
Abstract
Risk assessment plays a crucial role in ensuring the safety of process units. Artificial intelligence has become increasingly prevalent in risk assessment and prediction, offering the potential for more precise outcomes when integrated with other techniques. This study is both descriptive and analytical in nature. The dataset utilized comprises 160 deviations identified through the HAZOP technique. A variety of evaluation algorithms were employed in this study, ranging from ensemble methods like Random Forest, Hist Gradient Boosting, XGBoost, and CatBoost, to traditional methods such as Logistic Regression, K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and Convolutional Neural Network (CNN). This broad array of algorithms enabled a comprehensive comparison of diverse modeling approaches, encompassing conventional statistical methods and cutting-edge machine-learning techniques. Among the algorithms tested, Random Forest, XGBoost, and CatBoost exhibited exceptional performance on the training and test datasets, achieving near-perfect AUC scores and accuracy values of 1.0000. In the fusion of Bayesian networks and Multi-Criteria Decision Making (MCDM), the options “Corrosion in Electrolysis Cells” and “Damage and Explosion of Cells” were given higher priority over other options. The findings from this study suggest that machine learning techniques, along with the amalgamation of Bayesian networks and MCDM, can serve as effective tools for risk assessment and the prioritization of risk options. By leveraging these methodologies, suitable control and preventive measures can be implemented to mitigate risks effectively.
Similar content being viewed by others
Introduction
In recent decades, the widespread adoption of new technologies across industries has significantly enhanced human welfare. However, this progress has also introduced a new dilemma: workplace accidents, which have led to substantial human casualties1. According to the International Labour Organization (ILO) statistics, more than 2.78 million people lose their lives each year due to occupational accidents2. Occupational accidents cost the global economy $1.25 billion annually and lead to the death of 2 million people per year3. The rate of fatal occupational accidents is four times higher in developing countries compared to industrialized countries, and Iran is not an exception to this rule, with approximately 14,000 occupational incidents occurring annually4.Therefore, the need for prevention of accidents is considered a necessity for the survival of organizations. This requires identifying the causes of accidents before they occur, which today has been addressed in the form of a risk assessment and management approach5,6. The power industry is one of the high-risk industries among various sectors, as personnel working in power generation, transmission, and distribution are exposed to a range of occupational health hazards7. power plants are one of the most important factors and necessities for the growth and development of any country. They are a collection of industrial facilities used for the production of electrical energy8. Nuclear power plant One of the most efficient types of power plants is the combined cycle power plant, where optimal design can lead to reduced fuel costs9. In many power plants in Iran, due to geographical location and climatic conditions, the once-through cooling system, such as Heller towers and air-cooled condenser (ACC) systems, is used, which is the most suitable option for power plants located near the sea or rivers10. The chemical reactions in the chlorination unit of combined cycle power plants with a once-through cooling system result in the production of sodium hypochlorite and hydrogen gas11,12. Therefore, considering the risk of fire and explosion caused by hydrogen gas leakage, the evaluation of HSE risks in the chlorination unit of combined cycle power plants is essential. The significance of addressing these risks is not merely academic; it is of paramount importance for the sustainability and operational continuity of power plants13. The Hazard and Operability Study (HAZOP) technique is widely used for identifying system hazards and operational issues in industries like chemicals and power generation. This systematic method involves expert teams examining potential process deviations and their consequences based on operational parameters such as temperature and pressure14. Analyzing such large datasets requires advanced resources and techniques for data classification and pattern identification that cannot be achieved through traditional analytical tools15. With the development of artificial intelligence and the emergence of the era of big data, many researchers have utilized machine learning methods to conduct extensive research on risk assessment16,17.
Organizational risk management plays a crucial role in the sustainable performance of financial institutions domestically and internationally. Older assessment methods are no longer able to meet the needs of processing various types of data, handling a large number of users, and achieving high-risk prediction accuracy18,19. Many researchers employ machine learning methods20. Predictive models for occupational accidents can be based on statistical learning or machine learning (ML). Given the vast amount of available data, ML replaces traditional statistical counterparts in predicting future events and has been widely used in various fields such as engineering, medical sciences, and finance, providing highly valuable results21. Machine learning (ML) is a subset of artificial intelligence that enables systems to learn patterns and make predictions from data without explicit programming22. In this study, ML techniques are applied to predict risks by analyzing historical data and identifying relationships between critical variables. Ensemble algorithms, such as Random Forest, XGBoost, and CatBoost, are utilized to enhance predictive accuracy and robustness. These algorithms combine predictions from multiple models to create a stronger overall prediction23. Ensemble methods are particularly effective in handling classification tasks, managing imbalanced datasets, and reducing the impact of noise, making them suitable for risk assessment in complex systems24.
However, existing research indicates that machine-learning techniques have been limitedly used in occupational accident analysis25. In recent years, machine learning-based risk assessment models have emerged and proven to be more effective than traditional risk assessment methods26,27,28,29. Commonly used modern machine learning techniques include Backpropagation Neural Networks (BP), K-Nearest Neighbors (KNN), and Support Vector Machines (SVM)30. Additionally, tree-based machine learning methods are widely employed in risk assessment, such as basic decision tree models and more advanced ensemble approaches like Random Forest (RF), Gradient Boosting Decision Trees (GBDT), XGBoost, and LightGBM31.
The focus of this research lies in the dynamic risk assessment of a combined cycle power plant, where risks are continuously evolving due to varying operational conditions. A dynamic risk assessment involves updating the primary risk number based on various factors such as the control system’s performance, safety barriers, maintenance and inspection activities, human factors, and operational procedures. This method was developed to address limitations seen in other approaches like bow-tie32. Research on dynamic risk assessment in process facilities is ongoing33.
The Bayesian belief network is a widely used method in dynamic risk assessment due to its ability to handle uncertainty and belief updating. This approach is effective in addressing complex issues by combining robust probabilistic methods with graphical representations. Bayesian networks can pinpoint components that are most likely to contribute to system risk34. When objective data is lacking and expert opinion is necessary, the Bayesian belief network offers a natural framework for understanding relationships between model components. It also offers a way to manage uncertainty, unpredictability, and complexity in decision support systems. The graphical and easily updatable nature of Bayesian Networks has made them increasingly popular in the process industry35,36.
This study was conducted in a combined cycle power plant with a capacity of 968 megawatts. Seawater is used for cooling operations in this power plant. It consists of 162 units in the gas phase and 1 unit in the steam phase. One of the areas examined in this research is the chlorination unit, which is responsible for producing the required hypochlorite for chlorination purposes. Considering that this unit is one of the critical and hazardous units in the power plant, it was the focus of this study. Therefore, this study aimed to develop a method for risk assessment using machine learning and a Bayesian decision network based on multi criteria decision making37.
It should be noted that obtaining reliable data is often challenging, resulting in difficulties when eliciting conditional probability tables (CPTs) for each node in a Bayesian network (BN). In such cases, CPTs are typically derived from expert opinions. However, it is important to acknowledge that human judgment is subjective and ambiguous, leading to inherent uncertainty in probability analysis38. To address the fuzziness and uncertainty associated with vague decision-making, the fuzzy analytical hierarchy process (fuzzy AHP) is employed. Fuzzy AHP utilizes fuzzy sets, membership functions, and fuzzy numbers to more effectively handle subjective evaluations and convert linguistic variables into probability values39,40. Therefore, in this study, fuzzy AHP is utilized to calculate the CPTs of the BN.
By employing expert elicitation and fuzzy theory to determine probabilities, FBN utilizes the same reasoning and inference algorithms as conventional BN for predictive analysis and probability updating. this study compares the results of fuzzy Bayesian networks (FBN) with traditional Bayesian networks, showing that FBN offers more detailed, transparent, and realistic insights, particularly when analyzing critical risk factors41.
Literature review
The increasing complexity of industrial operations and the growing focus on safety management have driven significant advancements in risk assessment methodologies42. While traditional techniques remain valuable, they often encounter challenges in addressing uncertainties, evolving risk factors, and the intricate, nonlinear interactions between various contributing elements43. To overcome these limitations, researchers have introduced advanced computational approaches such as fuzzy logic, Bayesian networks, machine learning (ML) to improve risk prediction and decision-making in occupational and process safety44.
These approaches have contributed to a more systematic, data-driven evaluation of risks, allowing for improved hazard identification, mitigation strategies, and decision-making processes within industrial safety management frameworks. Table 1 presents a comparative analysis of methodologies and key findings in risk assessment and process safety.
Method
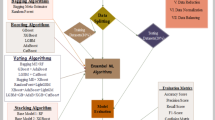
This study is applied research aimed at identifying and evaluating the risk of a power plant’s chlorine unit using machine learning, combining Bayesian networks and the fuzzy AHP method. Figure 1 illustrates the steps of implementing this method.

Phases of study implementation process.
Data collection of the examined process
The text describes the methodology used for gathering necessary information through technical review, document analysis, and interviews with employees and experts. In this regard, initially, the relevant company’s available resources and technical documents, as well as the chlorination unit’s equipment and related diagrams, were studied. Subsequently, the Process Flow Diagram (PFD) and the Overall Equipment Layout, communication lines, instrumentation, control systems, and Interlock (P&ID) diagrams of the chlorination unit were prepared by the risk assessment team members. The risk assessment team, composed of the head of the power plant’s chemical unit, the operator in charge of the chlorination unit, the shift supervisor, the technician responsible for instrument repairs, the technician responsible for electrical repairs, the technician responsible for mechanical repairs, and the power plant’s HSE specialist, was formed to conduct the study on operations and hazards (HAZOP).
HAZOP study
HAZOP study is a practical and systematic technique for identifying hazards and operational problems in a system and determining their effects62. This technique is based on the principle that a system is safe when all its operational parameters, such as temperature, pressure, etc., are within normal and acceptable ranges. In this method, a team of experts examines potential process deviations from standard conditions and their potential effects using a set of keywords63. HAZOP analysis considers the entire system and examines each part to discover disturbances and deviations from the design objectives and evaluate their causes and consequences64. Subsequently, a structured approach is followed, which includes a well-defined set of terms for precise communication of analysis elements and documentation of results.
In this phase, the expert group divided the chlorination unit into 7 nodes based on the type of work involved. These nodes include the rectifier section, MV electrolyzer feeders, acid tanks, profit storage tanks, brine skids, brine water filters, net pit, forward osmosis pits, and chlorine storage tanks. The operational parameters studied in this research included water flow rate, current, voltage, oil temperature, fluid pressure in pipelines, pH of incoming water, and salt concentration of incoming water. Therefore, the individual effects of malfunctioning in each component and ultimately the impact on the normal operation of the unit due to various reasons such as equipment defects and human errors by the team members were examined, and the risk level was determined.
Machine learning
After gathering relevant information on risk assessment using Machine Learning (ML) methods, it was utilized to improve and enhance the Hazard and Operability (HAZOP) approach. Based on the assigned risk level, the probability, severity, and detection probability for each hazard were calculated, and the associated risk was categorized as high, medium, or low.
Table 2 presents comprehensive statistics of the data used in this study, including minimums, maximums, means, standard deviations, quantiles, kurtosis, and skewness, to aid in understanding the process.
Data processing
Data exploratory analysis is an approach to analyzing a dataset to understand its main features, which can be accompanied by visualization methods. Data cleansing is performed to manage missing values and noise. If the data is collected from different sources with different formats and structures, data integration is necessary. To reduce computational and processing costs, if there is no need to use all available data, a portion of the surplus data is set aside in the data reduction section. Data transformation includes tasks such as normalization, numerical variable handling, and encoding categorical variables. The algorithms used in this study are selected based on the type of problem, which is supervised machine learning. To eliminate the scale of numerical data, all numerical features will be normalized. Non-normalization of data may disrupt the training process of algorithms due to differences in input data scales. Statistical normalization method according to Eq. 1 will be used for data normalization.
In this regard, x represents the input data, μx represents the mean of feature x, and ∂x represents the standard deviation of feature x. The nominal data values will also be encoded with numerical values of 0 and 1. After performing initial checks and data preparation, the mentioned algorithms will be applied to the dataset.
In this study, two sets of data, which are independent and dependent, were assigned to two different data frames, namely “X” and “y”, for further processing. Additionally, the data was divided into training and testing data for model development. An 80% test size was considered, meaning that 80% of the total data was used for training and the remaining 20% for model testing.
Model construction and performance evaluation
For this research project, we utilized Python software version 3.11.4 for both preprocessing and constructing our model. Our dataset was divided into two parts: 128 inputs were allocated for training and testing purposes, while the remaining 32 inputs were reserved for model evaluation.
The process of analyzing the dataset involved a systematic approach that aimed to preprocess the data and evaluate the performance of predictive models. Initially, we created a new column called ‘Risk_binary’, which transformed the ‘Risk’ values into a simpler binary classification format, making the subsequent analysis easier. By categorizing instances as either 1 or 0, we represented a risk level below 100 or 100 or higher, respectively. This made the dataset more amenable to classification algorithms.
In addition, it was deemed necessary to exclude the ‘Risk’ column from further calculations due to its strong correlation with the target variable, ‘Risk_binary.’ This precautionary measure was taken to address any potential issues of multicollinearity that could skew model predictions. By applying both the OneHotEncoder and LabelEncoder methods to the categorical data in the ‘Category’ column, we were able to effectively transform these variables into numerical formats, which are crucial for the proper implementation of machine learning algorithms.
In machine learning, selecting optimal parameter settings for algorithms is crucial as it directly influences the model’s performance and predictive accuracy. One effective method for parameter tuning involves utilizing insights from the dataset’s correlation matrix. The correlation matrix provides a comprehensive overview of the relationships between different features within the dataset. By examining the correlation coefficients between each pair of features, one can discern the degree and direction of their linear relationship. This information is invaluable for parameter selection as it helps identify relevant features and potential multicollinearity issues.
The values in this matrix range between [− 1, 1], and the closer these values are to 1, the stronger the positive correlation between the two variables. In other words, an increase in one variable is accompanied by an increase in the other variable. Negative values in the correlation matrix indicate a negative or inverse correlation between two variables, meaning that an increase in one is accompanied by a decrease in the other. A value of zero in this matrix indicates that there is no linear correlation between the two variables. Analyzing the values of the correlation matrix helps us identify patterns and relationships in the data, which can be useful in decision-making and modeling.
To improve the reliability of our model evaluations, we incorporated a cross-validation technique with 5 folds. This procedure entailed systematically splitting the dataset into training and testing subsets, resulting in a thorough evaluation of the model’s performance across different data subsets. This helped to minimize overfitting and enabled us to obtain more precise assessments of the model’s effectiveness, thereby ensuring increased dependability.
To obtain the best possible results from the algorithms considered in the analysis, the GridsearchCV method was employed. This method systematically explored a range of hyperparameter values, allowing for the identification of the optimal hyperparameters for each algorithm. By fine-tuning the models in this way, their predictive capabilities and generalization performance were significantly improved. Overall, this approach helped to ensure that the results obtained were as accurate and reliable as possible.
A wide range of evaluation algorithms were used, including various ensemble methods such as Random Forest, Hist Gradient Boosting, XGBoost, and CatBoost, as well as other methods like Logistic Regression, K-Nearest Neighbors (KNN), Support Vector Machine (SVM), and Convolutional Neural Network (CNN). This diverse selection of algorithms facilitated an extensive comparison of different modeling approaches, incorporating traditional statistical methods and cutting-edge machine-learning techniques.
The performance evaluation of the model was carried out utilizing the roc_auc_score, accuracy, and F1 score metrics.
Let, TP be the number of true positives (correctly predicted positive instances), FN be the number of false negatives (incorrectly predicted negative instances), FP be the number of false positives (incorrectly predicted positive instances), and TN be the number of true negatives (correctly predicted negative instances). In addition, let TPR represent the True Positive Rate (Sensitivity) and FPR represent the False Positive Rate (1—Specificity), calculated as:
The ROC curve is then plotted by varying the threshold for classifying instances as positive or negative and calculating \(\left( {{ }TPR{ }} \right)\) and \(\left( {{ }FPR{ }} \right)\) for each threshold value. The area under this curve is computed to obtain the ROC AUC score.
The ROC AUC score ranges from 0 to 1, where a score of 1 indicates perfect classifier performance (i.e., the classifier achieves a true positive rate of 1 and a false positive rate of 0), while a score of 0.5 suggests random performance (i.e., the classifier is no better than random guessing).
For accuracy and F1 score, we have the following relations, respectively:
The F1 score is the harmonic mean of precision and recall, providing a balance between these two metrics. It is calculated using the Eq. (4):
where:
Precision is the ratio of true positives to the total number of predicted positives and is calculated as:
Recall (also known as sensitivity or true positive rate) is the ratio of true positives to the total number of actual positives and is calculated as:
The F1 score ranges from 0 to 1, with 1 indicating perfect precision and recall, and 0 indicating the worst possible model performance. It is a useful metric for imbalanced datasets where the number of instances in one class is much larger than the other.
BN-FAHP
The Bayesian network is a hierarchical structure consisting of a set of objectives, options, criteria, and sub-criteria for decision-making. In this study, three types of nodes were chosen, including the probabilistic group, desirability node, and decision node, which are used in the BN structure. The decision nodes represent a set of options, the desirability node represents a set of objectives (decision priorities), and the probabilistic nodes consist of a set of criteria and sub-criteria. These criteria may be related to each other and can also be influenced by multiple factors. Figure 2 illustrates the hierarchical structure of BN networks in this study. Netica software was used for BN modeling in this study.

Illustrates the hierarchical structure in Bayesian networks.
In the hierarchical fuzzy AHP method, a hierarchical structure is used to describe and analyze various criteria. This method allows for the modeling of different criteria in decision-making and risk assessment processes in a fuzzy manner using fuzzy logic. By considering the existing uncertainty and ambiguity, better decisions can be made regarding the evaluation of factors affecting risk. This method also identifies risk options. The main risk options used in the BN method are also utilized in the hierarchical structure of the MCDM method.
After establishing a hierarchical structure, the next step is to evaluate elements through pairwise comparison. Pairwise comparison is a process for comparing the importance, preference, or correctness of two elements relative to a higher-level element. The comparisons of risk options were conducted in the form of pairwise comparison matrices. In the first row, comparing the probability of occurrence and the intensity of effects relative to the objective as criteria for effective risk options, these two factors, as the main components of risk, have equal importance and each receives a priority of 1 and a weight of 0.5.
The pairwise comparison tables of options related to factors influencing risk were also completed based on expert judgments and the complete process unit characteristics. Then, the weight of each indicator relative to higher-level indicators (relative weight) was calculated using the eigenvector method, and by combining them, the final weight for each option of factors influencing risk was determined.
The BN method based on the hierarchical structure of MCDM, considering the relationships between variables and adjusting uncertainties, provides persuasive and acceptable results and offers a proper prioritization for developing suitable strategies to reduce risk. After prioritizing the factors influencing the risk, solutions are presented for reducing and managing the risks of power plants and dealing with them, along with the utilization of appropriate measures before the occurrence of hazards.
Results
Hazop study
To identify and evaluate the risks of the target unit, a team consisting of process, safety, instrumentation, mechanical, and safety experts was formed. Table 3 shows a sample risk assessment conducted at the node related to the electrolyzer. The results of the hazop study for the selected nodes are presented in Table 3, based on the number of deviations in each node. As seen in Table 4, the highest number of deviations is related to the acid tank with 54 deviations, and the lowest number of deviations is related to the water storage tank with 2 deviations.
Machine learning
As previously mentioned, we determined risk levels based on other factors such as Probability, Severity, and Detection. Figure 3 illustrates the risk behavior for all samples. As observed, the risk values fluctuate between 2 and 180 within the range.

Risk behavior.
For parameter setting, the correlation matrix is used based on the Risk feature. Figure 4 denotes the correlation matrix between features. Based on this figure there are strong relationship between Risk and Detection, Severity and Probability, and a moderate relationship between Risk and Electrolyzer and Rectifier.

Correlation matrix.
A summary was compiled to provide a concise overview of the analysis results, outlining the algorithms utilized and their respective outputs. Table 5 serves as a valuable point of reference for evaluating and contrasting the performance of various models, aiding in selecting the optimal algorithm for the given task.
The table presents performance metrics for several machine learning models, each evaluated using different algorithms. The evaluation criteria focus on the models’ ability to accurately classify or predict outcomes, as indicated by the corresponding evaluation scores. Additionally, the confusion matrix (Table 6) was computed for all methods, providing the following results for each approach:
Table 6 illustrates the confusion matrix, summarizing classification results for 32 outcomes derived from the test dataset. These outcomes include True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). For instance, TP cases correctly identify high-risk scenarios like hydrogen gas leakage, while TN cases represent correctly classified low-risk scenarios. Conversely, FP outcomes overestimate risks (e.g., mislabeling minor deviations as high-risk), and FN outcomes miss significant risks (e.g., failing to detect potential equipment failure).
BN-FAHP
In this study, a total of 30 nodes were used in Bayesian networks, and the specifications of these nodes are shown in Table 7. These nodes include the node name, the level of the node in the hierarchical structure, the state of the node, and its type in the BN structure. This evaluation includes one decision node with a set of risk options and a utility node as the main objective (risk assessment), and 28 potential nodes in the network structure. The criteria, sub-criteria, and other factors are potential nodes. In this structure, two main risk indicators (probability of occurrence and severity of effects) are the main criteria, and each of these criteria can be influenced by sub-criteria such as physical environment, organizational environment, and socio-economic environment. Quantitative relationships between variables are modeled through CPTs associated with each of these nodes. The probability values in these tables are expressed as percentages based on expert opinions in the tables. To complete the probability of occurrence for each scenario in the tables and to achieve better coordination, the probability values entered in the variable CPTs were taken from Table 8.
By forming the BN structure and completing the CPT for each node, the probability distribution of decision node options was also determined. Figure 5 illustrates the Bayesian network for evaluating the risk of the studied unit Based on Nitica-V7.01 software, Corrosion in Electrolysis Cells (CEC), and Damage and Explosion of Cells (DEC) are the most significant risks with values of 0.252 and 0.222, respectively. Explosion in Cells due to High Voltage (ECHV) and Explosion in cells due to High Current Flow (EHCF) were lower priority risks with values of 0.115 and 0.122, respectively.

Bayesian network structure for risk assessment of the study unit based on nitica-V7.01(https://www.norsys.com).
To compare the results obtained from the Bayesian network, common methods such as MCDM were also used. The main risk options employed in the BN method were also utilized in a hierarchical structure. Figure 6 illustrates the hierarchical diagram of the studied unit.

Depicts the hierarchical structure of risk assessment for the studied unit.
The weights of each indicator relative to the higher level were calculated using the FAHP method, and the final weights for each risk option were determined. Based on the results obtained in this method, Corrosion in Electrolysis Cells (CEC) and Damage and Explosion of Cells (DEC) were assigned the first and second priorities, respectively, with final weights of 0.238 and 0.217. Figure 7 illustrates the prioritization of the options’ final weights using the FAHP method.

Final prioritization of options in the FAHP method.
The above text illustrates the prioritization of risk options using two methods, FAHP and Bayesian Networks, as shown in Table 9. In both approaches, the options “Damage and Explosion of Cells (DEC)” and “Corrosion in Electrolysis Cells (CEC)” are assigned higher priority relative to the other risk options.
Discussion
In the realm of risk assessment, machine learning serves as a potent tool within the domain of artificial intelligence and data analysis. When it comes to safety, identifying and predicting risks and hazards within work and industrial environments are crucial tasks. Machine learning systems, possessing high processing capabilities and analytical prowess, excel at uncovering intricate patterns and relationships in risk-related data. This capability aids in the identification and prediction of influential risk factors. By leveraging machine learning algorithms and drawing insights from historical data and relevant factors, it becomes possible to forecast the types of incidents and risks associated with a particular unit, thereby enabling the implementation of appropriate safety measures and preventive actions.
During this study, a thorough examination of the data characteristics was conducted, and their statistical properties were analyzed. This exploratory phase was instrumental in preparing and refining the dataset for predictive modeling. The significance of this initial exploration lies not only in feature identification but also in the discovery of latent patterns, laying the groundwork for a more in-depth analysis.
At the heart of this research was the implementation and comparative evaluation of various predictive models. These models, employing diverse algorithms and assumptions, were rigorously tested and juxtaposed against each other, offering a comprehensive insight into their respective strengths and weaknesses. The spectrum of models ranged from traditional machine-learning techniques to advanced ensemble methods. Their performance was assessed using multiple metrics to ensure a robust model selection process.
Based on the results obtained from the hyperparameter tuning and model evaluation process, it is evident that several machine learning algorithms have performed exceptionally well in classifying the data based on the given features. Among the algorithms tested, Random Forest, XGBoost, and CatBoost have demonstrated outstanding performance on the training and test datasets, achieving near-perfect AUC scores and accuracy values of 1.0000. These algorithms have been effectively tuned with appropriate hyperparameters, such as max_depth, n_estimators, learning rate, and iterations, leading to robust and highly accurate models.
Furthermore, K-Nearest Neighbors (KNN) and Support Vector Machine (SVM) have also exhibited commendable performance, achieving AUC scores and accuracy values close to 1.0000 on the test dataset. KNN has been optimized with hyperparameters including the choice of metric (Euclidean), number of neighbors7, and weights (distance), while SVM has been fine-tuned with parameters such as C (0.1), gamma (scale), and kernel (linear). These results highlight the effectiveness of these algorithms in capturing complex patterns in the data and making accurate predictions.
However, it is worth noting that Hist Gradient Boosting and Logistic Regression have shown comparatively lower performance compared to the other algorithms. Despite achieving reasonably high AUC scores on the training dataset, their performance on the test dataset is relatively lower, indicating potential issues with overfitting or suboptimal hyperparameter tuning.
The results of the current study underscore the significant effectiveness of machine learning techniques in the realm of risk prediction and assessment. All techniques evaluated in this study demonstrated the ability to classify and forecast risks with a high level of accuracy. This notable level of accuracy suggests that these techniques could be valuable additions to the risk assessment and prediction toolkit for process units. Given the relative ease of implementation of machine learning techniques, the abundance of risk evaluation data, and the computational capabilities of modern computers, it is recommended to develop an operational system utilizing artificial intelligence, specifically machine learning techniques, for risk prediction and assessment within process units. One limitation encountered in this study was the availability of limited data, which could potentially lead to suboptimal performance of trained algorithms in risk classification for certain features.
In discussing the capabilities of machine learning in risk classification, a comparison can be drawn with the results obtained by Heo et al. in their study on fall injury risk prediction. All machine learning-based models exhibited superior performance compared to logistic regression. However, the performance differences among the five models were marginal (AUROC values of 0.700, 0.700, 0.699, 0.699, and 0.698 for CatBoost, LightGBM, XGBoost, Random Forest, and logistic regression, respectively)65. In the study conducted by Bassey, the CatBoost model emerged as the top performer with 95% accuracy. This was attributed to its innate ability to effectively handle categorical variables and missing data, along with its strength in preventing overfitting. These characteristics equipped CatBoost with exceptional performance, particularly essential for accurate severity predictions of hydrocarbon releases. These findings align closely with the outcomes observed in our own study49.
An essential benefit of machine learning techniques lies in the abundance of powerful software tools available for their implementation. The presence of robust libraries in various programming languages has significantly simplified the application and adoption of machine learning principles. For those seeking a practical approach to automating the risk prediction process, the optimal choice would be to leverage machine learning techniques66.
In a study conducted by RK Mazumder, the mean accuracy of various machine learning models after fivefold cross-validation was reported as follows: KNN (77%), Decision Tree (80%), Random Forest (85%), Naive Bayes (78%), AdaBoost (70%), XGBoost (84%), LGBoost (84%), and CatBoost (78%). Among these algorithms, Random Forest (RF) exhibited the highest accuracy in prediction67.
The accuracy of these machine-learning algorithms was assessed using the confusion matrix, a method also employed in previous studies such as those by Mangalathu et al.68 and Robles-Velasco et al.69. In the context of a confusion matrix, accuracy represents the overall percentage of correct predictions. However, in cases of imbalanced datasets, accuracy alone might be misleading. Therefore, considering additional metrics from the confusion matrix, such as recall and precision, can be valuable in assessing algorithm performance. Recall indicates the percentage of correct predictions for ‘true positive’ instances, while precision signifies the percentage of correct predictions for ‘true negative’ instances. The presence of False Positives (FP) and False Negatives (FN) in prediction results carries critical implications. FP outcomes, while increasing operational costs due to unnecessary safety measures, are less harmful than FN outcomes, which can result in undetected high-risk scenarios and potential incidents. In high-risk environments like power plants, prioritizing recall to minimize FN is paramount, even at the expense of a slightly higher FP rate. This approach ensures a proactive safety-first methodology.
MCDM methods are widely used today for their ease of implementation and execution in various decision-making domains. However, in complex issues such as risk assessment, they sometimes suffer from uncertainty. Bayesian networks are one of the methods that can reduce uncertainty. This method has advantages such as considering relationships between variables and uncertainties, integrating information from different formats with data and expert opinions, organizing scattered thoughts and opinions on a subject visually and simply, and allowing updates with the addition of variables or new data. These features make Bayesian networks flexible models with high capabilities in risk assessment70.
To achieve a comprehensive solution for examining issues such as the assessment of risks in process units, integrating multi-criteria decision-making methods with Bayesian networks can be more effective compared to other approaches. Based on the results of Bayesian networks and prioritization of risk options, it can be stated that the options “Corrosion in Electrolysis Cells” and “Damage and Explosion of Cells” have a higher priority compared to other options. The BN method, based on a hierarchical structure considering relationships between variables and mitigating uncertainties, provides logical and acceptable results and offers a proper prioritization for developing suitable strategies to reduce process risks.
One of the main challenges of this research is the limited access to sufficient and high-quality data. The dataset, which includes 160 deviations identified through the HAZOP technique, may not be adequate to cover the full range of hazards and risks associated with the chlorination unit. This limitation can lead to issues such as overfitting of the model and a lack of generalizability to other process units. To address this issue, it is recommended to collaborate with various industries to collect more data and to use simulations to generate synthetic data related to different operational scenarios.
Incorporating contextual and behavioral factors into risk assessment can provide a better understanding of operational dynamics. To this end, collecting qualitative data through expert interviews and surveys, as well as considering operator behavior and their decision-making patterns in the model, can be beneficial.
This study shows that combined approaches based on machine learning and Bayesian networks can effectively be used to identify and assess risks in process units. However, to improve the accuracy and generalizability of the model, attention must be paid to data limitations, data quality, and contextual factors. By adopting the proposed approaches in future research, it is possible to develop stronger and more accurate models for risk assessment, ultimately contributing to improved safety and efficiency in industrial operations.
To improve risk assessment in process units, several promising directions can be explored. One critical step is broadening the range of data sources. Collaborating with diverse industries and utilizing publicly available databases can provide a richer dataset, enabling a more comprehensive understanding of potential risks. Another priority is the adoption of advanced data analytics. Techniques such as machine learning and real-time data monitoring systems offer significant potential for more dynamic and precise risk assessment.
Addressing uncertainty in risk models is another essential focus area. Developing Bayesian models that account for uncertainty and performing sensitivity analyses can help identify and prioritize the most critical factors influencing risk. Human factors also demand attention; understanding how human behavior impacts risk outcomes and designing tailored training programs can enhance operators’ decision-making and response capabilities in high-stakes situations.
Emerging technologies offer exciting opportunities for innovation. The Internet of Things (IoT) can facilitate real-time data collection, while artificial intelligence tools can enable predictive analytics and proactive risk management strategies. Additionally, cross-industry benchmarking is valuable for identifying best practices and working towards standardized methodologies that can be applied across various sectors.
Finally, fostering collaboration with regulatory bodies is essential. Aligning research efforts with industry standards and contributing to the development of policies that promote safety and efficiency can ensure that new methodologies have practical, real-world impact. By pursuing these avenues, researchers can make significant strides in enhancing the safety, reliability, and operational performance of process units.
Conclusion
In the realm of risk assessment, machine learning serves as a potent tool within the domain of artificial intelligence and data analysis. When it comes to safety, identifying and predicting risks and hazards within work and industrial environments are crucial tasks. Machine learning systems, possessing high processing capabilities and analytical prowess, excel at uncovering intricate patterns and relationships in risk-related data.
The findings of this study suggest that ensemble methods such as Random Forest, XGBoost, and CatBoost, along with KNN and SVM, are well-suited for the classification task at hand, offering high accuracy and robust performance. Further experimentation and fine-tuning may be required for algorithms that have shown relatively lower performance, aiming to improve their generalization capabilities and overall effectiveness in real-world applications.
By combining Bayesian networks and multi-criteria decision-making methods, it is determined that the options “Corrosion in Electrolysis Cells” and “Damage and Explosion of Cells” have a higher priority compared to other options. Using this model, appropriate measures can be taken to control and reduce risk in the studied unit. Furthermore, the approach presented in this model can be utilized for prioritizing and evaluating risk options in other process units as well.
Data availability
Te datasets used and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Abdullah, K. H. & Sofyan, D. Machine learning in safety and health research: a scientometric analysis. Int. J. Inf. Sci. Manag. 21(1), 17–37 (2023).
Shin, J., Kim, Y. & Kim, C. The perception of occupational safety and health (OSH) regulation and innovation efficiency in the construction industry: evidence from South Korea. Int. J. Environ. Res. Public Health 18(5), 2334 (2021).
Alves, A. M. S., Gonçalves Filho, C., Santos, Nd. M. & Souki, G. Q. Factors influencing occupational accidents: a multidimensional analysis in the electricity sector. Gestão & Produção 27, e4609 (2020).
Alizadeh, S. S. Estimation of economic costs of accidents at work in Iran: A case study of occupational accidents in 2012. Iran Occup. Health 12(1), 12–19 (2015).
Bahr, N. J. System Safety Engineering and Risk Assessment: A Practical Approach (CRC Press, 2014).
Zio, E. The future of risk assessment. Reliab. Eng. Syst. Saf. 177, 176–190 (2018).
Kh, A. Epidemiological study of occupational accidents in Yazd combined cycle power plant in years 1383 to 1390. Occup. Med. Q. J. 7(4), 88–97 (2016).
Atmaca, E. & Basar, H. B. Evaluation of power plants in Turkey using Analytic Network Process (ANP). Energy 44(1), 555–563 (2012).
Darwish, M. A., Al Awadhi, F. M. & Bin Amer, A. O. Combining the nuclear power plant steam cycle with gas turbines. Energy 35(12), 4562–4571 (2010).
Borgheipour, H. et al. Health safety and environmental hazards of the chlorination unit of combined cycle power plants by using HAZOP and bow-tie methods. Occup. Hygiene Health Promot. (2019).
Torres, M. J. F. & Beviá, F. R. Chlorine use reduction in nuclear or conventional power plants: A combined cooling-and-stripping tower for coastal power plants. J. Clean. Prod. 26, 1–8 (2012).
Corporation, B. V. White’s Handbook of Chlorination and Alternative Disinfectants (Wiley, 2011).
George, P. G. & Renjith, V. Evolution of safety and security risk assessment methodologies towards the use of bayesian networks in process industries. Process Saf. Environ. Prot. 149, 758–775 (2021).
Cagno, E., Caron, F. & Mancini, M. Risk analysis in plant commissioning: The multilevel hazop. Reliab. Eng. Syst. Saf. 77(3), 309–323 (2002).
Lee, K. M., Yoo, J., Kim, S.-W., Lee, J.-H. & Hong, J. Autonomic machine learning platform. Int. J. Inf. Manag. 49, 491–501 (2019).
Moradi Hanifi, S., Keighobodi, E. & Tabatabaei, S. H. Machine learning and its application regarding risk assessment and identification in complex processes. Arch. Occup. Health 6(4), 1318–1320 (2022).
Duan, Y., Edwards, J. S. & Dwivedi, Y. K. Artificial intelligence for decision making in the era of big data—evolution, challenges and research agenda. Int. J. Inf. Manag. 48, 63–71 (2019).
Fonseca, D. P., Wanke, P. F. & Correa, H. L. A two-stage fuzzy neural approach for credit risk assessment in a Brazilian credit card company. Appl. Soft Comput. 92, 106329 (2020).
Gurtu, A. & Johny, J. Supply chain risk management: Literature review. Risks 9(1), 16 (2021).
Paltrinieri, N., Comfort, L. & Reniers, G. Learning about risk: Machine learning for risk assessment. Saf. Sci. 118, 475–486 (2019).
Witten, I. H., Frank, E., Hall, M. A., Pal, C. J. & Data, M. editors. Practical machine learning tools and techniques. Data Mining. (Morgan Kaufmann Publishers, 2005).
Zhou, Z.-H. Machine Learning (Springer, 2021).
Sarker, I. H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2(3), 160 (2021).
Mienye, I. D. & Sun, Y. A survey of ensemble learning: Concepts, algorithms, applications, and prospects. IEEE Access. 10, 99129–99149 (2022).
Bevilacqua, M., Ciarapica, F. E. & Giacchetta, G. Industrial and occupational ergonomics in the petrochemical process industry: A regression trees approach. Accid. Anal. Prev. 40(4), 1468–1479 (2008).
Jin, K., Cho, J. & Kim, S.-Y. Machine learning-based categorization of source terms for risk assessment of nuclear power plants. Nucl. Eng. Technol. 54(9), 3336–3346 (2022).
Agarwal, V. et al. Machine learning and economic models to enable risk-informed condition based maintenance of a nuclear plant asset. Idaho National Lab (INL), Idaho Falls, ID (United States) (2021).
Xue, G., Liu, S., Ren, L. & Gong, D. Risk assessment of utility tunnels through risk interaction-based deep learning. Reliab. Eng. Syst. Saf. 241, 109626 (2024).
Kandel, R. & Baroud, H. A data-driven risk assessment of Arctic maritime incidents: Using machine learning to predict incident types and identify risk factors. Reliab. Eng. Syst. Saf. 243, 109779 (2024).
Sharifani, K. & Amini, M. Machine learning and deep learning: A review of methods and applications. World Inf. Technol. Eng. J. 10(07), 3897–3904 (2023).
Dong, X., Yu, Z., Cao, W., Shi, Y. & Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 14, 241–258 (2020).
Khan, F. et al. Dynamic risk management: A contemporary approach to process safety management. Curr. Opin. Chem. Eng. 14, 9–17 (2016).
Meel, A. & Seider, W. D. Plant-specific dynamic failure assessment using Bayesian theory. Chem. Eng. Sci. 61(21), 7036–7056 (2006).
Rausand, M. Risk Assessment: Theory, Methods, and Applications (Wiley, UK, 2013).
Kharajou B, Ahmadi H, Rafiei M, Hanifi S. Quantitative risk estimation of CNG station by using fuzzy bayesian networks and consequence modeling. Scientific Reports. 2024;14.
Kalantarnia, M., Khan, F. & Hawboldt, K. Dynamic risk assessment using failure assessment and Bayesian theory. J. Loss Prev. Process Ind. 22(5), 600–606 (2009).
Ramzan, N., Compart, F. & Witt, W. Methodology for the generation and evaluation of safety system alternatives based on extended Hazop. Process Saf. Progress. 26(1), 35–42 (2007).
Ferdous, R., Khan, F., Sadiq, R., Amyotte, P. & Veitch, B. Handling and updating uncertain information in bow-tie analysis. J. Loss Prev. Process Ind. 25(1), 8–19 (2012).
Qiao, W. et al. On the causation analysis for hazards involved in the engine room fire-fighting system by integrating STPA and BN. Ocean Eng. 288, 116073 (2023).
Wang, Y. F., Qin, T., Li, B., Sun, X. F. & Li, Y. L. Fire probability prediction of offshore platform based on Dynamic Bayesian Network. Ocean Eng. 145, 112–123 (2017).
Zarei, E., Khakzad, N., Cozzani, V. & Reniers, G. Safety analysis of process systems using Fuzzy Bayesian Network (FBN). J. Loss Prev. Process Ind. 57, 7–16 (2019).
Ab Rahim, M. S., Reniers, G., Yang, M. & Bajpai, S. Risk assessment methods for process safety, process security and resilience in the chemical process industry: A thorough literature review. J. Loss Prev. Process Ind. 88, 105274 (2024).
Adeniran, I. A., Efunniyi, C. P., Osundare, O. S. & Abhulimen, A. O. Enhancing security and risk management with predictive analytics: A proactive approach. Int. J. Manag. Entrep. Res. 6(8), 32–40 (2024).
Mitrakas, C., Xanthopoulos, A. & Koulouriotis, D. Techniques and models for addressing occupational risk using fuzzy logic, neural networks, machine learning, and genetic algorithms: A review and meta-analysis. Appl. Sci. 15(4), 1909 (2025).
Alauddin, M., Amyotte, P., Schrader, A., Addo, A. & Kamil, M. Z. A HAZOP of dust explosion testing and explosibility modelling using artificial neural networks. Can. J. Chem. Eng. 103(1), 110–125 (2025).
Contessotto, F. Towards phenomena-based HAZOP support.
Bozorgi, A., Roozbahani, A., Hashemy Shahdany, S. M. & Abbassi, R. Developing a risk management framework for agricultural water systems using fuzzy dynamic bayesian networks and decision-making models. Water Resour. Manag. 1–23 (2024).
Li, C.-y, Wang, J.-h, Zhi, Y.-r, Wang, Z.-r & Gong, J.-h. Simulation of the chlorination process safety management system based on system dynamics approach. Procedia Eng. 211, 332–342 (2018).
Bassey, M. E. Application of Data Mining and Machine Learning Techniques for Cause Analysis and Severity Prediction of Loss of Containment Incidents in Offshore Oil and Gas Facilities (The George Washington University, 2023).
Li, X., Wang, J. & Chen, G. A machine learning methodology for probabilistic risk assessment of process operations: A case of subsea gas pipeline leak accidents. Process Saf. Environ. Prot. 165, 959–968 (2022).
Wu, S., Zhang, L., Fan, J. & Zhou, Y. Dynamic risk analysis of hydrogen sulfide leakage for offshore natural gas wells in MPD phases. Process Saf. Environ. Prot. 122, 339–351 (2019).
Wang, F. & Gu, W. Intelligent HAZOP analysis method based on data mining. J. Loss Prev. Process Ind. 80, 104911 (2022).
Ekramipooya, A., Boroushaki, M. & Rashtchian, D. Predicting possible recommendations related to causes and consequences in the HAZOP study worksheet using natural language processing and machine learning: BERT, clustering, and classification. J. Loss Prev. Process Ind. 89, 105310 (2024).
Single, J. I., Schmidt, J. & Denecke, J. computer-aided hazop: Ontologies and ai for hazard identification and propagation. In Computer Aided Chemical Engineering vol. 48 1783–1788 (Elsevier, 2020).
Pirbalouti, R. G., Behnam, B. & Dehkordi, M. K. A risk-based approach to identify safety-critical equipment in process industries. Results Eng. 20, 101448 (2023).
Guo, X., Ji, J., Khan, F., Ding, L. & Tong, Q. A novel fuzzy dynamic Bayesian network for dynamic risk assessment and uncertainty propagation quantification in uncertainty environment. Saf. Sci. 141, 105285 (2021).
Liu, Z., Ma, Q., Cai, B., Liu, Y. & Zheng, C. Risk assessment on deepwater drilling well control based on dynamic Bayesian network. Process Saf. Environ. Prot. 149, 643–654 (2021).
Li, L., Xu, K., Yao, X. & Chen, S. Probabilistic analysis of aluminium production explosion accidents based on a fuzzy Bayesian network. J. Loss Prev. Process Ind. 73, 104618 (2021).
Li, M., Wang, D. & Shan, H. Risk assessment of mine ignition sources using fuzzy Bayesian network. Process Saf. Environ. Prot. 125, 297–306 (2019).
Xue, J., Yip, T. L., Wu, B., Wu, C. & Van Gelder, P. A novel fuzzy Bayesian network-based MADM model for offshore wind turbine selection in busy waterways: An application to a case in China. Renew. Energy 172, 897–917 (2021).
Gul, M., Yucesan, M. & Karci, C. A stratified Bayesian decision-making model for occupational risk assessment of production facilities. Eng. Appl. Artif. Intell. 133, 108283 (2024).
Marhavilas, P. K., Filippidis, M., Koulinas, G. K. & Koulouriotis, D. E. A HAZOP with MCDM based risk-assessment approach: Focusing on the deviations with economic/health/environmental impacts in a process industry. Sustainability 12(3), 993 (2020).
Penelas, Ad. J. & Pires, J. C. Hazop analysis in terms of safety operations processes for oil production units: A case study. Appl. Sci. 11(21), 10210 (2021).
Mokhtarname, R. et al. Application of multivariable process monitoring techniques to HAZOP studies of complex processes. J. Loss Prev. Process Ind. 74, 104674 (2022).
Heo, K.-N. et al. Development and validation of a machine learning-based fall-related injury risk prediction model using nationwide claims database in Korean community-dwelling older population. BMC Geriatr. 23(1), 830 (2023).
Hegde, J. & Rokseth, B. Applications of machine learning methods for engineering risk assessment—A review. Saf. Sci. 122, 104492 (2020).
Mazumder, R. K., Salman, A. M. & Li, Y. Failure risk analysis of pipelines using data-driven machine learning algorithms. Struct. Saf. 89, 102047 (2021).
Mangalathu, S., Hwang, S.-H. & Jeon, J.-S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 219, 110927 (2020).
Robles-Velasco, A., Cortés, P., Muñuzuri, J. & Onieva, L. Prediction of pipe failures in water supply networks using logistic regression and support vector classification. Reliab. Eng. Syst. Saf. 196, 106754 (2020).
Sun, Z. & Müller, D. A framework for modeling payments for ecosystem services with agent-based models, Bayesian belief networks and opinion dynamics models. Environ. Model. Softw. 45, 15–28 (2013).
Acknowledgements
The research team expresses gratitude for the sincere collaborations in the implementation of this power plant project.
Author information
Authors and Affiliations
Contributions
Hassan Mandali, Elham Keighobadi, Saber Moradi Hanifi: wrote the main manuscript. Seyed Majid Ayat, Hossein Ebrahimi, Mohammad Ghashghaei: prepared figures and data analysised.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mandali, H., Keighobadi, E., Ebrahimi, H. et al. Machine learning and bayesian network based on fuzzy AHP framework for risk assessment in process units. Sci Rep 15, 39083 (2025). https://doi.org/10.1038/s41598-025-25690-1
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-25690-1
