detection of personal protective equipment. Autom. Constr. https://doi.org/10.1016/j.autcon.2020.103085 (2020).
Wang, Z. et al. Fast personal protective equipment detection for real construction sites using deep learning approaches. Sensors https://doi.org/10.3390/s21103478 (2021).
Lee, Y. R., Jung, S. H., Kang, K. S., Ryu, H. C. & Ryu, H. G. Deep learning-based framework for monitoring wearing personal protective equipment on construction sites. J. Comput. Des. Eng. https://doi.org/10.1093/jcde/qwad019 (2023).
Nguyen, N. T., Tran, Q., Dao, C. H., Nguyen, D. A. & Tran, D. H. Automatic detection of personal protective equipment in construction sites using metaheuristic optimized YOLOv5. Arab. J. Sci. Eng. https://doi.org/10.1007/s13369-023-08700-0 (2024).
Park, S., Kim, J., Wang, S. & Kim, J. Effectiveness of image augmentation techniques on Non-Protective personal equipment detection using YOLOv8. Appl. Sci. 15, 2631. https://doi.org/10.48550/arXiv.2407.17950 (2025).
Wang, S. & Han, J. Automated detection of exterior cladding material in urban area from street view images using deep learning. J. Build. Eng. 96, 110466 (2024).
Imran, A., Hulikal, M. S. & Gardi, H. A. A. Real time American sign Language detection using Yolo-v9. arXiv Prepr. arXiv2407.17950. https://doi.org/10.48550/arXiv.2407.17950 (2024)
Hwang, D., Kim, J. J., Moon, S. & Wang, S. Image augmentation approaches for Building dimension Estimation in street view images using object detection and instance segmentation based on deep learning. Appl. Sci. 15, 2525. https://doi.org/10.3390/app15052525 (2025).
Wang, C. Y., Yeh, I. H. & Mark Liao, H. Y. Yolov9: Learning what you want to learn using programmable gradient information. in European Conference on Computer Vision 1–21Springer, (2025).
Sharma, A., Kumar, V. & Longchamps, L. Comparative performance of YOLOv8, YOLOv9, YOLOv10, YOLOv11 and faster R-CNN models for detection of multiple weed species. Smart Agric. Technol. 9, 100648 (2024).
Khan, A. et al. A survey of the vision Transformers and their CNN-transformer based variants. Artif. Intell. Rev. https://doi.org/10.1007/s10462-023-10595-0 (2023).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. in Proceedings of the IEEE/CVF international conference on computer vision 10012–10022 (2021).
Zhang, X., Zhang, Y. & Conv -PVT: a fusion architecture of Convolution and pyramid vision transformer. Int. J. Mach. Learn. Cybern. 14, 2127–2136 (2023).
Wang, S., Eum, I., Park, S. & Kim, J. A semi-labelled dataset for fault detection in air handling units from a large-scale office. Data Br. 57, 110956 (2024).
Wang, S., Korolija, I. & Rovas, D. Impact of Traditional Augmentation Methods on Window State Detection. CLIMA 2022 Conf. 1–8 (2022). https://doi.org/10.34641/clima.2022.375
Bai, Y., Cao, M., Wang, R., Liu, Y. & Wang, S. How street greenery facilitates active travel for university students. J. Transp. Heal. https://doi.org/10.1016/j.jth.2022.101393 (2022).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 1–9. https://doi.org/10.1016/j.protcy.2014.09.007 (2012).
Wang, S., Hae, H. & Kim, J. Development of easily accessible electricity consumption model using open data and GA-SVR. Energies https://doi.org/10.3390/en11020373 (2018).
Wang, S. Automated fault diagnosis detection of air handling units using real operational labelled data using Transformer-based methods at 24-hour operation hospital. Build. Environ. 113257 https://doi.org/10.1016/j.buildenv.2025.113257 (2025).
Wang, S., Kim, J., Park, S. & Kim, J. Fault diagnosis of air handling units in an auditorium using real operational labeled data across different operation modes. Comput Civ. Eng 39(5), 04025045. https://doi.org/10.1061/JCCEE5.CPENG-6677 (2025).
Wang, S., Eum, I., Park, S. & Kim, J. A labelled dataset for rebar counting inspection on construction sites using unmanned aerial vehicles. Data Br. 110720 https://doi.org/10.1016/j.dib.2024.110720 (2024).
SafetyHelmetWearing-Dataset. SafetyHelmetWearing-Dataset. (2019). https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset?tab=readme-ov-file
Project, S. H. C. V. Safety Helmet Computer Vision Project. (2024). https://universe.roboflow.com/digitalimage-114q6/safety-helmet-q3b8o
Safety Helmet Detection. Safety Helmet Detection. (2020). https://www.kaggle.com/datasets/andrewmvd/hard-hat-detection
Hard Hat Workers Dataset. Hard Hat Workers Dataset. (2022). https://public.roboflow.com/object-detection/hard-hat-workers
Berardini, D., Migliorelli, L., Galdelli, A. & Marín-Jiménez, M. J. Edge artificial intelligence and super-resolution for enhanced weapon detection in video surveillance. Eng. Appl. Artif. Intell. 140, 109684 (2025).
Xu, X. et al. ESOD-YOLO: an enhanced efficient small object detection framework for aerial images. Computing 107, 54 (2025).
Author information
Authors and Affiliations
Contributions
Author contributionConceptualization, Methodology, Software, Validation, Formal Analysis, Investigation, Data Curation, Resources, Writing—Original Draft Preparation, Writing—Review and Editing: Seunghyeon Wang.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, S. Automated non-PPE detection on construction sites using YOLOv10 and transformer architectures for surveillance and body worn cameras with benchmark datasets. Sci Rep 15, 27043 (2025). https://doi.org/10.1038/s41598-025-12468-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-12468-8
Keywords
This article is cited by
-
Domain-adaptive faster R-CNN for non-PPE identification on construction sites from body-worn and general images
Scientific Reports (2026)
-
Fault-class coverage–aligned combined training for AFDD of AHUs across multiple buildings
Scientific Reports (2025)
-
Domain adaptation using transformer models for automated detection of exterior cladding materials in street view images
Scientific Reports (2025)
-
Development of an automated transformer-based text analysis framework for monitoring fire door defects in buildings
Scientific Reports (2025)
-
Effectiveness of traditional augmentation methods for rebar counting using UAV imagery with Faster R-CNN and YOLOv10-based transformer architectures
Scientific Reports (2025)
