
Abstract
The increasing adoption of Connected and Autonomous Vehicles (CAVs) within intelligent transportation systems has amplified concerns over cybersecurity threats in the Internet of Vehicles (IoV). To address the limitations of centralized Intrusion Detection Systems (IDS), we propose an Adaptive Personalized Federated Learning (APFed) model integrated with a Lightweight Depthwise Convolutional Bottleneck Network (LDwCBN). The system is designed to ensure privacy-preserving, resource-efficient, and accurate intrusion detection under heterogeneous and non-IID data conditions. APFed enhances model personalization and generalization through fine-grained adaptive updates and dynamic weight fusion, while LDwCBN improves detection speed and efficiency on constrained vehicular hardware. Extensive evaluations on benchmark datasets, including CIC-IDS2017, CSE-CIC-IDS2018, Car-Hacking, and CAN-Train-Test, demonstrate that the proposed method outperforms several state-of-the-art federated IDS approaches. Specifically, it achieves accuracy improvements of up to 5% over FedAvg and FedProx models, with significant gains in precision (up to 4%), recall (up to 3%), and F1-Score (up to 4%).
Similar content being viewed by others
Introduction
Enhanced intelligent transportation infrastructures are being enabled by the rapid evolution of technology, such as Vehicular Ad Hoc Networks (VANETs)1,2. Transport will be safer and more efficient with VANETs since they enable seamless communications between vehicles and infrastructure. VANETs pose significant security and privacy challenges due to their openness and dynamism, making intrusion detection mechanisms crucial3. As a result of VANETs, smart cities can improve security, safety, and quality of life for residents by fostering collaboration between industry and academia. Thus, VANETs, intelligent transportation systems (ITS), internet of vehicles (IOVs), and vehicular network architectures must be understood in order to meet emerging challenges and maximize their potential4. By reducing accident risks and making traffic safer, CAVs are intended to reduce traffic accidents5. Further, self-driving cars are the main IoT devices in transportation. It is estimated that the autonomous driving market will reach 42 billion dollars by 2025, according to the Boston Consulting Group report. However, ensuring reliability and security is the major challenge with these devices6,7.
Communication between CAVs is part of their goal to reduce human errors on the road, traffic accidents, and fatalities. A connected vehicle is equipped with a variety of electronic control units (ECU), sensors, and communication systems both internally and externally8. The complexity of the network systems has resulted in several security vulnerabilities. It is, therefore, imperative to develop an accurate IDS in order to mitigate different types of threats8 effectively9. Furthermore, transportation IoT networks require constant computing resources, are cognitively demanding, and provide protection against unauthorized access. Through interconnected vehicles, sensors, and infrastructure, the IoV is transforming transportation systems, improving safety, efficiency, and convenience10,11. IoV systems are vulnerable to a wide range of network intrusion attacks because of their interconnectedness, which poses significant cybersecurity challenges12,13. Malicious actors can exploit the vulnerabilities to control vehicles remotely, steal sensitive data, and disrupt transportation networks, potentially causing catastrophic outcomes. IoV environments must, therefore, be protected by robust and effective Intrusion Detection Systems (IDSs).
IDSs that collect and analyze data centrally face several limitations in IoV. As connected vehicles generate enormous amounts of data, centralized approaches are impractical and undesirable due to privacy concerns14. A promising alternative is federated learning, which allows collaborative training without sharing participant data15. A central server aggregates the parameter values from every vehicle or edge node for FL, which uses one model per vehicle or edge node. By leveraging the collective knowledge of the entire network, we preserve data privacy while maximizing the value of each individual’s information. While FL offers several advantages, its application in IoV intrusion detection faces several challenges. Depending on the computational capabilities, the communication bandwidth, and the data distribution of IoV devices and networks, FL models can be significantly impacted16. As cyber threats evolve, IDSs must be adaptive and personalized to each vehicle or network segment’s characteristics17. Moreover, IoV devices are resource-constrained, which necessitates lightweight, efficient models that do not compromise detection accuracy.
The development of LDwCBNs for vehicular ad hoc networks (VANETs) was implemented with an adaptive Personalized Federated Learning (APFed) framework. LDwCBNs are lightweight, depthwise convolutional bottleneck networks that are embedded in an adaptive Personalized Federated Learning framework. It remains challenging to optimize VANET model complexity and ensure real-time responsiveness due to the resource limitations of VANET nodes. A novel framework for enhancing intrusion detection is presented that leverages the strengths of federated learning, personalized model adaptation, and lightweight deep learning techniques. We present a framework for enhancing ids leveraging federated learning (FL), personalized model adaptation, and lightweight deep learning (DL) techniques.
This paper introduces a novel approach for intrusion detection in the Internet of Vehicles (IoV) by combining Adaptive Personalized Federated Learning (APFed) with the Lightweight Depthwise Convolutional Bottleneck Network (LDwCBN). The innovation lies in the dynamic weight fusion mechanism within APFed, which adapts model updates based on the local data distribution, effectively handling non-IID data. Additionally, the LDwCBN model ensures efficient and real-time intrusion detection, optimized for the resource-constrained hardware typical in IoV devices. This integrated framework significantly improves detection accuracy, precision, recall, and F1-Score compared to existing federated learning-based intrusion detection systems.
The rapid growth of Connected and Autonomous Vehicles (CAVs) within intelligent transportation systems has significantly enhanced the convenience and safety of modern transportation. However, this increase in connectivity has also raised critical cybersecurity concerns in the Internet of Vehicles (IoV), which is highly vulnerable to various types of cyberattacks. Traditional centralized Intrusion Detection Systems (IDS) face substantial limitations in IoV environments due to issues such as scalability, data privacy concerns, and the resource constraints of IoV devices. The motivation for this work is to address these challenges by proposing a novel solution that enhances the security of IoV systems while maintaining efficiency and privacy. In this paper, we introduce an Adaptive Personalized Federated Learning (APFed) model integrated with a Lightweight Depthwise Convolutional Bottleneck Network (LDwCBN) to overcome the limitations of centralized IDS. The main contribution of this work lies in the development of the APFed framework, which enables personalized model updates for each vehicle, ensuring that the models are tailored to individual data distributions, while still benefiting from the global learning process. By incorporating dynamic weight fusion, our approach handles the challenges of non-IID data commonly found in IoV environments. Additionally, the LDwCBN model ensures real-time, resource-efficient intrusion detection suitable for resource-constrained vehicular devices. Through extensive evaluation on benchmark datasets, including CIC-IDS2017, CSE-CIC-IDS2018, Car-Hacking, and CAN-Train-Test, we demonstrate that our proposed solution significantly outperforms existing federated IDS models in terms of accuracy, precision, recall, and F1-Score. This paper provides a promising new direction for deploying scalable, efficient, and secure intrusion detection systems in IoV environments, offering a robust solution to the growing cybersecurity threats in the automotive sector.
Related work
Intrusion detection systems (IDS) in internet of vehicles
The IoV is protected by IDSs that identify and mitigate cyberattacks18. As a result of its unique characteristics, such as high mobility, stringent resource constraints and dynamic network topology, conventional IDS techniques are not directly applicable to the IoV19. To address this challenge, researchers developed a variety of approaches to develop effective IDSs tailored to the IoV environment. A number of machine learning (ML) techniques have been proposed for IDS in the IoV because of their ability to identify malicious behaviour in network traffic data as well as learn complex patterns20. The classification of network traffic has been done using several ML algorithms, such as Support Vector Machine (SVM), Random Forest (RF), and ANN. Researchers found that LCCDE was effective when it came to detecting intrusions on both intra-vehicle and external networks based on their experiments with IoV security datasets. In a VANET based on machine learning, sensitive information is used to make decisions, but privacy mechanisms protect the data. On-board units (OBUs) consume a great deal of resources, making traditional machine learning and misuse-based learning methods ineffective for vehicle networks. To ensure secure data transmission in VANETs, a lightweight protocol is necessary21. Thus, VANET systems require a lightweight protocol to transfer secure information. DL has gained significant attention; therefore, VANETs need a lightweight protocol to handle secure data transfers. Assesses vehicular communication anomalies analyses traffic on the network, and detects attacks in diverse areas using VANET22. In VANETs, DL-based models provide high performance using minimal resources. In VANETs, DL-based models provide high performance using minimal resources. The DL model achieves high performance in VANETs using minimal resources and raw traffic inputs.
In a recent study, Ashraf et al. used an LSTM autoencoder to identify suspicious network activity in vehicles, vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communication. Their experiments revealed a high degree of accuracy for detecting a variety of attack types. Similarly, Author23 proposed an IDS framework employing LSTM and ConvLSTM networks to detect anomalies and attacks on CAN buses based on the temporal correlation of message contents. IDSs based on ML and DL have been successful, but they often require centralized data collection and processing, which raises privacy concerns and scalability concerns. Furthermore, centralized IDS performance can be impacted by heterogeneous IoV devices and networks, and by evolving cyber threats.
IoV has evolved into an area where DL is a powerful tool for intrusion detection, allowing complex features to be learned from raw data automatically without manual feature engineering. CNN and long short-term memories are powerful deep learning models for detecting sophisticated cyberattacks. They capture delicate patterns and dependencies in network data24. CNNs are especially effective for analyzing spatially dependent data, such as network traffic viewed as images or matrixes25. Convolutional neural networks are capable of automatically extracting relevant features and identifying malicious patterns from data by applying convolutional filters. Detection hybrids combine multiple detection techniques in order to overcome their respective weaknesses and leverage their strengths. Hence, signatures, anomalies, and specifications can all be used to detect a variety of cyber threats26. Network traffic data is compared with an attack signature database for signature-based detection. A known attack can be detected with this approach, but a zero-day or novel attack is less successful with it. In anomaly-based detection, a baseline of normal network behaviour is established, and deviations from it are identified27,28,29. Detecting novel attacks with this method can lead to false positives due to legitimate deviations from normal behaviour.
FL-based intrusion detection system
As part of the IoV, FL delivers a distributed and privacy-preserving approach to intrusion detection. A central server aggregates the parameters of FL models, which are trained locally using data from individual vehicles or edge nodes. Data privacy is preserved, and communication costs are reduced by avoiding the sharing of raw data30. Multiple studies have examined the use of FL to detect intrusions in various IoT and IoV scenarios12. A ANN model was built to predict the ID sequence of IVN messages using the periodicity of ID sequences, and a framework was developed to train LSTM neural networks securely and efficiently. They found that the method based on federated LSTMs was 90% accurate in detecting various attacks in their simulations31,32,33.
Author18 under the SDN structure, the author proposed a FL-Based IDS for the IoV, incorporating trust metrics for network security. They validated the proposal through simulation experiments. With a maximum accuracy of 99.72%, author34 proposed a federated learning framework for detecting attacks in IOV networks. Based on the pairing of federated learning and active learning, the author35 demonstrated the creation of an IDS for protecting critical infrastructures. Each participant’s global model improved as a result of a few active learning queries locally personalized. In FL, raw data is not shared during model training, thus allowing collaborative model training15,36. A FL model is gathered globally by aggregating model updates from devices and sharing them with a central server37. While preserving data privacy, this solution allows students to learn collaboratively while keeping sensitive information on local devices. Google introduced FL in 2016, and since then, it has been applied to a wide range of fields, such as intrusion detection. ITS uses FL to detect intrusions in several ways. As a result, sensitive data is not transferred to a central location, which addresses privacy concerns37. In addition to supporting collaboration between entities, FL also supports collaboration between entities that cannot share datasets due to confidentiality concerns9. In addition to improving scalability and efficiency, FL can reduce the computational burden on edge devices and improve intrusion detection systems38. It is one of the most challenging aspects of real-world ITS applications to deal with non-independent, identically distributed data (non-IID). Models can be biased and perform poorly when they are built using non-IID data. A number of other issues confront edge devices, including limited storage and computing power, potential privacy concerns, and communication overhead, are also concerns39.
The FL has been applied to various intrusion detection tasks in ITS, including the detection of attacks on Software-Defined Networking (SDN) networks40, the identification of anomalous behaviour in IoT devices41, and the protection of vehicular networks. With FRHIDS, attacks originating from consumer IoT devices can be detected. The FL-IDS system was developed in order to enhance vehicle network security with the implementation of IoT edge devices. For FL-based IDS, several techniques have been developed to overcome non-IID data challenges. Transfer Learning (TL) is one approach to adapting local models to the specifics of each device42. Using instance-based TL, local models can be trained with non-ID data at the local level. The second approach is to use personalized FL techniques, where each device has its own customized model, but still benefits from collaboration.
IDS for ITS based on federated learning have used various ML and DL models. Four types of neural networks fall into this category: ANN, logistic regression models (LRs), CNNs, and graph neural networks (GNNs)43. FedAvg is one of the most commonly used aggregation algorithms in FL. In addition, other aggregation algorithms can be used, including FedAvgM, FedAdam, and FedAdagrad. In FL-based IDS, performance is typically measured through accuracy, precision, recall, and F1 scores. In studies, federated learning-based IDS can perform as well as or even better than centralized approaches while maintaining data privacy. An AdaBoost and Random Forest model with 95.97% accuracy and 73.70% accuracy, respectively, outperformed baseline models in one study.
-
Modify the discussion of existing FL-based IDS approaches by explicitly comparing them to your APFed model.
-
Highlight specific shortcomings or limitations of existing models (e.g., centralized data collection, lack of personalization, challenges with non-IID data) and show how your framework overcomes them.
-
Introduce a clear distinction between traditional FL approaches and APFed’s personalized updates, efficiency on resource-constrained devices, and handling of non-IID data.
The following table summarizes the key differences:
Feature | APFed framework | Existing FL-based IDS approaches |
|---|---|---|
Personalization | Personalized updates for each node | Global model without personalization |
Intrusion detection model | LDwCBN for lightweight and efficient detection | Traditional CNN or ANN-based models |
Non-IID data handling | Adaptive personalized updates to handle non-IID data | Standard FL model struggles with non-IID data |
Efficiency on edge devices | Optimized for resource-constrained devices | May not perform well on edge devices |
While many studies have explored intrusion detection in the Internet of Vehicles (IoV) using machine learning and federated learning approaches, our work makes several unique contributions that differentiate it from existing research. First, we propose an Adaptive Personalized Federated Learning (APFed) framework, which is specifically designed to address the challenges posed by non-IID (non-Independent and Identically Distributed) data in IoV environments. Unlike traditional federated learning models that aggregate global updates without considering the unique data characteristics of each vehicle, APFed enables personalized model updates. This ensures that each vehicle’s model adapts to its specific data distribution, leading to better detection accuracy, especially in heterogeneous environments. Second, our approach integrates a Lightweight Depthwise Convolutional Bottleneck Network (LDwCBN), which is optimized for the resource-constrained hardware typical of IoV devices. Many existing solutions rely on computationally expensive deep learning models, which are impractical for deployment in vehicular networks due to limited processing power and memory. In contrast, LDwCBN ensures that our intrusion detection system remains efficient and suitable for real-time applications, without compromising detection performance. Additionally, while other federated learning-based intrusion detection systems in IoV focus on basic model aggregation or non-personalized updates, our model uniquely combines personalization with dynamic weight fusion. This fine-grained adaptation to local data distributions enables better generalization and accuracy compared to other methods that struggle with non-IID data. Through extensive evaluation on benchmark datasets, including CIC-IDS2017, CSE-CIC-IDS2018, Car-Hacking, and CAN-Train-Test, our results demonstrate significant improvements over existing federated IDS approaches in terms of accuracy, precision, recall, and F1-Score. Our approach not only advances the field by tackling the personalization and efficiency challenges of federated learning but also presents a scalable and privacy-preserving solution suitable for the IoV’s unique requirements.
Proposed methodology
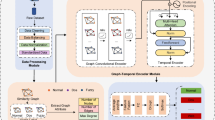
Adaptive Personalized Federated (APFed) is presented in this section, starting with an overview of its architecture before describing its algorithm, data preprocessing techniques, and the Lightweight Depthwise Convolutional Bottleneck Network (LDwCBN) in detail. IoV systems enhance intrusion detection’s performance by training and updating both global and local models using meta-parameters derived from these processes.
System model
The proposed model has three key elements: Trust Authority (TA), Cloud Server (CS), and Vehicle Layer participant. These entities collaborate to ensure the safety and efficiency of the Internet of Vehicles (IoV).
Trust authority
IOV and Cloud Server public and private keys are assigned by this entity, which ensures secure communication channels for intrusion detection.
Cloud server
Using the Cloud Server, the IOVs upload encrypted parameters of their intrusion detection models, which are aggregated and sent to each vehicle as part of the aggregated global model.
Vehicle layer
In this layer, each IOV vehicle that participates in the intrusion detection system uploads its encrypted model parameters to the Cloud Server.
Threat model
There are multiple security challenges arising from the proposed system’s three main components: the Trust Authority (TA), Cloud Server (CS), and Vehicle Layer (VL). TAs are susceptible to key compromises and insider attacks, which could compromise the security and authentication of the system. CS models are susceptible to model poisoning, data breaches, and DoS attacks that compromise data integrity and disrupt model aggregation. It is possible to eavesdrop, spoof, and update malicious models during the Vehicle Layer, resulting in degraded intrusion detection capabilities. A man-in-the-middle (MITM) attack or replay attack may also compromise communication channels between these entities, potentially interfering with data transmission.
Local data is maintained within APFed’s domain according to strict policies to prevent it from leaking. Nevertheless, model parameter leakage may occur when malicious entities intercept communications between participants and the Cloud Server in order to obtain sensitive model information. Collaboration can also be disrupted by adversarial participants uploading malicious parameters. The adaptive and personalized update phase of APFed employs a fine-grained fusion strategy to selectively incorporate only relevant information from the global feature extraction module, thereby preserving the overall integrity of the model.
Adaptive personalized federated learning (APFed)
APFed enhances traditional FL by addressing the problem of Non-IID data distributed between participants. As a result of data heterogeneity, global FL models often have difficulty generalizing. As part of APFed, this issue is mitigated by incorporating personalized updates that adapt the model to the data of individual participants while maintaining global consistency. APFed balances personalization and generalization by selectively integrating elements from the global model into local models. It is possible to significantly enhance intrusion detection performance using this adaptive approach in the Internet of Vehicles (IoV), which will ensure robust security and reliable detection regardless of the complexity of the environment. In FL applications, DL models offer high flexibility and scalability. In FedAvg, the IOVs \(\:{V}_{1},\dots\:\dots\:,{V}_{N}\) are assumed to have collaborative training using their respective local datasets \(\:{D}_{1},\dots\:\dots\:,{D}_{N}\) aimed at minimizing the overall empirical risk. Consequently, the optimization function looks like this:
\(\:{V}_{i}\) is usually optimized based on cross-entropy loss, with \(\:w\) denoting global parameters and \(\:L\) denoting local objectives.
The personalized update process in APFed is driven by dynamic weight fusion, where model updates from the global model are selectively incorporated based on each vehicle’s local data characteristics. Rather than applying a uniform update across all devices, APFed adjusts the weight of global model updates dynamically, ensuring that each vehicle’s model is tailored to its specific data distribution. This adaptive approach enables better generalization despite the non-IID nature of the data.
The FedAvg algorithm performs well when participants have evenly distributed data, but it degrades significantly when participants’ data distributions are highly unequal. To make FedAvg approximate consistent between local and global models, proximal operator regularization may be applied to FedAvg44. Non-IID data distributions are trained robustly and quickly. As a specific example, participants can be optimized as follows:
The coefficient in this example is \(\:\lambda\:,\) while the two-parameter number is \(\:{\left|\right|.\left|\right|}_{2}\). On the other hand, IOVs are interested in acquiring the capability of detecting unknown attacks locally through FL, which they want to optimize for their local distribution. Furthermore, FedAvg’s data sources are heterogeneous, making it susceptible to bias. Even though FedProx is adaptable, it still represents an average model for the world. Our proposed APFed model is based on PFL algorithms like FedRep, FedALA and FedPer45,46,47. As shown in Fig. 1, APFed generates custom models instead of a standard average model by applying the FL paradigm to every IOV. The following is a specific formulation of our optimization goal:

Proposed APFed framework for IOV network.
A personalized model parameter is denoted by \(\:{w}_{{V}_{i}}\), while an expectation is denoted by \(\:E\:[ \cdot ]\). Feature extraction and classifiers are implemented as two components of the local model (\(\:({w}_{{V}_{i}}=({w}_{{B}_{i}},{w}_{{C}_{i}})\) parameter form) in order to achieve this goal.
In contrast to existing federated learning methods such as FedRep, which handle personalization through separate heads, the proposed Adaptive Personalized Federated Learning (APFed) framework introduces dynamic weight fusion (θ and β) for personalized model updates. This mechanism adapts the global model updates based on the local data distribution, effectively addressing the challenges of non-IID data. Unlike FedRep’s standard aggregation strategy, APFed’s fine-grained fusion enables more robust handling of non-IID data, improving generalization and detection accuracy. Additionally, APFed incorporates a Lightweight Depthwise Convolutional Bottleneck Network (LDwCBN) for efficient, real-time intrusion detection, optimized for resource-constrained IoV devices, making it more suitable for vehicular environments compared to other federated models.
Using raw data, bases extract useful features, and classifiers use those features to learn decision boundaries. In our experiments, however, the proposed approach revealed that PFL algorithms with individualized heads tended to overfits. When it comes to predicting local distributions of data, they perform well, but when it comes to predicting unknown distributions, they perform badly. By aggregating all the information from the global model coarsely, local optimization is compromised, resulting in slower convergence and personalization. Using proposed model, global feature extractors benefit from a fine-grained adaptive personalized update phase. In order to calculate the fusion degree between the global and local base, \(\:{w}_{g}^{t-1}=\left({W}_{{B}_{g}}^{t-1},{W}_{{C}_{g}}^{t-1}\right)\) uses \(\:{\theta\:}_{i}\) and \(\:{\beta\:}_{i}\), denoted \(\:{\theta\:}_{i}\) and \(\:{\beta\:}_{i}\), respectively, with the assumption that the global parameters are represented by \(\:{V}_{i}\) in the \(\:t\) round of communication.
WBIT-1 is represented by \(\odot\), \(\:{\theta\:}_{i}\) and \(\:{\beta\:}_{i}\), and each element conforms to \(\:{\stackrel{\sim}{W}}_{{B}_{i}}^{t-1}\)
Combining Eqs. (5) and (6) gives Eq. (7)
The shape of \(\:{1}^{C}\) represents an all-ones matrix with the form \(\:{{W}_{C}}_{g}^{t-1}\).
The difficulty of finding high-dimensional parameters that suit individual needs will be increased if \(\:{\theta\:}_{i}\) is constant.
Weight allocation may vary depending on the global model architecture and the distribution of local data. Hence, dynamic learning is essential. A personalized model is represented by \(\:{\widehat{W}}_{{V}_{i}}={\widehat{W}}_{{V}_{i}}^{t-1}+\left[{\theta\:}_{t}^{t-1};{1}^{C}\right]\odot\:({w}_{g}^{t-1}-{\widehat{w}}_{{V}_{i}}^{t-1})\). In the case of frozen \(\:{w}_{g}^{t-1}\) and \(\:{\widehat{w}}_{{V}_{i}}^{t-1}\), the \(\:L({x}_{i},{y}_{i};{\widehat{w}}_{{V}_{i}}^{t-1})\) is dependent on the \(\:{\theta\:}_{i}^{t-1}\). The local training data can then be used to perform gradient-based updates.
As described above, \(\:\alpha\:\) represents the learning rate, \(\:{D}_{i}^{s,t}\)represents \(\:{D}_{i}\), and after training in each batch, \(\:\theta\:\) represents the elements restricted to [0, 1]. \(\:L({D}_{i}^{s,t},\:{\widehat{W}}_{{V}_{i}}^{t})\) gradient with respect to \(\:{\theta\:}_{i}:{\nabla\:}_{{\theta\:}_{i}^{t}}L\left({D}_{i}^{s,t},{\widehat{w}}_{{V}_{i}}^{t}\right)=\alpha\:\left(\right({w}_{g}^{t-1}-{\widehat{w}}_{{V}_{i}}^{t-1})⨀{\nabla\:}_{{\stackrel{\sim}{W}}_{{B}_{i}}^{t}}L\left({D}_{i}^{s,t},{\widehat{w}}_{{V}_{i}}^{t-1}\right)\) is obtained from \(\:{\widehat{W}}_{{V}_{i}}^{t}\) and Eq. (9). Hence, updating \(\:{\theta\:}_{i}^{t}\) equals iteratively estimating \(\:{\widehat{w}}_{{V}_{i}}^{t},\),
Adaptive, personalized algorithms adapt weight values according to each IOV’s data distribution using iterative learning. As a result, the proposed model is able to generalize more effectively in the presence of these weights.
LDwCBN intrusion detection model
The Lightweight Depthwise Convolutional Bottleneck Network (LDwCBN)48, is a 1D-DL architecture designed to process preprocessed 1D data frames to detect anomalies. The LDwCBN retains the LW-CNN’s lightweight nature but enhances training stability and generalization through Batch Normalization and ReLU6 activation layers. It was necessary to implement the Internet of Vehicles model in a highly constrained computing and storage environment for intelligent transport systems. LDwCBN backbone consists of three convolutional layers: a 1D layer, two depthwise layers, and two bottleneck structures. It is due to these residual connections that deep networks are able to train more effectively and mitigate degradation issues (see Fig. 2).

LDwCBN network layout.
The output of all computational units consists of 32 channels in order to ensure efficiency and consistency. In this network, the channel dimension is expanded to 32 based on a standard 1D convolutional layer. Feature dimensions are reduced using depth-wise convolution with a stride of 2. In the first depthwise convolutional layer (dwconv1), layers BN and ReLU6 accelerate convergence and stabilize training. After this, the bottleneck structure consists of two pointwise convolutions and one depthwise convolution, interleaved with layers of BNs and activations. Channel dimension transitions between 64 and 32, as well as 128 to 32, are handled by these bottleneck structures.
Embedded platforms with limited resources benefit from ReLU6 activation since it has a limited output range. A more efficient method of summarizing feature information is global average pooling (GAP), which computes a global average of channels instead of layer-by-layer. GAP is ideal for real-time classification because it has a reduced computational overhead and fewer parameters. A sigmoid function is used to detect attacks in the network.
Performance evaluation
Experimental settings and datasets
Car hacking
A number of datasets are included, such as DoS attacks, fuzzy attacks, gear spoofing, and spoofing RPM gauges. To construct these datasets, CAN traffic was logged from real vehicles while message injection attacks were being conducted via the OBD-II port. Every 300 injections of messages are contained in the datasets. We recorded CAN traffic for three to five seconds for each dataset, collecting data for thirty to forty minutes.
-
DoS attack: Each 0.3 millisecond, messages with CAN ID ‘0000’ are injected. There is a dominant number, ‘0000’.
-
Fuzzly attack: Every 0.5 milliseconds, CAN ID and DATA messages with totally random values are injected.
-
Spoofing attack (RPM/gear): Milliseconds later, certain CAN IDs containing information about RPM and gears are injected.
In the Car hacking dataset, there are a variety of attributes, including timestamps, CAN IDs, DLCs, DATA[0], DATA1, DATA2, DATA3, DATA4, DATA5, DATA6, DATA7, and Flag.
-
Timestamp: chronicled time (s).
-
CAN ID: The HEX code of the CAN message (ex. 043f).
-
DLC: Integers between 0 and 8 representing data bytes.
-
DATA[0 ~ 7]: Byte value (data).
-
Flag: Injected messages are represented by T, while R represents normal messages.
The data was split into training and testing sets using an 80/20 ratio. The training set included a diverse range of attack types and normal traffic, while the testing set was reserved to evaluate generalization. For the federated learning (FL) settings, we simulated a network of 50 vehicles (clients), with each vehicle receiving a local dataset that represented real-world data distribution. To simulate non-IID data, the dataset was partitioned such that each vehicle had access to a different subset of the data, with some vehicles exposed to specific attack types and others to general network traffic. This configuration mimicked the data heterogeneity typically found in IoV environments, where devices experience different traffic and attack patterns.
CIC-IDS2017
A CICFlowmeter-V3.0 dataset, which closely mimics real-world network data (PCAPs), was used to extract 78 features and 79 labels. A total of 25 users are represented in this dataset using HTTP, HTTPS, FTP, SSH, and email protocols. The collection of data occurs over some time. This dataset contains attacks classified according to the 2016 McAfee Report as brute force FTP attacks, brute force SSH attacks, denial of service attacks, heartbleed attacks, web attacks, as well as infiltrations, botnets, and DDoS attacks49. A B-Profile and an Alpha Profile are used in CIC-IDS2017 to profile interactions between humans abstractly. Benchmarks based on this dataset are realistic and reliable, giving it an edge over other datasets. The benchmarking process involves 11 criteria, including complete traffic and protocol availability50.
CSE-CIC-IDS2018
It was produced by a collaborative project between the Communications Security Establishment and the Canadian Institute for Cybersecurity. Researchers evaluated this dataset for intrusion detection research, which now serves as the basis for IDS evaluations for meticulous curation and development. This dataset mimics real-world cyber threats and attacks, offering a wide range of scenarios. A total of eighty columns were collected during ten days, and fifteen types of attacks were identified: FTP brute force, SSH brute force, Golden Eye, Slowloris, Hulk, Slow HTTP Test, DDoS-LOIC-HTTP, DDOS-HOIC, DDOS-LOIC-UDP, Brute Force-Web, Brute Force-XSS, SQL injection, infiltration, labelling, and bots. Since DDoS intrusions are so challenging, they receive a lot of attention51. During the 10 days of February 20th and 21st, DDoS attacks occurred. In light of this, the researcher decided to continue his investigation using this dataset.
Can-train-and-test
It is called Can-train-and-test because it is a curated dataset of CAN intrusion detections that are intended to train machine learning IDSs. Preprocessing, labelling, and arranging have been completed52. Approximately 7.5 GB of data is contained in Can-train-and-test, which includes 236 .csv files. This dataset contains four sub-datasets for training and testing:
Data preprocessing
It is crucial to prepare and clean raw data before ML algorithms can process it41. For a high-performance IDS, a few steps must be taken before performing any further experiments. The first step involves removing any unused columns, incomplete or incorrect data (missing values), and repeating features and columns because these affect the efficiency of the model. Next, the categorical and string values will be converted to numbers, and non-numerical strings will be encoded into integers for machine learning. To convert string and categorical features into numerical values in network traffic datasets, a LabelEncoder from Sklearn is applied, which is a powerful tool for encoding labels53. By doing this conversion, we convert non-numerical values into integer values between 0 and n, which makes them suitable for preprocessing by machine learning algorithms. Even though labels are categorical elements, they have not been modified because original categories are needed during processing to distinguish attack types. The label encoder encodes the network traffic datasets, and then we need to normalize them. In the absence of normalization, a dataset with many advantageous features might have one dominant feature that dominates all the others.
Data transformation
As the data stream was processed, it was discovered that dirty data was present, including missing and incorrect data items. Data collection errors may occur in real-world situations; therefore, removing or modifying errors is essential to prevent contamination of the dataset and ensure training and testing results are accurate. To begin with, the dataset must be cleaned by removing samples with abnormally positioned data, setting missing data to zero, and deleting samples with unusual formats. In this way, we generate images from tabulated network traffic data. Following data normalization, the network traffic dataset is analyzed for timestamps and feature sizes to create data blocks. A dataset containing nine important features is converted into images by multiplying the value of the nine features by the number of consecutive samples (27 × 9 = 243 feature values). This results in a three-channel colour square image for each transformed image as shown in Figs. 3, 4, 5. In this way, the original network data can be preserved in terms of their temporal sequence correlation using timestamps as a basis for image generation. An image is labeled ‘Normal’ if all samples are normal; otherwise, each block is labeled by the most frequent attack type it contains. The two-dimensionality of traffic data causes bicubic interpolation54 to be applied after upscaled images of 9 × 9 × 3 to 224 × 224 × 3.
Using the known pixel values at four adjacent data points, denoted by \(\:f\left({Q}_{11}\right),\:f\left({Q}_{12}\right),\:f\left({Q}_{21}\right),\:f\left({Q}_{22}\right)\:f\left({Q}_{11}\right),\:f\left({Q}_{12}\right),\:f\left({Q}_{21}\right),\:f\left({Q}_{22}\right),\) and having coordinates\(\:{(x}_{1},{y}_{1})\), \(\:{(x}_{1},{y}_{2})\), \(\:\left({x}_{2},{y}_{1}\right)\) and \(\:{(x}_{2},{y}_{2})\), the pixel value \(\:f(x,\:{y}_{1})\) for a particular data point \(\:(x,\:y)\) is estimated. Using one-dimensional linear interpolation, we calculate the pixel values \(\:\left(f\left(x,{y}_{1}\right)\:and\:f\left(x,\:{y}_{2}\right)\right)\) As follows:
Data points \(\:(x,\:y)\) are then interpolated in one dimension along the y-axis, and the pixel values \(\:f(x,\:y)\) are determined.
As a result of completing the data processing steps above, the input image set for the detection model can be generated in Figs. 3, 4 and 5.

Representative Samples of Car-Hacking Dataset.

Representative samples of CICIDS2017 Dataset.

Representative samples of can-train-test dataset.
Create a visual flowchart (or diagram) to represent the methodology visually. This could go alongside or immediately after the step-by-step explanation. The flowchart should:
-
Show the steps of the APFed framework (e.g., local training, model aggregation, personalized updates).
-
Illustrate the overall process of how data flows through the system, from local devices to the global server and back, highlighting key points like model updates, personalization, and aggregation.
-
Make sure that the flowchart complements the step-by-step explanation and provides a high-level view of the methodology.
In the Proposed Methodology, explicitly highlight that APFed introduces adaptive personalized updates, which differentiate it from FedProx and FedPer. Emphasize how APFed selectively integrates global model information into local models to handle non-IID data more effectively.
The choice of depthwise convolution in the LDwCBN model was driven by the need for computational efficiency, as it reduces the number of parameters and computation required, which is crucial for resource-constrained IoV devices. Depthwise convolution allows for effective feature extraction while minimizing computational cost, ensuring real-time performance. Additionally, the ReLU6 activation function was selected due to its bounded output, which helps prevent large gradient values during training, enhancing stability and preventing overfitting in constrained environments. These design choices make the model well-suited for the unique demands of IoV systems.
Result analysis and discussion
To determine the optimal subset of features required for accurate detection of Internet of Vehicles (IOV) attackers, we systematically varied the number of input features and assessed the model’s performance using standard evaluation metrics—accuracy, precision, recall, and F1-Score. Figure 6 illustrates how the classification accuracy evolves with respect to the number of features across four benchmark datasets: CIC-IDS2017, CSE-CIC-IDS2018, Car-Hacking, and CAN-Train-Test, utilizing the Feature-Driven Scheme (FD-Scheme) approach.
Experimental results show that the proposed model performs better on the Car-Hacking and CAN-Train-Test datasets than on the CIC-IDS2017 and CSE-CIC-IDS2018 datasets. Specifically, the model attained classification accuracies of 98.37% on CIC-IDS2017, 99.45% on CSE-CIC-IDS2018, and 99.35% on the Car-Hacking dataset. Notably, the highest accuracy was achieved on the CAN-Train-Test dataset, reaching 99.65%. In addition, this dataset recorded a precision of 95.92%, a recall of 95.99%, and an F1-Score of 96.01%, indicating a strong balance between false positives and false negatives.
Furthermore, as depicted in Figs. 6(c) and (d), the recall and F1-Score curves reveal that utilizing only 50 features is sufficient to attain perfect detection (i.e., 100% recall and 100% F1-Score) across all evaluated datasets. This finding underscores the effectiveness of the proposed feature selection method, which not only reduces the computational complexity but also maintains, and in some cases enhances, the detection performance.

Performance Analysis versus number of features in term of (a) accuracy, (b) precision, (c) recall and (d) F1-Score.
To comprehensively evaluate the effectiveness of the proposed intrusion detection scheme, we conducted a comparative analysis against several state-of-the-art approaches as shown in Fig. 7/. These include the FED-IDS55, a FL-based attack detection model for Vehicular Sensor Networks (VSN)56, the FL-Based IDS for CAV (FL-IDS-CAV)37, and the FL-Based Misbehaviour Detection framework for IOV (FL-IDS-IOV)34. The performance comparison was conducted using the CAN-Train-Test dataset as a benchmark. As illustrated in Fig. 7, the proposed model consistently outperforms all referenced approaches in terms of classification accuracy. This improvement underscores the robustness and enhanced generalization capability of the proposed FD-Scheme architecture in detecting malicious behavior within vehicular communication networks. The superior performance is attributed to the integration of an optimized feature selection strategy and the hybrid deep learning architecture, which together enable more accurate detection with reduced false positives and false negatives.

Comparative accuracy (\(\:\%\)) performance analysis with existing models.
While the datasets used in this study, including CIC-IDS2017, CSE-CIC-IDS2018, and Car-Hacking, are well-known and provide reliable benchmarks, we acknowledge that incorporating real-world IoV data would enhance the practical relevance of our study. Due to the complexity and privacy concerns associated with real-world IoV data, such datasets are challenging to obtain. However, we plan to explore the inclusion of real-world IoV data in future work to further validate the robustness and generalization of our model in actual IoV environments.
While the performance metrics used in this study, including accuracy, precision, recall, and F1-score, provide a solid evaluation of the model’s effectiveness, we acknowledge the need for a deeper analysis of its robustness under different conditions. Specifically, future work will explore how the model performs under varying levels of data heterogeneity (non-IID data distributions) and in the presence of adversarial attacks. This additional analysis will offer a more comprehensive evaluation of the model’s resilience and generalization in real-world IoV environments.
Conclusion
This paper presents the Adaptive Personalized Federated Learning (APFed) framework integrated with the Lightweight Depthwise Convolutional Bottleneck Network (LDwCBN) for intrusion detection in the Internet of Vehicles (IoV). The proposed method demonstrated significant improvements over existing federated IDS approaches, with a 5% increase in accuracy, 4% improvements in both precision and F1-Score, and 3% in recall, showing strong potential for deployment in real-world vehicular security systems. These results highlight the efficacy of APFed in handling non-IID data and resource constraints in IoV environments. Future work will explore optimizing communication efficiency and addressing hardware heterogeneity challenges to further enhance the practical applicability of the proposed system.
Data availability
The data supporting this study are available when reasonably requested from the corresponding author.
References
Omeiza, D., Webb, H., Jirotka, M. & Kunze, L. Explanations in Autonomous Driving: A Survey, IEEE Trans. Intell. Transport. Syst., vol. 23, no. 8, pp. 10142–10162 https://doi.org/10.1109/TITS.2021.3122865 (2022).
Hussain, N., Rani, P., Kumar, N. & Chaudhary, M. G. A deep comprehensive research architecture, characteristics, challenges, issues, and benefits of routing protocol for vehicular ad-hoc networks. Int. J. Distrib. Syst. Technol. (IJDST). 13 (8), 1–23 (2022).
Alaya, B., Sellami, L. & Lorenz, P. An ontological approach to the detection of anomalies in vehicular ad hoc networks. Ad Hoc Netw. 156, 103417. https://doi.org/10.1016/j.adhoc.2024.103417 (2024).
Islam, T. & Kwon, C. Survey on the state-of-the-art in device-to-device communication: A resource allocation perspective. Ad Hoc Netw. 136, 102978. https://doi.org/10.1016/j.adhoc.2022.102978 (2022).
Abdallah, E. E., Aloqaily, A. & Fayez, H. Identifying intrusion attempts on connected and autonomous vehicles: A survey. Procedia Comput. Sci. 220, 307–314. https://doi.org/10.1016/j.procs.2023.03.040 (2023).
He, Q., Meng, X. & Qu, R. May, Survey on cyber security of CAV, in 2017 Forum on Cooperative Positioning and Service (CPGPS), Harbin, China: IEEE, 351–354. doi: https://doi.org/10.1109/CPGPS.2017.8075153. (2017).
Agrawal, N. K. et al. Aug., TFL-IHOA: Three-Layer Federated Learning-Based Intelligent Hybrid Optimization Algorithm for Internet of Vehicle, IEEE Trans. Consumer Electron., vol. 70, no. 3, pp. 5818–5828,. https://doi.org/10.1109/TCE.2023.3344129 (2024).
Yang, Q., Fu, S., Wang, H. & Fang, H. Machine-Learning-Enabled cooperative perception for connected autonomous vehicles: challenges and opportunities. IEEE Netw. 35 (3), 96–101. https://doi.org/10.1109/MNET.011.2000560 (2021).
Li, Y., Ma, R. & Jiao, R. A hybrid malicious code detection method based on deep learning. Int. J. Secur. Its Appl. 9 (5), 205–216 (2015).
Otoum, Y., Wan, Y. & Nayak, A. May, Transfer Learning-Driven intrusion detection for internet of vehicles (IoV), in 2022 International Wireless Communications and Mobile Computing (IWCMC), Dubrovnik, Croatia: IEEE, 342–347. doi: https://doi.org/10.1109/IWCMC55113.2022.9825115. (2022).
Rani, P. & Sharma, R. Intelligent Transportation System Performance Analysis of Indoor and Outdoor Internet of Vehicle (IoV) Applications Towards 5G, Tsinghua Sci. Technol., vol. 29, no. 6, pp. 1785–1795,. https://doi.org/10.26599/TST.2023.9010119 (2024).
Yu, T., Hua, G., Wang, H., Yang, J. & Hu, J. Federated-LSTM based Network Intrusion Detection Method for Intelligent Connected Vehicles, in ICC 2022 - IEEE International Conference on Communications, Seoul, Korea, Republic of: IEEE, May pp. 4324–4329. https://doi.org/10.1109/ICC45855.2022.9838655 (2022).
Yang, L., Shami, A., Stevens, G. & De Rusett, S. LCCDE: A Decision-Based Ensemble Framework for Intrusion Detection in The Internet of Vehicles, In GLOBECOM 2022–2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil: IEEE, Dec. pp. 3545–3550. https://doi.org/10.1109/GLOBECOM48099.2022.10001280 (2022).
Nguyen, D. C. et al. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutorials. 23 (3), 1622–1658. https://doi.org/10.1109/COMST.2021.3075439 (2021).
Du, Z. et al. Federated learning for vehicular internet of things: recent advances and open issues. IEEE Open. J. Comput. Soc. 1, 45–61. https://doi.org/10.1109/OJCS.2020.2992630 (2020).
Wu, S. et al. Motley: Benchmarking Heterogeneity and Personalization in Federated Learning,., arXiv.https://doi.org/10.48550/ARXIV.2206.09262 (2022).
Huang, X., Liu, J., Lai, Y., Mao, B. & Lyu, H. Personalized federated learning of execution&evaluation dual network for CPS intrusion detection. IEEE Trans. Inf. Forensic Secur. 18, 41–56. https://doi.org/10.1109/TIFS.2022.3214723 (2023).
Hbaieb, A., Ayed, S. & Chaari, L. Federated learning based IDS approach for the IoV, in Proceedings of the 17th International Conference on Availability, Reliability and Security, Vienna Austria: ACM, Aug. pp. 1–6. https://doi.org/10.1145/3538969.3544422 (2022).
Asharf, J. et al. A review of intrusion detection systems using machine and deep learning in internet of things: challenges, solutions and future directions. Electronics 9 (7), 1177. https://doi.org/10.3390/electronics9071177 (2020).
Yang, L. & Shami, A. A Transfer Learning and Optimized CNN Based Intrusion Detection System for Internet of Vehicles, in ICC 2022 - IEEE International Conference on Communications, Seoul, Korea, Republic of: IEEE, May pp. 2774–2779. https://doi.org/10.1109/ICC45855.2022.9838780 (2022).
Zeng, Y. et al. DeepVCM: A Deep Learning Based Intrusion Detection Method in VANET, In IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Washington, DC, USA: IEEE, May 2019, pp. 288–293., Washington, DC, USA: IEEE, May 2019, pp. 288–293. https://doi.org/10.1109/BigDataSecurity-HPSC-IDS.2019.00060 (2019).
Kumar, P., Gupta, G. P., Tripathi, R., Garg, S. & Hassan, M. M. Deep Learning-Driven cyber threat intelligence modeling and identification framework in IoT-Enabled maritime transportation systems. IEEE Trans. Intell. Transp. Syst. 1–10. https://doi.org/10.1109/TITS.2021.3122368 (2021).
Mansourian, P., Zhang, N., Jaekel, A. & Kneppers, M. Deep Learning-Based Anomaly Detection for Connected Autonomous Vehicles Using Spatiotemporal Information, IEEE Trans. Intell. Transport. Syst., vol. 24, no. 12, pp. 16006–16017, https://doi.org/10.1109/TITS.2023.3286611 (2023).
Cheng, P., Xu, K., Li, S. & Han, M. TCAN-IDS: Intrusion Detection System for Internet of Vehicle Using Temporal Convolutional Attention Network, Symmetry, vol. 14, no. 2, p. 310, https://doi.org/10.3390/sym14020310 (2022).
Hu, R., Wu, Z., Xu, Y. & Lai, T. Multi-attack and multi-classification intrusion detection for vehicle-mounted networks based on mosaic-coded convolutional neural network, Sci Rep, vol. 12, no. 1, p. 6295, https://doi.org/10.1038/s41598-022-10200-4 (2022).
Yang, L., Moubayed, A. & Shami, A. MTH-IDS: A multitiered hybrid intrusion detection system for internet of vehicles. IEEE Internet Things J. 9 (1), 616–632. https://doi.org/10.1109/JIOT.2021.3084796 (2022).
Aziz, S. et al. Anomaly detection in the internet of vehicular networks using explainable neural networks (xNN). Mathematics 10, 1267. https://doi.org/10.3390/math10081267 (2022).
Khan, A. & Singh, J. A novel image captioning technique using deep learning methodology. ICCK Trans. Mach. Intell. 1 (2), 52–68. https://doi.org/10.62762/TMI.2025.886122 (2025).
Khan, M., Kumar, R. & Dhiman, G. A hybrid machine learning fuzzy Non-linear regression approach for neutrosophic fuzzy set. ICCK Trans. Mach. Intell. 1 (1), 42–51. https://doi.org/10.62762/TMI.2025.561363 (2025).
Zhang, T. et al. Federated Learning for Internet of Things, in Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, Coimbra Portugal: ACM, Nov. pp. 413–419. https://doi.org/10.1145/3485730.3493444 (2021).
Garg, M. Enhanced reinforcement Learning-Based resource scheduling for secure blockchain networks in IIoT. ICCK Trans. Mach. Intell. 1 (1), 29–41. https://doi.org/10.62762/TMI.2024.529242 (2025).
Gupta, S., Adhikari, U., Roy, D. & Hazra, S. IoT-Integrated reinforcement Learning-Based mine detection system for military and humanitarian applications. ICCK Trans. Mach. Intell. 1 (1), 17–28. https://doi.org/10.62762/TMI.2025.235880 (2025).
Myakala, P. K., Kamatala, S. & Bura, C. Privacy-Preserving federated learning for IoT botnet detection: A federated averaging approach. ICCK Trans. Mach. Intell. 1 (1), 6–16. https://doi.org/10.62762/TMI.2025.796490 (2025).
Rani, P. et al. Federated Learning-Based misbehavior detection for the 5G-Enabled internet of vehicles. IEEE Trans. Consumer Electron. 70 (2), 4656–4664. https://doi.org/10.1109/TCE.2023.3328020 (2024).
Kelli, V. et al. IDS for industrial applications: A federated learning approach with active personalization. Sensors 21 (20), 6743. https://doi.org/10.3390/s21206743 (2021).
Lavaur, L., Pahl, M. O., Busnel, Y. & Autrel, F. The Evolution of Federated Learning-Based Intrusion Detection and Mitigation: A Survey, IEEE Trans. Netw. Serv. Manage., vol. 19, no. 3, pp. 2309–2332, https://doi.org/10.1109/TNSM.2022.3177512 (2022).
Bhavsar, M. H., Bekele, Y. B., Roy, K., Kelly, J. C. & Limbrick, D. FL-IDS: federated Learning-Based intrusion detection system using edge devices for transportation IoT. IEEE Access. 12, 52215–52226. https://doi.org/10.1109/ACCESS.2024.3386631 (2024).
Hazra, A., Adhikari, M., Nandy, S., Doulani, K. & Menon, V. G. Federated-Learning-Aided Next-Generation edge networks for intelligent services. IEEE Netw. 36 (3), 56–64. https://doi.org/10.1109/MNET.007.2100549 (2022).
Zhang, S. et al. Federated learning in intelligent transportation systems: recent applications and open problems. IEEE Trans. Intell. Transp. Syst. 25 (5), 3259–3285. https://doi.org/10.1109/TITS.2023.3324962 (May 2024).
Babbar, H. & Rani, S. FRHIDS: Federated Learning Recommender Hybrid Intrusion Detection System Model in Software-Defined Networking for Consumer Devices, IEEE Trans. Consumer Electron., vol. 70, no. 1, pp. 2492–2499, https://doi.org/10.1109/TCE.2023.3329151 (2024).
De Caldas Filho, F. L. et al. Botnet detection and mitigation model for IoT networks using federated learning. Sensors 23, 6305. https://doi.org/10.3390/s23146305 (2023).
Otoum, Y., Chamola, V. & Nayak, A. Federated and Transfer Learning-Empowered Intrusion Detection for IoT Applications, IEEE Internet Things M., vol. 5, no. 3, pp. 50–54, https://doi.org/10.1109/IOTM.001.2200048 (2022).
Zhang, C., Zhang, S., Yu, J. J. Q. & Yu, S. FASTGNN: A Topological Information Protected Federated Learning Approach for Traffic Speed Forecasting, IEEE Trans. Ind. Inf., vol. 17, no. 12, pp. 8464–8474, https://doi.org/10.1109/TII.2021.3055283 (2021).
Li, T. et al. Federated optimization in heterogeneous networks, Proceedings of Machine learning and systems, vol. 2, pp. 429–450, (2020).
Collins, L., Hassani, H., Mokhtari, A. & Shakkottai, S. Exploiting shared representations for personalized federated learning, in International conference on machine learning, PMLR, pp. 2089–2099. https://proceedings.mlr.press/v139/collins21a.html (2021).
Arivazhagan, M. G., Aggarwal, V., Singh, A. K. & Choudhary, S. Federated learning with personalization layers. Dec 02, arXiv: arXiv:1912.00818. https://doi.org/10.48550/arXiv.1912.00818 (2019).
Zhang, J. et al. Fedala: Adaptive local aggregation for personalized federated learning, In Proceedings of the AAAI conference on artificial intelligence, pp. 11237–11244. https://ojs.aaai.org/index.php/AAAI/article/view/26330 (2023).
Huan, S. et al. Dec., T-Shaped CAN Feature Integration With Lightweight Deep Learning Model for In-Vehicle Network Intrusion Detection, IEEE Trans. Intell. Transport. Syst., vol. 25, no. 12, pp. 21183–21196, https://doi.org/10.1109/TITS.2024.3478371 (2024).
Sharafaldin, I., Habibi Lashkari, A. & Ghorbani, A. A. A Detailed Analysis of the CICIDS2017 Data Set, in Information Systems Security and Privacy, vol. 977, P. Mori, S. Furnell, and O. Camp, Eds., In Communications in Computer and Information Science, vol. 977., Cham: Springer International Publishing, pp. 172–188. https://doi.org/10.1007/978-3-030-25109-3_9 (2019).
Pelletier, Z. & Abualkibash, M. Evaluating the CIC IDS-2017 dataset using machine learning methods and creating multiple predictive models in the statistical computing Language R. Science 5 (2), 187–191 (2020).
Ullah, S., Mahmood, Z., Ali, N., Ahmad, T. & Buriro, A. Machine Learning-Based dynamic attribute selection technique for DDoS attack classification in IoT networks. Computers 12 (6), 115. https://doi.org/10.3390/computers12060115 (2023).
can-train-and-test. [Online]. Available: https://bitbucket.org/brooke-lampe/can-train-and-test/src/master/
Rani, P. & Sharma, R. Intelligent transportation system for internet of vehicles based vehicular networks for smart cities. Comput. Electr. Eng. 105, 108543 (2023).
Gribbon, K. T. & Bailey, D. G. A Novel Approach to Real-time Bilinear Interpolation, in Second IEEE International Workshop on Electronic Design, Test and Applications, Perth, Australia: IEEE, pp. 126–126. https://doi.org/10.1109/DELTA.2004.10055 (2004).
Abdel-Basset, M. et al. Federated intrusion detection in blockchain-based smart transportation systems. IEEE Trans. Intell. Transp. Syst. 23 (3), 2523–2537 (2021).
Driss, M., Almomani, I., Huma, Z. & Ahmad, J. A federated learning framework for cyberattack detection in vehicular sensor networks. Complex. Intell. Syst. 8 (5), 4221–4235 (2022).
Acknowledgements
This research work is funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R40), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Funding
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2025R40), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia
Author information
Authors and Affiliations
Contributions
Shahad Almansour wrote the paper, Kusum Yadav analyzed the work, Lulwah M. Alkwai simulated the work, Norah Saleh Alghamdi and Wattana Viriyasitavat supervised the work, Gaurav Dhiman simulated the work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Almansour, S., Yadav, K., Alkwai, L.M. et al. Adaptive personalized federated learning with lightweight depthwise convolutional bottleneck network for novel intrusion detection system in internet of vehicles. Sci Rep 15, 35604 (2025). https://doi.org/10.1038/s41598-025-17699-3
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-17699-3
