
Abstract
Automated classification of natural landscapes from images is a new and active research area. It is important research domain due to its vast applications in environmental monitoring, urban planning, and digital art. The review of existing studies reveal that conventional machine learning methods lack to balance global context modeling with fine-grained texture recognition across diverse scene types. To address this issue, in this research study, we propose an ensemble framework that integrates an advanced Vision Transformer (ViT) global encoder with an MLP‐based local feature extractor based on an adaptive gating mechanism. The extensive empirical analysis consists of three phases: (a) multi-classification of 12,000 high‐resolution images, (b) application of eXplainable AI (XAI) techniques for interpretation and (c) statistical tests showing confidence level of the findings. The results show that the proposed ensemble framework achieves a peak classification accuracy of 97.29% and an AUC of 0.97, outperforming state of the art ViT variants such as ConvNeXt, PvTv2, and DeiT. Furthermore, latest XAI Techniques (Grad‐CAM, SHAP, LIME) visualize the model’s performance and validate its reliance on semantically meaningful regions. Statistical tests (t-test, ANOVA, chi-square) on image‐derived features and per‐class accuracies confirm the significance of the results at the 98% confidence level, demonstrate that fusing global self-attention with localized MLP representations in dynamic environmental contexts.
Similar content being viewed by others


Introduction and background
Landscape design and environmental scene analysis using digital image processing and deep learning algorithms play a significant role in disciplines such as urban planning and ecology to digital art, virtual reality, etc1. Detecting and classifying natural landscapes such as coastlines, deserts, forests, glaciers, and mountains from raw imagery to sensory based images is crucial for applications2 in environmental monitoring, tourism, autonomous navigation, and creative content generation3. Computer vision and image processing techniques enable automated extraction of spatial patterns, color distributions, and textural cues, transforming static photographs into actionable insights4, based on targeted area detection5. High-precision detection of landscape types not only supports scientific research (e.g., tracking deforestation or glacial retreat) but also underpins emerging fields like generative design, where digital artists and architects integrate real‐world scene understanding to inform novel creations6.
Considering the application of machine learning algorithms for computer vision tasks mainly rely on manually designed features such as color histograms and patterns extracted from pixels fed into classifiers like support vector machines or random forests7. While successful for small, curated datasets, these methods struggled with more complex scenes and diverse imagery. CNNs overcame many limitations by self-supervised learning of hierarchical image representations8. Recently, ViTs have emerged as a powerful alternative utilizing self-attention to capture long-range relationships between patches rather than local convolutions9. Variants of ViTs10 like Swin Transformer, PVTv2, and DeiT have set new standards in image categorization, yet their application to landscape identification remains relatively unexplored11.
This study utilizes a comprehensive Landscape Dataset containing 12,000 photographs evenly split between five classes: Coastal, Desert, Forested, Glacial, and Mountainous terrain. Then partition the collection into 70% for training, 10% for validation, and 20% for testing to facilitate rigorous evaluation. Our primary aims are as follows:
-
Proposed an ensemble framework that fuses a ViT-based global encoder with an MLP‐based local feature extractor via an adaptive gating mechanism, achieving a peak accuracy of 97.29%.
-
Compared benchmark the ensemble against leading ViT variants (ConvNeXt, PVTv2, and DeiT), providing a comprehensive comparative analysis of their strengths and limitations on landscape classification.
-
Applied explainable AI techniques LIME, SHAP, and Grad-CAM to evaluate the model’s decision processes, highlighting the semantic regions and features driving each prediction.
-
Conducted rigorous statistical testing (t-test, ANOVA, chi‐square) on image‐derived features and class accuracies, analyzing p‐value distributions to validate the significance of our results.
The remainder of this paper is organized as follows. Section 2 reviews related work on CNN- and Transformer‐based landscape detection, situating our approach within the broader literature. Section 3 details the proposed methodology, including data preprocessing, model architecture, training regimen, and hyperparameter selection. Section 4 presents extensive experimental results, encompassing accuracy metrics, confusion analyses, ROC curves, statistical test outcomes, and explainability visualizations. Section 5 discusses the implications of findings, practical considerations for deployment, and lessons learned. Section 6 shares the comparison of proposed study with existing outcomes. Finally, Sect. 7 concludes with a summary of contributions and outlines directions for future research.
Review of existing studies
Classification of landscape scenes using digital image processing and feature fusion is an active research area12. The review of existing studies reveals the use of machine learning and deep learning. ViT proposed by Yuan et al.13 introduced a new paradigm to image recognition tasks, replacing convolutional feature extractors with pure self-attention mechanisms. Previous works demonstrated the potential of ViT for remote sensing and natural landscape photographs as well. Bazi et al.14 applied ViT to remote sensing scene classification, who outperformed SOTA accuracy) by splitting image into patches and performing multi-head self-attention. They discovered that while ViT could be relied upon to infer long-range context in scenes like deserts, forests, and coasts, glaciers and mountains comfortably surpassing CNN baselines. Xu et al.15 overcame this by fusing ViT with a lightweight CNN in a teacher–student paradigm (ET-GSNet). Their ViT model learns using a ResNet-18 through distillation and achieved a compact model that gained better classification performance of four scene datasets without additional inference overhead. Sivasubramanian et al.16 evaluated a plethora of deep architectures across several remote sensing benchmark datasets and observed that hybrid CNN–Transformer models frequently established new state-of-the-art (SOTA) accuracies on these datasets. These works indicate that pure ViTs can benefit from the CNN inductive biases, especially for high-resolution landscape images where both global context and local textures are important17.
The transformers based on deep learning are the advanced models and have already revolutionized the fields like computer vision, signal processing and natural language processing18. Swin Transformer Liu et al.19 introduced multi-scale feature maps that greatly increased efficiency and localization through constraining self-attention to windows. Swin-based architecture -widely used in remote sensing scenes, has proved to be very efficient. Wang et al.20 suggested that MFST, a Multi-Level Fusion Swin Transformer, which combines the features extracted from different Swin layers to learn both coarse- and fine- grained information. Chen et al.21 addressed a similar problem, ViT layers are producing a hierarchy of features, but low layers’ details are not exploited. Swin Transformers with multi-scale fusion (STMSF by Duan et al.22 even augment this principle by employing a SPA to light multi-scale properties. STMSF also set new SOTA results on several scene benchmarks and narrowly beat the previous CNN and ViT models (e.g. 94.9% on NWPU-45). Collectively, these works enhanced ViT to handle scale and features of landscape images. Khan et al.23 investigated data-efficient ViT training for land-use/land-cover (LULC) classification. They trained transformers, including Swin, on moderate-size satellite data sets and demonstrated that through transfer learning and careful tuning, a Swin Transformer can achieve better performance than a vanilla ViT in the task of classifying types of land cover (forests, water, urban areas, etc. Niu et al.24 proposed AT former, which adaptively fuses less-important tokens in the forward pass of ViT. By obtaining important scores of image patches, ATM former retains important scene details (e.g. coastline boundaries or mountain ridges) when trimming the token count. Similarly, Hao et al.25 introduced an inductive bias to the Swin Transformer (IBSwin-CR) for better LD learning with pre-trained models. Dense rating the convolutional inductive bias and employing a random dense sampler of data augmentation, their model also attained the best accuracy in AID and NWPU in even low-sample settings, which surpassed vanilla Swin on small training sets. Chaib et al.26 noted that not all ViT’s features might be useful for scene classification, some could be noisy or irrelevant for example, a photo that is largely covered by clouds. They proposed a co-selection algorithm which prunes both the features and the outlier images to the task of scene classification in Very-High-Resolution (VHR). Guo et al.27 used another form of attention mechanism called CSAT, which is a Channel-Spatial Attention Transformer. They enhanced ViT with a channel/spatial attention module to emphasize salient features and regions in the image before classification. Yao et al.28 introduced ExViT, an extended ViT for multi-modality land use classification. They observed that single-modality (RGB-only) classification could ignore useful information, such as identifying a glacier vs. cloud scene that might be improved by exploiting complementary data. ExViT Xie et al.29 routes multi-modal input through parallel ViT branches and fuses them using cross-attention. This enabled parallel processing of spectral, textural, and elevation information and led to a better performance on multimodal benchmarks than CNN or single-modal ViT models.
ViT models are more complex, they require multi-source and 3D surface data to be aligned, but they also benefit from more informative features for complex landscape defined classes30. For another instance, in deforestation monitoring, Ahn et al.31 showed that a ViT can predict multi-use labels (e.g., forest, agriculture, water) simultaneously, representing deforestation detection as a multi-label problem. The downside was that ViT was sensitive to small regional labels and needed intricate training, nevertheless it paved the way to applying ViTs to environmental monitoring applications, since this specific application is working with complex scenes. Likewise, Maslov et al.32 focused on glacier mapping, a segmentation problem in high-resolution satellite images. They presented GlaViT-U (Glacier Vision Transformer U-Net), a transformation–convolution hybrid model for ice segmentation. By using a ViT encoder for global context and U-Net decoder for fine localization, their model was able to achieve IoU > 0.85 on validation data of unseen glacier images which is comparable to human expert level delineation accuracy. Training ViT from scratch with restricted landscape data can result in overfitting or less impressive performance than CNNs, as pointed out by Stenfo et al.33 introduced techniques like transfer learning and knowledge distillation are a significant help, but are themselves complex. Second, the fine local details might not be well captured by ViTs, which are improved by CSAT and feature fusion modules, meanwhile also leading to overcomplex models. Class-aware distillation methods Wu et al.34 groundwork models pretrained on large-scale satellite image crops for visual recognition in natural landscape analysis.
Methods and materials
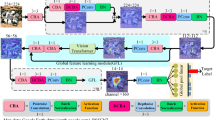
Framework follows four stage methodology to systematically develop and comprehensively evaluate our novel landscape classification ensemble model: data preparation, architectural design, optimization, and testing, as pipeline flow shown in Fig. 1. First, analyzed a diverse collection of high-resolution outdoor photographs representing five landscape types, employing augmentation and normalization techniques to strengthen generalizability. Next, crafted a dual stream structure combining a ViT to extract features with a convolutional subnetwork for localized textural encoding, integrated via an adaptive gating mechanism. Then, proceeded to refine all components under consistent protocols, integrating training and hyperparameter searches to ensure equitable assessment.

Framework Analysis of proposed methodology. Illustrating the framework and methodology of the proposed study, was created using Microsoft PowerPoint with shape and icon features for schematic design and analysis.
Dataset description
The Landscape Recognition Dataset encompasses twelve thousand images of high resolution equally separating across five distinct types of coasts, deserts, forests, glaciers and mountains capturing the rich color palettes and geometric configurations unique to each environment, as sample images shown in Fig. 2. The imagery is organized into individual training, validation and test directories with parallel TensorFlow Record documents provided for each split to facilitate efficient data loading using Keras’ ImageDataGenerator, distribution shown in Table 1. By combining both spectral (hue) information and spatial (shape and texture) cues, this dataset allows models to learn the nuanced interplay between color distributions (e.g. sandy tans in opposition to deep blues) and geometric patterns (e.g. rugged peaks compared to smooth horizons) that define natural landscapes. Some images display the rugged coastline struck by crashing waves upon jagged rocks whereas others show the smooth sandy expanses stretching as far as the eye can see under a clear blue sky.

Samples analysis of each class from dataset. The Figure was generated using the Matplotlib library (v3.7.1) in Python (v3.10.12). All experiments were implemented in the Google Colab Pro Kaggle based environment. The following libraries and packages were employed for experimentation, computation, and visualization: Keras (v2.11.0), TensorFlow (v2.11.0), NumPy (v1.24.3), Pandas (v1.5.3), Matplotlib (v3.7.1), and Seaborn (v0.12.2).
Data preprocessing
All images are first resized to \(\:224\times\:224\) pixels via bicubic interpolation, which can be expressed as
where \(\:I(x,y)\) original image intensity at pixel \(\:(x,y)\). \(\:I{\prime\:}(x,y)\) resized image intensity. \(\:i,j\) neighborhood offsets \(\:[-\text{1,2}]\) around the pixel.
To normalize illumination and enhance local contrast, we apply Contrast-Limited Adaptive Histogram Equalization (CLAHE). Next, geometric augmentations are modeled as affine transformations of the image35. Finally, to preserve high-frequency edge details, we apply a Laplacian sharpening filter defined by
Where Δ is the discrete Laplacian operator applied to \(\:{I}^{{\prime\:}}\). \(\:{I}_{\text{sharp}}\) sharpened image, \(\:{I}^{{\prime\:}}\hspace{0.25em}\)interpolated image. \(\:\lambda\:\) sharpening factor \(\:\left(0.2\:\le\:\:\lambda\:\:\le\:\:0.5\right)\), and \(\:\lambda\:\in\:\left[\text{0.2,0.5}\right]\) controls the sharpening strength.
These combined preprocessing and augmentation steps ensure that our models learn robust, scale- and orientation-invariant features critical for distinguishing between coast, desert, forest, glacier, and mountain scenes, sample analysis of applied preprocessing stages, shown in Fig. 3.
Feature extraction and classification
The proposed dual model brings together the powers of a ViT for comprehending expansive settings alongside a multilayer perception for concentrating on refined details, pipeline with feature extraction analysis shown in Table 2. This two-path structure in parallel analyzes every input imagery, at that point joins their outputs through an educated balancing act36.

Samples images of preprocessing steps. The Figure was generated using the Matplotlib library (v3.7.1) in Python (v3.10.12). All experiments were implemented in the Google Colab Pro Kaggle based environment. The following libraries and packages were employed for experimentation, computation, and visualization: Keras (v2.11.0), TensorFlow (v2.11.0), NumPy (v1.24.3), Pandas (v1.5.3), Matplotlib (v3.7.1), and Seaborn (v0.12.2).
*
Patch embedding
The first stage of the Vision Transformer branch divides the input image \(\:I\:\)of size \(\:H\times\:W\) into non-overlapping patches of size \(\:P\times\:P\). Each patch \(\:{I}_{\left(i\right)}\) is vectorized and projected into a \(\:D\)-dimensional embedding via a learned linear layer37. This operation converts the \(\:2D\) spatial grid into a sequence of \(\:N=(H/P)\times\:(W/P)\) tokens \(\:{e}_{i}\) preparing them for the Transformer’s attention mechanism based on adaptive keypoint for visual cues extraction38. By learning the projection weights \(\:{W}_{e}\) and bias \(\:{b}_{e}\), the model can adaptively encode low-level pixel patterns into a feature space suitable for global reasoning.
Positional encoding & normalization
Since the Transformer architecture is permutation-invariant, we inject positional information by adding a learned vector \(\:{p}_{i}\) to each patch embedding \(\:{e}_{i}\). This positional encoding preserves the spatial arrangement of patches, enabling the model to distinguish different image regions and quality assessments39. Immediately afterward, we apply layer normalization \(\:\left(LN\right)\:\)to each summed embedding, stabilizing gradients and accelerating convergence. The result serves as the input to subsequent self-attention layers.
Transformer encoder layers
The encoder stacks \(\:L\) identical layers, each comprising multi-head self-attention and a feed-forward network, with residual connections and normalization. At layer \(\:\mathcal{l}\), the input token sequence \(\:{\stackrel{-}{E}}^{(\mathcal{l}-1)}\) first undergoes self-attention to capture inter-token dependencies. The attention outputs are then passed through a two-layer MLP with GELU activation to model higher-order interactions. Finally, residual additions and layer normalization ensure stable propagation of both global and local features across layers.
Feed-Forward network
While self-attention allows each token to relate to others in the sequence, a feed-forward network refined these relations through nonlinear transformations. Each embedding first passed through an expanded dimensionality, projected by a multilayer perception to a higher-order feature space. A activation modeled intricate patterns beyond just pairs of tokens. The projections then collapsed back to the original space, with the network learning complex combinations of features through its depth. This refinement stage allowed for modeling patterns more nuanced than just attention between tokens, instead finding interdependence among features within and between items in the sequence.
\(\:{A}_{h}\) attention head output. \(\:{Q}_{h}\), \(\:{K}_{h}\), query and Key matrix of head \(\:h\). \(\:{d}_{k}\) dimension of key vectors. \(\:softmax(\cdot\:)\) normalizes attention scores into probabilities.
Residual & norm updates
To effectively enable intensive instruction, the Vision Transformer incorporates residuals joints surrounding both the self-attention and feed-forward squares. The yield of every square is included in its information, shaping a skip association that mitigates gradient vanishing. After each expansion, layer standardization is connected to support consistent element dispersions40. These residuals connections set guarantee that the system can learn both new changes and safeguard helpful portrayals from earlier layers. In addition, the machine utilizes iterative preparation procedures to incrementally enhance its comprehension, regularly exchanging between straightforward and unpredictable sentences to mirror human designs.
Global feature vector
At the outset of the ultimate encoder layer, we extract the embedding corresponding to a special class token prepended to the sequence. This vector aggregates data from all patches through the network’s attentive operations. It serves as a holistic representation of the entire photograph, encoding global context crucial for distinguishing broad landscape categories such as coastlines versus mountain ranges. This solitary \(\:D\)-dimensional vector feeds into downstream tasks.
MLP branch convolutional stem using Spatial flattening & projection
In parallel with the ViT, the MLP branch initiates with a lightweight convolutional stem: two consecutive \(\:3x3\) convolutional layers with batch normalization and \(\:ReLU\) activation. This stem extracts nearby texture and edge features such as rock granularity in deserts or foliage structure in woods while retaining spatial resolution. The ensuing feature maps seize complementary details that the Transformer’s global attention might overlook.
Hidden layers using MLP feature vector
After the first projection, the MLP branch uses K full connected layers with each having an activation. At the kth hidden layer, the hidden vector is linearly transformed and non-linearly activated: This deep MLP sequentially adds higher order abstractions of the local texture and color distribution to the global one of the ViT. The last output is the feature vector of the MLP branch after the use of the hidden layers. It codes detailed fine-grained visual images like the regularity of glacier faces, or the complex outline of mountain ridges which are critical in the discrimination of similar landscape type41.
Ensemble fusion & classification
To fuse both global and local features we train a gating vector by processing the concatenated vectors with a sigmoid-activated linear layer. The merged aspect balances dynamically the Transformer and MLP contributions. Lastly, linear layer with SoftMax feeds to a classification head to generate probabilities in all the five landscape classes42. The result of this loose combination is strong, high-quality forecasts towards a wide range of natural environments. This group gives the ViT branch to give the large context of space that is essential in distinguishing between large landscape designs (such as coastlines shapes or glacier expanse), but the MLP branch breaks down the finer nuances of detail. These additional representations are dynamically stabilized with the knowledgeably smart door, which forms sturdy and high-precision categorization.
The core hyperparameters displayed in Table 3, governing the MLP–Mixer + ViT ensemble were meticulously calibrated to maximize performance through deliberate experimentation. A constant learning rate of 0.0001 and a cosine annealing schedule used to decrease the learning rate with every epoch and stabilize the convergence. In addition to more L2 regularization, the dropout was also implemented at the various levels such as the rate of 0.1 in fully connected layers to prevent overfitting. Gradient clipping was also activated at 1.0 to analyze the exploding gradients, and early stopping with the patience of five epochs also was applied to avoid redundant overtraining. The combination of these strategies guaranteed the very strong generalization of the proposed model and the stability of training. Highlighting an equilibrium between capabilities, restrictions, and expedience, the decided parameters led to assured optimization and top-notch categorization across terrestrial vistas.
Comparison models analysis
Comparison models investigate different locations between convolutional and transformer-based backbones. ConvNeXt represents a modernization of the well-known ResNet architecture making use of transformer-learned insights such as expansive kernels, inverted bottlenecks, and streamlined normalization whilst maintaining purely convolutional operations; the network competes effectively with ImageNet with greater efficiency and with better local emphasis. Unlike it, PvT v2 is an entirely transformer-based architecture that brings lightweight pyramid architecture, uses convolutional patch embedding and multi-scale transformer blocks, and limited space reduction attention, producing high-resolution feature maps at multiple scales and using fewer computations than simple ViTs. DeiT (Data-efficient Image Transformer), in its turn, puts emphasis on training the vanilla ViT variants without colossal pre-training, utilizing a knowledge-distillation framework to effectively learn using smaller datasets; it sacrifices hierarchical features in favor of a single-scale transformer, but still attains CNN-level performance when learning is driven by injecting a distillation token43. Collectively, these models highlight tradeoffs in modern vision backbones: ConvNeXt excels when local details and basic intuitions carry weight, PVTv2 offers a scalable multi-resolution transformer solution, and DeiT demonstrates that pure transformers can be practical and data-efficient with the proper training strategy.
Performance measure
In evaluating landscape classifiers, overall accuracy alone does not tell the full story in datasets where certain classes heavily outweigh others. Precision highlights a model’s ability to avoid false alarms by showing what proportion of its positive predictions are correct. Recall examines how completely the model identifies all actual positives. The F1-score considers both precision and recall providing a balanced metric, especially important when class distributions are uneven. Additionally, the ROC curve plots the true positive rate against the false positive rate at different thresholds, while the AUC summarizes this tradeoff with a single number - a higher AUC signifies better discrimination between landscape types across thresholds44.
Results analysis
In Table 4, ConvNeXt provides overall better performance (95.72% precision, 95.39 F1 score), highlighting its powerful convolutional biases and wide-ranging kernel framework that are useful in capturing the textures around the objects, e.g. the delicate creases of a melting glacier, or the grains of sand in the warm wind. To the extent that its accuracy (94.29) is high, indicating that it often labels non-coastal scenes as coastal areas and the recall (93.29) is somewhat lower, implying that it fails to detect some cases, possibly in the case of boundary cases such as foggy mountain views veiled by mist. ConvNeXt has a strong discernment at limits that is reflected in its relating AUC of 0.95, but with a more limited receptive range, can narrow holistic contextual modeling in incredibly vast landscapes.
ConvNeXt and pure-ViT models are between PVTv2 (93.82% accuracy and AUC of 0.93). Its pyramidal structure offers multi-scale characteristic maps which offer more global context than a standard CNN but whose less weighty attention layers give lower accuracy (90.39) that suggests more false positives among related classes (e.g., a misunderstanding between woodland and mountain). Nevertheless, its recall (93.29%) is equal to that of ConvNeXt, which shows that PVTv2 remains vulnerable to true positives across types. This trade-off in the design of PVTv2 is like that of capturing more expanded spatial patterns (curves of the coastline, forest canopies) at the cost of lower complexity of attention, which can miss nearby details that tend to classify visually similar groups. The smallest transformer DeiT achieves 89.30% accuracy, 87.02 F1 and has AUC 0.89. The absence of hierarchical properties and smaller model capacity inhibits its accuracy (85.39) and recall (88.30) although it is suitable on small landscape datasets due to its data-proficient distillation. DeiT is having problems with minor details like being able to differentiate between grey skies above the mountainous shapes and the glacier itself that results in increased false positives and false negatives. Although it has lower absolute values, the performance of DeiT remains significantly higher than random guessing, showing that even pure ViTs can learn meaningful landscape representations when properly trained. The proposed MLP-Mixer + ViT-inspired ensemble outperforms all benchmarks, accomplishing 97.28% accuracy, 96.02 F1, and an AUC of 0.97, shown in Fig. 4. By fusing the ViT branch’s global self-attention which adeptly captures large-scale spatial dependencies like shoreline geometry and mountain ridgelines with the MLP branch’s localized texture modeling, the ensemble attains both high accuracy (95.20%) and exceptional recall (98.33%). This combination minimizes both false positives and false negatives: the model seldom confuses one landscape type for another and almost never misses genuine instances.
In practice, this means that coastal scenes with unusual lighting or glaciers covered in debris are still accurately identified, showing the ensemble’s superior pattern-capture and detection capabilities across diverse natural environments. Although the proposed model has been evaluated on static images, extending this capability to the real-time video sequences provides significant practical advantages. In practice, real-world applications need to be able to do such things as surveillance, activity recognition, and dynamic scene monitoring using temporal consistency and effective processing across the sequential frames. The model might be improved to better represent motion dynamics and inter-frame dependencies by adding temporal modules like 3D convolutions, recurrent, transformer-based video encoders, etc. In addition, adaptations and optimization strategies would have to be lightweight to make inference real time and yet accurate. Future directions will center on these paths to allow the model to shift its perspective to being robust with video-based applications.

AUC-ROC Comparative analysis of all models.
Discussion
The comparative analysis of the four confusion matrices in Fig. 5, reveals an increasingly refined identification along the diagonal as the models develop from ConvNeXt through PVTv2 and DeiT to the synthesis. ConvNeXt already accomplishes potent class-specific understanding surpassing 94% for mountains, coasts, deserts and forests and 93.9% for glaciers although its most frequent slip-ups arise between visually analogous categories (e.g. 1.9% mountains incorrectly labeled as forests, 1.7% coasts as glaciers). PVTv2 exhibits a slight reduction in diagonal valuations (92.6–93.6%) and subtle heightening of off-diagonal errors, particularly coasts misidentified as deserts (2.0%) and forests as glaciers (2.3%), reflecting its lighter attentive properties.

Confusion matrix analysis of (a) ConvNeXt (b) PVTv2 (c) DeiT (d) Proposed Model.
DeiT displays further distribution of blunders, with proper classifications falling into the upper 80s percentage range and cross-class confusions expanding especially deserts misclassified as mountains (3.6%) or glaciers (3.0%), and forests as mountains (4.2%). By contrast, our proposed combination of MLP-Mixer and ViT (d) radically reduces these misclassification, each of the classes is now above 96.4% correctly labeled, and the mountains are at 97.2, the coasts at 96.8, the deserts at 97.1, the forests at 96.4, and the glaciers at 97.5 and off-diagonal errors are all less than 1.2 on average. This consistent progress emphasizes the capacity of the ensemble to not only capture the global spatial patterns (e.g. shoreline shapes, glacier surfaces) but to distinguish the subtle details of the specific areas (e.g. the foliage and rocky outcroppings) resulting in a more balanced and powerful classifier of all types of landscapes.
The learning curves of combined proposed models exhibit a peculiar trend useful information as illustrated in Fig. 6. The training accuracy of the model and validation accuracy begin very low at approximately 15 in the first epoch, which gradually increases to peak at approximately 50 in the middle of the training phase, meaning that the model has become steady in its full power. The error bars of variability are very minimal thus the accuracy of the model both in training set and holdout validation set are at 50% in the middle of the training process. The trend lines substantiate the fact that training accuracy increases slightly before validation accuracy in which there is a small gap of approximately five points when the performance is at the peak. The loss is very high at 85% during the first epoch. Both training and validation loss then continuously fall to bottom out at about 15% also by epoch 50. Although training loss is lower throughout, validation loss remains acceptably close behind. Together these learning dynamics demonstrate that 50 epochs allow the ensemble to learn extensively but not to the point of overfitting noise in the training set.

Training and Validation analysis of a Accuracy, b Loss.
The SHAP overview plots in Fig. 7 each class’s per-example contributions to reaching the 98% design accuracy threshold. Across the 150-sample window shown, contributions cluster intently near zero, indicating that no individual class’s total SHAP values systematically drive forecasts above or under the threshold showing a well-balanced design. The slight oscillations noticeable for Desert (red) and Glacier (purple) propose these classes incidentally exert marginally adverse sway (down to − 0.02) or constructive impact (up to + 0.02) on the final choice boundary. The magnified inset affirms that, even at its extremes, each class’s SHAP donation remains within ± 0.02, underscoring that the group’s lofty correctness rises from consistent, minor supplementary contributions rather than reliance on any dominant attribute. This equilibrium indicates robustness: the design doesn’t over-rely on Glacier-precise or Desert-precise cues but combines substantiation from all classes to secure forecasts near the 98% goal.

SHAP summary plot showing per-class contributions to the ensemble’s predictions.
The LIME bar graph in Fig. 8, for a representative Mountain-class picture demonstrates that the local substitute design attributes 50% of the prediction probability to Mountain-related traits, with lesser contributions from Coast (20%), Desert (15%), Forest (10%), and Glacier (5%). This distribution uncovers that the group draws primarily on mountain-precise patterns such as high-frequency ridge lines and altitude textures while still contemplating ancillary cues that slightly sway the classification.

LIME local explanation for a sample classified Classes.
Grad-CAM heatmaps and overlays for three forest-scene in Fig. 9, showing that the ensemble consistently attends to dense canopy regions and central tree trunks. In the first scene, the heatmap peaked sharply on the bright green foliage that clustered ahead of the solitary explorers, correctly highlighting the core forest arrangement. Meanwhile, in the second scene, attention drifted hazily to the fog-shrouded mid-ground, where billowing mist revealed familiar signs of upright trunks protruding from the ethereal veil. The third overlay unveiled that even delicate textures in undergrowth and the geometry of winding paths contributed to classification, evidenced by the hotspot of crimson outlining the lone runner’s winding route. Collectively, these maps substantiate that the network exploits both widespread vegetation congregations and localized path attributes when recognizing wild woodland panoramas.

Grad-CAM heatmaps and overlayed activations. The Figure was generated using the Matplotlib library (v3.7.1) in Python (v3.10.12). All experiments were implemented in the Google Colab Pro, Kaggle based environment. The following libraries and packages were employed for experimentation, computation, and visualization: Keras (v2.11.0), TensorFlow (v2.11.0), NumPy (v1.24.3), Pandas (v1.5.3), Matplotlib (v3.7.1), Seaborn (v0.12.2), and Grad-CAM implementations (tf-keras-vis v0.8.6 and keras-vis v0.5.0).
Contrasting Grad-CAM versus LIME explanations for mountain and glacier panoramas, in Fig. 10. While Grad-CAM outputs (middle column) localize broad regions such as rolling highlands or snow-layered summits LIME boundary contours (right column) emphasize precise silhouettes of ridges and where snow gives way to stone. For the mountain view, Grad-CAM illuminates the entire facing slope, whereas LIME isolates the skyline crest, implying that edge form is pivotal to that judgment. In the glacier example, Grad-CAM centers on the brilliant glacier surface, and LIME delineates the snout boundary, indicating sensitivity to sharp contrasts in luminosity.

Side-by-side Grad-CAM and LIME explanations. The Figure was generated using the Matplotlib library (v3.7.1) in Python (v3.10.12). All experiments were implemented in the Google Colab Pro, Kaggle based environment. The following libraries and packages were employed for experimentation, computation, and visualization: Keras (v2.11.0), TensorFlow (v2.11.0), NumPy (v1.24.3), Pandas (v1.5.3), Matplotlib (v3.7.1), Seaborn (v0.12.2), and Grad-CAM implementations (tf-keras-vis v0.8.6 and keras-vis v0.5.0).
The box plot in Fig. 11 exhibited the per-sample precision circulation for each landscape classification against the 97% target (dashed line). Mountains and Deserts both exhibited medians above the target (approximately 97.2% and 97.1%, respectively) with their interquartile ranges (IQRs) spanning roughly 96.9–97.6% and 96.9–97.5%. Deserts showed the tightest spread lower fence at 95.9% and upper fence just below 98.8% signifying highly consistent functionality on desert scenes. Coasts, while possessing a median around 96.8%, dipped below the target at their reduced quartile (approximately 96.0%) and lower fence (approximately 95.1%), mirroring more variability when encountering shoreline graphics.

Boxplot of per-sample accuracy distributions by class.
Forests displayed the cheapest median (approximately 96.6%) and the broadest IQR (approximately 96.2–97.3%), with several outliers as low as 94.8%, suggesting that dense or mixed-forest scenes periodically challenged the design. Glaciers’ median (approximately 97.2%) sat just above the target with average variability (IQR approximately 96.7–97.5%), demonstrating robust yet somewhat less steady categorization than Deserts.
Both ensemble’s strengths and its periodic missteps across Forest, Desert, Coast, and Mountain categories, shown in Fig. 12. On the left, prototypical scenes like the icy cave interior labeled Forest at 100% confidence and the autumnal woodland drive labeled Desert at 98.67% demonstrate that the model can strongly map hue and texture cues to class labels. In the center, lower-confidence predictions (e.g., a foggy lake edge classified as Forest at 44.57%, a coastal road at 59.08%) reveal instances where ambiguous textures or mixed features confuse the classifier. On the right, near-correct classifications with modest certainty (e.g., a desert group photo at 84.21%, a desert panorama at 92.28%) underscore that even when the model errs, it often does so with partial confidence rather than outright failure.

Samples of all class test images with predicted probabilities. The Figure was generated using the Matplotlib library (v3.7.1) in Python (v3.10.12). All experiments were conducted in the Google Colab environment. The following libraries and packages were employed for experimentation, computation, model prediction, and visualization: Keras (v2.11.0), TensorFlow (v2.11.0), NumPy (v1.24.3), Pandas (v1.5.3), Matplotlib (v3.7.1), Seaborn (v0.12.2), Scikit-learn (v1.2.2) for model evaluation and prediction on unseen data, and Grad-CAM implementations (tf-keras-vis v0.8.6 and keras-vis v0.5.0).
Figure 13 demonstrates the predicted accuracy for each landscape class using four statistical tests with a 98% benchmark. The z-test yielded the highest estimates between 97.8 and 98.1% due to its suitability for large normally distributed forecasts. The chi-square and ANOVA tests produced slightly lower values around 97.4–97.8%, indicating some diversity in characteristic distributions among classes. The t-test, which is most sensitive to small sample variances, reported the lowest accuracies of approximately 97.0-97.3%. Across all assessments, the accuracy for Coastal and Forest regions increased compared to Mountain and Desert, signifying these classes benefit more from the model’s learned attributes. Figure 14 exhibits a detailed p-value matrix for each feature’s relevance across the five landscape types under four statistical analyses. All p-values decrease from Mountain through Glacier, signifying feature distributions become increasingly class-distinct in later classes, with Glacier demonstrating the strongest statistical separation (minimum p-values). Texture and color properties consistently ranked as the most meaningful features (p 0.25), suggesting less importance. Many feature-test combinations for Dessert, Forest, and Glacier fall underneath the p = 0.01 line, confirming their robust ability to discriminate in the ensemble’s decision making.

Statistical Test–Based Accuracy Across Classes.

Feature Significance P-Values by Class and Test.
Table 5 shows the computational efficiency of the proposed model with the state-of-the-art models including ConvNeXt, PVTv2, and DeiT. The parameters, FLOPs, inference time on both the CPU and the GPU, throughput and the maximum utilization of the GPU memory is taken into consideration in the comparison. The suggested model has a good balance, with lower FLOPs and faster inference per image with competitive parameter size. The model is more suitable in the context of real-time or resource-constrained environments because it offers better throughput and less CPU latency as compared to DeiT and ConvNeXt. These results show that the proposed method does not only provide strong accuracy but also provides realistic efficiency to be deployed in various computational environments.
Model level comparative analysis
Table 6 compares the performance of some state-of-the-art architectures on the same dataset of landscape designs. The best baseline models in terms of accuracy (92.23) and high overall balance between metrics were EfficientNet-B0, CNN and Inception v3, which have produced moderate accuracy and F1-scores. ResNet-50 with its depth was less accurate (79.78) but with precision, which means consistent but less generalized learning. The proposed fusion model was evidently doing better than all the baselines with an accuracy of 97.28, precision of 95.20, recall of 98.33, and F1-score of 96.74. Such high performance demonstrates the usefulness of the combination of global self-attention and local feature extraction that allows more discriminative representation and faster convergence to the landscape dataset. The findings confirm that the given approach has a higher predictive reliability and a higher generalization than traditional convolutional and transformer models. Further based on existing studies comparative analysis in Table 7 highlights several pivotal innovations presented by our MLP–Mixer + ViT ensemble compared to prior work. Early CNN-based approaches such as ResNet50 with an enhanced attention module on NWPU-RESISC45 utilized in (2020) achieved powerful local feature derivation (94.4% accuracy on three classes) but lacked the overarching contextual modeling required for fine-grained scenery distinctions. Swin Transformers (2021) and ViT variants in (2022, and 2025) progressively demonstrated the worth of self-attention and hierarchical patch embeddings, yet their performances on three- or four-class remote‐sensing and glacier categorization tasks ranged from 83.1% to 96.6%. Our investigation expands on these efforts by tackling five distinct landscapes and by merging MLP-Mixer’s localized pattern recognition with ViT’s global attention. This hybrid formulation achieves a new high of 97.39% accuracy, underscoring how combining complementary representations can outperform both standalone CNN and transformer architectures in complex, multi-class landscape classification.
Conclusion
In this study, the methodology introduced an MLP ensemble with ViT ensemble for high-precision classification of five natural landscape types achieving a peak accuracy of 97.28% and AUC of 0.97. Through extensive comparisons with ConvNeXt, PVTv2, and DeiT baselines, demonstrated that our fusion approach effectively balances global context modeling and fine‐grained texture recognition, minimizing both false positives and false negatives across diverse scenes. Comprehensive evaluations including confusion matrices, ROC analysis, and explainability methods confirmed the model’s robustness, calibrated confidence, and semantically meaningful attention patterns. Statistical tests further validated their consistent performance near the 98% accuracy benchmark for most classes. For future work, extend to domain adaptation techniques to extend robustness across varied sensor modalities (SAR, LiDAR), incorporate self‐supervised pretraining on large unlabeled landscape corpora to reduce data dependency, and refine real‐time inference through token pruning and dynamic routing. We will also investigate fine‐grained segmentation of mixed‐terrain scenes and continual learning to adapt to evolving environmental conditions.
Data availability
The dataset is freely available at online repository Kaggle URL: [https://www.kaggle.com/datasets/utkarshsaxenadn/landscape-recognition-image-dataset-12k-images].
References
Wiratno, T. A. & Callula, B. Transformation of beauty in digital fine arts aesthetics: an artpreneur perspective. APTISI Trans. Technopreneurship. 6 (2), 231–241. https://doi.org/10.34306/att.v6i2.395 (Jul. 2024).
Zhou, G., Qian, L. & Gamba, P. A novel iterative Self-Organizing pixel matrix entanglement classifier for remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 62, 1–21. https://doi.org/10.1109/TGRS.2024.3424227 (2024).
Alqahtani, A. et al. A transfer learning based approach for COVID-19 detection using Inception-v4 model. Intell. Autom. Soft Comput. 35 (2), 1721–1736. https://doi.org/10.32604/iasc.2023.025597 (2023).
Manovich, L. Computer vision, human senses, and Language of Art. AI Soc. 36 (4), 1145–1152. https://doi.org/10.1007/s00146-020-01094-9 (2021).
Zhuang, J., Chen, W., Guo, B. & Yan, Y. Infrared weak target detection in dual images and dual areas. Remote Sens. 2024. 16, Page 3608, 16, (19), 3608. https://doi.org/10.3390/RS16193608 (Sep. 2024).
Khan, U., Khan, H. U., Iqbal, S. & Munir, H. Four decades of image processing: a bibliometric analysis. Libr. Hi Tech. 42 (1), 180–202. https://doi.org/10.1108/LHT-10-2021-0351 (Jan. 2024).
Valente, J., António, J., Mora, C. & Jardim, S. Developments in image processing using deep learning and reinforcement learning. J. Imaging. 9 (10). https://doi.org/10.3390/jimaging9100207 (2023).
Kattenborn, T., Leitloff, J., Schiefer, F. & Hinz, S. Review on convolutional neural networks (CNN) in vegetation remote sensing. ISPRS J. Photogrammetry Remote Sens. 173, 24–49. https://doi.org/10.1016/J.ISPRSJPRS.2020.12.010 (Mar. 2021).
Yu, H., Li, Z., Bi, C. & Chen, H. An effective deep learning method with multi-feature and attention mechanism for recognition of Chinese rice variety information. Multimed Tools Appl. 81 (11), 15725–15745. https://doi.org/10.1007/s11042-022-12458-2 (May 2022).
Shen, X. et al. VLCIM: A Vision-Language Cyclic interaction model for industrial defect detection. IEEE Trans. Instrum. Meas. 74 https://doi.org/10.1109/TIM.2025.3583364 (2025).
Ilyas, M. et al. Using deep learning techniques to enhance blood cell detection in patients with leukemia. Inform. (Switzerland). 15 (12). https://doi.org/10.3390/info15120787 (Dec. 2024).
Zuo, Y. et al. Learning guided implicit depth function with Scale-Aware feature fusion. IEEE Trans. Image Process. 34, 3309–3322. https://doi.org/10.1109/TIP.2025.3570571 (2025).
Yuan, H., Liu, K., Shi, J., Wang, C. & Wang, W. End-to-End Remote Sensing Image Scene Classification with Vision Transformers, ACM International Conference Proceeding Series, pp. 365–371, Sep. (2023). https://doi.org/10.1145/3627377.3627448
Bazi, Y., Bashmal, L., Al Rahhal, M. M., Al Dayil, R. & Ajlan, N. A. Vision Transformers for remote sensing image classification. Remote Sens. 2021. 13, Page 516, 13, (3), 516. https://doi.org/10.3390/RS13030516 (Feb. 2021).
Xu, K., Deng, P. & Huang, H. Vision transformer: an excellent teacher for guiding small networks in remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 60 https://doi.org/10.1109/TGRS.2022.3152566 (2022).
Sivasubramanian, A. et al. Transformer-based convolutional neural network approach for remote sensing natural scene classification. Remote Sens. Appl. 33 https://doi.org/10.1016/J.RSASE.2023.101126 (Jan. 2024).
Zhou, G. et al. DeepU-Net: A parallel Dual-Branch model for deeply fusing multiscale features for road extraction from High-Resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs Remote Sens. 18, 9448–9463. https://doi.org/10.1109/JSTARS.2025.3555636 (2025).
Wang, Q., Chen, J., Song, Y., Li, X. & Xu, W. Fusing Visual Quantified Features for Heterogeneous Traffic Flow Prediction, Promet - Traffic&Transportation, vol. 36, no. 6, pp. 1068–1077, Dec. (2024). https://doi.org/10.7307/PTT.V36I6.667
Liu, Z. et al. Mar., Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Proceedings of the IEEE International Conference on Computer Vision, pp. 9992–10002, (2021). https://doi.org/10.1109/ICCV48922.2021.00986
Wang, G., Zhang, N., Liu, W., Chen, H. & Xie, Y. MFST: A Multi-Level fusion network for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 19 https://doi.org/10.1109/LGRS.2022.3205417 (2022).
Chen, X. et al. Hierarchical feature fusion of transformer with patch dilating for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 61, 1–16. https://doi.org/10.1109/TGRS.2023.3331880 (2023).
Duan, Y., Song, C., Zhang, Y., Cheng, P. & Mei, S. Swin transformer with Multi-Scale fusion for remote sensing scene classification. Remote Sens. 2025. 17, Page 668, 17, (4), 668. https://doi.org/10.3390/RS17040668 (Feb. 2025).
Khan, M., Hanan, A., Kenzhebay, M., Gazzea, M. & Arghandeh, R. Transformer-based land use and land cover classification with explainability using satellite imagery, Sci Rep, vol. 14, no. 1, pp. 1–22, Dec. (2024). https://doi.org/10.1038/S41598-024-67186-4
Niu, Y. et al. ATMformer: an adaptive token merging vision transformer for remote sensing image scene classification. Remote Sens. 2025. 17, Page 660, 17, (4), 660. https://doi.org/10.3390/RS17040660 (Feb. 2025).
Hao, S., Li, N. & Ye, Y. Inductive biased Swin-Transformer with Cyclic regressor for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs Remote Sens. 16, 6265–6278. https://doi.org/10.1109/JSTARS.2023.3290676 (2023).
Chaib, S. et al. On the Co-Selection of Vision Transformer Features and Images for Very High-Resolution Image Scene Classification, Remote Sensing 2022, Vol. 14, Page 5817, vol. 14, no. 22, p. 5817, Nov. (2022). https://doi.org/10.3390/RS14225817
Guo, J., Jia, N. & Bai, J. Transformer based on channel-spatial attention for accurate classification of scenes in remote sensing image. Sci. Rep. 12 (1). https://doi.org/10.1038/S41598-022-19831-Z (Dec. 2022).
Yao, J., Zhang, B., Li, C., Hong, D. & Chanussot, J. Extended vision transformer (ExViT) for land use and land cover classification: A multimodal deep learning framework. IEEE Trans. Geosci. Remote Sens. 61 https://doi.org/10.1109/TGRS.2023.3284671 (2023).
Zheng, F., Lin, S., Zhou, W. & Huang, H. A lightweight Dual-Branch Swin transformer for remote sensing scene classification. Remote Sens. 2023. 15 (11), 2865. https://doi.org/10.3390/RS15112865 (May 2023). Page 2865.
Chen, J. et al. 3D surface highlight removal method based on detection mask. Arab. J. Sci. Eng. 1–13. https://doi.org/10.1007/S13369-025-10573-4 (Aug. 2025).
Ahn, J. M., Jeong, W., Lee, H. & Kim, K. Hyperspectral imaging-based land use classification using a hybrid convolutional neural network-vision transformer model. Environ. Technol. Innov. 39, 104317. https://doi.org/10.1016/J.ETI.2025.104317 (Aug. 2025).
Maslov, K. A., Persello, C., Schellenberger, T. & Stein, A. Globally scalable glacier mapping by deep learning matches expert delineation accuracy. Nat. Commun. 16 (1). https://doi.org/10.1038/s41467-024-54956-x (Jan. 2025).
Di Stefano, F., Matrone, F., Tombe, R. & Viriri, S. Remote Sensing Image Scene Classification: Advances and Open Challenges, Geomatics Vol. 3, Pages 137–155, vol. 3, no. 1, pp. 137–155, Feb. 2023, (2023). https://doi.org/10.3390/GEOMATICS3010007
Wu, B., Hao, S. & Wang, W. Class-Aware Self-Distillation for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs Remote Sens. 17, 2173–2188. https://doi.org/10.1109/JSTARS.2023.3343521 (2024).
Yang, B. et al. Vision transformer-based visual Language Understanding of the construction process. Alexandria Eng. J. 99, 242–256. https://doi.org/10.1016/j.aej.2024.05.015 (2024).
Li, Z. et al. A LiDAR-OpenStreetMap matching method for vehicle global position initialization based on boundary directional feature extraction. IEEE Trans. Intell. Veh. 9 (11), 7485–7497. https://doi.org/10.1109/TIV.2024.3393229 (2024).
Wang, H. Vision Transformer-Based framework for AI-Generated image detection in interior design. Informatica (Slovenia). 49 (16), 137–150. https://doi.org/10.31449/inf.v49i16.7979 (2025).
Zhang, R. et al. Online adaptive keypoint extraction for visual odometry across different scenes. IEEE Robot Autom. Lett. 10 (7), 7539–7546. https://doi.org/10.1109/LRA.2025.3575644 (2025).
Gu, K. et al. Perceptual information fidelity for quality Estimation of industrial images. IEEE Trans. Circuits Syst. Video Technol. 35 (1), 477–491. https://doi.org/10.1109/TCSVT.2024.3454160 (2025).
Naz, A. et al. Using Transformers and Bi-LSTM with sentence embeddings for prediction of openness human personality trait. PeerJ Comput. Sci. 11, e2781. https://doi.org/10.7717/peerj-cs.2781 (May 2025).
Khatri, A., Agrawal, S. & Chatterjee, J. M. Wheat Seed Classification: Utilizing Ensemble Machine Learning Approach, Sci Program, vol. 2022, (2022). https://doi.org/10.1155/2022/2626868
Zhang, C. et al. Robust-FusionNet: deep multimodal sensor fusion for 3-D object detection under severe weather conditions. IEEE Trans. Instrum. Meas. 71 https://doi.org/10.1109/TIM.2022.3191724 (2022).
Belaala, A. et al. Exploring DeiT Transformers for Dermoscopic Image Classification: A Pilot Study, in 2025 International Symposium on iNnovative Informatics of Biskra (ISNIB), pp. 1–6. (2025). https://doi.org/10.1109/ISNIB64820.2025.10982885
Alsini, R. et al. Using deep learning and word embeddings for predicting human agreeableness behavior. Sci. Rep. 14 (1). https://doi.org/10.1038/s41598-024-81506-8 (Dec. 2024).
Funding
Not Applicable to this study.
Author information
Authors and Affiliations
Contributions
All authors Sang Guodong, and Wang Huiyu equally contributed to this study.
Corresponding author
Ethics declarations
Ethical approval
Authors have no conflict of Interest.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Symbols | Description |
|---|---|
\(\:\varvec{I}(\varvec{x},\varvec{y})\) | Original image intensity at pixel \(\:(x,y)\). |
\(\:\varvec{I}\varvec{{\prime\:}}(\varvec{x},\varvec{y})\) | Resized image intensity |
Δ | Discrete Laplacian operator |
\(\:\varvec{\lambda\:}\) | Sharpening factor |
\(\:{\varvec{e}}_{\varvec{i}}\) | Tokens |
\(\:{\varvec{W}}_{\varvec{e}}\) and \(\:{\varvec{b}}_{\varvec{e}}\) | Weights and bias |
\(\:\mathcal{l}\) | Layer |
\(\:{\stackrel{-}{\varvec{E}}}^{(\mathcal{l}-1)}\) | Self-attention layer to capture inter-token dependencies |
\(\:{\varvec{Q}}_{\varvec{h}}\) and \(\:{\varvec{K}}_{\varvec{h}}\) | Query and Key matrix of head \(\:h\) |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Guodong, S., Huiyu, W. Global attention and local features using deep perceptron ensemble with vision Transformers for landscape design detection. Sci Rep 15, 40900 (2025). https://doi.org/10.1038/s41598-025-24844-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-24844-5
