
Abstract
Task scheduling and load balancing in cloud computing represent challenging NP-hard optimization problems that often result in inefficient resource utilization, elevated energy consumption, and prolonged execution times. This study introduces a novel Cluster-based Federated Learning (FL) framework that addresses system heterogeneity by clustering virtual machines (VMs) with similar characteristics via unsupervised learning, enabling dynamic and efficient task allocation. The proposed method leverages VM capabilities and a derivative-based objective function to optimize scheduling. We benchmark the approach against established metaheuristic algorithms including Whale Optimization Algorithm (WOA), Butterfly Optimization (BFO), Mayfly Optimization (MFO), and Fire Hawk Optimization (FHO). Evaluated using makespan, idle time, and degree of imbalance, the Cluster-based FL model coupled with the COA algorithm consistently outperforms existing methods, achieving up to a 10% reduction in makespan, a 15% decrease in idle time, and a significant improvement in load balancing across VMs. These results highlight the efficacy of integrating clustering within federated learning paradigms to deliver scalable, adaptive, and resilient cloud resource management solutions.
Similar content being viewed by others


Introduction
Cloud computing has revolutionized the provisioning of computational resources by enabling users to access pooled resources on demand via the internet. This paradigm is underpinned by a vast network of interconnected computers that collaboratively manage the storage and execution of user data and applications. Incorporating principles of distributed and parallel computing, cloud environments facilitate the flexible and scalable allocation of resources, enabling the “pay-as-you-go” model where users are charged solely based on their actual resource consumption rather than upfront hardware or software investments1. Central to cloud computing infrastructure are virtual machines (VMs), which facilitate dynamic computation and resource sharing during task execution2. However, due to the sheer number of VMs concurrently utilizing shared resources in a non-preemptive manner, equitable access to computational capacity is often not guaranteed. Parallel execution of tasks across multiple VMs is critical for reducing execution times and improving system throughput3.
Load balancing—the process of distributing workloads evenly across VMs—has therefore emerged as a vital area of research to optimize resource utilization and minimize task latency4. While static load balancing strategies can be effective when workload demands remain relatively stable, they are ill-suited for the inherently dynamic and fluctuating resource demands characteristic of cloud workloads. Dynamic load balancing techniques, which continuously monitor and adjust resource allocations based on real-time load information, have demonstrated superior performance in adapting to such variability and maintaining system stability5,6. Motivated by these challenges, this study proposes a hybrid meta-heuristic approach to dynamically prioritize jobs within VM queues and maintain optimal load balance.
In cloud environments where certain VMs experience high task loads while others remain underutilized, redistributing workloads from overloaded VMs to less burdened ones can substantially improve overall system efficiency. This approach reduces task waiting times, increases throughput, and enhances load distribution across the cloud infrastructure7. The load balancer acts as the central orchestrator, managing task assignments based on VM fitness scores, which reflect current resource availability and performance metrics. When existing VMs cannot meet demand due to capacity constraints, new VMs are instantiated to maintain service quality, subject to hardware-imposed limits on VM density per host8,9.
This research focuses on long-term load balancing strategies for cloud data centers, which often operate remotely from end-users and support a diverse array of web hosting services over distributed networks10,11. Efficient scheduling across cloud nodes is crucial for achieving high Quality of Service (QoS), minimizing system imbalance, and ensuring equitable response times12. Load balancing not only prevents node overloads and underutilization but also optimizes resource usage, scalability, and task migration times within data centers. However, frequent VM migrations can adversely affect overall cloud efficiency, necessitating optimized migration strategies13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31.
To address these challenges, we propose a federated learning (FL) framework tailored for cloud environments. This approach facilitates collaborative model training across distributed participants without necessitating centralized data aggregation, thereby reducing network overhead and preserving data privacy. Specifically, we introduce a clustered FL methodology designed to mitigate global model convergence issues arising from client heterogeneity. The method involves grouping clients with similar local data distributions into clusters, enabling parallel FL training within each cluster. This clustered strategy enhances convergence rates and model performance in heterogeneous cloud settings. Our proposed Cluster-based FL framework advances beyond these limitations by combining adaptive clustering with decentralized model training to address heterogeneity, scalability, privacy, and efficiency simultaneously, thus offering a holistic and practical solution for modern cloud scheduling challenges.
The remainder of the manuscript is organized as follows: Section “Related works” reviews the pertinent literature. The proposed methodology is detailed in Section “Background and proposed system”. Section “Results and discussion” presents the experimental findings along with their interpretation. Finally, Section “Conclusion and future scope” offers the concluding remarks of the study.
Related works
Significant efforts have been devoted to improving load balancing and task scheduling within cloud computing environments, addressing critical challenges such as energy consumption, response time, security, and resource utilization. Javadpour et al.32 introduced a priority-aware task scheduling approach that classifies physical machines based on their configurations and applies Dynamic Voltage and Frequency Scaling (DVFS) to reduce power consumption for lower-priority workloads. Their experiments using CloudSim demonstrated notable reductions in energy and power usage, highlighting the importance of hardware-aware strategies. However, their method primarily focuses on energy efficiency and static grouping of machines, without dynamically adapting to fluctuating workloads or heterogeneous task profiles.
Saba et al.33 tackled the problem of minimizing response times while preserving secure communication by proposing a distributed load balancing mechanism integrated with trust evaluation. By migrating computationally intensive tasks closer to request sources, their protocol effectively reduces network latency and overhead. Simulation results indicate significant improvements over traditional approaches in network cost and energy efficiency. Nonetheless, their framework emphasizes communication overhead and security rather than comprehensive resource allocation or workload heterogeneity.Gutierrez-Garcia et al.34 proposed a coalition-based, agent-driven approach for live VM migration grounded in cooperative game theory. Agents managing neighboring hosts form coalitions and cooperate to balance load by migrating VMs, considering both migration costs and load distribution benefits. Their method outperforms baseline hill-climbing algorithms in data center simulations, yet the approach assumes relatively static coalitions and may struggle with rapid workload variability or large-scale deployments.
Chiang et al.35 presented the BCSV scheduling algorithm aimed at improving task dispatch efficiency by addressing load balancing within the scheduling process. While this method enhances throughput, it does not explicitly incorporate considerations for energy consumption or dynamic VM scaling, limiting its effectiveness in large and heterogeneous cloud environments.
Jangra and Mangla36 introduced a reinforcement learning-based load balancing framework tailored for cloud-enabled healthcare applications. Utilizing Q-learning, their approach optimizes resource allocation, achieving reductions in make-span, latency, and energy use, as validated in MATLAB simulations. The domain-specific nature of their model, however, restricts its generalizability to broader cloud scenarios with diverse workloads.
Jambulingam and Balasubadra37 developed an energy-aware agent-based resource allocation strategy that monitors system load and power consumption, dynamically adjusting resource assignments proportionally to workload demands. Their hyper-switching paradigm attains significant performance gains, outperforming previous techniques by up to 95.5%. Despite these advances, the agent-based approach may face scalability challenges in very large cloud infrastructures due to overhead in monitoring and coordination. Malathi and Priyadarsini38 explored heuristic optimization for load balancing via a hybrid lion optimizer and genetic algorithm, focusing on fine-tuning VM scheduling and resource selection probabilities. This heuristic framework achieves notable improvements in turnaround time and resource utilization. However, heuristic methods can lack adaptability and may require extensive parameter tuning, especially in heterogeneous and rapidly evolving cloud environments.While these contributions have advanced individual facets of cloud load balancing, gaps remain in holistically addressing dynamic heterogeneity, scalable coordination, and privacy-preserving model training. Most existing approaches treat resource management in isolation, neglecting the integration of data-driven, federated mechanisms capable of adapting to distributed and non-iid data across cloud clients.
To overcome these limitations, this study proposes a novel Cluster-based Federated Learning (FL) framework designed for cloud task scheduling. By embedding an unsupervised clustering technique within the FL pipeline, the approach partitions clients with similar data distributions into cohesive groups, enabling parallel and more efficient local model training. This clustered FL paradigm not only improves global model convergence but also enhances adaptability to workload heterogeneity, privacy preservation, and computational efficiency. Through this integration, our method offers a scalable, robust, and energy-efficient solution to cloud load balancing that directly addresses the shortcomings identified in prior works.
Background and proposed system
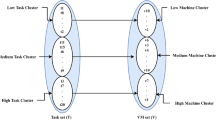
The process through which various (VMs) in a cloud computing setting is referred to as “load.” The subsequent are some ways in which we might characterize the load balancing issue. First, there’s task allocation, which involves assigning jobs to physical machines and then assigning each physical machine’s tasks to virtual machines. How well load balancing works depends on how well tasks are distributed over the cloud. Managing Virtual Machines and Tasks (2) Moving a virtual machine (VM) from one cloud provider’s primary (PM) node to another might help a data centre make better use of its available resources. Task migration is the process of moving an active task from one virtual machine (VM) to another or from one host’s VM to another host’s VM. For this reason, virtual machine (VM) or task migration plays a crucial part in the computing. Figure 1 depicts the scheduling methodology used in a cloud data centre.

Operational challenges of task and VM management within a cloud data center.
A substantial number of heterogeneous input tasks with varying resource requirements necessitate effective load balancing. The n input tasks T1, T2, T3, …, Tn are initially queued for scheduling. Upon dispatching tasks to the VM manager from the task queue, the manager maintains comprehensive awareness of the active VMs, available resources on each host, and the size of the task queues per server. The VM manager verifies whether the system possesses sufficient resources to execute the incoming tasks. If feasible, tasks are forwarded to the scheduler for assignment on existing VMs. Otherwise, should the host’s resources permit, the VM manager provisions new VMs accordingly.The task scheduler functions as a load balancer, dynamically allocating tasks to VMs based on their specific resource demands and capacities. It is important to note that each cloud host has a finite capacity limiting the maximum number of concurrently hosted VMs.
As depicted in Fig. 2, illustrates multiple Physical Machines (PM1, PM2, …, PMn), each hosting several Virtual Machines (VMs). The VM Manager monitors resource availability and workload across PMs and communicates with the Load Balancer, which orchestrates task allocation and migration. The COATI Optimization module performs unsupervised clustering of VMs to group similar resource profiles, facilitating federated learning model training within each cluster. It adaptively infers task assignments to optimize load distribution based on VM fitness, workload, and execution predictions. Although PMs are depicted separately for clarity, they are interconnected via the cloud data center network, enabling seamless coordination for task migration and resource management. COATI’s integration enhances scalability, load balancing efficiency, and system robustness in heterogeneous cloud environments.

Architecture of the proposed load-balancing framework incorporating COATI optimization.
Problem definition with solution framework
Assume a cloud environment, denoted as C, which consists of n physical machines (PMs). Each PM is part of a set containing m virtual machines (VMs):
Here, C represents the cloud, \(P{M}_{1}\) is the first physical machine, and \(P{M}_{n}\) is the n-th physical machine. Each \(P{M}_{n }\) contains a group of virtual machines, described as:
In this representation, \(V{M}_{1}\) is the initial virtual machine, and \(V{M}_{m}\) is the last. The total number of users in the cloud is denoted by I, which also reflects the number of tasks to be handled. The set of tasks assigned to a user is given by:
The main objective of these models is to ensure an even distribution of workload across all virtual machines within the cloud computing system. At the same time, the approach seeks to minimize both the time required to complete all tasks and the associated costs. Specifically, the goals are to reduce the total execution time and expenses, distribute the workload efficiently among as many VMs as possible, and improve overall system performance. Equation (4) defines the global Execution Time (ET):
The execution cost (EC) is calculated as follows (Eq. 5):
System load is determined using Eq. (6):
Additionally, the load balancing for each VM is evaluated by:
Effective load balancing is essential for meeting scheduling objectives. When the workload is not evenly distributed, task completion takes longer and costs increase. To address this, a multi-objective load balancing method is proposed, represented by the Multi-Objective Function (MOF) in Eq. (7):
This function aims to optimize execution time, cost, and load distribution at the same time.
Proposed load scheduling algorithm using clustered federated learning
Clustered FL is an extension of the generalized FL configuration provided by Reddi et al.39 for deploying FL. Algorithm 1 describes a generalized FL setting that incorporates adaptive optimization methods to outperform previous approaches to FL optimization, such as the well-known Federated Averaging (FedAvg)40. Algorithm 2 explains the clustered FL that was proposed. The model weights W0 are initialized, and the training hyperparameters are chosen, all via the aggregation server. These values are then transmitted from the server to all of the connected clients. Next, for epochs, each client trains W0 in part using only its local data. The CLIENTOPT39 gradient-based optimizer is used to minimize the local training loss during the local training phase. For optimizers like SGD, Adam, or RMSprop, there is CLIENTOPT, an abstraction layer. Once the local training is complete, each client will give the aggregated server their partially learned model. Based on shared commonalities in the training model parameters (weights and biases), the aggregation server groups the clients into K clusters (identified by the suggested coati optimization technique). In the following part, we’ll go deeper into the grouping procedure. Algorithm 1 involves running a parallel FL process, one for each cluster k. In order to obtain a collection of K global models, we run FL iterations converges. SERVEROPT generalizes the model aggregation function as presented in Algorithm 1. When compared to the FedAvg algorithm39, the CLIENTOPT and SERVEROPT abstraction makes it possible to use momentum or other adaptive optimization methods during aggregation. When SERVEROPT is set to SGD and the server learning rate is s = 1:0, the widely used FedAvg aggregation technique is a special case.

Federated learning framework with weighted aggregation.
The CLIENTOPT, SERVEROPT, their respective learning rates (η) and the pseudogradient concepts are explained in detail by Reddi et al.39. A single global model that is sophisticated enough in a FL context may be able to appropriately fit the data, but it may not be viable to train such a model in the devices themselves owing to hardware limitations. As a result, we’ll categorize the devices based on their behaviours and develop a set of global models that are uniquely suited to each class of devices. In this approach, each device is given an unsupervised group label to be utilized later in the FL procedure. Using the clustering method has several advantages over alternative approaches, including (i) not requiring the integration of any external device or manual approaches; (ii) not requiring waiting for a certain sum of time to identify procedure; and (iii) complete integration into the FL training pipeline. Parameter space compression via principal component analysis. The clustering calculation may be sped up, and the difficulties associated with clustering high dimensional data in models with a large sum of parameters can be mitigated by reducing the dimensionality. The suggested optimization approach is used to cluster the data in lower dimensions in this study. Assuming that all customers begin with the same random model, convergence to models with comparable parameter values is predicted for clients with similar data distributions. The model uses the fitness function to choose an optimal value for the sum of clusters K.

Enhanced clustered federated learning framework. Note: The ClientUpdate and Distributed Learning procedures reference Algorithm 1.
Optimization algorithm
To obtain the best possible outcomes, optimization algorithms employ complex operators. Various optimization algorithms exist. Traditional optimization techniques fall short when confronted with nonlinear or massive combinatorial issues. Because of this need, meta heuristic optimization algorithms41 have been created. Swarm-based algorithms are only a few examples of the many kinds of optimization methods available.
The coati optimization algorithm (COA) was first presented by Deghani et al.42. The benefits of the COA led us to adopt it. Engineering, economics, and business are just a few of the many possible applications for the Coati Optimisation Algorithm. As a result, the Coati optimization technique offers a great deal of adaptability. This method can find the optimal solution for several competing goals at once. The Coati algorithm is also resilient, which means it performs well in the face of both noisy data and unpredictability. The method is simple to construct since it relies on so few settings.
Coati’s unique way of living influenced the development of the Coati optimization algorithm. Coatis are small, nocturnal mammals found in many parts of the world. Coatis prefer green iguanas over any other food source. Some coatis are tree climbers and can frighten away herbivorous iguanas. Other coatis will swoop in to pick up an iguana that has fallen to the ground. Coatis are vulnerable to predators.
Algorithm initialization process
The coatis are treated as members of the population in the COA method, which is a metaheuristic based on the theory of natural selection. The values of the decision factors are determined by where each coati is located in the search space. Therefore, coatis’s stance is a potential answer in the COA. The coatis’s starting location in the search space is first determined using a random seed and Eq. (8) at the outset of the COA implementation.
where \({X}_{i}\) is the site of the ith coati in search space, \({x}_{i,j}\) is the value of the jth decision mutable, N is the number of coatis, m is the sum of choice variables, r is a chance real sum in the intermission [0, 1], and \({lb}_{j}\) and \({ub}_{j}\) are the bound of the jth decision variable, correspondingly.
The COA coati population is represented mathematically by the population matrix, denoted by the following matrix X.,
The assignment of solutions in decision variable quantity leads to the assessment of diverse values for problems. These values are shown using Eq. (10).
The value of the ith coati is denoted by F_i, and F is the vector containing the obtained objective function.
The value of the objective function is used in metaheuristic algorithms like the proposed COA to determine the quality of solution. Therefore, the best member of the population is the one whose assessment results in the highest function. Since the method iterates over possible solutions, the best solution in the population also evolves with time.
Mathematical model of COA
Coatis in the COA are re-ordered using a model of two of their natural behaviours. Examples of such conduct comprise:
-
(i)
Coatis’ approach when aggressive iguanas,
-
(ii)
Coatis’ escape policy from predators.
Accordingly, the COA populace is updated in two diverse phases.
Phase 1: Hunting and attacking approach on iguana (exploration stage)
The population modification mechanism for coatis initiates through behavioural modelling that simulates their natural response when encountering iguanas. This strategic approach involves a collective of coatis ascending a tree structure to intimidate the targeted iguana. Upon the iguana’s descent to ground level, multiple additional coatis position themselves strategically beneath the tree structure, awaiting its arrival. The fallen iguana becomes the target of coordinated assault and capture by the coati group once it reaches the terrestrial surface. This behavioural pattern results in coatis redistributing themselves across various positions throughout the exploration domain, demonstrating the COA algorithm’s capability for comprehensive exploration through global search mechanisms within the solution space.
The iguana represents the top-performing member of the population in the COA layout. Half of the coatis are said to ascend the tree in search of the iguana, while the other half wait below. Therefore, we use Eq. (11) to mimic the coatis’s ascent up the tree from a mathematical perspective.
When the iguana hits the floor, it is dropped into an undetermined location inside the search area. Coatis on the ground use this random starting point to navigate the simulated search space built with equations. (12) and (13).
If the goal function is improved by the novel position determined for each coati, then the update procedure will proceed with the new location. This update ailment is for \(i = 1, 2, . . . , N\) simulated using Eq. (14).
Here \({X}_{i}^{P1}\) is the novel site intended for the ith coati, \({X}_{i,j}^{P1}\) is its jth dimension, \({F}_{i}^{P1}\) is its impartial function value, r is a random real sum in the interval [0, 1], Iguana represents the.
iguana’s position in the search space, which to the member, Iguanaj is its jth dimension, I is an integer, which is arbitrarily chosen from the set {1, 2}, \({Iguana}^{G}\) is the site of the iguana on the ground, which is randomly produced, \({Iguana}_{j}^{G}\) is its jth dimension, \({F}_{{Iguana}_{G}}\) is its value of function, and ⌊·⌋ is the floor function.
Phase 2: The process of escaping from marauders (exploitation stage)
Coatis’ second-stage method of updating their position is modelled after their actual behaviour in the face of and flight from predators. A coati will quickly move out of the way of an oncoming predator. Coati’s exploitative prowess in local search is demonstrated by its ability to migrate into a secure position near to its present position.
To model this behaviour, we produce a random coordinate near where each coati is found using Eqs. (15) and (16).
This criterion, which is modelled using Eq. (17), determines whether or not the newly estimated location is acceptable.
Here \({X}_{i}^{P2}\) is the new position intended for the ith point of COA, \({X}_{i,j}^{P2}\) is its jth dimension, FiP2 is its value, r is a random sum in the intermission [0, 1], t is the iteration counter, \({lb}_{j}^{local}\) and \({ub}_{j}^{local}\) are the local bound of the jth decision variable respectively, \({lb}_{j}\) and \({ub}_{j}\) are bound of the jth decision variable, correspondingly.
Repetition procedure, pseudocode, and flowchart of COA
After the first and second stages of a COA are finished, the location of all search areas is updated. Until the last iteration of the method, the population is updated in a cycle based on Eqs. (11)–(17). The final result of a run of COA is the best answer found across all iterations of the algorithm.
If the new site has a higher objective function value (OBFV) than the old one, Coati will go to it. The optimization process used by Coati is a continual one. To choose inputs, we require a binary implementation of the coati optimization method. To get from a continuous representation to a binary one, a transfer function is used.
where \(Tanh\left({CO}_{j}^{i}(t+1)\right)\): Transfer function, \({\Delta }_{j}^{i}\left(t+1\right)\) binary value, and l: random value.
Results and discussion
The effectiveness of the proposed Cluster-based Federated Learning (FL) framework for cloud task scheduling was rigorously evaluated using the CloudSim 3.0.3 simulator, deployed on a workstation equipped with an Intel processor, 8 GB RAM, 3.4 GHz CPU, running Windows 7. The simulation parameters and environment settings are detailed in Table 1, including host configurations, virtual machine (VM) specifications, and data center properties.
Validation analysis of proposed FL model
The proposed FL approach was benchmarked against several established metaheuristic algorithms, including Whale Optimization Algorithm (WOA), Butterfly Optimization (BFO), Mayfly Optimization (MFO), and Fire Hawk Optimization (FHO). Table 2 summarizes the makespan results across varying workloads, measured by the number of tasks ranging from 1000 to 5000.
The proposed Cluster-based FL algorithm consistently achieved the lowest makespan values across all task volumes, with reductions ranging from approximately 5–10% compared to the best performing baseline method. This improvement indicates a more efficient scheduling strategy that effectively reduces the total execution time, which is critical for maintaining high throughput in large-scale cloud environments.
Table 3 presents the Degree of Imbalance (DI) metric, which evaluates the uneven distribution of workload across VMs. Lower DI values correspond to more balanced resource utilization. Figure 3 represents graphical based comparison on makspan.

Graphical comparison based on Makespan.
The proposed method demonstrates superior load balancing, exhibiting the lowest DI values across all task sets. This suggests that workloads are more evenly distributed, minimizing resource contention and improving VM utilization, which directly translates to reduced task waiting times and increased system responsiveness.
Idle time, representing the periods during which resources remain underutilized, is another critical performance metric. Table 4 compares the idle times for different algorithms over varying task volumes. Figure 4 represents degree of imbalance among various discussed models.

Analysis of the proposed model based on DI.
The COA model consistently registers the lowest idle times, confirming its efficiency in maximizing resource usage. Reduced idle times imply improved cost-effectiveness and energy efficiency, crucial factors in practical cloud deployments where operational expenses and environmental impact are significant concerns. Figure 5 represents idle time of the proposed model with existing models in graphical representation.

Idle time of the proposed model with existing models.
Conclusion and future scope
In this study, we proposed a cluster-based Federated Learning (FL) model designed to enhance load balancing within cloud computing environments by distributing individual tasks across multiple nodes efficiently. The COA model optimally selects the number of clusters, K, for federated training, ensuring equitable load redistribution by factoring in the fitness value of each virtual machine (VM). This approach effectively minimizes makespan and idle time, while balancing workloads to reduce operational costs associated with task execution across the cloud infrastructure.Our experimental evaluation demonstrates that the proposed method outperforms traditional standalone metaheuristic algorithms—including Whale Optimization Algorithm (WOA), Butterfly Optimization (BFO), Mayfly Optimization (MFO), and Fire Hawk Optimization (FHO)—by achieving a lower degree of imbalance and reduced job waiting times, all while improving makespan. These findings underscore the method’s potential to improve resource utilization and system responsiveness in cloud computing settings.However, certain limitations remain. The current model operates within a simulated environment and has yet to be validated in real-time cloud infrastructures, where network latency, system heterogeneity, and dynamic workload patterns introduce additional complexities. Moreover, while the cluster-based FL framework addresses client heterogeneity, the impact of asynchronous updates and communication overhead inherent to federated learning requires further investigation.
Future research will focus on implementing real-time load balancing among interdependent tasks, exploring adaptive clustering techniques that respond to evolving workload characteristics, and extending the model to tackle broader optimization problems such as energy-aware scheduling and fault tolerance. Additionally, integrating explainability mechanisms into the FL pipeline could enhance transparency and facilitate adoption in practical cloud service management.By addressing these challenges, future work aims to advance the practical applicability and robustness of federated load balancing solutions, contributing to more scalable, efficient, and sustainable cloud computing ecosystems.
Data availability
The datasets used during the current study are available from the corresponding author on reasonable request.
Change history
19 February 2026
The original online version of this Article was revised: The original version of this Article contained an error in the names of author Mohd Nadhir Ab Wahab, which was incorrectly given as MohdNadhir AbWahab.
References
Velliangiri, S., Karthikeyan, P., Xavier, V. A. & Baswaraj, D. Hybrid electro-search with genetic algorithm for task scheduling in cloud computing. Ain Shams Eng. J. 12(1), 631–639 (2021).
Shukri, S. E., Al-Sayyed, R., Hudaib, A. & Mirjalili, S. Enhanced multi-verse optimizer for task scheduling in cloud computing environments. Expert Syst. Appl. 168, 114230 (2021).
Bezdan, T. et al. Multi-objective task scheduling in cloud computing environment by hybridized bat algorithm. J. Intell. Fuzzy Syst. 42(1), 411–423 (2022).
Abd Elaziz, M. & Attiya, I. An improved Henry gas solubility optimization algorithm for task scheduling in cloud computing. Artif. Intell. Rev. 54, 3599–3637 (2021).
Bal, P. K., Mohapatra, S. K., Das, T. K., Srinivasan, K. & Hu, Y. C. A joint resource allocation, security with efficient task scheduling in cloud computing using hybrid machine learning techniques. Sensors 22(3), 1242 (2022).
Khan, M. S. A. & Santhosh, R. Task scheduling in cloud computing using a hybrid optimization algorithm. Soft. Comput. 26(23), 13069–13079 (2022).
Rajakumari, K. et al. Fuzzy-based ant colony optimization scheduling in cloud computing. Comput. Syst. Sci. Eng. 40(2), 581–592 (2022).
Jing, W., Zhao, C., Miao, Q., Song, H. & Chen, G. QoS-DPSO: QoS-aware task scheduling for a cloud computing system. J. Netw. Syst. Manage. 29, 1–29 (2021).
Albert, P. & Nanjappan, M. WHOA: Hybrid-based task scheduling in a cloud computing environment. Wireless Pers. Commun. 121(3), 2327–2345 (2021).
Manikandan, N., Gobalakrishnan, N. & Pradeep, K. Bee optimization based random double adaptive whale optimization model for task scheduling in cloud computing environment. Comput. Commun. 187, 35–44 (2022).
Masadeh, R., Alsharman, N., Sharieh, A., Mahafzah, B. A. & Abdulrahman, A. Task scheduling on cloud computing based on sea lion optimization algorithm. Int. J. Web Inf. Syst. 17(2), 99–116 (2021).
Gupta, S. et al. Efficient prioritization and processor selection schemes for heft algorithm: A makespan optimizer for task scheduling in a cloud environment. Electronics 11(16), 2557 (2022).
Reddy, H., Raghavendhar, K. L., Lathigara, A. & Aluvalu, R.. Survey on load balancing techniques and resource scheduling in cloud computing. (2021): 108–113.
Amer, D. A., Attiya, G., Zeidan, I., & Nasr, A. A. (2022). Elite learning Harris hawks optimizer for multi-objective task scheduling in cloud computing. J. Supercomput., 1–26.
Tera, S. P., Chinthaginjala, R., Natha, P., Pau, G., Dhanamjayulu, C. & Mohammad, F. CNN-based approach for enhancing 5G LDPC code decoding performance. IEEE Access, https://doi.org/10.1109/ACCESS.2024.3420106.
Renugadevi, M. et al. Machine learning empowered brain tumor segmentation and grading model for lifetime prediction. IEEE Access 11, 120868–120880. https://doi.org/10.1109/ACCESS.2023.3326841 (2023).
Kumar, S., et al. Enhancing underwater target localization through proximity-driven recurrent neural networks. Heliyon 10(7) (2024).
Sreenivasulu, V. & Ravikumar, C. FractalNet-based key generation for authentication in Voice over IP using Blockchain. Ain Shams Eng. J. 16(3), 103286 (2025).
Ravikumar, C. V. Developing novel channel estimation and hybrid precoding in millimeter-wave communication system using heuristic-based deep learning. Energy 268, 126600 (2023).
Sathish, K., et al. Review of localization and clustering in USV and AUV for underwater wireless sensor networks. Telecom. 4(1). MDPI, (2023).
Bagadi, K. et al. Detection of signals in MC–CDMA using a novel iterative block decision feedback equalizer. IEEE Access 10, 105674–105684 (2022).
Annepu, V. et al. Review on unmanned aerial vehicle assisted sensor node localization in wireless networks: Soft computing approaches. IEEE Access 10, 132875–132894 (2022).
Tera, S. P., et al. Towards 6G: An overview of the next generation of intelligent network connectivity. IEEE Access (2024).
Ravikumar, C. V., & Satish K. Modelling and design of a hexagonal grating structure for underwater acoustic wave sensing. Res. Eng. 104148 (2025).
Tera, S. P., et al. Deep learning approach for efficient 5G LDPC decoding in IoT. IEEE Access (2024).
MidhulaSri, J. & Ravikumar, C. V. Offloading computational tasks for MIMO-NOMA in mobile edge computing utilizing a hybrid Pufferfish and Osprey optimization algorithm. Ain Shams Eng. J. 15(12), 103136 (2024).
Vineela, P. & RaviKumar, C. V. Improved migration algorithms for uplink transmission secrecy sum rate maximization in MIMO-NOMA. Res. Eng. 24, 103275 (2024).
Kaveripakam, S. et al. Dingo optimization influenced arithmetic optimization–Clustering and localization algorithm for underwater acoustic sensor networks. Alexandria Eng. J. 85, 60–71 (2023).
Deepak, Upadhyay, M. K. & Alam, M. Load balancing techniques in fog and edge computing: Issues and challenges. In 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), Greater Noida, India, 210–215, https://doi.org/10.1109/IC2PCT60090.2024.10486765 (2024).
Haidri, R. A. et al. A deadline aware load balancing strategy for cloud computing. Concurr. Comput.: Pract. Exp. 34(1), 6496 (2022).
Shakeel, H. & Alam, M. Load balancing approaches in cloud and fog computing environments: a framework, classification, and systematic review. Int. J. Cloud Appl. Comput. (IJCAC) 12(1), 1–24 (2022).
Reddy, H. & Aluvalu, R. Literature survey on adaptive virtual machine scheduling strategy to optimize load balancing in cloud environment. In 2021 International Conference on Decision Aid Sciences and Application (DASA), 1092–1098. (IEEE, 2021).
Saba, T., Rehman, A., Haseeb, K., Alam, T., & Jeon, G. (2023). Cloud-edge load balancing distributed protocol for IoE services using swarm intelligence. Cluster Comput. 1–11.
Gutierrez-Garcia, J. O., Trejo-Sánchez, J. A. & Fajardo-Delgado, D. Agent coalitions for load balancing in cloud data centres. J. Paral. Distribut. Comput. 172, 1–17 (2023).
Reddy, H., Lathigara, A. & Aluvalu, R. Clustering based EO with MRF technique for effective load balancing in cloud computing. Int. J. Pervas. Comput. Commun. ahead-of-print (2023).
Laxman, K., Reddy, R., Lathigara, A., Aluvalu, R. & Viswanadhula, U. M. PGWO-AVS-RDA: An intelligent optimization and clustering based load balancing model in cloud. Concurr. Comput.: Pract. Exp. 34(21), e7136 (2022).
Jambulingam, U., & Balasubadra, K. (2023). An Energy-Aware Agent-Based Resource Allocation Using Targeted Load Balancer for Improving Quality of Service in Cloud Environment. Cybernetics and Systems, 1–21.
Malathi, K. & Priyadarsini, K. Hybrid lion–GA optimization algorithm-based task scheduling approach in cloud computing. Appl. Nanosci. 13(3), 2601–2610 (2023).
Reddi, S. J., Charles, Z., Zaheer, M., Garrett, Z., Rush, K., Konecny, J., Kumar, S. & McMahan, H. B. Adaptive federated optimization. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3–7, 2021. (OpenReview.net, 2021).
McMahan, B., Moore, E., Ramage, D., Hampson, S., & Arcas, B. A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, A. Singh and J. Zhu, Eds., vol 54, 1273–1282. (Fort Lauderdale, FL, USA: PMLR, 20–22, 2017).
Akyol, S. & Alatas, B. Plant intelligence-based metaheuristic optimization algorithms. Artif. Intell. Rev. 47, 417–462 (2017).
Dehghani, M., Montazeri, Z., Trojovská, E. & Trojovský, P. Coati Optimization Algorithm: A new bio-inspired metaheuristic algorithm for solving optimization problems. Knowl.- Based Syst. 259, 110011 (2023).
Acknowledgements
This work was supported by the Ministry of Higher Education Malaysia for the Fundamental Research Grant Scheme (FRGS) under Project FRGS/1/2020/STG06/USM/02/4 and by the Ongoing Research Funding Program (ORF-2025-681) at King Saud University, Riyadh, Saudi Arabia,
Funding
This work was supported by the Ministry of Higher Education Malaysia for the Fundamental Research Grant Scheme (FRGS) under Project FRGS/1/2020/STG06/USM/02/4 and by the Ongoing Research Funding Program (ORF-2025-681) at King Saud University, Riyadh, Saudi Arabia,
Author information
Authors and Affiliations
Contributions
All authors contributed equally to the conceptualization, formal analysis, investigation, methodology, and writing and editing of the original draft. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chennam, K.K., V, U.M., Aluvalu, R. et al. Load balancing for cloud computing using optimized cluster based federated learning. Sci Rep 15, 41328 (2025). https://doi.org/10.1038/s41598-025-25220-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-25220-z
