
Abstract
Artificial intelligence (AI) tools like ChatGPT-4o are increasingly utilized in prenatal care. However, their reliability and clinical applicability for healthcare providers in first-trimester screening remain unclear. This study aimed to evaluate the reliability, readability, and clinical utility of ChatGPT-4o’s responses to support clinicians in counseling regarding combined first-trimester screening and non-invasive prenatal testing (NIPT). Fifteen risk-stratified clinical scenarios were used to prompt ChatGPT-4o. Fourteen perinatologists rated the responses using mDISCERN and Global Quality Scale (GQS). Readability was assessed via five indices. Inter-rater agreement and internal consistency were evaluated using ICC and Cronbach’s alpha. AI responses showed high inter-rater reliability (ICC = 0.998) and internal consistency (α = 0.975). GQS and mDISCERN scores were highest in high-risk scenarios. Readability did not significantly differ across risk levels, nor correlate with quality scores. ChatGPT-4o demonstrates potential as a clinical decision-support and counseling tool for clinicians involved in prenatal screening, particularly in high-risk scenarios. Further refinement is needed for consistent performance across risk levels.
Similar content being viewed by others

Introduction
First-trimester screening for fetal trisomies 21, 18, and 13 can be effectively conducted between 11 and 13 weeks of gestation. This is achieved through a combined assessment of maternal age, fetal nuchal translucency (NT) thickness, fetal heart rate (FHR), and maternal serum biomarkers, including free β-human chorionic gonadotropin (hCG) and pregnancy-associated plasma protein-A (PAPP-A)1. Also, Non-invasive prenatal testing (NIPT) is used to screen for anomalies. It offers high sensitivity and specificity for screening prevalent aneuploidies, enhancing the accuracy of prenatal assessments2. First-trimester combined screening and non-invasive NIPT are valuable tools for detecting common aneuploidies. However, interpreting the results and selecting the most suitable screening method can be intricate. This may involve collaboration among specialists, including genetic counselors, obstetricians, and pediatricians/neonatologists3. This multidisciplinary approach ensures informed decision-making and the implementation of appropriate follow-up care. Decision-making tools and information about prenatal testing have been developed to enhance the counseling process4. Research indicates that these tools help patients better understand their options, minimizing confusion about their choices5,6.
Artificial intelligence (AI) is increasingly being integrated into healthcare to enhance patient education, improve access to medical information, and support clinical decision-making7. In the context of prenatal care, there is an increasing exploration of AI-powered chatbots as innovative tools for enhancing patient education8. However, the accuracy and reliability of AI-generated medical information remain areas of concern, particularly in sensitive fields such as prenatal care.
This study aimed to assess the reliability and readability of ChatGPT-4o’s responses on first-trimester prenatal screening and to evaluate its potential to assist healthcare providers in prenatal counseling.
Materials and methods
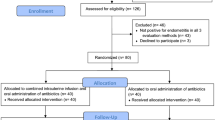
The present study formulated a series of structured clinical scenarios to assess the reliability of AI-generated counseling in prenatal screening contexts. The study was approved by the Gaziantep City Hospital Local Ethics Committee (Approval No: 112/2024, dated 15 January 2025), and all procedures were carried out in accordance with relevant guidelines and regulations, including the Declaration of Helsinki. The clinical scenarios used in this study were developed based on the recommendations of the American College of Obstetricians and Gynecologists (ACOG) Practice Bulletin on first-trimester screening and NIPT9. The risk groups were delineated based on NT measurements, maternal serum biochemical markers, specifically PAPP-A and free β-hCG, and the calculated aneuploidy risk ratios. Figure 1 presents an overview of the study design, including the risk stratification process and evaluation framework.

Study design.
A total of 14 perinatologists participated in this study, specializing in prenatal care and high-risk pregnancy management. The criteria for inclusion required that participants possess a minimum of 1 year of clinical experience in prenatal screening, be well-versed in the current prenatal screening guidelines, and willingly agree to participate in the research. To ensure a diverse and experienced panel for the evaluation process, participants were identified through academic institutions, professional medical networks, and obstetric associations.
Fifteen clinical scenarios were systematically developed to represent three distinct categories of pregnancy risk: low, intermediate, and high. The low-risk group includes cases with typical combined screening results, where the calculated risk for aneuploidy is equal to or greater than 1 in 1000. The intermediate-risk group comprises cases with a risk between 1 in 100 and 1 in 1000, often characterized by borderline test results or ambiguous findings. In contrast, the high-risk group consists of pregnancies with a calculated risk of less than 1 in 100, abnormal NIPT results, or significant ultrasound anomalies10,11. Table 1 summarizes the classification for these clinical scenarios.
Each scenario was designed to ensure clinical realism, incorporating biochemical markers, ultrasound findings, and genetic risk factors. To ensure authenticity, all scenarios were constructed based on current clinical guidelines and real-case examples. The scenarios were phrased in a patient-oriented manner to simulate real-world questions that clinicians commonly encounter during first-trimester prenatal counseling, while maintaining medical accuracy and consistency with guidelines. Each inquiry was submitted to ChatGPT-4o in a distinct session, with each response meticulously documented. This methodology facilitated an independent assessment of the AI-generated replies.
Each scenario was clearly and concisely presented to ChatGPT-4o using the following prompt: “You are assisting as a medical advisor specializing in prenatal screening and counseling. Your task is to provide a concise, evidence-based response to the question below. Your answer should be based on the latest ACOG guidelines and not exceed 150 words unless additional clarification is necessary”. A full transcript of all AI-generated responses is provided in the supplementary material. The prompt format reflects the study’s focus on AI as a clinical counseling support tool for healthcare providers.
The DISCERN instrument, commonly used to evaluate the reliability of health information12, and the GQS, a tool frequently applied in assessing the quality of online health content13 were adapted in this study to evaluate AI-generated responses. The mDISCERN version was tailored to focus on scientific reliability, adherence to clinical guidelines, objectivity, clarity, and clinical applicability. Similarly, the adapted GQS emphasized completeness, accuracy, clarity, and clinical usefulness to ensure relevance to the study objectives. The specific evaluation criteria for both scales are summarized in Table 2. For each question, the final GQS and mDISCERN scores were determined by summing the individual ratings provided by 14 experts. Since each expert could assign a maximum score of 5, the highest possible total score per question was 70. The final scores represent the cumulative ratings given by the experts, reflecting their overall assessment of the AI-generated responses.
Readability was measured using Flesch Reading Ease (FRE), Flesch-Kincaid Grade Level (FKGL), SMOG, Gunning Fog Index, and Coleman-Liau Index. The methodology for calculating these readability metrics is outlined in Table 2, providing a standardized approach to evaluating text complexity. These analyses facilitated a comparative evaluation between detailed and summary-format responses, offering insights into their accessibility and clarity. Readability scores were obtained using the Readability Test Tool14.
Statistical analyses were conducted to assess the reliability of expert ratings and examine potential relationships between response quality and readability metrics. Inter-rater reliability was evaluated using the Intraclass Correlation Coefficient (ICC) to measure agreement among expert raters, while Cronbach’s Alpha was calculated to assess the internal consistency of the ratings. Correlation analyses were performed in R to explore potential relationships between mDISCERN, GQS, and readability scores, with statistical significance set at p < 0.05.
Additionally, one-way ANOVA was conducted in R to compare differences in GQS, mDISCERN, and readability scores across the three risk groups (low, intermediate, and high risk). When a statistically significant difference was found (p < 0.05), post-hoc Tukey tests were performed to determine pairwise differences between groups. GQS and mDISCERN scores were reported as Mean (SD), while readability indices were presented as Median (Min–Max) to account for skewness in the data. Results were reported with mean differences, confidence intervals, and adjusted p-values to identify specific group differences.
All visualizations were created using Lucidchart and ChatGPT-4o to enhance data interpretation.
Results
The findings indicate that the content generated by artificial intelligence exhibited a high level of reliability among expert evaluators, as evidenced by significant ICC = 0.998 and excellent internal consistency (Cronbach’s Alpha = 0.975). Although scores derived from the Guideline for the Assessment of Scientific Content (GQS) and mDISCERN assessment varied markedly across different risk groups, the readability indices did not present substantial differences.
Table 3 presents the comparison of GQS, mDISCERN, and readability indices across the three risk groups (low, intermediate, and high). The GQS and mDISCERN scores differed among the risk groups. The high-risk group had the highest scores (GQS: 61.64 ± 1.59; mDISCERN: 62.00 ± 1.78), while the low-risk group had the lowest (GQS: 58.20 ± 2.72; mDISCERN: 59.44 ± 3.51). Further pairwise comparisons, detailed in Table 4, indicate that GQS scores were significantly higher in the high-risk group compared to the low-risk group (p = 0.002), while the difference between the intermediate and high-risk groups was not statistically significant (p = 0.199). Similarly, mDISCERN scores were significantly higher in the high-risk group compared to both the intermediate (p = 0.010) and low-risk groups (p < 0.001). Additionally, the intermediate-risk group had significantly higher mDISCERN scores than the low-risk group (p < 0.001). For readability indices, the results presented in Table 3 show that there were no statistically significant differences between risk groups for any of the indices (all p > 0.05).
Table 5 presents the correlation analysis between readability metrics and GQS/mDISCERN scores. The results indicate that none of the readability indices showed a statistically significant correlation with GQS/mDISCERN scores (all p > 0.05). The strongest correlation was observed between FKGL and GQS/mDISCERN (r = 0.43, p = 0.10), while the weakest correlation was found for CLI (r = − 0.09, p = 0.79).
A supplementary analysis was performed to examine whether the readability of the prompts influenced the readability of the AI-generated responses. The results showed no significant correlations across the five indices (FRE: r = 0.44, p = 0.10; FKGL: r = 0.32, p = 0.24; GFI: r = 0.05, p = 0.87; CLI: r = 0.26, p = 0.34; SMOG: r = 0.15, p = 0.59). No significant relationship was found between the readability of the prompts and the readability of the AI-generated responses across all indices.
Figure 2 presents the GQS/mDISCERN average scores and readability metrics (FRE, FKGL, GFI, CLI, and SMOG) for each question. The variation in readability scores across questions is evident, with FRE scores ranging from 1.7 to 38.3 and FKGL scores between 11.7 and 17.7. The highest FRE score was observed for Q10 (38.3), while Q15 had the lowest score (1.7), indicating substantial differences in readability across the dataset.Similarly, the GQS/mDISCERN scores also varied, with Q5 having the highest average score (4.59) and Q1 the lowest (4.03). However, no clear pattern emerged between readability and quality scores, suggesting that higher readability did not necessarily correspond to higher GQS/mDISCERN ratings.

GQS/mDISCERN scores and readability metrics for each question.
For instance, in a low-risk case (Q1), ChatGPT-4o correctly reassured that no further testing was necessary but did not mention the importance of continued routine screening, resulting in a lower quality score. In contrast, in a high-risk scenario (Q13) involving markedly increased nuchal translucency, ChatGPT-4o provided a comprehensive explanation of possible genetic causes and follow-up options such as CVS and amniocentesis, which contributed to higher GQS and mDISCERN ratings. These examples illustrate that the model performed more accurately and thoroughly in clinically complex, high-risk situations.
Discussion
Our study demonstrates that ChatGPT-4o offers structured and clinically relevant responses concerning first-trimester prenatal screening methods, including combined screening and NIPT. Notably, the accuracy of responses varies by risk group, showing higher precision in high-risk cases, satisfactory performance in intermediate-risk scenarios, and relatively lower—yet still informative—responses for low-risk cases.
Previous studies have emphasized the importance of genetic education and psychological factors in prenatal decision-making, highlighting that maternal anxiety and societal norms influence the autonomy of choice regarding prenatal screening15. This aligns with our findings, which indicate that AI-generated responses could be further refined to support both clinicians and expectant parents in navigating complex decisions regarding prenatal genetic screening.
A study investigating computerized decision aids for aneuploidy screening demonstrated that such tools can be as effective as genetic counseling in improving patient knowledge and reducing decisional conflict4. Our findings suggest that AI-driven tools, such as ChatGPT-4o, may serve as a complementary resource in prenatal screening counseling, particularly in clinical settings where access to genetic counselors is limited.
A recent study comparing ChatGPT and Google Bard AI emphasized the necessity for continuous refinement of these models, particularly in sensitive healthcare domains, due to observed discrepancies in information accuracy and responsiveness16. Similarly, our findings highlight that while ChatGPT-4o provides clinically relevant and guideline-adherent prenatal screening responses, ensuring AI-generated content’s reliability requires ongoing evaluation and expert oversight.
Chatbot-based tools in patient education have been shown to enhance knowledge and improve satisfaction among patients and healthcare providers17. In line with these findings, our study highlights the potential role of ChatGPT-4o in facilitating prenatal counseling and patient education. The clinical scenarios used in this study were derived from real-world patient inquiries, ensuring that the questions presented to the AI model reflected genuine concerns encountered in prenatal screening. Our results demonstrate that ChatGPT-4o provided high-quality responses, with expert evaluations ranking the AI-generated answers four or above on the quality scale, as illustrated in Fig. 2.
A recent study assessing ChatGPT’s performance as a fertility counseling tool demonstrated that the model provides relevant and meaningful responses comparable to established sources18. However, the study highlighted key limitations, including the inability to reliably cite sources and the risk of generating fabricated information, which may restrict its direct clinical applicability. These findings emphasize the necessity for continuous improvements in AI models to ensure transparency and trustworthiness in medical communication. Similarly, our study found that ChatGPT-4o generates clinically relevant responses in prenatal screening counseling. While the model consistently provided structured and evidence-based information, its limitations remain, particularly in ensuring the traceability of its sources and mitigating potential inaccuracies.
A study conducted in 2019 indicated that while many patients expressed a willingness to utilize AI-based health chatbots, notable hesitation remained a considerable barrier to engagement19. In our study, the responses generated by ChatGPT-4o were evaluated using the GQS and mDISCERN assessment tools. The findings revealed that while the model provides clinically relevant and comprehensible answers, it also received high scores in both evaluation metrics.
A recent study evaluating the application of ChatGPT in femoroacetabular impingement syndrome emphasized that while AI-driven chatbots hold significant promise as medical resources, their integration into clinical practice must be cautiously approached. The study highlighted the necessity of ongoing validation and expert oversight to minimize the risk of misinformation and ensure that AI-generated content adheres to stringent medical accuracy standards20. In line with this perspective, our study found that ChatGPT-4o’s response quality improved as the risk level increased in prenatal screening scenarios. As shown in Table 3, there were statistically significant differences in GQS (F = 10.98, p = 0.002) and mDISCERN (F = 50.45, p < 0.001) scores across the three risk groups.
The correlation analysis between GQS and mDISCERN scores highlights a strong internal consistency within expert evaluations, suggesting that response quality and medical accuracy were systematically assessed. However, the moderate correlation between GQS and mDISCERN implies that ChatGPT-4o’s generally well-structured and readable responses may not always align perfectly with evidence-based medical guidelines. This finding reinforces the need for expert oversight when utilizing AI-generated medical content. Furthermore, the lack of significant correlation between readability and expert-evaluated quality suggests that readability alone cannot indicate response accuracy or clinical relevance (Table 5).
The AI-generated information was generally reliable, with expert evaluations indicating that responses were clinically relevant and evidence-based. However, regarding readability, most responses required an advanced reading level, which may present challenges for users with lower health literacy. Because the system prompt instructed the model to act as a clinical advisor, this may have contributed to the professional tone of the responses. Additional analysis showed no significant relationship between the readability of the questions and the AI-generated responses. This suggests that the complex language used by the model mainly results from how it constructs its answers rather than from the way the questions were written. Simplifying AI-generated content before sharing it with users could therefore improve understanding and accessibility.
This study has several limitations. First, the evaluation was conducted by 14 perinatologists, which, while providing a valuable professional perspective, may not fully represent the diversity of opinions within a broader clinical community. Additionally, 15 standardized clinical scenarios were developed to simulate real-world patient inquiries; however, they may not entirely capture the complexity and nuances of actual patient interactions in clinical practice. The scenarios were phrased in a patient-oriented manner but contained structured clinical details to facilitate expert evaluation, which may differ from the language typically used in real consultations. Another limitation is that AI models, including ChatGPT-4o, are continuously evolving; thus, the performance observed in this study may not directly apply to future versions. In addition, the evaluation panel did not include genetic counselors. Although prenatal counseling is primarily provided by perinatologists in our national healthcare setting, the absence of genetic counselors may limit the generalizability of the findings to contexts where multidisciplinary counseling teams are standard practice. Furthermore, the study did not include patient perspectives, preventing an assessment of how AI-generated responses are perceived and understood by the intended audience. Finally, while this study focused on ChatGPT-4o, a comparison with other AI-based models such as Bard or MedPaLM could provide further insight into the relative strengths and weaknesses of different AI chatbots in prenatal counseling.
Conclusion
In conclusion, ChatGPT-4o demonstrates significant potential in providing information on first-trimester combined screening and NIPT, offering structured and clinically relevant responses. It may serve as a supplementary tool to support clinicians in genetic counseling and prenatal decision-making. However, response quality varies across risk groups, with the highest accuracy in high-risk cases, good performance in intermediate-risk cases, and relatively lower—but still informative—responses in low-risk cases. While AI-generated content shows promise for enhancing counseling quality, continued improvements in reliability and consistency are needed across all clinical scenarios. Ultimately, AI can complement but not replace human judgment; expert supervision is indispensable to prevent misinformation and maintain ethical standards in prenatal counseling.
Data availability
All data generated or analyzed during this study are included in this published article. No additional datasets were generated. Further information is available from the corresponding author upon reasonable request.
References
M Santorum D Wright A Syngelaki N Karagioti KH Nicolaides 2017 Accuracy of first-trimester combined test in screening for trisomies 21, 18 and 13 Ultrasound Obstet. Gynecol. 49 6 714 720 https://doi.org/10.1002/uog.17283
MS Alberry E Aziz SR Ahmed S Abdel-Fattah 2021 Non invasive prenatal testing (NIPT) for common aneuploidies and beyond Eur. J. Obstet. Gynecol. Reprod. Biol. 258 424 429 https://doi.org/10.1016/j.ejogrb.2021.01.008
DG Fiorentino F Hughes 2021 Fetal screening for chromosomal abnormalities NeoReviews 22 12 e805 e818
LM Carlson S Harris EE Hardisty 2019 Use of a novel computerized decision aid for aneuploidy screening: A randomized controlled trial Genet. Med. 21 4 923 929 https://doi.org/10.1038/s41436-018-0283-2
L Beulen M Berg van den BH Faas 2016 The effect of a decision aid on informed decision-making in the era of non-invasive prenatal testing: A randomised controlled trial Eur. J. Hum. Genet. 24 10 1409 1416 https://doi.org/10.1038/ejhg.2016.39
A Cernat C Freitas De U Majid F Trivedi C Higgins M Vanstone 2019 Facilitating informed choice about non-invasive prenatal testing (NIPT): A systematic review and qualitative meta-synthesis of women’s experiences BMC Pregnancy Childbirth 19 1 27 https://doi.org/10.1186/s12884-018-2168-4
M Dave N Patel 2023 Artificial intelligence in healthcare and education Br. Dent. J. 234 10 761 764 https://doi.org/10.1038/s41415-023-5845-2
K Chung HY Cho JY Park 2021 A Chatbot for perinatal women’s and partners’ obstetric and mental health care: Development and usability evaluation study JMIR Med. Inform. 9 3 e18607 https://doi.org/10.2196/18607
American College of Obstetricians and Gynecologists’ Committee on Practice Bulletins—Obstetrics; Committee on Genetics; Society for Maternal-Fetal Medicine. Screening for Fetal Chromosomal Abnormalities: ACOG Practice Bulletin, Number 226. Obstet. Gynecol. 136(4):e48–e69. https://doi.org/10.1097/AOG.0000000000004084 (2020).
KH Nicolaides K Spencer K Avgidou S Faiola O Falcon 2005 Multicenter study of first-trimester screening for trisomy 21 in 75 821 pregnancies: Results and estimation of the potential impact of individual risk-orientated two-stage first-trimester screening Ultrasound Obstet. Gynecol. 25 3 221 226 https://doi.org/10.1002/uog.1860
MM Gil R Revello LC Poon R Akolekar KH Nicolaides 2016 Clinical implementation of routine screening for fetal trisomies in the UK NHS: Cell-free DNA test contingent on results from first-trimester combined test Ultrasound Obstet. Gynecol. 47 1 45 52 https://doi.org/10.1002/uog.15783
D Charnock S Shepperd G Needham R Gann 1999 DISCERN: An instrument for judging the quality of written consumer health information on treatment choices J. Epidemiol. Community Health 53 2 105 111 https://doi.org/10.1136/jech.53.2.105
T Barlas D Ecem Avci B Cinici H Ozkilicaslan M Muhittin Yalcin AA Eroglu 2023 The quality and reliability analysis of YouTube videos about insulin resistance Int. J. Med. Inform. 170 104960 https://doi.org/10.1016/j.ijmedinf.2022.104960
Readable.com. The Readability Test Tool. Published 2013. Accessed 2 Feb 2025. http://www.readable.com.
S Oliveri G Ongaro I Cutica 2023 Decision-making process about prenatal genetic screening: How deeply do moms-to-be want to know from Non-Invasive Prenatal Testing? BMC Pregnancy Childbirth 23 1 38 https://doi.org/10.1186/s12884-022-05272-z
A Mediboina RK Badam S Chodavarapu 2024 Assessing the accuracy of information on medication abortion: A comparative analysis of ChatGPT and Google Bard AI Cureus 16 1 e51544 https://doi.org/10.7759/cureus.51544
B Su R Jones K Chen 2025 Chatbot for patient education for prenatal aneuploidy testing: A multicenter randomized controlled trial Patient Educ. Couns. 131 108557 https://doi.org/10.1016/j.pec.2024.108557
J Chervenak H Lieman M Blanco-Breindel S Jindal 2023 The promise and peril of using a large language model to obtain clinical information: ChatGPT performs strongly as a fertility counseling tool with limitations Fertil. Steril. 120 3 Pt 2 575 583 https://doi.org/10.1016/j.fertnstert.2023.05.151
T Nadarzynski O Miles A Cowie D Ridge 2019 Acceptability of artificial intelligence (AI)-led chatbot services in healthcare: A mixed-methods study Digit. Health 5 2055207619871808 https://doi.org/10.1177/2055207619871808
Y Chen S Zhang N Tang DM George T Huang J Tang 2024 Using Google web search to analyze and evaluate the application of ChatGPT in femoroacetabular impingement syndrome Front. Public Health. 12 1412063 https://doi.org/10.3389/fpubh.2024.1412063
Acknowledgements
We acknowledge the developers of the ChatGPT-4o platform from OpenAI, whose advanced tools significantly contributed to our data collection and analysis efforts. Additionally, we sincerely appreciate the experts and perinatologists who participated in this research and played a crucial role in the evaluation process.
Author information
Authors and Affiliations
Contributions
Taskum and Sınacı contributed to the conceptualization of the study. Data curation was performed by Sucu and Yetiskin. Formal analysis was conducted by Sınacı and Sucu. Taskum was responsible for funding acquisition. The investigation was carried out by Taskum, Sınacı, and Sucu. Methodology development was led by Taskum, Sınacı, and Yetiskin. Taskum administered the project, while resources were provided by Taskum and Sınacı. Software-related tasks were handled by Sucu and Yetiskin. Taskum and Sınacı supervised the study. Validation was performed by Taskum, Sınacı, and Sucu. Visualization efforts were undertaken by Sucu and Yetiskin. Taskum and Sınacı prepared the original draft, while Taskum, Sınacı, Sucu, and Yetiskin contributed to the review and editing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval and data security
This study was approved by the relevant ethics committee under approval number 112/2024. Written informed consent was obtained from all expert participants prior to their involvement in the study. The entire evaluation process was conducted anonymously, ensuring that the identities of the experts remained confidential. ChatGPT-4o responses were generated on February 2, 2025, and the AI-generated answers, along with expert evaluations, were used solely for research purposes. All collected data were securely stored in a protected data management system, following ethical guidelines for research integrity and confidentiality. Data sharing was conducted only after obtaining approval from the relevant ethics committees. This study was conducted for academic purposes only, with no commercial intent or financial interests involved.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Taşkum, İ., Sınacı, S., Sucu, S. et al. Evaluating the reliability and clinical utility of artificial intelligence in first trimester prenatal screening and noninvasive prenatal testing. Sci Rep 15, 41331 (2025). https://doi.org/10.1038/s41598-025-25224-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-25224-9
