
Abstract
Ship structural health monitoring (SHM) systems are essential for ensuring operational safety. Monitoring stress distribution is a critical function of such systems. Analysis of stress data collected by pressure sensors can enhance understanding of SHM performance and facilitate the prevention of structural failures. In this study, we propose a machine learning–based computational method to analyze the stress distribution of a crane ship. The method first employed extreme gradient boosting (XGBoost) to evaluate relationships among stress data from multiple pressure sensors, and then used multilayer perceptron (MLP) to construct regression models. For each pressure sensor, an optimal MLP regression model was established to infer its stress values from those of related sensors. These models demonstrated strong fitting performance on both training and independent test datasets. Furthermore, the method identified key pressure sensors whose measurements were particularly important for recovering stresses at most monitoring points. These findings improve interpretability of the method and provide insights into the mechanisms of the monitoring system. The robustness and rationality of the approach were further examined through ablation tests, confirming its effectiveness for ship SHM applications.
Similar content being viewed by others

Introduction
Ship structural health monitoring (SHM) systems are of critical importance, particularly for specialized vessels such as crane ships. Designing an SHM system that delivers reliable monitoring requires and decisions on numerous specifications, including sensor types, quantities, and placements, as well as data transfer, storage, and analysis techniques. However, the complexity of hull structures and the variability of marine environments present substantial challenges for system topology and data acquisition. The deployment of numerous sensors across wide areas can result in issues such as signal transmission delays, data conflicts, and insufficient real-time performance. Meanwhile, temperature fluctuations, vibration interference, and systematic errors may distort monitoring data, thereby compromising the accuracy of subsequent analyses. A well-functioning SHM system mitigates equipment failures and safety risks caused by structural deficiencies, ensuring personal safety, asset protection, ecological security, and effective vessel operation. One of the principal functions of an SHM system is to monitor stress distribution across the hull, which is achieved by deploying pressure sensors at key structural locations. Data from these sensors form the primary input for stress measurement and modeling, inform sensor placement strategies, and must be utilized for stress correction. In this study, feature attribution and ablation analyses are applied to identify sensors with disproportionately high influence and to quantify performance degradation under sensor loss, thereby providing evidence-based guidance for sensor prioritization, maintenance, and resilient operation. Stress values detected by pressure sensors are therefore considered essential data for analyzing and optimizing SHM systems.
Historically, pressure sensor outputs were displayed on screens, where crew members relied on empirical thresholds to assess ship structural health and trigger alarms. Advances in computer science have enabled more sophisticated data processing, allowing stress measurements to be exploited for deeper knowledge extraction. For example, Mincheul et al. estimated local ice loads from shear forces acting on transverse frames1, and Tak-Kee et al. employed a finite element model to derive influence coefficients for converting measured hull strains into local ice pressures2. In practice, however, the limited number of pressure sensors installed on vessels hinders comprehensive stress monitoring. Certain structural locations are also unsuitable for direct sensor deployment, leaving stress values at those points unmeasured. Furthermore, SHM systems must incorporate fault tolerance: if one pressure sensor fails, the system should recover the corresponding stress values. Stress recovery is closely related to these issues, as it enables reconstruction of full-field stress distributions and inference of stresses at unmonitored points. Several approaches have been proposed to address this problem, including modal methods3, Ko’s displacement theory4, and inverse finite element methods (iFEM)5,6,7,8,9,10,11. Among these, iFEM has gained wide application in stress recovery research. For example, Wei et al. developed an iFEM-based framework to construct a real-time digital twin of ship hull structures, where measured strains were assimilated online to reconstruct the full deformation field, subsequently visualized in a VR environment10. Similarly, Shen et al. employed a radial basis function approach to solve the inverse prediction problem and optimized sensor placement schemes to support SHM11.
In recent years, artificial intelligence (AI) algorithms, particularly machine learning (ML) and deep learning (DL), have opened new avenues for addressing the stress recovery problem. Hassani et al. discussed the use of optimization algorithms in SHM and confirmed the role of AI in analyzing the large volumes of data generated by monitoring systems12. Karvelis et al. framed ship SHM as a classification problem and employed a discrete cosine transform combined with a deep neural network to construct a classification model13. Sun et al. developed a data-driven approach to recover the full-field stress distribution in ship hull structures14 and later designed an end-to-end DL method for reconstructing full-field stress distributions15. Although these methods achieved strong performance, they did not identify the key factors underlying stress recovery. Such approaches are useful tools for reconstructing stress distributions but provide limited guidance for solving essential SHM problems, including optimal pressure sensor deployment and identification of the most critical monitoring points. This limitation reduces their capacity to advance fundamental understanding in ship engineering and support its development. Similar issues are evident in other SHM contexts, such as the connector structures of offshore platforms16 and the Shenzhen Bay stadium17. Current research tends to emphasize developing powerful computational techniques rather than uncovering the essence of the problem. ML and DL algorithms are highly effective in prediction and regression tasks across diverse fields, largely due to their ability to analyze large-scale datasets and extract meaningful patterns. However, these algorithms cannot address all challenges. Most ML and DL models operate as black boxes, relying on complex iterative processes that limit interpretability and obscure the essential information underlying a problem. Designing efficient computational methods based on ML and DL is valuable, but uncovering the mechanisms behind the problem with the aid of these algorithms is equally important, particularly in fields where theoretical development is critical. For stress recovery, ML and DL can serve as excellent tools, but extracting the underlying principles of the problem is essential for guiding the design of more powerful and resilient SHM systems. Few studies, however, have addressed this aspect.
In this study, we propose an ML-based computational approach to analyze stress distribution in ships. The contributions are twofold. First, we constructed optimal regression models to infer stress at monitoring points using ML algorithms. This contribution is comparable to those reported in previous ML- and DL-based studies. Second, we extracted key monitoring points for the entire system by analyzing the components of the optimal regression models, thereby enhancing the interpretability of the method. To our knowledge, this aspect has received little attention in prior research. Stress data were collected from a crane ship to build one training dataset and one independent test dataset. In the training dataset, stress values measured by a given pressure sensor were treated as the target, while stress values from other sensors served as explanatory variables. We adopted extreme gradient boosting (XGBoost)18, a powerful feature selection algorithm, to evaluate the relationships between targets and variables and to generate feature rankings. Incremental feature selection (IFS)19, incorporating a multilayer perceptron (MLP) as the regression algorithm, was then applied to the ranked features. An optimal regression model was constructed for each pressure sensor, enabling inference of its stress values based on readings from related sensors. These models achieved high performance on both training and independent test datasets. Moreover, we identified the key pressure sensors in the monitoring system, offering new insights into the mechanisms underlying stress distributions measured by SHM systems.
Materials and methods
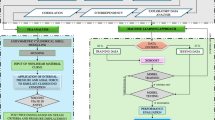
In this study, we designed a ML-based method for analyzing stress values on a crane ship. The objectives were twofold: (1) to construct a regression model for each pressure sensor to infer its stress values, and (2) to identify the essential pressure sensors of the ship SHM system. The overall workflow is illustrated in Fig. 1 and comprises four stages. In the first stage, stress data were collected from a crane ship, and preprocessing was performed to construct two well-defined datasets: a training dataset and an independent test dataset. In the second stage, each pressure sensor was treated in turn as a target feature, while the remaining sensors served as explanatory variables. For each target feature, an optimal regression model was built from these variables. XGBoost was adopted to evaluate the relationships between the target feature and the variables, yielding a ranked feature list that ordered variables by decreasing importance. In the third stage, each feature list was analyzed using IFS, with MLP regression models constructed and evaluated across all possible feature subsets. This process produced the optimal regression model and optimal feature subset for each target. Finally, in the fourth stage, the optimal models were further analyzed to extract feasible models for each target. Intersection analysis of the key features from these feasible models enabled the identification of essential features (pressure sensors) that are most critical for monitoring stress in the crane ship. Detailed descriptions of each step are provided below.

Flowchart to show the computational method. The method contains four stages. In the first stage, stress value data is collected from a crane ship, which is preprocessed to generate one training dataset and one independent test dataset. In the second stage, XGBoost is adopted to yield 27 feature lists. The incremental feature selection method is used in the third stage for analyzing the feature lists, yielding the optimal models and features. In the last stage, we further extract the feasible models for different target features and analyze the key features of these models to extract essential features and corresponding pressure sensors.
Dataset and problem description
Stress data were retrieved from a 1600-ton crane ship, “Zhongtian 9” (Fig. 2). The vessel is equipped with 27 identical pressure sensors, deployed in four monitoring areas. Specifically, four sensors were installed beneath the main deck, while 23 were installed at the ship bottom—five at midship and nine each at the port and starboard sides. The distribution and identifiers of these sensors are summarized in Table 1.

Picture of the crane ship “Zhongtian 9”.
Stress values were collected on March 3, 2023, yielding 65,535 data records that included monitoring time, sensor identifier, and stress value. These records were first grouped by sensor. Each sensor captured 2,427 or 2,428 values at different time points. Because stress values recorded by a sensor within a short interval were highly similar, homogenization could occur if all values were retained. To mitigate this, a sampling interval of five minutes was adopted. Accordingly, each sensor contributed 53 stress values at different time points. The selected values from all 27 sensors were arranged into a \(\:53\times\:27\) matrix, denoted by \(\:M\). Each row of \(\:M\) indicated the stress values of 27 sensors at one monitoring time, whereas each column corresponded to stress values detected by a single sensor across 53 time points.
In this formulation, each row of \(\:M\) was treated as a sample and each column as a feature. The system therefore consisted of 53 samples, \(\:{s}_{1},{s}_{2},\cdots\:,{s}_{53}\), each described by 27 features, \(\:{F}_{1},{F}_{2},\cdots\:,{F}_{27}\). The aim was to model the relationships among features by constructing a regression model for each feature using the others as explanatory variables. For each feature \(\:{F}_{k}\), a regression model \(\:{RM}_{k}\) was defined by the following optimization problem:
where \(\:\widehat{{F}_{k}}\) denotes the predicted value of \(\:{F}_{k}\) and the norm \(\:||{F}_{k}-\widehat{{F}_{k}}||\) measures the discrepancy between observed and predicted values. These models were trained on the dataset \(\:M\), which was designated as the training dataset.
To fully evaluate the regression models, an independent test dataset was constructed. Twelve monitoring time points not included in the training dataset were randomly selected from the original 65,535 records. The stress values of the 27 sensors at these time points formed the independent test dataset, organized into another matrix denoted as \(\:M^{\prime}\).
Extreme gradient boosting
In this study, we adopted XGBoost to assess relationships among features (pressure sensors). XGBoost is a classic and robust feature selection algorithm18 with broad applications in analyzing complex systems20,21,22,23,24,25,26,27.
XGBoost was originally designed for classification and regression tasks. It is based on a gradient boosting framework that enhances predictive performance by integrating multiple decision trees. Compared with traditional methods, XGBoost incorporates regularization, parallel computing, and automatic handling of missing values, thereby improving efficiency and reducing overfitting. It is particularly effective for large-scale, high-dimensional data. As a tree ensemble method, XGBoost builds additive functions in which the outputs of successive trees are aggregated until a predefined number of trees is reached. Suppose that there are K decision trees. The prediction of XGBoost is defined as:
where \(\:{f}_{k}\left({x}_{i}\right)\) is the output of the k-th decision tree for input \(\:{x}_{i}\), which is the weight of one leaf in this tree. The loss function to optimize the ensemble is:
where \(\:l\left({y}_{i},{\widehat{y}}_{i}\right)\) is a differentiable convex loss function between prediction \(\:{\widehat{y}}_{i}\) and target \(\:{y}_{i}\). The regularization term is defined as \(\:{\Omega\:}\left({f}_{k}\right)=\gamma\:T+\frac{1}{2}\lambda\:{||w||}^{2}\) (\(\:T\) stands for the number of leaves in the k-th tree and \(\:w\) represents the weights of the leaves. The first term of the loss function measures prediction error, whereas the second controls model complexity to avoid overfitting.
XGBoost is built by iteratively adding a decision tree to the current ensemble tree model. Suppose the current ensemble tree model contains t–1 trees. To construct the t-th tree, XGBoost determines the weights of leaves of the new tree by solving the following optimization problem:
where \(\widehat{y}_{i_{(t-1)}}\) denotes the prediction of the ensemble before adding the t-th tree, and \(\:{f}_{t}\) is the output of the candidate new tree. The tree is built by repeatedly selecting the optimal splitting features and thresholds. Once constructed, the tree is added to the ensemble. This process repeats until the predefined number of trees is reached. Figure 3 illustrates this procedure.

Flowchart to show the addition of a new decision tree to the current ensemble tree model in XGBoost. The weights of leaves in the new decision tree are determined by solving an optimization problem. Then, the new decision tree is constructed by repeatedly selecting optimal feature for splitting and optimal splitting threshold.
Beyond its predictive capabilities, XGBoost can also be used for feature selection. Because XGBoost builds an ensemble of decision trees, the importance of a feature can be quantified by how frequently it is chosen to split nodes across all trees. Features that appear more frequently are considered more influential. Thus, XGBoost provides a ranked feature list based on feature importance.
In this study, XGBoost was employed for feature selection. Each of the 27 features was treated in turn as the target, with the remaining 26 provided as explanatory variables. This process produced a feature list for each target, in which the 26 variables were ranked by their relevance to the target feature. Since the 27 features correspond to stress values measured by 27 pressure sensors, this procedure enabled extraction of inter-sensor relationships, forming the basis for inferring stress values at one monitoring point from those at others. For a given feature \(\:{F}_{i}\), the feature list generated by XGBoost was denoted as \(\:{FL}_{i}\). The XGBoost package was obtained from https://xgboost.readthedocs.io/en/stable/ and executed using default parameters.
Incremental feature selection
XGBoost provides a ranking of feature importance but does not specify which features should be selected for modeling or analysis. To address this, we employed IFS19 to refine the feature lists. Suppose the feature list for target feature \(\:{F}_{i}\) is \(\:{FL}_{i}=[{c}_{1}^{i},{c}_{2}^{i},\cdots\:,{c}_{m}^{i}]\), where \(\:m\) is the number of explanatory features (\(\:m=26\) in this study). IFS constructs a series of feature subsets, each containing the top features in the ranked list. The j-th feature subset is defined as \(\:{FS}_{j}=\{{c}_{1}^{i},{c}_{2}^{i},\cdots\:,{c}_{j}^{i}\}\). For each subset, the samples are represented by the selected features, and a regression model is built using these features to predict the target. Model performance is evaluated using a metric such as the root mean square error (RMSE). The model with the best performance is selected as the optimal model, and the features in this model are designated as optimal features. These features are considered to have particularly strong relationships with the target, as they enable the most accurate inference of its values.
Multilayer perceptron
Within the IFS procedure, a regression model must be constructed for each feature subset. In this study, we employed a MLP to build regression models, as relationships among stress values from different pressure sensors may be nonlinear, and MLPs can capture such nonlinearities.
An MLP is a feedforward neural network composed of an input layer, one or more hidden layers, and an output layer. Information is transmitted between nodes through weighted connections, with nonlinear transformations introduced by activation functions. For an input vector \(\:{x}^{\left(0\right)}\), the transformation through the j-th hidden layer is:
where \(\:{x}^{\left(j\right)}\) is the output of the j-th hidden layer, \(\:{W}^{\left(j\right)}\) and \(\:{b}^{\left(j\right)}\) are the trainable weight matrix and bias in the j-th hidden layer, and \(\:\sigma\:\) is an activation function. If there are l hidden layers, the output layer processes the \(\:{x}^{\left(l\right)}\) using the following equation:
where \(\:\widehat{y}\) is the output of the MLP, \(\:{W}^{{\prime\:}}\) and \(\:{b}^{{\prime\:}}\) are the trainable weight matrix and bias in the output layer. To quantify regression performance, we adopted the widely used loss function for regression, RMSE loss, defined as:
where \(\:n\) is the number of samples, \(\:{y}_{i}\) and \(\:{\widehat{y}}_{i}\) are the observed and predicted values of the i-th sample, respectively. The RMSE loss reflects the degree of deviation between observed and predicted values. In this study, \(\:{y}_{i}\) corresponds to the stress measured by a target pressure sensor, and \(\:{\widehat{y}}_{i}\) to the predicted stress value. A smaller RMSE indicates better performance. Using this loss can help the MLP to extract optimal trainable parameters through the back propagation, which were implemented by Adam optimizer28.
We implemented an MLP with three hidden layers containing 64, 32, and 16 neurons, respectively. These configurations were selected after testing several alternatives and optimizing through grid search. ReLU was used as the activation function in all hidden layers.
Model performance
Multiple metrics were used to evaluate regression models. While RMSE (Eq. 7) served as the primary evaluation metric, we also employed mean absolute error (MAE) and the coefficient of determination \(\:{R}^{2}\) for a more comprehensive assessment:
where \(\:n\), \(\:{y}_{i}\), and \(\:{\widehat{y}}_{i}\) are same as those in Eq. 7, and \(\:\stackrel{-}{y}\) is the mean of the observed values. RMSE and MAE measure error magnitude, with smaller values indicating better performance. \(\:{R}^{2}\) reflects the proportion of variance explained by the model, with values closer to 1 indicating stronger predictive capability.
Results and discussion
Results of XGBoost
As illustrated in Fig. 1, XGBoost was first applied to analyze the relationships among features (pressure sensors). Using the training dataset organized in matrix \(\:M\), each feature (one column in \(\:M\)) was treated sequentially as the target, while the remaining features served as explanatory variables. XGBoost was then applied to produce a ranked feature list for each target. Because the dataset contained 27 features in \(\:M\), 27 feature lists were obtained and are provided in Table S1. In this table, each column corresponds to a feature list for one target feature, identified by the pressure sensor label. For example, the first column (excluding the “Rank” header) represents the feature list generated when BM1 was the target. In this case, the stress values from BP7 showed the closest relationship with BM1, as BP7 occupied the highest rank. MD1 and BP6 followed as the second- and third-ranked related features, respectively. These feature lists served as the basis for subsequent analyses using the IFS method.
Results of the IFS method
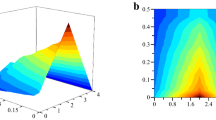
The IFS method was applied to each feature list. For every target, 26 MLP regression models were constructed using progressively larger subsets of top-ranked features. Their RMSE values are provided in Table S2. To facilitate interpretation, IFS curves were plotted for each target, with RMSE on the y-axis and the number of features used on the x-axis (Fig. 4).

IFS curves for 27 pressure sensors. (A) IFS curves for four pressure sensors under the main deck; (B) IFS curves for five pressure sensors at ship bottom (midship); (C) IFS curves for nine pressure sensors at ship bottom (port); (D) IFS curves for nine pressure sensors at ship bottom (starboard). The lowest RMSE and the corresponding number of features are marked on each curve.
For sensors located under the main deck, the IFS curves are shown in Fig. 4(A). The lowest RMSE values for MD1, MD2, MD3, and MD4 were 0.219, 0.358, 0.315, and 0.356, respectively. These results were achieved using 25, 19, 14, and 14 features. The corresponding feature subsets were selected as the optimal features, and the regression models built from them were designated as the optimal models. Table 2 lists the MAE and R2 values for these models, all of which exhibited MAE < 0.25 and R2 values approaching 1, confirming their strong predictive performance.
For the five midship sensors located at the ship bottom, the IFS curves are shown in Fig. 4(B). The lowest RMSE values for BM1, BM2, BM3, BM4, and BM5 were 0.449, 0.257, 0.286, 0.245, and 0.439, respectively, obtained using 15, 25, 6, 22, and 23 features. These models likewise demonstrated low MAE and high R2 values (Table 2), further validating their robustness.
For the nine portside bottom sensors, the IFS curves are shown in Fig. 4(C). The optimal models required 19, 7, 26, 17, 18, 8, 23, 6, and 20 features, yielding RMSE values of 0.347, 0.280, 0.659, 1.395, 0.289, 0.264, 0.480, 0.288, and 0.320, respectively. Except for BP4, which showed an RMSE above 1.0, all models achieved RMSE values below 0.7, indicating reliable performance. MAE and R2 values (Table 2) further confirmed the effectiveness of these models.
Finally, for the nine starboard bottom sensors, the IFS curves are presented in Fig. 4(D). The optimal models used 10, 24, 8, 13, 18, 7, 23, 14, and 22 features, and yielded RMSE values of 0.289, 0.270, 0.251, 0.198, 0.210, 0.219, 0.327, 0.250, and 0.287, all below 0.4. This consistently demonstrates high performance, which was corroborated by MAE and R2 values in Table 2.
In total, 27 optimal MLP regression models were obtained. The mean RMSE, MAE, and R2 values across all models were 0.354, 0.239, and 0.993, respectively (Table 2), highlighting the strong overall fitting ability of the models. Each optimal model enables inference of stress values at a specific monitoring point based on stress values recorded by a subset of highly related sensors.
Performance of the optimal models on the independent test dataset
As described in section "Dataset and problem description", an independent test dataset was constructed and organized in matrix \(\:M^{\prime}\). This dataset was used to evaluate the generalization performance of the optimal models obtained in section "Results of the IFS method". The results, expressed as RMSE, MAE, and R2, are summarized in Table 3. Overall, RMSE values increased for all 27 pressure sensors. Four sensors (BP1, BP7, MD4, and BM5) showed increases greater than one, with BP1 exhibiting the largest increase (8.784). For the remaining 23 sensors, the increase was below one. The average RMSE was 1.107, representing a 0.753 increase compared with the training dataset. Similar trends were observed for MAE. On three sensors (BP1, BP7, and BM5), MAE increased by more than one, while on the other 24 sensors, the increase was below one. The average MAE was 0.718, 0.479 higher than in the training dataset. For R2, values on eight sensors remained unchanged relative to the training dataset. The largest decrease was observed on BS5, where R2 dropped from 0.980 to 0.559. The average R2 was 0.958, which was 0.035 lower than that in the training dataset.
These results indicate that the optimal regression models exhibited reduced performance on the independent test dataset. However, the decrease was moderate, and the models still maintained acceptable accuracy, demonstrating their generalization capability.
Ablation tests
In the proposed computational method, XGBoost and MLP played central roles: XGBoost was used to assess feature importance, and MLP was used to construct regression models. To confirm that these choices were reasonable, ablation tests were conducted.
First, we replaced XGBoost with two widely used feature selection algorithms, LightGBM29 and CatBoost30. Feature lists generated by these algorithms were processed using the same pipeline as our method, producing 27 optimal regression models for each case. Their average performance on the training dataset is summarized in Table 4, together with the results of our original method for comparison. Using LightGBM yielded average RMSE, MAE, and R2 values of 0.407, 0.262, and 0.993, respectively, while CatBoost produced 0.406, 0.261, and 0.994. Compared with these, our method achieved an RMSE advantage of approximately 0.05 and an MAE advantage of about 0.02, while R2 values were similar across all three methods. On the independent test dataset, the differences were more pronounced. Models based on LightGBM showed substantially poorer generalization, with average RMSE and MAE values of 5.993 and 2.092, respectively, and an average R2 of 0.921. CatBoost performed better, with results closer to those of our method, but was still inferior: the average RMSE and MAE were approximately 0.6 and 0.2 higher, respectively. These findings indicate that using XGBoost provided better overall results than LightGBM or CatBoost, supporting its selection for this study.
Second, we replaced MLP with linear regression and least absolute shrinkage and selection operator (Lasso)31 as the regression algorithm. The corresponding computational methods were evaluated on both training and independent datasets, with results reported in Table 5. Compared with MLP, both linear regression and Lasso performed significantly worse. On average, RMSE increased by more than six and MAE by more than three. R2 was about 0.05 lower on the training dataset and about 0.1 lower on the independent dataset. These results demonstrate that MLP is more suitable for this task than linear regression or Lasso. The latter two algorithms can only capture linear relationships, whereas the stress values recorded by pressure sensors at different monitoring points are likely governed by nonlinear dependencies. Because MLP incorporates activation functions, it can model nonlinear relationships and therefore achieves superior performance.
Intersection analysis
As described in section "Results of the IFS method", 27 optimal MLP regression models were obtained, with their performance and numbers of selected features listed in Table 2. Some of these models required nearly all available features. For example, the optimal model for BM2 used the top 25 features out of 26, making it difficult to isolate the most influential features. To address this, further selection was carried out for the 20 optimal models that used more than ten features. By examining the IFS results in Table S2, we constructed 20 feasible MLP regression models that used fewer features than the corresponding optimal models, at the cost of only slightly higher RMSE values. The RMSE values and the number of selected features for these feasible models are listed in Table 6. For example, while the optimal model for BM2 required 25 features, the feasible model relied on only 8 features, a reduction of 17. The RMSE increased only modestly, from 0.257 to 0.349 (Δ = 0.092). This finding indicates that the 8 selected features were substantially more informative than the remaining 17 for predicting BM2 stress values. Similar observations were made for other feasible models. For the seven models that initially required ten or fewer features, no changes were made; they were retained as feasible models for consistency.
In total, 27 feasible models were obtained. Each model was capable of inferring the stress value at a specific monitoring point from a subset of related pressure sensors. At the system level, however, some sensors contributed disproportionately, being repeatedly selected across many feasible models. Such sensors should be considered essential for the SHM system, as they serve as key predictors of stresses at multiple monitoring points. To identify them, we counted the frequency with which each of the 27 pressure sensors appeared in feasible models (Fig. 5). The analysis revealed that BP8, BM2, BP3, BS6, and BM4 occupied the top five ranks, each being used to infer stresses at more than 11 monitoring points. BM2 and BM4, located on the bottom centerline (midship), likely owe their importance to their proximity to many other sensors (e.g., those at the port bottom). BP8, situated on the port side near L/4, is located in a region of high local stress. BP3 is positioned at the termination of a transverse framing member, a well-known site for stress concentration. BS6, located at frame 60, coincides with the on-bottom operating condition, where the bottom structure rests on seabed sediments and stress concentration occurs.

Bar chart to show the frequencies of 27 pressures for constructing feasible MLP regression models.
The locations of these five critical sensors (BP8, BM2, BP3, BS6, and BM4) are illustrated in Fig. 6. Their importance can be explained in terms of classic ship structural mechanics. For a longitudinally framed, double-bottom ship, the normal bending stress in hull plating can generally be expressed as:

Monitoring points of five key pressure sensors.
where \(\:M\) is the bending moment and \(\:t\) is the plate thickness.
According to this relation, larger bending moments M produces a larger stress σ. For rectangular thin plates used in hull structures, regardless of aspect ratio, the bending moment and stress attains its maximum at the midpoint of the long edge. From the standpoint of global longitudinal strength, the transverse section at the midpoint along the long-edge direction may therefore experience the peak stress. Therefore, on plating subjected to significant external loads, such as the upper deck and bottom shell, relatively large stresses tend to occur at the mid-length on the upper and lower surfaces of structure in way of the centerline, as well as at locations such as longitudinal primary members and structural discontinuities.
In addition, when the hull is in still water or waves, local hydrostatic and hydrodynamic pressures introduce transverse loads that may cause local deformation or even failure. Under China Classification Society (CCS) Rules, high local stresses are typically expected near one-quarter of the ship length from the bow and stern (\(\:L/4\) from amidship).
BM2 and BM4, located on the centerline at mid-length (\(\:L/2\)) and \(\:L/4\), respectively, are therefore prone to elevated stresses and were reinforced by the higher density of nearby sensors. BP8, positioned on the port side near \(\:L/4\), is also in a region of substantial local stress. BP3 is located at the termination of a transverse framing member, a typical stress concentration site. BS6, located at frame 60, aligns with the stress concentration region during on-bottom operations, where the bottom structure rests on seabed sediments. Finally, due to the longitudinal symmetry of the hull, stresses at port or starboard locations can often be inferred from symmetric counterparts (e.g., BP8, BP3, and BS6).
Taken together, the importance of BP8, BM2, BP3, BS6, and BM4 is consistent with structural mechanics and operational considerations. These findings confirm both the effectiveness and the interpretability of the proposed method, demonstrating its ability to uncover critical information underlying the monitoring system.
In this study, stress values at four monitoring areas were analyzed: main deck, ship bottom (midship), ship bottom (port), and ship bottom (starboard). For each area, we examined the features used to construct the feasible models. Upset graphs were plotted for each monitoring area (Fig. 7), showing that certain features were consistently related to multiple target pressure sensors. Features associated with more target sensors were evidently more important. To quantify this, we also calculated the frequency of each feature within each area (Fig. 8).

Upset graphs to show the intersections of features used to construct feasible regression models at four monitoring areas. (A) Upset graph for the monitoring area under the main deck; (B) Upset graph for the monitoring area at ship bottom (midship); (C) Upset graph for the monitoring area at ship bottom (port); (D) Upset graph for the monitoring area at ship bottom (starboard). The number for the black bar represents the number of features used to construct one feasible model. The number for the red bar denotes the number of features exactly used to construct some feasible regression models that are indicated by the dots and line below the bar.

Bar chart to show the frequencies of 27 pressures for constructing feasible MLP regression models at four monitoring areas. (A) Bar chart for the monitoring area under the main deck; (B) Bar chart for the monitoring area at ship bottom (midship); (C) Bar chart for the monitoring area at ship bottom (port); (D) Bar chart for the monitoring area at ship bottom (starboard).
From Fig. 7(A), two features, BS4 and BS8, were highly related to three target sensors beneath the main deck, as illustrated in Fig. 8(A). Because of structural constraints, relatively few sensors could be installed on the main deck, making stress recovery in this region dependent on sensors elsewhere. Structurally, the transverse bulkhead near BP8 and BS4 extends through multiple deck levels and ties the main deck to the bottom shell, thereby providing a load path that transmits stresses beneath the deck.
From Fig. 7(B), one feature (BP3, illustrated in Fig. 8(B)) was highly related to four target sensors at the midship bottom, and four features (BS6, BP8, BP4, and BM2, illustrated in Fig. 8(B)) were related to three target sensors each. Stresses in the bottom shell at midship are strongly coupled to those in the port and starboard side shells, as these regions lie in the same transverse section and are in close proximity. BP3 and BP4 are located near mid-length, where global longitudinal stresses peak, while BP8 and BS6 are positioned near frame 60 and approximately \(\:L/4\), where local stresses are pronounced. Since the midship bottom sensors are essentially co-located with these regions, they play a critical role in reconstructing the midship stress state.
From Fig. 7(C), three features (BM2, BP2, and BP8, illustrated in Fig. 8(C)) were highly related to six target sensors on the port-side bottom shell. Two additional features, BP9 and BS6 (Fig. 8(C)), were related to five target sensors. BP2, BP8, and BP9 are key monitoring points on the port bottom shell. BP8 and BP9, in particular, lie beneath the ship’s deck crane; when the crane operates in on-bottom conditions, this region is subjected to elevated loads.
From Fig. 7(D), one feature (BM4, illustrated in Fig. 8(D)) was related to six target sensors on the starboard bottom. Three additional features (BM2, MD1, and MD4, illustrated in Fig. 8(D)) were related to five target sensors each. MD1 and MD4 are located on the starboard main deck. Since the main deck and bottom shell form the primary load-bearing structure under hull-girder bending, stresses on the main deck provide a useful reference for inferring bottom-shell stresses. BM4 and BM2 are located at mid-length and approximately L/4, respectively, consistent with locations of high bending and local stresses.
Taken together, these findings show that many of the pressure sensors highlighted in the area-level analyses overlap with those identified as essential for the entire monitoring system. Their consistent selection demonstrates the effectiveness and interpretability of the proposed method. These key sensors should be prioritized for careful maintenance to ensure the reliable operation of the SHM system.
Limitations
This study proposed a ML method to analyze the stress distribution of a ship. A regression model was constructed for each pressure sensor, and several key sensors were identified. However, certain limitations remain. First, the dataset used in this study cannot fully represent the stress distribution of the crane ship. All stress values were collected on a single day, and the five-minute sampling interval was not sufficiently rigorous to capture the full variability of stress states. Second, some regression models (e.g., the model for BP1) showed risks of overfitting, indicating that the proposed method can be further improved. Techniques such as dropout or additional forms of regularization could help mitigate this issue. Future work will address these limitations by collecting stress data across longer time spans and under varied operating conditions, and by incorporating advanced algorithms and improved techniques to develop more practical and robust methods.
Conclusions
This study developed a ML–based computational method to analyze stress distribution in a ship. Stress data collected from a crane ship were used to evaluate the utility of the approach. For each pressure sensor, an optimal MLP regression model was constructed to infer its stress values from those recorded by other related sensors. All models demonstrated strong fitting performance. In addition, the proposed method identified several key sensors that play central roles within the monitoring system. These findings provide new insights into the mechanisms underlying stress monitoring and offer an interpretable framework for sensor prioritization. Overall, the proposed method presents a novel approach for analyzing stress data and has the potential to enhance the performance and reliability of ship SHM systems.
Data availability
The data is available upon request. Please contact Dr. Ji Zeng (zengji@shmtu.edu.cn).
References
Jeon, M. et al. Estimation of local ice load by analyzing shear strain data from the IBRV araon’s 2016 Arctic voyage. Int. J. Naval Archit. Ocean. Eng. 10 (3), 421–425 (2018).
Lee, T. K. et al. Field measurement of local ice pressures on the ARAON in the Beaufort sea. Int. J. Naval Archit. Ocean. Eng. 6 (4), 788–799 (2014).
Foss, G. & Haugse, E. Using modal test results to develop strain to displacement transformations. in Proceedings of the 13th international modal analysis conference. (1995).
Ko, W. L., Richards, W. L. & Tran, V. T. Displacement theories for in-flight deformed shape predictions of aerospace structures. (2007).
Li, M. et al. Structural health monitoring of an offshore wind turbine tower using iFEM methodology. Ocean Eng. 204, 107291 (2020).
Shkarayev, S., Krashantisa, R. & Tessler, A. An inverse interpolation method utilizing in-flight strain measurements for determining loads and structural response of aerospace vehicles. (2004).
Kefal, A. & Oterkus, E. Displacement and stress monitoring of a chemical tanker based on inverse finite element method. Ocean Eng. 112, 33–46 (2016).
Oboe, D., Sbarufatti, C. & Giglio, M. Physics-based strain pre-extrapolation technique for inverse finite element method. Mech. Syst. Signal Process. 177, 109167 (2022).
Kefal, A. et al. Three dimensional shape and stress monitoring of bulk carriers based on iFEM methodology. Ocean Eng. 147, 256–267 (2018).
Wei, P. et al. Real-time digital twin of ship structure deformation field based on the inverse finite element method. J. Mar. Sci. Eng. 12 (2), 257 (2024).
Li, S., Coraddu, A. & Brennan, F. A framework for optimal sensor placement to support structural health monitoring. J. Mar. Sci. Eng. 10 (12), 1819 (2022).
Hassani, S. & Dackermann, U. A systematic review of optimization algorithms for structural health monitoring and optimal sensor placement. Sensors 23 (6), 3293 (2023).
Karvelis, P. et al. Deep machine learning for structural health monitoring on ship hulls using acoustic emission method. Ships Offshore Struct. 16 (4), 440–448 (2021).
Sun, C. et al. A data-driven approach to full-field stress reconstruction of ship hull structure using deep learning. Eng. Appl. Artif. Intell. 133, 108414 (2024).
Sun, C. & Chen, Z. End-to-end deep learning method to reconstruct full-field stress distribution for ship hull structure with stress concentrations. Ocean Eng. 313, 119431 (2024).
Zhang, T. et al. Reconstructing the global stress of marine structures based on artificial-intelligence-generated content. Appl. Sci. 13 (14), 8196 (2023).
Lu, W. et al. Structural response Estimation method based on particle swarm optimisation/support vector machine and response correlation characteristics. Measurement 160, 107810 (2020).
Chen, T. & Guestrin, C. XGBoost: A Scalable Tree Boosting System. in The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery. (2016).
Liu, H. A. & Setiono, R. Incremental feature selection. Appl. Intell. 9 (3), 217–230 (1998).
Bao, Y. et al. Recognizing SARS-CoV-2 infection of nasopharyngeal tissue at the single-cell level by machine learning method. Mol. Immunol. 177, 44–61 (2025).
Liao, H. et al. Machine learning analysis of CD4 + T cell gene expression in diverse diseases: insights from Cancer, Metabolic, Respiratory, and digestive disorders. Cancer Genet. 290–291, 56–60 (2025).
Ma, Q. et al. Machine Learning-driven discovery of essential binding preference in Anti-CRISPR proteins. Proteom. – Clin. Appl. 19 (4), e70013 (2025).
Wu, W. et al. Machine learning based method for analyzing vibration and noise in large cruise ships. Plos One. 19 (7), e0307835 (2024).
Niazkar, M. et al. Applications of XGBoost in Water Resources Engineering: A Systematic Literature Review (Dec 2018–May 2023) Vol. 174, p. 105971 (Environmental Modelling & Software, 2024).
Chen, F. et al. Traffic accident severity prediction based on an enhanced MSCPO-XGBoost hybrid model. Sci. Rep. 15 (1), 25729 (2025).
Yao, S. et al. An interpretable XGBoost-based approach for Arctic navigation risk assessment. Risk Anal. 44 (2), 459–476 (2024).
Huang, M., Zhao, H. & Chen, Y. Research on SAR image quality evaluation method based on improved Harris Hawk optimization algorithm and XGBoost. Sci. Rep. 14 (1), 28364 (2024).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization, in 3rd International Conference on Learning Representations. Louisiana, USA. (2019).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural. Inf. Process. Syst. 30, 3146–3154 (2017).
Prokhorenkova, L. et al. CatBoost: unbiased boosting with categorical features. Adv. Neural. Inf. Process. Syst. 31 (2018).
Ranstam, J. & Cook, J. LASSO regression. J. Br. Surg. 105 (10), 1348–1348 (2018).
Author information
Authors and Affiliations
Contributions
J.Z. designed the research; B.J. and L.X. conducted the experiments; B.J., L.C. and Y.Z. analyzed the results. All authors have read and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jin, B., Zeng, J., Xu, L. et al. Machine learning–based method for analyzing stress distribution in a ship. Sci Rep 15, 39717 (2025). https://doi.org/10.1038/s41598-025-23356-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-23356-6
