
Abstract
Increasing water scarcity and climate variability have intensified the need for precise agricultural irrigation management. Accurate estimation of crop coefficients (Kc) is critical for determining crop water requirements, especially in arid and semi-arid regions. However, conventional methods for estimating Kc often rely on generalized plant characteristics, which may not account for local climatic variations. In this study, we address this challenge by predicting the daily crop coefficient for soybean using four machine learning models: Extreme Gradient Boosting (XGBoost), Extra Tree (ET), Random Forest (RF), and CatBoost. These models were trained on meteorological data from Suhaj Governorate, Egypt, spanning 1979–2014. Additionally, SHapley Additive exPlanations (SHAP), Sobol sensitivity analysis, and Local Interpretable Model-agnostic Explanations (LIME) were applied to evaluate model interpretability and consistency with physical processes. Among the models evaluated, the ET model achieved the highest accuracy, with r = 0.96, NSE = 0.93, RMSE = 0.05, and MAE = 0.02. XGBoost and RF also performed well, each obtaining r = 0.96, NSE = 0.92, RMSE = 0.06, and MAE = 0.02. In comparison, CatBoost demonstrated slightly lower accuracy, with r = 0.95, NSE = 0.91, RMSE = 0.06, and MAE = 0.02. SHAP and Sobol analyses consistently identified the antecedent crop coefficient [\(\:Kc(d-1)\)] and solar radiation (Sin) as the most influential variables. LIME results revealed localized variations in predictions, reflecting dynamic crop-climate interactions. This study underscores the importance of integrating interpretable machine learning models to enhance both predictive accuracy and reliability while maintaining alignment with critical physical processes. The proposed framework offers a robust tool for improving daily Kc estimation, thereby supporting more sustainable irrigation practices and climate-resilient agriculture.
Similar content being viewed by others

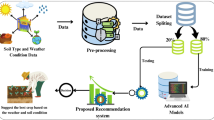

Introduction
With global population growth and socio-economic development, water demand has risen sharply in recent decades1,2,3,4. This trend underscores the growing importance of effective water resource management, particularly in semi-arid and arid regions such as North Africa and the Middle East, where severe water scarcity is expected5,6,7. Egypt is especially at risk due to prolonged droughts and increasing agricultural water needs. Accurate estimation of agricultural water requirements is thus critical for optimizing crop water use and promoting conservation8. However, most current crop models rely on non-spatial, point-based data for reference evapotranspiration and crop characteristics.
Researchers worldwide are prioritizing strategies to improve agricultural water use efficiency9,10,11,12,13,14,15. A key variable in understanding eco-hydrological systems is evapotranspiration (ET), which can make up as much as 95% of the water balance in arid regions16. In agriculture, crop evapotranspiration (ETc) is the primary water use, making its reduction essential for water conservation. Accurate ET estimates are critical for irrigation planning, system design, and yield forecasting17, and a better understanding of ET improves water use efficiency18,19,20,21. The crop coefficient (Kc), defined as the ratio of ETc to reference evapotranspiration (ETo), is a vital parameter for irrigation management17. Canopy dynamics such as leaf area index and greenness are primary drivers of Kc22. Crop coefficient (Kc) values vary by crop, and even within a single crop, they vary across different growth stages, climatic conditions, soil types, and irrigation methods.
Although previous studies provide useful crop coefficient (Kc) values for irrigation scheduling, their accuracy can be significantly affected by climate variability and soil differences23. As such, adjusting Kc values to reflect changing weather conditions is essential24,25,26,27,28. For example, Kang et al.29 reported average maize ETc and Kc values of 424.0 mm and 1.04 in northwest China. Li et al.30and Guo et al.31 investigated how plastic mulch affected spring maize ETc and Kc, while Yang et al.32 evaluated wheat ETc under drip irrigation. Pereira et al.33,34 incorporated ground and remote sensing data to parameterize Kc across different crop types. Three machine learning algorithms called Random Forest (RF), Extreme Gradient Boosting (XGBoost), and Gradient Boosting Decision Tree (GBDT) were employed by Dong et al.35 in combination with both single and dual crop coefficient methods. Among them, RF and XGBoost outperformed GBDT, achieving improvements in R² by 3.2% to 5.4% and reductions in RMSE by 22% to 57%. The same algorithm (RF) achieved the highest accuracy in estimating crop evapotranspiration (ETc) using remote sensing data and a limited number of meteorological variables36.
Kc estimation methods include lysimeters37,38,39, FAO’s dual Kc approach40, water balance methods41, numerical models, and tools like watermarks and atmometers42. Tyagi et al.28 noted that Kc estimates could be 11.6–74.2% higher than those from the FAO Penman-Monteith method. Despite their reliability, these techniques often demand considerable resources. As a result, machine learning (ML) has become popular for Kc modeling43,44,45, disease detection46,47, classification48,49, and ETo prediction50,51,52,53,54. ML has also been applied to real-time monitoring55,56,57,58, regulation extraction59, precision farming60,61, and hydro-environmental applications like flood prediction, groundwater estimation, and runoff modeling62,63,64.
Using the CROPWAT model, Hussain et al.65 assessed irrigation needs in Multan District, Southern Punjab. ET rates ranged from 1.8 to 10.24 mm/day, with effective rainfall between 2 and 31.3 mm. Irrigation requirements were 996.4 mm for rice, 623.3 mm for cotton, and 209.5 mm for wheat. The study emphasized the importance of groundwater harvesting and advanced water management technologies to mitigate regional water scarcity.
This study aims to predict the daily crop coefficient (Kc) of soybean in Upper Egypt using an interpretable machine learning (ML) approach—specifically CatBoost, Extra Trees, Random Forest (RF), and XGBoost—and to compare the predictions with Kc values estimated by the CROPWAT model. ML models are effective at extracting insights from complex, non-linear datasets66 and have been widely applied in agriculture for yield prediction67, irrigation scheduling, and disease forecasting. For instance, ML-based systems have demonstrated water savings of 20–46% when estimating Kc, and high prediction accuracy in areas like crop pricing68 and water demand forecasting69,70.
Soybean cultivation in Egypt is gaining attention due to increasing protein demand, with the governorates of Menia, Assiut, and Sohag contributing over 50% of national production in area (10,450 ha) and volume (29,766 tons). However, the southern region of Egypt faces agricultural challenges due to high temperatures and climate change, which intensify land and water stress, reduce productivity, and exacerbate poverty. Rising temperatures (2–4 °C) are projected to increase crop water requirements by 6–16%, with Southern Egypt expected to experience 200–400 mm higher evapotranspiration (ETo) by 2040.
Given these challenges, accurately estimating soybean Kc using daily climatic data and interpretable ML models presents a valuable opportunity for improving water management and agricultural productivity. Notably, daily Kc prediction for soybean using this ML-based approach has not been previously reported. Therefore, the study’s goals are: (1) to accurately predict daily Kc values for soybean in Upper Egypt using CatBoost, Extra Trees, RF, and XGBoost, and (2) to compare ML model outputs with actual Kc values to enhance crop water management. This study offers a novel, scalable, and practical framework for estimating daily Kc values for soybean using interpretable machine learning. It provides actionable insights for irrigation optimization, climate adaptation, and sustainable agriculture in water-scarce regions like Upper Egypt.
Materials and methods
Study area and datasets collections
Suhaj was selected as one of Upper Egypt’s rural governorates (Fig. 1). Suhaj City, its capital, is 467 km south of Cairo. Geographically, the Governorate is a 110-kilometer-long thin band of territory that runs along both banks of the River Nile. The cultivated breadth is between 15 and 21 km, although the boundaries of the Governorate stretch 110 km to the west and east based on the most recent boundary classification. The Assuit and Qena Governorates border the Governorate on both the north and south. The Red Sea Governorate and the Eastern Desert border it to the east, and the New Valley Governorate and the Western Desert border it to the west. The valley floor’s land surface features have mostly disappeared or have undergone significant modification to create an area that may be used for irrigation. Except for sections used for roads and buildings, the whole valley floor area is used for agriculture and related irrigation. Steep scarps that climb sharply onto the nearby plateau lands define the valley’s boundaries on the east and west flanks of the Nile. The year is divided into two seasons: a scorching summer from May to October and a chilly winter from November to April. This area has higher temperature changes than Egypt’s more northern regions. The differences are very noticeable on the earth’s surface, where the midday summer temperature can soar above 60 °C. Wintertime temperatures can occasionally drop below freezing; in February, the lowest recorded temperature was − 2 °C. The hottest month is June when the maximum temperature is 49 °C. The climate of Upper Egypt is distinguished by intense desertity. Rainfall varies throughout the year, with an average of 1 mm. Climate data variables, including minimum, maximum, and average temperatures, relative humidity, wind speed, and solar radiation, were collected daily from the National Centers for Environmental Prediction (NCEP) and the Climate Forecast System Reanalysis (CFSR) from 1979 to 2014. This dataset spans 36 years, covering the period from 1979 to 2014. The time series data for each variable were systematically organized for this duration. The CFSR, designed as an integrated system encompassing the atmosphere, ocean, land surface, and sea ice, was globally implemented to provide the most accurate representation of these interconnected domains during this time-frame. For the entire study period, daily CFSR data (including precipitation, wind, relative humidity, and solar radiation) were downloaded in a zip file format, organized by continent, and prepared in SWAT-compatible file formats. In this study, the FAO-56 standard Kc values provided within the CROPWAT model were initially used as a baseline. However, these values were subsequently adjusted to reflect the local climatic conditions in the Suhaj Governorate. The adjustment process followed the FAO-56 guidelines, which recommend modifying the mid-season and end-season Kc values based on local factors such as: Wind speed at 2 m, relative humidity and Crop height Specifically, we applied the adjustment formula provided in FAO-56 for the mid-season Kc:
Where:
WS = wind speed at 2 m height (m/s)
Hmin = minimum relative humidity (%)
h = crop height (m)

Map of the study area (Created by ArcGIS 10.8.2).
Model descriptions
The selection of XGBoost, Extra Tree, Random Forest, and CatBoost was guided by their proven efficacy in agricultural water management71,72,73,74,75. XGBoost’s regularization and handling of missing data align with the noisy nature of meteorological datasets. The Extra Tree model was specifically included for its ability to inject additional randomness in the selection of split thresholds and features, which not only improves generalization and reduces overfitting compared to conventional decision trees and even Random Forest, but also provides computational efficiency and scalability to large datasets. Random Forest’s ensemble approach reduces overfitting risks, while CatBoost’s native support for categorical variables ensures robust processing of terrain and wind direction features. These models’ compatibility with interpretability frameworks like SHAP further validated their suitability for linking ML outputs to physical processes.
XGBoost
The extreme gradient boosting (XGB) algorithm is a decision tree-based machine learning technique known for its robust performance and efficiency76,77. Key features of XGB include regularisation to reduce overfitting, effective handling of missing and skewed data, support for parallel and distributed computing, and built-in cross-validation. It addresses both classification and regression tasks through an additive boosting approach that transforms weak learners into strong predictors77. This design minimizes underfitting and overfitting while reducing computational cost. The prediction process at time t follows the procedures outlined by Mokhtar et al.78.:
where, \(\:{f}_{t\:}\left({x}_{i}\right)\) denotes the learning step at time t; \(\:{x}_{i}\) stands for the input variable; \(\:{f}_{i}^{\left(t\right)}\) and \(\:{f}_{i}^{(t-1)}\) denote the prediction output at time steps t and t-1, respectively. By estimating the model goodness derived from the original function using the analytical formulation as follows, the problem of overfitting in the model is eliminated:
Where n denotes the number of observations; l denotes the loss function, and Ω is the regularization term, it can be formulated as \(\:\varOmega\:\left(f\right)=\:\gamma\:T+\:\frac{1}{2}\:\lambda\:\:{\parallel\omega\:\parallel}^{2}\), where which \(\:\omega\:\) denotes the leaf node’s score; \(\:\lambda\:\) refers to the regularization parameter; \(\:\gamma\:\) shows the least amount of loss that could be used to segregate the leaf node further. The XGB ML technique improves prediction speed and computational efficiency.
Extra tree
The Extra Trees (Extremely Randomized Trees) algorithm is an ensemble learning method used for both regression and classification tasks. It builds multiple decision trees using randomly selected subsets of features and samples, enhancing model diversity and reducing overfitting compared to traditional decision trees79,80. At each node, a random subset of features is considered, and the optimal split is chosen based on criteria like information gain or mean squared error. The final prediction is obtained by aggregating the outputs from all trees—using majority voting for classification or averaging for regression.
Random forest
Random Forest (RF), introduced by Breiman81, combines classification and regression trees (CART) with bootstrap aggregation (bagging) to build an ensemble of decision trees. This method generates multiple trees by training on bootstrapped subsets of the data, improving model stability and accuracy82. Each tree starts from a root node and ends in leaf nodes, where data points falling in the same leaf are considered similar. The similarity between two data points, such as x and y, is measured by how often they share the same leaf across trees. This forms a similarity matrix that is random, positive, and symmetric, and from which a non-similarity matrix can be derived83.
The system’s estimating of the RF technique can significantly improve efficiency with the fewest errors and most minor noise. The RF can operate effectively with a large, high-dimensional dataset84,85.
CatBoost
CatBoost is an advanced implementation of the Gradient Boosting Decision Tree (GBDT) framework, specifically optimized for handling categorical features. It uses oblivious trees with minimal parameters and addresses key challenges such as gradient bias and prediction shift, enhancing generalization and robustness86,87. CatBoost processes categorical variables efficiently by transforming them during training through dataset shuffling and filtering based on shared category attributes88,89. In this study, categorical factors such as rainfall, wind direction, slope direction, and terrain type are considered, with CatBoost computing goal values, weights, and priorities before numerical transformation.
Where p is the weight coefficient greater than zero and the added prior value. To drastically reduce the noise points brought on by low-frequency features, an a priori value is provided, helping to both lessen the model’s overfitting and increase its capacity for generalization.
SHapley additive explanations (SHAP) method
SHapley Additive exPlanations (SHAP) is an interpretability technique derived from cooperative game theory. It assigns an importance value (Shapley value) to each feature by evaluating its marginal contribution to the model’s output. Given a prediction model \(\:f\) and a feature set \(\:X=\{{x}_{1},{x}_{2},\dots\:,{x}_{n}\}\), the Shapley value \(\:{\phi\:}_{i}\) for feature \(\:{x}_{i}\) is calculated using Eq. 5.
Here, \(\:S\) represents all possible subsets of features excluding \(\:{x}_{i}\). The formula ensures fair attribution of feature contributions by averaging the marginal effect of \(\:{x}_{i}\) across all possible feature combinations.
SHAP assigns an importance value to each feature by measuring the impact on model predictions when the feature is included or excluded. It calculates Shapley values by averaging a feature’s contributions across all possible feature combinations, ensuring a fair and consistent attribution of importance. SHAP is particularly effective for interpreting complex models such as XGBoost, Extra Trees, Random Forest, and CatBoost, which are used in this study. It offers both global interpretability—by revealing the overall influence of each feature across the dataset—and local interpretability, by explaining individual predictions based on feature contributions.
Sobol sensitivity analysis method
The Sobol sensitivity analysis method is a global sensitivity analysis technique based on variance decomposition. It quantifies each input variable’s contribution and interactions to the model output variance. In this study, Sobol analysis is used to determine the influence of meteorological factors on predicting daily crop coefficients. Given a prediction model \(\:f\left(X\right)\), where \(\:X=\{{x}_{1},{x}_{2},\dots\:,{x}_{n}\}\) represents the input features (e.g., wind speed, relative humidity, etc.), the total variance \(\:V\) of the model output is decomposed using Eq. 6.
Here, \(\:{V}_{i}\) represents the main effect of the i−th variable, \(\:{V}_{ij}\) represents the interaction between variables \(\:{x}_{i}\)and \(\:{x}_{j}\), and so forth. The first-order Sobol index \(\:{S}_{i}\) for variable \(\:{x}_{i}\) is given by Eq. 7.
This index measures the direct contribution of \(\:{x}_{i}\) to the output variance. The total Sobol index \(\:{S}_{Ti}\), which also accounts for higher-order interactions involving \(\:{x}_{i}\), is defined using Eq. 8.
In this study, the Sobol analysis evaluates both first-order and total effects, identifying the dominant factors influencing daily crop coefficient values. The method is beneficial for understanding complex, non-linear interactions among input features, which is crucial for reliable prediction models.
Local interpretable Model-agnostic explanations (LIME) method
The Local Interpretable Model-agnostic Explanations (LIME) method is an interpretability technique that provides insights into complex, “black-box” models by approximating them with interpretable local models. LIME explains individual predictions by generating locally weighted linear models that mimic the behavior of the original model within a small neighborhood of the input instance. In this study, LIME was employed to analyze the influence of meteorological factors on the predicted daily crop coefficient (Kc). Given a black-box model \(\:f\) and an instance \(\:x\), LIME creates a set of perturbed samples \(\:\{{x}_{1},{x}_{2},\dots\:,{x}_{n}\}\) around \(\:x\) by adding small variations. The black-box model is then used to predict outputs for these perturbed samples, \(\:f\left({x}_{1}\right),f\left({x}_{2}\right),\dots\:,f\left({x}_{n}\right)\). Next, LIME fits a simple interpretable model (e.g., linear regression) \(\:g\) to approximate \(\:f\) locally around \(\:x\), minimizing the objective shown in Eq. 9.
where \(\:\pi\:\left(x,{x}_{i}\right)\:\)is a weighting function that assigns higher importance to instances closer to \(\:x\). The coefficients of the linear model \(\:g\) provide an interpretation of the local importance of each feature. In the context of this study, LIME was used to evaluate the significance of input variables such as wind speed (WS), relative humidity (H), solar radiation (Sin), and antecedent crop coefficient values [\(\:Kc(d-1)\:and\:Kc(d-2)\)] at a local scale. By interpreting individual predictions, LIME helps identify critical variables affecting the crop coefficient at specific time points, offering insights into model behavior under different climatic scenarios. LIME’s strength lies in its ability to provide human-interpretable explanations for complex models, making it particularly valuable for validating predictions and ensuring consistency with physical processes. This analysis complements the global interpretability provided by SHAP and Sobol sensitivity methods, offering a holistic approach to understanding model predictions.
Statistical analysis
The following five performance factors were used to assess how well the implemented algorithm performed: Correlation coefficient (r), Mean Absolute Error (MAE), Root Mean Square Error (RMSE) and Nash–Sutcliffe model efficiency coefficient (NSE). The following formulae have been used to determine these parameters:
In these equations, Kcobs, i and Kcsim, i represent the observed and simulated observations, respectively, and N is the total number of measurements. \(\:\stackrel{-}{{\text{K}\text{c}}_{obs}}\) and \(\:\stackrel{-}{{Kc}_{sim}}\:\) are the means of the measured and simulated observations, respectively.
Methodology
This study implemented a comprehensive workflow to predict daily soybean crop coefficients (Kc) using XGBoost, Extra Tree, Random Forest, and CatBoost. The methodology integrated data preprocessing, model development, hyperparameter optimization, and interpretability analysis, ensuring alignment with agro-hydrological processes and reproducibility. Descriptive statistic for the input variables and kc values is presented in Table 1.
Data Preprocessing and Input Variables: Input variables comprised daily meteorological data—solar radiation, wind speed, relative humidity, minimum/maximum/mean temperature—and antecedent Kc values (lagged by one and two days). Normalization was not performed, as all four tree-based models are inherently robust to feature scale variations and can handle non-linear relationships without the need for scaling. The dataset, spanning 1979–2014, was systematically partitioned into a training set (1979–2003) and a validation set (2004–2014) to rigorously assess temporal generalizability. Model implementation was conducted in Python using the scikit-learn and CatBoost libraries, with fixed random seeds to ensure reproducibility.
Model Training and Hyperparameter Optimization: All four ML models, XGBoost, Extra Tree, Random Forest, and CatBoost, were trained and optimized using grid search with 5-fold cross-validation to minimize overfitting and maximize predictive accuracy. The hyperparameters and structures for each model are detailed in Table 3. The optimization process prioritized NSE and RMSE to balance bias-variance trade-offs and ensure robust model performance.
The Table 2 summarizes the calibration of crop coefficient (Kc) values using lysimeter-based ETc data and local observations. Data were collected over three years from 2012 to 2014, with the number of observations, mean values, ranges, and correlation coefficients presented for each year.
Interpretability and Validation: After model training, SHAP, Sobol, and LIME interpretability frameworks were applied to assess feature importance and the consistency of model predictions with underlying physical processes. Crop coefficient measurements for model validation were derived from the FAO CROPWAT model and calibrated against lysimeter-based ETc data, ensuring the reliability of the reference Kc values. Model performance was evaluated using RMSE, MAE, correlation coefficient (r), and NSE, with results compared against observed Kc values to confirm robustness across all soybean growth stages.
Results
Evaluating machine learning model performances
The best magnitudes of hyperparameters and model architectures for the retained models are listed in Table 3. All models ran at this stage in less than 0.5 min. The models demonstrated high accuracy, with NSE values between 0.8 and 0.86. Daily model training was carried out between 1979 and 2003. Daily validation of the trained models was placed between 2004 and 2014. Correlation coefficient (r), root mean square error (RMSE), mean absolute error (MAE), and Nash-Sutcliffe Efficiency (NSE) were the four statistical matrices used in the investigation. Table 4 demonstrates that the generated models often had acceptable forecast accuracies for modeling daily crop coefficients. Extra Tree performed the best during the training process, followed by Random Forest. XGBoost and CatBoost performance remained marginal compared to the former two models. During the validation process, the Extra Tree model was again observed as the best-performing model compared to other models. However, it is imperative to highlight that the best performance here merely indicates slightly better performance than other models.
Using scatter plots and superimposed plots from the models, Fig. 2 compares the magnitudes of the observed and predicted crop coefficients. The scatter plots of the crop coefficient displayed a consistent distribution along the regression line, demonstrating strong model performance. The results indicate a satisfactory alignment between the simulated and observed crop coefficient values during the validation phase. Visual inspection of these plots for all models at this stage showed that the predictions were generally robust regarding direction (whether above or below the normal) and magnitude of the crop coefficient. Among the models, the Extra Tree model exhibited the highest prediction accuracy, effectively capturing the peaks in the data. Although the other three models also identified the peaks, they did so with slightly less precision than the Extra Tree model. Despite this, the overall correlation remained comparable and appropriate. These observations were consistent with the statistical measures presented in Table 4 and the r-values derived from the scatter plots. The models demonstrated sufficient reliability and generalizability to replicate the daily crop coefficient magnitude over a year accurately. While formal statistical tests were not conducted, the consistent superiority of the Extra Tree model across all performance metrics (RMSE, MAE, r, NSE) and its interpretability outcomes (Figs. 3, 4, 5, 6 and 7) underscores its robustness for daily Kc prediction. Such practical disparities are widely accepted in agro-hydrological ML research to justify model selection21,35,90.

Superimposed plots (left) and scatter plots (right) of predicted and actual crop coefficient magnitudes (Kc) during the validation process; in the scatter plots, dotted red lines show the 45° line (1:1; line of perfect prediction).
Interpretability of machine learning models
SHAP is a popular interpretation technique for tree-based ML models. The present study employed SHAP to interpret the XGBoost, Extra Tree, RF, and CatBoost models since they are shapely interpretable and offer prediction accuracies that show their value in forecasting the daily crop coefficients. The interpretation of these models is shown in Fig. 3. the sizes and orientations of their impacts on the crop coefficient illustrate the significance of the nine input variables.
From Fig. 3(a), it is observed that the antecedent crop coefficient with a lag of one day [\(\:Kc(d-1)\)] and Sin, followed by Ws and H, are the input variables that most impact daily crop coefficient magnitudes for the XGBoost model. As for the Extra Tree model [Fig. 3(b)], \(\:Kc(d-1)\), antecedent crop coefficient with a lag of two days [\(\:Kc(d-2)\)], and Ws input variables are the most important factors, followed by Sin and H. Referring to Fig. 3(c), for the RF model, the findings are similar to that of the XGBoost model such that \(\:Kc(d-1)\), Sin, and Ws are the factors of importance. While for the CatBoost model [Fig. 3(d)], \(\:Kc(d-1)\), Sin, \(\:Kc(d-2)\), and Ws are the important factors. However, for all models, the distribution of the solar radiation (Sin) and the temperature (T; mean, minimum, and maximum magnitudes) were comparatively less important compared to aforesaid variables. Also, \(\:Kc(d-2)\) was an important factor for Extra Tree but not for XGBoost. In general, increasing \(\:Kc(d-1)\), \(\:Kc(d-2)\), and Sin magnitudes globally match rising SHAP values for all models. In a similar manner, a rise in relative humidity causes a fall in SHAP values.
To summarize, \(\:Kc(d-1)\), \(\:Kc(d-2)\), and Sin variables significantly impact the predictions, as indicated by their high or low Shapley values. In contrast, the other variables have a lesser impact since their Shapley values are closer to zero. Hence, it can be inferred that the soybean crop coefficient’s physical mechanism is well-represented globally by this reasoning. These findings demonstrate the ability of these models (XGBoost and Extra Tree models in particular) to extract physical information about the interactions between the crop coefficient (output) and the climatic factors.
The local interpretation of the machine learning models reveals how individual features influence the model’s output through their interactions and dependencies. In contrast, the global interpretation provides an overall understanding of how climatic factors collectively affect the model’s predictions. To evaluate the local interpretability of the models, the SHAP dependence for specific significant climatic variables \(\:Kc(d-1)\), \(\:Kc(d-2)\), and Sin) was undertaken in this investigation and depicted in Fig. 4. It was observed that the antecedent Kc is the most important factor for all trained models (as an example of the explaination) (also the seasonality Sin was more important than Tmin, Tmax,….).


Global interpretability plots of the (a) XGBoost, (b) Extra Tree, (c) RF and (d) CatBoost ranking the input variables. (Note: The list of input variables is on the vertical axis, and their impacts on the daily crop coefficient are on the horizontal axis. Pink denotes high magnitude for a characteristic, whereas blue denotes low magnitude).

Local interpretability plots of the models according to the SHAP method. (Note: Positive SHAP values imply high variables’ impacts, while negative SHAP values suggest low variables’ effects).
Sobol-based interpretability result analysis
The Sobol-based method was employed to interpret the trained machine learning models despite SAHP being a robust approach for understanding the predictions of tree-based models. Given the complexity and non-linearity of machine learning models, the Monte Carlo integration technique was utilized to evaluate this strategy. The simulation was run 65,000 times to guarantee the Si values’ convergence. The running times for the XGBoost, Extra Tree, RF, and CatBoost models were around 3.11 min, 2.27 min, 3.10 min, and 2.11 min, respectively.
The first-order indices (S1i) and Total Sobol indices (STi) are the fundamental outcomes of the Sobol approach, as was previously indicated. The Sobol results are shown in Fig. 5. The graphs’ left and right halves, respectively, show the Total Sobol index (ST) and the first Sobol order (S1). As far as the ST index is concerned [Fig. 5 (left)], for the XGBoost model, it was observed that the \(\:Kc(d-1)\) (abbreviated as Kc1) was the main climatic factor contributing to the total variance of the daily crop coefficient of soybean crop predicted with values close to 0.9. Moreover, the daily Sin variable was also an important climatic factor after \(\:Kc\left(d-1\right)\), having the value close to 0.2. At the same time, the remaining variables were observed to be less important, considering their influence on crop coefficient. On the other hand, for the Extra Tree model, it was again clearly observed that the Kc1 was the main climatic factor contributing to the total variance of the daily crop coefficient predicted with values greater than 0.9. Moreover, on the contrary, instead of the daily Sin variable, it was the Kc2 variable, which was an important climatic factor, while the Sin variable followed Kc2. More or less, it can be proclaimed that Kc2 and especially Sin variables were not as important for the Extra Tree model (their values ranging between 0.01 and 0.04) as they remained for the XGBoost model. Like XGBoost, the remaining variables were considered less important, given their influence on the crop coefficient for the Extra Tree model.
As far as the S1 is concerned [Fig. 5 (right)], for the XGBoost model, it was observed that the Kc1 was the main climatic factor contributing to the total variance of the daily soybean crop coefficient predicted by values close to 0.8. Moreover, the daily Sin variable was also an essential climatic factor, having a value close to 0.05 (both magnitudes are less than the ST index). At the same time, the remaining variables were observed to have negligible importance, considering their influence on crop coefficient. On the other hand, for the Extra Tree model, it was again clearly observed that the Kc1 was the main climatic factor contributing to the total variance of the daily crop coefficient predicted with values greater than 0.9 (similar to the ST index). Moreover, on the contrary, instead of the daily Sin variable, it was the Kc2 variable, which was the next important climatic factor with a value close to 0.01. More or less, apart from Kc1, no other variables were necessary for the Extra Tree model (their values remained close to zero), considering their influence on the crop coefficient. The findings suggest that there were only minor differences between the S1 and ST magnitudes, indicating that the combined effects of the input variables on the ML model’s outputs were less significant than their individual contributions.

Plots of Total Sobol (ST; left) and first-order (S1; right) indices for (a) the XGBoost (xgb) model, (b) the Extra Tree model.
Local interpretable Model-Agnostic explanations (LIME) analysis
Global interpretation techniques, such as SHAP and Sobol, illustrate the extent to which input variables influence the variance in model outputs. The LIME approach was employed to enhance the local interpretability of the machine learning models, providing a clearer understanding of the model’s behavior. Local interpretation involved projecting 16 instances into the future using the XGBoost and Extra Tree models. This analysis confirms the importance of the antecedent crop coefficient with a lag of one day [\(\:Kc(d-1)\)] and two days [\(\:Kc(d-2)\)], and Sin apart from wind speed (Ws), relative humidity (H), and minimum temperature (Tmin) in predicting daily Kc. These situations are helpful in determining the pivotal points at which the chosen climatic variables change. This work examined 16 executed examples, as indicated in Figs. 6 and 7, to further investigate the crucial climatic inflection points of the \(\:Kc(d-1)\) and Sin and other factors (Case 1 to 16 or 17).
For the XGBoost model (Fig. 6), the variables of importance (in the sequence) included \(\:Kc(d-1)\), Sin, Ws, H, and Tmin. The inflection points of the \(\:Kc(d-1)\), Sin, Ws, H, and Tmin are 0.68, ̶ 0.79 and + 0.4, 2.56 m/s, 24% (0.24), and 18.98 °C respectively. For example, it can be hypothesized that the crop coefficient of soybean is low (less than historical median value) when \(\:Kc\left(d-1\right)\) < 0.68, Sin < ̶ 0.79, Sin > 0.40, Ws < 2.56 KW/m2, H > 24%, and Tmin < 18.98 °C. Hence at the lower crop coefficient of soybean, the LIME values for \(\:Kc\left(d-1\right)\:\)ranged from − 0.23 to −0.16, Sin ranged from − 0.08 to −0.02, Ws ranged from − 0.03 to −0.01, H became − 0.035, and Tmin ranged from − 0.02 to −0.01. To summarize, for the XGBoost model, the LIME values acquired a negative magnitude for a lower crop coefficient value. Besides, during local interpretation of the XGBoost model, the Ws, H, Tmin, and all other variables’ inflection points are closer to those corresponding to zero SHAP values [Fig D(a)]. These findings indicate the XGBoost model’s superior local interpretability for daily crop coefficient prediction compared to the SHAP technique.
For the Extra Tree model (Fig. 7), the variables of importance (in the sequence) included \(\:Kc(d-1)\), \(\:Kc(d-2)\), H, Sin, and Ws. The inflection points of the \(\:Kc(d-1)\), \(\:Kc(d-2)\), H, Sin, and Ws are 0.68, 0.68, 24% (0.24), ̶ 0.79 and + 0.4, and 2.56 m/s, respectively. For example, it can be hypothesized that the crop coefficient of soybean is low (less than historical median value) when \(\:Kc\left(d-1\right)\) < 0.68, \(\:Kc\left(d-2\right)\) < 0.68, H > 24%, Sin < ̶ 0.79, Sin > 0.40, and Ws < 2.56 KW/m2. Hence at the lower crop coefficient of soybean, the LIME values for \(\:Kc\left(d-1\right)\:\)ranged from − 0.23 to −0.15, \(\:Kc\left(d-2\right)\:\)ranged from − 0.035 to −0.030, H became − 0.015, Sin ranged from − 0.02 to −0.01, and Ws ranged from − 0.015 to −0.010. To summarize, for the Extra Tree model, the LIME values acquired a negative magnitude for a lower crop coefficient value. Besides, during local interpretation of the Extra Tree model, the inflection points of the \(\:Kc(d-2)\), H, Sin, Ws, and all other variables are closer to those that correspond to zero SHAP values [Fig D(b)]. These findings indicate the Extra Tree model’s superior local interpretability for daily crop coefficient prediction compared to the SHAP technique.


Inflection points of the climate variables for the XGBoost model. (Note: Negative LIME values indicate low crop coefficient values for soybean crops (less than the historical median), while positive LIME values indicate important variables resulting in high crop coefficient.).


Inflection points of the climate variables for the Extra Tree model (Note: Negative LIME values indicate low crop coefficient values for soybean crops (less than the historical median), while positive LIME values indicate important variables resulting in high crop coefficient.).
Discussion
Key findings and alignment with research objectives
This study demonstrates the efficacy of interpretable ML models in predicting daily soybean crop coefficients (Kc) with high accuracy (r = 0.9672, NSE = 0.9350 for Extra Tree). The Extra Tree model outperformed XGBoost, Random Forest, and CatBoost, consistent with prior findings on ensemble models in agro-hydrology52. While Deep Neural Networks (DNNs) were not explored, the performance of tree-based models remained robust and comparable to studies on evaporation and evapotranspiration prediction90,91. These results directly address the primary objective of developing a reliable ML framework for Kc estimation, integrating antecedent Kc values and meteorological variables (Figs. 3 and 4).
Novelty and contribution to the field
The principal innovation of this research lies in the integrated application of SHAP, Sobol sensitivity analysis, and LIME to assess both the interpretability and physical consistency of ML models for crop coefficient (Kc) prediction—an approach rarely combined in previous Kc studies. While most earlier works have emphasized predictive accuracy alone92,93, this study advances the field by systematically quantifying feature importance at both global (SHAP, Sobol) and local (LIME) levels (Figs. 3, 4, 5, 6 and 7). The analysis reveals that antecedent Kc values (with one- and two-day lags) and solar radiation are the dominant drivers of daily Kc variability, which is consistent with established crop-climate interactions reported in ecological literature94,95. By providing transparent, multi-scale interpretability, this framework bridges the gap between “black-box” ML outputs and agronomic process understanding, thereby addressing a critical limitation identified in the literature. This methodological advancement not only improves the reliability and practical relevance of Kc predictions but also establishes a robust foundation for the adoption of interpretable AI in agricultural water management.
Model performance and interpretability insights
The Extra Tree model’s superiority (RMSE = 0.0574, MAE = 0.0242) stems from its randomized feature selection, which improves generalization—a finding consistent with ensemble model advantages79. SHAP and Sobol analyses revealed that Kc(d-1) contributed > 90% to output variance (Figs. 3 and 4), while LIME localized interactions between Kc(d-2), wind speed (Ws), and humidity (H) (Figs. 6 and 7). Discrepancies in variable importance between models (e.g., XGBoost prioritized Sin, while Extra Tree emphasized Kc(d-2)) highlight structural sensitivities but confirm the dominance of antecedent Kc. These understandings align with crop physiology, where prior soil moisture and growth stage transitions drive Kc dynamics96,97.
Implications for Climate-Resilient agriculture
In semi-arid regions like Sohag, climate change exacerbates water scarcity through intensified droughts and evaporation. The present interpretable framework enables precise irrigation scheduling by linking ML predictions to actionable variables (Ws, H, Sin). For instance, LIME identified critical thresholds (e.g., Ws < 2.56 m/s, H > 24%) for low Kc values, guiding targeted water management. This aligns with strategies to mitigate climate impacts through data-driven decisions98,99,100.
Strengths, Limitations, and future directions
This study demonstrates several key strengths. It is the first to integrate SHAP, Sobol sensitivity analysis, and LIME in a unified interpretability framework for crop coefficient (Kc) modeling in arid agroecosystems, enabling robust validation of both predictive accuracy and physical relevance. Validation against a 36-year dataset ensures temporal robustness, capturing interannual climate variability and extremes. The methodology’s compatibility with FAO CROPWAT improves its practical utility for irrigation management and planning. However, some limitations exist. DNN models, which may provide higher predictive power, were not included due to computational demands and limited applicability in resource-constrained settings. The study also did not incorporate soil moisture and canopy cover as input variables because of data constraints, potentially limiting the mechanistic understanding of Kc variability. Furthermore, as the models were calibrated for the Sohag region in Egypt, their generalizability to other agro-climatic zones requires further validation. Future research should integrate high-resolution remote sensing data, such as NDVI and satellite-derived soil moisture, to better capture canopy and root-zone dynamics. Testing hybrid model architectures and expanding the interpretability framework to multi-crop systems and diverse climates will be essential for developing universally applicable Kc prediction protocols.
Conclusions
This study demonstrates the potential of interpretable machine learning models for precise daily estimation of the soybean crop coefficient (Kc) in arid and semi-arid environments. Using 36 years of meteorological data from Suhaj Governorate, Egypt, we evaluated four ensemble models—XGBoost, Extra Tree, Random Forest, and CatBoost—alongside SHAP, Sobol, and LIME interpretability techniques. Among these, the Extra Tree model achieved the highest predictive accuracy (r = 0.9672, NSE = 0.9350, RMSE = 0.0574, MAE = 0.0242), with XGBoost and Random Forest also performing robustly. Interpretability analyses consistently identified the antecedent crop coefficient (with one- and two-day lags) and solar radiation as the most influential variables across all models, aligning with established physical understanding of crop-climate interactions. SHAP and Sobol sensitivity analyses highlighted the dominant role of recent Kc values and seasonality, while LIME provided additional understanding of localized prediction dynamics. These findings reinforce the reliability of the machine learning framework and its consistency with underlying agronomic processes.
By integrating predictive accuracy with model interpretability, this research yields a transparent and transferable approach for crop coefficient estimation, supporting improved irrigation scheduling and sustainable water management. The methodology can be extended to other crops and regions, especially where ground-based measurements are limited. While the models performed well, future work should explore the inclusion of additional agronomic variables, remote sensing data, and advanced deep learning architectures to further improve prediction accuracy and generalizability. In summary, the interpretable ML-based framework developed here advances daily Kc estimation and provides implementable steps for climate-resilient agriculture. This approach supports data-driven decision-making for efficient water use and agricultural planning in water-scarce regions.
Data availability
The data presented in this study are available at a reasonable request from the first author.
References
Lu, S., Jiang, Y., Deng, W. & Meng, X. Energy and food production security under water resources regulation in the context of green development. Resour. Policy. 80, 103236 (2023).
Novoa, V. et al. Water footprint and virtual water flows from the global south: foundations for sustainable agriculture in periods of drought. Sci. Total Environ. 869, 161526 (2023).
Kang, S. et al. The impacts of human activities on the water–land environment of the Shiyang river basin, an arid region in Northwest China / Les impacts des activités humaines Sur l’environnement pédo-hydrologique du Bassin de La Rivière Shiyang, Une région Aride du nord-ouest de La Chine. Hydrol. Sci. J. 49, 5 (2004).
Deng, X. P., Shan, L., Zhang, H. & Turner, N. C. Improving agricultural water use efficiency in arid and semiarid areas of China. Agric. Water Manag. 80, 23–40 (2006).
Naorem, A. et al. Soil constraints in an arid Environment—Challenges, Prospects, and implications. Agronomy 13, 220 (2023).
Mehrim, A. I. & Refaey, M. M. An overview of the implication of climate change on fish farming in Egypt. Sustainability 15, 1679 (2023).
Farg, E., Arafat, S. M., El-Wahed, A., EL-Gindy, A. M. & M. S. & Estimation of evapotranspiration ETc and crop coefficient Kc of Wheat, in South nile delta of Egypt using integrated FAO-56 approach and remote sensing data. Egypt. J. Remote Sens. Space Sci. 15, 83–89 (2012).
Pôças, I., Paço, T. A., Paredes, P., Cunha, M. & Pereira, L. S. Estimation of actual crop coefficients using remotely sensed vegetation indices and soil water balance modelled data. Remote Sens. 7, 2373–2400 (2015).
Molden, D. et al. Improving agricultural water productivity: between optimism and caution. Agric. Water Manag. 97, 528–535 (2010).
Pereira, L. S., Cordery, I. & Iacovides, I. Improved indicators of water use performance and productivity for sustainable water conservation and saving. Agric. Water Manag. 108, 39–51 (2012).
Levidow, L. et al. Improving water-efficient irrigation: prospects and difficulties of innovative practices. Agric. Water Manag. 146, 84–94 (2014).
Zhao, S. et al. Integrating proximal soil sensing data and environmental variables to enhance the prediction accuracy for soil salinity and sodicity in a region of Xinjiang Province, China. J. Environ. Manage. 364 https://doi.org/10.1016/j.jenvman.2024.121311 (2024).
Kang, S. et al. Improving agricultural water productivity to ensure food security in China under changing environment: from research to practice. Agric. Water Manag. 179, 5–17 (2017).
Mega, R. et al. Tuning water-use efficiency and drought tolerance in wheat using abscisic acid receptors. Nat. Plants. 5, 153–159 (2019).
Kool, D. et al. A review of approaches for evapotranspiration partitioning. Agric. Meteorol. 184, 56–70 (2014).
Stewart, B. A. & Howell, T. Encyclopedia of Water Science (Print) (CRC, 2003).
Allen, R. G., Pereira, L. S., Raes, D. & Smith, M. Crop evapotranspiration - Guidelines for computing crop water requirements - FAO Irrigation and drainage paper 56.
Kite, G. Using a basin-scale hydrological model to estimate crop transpiration and soil evaporation. J. Hydrol. 229, 59–69 (2000).
Zhao, N. et al. Dual crop coefficient modelling applied to the winter wheat–summer maize crop sequence in North China plain: basal crop coefficients and soil evaporation component. Agric. Water Manag. 117, 93–105 (2013).
Pereira, L. S., Paredes, P., Hunsaker, D. J. & López-Urrea, R. Mohammadi Shad, Z. Standard single and basal crop coefficients for field crops. Updates and advances to the FAO56 crop water requirements method. Agric. Water Manag. 243, 106466 (2021).
Al-Mukhtar, M., Srivastava, A., Khadke, L., Al-Musawi, T. & Elbeltagi, A. Prediction of irrigation water quality indices using random Committee, discretization regression, REPTree, and additive regression. Water Resour. Manag. 38, 343–368 (2024).
Hong, M. et al. Determination of growth Stage-Specific crop coefficients (Kc) of sunflowers (Helianthus annuus L.) under salt stress. Water 9, 215 (2017).
Jagtap, S. S. & Jones, J. W. Stability of crop coefficients under different climate and irrigation management practices. Irrig. Sci. 10, 231–244 (1989).
Corbari, C., Ravazzani, G., Galvagno, M., Cremonese, E. & Mancini, M. Assessing crop coefficients for natural vegetated areas using satellite data and eddy covariance stations. Sensors 17, 2664 (2017).
Gontia, N. K. & Tiwari, K. N. Estimation of crop coefficient and evapotranspiration of wheat (Triticum aestivum) in an irrigation command using remote sensing and GIS. Water Resour. Manag. 24, 1399–1414 (2010).
Guerra, E., Ventura, F., Spano, D. & Snyder, R. L. Correcting midseason crop coefficients for climate. J. Irrig. Drain. Eng. 141, 04014071 (2015).
Irmak, S., Odhiambo, L. O., Specht, J. E. & Djaman, K. Hourly and daily single and basal evapotranspiration crop coefficients as a function of growing degree days, days after emergence, leaf area index, fractional green canopy cover, and plant phenology for soybean. Trans. ASABE. 56, 1785–1803 (2013).
Tyagi, N. K., Sharma, D. K. & Luthra, S. K. Determination of evapotranspiration and crop coefficients of rice and sunflower with lysimeter. Agric. Water Manag. 45, 41–54 (2000).
Kang, S., Gu, B., Du, T. & Zhang, J. Crop coefficient and ratio of transpiration to evapotranspiration of winter wheat and maize in a semi-humid region. Agric. Water Manag. 59, 239–254 (2003).
Li, S., Kang, S., Li, F. & Zhang, L. Evapotranspiration and crop coefficient of spring maize with plastic mulch using eddy covariance in Northwest China. Agric. Water Manag. 95, 1214–1222 (2008).
Guo, H. et al. Crop coefficient for spring maize under plastic mulch based on 12-year eddy covariance observation in the arid region of Northwest China. J. Hydrol. 588, 125108 (2020).
Yang, D. et al. Effect of drip irrigation on wheat evapotranspiration, soil evaporation and transpiration in Northwest China. Agric. Water Manag. 232, 106001 (2020).
Pereira, L. S. et al. Standard single and basal crop coefficients for vegetable crops, an update of FAO56 crop water requirements approach. Agric. Water Manag. 243, 106196 (2021).
Pereira, L. S. et al. Prediction of crop coefficients from fraction of ground cover and height. Background and validation using ground and remote sensing data. Agric. Water Manag. 241, 106197 (2020).
Dong, S. et al. Comparative analysis of crop coefficient approaches and machine learning models for predicting water requirements in three major crops in coastal Saline-Alkali land. Agronomy 15, 492 (2025).
Alavi, M., Albaji, M., Golabi, M., Ali Naseri, A. & Homayouni, S. Estimation of sugarcane evapotranspiration from remote sensing and limited meteorological variables using machine learning models. J. Hydrol. 629, 130605 (2024).
Abedinpour, M. Evaluation of growth-stage-specific crop coefficients of maize using weighing lysimeter. Soil. Water Res. 10, 99–104 (2015).
institute (sedinst. ), s. and e. d. determination of crop coefficients of maize for the estimation of crop water use. https://doi.org/10.5707/cjengsci.2013.8.2.1.6
Shahrokhnia, M. H. & Sepaskhah, A. R. Single and dual crop coefficients and crop evapotranspiration for wheat and maize in a semi-arid region. Theor. Appl. Climatol. 114, 495–510 (2013).
Üzen, N., Çeti̇n, Ö. & Yolcu, R. Possibilities of using dual Kc approach in predicting crop evapotranspiration ofsecond-crop silage maize. Turk. J. Agric. For. 42, 272–280 (2018).
Trout, T. J. & DeJonge, K. C. Crop water use and crop coefficients of maize in the great plains. J. Irrig. Drain. Eng. 144, 04018009 (2018).
Anwer Dawood Almaraf, S. & Fahkre Hikmat, E. Predicting the crop coefficient values for maize in Iraq. Eng. Technol. J. 34, 284–294 (2016).
Ferreira, L. B. & da Cunha, F. F. New approach to estimate daily reference evapotranspiration based on hourly temperature and relative humidity using machine learning and deep learning. Agric. Water Manag. 234, 106113 (2020).
Saggi, M. K. & Jain, S. Application of fuzzy-genetic and regularization random forest (FG-RRF): Estimation of crop evapotranspiration (ETc) for maize and wheat crops. Agric. Water Manag. 229, 105907 (2020).
Saggi, M. K. & Jain, S. Reference evapotranspiration Estimation and modeling of the Punjab Northern India using deep learning. Comput. Electron. Agric. 156, 387–398 (2019).
Lee, S. H., Goëau, H., Bonnet, P. & Joly, A. New perspectives on plant disease characterization based on deep learning. Comput. Electron. Agric. 170, 105220 (2020).
Ma, J. et al. A recognition method for cucumber diseases using leaf symptom images based on deep convolutional neural network. Comput. Electron. Agric. 154, 18–24 (2018).
Picon, A. et al. Deep convolutional neural networks for mobile capture device-based crop disease classification in the wild. Comput. Electron. Agric. 161, 280–290 (2019).
Thenmozhi, K. Srinivasulu Reddy, U. Crop pest classification based on deep convolutional neural network and transfer learning. Comput. Electron. Agric. 164, 104906 (2019).
Raza, A. et al. Comparative assessment of reference evapotranspiration Estimation using conventional method and machine learning algorithms in four Climatic regions. Pure Appl. Geophys. 177, 4479–4508 (2020).
Raza, A. et al. Application of non-conventional soft computing approaches for Estimation of reference evapotranspiration in various Climatic regions. Theor. Appl. Climatol. 139, 1459–1477 (2020).
Elbeltagi, A. et al. Data intelligence and hybrid metaheuristic algorithms-based Estimation of reference evapotranspiration. Appl. Water Sci. 12, 152 (2022).
Wang, J. et al. Development of monthly reference evapotranspiration machine learning models and mapping of Pakistan—A comparative study. Water 14, 1666 (2022).
Hadria, R. et al. Hadria.Comparative assessment of different reference evapotranspiration models towards a fit calibration for arid and semi-arid areas. J. Arid Environ. 184, 104318 (2021).
Kang, H. & Chen, C. Fast implementation of real-time fruit detection in Apple orchards using deep learning. Comput. Electron. Agric. 168, 105108 (2020).
Rezaei, M. et al. Incorporating machine learning models and remote sensing to assess the Spatial distribution of saturated hydraulic conductivity in a light-textured soil. Comput. Electron. Agric. 209, 107821 (2023).
Zhang, Y., Cai, J., Xiao, D., Li, Z. & Xiong, B. Real-time Sow behavior detection based on deep learning. Comput. Electron. Agric. 163, 104884 (2019).
Zhao, X. & Fan, J. Response of tree Sap flow rate to soil water and atmospheric environment, and adaptability to drought in the loess plateau region of China. Ecol. Manag. 565, 122007 (2024).
Espejo-Garcia, B. et al. End-to-end sequence labeling via deep learning for automatic extraction of agricultural regulations. Comput. Electron. Agric. 162, 106–111 (2019).
Kounalakis, T., Triantafyllidis, G. A. & Nalpantidis, L. Deep learning-based visual recognition of Rumex for robotic precision farming. Comput. Electron. Agric. 165, 104973 (2019).
Mousavi, S. R., Mahjenabadi, J., Khoshru, V. A., Rezaei, M. & B. & Spatial prediction of winter wheat yield gap: agro-climatic model and machine learning approaches. Front. Plant. Sci. 14 https://doi.org/10.3389/fpls.2023.1309171 (2024).
Gude, V., Corns, S. & Long, S. Flood prediction and uncertainty Estimation using deep learning. Water 12, 884 (2020).
Afzaal, H., Farooque, A. A., Abbas, F., Acharya, B. & Esau, T. Groundwater Estimation from major physical hydrology components using artificial neural networks and deep learning. Water 12, 5 (2020).
Fan, H. et al. Comparison of long short term memory networks and the hydrological model in runoff simulation. Water 12, 175 (2020).
Hussain, S. et al. Investigation of irrigation water requirement and evapotranspiration for water resource management in Southern Punjab, Pakistan. Sustainability 15, 1768 (2023).
Adisa, O. M. et al. Application of artificial neural network for predicting maize production in South Africa. Sustainability 11, 1145 (2019).
Fu, H. et al. Winter wheat yield prediction using satellite remote sensing data and deep learning models. Agronomy 15(1), 205. https://doi.org/10.3390/agronomy15010205 (2025).
Nema, M. K., Khare, D. & Chandniha, S. K. Application of artificial intelligence to estimate the reference evapotranspiration in sub-humid Doon Valley. Appl. Water Sci. 7, 3903–3910 (2017).
Dhanke, J. A. et al. Climatic condition–based comparative study of deep learning models for yield forecasting in smart agriculture. Remote Sens. Earth Syst. Sci. 8, 365–374. https://doi.org/10.1007/s41976-024-00186-0 (2025).
Khan, M. A., Islam, Z. & Hafeez, M. Irrigation Water Demand Forecasting – A Data Pre-Processing and Data Mining Approach based on Spatio-Temporal Data. 121, (2011).
Elbeltagi, A. et al. Advanced stacked integration method for forecasting long-term drought severity: CNN with machine learning models. J. Hydrol. Reg. Stud. 53, 101759 (2024).
Li, X. et al. Coefficient of variation method combined with XGboost ensemble model for wheat growth monitoring. Front. Plant. Sci. 14, 1267108. https://doi.org/10.3389/fpls.2023.1267108 (2024).
Ko, J., Shin, T., Kang, J., Baek, J. & Sang, W. G. Combining machine learning and remote sensing-integrated crop modeling for rice and soybean crop simulation. Front Plant. Sci 15, 1320969. https://doi.org/10.3389/fpls.2024.1320969 (2024).
Sakamoto, T. Incorporating environmental variables into a MODIS-based crop yield Estimation method for united States corn and soybeans through the use of a random forest regression algorithm. ISPRS J. Photogramm Remote Sens. 160, 208–228 (2020).
Vishwakarma, D. K. et al. Evaluation of catboost method for predicting weekly Pan evaporation in subtropical and Sub-Humid regions. Pure Appl. Geophys. 181, 719–747 (2024).
Chen, T., Guestrin, C. & XGBoost: A Scalable Tree Boosting System. in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794Association for Computing Machinery, New York, NY, USA, (2016). https://doi.org/10.1145/2939672.2939785
Dai, H., Huang, G., Zeng, H. & Yang, F. PM2.5 concentration prediction based on Spatiotemporal feature selection using XGBoost-MSCNN-GA-LSTM. Sustainability 13, 12071 (2021).
Mokhtar, A., Elbeltagi, A., Gyasi-Agyei, Y., Al-Ansari, N. & Abdel-Fattah, M. K. Prediction of irrigation water quality indices based on machine learning and regression models. Appl. Water Sci. 12, 76 (2022).
Galar, M., Fernandez, A., Barrenechea, E., Bustince, H. & Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, Boosting-, and Hybrid-Based approaches. IEEE Trans. Syst. Man. Cybern Part. C Appl. Rev. 42, 463–484 (2012).
Sagi, O. & Rokach, L. Ensemble learning: A survey. WIREs Data Min. Knowl. Discov. 8, e1249 (2018).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Yoo, C., Han, D., Im, J. & Bechtel, B. Comparison between convolutional neural networks and random forest for local climate zone classification in mega urban areas using Landsat images. ISPRS J. Photogramm Remote Sens. 157, 155–170 (2019).
Shi, T., Horvath, S. & and Unsupervised learning with random forest predictors. J. Comput. Graph Stat. 15, 118–138 (2006).
Khosravi, K. et al. Meteorological data mining and hybrid data-intelligence models for reference evaporation simulation: A case study in Iraq. Comput. Electron. Agric. 167, 105041 (2019).
Li, Y., Zhang, Y. & Lv, J. Interannual variations in GPP in forest ecosystems in Southwest China and regional differences in the Climatic contributions. Ecol. Inf. 69, 101591 (2022).
Chen, J. X., Cheng, T. H., Chan, A. L. F. & Wang, H. Y. An application of classification analysis for skewed class distribution in therapeutic drug monitoring - the case of vancomycin. in 2004 IDEAS Workshop on Medical Information Systems: The Digital Hospital (IDEAS-DH’04) 35–39 (2004). https://doi.org/10.1109/IDEADH.2004.6
Huang, J. et al. Climatic controls on Sap flow dynamics and used water sources of Salix psammophila in a semi-arid environment in Northwest China. Env Earth Sci. 73, 289–301 (2015).
Dorogush, A. V., Ershov, V. & Gulin, A. CatBoost: gradient boosting with categorical features support. Preprint at. https://doi.org/10.48550/arXiv.1810.11363 (2018).
Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V. & Gulin, A. CatBoost: unbiased boosting with categorical features. Preprint at. https://doi.org/10.48550/arXiv.1706.09516 (2019).
El Bilali, A. et al. An interpretable machine learning approach based on DNN, SVR, extra Tree, and XGBoost models for predicting daily Pan evaporation. J. Environ. Manage. 327, 116890 (2023).
Chakraborty, D., Başağaoğlu, H. & Winterle, J. Interpretable vs. noninterpretable machine learning models for data-driven hydro-climatological process modeling. Expert Syst. Appl. 170, 114498 (2021).
Han, X. et al. Crop evapotranspiration prediction by considering dynamic change of crop coefficient and the precipitation effect in back-propagation neural network model. J. Hydrol. 596, 126104 (2021).
Ohana-Levi, N., Ben-Gal, A., Munitz, S. & Netzer, Y. Grapevine crop evapotranspiration and crop coefficient forecasting using linear and non-linear multiple regression models. Agric. Water Manag. 262, 107317 (2022).
Helfer, F., Lemckert, C. & Zhang, H. Impacts of climate change on temperature and evaporation from a large reservoir in Australia. J. Hydrol. 475, 365–378 (2012).
Woolway, R. I. et al. Global lake responses to climate change. Nat. Rev. Earth Environ. 1, 388–403 (2020).
Minhas, P. S., Ramos, T. B., Ben-Gal, A. & Pereira, L. S. Coping with salinity in irrigated agriculture: crop evapotranspiration and water management issues. Agric. Water Manag. 227, 105832 (2020).
Sultan, B., Defrance, D. & Iizumi, T. Evidence of crop production losses in West Africa due to historical global warming in two crop models. Sci. Rep. 9, 12834 (2019).
Elbeltagi, A. et al. Meteorological data fusion approach for modeling crop water productivity based on ensemble machine learning. Water 15, 30 (2023).
Malhi, G. S., Kaur, M. & Kaushik, P. Impact of climate change on agriculture and its mitigation strategies: A review. Sustainability 13, 1318 (2021).
Pande, C. B. et al. Forecasting of SPI and meteorological drought based on the artificial neural network and M5P model tree. Land 11, 2040 (2022).
Author information
Authors and Affiliations
Contributions
Ahmed Elbeltagi had the main idea of paper, Conceptualization, Data Collection, Writing – original draft, Data curation; Formal analysis; Investigation; Methodology; Software; Visualization; Supervision, Project administration, Writing – review & editing. Ali El Bilali: Methodology and developed plots. Aman Srivastava and Leena Khadke: Conceptualization; Investigation; Writing – original draft; Writing – review& editing. Xinchun Cao: Visualization; Supervision, Project administration, Investigation, Funding acquisition, Conceptualization. Ali Raza wrote introduction section. Ali Salem: Funding acquisition. Ahmed Elbeltagi described study area and wrote abstract and conclusion; All authors read and approved the final version for submission.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Elbeltagi, A., Srivastava, A., Cao, X. et al. An interpretable machine learning approach based on SHAP, Sobol and LIME values for precise estimation of daily soybean crop coefficients. Sci Rep 15, 36594 (2025). https://doi.org/10.1038/s41598-025-20386-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-20386-y
