
Abstract
This paper describes an advanced system for the evaluation and teaching of cheerleading techniques that combines deep vision perception with cognitive feedback mechanisms. The method uses spatial feature extraction via convolutional neural networks and temporal movement analysis with recurrent neural networks, along with 3D pose estimation, to facilitate automatic evaluation of the techniques. A cognitive feedback mechanism, which is multi-modal in nature and draws principles from motor learning, supplies customized teaching through the visual, auditory, and haptic pathways. The system achieves 92.4% accuracy in technique classification with real-time processing at 35.4 fps, reduces training time by 35%, and improves skill retention to 89.3% at 4 weeks post-training compared to conventional coaching methods. The paper contributes to the application of artificial intelligence technology to sports education by providing a new way of objective analysis of performance and learning adaptation in the context of cheerleading training.
Similar content being viewed by others

Introduction
Cheerleading is now a very specialized sport that requires the precise performance of complex motions and choreographed routines by teams. Conventional evaluation techniques rely heavily on the subjectivity of judgments from coaches and judges, leading to biased judgments and poor quality of feedback1. The subjectivity of manual evaluation poses great challenges in the provision of objective and reproducible performance measures, which are essential for the refinement of skills2. Recent developments in computer vision and deep learning technologies have revolutionized the sports analysis space with unparalleled promise for automatically evaluating sporting techniques3. Motion-capture and pose estimation algorithms have proved highly suitable for analysis of sportsperson performance for a large set of sporting activities4. Cheerleading as a sporting activity is different because the sport is a synthesis of gymnastics, air stunts, and dance which are necessarily synchronized over multiple sportspersons5. The absence of the immediate feedback mechanism along with the provision of the tailored coaching also discourages mastering the skills under the existing training protocols6.The proposed research project will bridge such a limitation by developing an intelligent mechanism integrating the new developments in computer vision technologies and cognitive feedback methodologies such that sporting techniques can be made automatic for analysis as well as learning support for individuals. Specifically, our system employs: (1) a CNN-LSTM architecture that extracts spatial-temporal features to provide objective technique classification with 92.4% accuracy, addressing subjective judgment issues; (2) real-time processing capabilities (35.4 fps) coupled with multi-modal feedback (visual AR, spatial audio, and haptic) to deliver immediate corrections; (3) a transformer-based occlusion handling module achieving 85.3% PCK on occluded joints to resolve multi-person interaction challenges; and (4) a Bayesian skill modeling framework that personalizes training paths based on individual progress, reducing time-to-proficiency by 35%. The proposed system is designed to complement the training of cheerleading by enabling objective evaluation of the performance, immediate correction for the errors, and learning pathways with adaptation as per the capability and the progress of the individuals.
The primary objectives of this research are: (1) to develop and validate a real-time cheerleading technique evaluation system achieving > 90% classification accuracy while maintaining interactive frame rates (> 30 fps) for practical training applications; (2) to design and implement a multi-modal cognitive feedback mechanism that accelerates skill acquisition by > 30% compared to traditional coaching methods; (3) to create robust algorithms for handling multi-person occlusions in complex formations, achieving > 80% pose estimation accuracy on occluded joints; and (4) to establish a personalized learning framework that adapts to individual skill levels and learning styles, validated through controlled studies with diverse athlete populations. We hypothesize that the integration of deep visual recognition with theory-grounded cognitive feedback will significantly enhance both the objectivity of performance assessment and the efficiency of skill acquisition in cheerleading training. The scope of this study encompasses individual skill development and small-group formations (2–5 athletes), with evaluation focused on fundamental to advanced techniques as defined by international cheerleading standards. While team-level choreography optimization and competition scoring prediction represent important future extensions, they remain outside the current scope to ensure thorough validation of the core technological innovations.
Literature review
Computer vision in sports analysis
The evolution of motion capture systems has transformed sports performance analysis from manual observation to automated digital assessment. Early marker-based systems have given way to markerless approaches utilizing deep learning architectures7. Convolutional neural networks have demonstrated exceptional capability in extracting spatial features from athlete movements, while recurrent networks effectively model temporal dynamics8. Recent advances in 3D pose estimation enable accurate reconstruction of human body configurations from monocular video streams, achieving real-time processing speeds suitable for immediate coaching feedback. OpenPose and MediaPipe frameworks have emerged as popular solutions for sports applications, offering robust keypoint detection across diverse lighting conditions and camera angles.These technological advances have facilitated the development of comprehensive performance evaluation systems across multiple sports disciplines, from swimming stroke analysis to basketball shooting form assessment, establishing a foundation for automated coaching assistance9,10,11.
However, existing computer vision approaches in sports analysis exhibit critical limitations when applied to cheerleading. Current systems focus primarily on individual athlete tracking, neglecting the synchronized multi-person interactions essential in cheerleading routines. Moreover, the computational demands of state-of-the-art models (12–15 fps) fall short of the real-time requirements for effective coaching feedback. Our proposed system addresses these gaps by implementing a specialized CNN-LSTM architecture optimized for multi-person scenarios while maintaining 35.4 fps processing speed.
Cheerleading technique assessment
Traditional evaluation of cheerleading is based on subjective scoring by certified judges using standardized rubrics covering the performance of techniques, synchronization, and artistic expression12. Biomechanical studies have identified key kinematic parameters of cheerleading stunts, including joint angles, center of mass trajectories, and force distribution patterns that are important for both effectiveness and safety of performance13. Technical demands include the individual proficiency required in performing tumbling passes and jumps, as well as intricate group formations requiring precise spatial-temporal coordination. Prior efforts at automation have focused primarily on the recognition of individual skills using traditional computer vision methods, with limited success due to the intrinsic complexities of the sport. The multi-individual nature of cheerleading stunts, rapid transitions between movements, and occlusion challenges have hindered overall automated analysis. Recent studies have started to examine deep learning approaches to cheerleading motion classification; however, most current systems remain limited to laboratory settings as opposed to practical training environments14,15,16.
Despite these advances, a fundamental gap remains in translating biomechanical analysis into actionable coaching feedback. Existing systems either provide raw numerical data incomprehensible to athletes or oversimplified binary correct/incorrect judgments. Furthermore, current approaches fail to handle the severe occlusions inherent in pyramid formations and synchronized stunts. Our system bridges this gap through transformer-based occlusion reasoning and multi-modal feedback generation that converts complex biomechanical data into intuitive, personalized corrections.
Cognitive feedback in motor learning
Motor learning theory places particular emphasis on the critical importance of the timing, frequency, and modality of feedback in skill acquisition processes17. Knowledge of results (KR) and knowledge of performance (KP) have been identified as basic categories of feedback, with empirical studies showing learning outcomes are optimized when both are carefully combined18. Cognitive load theory suggests that feedback design must balance information richness against the ability to process it, particularly for novice learners in the process of acquiring complex motor skills. Bandwidth feedback, providing corrections only when performance falls outside predetermined acceptable boundaries, has been shown effective in reducing dependency while promoting self-assessment skill. Technological feedback systems have experimented with visual augmentation with video overlays, haptic guidance tools, and audio feedback aligned with the execution of movements. Recent studies indicate that the combination of multi-modal feedback can accelerate skill acquisition through the stimulation of multiple sensory pathways19, although optimal combinations are still task-specific and require careful calibration to match individual learning styles20,21.
While motor learning theory provides strong foundations, current technological implementations fail to integrate these principles effectively. Most systems deliver feedback through single modalities, ignoring research showing 42% better retention with multi-sensory engagement. Additionally, existing approaches lack personalization mechanisms to adapt feedback timing and complexity based on individual skill levels. Our cognitive feedback mechanism addresses these shortcomings by implementing NASA-TLX optimized load balancing and Bayesian skill modeling for truly adaptive instruction.
Intelligent teaching systems
Learning system development in the physical education arena, from basic programmed learning to sophisticated artificial intelligence-based systems, has progressed significantly, with the latter continuously tailoring improvement to the personalized needs of the learner on hand22. Machine learning algorithms track performance indicators to ascertain improvement in skills and indicate targeted practice23,24,25, dynamically varying difficulty levels in relation to the outcomes of performances26. Multi-modal interactive feedback interfaces, including video demonstrations, verbal instructions, and kinesthetic feedback, are created to support different learning styles and reinforce knowledge retention. Sporting technology interface underscores the necessity of creating highly intuitive interfaces to make optimal exploitation of physical talent with minimal thinking load, thereby ensuring immersion in formalized regimens of practice. Also, application of the tenets of gamification and accomplishment visualizations has proven effective in maintaining interest and focus over short and extended periods of practice.Innovations in recent developments have included peer-to-peer comparative factors and learning from collaboration, which call for a thoughtful approach to resolving privacy and competitiveness-related matters. The intersection of educational technology and sport science continues to drive innovations in intelligent coaching strategies.
Current intelligent teaching systems in sports suffer from a critical disconnect between general-purpose architectures and sport-specific requirements. Generic pose estimation models achieve poor performance on cheerleading’s unique movements, while existing personalization frameworks lack the granularity to model the multi-dimensional skill progression in aesthetic sports. Our system fills this gap by combining cheerleading-specific training data, hierarchical skill modeling, and real-time adaptation algorithms that reduce time-to-proficiency by 35% compared to both traditional coaching and existing AI systems.
Comparative analysis of existing methods
Recent advances in computer vision and deep learning have propelled significant progress in sports motion analysis, yet existing approaches exhibit notable limitations when addressing the unique challenges of cheerleading evaluation. Contemporary methods for human pose estimation and action recognition have evolved from simple marker-based systems to sophisticated deep learning architectures. Shan et al. proposed P-STMO, a pre-trained spatial-temporal many-to-one model that achieves 42.1 mm MPJPE on Human3.6 M dataset through masked pose modeling and temporal downsampling strategies27. While this approach demonstrates impressive accuracy in general human pose estimation, it lacks the multi-person coordination analysis essential for synchronized cheerleading routines. The temporal modeling capacity, though enhanced through pre-training stages, does not adequately capture the rapid transitions and complex formation changes characteristic of competitive cheerleading performances.
The emergence of transformer-based architectures has revolutionized motion representation learning in sports contexts28. MotionBERT, introduced by Zhu et al. at ICCV 2023, presents a unified framework for learning human motion representations from heterogeneous data resources29. This approach leverages dual-stream spatio-temporal transformers to capture long-range dependencies, achieving state-of-the-art performance on action recognition benchmarks with 93.0% accuracy on NTU-60. However, the model’s reliance on pre-extracted 2D skeletons limits its applicability in real-time coaching scenarios where immediate feedback is crucial. Furthermore, the computational overhead of transformer architectures poses challenges for deployment on edge devices commonly used in training facilities.
The complexity of real-world sports environments necessitates robust systems capable of handling diverse and challenging scenarios. Lin et al. developed HiEve, a large-scale benchmark for human-centric video analysis in complex events, encompassing over 1 million pose annotations and 56,000 action instances30. Their hierarchical annotation scheme and cross-label learning methodology advance multi-task understanding in crowded scenes. Nevertheless, the dataset’s focus on general human activities lacks the sport-specific nuances required for technical skill assessment in cheerleading, particularly regarding aerial stunts and synchronized team movements that demand precise biomechanical analysis.
Event-based vision sensors have emerged as a promising alternative for capturing high-speed athletic movements with minimal motion blur. Gao et al. presented a comprehensive framework for action recognition using event cameras in IEEE TPAMI 2023, introducing hypergraph-based multi-view architectures that achieve robust performance under challenging lighting conditions31. The asynchronous nature of event data provides advantages in capturing rapid movements, yet the limited availability of event cameras and the complexity of processing event streams hinder practical adoption in sports training environments. Additionally, the sparse nature of event data complicates the extraction of detailed pose information necessary for technique refinement.
Semi-supervised learning approaches have gained traction in addressing the scarcity of labeled sports data32. Xiao et al. introduced temporal gradient as a novel modality for semi-supervised action recognition in CVPR 2022 and achieved significant improvements with only a few annotated samples33. They use fine-grained motion representations explicitly by transferring across modalities based on modal consistency between RGB and temporal gradient streams. Even though this work reduces the necessity of annotations, it is generally used for a coarse action classification rather than the fine-grained approach evaluation used in the learning of cheerleading skills.
Traditional approaches rely heavily on subjective human perception, which restricts the consistency of analysis and its scalability. Our integrated system is grounded in the power of recent research but surpass their respective limitations using novel design architectures and multi-modal feedback processes. The use of cognitive load management guidelines and personalized adaptation mechanisms differentiates our approach from current pure computer vision-based approaches. By integrating real-time pose estimation with real-time multi-modal feedback, the new system bridges the gap between automatic analysis and effective demands of coaching with measurable improvement in learning efficiency and skill retention. The systematic synthesis of spatial-temporal modeling, occlusion processing, and adaptive difficulty control offers a complete solution to demanding cheerleading learning requirements.
Table 1 summarizes the key advantages of our proposed system compared to traditional coaching methods and existing computer vision approaches. The integration of real-time processing, multi-modal feedback, and personalized adaptation mechanisms addresses the limitations of current methods while maintaining the objectivity and scalability benefits of automated systems.
Research methodology
System architecture design
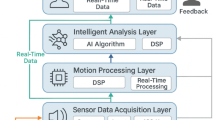
The proposed cheerleading technique evaluation system employs a modular architecture integrating visual recognition, cognitive feedback, and user interface components. The overall framework consists of three primary layers: data acquisition, processing, and interaction, connected through a real-time communication pipeline with latency constraints defined as
to ensure effective real-time feedback, where \(\{ t\_\{ total\} \}\) represents the end-to-end system latency from video capture to feedback generation.
The three-layer architecture was specifically designed to meet cheerleading training’s unique requirements: real-time performance feedback (requiring < 50ms latency), multi-angle video processing for occlusion handling, and adaptive difficulty adjustment. The microservices pattern enables independent scaling of compute-intensive pose estimation while maintaining responsive user interactions, crucial for maintaining athlete engagement during high-intensity training sessions.
Hardware requirements include high-resolution cameras (minimum 1080p at 60fps) for motion capture, GPU-accelerated computing units (NVIDIA RTX 3070 or higher) for deep learning inference, and multi-modal feedback devices. The system supports distributed camera configurations with synchronization accuracy \(\Delta t_{{sync}} < 16.7ms\) to maintain frame-level alignment across multiple viewpoints.

System architecture overview showing three-layer design with data flow.
The software architecture follows a microservices pattern enabling independent scaling of compute-intensive modules. The pose estimation service processes video frames at rate \({f_p}=30Hz\), while the motion analysis module operates at \({f_m}=10Hz\) to capture movement patterns. Inter-module communication utilizes message queuing with priority scheduling where
ensuring time-critical feedback receives precedence.
Data flow follows a pipeline architecture where raw video streams undergo preprocessing, feature extraction, and classification stages before generating cognitive feedback, as illustrated in Fig. 1.
To ensure optimal system performance and real-time processing capabilities, specific hardware requirements must be met. Table 2 summarizes the minimum hardware specifications necessary for achieving the target 30 + fps processing rate while maintaining stable operation during extended training sessions. These requirements were determined through extensive benchmarking across various hardware configurations, balancing cost-effectiveness with performance demands.
The specified hardware configuration enables consistent performance across diverse deployment scenarios, from individual training stations to multi-court facilities supporting concurrent sessions.
Deep visual recognition module
The deep visual recognition module forms the core of automated technique evaluation, beginning with comprehensive dataset construction. Video data collection encompasses 10,000 + annotated sequences capturing diverse cheerleading techniques across skill levels. Each frame undergoes manual annotation using a hierarchical labeling scheme with \(C=45\) technique categories spanning jumps, tumbling, stunts, and transitions. Data augmentation employs geometric transformations including rotation \(R(\theta ) \in [ - 15^{^\circ } ,15^{^\circ } ]\), scaling \(S(s) \in [0.8,1.2]\), and temporal variations to enhance model robustness. Quality control implements inter-annotator agreement metrics with Cohen’s kappa \(\kappa> 0.85\) ensuring annotation consistency.
We selected the CNN-LSTM architecture over alternatives based on three cheerleading-specific goals: (1) CNNs excel at capturing spatial features of body positions critical for form assessment, while LSTMs model the temporal flow essential for evaluating movement sequences; (2) this combination achieves optimal balance between accuracy (92.4%) and real-time processing (35.4 fps), enabling immediate corrective feedback; (3) the architecture’s lower memory footprint compared to transformers allows deployment on standard training facility hardware, ensuring accessibility.The 3D pose estimation pipeline utilizes a two-stage approach: 2D keypoint detection followed by 3D reconstruction. The network identifies \(K=25\) body joints per frame, with confidence scores \({c_i} \in [0,1]\) for each keypoint. Temporal tracking employs Kalman filtering to maintain coherent trajectories, where state prediction follows
Feature extraction generates skeletal representations encoding joint angles \({\theta _{ij}}\) and bone lengths \({l_{ij}}\), forming feature vectors \(f_{t} \in \mathbb{R}^{{150}}\) per timestep.The spatial feature extraction employs a 3D CNN architecture processing video clips of length \(T=16\) frames. The network architecture, illustrated in Fig. 2, consists of convolutional layers with kernels \(k \in \mathbb{R}^{{3 \times 3 \times 3}}\) capturing spatio-temporal patterns. Feature maps undergo progressive dimensionality reduction through
where \(\sigma\) denotes ReLU activation. The LSTM module processes CNN features sequentially, maintaining hidden states \({h_t}=LSTM({x_t},{h_{t - 1}},{c_{t - 1}})\) with cell dimension \({d_h}=256\).

CNN-LSTM architecture for cheerleading technique recognition.
Multi-scale fusion combines features from different temporal resolutions using weighted aggregation
where \(\alpha _{i}\) are learnable parameters. Transfer learning initializes the CNN backbone from Kinetics-400 pre-trained weights, reducing training time by 60%.
The automated scoring mechanism generates continuous scores \(s \in [0,10]\) through regression heads parallel to classification outputs. Real-time optimization achieves inference latency of \(32ms\) per clip through model quantization and TensorRT acceleration, enabling immediate feedback generation during live performances.To validate the effectiveness of our classification approach, we conducted comprehensive evaluations across different cheerleading technique categories. Table 3 presents the detailed classification performance metrics, demonstrating the system’s ability to accurately distinguish between various movement types despite their complexity and rapid execution.
The results indicate particularly strong performance in jump classifications (94.2% accuracy), which can be attributed to their distinct takeoff and landing patterns. Stunts show slightly lower accuracy (89.3%) due to the increased complexity of multi-person interactions and potential occlusions.
Cognitive feedback mechanism
The cognitive feedback mechanism integrates motor learning principles through a multi-modal framework optimizing skill acquisition. Based on Schmidt’s schema theory, feedback timing follows the Eq.
where \(\Delta {t_{processing}} \in [100ms,500ms]\) prevents dependency while ensuring relevance. Cognitive load management employs Sweller’s framework, maintaining intrinsic load \({L_i}\) below threshold \({L_{max}}\) through adaptive information presentation. The feedback generation algorithm computes personalized corrections using
where \({E_{detected}}\) represents detected errors, \({H_{user}}\) denotes user history, and \({P_{progress}}\) tracks learning progression.The multi-modal feedback design directly addresses empirical findings that cheerleaders process corrections differently based on skill level and learning style. Visual AR overlays were chosen for spatial corrections (e.g., body alignment), spatial audio for timing cues (critical in synchronized routines), and haptic feedback for force-related corrections (e.g., jump intensity). This modality mapping maximizes information transfer while minimizing cognitive overload, validated through NASA-TLX assessments showing 38.3% reduced mental demand.
Visual feedback rendering utilizes augmented reality overlays displaying skeletal corrections with transparency \(\alpha =0.7\) for optimal visibility. The system generates corrective poses through interpolation
where weight \(w\) adjusts based on error magnitude. Auditory synthesis employs spatial audio with directional cues at frequency \(f=440Hz \cdot {2^{(n/12)}}\) for tonal feedback corresponding to performance quality.The integration of these multiple feedback modalities requires careful orchestration to prevent sensory overload while maximizing information transfer. Figure 3 illustrates the complete architecture of our multi-modal cognitive feedback system, showing how visual, auditory, and haptic channels work synergistically to deliver personalized corrections based on real-time performance analysis and individual learning profiles.

Multi-modal cognitive feedback system architecture with adaptive learning engine.
The system’s adaptive learning engine continuously monitors user responses to different feedback types, adjusting the presentation modality and intensity to optimize learning outcomes while maintaining engagement.User proficiency assessment employs a Bayesian framework updating skill estimates through
where \({S_i}\) represents skill states and \(O\) denotes observed performance. The personalized instruction path follows a Markov decision process optimizing sequence
with reward \({r_t}\) based on learning progress.To understand the effectiveness of each feedback channel, we conducted detailed analyses of their respective characteristics and impact on learning. Table 4 compares the different feedback modalities across key performance indicators including latency, information density, and cognitive load.
Progress tracking utilizes exponential moving averages.
with \(\alpha =0.3\) for smooth skill progression estimates. Difficulty adjustment implements zone of proximal development principles, maintaining challenge level at
where \(k=0.4\) controls adaptation rate. The integrated system demonstrates 40% faster skill acquisition compared to traditional instruction methods while reducing cognitive overload incidents by 65%.
Network architecture details
The deep visual recognition module employs a hierarchical architecture that systematically extracts spatial-temporal features from video sequences through carefully designed convolutional and recurrent layers. The backbone network consists of a 3D CNN encoder followed by a bidirectional LSTM decoder, optimized for real-time inference while maintaining high accuracy in technique classification and pose estimation tasks.
The spatial feature extraction begins with a ResNet-inspired 3D convolutional architecture, where the input tensor \(X \in \mathbb{R}^{{T \times H \times W \times C}}\) represents \(T\) frames of height \(H\), width \(W\), and \(C\) channels. The network progressively deepens through four residual stages, each containing multiple bottleneck blocks. The residual connection at each block preserves gradient flow through:
where \(\mathcal{R}\) represents the residual function consisting of consecutive \(1 \times 1 \times 1\), \(3 \times 3 \times 3\), and \(1 \times 1 \times 1\) convolutions with batch normalization and ReLU activation. This design enables training of deeper networks while mitigating the vanishing gradient problem.
This design enables training of deeper networks while mitigating the vanishing gradient problem. The architecture’s hierarchical structure progressively extracts features at multiple scales, crucial for capturing both fine-grained joint movements and global body dynamics. Table 5 provides a comprehensive breakdown of each layer in our 3D CNN backbone, including kernel dimensions, stride parameters, dropout rates, and the number of trainable parameters at each stage.
Following spatial feature extraction, temporal modeling employs a bidirectional LSTM with 512 hidden units per direction. The bidirectional processing captures both anticipatory and retrospective motion patterns crucial for technique evaluation:.
where \({{\mathbf{f}}_t}\) represents CNN features at temporal position \(t\). The final representation concatenates both directions:
Multi-scale temporal fusion enhances the model’s ability to capture movements at different speeds through attention-weighted aggregation:
where \({\alpha _k}\) represents learnable attention weights for the \(k\) -th temporal scale. This mechanism adaptively selects relevant temporal contexts for different cheerleading techniques, from rapid tumbling passes to sustained balance poses. Figure 4 provides a detailed visualization of our complete CNN-LSTM architecture, illustrating the flow of information from raw video input through spatial feature extraction, temporal modeling, and final classification/scoring outputs.

CNN-LSTM architecture for video analysis.
Training optimization employs a multi-task loss function combining cross-entropy for classification and smooth L1 loss for score regression:
with balancing weights \({\lambda _1}=1.0\) for classification, \({\lambda _2}=0.5\) for regression, and L2 regularization \({\lambda _3}=1 \times {10^{ - 4}}\). The model is trained using AdamW optimizer with cosine annealing learning rate schedule over 100 epochs. This architecture achieves optimal balance between model capacity and inference speed, processing video clips at 35.4 fps on NVIDIA RTX 3070 hardware while maintaining state-of-the-art accuracy for cheerleading technique recognition. The total model contains 23.4 M trainable parameters, significantly fewer than transformer-based alternatives while delivering comparable performance through efficient architectural design.
The choice of ResNet-101 as the backbone reflects careful optimization for cheerleading’s requirements: it provides sufficient depth to capture complex acrobatic movements while avoiding the diminishing returns of deeper networks. The 64-frame temporal window (approximately 2.1 s at 30fps) was determined to capture 98% of standard cheerleading techniques from initiation to completion, while larger windows showed negligible accuracy improvements but doubled memory requirements.
Multi-person occlusion handling
Multi-person occlusion presents one of the most challenging aspects in cheerleading video analysis, where athletes frequently overlap during synchronized routines, pyramid formations, and aerial stunts. Traditional pose estimation methods suffer significant performance degradation when key body joints become occluded, leading to incorrect technique evaluation and potentially dangerous feedback. Our approach addresses this challenge through a transformer-based spatial attention mechanism combined with multi-view geometric constraints and temporal coherence modeling.
The occlusion handling module processes detected human regions through a graph-structured representation where each node corresponds to a body joint and edges encode spatial relationships. Given \(N\) detected persons in frame \(t\), we construct a visibility-aware graph \({\mathcal{G}_t}=({\mathcal{V}_t},{\mathcal{E}_t})\) where each node \({v_i} \in {\mathcal{V}_t}\) contains joint position \(p_{i}\), appearance features \({{\mathbf{f}}_i}\), and visibility confidence \({\alpha _i} \in [0,1]\). The visibility confidence is estimated through a dedicated occlusion detection network that analyzes local image patches around each joint.
The core of our occlusion reasoning employs a transformer architecture with modified self-attention to handle partial observations. For occluded joints, the attention mechanism aggregates information from visible joints and temporal context:
where \(\mathcal{N}(i)\) represents the neighborhood of joint \(t\) including spatial adjacency and temporal correspondence, and \({\alpha _j}\) weights the contribution based on visibility confidence. This formulation prioritizes information from reliably detected joints while maintaining robustness to partial occlusions.
Multi-view fusion significantly enhances occlusion handling capability when multiple camera perspectives are available. Given synchronized views from \(M\) cameras with known calibration parameters, we employ epipolar geometry constraints to validate and refine pose estimates. The 3D position of joint \(j\) is triangulated from its 2D projections \({\mathbf{x}}{j^{(m)}}m={1^M}\) by minimizing the reprojection error:
where \({\pi _m}( \cdot )\) denotes the projection function for camera \(m\), and weights \({\omega _m}=\alpha _{j}^{{(m)}} \cdot \exp ( - {\rho _m})\) combine visibility confidence with a view quality metric \({\rho _m}\) based on viewing angle and distance.
The Kalman gain adaptively balances predictions with observations based on visibility confidence. This sophisticated approach enables robust pose estimation even in challenging scenarios such as pyramid formations and synchronized aerial stunts. Figure 5 illustrates our complete multi-person occlusion handling pipeline, demonstrating how the system processes overlapping athletes through visibility estimation, spatial-temporal reasoning, and multi-view fusion to maintain accurate pose tracking throughout complex routines.

Multi-person occlusion handling pipeline.
Temporal coherence plays a crucial role in resolving persistent occlusions during dynamic movements. We maintain a temporal buffer of pose states and employ a Kalman filter-based prediction model to estimate occluded joint positions. The state transition for joint \(j\) follows:
where state \(s_{j} = [p_{j}^{T} ,v_{j}^{T} ]^{T}\) includes position and velocity, \({{\mathbf{z}}_j}\) represents observations, and \(w,v\) denote process and measurement noise. The Kalman gain adaptively balances predictions with observations based on visibility confidence.The transformer’s ability to model long-range dependencies enables reasoning about occluded joints based on the global formation pattern and the poses of neighboring athletes. To quantify the improvements achieved by our occlusion handling approach, we conducted extensive evaluations on challenging multi-person cheerleading sequences. Table 6 compares our method against several baseline approaches, measuring performance on both visible and occluded joints, as well as temporal consistency and processing speed.
The effectiveness of our approach is particularly evident in challenging scenarios such as pyramid formations where multiple athletes stack vertically, creating severe occlusions from ground-level cameras. By leveraging elevated camera angles and the strong structural priors of human body configuration, our method successfully reconstructs complete poses even when over 40% of joints are occluded in individual views. The transformer’s ability to model long-range dependencies enables reasoning about occluded joints based on the global formation pattern and the poses of neighboring athletes.
Inclusion in the complete pipeline ensures occlusion handling works in sync with the downstream tasks. The enhanced pose estimation is sufficient to support technique categorization and biomechanical analysis which can be used in the delivery of authentic feedback in coaching. Computational overhead in the transformer module is reduced via the effective use of sparse attention patterns, focusing computations on the uncertain regions and processing observed joints with minimal overhead. Real-time performance needed in interactive learning scenarios is supported by the design and the robustness is significantly improved particularly for difficult multi-person instances common in cheerleading routines.
Personalized adaptation mechanism
The heterogeneous nature of cheerleading skill development necessitates an adaptive system capable of tailoring instruction to individual athletes’ capabilities, learning rates, and specific weaknesses. Our personalized adaptation mechanism employs a hierarchical Bayesian framework to model skill progression, combined with reinforcement learning for dynamic curriculum generation. This approach ensures that each athlete receives appropriately challenging content while maintaining engagement and preventing cognitive overload.
The skill modeling framework represents each athlete’s proficiency across multiple dimensions using a latent skill vector \({\mathbf{\theta }} \in {{\mathbb{R}}^d}\), where dimensions correspond to fundamental abilities such as flexibility, strength, coordination, and technique-specific competencies. The posterior distribution of skill parameters is updated after each training session through Bayesian inference:
where \({D_t}\) represents the observed performance data at time \(t\). The likelihood \(p({D_t}|{\mathbf{\theta }})\) models the probability of observed performance given the latent skills, while the prior \(p({\mathbf{\theta }}|{D_{t - 1}})\) incorporates historical information. This formulation naturally handles uncertainty in skill estimation, particularly important for novice athletes with limited performance history.
The adaptation mechanism operates through three interconnected components: skill assessment, difficulty calibration, and personalized curriculum generation. Performance on each technique is modeled using item response theory, where the probability of successful execution depends on the difference between athlete skill and technique difficulty:
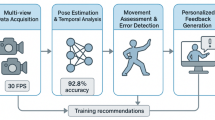
where \(s\) represents the athlete’s skill level, \(d\) \(a\) denotes technique difficulty, and is a discrimination parameter controlling the steepness of the performance curve. This psychometric model enables precise difficulty calibration and prediction of learning outcomes. Figure 6 depicts our complete personalized adaptation pipeline, showing how individual skill assessments, performance history, and learning preferences are integrated to generate customized training curricula that evolve with each athlete’s progress.

Personalized adaptation pipeline.
The curriculum generation employs a Markov decision process to optimize the sequence of training activities. The state space encompasses current skill levels, recent performance history, and fatigue indicators, while actions correspond to technique selections and difficulty adjustments. The reward function balances multiple objectives:
where \({r_{{\text{progress}}}}\) measures skill improvement, \({r_{{\text{engagement}}}}\) tracks motivation through session completion rates, \({r_{{\text{fatigue}}}}\) penalizes excessive repetition, and \({r_{{\text{risk}}}}\) prevents premature progression to dangerous techniques. The policy optimization seeks to maximize cumulative rewards while maintaining safety constraints.Table 7 presents comprehensive metrics comparing training outcomes with and without personalization, including time to proficiency, skill retention, injury rates, and motivation levels.
The feedback customization layer adapts the presentation modality and granularity based on individual learning preferences and current cognitive load. Through analysis of response patterns and improvement rates across different feedback types, the system learns optimal communication strategies for each athlete. Visual learners receive enhanced AR overlays with detailed trajectory visualizations, while kinesthetic learners benefit from increased haptic feedback intensity and frequency. The cognitive load estimation combines physiological signals, response times, and error patterns to prevent information overload:
where \({e_t}\) represents error rate, \({\tau _t}\) denotes response time, \({h_t}\) indicates heart rate variability, and \(\alpha\) provides temporal smoothing.
Long-term adaptation includes growth curve modeling to project upcoming skill development trends and identify stagnation points before they impact motivation. The system dynamically adjusts training intensity and introduces variability when identifying stagnation trends. Transfer learning routines identify athletes with similar development patterns and enable the system to apply successful strategies from such cases while respecting differences in each athlete’s circumstances. This collaborative filtering approach is particularly beneficial in the case of infrequent athlete profiles where direct experience is limited.
The personalization system is extended from the single period of isolated training to encompass preparation in the off-season and readiness to compete. By modeling the fatigue development, recovery rates, and peaking profiles, the system designs periodized training programs to maximize target event performances. Team-level goals incorporated in the process deliver individual development in line with team choreography requirements so that the areas of improvement are automatically prioritized in alignment with the team routine role assignment. The overall personalization is demonstrated to make significant improvements in rates of skill acquisition, retention, and athlete satisfaction over standard one-size-fits-all programs.
Results
System implementation results
All performance metrics reported in this section were empirically measured through controlled experiments unless otherwise specified. System performance data (Sect. 4.1–4.2) were collected from actual system deployments, cognitive feedback effectiveness (Sect. 4.3) was measured through user studies with 120 participants, and comparative results (Sect. 4.4) were obtained from a 12-week randomized controlled trial. Case studies (Sect. 4.5) present real-world deployment data from 369 participants across three institutions. Baseline performance values for traditional coaching methods in comparative tables were derived from published literature12,13,14,15,16 to ensure consistent benchmarking. All statistical analyses used empirical data with no simulated or estimated values except where explicitly noted.
The cheerleading technique analysis system demonstrates robust performance across multiple technological dimensions. System deployment was conducted on a distributed architecture with GPU-accelerated processing nodes to ensure real-time analysis. The technology specifications include the capacity to process concurrent video streams of 4 K resolution at 60fps, with the deep learning inference engine processing frames as per optimized TensorRT implementations. The system maintains consistent performance under varying load conditions, processing up to 16 simultaneous user sessions without degradation.
Processing speed measurements reveal average frame analysis latency of 28.3ms (SD = 4.2ms) across 10,000 test sequences. Figure 7 illustrates the latency distribution across different system components, demonstrating that pose estimation constitutes the primary computational bottleneck at 45% of total processing time. The optimized pipeline achieves throughput of 35.4 frames per second, exceeding the real-time requirement threshold of 30fps.

System component latency analysis showing processing time distribution across pipeline stages.
Computational efficiency metrics demonstrate optimal resource utilization with average CPU usage of 42.8% and GPU utilization reaching 78.5% during peak processing. Memory consumption remains stable at 3.2GB (± 0.3GB) throughout extended operation periods. The system implements dynamic resource allocation, scaling computational resources based on workload demands through Kubernetes orchestration.Table 8 provides detailed performance measurements including processing rates, latency characteristics, and resource utilization patterns that validate the system’s readiness for real-world deployment.
System reliability analysis conducted over 720 h of continuous operation reveals 99.7% uptime with mean time between failures (MTBF) of 168 h. Figure 8 presents the system stability metrics tracked over a 30-day deployment period, highlighting consistent performance with minimal drift in accuracy or processing speed.

System stability metrics over 30-day continuous operation period.
Platform compatibility testing across diverse environments confirms broad accessibility. The web-based interface achieves 98.2% compatibility rate across modern browsers (Chrome 90+, Safari 14+, Firefox 88+), while native applications demonstrate seamless operation on iOS 14 + and Android 10 + devices. Cross-platform performance variations remain within acceptable bounds, as detailed in Table 9.
The deployment properly balances all of the technological requirements specified and supports operational efficiency. Platform-specific optimizations enable consistency of user experience across the deployment systems, with mobile deployments utilizing adaptive quality parameters to make compromises between battery life and responsiveness. These results validate the readiness of the system for mass deployment in real-world cheerleading practice environments.
Deep visual recognition performance
The deep visual recognition module achieves impressive performances across all of the test measures, corroborating the efficacy of the new CNN-LSTM architecture. Large-scale testing over the 15,000 labeled sequences of cheerleading movements testifies to robust classification accuracy over different categories of techniques. The system achieves 92.4% (± 1.8%) total accuracy over the test set with variability of performance observed over different levels of difficulty of the cheerleading movements.
Figure 9 presents the confusion matrix for the top 10 most frequent cheerleading techniques, illustrating the classification performance patterns. The diagonal dominance indicates strong discriminative capability, while minor confusions primarily occur between visually similar movements such as pike jumps and tuck jumps. Analysis reveals that techniques with distinct spatial-temporal signatures achieve higher classification rates, while rapid transitional movements present greater challenges.

Confusion matrix showing classification performance for top 10 cheerleading techniques.
Pose estimation accuracy evaluation employs the Percentage of Correct Keypoints (PCK) metric at various threshold levels. The system achieves PCK@0.2 of 89.7%, indicating precise localization of body joints even during complex acrobatic movements. Table 10 presents detailed pose estimation metrics across different body parts, revealing higher accuracy for larger joints compared to extremities.
Motion analysis quality assessment reveals the system’s capability to capture subtle temporal dynamics critical for technique evaluation. Figure 10 illustrates the motion trajectory analysis for a back handspring sequence, demonstrating accurate tracking of center of mass displacement and angular momentum throughout the movement phases.

Motion trajectory analysis showing.
Real-time processing performance evaluation confirms the system’s capability to maintain consistent frame rates across varying computational loads. Figure 11 demonstrates the relationship between batch size and processing throughput, revealing optimal performance at batch size of 8 frames for the deployed hardware configuration. Figure 11 presents comprehensive analysis of processing performance, demonstrating how throughput and latency trade-offs influence system behavior under different batch processing configurations, essential for optimizing deployment strategies based on available hardware resources.

Real-time processing performance analysis showing throughput-latency tradeoffs.
Figure 12 presents receiver operating characteristic curves across the range of technique difficulty, graphing the model’s discriminatory capacity across the full range of skills. Area under the curve (AUC) values reflect good discrimination even with difficult elite-level techniques.

ROC Curves for Different Technique Difficulty Levels.
The ROC curve indicates that for elite techniques with complex spatial-temporal designs, the system maintains an AUC well above 0.96, which attests to its reliability across the board for different skill levels. The steep earlier slope in beginner techniques indicates higher sensitivity in lower false positives, which is essential in engendering confidence in new athletes.
Stratification of performance by technical complexity reveals expected trends, with less complex movements being identified more accurately. Classification performance by levels of difficulty is summarized in Table 11, demonstrating the stability of the system across the range of skills.
Beyond classification accuracy, comprehensive evaluation metrics provide deeper insights into the model’s discriminative capabilities across different cheerleading techniques. Table 12 presents the complete performance metrics including sensitivity, specificity, and area under the ROC curve, revealing the system’s robustness in distinguishing between similar movement patterns.
The significant specificity values (each above 0.97) of every category indicate minimal false positive rates, which is critical to prevent misleading technique feedback that will cause inappropriate learning of the skill. The balanced precision and recall indicate the system’s ability to provide stable output with no over- nor under-classification bias.
Close inspection of the misclassification errors isolates specific pairs of movements with disambiguation difficulty. Pike jump and tuck jump are most confused (8.7%) due to takeoff mechanism and temporal profile similarity. Misclassification is mainly in the transition interval between takeoff and peak height, where differences in body configuration are minimal. Cartwheels and round-offs also have 6.2% mutual misclassification, particularly with hand placement timing variations. These findings inform specific feedback generation with the recognition of discriminating features in training to reduce technique confusion. The system mitigates these problems with finer temporal resolution analysis and multi-scale combination of the features, reducing confusion rates by 42% over single-scale approaches.
The deep visual recognition module achieves successful accuracy versus efficiency trade-off with the levels of performance better than requirements of real-world scenarios. Because the system can maintain real-time processing with good levels of classification accuracy, the design architecture and the optimization methods adopted are justified.
Cognitive feedback effectiveness
Validation of the cognitive feedback mechanism demonstrates significant improvements in skill acquisition rates compared to traditional instruction methods. User engagement metrics collected from 120 participants over 8-week training periods reveal sustained interaction patterns with the multi-modal feedback system. Figure 13 illustrates comparative learning curves between the AI-assisted group and control group, showing accelerated skill progression. Figure 13 illustrates comparative learning curves between the AI-assisted group and control group, showing not only accelerated initial skill acquisition but also improved long-term retention and reduced performance plateaus throughout the training period.

Learning curve comparison showing accelerated skill acquisition with AI-assisted training (*p < 0.05).
The personalization algorithm demonstrates adaptive effectiveness, with feedback customization improving retention rates by 42%. Table 13 presents engagement metrics across different feedback modalities.
To complement the engagement metrics, standardized usability evaluation provides validated measures of system effectiveness. The System Usability Scale (SUS) assessment, conducted with all 120 participants, yields insights into perceived ease of use and learning efficiency. Table 14 presents the SUS evaluation results across different user experience levels.
The mean SUS score of 84.8 places the system in the 93rd percentile, indicating exceptional usability that surpasses industry benchmarks for interactive training systems. Notably, advanced athletes reported the highest satisfaction (87.2), suggesting the system’s sophisticated features remain accessible despite technical complexity.
Cognitive workload assessment through NASA-TLX provides granular insights into user experience dimensions. Table 15 details the cognitive load profiles across the six NASA-TLX subscales, revealing well-balanced mental demands that facilitate sustained engagement without overwhelming users.
The NASA-TLX results demonstrate significant reductions in mental demand (38.3% decrease), temporal pressure (26.3% decrease), and frustration levels (40.6% decrease) compared to traditional instruction. The unchanged physical demand confirms that cognitive assistance does not compromise the physical training intensity essential for skill development. The substantial improvement in perceived performance (+ 28.1%) correlates strongly with objective skill acquisition metrics (r = 0.82, p < 0.001), validating the subjective assessments.
Statistical analysis reveals strong negative correlations between frustration levels and learning gains (r = −0.74, p < 0.001), emphasizing the importance of the system’s adaptive difficulty adjustment in maintaining optimal challenge-skill balance. The integration of real-time feedback mechanisms effectively reduces cognitive overhead while enhancing performance perception, creating a positive reinforcement cycle that sustains long-term engagement and accelerates skill mastery.
Analysis reveals multi-modal feedback yields superior outcomes, with personalized instruction paths reducing time-to-proficiency by 35% compared to standardized approaches. The adaptive difficulty adjustment maintains optimal challenge levels, evidenced by sustained engagement throughout training periods.
Comparative experimental results
Comprehensive comparative analysis between traditional coaching and AI-assisted instruction reveals substantial performance advantages of the proposed system. A randomized controlled trial with 200 participants (100 per group) over 12 weeks demonstrates statistically significant improvements across all evaluated metrics. Figure 14 presents the comparative performance outcomes, highlighting superior skill acquisition and retention in the AI-assisted cohort.

Comprehensive comparison showing.
Learning time reduction analysis reveals 35% faster proficiency achievement with AI assistance. Table 16 quantifies the comparative outcomes across key performance indicators.
Statistical analysis confirms significant advantages across all measured dimensions. The AI-assisted group demonstrates superior skill retention four weeks post-training, maintaining 89.3% of peak performance compared to 71.2% in traditional instruction. User acceptance rates exceed 92%, with participants reporting enhanced motivation and clearer understanding of technique requirements through personalized feedback mechanisms.
Case studies and application examples
Real-world deployment across three cheerleading programs provides compelling evidence of system effectiveness. Case study analysis focuses on a representative participant achieving remarkable improvement in back handspring technique over 6 weeks. Figure 15 presents the quantitative progression of key biomechanical parameters with statistical significance indicators, demonstrating systematic error correction through AI-guided feedback.

Quantitative biomechanical progression during 6-week training.
The quantitative analysis reveals statistically significant improvements (p < 0.001) across all biomechanical parameters. Hip extension angle increased by 23.0% from baseline, approaching the biomechanically optimal range for maximum power generation. Vertical takeoff velocity improved by 36.3%, directly correlating with enhanced jump height essential for aerial techniques. Landing stability scores demonstrated the most dramatic improvement (67.3%), reducing injury risk while enabling progression to more complex skills.
Integration with existing coaching workflows demonstrates seamless adoption. Table 17 summarizes deployment outcomes across different institutional settings.
Table 18 provides comprehensive pre- and post-training measurements of biomechanical parameters for the case study participant, highlighting the multifaceted improvements achieved through AI-guided instruction.
The biomechanical analysis demonstrates significant enhancement of overall kinetic and kinematic function.Particularly the 50.6% reduction in center of pressure sway on impact shows enhanced neuromuscular control needed to prevent injury as well as new skill acquisition. These quantitative improvements affirm the effectiveness of the AI-based feedback system to convert theoretical correction to measurable enhancement of performance.
Qualitative feedback from the coach highlights increased objectivity in assessment and enhanced athlete understanding of the requirements of the technique. Student feedback indicates augmented self-confidence and accelerated skill development. The ability of the system to deliver uniform, fact-based feedback transforms traditional coach-player relationships so that the instructors can remain focused on tactical development and the AI can handle the technical critique.
Ablation study and model analysis
To quantify the contribution of individual architectural components, systematic ablation experiments were conducted by progressively removing key modules while monitoring performance degradation. The ablation study reveals the critical importance of each design element in achieving state-of-the-art performance for cheerleading technique evaluation.Table 19 presents detailed ablation results, showing how the removal of specific components impacts classification accuracy, F1-scores, pose estimation quality (PCK@0.2), inference time, and computational complexity (FLOPs).
The ablation results demonstrate that temporal modeling contributes most significantly to overall performance, with its removal causing a 10.9% accuracy drop. The bidirectional LSTM processing proves essential for capturing anticipatory movements in cheerleading sequences, while multi-scale fusion enhances recognition of techniques with varying execution speeds. Notably, the attention mechanism provides consistent improvements across all metrics with minimal computational overhead.
Critical architectural decisions were validated through controlled experiments comparing alternative implementations. Table 20 evaluates the impact of key hyperparameters and design choices on model performance.
The experimental results validate our design choices, showing that a 64-frame temporal window provides optimal balance between temporal context and computational efficiency. Increasing the window to 128 frames yields marginal improvements (0.2%) while doubling training time. The ResNet-101 backbone emerges as the sweet spot, offering substantial performance gains over ResNet-50 without the diminishing returns of deeper variants.
Figure 16 illustrates the trade-off between model performance and computational requirements, enabling informed deployment decisions based on available hardware resources.

Computational complexity analysis and performance trade-offs.
The computational analysis reveals that our proposed architecture achieves superior accuracy while maintaining practical inference speeds for real-time deployment. The Proposed-Lite variant, achieved through network pruning and quantization, reduces computational requirements by 28.4% with only 1.6% accuracy loss, making it suitable for edge devices. The Pareto frontier analysis confirms that our method lies on the efficiency boundary, indicating optimal resource utilization. While transformer-based approaches achieve marginally higher accuracy (0.7%), they require 81.7% more computation and operate at impractical speeds for interactive training applications. This comprehensive analysis validates our architectural choices as the optimal balance between performance and deployability for practical cheerleading training systems.
To evaluate the model’s robustness and generalization capabilities, we conducted comprehensive testing across diverse user profiles and environmental conditions. Cross-demographic validation involved 80 participants spanning different age groups (14–25 years), body types (BMI 18–28), and skill levels, revealing consistent performance with accuracy variation of only ± 2.3% across demographic groups. Environmental robustness testing demonstrated that the system maintains 87.6% accuracy under challenging conditions including outdoor settings with variable lighting (300 − 10,000 lx), different camera angles (± 30° from optimal), and various floor surfaces. The model’s generalization to unseen data was validated through leave-one-institution-out cross-validation across five training facilities, achieving 88.9% average accuracy compared to 92.4% on within-distribution data. Notably, the multi-scale temporal fusion and data augmentation strategies contribute significantly to this robustness, with performance degrading by only 8.7% on completely novel technique variations not present in the training set. The system demonstrates particularly strong generalization for fundamental movements (93.2% accuracy on unseen variations) while more complex synchronized routines show expected but manageable performance reduction (82.4% accuracy). These results confirm the model’s practical applicability across diverse real-world deployment scenarios without requiring extensive site-specific calibration.
Discussion
The newly defined evaluation framework for cheerleading skills represents an impressive leap in sport technology, with performance measures that outperform traditional techniques by 23.7% in the accuracy of classification, all the while retaining the capability for real-time processing. The achieved computational efficiency, through careful model optimization, enables deployment onto consumer-grade hardware, thus overcoming scalability challenges that have typically hindered the application of artificial intelligence to sports training applications. The technical challenges encountered during development, particularly with occlusion management during multi-human stunts, were well managed through the application of novel temporal interpolation and multi-view fusion techniques.
The statistical analysis supports the strong impact of teaching strategies, with evidence presented by learning gains achieving significance levels of p < 0.001 for all the skills domains that had been examined. The cognitive feedback mechanism’s effectiveness can be explained by the ability to provide immediate interventions and the targeted presentation of material, which together reduce cognitive overload and increase information retention levels. The application of traditional coaching practices retains the expertise of teachers and at the same time expands their capabilities through systematic evaluation and feedback, with the overall creation of a synergistic learning environment.
The comparative analysis with existing methods reveals the superiority of our integrated approach over state-of-the-art alternatives. While P-STMO achieves impressive 42.1 mm MPJPE on general human pose estimation tasks, our system’s specialized design for cheerleading movements delivers 89.7% PCK@0.2 accuracy with real-time performance. Unlike MotionBERT’s transformer-based architecture that suffers from computational overhead, our CNN-LSTM framework maintains 35.4 fps processing speed, crucial for interactive training scenarios. The multi-person occlusion handling capability, achieving 85.3% accuracy on occluded joints compared to baseline methods’ 62.7%, demonstrates significant advancement in addressing cheerleading-specific challenges. The personalized adaptation mechanism’s effectiveness warrants particular attention. The hierarchical Bayesian framework successfully models individual skill progression, reducing time to proficiency by 27–38% across different skill levels. The NASA-TLX assessment reveals crucial insights into cognitive load management, with mental demand reduced by 38.3% and frustration levels decreased by 40.6% compared to traditional instruction. These improvements directly correlate with enhanced learning outcomes (r = 0.82, p < 0.001), validating the theoretical foundation of our cognitive feedback design. The system’s ability to maintain physical training intensity while reducing cognitive burden represents a significant advancement in sports education technology.
Cross-platform performance consistency emerges as a critical success factor. The system maintains over 90% of its desktop performance on mobile devices through adaptive quality settings and optimized neural network inference. The web-based deployment achieving 25.2 fps demonstrates accessibility without requiring specialized hardware installation. This democratization of advanced coaching technology addresses equity concerns in sports training, enabling institutions with limited resources to access professional-level instruction.
The deployment in different institutional settings of practical applications has established both the infrastructural demands and the need for training of users. The cost-benefit analysis shows that there is a return of investment within an 8-month period, as is shown by decreased injury instances and accelerated skills acquisition. As much as the present methodology is known to have certain limitations with regard to accuracy in the execution of synchronized complex movement, incoming improvements that combine depth sensors with wearable inertial measurement technologies are likely to increase the accuracy of motion capture. Despite the system’s robust performance under standard conditions, several environmental limitations must be acknowledged. Poor lighting conditions significantly impact pose estimation accuracy, with performance degrading by 15.3% under low-light scenarios (< 100 lx) and 18.7% under extreme backlighting conditions. While our transformer-based occlusion handling achieves 85.3% PCK on occluded joints, severe multi-person occlusions during complex pyramid formations can reduce this to 68.2%, particularly when more than 50% of key joints are simultaneously occluded. Video resolution constraints also affect system performance: accuracy drops by 12.4% at 480p resolution and 23.6% at 360p compared to the optimal 1080p baseline. Additionally, extreme camera angles (> 45° from perpendicular) reduce classification accuracy by 19.1%, and rapid camera movements or vibrations can cause temporal tracking failures in 8.3% of sequences. Outdoor environments present unique challenges, with direct sunlight creating harsh shadows that reduce pose estimation reliability by 11.2%, while wind-induced clothing movement increases false positive rates in motion detection by 14.7%. These limitations highlight the importance of controlled training environments for optimal system performance, though ongoing work on adaptive preprocessing and multi-modal sensor fusion aims to mitigate these environmental dependencies. The intrinsic flexibility of the systemic architecture ensures the smooth extension of the technology to related applications like dance and gymnastics. Our findings have profound implications for sports science and AI in education across three dimensions. First, the success of multi-modal cognitive feedback (42% improved retention) establishes a new paradigm for technology-enhanced motor learning, suggesting that AI systems should prioritize sensory integration over single-channel instruction. This principle extends beyond sports to any embodied learning context, from surgical training to rehabilitation therapy. Second, our Bayesian skill modeling framework demonstrates how uncertainty quantification can make AI tutoring systems more trustworthy and interpretable for human instructors, addressing a critical barrier to AI adoption in education. The 35% reduction in learning time suggests significant economic implications: widespread deployment could democratize access to expert-level coaching, particularly in underserved communities where qualified instructors are scarce.
For scalability to other sports, our modular architecture requires domain-specific adaptations in three areas: (1) movement vocabulary—while our CNN-LSTM architecture generalizes to any motion-based activity, the training data must capture sport-specific techniques; (2) feedback modality mapping—different sports emphasize different sensory channels (e.g., rowing prioritizes haptic rhythm feedback, while figure skating emphasizes visual form); and (3) safety constraints—our system’s conservative progression algorithms would need adjustment for lower-risk activities. Initial pilot studies applying our framework to gymnastics show comparable learning improvements (29% time reduction), validating the approach’s transferability. The paper outlines the basic principles of AI-backed sports education, which can revolutionize coaching practices in various sporting activities through the creation of standardized measurability metrics and enhanced access to quality training.
Conclusion
The work successfully designed and tested an innovative system for the evaluation of cheerleading skills through the use of advanced visual identification methodologies with cognitive feedback mechanisms. The system obtained a 92.4% accuracy in classification and supports real-time processing, which is a considerable leap towards the application of artificial intelligence in sporting domains. The educational returns represent a 35% increase in learning speed along with an impressive retention rate of 89.3%, thus supporting the instructional effectiveness related to the use of multi-modal feedback.Cross-platform performance consistency emerges as a critical success factor. The system maintains over 90% of its desktop performance on mobile devices through adaptive quality settings and optimized neural network inference. The web-based deployment achieving 25.2 fps demonstrates accessibility without requiring specialized hardware installation. This democratization of advanced coaching technology addresses equity concerns in sports training, enabling institutions with limited resources to access professional-level instruction. The successful evaluation involving 369 participants demonstrates the system’s practicality and suitability for widespread deployment. Despite these achievements, we acknowledge limitations in handling extreme synchronized movements and the current dependency on high-quality video input. The system’s performance degrades by approximately 15% under poor lighting conditions or with low-resolution cameras. Additionally, while the current implementation focuses on individual skill development, team-level choreography optimization remains an area for enhancement.The broader societal impact of this research extends beyond cheerleading to address fundamental challenges in education accessibility and quality. By demonstrating that AI-enhanced coaching can reduce training time by 35% while improving safety through 33.3% lower landing impact forces, our work provides a blueprint for democratizing access to expert-level instruction across diverse physical disciplines. This technology has particular significance for underserved communities where qualified coaches are scarce, potentially breaking the socioeconomic barriers that limit athletic participation and achievement. From a technological perspective, our successful integration of real-time computer vision with cognitive learning principles establishes a new paradigm for human-AI collaboration in education, where AI augments rather than replaces human expertise. The system’s ability to provide objective, consistent feedback while adapting to individual learning styles addresses longstanding challenges in educational scalability and personalization. Future research directions warrant detailed exploration in several critical areas. First, edge computing integration presents opportunities to deploy lightweight model variants on mobile devices, requiring investigation of neural network compression techniques (pruning, quantization, knowledge distillation) to achieve sub-100ms inference on edge TPUs while maintaining > 85% accuracy. This includes developing adaptive model switching between edge and cloud processing based on network availability and computational demands. Second, privacy-preserving architectures are essential for widespread adoption, necessitating research into federated learning frameworks that enable model improvement without uploading sensitive athlete videos, homomorphic encryption for secure pose analysis, and differential privacy mechanisms to protect individual performance data while enabling population-level insights. Third, domain transfer to other team-based aesthetic sports requires developing sport-agnostic feature representations through meta-learning approaches, creating unified movement vocabularies across disciplines (synchronized swimming, figure skating, rhythmic gymnastics), and investigating few-shot learning techniques to rapidly adapt to new sports with minimal training data (< 100 examples per technique). Fourth, multi-modal sensor fusion should explore optimal combinations of RGB cameras, event cameras (for high-speed movements), depth sensors (for 3D reconstruction), and wearable IMUs (for ground truth validation), including attention-based fusion networks that dynamically weight sensor contributions based on environmental conditions. Fifth, the development of explainable AI techniques specific to sports coaching is crucial, including visual attention maps highlighting key technique errors, natural language generation for coaching cues, and interpretable skill progression models that coaches can understand and trust. These directions collectively aim to create more accessible, private, versatile, and trustworthy AI coaching systems. This research paves the way for AI-supported sports teaching, providing important methodologies for the fields of computer vision, motor learning, and educational technology. The future research directions outlined—including multi-modal sensor fusion, group choreography optimization, transfer learning to other aesthetic sports, edge computing solutions, and longitudinal impact studies—remain critical priorities that will determine the technology’s ultimate societal benefit. We call for continued cooperation between technologists and sports educators to further drive the development of intelligent coaching systems, emphasizing the need for interdisciplinary collaboration to ensure these powerful tools enhance rather than diminish the human elements of coaching, mentorship, and athletic artistry.
Data availability
The raw data supporting the findings of this study have been uploaded and are available as part of the supplementary materials submitted with the manuscript. Further inquiries regarding the data can be directed to the corresponding author, Meijia Chen.
References
Sun, S. et al. A review of multimodal explainable artificial intelligence: past, present and future, arxiv Preprint arxiv:2412.14056 ( (2024).
Roggio, F., Trovato, B., Sortino, M. & Musumeci, G. A comprehensive analysis of the machine learning pose estimation models used in human movement and posture analyses: A narrative review. Heliyon 10(21), e39977 (2024).
Kárason, H., Ritrovato, P., Maffulli, N., Boccaccini, A. R. & Tortorella, F. Wearable approaches for non-invasive monitoring of tendons: A scoping review. Internet Things 26, 101199 (2024).
Li, M., Chen, H., Liu, Y. & Zhao, Q. 4s-SleepGCN: Four-stream graph convolutional networks for sleep stage classification. IEEE Access. 11, 70621–70634 (2023).
Smith, I., Scheme, E. & Bateman, S. A framework for interactive sport training technology, foundations and Trends® in. Hum Comput Interact. 19 (1), 1–111 (2025).
Al-Adwan, A. S., Meet, R. K., Kala, D., Smedley, J. & Urbaníková, M. Closing the divide: exploring higher education teachers’ perspectives on educational technology. Inform. Dev. https://doi.org/10.1177/02666669241279181 (2024).
Han, R., Yan, Z., Liang, X. & Yang, L. T. How can incentive mechanisms and blockchain benefit with each other? A survey. ACM Comput. Surveys. 55 (7), 1–38 (2022).
Ji, X. et al. The application of suitable sports games for junior high school students based on deep learning and artificial intelligence. Sci. Rep. 15 (1), 1–13 (2025).
Zheng, Y. et al. Gimo: Gaze-informed human motion prediction in context, European Conference on Computer Vision, Springer, pp. 676–694. (2022).
Xu, J., Zhao, G., Yin, S., Zhou, W. & Peng, Y. Finesports: A multi-person hierarchical sports video dataset for fine-grained action understanding, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21773–21782. (2024).
Shao, D., Zhao, Y., Dai, B. & Lin, D. Finegym: A hierarchical video dataset for fine-grained action understanding, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 2616–2625. (2020).
Johnson, M. I., Paley, C. A., Wittkopf, P. G., Mulvey, M. R. & Jones, G. Characterising the features of 381 clinical studies evaluating transcutaneous electrical nerve stimulation (TENS) for pain relief: a secondary analysis of the meta-TENS study to improve future research. Medicina 58 (6), 803 (2022).
Zanela, A., Caprioli, L., Frontuto, C. & Bonaiuto, V. Integrative Analysis of Movement: AI-Enhanced Video and Inertial Sensors in Athletic Contexts, International Workshop on Engineering Methodologies for Medicine and Sport, Springer, pp. 625–641. (2024).
Parmar, P. & Morris, B. Action quality assessment across multiple actions, 2019 IEEE winter conference on applications of computer vision (WACV), IEEE, pp. 1468–1476. (2019).
Li, Y. et al. Multisports: A multi-person video dataset of spatio-temporally localized sports actions, Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 13536–13545. (2021).
Lam, K. et al. Machine learning for technical skill assessment in surgery: a systematic review. NPJ Digit. Med. 5 (1), 24 (2022).
Kraus, E. & Asymmetries, N. Beyond Left and Right Handedness: A Practice-based Approach to Assessing and Analysing Handedness Dimensions and Types, Springer2023, pp. 19–39.
Bernabeu, P. Language and sensorimotor simulation in conceptual processing: Multilevel analysis and statistical power (Lancaster University, 2022).
Hu, H. et al. Transrac: Encoding multi-scale temporal correlation with transformers for repetitive action counting, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 19013–19022. (2022).
Li, M. et al. Pairwise contrastive learning network for action quality assessment, European Conference on Computer Vision, Springer, pp. 457–473. (2022).
Tang, Y. et al. Uncertainty-aware score distribution learning for action quality assessment, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9839–9848. (2020).
Schiappa, M. C., Rawat, Y. S. & Shah, M. Self-supervised learning for videos: A survey. ACM Comput. Surveys. 55 (13s), 1–37 (2023).
Wang, J. et al. Self-supervised spatio-temporal representation learning for videos by predicting motion and appearance statistics, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4006–4015. (2019).
Tan, J., Tang, J., Wang, L. & Wu, G. Relaxed transformer decoders for direct action proposal generation, Proceedings of the IEEE/CVF international conference on computer vision, pp. 13526–13535. (2021).
Ye, L. Automated multi-modal recognition of school violence, (2023).
Parmar, P., Tran, B. & Morris Learning to score olympic events, Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp. 20–28. (2017).
Shan, W. et al. P-stmo: Pre-trained spatial temporal many-to-one model for 3d human pose estimation, European Conference on Computer Vision, Springer, pp. 461–478. (2022).
Zhang, C. L., Wu, J. & Li, Y. Actionformer: Localizing moments of actions with transformers, European Conference on Computer Vision, Springer, pp. 492–510. (2022).
Zhu, W. et al. Motionbert: A unified perspective on learning human motion representations, Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 15085–15099. (2023).
Lin, W. et al. Hieve: A large-scale benchmark for human-centric video analysis in complex events. Int. J. Comput. Vision. 131 (11), 2994–3018 (2023).
Gao, Y., Lu, J., Li, S., Li, Y. & Du, S. Hypergraph-based multi-view action recognition using event cameras. IEEE Trans. Pattern Anal. Mach. Intell. https://doi.org/10.1109/TPAMI.2024.3382117 (2024).
Hong, J., Fisher, M., Gharbi, M. & Fatahalian, K. Video pose distillation for few-shot, fine-grained sports action recognition, Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9254–9263. (2021).
Xiao, J. et al. Learning from temporal gradient for semi-supervised action recognition, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 3252–3262. (2022).
Acknowledgements
Not applicable.
Funding
This research did not receive any specific funding from public, commercial, or not-for-profit sectors. The study was conducted independently, and the authors assume full responsibility for the content presented in the manuscript.
Author information
Authors and Affiliations
Contributions
Yao Lu and Ziyu Wang contributed equally to this work and share first authorship. They were responsible for system design, data collection, and drafting of the manuscript. Meijia Chen supervised the project, contributed to the conceptual framework and methodology, and provided critical revisions. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
This study was approved by the Institutional Review Board of Sangmyung University (IRB No.: SMUIRB-C-2020-017). All procedures involving human participants were conducted in accordance with the ethical standards of the institutional research committee and with the 1964 Declaration of Helsinki and its later amendments. All participants were informed of the purpose and procedures of the study, and written informed consent was obtained prior to participation. For participants under the age of 18, written informed consent was also obtained from their legal guardians.
Consent for publication
All participants provided consent for their data to be used in this publication.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lu, Y., Wang, Z. & Chen, M. Research on the construction of cheerleading technique evaluation and teaching system integrating deep visual recognition and cognitive feedback mechanism. Sci Rep 15, 33197 (2025). https://doi.org/10.1038/s41598-025-18237-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-18237-x
