
Abstract
Falls are the primary basis of autonomy loss, injuries, and deaths among disabled persons and the elderly. With the development of technologies, falls are extensively researched by scientists to diminish severe consequences and adverse effects. Reliable fall recognition is crucial in humanoid robotics and healthcare research, as it helps minimize damage. The detection methods for falls are classified into three categories: wearable sensors, ambient sensors, and vision-based sensors. Over the last few years, computer vision and deep learning (DL) have been widely applied to fall detection systems. The application of DL for fall activity recognition has led to major developments in detection accuracy by overcoming numerous obstacles met by conventional models. This study presents a Vision Transformer and Self-Attention Mechanism with Recurrent Neural Network-Based Fall Activity Recognition System (VTSAMRNN-FARS) method. The primary objective of the VTSAMRNN-FARS method is to improve the fall detection and classification method for individuals with disabilities in smart IoT environments. Initially, the bilateral filtering (BF) model is used for image pre-processing to remove the noise in input image data. Furthermore, the feature extraction process is performed by the Vision Transformer (ViT) model to convert raw data into a reduced set of relevant features, thereby enhancing model performance and efficiency. For detecting fall activities, a bidirectional gated recurrent unit with a self-attention mechanism (BiGRU-SAM) model is implemented. Finally, the enhanced wombat optimization algorithm (EWOA) model optimally adjusts the hyperparameter values of the BiGRU-SAM approach, resulting in improved classification results. The simulation analysis of the VTSAMRNN-FARS methodology is examined under the UR_Fall_Dataset_Subset dataset. The comparison study of the VTSAMRNN-FARS methodology is reviewed and found to be 99.67% more effective than existing models.
Similar content being viewed by others

Introduction
Falling is a major problem suffered by disabled and ageing people who live individually1. They require a responsible search so they might be aided in the event of a fall occurrence. Falls can bring on modest injuries like fainting, to severe injuries like death, specifically in elderly individuals who suffer repeated physical imbalances, including disabled and ageing persons2. A successful fall recognition approach is necessary to provide superior attention to these individuals, as they are willing to communicate with caregivers. Such approaches will decrease the medical cost associated with falls and additionally result in the lowest death rate amongst disabled and aged persons owing to falls3. This higher percentage of falls among the ageing creates road traffic damage, which is the most common reason for death. Around the world, falls are a public health care problem for elderly people. The independent life of a disabled person is radically changed after a fall. Typically, these emergencies occur without warning, significantly reducing the detection of earlier emergency events4. Therefore, the fall recognition approach is enhanced, and this approach is a lifesaver in medical warning approaches. Thus, a constant fall detection approach is necessary to prevent the severe consequences of falls. The automated services provided to a disabled and ageing population enable them to live independently in their homes, paving the way for innovative economic fields5. With evolutions in the Internet of Things (IoT), the smart home is the solution for delivering home services, such as security, energy management, assistance with daily tasks, and medical care monitoring. A smart home is equipped with numerous sensors and actuators that can detect humidity and temperature, the room’s luminosity, door openings, and other environmental factors6. Likewise, it regulates various instruments, including heating, household appliances, shutters, lights, and more. Nowadays, many of these gadgets are controlled and connected remotely. In recent years, the enlargement of the fall recognition method has become an area of research. A plethora of fall recognition methods are being introduced, utilizing diverse approaches7. The current fall recognition methods can be categorized into two major categories: (I) wearable device-based methods and (II) context-aware methods. Wearable device-based methods utilize a gadget that the user wears to detect falls. This gadget incorporates an accelerometer and gyroscope that could determine the angular velocity and acceleration8. The activity and movement of the user outcomes in a temporal variation of the angular velocity data and determined acceleration, leaving diverse fingerprints for dissimilar activities. Preventing falls is significant, and it is very efficient by employing Artificial Intelligence (AI) and IoT to generate a method that could rapidly spot falls and fit into an individual’s everyday practices. In recent times, with the advancement in Deep Learning (DL) and Machine Learning (ML)-based techniques, multiple studies have effectively demonstrated substantial performance for fall recognition9. Currently, DL has achieved notable improvements in making higher-level abstractions from complex data in various domains. In addition to the remarkable development of DL in fall recognition, recent investigations are being performed to resolve major problems10.
This study presents a Vision Transformer and Self-Attention Mechanism with Recurrent Neural Network-Based Fall Activity Recognition System (VTSAMRNN-FARS) method. The primary objective of the VTSAMRNN-FARS method is to improve the fall detection and classification method for individuals with disabilities in smart IoT environments. Initially, the bilateral filtering (BF) model is used for image pre-processing to remove the noise in input image data. Furthermore, the feature extraction process is performed by the Vision Transformer (ViT) model to convert raw data into a reduced set of relevant features, thereby enhancing model performance and efficiency. For detecting fall activities, a bidirectional gated recurrent unit with a self-attention mechanism (BiGRU-SAM) model is implemented. Finally, the enhanced wombat optimization algorithm (EWOA) model optimally adjusts the hyperparameter values of the BiGRU-SAM approach, resulting in improved classification results. The simulation analysis of the VTSAMRNN-FARS methodology is examined under the UR_Fall_Dataset_Subset dataset. The significant contribution of the VTSAMRNN-FARS methodology is listed below.
-
The VTSAMRNN-FARS model applies BF to effectively mitigate noise while preserving significant edges, improving image clarity. This step enhances the quality of input data, leading to more reliable feature extraction. It plays a crucial role in improving the overall performance of the fall detection system.
-
The VTSAMRNN-FARS approach employs ViT for feature extraction to capture long-range dependencies and spatial relationships in input frames. This enables more effective representation of subtle fall patterns across sequences. It significantly enhances the technique’s capability to distinguish between fall and non-fall events.
-
The VTSAMRNN-FARS methodology integrates the BiGRU-SAM model to effectively capture temporal dynamics and emphasize relevant features in sequential data. This enhances the technique’s capability to detect fall events with greater accuracy. It enhances temporal pattern recognition, critical for real-time fall detection.
-
The VTSAMRNN-FARS method employs the EWOA technique for fine-tuning hyperparameters, leading to enhanced convergence speed and improved detection accuracy. This optimization step ensures more stable and efficient model training. It enhances the overall reliability and robustness of the fall detection framework.
-
The integration of ViT and BiGRU-SAM, integrated with EWOA-based tuning, presents a novel hybrid process for fall detection. This approach uniquely utilizes spatial-temporal modelling and adaptive optimization to improve accuracy and efficiency. The novelty lies in incorporating transformer-based vision with recurrent learning and metaheuristic tuning within a single, lightweight framework. It is particularly effective in real-time, resource-constrained environments.
Related works
Alhazmi et al.11 utilize a millimetre-wave (mmWave) radar sensor (IWR6843ISK-ODS) for continuous observation of human activities. They introduced a PointNet NN for real-world HAR, which can present tracking maps, fall alerts, and activity data reports. Utilizing radar assists in protecting patients’ confidentiality by preventing camera recording images. Li et al.12 proposed an affordable, contactless, and easy-to-deploy health monitoring method, HealthDAR. Specifically, HealthDAR encompasses three key components: timely symptom recognition, vital sign monitoring, and cough recognition; social distancing and tracking; and preventive actions. HealthDAR has three main elements: (1) A low-energy, low-cost, and integrated radar method; (2) The Simultaneous Signal Processing associated DL (SSPDL) model for cough recognition; and (3) The DL approach for the daily activity classifications. Campanella et al.13 developed an innovative DL technique explicitly enhanced for the edge gadget’s capability to detect falls. The introduced method was applied in the real world with two primary goals: to identify activities and classify them as either falls or everyday routines. This work valued this method by utilizing either the self-collected dataset or a publicly available one (SisFall). Toupas et al.14 introduce a digital supporter capable of precisely detecting a broad array of human activities, thereby establishing novel technologies and methodologies for dynamically adaptive multimodal data analysis and fusion. Moreover, the scientific study aimed to integrate a mobile robotic framework to facilitate human activity monitoring in dynamic settings.
In15, an intellectual guide dog harness called iDog, which accepts edge computing technology and AI, is presented. The presented smart gadget is designed for dogs that don’t distract the guide dog’s performance. An RGB-D image sensor is utilized to collect data about the outside environment, which is then analyzed through an edge computing element and delivered to visually impaired pedestrians via voice alerts. This guarantees the safety of visually impaired pedestrians. Guamán-Egas and Castro-Martin16 projected the growth of bracelet-type gadgets with an IoT structure for vital signs monitoring and automated fall detection. Fall detection is implemented by employing ML methods that are trained on data obtained from the accelerometer. The Edge Impulse framework was utilized during data processing and the design of the learning blocks. Kausar et al.17 introduce an approach to detect and differentiate falls in elderly adults employing wearable fall detection gadgets. Innovative feature extraction and pre-processing models were established to remove features from accelerometer data. Additionally, ML models like k-NN, SVM, ANN, and RF were utilized to categorize the rotation signals and acceleration into ADL or fall. The study’s significant contributions include the application of the dual-class classification model for fall recognition and the examination of the effects of sliding window size on method implementation. In18, a smart wheelchair with an IoT-based responsive health-related monitoring method is projected. The medical parameters, such as pressure, temperature, an emergency notification button, and fall detection, indicate emergencies to the caretaker so that the caretaker can provide guidelines from an IoT application monitoring the wheelchair method and further assist the elderly individual in getting up and sitting in the chair, utilizing hydraulics.
Materials and methods
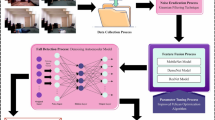
In this article, the VTSAMRNN-FARS method is proposed. The primary objective of the VTSAMRNN-FARS method is to improve the fall detection and classification system for individuals with disabilities in smart IoT environments. It comprises four major processes: BF-based image pre-processing, feature extraction, a hybrid model for fall activity detection, and EWOA-based parameter tuning. Figure 1 represents the flow of the VTSAMRNN-FARS model.

Workflow of VTSAMRNN-FARS approach.
Image pre-processing: BF model
Initially, the VTSAMRNN-FARS model performs an image pre-processing stage using BF to remove noise from the input image data19. This model is chosen for its ability to mitigate noise while preserving crucial edge details, which is significant for accurately capturing the shape and contours of human subjects in fall detection. This model performs both domain and range filtering, allowing it to maintain fine structural details, unlike conventional filters such as Gaussian or median filters that may blur edges. This edge-preserving property is beneficial when working with complex or low-quality input frames, which are commonly encountered in real-world surveillance scenarios. Moreover, BF operates efficiently, making it appropriate for real-time applications on low-resource devices. Its balance between smoothing and edge retention presents superior pre-processing performance compared to standard filtering techniques.
BF is a vital pre-processing model in fall activity detection methods for individuals with disabilities. It improves sensor data by decreasing noise while maintaining crucial edge data. This is particularly beneficial for accurately detecting sudden changes in activity patterns, such as falls. The filter combines intensity and spatial domain data to enhance data quality, ensuring the accurate extraction of features. By upholding data reliability, BF supports strong DL methods in identifying falls and differentiating them from other actions. Its combination enhances the reliability of the system, which is vital for certifying appropriate and precise fall detection in smart IoT environments.
Feature extractor: ViT method
Furthermore, the feature extraction process is performed by the ViT model to convert raw data into a reduced set of relevant features, thereby enhancing model performance and efficiency20. This model is chosen for its superior capability for recognizing subtle spatial cues in fall detection, and also effectively models global contextual relationships within images. This model segments images into patches and utilizes self-attention to capture long-range dependencies, enabling a more holistic understanding of the scene, unlike conventional CNNs that rely on local receptive fields. This is particularly advantageous for distinguishing between fall and non-fall postures, where global body orientation is crucial. ViT also generalizes well across varying input conditions, such as lighting and pose variations. Additionally, its transformer-based architecture scales effectively and provides robust feature representations with fewer inductive biases than CNNs.
ViT is introduced as an alternative for overcoming the drawbacks of CNNs. They are a DL-based self-attention (SA) approach tailored for analyzing relationships across various parts of the images. \(\:ViT\) requires a large amount of data to improve the accuracy of its features; therefore, this study necessitates data augmentation during the data pre-processing stage. Unlike the CNN method, the \(\:ViT\) approach presents a novel method for recognizing images inspired by the Transformer technique applied in natural language processing (NLP). It is identified as having improved performance in image recognition tasks. Its computational time relies on the token counts due to the SA mechanism and the dimensionality of the token embeddings. However, it requires more parameters and intensive processes compared to CNN; the training time is lengthier, particularly for larger datasets and complex calculations. In general, the structure itself is separated into patch embedding, classification head, transformer encoder, and positional encoding. Among the various changes made to CNN, one aspect that distinguishes the two methods is the input model. Whereas CNN captures the value of a raw pixel as the input, \(\:ViT\) splits the images into small patches, which are then expanded from 2D into a 1D vector and converted into lower-dimensional linear embeddings using linear projection. Therefore, a patch sequence embedding is acquired as the input to the \(\:ViT\) method. Here, the sequence is treated similarly to the input tokens for the layers. The output of these methods is referred to as patch embedding, a term that corresponds to tokenization in NLP.
Positioned encodings (1) and (2) will later be added to present positional information in the patch embedding, as Transformers are not constructed based on the theory of locations. The variety of image patches is valuable as it assists the method in recognizing the location of the images and learning their spatial relationships. The process is completed by adding learnable parameters to all embedded patches at the input phases. The system would then learn the positional encoding separately. The equation establishes the computations of positional encoding:
The equation above computes the positional encoding for every position within the sequence and for all dimensions of the vector. \(\:PE\) denotes Positional Encoding, \(\:pos\) represents the position inside the sequence, \(\:i\) signifies the dimensional index, and \(\:d\) refers to the size of the embedding vector.
Dive into the basic module of \(\:ViT\), namely the encoding transformer, containing numerous encoding layers. All these layers comprise feed-forward neural networks (FFNNs) and multi-head self-attention (MHSA). Self-attention is designed to help the system focus attention on the most significant patches by creating attention maps. The SA mechanism permits the approach for attending to various fields of the data and learning the relationships among all dissimilar patches. Thereafter, it will calculate a weighted amount of each of the input values (3). The weight is gained from the patch’s importance to the task. By doing this, the method can handle significant portions of the data, effectively representing the input data in both global and local contexts. In the meantime, the multi-head attention represents the addition of the SA idea. It is applied for running the numerous SA mechanisms in parallel, and all those seizures have different kinds of relationships. The attention weights (scores) of the SA mechanism are computed using the following equation:
whereas \(\:Q\) refers to the query that represents the present token search for significant information within the sequences, \(\:K\) denotes the key that represents tokens’ encoding information, \(\:V\) signifies the value that represents real information being clustered, and \(\:{d}_{k}\) symbolizes the size of the key vectors.
Switching from the MHSA, the information will then be accessed by the FFNN (4). In contrast, it should be converted into a token-to-token method and presented with nonlinearity, allowing the technique to learn composite relationships among them. In other words, the FFNN plays a role in converting the output from the MHSA into a method that is efficient and sufficient for application in the subsequent stage of the process. The FFNN architecture comprises the function of \(\:ReLU\) lined by a linear transformation on all sides. The equation of FFNN is mathematically expressed as:
Here, \(\:X\) refers to the input matrix, \(\:{W}_{1}\) and \(\:{W}_{2}\) represent weighted matrices, and \(\:{b}_{1}\) and \(\:{b}_{2}\) denote biased vectors.
The output of either the MHSA or FFNN is still unprepared and is being passed into the classification head. There is a final layer named Residual Connections and Layer Normalisation, which are two of the layers used to enhance the method’s functionality. However, the normalization layer is responsible for ensuring stability and speeding up the training process by standardizing the inputs based on the characteristics of all data. The residual links, which are otherwise called skip connections, are in charge of avoiding the problem of vanishing gradient by adding the novel input embedding to their output. This normalization procedure involves ensuring that the input to all layers has a mean of \(\:0\:\)and a variance of \(\:1\). The sub-layer output (5) mixed with the novel input utilizing layer normalization and residual links is inscribed as:
whereas \(\:x\) denotes the input tensor to the transformer layer, LayerNorm \(\:\left(x+Sublayer\left(x\right)\right)\) refers to the equation of layer normalization, and \(\:Sublayer\:\left(x\right)\) signifies the sub-layer process in the transformer, like FFNN and MHSA. Finally, the output from the transformer encoding reaches the classification head, providing the final class classifications. It captures the learned features from the preceding layers that are passed to make the class possibilities.
Hybrid model classification: BiGRU-SAM
For the detection of fall activities, the VTSAMRNN-FARS method employs the BiGRU-SAM model21. This method shows efficiency in capturing temporal dependencies in sequential data while focusing on the most relevant features. The model also processes input in both forward and backwards directions, allowing it to comprehend the context from the entire sequence, which is significant for accurately detecting falls over time. The integration of the SAM further enhances the model by dynamically weighting crucial time steps, thereby improving sensitivity to critical motion cues. Compared to standard RNNs or unidirectional GRUs, BiGRU-SAM presents better performance in terms of accuracy and interpretability. It is also computationally more efficient than LSTM while maintaining comparable temporal modelling capabilities. Figure 2 depicts the infrastructure of BiGRU-SAM.

Architecture of the BiGRU-SAM model.
This layer contains a SAM and a Bi-GRU network. The Bi-GRU model utilizes contextual information within its bi-directional architecture. In contrast, the SAM dynamically fine-tunes the weighting of various locations, allowing the method to focus on the significant portions of the sequence. The integration of this dual component enables the complete modelling of text sequences, providing precise data for the following components. Bi-GRU is a bi-directional recurrent neural network (RNN) whose recurrent architecture components are named GRUs. The significant elements of the GRU are as demonstrated: Reset Gate: Establishes several of an HL must be forgetting; Update Gate: Controlling the quantity of data from the prior HL, which is given to the present time steps; Current Memory: Calculates the novel memory according to the present input, the preceding HL, and the data of reset gate; Updated State: Computes the present state according to the gate of update and the present memory. The computation of the gates of update within the GRU at timestep \(\:t\) in \(\:the\:lth\) layer is exposed as shown:
whereas \(\:{A}_{t}^{l}\) characterizes the output at timestep \(\:t\) in \(\:l\:th\) layers, \(\:\sigma\:\) denotes the activation function of the sigmoid, \(\:{W}_{u}\) signifies the weighted matrix of the gates of update in the preceding layer, \(\:{S}_{u}\) characterizes the weighted matrix of the gates of update from the prior timestep, and \(\:{B}_{r}\) signifies biased matrix of the gate of update.
Also, the computation of the gate of reset in the GRU at \(\:tth\) timestep \(\:of\:the\:lth\) layer is exposed as shown:
Here, \(\:{W}_{r}\) characterizes the weighted matrix of the gate of reset in the preceding layers, \(\:{S}_{r}\) signifies the weighted matrix of the gates of reset from the preceding timestep, and \(\:{B}_{r}\) denotes the biased matrix of the gates of reset.
The output of the GRU is described as demonstrated:
Now, the \(\:{A}_{t}^{l}\) characterizes the output at timestep \(\:t\) in \(\:the\:lth\) layer. \(\:Tanh\) refers to the activation function. \(\:W\) signifies the weighted matrix from the preceding layer, \(\:S\) symbolizes the weighted matrix through the preceding timestep, and \(\:B\) represents a biased matrix.
Once the gates of the reset value approach zero, the impact of the output from the preceding time step should be \(\:forgotten\). The gates of update additionally control the quantity of data from the prior timestep, which is reserved over the weighted matrix values. Then, all units within the system can take significant previous information, but forget insignificant previous data.
The attention mechanism (AM) computes the importance of the relationships among all pairs of characters within the sequence of text at various places. This method utilizes the MHSA mechanism. They present the AM, self-attention, and multi‐head attention as demonstrated.
AM: The AM’s input typically contains three modules: the Key, the Value, and the Query. The Query represents the tensor, which symbolizes the present location or data of the method, gained over a learnable NN that is typically the last hidden layer output at every sequence stage of the previous NN. The Key is a tensor, which signifies various information or locations within the sequence of input. The Value is a tensor demonstrating the data related to all Keys, which is established by the algorithm’s context and task. The AM’s output contains attention output and attention weights. The Attention weight is a tensor that signifies the significance weighting assigned by the method among the keys and queries. The AM computes the similarities between keys and questions and then standardizes them, utilizing softmax to gain the attention weights. Attention outputs are tensors that represent the weighting amount calculated based on the values, queries, and keys. Initially, this approach utilizes the function of attention to calculate the similarities amongst a query and all keys as demonstrated:
Here, \(\:Q\) denotes query, \(\:K\) means key, \(\:AttF\) signifies attention function, \(\:S\) characterizes the similarities amongst the keys, and the query and \(\:l\) refer to the distance of the targeted sequence.
Formerly, the similarities for gaining the attention weights \(\:(W\)) were standardized.
At last, the output of the attention \(\:O\) is gained.
The AM, as in the MB-GAP approach, is applied. The equation is presented as shown:
The calculation of the AM is presented as shown:
Self-AM
Once the three inputs to the AM are similar tensors, a variation of the AM, known as Self-Attention, is designed. This mechanism design reduces reliance on external information, allowing the method to focus more on the internal structure of the sequence after processing it, and thus enhancing the model’s ability to extract fundamental data structures. This is signified as shown:
whereas the value \(\:\left(V\right),\) the key \(\:\left(K\right),\) and query \(\:\left(Q\right)\) are just the same tensor \(\:A.\).
Multi-head attention is applied to enhance the method’s capability to capture global dependencies within sequences. It can concurrently learn numerous collections of attention weights, all of which are referred to as heads. That permits the method to concentrate on various portions of the sequence of input in dissimilar subsets of attention, thus identifying composite patterns within the sequence. The calculation procedure for this attention is as demonstrated:
-
Linear transformations were applied to the input \(\:Q,K\), and \(\:V\) for mapping them to various attention subsets:
whereas \(\:i=\text{1,2},\dots\:,nu{m}_{-}heads\) denotes the attention head counts, however, \(\:{U}_{{Q}_{i}},{U}_{{K}_{j}}\), and \(\:{U}_{{V}_{i}}\) represent weighted matrices.
-
Multi-head attention is computed, and dissimilar AMs are used to call attention heads:
-
The Multi-head attention outputs are joined, and the outputs of all attention heads are connected:
-
A linear transformation is applied to the connected outputs of the multi-head to gain the last output:
Now, \(\:{U}_{O}\) signifies linear transformations.
Hyperparameter tuning: EWOA
Ultimately, the EWOA optimally adjusts the hyperparameter values of the BiGRU-SAM approach, yielding improved classification performance22. This model is chosen for its ability to explore the search space and avoid local optima, resulting in improved model performance. Compared to conventional optimization methods like grid or random search, EWOA presents faster convergence and requires fewer evaluations, making it computationally efficient. It improves upon the original WOA model by incorporating adaptive mechanisms that balance exploration and exploitation more effectively. This results in more precise parameter tuning, improving both the accuracy and robustness of the fall detection model. Additionally, a population-based approach makes it appropriate for optimizing complex, non-linear problems common in DL models.
The EWOA model is a population-based metaheuristic technique, where the wombats establish the associates of the population. Naturally, the wombats reflect the problem-solving field that is hypothesized, and a structure is recognized as a result. Each wombat serves as an assistant to EWOA and represents candidate elucidation, which is described in terms of vectors. Throughout the implementation of the technique, the position of every wombat is extensively set as per Eq. (19).
whereas, \(\:X\) signifies the matrix of the wombat population; \(\:{X}_{i}\) denotes the \(\:i\)th wombat.
Here, \(\:X\) signifies the population matrix of wombats. Every \(\:{X}_{i}\) relates to the features of the \(\:ith\) wombat. Particularly, \(\:{x}_{i,d}\) represents the wombat value of \(\:the\:dth\) dimension. \(\:N\) and \(\:m\) refer to the total number of wombats and decision variables, respectively; \(\:r\) refers to a random value produced in the interval of 0 to 1. Moreover, \(\:u{b}_{d}\) and \(\:l{b}_{d}\:\)signify the upper and lower limits of \(\:dth\) decision variables, respectively.
Therefore, the fitness function (FF) is assessed for every location of the wombat. The resultant value of an objective function is gathered as a vector, which is exhibited over Eq. (21).
Here, \(\:F\) signifies the vector covering the measured values of FF, with \(\:{F}_{i}\) signifying the FF value calculated for \(\:the\:ith\) wombat. The optimum value achieved for the FF states the finest executing connection in the EWOA. At the same time, the worst value of the objective function is linked to the least effective member. The wombat’s locations are upgraded throughout every iteration in the space of problem-solving.
The presented EWOA efficiently tackles the optimization challenges over an iterative process where the search abilities of its associates in the problem-solving area are optimized. Stimulated by the standard wombat’s behaviour, the complex strategy of EWOA reflects the escape and foraging tactics detected naturally. This method upgrades the location of wombats in the space of problem-solving over two dissimilar stages, such as exploration, which mimics the foraging behaviour. Where exploitation pretends to be an escape tactic near the tunnels to avoid predators. The complete explanation of these dual phases is explained below:
Phase 1: foraging method (exploration phase)
In this phase, the wombats’ locations in the problem-solving area were altered based on their foraging behaviour and the features of this type. Wombats have an extraordinary ability to search for food through vast regions of their environment. Therefore, this augmentation enhances the model’s exploratory ability, enabling efficient global exploration organization. Here, each wombat esteems the location of remaining population members, demonstrating superior FF value as latent exploration locations. Its mathematical formulation is expressed in Eq. (22).
Here, CFPi signifies a range of potential exploration locations for \(\:the\:ith\) wombat; \(\:{X}_{k}\) signifies a member of the population, which claims a superior value of FF when equated to the \(\:ith\) wombat. \(\:{F}_{k}\) is the consistent value of FF. It is assumed that the wombat selects accessible fodder locations randomly and remains near them. A revised location is computed for each EWOA associate using Eq. (23). If the upgraded location produces any improvement in the FF valuation, then it is inclined to succeed the previous location of the relevant member over the below-mentioned Eq. (24).
Here, \(\:SF{P}_{i}\:\)signifies the selected exploration location for the \(\:ith\) wombat, \(\:and\:SF{P}_{i,j}\) signifies its \(\:jth\) dimension. \(\:{X}_{i}^{P1}\) denotes the freshly-calculated location for \(\:the\:ith\) wombat, \(\:{x}_{i,j}^{P1}\) signifying its \(\:jth\) dimension. \(\:{F}_{i}^{P1}\) connects to the value of the objective function.
The randomly generated number in Eq. (23) is generated utilizing a chaotic sine map. The a and \(\:{C}_{t}\:\)parameters are fixed as 2.8 and 0.36, respectively. It generally improves the exploration stage by presenting better arbitrariness. Its mathematical formulation is expressed below:
where \(\:t\:\) signifies the current count of iterations.
Phase 2: escape tactic (exploitation phase)
Next, in the problem solving, the locations of the wombat’s area were studied by pretending their escape tactic from their predators. It is demonstrated to cause slight alterations in the locations of EWOA links during problem-solving, thus improving the model’s exploitation ability for local hunting. During this EWOA approach, an upgraded location is defined for every member of EWOA using Eq. (23) based on the behaviour displayed by wombats when jumping near the tunnels. After this upgraded location improves the values of FF, it switches to the previous location of the member, utilizing Eq. (24).
The exploitation stage is designed to enhance solutions by thoroughly exploring nearby promising regions. This phase utilizes Levy flight (LF) to present measured randomness, enabling effective local search and avoiding early convergence. This incorporation enhances the local searching ability. LF presents longer-range step dimensions using greater jumps, which permits the technique to improve the solution well when evading early convergence compared to conventional models.
where \(\:\sigma\:\) is defined below in the mathematical formulation
While \(\:\varGamma\:\left(x\right)=(x-1)!\), \(\:{r}_{5}\) and \(\:{r}_{6}\) are the indiscriminate amounts within the range of \(\:\left[\text{0,1}\right]\). Where \(\:1<\beta\:\le\:2\) means the value of persistent, i.e., \(\:\beta\:\) is 1.5. \(\:Levy\left(\lambda\:\right)\) interacts with the step length with a variance and mean of \(\:1<\lambda\:<3\). \(\:\lambda\:\) means the factor of distribution, and \(\:{\Gamma\:}(\cdot\:)\) represents the function of the gamma distribution.
Here, \(\:{X}_{i}^{P2}\) signifies the upgraded location for \(\:the\:ith\) wombat. \(\:{X}_{i,j}^{P2}\) means the \(\:jth\) dimension of this novel location, \(\:{F}_{i}^{P2}\) connects to the valuation of FF in this upgraded location, \(\:{r}_{i,j}\) refers to the indiscriminate numbers in the range of \(\:[0,\:1]\), and \(\:t\) denotes the count of iterations. The EWOA model proposes an FF for achieving an enhanced classification outcome. It designates a positive numeral to designate the enriched candidate solution performance. The reduction in the classifier error rate is determined as FF in this article. Its mathematical formulation is expressed in Eq. (30).
Experimental validation
In this paper, the fall detection outcomes of the VTSAMRNN-FARS approach are examined under the UR_Fall_Dataset_Subset23 dataset. The database contains 620 images under dual class labels, such as fall and non-fall, as demonstrated in Table 1. Figure 3 represents the sample images.

Sample images of (a) fall and (b) non-fall.
Figure 4 presents the confusion matrix generated by the VTSAMRNN-FARS model for various epoch counts. The results recognize that the VTSAMRNN-FARS methodology has effective detection and recognition of both class labels specifically.

Confusion matrix of VTSAMRNN-FARS methodology (a–f), Epochs 500–3000.
The fall detection results of the VTSAMRNN-FARS technique are shown under dissimilar epochs in Table 2; Fig. 5. The table values state that the VTSAMRNN-FARS technique properly recognized the dual class labels. At 500 epoch counts, the VTSAMRNN-FARS technique provides an average \(\:acc{u}_{y}\) of 99.02%, \(\:pre{c}_{n}\) of 99.02%, \(\:sen{s}_{y}\) of 99.02%, \(\:spe{c}_{y}\) of 99.02%, \(\:{F1}_{score}\) of 99.02%, and Kappa of 99.08%. Besides, at 1000 epochs, the VTSAMRNN-FARS method delivers an average \(\:acc{u}_{y}\) of 99.16%, \(\:pre{c}_{n}\) of 99.20%, \(\:sen{s}_{y}\) of 99.16%, \(\:spe{c}_{y}\) of 99.16%, \(\:{F1}_{score}\) of 99.18%, and Kappa of 99.24%. Furthermore, at 2000 epochs, the VTSAMRNN-FARS method presents an average \(\:acc{u}_{y}\) of 99.34%, \(\:pre{c}_{n}\) of 99.34%, \(\:sen{s}_{y}\) of 99.34%, \(\:spe{c}_{y}\) of 99.34%, \(\:{F1}_{score}\) of 99.34%, and Kappa of 99.25%. Also, at 2500 epochs, the VTSAMRNN-FARS method provides an average \(\:acc{u}_{y}\) of 99.53%, \(\:pre{c}_{n}\) of 99.49%, \(\:sen{s}_{y}\) of 99.53%, \(\:spe{c}_{y}\) of 99.53%, \(\:{F1}_{score}\) of 99.51%, and Kappa of 99.59%. In addition, at 3000 epochs, the VTSAMRNN-FARS method provides an average \(\:acc{u}_{y}\) of 99.67%, \(\:pre{c}_{n}\) of 99.67%, \(\:sen{s}_{y}\) of 99.67%, \(\:spe{c}_{y}\) of 99.67%, \(\:{F1}_{score}\) of 99.67%, and Kappa of 99.73%.

Average of the VTSAMRNN-FARS model under distinct epochs.
In Fig. 6, the training (TRA) \(\:acc{u}_{y}\) and validation (VAL) \(\:acc{u}_{y}\) analysis of the VTSAMRNN-FARS methodology under different epochs is illustrated. The \(\:acc{u}_{y}\:\)analysis is calculated across the range of 0-3000 epochs. The figure highlights that the TRA and VAL \(\:acc{u}_{y}\) analysis exhibitions showed improved tendencies, which informed the capacity of the VTSAMRNN-FARS methodology, maximum performance across multiple iterations. Simultaneously, the TRA and VAL \(\:acc{u}_{y}\) specify inferior overfitting and exhibit maximal performance of the VTSAMRNN-FARS model, pledging reliable prediction on undetected instances.

\(\:Acc{u}_{y}\) curve of VTSAMRNN-FARS method (a–f), Epochs 500–3000.
In Fig. 7, the TRA loss (TRALOS) and VAL loss (VALLOS) curve of the VTSAMRNN-FARS methodology under dissimilar epochs is presented. The values of loss are computed throughout 0-3000 epoch counts. The TRALOS and VALLOS analyses exemplify a diminishing trend, informing the capacity of the VTSAMRNN-FARS technique to balance an exchange between data fitting and simplification. The constant fall in values of loss also assures the superior outcomes of the VTSAMRNN-FARS technique and tuning the prediction outcomes in time.

Loss graphs of VTSAMRNN-FARS method (a–f), Epochs 500–3000.
In Fig. 8, the precision-recall (PR) graph analysis of the VTSAMRNN-FARS methodology in terms of different epoch counts presents clarification into its results by plotting Precision beside Recall for all classes. This figure demonstrates that the VTSAMRNN-FARS technique constantly accomplishes superior PR analysis over distinct classes, indicating its capacity to maintain an essential proportion of true positive predictions amongst all positive predictions (precision), which likewise takes a vast part of actual positives (recall). The balanced rise in PR analysis among each class describes the efficiency of the VTSAMRNN-FARS technique in the classifier procedure.

PR curve of VTSAMRNN-FARS method (a–f), Epochs 500–3000.
In Fig. 9, the ROC graph of the VTSAMRNN-FARS model for different epochs is examined. The results suggest that the VTSAMRNN-FARS model achieves the optimal ROC results across all class labels, demonstrating a significant capacity for discriminating between class labels. This dependable tendency of higher ROC analysis across several class labels implies the capable outcomes of the VTSAMRNN-FARS methodology on predicting class labels, emphasizing the strong nature of the classification procedure.

ROC graph of VTSAMRNN-FARS method (a-f), Epochs 500–3000.
Table 3 presents a comparative analysis of the VTSAMRNN-FARS method with existing approaches under various measures24,25,26.
The \(\:acc{u}_{y}\) and \(\:pre{c}_{n}\) results of the VTSAMRNN-FARS approach compared to existing methodologies are illustrated in Fig. 10. The simulation results indicate that the VTSAMRNN-FARS approach outperforms other models. Based on \(\:acc{u}_{y}\), the VTSAMRNN-FARS approach has a higher \(\:acc{u}_{y}\) of 99.67% while the Open Pose-LSTM, 2D-ConvNN, ResNet50, 2D Pose estimation, TD_CNN-LSTM, RetinaNet, YOLOv7, and YOLOv5 models have a lower \(\:acc{u}_{y}\) of 92.72%, 95.88%, 96.21%, 95.60%, 99.23%, 94.69%, 91.51%, and 94.83%, respectively. Likewise, depending on \(\:pre{c}_{n}\), the VTSAMRNN-FARS method has a better \(\:pre{c}_{n}\) of 99.67% where the Open Pose-LSTM, 2D-ConvNN, ResNet50, 2D Pose estimation, TD_CNN-LSTM, RetinaNet, YOLOv7, and YOLOv5 models have \(\:pre{c}_{n}\) of 94.85%, 94.35%, 95.15%, 92.00%, 93.99%, 96.75%, 96.68%, and 91.94%, correspondingly.

\(\:Acc{u}_{y}\) and \(\:Pre{c}_{n}\) outcome of the VTSAMRNN-FARS approach with existing methods.
Figure 11 represents the comparative outcomes of the VTSAMRNN-FARS method with existing techniques in terms of \(\:sen{s}_{y}\), and \(\:spe{c}_{y}\). Based on \(\:sen{s}_{y},\) the VTSAMRNN-FARS method has a maximal \(\:sen{s}_{y}\) of 99.67% while the Open Pose-LSTM, 2D-ConvNN, ResNet50, 2D Pose estimation, TD_CNN-LSTM, RetinaNet, YOLOv7, and YOLOv5 approaches have a lower \(\:sen{s}_{y}\) of 97.53%, 94.93%, 95.40%, 91.90%, 93.64%, 95.03%, 92.34%, and 97.16%, respectively. Moreover, concerning \(\:spe{c}_{y},\) the VTSAMRNN-FARS methodology has a maximum \(\:spe{c}_{y}\) of 99.67% whereas the Open Pose-LSTM, 2D-ConvNN, ResNet50, 2D Pose estimation, TD_CNN-LSTM, RetinaNet, YOLOv7, and YOLOv5 approaches have a minimum \(\:spe{c}_{y}\) of 95.01%, 97.70%, 91.89%, 98.16%, 96.85%, 95.61%, 96.10%, and 94.34%, correspondingly.

\(\:Sen{s}_{y}\) and \(\:Spe{c}_{y}\) outcome of the VTSAMRNN-FARS approach with existing methods.
In Table 4; Fig. 12, the comparison outcomes of the VTSAMRNN-FARS methodology are presented in terms of running time (PT). The results suggest that the VTSAMRNN-FARS methodology achieves the best performance. Based on RT, the VTSAMRNN-FARS methodology presents an inferior RT of 4.74 s, where the Open Pose-LSTM, 2D-ConvNN, ResNet50, 2D Pose estimation, TD_CNN-LSTM, RetinaNet, YOLOv7, and YOLOv5 approaches achieve better RT values of 10.71 s, 7.73 s, 7.49 s, 5.62 s, 6.09 s, 6.19 s, 8.46 s and 9.78 s, respectively.

RT outcome of VTSAMRNN-FARS technique with existing methods.
Table 5; Fig. 13 specifies the ablation study of the VTSAMRNN-FARS methodology to evaluate the performance impact of different methods on a classification task. The baseline method VTSAMRNN-FARS achieved the highest results with an \(\:acc{u}_{y}\) of 99.67%, \(\:pre{c}_{n}\) of 99.67%, \(\:sen{s}_{y}\) of 99.67%, and \(\:spe{c}_{y}\) of 99.67% for all metrics, indicating slightly improved performance. The BiGRU-SAM model followed closely, delivering an \(\:acc{u}_{y}\) of 98.92%, \(\:pre{c}_{n}\) of 99.13%, \(\:sen{s}_{y}\) of 99.16%, and \(\:spe{c}_{y}\) of 99.03%, highlighting robust consistency across all evaluation parameters. The EWOA method reported an \(\:acc{u}_{y}\) of 98.28%, \(\:pre{c}_{n}\) of 98.61%, \(\:sen{s}_{y}\) of 98.62%, and \(\:spe{c}_{y}\) of 98.28%, reflecting a slight performance drop compared to BiGRU-SAM. Finally, the ViT model obtained an \(\:acc{u}_{y}\) of 97.64%, \(\:pre{c}_{n}\) of 97.90%, \(\:sen{s}_{y}\) of 98.02%, and \(\:spe{c}_{y}\) of 97.74%, which, although the lowest among the methods compared, still demonstrated robust overall results.

Ablation study results of the VTSAMRNN-FARS methodology.
Conclusion
In this article, the VTSAMRNN-FARS method is proposed. The primary objective of the VTSAMRNN-FARS method is to improve the fall detection and classification system for individuals with disabilities in smart IoT environments. It contains four major processes: BF-based image pre-processing, feature extraction, a hybrid model for fall activity detection, and EWOA-based parameter tuning. Initially, the VTSAMRNN-FARS method performs an image pre-processing stage using BF to remove noise from the input image data. Furthermore, the feature extraction process is performed by the ViT model to convert raw data into a reduced set of relevant features to enhance model performance and efficiency. For detecting fall activities, the BiGRU-SAM model is employed. Ultimately, the EWOA optimally adjusts the hyperparameter values of the BiGRU-SAM model, yielding improved classification performance. The simulation analysis of the VTSAMRNN-FARS methodology is examined under the UR_Fall_Dataset_Subset dataset. A comparison study of the VTSAMRNN-FARS methodology reveals it to be 99.67% more effective than existing models. The limitations of the VTSAMRNN-FARS methodology comprise its reliance on a relatively small and specific dataset, which may affect the generalizability of the results to more diverse populations and environments. The model lacks testing under varying lighting conditions or with occlusions, which are common challenges in real-world scenarios. The computational demands still pose threats to deployment on very low-power or resource-constrained devices. Furthermore, user privacy and data security aspects require deeper exploration to ensure ethical implementation. Future work should focus on expanding dataset diversity, incorporating multimodal sensor data to enhance robustness, and developing lightweight algorithms optimized for embedded and edge computing platforms. Improving interpretability and response mechanisms for false detections would also enhance practical usability.
Data availability
The data that support the findings of this study are openly available in the Kaggle repository at https://www.kaggle.com/datasets/aftabhussaincui/ur-fall-dataset-subset, reference number23.
References
Alotaibi, F. et al. Internet of Things-driven human activity recognition of elderly and disabled people using arithmetic optimization algorithm with LSTM autoencoder. J. Disabil. Res. 2 (3), 136–146 (2023).
Sumi, L., Longchar, I. & Dey, S. December. IoT-based fall prevention and detection for senior citizens, physically and intellectually disabled. In 2019 International Conference on Information Technology (ICIT) (pp. 190–195). IEEE. (2019).
Perez, A. J., Siddiqui, F., Zeadally, S. & Lane, D. A review of IoT systems to enable independence for the elderly and disabled individuals. Internet of Things 21, 100653 (2023).
Deepaletchumi, N. & Mala, R. Leveraging variational autoencoder with hippopotamus Optimizer-Based dimensionality reduction model for attention deficit hyperactivity disorder diagnosis data. J. Intell. Syst. Internet Things 16(1). (2025).
Alharbi, H. A., Alharbi, K. K. & Hassan, C. A. U. Enhancing elderly fall detection through IoT-enabled smart flooring and AI for independent living sustainability. Sustainability 15(22), 15695 (2023).
Qi, J. et al. Examining sensor-based physical activity recognition and monitoring for healthcare using internet of things: A systematic review. J. Biomed. Inform. 87, 138–153 (2018).
Tariq, M., Majeed, H., Beg, M. O., Khan, F. A. & Derhab, A. Accurate detection of sitting posture activities in a secure IoT based assisted living environment. Future Gen. Comput. Syst. 92, 745–757 (2019).
Eltahir, M. M. et al. A.S.A. and Deep transfer Learning-Enabled activity identification and fall detection for disabled people. Comput. Mater. Contin. 75(2). (2023).
Kolobe, T. C., Tu, C. & Owolawi, P. A. A review on fall detection in smart home for elderly and disabled people. J. Adv. Comput. Intell. Intell. Inf. 26 (5), 747–757 (2022).
Jubbori, T. A., Khaldi, A. & Zayood, K. Whale optimization algorithm with deep learning based indoor monitoring of elderly and disabled people. In. J. Adv. Appl. Comput. Intelligence 2, 24 – 4 (2024).
Alhazmi, A. K. et al. Intelligent Millimeter-Wave System for Human Activity Monitoring for Telemedicine. Sensors 24(1), 268 (2024).
Li, A. et al. A contactless health monitoring system for vital signs monitoring, human activity recognition and tracking. IEEE Internet Things Journal (2023).
Campanella, S. et al. A novel embedded deep learning wearable sensor for fall detection. IEEE Sens. J. (2024).
Toupas, P. et al. July. A Framework Towards Ambient Assisted Living Enhanced by Service Robots. In Proceedings of the 16th International Conference on PErvasive Technologies Related to Assistive Environments (pp. 423–428). (2023).
Chen, L. B., Pai, W. Y., Chen, W. H. & Huang, X. R. iDog: an intelligent guide dog Harness for visually impaired pedestrians based on artificial intelligence and edge computing. IEEE Sens. J. (2024).
Guamán-Egas, J. & Castro-Martin, A. P. October. Fall Detection with Artificial Intelligence and IoT Health Monitoring System. In 2023 IEEE Seventh Ecuador Technical Chapters Meeting (ECTM) (pp. 1–6). IEEE. (2023).
Kausar, F., Mesbah, M., Iqbal, W., Ahmad, A. & Sayyed, I. Fall detection in the elderly using different machine learning algorithms with optimal window size. Mob. Networks Appl. 29 (2), 413–423 (2024).
Narayanan, K. L. et al. April. Internet of Things and Artificial Intelligence Enabled Smart Wheel Chair. In 2023 International Conference on Inventive Computation Technologies (ICICT) (pp. 1436–1440). IEEE. (2023).
Geng, J., Jiang, W. & Deng, X. Multi-scale deep feature learning network with bilateral filtering for SAR image classification. ISPRS J. Photogrammetry Remote Sens. 167, 201–213 (2020).
Saputra, V. A., Devi, M. S. & Kurniawan, A. Comparative analysis of convolutional neural networks and vision Transformers for dermatological image classification. Procedia Comput. Sci. 245, 879–888 (2024).
Yuan, C. et al. Exploring Named Entity Recognition via MacBERT-BiGRU and Global Pointer with Self-Attention. Big Data Cogn. Comput. 8(12), 179 (2024).
Nagarajan, K., Rajagopalan, A., Bajaj, M., Raju, V. & Blazek, V. Enhanced Wombat optimization algorithm for Multi-Objective optimal power flow in renewable energy and electric vehicle integrated systems. Res. Eng. 103671 (2024).
https://www.kaggle.com/datasets/aftabhussaincui/ur-fall-dataset-subset.
Alabdulkreem, E. et al. Artificial rabbit optimizer with deep learning for fall detection of disabled people in the IoT environment. AIMS Math. 9 (6), 15486–15504 (2024).
Salimi, M., Machado, J. J. & Tavares, J. M. R. Using deep neural networks for human fall detection based on pose estimation. Sensors 22(12), 4544 (2022).
Zi, X., Chaturvedi, K., Braytee, A., Li, J. & Prasad, M. Detecting human falls in poor lighting: object detection and tracking approach for indoor safety. Electronics, 12(5), 1259. (2023).
Acknowledgements
The authors extend their appreciation to the King Salman center For Disability Research for funding this work through Research Group no KSRG-2024- 069.
Author information
Authors and Affiliations
Contributions
Abdulrahman Alzahrani: Conceptualization, methodology, validation, investigation, writing—original draft preparation, funding, project administrationAsmaa Mansour Alghamdi: Conceptualization, methodology, writing—original draft preparation, writing—review and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Alzahrani, A., Alghamdi, A.M. A vision transformer with recurrent neural network-based fall activity recognition system for disabled persons in smart IoT environments. Sci Rep 15, 33187 (2025). https://doi.org/10.1038/s41598-025-17497-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-17497-x
