
Abstract
Modeling lithium-ion battery (LIB) degradation offers significant cost savings and enhances the safety and reliability of electric vehicles (EVs) and battery energy storage systems (BESS). Whilst data-driven methods have received great attention for forecasting degradation, they often demonstrate limited generalization ability and tend to underperform particularly in critical scenarios involving accelerated degradation, which are crucial to predict accurately. These methods also fail to elucidate the underlying causes of degradation. Alternatively, physical models provide a deeper understanding, but their complex parameters and inherent uncertainties limit their applicability in real-world settings. To this end, we propose a new model – ACCEPT. Our novel framework uses contrastive learning to map the relationship between the underlying physical degradation parameters and observable operational quantities, combining the benefits of both approaches. Furthermore, due to the similarity of degradation paths between LIBs with the same chemistry, this model transfers non-trivially to most downstream tasks, allowing for zero-shot inference. Additionally, since categorical features can be included in the model, it can generalize to other LIB chemistries. This work demonstrates a pathway towards a foundational battery degradation model, providing reliable forecasts across a range of battery types and operating conditions.
Similar content being viewed by others

Introduction
Lithium-ion batteries (LIBs) are a vital technology for advancing the transition from fossil fuels towards renewable energy solutions1. Their high energy density, long cycle life, and steadily decreasing costs2 have spurred rapid adoption in both electric vehicles (EVs) and grid-scale battery energy storage systems (BESS). Modeling the inherent degradation of LIBs is challenging for several reasons. First, due the rapid development of LIB technology and the commercial value of battery data, operational or experimental datasets with batteries near their end-of-life are often either limited in size, or lack relevant information such as temperature, voltage, or current3. Second, the degradation is driven by several internal non-linear chemical processes, and depends strongly on the operating conditions. In particular, degradation, sometimes referred to as State of Health (SoH), is affected by the number of operating cycles, temperature, charge/discharge rate, and depth of discharge4. Battery degradation can be accurately parameterized by the combination of loss of \(\hbox {Li}^+\) inventory (LLI) and loss of active material (LAM)5,6.
Methods for modeling degradation can be broadly divided into two categories – physics-based and data-driven techniques. Physics-based techniques attempt to model the underlying physical and chemical mechanisms that cause degradation, such as lithium plating7 and solid-electrolyte interface (SEI) growth8. On the other hand, data driven methods predominantly use operational characteristics to predict the future capacity.
Physics-based modelling of lithium-ion batteries aims to describe the internal electrochemical, thermal, and mechanical processes governing battery behaviour using first-principles equations9,10. Unlike empirical or data-driven models, these approaches are grounded in the fundamental laws of physics such as mass conservation, charge conservation, and thermodynamics, and offer physically interpretable parameters that often generalize well across operating conditions and battery types11,12,13,14. The most widely used and foundational physics-based model is the pseudo-two-dimensional (P2D) model, also known as the Doyle-Fuller-Newman (DFN) model or the Porous Electrode Theory (PET) model. This model represents the battery cell as a one-dimensional domain in the through-plane direction (from anode to cathode), while resolving lithium diffusion in spherical particles in the electrode materials. It includes coupled partial differential equations (PDEs) for the underlying intra-cell electrochemical dynamics governing mass and charge transport, potential distributions, and chemical reactions across (and between) the electrolyte and solid-phases15,16,17,18,19.
One major benefit to the physics-based models is that they can be extended to include additional physics. These include side reactions such as SEI layer growth and lithium plating20,21,22, and particle and binder fracture due to mechanical strain and stress23,24,25. The resulting models are typically much more complex than the P2D and, despite the fact that many built from reduced-order models, typically the Single Particle Model (SPM)26,27,28, parametrisation of such models is challenging and often not possible for many commercial use-cases.
Despite its accuracy and rigor in the formulation, P2D-based models are not appropriate for all use-cases. They require sophisticated techniques for numerical solutions, which can be sensitive changes in parametrisation and are computationally expensive29. Models vary in accuracy across different use-cases, requiring extensive research and development, and model parametrisation typically has stringent data requirements and is difficult to automate. These inevitably make it difficult to deal with many practical use-cases where data-drift and scaling are an issue, such as in grid energy storage or electric vehicle fleets.
Data-driven methods include recursive algorithms such as Kalman filters30 and Sequential Monte Carlo methods31. Whilst these techniques can yield useful predictions, they are model dependent and struggle to handle measurement noise and inaccuracies effectively. Consequently, there has been a growing shift toward time-series machine learning models for forecasting lithium-ion battery (LIB) degradation, including recurrent neural networks (RNNs), long short-term memory (LSTM) networks, and convolutional neural networks (CNNs)32,33.
Although deep-learning models have achieved some success in forecasting LIB degradation, most studies primarily focus on estimating remaining useful life (RUL) or capacity curves. These approaches face two significant limitations: First, they generalize poorly to conditions not seen in the training set and often fail to predict knee-points, particularly in cases with unusual degradation paths34. Second, they make no attempt to diagnose the degradation by quantifying the underlying LLI and LAM. This work aims to address both of these challenges.
On the other hand, generating data purely from pre-parameterized physics-based models (either through direct simulation or training data-driven models on synthetic datasets) is often insufficient for accurate degradation prediction. Real-world factors such as manufacturing defects, subtle variations in operating conditions, or inaccuracies in model parameters can lead to large discrepancies between simulated and actual battery performance35. Whilst parametrizing the physics-based models can mitigate this, the process is computationally expensive, has strict data requirements, and depends heavily on knowledge of LIB design. Additionally, the accuracy of physics-based models relies on a detailed understanding of the degradation mechanisms for the specific LIBs in question – an ongoing area of research with no one-size-fits-all solution36,37,38,39,40. Therefore, in many real-world scenarios where data is incomplete and real-time solutions are required, purely physics-based approaches can be impractical.
An alternative approach is offered by Dubarry et al., who employ a modified equivalent-circuit model (ECM) to emulate LIB performance under various states of degradation41. The authors propose a broad set of potential degradation behaviours that the ECM can simulate, thus reproducing voltage curves and (dis)charging characteristics for a wide variety of degradation paths. By comparing these simulated curves with experimental data, Dubarry et al. demonstrate that it is possible to identify the state of degradation in LIBs and infer their physical state, including LAM and LLI. However, this method doesn’t allow accurate degradation forecasting, as different degradation pathways are often similar in the early stage, so extrapolating a simulated curve introduces prohibitively large uncertainties.
In this work, we introduce ACCEPT (Adaptive Contrastive Capacity Estimation Pre-Training), a novel model that forecasts degradation by combining the strengths of both data-driven and physics-based approaches. The model structure is inspired by OpenAI’s CLIP42, which demonstrated the power of contrastive learning for zero-shot prediction. ACCEPT learns to predict the most probable future degradation path from a large range of simulated curves, by using combination of historical capacity sequences and operational features, including temperature, current, and voltage.
This approach offers a significant advantage: by incorporating a physics-based battery model, we can quickly and cheaply simulate a wide range of degradation paths without the need for extensive experimentation. These simulated curves can be matched to capacity curves from real, operational data of batteries in open-source datasets to create a labeled dataset. Thus, information from both the operational and simulated data is leveraged to accurately forecast the degradation path.
Using the physics-based model, each simulated data point can be associated with a combination of LLI and LAM. The operational data and the simulated data are encoded separately using time-series models. These encoded representations are then projected into a shared embedding space, enabling the model to learn complex relationships between observed and simulated degradation patterns. During inference, an LIB’s operational features are encoded and the closest matching simulated degradation curve is retrieved. This simulated curve is taken as the prediction for its future degradation.
To embed the operational data, a modified Temporal Fusion Transformer (TFT)43 is used. This allows battery metadata, such as the chemistry of the LIB and the initial capacity, to be included in the model, allowing the model to be generalized across different LIB types. To embed the simulated degradation curves, a CNN-based architecture is used. This retrieval-based method allows the quantification of degradation modes, which is not feasible in existing data-driven methods.
This approach allows for the degradation pathway to be estimated from as few as 100 cycles. We show that this generalizes better than existing approaches to unknown operational scenarios, helping to mitigate the data availability problem encountered in battery research. Additionally, if the parameters of an LIB are not known and therefore curves cannot be generated using physics-based models, users can still obtain accurate results using curves generated for LIBs with similar chemistries.
Sec. 2 outlines the method for generating the simulated curves and then describes the model in detail. The model training and results are shown in Sec. 3.
Proposed approach
The proposed approach is to train a model to match a set of operational data associated with a specific degradation pathway with the corresponding simulated scenario. This allows both diagnosis of historic degradation and forecasting of the future capacity fade. The operational and simulated data are embedded separately to perform the comparison. Features such as temperature, voltage, and current are included in the operational embedding so that the model can generalize to unseen scenarios. Before training, a set of simulated curves is generated from a simple set of degradation equations, as described in Sec. 2.1. The model architecture is shown in Sec. 2.2.
Generating simulated degradation curves
The choice of degradation model is not fundamental to ACCEPT. In principle, any method capable of generating simulated degradation curves that sufficiently describe the full range of operational curves under study can be used. Below, we present a simple dimensionless set of equations as a proof of concept, but acknowledge that other methods, such as44, may be more suitable for real-world applications.
A mathematical model, in the form of a system of ordinary differential equations describing capacity fade as a combination of LLI and LAM, is proposed. This is built on the idea of41,45, which proposes that capacity fade can be described as a combination of LLI and LAM. This model is built on simplified physics as the product of remaining active material and lithium inventory. The LIB’s active material is assumed to degrade exponentially over time, while lithium lost is described as a combination of SEI growth and lithium plating. SEI growth is assumed to increase linearly, whereas for plating a time delay is included in order to simulate that this mode of degradation may not begin at start of life. This former mechanism aims to emulate the idea that plating often occurs only once local voltages within the LIB are large enough, an effect which occurs only during extreme operating conditions e.g., high C-rates, low temperatures or unsafe voltage ranges, and once other degradation mechanisms have accumulated to cause such effects, e.g., low porosity due to SEI growth or high effective C-rates due to reduced capacity36,37,38,39,40,46.
During the inference process, any number of positive samples from one to infinity (constrained by available computing power) can be fed into the simulated profile encoder. The model will then return the similarity score of the operational data to each of these samples. This allows for the creation of custom simulated curves that can be used for specific use-cases, or curves from pre-existing data. Two curves can be compared to see how likely it is a LIB’s trajectory will follow each of them (linear projection vs expected knee), or a large number can be used for accurate curve estimation.
Degradation Equations
The proposed dimensionless model that describes the decline of LIB capacity due to SEI growth and lithium plating in \(t\in [0,\infty )\) is given by (1)-(4). Here, t can be defined as both time and cycle number, which are equivalent under transformations to the model parameters. LAM degradation is modeled by,
where M is the material-capacity of the LIB, with initial condition \(M(0)=1\), and k is the rate of material degradation. LLI degradation is modeled by,
where S and P are the lithium-loss due to SEI and plating, respectively, which have initial conditions \(S(0)=P(0)=0\), a and b are growth rates of SEI and plating, respectively, c determines the sharpness of the knee, and \(t_p\) is the point in time which plating begins. Capacity is modeled by,
where L is the total loss of lithium inventory and C is the LIB capacity. \(L\in [0,1]\), where \(L=1\) corresponds to the complete loss of lithium inventory. The SEI and plating growth rates, a and b, are defined as functions of time by,
where \(a_0\) and \(b_0\) are the typical rate parameters for a and b, respectively. To simulate a sharp gradient we take \(\kappa =100\). We could have instead taken a and b to be step functions with discontinuities at \(L=1\), however, discontinuous functions often cause instabilities in numerical methods and so this was instead modelled as a continuous function with a sharp gradient.
In equations (2) and (4), the hyperbolic tangent function, \(\tanh\), is used as a way to continuously activate or deactivate processes as the battery state evolves. In equation (2), plating does not begin until \(t\approx t_p\), which simulates a knee in the capacity curve, where the sharpness of the knee is determined by c. In equations (4) LLI growth is switched off as \(L\rightarrow 1\), accounting for scenarios where all lithium inventory is lost.
Numerical Simulation
The system of ordinary differential equations (1)-(4) are solved numerically using the classic fourth-order Runge-Kutta method, RK447, with a step size of \(h = 0.01\). An early stop criterion is applied when \(C<0.7\) (70% SoH), since the experimental data does not include degradation beyond this point. The total accumulated error of the RK4 method is \(\mathbb {O}(h^4)\) and hence, given the method’s stability, the numerical error is negligible.
Each curve in the operational dataset is parametrized by finding optimal values for the parameters k, \(a_0\), \(b_0\), and \(t_p\). This is achieved using Python’s SciPy48 minimize function which minimizes the L2-norm (approximated by the midpoint rule) between the data and simulation.
To create a comprehensive training set, simulations are generated by solving the model for a large set of parameter values sampled uniformly within the ranges identified from the parameterized data curves. Fig. 1 shows an example of an operational curve and the best matching simulated curve.

Example of an operational degradation curve with the corresponding matched simulated curve.
Model architecture

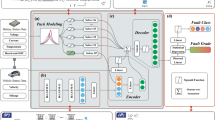
Overview of the contrastive pre-training approach. The two encoders are trained jointly using a contrastive loss. Operational data—including current, temperature, voltage, and static metadata (e.g., cell chemistry)—is mapped into a shared latent space with simulated degradation curves. The model learns to align operational data with its corresponding simulated behaviour by maximising similarity for matched pairs and minimising it for mismatched ones.

Schematic showing inference (a) and diagnosis (b) using the trained model. At inference time, the encoder maps new operational data (observed mid-life measurements) into the latent space and retrieves the most similar simulated degradation curve from a database. This provides a degradation prediction and enables diagnosis by retrieving the underlying simulation parameters associated with the predicted trajectory.
An overview of the training and inference procedure for ACCEPT is shown in Figs. 2 and 3. Below is detailed a description of the model architecture.
Let \(\mathbb {S}\) and \(\mathbb {O}\) represent the vector spaces for the simulated and operational data, respectively, where \(\mathbb {S}\) consists solely of the capacity (degradation) curves, while \(\mathbb {O}\) includes both the degradation curves and associated operational features such as temperature, voltage, and current. The architecture consists of two distinct encoders: (i) a simulation encoder \(E_s: \mathbb {S} \rightarrow \mathbb {R}^{d}\), and; (ii) an operational encoder \(E_o: \mathbb {O} \rightarrow \mathbb {R}^{d}\), where d is the dimension of the shared latent space (\(d=512\) is used in this case).
The simulation encoder, \(E_s\), employs a CNN architecture:
where CNN consists of L layers of 1D convolutions with ReLU activations. Each layer l applies:
where \(C_l\) represents the number of channels in layer l, and \(T_l\) represents the temporal length of the sequence at that layer. This model showed a good trade-off between extracting long-term trends and computational efficiency, although it is possible to replace this block with other architectures well suited for time-series processing.
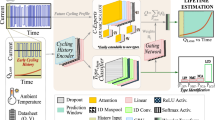
Operational Encoding We adopt the TFT43 as the basis of the operational encoder due to its state-of-the-art performance in time-series forecasting. The TFT effectively captures temporal dependencies at multiple scales and includes specialized components such as the Variable Selection Network for identifying the most relevant features at each time step. Moreover, it naturally integrates static real-valued and categorical data, enabling us to incorporate crucial information like LIB type and chemistry. This flexibility is vital for the zero-shot setting, as we aim to learn general representations that transfer effectively to a wide range of battery configurations and operational conditions. In theory, any model that captures this information could be used as the operational encoder. When passing the data to the operational encoder, multiple input sequences of varying lengths are created from each operational curve, as shown in Fig. 4. This enhances the model’s ability to make predictions at different points in the LIB lifecycle. Note that since different cells are used for training and testing, there is no possibility of data leakage from future observations of the same cell during inference.

On the left of the image, a degradation curve from the same battery at different points in its lifecycle is shown. In the training process, each of these curves would form a positive and negative pair with the simulated curves on the upper right and lower right, respectively.
The operational encoder \(E_o\) modifies the TFT by replacing the forecasting head with a dense embedding layer:
where:
-
\(\text {TFT}_{\text {base}}\) is the standard TFT encoder-decoder architecture until the final forecasting layer
-
\(h \in \mathbb {R}^{d_h}\) is the final hidden state of the TFT
-
\(W_e \in \mathbb {R}^{d \times d_h}\) and \(b_e \in \mathbb {R}^{d}\) are learnable parameters of the embedding layer
-
\(z_o \in \mathbb {R}^{d}\) is the final operational embedding
Specifically, \(\text {TFT}_{\text {base}}\) processes the input through:
where VSN is the variable selection network and MHA is multi-head temporal attention. Unlike the original TFT, we omit the quantile forecast layer and instead map the pooled representations directly to the embedding space.
Contrastive Learning Contrastive learning is a self-supervised learning technique that has gained significant attention in machine learning, especially in the domain of computer vision and natural language processing. It learns useful representations by comparing pairs of examples and pulling similar ones together while pushing dissimilar ones apart in a high-dimensional latent space49.
For a batch of paired samples \({(s_i, o_i)}_{i=1}^N\), the contrastive loss function can be constructed as:
where the normalized embeddings are:
\(\text {sim}(a, b) = a^\top b\) is cosine similarity, and \(\tau\) is a temperature parameter. j indexes all positive and negative matches in the batch. In equation (5), \(\tau\) is a learnable parameter which specifies the size of the penalty for negative matches and is determined as part of the training process.
Additionally, we employ a queue of negative pairs to enhance the in-batch negatives and diversify the examples learned by the model. Let \({\textbf{Q}}\) be a queue that stores all the additional negative embeddings \(\{p_{o_i}^{-}\}_{i=1}^M\). During training, for each batch, \(K = 2048\) random elements are selected from \({\textbf{Q}}\). For each positive pair \((p_{s_i}, p_{o_i})\) in a mini-batch, the denominator in Eq. (5) is replaced by this term:
where \(p_{o_k}^{-}\) represents a negative match from the queue. The full loss function becomes:
This design ensures that each sample is contrasted against a large and continually refreshed set of negatives, improving the robustness of the learned embeddings. The queue is dynamic, a different sample of negatives is randomly selected for each batch.
Zero-shot
When creating data-driven models for the estimation of battery degradation, a big problem faced by researchers is the poor transferability to downstream tasks. This is due to the inability of most data-driven models to generalize to unseen operating conditions. Through matching operational data to degradation curves using embedding models, ACCEPT is better able to handle unforeseen circumstances. Zero-shot learning refers to the ability of a model to generalize to new classes without being specifically trained on them50. Due to the large testing times of Li-ion batteries under development, as well as the importance of early detection of LIBs set to experience accelerated degradation, models with this capability are of great interest to the industry.

ACCEPT Training
Experiments
Dataset
Severson et al.51 generated a comprehensive dataset consisting of 124 lithium iron phosphate/graphite LIBs that were cycled under fast-charging conditions. The experiments were stopped when the batteries reached end-of-life (EOL) criteria. EOL cycle number ranged from 150 to 2300. For zero-shot estimation, as described in Sec. 3.6, we used a separate dataset of LIBs with end-of-life (EOL) cycle numbers ranging from 450 to 1200, which was not included in the training process52.
Training procedure
A pseudocode outline of the model training procedure is shown in Algorithm 1. ACCEPT was trained using an Adam optimizer53 and a learning rate of \(1\times 10^{-5}\). The model was trained until convergence, which typically happened around the 7th epoch. The model was relatively quick to train, taking around two hours on a single Nvidia A100 GPU. Eight LiBs were reserved from the total dataset as validation LiBs during the training process. 16 LIBs were used as the test and evaluation set. Unique groups of cells were used in the training, test, and validation samples respectively to ensure that there is no accidental data leakage. Hyperparameter optimisation was performed using a grid search, the configuration with the lowest validation loss was selected. Full search ranges and optimal values for hyperparameters are shown in Tab. 1.
Accuracy comparison with state-of-the-art results
The model was compared to a variety of conventional data-driven techniques for estimation of future degradation. It was shown that by using as Little as 100 cycles of input data the model was capable of producing accurate degradation curves. The prediction for several test cells is shown in Fig. 5. An additional benefit of this approach is that we are not limited by the output sequence length of the model, meaning that we can return a degradation pathway of any length, rather than just the model output dimension n, as with other data-driven techniques.
In Tab. 2 it can be seen that ACCEPT achieves state-of-the-art results compared to existing methods for accuracy.

Future capacity degradation curves as predicted by the model against test LiBs no. 1−4 from 100 cycles of input data. The model has the added benefit against current techniques that it is not limited to a certain output (context) length.
Quantifying degradation modes
Once the future degradation curve has been returned, the corresponding degradation modes that led to capacity fade can be deduced, as the parameters used to generate them are known. The results for Test LiB 1 can be seen in Fig. 6, and values are given according to the quantification scheme in section 2.1.

Quantitative results of degradation modes for capacity loss of Test LiB 1.
Estimated uncertainty

Top five most Likely degradation paths for test LiB 2 where “Prediction k” represents the \(k^{\text {th}}\) most likely scenario. They all have relatively similar shapes, indicating that the model has learned the degradation behaviour well.

Prediction for two test cells with calculated uncertainty. In both cases, the real degradation curve is consistent with the prediction.
As the model returns a similarity score for each simulated scenario, it is possible to return a number of most likely degradation paths for each input. By returning more than one simulated scenario, it is possible to assess the consistency of the model’s predictions. An example of the best five predictions for a single LIB is shown in Fig. 7. This process can also be used to estimate how likely it is a particular LIB is to experience a knee-point.
Furthermore, when the model makes a prediction, additional degradation simulations can be generated by introducing small variations to the simulation parameters of the best-matching curve. These new curves are passed to the model and a new prediction is made. This process can be repeated many times, giving a distribution of selected curves from the many iterations of alternative simulations. This distribution reflects the prediction uncertainty resulting from the granularity of the simulations. Two examples are shown in Fig. 8.
Zero-shot
Zero-shot estimation for LIB degradation is difficult due to inherent cross-domain variability between LIBs of different sizes and chemistries. Enabling zero-shot transfer to downstream tasks presents the possibility of reducing testing times in battery development cycles. To model the zero-shot capabilities of ACCEPT, we took two battery LIBs from the dataset described in Ref.58: one with a standard degradation profile and one with accelerated degradation. The purpose of this was to test whether our method could correctly differentiate between LIBs likely to experience the critical scenario of accelerated degradation. The corresponding simulated curves, one with accelerated degradation and one with standard degradation, were fed to the simulated curve encoder.
Despite the similarity in input between the two LIBs, ACCEPT was able to differentiate between the two profiles and chose the correct degradation pathway, as shown in Fig. 9. This is a significant result given that these two cells were taken from a completely independent dataset to the one used to train ACCEPT.

(A) Zero-shot predictions against test LIB with accelerated degradation and (B) Zero-shot predictions against test LIB with standard degradation. Both LIBs taken from dataset from different source to the training set. The model was able to detect whether a particular LIB will experience accelerated degradation, a critical scenario to detect in the operation of LIBs.
Ablations
To assess the significance of individual model components, an ablation study was performed. A transformer architecture was evaluated as a substitute for the original one-dimensional convolutional embedding model for simulated degradation pathways; however, it yielded lower performance and imposed greater hardware constraints due to an increased memory footprint. The negative queue was omitted in one training configuration to evaluate its impact, resulting in decreased test performance, indicating a reduced contrastive effect. In a separate experiment, the queue was initialized with hard negatives exhibiting high dissimilarity to the positive match, which also led to diminished model effectiveness. The results of this study are summarized in Tab. 3.
Conclusion
We have aimed to address the challenge of using data-driven techniques to accurately forecast degradation of Li-ion batteries and quantify the underlying electrochemical causes. Our method (ACCEPT) showed state-of-the-art accuracy for degradation modeling. Our approach differs from purely data-driven time-series by utilizing known physics to generate a number of simulated curves. ACCEPT then matched operational data to these simulations. As the underlying physical parameters of the model used to generate the simulated profiles are known, our framework made it possible to quantify the underlying degradation mode causing this. Our experiments showed that ACCEPT was able to generalize well to unseen scenarios, and could correctly anticipate if an LIB from an unseen dataset was likely to experience accelerated degradation, a critical phenomenon in the operation of EVs and BESSs.
Future work
This preliminary work aimed to demonstrate how a new class of machine learning models, paired with information from known physics about \(\hbox {Li}^+\) batteries, can be used to accurately model degradation, whilst also quantifying the underlying degradation mode, something previous data-driven techniques have been unable to achieve. Currently, the model is purely trained on the Severson dataset; however the model can be fine-tuned on any dataset. Further open-source data on battery degradation could also be used to broaden the models applicability and increase its generalization to unseen LIB types. In this study, a TFT was used as the embedding model for the LIB’s operational data. This model has the additional benefit of providing interpretable results through its variable selection network. This was not explored in this work, however future studies could use this to quantify the impact of different stress factors in the operational data on the overall degradation pathway.
Impact statement
This paper presents work whose goal is to advance application of machine learning to battery modeling. There are many potential societal consequences of this work. By improving the accuracy and efficiency of degradation forecasting, this work contributes to the development of more reliable and sustainable battery technologies, which are essential for reducing greenhouse gas emissions and enabling widespread adoption of clean energy solutions. We recognize the need for further research in this direction before practical use in production settings.
Data availability
The datasets used in this study are publicly available. The Severson et al. dataset, used for training and validation, can be accessed at the Materials Project repository: https://data.matr.io/1/. The second dataset, used for zero-shot testing, is available through the Battery Archive: https://www.batteryarchive.org/cycle_list.html?t=0001. All additional data supporting the findings of this study are available from the corresponding author upon reasonable request.
References
Clarke, L. et al. "Energy systems supplementary material," in Climate Change 2022: Mitigation of Climate Change. (eds. P. Shukla et al.). (Cambridge University Press, Cambridge, UK and New York, NY, USA, 2022) book section 6.
Ziegler, M. S. & Trancik, J. E. Re-examining rates of lithium-ion battery technology improvement and cost decline. Energy Environ. Sci. 14, 1635–1651. https://doi.org/10.1039/D0EE02681F (2021).
Madani, S. S. et al. A Comprehensive Review on Lithium-Ion Battery Lifetime Prediction and Aging Mechanism Analysis. Batteries 11(4), 127 (2025).
Rahman, T. & Alharbi, T. Exploring Lithium-Ion Battery Degradation: A Concise Review of Critical Factors, Impacts, Data-Driven Degradation Estimation Techniques, and Sustainable Directions for Energy Storage Systems. Batteries 10(06), 220 (2024).
Birkl, C. R., Roberts, M. R., McTurk, E., Bruce, P. G. & Howey, D. A. Degradation diagnostics for lithium ion cells. Journal of Power Sources 341, 373–386 (2017). [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0378775316316998.
Xu, J. et al. High-energy lithium-ion batteries: recent progress and a promising future in applications. Energy & Environmental Materials 6(5), e12450 (2023).
Sahu, S. & Foster, J. M. A continuum model for lithium plating and dendrite formation in lithium-ion batteries: Formulation and validation against experiment. Journal of Energy Storage 60, 106516 [Online]. Available: https://www.sciencedirect.com/science/article/pii/S2352152X22025051 (2023).
Wang, A., Kadam, S., Li, H., Shi, S. & Qi, Y. Review on modeling of the anode solid electrolyte interphase (SEI) for lithium-ion batteries. npj Computational Materials 4(1), 15. https://doi.org/10.1038/s41524-018-0064-0 (2018).
Newman, J. & Balsara, N. P. Electrochemical systems (John Wiley & Sons, 2021).
Richardson, G. W., Foster, J. M., Ranom, R., Please, C. P. & Ramos, A. M. Charge transport modelling of lithium-ion batteries. European Journal of Applied Mathematics 33(6), 983–1031 (2022).
Wang, A. et al. Review of parameterisation and a novel database (liiondb) for continuum li-ion battery models. Progress in Energy 4(3), 032004 (2022).
Chen, C.-H. et al. Development of experimental techniques for parameterization of multi-scale lithium-ion battery models. Journal of The Electrochemical Society 167(8), 080534 (2020).
Ecker, M. et al. Parameterization of a physico-chemical model of a lithium-ion battery: I. determination of parameters. Journal of The Electrochemical Society 162(9), A1836 (2015).
Ecker, M., Käbitz, S., Laresgoiti, I. & Sauer, D. U. Parameterization of a physico-chemical model of a lithium-ion battery: Ii. model validation. Journal of The Electrochemical Society 162(9), A1849 (2015).
Doyle, M., Fuller, T. F. & Newman, J. Modeling of galvanostatic charge and discharge of the lithium/polymer/insertion cell. Journal of the Electrochemical society 140(6), 1526 (1993).
Doyle, M., Newman, J., Gozdz, A. S., Schmutz, C. N. & Tarascon, J.-M. Comparison of modeling predictions with experimental data from plastic lithium ion cells. Journal of the Electrochemical Society 143(6), 1890 (1996).
Fuller, T. F., Doyle, M. & Newman, J. Simulation and optimization of the dual lithium ion insertion cell. Journal of the electrochemical society 141(1), 1 (1994).
Newman, J. & Tiedemann, W. Porous-electrode theory with battery applications. AIChE Journal 21(1), 25–41 (1975).
Richardson, G., Denuault, G. & Please, C. Multiscale modelling and analysis of lithium-ion battery charge and discharge. Journal of Engineering Mathematics 72, 41–72 (2012).
Safari, M., Morcrette, M., Teyssot, A. & Delacourt, C. Multimodal physics-based aging model for life prediction of li-ion batteries. Journal of The Electrochemical Society 156(3), A145 (2008).
Sahu, S. & Foster, J. M. A continuum model for lithium plating and dendrite formation in lithium-ion batteries: Formulation and validation against experiment. Journal of Energy Storage 60, 106516 (2023).
O’Kane, S. E., Campbell, I. D., Marzook, M. W., Offer, G. J. & Marinescu, M. Physical origin of the differential voltage minimum associated with lithium plating in li-ion batteries. Journal of The Electrochemical Society 167(9), 090540 (2020).
Foster, J., Hahn, Y., Patanwala, H., Oancea, V. & Sahraei, E. “Mechanical deformation in lithium-ion battery electrodes: Modeling and experiment,’’. Journal of Electrochemical Energy Conversion and Storage 22, 1 (2025).
Christensen, J. & Newman, J. A mathematical model of stress generation and fracture in lithium manganese oxide. Journal of The Electrochemical Society 153(6), A1019 (2006).
Lu, X. et al. Microstructural evolution of battery electrodes during calendering. Joule 4(12), 2746–2768 (2020).
Richardson, G., Korotkin, I., Ranom, R., Castle, M. & Foster, J. Generalised single particle models for high-rate operation of graded lithium-ion electrodes: Systematic derivation and validation. Electrochimica Acta 339, 135862 (2020).
Marquis, S. G., Sulzer, V., Timms, R., Please, C. P. & Chapman, S. J. An asymptotic derivation of a single particle model with electrolyte. Journal of The Electrochemical Society 166(15), A3693 (2019).
Marquis, S. G., Timms, R., Sulzer, V., Please, C. P. & Chapman, S. J. A suite of reduced-order models of a single-layer lithium-ion pouch cell. Journal of The Electrochemical Society 167(14), 140513 (2020).
Korotkin, I., Sahu, S., O’Kane, S. E., Richardson, G. & Foster, J. M. Dandeliion v1: An extremely fast solver for the newman model of lithium-ion battery (dis) charge. Journal of The Electrochemical Society 168(6), 060544 (2021).
Mu, A. X. et al. Estimating soc and soh of energy storage battery pack based on voltage inconsistency using reference-difference model and dual extended kalman filter. Journal of Energy Storage 81, 110221 [Online]. Available: https://www.sciencedirect.com/science/article/pii/S2352152X23036204 (2024).
Li, L., Saldivar, A. A. F., Bai, Y. & Li, Y. Battery remaining useful life prediction with inheritance particle filtering. Energies 12, 14 (2019). [Online]. Available: https://www.mdpi.com/1996-1073/12/14/2784
Zhao, J. et al. Method of Predicting SOH and RUL of Lithium-Ion Battery Based on the Combination of LSTM and GPR. Sustainability 14, 19 (2022). [Online]. Available: https://www.mdpi.com/2071-1050/14/19/11865
Ren, L. et al. A Data-Driven Auto-CNN-LSTM Prediction Model for Lithium-Ion Battery Remaining Useful Life. IEEE Transactions on Industrial Informatics 17(5), 3478–3487 (2021).
Attia, P. M. et al. Review–“Knees” in Lithium-Ion Battery Aging Trajectories. Journal of The Electrochemical Society 169(6), 060517 . [Online]. Available: https://doi.org/10.1149/1945-7111/ac6d13 (2022).
Miguel, E. et al. Review of computational parameter estimation methods for electrochemical models. Journal of Energy Storage 44, 103388 (2021).
Chen, C.-F., Barai, P. & Mukherjee, P. P. An overview of degradation phenomena modeling in lithium-ion battery electrodes. Current Opinion in Chemical Engineering 13, 82–90 (2016).
O’Kane, S. E. et al. Lithium-ion battery degradation: how to model it. Physical Chemistry Chemical Physics 24(13), 7909–7922 (2022).
Reniers, J. M., Mulder, G. & Howey, D. A. Review and performance comparison of mechanical-chemical degradation models for lithium-ion batteries. Journal of The Electrochemical Society 166(14), A3189–A3200 (2019).
Birkl, C. R., Roberts, M. R., McTurk, E., Bruce, P. G. & Howey, D. A. Degradation diagnostics for lithium ion cells. Journal of Power Sources 341, 373–386 (2017).
Edge, J. S. et al. Lithium ion battery degradation: what you need to know. Physical Chemistry Chemical Physics 23(14), 8200–8221 (2021).
Dubarry, M., Truchot, C. & Liaw, B. Y. Synthesize battery degradation modes via a diagnostic and prognostic model. Journal of power sources 219, 204–216 (2012).
Radford, A. et al. “Learning Transferable Visual Models From Natural Language. Supervision” [Online]. Available: https://arxiv.org/abs/2103.00020 (2021).
Lim, B., Arık, S. Ö., Loeff, N. & Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. International Journal of Forecasting 37(4), 1748–1764 (2021).
Dubarry, M. & Beck, D. Big data training data for artificial intelligence-based li-ion diagnosis and prognosis. Journal of Power Sources 479, 228806 (2020). [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0378775320311101
Mohtat, P., Lee, S., Siegel, J. B. & Stefanopoulou, A. G. Towards better estimability of electrode-specific state of health: Decoding the cell expansion. Journal of Power Sources 427, 101–111 (2019).
Lin, X., Khosravinia, K., Hu, X., Li, J. & Lu, W. Lithium plating mechanism, detection, and mitigation in lithium-ion batteries. Progress in Energy and Combustion Science 87, 100953 (2021).
Griffiths, D. F. & Higham, D. J. Numerical methods for ordinary differential equations: initial value problems (Springer vol. 5., 2010).
Virtanen, P. et al. Scipy 1.0: fundamental algorithms for scientific computing in python. Nature methods 17(3), 261–272 (2020).
Chen, T., Kornblith, S., Norouzi, M. & Hinton, G. A simple framework for contrastive learning of visual representations in. International conference on machine learning. PMLR, , pp. 1597–1607 (2020).
Xian, Y., Lampert, C. H., Schiele, B. & Akata, Z. Zero-shot learning–a comprehensive evaluation of the good, the bad and the ugly. IEEE transactions on pattern analysis and machine intelligence 41(9), 2251–2265 (2018).
Severson, K. A. et al. Data-driven prediction of battery cycle life before capacity degradation. Nature Energy 4(5), 383–391 (2019).
Attia, P. M. et al. Closed-loop optimization of fast-charging protocols for batteries with machine learning. Nature 578(7795), 397–402 (2020).
Kingma, D. P. & Ba, J. “Adam: A Method for Stochastic Optimization,” [Online]. Available: https://arxiv.org/abs/1412.6980 (2017).
Li, X., Zhang, L., Wang, Z. & Dong, P. Remaining useful life prediction for lithium-ion batteries based on a hybrid model combining the long short-term memory and elman neural networks. Journal of Energy Storage 21, 510–518 (2019).
Zhou, D., Li, Z., Zhu, J., Zhang, H. & Hou, L. State of health monitoring and remaining useful life prediction of lithium-ion batteries based on temporal convolutional network. IEEE Access 8, 53 307–53 320, (2020).
Mittal, D. A. et al. “Two-stage early prediction framework of remaining useful life for lithium-ion batteries,” in IECON 2023-49th Annual Conference of the IEEE Industrial Electronics Society. IEEE, pp. 1–7 (2023).
Suh, S. et al. Remaining useful life prediction of lithium-ion batteries using spatio-temporal multimodal attention networks. Heliyon 10, no. 16 (2024).
Preger, Y. et al. Degradation of Commercial Lithium-Ion Cells as a Function of Chemistry and Cycling Conditions. Journal of The Electrochemical Society 167(12), 120532. [Online]. Available: https://doi.org/10.1149/1945-7111/abae37 (2020).
Author information
Authors and Affiliations
Contributions
JS - Designed the study, wrote the manuscript, prepared figures and analysed results. RM - Conducted experiments, analysed results, and helped write manuscript. MC - Provided technical guidance, wrote the manuscript and reviewed the manuscript. KU - Reviewed the manuscript, analysed results
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Sadler, J., Mohammed, R., Castle, M. et al. Diagnostic forecasting of battery degradation through contrastive learning. Sci Rep 15, 33360 (2025). https://doi.org/10.1038/s41598-025-17183-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-17183-y
