
Abstract
To investigate the impact of real estate market sentiment on demand forecasting, this paper constructs a Weibo sentiment index incorporating emotional polarity and verifies its predictive advantage for market demand. Based on the Bidirectional Encoder Representations from Transformers - Bidirectional Long Short-Term Memory (BERT-BiLSTM) and the characteristics of China’s housing market, we classify sentiments in crawled Weibo texts and train a sentiment analysis model specifically for the Chinese real estate domain. This model accurately extracts positive, neutral, and negative sentiment features to build a high-frequency sentiment index. Simultaneously, Internet Concern index is constructed using Baidu search data as a non-directional sentiment proxy variable. Further adopting the Autoregressive Distributed Lag Mixed Data Sampling model (ADL-MIDAS), we compare the predictive performance of these two sentiment indices alongside macroeconomic variables on market demand. Experimental results show that: (1) The BERT-BiLSTM model achieves 78.5% accuracy in sentiment classification, with its F1-score outperforming traditional methods (SVM, LSTM, etc.) by over 30%; (2) The Weibo sentiment index yields a Root Mean Squared Forecast Error (RMSFE) of 1.6%-4.7% under the ADL-MIDAS framework, significantly lower than the Internet Concern index (6.7%-7.0%). The study demonstrates that integrating deep learning with high-frequency social media sentiment indiex containing emotional polarity can more effectively capture market expectation fluctuations, while simultaneously yielding superior performance for real estate market demand forecasting.
Similar content being viewed by others
Introduction
Modern economic theory posits that the most fundamental distinction between economics and natural sciences lies in the forward-looking nature of economic agents. This foresight influences the decision-making behaviors of firms and households, thereby affecting market prices and macroeconomic fluctuations. Due to characteristics such as long production cycles and low liquidity, the real estate market is more susceptible to expectations compared to other financial markets like the stock market1. Consequently, expectations are regarded as a key factor driving market volatility and shaping the effectiveness of real estate regulation policies2. Expectation management has thus become one of the top priorities for policymakers worldwide, with its core objective being to guide public sentiment properly. Against this backdrop, this study focuses on the quantification of sentiment indices and their predictive power over market demand.
Existing research on the construction of sentiment indices can be primarily categorized into two approaches. The first approach relies on structured indicators such as market transaction data, employing traditional econometric methods to fit and construct sentiment indices from these indicators. In this regard, Baker and Wurgler made groundbreaking contributions by aggregating information from six sentiment proxy variables into a composite investor sentiment index. Their findings revealed that elevated investor sentiment could predict lower future returns3. Chen et al. addressed the limitation of using a single variable to represent investor sentiment by considering multiple dimensions of influencing factors4. They screened a series of direct and indirect indicators and selected seven proxy variables that effectively captured sentiment, subsequently constructing a comprehensive investor sentiment index using principal component analysis (PCA). However, directly fitting regression models to proxy variables may introduce distortions in the results. To mitigate this issue, Huang et al. first eliminated common noise components from sentiment proxy variables before constructing the sentiment index. Their refined index demonstrated significantly improved predictive power for returns5. Stambaugh et al. employed extensive random simulations of persistent variables, substituting these variables for sentiment indices in regression analyses. By comparing the regression outcomes between persistent variables and sentiment indices, they provided empirical evidence that sentiment indices can effectively forecast future returns6.
The second approach leverages unstructured data such as online texts, employing machine learning techniques and large language models (LLMs) to extract deep sentiment features for constructing sentiment indices. This methodology benefits from advancements in artificial intelligence (AI), where the “AI+” initiative has emerged as a pivotal pathway for developing new quality productive forces. The “AI+” campaign provides fresh directions for high-quality development and transformation across industries. In scientific research, AI-powered LLMs like ChatGPT and BERT have become focal points for scholars, particularly in finance, where continuous model upgrades are reshaping research paradigms in economics and related disciplines. Initially, researchers relied on lexicon-based methods to extract sentiment from texts and study its impact on asset returns, stock index volatility, and price fluctuations. Among these, the most influential is the Loughran-McDonald (LM) dictionary, which caters specifically to financial text analysis and has been widely applied in stock return prediction7. Olga Kolchyna et al. conducted a comparative study on sentiment classification using different lexicon combinations based on Twitter messages. They found that incorporating emojis, abbreviations, and social media slang into sentiment dictionaries improved classification accuracy for Twitter texts8. Maite Taboada et al. proposed a lexicon-based semantic orientation calculator (SO-CAL) for sentiment polarity classification, demonstrating its robust performance across diverse textual domains9.
Although lexicon-based methods offer simplicity and interpretability, they suffer from notable limitations. Domain-specific dictionaries must be manually compiled for different fields, and the selection of sentiment-bearing words is inevitably influenced by compilers’ subjective judgments—given that emotional perception varies across individuals10. More critically, these methods’ most severe drawback lies in their inability to capture nonlinear relationships between sentiment and asset returns/price movements11. Consequently, subsequent research has increasingly turned to machine learning techniques. Leveraging their inherent nonlinear algorithmic advantages, these methods enable deeper semantic mining of textual data for sentiment extraction. Online texts exhibit unstructured and asymmetric characteristics, making it impossible to determine sentiment polarity through isolated keywords. To better extract textual information, scholars have widely adopted BERT (Bidirectional Encoder Representations from Transformers). As a transformer-based pre-trained model, BERT effectively learns contextual relationships between words and sentences. Compared to traditional approaches, it excels at uncovering implicit sentiment polarity in financial texts, providing an efficient solution for constructing directional sentiment indices. Li et al. employed BERT to extract sentiment values from stock investors’online posts, weighting these values through attention mechanisms to compute an investor sentiment index12. Jiang and Liu et al. developed a novel textual sentiment index for China’s stock market by applying BERT to asset pricing-related texts13. In real estate research, Xu and Zhao et al. identified sentiment from historical Chinese property news using BERT, constructing a monthly real estate sentiment index14. Wang and Fang et al. analyzed over 2.44 million social media posts with BERT to build a housing sentiment index15. In addition, BERT has demonstrated robust classification capabilities across a wide range of domains. Chen propose an enhanced medical text classification framework by integrating a self-attentive adversarial augmentation network (SAAN) for data augmentation and a disease-aware multi-task BERT strategy, He discovered that this strategy can simultaneously learn medical text representations and disease co-occurrence relationships, thereby enhancing feature extraction from rare symptoms16. Zhang and Jin et al. employs the BERT model to analyze public discourse on rural landscapes from Sina Weibo, aiming to explore the developmental trajectories of rural landscapes from the perspective of the Chinese public17. Jin employs BERT for in-depth semantic analysis of tourist reviews, utilizes CNN to extract local textual features, and combines MADM methods to generate comprehensive scores. The experimental results indicate that the optimized model performs well in dealing with complex unstructured text data while showing high efficiency and stability in weight allocation and multidimensional decision-making tasks18.
The integrated model also presents certain limitations, including its inability to promptly learn the semantics of emerging online vocabulary and its dependence on sufficiently powerful hardware for training. Moreover, domain-specific terminology requires domain-adaptive pretraining, as the model cannot be directly transferred for use. BERT’s pretraining relies on large-scale corpora, but many low-resource languages lack sufficient high-quality textual data, leading to significant performance degradation during model transfer. Additionally, semantic expressions in historical texts may differ substantially from modern usage, making precise semantic recognition challenging for the model. Nevertheless, the advantages of the integrated model remain adequate for the experimental requirements of this study. The research employs the BERT-BiLSTM model to extract sentiment features from text, constructs an index reflecting real estate market sentiment, and investigates the predictive capability of this index for market demand. Since public sentiment towards specific events or policies manifests rapidly, low-frequency sentiment indices fail to capture these timely fluctuations, resulting in distorted and lagged measurements. Furthermore, existing studies predominantly align sentiment indices with other factors at identical frequencies19,20thereby neglecting the potential of high-frequency sentiment indicators. To address these limitations, this study investigates the predictive capability of high-frequency sentiment indices. Existing literature predominantly focuses on how market sentiment indices forecast market prices, with limited exploration of their ability to predict market demand. Wang and Shao et al. proposed a method integrating multi-source heterogeneous data to improve short-term housing price predictions, demonstrating that incorporating sentiment information significantly enhances forecasting accuracy21. Zheng et al. developed a confidence index for 35 major Chinese cities using Google Trends data, proving its effectiveness in predicting housing price increases22. Moreover, most studies rely on same-frequency indicators (e.g., market sentiment and macroeconomic variables) to predict market prices, neglecting the rapid fluctuations in sentiment and the valuable high-frequency information embedded in sentiment indices. Ghysels et al. pioneered the mixed-data sampling (MIDAS) model to leverage high-frequency macroeconomic data, avoiding information loss when predicting low-frequency indicators and improving accuracy23. Subsequent work by Ghysels24Clements and Galvão25and Ghysels and Ozkan26 expanded the model’s structure and estimation methods, proposing the autoregressive distributed lag MIDAS (ADL-MIDAS). Compared to traditional MIDAS, ADL-MIDAS better captures variable dynamics by incorporating lagged distribution information, further enhancing predictive performance.
Compared with previous studies, the contributions of this study are mainly reflected in the following aspects: First, this study trains a large language model based on Chinese Weibo text. Existing literature predominantly explores English texts27,28,29with limited research on emotion measurement in the Chinese context using BERT models30as well as a lack of integration between emotion measurement and the real estate market. The study partially addresses the limitations of existing research. Second, leveraging the algorithmic efficiency of large language models, this study identifies complex sentiment polarity in the real estate market and constructs a high-frequency index to quantify sentiment. The findings demonstrate that a high-frequency sentiment index with polarity outperforms low-frequency and non-polarized sentiment index in predicting market demand. The study providing empirical evidence for future indicator selection in real estate demand forecasting. In summary, this paper develops a large language model closely linked to China’s real estate market, offering new insights into the application of such models in real estate sentiment analysis and exploring the technical pathways and theoretical logic of “AI + real estate” initiatives.
The remainder of this paper is organized as follows: Sect. 2 describes the methodology, Sect. 3 constructs the sentiment index, Sect. 4 presents the experimental results and analysis, and Sect. 5 concludes the paper.
Methodology
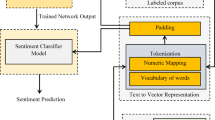
The BERT-BiLSTM model is employed due to its demonstrated efficacy in capturing contextual semantics and sentiment polarity in textual expressions31along with its capacity for batch-processing large-scale text classification tasks, thereby enhancing operational efficiency. Accordingly, this study constructs a Weibo text sentiment classification framework based on BERT-BiLSTM, as shown in Fig. 1. The Weibo text sentiment classification model mainly consists of four components:
-
i)
Text data cleaning, including operations such as data filtering, standardization, removal of advertisement links, and elimination of noisy content.
-
ii)
Employing BERT as a pre-trained text vectorization representation method to perform preliminary sentiment feature extraction from the text.
-
iii)
Utilizing BiLSTM for deep-level extraction of key textual information and contextual semantics.
-
iv)
Applying the Softmax function to output the final sentiment classification results of the text.

BERT-BiLSTM Model Architecture.
Upon obtaining the sentiment index results, the ADL-MIDAS model was selected to investigate its predictive capacity for real estate market demand, addressing the frequency disparity between the sentiment index and other variables32. The following section introduces the models’ methodology.
BERT model
The BERT model is a deep learning-based language representation model released by Google AI in October 2018. It employs the encoder portion of Transformer to construct a bidirectional, multi-layer architecture, enabling it to preserve richer semantic information in word vector representations. Figure 2 was constructed with reference to the BERT model framework diagrams available on Google, Hugging Face, and GitHub platforms.

BERT Model Architecture.
As shown in Fig. 2, in the BERT model, E represents the input vector, the middle layer employs Transformer encoders, and T denotes the output vector. The operational logic of the BERT model is as follows: the hidden text is input into BERT to obtain the input vector E, which is coupled with character encoding, segment encoding, and position encoding. After feature extraction by the Transformer encoder, the vectorized representation E0 of the hidden text is output.
The Transformer serves as the core structure of BERT, designed to extract multiple features from text. In Fig. 1, each “Trm” corresponds to a Transformer encoder module shown on the right. When processed by the Transformer encoder, the data first undergoes the multi-head attention mechanism to obtain weighted feature vectors.
Within the attention mechanism, each character is associated with three distinct vectors: the Query vector (Q), Key vector (K), and Value vector (V). To prevent excessively large inner products in the attention computation, scaled dot-product is employed. The calculation for a single-head attention mechanism is as follows:
Where \(\sqrt {{d_k}}\) represents the dimension of K and V.
To capture text features across different dimensions, the multi-head attention mechanism in the BERT model projects Q, K, and V through h distinct linear transformations. It then concatenates the multiple attention results to form a word vector matrix. The calculation formula is as follows:
Where W0 represents randomly initialized matrices.
To address potential issues such as slow training and gradient vanishing, an “add & norm” layer is introduced, feeding the above results into a feedforward neural network. To enhance the nonlinear fitting capability of the encoder, this module consists of a two-layer linear transformation structure, employing ReLU activation and linear activation functions, respectively. The calculation formula is as follows:
Where:W1 and b1 represent the weights and bias of the first layer respectively;W2 and b2 represent the weights and bias of the second layer respectively. The Weibo text, represented by BERT’s output vectors as semantic representations, is then fed into BiLSTM for deep feature extraction of the microblog content.
BiLSTM model
LSTM (Long Short-Term Memory) is a special type of recurrent neural network33. By introducing gating mechanisms—including forget gate, input gate, and output gate—it selectively retains and updates information in the hidden state. The structural unit of LSTM is shown in Fig. 3.

LSTM Model Architecture.
The cell state update formula is as follows:
The formula for the forget gate is as follows:
The formula for the input gate is as follows:
The formula for the output gate is as follows:
Where ft, it, ot represent the forget gate, input gate, and output gate states at time step t respectively; Ct denotes the cell state at time step t; \(\widetilde {{{{\text{C}}_{\text{t}}}}}\)indicates the cell state update value at time step t; σ and tanh are the sigmoid activation function and hyperbolic tangent activation function; W and b represent the weight matrices and bias terms; ht−1 is the hidden state at time step t-1.
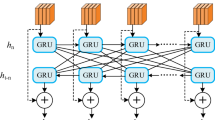
In the LSTM model, information propagates unidirectionally, which can lead to information loss as the sequence length increases. In contrast, BiLSTM34 combines forward and backward LSTM layers, enabling it to simultaneously capture contextual information at each position in the sequence data. At each time step, the input includes both the current position’s features and the hidden state from the previous time step. The output for the current time step is obtained by concatenating the forward and backward hidden states. BiLSTM demonstrates excellent performance in processing sequential data and holds advantages in natural language processing tasks such as text classification, named entity recognition, and sentiment analysis35. The structure of the BiLSTM model is illustrated in Fig. 4.

BiLSTM Model Architecture.

Precision-Recall Curve.
In natural language processing, BERT effectively captures text semantic representations through its pre-training mechanism and bidirectional Transformer architecture. However, its sensitivity to local sequence features and reliance on positional encoding may leave room for optimization when handling fine-grained sequence labeling tasks36. Particularly when dealing with long-range dependencies or requiring explicit modeling of sequential dynamic features, BiLSTM’s bidirectional temporal modeling capability demonstrates unique advantages through its gating mechanism that adaptively captures both local contextual features and long-range dependencies. The BERT-BiLSTM hybrid model aims to achieve complementary advantages through hierarchical feature interaction: first utilizing BERT’s pre-trained semantic representation layer to obtain word-level contextual embeddings, then performing secondary sequence modeling through the BiLSTM network to enhance the model’s collaborative learning capability for both local contextual sensitivity and global semantic stability. Experiments show this architecture effectively mitigates BERT’s short-range semantic drift issues and BiLSTM’s limitations in deep semantic understanding, achieving improved accuracy in subsequent Weibo text sentiment classification tasks.
ADL-MIDAS model
The main objective of this study is to use daily high-frequency sentiment indices to predict monthly low-frequency commercial housing sales areas and examine the relative predictive effects of sentiment indices and other macroeconomic variables on commercial housing sales. The following ADL-MIDAS model is established:
Where:\({\text{Y}}_{{{\text{T+H}}}}^{{\text{A}}}\) represents the low-frequency variable predicted h steps ahead with monthly frequency (A);\({\text{X}}_{{\text{t}}}^{{{\text{Q/M}}}}\) denotes the high-frequency data used for prediction with quarterly or monthly frequency (Q/M);\({\text{P}}_{{\text{Y}}}^{{\text{A}}}\)and \({\text{q}}_{{\text{X}}}^{{{\text{Q}}/{\text{M}}}}\) represent the distributed lag orders of the low-frequency and high-frequency variables, respectively;\(\mu\)stands for the random disturbance term.
The weight function polynomial vector ω is the core of the ADL-MIDAS model. Different forms of weight function polynomials can be specified, thereby constructing various types of ADL-MIDAS models. Referring to existing research, commonly used weight functions include: Zero-order beta density function (Beta); Non-zero-order beta density function(BetaNN); Exponential Almon function(ExpAlmon); Almon function(Almon); Step function(StepF); Unrestricted weight function (UMIDAS)37. Based on these six weight functions, six commonly used model forms can be constructed. This paper further provides a brief introduction to the forms of these six weight functions.
The basic form of the Beta density function can be expressed as follows:
Where l represents the lag order of the weight function, taking values from 0 to lmax; \({{\text{X}}_1}={\text{l/}}{{\text{l}}_{\hbox{max} }}\),
When \({\theta _3}=0\): \({\omega _1}(\theta )={\omega _1}({\theta _1},{\theta _2})=\frac{{{\text{f}}({{\text{X}}_{\text{1}}},{\theta _{\text{1}}},{\theta _{\text{2}}})}}{{\sum\nolimits_{{l=1}}^{{l\hbox{max} }} {{\text{f}}({{\text{X}}_{\text{1}}},{\theta _{\text{1}}},{\theta _{\text{2}}})} }}+{\theta _3}\), namely the zero-order beta density function.
When \({\theta _1}=1\): \({\omega _1}(\theta )={\omega _1}(1,{\theta _2},{\theta _3})=\frac{{{\text{f}}({{\text{X}}_{\text{1}}},{\text{1}},{\theta _{\text{2}}})}}{{\sum\nolimits_{{l=1}}^{{l\hbox{max} }} {{\text{f}}({{\text{X}}_{\text{1}}},{\text{1}},{\theta _{\text{2}}})} }}+{\theta _3}\), namely the non-zero-order beta density function.
The basic form of the ExpAlmon weight function can be expressed as follows:
The basic form of the Almon weight function can be expressed as follows:
The basic form of the StepF weight function can be expressed as follows:
Where I represents the indicator function, which takes the value 1 when I falls within the specified interval and 0 when outside the interval.
After selecting the weight function, the model can be estimated using nonlinear least squares (NLS) or generalized least squares (GLS). During the estimation process, the prediction methods for the ADL-MIDAS model mainly include fixed window, rolling window, and recursive identification. Therefore, once the lag orders of the dependent and explanatory variables are determined, all three prediction methods can be freely combined with the six weight function forms, resulting in 18 ADL-MIDAS model specifications. To ensure the scientific rigor of the research methodology, this paper attempts to estimate all model specifications and compare their prediction results to identify the optimal model form. For the ADL-MIDAS model, evaluating its estimation performance is equivalent to assessing its prediction accuracy. Thus, by comparing the prediction accuracy across different models, the optimal forecasting model can be determined. Currently, the root mean squared forecast error (RMSFE) is a universally accepted metric for evaluating prediction accuracy, calculated as follows:
where T0 represents the starting time point of the forecast, y denotes the actual value, and \(\widehat {{\text{y}}}\) denotes the predicted value.
Constructing the sentiment index
Constructing the Weibo sentiment index
Weibo text acquisition and preprocessing
Weibo, as the most commonly used social media platform in mainland China, has seen people increasingly inclined to post their personal opinions and insights. These views often reflect individuals’ real-time reactions to current events or trending topics, to some extent revealing their emotions and behaviors38. To better capture public sentiment toward China’s real estate market, this study attempts to extract real-time emotional information from vast amounts of Weibo text and construct a Weibo Sentiment Index (WSI) for China’s real estate market.
This study employs Python web scraping techniques, utilizing the Selenium and Pandas libraries to crawl data from Weibo. Due to Weibo’s restrictions on long-time-span searches, which prevent the retrieval of comprehensive data, the study crawls all Weibo posts published daily from January 1, 2019, to December 31, 2024. Each data entry includes the user’s nickname, publication time, content source, full text, number of reposts, number of comments, and number of likes.
In the text crawling process, we commit to collecting only data directly relevant to the research objectives, avoiding the acquisition of personal private information. We prioritize the use of official APIs and strictly adhere to platform rate limits. Additionally, we ensure that crawled texts are used exclusively for academic research purposes. All collected texts are stored with encryption to prevent data leakage or misuse.
Given the sparse, noisy, and ambiguous nature of Weibo texts, this study cleanses and filters the acquired data by removing noise and irrelevant content to obtain concise and accurate text, laying the foundation for subsequent analysis. Following the method of Zhang et al.39,the preprocessing follows three steps: data filtering, standardization, and denoising. Specific steps include: First, using regular expressions to filter out advertisements containing promotional phrases like “free onlookers,"“1-yuan lottery,"or “repost Weibo” posted by marketing accounts; Second, retaining only three fields: “user nickname,"“publication time,"and “full text”;Third, standardizing formats for numbers, characters, dates, and encoding, as well as converting traditional Chinese to simplified Chinese; Fourth, removing invalid characters, stopwords, and emojis via regular expressions. After preprocessing, a total of 440, 866 valid text entries were obtained. Table 1 presents the preprocessed Weibo text data.
Prior to the annotation process, annotators undergo a one month training program. We first prepare pre-annotated test samples and remove their original labels. Annotators are paired into groups, with each group assigned different test samples for initial labeling. After the first round, samples are exchanged within groups for cross-validation. An annotator is deemed qualified only after achieving over 90% accuracy in both labeling tests. Throughout the training period, daily tests are conducted to ensure consistency in dataset annotation.
Constructing the BERT-BiLSTM model
After determining the experimental data, this study selected 24, 706 Weibo texts from 2019 for manual sentiment annotation. To facilitate model mapping learning, the texts were categorized into three classes: 0 mapped to “negative sentiment”, 1 to “neutral sentiment”, and 2 to “positive sentiment”. The experiment addresses a three-class classification problem, with the annotated Weibo text data split into training and test sets in an 8:2 ratio.
This study adopts the Bert-Base-Chinese pretrained model from Hugging Face’s Transformer framework as the foundational architecture, given its strong compatibility with Chinese social media corpora. To address the sequential nature of Weibo texts and the contextual dependencies in sentiment expression, a hierarchical fusion of Bidirectional Long Short-Term Memory (BiLSTM) and BERT is implemented: BERT provides deep semantic encoding to capture global text representations. BiLSTM extracts dynamic relational patterns in sentiment word sequences. The hardware/software configuration is detailed in Table 2. This dual-modality architecture effectively mitigates the limitations of traditional sentiment analysis methods in local context sensitivity: BERT’s multi-head attention mechanism precisely identifies sentiment polarity markers. BiLSTM’s time-series modeling capability enhances the detection of sentiment evolution trends.
Meanwhile, this study configures the model with the parameter settings as shown in Table 3.
Where Epoch refers to the number of complete passes the model makes over the entire training dataset, controlling the total duration of model learning. Batch Size denotes the number of samples used in each iteration to update the model weights, influencing the stability of training. Learning Rate determines the step size for weight updates during gradient descent, governing the magnitude of adjustments in each optimization step. Dropout represents the proportion of neurons randomly deactivated during training to enhance model generalization. BiLSTM Hidden Size specifies the dimensionality of both forward and backward hidden states in the bidirectional LSTM layer, improving the model’s learning capacity.
Weibo sentiment index results
To compare the performance of the BERT-BiLSTM model with sentiment classification models based on algorithms such as Random Forest and Support Vector Machine, this study employs two classic classification algorithms—Random Forest (RF) and Support Vector Machine (SVM)—on the same dataset for sentiment classification. Additionally, the individual components of the BERT-BiLSTM model (BERT and BiLSTM separately) are also used for classification tasks to provide a more comprehensive evaluation of the BERT-BiLSTM model’s classification efficiency.
For classification tasks, common evaluation metrics include accuracy, precision, recall, and F1-Score. This study uses the classification_report function from the sklearn library to compute these metrics. Table 4 compares the evaluation results of the five models on the test set. As shown in Table 4, the BERT-BiLSTM model achieves the best performance across all metrics, demonstrating its effectiveness in sentiment classification for Weibo texts.
As shown in Fig. 5, the Precision-Recall (PR) curve demonstrates the robustness of the BERT-BiLSTM model in multi-sentiment classification. The micro-average PR curve area (0.849) is significantly higher than the independent performance of Class 2 (positive sentiment, 0.721), indicating room for optimization in identifying positive sentiment, though the classification boundaries among all three sentiment categories remain clear. Notably, the PR curve areas for Class 0 (negative sentiment) and Class 1 (neutral sentiment) are close, suggesting balanced discrimination between neutral and negative sentiments. Figure 6 further validates the model’s generalization capability through the ROC curve, with a micro-average AUC of 0.92. All three sentiment categories achieve AUC values above 0.85, indicating stable true positive rates across different sentiment thresholds. This strong robustness provides technical assurance for cross-year sentiment feature extraction.
Based on the temporal sentiment features extracted by the model, the Weibo Sentiment Index (WSI) is constructed using the following formula:
Where \({\text{M}}_{{\text{i}}}^{{{\text{pos}}}}\)and \({\text{M}}_{{\text{i}}}^{{{\text{neg}}}}\) represent the number of positive sentiment texts and negative sentiment texts published by users on Weibo in the i-th month. When the number of texts expressing positive emotions exceeds those expressing negative emotions on a given day, the sentiment index exceeds 0, indicating optimistic market sentiment. Otherwise, it reflects pessimistic market sentiment. To prevent computational failure due to zero positive or negative texts on certain days, we add 1 to both the numerator and denominator of the formula. Additionally, a natural logarithm transformation is applied to the fractional result to mitigate extreme values and ensure proper visualization of the index.
This study fully leverages the model’s performance advantage in the high-recall region of the PR curve to ensure effective capture of long-tail sentiment samples, while the high-discriminative features revealed by the ROC curve Fig. 6 guarantee the accuracy of sentiment polarity classification. By combining deep semantic modeling with statistical quantification methods, this index overcomes the subjectivity limitations of traditional lexicon-based approaches and avoids the interpretability shortcomings of purely machine-learning-based methods.

ROC Curve.
Based on the aforementioned construction method, the Weibo Sentiment Index derived from this study is shown in Fig. 7. Given that the selected time period coincides with a phase of deep adjustment in the real estate market—marked by severe downturns, pandemic-related disruptions, and market volatility—the sentiment index reflects a generally subdued trend. In 2019, sentiment remained stable without sharp fluctuations; however, on January 23, 2020 (Wuhan lockdown), the index plummeted to −1.90, indicating public panic. Following the December 7, 2022 announcement of the “New Ten Measures” for pandemic policy relaxation, the index rebounded rapidly to −0.31 by December 28, demonstrating the confidence-boosting effect of policy easing. The July 24, 2023 Politburo meeting’s proposal for “timely optimization of real estate policies” - including abolishing dual mortgage recognition rules and lowering down-payment ratios - improved market expectations, lifting the index to −0.66 by July 31, though short-term volatility persisted due to developer debt risks. Most notably, after the State Council introduced a “comprehensive incremental policy package” on September 26, 2024 (e.g., cutting existing mortgage rates, consumer subsidies, expanding affordable housing), the index rose to −0.12 by October 27, reaching its highest level since 2019 and signaling significant market confidence recovery.

Weibo Sentiment Index Results.
Construction of the internet concern index
Construction of the Baidu keyword database
In constructing the Internet Concern index, this study fully considers the characteristics of China’s internet ecosystem and selects Baidu search volume as the core proxy variable for the Internet Concern Index. This choice is based on three theoretical grounds: first, Baidu holds an 82.3% market share in the Chinese search engine market, and its search behavior data offers broad population coverage, high temporal resolution (daily/weekly/monthly frequency options), and strong social mirroring effects, dynamically reflecting public psychological expectations and behavioral tendencies toward specific economic phenomena; second, real estate, as a typical high-attention, high-decision-cost sector, exhibits strong correlations between online search behavior and market supply-demand relationships; third, high-frequency search data can overcome the statistical lag of traditional economic indicators, providing forward-looking information for subsequent index construction.
To effectively gauge public attention toward China’s real estate market and comprehensively capture diverse search behaviors, this study adopts a maximization principle to compile Baidu search keywords through three approaches: literature review, keyword recommendation technology, and expert surveys. The established keyword database is presented in Table 5. The keyword selection follows two criteria: (1) relevance to current national policy-making and economic activities, ensuring practical significance; (2) statistical validity, requiring complete time-series data at matching frequencies with the research subject while excluding low-search-volume terms.
Construction method of the internet concern index
The construction of the Internet Concern Index proceeds as follows: First, a distributed crawler system is built based on the Scrapy framework to acquire daily search volume data (2019–2024) via Baidu Index’s open API, and the data is aggregated into monthly frequency to align with housing price measurements. Second, cross-correlation analysis is employed to quantify the lead-lag relationship between keywords and housing prices, where a keyword is identified as having a leading property if the maximum cross-correlation coefficient occurs at l > 0. The cross-correlation formula is given by:
Where \({\text{r}}{{\text{e}}_{\text{l}}}\) represents the correlation at lag l, yt denotes the housing price at period t, \({\text{ {y}}}\) is the average housing price, \({{\text{x}}_{{\text{t-l}}}}\) refers to the search keyword at period t − l, \({\text{ {x}}}\) is the mean search volume of this keyword, and n is the sample size.
The calculation reveals that 31 indicators, including “new homes” and “home-buying considerations,"exhibit leading characteristics of 1–6 months, with an average cross-correlation coefficient of 0.53 (p < 0.01). Finally, partial least squares (PLS) is employed for dimensionality reduction of the leading indicators, retaining 4 principal components through cross-validation (cumulative explained variance: 94.42%). The resulting composite index not only effectively addresses multicollinearity issues but also amplifies the influence coefficients of policy-sensitive keywords through asymmetric weight allocation. This theoretically constrained and data-supported index construction method enables the Internet Concern index to capture subtle market sentiment fluctuations while maintaining cointegration with economic fundamentals.
Assuming the filtered Baidu search keywords are:
Where P represents the number of keywords and n denotes the sample size. The following outlines the specific steps for constructing the Baidu Search Index using the PLS method in this study:
First, orthogonal decomposition is employed to calculate the projection onto the subspace:
Where \({{\text{u}}_1}\) and \({{\text{v}}_1}\) represent the projections onto the subspace, and \({{\text{p}}_1}\), \({{\text{q}}_1}\) are the eigenvectors corresponding to the covariance matrix. Subsequently, a regression equation is established to map the independent variables to the dependent variable:
Where \({\text{p}}_{{\text{1}}}^{{\text{T}}}\) and \({\text{q}}_{{\text{1}}}^{{\text{T}}}\) represents the regression coefficients of the least squares regression, and X1, Y1 are the residual matrices. Subsequently, by replacing X1, Y1 to X, Y and repeating the above steps until the cumulative contribution rate of the extracted principal components reaches 90%, we obtain:
Where r is the number of principal components. The reduction equation is as follows:
Where a1, a2, and at are the regression coefficients of PLS, and y* is the synthesized Internet Concern Index derived from Baidu search keywords.
Experimental results and analysis
Variable selection
The primary objective of this study is to investigate the predictive effects of the constructed sentiment index and macroeconomic indicators on market demand, while comparing the predictive performance between the Weibo Sentiment Index (with explicit emotional orientation) and the Internet Concern Index (reflecting public attention) regarding market demand. Therefore, in addition to the aforementioned sentiment indices, considering that changes in market sales volume serve as a barometer of the real estate market and reflect overall market activity, this study selects the sales area of commercial housing as the proxy variable for market demand; adopts the New Residential Property Price Index for 70 Large and Medium-sized Cities published by China’s National Bureau of Statistics as the proxy variable for commercial housing prices to visually characterize fluctuations in the commercial housing market; meanwhile, from the perspective of supply-demand balance, the total amount of real estate development investment directly determines the market supply during a given period, hence the completed real estate development investment is included as an independent variable in the demand forecasting model. These indicators collectively reflect internal factors influencing demand in the real estate market. Since regulatory policies such as purchase restrictions and credit easing directly affect market demand, the broad money supply (M2) is selected as the proxy variable for the external policy environment of the real economy.
Optimal forecasting model selection
The optimal forecasting model mentioned in this study does not imply superiority over all other possible models, but rather indicates the best-performing model among all different model specifications constructed within the ADL-MIDAS framework for predicting commercial housing sales area. Specifically, the study forecasts commercial housing sales area data for 1–3 months ahead. In each forecasting period, predictions will be made based on daily-frequency Weibo sentiment index, monthly-frequency Internet Concern Index, monthly-frequency New Residential Property Price Index, monthly-frequency completed real estate development investment, and monthly-frequency M2. For each indicator, predictions will be conducted under six weight function settings and three forecasting methods, ultimately generating 90 forecasting models for each prediction period. The optimal model will be determined by comparing root mean square prediction errors. Furthermore, following empirical time-series forecasting conventions and relevant criteria, the lag periods are set as 30 for daily-frequency data and 12 for monthly-frequency data, corresponding to the construction of ADL-MIDAS(12, 30) and ADL-MIDAS(12, 12) models respectively. Where ADL-MIDAS(X, Y), X denotes the distributed lag order of the dependent variable, while Y represents the distributed lag order of the independent variable.
The forecasting results based on the daily-frequency Weibo Sentiment Index are presented in Table 6. For one-period-ahead forecasts, the unconstrained weight function with the fixed-window estimation method achieved optimal performance. For two-period-ahead forecasts, the unconstrained weight function with the recursive estimation method yielded the best results. For three-period-ahead forecasts, the step-function weight with the recursive estimation method demonstrated superior performance. The prediction errors of the optimal forecasting models ranged between 1.6% and 4.7%.
The prediction results based on monthly-frequency Intertnet Concern index modeling are shown in Table 7. When forecasting 1 period ahead, the step-weight function using the recursive identification estimation method delivers optimal performance; for 2-period-ahead forecasts, the zero-order beta density weight function with recursive identification estimation achieves the best results; this remains true for 3-period-ahead forecasts. The prediction errors of the optimal models range between 6.7% and 7.0%.
Table 8 presents the forecasting results based on the monthly-frequency New Residential Property Price Index. For one- to two-period-ahead forecasts, the unconstrained weight function with recursive estimation yielded optimal performance, while for three-period-ahead forecasts, the unconstrained weight function with rolling-window estimation achieved the best results. The prediction errors of the optimal forecasting models ranged between 0.6% and 1.4%.
Table 9 presents the forecasting results based on the monthly-frequency completed real estate development investment. For one-period-ahead forecasts, the unconstrained weight function with fixed-window estimation achieved optimal performance. For two-period-ahead forecasts, the step-function weight with fixed-window estimation yielded the best results. For three-period-ahead forecasts, the Almon weight function with fixed-window estimation demonstrated superior performance. The prediction errors of the optimal forecasting models ranged between 0.2% and 1.3%.
Table 10 presents the forecasting results based on the monthly-frequency M2 data. For one- to two-period-ahead forecasts, the unconstrained weight function with a recursive estimation method achieved optimal predictive performance. For three-period-ahead forecasts, the non-zero-order beta density weight function with a recursive estimation method yielded the best results. The prediction errors of the optimal forecasting models ranged between 8.6% and 10.8%.
From the comparative results above, the Weibo Sentiment Index demonstrates ideal predictive performance for commercial housing sales area, outperforming the Internet Concern Index. The minimum prediction error of the latter for commercial housing sales area was four times higher than that of the former, further indicating that directional sentiment indices have stronger explanatory power for market conditions than attention-based indices that merely reflect market focus. Additionally, the minimum prediction error of the optimal forecasting model based on the Weibo Sentiment Index was second only to those of the New Residential Property Price Index and completed real estate development investment.
Conclusions
This study constructs a Weibo Sentiment Index and an Internet Concern Index based on social media texts and web search volume while establishing an ADL-MIDAS model to examine the predictive power of these two sentiment indices on real estate market demand using mixed-frequency data. The following conclusions are drawn:
-
i)
The BERT-BiLSTM model effectively enhances the classification performance of unstructured text data, demonstrating significant improvements across all evaluation metrics compared to traditional sentiment classification methods, thereby enabling accurate and efficient measurement of the Weibo Sentiment Index. This model not only increases the accuracy of text sentiment classification but also reduces its difficulty and cost. The fine-tuned language model can be reused, exhibiting robust classification performance for texts in the same domain. The Weibo Sentiment Index construction method based on the BERT-BiLSTM model holds substantial practical significance for real estate market sentiment research and provides a novel methodological reference for text classification studies in the real estate sector.
-
ii)
In the ADL-MIDAS model, the directional Weibo Sentiment Index constructed in this study exhibits prediction errors within a relatively low range, demonstrating its explanatory power. This research emphasizes that constructing sentiment indices requires particular attention to both the directionality of sentiment and the high frequency of the index. Emotion indices incorporating these two features demonstrate stronger explanatory power for market dynamics and provide more scientifically grounded support for real-world decision-making.
Market sentiment fundamentally reflects investors’ irrational expectations, whose impact intensifies as these expectations gain wider public recognition and dissemination. The current real estate policy framework prioritizes expectation stabilization, risk prevention, and sector transformation. Consequently, relevant authorities should strengthen proper guidance of market expectations and institutionalize sentiment monitoring mechanisms. Integrating short-term relief measures with long-term structural reforms can facilitate the development of a new real estate paradigm that achieves positive interaction with both the real economy and public welfare needs. Effective expectation management requires boosting public confidence and counteracting pessimistic sentiment stemming from market downturns and COVID-19 impacts.
Based on our research findings, we propose the following policy recommendations: First, establish institutionalized sentiment monitoring mechanisms for real estate markets. By integrating sentiment measurement outcomes with city-specific conditions, implement differentiated regulatory thresholds and corresponding policy interventions based on sentiment index fluctuations. Second, develop both short-term and long-term contingency mechanisms. When sentiment index breach lower thresholds, implement temporary demand-stimulus measures such as enhanced purchase subsidies. For sustained sentiment downturns, deploy comprehensive policy packages including mortgage rate reductions and increased subsidy standards to recalibrate market expectations. During periods of stable or elevated sentiment, accelerate inventory absorption through expanded existing home acquisitions while strengthening price supervision to maintain market equilibrium.
Data availability
Data generated or analyzed during the study are available from the corresponding author by request.
References
Clayton, J., Ling, D. C. & Naranjo, A. Commercial real estate valuation: fundamentals versus investor sentiment. J. Real. Estate Finance Econ. 38 (1), 5–37 (2009).
Landvoigt, T. Housing demand during the boom: the role of expectations and credit constraints. Rev. Financial Stud. 30 (6), 1865–1902 (2017).
Baker, M. & Wurgler, J. Investor sentiment and the cross-section of stock returns. J. Finance. 61 (4), 1645–1680 (2006).
Chen, H., Chong, T. T. L. & Duan, X. A principal-component approach to measuring investor sentiment. Quant. Finance. 10 (4), 339–347 (2010).
Huang, D. et al. Investor sentiment aligned: A powerful predictor of stock returns. Rev. Financial Stud. 28 (3), 791–837 (2015).
Stambaugh, R. F., Yu, J. & Yuan, Y. The long of it: odds that investor sentiment spuriously predicts anomaly returns. J. Financ. Econ. 114 (3), 613–619 (2014).
Loughran, T. & McDonald, B. When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. J. Finance. 66 (1), 35–65 (2011).
Kolchyna, O. et al. Twitter sentiment analysis: lexicon method, machine learning method and their combination. ArXiv Preprint. arXiv:1507.00955 (2015).
Taboada, M. et al. Lexicon-based methods for sentiment analysis. Comput. Linguistics. 37 (2), 267–307 (2011).
Basu, S., Ma, X. & Briscoe-Tran, H. Measuring multidimensional investment opportunity sets with 10-K text. Acc. Rev. 97 (1), 51–73 (2022).
Benhabib, J., Liu, X. & Wang, P. Sentiments, financial markets, and macroeconomic fluctuations. J. Financ. Econ. 120 (2), 420–443 (2016).
Li, M. et al. Applying BERT to analyze investor sentiment in stock market. Neural Comput. Appl. 33, 4663–4676 (2021).
Jiang, F. et al. Deep learning, textual sentiment, and financial market. Inf. Technol. Manag. https://doi.org/10.1007/s10799-024-00428-z (2024).
Xu, T., Zhao, Y. & Yu, J. A real estate price index forecasting scheme based on online news sentiment analysis. Systems, 13(1) ,42(2025).
Wang, X., Fang, Z. & Wang, Z. The dual role of sentiment on housing prices in China. Int. Rev. Econ. Finance. 97, 103732 (2025).
Chen, X. & Du, Y. Enhancing medical text classification with GAN-based data augmentation and multi-task learning in BERT. Sci. Rep. 15, 13854 (2025).
Zhang, J. et al. Attention and sentiment of Chinese public toward rural landscape based on Sina Weibo. Sci. Rep. 14, 13724 (2024).
Jin, H. Application of multi-attribute decision-making combined with BERT-CNN model in the image construction of ice and snow tourism destination. Sci. Rep. 15, 10613 (2025).
Jiang, F. et al. Manager sentiment and stock returns. J. Financ. Econ. 132 (1), 126–149 (2019).
Kleinberg, J. et al. Human decisions and machine predictions. Q. J. Econ. 133 (1), 237–293 (2018).
Wang, X., Shao, J. & Hong, J. Short-term house prices forecasting approach with multi-source heterogeneous information and data traits. Systems Engineering — Theory & Practice, (2025). https://link.cnki.net/urlid/11.2267.N.20250313.1355.014
Zheng, S., Sun, W. & Kahn, M. E. Investor confidence as a determinant of china’s urban housing market dynamics. Real Estate Econ. 44 (4), 814–845 (2016).
Ghysels, E., Sinko, A. & Valkanov, R. MIDAS regressions: further results and new directions. Econom. Rev. 26 (1), 53–90 (2007).
Ghysels, E., Santa-Clara, P. & Valkanov, R. Predicting volatility: getting the most out of return data sampled at different frequencies. J. Econ. 131 (1–2), 59–95 (2006).
Clements, M. P. & Galvão, A. B. Macroeconomic forecasting with mixed-frequency data: forecasting output growth in the united States. J. Bus. Economic Stat. 26 (4), 546–554 (2008).
Ghysels, E. & Ozkan, N. Real-time forecasting of the US federal government budget: A simple mixed frequency data regression approach. Int. J. Forecast. 31 (4), 1009–1020 (2015).
Huang, A., Wang, H. & Yang, Y. FinBERT: A large Language model for extracting information from financial text. Contemp. Acc. Res. 40 (2), 806–841 (2023).
Pota, M. et al. An effective BERT-based pipeline for Twitter sentiment analysis: A case study in Italian. Sensors 21 (1), 133 (2020).
Correa, R. et al. Sentiment in central banks’ financial stability reports. Rev. Financ. 25 (1), 85–120 (2021).
Fan, J., Xue, L. & Zhou, Y. How much can machines learn finance from Chinese text data? Manage. Sci. 70 (12), 8962–8987 (2024).
Li, X., Lei, Y. & Ji, S. BERT-and BiLSTM-based sentiment analysis of online Chinese buzzwords. Future Internet. 14 (11), 332 (2022).
Gong, X., Sun, Y. & Du, Z. Geopolitical risk and china’s oil security. Energy Policy. 163, 112856 (2022).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9 (8), 1735–1780 (1997).
Aslan, M. F. et al. CNN-based transfer learning–BiLSTM network: A novel approach for COVID-19 infection detection. Appl. Soft Comput. 98, 106912 (2021).
Xu, G. et al. Sentiment analysis of comment texts based on BiLSTM. Ieee Access. 7, 51522–51532 (2019).
Rogers, A., Kovaleva, O. & Rumshisky, A. A primer in bertology: what we know about how BERT works. Trans. Association Comput. Linguistics. 8, 842–866 (2021).
He, Y. & Lin, B. Forecasting china’s total energy demand and its structure using ADL-MIDAS model. Energy 151, 420–429 (2018).
Zhang, J. Weibo text sentiment classification model based on FastText-BERT-Attention. J. Big Data Comput. 2, 29–35 (2024).
Zhang, S. & Su, C. Research on stock index prediction based on sentiment lexicon and BERT-BiLSTM. Comput. Eng. Appl. 61 (04), 358–367 (2025).
Funding
This work was supported by grants from the National Natural Science Foundation of China [number: 72204002]; Outstanding Youth Research Project for Universities in Anhui Province [number: 2023AHO20021].
Author information
Authors and Affiliations
Contributions
Mengkai Chen and Jun Wang conducted experiments, analyzed data, and drafted the manuscript. Feilong Zhao and Gaopeng Jiang contributed to the study design and provided intellectual input throughout the research process.All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
Written informed consent for publication of this paper was obtained from Anhui University of Technology and all authors.
Correspondence and requests for materials should be addressed to G.P.J.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, M., Wang, J., Zhao, F. et al. Research on sentiment index and real estate demand forecasting based on BERT-BiLSTM and ADL-MIDAS models. Sci Rep 15, 30240 (2025). https://doi.org/10.1038/s41598-025-16153-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-16153-8
