
Abstract
Complex networks play a vital role in various real-world systems, including marketing, information dissemination, transportation, biological systems, and epidemic modeling. Identifying influential nodes within these networks is essential for optimizing spreading processes, controlling rumors, and preventing disease outbreaks. However, existing state-of-the-art methods for identifying influential nodes face notable limitations. For instance, Degree Centrality (DC) measures fail to account for global information, the K-shell method does not assign a unique ranking to nodes, and global measures are often computationally intensive. To overcome these challenges, this paper proposes a novel approach called Entropy Degree Distance Combination (EDDC), which integrates both local and global measures, such as degree, entropy, and distance. This approach incorporates local structure information by using entropy as a local metric and enhances the understanding of the overall graph structure by including path information as part of the global measure. This innovative method makes a substantial contribution to various applications, including virus spread modeling, viral marketing etc. The proposed approach is evaluated on six different benchmark datasets using well-known evaluation metrics and proved its efficiency.
Similar content being viewed by others

Introduction
Numerous real-world systems can be conceptualized as distinct complex networks1, such as marketing networks2, information dissemination networks3, urban transportation networks4, protein interaction networks5, epidemic transmission networks6,7, and many others. With the advancement in graph theory, research on complex networks is a more alluring topic in recent years due to its diverse application in social, chemical, and biological domains8,9,10. The nodes and edges are two primary components in complex networks11, representing the entities (such as humans, organizations, etc.) and the interactions among entities, respectively. The nodes, and edges play diverse roles in network structure and also its function12. According to8, spreading processes are basic and pervasive in many fields. They are crucial for a variety of purposes, such as the spread of ideas and news, the growth of social movements, the occurrence of disease outbreaks, and the promotion of products. Influential spreaders are nodes that contribute significantly to the spreading process in such complex networks.
Critical nodes have a completely different impact on the operation and structure of the network than other nodes. The enhancement or failure of critical nodes will result in a major change in the functioning of the network13. So, in recent research domain, a number of fields, including viral marketing, rumor analysis, infectious disease prevention, spreading dynamics, and evidence theory, have shown interest in the identification of vital nodes in networks14,15,16,17,18,19,20. For example, identifying influential entities in commercial networks will accelerate the spreading of marketing-related information and, in turn, will lead to a favorable income. Locating vital spreaders in information propagation networks will efficiently control the flow of rumors and lead to a healthy environment in society. Similarly, identifying vital nodes in epidemic models will significantly prevent the spreading of dangerous diseases among people.
The complex network research community proposed numerous centrality measures to identify crucial network nodes21. Most of the classical centrality include Degree Centrality (DC)22, Closeness Centrality (CC)22, Betweenness Centrality (BC)23, K-shell (KS) method24, Eigen-Vector Centrality (EC)25, and so on. The DC of a node is decided by the number of direct neighbors it has. According to DC, higher DC signifies that the node is connected to more neighbors and therefore is deemed more influential. However, this metric solely focuses on the node’s local connectivity and does not account for the broader structural information or the influence of its neighbors in the overall network.
The literature contains numerous examples of additional centrality measures that have been developed to address the weaknesses of traditional approaches by quantifying the significance of the node using the global structure of the network. For instance, the CC and BC measures rely on global information that is computationally expensive. These two methods are based on the concept of a shortest path between nodes13. CC evaluates the significance of a node by calculating the shortest distance between the node in question and all other nodes in the network. In contrast, BC evaluates the part of shortest paths in the whole complex network in which the respective node under consideration is a participant.
EC assesses the importance of a node by evaluating the significance of its neighborhood and the network as a whole. Consequently, EC states that a node has greater influence if its neighbors have greater influence. According to the K-shell approach24, the nodes in the center of the network are more important than others. K-shell, however, can produce the same value for many nodes in some networks, which can lead to confusion26.
Recently, research on complex networks to identify vital nodes, extending and improving upon the classical algorithms discussed earlier using local information and global structure, is a very alluring topic. K-shell decomposition and DC are among the most extensively studied methods for interpreting global and local network information. Due to their simplicity, these approaches have been widely adopted across networks of varying sizes. However, neither KS nor DC can reliably determine the relative importance of network nodes27. The Gravity Centrality (GC) measure was proposed by28 to determine the impact of a node by analyzing the K-shell values of the nodes and their minimal distances.
The importance of a node is quantified by Local-Global Centrality (LGC)29, which utilizes local and global information from DC and the shortest path, respectively. A K-shell and Structural Hole (SH) combination-based approach30 enhances the efficacy of K-shell by incorporating SH. Authors in20 introduced the Extended Clustering Coefficient Local Global Centrality (ECLGC) measure, which integrates the CLC with LGC. This measure is designed to identify influential nodes by focusing on both local and global data. As a consequence, the original structural information of the network may be significantly compromised when the nodes are sampled. A local structure entropy based method is proposed in31. Authors in32 proposed an approach for identifying influential nodes using gravity model-based H-index. In addition to more effectively identifying nodes with lesser K-shell values that bridge various network segments, this measure considers the role of adjacent nodes, path details, and node positions within the network.
Several approaches, for example33,34,35, based on the gravity model, are proposed in the existing literature to identify influential nodes. These methods benefit from node interaction details obtained through gravity-based models. In addition, several models proposed in the literature combine the K-shell with other structural properties of the complex network to improve the performance in vital node identification. Some of these methods, such as16,36,37,38,39, investigate advancements in the K-shell algorithm to identify influential nodes. They introduce enhancements, including the integration of K-shell with PageRank, the incorporation of iterative factors, and the adaptation of the system for community-based networks. These methods enhance the ranking of critical nodes, illustrating the algorithm’s adaptability and efficacy in a variety of scenarios by addressing challenges such as cascading failures and optimizing influence propagation.
Existing approaches to recognize influential nodes in complex networks face several significant challenges. DC exclusively concentrates on local connectivity, disregarding the global structural context and the influence of neighboring nodes. CC and BC are computationally intensive due to their reliance on shortest path computations, which restricts their scalability to more extensive networks, despite the fact that they leverage global structural information. Frequently, the K-shell decomposition process generates identical scores for multiple nodes, which leads to ambiguity in the ranking of their influence. Despite the fact that EC takes into account the significance of neighboring nodes, it is predicated on the assumption that influential neighbors naturally increase a node’s significance. However, this assumption may not be universally applicable across an array of network types. GC relies heavily on specific structural characteristics, such as K-shell values and minimum distances, reducing adaptability to different networks. LGC struggles to integrate local and global metrics effectively, leading to a less comprehensive assessment of node importance. Similarly, the ECLGC approach suffers from the loss of critical structural information due to node sampling, undermining its accuracy and effectiveness across various network applications. These limitations emphasize the need for a more robust and integrative approach to identify influential nodes accurately. In this paper, a novel measure of Entropy Degree Distance Combination (EDDC) is proposed to address these challenges, and its unique characteristics are as follows:
-
The proposed approach incorporates three distinct measures: degree, entropy, and distance. This integration helps to identify influential nodes across various network structures.
-
The proposed approach resolves the monotonicity ranking issue by assigning a unique ranking to each node, outperforming other recent methods.
-
By utilizing entropy as a local measure, we have demonstrated the significance of Shannon’s entropy in gaining a deeper understanding of local influence, which plays a crucial role in formulating the proposed approach.
Preliminaries
The literature suggests a variety of approaches to identify influential spreaders in intricate networks. In this section, we emphasize several fundamental methods that served as the impetus for the development of a novel centrality measure to identify influential nodes. In mathematical notations, the complex networks are represented as a graph \(G = (V(G), E(G))\) with \(N=|V(G)|\) nodes and \(E=|E(G)|\) edges. Where, \(V(G) = \{v_{1}, v_{2},..., v_{N}\}\) and \(E(G) = \{e_{1}, e_{2},..., e_{E}\}\) represents the node and edge set respectively. The network is represented as adjacency matrix, \(A_{G}=(a_{v_{i}v_{j}})_{N \times N}\). Where the entry \(a_{v_{i}v_{j}}\) represents whether node \(v_{i}\) and \(v_{j}\) are directly connected (value 1) or not (value 0). Further, \(\Gamma (v_{i})\), and \(dist(v_{i},v_{j})\) represents the set of single hop neighborhood of node \(v_{i}\), and smaller path distance between pair of nodes (\(v_{i}\), \(v_{j}\)). The proposed work targets undirected and unweighted networks with N nodes. The following is a description of existing node centrality measures explored in the literature to identify vital nodes based on local, global, and hybrid measures.
Degree Centrality (DC)
DC22 is a measure that assesses the direct influence of a node among other nodes in the network utilizing only local information. So, the node with a higher DC indicates more influence. Mathematically, DC32 is represented as shown in Eq. (1).
Where, \(DC(v_{i})\), \(\left| \Gamma (v_{i}) \right|\), denotes the DC of node \(v_{i}\), and count of one-hop neighbors or degree of a node, respectively.
Betweenness Centrality (BC)
BC23 is a metric that assess the influence of a node by analyzing global data. A node \(v_{i}\)’s BC is computed by the percentage of shorter paths that pass through it. Thus, the node with the highest BC is easily accessible to other nodes in the network and exerts a significant influence on them. Mathematically, BC is defined as shown in Eq. (2).
Where, \(BC(v_{i})\), \(SP_{v_{j}v_{k}}(v_{i})\), and \(SP_{v_{j}v_{k}}\) represents BC of node \(v_{i}\), shortest paths between nodes \(v_{j}\), and \(v_{k}\) which passes through node \(v_{i}\), and shortest paths between nodes \(v_{j}\), and \(v_{k}\) respectively.
Closeness Centrality (CC)
CC22 of a node measures the influence utilizing the global data. According to CC, node closer to remaining set of nodes is more prominent node in the network. Finally, CC of node \(v_{i}\) is determined by analyzing the shortest path distances between node \(v_{i}\) and remaining nodes in the network, mathematically expressed as given in Eq. (3).
Clustering Coefficient Centrality (CLC)
CLC40 measures the level of involvement of a node in tightly connected clusters in the graph. It is computed as the ratio between the count of edges between the neighbors of the node under consideration and the total number of possible such edges. Eq. (4) is the mathematical representation of CLC of node \(v_{i}\).
Where, \(|\Gamma (v_{i})|\) represents the count adjacent nodes of node \(v_{i}\). Whereas |E(i)| represents the count of edges present between nodes in the set \(\Gamma (v_{i})\). As the proposed work utilizes only an undirected graph, the constant 2 is used in the numerator of the equation.
Isolating Centrality (ISC)
ISC41 measure aims to identify critical nodes that divide the network into distinct components. It is determined using two factors: the degree of the node and the minimum degree among its neighboring nodes. Mathematically, it is expressed as shown in Eq. (5). Based on this, a high-degree node is not influential if its neighbor’s degree is less than a threshold.
where \(v_{i}\) is the node under consideration. The first component \(\left| N(v_{i}) \cap \text {Deg}_{\delta } \right|\) in the equation is the isolating coefficient of the node and is defined by its neighbor nodes with a degree of \(\delta\). The second component \(\left| \Gamma (v_{i})\right|\) is the degree of the node under consideration.
Local-Global Centrality (LGC)
Recently, identifying vital nodes by fusion of both local and global data in the network is more trending among researchers. As the size of complex networks is increasing rapidly, the connectivity information of the node at local and global levels is essential to decide its role in the whole network. One such measure is the LGC29 of a node considering both local and global influence of the node is shown in Eq. (6).
Where, the first component of the equation \(\frac{|\Gamma (v_{i})|}{N}\) is the local influence of node \(v_{i}\). In which, \(|\Gamma (v_{i})|\), N represents the degree of node \(v_{i}\) and the count of nodes in the network, respectively. The second component \(\sum _{i \ne j}\frac{\sqrt{|\Gamma (v_{j})|}}{dist(v_{i},v_{j})}\) quantifies the global influence of the node \(v_{i}\).
K-shell value
The K-shell value42 of node is computed as follows24,43: at first, eliminate all nodes with a degree \(k=1\), and proceed until there are no more nodes with a degree of one. To all eliminated nodes assign \(k=1\) as K-shell value. Next, iteratively repeat the process of removing nodes by increasing the degree threshold k. Process termination occurs when there are no additional nodes to be removed.
Clustering Coefficient Local-Global Centrality (CLGC)
CLGC20 of a node is based on local and global influence. This approach computes the node’s CLC in 2 different levels to get local and global information. The CLGC of a node \(v_{i}\) is denoted by Eq. (7).
Where, the first component CLC of node \(v_{i}\) captures the local influence. Where as the second component \(\sum _{i \ne j}\frac{\sqrt{CLC(v_{j})}}{dist(v_{i},v_{j})}\) is based on global information, where \(CLC(v_{j})\) is the CLC of node \(v_{j}\).
Extended Clustering Coefficient Local Global Centrality (ECLGC)
ECLGC20 is another way of finding vital nodes combining CLC in different levels. Mathematically, it is expressed as Eq. (8).
Where, \(CLC(v_{i})\), \(CLC(v_{j})\), \(CLC(v_{k})\) denotes CLC of nodes \(v_{i}\), \(v_{j}\), and \(v_{k}\) respectively. The neighbors of nodes \(v_{i}\), and \(v_{j}\) denoted as \(\Gamma (v_{i})\), and \(\Gamma (v_{j})\), respectively.
Proposed method
The proposed EDDC method aims to develop a generalized approach that integrates three key measures: degree, distance, and entropy influence scores. Combining these important metrics into a single formula allows the EDDC measure to identify influential nodes in the network effectively. Each component captures distinct yet complementary aspects of a node’s role in the network:
-
DC captures local structural importance by measuring how well-connected a node is to its immediate neighbors. However, it lacks the ability to distinguish between nodes that have the same degree but differ in how information is distributed across their connections.
-
Entropy compensates for this limitation by introducing local information diversity. Even among nodes with the same degree, those connected to nodes of varying importance or edge strength will exhibit different entropy values. This helps refine the influence measure by considering the variability in local interactions, rather than just their count.
-
Distance (shortest path) introduces a global structural dimension. It enables the method to consider how far a node’s influence can potentially reach in the network, thus addressing the network-wide spread of influence. By inversely weighting the entropy contributions by distance, the method ensures that closer nodes contribute more to the influence score, reflecting the intuition that influence weakens over distance.
The behavior of entropy, whether it is considered a local or global measure, depends on the scope of the information utilized. Specifically, it varies based on whether the entropy is calculated using the data from a node’s immediate surroundings (local) or from the entire graph (global). In our study, we treat node entropy as a local measure because we calculate the entropy score for each node based solely on the information from its immediate neighbors. Shannon’s entropy44 measures the expected amount of information in an event and is expressed as follows:
Where, \(e(v_i)\) denote the entropy of node \(v_i\), \(p(v_j)\) refers to the probability value based on neighbor degree of node \(v_{i}\) and its computation method is shown in Eq. (10). The \(\sum _{j}\) is over all neighbors of node \(v_{i}\), and \(\log _2\) is the base-2 logarithm, which quantifies the information content of the node.
Where, \(v_i\) denotes the node for which entropy is computed, \(deg(v_j)\) is the degree of the neighbor node \(v_j\) of \(v_i\), and \(\Gamma (v_i)\) represents set of immediate neighbors of node \(v_i\). In addition to the entropy measure, the proposed method includes two critical factors: the degree and distance measures. The shortest path between node under consideration and the remaining nodes of the network is incorporated into the proposed method. The proposed method, called the Entropy Degree Distance Combination (EDDC), is expressed as follows:
Where, \(EDDC(v_{i})\), N, \(\left| \Gamma (v_i)\right|\), \(e(v_{i})\), \(e(v_{j})\), and \(dist(v_{i},v_{j})\) denotes EDDC of node \(v_{i}\), total nodes in the network, number of neighbors of node \(v_{i}\), entropy of node \(v_{i}\), entropy of node \(v_{j}\), and shortest distance between node \(v_{i}\) and \(v_{j}\) respectively. The formula initially computes a weighted sum of the entropies of neighboring nodes, adjusted by their distances, and then scales it by the node’s degree, normalized by node count \(N\). This integrated measure aids in identifying influential nodes by considering local structural features (degree), informational content (entropy), and spatial relationships (distance) between nodes. It proves to be a powerful tool for network analysis, particularly in complex systems where proximity and information flow determine influence.
The proposed method is formulated to incorporate \(e(v_i)\) within the summation to reflect the intrinsic information diversity of node \(v_i\) as it interacts with other nodes across the network. This approach captures the idea that a node’s influence is not only shaped by the entropy of other nodes but also moderated by its own informational richness. Even when \(dist(v_i, v_j)\) is large, the inverse distance weighting significantly reduces the contribution of distant nodes. Thus, while \(e(v_i)\) appears in every term, its impact on distant contributions is naturally minimized by the denominator. This aligns with influence propagation models where a node’s structural diversity serves as a baseline factor in assessing its global influence.
The use of the square root aggregation was motivated by the need to avoid domination by large entropy values in densely connected regions. A linear sum \(e(v_i)+e(v_j)\) tends to overemphasize high-entropy nodes, which may bias the ranking towards nodes in high-degree clusters. The radical formulation introduces a sublinear growth that moderates such effects, resulting in more balanced and robust rankings across networks with heterogeneous degree distributions (as observed in preliminary experiments). Conceptually, this means that as two diverse neighborhoods interact, their combined contribution increases more slowly because some of their information may overlap or repeat.
The Algorithmic representation of EDDC computation of all the nodes in the network and the entropy of a node calculation are shown in Algorithm 1 and 2, respectively.

Compute EDDC for Nodes in a Complex Network.

Compute Shannon Entropy \(e(v_i)\) for a Node.

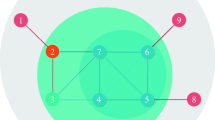
Toy network used in experimentation having 16 nodes and 21 edges.
Computation steps
Here, we present a step-by-step calculation of our proposed approach. Our objective is to assess the influence score of every node in the network. For demonstration purposes, we focus specifically on calculating the influence score of node 2. The process begins with the computation of entropy using a small toy network (Fig. 1) as an example. Node 2 neighbors are node {1, 3, 4, 5}. The no. of degrees of those neighbor nodes are {1, 3, 1, 4} respectively. According to Eq. (10), the total no of edges = 1+3+1+4 = 9. Further, we need to calculate \(p(e_1) = \frac{1}{9}\) = 0.111, \(p(e_3) = \frac{3}{9}\) = 0.333, \(p(e_4) = \frac{1}{9} = 0.111\), \(p(e_5) = \frac{4}{9} = 0.444\).
In Step 2, by applying Eq. (9), we compute the entropy of node 2 by aggregating the individual scores from its neighboring nodes.
Similarly, the entropy needs to be calculated for all the nodes. The computed entropy scores are as follows: \(e(1) = 0\), \(e(3) = 1.530\), \(e(4) = 0\), \(e(5) = 1.855\), \(e(6) = 1.989\), \(e(7) = 1.572\), \(e(8) = 1.989\), \(e(9) = 1.854\), \(e(10) = 1.521\), \(e(11) = 1.950\), \(e(12) = 0.985\), \(e(13) = 0\), \(e(14) = 0\), \(e(15) = 0.811\), and \(e(16) = 0\). After calculating the entropy score, our objective is to determine the DC of node 2, which is equal to 4. With \(N = 16\), the subsequent phase entails considering the computed quantity in conjunction with the distance measure, as defined by Eq. (11).
Experimental setup
Here, we started by providing dataset descriptions along with the evaluation metrics, such as Kendall’s correlation score. The experiments that were conducted to illustrate the efficacy of our algorithm are detailed in this section. First, we evaluated Kendall’s correlation between the SIR model and different comparison algorithms. Next, we analyzed the monotonicity ranking among the various algorithms. Finally, we calculate the percentage of improvement of proposed EDDC measure compared to the baseline methods.
Datasets
To evaluate the efficacy of the proposed EDDC method, we analyzed six complex networks with distinct structural properties. Table 1 provides an overview of these networks, highlighting their varying sizes, where \(\beta\) denotes the infection probability rate, and \(\beta _{th}\) indicates the threshold for network infection probability.
Discussion on scale-free and small-world networks
To investigate whether the given network exhibits scale-free characteristics, we analyzed its degree distribution using the methodology proposed by45. The degree distribution was fitted with a power-law model, and its plausibility was evaluated using the Kolmogorov-Smirnov (KS) statistic and a likelihood ratio test against alternative distributions (specifically the lognormal). Table 2 provides a detailed analysis of the scale-free properties across the various networks examined in our study.
The concept of small-world networks40, is characterized by a high CLC and a short average path length (L), where CLC is significantly higher than that of a comparable random network, and L is approximately similar. While the original methodology relies on comparison with random graphs to establish small-world behavior, in real-world network analysis, these properties can also be evaluated intrinsically. In our study, we adhered to the traditional approach by comparing the CLC and average path length of the given networks with those of corresponding random graphs with equal size and density. This allowed us to quantitatively assess the extent to which the networks exhibit small-world characteristics. Empirical evidence supporting the small-world properties of the networks is presented in Table 3. Based on the above observations, we conclude that the majority of the networks used in our experimental study exhibit both scale-free and small-world properties.
Evaluation metrics
The performance of the proposed centrality measure to find influential nodes in complex networks is evaluated using the SIR model and Kendall’s correlation score.
-
SIR Model: The SIR model52 is a compartmental model that has been widely used to analyze the dynamics of information transmission in complex networks. It is used to characterize the spread of infectious diseases within a population. The population is divided into three states: S (Susceptible) individuals who are at risk of infection; I (Infected) individuals who are infected and have the potential to transmit the disease to susceptible; and R (Recovered) individuals who have recovered and acquire immunity. Every node is initially in the S state, except the node that is initialized in the I state. The infectious node acts as the seed for information spread. The model progresses through interactions where infections spread until the system stabilizes with no further infections. In every time step, I state nodes spread the information to their S state neighbors with a probability \(\beta\). Afterward, they are transferred to the R state with a rate of \(\lambda\), where they gain immunity and can no longer be infected. In our experiments, the spreading probability \(\beta\) is varied between 0.01 to 0.15. The recovery probability \(\lambda\) and total iterations are set as 1 and 1000, respectively.
-
Kendalls correlation score: Additionally, Kendall’s tau53, a widely used metric for evaluating the level of the correlation analysis between two sequences. For every one of the previously discussed approaches, we derive the final node ranking. The correlation analysis between a given topology-related ranking and the ranking determined by the nodes’ true spreading ability is subsequently assessed using Kendall’s tau rank correlation coefficient \(\tau\). Let \(X\) and \(Y\) be two sequences of equal length. Two pairs of elements, \((x_i,y_i)\) and \((x_j,y_j)\), are picked from corresponding locations in the sequences. The counts of concordant and discordant pairs for the two sequences \(X\) and \(Y\) of length n are denoted by \(N_c\) and \(N_d\), respectively. Kendall’s tau (\(\tau\)) for these sequences is then expressed as:
$$\begin{aligned} \tau =\frac{N_c - N_d}{0.5n(n-1)} \end{aligned}$$(12)\(\tau\) values vary from -1 to 1. Positive and negative correlation are denoted by \(\tau > 0\) and \(\tau < 0\), respectively. In other terms, the ranking is more precise when the \(\tau\) value is higher. To validate the efficiency of the EDDC method, we initially implement the SIR model to determine the ranking of nodes according to their propagation capacity. Subsequently, we compute the node influence ranking sequence that was obtained using the proposed approach. Finally, we compare the two sequences using this metric.
Results and discussions
The proposed EDDC and baseline methods, including BC, CC, CLC, LGC, ISC, CLGC, and ECLGC, have been compared to quantify, evaluate, and compare the influence of nodes across various complex networks. The study involved three types of experiments:
-
Experiment 1: The SIR model and the Kendall \(\tau\) correlation coefficient were employed to assess the efficacy of the proposed indexing method. The indexing method’s efficiency is denoted by the \(\tau\) value.
-
Experiment 2: This experiment assessed the uniqueness of node rankings, focusing on the monotonicity of rankings within the network for various indexing methods.
-
Experiment 3: The ranking relationships between the proposed technique, EDDC, and various baseline measures were examined. This analysis evaluates the extent to which the EDDC technique enhances the current indexing methods. The performance gain metric is represented as \(\eta \%\)54.
Analysis of the Kendall \(\tau\) coefficient in the SIR model across various indexing methods
To evaluate the rankings generated by different indexing methods, we employ the Kendall \(\tau\) coefficient24,8, with the SIR model ranks serving as the reference baseline. Figure 2 compares six distinct complex networks. The X-axis represents the probability of infection \(\beta\) (varies from 0.01 to 0.15), while Y-axis displays the \(\tau\) values achieved by various indexing approaches against the SIR baseline. Notably, the EDDC method demonstrates superior performance compared to other techniques, especially in scenarios where \(\beta\) exceeds the threshold \(\beta _{th}\). For various complex networks, the global measures BC, CC, ISC, and CLC demonstrate poor performance, while the LGC method performs moderately. The more recent methods, CLGC and ECLGC, show a decline in performance compared to the proposed EDDC approach, which effectively outperforms all recent indexing measures.

Kendall \(\tau\) coefficient analysis between the SIR model and baseline methods at different infection probabilities \(\beta\) across six networks.
Table 4 presents the comparison of the Kendall coefficient \(\tau\) across different networks. To evaluate the consistency of the results, we determine the average Kendall value \(\tau\) for scenarios where \(\beta\) exceeds the threshold \(\beta _{th}\), using Eq.(13).
In this experiment, 15 iterations were conducted, with the value of \(\beta\) increased by 0.01 in each iteration. The findings indicate that the EDDC method works effectively in both small- and large-scale networks. In addition, no tunable parameters were required to calculate the influence scores.
Ranking uniqueness
Different baseline indexing methods and proposed measure are analyzed in this study to determine the unique ranking of the nodes. Monotonicity refers to the capacity to distinguish each and every node within the complex network. As described in55, monotonicity is expressed as \(M_c(I)\), where I represents the ranking list produced by an indexing method, and is defined by the following formula:
In this context, N represents the number of nodes, while \(N_i\) denotes the set of nodes sharing the same score i. The monotonicity measure, \(M_c(I)\), takes values within the range [0, 1], where 0 indicates identical rankings, and 1 signifies completely distinct rankings. The monotonicity values for the eight indexing methods are provided in Table 5. The CLC approach demonstrates poor performance in assigning unique rankings to the nodes within the network. In contrast, the proposed EDDC method offers distinct rankings for all the datasets examined in this study, outperforming the other seven baseline indexing methods.

The percentage improvement \(\eta \%\) of EDDC compared to the baseline indexing methods.
Evaluating the percentage improvement \(\eta \%\)
This assesses the degree of improvement of the EDDC metric compared to the existing indexing methods. The performance gain metric (\(\eta \%\))54 is denoted as:
In this context, \(\tau _C(\phi )\) denotes the Kendall \(\tau\) between the EDDC and the SIR model, whereas \(\tau _\phi\) represents the Kendall \(\tau\) between the existing indexing metrics and the SIR model. When \(\eta = 0\), \(\eta > 0\), and \(\eta < 0\), indicates that the proposed centrality measure performs similar, better, and worse to the baseline methods, respectively. Figure 3 shows the percentage improvement \(\eta \%\) across the different complex networks analyzed. Across all the evaluated networks, the \(\eta \%\) values for C(BC), C(CC), C(CLC), C(LGC), C(ISC), C(CLGC), and C(ECLGC) consistently show substantial improvement when \(\beta > \beta _{th}\). Overall, the empirical results showed that the proposed EDDC measure performs better compared to the existing benchmark approaches in terms of \(\eta \%\).
Furthermore, we have included the Top-10 node ranking distributions for the X and Y networks (refer to Table and Table 7) to demonstrate the effectiveness of EDDC compared to various indexing approaches. A significant overlap was found between the Top-10 nodes ranked by our method and those identified by existing algorithms, which reinforces the reliability and robustness of the proposed EDDC approach.
Time complexity analysis of EDDC
The EDDC method computes an influence score for each node by integrating degree, entropy, and shortest-path-based distance metrics. The main computational cost arises from calculating the shortest paths from each node to all others. To efficiently compute these distances, we use Dijkstra’s algorithm with a min-heap (priority queue). For a single node, Dijkstra’s algorithm runs in \(O((N + E)\log N)\). Repeating this for each of the \(N\) nodes (to compute all-pairs shortest paths) results in an overall complexity of \(O(N(N + E)\log N)\). Compared to various traditional approaches, BC and CC exhibit a time complexity of \(O(N^3)\). Therefore, we have conducted an experimental comparison of the time complexity of EDDC, BC, and CC by generating Erdõs-Rényi graphs56 with N nodes, where N ranges from 100 to 1000. Table 8 presents a comparison of the time complexity between BC, CC, and the proposed EDDC measure. It is important to acknowledge that there is often a trade-off between performance and computational complexity. In line with this, the proposed EDDC measure consistently demonstrates superior performance across all the considered networks when compared to traditional centrality measures. However, this improved performance comes at the cost of slightly higher time complexity relative to BC. To mitigate the computational load when applying EDDC to large-scale networks, practical optimizations can be employed. Notably, since Dijkstra’s algorithm computes the shortest paths from a single source to all other nodes in the network, the process can be computationally intensive. To reduce this burden, the computation can be restricted to nodes within a limited hop distance, such as 2 or 3 hops from the source node. This localized approach significantly reduces the number of shortest path calculations while still capturing meaningful topological information for the EDDC measure.
Conclusions
The paper addresses the shortcomings of current state-of-the-art methods and newly suggested hybrid approaches by introducing a novel measure for finding prominent nodes in a variety of complex network configurations. The proposed approach demonstrates high efficiency in selecting influential nodes, yielding results closely aligned with the SIR model, as validated through Kendall’s correlation metrics. The EDDC approach addresses the shortcomings of the K-shell method by assigning a unique ranking to all nodes. Furthermore, using entropy as a local measure improves the accuracy of structural information derived from neighboring nodes. Unlike more recent methods such as CLGC and ECLGC, our approach demonstrates superior performance compared to the SIR model. All the experiments show significantly better results compared to the existing baseline approaches. In future work, our aim is to address the dynamic nature of networks by incorporating temporal information. To enhance the robustness of our methodology, future extensions could integrate complementary metrics such as the CLC (to capture neighborhood density), EC or PageRank (to account for recursive importance), or coreness (to identify nodes within cohesive subgroups). These could either support or replace the entropy term depending on the structural properties of the specific network under analysis. Additionally, we plan to expand this research by using deep learning techniques, such as studying graph neural networks, node embeddings etc.
Data availability
The proposed work used six publicly available complex networks datasets, namely, soc-wiki-vote, jazz, fb-pages-food, fb-pages-politician, Conference, and Contacts in a workplace-1. The datasets are downloaded from the following links: https://networkrepository.com/ and http://www.sociopatterns.org/datasets/.
References
Aral, S. & Walker, D. Identifying influential and susceptible members of social networks. Science (New York, N.Y.) 337, 337–341, https://doi.org/10.1126/science.1215842 (2012).
Zhang, Z., Shi, Y., Willson, J., Du, D.-Z. & Tong, G. Viral marketing with positive influence. In IEEE INFOCOM 2017 - IEEE Conference on Computer Communications, 1–8, https://doi.org/10.1109/INFOCOM.2017.8057070 (2017).
Xu, W. et al. Identifying structural hole spanners to maximally block information propagation https://doi.org/10.1016/j.ins.2019.07.072 (2019).
Guerrero, D., Letrouit, L. & Pais-Montes, C. The container transport system during Covid-19: An analysis through the prism of complex networks. Transp. Policy 115, 113–125, https://doi.org/10.1016/j.tranpol.2021.10 (2022). 1
Ahmed, H. et al. Network biology discovers pathogen contact points in host protein-protein interactomes. Nat. Commun. 9, 2312. https://doi.org/10.1038/s41467-018-04632-8 (2018).
Zhu, P., Zhi, Q., Guo, Y. & Wang, Z. Analysis of epidemic spreading process in adaptive networks. IEEE Trans. Circuits Syst. II: Express Br. 66, 1252–1256. https://doi.org/10.1109/TCSII.2018.2877406 (2019).
Shetty, R. D. & Bhattacharjee, S. Pertinence of contact duration as edge feature for epidemic spread analysis. Sci. Rep. 15, 10703. https://doi.org/10.1038/s41598-025-94637-3 (2025).
Ahajjam, S. & Badir, H. Identification of influential spreaders in complex networks using hybridrank algorithm. Sci. Rep. 8, 11932. https://doi.org/10.1038/s41598-018-30310-2 (2018).
Sheikhahmadi, A. & Zareie, A. Identifying influential spreaders using multi-objective artificial bee colony optimization. Appl. Soft Comput. J. 94, 106436. https://doi.org/10.1016/j.asoc.2020.106436 (2020).
Génois, M. & Barrat, A. Can co-location be used as a proxy for face-to-face contacts? EPJ Data Science 7, https://doi.org/10.1140/epjds/s13688-018-0140-1 (2018).
Newman, M. E. J. The structure and function of complex networks. SIAM Review 45, 167–256. https://doi.org/10.1137/S003614450342480 (2003).
Wang, G. et al. Finding influential nodes in complex networks based on kullback-leibler model within the neighborhood. Sci. Rep. 14, 13269. https://doi.org/10.1038/s41598-024-64122-4 (2024).
Liu, X., Ye, S., Fiumara, G. & De Meo, P. Influential spreaders identification in complex networks with topsis and k-shell decomposition. IEEE Trans. Comput. Soc. Syst. 10, 347–361. https://doi.org/10.1109/TCSS.2022.3148778 (2023).
Shetty, R. D., Bhattacharjee, S. & Thanmai, K. Node classification in weighted complex networks using neighborhood feature similarity. IEEE Trans. Emerg. Top. Comput. Intell. 8, 3982–3994. https://doi.org/10.1109/TETCI.2024.3380481 (2024).
Lei, M., Liu, L., Ramirez-Arellano, A., Zhao, J. & Cheong, K. H. Influential node detection in multilayer networks via fuzzy weighted information. Chaos, Solitons & Fractals 191, 115780. https://doi.org/10.1016/j.chaos.2024.115780 (2025).
Yang, X. & Xiao, F. An improved gravity model to identify influential nodes in complex networks based on k-shell method. Knowl.-Based Syst. 227, 107198. https://doi.org/10.1016/j.knosys.2021.107198 (2021).
Wang, Z., Sun, C., Xi, J. & Li, X. Influence maximization in social graphs based on community structure and node coverage gain. Future Gener. Comput. Syst. 118, 327–338. https://doi.org/10.1016/j.future.2021.01.025 (2021).
Xiao, L., Wang, S. & Mei, G. Efficient parallel algorithm for detecting influential nodes in large biological networks on the graphics processing unit. Future Gener. Comput. Syst. 106, 1–13. https://doi.org/10.1016/j.future.2019.12.038 (2020).
Lei, M. & Cheong, K. H. Embedding model of multilayer networks structure and its application to identify influential nodes. Inf. Sci. 661, 120111. https://doi.org/10.1016/j.ins.2024.120111 (2024).
Chiranjeevi, M., Dhuli, V. S., Enduri, M. K. & Cenkeramaddi, L. R. Identifying and ranking of best influential spreaders with extended clustering coefficient local global centrality method. IEEE Access 12, 52539–52554. https://doi.org/10.1109/ACCESS.2024.3387745 (2024).
Lei, M., Liu, L. & Ramirez-Arellano, A. Weighted information index mining of key nodes through the perspective of evidential distance. J. Comput. Sci. 78, 102282. https://doi.org/10.1016/j.jocs.2024.102282 (2024).
Freeman, L. C. Centrality in social networks conceptual clarification. Soc. Netw. 1, 215–239. https://doi.org/10.1016/0378-8733(78)90021-7 (1978).
Freeman, L. C. A set of measures of centrality based on betweenness. Sociometry 40, 35–41. https://doi.org/10.2307/3033543 (1977).
Kitsak, M. et al. Identification of influential spreaders in complex networks. Nat. Phys. 6, 888–893. https://doi.org/10.1038/nphys1746 (2010).
Bonacich, P. & Lloyd, P. Eigenvector-like measures of centrality for asymmetric relations. Soc. Netw. 23, 191–201. https://doi.org/10.1016/S0378-8733(01)00038-7 (2001).
Wang, L. et al. Influential nodes identification based on hierarchical structure. Chaos, Solitons & Fractals 186, 115227. https://doi.org/10.1016/j.chaos.2024.115227 (2024).
Mukhtar, M. F. et al. Integrating local and global information to identify influential nodes in complex networks. Sci. Rep. 13, 11411. https://doi.org/10.1038/s41598-023-37570-7 (2023).
ling Ma, L., Ma, C., Zhang, H.-F. & Wang, B.-H. Identifying influential spreaders in complex networks based on gravity formula. Phys. A: Stat. Mech. Appl. 451, 205–212, https://doi.org/10.1016/j.physa.2015.12.162 (2016).
Ullah, A. et al. Identifying vital nodes from local and global perspectives in complex networks. Expert Syst. Appl. 186, 115778. https://doi.org/10.1016/j.eswa.2021.115778 (2021).
Zhao, Z., Li, D., Sun, Y., Zhang, R. & Liu, J. Ranking influential spreaders based on both node k-shell and structural hole. Knowl.-Based Syst. 260, 110163. https://doi.org/10.1016/j.knosys.2022.110163 (2023).
Lei, M. & Cheong, K. H. Node influence ranking in complex networks: A local structure entropy approach. Chaos, Solitons & Fractals 160, 112136. https://doi.org/10.1016/j.chaos.2022.112136 (2022).
Zhu, S., Zhan, J. & Li, X. Identifying influential nodes in complex networks using a gravity model based on the h-index method. Sci. Rep. 13, 16404. https://doi.org/10.1038/s41598-023-43585-x (2023).
Zhao, N. et al. Estimating the relative importance of nodes in complex networks based on network embedding and gravity model. J. King Saud Univ. - Comput. Inf. Sci. 35, 101758. https://doi.org/10.1016/j.jksuci.2023.101758 (2023).
Curado, M., Tortosa, L. & Vicent, J. F. A novel measure to identify influential nodes: Return random walk gravity centrality. Inf. Sci. 628, 177–195. https://doi.org/10.1016/j.ins.2023.01.097 (2023).
Yang, P., Meng, F., Zhao, L. & Zhou, L. Aogc: An improved gravity centrality based on an adaptive truncation radius and omni-channel paths for identifying key nodes in complex networks. Chaos, Solitons & Fractals 166, 112974. https://doi.org/10.1016/j.chaos.2022.112974 (2023).
Esfandiari, S. & Fakhrahmad, S. M. The collaborative role of k-shell and pagerank for identifying influential nodes in complex networks. Phys. A: Stat. Mech. Appl. 658, 130256. https://doi.org/10.1016/j.physa.2024.130256 (2025).
Yang, Q., Wang, Y., Yu, S. & Wang, W. Identifying influential nodes through an improved k-shell iteration factor model. Expert Syst. Appl. 238, 122077. https://doi.org/10.1016/j.eswa.2023.122077 (2024).
HamaKarim, B. R., Mohammadiani, R. P., Sheikhahmadi, A., Hamakarim, B. R. & Bahrami, M. A method based on k-shell decomposition to identify influential nodes in complex networks. J. Supercomput. 79, 15597–15622. https://doi.org/10.1007/s11227-023-05296-y (2023).
Xiao, Y. & Ren, Y. Application of k-shell algorithm in key point identification and cascading failure in urban public safety transportation network. IEEE Access 12, 32152–32163. https://doi.org/10.1109/ACCESS.2024.3369175 (2024).
Watts, D. J. & Strogatz, S. H. Collective dynamics of ‘small-world’networks. Nature 393, 440–442. https://doi.org/10.1038/30918 (1998).
Ugurlu, O. Comparative analysis of centrality measures for identifying critical nodes in complex networks. J. Comput. Sci. 62, 101738. https://doi.org/10.1016/j.jocs.2022.101738 (2022).
Seidman, S. B. Network structure and minimum degree. Soc. Netw. 5, 269–287. https://doi.org/10.1016/0378-8733(83)90028-X (1983).
Zeng, A. & Zhang, C.-J. Ranking spreaders by decomposing complex networks. Phys. Lett. A 377, 1031–1035. https://doi.org/10.1016/j.physleta.2013.02.039 (2013).
Shannon, C. E. A mathematical theory of communication. Bell System Technical Journal 27, 379–423. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x (1948).
Clauset, A., Shalizi, C. R. & Newman, M. E. J. Power-law distributions in empirical data. SIAM Review 51, 661–703. https://doi.org/10.1137/070710111 (2009).
Rossi, R. & Ahmed, N. The network data repository with interactive graph analytics and visualization. Proceedings of the AAAI Conference on Artificial Intelligence 29, https://doi.org/10.1609/aaai.v29i1.9277 (2015).
Leskovec, J., Huttenlocher, D. & Kleinberg, J. Signed networks in social media. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’10, 1361–1370, https://doi.org/10.1145/1753326.1753532 (New York, NY, USA, 2010).
Gleiser, P. M. & Danon, L. Community structure in jazz. Adv. Complex Syst. 06, 565–573. https://doi.org/10.1142/S0219525903001067 (2003).
Rozemberczki, B., Davies, R., Sarkar, R. & Sutton, C. Gemsec: Graph embedding with self clustering. In 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), 65–72, https://doi.org/10.1145/3341161.3342890 (2019).
Génois, M., Zens, M., Lechner, C. M., Rammstedt, B. & Strohmaier, M. Building connections: How scientists meet each other during a conference. arXiv:1901.01182 (2019).
GéNOIS, M. et al. Data on face-to-face contacts in an office building suggest a low-cost vaccination strategy based on community linkers. Netw. Sci. 3, 326–347. https://doi.org/10.1017/nws.2015.10 (2015).
Kermack, W. O. & McKendrick, A. G. Contributions to the mathematical theory of epidemics. ii.-the problem of endemicity. Proceedings of the Royal Society of London. Series A, Containing Papers of a Mathematical and Physical Character 138, 55–83, https://doi.org/10.1016/S0092-8240(05)80041-2 (1932).
KENDALL, M. G. A new measure of rank correlation. Biometrika 30, 81–93, https://doi.org/10.1093/biomet/30.1-2.81 (1938).
Wang, J., Hou, X., Li, K. & Ding, Y. A novel weight neighborhood centrality algorithm for identifying influential spreaders in complex networks. Phys. A: Stat. Mech. Appl. 475, 88–105. https://doi.org/10.1016/j.physa.2017.02.007 (2017).
Bae, J. & Kim, S. Identifying and ranking influential spreaders in complex networks by neighborhood coreness. Phys. A: Stat. Mech. Appl. 395, 549–559. https://doi.org/10.1016/j.physa.2013.10.047 (2014).
Erdõs, P. & Rényi, A. On random graphs. i. Publicationes Mathematicae Debrecen 6, 290–297, https://doi.org/10.5486/pmd.1959.6.3-4.12 (2022).
Funding
Open access funding provided by Manipal Academy of Higher Education, Manipal
Author information
Authors and Affiliations
Contributions
RD, RM, KRS, and MT contributed equally to formalizing the problem statement. The proposed approach was designed and implemented by RD, RM, and KRS. The evaluation was conducted by RD, RM, and KRS. Finally, all authors reviewed and edited the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shetty, R.D., M., R., Shetty, K.R. et al. Enhanced complex network influential node detection through the integration of entropy and degree metrics with node distance. Sci Rep 15, 31227 (2025). https://doi.org/10.1038/s41598-025-15968-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-15968-9
