
Abstract
Nowadays, cost-sensitive customers need customized products that demand consumption-based production. The Internet of Things (IoT) makes ubiquitous sensing and data more available, integrating with the semantic web and advanced sensor technologies. Augmented reality (AR) is a collaborative technology that boosts user experience by coating virtual digital content into reality. Holographic communication is a transformative technology that redefines digital interaction by enabling immersive, realistic, and collaborative 3D experiences. It utilizes advanced holography to create virtual projections in real-time environments. Object detection (OD) is the most significant and challenging problem in computer vision (CV). The massive developments in deep learning (DL) models have recently considerably speeded up the OD momentum for consumer goods utilizing holographs. This article presents Object Detection with Holographic Visualization for Consumer products using a Hippopotamus Optimization Algorithm and Deep Learning (ODHVCP-HOADL) model. The aim is to develop an effective IoT-based OD system for consumer products integrated with a holographic display to provide an interactive and immersive visualization experience. Initially, the wiener filtering (WF) is utilized for image pre-processing to enhance image quality by removing unwanted noise. Furthermore, the Faster R-CNN model is employed for the OD process. The SqueezeNet model extracts and isolates relevant features from raw data. Moreover, the convolutional autoencoder (CAE) model is implemented for classification. Additionally, the hippopotamus optimization algorithm (HOA)-based hyperparameter selection model is implemented to improve the classification result of the CAE technique. Finally, the holographic process is performed by using the binary amplitude hologram (BAH) generation. The performance validation of the ODHVCP-HOADL approach is examined under the Indoor OD dataset. The comparison study of the ODHVCP-HOADL approach portrayed a superior accuracy value of 99.64% over existing models.
Similar content being viewed by others

Introduction
The IoT exemplifies the model where the Internet extends into the physical realm. Eventually, every tangible object will be linked to the Internet, acting as a digital sensor for innovative services and applications1. Initially focused on machine-machine interaction, the introduction of smartphones brought users into the loop. Smartphones are intermediaries, connecting people with physical and digital entities and/or their surroundings2. They simplify the process of enriching physical items with extra data or accessing associated digital utilities. Smartphones are the devices most familiar to us, staying throughout everyday routines. As computers become less visible and blend into the background, AR and virtual reality (VR) techniques can elevate the smartphone’s function within IoT for consumer products3. The utilization of virtual hologram technology helps in the making of virtual intersections of real-life situations. Using the range of available solutions, this technique makes the prospective revolutionary. This method can also build virtual backgrounds for practical visualization, education, and training4. There are numerous modes to create holographic records. But the laser is often the key driver of coherent light. Therefore, any phase difference triggered via laser during operation will mess with the resolution or considerably reduce the possible depth field of the final image5. Instantaneous 3D holography may advance several techniques, including VR and 3D manufacturing.
These benefits submerge VR spectators in a more accurate setting, decreasing the adversarial impacts of eye strain and additional durable VR usage. Additionally, this technique might be willingly employed on screens, which will modify light wave aspects. More reliably, holography involves creating and capturing light configurations produced by the interference of double beams of light6. The orientation beam is directly recorded onto the medium, while the object beam interacts with the recording surface through transmission or reflection. Several kinds of holographic approaches utilize light, frequently in laser form, to produce numerous impacts. A tilted mirror segments a laser beam into dual separate beams for generating such holograms7. The holographical image appears in 3D since it gives the viewer a visual perspective cue. It is because of the restructuring of the entire light field that is distributed through OD for consumer products8. The viewer might roam, investigating the object from various angles, perhaps even looking at an item in front of their eyes. At the same time, a 2D snapshot may show only the act from the viewpoint selected in the recording. Digital holography improves the imaging system’s performance in reconstruction, super-resolution, and autofocusing9. Object classification, consumer product detection, and digital holography still need improvement despite convolutional neural networks (CNN)-based DL outperforming conventional machine learning (ML) with advances in computing and data. The growing need for accurate and efficient product recognition in digital environments calls for novel approaches that combine advanced imaging and intelligent analysis. Enhancing these technologies can revolutionize how we interact with and interpret visual data in real time10.
This article presents Object Detection with Holographic Visualization for Consumer products using a Hippopotamus Optimization Algorithm and Deep Learning (ODHVCP-HOADL) model. The aim is to develop an effective IoT-based OD system for consumer products integrated with a holographic display to provide an interactive and immersive visualization experience. Initially, the wiener filtering (WF) is utilized for image pre-processing to enhance image quality by removing unwanted noise. Furthermore, the Faster R-CNN model is employed for the OD process. The SqueezeNet model extracts and isolates relevant features from raw data. Moreover, the convolutional autoencoder (CAE) model is implemented for classification. Additionally, the hippopotamus optimization algorithm (HOA)-based hyperparameter selection model is implemented to improve the classification result of the CAE technique. Finally, the holographic process is performed by using the binary amplitude hologram (BAH) generation. The performance validation of the ODHVCP-HOADL approach is examined under the Indoor OD dataset. The significant contribution of the ODHVCP-HOADL approach is listed below.
-
The ODHVCP-HOADL model applies WF for image pre-processing, effectually mitigating noise and improving image clarity. This improves input quality for subsequent stages, enabling more accurate OD and classification. It ensures robust performance even with low-quality or noisy image data.
-
The ODHVCP-HOADL method integrates Faster R-CNN for precise and rapid object localization, effectively handling intrinsic image scenes with high variability. This enhances detection accuracy and speeds up processing time, strengthening the model’s capability to identify relevant objects in cluttered environments.
-
The ODHVCP-HOADL approach employs SqueezeNet, a lightweight deep architecture, for efficient and rapid feature extraction with lesser computational overhead. This enables deployment on resource-constrained systems, enhancing scalability and real-time processing capabilities. It also assists in high detection performance with lower model complexity.
-
The ODHVCP-HOADL methodology integrates a CAE method to improve classification accuracy by learning compact and discriminative feature representations, effectively mitigating dimensionality. This approach enhances the generalization of unseen data. It ensures robust performance even with limited labelled samples.
-
The ODHVCP-HOADL technique implements the HOA technique for fine-tuning the hyperparameters, resulting in optimal detection and classification outcomes. It improves convergence efficiency during training. This optimization ensures improved accuracy and stability across tasks.
-
The ODHVCP-HOADL model introduces a novel integration of DL and optimization techniques to improve object detection performance in IoT-driven environments. A visualization enhancement layer is included to support better interpretability of detected objects, contributing to more informative outputs without modifying the core detection architecture.
Literature review
Zhang et al.11 developed a lightweight and robust You Only Look Once version 8 (YOLOv8)-based model integrating soft thresholding, hue, saturation, and value (HSV) augmentation, and a multiscale domain-adapted loss function to enhance OD accuracy and speed on resource-constrained unmanned aerial vehicles (UAVs) in complex environments. Alabdan et al.12 presented an Improved Crayfish Optimization Algorithm with Interval Type-2 Fuzzy DL (ICOA-IT2FDL) technique. The model employs linear scaling normalization (LSN) for data pre-processing, feature selection using the improved crayfish optimization algorithm (ICOA), applies the interval type-2 fuzzy deep belief network (IT2-FDBN) for intrusion identification, and uses the bald eagle search (BES) method to optimize recognition performance. Wang et al.13 presented Pseudo-Depth SORT (PD-SORT), which enhances multi-object tracking by integrating pseudo-depth cues into the Tracking-by-Detection framework. It extends the Kalman filter state, introduces Depth Volume IoU ((DVIoU)) for better data association, and incorporates CMC to improve tracking accuracy in complex, occluded scenes. Moreover, an advanced quantized PD measurement (QPDM) approach is employed to establish a strong data connection. Asiri et al.14 presented blockchain-based access management with a DL threat modelling (BCAM-DLTM) technique. The technique follows a two-phase process involving access management using BC technology and threat detection through a DBNs model. Tuning is performed using the reptile search algorithm (RSA) to improve the threat recognition performance of the DBNs model. The efficiency is evaluated using the NSL-KDD dataset. Bhatt and Sharma15 proposed a model to enhance the recognition of event-related potentials (ERP), specifically for visual OD, integrating a next-generation imaging approach personalized for end-user electronics. It combines CNN through an LSTM network, generating a strong CNN-LSTM framework and dual-attention tool. Cherian et al.16 suggested an innovative model for handling smart applications through vocal controls, named Voice Assisted Smart Appliance Control (VASAC). The efficiency and output of the recommended model are compared in contradiction to the conventional GPRS-based Smart Appliance Control SAC. Zhang et al.17 concentrated on addressing those restrictions by suggesting the formation of a consumer analysis method that relies on the IoT environment. This method connects the ability of radio frequency identification devices (RFID) for product classification encoder by enabling the observation of the product selling process. This method unites a k-means structure in its conceptual design to classify users.
Yang et al.18 recommended a valuable approach for UAVs depending on Robot Operating Systems (ROSs). This analysis addressed the issues in real-time target tracking and effective OD for UAVs. This technique deploys a shortened YOLOv4 design for SiamMask and quick OD for constant targeted tracing. A proportional integral derivative (PID) system adapts flight view, permitting steady target tracking spontaneously in outdoor and indoor landscapes. Alabduallah et al.19 presented a feature fusion DL-based next-generation consumer product detection (FFDL-NGCPD) methodology using ShuffleNet, MobileNet, spider monkey optimization (SMO), and extreme learning machine (ELM) to detect and classify consumer products in video surveillance feeds accurately. Hoang, Lee, and Park20 improved fire detection performance by optimizing the training hyperparameters of YOLOv8 and YOLOv10 models utilizing Bayesian tuning. This approach aims to improve accuracy on the D-Fire dataset, illustrating superior results, particularly in larger model variants. Malkocoglu and Samli21 integrated Super-Resolution (SR) techniques comprising the proposed deep channel attention super-resolution (DCASR), fast super-resolution CNN (FSRCNN), efficient sub-pixel CNN (ESPCNN), and laplacian pyramid super-resolution network (LapSRN) with the YOLOv5 OD model, illustrating enhanced detection accuracy. Bilal et al.22 presented a transfer learning (TL)-based Internet of Robotic Things (IoRT) model using a hybrid multichannel CNN and recurrent neural network (MCNN-RNN) for accurate fault detection in industrial manipulator joints under varying work conditions. Abu-Khadrah et al.23 proposed an OD technique integrating whale optimization algorithm (WOA) and deep reinforcement learning (DRL) methods for accurate human and OD in UAV surveillance by optimizing pixel-based feature extraction across image frames. Bello et al.24 proposed a TL-based animal activity recognition system using enhanced mask region-based CNN (Enhanced Mask R-CNN) for accurate and efficient instance segmentation in farm environments. Achmadiah et al.25 introduced a lightweight OD method utilizing frame difference and artificial intelligence (AI) classifiers for fast-moving OD in IoT systems, prioritizing accuracy, low latency, and energy efficiency on edge devices. Vats et al.26 presented an enhanced CNN integrated with TL for accurate and efficient object recognition and classification in satellite imagery across diverse geospatial datasets. Jin et al.27 proposed a lightweight RGB–thermal salient OD (RGB-T SOD) method called local and global perception network to efficiently fuse multimodal features with lesser parameters and faster speed, enabling real-time deployment on edge computing platforms. Dalal et al.28 introduced a quantized You Only Look Once (YOLO) model with TL for efficient and accurate OD in IoT-enabled smart city surveillance optimized for edge devices.
The limitations of the existing studies comprise high computational demands and large model sizes, restricting deployment on resource-constrained edge devices. Several techniques depend heavily on extensive labelled data, often unavailable, resulting in potential overfitting and mitigated generalizability. Integrating optimization and TL techniques enhances performance but may increase complexity and training time. Additionally, robustness under diverse environmental conditions, such as varying lighting or occlusions, remains challenging. A research gap exists in developing lightweight, adaptive models that balance accuracy and efficiency while maintaining real-time performance across heterogeneous platforms and dynamic scenarios.
Methodological framework
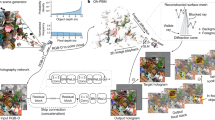
In this paper, the ODHVCP-HOADL model is proposed. The objective is to develop an effective IoT-based OD system for consumer products integrated with a holographic display to provide an interactive and immersive visualization experience. The model comprises distinct levels of image pre-processing, Faster R-CNN-based OD, TL, classification, hyperparameter selection, and BAH generation. Figure 1 signifies the complete workflow of the ODHVCP-HOADL model.

Complete workflow of ODHVCP-HOADL method.
Image pre-processing
At the primary stage, the image pre-processing stage uses WF to enhance image quality by removing unwanted noise29. This model was chosen due to its optimal noise reduction capability in Gaussian noise, making it highly effective for real-world surveillance and imaging scenarios. This technique adapts based on local image statistics, preserving edge details while minimizing blurring. This balance between noise suppression and detail retention is critical for downstream tasks like OD and feature extraction. Additionally, WF requires minimal parameter tuning and operates efficiently in spatial and frequency domains, making it appropriate for real-time or resource-constrained applications. Its proven robustness across diverse image quality conditions additionally validates its selection over conventional denoising techniques.
WF is a signal processing method that minimizes noise and improves image quality by reducing the mean square error among the predictable and true signals. During the IoT-based OD method for customer products, WF is used as a pre-processing stage to enhance image clearness before data feeds into DL methods. It successfully processes blurring and normal sensor noise in real-world image capture surroundings. Improving visual data quality assists in enhancing the precision of OD methods. This filtering method is mainly effective in lower-light or variable lighting states, frequently met in retail IoT or smart home setups. Finally, WF participates in more consistent and reliable detection performance through different consumer product setups.
OD using faster R-CNN
The Faster R-CNN method is then deployed for the OD process30. This method is chosen for its superior accuracy and efficiency in handling intrinsic and cluttered image scenes. It introduces a region proposal network (RPN) that shares convolutional layers with the detection network, significantly mitigating computation time compared to conventional R-CNN variants. Unlike single-stage detectors like YOLO or SSD, Faster R-CNN outperforms in detecting small and overlapping objects with higher localization precision. Its modular architecture allows fine-tuning for various datasets, improving adaptability. Moreover, it effectively balances detection speed and accuracy, making it an ideal choice for tasks requiring reliable object localization and classification. Figure 2 illustrates the framework of the Faster R-CNN method.

Structure of Faster R-CNN technique.
This method is applied to detect and localize objects. It elaborates on its prototypes, RCNN and Faster RCNN, by presenting the RPN that considerably accelerates the creation of possible object regions. It contains three major modules: the RPN, ROI pooling Layer, and backbone ConvNet. The ConvNet removes a richer feature mapping from the pre-processed images that are later handled via the RPN to region proposals prone to have entities. The region is advanced and categorized into particular object types over the softmax layer afterwards, the fully connected (FC) layer for bounding box regression and classification for accurate localization.
ConvNet refers to the input phase. The pre-processed images are normally fed into ConvNet as a cornerstone structure. It creates a convolute feature mapping that takes spatial attributes and models from the images. Assume \(\:I\) remain input images of the dimension \(\:W\)x\(\:H\), which gives the feature mapping F of decreased dimension \(\:{^\prime\text{x}H{^\prime\:}\text{x}D}\), whereas \(\:D\) refers to depth.
RPN utilizes sliding windows on the feature mapping to propose possible regions of the object. All outputs of the sliding window are dual projections for the group of anchor boxes with the likelihood that regions have the object. For all anchor boxes, it reduces the succeeding loss:
The loss \(\:L\) denotes the classification’s weighted amount, \(\:{L}_{cls}\), and loss of regression \(\:{L}_{reg}\). The rationale for selecting the balancing parameter \(\:\lambda\:\) empirically is to achieve an effective trade-off between classification accuracy and bounding box localization precision. A high \(\:\lambda\:\) prioritizes bounding box improvement, whereas a low \(\:\lambda\:\) highlights the precision of the classification. Optimize \(\:\lambda\:\) guarantees the model is implemented meaningfully and is essential for precise recognition in the method is the loss of classification among the forecast object score \(\:{p}_{i}\) and the truth on the ground \(\:{p}_{i}^{*}\) then \(\:{L}_{reg}\) refers to loss of regression for the coordinates of bounding box \(\:{t}_{i}\) and the ground reality \(\:{t}_{i}^{*}\) and \(\:\lambda\:\) means balanced parameter among the two-loss, \(\:{N}_{cls}\) and \(\:{N}_{reg}\) represents the sum of anchor boxes for regression and classification. By tuning \(\:\lambda\:\) based on validation performance, the model maintains stable training while optimizing overall detection results. The balancing of \(\:\lambda\:\) ensures reliable and accurate object detection while avoiding exhaustive manual tuning.
The regions projected through the RPN are maps that revert to the feature mapping. This method utilizes pooling of the Region of Interest (RoI) to process changing dimensions to remove determined size feature vectors from all presented areas. The layers of FC, which handle the determined size feature vectors, give dual outputs: a softmax layer, which predicts the possibility and background classes for all recommended placements. This model for bounding box refinement forecasts the offsets (\(\:\varDelta\:x,\:\varDelta\:y,\:\varDelta\:w,\:\varDelta\:h\)) dealing with the anchor boxes:
Whereas \(\:{t}_{x}\) and \(\:{t}_{y}\) characterize a standardized offset of the \(\:x\)- and \(\:y\)-coordinates, \(\:{t}_{w}\) signifies the width ratio’s logarithmic scale among the anchor box and the predicted box, and \(\:{t}_{h}\) characterizes the height ratio’s logarithmic scale. Now \(\:({x}_{a},\:{y}_{a},\:{w}_{a},{\:h}_{a})\) represents the coordinates of the anchor box, and \(\:(x,y,w,h)\) denotes advanced coordinators of the bounding box. Afterwards, processed through the FC layers, this model outputs the subsequent classes for every identified object utilizing Softmax and coordinates of the bounding box, which accurately localizes the objects. It attains important accuracy and speed developments over preceding models by categorizing and proposing regions into the particular network.
Discriminative data representation via SqueezeNet
For the feature extraction process, the ODHVCP-HOADL technique utilizes the SqueezeNet model to identify and isolate relevant features from raw data31. This is chosen due to its lightweight architecture, significantly mitigating model size and computational requirements without losing accuracy. The utilization of fire modules enables efficient parameter reduction by integrating squeeze and expand layers, making it ideal for resource-constrained environments. Compared to deeper networks such as VGG or ResNet, SqueezeNet presents faster training and inference times, improving real-time applicability. Despite its compact design, it maintains robust feature extraction capabilities, ensuring robust and discriminative representations. This balance of efficiency and performance makes this model preferable for applications needing quick yet reliable feature learning.
SqueezeNet targets minimizing the parameter quantity by 50 times or greater; however, attaining an AlexNet-level top‐5 error rate to help utilize in FPGAs and other resource‐scarcity methods. To obtain this, three core design tactics are applied: converting \(\:3\text{x}3\) convolutional filters into lxl filters that need 9 times smaller parameters, decreasing the input counts to the \(\:3\text{x}3\) filters across the overview of squeeze layers, and implementing downsampling at the later phase of the network for maintaining the high spatial features resolution in the initial layers, thus improving the precision of the classifiers. Each approach guarantees a compact, effective method for organizations and companies without compromising output.
It is built utilizing a module identified as the fire module. The objective of the fire module is to create a method that is more parameter-effective than another model. It comprises dual primary modules: a squeeze layer with \(\:1\times\:1\) filters to lower the input channel counts and an expand layer combining \(\:1\text{x}1\) and \(\:3\text{x}3\) filters to restore the complexity needed for feature extraction tasks. This framework permits the Fire Module to strike the proper balance between computational efficiency and parameter reduction, as the squeeze layer restricts the sizes of the input to the expanded layer and, therefore, decreases the entire parameter counts. Then, the fire module assists with a more adjustable, slim strategy for efficient and reliable CNNs (CNNs), performing particularly tuned expand and squeeze layer structures.
This model starts with a primary convolution layer (conv1), accompanied by eight fire layers (from fire2 to fire9), and then a last convolution layer (conv10). The filter counts in every fire module gradually improve from the first to the previous network step. Max-pooling is carried out on each dual-layer afterwards fire4, fire8, conv1, and conv10. The well-known application of pooling takes place later in this architecture than in others. The SqueezeNet structure combines various design selections and optimizations to improve its compactness and performance. To guarantee that:
-
During the expansion layers, a 1-pixel zero‐padding border is added to the input of \(\:3\text{x}3\) filters to guarantee that the output activations from \(\:1\text{x}1\) and \(\:3\text{x}3\) filters are similar in size.
-
Rectified Linear Unit (ReLU) activations are used to the outputs from either the squeeze or expand layers that present non-linearity.
-
After the last Fire Module (fire9), a dropout layer using a 50% ratio is utilized to decrease overfitting and improve performance generalization.
-
The structure prevents FC layers, drawing influence from the Network-in‐Network (NiN) model to decrease the number of parameters and improve efficiency density.
-
Training begins with a rate of learning of 0,04 that reduces linearly in time training.
-
Owing to the framework’s limitations, the expanding layer is applied as dual convolutional layers—one for \(\:1\text{x}1\) filters and the other for \(\:3\text{x}3\) filters—and their outputs are connected along with the channel size.
-
Initially developed with the Cafe architecture, SqueezeNet is designed for platforms such as Chainer Keras, Torch, and MXNet to safeguard broad compatibility.
Consumer product classification using CAE
The CAE method is also implemented for the classification process32. This model is chosen for its capability to learn compact, high-level feature representations by unsupervised reconstruction of input data. This mitigates dependence on large labelled datasets, which is beneficial in scenarios with limited annotations. CAEs effectually capture spatial hierarchies and subtle discrepancies in product images, improving classification accuracy. Compared to conventional classifiers, CAEs provide better noise robustness and generalization by concentrating on crucial features. Their architecture also allows dimensionality reduction, speeding up downstream classification tasks while maintaining discriminative power. This integration of efficiency, accuracy, and reduced data dependency makes CAE a robust choice over existing techniques.
CAE is a DL technique that enlarges conventional AE by combining convolution layers rather than FC layers. Dissimilarly, classical AE, with only FC layers that fatten input data, has a mainly efficient structure for spatially and temporally organized data, like images and time series. CAEs preserve temporal and spatial frameworks over pooling and convolutional operations. This method contains dual major factors:
Encoder: This removes hierarchical temporal or spatial characteristics from the input utilizing pool and convolutional layers. The encoding decreases input data \(\:y\) into low-dimensionality latent representations \(\:z\in\:{\mathbb{R}}^{d}\), while \(\:d\) represents the predetermined latent area width. The latent vector might be considered a flattened, however informative, model of the new data\(\:y.\).
Decoder: Rebuilds the new input from the latent area by employing up-sampling and transferring the convolutional layer.
Assumed an input dataset \(\:Y=\{{y}_{i}{\}}_{i=1}^{N}\), here every instance \(\:y\in\:{\mathbb{R}}^{m}\) is a time-series, CAE encoding every instance into a compressed latent space representation \(\:Z=\{{z}_{i}{\}}_{i=1}^{N}\) over encoding and rebuild an approximate version \(\:\widehat{Y}\) over the decoding. The procedure of encoding might be specified:
Now \(\:{f}_{\theta\:}\) specifies the encoder that contains convolution layers succeeded by pooling layers and activation functions; \(\:\sigma\:\) indicates non-linear activation function; \(\:b\) and \(\:W\) refer to bias and learnable convolution kernel. The process of decoding might be stated as follows:
Here, \(\:{W}^{{\prime\:}}\) and \(\:{b}^{{\prime\:}}\) represent the parameters of the decoder, and \(\:{g}_{\phi\:}\) specifies the decoder contains up-sampling and transposed convolution layers. The loss function utilized by Mean Squared Error (MSE):
Hyperparameter optimization using HOA
In this section, the HOA-based hyperparameter selection is implemented to improve the classification result of the CAE model33. This model is chosen due to its efficient exploration and exploitation balance, which assists in avoiding local optima and ensures global search capabilities. HOA replicates the social behaviour of hippopotamuses, enabling adaptive parameter updates and faster convergence compared to conventional optimization methods such as grid or random search. Its population-based approach allows simultaneous evaluation of multiple solutions, mitigating computational time (CT). HOA performs superior in complex, high-dimensional search spaces, making it appropriate for fine-tuning DL models. This enhances model accuracy and robustness, giving it an edge over other metaheuristic algorithms.
The HOA draws motivation from 3 well-known behavioural patterns witnessed in the existence of hippopotamuses. The Hippopotamus group contains various hippopotamus calves, female hippopotamuses, many adult male hippopotamuses, and the prevailing male hippopotamus (the herd leader). Because of their inherent curiosity, younger and calves’ hippopotamuses frequently exhibit a trend to wander apart from the group. Consequently, they became isolated and targeted for predators.
The HOA is a population-based optimizer model that searches for agents as hippopotamuses. In this HOA, the hippopotamus has candidate solutions for optimizer concerns, which means the location upgrade of every hippopotamus in the searching area depicts values for the decision variables. Therefore, every hippopotamus is denoted as a vector. Based on the initialized population of the hippopotamus, every hippopotamus is illustrated by one vector. The population matrix of the hippopotamus is denoted.
Here, \(\:r\) signifies an arbitrary number among Zero and one, \(\:X\) denotes the location of the candidate solution; \(\:ub\) and \(\:lb\) refer to upper and lower boundaries of decision variables; \(\:m\) denotes decision variable counts in the problem, and \(\:N\) signifies the population size of hippos; \(\:i=\text{1,2},\dots\:,\:N,j=\text{1,2},\dots\:,m.\)
Phase 1: Exploration
Based on the location of the primary hippopotamus, the population member upgraded their location in the place of residence. The model is stated as increasing the search area:
As the iteration counts rise, juvenile hippopotamuses originate from curiosity and gradually depart from the group to discover the neighbouring setting:
Now \(\:{\text{D}}_{hippo}\) refers to the location of the prevailing hippopotamus, \(\:{h}_{1}\) indicates an arbitrary vector or number, \(\:{x}_{ij}^{Mhippo}\) represents the position of a male hippopotamus, \(\:M{G}_{i}\) signifies the average value of arbitrary hippopotamuses, \(\:{y}_{1}\) signifies random numbers, \(\:{I}_{1}\) and \(\:{I}_{2}\) are integers between one and two, \(\:i=\text{1,2},\dots\:,\:N/2\), and \(\:j=\text{1,2},\dots\:,m.\)
Phase 2: Exploration
Upgrade the location of predators and pretend the random walks them based on the vector of Levy flight. While the fitness value of hippos is superior to the predator, the hippopotamus protects the hunters based on Eq. (10).
Then, the hippopotamus escaping from the hunters based on Eq. (11). It is reflected in the model as an adjustment of the existing solution to evade being substituted by a poor solution:
Here, \(\:\overrightarrow{R}L\) depicts a random vector with levy distribution; \(\:Predato{r}_{j}\) denotes the location of the predator in dimension \(\:j\), \(\:\overrightarrow{D}\) refers to the distance between hippopotamus and hunter; \(\:{x}_{ij}^{HhippoR}\) signifies the location of hippopotamus relative to the predator; \(\:\overrightarrow{r}\) indicates an arbitrary matrix of dimension; \(\:c,d,f\), and \(\:g\) refers to random numbers; \(\:i=\text{1,2},\dots\:,N\), and \(\:j=\text{1,2},\dots\:,m.\)
Phase 3: Exploitation
By pretending the hippo’s behaviour escape from predators and endeavouring to travel to a protected location, the model is enhanced for discovering a more optimum solution in the local searching area:
Now \(\:{s}_{1}\) denotes an arbitrary number or vector, \(\:\overrightarrow{r}\) represents an arbitrary vector from zero to one, and \(\:{x}_{i{j}^{Hippo\epsilon\:}}\) signifies the nearest safe location; \(\:i=\text{1,2},\dots\:,N,j=\text{1,2},\dots\:,m.\) The HOA initiates a fitness function (FF) to enhance classification performance. It defines a progressive number to characterize the greater performance of the candidate solutions. In this paper, the reduction of the classification error rate is measured as the FF, as provided in Eq. (13).
Holography processing through BAH generation
Finally, the holographic process is performed through BAH generation34. To exemplify the multiple prominent CGH models, primarily project dual models employed for BAH generation. The minimum precision is projected to be eminent for its simplicity in computation. The model is executed as follows.
Stage 1: A target amplitude with dimension \(\:XxY\) is described. It has a zero-valued array while the targeted objects with dimension \(\:Lx\times\:Ly\) are positioned at a distance \(\:W\times\:\) from the centre.
Stage 2: The targeted amplitudes are multiplied by the primary random stage.
Stage 3: The inverse Fourier transform (IFT) of the preceding outcomes is computed to attain the equivalent optical area in the plane of the hologram.
Stage 4: The data magnitude of the region in stage 3 is rejected, maintaining stage.
Stage 5: The stage gained in stage 4 is changed within the BAH employing straightforward binarization of global thresholding using the succeeding Eq. (14)
Now, the stage is in range \(\:\left[\text{0,2}\pi\:\right]\). Various thresholding models are utilized to create a hologram at this step. The 1 st expression was chosen since it depicts the direct method to stage binarization with range \(\:\left[\text{0,2}\pi\:\right]\), evading the requirement for the iterative study phase of the histogram or the computationally intensive calculation engaged in another binarization model. While it creates BAH, its efficacy is restricted owing to substantial counts of speckle noise influencing the object reconstructed, generally induced by the procedure of binarization. The initial value of this method is to present a baseline compared with more effectual models.
The succeeding general method for BAH generation depends on the threshold binarization of the Gerchberg-Saxton enhanced stage‐only hologram.
-
1)
Succeeding stages 1 to 3 of the B-OPR model explained earlier attained the primary area within the hologram’s plane.
-
2)
The initial size constraint (C1) is implemented to the region in the plane of the hologram by substituting the size attained in stage 1 using the constant value while maintaining the stage.
-
3)
The area resulting from the preceding step implements an FT, achieving the region in the reconstruction plane.
-
4)
A second constraint (C2) is utilized by substituting the amplitudes within the reconstruction plane with targeted amplitudes while maintaining the stage.
-
5)
The IFT of the preceding step outcome is considered, accomplishing once again the region in the plane of the hologram. Steps 2 to 5 are repetitive iterations, resulting in a greater estimation of the targeted amplitude in every iteration. Once these iterations are completed, the resultant stage in the plane of the hologram is removed and changed to a BAH employing the thresholding operation specified as 1. The B-GS generated BAH and was reconstructed with substantially fewer noises than the reconstruction from BAH gained through B‐OPR.
Empirical results and evaluation
The performance analysis of the ODHVCP-HOADL method is investigated under the Indoor OD dataset35. The technique is simulated using Python 3.6.5 on a PC with an i5-8600k, 250GB SSD, GeForce 1050Ti 4GB, 16GB RAM, and 1 TB HDD. Parameters include a learning rate of 0.01, ReLU activation, 50 epochs, 0.5 dropouts, and a batch size of 5. This dataset holds 6642 total counts under 10 objects. The complete details of this dataset are shown below in Table 1. Figure 3 indicates the sample image. Figure 4 represents the normal and detected image.

Sample image.

(a) normal image and (b) detected image.
Figure 5 shows the classifier results of the ODHVCP-HOADL technique under 80:20. Figure 5a and b demonstrates the confusion matrices, showing precise detection and classification of all classes. Figure 5c reveals the PR evaluation, reflecting optimal performance across each class. Finally, Fig. 5d depicts the ROC evaluation, illuminating effective outcomes with elevated ROC scores for individual classes.

80:20 of (a-b) confusion matrices, (c) curve of PR, and (d) curve of ROC.
Table 2; Fig. 6 present the OD result of the ODHVCP-HOADL technique under 80:20. The outcomes imply that the ODHVCP-HOADL technique precisely identified the instances. With 80%TRPHE, the ODHVCP-HOADL model provides an average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\:{F1}_{Measure}\), and \(\:{AUC}_{score}\) of 99.64%, 95.71%, 88.31%, 90.98%, and 94.03%, respectively. Also, based on 20%TSPHE, the ODHVCP-HOADL model presents an \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\:{F1}_{Measure}\), and \(\:{AUC}_{score}\) of 99.56%, 91.36%, 81.98%, 84.29%, and 90.84%, correspondingly.

Average values of ODHVCP-HOADL model under 80:20.
Figure 7 illustrates the training (TRNG) \(\:acc{u}_{y}\) and validation (VALID) \(\:acc{u}_{y}\) results of the ODHVCP-HOADL model under 80:20. Both metrics are calculated across a range of 0–25 epochs. The figure specified that both \(\:acc{u}_{y}\) values show an upward trend, confirming the ODHVCP-HOADL model’s efficiency with greater performance through multiple iterations. Moreover, both \(\:acc{u}_{y}\) values remain closely aligned across epochs, suggesting minimal overfitting and exhibiting improved capability of the ODHVCP-HOADL technique.

\(\:Acc{u}_{y}\) curve of ODHVCP-HOADL model under 80:20.
Figure 8 shows the TRNG loss and VALID loss graph of the ODHVCP-HOADL model in terms of 80:20. Both values are measured for 0–25 epochs. Both values determine a downward trend, indicating the effectiveness of the ODHVCP-HOADL technique in managing the balance between generality and data fitting. The consistent decline further supports the enriched performance of the ODHVCP-HOADL technique.

Loss curve of ODHVCP-HOADL model under 80:20.
Figure 9 portrays the classifier findings of the ODHVCP-HOADL technique under 70:30. Figure 9a and b indicates the confusion matrices with accurate detection and classification of all classes. Figure 9c displays the PR investigation, demonstrating maximum performance in every class. At Last, Fig. 9d exemplifies the ROC inspection, illustrating capable results with higher values of ROC for separate class labels.

70:30 of (a-b) confusion matrices, (c) curve of PR, and (d) curve of ROC.
Table 3; Fig. 10 institute the ODHVCP-HOADL technique’s OD result under 70:30. With 70%TRPHE, the ODHVCP-HOADL approach gives average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\:{F1}_{Measure}\), and \(\:{AUC}_{score}\) of 99.58%, 95.27%, 85.86%, 89.35%, and 92.78%, respectively. Moreover, under 30%TSPHE, the ODHVCP-HOADL approach presents an average \(\:acc{u}_{y}\), \(\:pre{c}_{n}\), \(\:rec{a}_{l},\:\) \(\:{F1}_{Measure}\), and \(\:{AUC}_{score}\) of 99.47%, 90.95%, 84.32%, 86.72%, and 91.96%, correspondingly.

Average values of ODHVCP-HOADL model under 70:30.
Figure 11 displays the TRNG \(\:acc{u}_{y}\) and VALID \(\:acc{u}_{y}\) findings of the ODHVCP-HOADL approach under 70:30. Both values are measured for 0–25 epochs. The figure emphasized that both \(\:acc{u}_{y}\) values reveal growing tendencies, designating the abilities of the ODHVCP-HOADL approach across developed performance in several iterations. Furthermore, both \(\:acc{u}_{y}\) stays close to the epochs that specify marginal overfitting and depict the improved performance of the model.

\(\:Acc{u}_{y}\) curve of ODHVCP-HOADL model under 70:30.
Figure 12 presents the TRNG and VALID loss graph of the ODHVCP-HOADL approach under 70:30. Both values total 0–25 epochs. It is signified that both values elucidate a declining trend, representing the ODHVCP-HOADL model’s ability to balance a trade-off. The persistent decline further reports the ODHVCP-HOADL model’s boosted performance.

Loss curve of ODHVCP-HOADL model under 70:30.
Table 4; Fig. 13 outline the comparative study of the ODHVCP-HOADL method with the present techniques across several metrics20,21,36,37,38. The results underlined that the current methodologies, namely WKNN, ANN, VoteNet, VoteNet + 3DRM, MLCVNet, YOLOv3, YOLOv4 + tiny, YOLOv10, DCASR, and FSRCNN models attained lesser results. In the meantime, the presented ODHVCP-HOADL technique achieves an enhanced performance with the highest \(\:acc{u}_{y}\) of 99.64%, \(\:pre{c}_{n}\) of 95.71%, \(\:rec{a}_{l}\) of 88.31%, and \(\:{F1}_{Measure}\) of 90.98%.

Comparative analysis of ODHVCP-HOADL technique with existing methods.
The CT of ODHVCP-HOADL methodology with existing models is recognized in Table 5; Fig. 14. Depending upon CT, the ODHVCP-HOADL methodology presents the least value of 9.35 s while the existing techniques such as WKNN, ANN, VoteNet, VoteNet + 3DRM, MLCVNet, YOLOv3, YOLOv4 + tiny, YOLOv10, DCASR, and FSRCNN attained improved CTs of 11.17 s, 22.96 s, 27.59 s, 22.51 s, 29.31 s, 13.57 s, 27.85 s, 18.09 s, 20.12 s, and 15.45 s, correspondingly.

CT outcome of ODHVCP-HOADL approach with existing models.
Table 6; Fig. 15 specify the ablation study of the ODHVCP-HOADL method with existing techniques. Faster R-CNN achieved an \(\:acc{u}_{y}\) of 96.47% with an \(\:{F1}_{Measure}\) of 87.69%, while the SqueezeNet improved slightly with an \(\:acc{u}_{y}\) of 97.04% and an \(\:{F1}_{Measure}\) of 88.48%. The HOA method additionally increased \(\:acc{u}_{y}\) to 97.66% and the \(\:{F1}_{Measure}\) to 89.19%. The BAH technique showed gains, reaching an \(\:acc{u}_{y}\) of 98.44% and an \(\:{F1}_{Measure}\) of 89.80%. CAE achieved an \(\:acc{u}_{y}\) of 99.12% and an \(\:{F1}_{Measure}\) of 90.33%. The optimum performance was observed with the ODHVCP-HOADL model, which attained the highest \(\:acc{u}_{y}\) of 99.64%, \(\:pre{c}_{n}\) of 95.71%, \(\:rec{a}_{l}\) of 88.31%, and an \(\:{F1}_{Measure}\) of 90.98%, indicating its superior effectiveness.

Ablation study results comparing ODHVCP-HOADL method with existing techniques.
Conclusion
This article presents an ODHVCP-HOADL model. This paper aims to develop an effective IoT-based OD system for consumer products integrated with a holographic display to provide an interactive and immersive visualization experience. At first, the image pre-processing step utilizes WF to enhance image quality by removing unwanted noise. The Faster R-CNN model is then deployed for the OD process. For the extraction of feature procedure, the proposed ODHVCP-HOADL method executes the SqueezeNet model to identify and isolate relevant features from raw data. Additionally, the CAE model is implemented for the classification process. Besides, the HOA-based hyperparameter selection model is implemented to improve the classification result of the CAE model. Finally, the holographic process is performed through BAH generation. The performance validation of the ODHVCP-HOADL approach is examined under the Indoor OD dataset. The comparison study of the ODHVCP-HOADL approach portrayed a superior accuracy value of 99.64% over existing models. The limitations of the ODHVCP-HOADL approach comprise the reliance on high-quality labeled data, which may not always be available to obtain in real-world scenarios. Additionally, the performance may fall low when exposed to highly noisy or occluded environments. The computational complexity of the entire process might limit its deployment on low-resource or real-time systems. The study also lacks extensive validation across diverse datasets, which may affect its generalizability. Research gap while addressing it could include exploring lightweight models for resource-constrained devices, improving robustness against adversarial conditions, and incorporating unsupervised or semi-supervised learning techniques to mitigate dependency on labeled data.
Data availability
The data supporting this study’s findings are openly available in the Kaggle repository at https://www.kaggle.com/datasets/thepbordin/indoor-object-detection, reference number35.
References
Ghasemi, Y., Jeong, H., Choi, S. H., Park, K. B. & Lee, J. Y. Deep learning-based object detection in augmented reality: A systematic review. Computers in Industry, 139, 103661 (2022).
Michalikova, K. F., Ondrejka, R. & Johnson, E. Deep Learning-Based object detection and holographic virtual imaging technologies, mobile biometric and sentiment data, and digital twin simulation and modeling tools in the metaverse economy. Linguistic Philosophical Investigations. 22, 247–263 (2023).
Cárdenas-Robledo, L. A., Hernández-Uribe, Ó., Reta, C. & Cantoral-Ceballos, J. A. Extended reality applications in industry 4.0.–A systematic literature review. Telematics and Informatics. 73, 101863 (2022).
Haleem, A., Javaid, M., Singh, R. P., Suman, R. & Rab, S. Holography and its applications for industry 4.0: An overview. Internet of Things and Cyber-Physical Systems2, 42–48 (2022).
Ay, B. Open-set learning-based hologram verification system using generative adversarial networks. IEEE Access. 10, 25114–25124 (2022).
Li, R. Y. M., Chau, K. W. & Ho, D. C. W. AI object detection, holographic hybrid reality and haemodynamic response to construction site safety risks. In Current State of Art in Artificial Intelligence and Ubiquitous Cities 117–134 (Springer Nature Singapore, 2022).
Pavlopoulou, M. E. G. & Deligiannakis, N. N. A Mixed reality application for Object detection with audiovisual feedback through MS HoloLenses (2022).
Salloum, S. A., Alhumaid, K., Alfaisal, A. M., Aljanada, R. A. & Alfaisal, R. Adoption of 3D Holograms in Science Education: Transforming Learning Environments. Ieee Access 12, 70984–70998 (2024).
Mohamed, K. S. Deep learning for Spatial computing: augmented reality and metaverse the digital universe. In Deep Learning-Powered Technologies: Autonomous Driving, Artificial Intelligence of Things (AIoT), Augmented Reality, 5G Communications and Beyond 131–150 (Springer Nature Switzerland, 2023).
Pareek, P. K. & Pareek, P. K. Pixel level image fusion in moving objection detection and tracking with machine learning. J. Fusion: Pract. Appl. 2 (1), 42–60 (2020).
Zhang, X. Y. et al. Robust lightweight UAV inspection system for consumer electronics applications in smart grids. IEEE Trans. Consum. Electron. (2025).
Alabdan, R. et al. Blockchain-assisted improved interval type-2 fuzzy deep learning-based attack detection on internet of things driven consumer electronics. Alexandria Eng. J. 110, 153–167 (2025).
Wang, Y., Zhang, D., Li, R., Zheng, Z. & Li, M. PD-SORT: Occlusion-Robust multi-object tracking using pseudo-depth cues. IEEE Trans. Consum. Electron. (2025).
Asiri, M. M. et al. Securing consumer electronics devices: A blockchain-based access management approach enhanced by deep learning threat modeling for IoT ecosystems. IEEE Access. (2024).
Bhatt, M. W. & Sharma, S. Next generation imaging in consumer technology for ERP detection based EEG cross-subject visual object recognition. IEEE Trans. Consum. Electron. (2024).
Cherian, A. K. et al. An IoT based Voice Assisted Smart Residential Appliance Control Mechanism using Intelligent Node MCU Controller. In 2024 5th International Conference on Electronics and Sustainable Communication Systems (ICESC). IEEE. 381–387 (2024).
Zhang, M. Consumer behavior analysis based on internet of things platform and the development of precision marketing strategy for fresh food e-commerce. PeerJ Comput. Sci. 9, e1531 (2023).
Yang, S. Y., Cheng, H. Y. & Yu, C. C. Real-time object detection and tracking for unmanned aerial vehicles based on convolutional neural networks. Electronics 12(24), 4928 (2023).
Alabduallah, B. et al. S., Exploiting feature fusion with deep learning based Next-Generation consumer products detection on video surveillance monitoring systems. IEEE Trans. Consum. Electron. (2024).
Hoang, V. H., Lee, J. W. & Park, C. S. Enhancing fire detection with YOLO models: A bayesian hyperparameter tuning approach. Computers Mater. Continua. 83 (3), 4097–4116 (2025).
Malkocoglu, A. B. V. & Samli, R. A novel model for higher performance object detection with deep channel attention super resolution. Eng. Sci. Technol. Int. J, 64, 102003. (2025).
Bilal, H. et al. Online fault diagnosis of industrial robot using IoRT and hybrid deep learning techniques: An experimental approach. IEEE Internet Things J 11(19), 31422–31437 (2024).
Abu-Khadrah, A., Al-Qerem, A., Hassan, M. R., Ali, A. M. & Jarrah, M. Drone-assisted adaptive object detection and privacy-preserving surveillance in smart cities using whale-optimized deep reinforcement learning techniques.. Sci. Rep. 15(1), 9931 (2025).
Bello, R. W., Owolawi, P. A., van Wyk, E. A. & Tu, C. Transfer learning-driven cattle instance segmentation using deep learning models.. Agriculture 14(12), 2282 (2024).
Achmadiah, M. N., Ahamad, A., Sun, C. C. & Kuo, W. K. Energy-Efficient fast object detection on edge devices for IoT systems. IEEE Internet Things J. (2025).
Vats, P., Upadhyay, G. M., Shanker, S., Phogat, A. K. spsampsps Gupta, S. Enhanced Object Detection and Segmentation in Satellite Imagery Through Modified Convolutional Networks Utilizing Transfer Learning Techniques. In International Conference on Information and Communication Technology for Intelligent Systems (pp. 95–106). Singapore: Springer Nature Singapore. (2024).
Jin, D., Shao, F., Xie, Z., Mu, B. & Chen, H. Rethinking lightweight RGB-Thermal salient object detection with local and global perception network. IEEE Internet Things J. (2025).
Dalal, S. et al. Improving smart home surveillance through YOLO model with transfer learning and quantization for enhanced accuracy and efficiency.. PeerJ Computer Science 10, e1939 (2024).
Gupta, D., Sun, L., Geman, O. & Priyadarshini, I. Guest editorial Next-Generation imaging technology for consumer electronics. IEEE Trans. Consum. Electron. 70(4), 7129–7134 (2025).
Anitha Selvasofia, S. D., SivaSankari, B., Dinesh, R. & Muthukumaran, N. GINSER: Geographic Information System Based Optimal Route Recommendation via Optimized Faster R-CNN.. Int. J. Comput. Intell. 18(1), 75 (2025).
Najm, H., Mahdi, M. S. & Mohsin, S. Novel Key Generator-Based SqueezeNet Model and Hyperchaotic Map. Data Metadata 4, 743 (2025).
Fan, Y., Giovanis, D. G. & Kopsaftopoulos, F. Guided wave-based structural awareness under varying operating states via manifold representations. arXiv preprint arXiv:2504.11235. (2025).
Zhong, Z. et al. Research on Denoising of Bridge Dynamic Load Signal Based on Hippopotamus Optimization Algorithm–Variational Mode Decomposition–Singular Spectrum Analysis Method. Buildings 15(8), 1390 (2025).
Velez-Zea, A., Hoyos-Peláez, C. A. & Barrera-Ramírez, J. F. High-quality binary amplitude hologram generation for digital micromirror device based holographic display.. Opt. Lasers Eng. 191, 108994 (2025).
https://www.kaggle.com/datasets/thepbordin/indoor-object-detection
Sun, Y. et al. Human localization using multi-source heterogeneous data in indoor environments. IEEE Access. 5, 812–822 (2017).
Lan, Y. et al. ARM3D: Attention-based relation module for indoor 3D object detection. Comput. Visual Media. 8 (3), 395–414 (2022).
Lv, Y., Fang, Y., Chi, W., Chen, G. & Sun, L. Object detection for sweeping robots in home scenes (ODSR-IHS): A novel benchmark dataset. IEEE Access. 9, 17820–17828 (2021).
Acknowledgements
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project under grant number RGP2/288/46. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R732), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors extend their appreciation to the Deanship of Scientific Research at Northern Border University, Arar, KSA for funding this research work through the project number “NBU-FFR-2025- 2847-06. The authors are thankful to the Deanship of Graduate Studies and Scientific Research at University of Bisha for supporting this work through the Fast-Track Research Support Program. This study is supported via funding from Prince Sattam bin Abdulaziz University project number (PSAU/2025/R/1447).
Author information
Authors and Affiliations
Contributions
Amnah Alshahrani: Conceptualization, methodology development, experiment, formal analysis, investigation, writing. Mukhtar Ghaleb: Formal analysis, investigation, validation, visualization, writing. Hany Mahgoub: Formal analysis, review and editing. Nojood O Aljehane: Methodology, investigation. Mohammed Yahya Alzahrani: Review and editing. Hasan Beyari: Discussion, review and editing. Sultan Alanazi: Discussion, review and editing. Achraf Ben Miled: Conceptualization, methodology development, investigation, supervision, review and editing. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This article contains no studies with human participants performed by any authors.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Alshahrani, A., Ghaleb, M., Mahgoub, H. et al. Internet of things driven object detection framework for consumer product monitoring using deep transfer learning and hippopotamus optimization. Sci Rep 15, 30109 (2025). https://doi.org/10.1038/s41598-025-13224-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-13224-8
