
Abstract
Grout veins formed by advance grouting influence bulk stiffness and permeability. We present a width‑centric, image‑to‑mechanics framework that performs SES preprocessing (HDMR‑based multi‑feature fusion and a moment‑based sub‑pixel localizer), extracts graph‑theoretic centerlines, and estimates vein widths via TMSE-adaptive segmentation, which directly supports property estimation. On a lab‑scale image set, SES improves segmentation across seven backbones, and the resulting width/orientation statistics yield laboratory‑scale estimates of elastic modulus and permeability. Worst‑case errors are 8.83% (modulus) and 10.42% (permeability); these do not meet design‑grade tolerances. The method is therefore positioned for screening/monitoring under controlled conditions, not for design decisions. We clarify assumptions (local monotonic edge profile, 2‑D effective analysis), provide stopping criteria and parameters for reproducibility.
Similar content being viewed by others
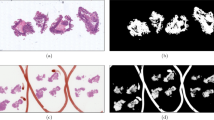
Introduction
Grouting is central to deformation control in underground works—metros, tunnels, and roadways—where the stability of the surrounding rock governs safety and serviceability1,2,3. Fracture grouting increases the self-support capacity of rock and soils4,5 and has demonstrated strong effectiveness in high-stress rock masses6,7,8 and cohesive soils9,10,11,12 by forming skeleton-like networks of grout veins12,13,14. This creates a heterogeneous composite material made up of rock, grout, and soil15. This composite material exhibits varying mechanical properties, which can make structural performance evaluation challenging16,17.
Prevailing assessments rely on macroscopic grout-compensation metrics (e.g., the volume–deformation ratio ξ = VSH/Vinj) to predict parameters18,19,20, but neglect the micromorphology of grout veins11,21,22. Two gaps follow: (i) the mechanical contribution of inclined veins remains unquantified, and (ii) permeability pathways in complex vein networks are unresolved. Similar limitations appear in performance prediction of fiber-reinforced composites23 and in remediation monitoring of contaminated soils24.
Existing sensing platforms—acoustic emission, NMR, and grout-diffusion visualization—capture distribution patterns25,26,27,28,29, yet fall short of (i) sub-millimeter morphological characterization and (ii) cross-scale correlations between microgeometry and bulk parameters. This motivates a vision-based analysis of vein microstructures.
Modern crack/microstructure segmentation has progressed rapidly with CNN and Transformer backbones such as U-Net30, FCN31, DeepLab32, and SegFormer33, alongside crack-specialized models (e.g., DeepCrack34, the CrackNet35 family, and RCF-based methods36). While these approaches excel on thin, filamentary cracks, grout veins are often thicker, more diffusive, and plume-like, creating a distribution shift that reduces recall unless the input representation is tailored. Benchmarking specifically on grout-vein imagery remains scarce, and principled representation enhancement—as opposed to proposing yet another architecture—has been underexplored.
To address this mismatch, we adopt a representation-first route. We introduce a structure-enhanced, subpixel-aided representation (SES) that couples HDMR37-based multi-feature reconstruction with gray-moment subpixel edge emphasis before feeding standard backbones (Deepcrack/FCN/DeepLab/SegFormer…), thereby improving the separability of diffuse boundaries and thickness variations30,31,32,33,38,39,40. From the resulting masks, a graph-theoretic centerline with TMSE -adaptive width extraction yields stable geometric statistics {hi, li, θi}, which are passed to a microstructure-aware mechanics model to estimate anisotropic modulus and permeability. We benchmark SES on a multi-source merged crack corpus spanning numerous public datasets and on an in-house laboratory image set to examine robustness and end-to-end consistency. Method assumptions and scope (e.g., locally monotonic gray transitions for subpixel localization; equivalent-parameter superposition for vein–matrix coupling), computational costs, and typical failure modes (specular highlights, highly textured backgrounds) are discussed where relevant. The method flowchart is shown in Fig. 1. Our images are acquired under laboratory conditions; Worst-case errors (7–10%) is insufficient for design-grade characterization. We therefore restrict claims to lab-scale feasibility.

Method flowchart.
Structure-enhanced and subpixel-aided representation (SES)
Grout veins differ fundamentally from the thin, filamentary cracks that dominate public benchmarks: they are typically thicker, exhibit diffuse/plume-like transitions, and often coexist with textured substrates and moisture-induced highlights (Fig. 2). These factors create broad transition bands and locally ambiguous edges, which in turn depress recall and destabilize width-related measurements when off-the-shelf networks are trained on crack datasets and applied directly to grout imagery. To address this distribution shift without introducing yet another architecture, we adopt a representation-first strategy. The proposed SES pipeline enhances class separability prior to inference by (i) reconstructing a structure-aware grayscale via HDMR37-based multi-feature fusion (section “HDMR-based multi-feature reconstruction”) that preserves chroma contrast, edge gradients, and directional textures, and (ii) sharpening boundary transitions with a gray-moment subpixel formulation (section “Subpixel structural edge segmentation methodology”) to localize edges within narrow transition bands. We then demonstrate SES is architecture-agnostic by benchmarking mainstream networks (section “Neural Segmentation evaluation of SES”). Finally, geometry needed by downstream mechanics—centerlines and widths—is obtained with a graph-theoretic extractor and TMSE-adaptive measurement (section “TMSE adaptive width measurement approach”).

Representative field photos from post-excavation faces.
HDMR-based multi-feature reconstruction
We use HDMR (High-Dimensional Model Reduction)37, a technique for simplifying complex models that reduces computational complexity while preserving key features of the image. This helps in enhancing the separability of grout veins in complex media.We reconstruct a structure-aware grayscale that enhances grout-vein separability in complex substrates (Fig. 3). Four complementary cues are fused:
-
(i)
chroma-contrast
-
(ii)
luminance
-
(iii)
edge strength from Sobel gradients
and
-
(iv)
multi-scale directional texture via a Gabor bank
where: \(x^{\prime} = x\cos \theta + y\sin \theta\), \(y^{\prime} = - x\sin \theta + y\cos \theta\). Stacking \(X = \left[ {x_{1} , \ldots ,x_{p} } \right]\) from (1)–(4) over scales/orientations yields a feature matrix \(X \in {\mathbb{R}}^{N \times p}.\)

Grayscale reconstruction algorithm.
To fuse cues, we use a second-order HDMR expansion for the grayscale target Y:
which captures first-order contributions and pairwise interactions while keeping parameters tractable. Prior grayscale conversions often compromise between contrast, edges, and texture in complex media41,42,43. Some variants address only part of these issues44, but none explicitly target diffuse grout veins.
Optimization to estimate HDMR37 coefficients. We estimate \(\left\{ {c_{0} ,c_{i} ,c_{ij} } \right\}\) by minimizing MSE47:
A genetic algorithm (selection–crossover–mutation) performs global search, followed by a short least-squares refinement. GA uses crossover Pc = 0.8, mutation Pm = 0.01, and early stopping on validation MSE (tolerance 10–6 or max 500 generations). The final reconstruction is
where \(T = 1 + p + \left( {\begin{array}{*{20}c} p \\ 2 \\ \end{array} } \right)\) enumerates singleton and pairwise terms per (5). Comparative results versus cv2.cvtColor/HSV45/fuzzy46/adaptive47 baselines are summarized in Fig. 4.

Comparison and visualization of gray-scale conversion methods.
Subpixel structural edge segmentation methodology
This is the standard assumption: at each candidate edge pixel, the intensity along the local edge normal is monotonic and can be modeled as a step. This is a common working assumption used in subpixel edge localization.
In a local coordinate x aligned with the edge normal,
Here \(0 \le s_{1} \le s_{1}^{\prime }\) is the (unknown) edge position inside the strip, and \(s_{1} ^{\prime}\) is the strip endpoint.
Treating the intensity as a two-point mixture at \(h_{1} { }\),\(h_{2}\) with proportions: \(p_{1} = \frac{{s_{1} }}{{s_{1}{\prime} }}\), \(p_{2} = \frac{{s_{1}^{\prime } - s_{1} }}{{s_{1}^{\prime } }}\),\(p_{1} + p_{2} = 1\), the probability moments are:
Hence,
Eliminating \(h_{1} { }\),\(h_{2}\) from Eq. (10) yields the subpixel edge coordinate inside the strip,
Pre-edge and normal. Apply Sobel to the SES grayscale, followed by non-maximum suppression and light hysteresis, to obtain candidate edge pixels and a coarse normal direction. We avoid any global x-axis assumption by rotating into the local normal frame at each candidate point (normal from the Sobel gradient), and applying Eqs. (8)–(11) there. The operational workflow shown in Fig. 5.

Schematic of subpixel edge segmentation of grout veins.
Default parameters (reproducible settings):
Strip endpoint / width: \(s_{1}^{\prime } = c\sigma_{g}\);
Edge-aware weighting: Tukey biweight with c = 4.685;
Gaussian prefilter for gradient stability: standard deviation \(\sigma_{g} = 0.5 - 1.5\) pixel (use 0.01 − 0.1 if needed);
Discretization n = 3. (use n = 4–10 in high accuracy situation);
Hysteresis thresholds (Sobel): low/high = 0.1/0.3 of in-strip gradient quantiles;
Monotonicity/unimodality test: Spearman ∣ρ∣ > 0.8 or Hartigan’s dip p > 0.05;
Saturation guard: if the saturated-pixel ratio in the strip exceeds τ = 10%, clip saturated samples and fall back to pixel-level localization.
Failure modes and fallbacks.
-
(1)
Saturation: if saturation ratio > τ, clip and fall back to pixel-level localization.
-
(2)
Non-monotone/non-unimodal: increase only in-strip smoothing: σ′ = min(2σ, 3), then re-evaluate.
-
(3)
Multimodal histogram: shrink half-width to preserve robustness.
Neural segmentation evaluation of SES
Datasets and training setup
We evaluate grout-vein segmentation under a distribution shift from thin cracks to thicker, diffusive, plume-like veins.
For training/validation, we adopt a merged crack corpus of 11,298 images from 12 available crack segmentation datasets48,49,50,51,52, resized to 448 × 448 pixels, including crack and non-crack negatives. A stratified split ensures proportional representation of each source.
The laboratory test set consists of 52 original photos; for robustness diagnosis we additionally generate 1,137 tiles (448 × 448) by patch tiling with random rotations, which are used for metric reporting.
We compare two input pipelines: the Baseline pipeline, using standard RGB images, and the SES pipeline, which uses the SES-enhanced grayscale image (replicated into three channels for compatibility). Both pipelines use identical preprocessing and network settings.
Seven representative image segmentation networks are employed for comparative experiments, including U-Net30, Attention U-Net40, PP-LiteSeg39, DeepLabV3 + 32, FCN31, DeepCrack34, SegFormer33. All models are trained with batch size = 1 and evaluated after 10 epochs. Binary predictions are obtained by applying softmax activation followed by argmax, with a threshold fixed at 0.5.
Evaluation metrics include mean Intersection over Union (mIoU; averaged across classes with zero-denominator cases excluded), Dice coefficient (foreground F1), Recall derived from global TP/FP/FN counts, Average Precision (AP) based on pixel-wise PR-AUC, and Inference Per Second (IPS), which measures throughput (images/s) under identical test conditions.
All experiments are conducted on the PyTorch platform using a workstation equipped with an AMD Threadripper 3970X CPU, 128 GB of RAM, and an NVIDIA GeForce GTX 1660 SUPER GPU with 6 GB memory.
Quantitative results
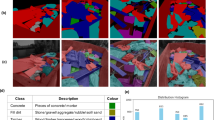
Figure 6a–e shows segmentation results for fine veins. Across fine‑scale vein patterns (Pic1–Pic2), SES consistently suppresses speckle‑like noise and preserves thin structures. Notably for DeepCrack, SES further reduces background noise in Pic1 and Pic2, yielding cleaner, more continuous responses along fine traces. For coarser veins (Pic2–Pic3), Baseline models (e.g., U‑Net, PP‑LiteSeg) exhibit contour loss and spurious responses, whereas SES recovers most coarse edges and attenuates noise. For mixed coarse–fine cases (Pic4), SES restores coarse boundaries and part of the internal textures, but predictions still emphasize edge bands, leaving portions of the broad interior as background. In complex backgrounds with diffuse veins (Pic5), SES’s enhancement is visually evident; however, for some CNNs (e.g., U‑Net, Attention U‑Net) a small amount of extra texture‑like activation can appear—consistent with SES amplifying low‑contrast structures that resemble the target. These behaviors are plausibly linked to the training data being crack‑centric (thin, high‑contrast structures); performance on broad, diffuse veins would further benefit from a specialized vein dataset.


Segmentation results using different models on Baseline and SES. (a) Input image. (b) U-Net. (c) Attention U-Net. (d) PP-LiteSeg. (e) Ground truth. (f) DeepLabV3+. (g) DeepCrack. (h) FCN. (i) SegFormer.
Adding a crack-specialized SOTA (DeepCrack) strengthens the baseline comparison.Following best practice for fair comparisons with crack-oriented methods, we include DeepCrack. On this strong baseline, SES still provides clear gains in structure fidelity: mIoU rises from 0.7405 to 0.7911 (+ 0.0506), Dice from 0.8139 to 0.8820 (+ 0.0681), and AP from 0.5762 to 0.7721 (+ 0.1959) with a modest trade-off in Recall (0.7851 → 0.7668, − 0.0183). This pattern—higher overlap/precision with slightly more conservative coverage—is consistent with SES’s noise suppression and boundary sharpening effects.
Aggregate quantitative trends (Table 1; Fig. 7).

Performance comparison of segmentation models based on mIoU, Recall, Dice, AP, and IPS metrics.
Across all seven models:
mIoU improves for every backbone with SES (mean + 0.0841, max + 0.1462 on PP‑LiteSeg).
Dice also improves for every backbone (mean + 0.1012, max + 0.1724 on PP‑LiteSeg).
AP increases in 5/7 models (mean + 0.0903), with the largest jumps on FCN (+ 0.2001) and DeepCrack (+ 0.1959).
Recall shows a model‑dependent trade‑off: large gains for U‑Net (+ 0.4582), PP‑LiteSeg (+ 0.4041), and DeepLabV3 + (+ 0.2050), but slight drops for FCN (− 0.0146), DeepCrack (− 0.0183), and SegFormer (− 0.1189). In these latter cases, SES appears to favor precision and boundary accuracy over aggressive coverage—consistent with the visual suppression of background noise.
Taken together, SES shifts models toward higher‑quality overlaps (mIoU/Dice) and stronger precision–recall curves (AP) while inducing a modest recall reduction in a subset of architectures.
Runtime considerations.IPS in Table 1 reflects segmentation inference only; SES adds a constant 0.13 s per image for preprocessing. End-to-end throughput therefore decreases proportionally more for fast models. For example, PP-LiteSeg drops from 2.78 IPS (segmentation-only) to approximately 2.04 IPS end-to-end (− 26.6%), and FCN from 1.32 IPS to roughly 1.13 IPS (− 14.6%). The effect is negligible for heavy models (e.g., DeepCrack ≈ 0.04IPS, < 1% relative change). This constant overhead can be amortized or fused in deployment via batching or hardware-accelerated preprocessing.
Relation to subpixel localization.Recent subpixel localization methods aim to refine centerlines/edges at sub-pixel precision and are typically applied after detection/segmentation. By contrast, SES is an input-level structure enhancer that improves the quality of the segmentation probability maps. The two are therefore complementary: SES can feed cleaner, sharper logits to a downstream subpixel localizer, potentially yielding further gains in geometric accuracy. A comprehensive integration with subpixel refinement is orthogonal to our focus here and remains promising future work.
Take-home message.SES improves structural fidelity across a wide range of backbones—including the crack-specific DeepCrack—raising mIoU/Dice universally and boosting AP in the majority of models. Where recall decreases, it is typically accompanied by marked gains in AP and overlap metrics, indicating a shift toward more precise, less noisy predictions. These results demonstrate that SES is a broadly applicable, architecture-agnostic enhancer that remains effective even when paired with state-of-the-art crack detectors.
Graph-theoretic centerline extraction
The skeletonization stage converts each skeletal pixel into a graph vertex and builds an 8-connected, undirected graph representation (Eq. (12)).
Let V = {p} be the coordinate set of skeletal pixels. The edge set is
where r = 1 corresponds to direct 4-connected neighbors, and r = \(\sqrt 2\) includes diagonals under the 8-neighborhood constraint. Figure 8 schematically illustrates edge formation.

Schematic of the centerline search in the graph.
A two-phase refinement is applied to suppress pseudo-redundant bifurcations: (1) DFS-based consolidation merges 8-neighboring bifurcation nodes to preserve only functionally significant junctions. (2) Manhattan-distance prioritization selects geometrically representative nodes when multiple candidates remain. The selection mechanism is illustrated in Figs. 9 and 10.

Illustration of branch point labeling.

Pruning of the micro-pulse centerline.
After refinement, a Breadth-First Search (BFS) protocol enumerates branches in four steps: (1) Initialize branch origins at unvisited neighbors of bifurcation nodes. (2) Propagate BFS until a terminal node is reached (endpoint or new bifurcation). (3) Prioritize connections belonging to the main structural backbone. (4) Apply length thresholds and topological-coherence checks to filter out secondary or spurious branches.
T MSE adaptive width measurement approach
TMSE stands for Total Mean Squared Error. It is used to determine the optimal measurement scale for vein width estimation. By adjusting the TMSE threshold, we can balance between capturing fine details and minimizing computational cost.
Width measurement methodology
Accurate vein-width estimation requires both continuity and sequential ordering of centerline points. The undirected graph G = (V, E) from section “Subpixel structural edge segmentation methodology”, constructed on skeleton pixels, is used to determine ordered centerline coordinates {c1, c2, ⋯ , cn} for each branch. Graph edges (ci-cj) ∈ E are formed when ||ci−cj||≤ r using a K-nearest neighbor (KNN) search.
For each center point ci, a decentralized covariance matrix A is computed from its k nearest neighbors \(\left\{ {c_{i}^{1} , \cdots ,c_{i}^{k} } \right\}\) within the branch:
Performing singular value decomposition (SVD) A = UΣVT yields eigenvectors of principal directions. The eigenvector associated with the smallest singular value defines the local normal vector nv (y-axis), while the orthogonal eigenvector nh (x-axis) defines the tangential direction (Fig. 11).

Schematic diagram of width computation.
Dynamic search zones are generated along nv at each ci, with search range Δh = h1−h2 and bandwidth www. Boundary points are identified as the closest pixels intersecting the normal axis in both directions, and interfering signals are discarded if adjacent vein pixels exceed the zone limits. The vein width is then calculated as \(\left| {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\rightharpoonup}$}}{{AB}} } \right|\), where A and B are the detected boundary points.
Comparative analysis of methods
To evaluate performance, representative regions containing bifurcations and strong width variations (Fig. 12a, b) were measured using four methods: (1) ESD: Euclidean Shortest Distance53. (2) OP: Orthogonal Projection54. (3) OB: OrthoBoundary55.

Visualization of width measurement results obtained by different algorithms.
All methods used identical preprocessing with matched parameters. Figure 12c–f shows annotated results.
In bifurcation zones, the OP and OB methods exhibited 8.7% and 14.5% of measurements exceeding the true edge boundaries, respectively. In contrast, the ESD method showed 31.1% of measurements as either duplicated or missing. In comparison, the proposed method maintained the measurement within edge boundaries and provided the most reliable quantification.
Adaptive optimization strategy for width measurement
Conventional width measurement uses a fixed sampling interval k for center points, which can be suboptimal: In uniform-width regions, smaller k yields negligible accuracy gain but higher computational cost. In heterogeneous regions, large k risks undersampling and missing local variations.
We propose a TMSE-driven adaptive segmentation:
-
(1)
Measurement acquisition—Record width values \(W_{j1} ,W_{j2} , \cdots ,W_{{jn_{i} }}\) for each segment j.
-
(2)
Fluctuation quantification—Compute segmental MSE:
$$MSE_{j} = 1/n_{j} \mathop \sum \limits_{i = 1}^{{n_{j} }} \left( {W_{ji} - \overline{W}_{j} } \right)^{2} ,\;\overline{W}_{j} = \frac{1}{{n_{j} }}\mathop \sum \limits_{i = 1}^{{n_{j} }} W_{ji}$$(14) -
(1)
Threshold detection—Apply a global threshold TMSE; mark segments with cumulative MSE > TMSE as abrupt-change zones.
-
(2)
Feature extraction—For each partition, compute mean width \(\overline{W}_{j}\) and segment length Lj as feature descriptors.
As shown in Fig. 13, low TMSE values (0.1–0.5) improve sensitivity to local anomalies, while higher TMSE values (> 1.0) reduce noise and segment fragmentation. This adaptivity balances local detail preservation with computational efficiency.

Impact of TMSE on width measurement.
Calculation method for parameters of heterogeneous composite structures
Reinforcement effect analysis of individual microstructure units
Because the available observations are planar photographs of the excavation face, we formulate an effective 2‑D problem aimed at screening rather than design‑grade characterization. Extending to 3‑D would require volumetric vein mapping (e.g., ultrasound or radar/GPR) and a 3‑D homogenization framework; we outline this as future work. We adopt a conservative bonding assumption whereby the grout–matrix interface cohesion is comparable to that of the surrounding matrix, consistent with the skeleton-like vein network concept that enhances self-support. Where site measurements are available, interfacial parameters may be calibrated. The directional participation factors used to close the Voigt → Reuss mixture are empirical and are computed from image-derived geometry (length, width, orientation), serving as pragmatic weights rather than first-principles quantities.
Building on prior work that models grouted fractures as effective transversely isotropic media56, we adopt a directional parallel–series (Voigt → Reuss) closure for inclined grout veins to obtain axis-wise effective properties within a plane-strain compliance framework57,58. The orthogonal decomposition of a vein into vertical and horizontal projections provides the participation factors that drive the parallel (cross-section) and series (path) mixing steps59. This cell-based homogenization strategy is consistent with composite bounds and with directional reassembly schemes used in reinforced soil–pile systems59, and it extends naturally to steady Darcy permeability via the same closure60.
We work in the material principal axes \(\left( {X,Y,Z} \right)\), where \(X\) is horizontal, \(Y\) is vertical, and \(Z\) is out of plane. Under plane strain \(\left( {\varepsilon_{Z} = \gamma_{XZ} = \gamma_{YZ} = 0} \right)\), the in-plane compliance reads
with the usual reciprocity \(\nu_{ij} /E_{i} = \nu_{ji} /E_{j}\). Steady Darcy flow in the same axes is
or, equivalently, by the hydraulic compliance \({\text{R}}_{0} = {\text{K}}_{0}^{ - 1} = {\text{diag}}\left( {1/k_{X} ,1/k_{Y} } \right)\).
To close \({\text{S}}_{0}\) and \({\text{K}}_{0}\) for a single inclined vein inside a matrix cell of size \(l \times h\), we use a two-step Voigt → Reuss mixture written in a unified notation. Let the vein have length \(l_{g}\), width \(h_{g}\), and inclination \(\theta\). Define the directional participation factors
which quantify, respectively, the fraction of transverse cross-section (parallel/Voigt step) and the fraction of axial path (series/Reuss step) engaged by the vein’s projection in each principal direction. For any property \(P \in \left\{ {E,k} \right\}\) (Young’s modulus or permeability), the parallel → series closure along axis \(i \in \left\{ {X,Y} \right\}\) is
yielding directly \(E_{X} ,E_{Y} ,k_{X} ,k_{Y}\) once \(P_{s} ,P_{g}\) are set to the matrix and grout values, As shown in Fig. 14.

Schematic of the microstructural unit and its orthogonal decomposition.

Variation of \(E_{y}^{i}\) and \(k_{y}^{i}\) with the discretization index i under different TMSE. (a) Eyi vs. i, (b) kyi vs. i thresholds.
Poisson ratios are obtained consistently by weighting compliances along the loading axis. For the vertical axis \(Y\),
and reciprocity gives \(\nu_{XY} = \left( {E_{X} /E_{Y} } \right)\nu_{YX}\). Out-of-plane parameters used in the plane-strain reduction can be taken as \(E_{Z} \simeq E_{s}\) (or from a first-stage homogenization) and \(\nu_{XZ} \simeq \nu_{YZ} \simeq \nu_{s}\). An in-plane shear modulus \(G_{XY}\) can be estimated with the same parallel → series template by substituting \(P \to G\); in practice, using participation factors averaged between the two axes provides a consistent first-order closure.
This closure recovers the matrix in the limits \(h_{g} \to 0\) or \(l_{g} \to\) 0, and reproduces the expected orientation limits: \(\theta = 0^{ \circ }\) increases \(Y\)-stiffness and \(\theta = 90^{ \circ }\) increases \(X\)-stiffness; identical phase properties collapse to the matrix.
Analysis of multi-microstructure coupling effects
Multi-microstructure coupling model
The composite is discretized into a set of vein units with geometry \(\left( {l_{g}^{i} ,h_{g}^{i} ,\theta_{i} } \right)\). At step \(i\), the effective matrix for mixing is taken as the current effective composite (consistent with multiscale superposition). Let \(e_{0}\) denote the initial void ratio. Assuming mass conservation—reinforcement volume equals pore-volume reduction—the void ratio after inserting the first \(i\) veins with total area \(\mathop \sum \limits_{j = 1}^{i} h_{g}^{j} l_{g}^{j}\) reads
Axis-wise effective moduli and permeabilities are first computed by the unified parallel → series closure (section “Reinforcement effect analysis of individual microstructure units”) with the current effective properties used as matrix inputs \(\left( {E_{s} ,k_{s} ,\nu_{s} } \right)\). Empirical porosity–property couplings are then applied multiplicatively:
Poisson ratios are updated by the same compliance-weighting and reciprocity as in Sect. 3.1.1 using the step-\(i\) axis-wise moduli. Repeating this procedure over all units yields the macroscopic properties while consistently accounting for (i) geometry and orientation through \(\alpha_{i} ,\beta_{i}\), (ii) phase contrast through \(P_{s} ,P_{g}\), and (iii) pore evolution through \(e_{i}\).
Analysis of structural discretization accuracy
To investigate the effects of discretization, the composite material is divided into microstructural units, with characteristic dimensions—width \(\left\{ {h_{g}^{i} ,l_{g}^{i} ,\theta_{i} } \right\}\),which extracted under varying TMSE thresholds (as detailed in section “TMSE adaptive width measurement approach”). A representative reinforcement zone of h × l = 0.1 m × 0.1 m is considered. Using the material parameters listed in Table 2, the sequences of \(E_{y}^{i}\) and \(k_{y}^{i}\) are computed, and their convergence is studied as the number of units increases. The results are summarized in Fig. 15 and Table 3.
Through the analysis of the results under different TMSE thresholds, it is observed that lower TMSE values (i.e., finer discretization) tend to overestimate \(E_{y}^{i}\) and underestimate \(k_{y}^{i}\), with the accuracy difference between \(E_{y}^{i}\) and \(k_{y}^{i}\) being relatively small, typically ranging from 0.84% to 1.85%. When the TMSE is reduced from 2.0 to 0.1, the number of units increases from 5 to 27, resulting in a 17.56% improvement in the accuracy of \(E_{y}^{i}\) and an 8.14% increase in the accuracy of \(k_{y}^{i}\). However, the accuracy improvements diminish once the number of units exceeds 20, with further enhancements being less than 3%. Therefore, it is recommended to use smaller TMSE values (below 0.5) to effectively reduce discretization errors, keeping them below 3% while maintaining computational stability.
Method validation
Fracture grouting test system
To validate the proposed methodology, we designed and constructed a split-grouting test system (Fig. 16). The platform comprises two integrated modules.

Experimental setup and procedure. (a) Apparatus overview, (b) Assembly and inspection, (b) Filling the soil to be grouted, (c) Grouting, (d) Excavation/exposure.
-
(1)
Visual testing module. A steel chamber (800 mm × 100 mm × 650 mm) with:
-
(a)
10 mm-thick tempered glass observation windows on both sides;
-
(b)
top-mounted universal joints with sensor ports;
-
(c)
a 200 kN reaction frame coupled to hydraulic actuators;
-
(d)
an M16 bolt-connected steel stabilization frame. Ethylene propylene diene monomer (EPDM) gaskets and aluminum-foil adhesive are used to ensure airtight sealing at joints.
-
(a)
-
(2)
Grouting module. A pneumatic–hydraulic subsystem including:
-
(a)
a 0.7 MPa air compressor with a 0–1 MPa pressure regulator;
-
(b)
a 4 MPa-rated grout reservoir with precision manometer;
-
(c)
Φ10 mm high-pressure grout lines rated to 0.8 MPa;
-
(d)
a 700 rpm high-speed mixer. Rubber O-rings seal all pipeline connections. Injection nozzles are embedded 10 cm into the soil specimens.
-
(a)
Parameter measurement methodology
Triaxial compression tests
Triaxial compression tests were conducted using a TSZ automated triaxial system (Fig. 17). Specimens were prepared at a constant moisture content of 23% and tested under confining pressures of 100, 200, and 300 kPa. The protocol includes six steps: (a) weighing; (b) bagging; (c) compaction; (d) base placement; (e) specimen encapsulation; and (f) loading/pressurization. Two replicates per mixture ratio were tested.

Triaxial test procedure. (a) weighing, (b) bagging, (c) compaction, (d) base placement, (e) encapsulation, (f) pressurization.
Permeability tests
Permeability was measured using the setup in Fig. 18. The sequence was: (1) bottom-up pre-saturation at 30 kPa for 24 h; (2) application of a 200 kPa top pressure to establish a steady hydraulic gradient; (3) recording stabilized seepage volume (≥ 5000 mL); and (4) computing the coefficient of permeability from steady-flow Darcy relations. Under constant-head conditions, the coefficient k (cm/s) is obtained as
where Q is the collected volume (mL), L is the specimen height (cm), dh is the head difference (cm), t is the collection time (s), and A is the specimen cross-sectional area (cm2). Units are chosen such that k is reported in cm/s.

Schematic of permeability coefficient measurement.
Materials. Different strata were simulated using a kaolin–gypsum composite soil (mixture ratios and physical parameters in Table 4). The grout was a cement slurry (water–cement ratio 1:1) with a 2% iron-oxide tracer. Measured grout-vein properties were Eg = 12.7 GPa and kg = 2.3 × 10–11 m/s.
Test results
For each mixture ratio, two replicates were conducted with the TMSE threshold fixed at 0.1 for image-based geometric extraction of grout-vein morphology. Permeability was measured prior to disassembly for triaxial testing. Table 5 contrasts measured and calculated parameters after reinforcement, and Fig. 19 shows representative vein morphologies with width annotations.

Representative grout-vein morphologies and width annotations. (a) Mixture 1:0.25, (b) Mixture 1:1, (c) Mixture 1:4.
Across all six tests, the effective modulus errors remain at or below 8.83% (MAE ≈ 7.1%), with a small positive signed bias of about + 2.1% (over-prediction). The permeability coefficient errors are at or below 10.42% (MAE ≈ 5.5%), with a small negative signed bias of about –1.4% (under-prediction). Thus, 100% of test groups fall within ≤ 10.5% for ky and ≤ 8.9% for Ey, indicating that the image-to-mechanics pipeline achieves consistent accuracy under the laboratory configurations considered.
Error characterization. The error signs in Table 5 include both over- and under-predictions. This pattern is consistent with (i) local segmentation variability at dense bifurcations or diffuse plumes, which can slightly bias width statistics after TMSE partitioning; and (ii) hydraulic channeling during constant-head tests, which occasionally elevates the measured ky relative to equivalent-parameter predictions. Within the current setup, practical mitigations are (a) maintaining stable illumination and surface moisture to preserve monotonic gray transitions for subpixel localization, and (b) excluding a narrow margin near specimen boundaries in centerline/width extraction to reduce boundary-induced bias. Replicate reporting in Table 5 demonstrates that, under these controls, the deviations remain bounded and balanced without systematic drift across mixture ratios.
Discussion
Limitations and applicability
This study assumes a locally monotonic edge profile for sub-pixel localization and treats reinforcement as a 2-D effective problem derived from tunnel face images. Under strong texture or specular highlights, the sub-pixel step may be unreliable; we therefore perform monotonicity/unimodality checks and fall back to pixel-level edges in such regions. The mechanics closure is a first-order approximation without explicit 3-D geometry or interfacial laws; we adopt a conservative bonding assumption and recommend site-specific calibration when data permit.
Our results are laboratory-scale under controlled imaging. Worst-case errors (7–10%) are not design-grade; the method is intended for screening/monitoring until field-domain training (for segmentation baselines) and 3-D data are available.
Complexity and scalability
Let N be the number of pixels per image, p the number of fused feature channels, and \(T = 1 + p + \frac{{p\left( {p + 1} \right)}}{2}\) the number of second-order HDMR terms.
HDMR reconstruction (inference): O(NT).
GA-assisted coefficient estimation (one-time, sampled M ≪ N pixels): O(G⋅P⋅T⋅M), where G is the number of generations and P the population size; early stopping at ΔMSE < 10−6 over 30 generations or 500 generations max.
Sub-pixel localization: O(K⋅n) for K candidate edge points and strip discretization n (default n = 3).
Skeletonization and graph:O(∣V∣ + ∣E∣) on the skeleton, typically ∣V∣,∣E∣ ≪ N.
Width probing along normals: O(B⋅R), with B centerline samples and per-sample normal search range R.
Typical runtimes (illustrative, 448 × 448 images on our workstation).
SES preprocessing adds about 0.13 s/image (HDMR + sub-pixel), with a representative breakdown: HDMR 60–70 ms, sub-pixel 50–60 ms, and skeleton/width routines 10–20 ms. These stages are data-parallel and can be batched across tiles or frames. (Numbers are indicative and should be replaced by your measured medians/percentiles.)
Conclusions
We have demonstrated a width-centric SES → centerline → TMSE pipeline that links images to laboratory-scale estimates of stiffness and permeability. While segmentation and width accuracy improve across diverse backbones, the present error levels indicate utility for screening and monitoring rather than final design. Future work will emphasize field-domain datasets under complex textures and lighting, 3-D vein information, and interface-aware homogenization to close the gap to design-grade applications.
References
Zeng, L. et al. Measuring annular thickness of backfill grouting behind shield tunnel lining based on GPR monitoring and data mining. Autom. Constr. 150, 104811 (2023).
Xie, X., Zhai, J. & Zhou, B. Back-fill grouting quality evaluation of the shield tunnel using ground penetrating radar with bi-frequency back projection method. Autom. Constr. 121, 103435 (2021).
Yu, J., Zhang, Y., Li, D., Zheng, J. & Zhang, W. Analytical study of steady state seepage field in tunnels with localized water leakage under the effect of grouting circle. Tunn. Undergr. Space Technol. 150, 105854 (2024).
Zhang, J., Liu, L. & Li, Y. Mechanism and experiment of self-stress grouting reinforcement for fractured rock mass of underground engineering. Tunn. Undergr. Space Technol. 131, 104826 (2023).
Gu, S. T., Liu, J. T. & He, Q. C. Size-dependent effective elastic moduli of particulate composites with interfacial displacement and traction discontinuities. Int. J. Solids Struct. 51, 2283–2296 (2014).
Sakhno, I. & Sakhno, S. Numerical studies of floor heave mechanism and the effectiveness of grouting reinforcement of roadway in soft rock containing the mine water. Int. J. Rock. Mech. Min. Sci. 170, 105484 (2023).
Kang, H., Gao, F., Xu, G. & Ren, H. Mechanical behaviors of coal measures and ground control technologies for china’s deep coal mines - a review. J. Rock. Mech. Geotech. Eng. 15, 37–65 (2023).
Wang, M., Guo, G., Wang, X., Guo, Y. & Dao, V. Floor heave characteristics and control technology of the roadway driven in deep inclined-strata. Int. J. Min. Sci. Technol. 25, 267–273 (2015).
Lu, C. et al. Experimental study on the propagation characteristics of hydraulic fracture in clayey-silt sediments. Geofluids 2021, 6698649 (2021).
Feng, L., Huang, F., Wang, G., Huang, T. & Qian, Z. Experimental investigation on pneumatic pre-fracturing grouting in low-permeability soil. Tunn. Undergr. Space Technol. 131, 104798 (2023).
Reinforcement of clay soils through fracture grouting. Fluid Dyn. Mater. Process. 18, 1649–1665 (2022).
Komiya, K., Soga, K., Akagi, H., Jafari, M. R. & Bolton, M. D. Soil consolidation associated with grouting during shield tunnelling in soft clayey ground. Geotechnique 51, 835–846 (2001).
Meng, L., Han, L., Zhu, H., Dong, W. & Li, W. Study of the effects of compaction and split grouting on the structural strengthening characteristics of weakly cemented argillaceous rock masses. KSCE J. Civ. Eng. 26, 1754–1772 (2022).
Hao, Y. et al. Application of polymer split grouting technology in earthen dam: diffusion law and applicability. Constr. Build. Mater. 369, 130612 (2023).
Gu, L., Kumar, D., Unluer, C., Yang, E. H. & Monteiro, P. J. M. Investigation of non-uniform carbonation in strain-hardening Magnesia composite (SHMC) and its impacts on fiber-matrix interface and fiber-bridging properties. Cem. Concr. Compos. 153, 105726 (2024).
Chen, T. et al. Synergy between Fenton reagent and solid waste-based solidifying agents during the solidification/stabilization of lead(II) and arsenic(III) contaminated soils. J. Environ. Manage. 370, 122601 (2024).
Lei, J., Ma, Q., Xiao, H., Shu, H. & Wu, J. Sustainable stabilization/solidification of cu-contaminated seasonal frozen soil by epoxy resin: environmental risk assessment and engineering applicability. J. Environ. Chem. Eng. 12, 114460 (2024).
Masini, L., Rampello, S. & Soga, K. An approach to evaluate the efficiency of compensation grouting. J. Geotech. Geoenviron Eng. 140, 04014073 (2014).
Xu, X. H., Xiang, Z. C., Zou, J. F. & Wang, F. An improved approach to evaluate the compaction compensation grouting efficiency in sandy soils. Geomech. Eng. 20, 313–322 (2020).
Huang, H., Hua, Y., Zhang, D., Wang, L. & Yan, J. Recovery of longitudinal deformational performance of shield tunnel lining by soil grouting: A case study in Shanghai. Tunn. Undergr. Space Technol. 134, 104929 (2023).
Wang, X. et al. 2D discrete element simulation on the marine natural gas hydrate reservoir stimulation by splitting grouting. Gas Sci. Eng. 110, 204861 (2023).
Wang, X. et al. Diffusion mechanism of cement-based slurry in frozen and thawed fractured rock mass in alpine region. Constr. Build. Mater. 411, 134584 (2024).
Cai, Y., An, X., Zou, Q. & Yao, D. Damage behaviors of plain-woven fiber reinforced composites with different orientations: from mesoscopic evolution to macroscopic performance prediction. Compos. Struct. 324, 117569 (2023).
Lee, S. H., Park, I. W., Lee, S. S. & Lee, K. K. Evaluation of intensive remediation using simulation-optimization modeling based on long-term monitoring at a DNAPL contaminated site. J. Environ. Manage. 370, 122699 (2024).
Weng, L., Wu, Z., Zhang, S., Liu, Q. & Chu, Z. Real-time characterization of the grouting diffusion process in fractured sandstone based on the low-field nuclear magnetic resonance technique. Int. J. Rock. Mech. Min. Sci. 152, 105060 (2022).
Wang, S. et al. Characteristic analysis of cement grouted asphalt mixture cracking based on acoustic emission. Constr. Build. Mater. 375, 130927 (2023).
Yang, P., Liu, Y., Gao, S. & Xue, S. Experimental investigation on the diffusion of carbon fibre composite Grouts in rough fractures with flowing water. Tunn. Undergr. Space Technol. 95, 103146 (2020).
Ding, W. et al. The behavior of synchronous grouting in a quasi-rectangular shield tunnel based on a large visualized model test. Tunn. Undergr. Space Technol. 83, 409–424 (2019).
Ding, W., Lei, B., Duan, C. & Zhang, Q. Grout diffusion model for single fractures in rock considering influences of grouting pressure and filling rate. Tunn. Undergr. Space Technol. 158, 106392 (2025).
Ronneberger, O., Fischer, P. & Brox, T. U-net: convolutional networks for biomedical image segmentation. in Medical Image Computing And Computer-Assisted Intervention, PT III (eds. Navab, N. et al.) 234–241 (Springer International Publishing, 2015).
Wang, J. et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 43, 3349–3364 (2021).
Chen, L. C., Zhu, Y., Papandreou, G., Schroff, F. & Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In COMPUTER VISION - ECCV 2018, PT VII (eds. Ferrari, V. et al.) 833–851 (Springer International Publishing, 2018).
Xie, E. et al. SegFormer: Simple and efficient design for semantic segmentation with transformers. In Advances In Neural Information Processing Systems 34 (NEURIPS 2021) (eds. Ranzato, M. et al.) (Neural Information Processing Systems (nips), (2021).
Zou, Q. et al. DeepCrack: learning hierarchical convolutional features for crack detection. IEEE Trans. Image Process. 28, 1498–1512 (2019).
Zhang, A. et al. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network. Comput. -Aided Civil Infrastruct. Eng. 32, 805–819 (2017).
Liu, Y. et al. Richer convolutional features for edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 41, 1939–1946 (2019).
Ceylan, A., Korkmaz Özay, E. & Tunga, B. Contrast and content preserving HDMR-based color-to-gray conversion. Computers Graphics. 125, 104110 (2024).
Badrinarayanan, V., Kendall, A. & Cipolla, R. SegNet A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39, 2481–2495 (2017).
Zhang, W. & Ling, M. An improved point cloud denoising method in adverse weather conditions based on PP-LiteSeg network. PeerJ Comput. Sci. 10, e1832 (2024).
Bougourzi, F., Distante, C., Dornaika, F. & Taleb-Ahmed, A. PDAtt-unet: pyramid dual-decoder attention Unet for covid-19 infection segmentation from CT-scans. Med. Image Anal. 86, 102797 (2023).
Ong, J. C. H., Ismadi, M. Z. P. & Wang, X. A hybrid method for pavement crack width measurement. Measurement 197, 111260 (2022).
Zhang, L. O. et al. A multi-tasking novel variational model for image decolorization and denoising. Inverse Probl. Imaging (2023). https://doi.org/10.3934/ipi.2023020.
Ceylan, A., Ozay, E. K. & Tunga, B. Contrast and content preserving HDMR-based color-to-gray conversion. Comput. Graph -UK. 125, 104110 (2024).
Kim, Y., Jang, C., Demouth, J. & Lee, S. Robust color-to-gray via nonlinear global mapping. ACM Trans. Graph. 28, 161 (2009).
Lee, K., Lee, C. & Muhammad, M. S. Content-based image retrieval using LBP and HSV color histogram. J. Broadcast Eng. 18, 372–379 (2013).
Roy, S., Sengupta, A., Maity, R. & Sengupta, S. Yarn parameterization based on image processing. In 2013 IEEE International Conference On Signal Processing, Computing And Control (ISPCC) (IEEE, 2013).
Tian, Y. & Han, M. Adaptive binarization for vehicle state images based on contrast preserving decolorization and major cluster Estimation. IEICE Trans. Inf. Syst. E105D, 679–688 (2022).
Shi, Y., Cui, L., Qi, Z., Meng, F. & Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 17, 3434–3445 (2016).
Amhaz, R., Chambon, S., Idier, J. & Baltazart, V. Automatic crack detection on two-dimensional pavement images: an algorithm based on minimal path selection. IEEE Trans. Intell. Transp. Syst. 17, 2718–2729 (2016).
Zou, Q., Cao, Y., Li, Q., Mao, Q. & Wang, S. Crack tree: automatic crack detection from pavement images. Pattern Recognit. Lett. 33, 227–238 (2012).
Eisenbach, M. et al. How to get pavement distress detection ready for deep learning? A systematic approach. in 2017 International Joint Conference On Neural Networks (IJCNN) 2039–2047 (IEEE, 2017).
Zhang, L., Yang, F., Zhang, Y. D. & Zhu, Y. J. Road crack detection using deep convolutional neural network. In IEEE Iinternational conference on image processing (ICIP) 3708–3712 (IEEE, 2016). https://doi.org/10.1109/icip.2016.7533052.
Liu, Y., Zhou, T., Hong, Y., Pu, Q. & Wen, X. Neighborhood shortest distance method for concrete crack width detection in images. Eng. Struct. 326, 119519 (2025).
Qiu, S., Wang, W., Wang, S. & Wang, K. C. P. Methodology for accurate AASHTO PP67-10-based cracking quantification using 1-mm 3D pavement images. J. Comput. Civil Eng. 31, 04016056 (2017).
Li, Z., Miao, Y., Torbaghan, M. E., Zhang, H. & Zhang, J. Semi-automatic crack width measurement using an orthoboundary algorithm. Autom. Constr. 158, 105251 (2024).
Liu, Q. et al. Equivalent elastic model of splitting grouting reinforcement in weak strata. Sci. Rep. 15, 11272 (2025).
Hill, R. The elastic behaviour of a crystalline aggregate. Proc. Phys. Soc. Section A 65, 349 (1952).
Luo, Y. Improved Voigt and Reuss formulas with the Poisson effect. Mater. (Basel). 15, 5656 (2022).
Bae, G. J., Shin, H. S., Sicilia, C., Choi, Y. G. & Lim, J. J. Homogenization framework for three-dimensional elastoplastic finite element analysis of a grouted pipe-roofing reinforcement method for tunnelling. Int. J. Numer. Anal. Methods Geomech. 29, 1–24 (2005).
Harmonic-average permeability. | fundamentals of fluid flow in porous media. Special Core Analysis & EOR Laboratory | PERM Inc. at https://perminc.com/resources/fundamentals-of-fluid-flow-in-porous-media/chapter-2-the-porous-medium/permeability/harmonic-average-permeability/.
Acknowledgements
We would like to express our gratitude to the editors for their valuable suggestions and meticulous assistance during the manuscript submission and review process. We appreciate the valuable comments and suggestions from the anonymous reviewers, which helped us improve the manuscript.
Funding
This study was financially supported by the National Energy Shuohuang Railway Development Co., Ltd.Science and Technology Innovation Fund (SHYP-23-01) and National Key R&D Program of China (51738002).
Author information
Authors and Affiliations
Contributions
Pengcheng Zhu and Zhilei Zhang completed the experiment, programmed the computer code, and reviewed the published work, Tielin Chen and Rongxin Wang wrote the initial draft. Dingli Zhang and Li Zhu and Jing Guo revised the manuscript. All authors have read the final manuscript and approved it for publication.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests, All authors have read and approved the final manuscript and consent to its submission. 'There are no known conflicts of interest associated with this publication, and there has been no significant financial support for this work that could have influenced its outcome.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhu, P., Zhang, Z., Chen, T. et al. A width centric image to mechanics framework for assessing advance grouting with TMSE adaptive width segmentation and lab scale validation. Sci Rep 15, 40950 (2025). https://doi.org/10.1038/s41598-025-24835-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-24835-6
