
Abstract
In power systems, the accurate identification of partial discharge (PD) in cables is crucial for the early detection of insulation defects and for maintaining power grid reliability. However, the low amplitude of PD signals and their susceptibility to noise interference increase the complexity of the identification process. To address this challenge, this paper proposes a novel deep learning architecture: the Adaptive Residual Diffusion Denoising Morphological Attention Network (ARDDMA-Net). ARDDMA-Net employs a two-stage design. In the first stage, an adaptive residual diffusion denoising module dynamically suppresses noise, while a morphological attention mechanism preserves critical features of PD signals, such as pulse width and edge structures. This effectively mitigates the masking and misclassification of weak PD pulses caused by noise. In the second stage, a multi-scale attention-enhanced ResNet-1D convolutional neural network extracts multi-scale features and performs precise classification, thereby addressing the limitations of traditional convolutional neural networks (CNNs) in handling low signal-to-noise ratio (SNR) conditions and multi-scale characteristics. Experimental results demonstrate that ARDDMA-Net maintains stable recognition performance under various noise levels and data loss conditions, outperforming traditional machine learning methods and existing deep learning models in terms of identification accuracy.
Similar content being viewed by others
Introduction
As urbanization accelerates and national power grids continue to evolve, power cables have taken on an increasingly pivotal role within modern power systems. It is projected that the global power cable market will witness substantial growth over the forthcoming years, highlighting its crucial significance in infrastructure development1. The reliability of cable insulation systems is directly linked to the safe operation of power grids, with partial discharge (PD) serving as an early warning indicator of insulation degradation, crucial for predicting defect evolution and assessing cable condition2. Nevertheless, the detection of PD signals is rendered challenging on account of their inherently low amplitude and complex time-domain characteristics, compounded by the influence of white noise, periodic interference, and pulse noise in field measurements3,4. As a consequence, how to efficiently develop robust PD identification methods has become an urgent issue in the field of electrical engineering.
In an effort to materialize automated PD pattern recognition, a diverse spectrum of approaches were proposed by domestic and international scholars, which were universally categorized into traditional machine learning and deep learning methods. Traditional machine learning methods have been applied to PD identification for an extended period, typically involving two steps: feature extraction5 and classification6. Feature extraction was commonly performed using wavelet transform, Fourier transform, or statistical analysis, followed by the application of classifiers such as support vector machines (SVM), K-nearest neighbors (KNN), or artificial neural networks (ANN) for pattern recognition. For instance, Sahoo and Karmakar employed wavelet-denoised PD signals to extract statistical features (e.g., skewness, kurtosis, standard deviation) for training a vast array of machine learning models7. Likewise, Carvalho et al. developed a signal conditioning system to extract features from PD signals, utilizing SVM and clustering algorithms for classification8. Riedmann et al. revolved around PD classification in direct current (DC) voltage applications, extracting features to address the specific challenges of DC systems9. Aside from that, a review by Lu et al. suggested that traditional methods performed well in laboratory settings but were limited in field applications as a consequence of noise interference and data complexity.
Attributable to their capability for automatic feature extraction, deep learning techniques have been universally employed to conduct PD identification in recent years. Convolutional neural networks (CNNs) and their variants (e.g., ResNet, DenseNet) have showcased exceptional performance in processing phase-resolved partial discharge (PRPD) images and time-domain signals. For example, Florkowski utilized CNNs to classify PD images, which sufficiently expanded their application in signal processing10. Rauscher et al. optimized models by conducting data augmentation and time-frequency representations, successfully applying them to PD detection in electrical equipment11. Fei et al. put forth an ensemble method combining a simple CNN with a quadratic support vector machine (QSVM). While achieving efficient recognition via phase-resolved pulse sequence (PRPS) spectrograms, its performance fell short under complex noise conditions12. Furthermore, other deep learning architectures have been explored for PD identification. Liu et al. proposed an innovative CNN-LSTM model for PD pattern recognition in gas-insulated switchgear (GIS), integrating CNN’s spatial feature extraction with LSTM’s time-series processing capabilities13. Zheng et al. proposed an innovative real-time transformer discharge pattern recognition approach, leveraging a CNN-LSTM framework powered by few-shot learning, tailored specifically for data-scarce scenarios14. Zhou et al. employed a bidirectional LSTM (Bi-LSTM) network with an attention mechanism to detect and identify PD in insulated overhead conductors15.
Although researchers developed various noise-robust deep learning models to address noise interference, these models still faced multiple challenges in practical applications. Raymond et al. proposed a CNN-based noise-invariant PD classification method, which was trained on clean data and tested on noisy data, which ultimately maintained outstanding precision16. While CNNs performed well in PD signal classification, further improvements were needed to handle complex interference types such as Gaussian white noise, periodic narrowband noise, and pulse noise. Rauscher et al. employed data augmentation techniques to enhance the robustness of PD detection, which was particularly conspicuous under low signal-to-noise ratio (SNR) conditions11. Nonetheless, deep learning models struggled to distinguish small PD pulses from noise in the absence of appropriate data augmentation. Sahoo and Karmakar first applied wavelet transform for denoising before using CNN for classification. Despite the fact that the above approach achieved desirable performance even with small sample sizes7, wavelet transform denoising resulted in the loss of certain signal details.
With an aim to address the multi-scale characteristics of PD signals, researchers innovated multi-resolution CNNs and CNN-LSTM models to capture features at different scales. Nevertheless, the direct application of standard CNNs to the time-frequency representations of PD signals induced distribution distortions ascribable to their inherent non-local and sequential traits, which in turn undermined diagnostic precision17. Consequently, a method integrating multi-resolution CNN with ultra-high frequency (UHF) spectrograms was recommended in the literature. While their approach considerably improved classification accuracy, its performance was less satisfactory for extremely multi-scale signals. Liu et al. adopted a CNN-LSTM model, integrating CNN’s spatial feature extraction with LSTM’s time-series processing capabilities, which further optimized PD identification performance. Nevertheless, this methodology presented tremendous computational complexity, rendering it unsuitable for real-time applications13. Apart from that, in the realm of multi-source PD diagnosis, the intricate complexity and inherent scarcity of multi-source PD signal data posed significant challenges to the effective training of conventional deep learning approaches. Relying solely on single-source training data, Mantach et al. introduced a CNN-based model for classifying multi-source and single-source PD patterns. This work showcased the promise of deep learning in managing intricate PD data, yet additional research is imperative to substantiate its reliability in real-world applications18.
Despite a series of breakthroughs in deep learning methods, they still face numerous challenges in practical engineering applications. First and foremost, noise is a particularly prominent issue, especially under low signal-to-noise ratio (SNR) conditions. In such scenarios, noise can easily distort waveform and polarity identification, and even misclassify noise pulses as PD pulses, leading to incorrect detection and impacting maintenance decisions. Additionally, in field measurements, white noise, electromagnetic interference, and periodic noise often cause feature extraction distortions. Kumar et al. pointed out that noise could obscure weak PD pulses, thereby reducing classification accuracy2. Riedmann et al. used unsupervised and semi-supervised learning for PD and noise classification in high-voltage direct current (HVDC) environments, highlighting the significant impact of noise on classification accuracy19. While traditional wavelet threshold denoising can partially alleviate noise issues, it may lead to the loss of signal details. Finally, because cable PD signals exhibit multi-scale characteristics influenced by defect types and propagation paths, standard CNNs with fixed convolution kernels struggle to capture all critical information simultaneously. This has prompted researchers to explore multi-scale convolution and time-frequency analysis techniques to improve model robustness, but this inevitably increases computational complexity. In fact, this trade-off between model performance, computational efficiency, and real-world robustness is a core challenge faced by current advanced deep learning architectures. Even in demanding fields like medical image analysis, researchers have found that models encounter performance bottlenecks when dealing with data artifacts or scaling up20.
To address the above challenges, this paper proposes a cable partial discharge identification network called ARDDMA-Net. The network employs a cascaded two-stage design to jointly handle noise interference and multi-scale feature extraction issues in an end-to-end manner, which differs from the traditional separate denoising and classification process. Specifically:
First stage: Deep collaborative denoising and morphological feature enhancement. The Adaptive Residual Diffusion Denoising (ARDD) module is introduced, which is based on diffusion model principles21. This module dynamically adjusts the denoising intensity according to local signal characteristics, thereby reducing noise while preserving the complete waveform of weak PD pulses. Unlike traditional fixed filters or data augmentation-based CNN methods, which often lose critical pulse details while suppressing noise, this approach aims to retain more pulse information. At the same time, a Morphological Attention (MA) mechanism is integrated. Unlike common channel/spatial attention mechanisms, MA is customized to model the physical morphological features of PD signals. It is a lightweight, parameter-free attention method. This design is aligned with the recent direction of “parameter-efficient attention” in computer vision22. The MA module uses morphological gradients to model and enhance time-domain pulse shapes, focusing on the width and edge structure features of PD pulses. Compared to methods like CNN-LSTM, which require complex recurrent structures, MA is more targeted and can maintain good real-time performance while reducing computational complexity.
Second stage: Multi-scale feature extraction and classification. Based on the denoised and morphology-enhanced signals generated in the first stage, multi-scale attention23 is used for classification. The MSA-ResNet-1D module extracts features at different scales through parallel convolution paths and applies an attention mechanism for adaptive weighting, thereby improving classification performance. Benefiting from the high-quality input provided by ARDD and MA, this module extracts more discriminative features in low SNR environments. Additionally, the residual connections in the ResNet structure mitigate the gradient vanishing problem during deep network training, improving training stability. Overall, ARDDMA-Net demonstrates stable recognition performance under complex conditions.
Adaptive residual diffusion denoising morphological attention network
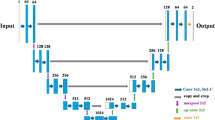
PD signals, typically characterized by low amplitude and complex time-domain features, present substantial obstacles for detection in high-noise environments. It is considerably noteworthy that conventional diffusion models and fixed residual networks often sacrifice critical signal details throughout noise removal, falling short of meeting the demands for practical engineering. As illustrated in Fig. 1, a cascaded two-stage network was pioneered to overcome the above limitation. In the first stage, an adaptive residual diffusion denoising (ARDD) module was employed to progressively remove noise, while a morphological attention (MA) mechanism dynamically adjusted feature retention. In the second stage, a multi-scale attention-enhanced ResNet-1D CNN was utilized to perform signal classification.

Structure of the ARDDMA-Net.
Diffusion process and reverse denoising theory
Forward diffusion process
In the forward diffusion process, the original signal is gradually corrupted by noise according to the following formula:
Here,\(\:\:{x}_{t}\) denotes the noisy signal at step \(\:\text{t}\),\(\:\:{x}_{0}\) is the original signal, and \(\epsilon\) is sampled from the standard normal distribution\(\:\mathcal{\:}\mathcal{N}\left(0,I\right)\). The term \(\:{\stackrel{-}{\alpha\:}}_{t}\) is the signal retention coefficient, defined as \(\:{\stackrel{-}{\alpha\:}}_{t}=\prod\:_{i=1}^{t}\:(1-{\beta\:}_{i})\), where \(\:{\beta\:}_{t}\) is the noise injection ratio at step \(\:t\) and satisfies\(\:{\beta\:}_{t}\in\:\left(\text{0,1}\right)\).
To ensure the stability of the diffusion process and convergence to an isotropic Gaussian distribution, the constraint \(\:\sum\:_{t=1}^{T}\:{\beta\:}_{t}<{\infty\:}\) should be satisfied. In this study, the total number of diffusion steps is set to \(\:\text{T}=1000\), and a linear schedule is applied for \(\:{\beta\:}_{t}\). Specifically,\(\:\:{\beta\:}_{1}=1\times\:{10}^{-4}\)and \(\:{\beta\:}_{T}=0.02\), increasing linearly in between. This setting provides a smooth and gradually enhanced perturbation, which allows the signal to be effectively degraded into a Gaussian form while preserving the overall structure. By progressively injecting Gaussian noise, the forward diffusion process achieves a mixture of signal and noise, thereby laying the foundation for the subsequent reverse denoising process.
Reverse denoising process
To avoid confusion with the forward process, the variables in the reverse process are denoted as \(\:{\stackrel{\sim}{x}}_{t}\). The reverse denoising process introduces a parameterized conditional probability \(\:{p}_{\theta\:}\left({\stackrel{\sim}{x}}_{t-1}\right|{\stackrel{\sim}{x}}_{t})\), expressed as:
Where \(\:{\mu\:}_{\theta\:}\) \(\:{{\Sigma\:}}_{\theta\:}(\cdot\:)\) represent the mean and covariance functions, which are learned by network parameters. The denoiser is implemented using a U-Net architecture adapted for one-dimensional time-series signals. The network consists of an encoder (four downsampling blocks: Conv1D, BatchNorm, ReLU), a bottleneck layer, and a decoder (four upsampling blocks), with sinusoidal positional encoding for the time step \(\:t\). The training objective is ε-prediction, where the model predicts the noise \(\epsilon\). The corresponding loss function is defined as:
Through multi-step reverse sampling, the denoised signal is reconstructed as:
This \(\:{\widehat{x}}_{0}\) serves as the reconstruction of the original signal \(\:{x}_{0}\) and is used as the input to the subsequent residual network (ResNet-1D CNN) model. During training, ancestral sampling is employed, while inference uses the DDIM schedule with 50 steps. Compared with the standard DDPM sampling, this strategy accelerates the inference process while maintaining reconstruction quality and reducing sampling variance.
Adaptive residual connection mechanism
Dynamic adjustment and information entropy correlation
Throughout the reverse denoising process, an adaptive residual connection mechanism was put forward to dynamically adjust for local noise and critical information. The residual connection is expressed as:
Where \(\:f(x,t)\) defines the original features retained at time step \(\:\text{t}\), \(\:F(x,t)\) denotes the feature supplement obtained through convolution and non-linear mapping, and \(\:a(x,t)\) refers to the dynamic adjustment coefficient. Specifically, the relationship between \(\:a(x,t)\) and the local information entropy \(\:H(x,t)\) is given by the following equations:
In these equations, \(\:{\upalpha\:}\) is an adjustment factor. It controls the amplification of \(\:a(x,t)\) and determines the degree of influence that entropy has on the coefficient. \(\:H(x,t)\) is the local information entropy, and \(\:{H}_{max}\) is its maximum value. This design helps reduce the model’s reliance on residual features in regions with more noise. At the same time, it strengthens feature information in regions where local pulse features are distinct. This ultimately optimizes the denoising process.
Lipschitz continuity analysis
In order to guarantee the stability of the adaptive residual connection, the mapping was required to satisfy Lipschitz continuity. For any inputs \(\:{x}_{1}\) and \(\:{x}_{2}\), the following condition was established:
Where L denotes the Lipschitz constant. This characteristic ensures that output fluctuations stay regulated amid input perturbations, thereby bolstering the stability of model training. This analysis guarantees that the model’s output remains stable, avoiding drastic shifts under noise and signal perturbations, thus preserving the denoising effect’s consistency.
Multi-scale morphological attention module
Input signal and morphological gradient
The input to the multi-scale morphological attention module24 was derived from the intermediate features \(\:x\left(t\right)\) of the denoising module (or an intermediate representation of \(\:{\stackrel{\sim}{x}}_{t}\) in the reverse process). At scale s, morphological operations were defined as:
The morphological gradient was subsequently defined as:
In accordance with Matheron’s morphological theory25, if there exists a threshold τ such that:
On the above basis, there exists a point \(\:\varDelta\:t\) where \(\:x\left({\Delta\:}t\right)\) belongs to the topological connected domain of the partial discharge (PD) pulse signal within the interval \(\:[t-s,t+s]\), demonstrating that the local region exhibits prominent pulse characteristics.
Method for selecting the threshold \(\:\tau\:\): This paper uses the Otsu method to automatically determine the threshold26. The Otsu method is a classic adaptive thresholding technique. It selects the optimal threshold by maximizing the inter-class variance. The specific steps are as follows:
① Calculate the feature histogram: Compute the grayscale histogram of the input feature \(\:x\left(t\right)\). Based on the histogram, calculate the inter-class variance for different candidate thresholds \(\:\tau\:\).
Here, \(\:{\omega\:}_{0}\) and \(\:{\omega\:}_{1}\) are the weights of the two classes under the threshold \(\:\tau\:\), and \(\:{\mu\:}_{0}\) and \(\:{\mu\:}_{1}\) are the means of these two classes.
② Select the optimal threshold τ: Choose the threshold that maximizes the inter-class variance \(\:{\sigma\:}_{B}^{2}\left(\tau\:\right)\) as the final threshold.
Multi-scale fusion and convergence
Across the set of scales, cross-scale fusion was achieved through max-pooling, with the baseline attention weight defined as:
The convergence of the max-pooling operation was demonstrated, substantiating the reasonableness and representativeness of choosing a finite set of scales in real-world applications. Ultimately, the attention coefficient was derived through normalization. (e.g., using the Sigmoid function):
This coefficient is harnessed within the adaptive residual connection to refine the network’s emphasis on local pulse characteristics, thereby amplifying the model’s efficacy in partial discharge signal pattern recognition.
ResNet-1D CNN network
Feature extraction and residual block mapping
The denoised signal \(\:{\widehat{x}}_{0}\) was utilized as the input to the 1D convolutional neural network (CNN), with the initial layer feature defined as:\(\:\:{h}^{\left(0\right)}={\widehat{x}}_{0}\)
In each residual block, the mapping for the l-th layer was formulated as:
The input to the subsequent layer was then derived as:
Where \(\:{H}^{\left(l\right)}(\cdot\:)\) represents a non-linear mapping composed of the convolutional kernel \(\:{W}^{\left(l\right)}\), bias \(\:{b}^{\left(l\right)}\), activation function , and batch normalization (BN). The symbol * denotes the one-dimensional convolution operation.
Global pooling and final output
Subsequent to the output of the final layer \(\:{H}^{\left(L\right)}\), global average pooling (GAP) was applied to obtain a fixed-dimensional feature vector:
Afterwards, a fully connected (FC) layer with a Softmax activation function was employed to produce the final classification probability distribution:
Where W and b are learnable parameters, and the spectral norm \(\:\parallel\:W{\parallel\:}_{2}\) constrains the output stability.
Experimental design and result analysis
Construction of the partial discharge experimental platform
In a high-voltage laboratory, an experimental platform for PD was established to ensure that the collected PD data accurately reflects the insulation condition of cables during actual operation, as illustrated in Fig. 2. Featured by strong anti-interference capability, high sensitivity, and excellent accuracy, the pulse current detection method was employed to acquire PD signals from the fault model. The experimental platform consisted of a transformer, a protection resistor, a current-limiting resistor, a fault model, a coupling capacitor, a detection impedance, and an oscilloscope. The voltage control console and transformer were operated in tandem to generate the required test voltages for the fault model. The protection resistor was incorporated to limit large currents in the circuit, ensuring equipment safety. The coupling capacitor served dual purposes: coupling high-frequency signals while isolating DC high voltage and acting as a voltage divider. A high-frequency current transformer was utilized to measure pulse currents across the detection impedance. The oscilloscope, with a sampling frequency of 50 MHz, was used to record time-series samples of discharge waveforms for four types of faults. To simulate PD behavior under various operating conditions, four fault models corresponding to actual cable insulation defects were designed: tip discharge, suspended discharge, surface discharge, and air gap discharge. Throughout the experiment, the fault model was exposed to a progressive voltage increase via the voltage control console, commencing at a low-voltage level and gradually elevated to a high-voltage state until stable PD wave-forms were achieved.

Schematic diagram of the partial discharge experimental platform.
Construction of the experimental dataset
The data used for model training and testing were formatted as one-dimensional time-series data27, with each waveform signal’s time-series sample points serving as training samples. Each sample in the dataset comprised 3,600 time-series data points. To prevent class imbalance, 800 samples were collected for each of the four PD fault types, resulting in a total of 3,200 samples. These were divided into training and testing sets in an 8:2 ratio. All samples were processed using min-max normalization to ensure data consistency and comparability. As illustrated in Fig. 3, the time-domain waveforms of the four PD types, compiled from sample points captured by the oscilloscope, indicate that the acquired signals are heavily contaminated with noise.

Time-domain waveforms of partial discharge for four fault types. (a) Floating discharge; (b) Tip discharge; (c) Air gap discharge; (d) Surface discharge.
Experimental environment and model parameter settings
The experiments were conducted on the following hardware: GPU — NVIDIA GeForce GTX 1650 (4GB memory), CPU — 11th Gen Intel(R) Core(TM) i5-11320 H @ 3.20 GHz. The software environment included Python 3.10 and the PyTorch 1.10.1 deep learning framework. During model training, the learning rate was set to 0.0001, with 120 epochs and a batch size of 32. The Adam optimizer was used for model optimization, and cross-entropy loss was applied to evaluate the difference between classification results and ground-truth labels.The parameter settings for the proposed ARDDMA-Net model are presented in Table 1. The parameters for the Conv1D and Residual Block modules are specified as [input channel number, output channel number, convolutional kernel size, convolutional stride size]. The parameters for the fully connected (FC) module are denoted as [input channel number, output channel number]. The final FC layer outputs four neurons, corresponding to the number of PD fault types. The final column of the table outlines the output sizes of feature maps at diverse layers, where three-dimensional formats indicate batch size × channel number × length, and two-dimensional ones represent batch size × channel number.
Experimental evaluation metrics
In the experiments, the classification performance of the model was evaluated using Accuracy (A), Precision (P), Recall (R), and the harmonic mean F1. Since this study focuses on a multi-class classification task, the final Precision, Recall, and F1-Score results were calculated using the macro-average strategy. That is, the metrics were computed for each class and then averaged arithmetically. The specific formulas are as follows:
Here, \(\:{T}_{P}\) denotes the number of positive samples correctly predicted,\(\:\:{T}_{N}\) denotes the number of negative samples correctly predicted,\(\:\:{F}_{P}\) denotes the number of negative samples incorrectly predicted as positive, and \(\:{F}_{N}\) denotes the number of positive samples incorrectly predicted as negative.
Model performance comparison
To comprehensively evaluate the performance and computational efficiency of ARDDMA-Net in PD pattern recognition tasks, it was compared with five deep learning methods (ResNet, DenseNet, Swin Transformer, MobileNet, WCNN) and three traditional machine learning methods (SVM, BPNN, XGBoost). All experiments were conducted under a unified training strategy. The results are summarized in Table 2, which reports Accuracy(A%), Precision(P%), Recall(R%), F1-Score(F1%), number of parameters(Params), FLOPs, memory usage(Memory), and training time(Time).
In terms of classification performance, ARDDMA-Net achieved higher results across multiple metrics. Its accuracy reached 98.36%, while Precision, Recall, and F1-Score were 98.21%, 98.48%, and 97.76%, respectively. By contrast, traditional methods such as SVM, BPNN, and XGBoost showed limitations in modeling high-dimensional nonlinear features, with the highest accuracy not exceeding 86.45%. Deep learning methods like ResNet, DenseNet, and Swin Transformer significantly improved recognition ability through automatic feature extraction. Among them, Swin Transformer leveraged its multi-head self-attention mechanism to capture global dependencies, reaching an accuracy of 93.25%, though it still showed shortcomings when handling noisy signals.
In terms of computational complexity, the results indicate that ARDDMA-Net strikes a relative balance between accuracy and efficiency. Compared with traditional methods, it requires more parameters and training time, but achieves more than a 10% improvement in accuracy, which is reasonable for engineering applications. When compared with other deep learning methods, ARDDMA-Net achieved 860 M FLOPs and 213.5 MB of memory usage, which are approximately 13% and 17% of those of Swin Transformer, respectively. Its parameter count (2303 K) is also significantly lower than ResNet (8124 K) and DenseNet (5021 K). Moreover, its training time (55 min) is shorter than most of the baseline models. Overall, the results in Table 2 demonstrate that ARDDMA-Net not only achieves high recognition accuracy but also effectively controls computational cost. This balance between performance and complexity provides strong support for its further application in power systems.
Figure 4 illustrates the classification performance of different models on the four types of PD faults, which are evaluated in detail through confusion matrices. In the matrix, labels 1, 2, 3, and 4 correspond to air gap discharge, surface discharge, tip discharge, and suspended discharge, respectively. The depth of the diagonal color in the confusion matrix reflects the recognition accuracy of the model for each class. As shown in Fig. Figure 4, most models achieve higher accuracy in identifying air gap discharge, but different degrees of confusion occur in the other fault categories. For example, the SVM model shows weak recognition ability for suspended discharge, with many samples misclassified as tip or surface discharge, which reflects its limitation in handling class boundary issues. XGBoost still misclassifies many suspended discharge samples as tip discharge, and errors also appear in surface discharge recognition. DenseNet performs well among deep learning methods, but errors still occur in suspended discharge judgment, with some samples classified as tip discharge. In contrast, the proposed ARDDMA-Net shows higher accuracy across all fault types, further confirming its effectiveness in fault classification tasks.
Further analysis indicates that Class 3 (tip discharge) and Class 4 (suspended discharge) are the most likely to be confused, since the two signals share overlapping features in the time and frequency domains, especially in high-frequency noise and fluctuation characteristics. This is also the reason why traditional methods generally find it difficult to distinguish between them accurately. However, ARDDMA-Net demonstrates significantly stronger discrimination between these two classes. This advantage mainly comes from two aspects: (1) the adaptive residual diffusion denoising module effectively suppresses noise interference on weak pulses and restores the true signal characteristics of tip and suspended discharge; (2) the morphological attention module emphasizes pulse shapes and edge details, where the two discharges have subtle differences. By combining these two designs, ARDDMA-Net preserves the discriminative features between Class 3 and Class 4, greatly reducing confusion, and thus exhibits more robust and differentiated classification results in the confusion matrix.

Confusion matrices of different models. (a) SVM model; (b) XGBoost model; (c) ResNet model; (d) Wavelet-CNN model; (e) MobileNet model; (f) DenseNet model; (g) Swin transformer model; (h) ARDDMA-Net model.
Ablation study
Through the adoption of a field PD dataset, ablation experiments were conducted to evaluate the impact of the adaptive residual (AR) and diffusion model (DM) modules on model performance, with results presented in Table 3. The ResNet-1D CNN was adopted as the baseline model for comparison, and each module was incrementally incorporated into the baseline model. On top of that, three typical denoising algorithms, including wavelet transform (WT), singular value de-composition (SVD), and principal component analysis (PCA), were compared to further assess the denoising capability of ARDDMA. These denoising algorithms were applied to preprocess the PD signals before feeding them into the baseline model for comparison. All experiments were performed under identical training parameters and environmental conditions. Figure 4 illustrates the comparison of different denoising methods, including the noisy PD signal with additional noise, signal comparisons in the 0.8–1.2 ms interval, and signals processed by the proposed method alongside the three denoising algorithms. In Table 3, a mark “√” suggests the inclusion of a module, while a mark “—” reveals its absence.
As delineated in Table 3, when compared to the baseline model, pre-processing PD signals using conventional denoising techniques (such as WT, SVD, and PCA) prior to network input enhanced recognition accuracy to a certain degree. In particular, the WT denoising algorithm displayed the most significant improvement, increasing accuracy from 75.81% to 86.52%. On the contrary, the model incorporating only the DM module achieved a recognition accuracy of 91.34% without any pre-processing, demonstrating the diffusion model’s substantial advantage in feature extraction and noise suppression. Though the improvement was somewhat constrained, the model featuring only the AR module still enhanced performance, reaching an accuracy of 81.44%. Notably, the integration of both AR and DM modules in the ARDDMA-Net model fully leveraged their synergistic effects, further elevating the recognition accuracy to 98.36%, which representing a significant improvement over single-module configurations. These results robustly validate the effective-ness of the proposed module design.

Comparison of denoising effects of different algorithms. (a) Noisy PD signal; (b) comparison of four denoising algorithms; (c) SVD-denoised signal; (d) PCA-denoised signal; (e) ARDDMA-denoised signal; (f) WT-denoised signal.
As shown in Fig. 4, the signal obtained by the ARDDMA denoising method is very smooth and exhibits clear periodic components. Most of the high-frequency noise is removed while the basic structure of the signal is preserved. Although high-frequency oscillations are minimized, the final signal presents a consistent periodic pattern, indicating that ARDDMA performs well in identifying and isolating the core components of the signal. The WT denoising method also produces a smoother signal compared with the SVD and PCA algorithms, but some residual noise remains, especially in the higher frequency range. In addition, the filtered signal shows distortion, and compared with the ARDDMA output, WT denoising is less effective in preserving fine details. The PCA method improves signal quality compared with the noisy input, but some noise is still retained. The result is less smooth than ARDDMA and WT denoising, with visible irregularities in some parts. The SVD method reduces noise to some extent, but the result remains quite noisy and still contains a large amount of interference. Overall, its denoising performance is inferior to ARDDMA.
Robustness experiments
To evaluate the robustness of the proposed ARDDMA-Net model in cable PD pattern recognition tasks, experiments were conducted under complex conditions such as noise interference and signal loss based on the experimental dataset.
Noise interference testing
In practical applications, PD signals are usually affected by various types of noise interference. To better approximate real electromagnetic environments, this study employed composite industrial noise (CIN) instead of simple Gaussian white noise. The CIN was composed of three parts: (1) Gaussian white noise to simulate background thermal noise; (2) Pink noise (1/f noise) to simulate low-frequency electronic device noise; (3) Power frequency narrowband interference, consisting of the fundamental 50 Hz signal with its 3rd (150 Hz) and 5th (250 Hz) harmonics, to reflect periodic disturbances from operating power equipment.
Different levels of noise were added to 20% of the test samples, with the signal-to-noise ratio (SNR) ranging from + 3 dB to − 12 dB in 3 dB steps, in order to observe performance trends as noise intensity increased. Specifically, + 3 dB indicates that the signal power is approximately twice the noise power, representing a mild but noticeable interference scenario, while − 12 dB means the noise power greatly exceeds the signal power, corresponding to extremely harsh conditions. The step size of 3 dB was chosen because it represents a doubling or halving of power in signal processing, effectively capturing the trend of model performance degradation under noise variation.
Under these conditions, ARDDMA-Net was compared with several baseline models, including SVM, ResNet-1D, Swin Transformer, and MSA-ResNet-1D. The experimental results are shown in Table 4; Fig. 6. It can be seen that the performance of all models declined as the noise level increased, which validates the effectiveness of the test. However, significant differences in anti-noise capability were observed among the models. While the baseline models exhibited substantial performance degradation, ARDDMA-Net experienced a relatively smaller accuracy drop of only 22.6% points across the full SNR range from + 3 dB to − 12 dB. This indicates that ARDDMA-Net possesses superior robustness under complex noise conditions.

Performance comparison curves of different models under CIN.
Data missingness testing
During the acquisition or transmission of partial discharge signals, data loss may occur due to equipment or communication issues. In particular, continuous data loss can have a significant impact on the structure of time-series signals. To evaluate the robustness of the model under such conditions, this study designed a burst continuous data missing experiment. Specifically, for each test sample, a random starting point was selected, and a certain proportion of consecutive sampling points were set to zero. The missing ratio was set from 5% to 15%. The experimental results are shown in Table 5; Fig. 7.

Performance comparison curves of different models under consecutive signal loss.
The results demonstrate that all models suffered performance degradation as the missing rate increased. Compared with other models, ARDDMA-Net maintained relatively high accuracy even under high missing ratios. For example, at a 15% missing rate, its classification accuracy reached 79.8%. In addition, its performance degradation was smaller than that of the baseline models, which indicates that ARDDMA-Net can effectively preserve temporal feature utilization when dealing with incomplete signals.
Conclusion
To sum up, a novel PD identification network grounded in adaptive residual diffusion denoising and morphological attention (ARDDMA-Net) is proposed to address the challenge of recognizing PD signals in complex noisy environments. The main conclusions are outlined below:
-
1.
ARDDMA-Net demonstrates satisfactory performance in cable PD identification, achieving an accuracy of 98.36%, surpassing traditional machine learning methods (SVM, XGBoost, BPNN) and five advanced deep learning methods (ResNet, DenseNet, Swin Transformer, MobileNet, Wavelet-CNN).
-
2.
As further validated by our ablation experiments, the adaptive residual and diffusion model modules play irreplaceable roles in denoising and feature enhancement. More importantly, their synergistic effects can significantly improve the overall performance of the model.
-
3.
Under complex conditions with noise interference and data missing, ARDDMA-Net shows relatively stable performance. For example, under composite industrial noise consisting of Gaussian white noise, pink noise, and periodic narrow-band interference, the model still maintains an accuracy of 71.5% when the signal-to-noise ratio drops to − 12 dB. Under 15% burst continuous data missing, the accuracy reaches 79.8%. These results indicate that the proposed method has a certain degree of adaptability and reliability when facing incomplete or disturbed data, but further validation on data closer to real operating conditions is still needed.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Zhang, X., Pang, B., Liu, Y., Liu, S., Xu, P., Li, Y., … e, Q. Review on detection and analysis of partial discharge along power cables. Energies. 14(22) 7692 (2021).
Kumar, H., Shafiq, M., Kauhaniemi, K. & Elmusrati, M. A review on the classification of partial discharges in Medium-Voltage cables: Detection, feature Extraction, artificial Intelligence-Based classification, and optimization techniques. Energies 17 (5), 1142 (2024).
Govindarajan, S., Morales, A., Ardila-Rey, J. A. & Purushothaman, N. A review on partial discharge diagnosis in cables: Theory, techniques, and trends. Measurement 216, 112882 (2023).
Hussain, M. R., Refaat, S. S. & Abu-Rub, H. Overview and partial discharge analysis of power transformers: A literature review. Ieee Access. 9, 64587–64605 (2021).
Banjare, H. K., Sahoo, R. & Karmakar, S. Study and analysis of various partial discharge signals classification using machine learning application. In 2022 IEEE 6th International Conference on Condition Assessment Techniques in Electrical Systems (CATCON). 52–56 (IEEE, 2022).
Lu, S., Chai, H., Sahoo, A. & Phung, B. T. Condition monitoring based on partial discharge diagnostics using machine learning methods: A comprehensive state-of-the-art review. IEEE Trans. Dielectr. Electr. Insul. 27 (6), 1861–1888 (2020).
Sahoo, R. & Karmakar, S. Comparative analysis of machine learning and deep learning techniques on classification of artificially created partial discharge signal. Measurement 235, 114947 (2024).
Carvalho, I. F., da Costa, E. G., Nobrega, L. A. M. M. & Silva, A. D. Identification of partial discharge sources by feature extraction from a signal conditioning system. Sensors 24 (7), 2226 (2024). D. C.
Schober, B. & Schichler, U. Application of machine learning for partial discharge classification under DC voltage. In Proceedings of the Nordic Insulation Symposium. 26 16–21 (2019).
Florkowski, M. Classification of partial discharge images using deep convolutional neural networks. Energies 13 (20), 5496 (2020).
Rauscher, A., Kaiser, J., Devaraju, M. & Endisch, C. Deep learning and data augmentation for partial discharge detection in electrical machines. Eng. Appl. Artif. Intell. 133, 108074 (2024).
Fei, Z., Li, Y. & Yang, S. Partial discharge pattern recognition based on an ensembled simple convolutional neural network and a quadratic support vector machine. Energies 17 (11), 2443 (2024).
Liu, T., Yan, J., Wang, Y., Xu, Y. & Zhao, Y. GIS partial discharge pattern recognition based on a novel convolutional neural networks and long short-term memory. Entropy 23 (6), 774 (2021).
Zheng, Q. et al. A real-time transformer discharge pattern recognition method based on CNN-LSTM driven by few-shot learning. Electr. Power Syst. Res. 219, 109241 (2023).
Zhou, Y., Zhang, W. & F., & Partial discharge detection and recognition in insulated overhead conductor based on bi-LSTM with attention mechanism. Electronics 12 (11), 2373 (2023).
Raymond, W. J. K. et al. Noise invariant partial discharge classification based on convolutional neural network. Measurement 177, 109220 (2021).
Li, G., Wang, X., Li, X., Yang, A. & Rong, M. Partial discharge recognition with a multi-resolution convolutional neural network. Sensors 18 (10), 3512 (2018).
Mantach, S., Ashraf, A., Janani, H. & Kordi, B. A convolutional neural network-based model for multi-source and single-source partial discharge pattern classification using only single-source training set. Energies 14 (5), 1355 (2021).
Morette, N., Heredia, L. C., Ditchi, T., Mor, A. R. & Oussar, Y. Partial discharges and noise classification under HVDC using unsupervised and semi-supervised learning. Int. J. Electr. Power Energy Syst. 121, 106129 (2020).
Manzari, O. N., Asgariandehkordi, H., Koleilat, T., & Rivaz, H. Medical image classification with kan-integrated Transformers and dilated neighborhood attention. Arxiv Preprint Arxiv :250213693. (2025).
Croitoru, F. A., Hondru, V., Ionescu, R. T. & Shah, M. Diffusion models in vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 45 (9), 10850–10869 (2023).
Semiromizadeh, N., Manzari, O. N., Shokouhi, S. B. & Mirzakuchaki, S. Enhancing Vehicle Make and Model Recognition with 3D Attention Modules. In 2024 14th International Conference on Computer and Knowledge Engineering (ICCKE). 087–092 (IEEE, 2024).
Du, Y., Chen, X. & Fu, Y. Multiscale Transformers and multi-attention mechanism networks for pathological nuclei segmentation. Sci. Rep. 15 (1), 12549 (2025).
Zhu, Y., Qiao, Y., Zhou, Q. & Yang, X. Edge morphology attention mechanism and optimal geometric matching connection model for vascular segmentation. Biomed. Signal Process. Control. 99, 106849 (2025).
Maragos, P. A representation theory for morphological image and signal processing. IEEE Trans. Pattern Anal. Mach. Intell. 11 (6), 586–599 (1989).
Zhong, J., Du, S., Shen, C., Chen, Y., Gao, M., Naidu, M., Fu, Y. Energy-based segmentation methods for images with non-Gaussian noise. Sci. Rep., 15(1) 25707 (2025).
Liu, Z., Wang, H., Liu, J., Qin, Y. & Peng, D. Multitask learning based on lightweight 1DCNN for fault diagnosis of wheelset bearings. IEEE Trans. Instrum. Meas. 70, 1–11 (2020).
Funding
This research was funded by the Jiangxi Electric Power Co., Ltd. Science and Technology Project [grant number 52182023000X]; and the National Natural Science Foundation of China [grant number 52267008].
Author information
Authors and Affiliations
Contributions
writing—original draft preparation, Long Chen; writing—review and editing, Qiong Li; supervi-sion, Yang Zou and Jian Deng; project administration, Guohua Long. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, L., Li, Q., Long, G. et al. Cable partial discharge identification network based on adaptive residual diffusion denoising and morphological attention. Sci Rep 15, 42848 (2025). https://doi.org/10.1038/s41598-025-25197-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-25197-9
