
Abstract
Digital twins are living digital surrogates of objects and processes from the world around us and serve many purposes in situations where a physical model cannot be used. Digital twins can be considered to still be in their nascent phase, be it in the variety of application domains or in the science of creating and manipulating them. The DIDYMOS-XR project uses digital twins to create large-scale (city-wide) and long-term eXtended Reality (XR) applications. In this paper, we propose three use cases—city planning, city maintenance, and city tourism—along with an industrial use case for manufacturing environments, demonstrated through evaluation sites in Germany and Spain. The paper introduces cutting-edge solutions in the creation, simulation, and manipulation of DTs, including advancements in 3D scene reconstruction, data enhancement, data compression, sensor fusion, localization, rendering, and scene understanding. Additionally, we address the ethical and privacy challenges of digital twin systems and propose strategies for mitigating these issues. This work offers a comprehensive framework for creating semantically rich, scalable, and interactive digital twins, providing valuable insights for diverse applications in urban planning, maintenance, tourism, and industrial optimization.
Similar content being viewed by others


Introduction
The digital transformation and the availability of diverse and cost-effective methods for 3D capture have led to the creation of digitized representations of parts of our public spaces, machines and objects, commonly referred to as Digital Twins (DTs). DTs can be used in lieu of their twinned objects in many areas, such as in simulation, testing, monitoring, and maintenance.
DTs representing real objects are built upon 3D computerized models; however, they are much more than that. While 3D models are typically static in nature, DTs live alongside their physical twins, being regularly updated by the events that happen in the real world. DTs can be interactive data-driven models that evolve over time based on input from sensors, devices, and other sources. Moreover, digital twins are not only actionable but also responsive to real-time and semantic updates. The ability to modify, augment, and scale a DT in real-time ensures its adaptability to changes in the physical environment. Real-time updates synchronize alterations in the digital twin with corresponding changes in the real world. This dynamic nature allows for the application of ‘what if’ scenarios, particularly useful in simulating and planning.
The versatility of digital twins extends to on-site and off-site applications. On-site, they enhance experiences by providing real-time access to live operations. For instance, a digital twin can dynamically reflect interior details, even within closed spaces. This on-site enhancement is particularly valuable for immersive experiences or operational monitoring. In contrast, off-site applications involve documentation and editing, allowing for remote collaboration, analysis, and decision-making. The dynamic mapping of real-world changes into the digital twin captures the essence of what happens in the 3D world. This synchronization facilitates a comprehensive understanding and manipulation of the virtual counterpart in response to real-world dynamics. Whether on-site for live operations and enhanced experiences or off-site for documentation and collaborative editing, digital twins stand at the forefront of bridging the physical and virtual realms, offering a rich platform for exploration, analysis, and decision-making across various domains.
In order to turn digital representations into actual digital twins, they need to be extended to (i) cover all relevant parts of their environment, covering possibly a large area of the real world, (ii) be kept in sync with changes in the real world, and (iii) represent the semantics of objects and structures in order to link sensor data to functionalities.
The adoption of Digital Twins within Industry 4.0 is transforming industrial practices by enabling enhanced predictive analytics, real-time monitoring, and integration with advanced enterprise architectures. Javaid et al.1 provide a comprehensive review of DT applications in Industry 4.0, highlighting their role in improving operational efficiency and decision-making processes across various domains, including manufacturing and logistics in the automotive sector for the purpose of being able to predict future maintenance scenarios and to reduce production friction through optimization, Pfeiffer et al.2 explore the specific challenges and modeling languages employed for developing automotive digital twins, emphasizing their growing importance in aligning with industry standards and practices. Further alignment of DT frameworks with enterprise architectures and reference models, such as RAMI 4.0, demonstrates their potential in bridging cyber-physical systems (CPS) and Industrial IoT environments. Koulamas et al.3 discuss the pivotal role of DTs in enhancing CPS integration and industrial applications, further reinforcing their relevance in the evolving landscape of smart manufacturing.
Most of today’s digital twins cover only small parts of the real world, and most of them represent the static state at the time of capture. Staczek et al.4 employed a digital twin to validate design assumptions during the initial stages of implementing an autonomous mobile robot within a company’s production hall, effectively addressing the challenge of testing and validating navigation algorithms under various vehicle operating conditions. Brunner et al.5 propose a DT for the urban road network in Ingolstadt, Germany. The purpose of the twin is to perform cheap and risk-free virtual test drives particularly at busy intersections to identify and gain insight into critical scenarios. They highlighted the need for virtual testing in the development and deployment of automated driving functions, focusing on interactions between automated vehicles and vulnerable road users in urban intersections. Although, environments are changing and so DTs should be updated to reflect these changes. While it is feasible to use high-end equipment for the initial capture, continuous updates need to be obtained in a cost-effective manner, using the numerous but heterogeneous sensors already deployed. Automated methods are needed in order to fuse information from these sensors, analyse the semantics of the scene, and make the appropriate changes to the DT. In the spectrum of 3D modeling, the distinction between high and low resolution as well as high and low frequency usage arises from diverse applications. Enriching DTs with real-time information (e.g., captured through sensors) from the environment it covers, yields a number of promising opportunities. Currently, these connections have to be mostly hand-crafted.
High-resolution 3D models, with their detailed and intricate representations, are suitable for applications such as architectural visualization or product design. On the other hand, low-resolution models find utility in scenarios where computational efficiency or quick overviews are prioritized, as seen in some gaming environments or onsite immersive experiences.
The potential and use cases of DTs really comes to life when coupled with Extended Reality (XR) applications. The advent of mature products and the entry of tech giants into this realm, such as META and Apple, opens the possibilities for mass applications capitalizing on DTs. However, extended reality applications making use of these digital twins also require means of accurate positioning in the environment to align real and virtual representations. These methods must be aware of the dynamics of the scene in order to efficiently obtain reliable information for localisation. Rendering methods feeding XR applications must adapt the content to the needs of the applications and allow for efficient real-time onsite rendering. As with any new technological advancement, there are concerns. The capture of scenes at scale, as well as using cameras and other sensor data for synchronising the digital representation, bears the risk of capturing personal and sensitive data and using them for unethical applications. Hence, the technologies must be ethical and privacy-aware by design.
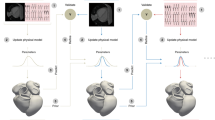
The DIDYMOS-XR project (didymos, ancient Greek for ‘twin’) aims at creating digital twins and interacting with them using XR. Figure 1 presents an overview of the DIDYMOS-XR project: to construct any digital twin, the process begins by creating a 3D model of the twin using accurate methods such as photogrammetry (structure from motion) and/or total stations (e.g.Leica). These scanning methods are time consuming to deploy and process but their outcome is usually highly accurate. To transform the model into a digital twin (we refer to as Day0 twin), additional layers of information are mapped to the twin. For example, one layer could represent the semantics (segmentation of things and stuff); another layer could represent static and mobile objects inside the scene. Once the Day0 twin is complete, the applications can begin interacting with the digital twin, but require accurate localization in order for the system to render the model to the users from the correct perspective. During the lifetime of the digital twin, various sensors (inter alia on vehicles) are used to automatically update the digital twin. Technologies such as real-time mapping, 3D reconstruction, scene understanding, and sensor fusion are required.

Approach to creating and updating DTs in the DIDYMOS-XR project. We start by producing a highly accurate digital twin (Day 0) using a reconstruction method (e.g.structure from motion, SfM) and/or a total station. During the lifetime of a DT, it will be continuously updated using various sensors deployed already for other tasks. The DTs will be interacted with using XR equipment. Research produced in DIDYMOS-XR will be along the lines presented inside the colored blocks.
The contribution of this paper is an in-depth analysis of the requirements and enabling technologies of DTs, which facilitate large-scale and long-term XR applications in city and industrial use cases. We introduce three innovative use cases focused on city planning, maintenance, and tourism, along with an industrial use case for manufacturing environments, demonstrated through evaluation sites in Germany and Spain. Key contributions include the development and integration of advanced technologies for 3D scene reconstruction, data enhancement, data compression, sensor fusion, and localization, rendering and XR rendering. Additionally, the ethical and privacy considerations associated with DTs are addressed, with proposed mitigation strategies to ensure the responsible use of these technologies.
The remainder of this paper is structured as follows. Section “Digital twin use cases” describes the four digital twin use cases proposed. Section “Enabling technologies for digital twins” describes the enabling technologies being developed for the creation and update of digital twins. Section “Ethical and privacy dimensions” presents a discussion of the ethical considerations and challenges. Section “Conclusion” concludes the paper.
Digital twin use cases
We propose four representative applications for digital twins, including three in cities, and one in industry. These applications differ in nature and in scale, and are aimed at demonstrating the potential of the highlighted technologies.
Digital twins for cities
The paradigm shift in urban planning brought about by the fourth industrial revolution is exemplified by the introduction of digital twins. At the heart of this paradigm shift lies the utilization of digital twins, sophisticated virtual replicas of real-world cities, to facilitate data-driven decision-making, optimize resource allocation, and enhance overall urban efficiency6. A digital twin in the context of a cityscape refers to a virtual representation of spaces, assets, processes, and systems. It encompasses a wide range of data sources and technologies, including sensors, GNSS data, satellite imagery, and real-time data feeds, to create a detailed and dynamic model of the urban environment. This digital twin allows city planners, policymakers, tourism managers, and other interested stakeholders to simulate, monitor, and manage various aspects of the city, such as transportation networks, infrastructure, utilities, buildings, environmental conditions and offer innovative tourism solutions7. By integrating data from multiple sources and simulating different scenarios, digital twins enable better decision-making, optimization of resources, and improved urban resilience and sustainability.
We focus on three applications related to cityscape digital twins: City Planning, City Maintenance, and City Tourism. Each of these applications requires the creation of a dependable digital twin of the targeted area of interest, serving as the foundational element. The initial phase involves constructing a digital twin of (parts of) the city through the integration of geospatial data, GIS databases, and 3D modelling. The digital twin is continuously updated using data from various sensors, ensuring its accuracy and relevance. Updates are ensured via different kinds of sensors (on vehicles or drones; static), and occur either upon user request (proper time, when a user makes a request) or periodically offline (every few days/weeks/months), depending on the application’s requirements and frequency needs.

Architecture diagram for digital twin creation, quality assessment, and city planning; highlighting the main functional entities including three key components: creating a city map with 3D assets at accurate geo-locations (digital twin base layer), simulating the digital twin in a simulator, and updating it using vehicle data with sensor fusion and reconstruction methods.
City planning
The City Planning use case involves utilizing digital twins of city environments in order to explore and evaluate various scenarios that could impact urban infrastructure, transportation systems, and overall city functionality. The idea is to apply changes to the digital twin of a city environment to test ‘what if’ scenarios. For example, one could change the configuration of city lights/traffic lights to simulate different traffic scenarios. Or, one could simulate how an increasing number of autonomous vehicles can affect utilisation of parking lots, or is influenced by different traffic light signalling patterns. In yet another example, one could change the configuration of traffic routes (even by creating new buildings and /or removing existing ones) to observe how this affects city traffic and crowds inside streets. To effectively implement this use case, a combination of technologies and methodologies is required. The first step involves deploying a network of sensors throughout the city to collect real-time data on various parameters such as traffic flow, pedestrian movement, environmental conditions (e.g.air quality, temperature), and infrastructure usage. These sensors can include cameras, traffic and environmental sensors, LiDAR for the 3D reconstruction of the scene, and IoT devices embedded in infrastructure. The collected data are then integrated into a centralized platform where it is processed and analyzed.
Using the integrated data, a digital twin of the city is created, which accurately represents the physical city environment, including buildings, roads, parks, utilities, and other infrastructure elements, allowing planners or qualified experts to experiment with different scenarios through simulations. The results of the simulations are visualized through interactive dashboards as well as the digital twin, allowing stakeholders to understand the implications of different planning decisions, and help planners identify optimal solutions to urban challenges. Regular updates to the DT enable planners to adapt to changing urban dynamics and emerging trends.
We incorporate state-of-the-art simulation environments using the Carla simulator8 and real-time control interfaces using Unity3D9,10. As a result, stakeholders can manipulate various parameters, from traffic flow and pedestrian dynamics to environmental conditions and infrastructure configurations, and observe their impact on the city’s behavior and performance. Digital twins were developed in a holistic manner, encompassing not only geometric accuracy but also semantics and user-centric interaction. Furthermore, we follow a centralized method in the creation and maintenance of the cityscape’s digital twin, where the main functionalities include three principle components (depicted in Fig. 2): (i) creation of the city map with 3D assets placed at the correct geo-location (i.e.creation of the digital twin base layer), (ii) simulation of the digital twin in a simulator (e.g.Carla) and (iii) update of the digital twin using the vehicle data and different methods of sensor fusion, and 3D reconstruction.
As shown at the top of the diagram in Fig. 2, the city planner can simulate various scenarios involving geometric changes, such as new infrastructure or modifications to existing structures, as well as different traffic scenarios (e.g., adding traffic lights, changing the volume of vehicles on the road, changing the speed of the vehicles, changing the direction of a road, blocking a road i.e., changing the capacity of a road). Additionally, the digital twin can reflect the current weather conditions by integrating real-time environmental data from IoT sensors into the simulator. Furthermore, historical data can be stored and utilized to simulate weather conditions across different seasons on the digital twin.
Development of the DT: The creation of a comprehensive digital twin for urban environments requires one to first acquire 3D data using sensors such as LIDARs or cameras (Figure 3), followed by post-processing steps to refine point clouds. Subsequently, high-fidelity 3D assets are generated, integrating textures, vegetation, and road networks to enhance realism. This phase establishes the foundational framework necessary for the subsequent simulation and analysis of urban environments.
Simulation of the DT: Subsequent to the creation of a robust 3D model, the digital twin is integrated into a simulation environment for comprehensive analysis of urban dynamics. Integration with the Carla simulator facilitates the simulation of diverse scenarios, encompassing meteorological phenomena, vehicular traffic patterns, and the deployment of infrastructure elements such as smart lighting systems and buildings. This framework is then augmented into a Unity3D interface that enables city planners to dynamically manipulate simulation parameters such as vehicle velocities, traffic densities, and environmental conditions. Furthermore, the incorporation of a virtual reality (VR) exploration framework enables immersive pedestrian-level exploration of the digital twin, facilitating nuanced insights into urban spatial dynamics and enhancing decision-making capabilities.
Iterative update of the DT: Ensuring the fidelity and relevance of the digital twin necessitates periodic update and refinement. To do so, we collect data from vehicles equipped with cameras, GPS, and odometry sensors, and fuse changed information into the digital twin using 3D scene reconstruction, 2D segmentation, and object detection.
These use cases highlight the significance of data in DT development, as demonstrated by previous DT deployments, such as those in Helsinki11 and Zurich12, which rely on extensive sensor networks to gather and integrate real-time urban data13,14. The use case, like the Zurich DT, focuses on visualizing urban situations to help with decision-making13. In line with the simulation objectives of the present implementation, Helsinki’s DT emphasizes the advantages of simulation for scenario analysis, including environmental modeling and traffic optimization14. However, there are a few instances where the present use case might be enhanced by the information gathered from earlier implementations. Zurich’s DT, for example, promotes open data and public involvement in urban planning, which may increase the framework’s inclusiveness13. In contrast, Helsinki’s DT incorporates varying degrees of authenticity in various urban areas based on the simulations’ emphasis, offering a paradigm for striking a balance between scalability and detail14.

Capture from FICOSA’s vehicle onboard sensors: (a) front camera, (b) rear camera, (c) left camera, (d) right camera, (e) lidar pointcloud.
City maintenance
City maintenance is a critical aspect of urban management, and leveraging sensor data can greatly enhance the efficiency and effectiveness of maintenance activities. In the case of city maintenance, one could exploit sensor updates to make decisions to safeguard the welfare of the city. Uses may concern vandalism prevention, rubbish collection, smart parking management, and pollution detection, among others. The architecture for the DT creation in this use case is the same as the one constructed for the use case City Planning, nevertheless using different vehicle and infrastructure sensors. The development of the use case is performed in the town of Vilanova i la Geltrú located in Spain. The DT is continuously updated with sensor data to reflect the latest city conditions. This requires high-frequency data capture and processing to ensure that the relevant stakeholders have access to up-to-date information for decision-making. Computer vision algorithms are employed to identify and analyze changes in the city environment over time to detect specific objects, e.g.street furniture or road works, and provide information for further processing tailored to specific city maintenance needs. The collected information can be further analysed by the city administrators and city workers to support the city maintenance tasks. Detection of persons and dynamic objects, such as vehicle license plates, could contain sensitive personal information, which by the means of classification algorithms can be removed from the DT updates.
One maintenance task that has received considerable attention is the preservation of roads, a vital infrastructure component. Through advancements in computer vision and Digital Twin technology, damage in the streets’ condition, such as cracks and potholes can be detected from camera and depth sensor data15,16. Similar to other approaches, DIDYMOS-XR utilizes primarily data from sensor-equipped cars that traverse the city. Combined with the localization algorithms being developed in the project, defects detected will be displayed in a Digital Twin user interface at their precise location. We propose an application with human operators, enabling them to review identified defects. By combining the detection and localization algorithms with an intuitive interface, DIDYMOS-XR aims to facilitate informed decision-making and efficient resource allocation for city workers.
City tourism
While ideas of using Digital Twin technology for tourism applications have appeared in recent years, the use case is still underrepresented in the area of urban digital twins. Gallist et al., for instance, have created a DT of an Austrian city to use for immersive remote visits in the context of the emerging Metaverse17. However, in the creation process, captured city locations and buildings often require manual modeling and adaptation to make them game-ready. The goal of DIDYMOS-XR is to integrate the Digital Twin of the city seamlessly into the Tourism use case by leveraging the 3D reconstruction methods developed, significantly reducing the need for manual processing.
The City Tourism application exploits XR technologies to offer different remote or on-site experiences to the user according to their location. The remote experience, using VR, aims to immerse the user in the life of the city. Users can explore the city virtually, checking when places are more crowded, when there is the most traffic, when it is better to get public transportation, or when it is better to go out due to weather or pollution conditions. The tourist can also check information about opening times of shops/museums and restaurants. A tourist planner can use this app to organize groups, and plan tours in a specific area of the city or at specific times/days of the week to avoid traffic and problems with urban mobility. Having information about the opening times of museums allows tourist planners, for instance, to create consistent city tours. On the other hand, AR can be used for on-site experiences. With AR users will see augmented information on top of the real world. For example, in the ‘transparent wall’ application, a person standing outside a closed museum can see the exhibits inside from the person’s viewpoint in AR.
Digital twins in industry
Industry is pushing for flexible, lean, and automated manufacturing systems18, which are leading to the remodeling of logistics processes, from traditional solutions revolving around manual work to fully connected robotic ecosystems consisting of autonomous mobile robots (AMRs). Digital twins are very important in this situation because they allow real-time monitoring, diagnostics, and predictive insights that help reach the goals of Industry 4.0, as Tao et al.19 pointed out. Del Vecchio et al. say that digital twins are not just static copies of things, but also dynamic models that include multidimensional data flows and exchanges between the real and virtual worlds20. They have worked well in a wide range of situations, from anticipating maintenance to making industries more human-centered under the Industry 5.0 paradigm21. In many industries, AMRs have replaced automated guided vehicles (AGVs), which are robots that are guided along the plant thanks to wires in the floor or magnets, or lasers. Unlike AGVs, AMRs can freely navigate inside dynamic and new environments thanks to their ability to perceive their surroundings and adapt accordingly, thereby enabling the creation of complex and efficient logistics/production workflows. AMRs in a plant are overseen by fleet managers, cloud-based platforms responsible for the control and monitoring of the AMR fleet. Typically, a fleet manager system holds a copy of plant navigation maps, receives live state updates from individual robots inside the plant, assigns tasks subject to logistical constraints, and resolves traffic bottlenecks. Additionally, fleet managers can be connected to industrial Internet of Things (IoT) devices, enabling an extra layer of automation and efficiency.
Real-time dynamic 3D representations of industrial environments enable companies to continuously monitor, analyze, and improve their operations, driving greater efficiency and productivity22. Virtual manufacturing allows manufacturers to optimize production processes using real-time data from sensors and other interconnected devices in smart manufacturing systems. This results in improved efficiency, productivity, and quality, while also reducing costs and waste during parts production23. Smart manufacturing further facilitates the real-time monitoring, analysis, and optimization of production workflows, leading to higher productivity, lower operational costs, and improved output quality24. Consequently, major industrial players are heavily investing in the digitization of their manufacturing facilities; meanwhile, industrial settings are populated with autonomous robots navigating the environment for various purposes. To localize itself inside a plant, an AMR relies on a 2D or 3D representation of the industrial environment (so called occupancy grid), which could be produced while the robot is navigating (in the spirit of SLAM), or during a pre-processing stage using accurate mapping equipment, such as a total station, e.g.25. The 3D maps that are generated are typically semantically-poor and carry little use beyond that of navigation. Furthermore, autonomous mapping often misses important environmental landmarks such as hanging obstacles, barriers, and damaged ground. Therefore, maps often need to be post-processed by humans which also includes adding points of interest (POIs, e.g.chargers, parking spots) at their correct position inside the map. Unfortunately, post-processing is tedious, time-consuming, expensive, and inaccurate. Therefore, in addition to generating a dynamic 3D representation of the environment, companies are keen on incorporating specific semantic data into their generated maps to facilitate autonomous decision-making. Towards this end, our proposed system integrates both manual and automatic labeling functionalities. Objects of interest such as charging stations, robots, and pallets can be added to the CAD model library, and automatically labeled, enriching the map with valuable information for improved decision-making and contributing to enhanced navigation processes.

Architecture diagram for the digital twin creation for industrial use case; the different functional entities involved in the creation of the industrial DT: Mapping Agents where the 3D map is generated from different agents, Central Unit responsible for the computations and the communication between the agents, and Client that supports the mapping, the alignment, and the editing of the 3D map..
The industry use case lends itself very well to a digital twin application. Once a rich digital twin is created, including semantics and a 3D digital model, 2D sections of the digital twin can be extracted at any desired height (corresponding to the height a specific robot is operating on) and used as a map for navigation. Given that the DT is perpetually being updated both metrically and semantically, the navigating robot will always possess just-in-time information that is necessary to realize its operational and navigational tasks. One additional dimension worth mentioning is the inclusion of a human-in-the-loop in the mapping and creation of the digital twin. Augmented Reality complements DTs by providing an interactive user interface that connects virtual insights to physical decision-making processes26. This synergy enables operators to see, align, and modify DT models right in their workspaces. In circumstances when autonomous mapping fails, a human user can alter the digital twin in situ using interactive head-mounted displays, such as Microsoft HoloLens. These modifications also include the proper positioning of POIs within the digital twin, as well as the required semantic labeling. Recognizing a certain POI allows the robot to operate appropriately, such as autonomous parking at a charging station.
AR-enabled DTs not only improve operational elements of industries but also foster intuitive human-machine communication, which is crucial in Industry 5.0 settings20. For instance, the system proposed in26 integrates AR tools that enable real-time editing and validation of DTs in reconfigurable factory environments, emphasizing ease of use for operators without AR expertise. Similarly, the methodology presented in21 showcases the integration of ontology-based digital twin descriptions to streamline XR applications in industrial contexts, thereby unlocking the potential of DTs for extended interactivity.
Our proposed system27 facilitates the generation of a 2D occupancy grid based on 3D-generated maps, allowing the robot to employ a human-inspected and corrected map in the navigation process, mitigating the risk of catastrophic crashes. Furthermore, it provides the fleet manager with the capability to add virtual obstacles, prescribing a specific path, or enforcing a particular rotation angle during the deployment phase. This feature adds flexibility and ease to the deployment of robots in industrial settings.
The use case for the Digital Twins of an Industrial Environment, illustrated in Figure 4, involves several functional entities. The first is the Mapping Agents Application, which is responsible for generating a 3D map of the environment navigated by each agent (e.g., mobile robots) and providing paths for the agents. The second is the Central Unit, which handles the main computations and facilitates communication between the various agents. The third entity is the Client or User Application, which supports three main functionalities. First, Mapping, where the user utilizes raycasting techniques to map the surrounding environment in 2D or 3D. Second, Aligning, which allows the user to visualize a minimap of the submaps and manually align them using hand gestures. Finally, Editing, where the user can modify the environment by adding or deleting random shapes, inserting predefined 3D assets, and labeling point clouds (points of interest).
We adopt a centralized methodology where all computations, except for mapping, are executed at the central unit level. The connectivity framework involves mapping agents and AR devices linked to the central unit, which is comprised of four key nodes: the communication node, the merger node, the semantic node, and the navigation node.
Communication node: The communication node operates as a multi-threaded entity responsible for managing communication among various agents, functioning as a communication layer with multiple callbacks. Each mapping agent, identified by a unique ID, publishes its generated map as an octomap. The communication node also triggers custom services that produce down-sampled versions of the agent sub-maps, making visualization easier. Additionally, it computes a refined transformation between the different submaps using the Iterative Closest Point (ICP) algorithm28, based on the rough alignment provided by humans. The node also allows to save the generated map in a binary terrain (BT) and point cloud data (PCD) format as well as load previously generated offline maps.
Merger node: The merger node undertakes the task of integrating sub-maps from all agents into a cohesive and comprehensive map. Each agent is assigned a confidence level that influences its weight in contributing to the final merged map. A weighted average is subsequently employed to calculate the occupancy probability of a particular voxel. It also handles the incorporation of human edits received from the communication node into the merging process.
Semantic node: The semantic node holds the responsibility of associating semantic data with the fused map by adding a probability field indicating the confidence of occupancy, a label field denoting the class to which a point belongs, and an instance field used for tracking the available instances of a certain class.
Navigation node: The navigation node plays a crucial role in preparing the necessary data for enabling robot navigation, it generates a 2D occupancy grid derived from the 3D octomap29, projecting obstacles within a specified height range onto the robot plane for navigation purposes. On the other hand, it establishes the transformation between the map frame (world frame), upon which the merged map is based, and the baselink frame (robot frame) of localised robots to allow for autonomous navigation based on the resultant map.
The user application comprises five primary functionalities. The first is the mapping feature, where users utilize ray casting techniques to map the surrounding environment in either 2 or 3 dimensions. The second functionality is alignment, where users are presented with a mini-map (down-sampled) version of the sub-maps and manually align them using hand gestures (Fig. 5). Third, the editing feature enables users to add or delete random shapes, insert predefined 3D assets, and label parts of the point cloud, designating points of interest within the generated map. Fourth, the application allows users to automatically label assets of interest. Finally, the user application enables the user to localize a robot or assign specific goals.

Captures from the AR-Head-mounted displays. Figure (a) features the interactive AR menu. Figure (b) shows the process of aligning the minimaps. Figure (c) displays automatically labeled voxels. Figure (d) shows the process of editing the generated map. Figure (e) shows a path planned by autonomous agents overlayed on the real environment. Figure (f) shows a one-to-one representation of the fused map. Figure (g) displays the process of asset addition.
The system follows a structured sequence of steps, initiating with system initialization. As each autonomous agent navigates the environment, it produces a 3D map, subsequently converted into octomaps along with the agent’s path, and transmitted to the central unit. Upon achieving significant overlap in the agents’ maps (judged by the human operator), the human user triggers the align functionality, leading to down-sampling of all sub-maps. These sub-maps, represented as point clouds, are transmitted to the human user, who, wearing an AR headset, aligns them manually through hand gestures. The transformation generated is refined using the ICP algorithm, and the aligned sub-maps are sent to the merger node for fusion. The user can then request the merged map, which is displayed on the AR headset, overlaying the real environment in 1:1 scale. Optionally, the user can add 3D assets, adjust their position, and even apply manual edits to the map. Semantic data, including labels, can be assigned to point clouds in the merged map. The system also allows virtual localization of mapping agents and the correction of their positions. Finally, the user can request to save both the generated map and the merged labeled map for future use.
Table 1 presents a comparison between urban and industrial digital twin settings, highlighting differences in dynamicity, scale, environmental effects, and data integration. Urban scenes tend to be more dynamic and operate on a larger scale, whereas industrial settings are generally more static and confined to smaller, controlled (more structured) spaces.
The comparison also considers the impact of weather and lighting on the scenes. Weather plays a significant role in urban settings, introducing variability and challenges, while industrial indoor scenes benefit from more controlled lighting conditions and limited exposure to weather-related effects.
Privacy concerns are particularly pronounced in urban settings due to the presence of sensitive elements like human activity, car license plates, and private property details, which require proper authorization for data sharing. Conversely, industrial scenes are less likely to involve such privacy-sensitive details but demand strict handling of proprietary or operational data.
Furthermore, outdoor urban scenes can leverage GPS data for localization, which is not applicable in indoor industrial environments. However, industrial scenes often feature detailed CAD models of specific objects (e.g., a pump or forklift with serial numbers and specifications), enabling the creation of a highly semantic and accurate digital twin for industrial applications. These CAD models provide rich metadata that can enhance the utility of the digital twin in predictive maintenance, process optimization, and real-time monitoring.
Enabling technologies for digital twins
The creation of a digital twin for cityscape and industrial use cases involves the integration of several advanced technologies, including 3D scene reconstruction, data enhancement, data compression, scene understanding, sensor fusion, localization, rendering, and XR. This section outlines the various solutions implemented for each technology, emphasizing their contributions to the field and their roles in developing a robust and semantically rich digital twin. By presenting these solutions and their innovations, summarized in Table 2, we aim to highlight their significance in the digital twin creation process.

3D reconstruction of the City model, simulation of the 3D model in Carla and GUI in Unity3D—(a) shows the reconstructed 3D model of the city with 3D assets (with Texture and Geometry), (b) shows the reconstructed 3D model of the city in Carla; the car‘s perspective is on the top-left side, (c) shows the reconstructed 3D model of a specific area in the city in Blender, (d) shows the simulation window in Carla of a specific part of the city, and (e) shows the Carla Simulation Control UI designed in Unity3D to control different options in Carla.
3D reconstruction: Creating a digital twin of a city or factory begins with 3D data acquisition (e.g.point clouds) of the location of interest. This is followed by point cloud pre-processing tasks such as splitting, mesh reduction, and other enhancements to facilitate faster development of a detailed 3D model with enriched 3D assets (e.g.buildings, traffic lights, smart city lights). For the cityscape use case, we focus on creating the 3D reconstructed model of Etteln, a town in Germany.
The reconstruction process involves pre-processing the initial point cloud to prepare it for further enhancement. Enhanced 3D assets are then developed, featuring textures, precise geometry, road networks, and vegetation. These assets are modeled using Blender31, which serves as a versatile tool for creating high-fidelity 3D representations.
The reconstructed model is further integrated into the Carla simulator for simulation and analysis. Figure 6 illustrates the reconstructed 3D model of Etteln, its visualization in Carla, and the associated User Interface (UI). The interactive UI, developed in Unity3D, connects to the Carla simulator via a Python-based communication API, allowing users to control various simulation parameters such as car speed, the number of cars, and wind speed. Additionally, the system supports a VR pawn (virtual character) to enable immersive exploration of the city’s digital twin. This feature allows users to navigate the digital twin streets and experience the reconstructed environment from a first-person perspective.
3D reconstruction contributions: Our contributions to 3D reconstruction technology focus on accuracy, scalability, and user interaction. By leveraging Blender, we create high-fidelity 3D assets that incorporate detailed textures, precise geometries, and environmental elements essential for realistic digital twins. These assets are critical for achieving immersion and usability in urban and industrial applications. Unity3D enhances interactivity by providing a dynamic UI that facilitates real-time simulation control and scenario testing. The seamless integration with the Carla simulator allows for comprehensive testing of urban dynamics, supporting stakeholders in analyzing and optimizing city layouts or operational workflows. The inclusion of VR exploration capabilities further enriches the digital twin experience by offering an immersive perspective, enabling stakeholders to engage directly with the reconstructed environment. Together, these technologies and methodologies deliver a robust pipeline for 3D data acquisition, enhancement, and interaction, meeting the complex requirements of large-scale, semantically rich digital twins.
Data enhancement: Current technology allows us to capture 3D data in ways analogous to 2D data acquisition. While cameras capture 2D projections of scenes, 3D sensors directly record spatial content. Just as 2D data enhancement techniques address limitations in 2D images–such as low resolution–3D data enhancement aims to resolve similar issues in 3D data, including device noise and resolution constraints. Examples of 2D enhancement techniques include GAN-based approaches like SRGAN32, which introduced an adversarial term to traditional CNN training; ESRGAN33, which utilized channel-wise attention; and transformer-based models such as SwinIR34. In a similar vein, 3D data enhancement methods tackle issues specific to spatial data acquisition.
One key area of focus in 3D data enhancement is 3D Super-Resolution (3DSR), which enhances the resolution of 3D captures. Much like 2D resolution defines the detail in an image, 3D resolution determines the granularity of spatial data. For point clouds, 3DSR involves increasing the number of points to represent volumes with greater detail, improving the textures and shapes in the scene. PU-Net35 pioneered deep learning for 3DSR by focusing on point cloud upsampling. Subsequent advancements include ARGCN36, which incorporated graph convolutions and adversarial training, and PU-GAN37, an adversarial extension of PU-Net with self-attention mechanisms.
Data enhancement contributions: Processing 3D data directly is often time-intensive and constrained by current computational limitations. To address these challenges, our approach projects 3D spatial coordinates into 2D space using a Projected Normalized Coordinate Code (PNCC). This projection maintains the intrinsic parameters of the capturing device, enabling seamless transitions between depth maps and point clouds while embedding 3D positional data into a 2D representation. By transforming 3D data into a 2D space, we can leverage cutting-edge 2D feature-processing architectures, such as SwinIR38, which employs Swin Transformers for enhanced performance. This innovative method achieves up to twice the accuracy of traditional 3D processing techniques for single-view tasks and operates at four times the speed. By merging 3D and 2D processing methodologies, our approach provides a more efficient and powerful solution for enhancing 3D data, significantly advancing the field of digital twin creation.
Data compression: When implementing XR applications that utilize 3D data over large areas, transmitting this data poses significant challenges39. These challenges include high bandwidth demands, limited scalability40, and the complexity of distributing large amounts of data to accurately represent 3D objects or scenes41. These difficulties are further exacerbated by real-time constraints, emphasizing the need for efficient compression, delivery, and rendering mechanisms to reduce memory and bandwidth requirements.
The Moving Picture Experts Group (MPEG) has developed compression standards, such as Video-based Point Cloud Compression (V-PCC)42, which demonstrate considerable efficiency in reducing volumetric data bandwidth. However, V-PCC has limitations, particularly in scenarios involving complex or extensive point cloud datasets. The only real-time application currently available is Nokia’s V-PCC standard-compliant decoder, which is effective for offline compression of relatively simple point clouds, such as those representing a single person. Alternatively, leveraging graphics hardware (GPUs) offers significant advantages for implementing both offline and real-time compression pipelines. GPUs are optimized for parallel computations, where each pixel can be processed independently, making them well-suited for per-pixel operations in point cloud compression workflows.
To address the limitations of existing compression technologies, we developed a volumetric video pipeline that leverages traditional video codecs while addressing specific challenges of volumetric data compression. Video codecs are designed for 2D image compression, assuming strong spatial and temporal correlations within the data. However, such correlations are not always present in volumetric data, resulting in inefficiencies. Furthermore, traditional codecs are constrained to an 8-bit positive integer range, which is insufficient for accurately representing volumetric geometry. These shortcomings often lead to significant geometry loss before compression begins and noticeable artifacts after compression.
Data compression contributions: Our solution introduces a color gradient encoding system to represent geometric values, effectively expanding the value range from 8 bits to 24 bits. This enables a more accurate representation of volumetric data. By transforming geometric data into a 2D image format, we leverage traditional video codecs, such as H.264 or H.265, to compress and stream the content. This approach achieves compression rates of up to 30\(\times\) while maintaining real-time performance. Additionally, it allows for seamless integration into XR workflows, enabling efficient transmission and rendering of complex 3D scenes. Figure 7 illustrates the results of compressing a point cloud using this pipeline, highlighting its effectiveness and potential for practical applications.

On the left, the original point cloud is shown. On the right, the compressed point cloud is rendered, less than 8 percent of the original information is required to reconstruct the volume with a PSNR of 59.997dB.
Scene understanding: In order to enable understanding of the semantics of a scene, and separate individual objects, instance segmentation is performed. This step determines a pixel mask or polygon region for each object/background instance, and assign a semantic label to it. In the cityscape use case, we have assessed two recently proposed segmentation methods, Mask2Former43 and ConvNext44 (both exist in variants that can be applied to both semantic and instance segmentation) and a semantic segmentation approach, BEiT45, on synthetic images of city scenes. The results for semantic segmentation for images simulating daylight conditions are better than those simulating more challenging light conditions. In practical applications, it may not be feasible to train all classes on the same dataset, as only annotations for a subset of them may be available. In our earlier work46, we have shown that this can be achieved with freezing the backbone and training segmentation heads for different classes which can then be combined for efficient inference.
In the industrial scenario, scene understanding requires detection and segmentation of particular assets, such as charging stations. Such assets are available as 3D models, which can be leveraged for training. We implemented a data generation pipeline rendering these objects in different environments and under different lighting conditions. An instance segmentation approach based on Swin Transformer47 has been trained on images generated from 3D models and tested on real instances of these assets, using a dataset from the ADAPT Sim2Real challenge48. Moreover, we use a combination of Mask R-CNN and ODISE49 to perform a panoptic segmentation for more than 2000 classes in both cityscape and industrial scenes (Figure 8).
Scene understanding contributions: Compared to a pretrained baseline model (trained on ADE20K), we showed that the Mask2Former model, further trained on synthetic data, clearly improves performance on real images captured by the sensor-equipped vehicle, with IoU increasing from 0.53 to 0.77 and accuracy from 0.60 to 0.81. Further details can be found in 50. Additionally, using the model soup approach to combine a set of models trained with different parameters, we demonstrated that the overall mAP50 segmentation performance on the real images of the Sim2Real dataset increased from 0.45 to 0.69, clearly improving model generalization 51. These findings highlight the potential of synthetic data for rare and underrepresented classes and the effectiveness of recent approaches like model soup in enhancing generalization to real data.

Panoptic segmentation in (a) an industrial warehouse and (b) a cityscape scene. Using a combination of Mask R-CNN and ODISE, we segment all the objects in both scenes.
Sensor fusion: A multi-sensor vehicle perception system is developed and is capable of capturing relevant cityscape elements to continuously update the city’s digital twin and allow development of XR applications. The demo vehicle equipped with a camera-based surround view system52, LiDAR and GPS shown in Figure 9a allow continued capture of the vehicle’s surroundings. Significant progress has been achieved in sensor synchronization and calibration to enhance data accuracy, consistency, and robustness. This enables efficient early sensor fusion, as shown in Fig. 9b and c and real-world dataset generation, which is complemented by generation of synthetic datasets to be used for training of deep learning models and thus enhance the digital twin creation.

A demo vehicle equipped with multiple sensors and communication units onboard is developed to generate multiple datasets for training various scene understanding models.
Multi-sensor depth fusion enhances the robustness and accuracy of 3D reconstruction methods. In the FICOSA car setup with four fisheye cameras (front, rear, and two sides) and a LiDAR, the goal was to implement SLAM on each sensor and fuse the resulting point clouds for 3D reconstruction. However, visual SLAM struggled with the side and rear cameras due to fisheye distortion, static regions, motion blur, and poor camera orientation. As a result, SLAM was successfully applied only to the front camera using H-SLAM53, which localized the vehicle’s trajectory. This motion estimate was propagated to the other cameras, and a spatial mapper was used to create a comprehensive 3D representation of the environment. The resulting depth maps were then fused into a semantically rich 3D map using FGICP method54 for point cloud registration.
To improve localization, outputs from LiDAR-based methods, such as those in55, were combined with visual SLAM approaches like H-SLAM53, enhancing localization accuracy. Sensor fusion also plays a critical role in semantic segmentation for digital twin creation, where 2D panoptic segmentation is performed on camera data using methods like Mask DINO56, and the resulting 2D segments are projected onto the LiDAR-based 3D point cloud, enriching the map with semantic details.

(a)–(e): Visualization of the 3D point cloud outputs from the front, rear, left, and right cameras, along with the point cloud generated by the LiDAR sensor, respectively. (f): Bird’s eye view of the final point cloud obtained by fusing the outputs of the four cameras and the LiDAR sensor using FGICP.
Sensor fusion contributions: To create a robust and semantically rich digital twin, multiple sensors are employed to capture and process data for various tasks. Multi-sensor depth fusion enhances the quality and accuracy of 3D reconstructions. As demonstrated in Fig. 10, point clouds generated from diverse sensors, including four cameras and one LiDAR, are fused to create a detailed 3D map of the environment. Moreover, the combination of LiDAR data with visual SLAM outputs further improves localization accuracy. Additionally, the digital twin is enriched with semantic information by integrating 2D camera-based segmentation results into the LiDAR-based 3D reconstructed point cloud. This comprehensive sensor fusion approach ensures the creation of a highly detailed and reliable digital twin, making it well-suited for real-world applications.
Localization: For high-accuracy self-localisation we aim to leverage 3D information in the city scene. However, as LiDAR sensors only provide sparse depth data we aim to reconstruct dense depth information from the RGB image and the sparse depth measurements. We assessed approaches proposed for depth completion such as 57 and more recent methods such as 58, but we found that these methods do not generalise well to images that are less similar to the scenes used for training. In contrast, we found that relative depth map estimation approaches from RGB data, which are trained on huge heterogeneous image datasets, such as 30, perform more reliably. Their output can be re-scaled using the sparse measurements known for some locations in the image. Examples of outputs of depth completion and monocular depth estimation are shown in Fig. 11. State of the art monocular depth estimation methods are a useful tool to provide a dense basis that can be adjusted with sparse depth measurements.

Comparison of depth completion and monocular depth estimation..
We are working on IBL (Image-based localization) and NeRF-based localization which will be used in combination with SLAM approaches. We have been working with H-SLAM approach for the localization component. However, since H-SLAM always takes the origin as the starting point instead of the original position, we are working on using IBL and NeRF-based localization to address the global localization issue with H-SLAM. While working with H-SLAM, we set up a workflow where we used external cameras, performed calibration, and tested the H-SLAM. After that, we worked on connecting the Unity3D virtual camera to H-SLAM. The reason is that geo-referenced images are required for the IBL approach which we planned to achieve using Unity3D’s cameras as a test case. In Fig. 12, an actor (gray cube marked with yellow circle) moves inside a scene (created in Unity3D), and collects the geo-referenced image data from a set of 300 images. We apply IBL on these collected images and then create a database that contains image features using SIFT algorithm and the gps locations.

Actor (gray cube marked with yellow circle) at different positions inside the 3D scene.
Here, the IBL algorithm combines the SIFT with the Brute-Force (BF) feature matching technique. Initial feature matches, containing both inliers and outliers, are refined using RANSAC to detect and remove outliers between the query image and the geo-referenced image. The IBL algorithm estimates the 6-DoF camera pose by matching features between the query image and the geo-referenced image. The 6-DoF camera poses obtained from IBL are used to replace the origin as the starting point in H-SLAM, effectively addressing the global localization challenge. This pose information is then transmitted to H-SLAM via ROS, where it initializes the camera’s position, enabling H-SLAM to generate the point cloud from the updated starting location.
Figure 13 (a) and (b) depict two scenarios of the point cloud generated inside H-SLAM following the image data sent by the virtual camera from the Unity scene: (a) without using IBL: in this scenario, the H-SLAM uses its default initial pose to start generating the point cloud data (red points are current tracking points of the scene and blue points are built map), (b) using IBL with H-SLAM: in this scenario, the H-SLAM waits for the IBL to first generate the 6-DoF pose to update the initial pose and then start generating the point cloud data. In both cases, H-SLAM uses the following color schema to differentiate the point cloud data points in the H-SLAM UI:
-
The red color indicates the tracking points by the HSLAM given the current state of the actor; these points act as the input to build the world map of the scene.
-
The blue color indicates the points present in the final world map of the scene.
Finally, Fig. 13 (c) shows the final point cloud generated by the H-SLAM based on the received image data from the camera sensor in the synthetic Unity scene. As the next step, we will work on quantifying the effect of IBL on the overall localization accuracy of the actor within the H-SLAM generated pointcloud.

Trajectory of the camera (i.e.location of the actor) inside the pointcloud generated via H-SLAM: (a) H-SLAM output; without using IBL, (b) IBL along with H-SLAM, (c) generated point cloud after the path is traversed by the camera.
Localization contributions: Our work introduces a high-accuracy localization pipeline comprising two main modules that enhance both precision and adaptability. The first module is a CNN-based pose regressor, similar to the approach in59, designed to provide an initial pose estimation. This module is trained on a dataset augmented with high-quality rendered views generated using Nerfacto60. The second module features a test-time refinement process that utilizes a Monte Carlo particle filter inspired by61. Unlike traditional methods, this particle filter focuses on refining an initial pose prediction rather than performing global localization. NeRF models play a critical role in this refinement process by iteratively updating particle weights to improve localization accuracy. A significant contribution of our work is the replacement of Vanilla NeRF62, previously used in59, with the more sophisticated Nerfacto during the training process. This improvement enhances the quality of synthesized views and optimizes rendering efficiency, leading to a more computationally efficient pipeline.
Moreover, by incorporating Nerfacto, our localization pipeline achieves superior accuracy and adaptability across diverse scenes. On the 7-Scenes63 dataset, an indoor dataset, and the Cambridge Landmarks dataset64, an outdoor dataset, the translation errors were 0.025m and 0.04m, respectively, while the rotation errors were 0.59°and 0.58°. These results highlight the pipeline’s accuracy across both indoor and outdoor environments, albeit with the trade-off of increased computational time.
Rendering: Diverging from traditional 3D modeling methods that rely on polygons or voxels, NeRF62 introduces a continuous 5D function for scene representation, enabling the creation of hyper-realistic images from standard photography. This innovation marks a significant advancement in 3D scene representation and rendering, producing highly detailed images that accurately depict real-world scenarios. NeRF is reshaping how digital twins (DTs) are constructed and visualized.
For the cityscape use case, we employ the Nerfacto model within the Nerfstudio framework60 to create 3D outdoor scene representations using NeRF. The training dataset, provided by FICOSA (see Fig. 9), is carefully pre-processed to ensure compatibility and optimal performance with the Nerfacto model. Two distinct methods are utilized to spatially position images within the 3D environment, a critical step in achieving accurate and realistic rendering.
The first method uses the COLMAP framework65,66, which aligns images in 3D space through feature extraction and matching. However, this method encounters limitations with non-overlapping images, particularly those captured from opposing viewpoints. The second method leverages the capture car’s GPS data and camera calibration parameters, bypassing the need for feature extraction and significantly accelerating the process.
Both approaches yield similar results, with an average Euclidean distance difference of just 0.06 meters in image placement. However, while GPS completes the placement in seconds, COLMAP’s processing time ranges from minutes to days, influenced by image resolution, the number of images, and the feature matching algorithm. The GPS-based approach is consistently faster, requiring only minor adjustments to adapt to different setups, and is highly versatile across various 3D reconstruction methods and use cases.
The extensive viewpoint requirements for NeRF training—often dozens to hundreds of views—present a significant challenge, as surrounding a scene with so many cameras is impractical. To address this, methods have been developed to reduce the number of input views, such as DietNeRF67, which supplements the training process with auxiliary information, improves sampling strategies, and incorporates novel components into the training loss.
Another strategy to tackle insufficient viewpoint coverage involves utilizing RGB-D data during training, as demonstrated in DS-NeRF68, which incorporates depth loss. Additionally, traditional NeRF algorithms are designed to overfit a single scene, limiting their ability to generalize. To address this, generalizable NeRF algorithms, such as MVSNeRF69 and ENeRF70, have been developed. MVSNeRF warps 2D image features onto a plane sweep volume for feature interpolation along novel view rays, while ENeRF estimates depth bounds using a cost volume derived from the plane sweep volume.
For industrial applications, NeRF enables detailed and photorealistic 3D rendering of factory environments, enhancing spatial understanding and supporting precise planning for layout changes, equipment installations, and workflow optimizations.
Rendering contributions: In this work, we contribute to the field of NeRF-based rendering in several meaningful ways. First, we introduce a robust pre-processing pipeline that integrates GPS data with camera calibration parameters for efficient spatial placement of images, significantly reducing processing time compared to traditional COLMAP methods. Second, we demonstrate the adaptability of this pipeline across varying setups, ensuring versatility for different 3D reconstruction tasks. Third, we address the challenge of viewpoint scarcity by exploring strategies such as reducing input views through auxiliary data and leveraging RGB-D data for enhanced training. These contributions collectively improve the efficiency and scalability of NeRF-based rendering, making it applicable to a broader range of real-world use cases, including both cityscape and industrial environments.
XR rendering: Our aim is to create adaptive and scalable XR rendering for different content, integrating data based on point cloud geometry and the user’s viewpoint71. These implementations must meet users’ needs in a personalized manner as emphasized by Arvanitis et al.72. The XR content must cater to diverse user profiles including their capabilities, preferences, and experience levels, while also being compatible with a range of devices such as heads-up displays, smartphones, and tablets, across various environments featuring different lighting and weather conditions.
In demanding applications, dense and realistic point cloud representations entail substantial memory usage, suggesting the need for efficient methods that can adapt the rendering to the content and achieve optimal performance and visual accuracy while preserving minimal bit rates for transmission. The compression process involves encoding each point’s position based on its ‘extended saliency’, which combines the viewer’s relative position and geometric saliency of the rendered object. The visible and non-visible points are segregated, and we compute four saliency maps corresponding to (1) the point cloud’s geometry, (2) the distance from the user, (3) the visibility data, and (4) the user’s viewpoint. During the encoding phase, visible points are compressed with a bit rate proportional to their saliency, whereas non-visible points are omitted. However, during the decoding phase, non-visible points are estimated through interpolation solely based on their connectivity details.
In AR rendering applications, shadows and occlusions play important roles in enhancing the realism of digital elements within the physical world. Accurately casting shadows from virtual objects onto the physical scene enhances the illusion of depth and spatial relationships. It enriches user immersion by fostering a sense of depth and tangibility, allowing users to interact more naturally with the augmented content. Custom surface shaders allow us to manage multiple light sources in real-time, enhancing depth perception and spatial coherence. Using hardware, we estimate the direction of primary light sources in the current environment as well as the ambient light intensity. By creating custom shaders that utilize the ‘negative’ shadow effect73 and support multiple shadows and shadow-hue changes, along with appropriate shaders for occlusion, we achieve a more natural integration of the virtual and real worlds.
Occlusion, the technique of rendering virtual objects to appear behind real-world obstacles, creates a seamless integration between the virtual and real. It enables digital elements to behave realistically, hiding behind physical objects as they would in the natural environment. Without occlusion, virtual objects may appear disjointed or disconnected from the surroundings, diminishing the overall sense of believability in the AR experience.
In our applications, we consider various lighting and spatial conditions, employing different cases and methods to promise an enhanced and immersive user experience across various AR domains. For example, in one use case, the rendering we apply is used to enhance driver situational awareness, where hazardous objects are rendered in the driver’s field of view according to their location in a scene. First, automated obstacle detection, AR visualization, and information sharing with other connected vehicles or road infrastructures are applied to identify objects to be rendered. Then, each object is rendered in the real-world based on the degree of hazard it poses to the driver74. Our objective is to maximize the driver’s awareness of hazardous obstacles while minimizing distraction.
XR rendering contributions: This work presents several contributions to the field of extended reality. First, the saliency-driven point cloud compression and reconstruction method significantly enhances rendering efficiency while maintaining visual fidelity, even in resource-constrained environments. Specifically, for low bit rates (0.5 bpp), the method delivers superior quality results, outperforming Geometry-based Point Cloud Compression Triangle soup (G-PCC trisoup) by + 20 dB Peak Signal-to-Noise Ratio (PSNR) and G-PCC octree by + 10 dB PSNR. Second, the development of adaptive rendering techniques including customized surface shaders and multi-source light management, improves AR realism by effectively addressing challenges such as shadows, occlusions, and lighting variations in dynamic environments. Third, the integration of these methods into safety-critical applications, such as enhancing driver awareness through AR, demonstrates a compelling and practical use case. Notably, 83.3% of participants expressed a positive inclination toward using the proposed visualization system to reduce nervousness while driving in unfamiliar areas. This highlights the system’s ability to bridge the gap between user-centered design and industry needs, particularly in the context of Industry 4.0.
Ethical and privacy dimensions
The development of large-scale digital twins may present various ethical, legal and social challenges, in particular around privacy. The potential for addressing these issues through design choices before they materialise is a central tenet of the ethics by design approach, which holds that embedding ethical considerations into and throughout the design and development process is necessary (but not of itself sufficient) to operationalise different ethical principles into resultant technological systems75. According to guidance from the European Commission, as informed by the work of the Independent High-Level Expert Group on Artificial Intelligence (AI-HLEG), there are six general ethical principles of ethics by design, namely respect for human agency, privacy and data governance, fairness, well-being, transparency, and oversight and accountability76. These general principles are predicated on international and European Union (EU) human rights law, in particular the Charter of Fundamental Rights of the EU77, and are linked with a series of ethics requirements for their operationalisation. Utilising this ethics by design approach, we have developed a methodology for identifying the issues that arise in the specified context of applications for digital twins, namely cityscape and industry environments, and then revolving such issues in line with accepted ethical principles and established legal requirements.
Identifying issues The first step in the process of identifying potential ethical, legal and socio-economic issues is to conduct a preliminary assessment. This enables the identification of different categories of risks, such as those relating to the involvement of human participants, the collection and processing of personal data, and the development, deployment and/or use of AI. As the risks and impacts will be specific to the environment and affected groups therein, it is necessary to tailor the impact assessment methodology to the needs of the use case. In DIDYMOS-XR, a key area of focus is on mitigating risks to privacy as a result of large-scale data capture. In the cityscape environment, for instance, the capture of scenes at scale using SVS cameras and other sensors may involve the capture of personal data, such as image data of pedestrians and vehicle licence plates, as well as GPS data of vehicle drivers. Similarly, the use of interactive head-mounted displays (HMDs) in the industry environment may lead to the processing of personal data, for instance when provided by or collected from the end-user as part of the authentication process. Without clarification of, inter alia, technical, organizational and security measures for the collection, processing and storage of these data, there is a risk of an adverse impact on individuals’ rights to privacy and data protection under the GDPR. These potential risks may arise, for instance, through a data breach, a failure to inform data subjects of the data processing, or an international data transfer to a third country without an adequate level of protection for personal data.
As part of assessing the potential impacts, it is important to consider who may be affected by the creation of large-scale digital twins78. This includes the people present at the point of data capture, the developers, the end-users and, depending on the application or use case, others within wider society who may be affected. To validate the issues identified and the suggested mitigation measures, it is necessary to consult with internal and external stakeholders who should be representative of all the groups affected and inclusive of other socio-demographics (e.g.age, sex, education) that may affect how the user interacts with the solution. In DIDYMOS-XR, as part of a co-creation process, consultations are carried out with an Ethics Advisory Board, as convened to provide independent expert advice, and a Stakeholder Board, as comprised of representatives from target groups identified on the basis of the project’s use cases, whose members are asked to provide feedback as prospective end-users on the suitability and desirability of proposed ethical and technical solutions (Fig. 14).

Steps in the process for identifying and mitigating risks.
It is well-documented that some users may experience side effects from using AR headset devices, such as nausea, motion-sickness, dizziness, disorientation, headache, fatigue, eye strain, dry eyes, and seizures.79. These concerns are exacerbated by the lack of clarity regarding which preconditions in users might trigger such side effects. while factors like age or pre-existing eye conditions can influence the severity of the impact, users themselves may not always be aware of these underlying conditions. In technical tasks, equality may be compromised through poor data quality, which leads to unfair biases in the models. Therefore, it is essential to prioritize equitable access and experience with the technology when designing the applications, ensuring that final products do not discriminate against any group. To reduce the likelihood and severity of these risks, it is necessary to apply appropriate mitigation measures.
Mitigation strategy By consulting existing ethical and legal frameworks and established best practices, and engaging in collaborative dialogue with stakeholders, mitigation measures should be identified, discussed and agreed. Where possible, interventions should be integrated into the technological solution by design. As identified previously, the privacy of individuals can be impacted by developing a digital twin, including at data capture, through data processing pipelines, and in application. This section explores some of the mitigation measures that can be implemented to reduce risks to privacy.
Firstly, when conducting “a systematic monitoring of a publicly accessible area on a large scale”, it is required under Article 35 GDPR to conduct a Data Protection Impact Assessment (DPIA) in order to assess the risks to the rights of data subjects and the measures envisaged to address these risks, including safeguards, security measures and mechanisms to ensure the protection of personal data. In DIDYMOS-XR, a DPIA was conducted following guidance from the Spanish Data Protection Agency80, based on which a number of control measures have been implemented. These include transparency measures to inform data subjects affected at the point of the data capture, such as by displaying a data protection notice with information on the purpose, legal basis and retention period for any personal data that is collected, as well as creating a privacy policy to inform data subjects of the identity of the data controller, the data processing operations, and their rights under the GDPR, including how they may be exercised.
An additional recommended measure for reducing the risk of interfering with individuals’ rights to privacy and data protection is to pseudonymise or anonymise any personal data that is incidentally captured as part of the creation of a digital twin. Either technique may be employed as part of a data protection by design approach, although it is important to note that only anonymous information, as defined under Recital 26 GDPR as “information which does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or is no longer identifiable”, is outside the scope of the GDPR. These measures can reduce the privacy and data protection risks for both data subjects and data controllers and processors alike, such as by lowering the risk of harm that may arise from a data breach and fostering public trust in the existence of appropriate safeguards for data handling81. Finally, data management policies should be in place to limit the risk of mishandling data and reduce the number of people who may be affected by a data breach. Best practice guidelines, such as ISO/IEC 270001:2022, recommend establishing organisational policy measures that, among other things, determine the procedures for data handling, access processes and incident management. Establishing clear lines of accountability can help to build trust and increase acceptance of technological solutions.
Established research practices for implementing fairness emphasize that models should be trained using mostly open datasets. Selection of datasets must consider the relevance of the objects and subjects they contain and their representativeness of the use case. Datasets quality should be assessed as part of the fine-tuning of models based on the needs of the application to ensure robustness and alignment with application requirements. Representing a diverse range of stakeholder categories as well as mix of socio-economic backgrounds will give a better chance of any systemic issues affecting certain groups of stakeholders to be raised in discussions. For instance, early research shows that AR devices can have greater physical side effects in women82 and in people with vision impairments83. By including such users in validation activities developers will be more likely to better understand and accommodate their needs in the design of the application e.g.by creating more static elements that have been found to be less likely to induce motion sickness in users.
Table 3 provides an overview of the potential ethical, data protection, and socio-economic challenges identified in the development of digital twins. It also outlines the proposed mitigation measures to address these challenges across various use cases, including city tourism, city planning and simulation, city maintenance, and industrial applications. We stress the importance of considering these issues throughout the digital twin creation process to ensure responsible and sustainable implementation.
Conclusion
In this paper, we present our approach to create, update and visualize Digital Twins as part of the DIDYMOS-XR project, showcasing multiple digital twin use cases alongside frameworks for DT construction and interaction, aimed at enabling large-scale and long-term XR applications. These include three cityscape applications addressing city planning, maintenance, and urban tourism, complemented by an industrial application. Additionally, we outline the diverse array of enabling technologies utilized in crafting digital twins for both use cases, covering 3D scene reconstruction, data enhancement, data compression, scene comprehension, sensor fusion, localization, and rendering, with a focus on those integral to our specific use cases. Looking ahead, the DIDYMOS-XR project sets a foundation for continued exploration in the realm of digital twin technology, paving the way for enhanced virtual experiences and improved real-world applications.
Data availability
Some datasets will be provided upon request. Contact corresponding author for any inquiries.
References
Javaid, M., Haleem, A. & Suman, R. Digital twin applications toward industry 4.0: a review. Cogn. Robot. 3, 71–92 (2023).
Pfeiffer, J. et al. Modeling languages for automotive digital twins: a survey among the german automotive industry. In Proceedings of the ACM/IEEE 27th International Conference on Model Driven Engineering Languages and Systems 92–103 (2024).
Koulamas, C. & Kalogeras, A. Cyber-physical systems and digital twins in the industrial internet of things [cyber-physical systems]. Computer 51, 95–98 (2018).
Stączek, P., Pizoń, J., Danilczuk, W. & Gola, A. A digital twin approach for the improvement of an autonomous mobile robots (amr’s) operating environment—a case study. Sensors 21, 7830 (2021).
Brunner, P., Denk, F., Huber, W. & Kates, R. Virtual safety performance assessment for automated driving in complex urban traffic scenarios. In 2019 IEEE Intelligent Transportation Systems Conference (ITSC) 679–685 (IEEE, 2019).
Mylonas, G. et al. Digital twins from smart manufacturing to smart cities: a survey. Ieee Access 9, 143222–143249 (2021).
Mazzetto, S. A review of urban digital twins integration, challenges, and future directions in smart city development. Sustainability 16, 8337. https://doi.org/10.3390/su16198337 (2024).
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A. & Koltun, V. Carla: an open urban driving simulator. In Conference on robot learning 1–16 (PMLR, 2017).
Unity3D. https://unity.com (2024,accessed 2 Mar 2024).
Indraprastha, A. & Shinozaki, M. The investigation on using unity3d game engine in urban design study. ITB J. Inf. Commun. Technol. 3, 1–18. https://doi.org/10.5614/itbj.ict.2009.3.1.1 (2009).
Hämäläinen, M. Urban development with dynamic digital twins in helsinki city. IET Smart Cities 3, 201–210 (2021).
Schrotter, G. & Hürzeler, C. The digital twin of the city of zurich for urban planning. PFG-J. Photogram. Remote Sens. Geoinf. Sci. 88, 99–112 (2020).
Schrotter, G. & Hürzeler, C. The digital twin of the city of zurich for urban planning. PFG 88, 99–112. https://doi.org/10.1007/s41064-020-00092-2 (2020).
Lehtola, V. V. et al. Digital twin of a city: review of technology serving city needs. Int. J. Appl. Earth Obs. Geoinf. 114, 102915. https://doi.org/10.1016/j.jag.2022.102915 (2022).
Fan, R. et al. Urban digital twins for intelligent road inspection. In 2022 IEEE International Conference on Big Data (Big Data) 5110–5114. https://doi.org/10.1109/BigData55660.2022.10021042 (2022).
Cao, T., Wang, Y. & Liu, S. Pavement crack detection based on 3d edge representation and data communication with digital twins. IEEE Trans. Intell. Transp. Syst. 24, 7697–7706. https://doi.org/10.1109/TITS.2022.3194013 (2023).
Gallist, N. & Hagler, J. Tourism in the metaverse: Digital twin of a city in the alps. In Proceedings of the 22nd International Conference on Mobile and Ubiquitous Multimedia, MUM ’23 568–570 (Association for Computing Machinery, 2023). https://doi.org/10.1145/3626705.3631880.
Nassif, J., Tekli, J. & Kamradt, M. Synthetic Data: Revolutionizing the Industrial Metaverse (Springer Nature, 2024).
Tao, F., Zhang, H., Liu, A. & Nee, A. Y. C. Digital twin in industry: state-of-the-art. IEEE Trans. Industr. Inf. 15, 2405–2415 (2019).
Del Vecchio, V., Lazoi, M. & Lezzi, M. Digital twin and extended reality in industrial contexts: a bibliometric review. In XR Salento 2023 (Springer, 2023).
Tu, X., Autiosalo, J. & Ala-Laurinaho, R. E. A. Twinxr: method for using digital twin descriptions in industrial extended reality applications. Front. Virtual Reality 4, 562 (2023).
Martínez-Peláez, R. et al. Role of digital transformation for achieving sustainability: mediated role of stakeholders, key capabilities, and technology. Sustainability 15, 11221 (2023).
Castelo-Branco, I., Cruz-Jesus, F. & Oliveira, T. Evidence for the european union. Assessing industry 4.0 readiness in manufacturing. Comput. Ind. 107, 22–32 (2019).
Zheng, T., Ardolino, M., Bacchetti, A. & Perona, M. The applications of industry 4.0 technologies in manufacturing context: a systematic literature review. Int. J. Prod. Res. 59, 1922–1954 (2021).
Leica Total Station. https://leica-geosystems.com/products/total-stations (2024, accessed 28 Feb 2024).
Begout, P., Kubicki, S., Bricard, E. & Duval, T. Augmented reality authoring of digital twins: design, implementation and evaluation in an industry 4.0 context. Front. Virtual Reality 3, 526 (2022).
Sayour, M. et al. Hac-slam: human assisted collaborative 3d-slam through augmented reality. In IEEE International Conference on Robotics and Automation (ICRA) (2024).
Besl, P. J. & McKay, N. D. Method for registration of 3-d shapes. In Sensor Fusion IV: Control Paradigms and Data Structures, vol. 1611 586–606 (Spie, 1992).
Hornung, A., Wurm, K. M., Bennewitz, M., Stachniss, C. & Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Autonomous Robots (2013). https://doi.org/10.1007/s10514-012-9321-0.
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K. & Koltun, V. Towards robust monocular depth estimation: mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 44, 1623–1637 (2020).
Community, B. O. Blender - a 3D modelling and rendering package (Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018).
Ledig, C. et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition 4681–4690 (2017).
Wang, X. et al. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European conference on computer vision (ECCV) workshops (2018).
Liang, J. et al. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF international conference on computer vision 1833–1844 (2021).
Yu, L., Li, X., Fu, C.-W., Cohen-Or, D. & Heng, P.-A. Pu-net: Point cloud upsampling network. In Proceedings of the IEEE conference on computer vision and pattern recognition 2790–2799 (2018).
Jiang, J., Wang, A. & Aizawa, A. Attention-based relational graph convolutional network for target-oriented opinion words extraction. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume 1986–1997 (2021).
Li, R., Li, X., Fu, C.-W., Cohen-Or, D. & Heng, P.-A. Pu-gan: a point cloud upsampling adversarial network. In Proceedings of the IEEE/CVF international conference on computer vision 7203–7212 (2019).
Liang, J. et al. Swinir: image restoration using swin transformer. In Proceedings of the IEEE/CVF international conference on computer vision 1836–1844 (2021).
Fernandez, S., Montagud, M., Rincón, D., Moragues, J. & Cernigliaro, G. Addressing scalability for real-time multiuser holo-portation: Introducing and assessing a multipoint control unit (mcu) for volumetric video. In Proceedings of the 31st ACM International Conference on Multimedia, MM ’23, 9243–9251. 10.1145/3581783.3613777 (Association for Computing Machinery, New York, NY, USA, 2023).
Cernigliaro, G., Cabré, M. M., Montagud, M., Ansari, A. & Fernández, S. Pc-mcu: point cloud multipoint control unit for multi-user holoconferencing systems. In Proceedings of the 30th ACM Workshop on Network and Operating Systems Support for Digital Audio and Video (2020).
Liu, Z. et al. Point cloud video streaming: challenges and solutions. IEEE Netw. 35, 202–209. https://doi.org/10.1109/MNET.101.2000364 (2021).
MPEG-PCC. https://mpeg-pcc.org/ (2024, accessed 11 Mar 2024).
Cheng, B., Misra, I., Schwing, A. G., Kirillov, A. & Girdhar, R. Masked-attention mask transformer for universal image segmentation (2022).
Liu, Z. et al. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022).
Bao, H., Dong, L., Piao, S. & Wei, F. BEiT: BERT pre-training of image transformers. In International Conference on Learning Representations (2022).
Onsori-Wechtitsch, S. & Bailer, W. Multi-head instance segmentation of indoor scenes for ar/dr applications. In Knauss, S. & Ornella, A. D. (eds.) Proceedings of IEEE International Conference on Artificial Intelligence and Virtual Reality, vol. 1 of Studies in Computational Intelligence 26–35. https://doi.org/10.1145/3591106.3592304(LIT, online, 2022).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision 10012–10022 (2021).
ADAPT - Sim2Real Challenge. https://codalab.lisn.upsaclay.fr/competitions/15873 (2024,accessed 2 Mar 2024).
Xu, J. et al. Open-vocabulary panoptic segmentation with text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2955–2966 (2023).
Fürntratt, H. et al. Learning scene semantics from vehicle-centric data for city-scale digital twins. In Proceedings of Conference on Content-based Multimedia Indexing (2024).
Onsori-Wechtitsch, S., Fürntratt, H., Fassold, H. & Bailer, W. Data-efficient domain transfer for instance segmentations for ar scenes. In Proceedings of Conference on Content-based Multimedia Indexing (2024).
Delgado, G. et al. Virtual validation of a multi-object tracker with intercamera tracking for automotive fisheye based surround view systems. In 2022 IEEE 14th Image, Video, and Multidimensional Signal Processing Workshop (IVMSP) 1–5 (2022). https://doi.org/10.1109/IVMSP54334.2022.9816285.
Younes, G., Khalil, D., Zelek, J. & Asmar, D. H-slam: hybrid direct-indirect visual slam. arXiv preprintarXiv:2306.07363 (2023).
Koukoulis, E., Arvanitis, G. & Moustakas, K. Unleashing the power of generalized iterative closest point for swift and effective point cloud registration. In 2024 IEEE International Conference on Image Processing (ICIP) 3403–3409 (IEEE, 2024).
Belkin, I., Abramenko, A. & Yudin, D. Real-time lidar-based localization of mobile ground robot. Procedia Comput. Sci. 186, 440–448 (2021).
Li, F. et al. Mask dino: Towards a unified transformer-based framework for object detection and segmentation. arxiv. arXiv preprint arXiv:2206.02777 (2022).
Xu, Y. et al. Depth completion from sparse lidar data with depth-normal constraints. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2811–2820 (2019).
Zhang, Y. et al. Completionformer: Depth completion with convolutions and vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 18527–18536 (2023).
Chen, S., Li, X., Wang, Z. & Prisacariu, V. A. Dfnet: enhance absolute pose regression with direct feature matching. In European Conference on Computer Vision 1–17 (Springer Nature Switzerland, 2022).
Tancik, M. et al. Nerfstudio: a modular framework for neural radiance field development 1–12 (2023).
Maggio, D., Abate, M., Shi, J., Mario, C. & Carlone, L. Loc-nerf: Monte carlo localization using neural radiance fields 4018–4025 (2023).
Mildenhall, B. et al. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 65, 99–106 (2021).
Shotton, J. et al. Scene coordinate regression forests for camera relocalization in rgb-d images. In Proceedings of the IEEE conference on computer vision and pattern recognition 2930–2937 (2013).
Kendall, A., Grimes, M. & Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE international conference on computer vision 2938–2946 (2015).
Schonberger, J. L. & Frahm, J.-M. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition 4104–4113 (2016).
Schönberger, J. L., Zheng, E., Frahm, J.-M. & Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14 501–518 (Springer, 2016).
Jain, A., Tancik, M. & Abbeel, P. Putting nerf on a diet: Semantically consistent few-shot view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision 5885–5894 (2021).
Deng, K., Liu, A., Zhu, J.-Y. & Ramanan, D. Depth-supervised nerf: fewer views and faster training for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 12882–12891 (2022).
Chen, A. et al. Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision 14124–14133 (2021).
Lin, H. et al. Efficient neural radiance fields for interactive free-viewpoint video. In SIGGRAPH Asia 2022 Conference Papers 1–9 (2022).
Psatha, E., Laskos, D., Arvanitis, G. & Moustakas, K. Aggressive saliency-aware point cloud compression. In Proceedings of the 20th EuroXR International Conference, vol. 422 199 (VTT Technical Research Centre of Finland, 2023).
Arvanitis, G. & Moustakas, K. Digital twins and the city of the future: sensing, reconstruction and rendering for advanced mobility. In ITS2023: Intelligent Systems and Consciousness Society (2023).
Osti, F., Santi, G. M. & Caligiana, G. Real time shadow mapping for augmented reality photorealistic rendering. Appl. Sci. 9, 562. https://doi.org/10.3390/app9112225 (2019).
Arvanitis, G., Stagakis, N., Zacharaki, E. I. & Moustakas, K. Cooperative saliency-based pothole detection and ar rendering for increased situational awareness. IEEE Trans. Intell. Transport. Syst. 2023, 1–17. https://doi.org/10.1109/TITS.2023.3327494 (2023).
Brey, P. & Dainow, B. Ethics by design for artificial intelligence. AI and Ethics 2023, 1–13 (2023).
Dainow, B. & Brey, P. Ethics by design and ethics of use approaches for artificial intelligence (European Commission, Brussels, 2021).
Eu, E. Charter of fundamental rights of the european union. Rev. Int. Affairs 63, 109–123 (2012).
Rodrigues, R., Rituerto, M. & Diez, M. Socio-economic impact assessments for new and emerging technologies. J. Respons. Technol. 9, 963 (2022).
Saredakis, D. et al. Factors associated with virtual reality sickness in head-mounted displays: a systematic review and meta-analysis. Front. Hum. Neurosci. 14, 96 (2020).
protección datos, A. E. Guía práctica para LAS Evaluaciones de Impacto en la Protección de LOS datos sujetas al RGPD. Regulation (eu) (2018).
Office, I. C. Introduction to anonymisation. Regulation (eu) (2021).
Jasper, A. et al. Visually induced motion sickness susceptibility and recovery based on four mitigation techniques. Front. Virtual Reality 1, 582108 (2020).
Pladere, T., Svarverud, E., Krumina, G., Gilson, S. J. & Baraas, R. C. Inclusivity in stereoscopic xr: human vision first. Front. Virtual Reality 3, 1006021 (2022).
Acknowledgements
This work was supported by the European Union’s Horizon Europe programme under grant number 101092875 “DIDYMOS-XR” (https://www.didymos-xr.eu).
Author information
Authors and Affiliations
Contributions
Imad H. Elhajj and Daniel Asmar provided supervision for the industrial use case study and developed the overall paper structure. Maya Antoun contributed to developing the paper structure, writing the abstract, introduction, and conclusion sections and the Sensor fusion paragraph of the manuscript and conducted a comprehensive review of the entire document. Daniel Asmar was responsible for creating Figures 1 and 2 and also participated in manuscript review. Malak Sayour spearheaded the implementation of the digital twin in the industrial use case, contributed significantly to writing sections related to the digital twin for industry (Section 2.2), and prepared Figures 4 and 5. Imad H. Elhajj conducted a thorough review of the manuscript. Maya Antoun and Imad H. Elhajj coordinated with the co-authors regarding all the contributions. Panos K. Papadopoulos contributed to the sections of the paper focusing on NeRF. Particularly in the localization section, he introduced an approach utilizing NeRF as a mapping tool, resulting in accurate global localization. Additionally, he presented a NeRF model for the representation of 3D outdoor scenes. Dimitrios Zarpalas reviewed and provided revisions to the paper. Anthony Rizk contributed to the implementation of the industrial use case study at Idealworks. He also authored the manuscript section highlighting the solution’s benefits within robotics ecosystems. Anthony, additionally reviewed and revised the paper. ABM Tariqul Islam contributed significantly to the conceptualization, development, and implementation of the City planning use case which entails the overall technical aspects of creating, simulating, and updating a city digital twin, described in Section 2.1.1. This involves orchestrating a comprehensive process from data acquisition to 3D reconstruction, to simulation integration using state-of-the-art technologies. Moreover, he also spearheaded one of the key technologies for Digital Twin creation described in Section 3, focusing on the intricate 3D reconstruction process of 3D city assets, simulation within Carla, and designing the interactive GUI in Unity3D showcased in Figure 6. Ivan Huerta contributed to the subsections on data enhancement and data compression, while Leonel Toledo reviewed and expanded the data compression subsection of the paper, providing a general overview of the application of these technologies within the project. Gerasimos Arvanitis and Konstantinos Moustakas significantly contributed to conceptualizing, developing, and implementing the city planning use case outlined in Section 2.1.1. They specifically focused on describing the utilization of digital twins in city planning, maintenance, and tourism applications. Moreover, they led the development of one of the key technologies for Digital Twin creation described in the “Enabling technologies for digital twinning” Section 3, focusing on the XR rendering. Additionally, they conducted a thorough review of the entire paper. Aleksandar Jevtić and Isaac Agustí contributed to conceptualizing, developing, and implementing the City maintenance use case outlined in Section 2.1.2. They contributed to the development of the paper section on enabling technologies for Digital Twins outlined in Section 3, more specifically to the development and deployment of Sensor Fusion on-board vehicles and prepared Figures 3 and 9. Francesco Vona and Jan-Niklas Voigt-Antons contributed substantially to conceptualizing and developing the use cases. Francesco Vona provided text to define and describe the different use cases and proofread the paper. Jan-Niklas Voigt-Antons reviewed and revised the paper. Maximilian Warsinke contributed substantially to conceptualizing and developing the use cases. He contributed to the text that defines and describes the use cases. He proofread the text of the paper and revised minor spelling mistakes. Werner Bailer provided text on semantic segmentation. Georg Thallinger reviewed and revised the paper. They are both managing the DIDYMOS-XR project. Ben Howkins, Irma Poder and Maj Ruess developed the section on ethical and privacy dimensions. Ben Howkins and Irma Poder developed a structure and drafted the text outlining the methodology, the identification of issues, and the implementation of mitigation measures. Maj Ruess provided text on the role of the Stakeholder Board and designed Figure 14.
Corresponding author
Ethics declarations
Competing interests
Anthony Rizk is with IDEALworks GmbH, where the Industry use case is being tested. The AMRs shown in the figures are IDEALworks products. ABM Tariqul Islam is with DigitalTwin Technology GmbH. Aleksandar Jevtić and Isaac Agustí are with Ficosa Automotive SLU. The vehicle mentioned in the paper and depicted in Figure 9 is a FICOSA vehicle. Ben Howkins, Irma Poder and Maj Ruess are with Trilateral Research Ltd., which provides consultancy services around the ethics of new and emerging technologies.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Antoun, M., Elhajj, I.H., Sayour, M. et al. Interactive digital twins enabling responsible extended reality applications. Sci Rep 15, 34539 (2025). https://doi.org/10.1038/s41598-025-17855-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-17855-9
