
Abstract
Underwater imagery frequently exhibits low clarity and is subject to significant color distortion as a result of the inherent conditions of the marine environment and variations in illumination. Such degradation in image quality fundamentally undermines the efficacy of marine ecological monitoring and the detection of underwater targets. To address this issue, we present a Mamba-Convolution network for Underwater Image Enhancement (MC-UIE). Concretely, we first use a standard convolution layer with a 3\(\times\)3 kernel to obtain initial image feature maps. Then, we develop an iterable Mamba-Convolution Hybrid Block (M-C HB) to enhance the global and local dependency of image feature maps. The core of the M-C HB is the 2D Selective Scan (SS2D) and Feature Attention Module (FAM), which can more efficiently learn the global and local dependency of images. After that, a Cross Fusion Mamba Block (CFMB) is designed to fuse image feature maps of different levels. Finally, extensive qualitative and quantitative experiments on mainstream datasets demonstrate that the proposed method significantly outperforms existing methods in color, illumination, and detail restoration. Our code and results are available at: https://github.com/WYJGR/MC-Net/.
Similar content being viewed by others

Introduction
As human exploration and resource development of the oceans continue to expand, underwater robots have become a popular field1,2. However, the complex wavelength degradation seriously hinders the application of underwater robots in ocean exploration3,4, due to images obtained by underwater robots showing severe degradation, such as color casts, blurry structures and details, and poor visibility.
In the underwater environment, where the light captured by an imaging camera is primarily composed of three components: the direct component (light reflected from the target without scattering), the forward scattering component (light reflected from the target scattered at a small angle), and the backward scattering component (light reflected from floating particles). Underwater images are regarded as a linear combination of these three components. The forward scattering component blurs underwater image structures, while the backward scattering masks edges and details. Meanwhile, color casts of underwater images are mainly derived from different absorption rates of different wavelengths. Different wavelengths of visible light are attenuated at different rates. Specifically, the red light disappears fastest due to its longest wavelength or minimal energy. The blue or green light exhibits the opposite behavior. Consequently, captured underwater images commonly present bluish or greenish tones.
To improve the visual quality of underwater images, numerous Underwater Image Enhancement (UIE) methods have been proposed. Fu et al.5 proposed a lightweight UIE method based on probabilistic networks, which enhanced underwater images by learning the enhancement distribution of degraded underwater images. Li et al.6 proposed a lightweight convolutional neural network (CNN) for UIE, and reconstructed clear underwater images based on the prior knowledge of underwater scenes. Wang et al.7 designed the UIEC\(\hat{\,}\)2-Net driven by both RGB and HSV color spaces, which performed denoising and color correction in the RGB color space, and adjusted brightness and saturation in the HSV color space. Li et al.8 presented a UIE network (Ucolor) via medium transmission-guided multi-color space embedding. This method integrated a multi-color space encoder and a medium transmission-guided decoder, in which incorporated characteristics of different color spaces into a unified structure and select representative color features to enrich the network input. Although these above-mentioned methods achieve obvious enhancement improvement, their enhancement performance is limited due to the limited receptive field of CNN architecture. To address this issue, we present a novel Mamba-Convolution network for UIE (MC-UIE), where the Mamba architecture provides efficient global dependencies, while the CNN architecture offers efficient local dependencies. Concretely, we use a standard convolution layer with a 3\(\times\)3 kernel to obtain initial image feature maps. Then, we develop an iterable Mamba-Convolution Hybrid Block (M-C HB) to enhance the global and local dependency of image feature maps. After that, a Cross Fusion Mamba Block (CFMB) is designed to effectively fuse the image feature maps of different levels. Finally, we also utilize a standard convolution layer with a 3\(\times\)3 kernel to obtain the enhanced underwater image.
The main contributions of our work are summarized as follows:
-
1.
We develop a Mamba-Convolution network for UIE (MC-UIE), which effectively combines the advantages of Mamba and CNN architectures for learning enhancement mapping between raw underwater images and clear underwater images.
-
2.
We design an iterable Mamba-Convolution Hybrid Block (M-C HB) and a Cross Fusion Mamba Block (CFMB), where M-C HB provides richer local dependency information than the naive Mamba module, while CFMB offers a more effective feature maps fusion of different levels.
-
3.
Extensive qualitative and quantitative experiments on mainstream datasets demonstrate the impressive performance of our proposed method.
Related works
CNN-based UIE methods
These CNN-based UIE methods are characterized by linear computational complexity and general modeling capabilities. Fu et al.9 introduced an Unsupervised Underwater Image Restoration method (USUIR) that utilizes the relationship between a raw underwater image and a re-degraded version of the same image. Fu et al.10 proposed a UIE method utilizing normalization schemes across both spatial and channel dimensions, called SCNet, to enhance image quality while addressing the diverse degradation caused by water. Li et al.8 presented a multi-color space embedding network guided by medium transmission (Ucolor), which successfully improves the visual quality of underwater images by leveraging the advantages of multi-color space embedding. Zhou et al.11 developed a Hybrid Contrastive Learning Regularization Network (HCLR-Net) for UIE, which is based on a unique hybrid contrastive learning regularization approach that allows the network to establish a more resilient sample distribution. Zhang et al.12 proposed a Synergistic Multiscale Detail Refinement via Intrinsic Supervision (SMDR-IS) for UIE, which addresses the limited scale-related features in current UIE methods. However, UIE methods based on CNN are limited in modeling long-range dependencies, resulting in poor generalizability.
Transformer-based UIE methods
These Transformer-based UIE methods achieve excellent global enhancement capabilities with self-attention mechanisms and image serialization as their core. Huang et al.13 proposed a Swin Transformer module based on adaptive group attention (AGA) for UIE, which can dynamically select visually complementary channels based on the dependencies, reducing the number of further attention parameters. Peng et al.14 proposed a U-shape transformer and a multi-color space loss function that combined the advantages of RGB, LCH, and LAB color spaces to enhance the underwater contrast and saturation. Ren et al.15 designed a U-Net-based reinforced Swin-Convs Transformer for simultaneous underwater image enhancement and superresolution. Shen et al.16 proposed a dual-attention transformer-based UIE method to address the characteristics of uneven degradation and loss of color channels in underwater images. Transformer-based UIE methods excel at modeling long-range dependencies, which often involve a large number of parameters and complex self-attention mechanisms. This poses challenges for efficiency due to the quadratic computational complexity relative to image size.
Mamba-based UIE methods
The Mamba architecture based on state space models (SSM) excels at modeling long distances while maintaining linear complexity, which enables the Mamba-based UIE method to better map the original underwater image to the reference underwater image. As a pioneering work, Chen et al.17 proposed the first Mamba network for UIE, which is characterized by extreme lightweight. Guan et al.18 proposed a Mamba network with linear computational complexity for UIE to address the non-uniform degradation and color channel loss in underwater image processing. Lin et al.19 presented a PixMamba based on the patch-level Efficient Mamba Net (EMNet) and the pixel-level PixMamba Net (PixNet) to improve the overall clarity, color balance, and global consistency of underwater images. An et al.20 proposed a hybrid network called UWMamba that integrates SSM and convolution for enhancing underwater images. Dong et al.21 proposed a novel UIE framework called O-Mamba to deal with the cross-color channel dependency problem in underwater images caused by the differential attenuation of light wavelengths. Although these Mamba-based methods attain significant improvements, the 2D selective scan (SS2D) used in these methods cannot fully consider the spatial information of the image, resulting in limited performance.
In contrast, the proposed MC-UIE is designed to extract richer local dependency information by combining the Mamba module and convolution-based feature attention module.

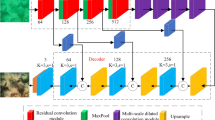
The overview of MC-UIE. First, an underwater image passes a convolution layer with a 3\(\times\)3 kernel (Conv3) to produce initial feature maps. Then, the initial feature maps are fed into the Mamba-Convolution Hybrid Block (M-C HB) to enhance the global and local dependency of image feature maps. Finally, the enhanced image is produced by a Conv3 module.
Preliminaries
The core of Mamba architecture is the State Space Model (SSM) which is inspired by continuous linear time-invariant (LTI) systems. The SSM is renowned for its powerful sequence-to-sequence modeling capabilities, which maps a 1D input signal \(x(t) \in \mathbb {R}\) to a 1D output signal \(y(t) \in \mathbb {R}\) through an N-D latent state \(h(t) \in \mathbb {R}^N\), as follows:
where \(A \in \mathbb {R}^{N \times N}\), \(B \in \mathbb {R}^{N \times 1}\), \(C \in \mathbb {R}^{1 \times N}\) are parameters of neural networks in deep learning. To deal with the discrete input \(X \in (x_0,x_1,...)\), such as images, the Eq. 2 can be discretized by the zero-order hold:
where \(\Delta\) is the step size. After that, the Eq. 2 can be reformulated as:
Then SSM can be efficiently computed by RNN, Eq. 2 also be reformulated and computed as a convolution:
where L is the length of the image sequence x, \(\overline{\textbf{K}}\) represents the SSM convolution kernel, and \(*\) denotes convolution operation.
Proposed method
The overall architecture of the proposed Mamba-Convolution hybrid network for Underwater Image Enhancement (MC-UIE) is shown in Fig. 1. MC-UIE is composed of two 3\(\times\) 3 convolution layers and seven Mamba-Convolution Hybrid Blocks (M-C HB). In Fig. 1a, the output size is shown around each module. MC-UIE is a multi-scale encoder-decoder network with skip connections by Cross Fusion Mamba Blocks (CFMB) across encoder-decoder layers at different levels. This multi-scale encoder-decoder network was inspired by the UNet architecture, which allows the model to effectively capture both local fine details and global contextual cues, which are crucial for restoring realistic underwater scenes. Specifically, we adopt a four-scale structure to progressively extract features from high to low resolution. This configuration enables sufficient receptive field expansion and hierarchical feature learning, while avoiding excessive downsampling that may lead to spatial detail loss. Compared to shallower designs, it improves the model’s ability to handle varying degradation patterns. On the other hand, introducing more scales would inevitably increase model complexity and computational cost, with diminishing returns in feature utility due to over-compression or over-aggregation. Thus, the adopted scale number represents a balanced trade-off between enhancement effectiveness and computational feasibility, supporting the overall goal of practical and robust underwater image enhancement. In addition, the proposed CFMB is specifically designed for the fusion of shallow spacial and deep semantic features, dynamically aggregating multi-scale features for image restoration. Given an underwater image, we first use a 3 \(\times\) 3 convolution layer (Conv3) to build initial image feature maps. Then, Mamba-Convolution Hybrid Blocks (M-C HB) are used iteratively to enhance the global and local dependency of image feature maps. After up sampling, we use CFMB to fusion image feature maps of encoder-decoder layers at different levels. At last, the enhanced image is produced by a Conv3 module.
In what follows, we detail key components of MC-UIE, including the Mamba-Convolution Hybrid Block (M-C HB), Cross Fusion Mamba Blocks (CFMB), and loss function, respectively.
Mamba-convolution hybrid block
The naive mamba block has limitations when applied to image processing tasks, as its local dependency modeling is inferior to the convolutional architecture22. In order to make mamba blocks more effectively applied to image processing images, we propose a Mamba-Convolution Hybrid Block (M-C HB), as shown in Fig. 1b. The proposed Mamba-Convolution Hybrid Block (M-C HB) integrates the global modeling capability of mamba blocks and the local modeling capability of the feature attention module (FAM)23. The executive process of M-C HB can mathematically express as:
where \(Linear(\cdot )\) is the linear projection layer, \(Conv3(\cdot )\) represents the convolution operation with a kernel size of 3\(\times\)3, \(SiLU(\cdot )\) is the Sigmoid Linear Unit, and \(FAM(\cdot )\) is the Feature Attention Module23, as shown in Fig. 1c. The \(FAM(\cdot )\)23 treats different features and pixel regions unequally, which can provide additional flexibility in dealing with different types of information, which can be formulated as follows:
where the x is input feature maps, AP denotes an average pooling layer, \(ReLU(\cdot )\) is the Rectified Linear Unit, and \(\otimes\) denotes element-wise multiplication. SS2D is the naive 2D selective scan, as shown in Fig. 1d.
Cross fusion mamba block
The naive mamba block has limitations when applied to image processing tasks, as its local dependency modeling is inferior to the convolutional architecture22. In previous literature24, the 1 \(\times\)1 convolution layer was often used to fuse image feature maps of encoder-decoder layers at different levels. Although this fusion strategy is fast, it cannot fully utilize the image feature maps of different levels. Therefore, we propose a Cross Fusion Mamba Block (CFMB) to effectively fuse the image feature maps of different levels, as shown in Fig. 1e. Concretely, we first adopt a random channel mix (RCM) on \(F_1\) and \(F_2\), which does not require additional parameters or computational operations, to achieve a fast exchange of features, as expressed:
where M(B, C) denotes the 0-1 mask used for channel exchange, B is the batch size, and C refers to channels. \(M(B, C)=0\) indicates no exchange, while \(M(B, C)=1\) indicates to exchange feature channel of \(F^i_1\) and \(F^i_2\). The superscript i is a random index of the feature maps. The core idea of RCM is to introduce a stochastic yet structure-preserving perturbation by randomly shuffling feature channels across groups. This randomness improves the robustness of the model by encouraging it to rely on more global and discriminative cues rather than fixed channel dependencies. The RCM helps the model explore diverse channel-wise interactions between the two inputs, leading to more effective feature fusion and better recovery of semantic and structural information from underwater images. The exchanged features then undergo processing through their respective M-C HB. After repeating the above steps, we concatenate these feature maps and then utilize a 1 \(\times\) 1 Convolution layer to obtain the desired number of channels.
Loss function
We use the L1 loss function \(L_{1}\) to measure the difference between the enhanced underwater image x and the reference underwater image y as follows:
where H and W represent the height and width of an underwater image.
Experimental results
To demonstrate the superior performance of our MC-UIE, we present the qualitative evaluation, quantitative assessment, ablation study, complexity comparison, and application test.
Experiment settings
Implementation details
We implement the proposed MC-UIE on PyTorch 2.1 framework with an Intel(R) i9-12900K CPU, 64GB of RAM, and an NVIDIA RTX 4090 GPU. We set the learning rate to 10\(\phantom{0}^{-4}\) and use the Adam optimizer for network optimization. The model is trained for 50 epochs with a batch size of 4, and all input images are resized to \(256\times 256\).


Compared methods
We compared the proposed method with eight leading UIE methods including two physical-based methods (BRUIE25 and HLRP26), two CNN-based methods (USUIR9 and PUIE-Net5), one Transformer-based method (U-Shape14), three Mamba-based methods (WaterMamba18, UWMamba20, and PixMamba19) For a fair comparison, we employ the source code provided by the authors, retrain each method on our training set, and save the best enhancement results.
Benchmark datasets
We utilize two publicly available real-world UIE datasets ( LSUI14, and UIEB27 ) for training and testing. The LSUI dataset provides a large collection of real underwater images across diverse scenarios, making it suitable for training data-driven enhancement models. The UIEB dataset, on the other hand, includes real underwater images along with a curated subset of reference images, facilitating both full-reference quality evaluations. For training, we adopt 3794 images from the LSUI14 dataset and 800 images from the UIEB27 dataset. For testing, we use the rest 485 images from the LSUI14 dataset (Test-485) and the rest 90 images from the UIEB27 dataset (Test-90).

Ablation study on underwater images exhibiting various color degradation.
Evaluation metrics
We employ two full-reference and two non-reference metrics to measure the performance of different methods on Test-485, and Test-90. Two widely used full-reference image quality metrics are the Peak Signal-to-Noise Ratio (PSNR)28 and the Structural Similarity Index Measure (SSIM)29. PSNR quantifies the pixel-level differences between the enhanced image and the ground truth, while SSIM evaluates perceptual similarity by incorporating luminance, contrast, and structural information. In both cases, higher scores indicate better fidelity to the reference image in terms of both content and structure. Meanwhile, two non-reference metrics, the Underwater Color Image Quality Evaluation (UCIQE)30 and the Underwater Image Quality Measure (UIQM)31, are used to assess enhanced underwater image quality without reference images. UCIQE measures image quality based on colorfulness, sharpness, and contrast, while UIQM integrates colorfulness, sharpness, and contrast into a single quality score. For both metrics, higher values suggest improved perceptual quality in underwater environments.
Qualitative evaluation
We show visual comparisons of different UIE methods on Test-485 and Test-90, as shown in Figs. 2 and 3. Raw underwater images are shown in Fig. 2a and 3b. As shown in Figs. 2b, 3b, 2c, and 3c, BRUIE25 and HLRP26 handle various color casts, but enhanced images of BRUIE25 tend to lack authentic underwater color, while HLRP26 introduces noticeable over-brightness. USUIR9 improves the contrasts of the image, but its images exhibit unnatural color balance in Figs. 2d and 3d. PUIE-Net5 and U-Shape14 effectively improve the visibility of underwater images but its results show poor clarity, as evidenced in Figs. 2e, 3e, 2f and 3f. As shown in Figs. 2g, 3g, 2h, and 3h, WaterMamba18 and UWMamba20 significantly restore the details of low-light underwater images, but WaterMamba18 fail to eliminate color cast, while UWMamba20 introduces local color cast. PixMamba19 achieves satisfactory visual results in restoring underwater image visibility and eliminating color casts, but it also results in local color casts as shown in Figs. 2i and 3i. In contrast, in Figs. 2j and 3j, the proposed MC-UIE effectively handles color casts, restores image details, and improves image visibility. To sum up, our MC-UIE can effectively handle both conventional degraded underwater images and extremely degraded low-light underwater images.

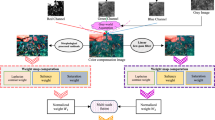
Application examples of underwater depth estimation (top row), underwater edge detection (second row), underwater keypoint detection (third row), underwater saliency detection (fourth row), and underwater image segmentation (bottom row). The top numbers of each row refer to each image’s REL32, AP33, keypoint numbers34, MAE35, and GCE36. The compared methods are BRUIE25 , HLRP26 , USUIR9, PUIE-Net5, U-Shape14, WaterMamba18, UWMamba20, PixMamba19, and the proposed MC-UIE, respectively.
Quantitative assessment
We evaluate the performance of different UIE methods using PSNR28, SSIM29, UCIQE30 , and UIQM31 on Test-485 and Test-90, as shown in Table 1. For PSNR28 and SSIM29, the proposed MC-UIE yields the best scores, which indicates that our results closely resemble the reference images in terms of both content and structure. For UCIQE30, MC-UIE achieves the best score, which demonstrates that the proposed approach mitigates non-uniform color bias, reduces blurriness, and enhances contrast. Besides, MC-UIE obtains the best UIQM31 scores, which indicate exceptional performance in terms of colorfulness, sharpness, and contrast enhancement.
Ablation study
As shown in Fig. 4, we analyze the importance of M-C HB and CFMB module through comprehensive ablation studies on bluish, greenish, yellowish, and low-visibility degeneration scenes, including 3 settings: 1) replacing the M-C HB with a naive mamba block (Our-settingI), 2) replacing the CFMB with a 1 \(\times\) 1 convolution layer (Our-settingII), 2) replacing the L1 loss function with an L2 and structural similarity loss function in8 (Our-settingIII), 3) full method (Our). Our-settingI underperforms in mitigating color casts and visibility. Our settingII improves color and increases visibility but fails to fully restore color casts. Our settingIII restores more image details but fails to efficiently remove color casts. Our full method achieves true-to-life colors while enhancing sharpness and visibility. Furthermore, we show a quantitative comparison in Table 2. As shown, there is a significant improvement in PSNR28 and SSIM29 scores from Our-setting I to Our-settingII. Compared with Our-settingII and Our-settingIII, our full method (Our) achieves the highest PSNR28 and SSIM29 scores, underscoring the superior performance of our MC-UIE in restoring underwater content and structure.
Application tests
We demonstrate the utility of our MC-UIE on several underwater application tests, including depth estimation, edge detection, keypoint detection, saliency detection, and image segmentation. We employ the non-local prior37 for underwater depth estimation, utilize the Canny operator38 for underwater edge detection, employ the SIFT keypoint detection39 for underwater keypoint detection, adopt BASNet40 for underwater saliency detection, and apply a superpixel-based clustering algorithm41 for underwater image segmentation. We evaluate the performance of underwater application tests of different methods using the following metrics: absolute relative error (REL) for depth estimation32, average precision (AP) for edge detection33, the number of detected keypoints for keypoint detection34, mean absolute error (MAE) for saliency detection35, and global consistency error (GCE) for image segmentation36. A lower REL32 score reflects more accurate depth predictions, with fewer discrepancies from the reference depth map. Conversely, a higher AP33 score suggests that the detected edges align more closely with the ground truth edges. Similarly, a lower MAE35 score indicates that the predicted saliency map deviates less from the ground truth mask. For image segmentation, a lower GCE36 score means the predicted segmentation results are more consistent with the reference annotations. All results are shown in Fig. 5. Compared to other competitors, our enhanced results achieve more accurate depth maps, indicating the superiority of our MC-Net on restoring more reliable depth structures. Moreover, our MC-UIE yields more edge and keypoint numbers, which suggests that our MC-Net recovers richer local details and sharper structures. compared to other methods, the segmentation results of our MC-Net are more consistent and accurate, and the saliency maps by our MC-Net contain more salient objects and better boundaries. These results suggest that MC-UIE can effectively boost underwater image segmentation and saliency detection.
Complexity analysis
We compare the complexity of all UIE methods, including the running time (s), trainable parameters (M), and FLOPs (G). The results are shown in Table 3. It can be seen that our MC-UIE has relatively few parameters, FLOPs, and running time. WaterMamba18 has the fewest parameters, but its FLOPs are relatively high and its running time (0.0244) is slower than our MC-UIE (0.0126). Although USUIR9 has fewer FLOPs and running time, its enhancement performance is worse than our MC-UIE. Comprehensively, our MC-UIE can achieve the best enhancement performance with relatively less complexity and shorter running time.
Conclusion
This work proposes a Mamba-Convolution network for Underwater Image Enhancement (MC-UIE). MC-UIE inherits the powerful global dependencies modeling of Mamba architecture and the local dependencies modeling of Convolution architecture to improve enhancement performance. In order to obtain richer global and local dependencies of image features, a Mamba-Convolution Hybrid Block (M-C HB) is proposed, which integrates the global modeling capability of mamba blocks and the local modeling capability of the CNN-based feature attention module. Moreover, a Cross Fusion Mamba Block (CFMB) is proposed to fuse image feature maps of encoder-decoder layers at different levels. Final experiments show the superior performance of our MC-UIE in restoring color, illumination, and detail of underwater images.
Data availability
The dataset used in this article is publicly available and can be accessed at https://li-chongyi.github.io/proj_benchmark.html and https://github.com/LintaoPeng/U-shape_Transformer_for_Underwater_Image_Enhancement.
References
Chen, W., Cai, B., Zheng, S., Zhao, T. & Gu, K. Perception-and-cognition-inspired quality assessment for sonar image super-resolution. IEEE Trans. Multimed. 10, 1–13 (2024).
Chen, W. et al. Reference-free quality assessment of sonar images via contour degradation measurement. IEEE Trans. Image Process. 28, 5336–5351 (2019).
Xu, X. et al. Exploring underwater image quality: A review of current methodologies and emerging trends. Image Vis. Comput. 14, 105389 (2024).
Wang, M., Zhang, K., Wei, H., Chen, W. & Zhao, T. Underwater image quality optimization: Researches, challenges, and future trends. Image Vis. Comput. 146, 104995 (2024).
Fu, Z., Wang, W., Huang, Y., Ding, X. & Ma, K. Uncertainty inspired underwater image enhancement. In Proc. Eur. Conf. Comput. Vis. (ECCV) 10, 465–482 (2022).
Li, C., Anwar, S. & Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 98, 107038 (2020).
Wang, Y., Guo, J., Gao, H. & Yue, H. Uiec 2-net: Cnn-based underwater image enhancement using two color space. Signal Process Image Commun. 96, 116250 (2021).
Li, C. et al. Underwater image enhancement via medium transmission-guided multi-color space embedding. IEEE Trans. Image Process. 30, 4985–5000 (2021).
Fu, Z. et al. Unsupervised underwater image restoration: From a homology perspective. Proc. AAAI Conf. Artif. Intell. (AAAI) 36, 643–651 (2022).
Fu, Z., Lin, X., Wang, W., Huang, Y. & Ding, X. Underwater image enhancement via learning water type desensitized representations. In ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2764–2768 (2022).
Zhou, J. et al. HCLR-Net: Hybrid contrastive learning regularization with locally randomized perturbation for underwater image enhancement. Int. J. Comput. Vis. 1–25 (2024).
Zhang, D., Zhou, J., Guo, C., Zhang, W. & Li, C. Synergistic multiscale detail refinement via intrinsic supervision for underwater image enhancement. Proc. AAAI Conf. Artif. Intell. 38, 7033–7041 (2024).
Huang, Z., Li, J., Hua, Z. & Fan, L. Underwater image enhancement via adaptive group attention-based multiscale cascade transformer. IEEE Trans. Instrum. Meas. 71, 1–18 (2022).
Peng, L., Zhu, C. & Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 32, 3066–3079 (2023).
Ren, T. et al. Reinforced swin-convs transformer for simultaneous underwater sensing scene image enhancement and super-resolution. IEEE Trans. Geosci. Remote Sens. 60, 1–16 (2022).
Shen, Z., Xu, H., Luo, T., Song, Y. & He, Z. Udaformer: Underwater image enhancement based on dual attention transformer. Comput. Graphics 111, 77–88 (2023).
Chen, Z. & Ge, Y. Mambauie &sr: Unraveling the ocean’s secrets with only 2.8 flops. ArXiv arXiv:2404.13884 (2024).
Guan, M. et al. Watermamba: Visual state space model for underwater image enhancement. ArXiv arXiv:2405.08419 (2024).
Lin, W.-T., Lin, Y.-X., Chen, J.-W. & Hua, K.-L. Pixmamba: Leveraging state space models in a dual-level architecture for underwater image enhancement. In Proc. Asi. Conf. Comput. Vis. (ACCV), 176–191 (2025).
An, G., He, A., Wang, Y. & Guo, J. Uwmamba: Underwater image enhancement with state space model. IEEE Signal Process. Lett. 31, 2725–2729 (2024).
Dong, C., Zhao, C., Cai, W. & Yang, B. O-mamba: O-shape state-space model for underwater image enhancement. ArXiv arXiv:2408.12816 (2024).
Yu, W. & Wang, X. Mambaout: Do we really need mamba for vision? ArXiv (2024).
Qin, X., Wang, Z., Bai, Y., Xie, X. & Jia, H. Ffa-net: Feature fusion attention network for single image dehazing. Proc. AAAI Conf. Artif. Intell. (AAAI) 34, 11908–11915 (2020).
Zamir, S. W. et al. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR), 5728–5739 (2022).
Zhuang, P., Li, J. & Chongyi, W. Bayesian retinex underwater image enhancement. Eng. Appl. Artif. Intell. 101, 10244 (2021).
Zhuang, P., Wu, J., Porikli, F. & Li, C. Underwater image enhancement with hyper-laplacian reflectance priors. IEEE Trans. Image Process. 31, 5442–5455 (2022).
Li, C. et al. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 29, 4376–4389 (2020).
Korhonen, J. & You, J. Peak signal-to-noise ratio revisited: Is simple beautiful? In Fourth International Workshop on Quality of Multimedia Experience, 37–38 (2012).
Horé, A. & Ziou, D. Image quality metrics: Psnr vs. ssim. In International Conference on Pattern Recognition, 2366–2369 (2010).
Yang, M. & Sowmya, A. An underwater color image quality evaluation metric. IEEE Trans. Image Process. 24, 6062–6071 (2015).
Panetta, K., Gao, C. & Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Oceanic Eng. 41, 541–551 (2016).
Hambarde, P., Murala, S. & Dhall, A. UW-GAN: Single-image depth estimation and image enhancement for underwater images. IEEE Trans. Instrum. Meas. 70, 1–12 (2021).
Jing, J., Liu, S., Wang, G., Zhang, W. & Sun, C. Recent advances on image edge detection: A comprehensive review. Neurocomputing 503, 259–271 (2022).
Lowe, D. G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 60, 91–110 (2004).
Qin, X. et al. BASNet: Boundary-aware salient object detection. In Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 7471–7481 (2019).
Lei, T. et al. Superpixel-based fast fuzzy C-Means clustering for color image segmentation. IEEE Trans. Fuzzy Syst. 27, 1753–1766 (2019).
Berman, D., treibitz, T. & Avidan, S. Non-local image dehazing. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 1674–1682 (2016).
Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. X8, 679–698 (1986).
Lowe, D. G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision 60, 91–110 (2004).
Qin, X. et al. Basnet: Boundary-aware salient object detection. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 7471–7481 (2019).
Lei, T. et al. Superpixelbased fast fuzzy c-means clustering for color image segmentation. IEEE Trans. Fuzzy Syst. 27, 1753–1766 (2019).
Acknowledgements
This work is supported by Natural Science Foundation of Fujian Province (2023J01807, 2023J05250), School Start-up Fund of Jimei University (ZQ2021028), 2024 University-level Special Project of Minjiang University (K-MJKJ24006), Fujian Association for Science and Technology (FJKX-2024XKB012), Fuzhou Science and Technology Project of China (2024-S-003), Science and Education Joint Special Project of Minjiang University (MJKJ24001).
Author information
Authors and Affiliations
Contributions
Conceived and designed the experiments: H.C., L.W., J.Y., G.L., and H.X.; Performed the experiments: Y.W. and H.H.; Analyzed the data: H.C., L.W., J.Y., G.L., and H.X.; Wrote and reviewed the paper: H.C., Y.W., L.W., H.H., J.Y., G.L., and H.X.;
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, H., Wang, Y., Wu, L. et al. Mamba-convolution hybrid network for underwater image enhancement. Sci Rep 15, 31975 (2025). https://doi.org/10.1038/s41598-025-15404-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-15404-y
