
Abstract
Pedestrian detection in complex scenes is a major challenge in the field of computer vision, and the existing algorithms have problems such as high leakage rate and a large number of model parameters. In this paper, an improved REG-YOLO model based on the YOLO model framework is proposed after experimental validation of several models. By coordinating multiple modules, the detection performance in complex scenarios is improved in terms of improving detection accuracy and lightweight model. The generalization of the improved model is further validated by data enhancement through a large language model image generation technique. The proposed optimization strategies enhance the model’s feature extraction capability, significantly reduce both the computational complexity and the number of model parameters, and further improve the detection stability of the model in complex scenes. Experimental results demonstrate that, compared to the baseline model, the improved model achieves respective increases of 0.5%, 1.3%, 1.1%, and 0.9% in mAP@0.5, mAP@0.5:0.95, Precision, and Recall. Meanwhile, the number of parameters and the computational complexity of the model are reduced by 29.2% and 26.4%, respectively. Compared to lightweight models, the REG-YOLO model achieves modest improvements in recall and mAP@0.5 while maintaining comparable accuracy to YOLOv11n and YOLOv12n. Notably, its recall outperforms both by 1.6% and 1.0% respectively. This demonstrates that the enhanced model improves detection accuracy and speed, exhibits superior stability in complex scenarios, more effectively reduces pedestrian detection failures in challenging environments, while maintaining low energy consumption. Moreover, addressing the issue of sample deficiency in complex scenarios within existing datasets, an augmented dataset covering extreme conditions was constructed based on large language models. By precisely controlling the scene characteristics and target structures of generated images through textual prompts, sample gaps were supplemented. This further enhanced REG-YOLO’s generalization capability on the augmented dataset, validating its efficient utilization of computational resources.
Similar content being viewed by others


Introduction
In contemporary society, the accelerated pace of urbanization has resulted in an increase in the density of the urban population. Within these densely populated urban areas, the high mobility of the public presents significant challenges to the domains of traffic management and security surveillance. With the rapid development in the field of deep learning technology and target recognition algorithms, pedestrian detection has attracted extensive research interest. The applications span smart cities, driverless driving, and intelligent surveillance, demonstrating their broad impact.
Its core objective is to achieve automatic identification and localization of pedestrians from complex scenes by analyzing visual information extracted from images or videos. Current algorithms are generally classified into two types: two-stage algorithms and one-stage algorithms. Two-stage algorithms, such as R-CNN1 and Faster R-CNN2, first identify target regions in an image, and then use a classification network to detect objects in these regions. In contrast, one-stage algorithms such as SSD3, YOLO (you only look once) series4, and RetinaNet5, directly predict object locations and categories without extraction of region detection. These algorithms show a significant improvement in detection performance by eliminating the region detection step. Among them, the YOLO family of models has become one of the main models for target detection tasks because of its efficient detection and excellent detection performance.
The current issues of missed detections, false positives, and high computational costs in existing algorithms are key constraints hindering the safe implementation and efficient operation of intelligent driving and smart city development. Within intelligent driving, as Level 2+ assisted driving systems become widespread, the reliability of pedestrian detection directly impacts the safety of both occupants and road users. Previous autonomous driving incidents involving companies like Uber and Cruise have demonstrated that failing to detect fallen pedestrians or those crossing roads can lead to fatal consequences. Moreover, reducing computational costs is essential for achieving low-cost mass production of autonomous driving systems. The in-vehicle edge computing unit must simultaneously process multi-source data from LiDAR, cameras, and millimetre-wave radar, with its computational power and power consumption subject to strict constraints. Employing traditional detection models exceeding 50 million parameters would induce detection delays surpassing 200 milliseconds, rendering them incapable of meeting vehicles’ real-time obstacle avoidance requirements for sudden pedestrians. While current mainstream lightweight models reduce parameters to under 10 million, the trade-off between speed and accuracy typically involves simplifying the feature extraction network’s channel count and layer depth. This significantly diminishes the model’s adaptability to complex scenes, severely compromising the reliability of intelligent driving systems. Within smart city traffic scenarios, the 2023 Smart City Traffic Technology Report indicates that during peak hours in tier 1 cities, traditional visual algorithms exhibit over 35% false detection rates for pedestrians under adverse conditions such as backlighting or heavy rain. At certain intersections, complaints about “erroneous violations” due to strong light reflections account for 28% of the total reports. At complex intersections near commercial districts and schools, where pedestrians and vehicles coexist in traffic queues, single-modal visual models exhibit 40% reduced detection rates for obscured pedestrians. An important example occurred at a key intersection in a major city’s commercial hub, where vehicle obstructions during the evening rush hour caused pedestrian detection failures that exceeded 35%, directly increasing the risks of traffic accidents and the probability of congestion. These practical challenges demonstrate the urgent need to address pedestrian detection oversights and computational burdens in complex scenarios. Achieving synergistic optimization of accuracy and lightweight design while bridging the gap in complex scenario samples will not only provide more reliable technical support for autonomous driving and smart cities, but will also transcend the limitations of traditional algorithms. This has significant theoretical innovation value and practical engineering significance.
In the field of computer vision, pedestrian recognition and detection in complex environments face many challenges.
Complex environments refer to images6 that contain unstable lighting conditions, diverse scenes, dynamic changes in targets, occlusion and severe blocking situations, and dynamic environmental changes. For example, in low light or high shadows, the appearance of pedestrians can change significantly, making traditional feature extraction difficult. In crowded scenes with large numbers of people, distracting objects in the background are highly similar to pedestrians, increasing the difficulty of accurately recognizing pedestrian locations. In addition, the dynamic behavior of pedestrians, such as turning or moving occluded, inevitably makes it difficult for traditional intrinsic feature-based detection algorithms to work stably. In the event of bad weather or sudden changes in lighting, the image quality and contrast change, placing higher demands on the model’s adaptability. At the same time, the pedestrian population itself varies widely, such as different skin colors, clothing types, and hairstyles, further increasing the difficulty in recognizing the detection algorithms. At the data set level, challenges such as the alternation of light and darkness in real environments, severe occlusion, a high overlap between human instances, and variations in character texture features and poses lead to numerous misdetections and omissions in detection models7. At the algorithm level, it is necessary to overcome challenges such as the difficult feature extraction in dense crowd environments and the complexity of the bounding-box loss calculation. In addition, the high computational cost caused by specific factors is also one of the important obstacles limiting its practical deployment. Together, these factors constitute a huge challenge for pedestrian detection in complex scenarios, which makes it particularly challenging to improve detection performance and realize practical applications.
In the face of these challenges, traditional pedestrian detection algorithms often exhibit low accuracy and recall. To improve the effectiveness of pedestrian recognition and detection, it must be achieved by optimizing the model structure and improving the data. The question of how to lightweight the model design and improve the fast detection performance, as well as reduce the influence of environmental factors on detection to cope with the problem of poor inference speed and accuracy in complex scenarios has become the focus of researchers’ attention.
For example, Fang et al.8 proposed YOLO-RAD, an improved YOLOv8 pedestrian detection algorithm for dense scenarios, which combines the receptive domain attention mechanism and the adaptive spatial feature fusion module in order to enhance multiscale feature fusion capability and improve the detection of small targets through dynamic head structure. Similarly, Su et al.9 proposed a PT-YOLO network in complex scenes by introducing the SE attention mechanism and the bidirectional feature pyramid module to effectively improve the accuracy and occlusion resistance of pedestrian detection. Ke et al.10 proposed a lightweight end-to-end pedestrian detection and re-recognition model using the data augmentation method with non-overlapping image blocks and LCNN to extract features, which improves the robustness and accuracy of the model. The model not only has a small number of parameters, but can also show good detection and re-identification performance in a variety of scenarios. Shen et al.11 proposed an instrument indicator acquisition algorithm based on RegNet enhancements, integrating multi-scale features and employing intermediate-scale feature maps for detection. This approach significantly improved detection accuracy and automation levels for target objects. The algorithm not only substantially reduced parameter complexity but also demonstrated robust positioning and reading performance across diverse industrial instrument types with minor variations. Shen et al.12 introduced a finger vein recognition algorithm based on lightweight convolutional neural networks. This approach incorporates Mini-ROI region extraction technology and a triplet loss function, effectively enhancing the accuracy of finger vein feature extraction and matching real-time performance. The model not only features a compact parameter size but also demonstrates robust recognition and generalization capabilities in resource-constrained biometric scenarios. Xiao et al.13 In the multitarget pedestrian tracking task, by improving the YOLOv8 model and introducing GhostConv and C3Ghost modules, the model parameters and computation are effectively reduced, which is very suitable for edge devices and real-time detection scenarios with limited resources. Shen et al.14 proposed an ancient mural element detection algorithm by incorporating an adaptive random erasure data augmentation strategy and a residual attention semantic feature module. This approach effectively enhances the recognition accuracy and scene adaptability of elements within damaged and blurred murals. The model not only exhibits low computational complexity but also demonstrates robust detection performance in scenarios characterised by numerous fine-grained mural elements and prevalent defects. Shen et al.15 addressed the challenges of vehicle detection in aerial scenes—characterized by dense small targets, complex backgrounds, and stringent real-time requirements—by proposing a detection framework combining anchor-free bounding boxes, lightweight feature extraction, and multi-layer attention fusion. This approach overcomes reliance on traditional anchors, with an adaptive sample selection strategy boosting positive recall by 18%. With lightweight parameters of 52.6MB, channel stacking enhances small object feature retention by 25%, while multi-layer attention improves occlusion detection accuracy by 15%. Combined with uniform internal channel counts and hard sigmoid activation, inference speed surpasses CBAM-based models by 40%, meeting real-time aerial monitoring demands. Tang et al.16 proposed a lightweight pedestrian detection model, PFEL-Net, specifically for multiscale pedestrian detection tasks. By designing the parallel expansion residual module, selective bidirectional diffusion pyramid network, detail feature layer, and lightweight shared detector head, PFEL-Net significantly reduces the number of parameters and computational complexity of the model while maintaining high accuracy, effectively reduces the model parameters and computation, and is well suited for resource-limited edge devices and real-time detection scenarios. In terms of data augmentation, Son et al.17 proposed the URIE model, a general-purpose image augmentation network designed to improve the performance of the model in visual recognition tasks in the field. The model enhances the input image by preprocessing, thus improving the performance of subsequent recognition models without retraining the recognition model. Gu et al.18 proposed a reference-free image quality assessment model based on big data learning, which improves the visual quality of the enhanced image by analyzing several features, such as contrast, sharpness, etc., and at the same time optimizes the data augmentation strategy. These studies demonstrate the importance and potential of data augmentation techniques in coping with image quality degradation and image recognition tasks under adverse weather conditions.
The above researches have improved the pedestrian detection technology in many aspects, which has strongly promoted the development of this field; however, the phenomenon of leakage and false detection in complex scenes is still serious; in view of the problems of the YOLO model in complex scenes, this paper proposes a lightweight and efficient pedestrian detection algorithm REG-YOLO for complex scenes from the perspective of the influence of environmental factors in complex scenes and the lightweighting of the model. The detection performance is optimized through multilevel modular improvement. The main work of this paper consists of two stages:
-
In the first stage, based on the YOLO model framework, we design the C2f-RVB module to replace the original C2f module in the YOLO framework, and introduce RepViTBlock to reconstruct the model parameters. This design significantly improves the model’s inference speed and efficiency while ensuring its feature extraction capability remains unaffected.
-
Based on the C2f-RVB module, the EMA attention mechanism is selected to replace the default attention mechanism in the module, and the C2f-RVE module is constructed and applied to part of the C2f-RVB module of the backbone network, and the improved module has stronger feature extraction capability while reducing the number of parameters.
-
In the YOLO model framework, the GSConv convolutional module is introduced to improve the lightness and detection accuracy of the network; while maintaining the feature extraction capability of the convolutional network, the compu- tational complexity of the model and the amount of model computation are substantially reduced, which significantly improves the inference speed. This scheme provides an effective solution for pedestrian detection in resources-constrained devices, ensuring that the model strikes a good balance between speed and accuracy.
-
In the second stage, data augmentation of the dataset using large language model image generation technique to construct a new augmented dataset and experimental validation to ensure the effectiveness and generalization ability of the model improvement.
The framework of this paper is arranged as follows:
Section “Introduction”, introduces the research background and significance of the pedestrian recognition model in complex scenes and illustrates the difficulties of pedestrian recognition in complex environments, as well as briefly describes the current state of research on pedestrian recognition models.
Section “Related work”, mainly introduces the method of the YOLO series model in pedestrian recognition, briefly describes the idea of model improvement in this paper, and introduces the application of large language model data augmentation method in the field of target recognition.
Section “Research methods”, an improvement scheme is proposed that improves some modules of the original model and data augmentation of the dataset in combination with the large language model, and a detailed description of the improvement method of each module is given.
Section “Experiments and results”, multiple sets of experiments are conducted on the improvement scheme proposed in this paper, and the effectiveness of the improvement method proposed in this paper’s work is fully verified through a comprehensive and in-depth analysis of the experimental results.
Section “Conclusions”, summarizes the contribution of the pedestrian recognition detection method in complex scenes proposed in this paper’s work, as well as the openness of the subsequent improvement.
Related work
Introduction to the YOLO model
First proposed in 2015 by Joseph Redmon and Ali Farhadi from the University of Washington, YOLO has emerged as a widely used model for object detection and image segmentation. The core concept of this algorithm involves dividing an input image into numerous grids, conducting bounding box prediction and class identification of objects within each grid, and removing overlapping bounding boxes through the application of non-maximal suppression. YOLOv119 is fast in detection but performs poorly on similar or small objects. Subsequent versions are continuously optimized: YOLOv220 introduces Darknet-19 feature network and anchor frame strategy to improve the accuracy; YOLOv321 integrates FPN and SPP modules to enhance the multi-scale detection capability; YOLOv422 adopts CSPDarknet architecture to optimize the recognition of small targets; YOLOv523,24 simplifies the architecture and adds C3 and SPPF modules to improve efficiency; YOLOv725,26 improves the feature extraction capability through E-ELAN and reparameterised architecture.
Proposed by Ultralytics in 202327, YOLOv8 is a one-stage object detection algorithm whose framework comprises three core components: backbone, neck, and head. Specifically, the backbone employs the Darknet-53 architecture and integrates the C2f module to enable residual learning. For the neck component, the model is further optimized through two key measures: adopting the PAN-FPN structure to facilitate feature fusion, and replacing the original C3 module with the C2f module to enhance overall detection performance. The Head part of the model uses a distribution focal loss function to improve the detection accuracy. While further improving the model performance and flexibility, it can be faster, more accurate, and easier to use. YOLOv11, released in 2024, is the latest official version of the YOLO series of real-time object detectors, with improved backbone and necking architectures, enhanced feature extraction capabilities, faster processing speeds, and an optimal balance between accuracy and performance. YOLOv12, on the other hand, both builds on the official versions to achieve somewhat lower computational overhead and higher performance.
In view of the subsequent conclusions and validations in the comparative experiments, as well as the computational requirements of this paper, YOLOv8n, which has the least number of parameters in the YOLOv8 model, is chosen as the baseline model in this paper.
Improved YOLO model
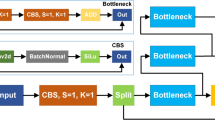
In pedestrian detection tasks, lightweight models, while favored for resource-constrained device deployment due to their low parameter count and computational demands, exhibit shortcomings in extreme environments and complex interaction scenarios: Firstly, their feature extraction adaptability is limited, with the C2f module in their backbone network demonstrating weak learning capabilities for small-scale feature maps during multi-scale feature fusion, leading to high false-negative rates in complex scenes; Secondly, their attention mechanisms are singular. Under dynamic lighting conditions such as backlighting or heavy rain, reliance solely on channel features struggles to distinguish pedestrians from similar backgrounds, leading to false detections. Finally, they struggle to balance computational efficiency with accuracy, failing to meet practical application requirements. The existing research work mentioned in the introduction, while demonstrating performance improvements, exhibits limitations in balancing robustness and computational efficiency in complex scenarios. It suffers from insufficient generalization capabilities in complex environments and struggles to meet low-latency requirements. To address the aforementioned limitations, this paper proposes an improved model, REG-YOLO, based on the YOLO framework in the first phase of research. Its structure is illustrated in Fig. 1. This refinement significantly reduces computational complexity and the number of parameters while maintaining high detection accuracy.

Structure of REG-YOLO.
Firstly, the C2f-RVB module is proposed to replace the C2f module in the network model, aiming at better access to contextual information, enhanced adaptability to deformation targets, and enhanced ability to extract multiscale features; secondly, based on the C2f-RVB module, the EMA attention mechanism is selected to replace the default attention mechanism, and the hierarchical attention weight is constructed by fusion of the multiscale feature maps, which has a stronger feature weight while reducing the number of parameters. Number while having a stronger feature extraction capability. GSConv is used to replace the traditional convolutional layer in the head layer of the network to process global information more efficiently and reduce the consumption of computational resources, and it can improve the generalization ability of the model as much as possible while reducing complexity. With these improved methods, the REG-YOLO model is able to perform the pedestrian detection task more efficiently while meeting real-time and accuracy requirements.
The synergistic mechanism proposed herein, comprising the RepViTBlock, EMA, and GSConv modules, fundamentally differs from existing single-module enhancement approaches. Its innovation manifests in three aspects: Firstly, the RepViTBlock overcomes the functional limitations of single modules. Unlike existing approaches that focus solely on the channel dimension or rely on local features, this module integrates reparameterization with attention mechanisms. It simultaneously achieves cross-scale feature fusion and dual-dimensional (spatial-channel) feature enhancement, effectively addressing information loss caused by feature blurring and local occlusion in complex scenes. Secondly, the EMA module fills a gap in training process optimization. Existing approaches lack tailored training strategies for unevenly distributed samples in complex scenarios, often leading to fluctuating training losses. EMA employs a sliding parameter average to dynamically suppress the interference of anomalous samples during model training, stabilizing the process and significantly enhancing the model’s adaptability to extreme scenarios. Thirdly, GSConv achieves synergistic optimization of efficiency and accuracy. Unlike existing approaches where module stacking leads to excessive parameter counts and computational demands, this module employs grouped sparse convolutions. This ensures robustness in complex scenarios while fully meeting the efficiency requirements of lightweight models, simultaneously advancing adaptability to complex environments and computational efficiency.
Data augmentation based on large language models
In complex scenes, the pedestrian recognition model often misses and misdetects due to factors such as lighting changes, poor environment, diverse backgrounds, etc. Although traditional data augmentation means can improve the generalization ability of the model to a certain extent, it is still insufficient in the face of the robustness problem of complex scenes. In recent years, the large language model technology represented by ChatGPT has opened up a new path to solve this problem, especially in the field of image generation and augmentation, showing great potential.
Due to its large parameter scale and powerful cross-modal generation capability, large language model technology is capable of generating high-quality pedestrian images with complex lighting, dense occlusion, and diverse backgrounds, providing a brand new strategy for data augmentation of pedestrian recognition models, and effectively fills the sample gaps of existing publicly available datasets in complex environments28. On the one hand, the images generated by the large language model significantly increase the diversity of the dataset, which can be significantly increased by zero sample generation, image variants, and synthetic functions, which can effectively improve the generalization ability and robustness of the model even when training samples are scarce29. On the other hand, synthetic data can help the model learn richer feature representations and reduce the risk of overfitting, thus improving the accuracy of recognition in complex scenes30. This data augmentation strategy based on large language model, through the text-guided generation technique, can be targeted to construct synthetic data containing extreme lighting and complex backgrounds, which provides strong support to improve the performance of pedestrian recognition models in complex scenes and promotes the development of pedestrian recognition technology in the direction of more reliable and robust31.
The large language model image generation technique takes the diffusion model as the core framework and performs image generation through text, which has significant advantages in complex scene data augmentation. In recent years, research achievements in the fields of data augmentation for visual tasks and cross-modal fusion within large language models have provided additional theoretical underpinnings and technical references for the methodology presented herein. For example, in the field of nuclear energy, models such as DALL-E can generate abstract scene images such as “uranium mining impacts on aboriginal land”through prompt engineering, and its cross-modal association can simulate dynamic and complex backgrounds in pedestrian recognition32. In the medical field, the large language model that incorporates the LoRA strategy achieves a Dice coefficient of 0.75–0.79 by optimizing the parameters through a custom module, proving that it can improve the model’s ability to capture targets in complex scenes by generating synthetic data containing detailed features33,34. The Image Augmentation Agent (IAA) framework proposed by Wu et al. enhances WSSS performance from a data generation perspective. By integrating large language models and diffusion models, it automatically generates high-quality, diverse synthetic training data35. This marks the first collaborative application of large language models and diffusion models for data augmentation in weakly supervised semantic segmentation, resolving semantic inconsistencies inherent in direct generation. Concurrently, an online filter embedded within the diffusion process dynamically ensures the quality and category balance of generated images. To tackle cross-domain semantic alignment challenges, Wu et al. proposed the LLM-Enhanced Multimodal Fusion (LLM-EMF) framework36, demonstrating large language models’ strengths in text information enrichment and cross-domain preference modelling. LLM-EMF integrates text enhancement from large language models, multimodal fusion, and domain-balanced attention to guide the generation of domain-agnostic item semantic attributes. By combining visual-text embedding fusion via the CLIP model and employing hierarchical attention mechanisms to balance multi-domain contributions, it effectively mitigates data sparsity and domain imbalance in cross-domain recommendation. Addressing quality control and model adaptation for generated data, Wu et al.’s Generative Prompt Controlled Diffusion (GPCD) method37 designs an end-to-end data augmentation pipeline for weakly supervised semantic segmentation. This approach employs a WSSS enhancement paradigm combining large language models and conditional diffusion to generate semantically controllable synthetic data, thereby overcoming limitations of traditional data augmentation. Furthermore, incorporating source information tokens into ViT resolves distribution shifts between original and synthetic data.
The aforementioned studies collectively validate the pivotal role of large language models in enhancing the diversity, semantic consistency, and task adaptability of generated data. Building upon this foundation, this paper extends such methodologies to the complex task of pedestrian detection. By precisely controlling the lighting conditions, environmental interference factors, and background complexity of generated data through textual prompts, we provide models with training samples that more closely approximate real-world scenarios. This fundamentally addresses the issues of missed detections and false positives. Consequently, the second stage of research employs large language models for data augmentation experiments.
Research methods
This paper is divided into two stages. The first stage involves improving the YOLO model framework with the aim of developing improved solutions suitable for different versions of YOLO and experimentally validating these solutions. Through comparative experiments on various model improvements, it was found that overly lightweight model structures resulted in a loss of detection accuracy after model improvements. Therefore, data augmentation was considered for the existing dataset to address the issue of insufficient feature representation caused by lightweight models by providing more diverse samples. In the second stage, large language model image generation technology was selected for data augmentation, followed by experimental validation.The research flowchart for this paper is shown in Fig. 2:

Research flowchart.
Model improvement
C2f-RVB module
Within the YOLO model, the C2f module primarily functions to extract features. However, the downsampling operation in the feature pyramid architecture causes the C2f module to mainly target small-sized feature maps for extraction, thereby limiting its learning capability in complex scenarios. To overcome the limitations of C2f in the backbone network, RepViTBlock is introduced to construct an improved C2f-RVB module to replace the C2f module in the original network, and the improved model has a stronger feature extraction capability and effectively reduces the number of parameters38.
RepViTBlock is derived from the RepViT model, a convolutional neural network that combines the advantages of Vision Transformer with the reparameterization technique, which significantly improves the inference speed while ensuring high accuracy39. The model is simulated using MobileNetV340 as shown in Fig. 3a39, the original MobileNetV3 module uses a 1 × 1 extended convolution and a 1 × 1 projection layer to implement inter-channel interactions (i.e., a channel mixer), and RepViTBlock adds a 3 × 3 depth separable convolution after a 1 × 1 extended convolution Depthwise Separable Convolution after the 1 × 1 extended convolution, RepViTBlock adds a 3 × 3 Depthwise Separable Convolution to fuse the spatial information (marker mixer). In order to optimize the marker mixer and channel mixer separation, as shown in Fig. 3b39 demonstrates the design idea of shifting the position of the Depthwise Separable convolution layer and the SE excitation layer upward, which allows the multi-branched structure of the deep convolution to be merged into a single-branched one at the inference stage, thus reducing the additional computational requirements and GPU burden. The ability to eliminate the computational and memory consumption associated with jump connections in the inference stage is particularly important for lightweight device deployments.

Comparison of MobileNet and RepViT lightweight structures: (a) MobileNet block. (b) RepViT block.
In the feature extraction of the YOLO model, the Bottleneck module of the C2f module first reduces the number of channels using 1 × 1 convolution and then performs deep convolution using 3 × 3 convolution, which introduces complex branching structures and fusion operations, leading to an increase in computation and excessive consumption of system resources. In contrast, RepViTBlock exhibits different characteristics in its training and output stages. Based on this, the C2f-RVB module combines the concept of RepViTBlock by reconstructing the model parameters and merging the multibranch structure of the deep convolution into a singlebranch structure in the output stage for optimization purposes. As shown in Fig. 4 , the original Bottleneck module within the C2f module is replaced by RepViTBlock, which effectively reduces the number of network parameters, achieves the purpose of lightweighting, and also improves the efficiency and precision of target recognition.

Structure of C2f-RVB module.
C2f-RVE module
Attention mechanism is particularly important in the field of computer vision, especially when dealing with target detection tasks in complex scenes. In complex scenes, a large gathering of pedestrians may lead to errors or omissions in detection. Therefore, the introduction of an attention mechanism can guide the model to focus more on the pedestrian area while ignoring unnecessary background information. However, the default SE attention mechanism of RepViTBlock only focuses on the attention in the channel dimension, which is unable to handle the information in the spatial dimension efficiently, and at the same time, the computational cost is high. To cope with this challenge, an efficient multi-scale attention (EMA) module is introduced to replace the original SE attention mechanism, and the reconstructed C2f-RVB module, named the C2f-RVE module. The structural counterpart is shown in Fig. 5.

Comparison of C2f-RVE and C2f structures: (a) C2f-RVE structure. (b) C2f structure.
This module uses a cross-space dynamic learning mechanism to generate spatial attention weights, which realizes the effective combination of multi-scale spatial information and precise location information, thus strengthening the model’s ability to pay attention to key spatial regions. This improvement not only improves the detection accuracy of the model, but also enhances its robustness in complex environments, bringing significant accuracy gains and more robust performance to the pedestrian recognition task.
The EMA (Efficient multi-scale attention) module is an efficient multiscale attention mechanism characterized by a grouping structure and no dimensionality reduction. It employs a cross-spatial learning approach to build a multiscale parallel subnetwork, which helps establish a broad range of dependencies—including both local short-range dependencies and global long-range dependencies. The information of each channel is preserved through cross-dimensional interactions, and the channel dimensions are divided into multiple sub-features to ensure that the spatial semantic features are uniformly distributed in each feature map. The EMA follows the processing of the CA (Coordinate attention) attention mechanism, which decomposes the channel attention into two one-dimensional feature encoding processes along the two spatial directions, respectively, feature aggregation along two spatial directions. Meanwhile, EMA introduces a parallel branch of 3 × 3 convolutional kernels to improve processing power41. With this feature grouping and multi-scale architecture, EMA effectively establishes short-term and long-term dependencies, significantly improves the detector performance, and reduces the number of required parameters and computational cost. In addition, EMA uses a parallel substructure to avoid performance degradation caused by complex sequential processing and deep convolution to extract pixel-level attention feature values. This approach provides a new way to aggregate cross-spatial information to achieve richer aggregation of features from different spatial dimensional directions42, which further enhances the expressiveness and adaptability of the model. The comparison of different attention modules is shown in Fig. 6.

Comparison of different attention mechanisms: (a) CA attention mechanism. (b) EMA attention mechanism.
In EMA, “X Avg Pool”refers to one-dimensional global pooling in the horizontal direction, while “Y Avg Pool”denotes one-dimensional global pooling in the vertical direction, assuming that the input feature X is X ∈ Rc×h×w, where c represents the number of channels in the feature map, h and w represent the height and width of the feature map, respectively. EMA divides X into G sub-features based on the cross-channel dimension learning method, and its operational formula is shown below
In order to achieve richer feature fusion, EMA first performs an average pooling operation for both directions in its 1 × 1 branch and processes 3 × 3 convolution operations in parallel at the same time. Specifically, the first branch is the horizontal branch, which employs a size-aggregation kernel (H,1) to encode each channel, producing the output of the c-th channel with height h, denoted by \(Z_{c}^{{\text{h}}}\), and the operational formula is shown below:
The second branch is a vertical branch that encodes each channel using a size-aggregation kernel (1,W) to produce the output of the c-th channel based on the width w, denoted by \(Z_{c}^{{\text{W}}}\). The operational equation is shown below:
The third branch is an ordinary convolution with a convolution kernel size of 3 × 3. In the cross-space learning stage, the output of the 1 × 1 branch is encoded with global information using 2D global average pooling to preserve the spatial information of the feature map, and the output of this process is fitted by a normalization function. Similarly, 2D global average pooling is used in the 3×3 convolutional branch. The formula for the average pooling operation is shown below:
where Xc(i, j) denotes the element at position (i,j) in the feature map. Eventually, the output feature maps within each group are converted into a pair of generated spatial attention weight values and processed by an activation function to highlight contextual information, thus completing the entire feature fusion process. This approach effectively enhances the model’s ability to focus on key features while reducing unnecessary computational overhead.
GSConv module
With the development of technology, the demand standard for real-time target detection tasks is increasing, and many existing high-precision target detection methods are often difficult to meet real-time requirements when faced with complex scenes or large-scale data. Even if some target detection systems achieve excellent detection accuracy, embedding them into hardware devices is a technical challenge. High accuracy is usually accompanied by increased algorithm complexity and computational demand, which puts higher demands on the processing power and storage capacity of the hardware. However, due to limited hardware resources in practice, these high standards cannot be fully met, so the adoption of lightweight models becomes an effective strategy to reduce the overall complexity and resource consumption. In this context, the introduction of GSConv43 aims to solve the problem of balancing the speed and accuracy of the model, achieving lightweight model and maintaining accuracy.
In order to significantly improve the prediction speed, the input image needs to go through a series of transformation steps in the core part of the model. In this process, the spatial information is gradually passed towards the channel, and each compression of the spatial dimension (width and height) of the features and the expansion of the channel dimension results in the loss of some semantic information. Channel dense convolution maximally preserves the hidden connections between each channel, while channel sparse convolution completely cuts these connections off. GSConv preserves these connections as much as possible with a lower time complexity. GSConv is a global sparse convolution operation44, which achieves efficient aggregation of global information by adding global sparsity to the feature map. Compared to traditional convolution, GSConv performs convolution operations only at selected sparse locations, which improves the efficiency of the model by maintaining the integrity of global information and reducing computational complexity.
The structure aims to minimize the possible negative effects of the separable convolution in depth while fully exploiting its advantages45. The core idea of GSConv is to reduce computational burden by using grouped convolution and selective activation strategies while ensuring that rich feature information can be extracted efficiently. By doing so, it not only optimizes the efficiency of the use of computational resources, but also enhances the model’s ability to handle complex tasks, allowing the model to maintain a low computational cost while ensuring high performance.The structure of the GSConv module is shown in Fig. 7

Structure of GSConv module.
Initially, if the number of channels in the input feature map is C1, after passing through a convolutional layer, the number of channels in the output feature map becomes C2/2. During the DWConv operation, the convolution operation is executed independently for each input channel to generate new features; this process helps to reduce the number of references and computational complexity while keeping the number of output channels constant. Subsequently, the results of Conv and DWConv are fused to obtain a feature map with the number of channels as C2. Finally, the channel order is realigned by performing the shuffle operation, a process that aims to facilitate the efficient flow and interaction of information between different channels, thus facilitating the fusion of information across channels, and ultimately produces a feature map with channel number C2. Shuffle is a type of homogeneous blending that allows information from Conv to be completely blended into the output of DWConv by exchanging local feature information uniformly across different channels. Exchanging local feature information uniformly across different channels. The use of GSConv instead of traditional Conv operations allows for more efficient processing of global information while reducing the use of computational resources. This approach improves the generalization ability of the model as much as possible on the basis of reducing the model complexity.
Data augmentation based on large language model
In this article, large language model image generation technology is used to enhance the dataset. Data augmentation methods for large language models leverage the generative capabilities of large models and diffusion models to expand data diversity across multiple dimensions. Image enhancement leverages diffusion models to generate diverse image samples driven by text prompts, and can also combine technologies like ControlNet to achieve structurally controllable image editing. By inputting text descriptions, diffusion models can generate corresponding images based on semantic understanding, while ControlNet can further constrain structural features of the images, such as specifying composition ratios or object positions, thereby enhancing the controllability and task adaptability of the generated images46.
After various comparisons and technical research, the Doubao AI developed by ByteDance47 and the WanX-v1 model developed by Alibaba48 are chosen as core tools to expand the scene and generate samples for the pedestrian recognition dataset. During technical research, Doubao AI provides richer character samples for the enhanced dataset by virtue of its more realistic character generation ability, while wanx-v1 model has more advantages in scene generation in different environments, so the combination of the two was chosen to generate a more comprehensive pedestrian image augmentation dataset for complex scenes.
The core process encompasses data creation, annotation, and post-processing. When using large language model image generation technology for data augmentation, the first step is to define the generation requirements and randomly select reference examples from the dataset; textual semantic descriptions of the images are extracted using the large language model, which are then used as input prompts for the diffusion model to achieve cross-modal data augmentation from “text-to-image.”Subsequently, instructions are further refined for the generation task. The large language model parses natural language instructions to construct visual content that meets multiple conditional constraints from the model’s image generation algorithm and material library, ultimately outputting a series of images that meet the specified requirements. In the post-processing stage, samples with semantic deviations are filtered out using model filtering methods. Pedestrian images from complex scenes that meet the generation requirements are selected from the generated images, organized, and used to create an augmented dataset.
In this study, 300 images of typical complex scenes (e.g., rainstorms, backlighting, and dense crowds) are randomly selected from the training set of the WiderPerson data set. Synthetic samples are then generated at a 1:1 ratio relative to the selected images, covering these extreme scenes to supplement the dataset. Pedestrian targets in the synthetic images are annotated using labelImg; At the same time, 60 images were randomly selected from the original validation set and test set to form an enhanced validation data set for experimentation to verify the effectiveness of data augmentation.Some images from the large language model synthetic dataset are shown in Fig. 8. The diagram illustrating the data augmentation process based on large language models is shown in Fig. 9. This text prompt guides large language models in generating complex scene pedestrian imagery, explicitly covering elements such as “scene type” “extreme environments” and “lighting intensity.” Specific content examples include: Based on the reference image, generate pedestrian imagery of consistent scale within complex scenes, incorporating both the pedestrian figure and original textual content; The scene must incorporate an extreme, specialized complex environment, selecting one from the following: sandstorm, torrential rain/snow, hailstorm, or dense fog. This is to be paired with extreme lighting conditions, selecting one from the following: excessively bright, excessively dark, or sunset/twilight lighting. Simultaneously, adjust the overall color scheme of the image, such as altering background tones or pedestrian clothing colors, to ensure distinct visual differentiation from the reference image, thereby meeting extreme scenario detection requirements. Generated images shall be filtered based on “semantic accuracy, target fidelity, and environmental coherence”. Pedestrian eye accuracy must be maintained without non-pedestrian objects present. Pedestrian forms must adhere to realistic logic, free from anomalies such as levitation or limb distortion. Manual sampling verification shall ensure morphological plausibility. Extreme environments must appear realistic and unremarkable. Extreme lighting scenarios must ensure that excessively bright, dark, or sunset/twilight lighting effects adhere to real-world physical laws, with no abrupt localized light/shadow issues. This process filters out semantically biased samples, ensuring enhanced data quality.

Some images from the large language model synthetic dataset. According to the user agreement between Volcano Engine Doubao and AliCloud, images could be used for non-profit academic research, including publication in papers. These synthetic example images encompass extreme scenarios including night-time, sunset, backlighting, rainy and snowy conditions, dust storms, and densely populated settings.

Schematic diagram of the large language model augmentation process: (a) WanX-v1 model interface. (b) Doubao AI interface. According to the user agreement between Volcano Engine Doubao and AliCloud, images could be used for non-profit academic research, including publication in papers. The figure illustrates the process and examples of image generation using large language models as described in this paper.
Experiments and results
Datasets and experimental setup
Datasets
In this paper, the WiderPerson dataset49, which is widely used for human body detection in complex real-world scenarios, is chosen as the baseline test set. The dataset is carefully selected from diverse real-world scenarios, contains a total of 13,382 images, and provides about 400,000 annotations covering a wide range of occlusion scenarios.Images in WiderPerson exhibit rich features of outdoor scenarios, e.g., walking, cycling, running, marathon events, square dancing, etc. In addition, the dataset provides multiple forms of annotations, including full-body-visible frames, cyclist frames, semi-obscured pedestrian frames, and dense crowd frames, which present a high degree of diversity and complexity and pose significant challenges for model training and testing. In this paper, we focus on the task of pedestrian detection in complex scenarios, using images labeled as pedestrian category in the WiderPerson dataset. The randomly selected images are divided into training and testing sets. Some images of the WiderPerson dataset are shown in Fig. 10.

Partial images of WiderPerson dataset. According to the research paper on the WiderPerson dataset, the WiderPerson dataset and its images can be used for non-commercial scientific research. These example images showcase a portion of the original WiderPerson dataset, though regrettably the research team behind the WiderPerson dataset has not publicly disclosed the specific proportion of complex scene samples within it.
Experimental setup
The hardware configuration for this experiment includes a 13th generation Intel Core i7-13700H processor (2.40 GHz), 16 GB of RAM and an NVIDIA GeForce RTX 4060 laptop GPU. The software environment is based on the Linux operating system, using the Python programming language and support for the CUDA version 11.8 runtime library, and the deep learning framework is PyTorch 2.1.0+cu118.
The experiments were carried out on the WiderPerson dataset and all images were pre-processed and resized to 640 × 640 pixels. A stochastic gradient descent optimizer with default settings was used uniformly during model training, the batch size was set to 16, and the total number of training times was 100 epochs.This configuration aims to standardize the experimental conditions to facilitate the comparison of the effects of different models or parameter adjustments on the performance of target detection.
Experimental evaluation metrics
To measure the detection performance of the model, the following six evaluation metrics are used in this document:
The experimentally selected precision P is used to measure the misdetection rate of the model, and the recall R is used to measure the missed detection rate. The mean average precision (mAP@0.5) is calculated using an IoU threshold of 0.5, and the average precision after weighted average between 0.5 and 0.95 is calculated using mAP@0.5:0.95. Its calculation formula is shown below:
where TP represents the number of correctly determined positive samples, FP represents the number of incorrectly determined positive samples, and FN represents the number of incorrectly determined negative samples. P(R) represents the smoothed precision rate, C represents the number of categories and APi represents the precision rate of the i-th category.
The number of model parameters (Params) refers to the total number of parameters in the model training process, including weights, bias values, and so on. It is used to measure the spatial complexity of the model and its size; therefore, a low number of parameters is a key criterion to assess whether the model is lightweight or not.
The amount of model computation (GFLOPs) is the number of floating point operations required for the model to perform one forward propagation. It is used to evaluate the model’s demand for computational resources, and a lower computation volume makes the model more suitable for devices and application scenarios with limited memory or restricted computational power.
Experimental results and analysis
This paper’s experiment was conducted in two stages. In the first stage, the effectiveness of each module of the improved model framework was verified, and its improvement performance on different versions of the model was also verified. In the second stage, based on the experiments in the first stage, the effectiveness of large language model data augmentation in compensating for insufficient feature expression and the generalisability of each version of the model were verified.The first three sets of experiments were the first stage and the last set was the second stage.
Ablation experiment
In order to verify the effectiveness of the optimization of each module, this paper performs ablation experiments on the WiderPerson dataset, and the experimental results are shown in Table 1. The C2f-RVB module replaces C2f in the network and achieves an increase in precision: the precision is improved by 0.1% and the recall by 0.3%, mAP@0.5 increased by 0.1% and mAP@0.5:0.95 increased by 0.3%. In addition, the number of parameters and the computational effort were reduced by 26.1% and 25.3%, respectively. This improvement confirms the effectiveness of merging multiple branches into a single branch at the inference stage by introducing RepViTBlock to replace the Bottleneck module, which not only eliminates redundant computations but also preserves key features, simplifies the network structure, and reduces the number of network parameters, proving the advantages of lightweight design.
In order to further increase the accuracy of the model, the C2f-RVB module in the last two layers of the backbone network is improved using the EMA attention mechanism to form the C2f-RVE module. This resulted in an increase of 1.1% in precision, an increase of 0.8% in recall, and improvements of 0.4% and 0.7% in mAP@0.5 and mAP@0.5:0.95, respectively.The number of parameters and computation are reduced by approximately 25.9% and 24.7%, respectively, compared to BASELINE. This indicates that the EMA mechanism dynamically generates multiscale spatial attention weights through cross-space learning, which enhances the model’s ability to focus on pedestrian-dense areas, compensates for the lack of SE attention that focuses only on the channel dimension, and significantly improves the robustness in complex scenarios. Although the EMA mechanism slightly increases the computation and number of parameters, its efficient design substantially improves the performance with a small increase in resource consumption.
To further reduce the number of model parameters and computational requirements, the C2f-RVB-based GSConv module was introduced for experimental verification. The results showed that the accuracy improved by 0.4% after using GSConv, while the recall rate remained unchanged. mAP@0.5 and mAP@0.5:0.95 all improved by 0.3%, and the number of parameters and computational requirements were reduced by 29.3% and 27.1%, respectively.The GSConv module effectively aggregates global information by introducing global sparsity, while reducing computational burden and improving model efficiency. Reducing computational complexity through grouping operations and focusing on convolutional computation at sparse locations while maintaining global information effectively reduces the number of parameters and computational effort.
However, the use of GSConv alone may weaken the ability to express deep features, and the lack of combining the spatial attention mechanism leads to a limited improvement in the detection of small targets, but after C2f integrates all three of RepViTBlock, the EMA attention mechanism, and the GSConv module, the model achieves a relative balance between the detection accuracy of the target and the computational speed in complex scenarios, and all indicators have been significantly improved.
Comparison experiments of different models
In order to evaluate the accuracy difference between the improved model and different detection models, several representative network models are selected for comparison, including Faster R-CNN, YOLOv3-tiny, YOLOv5n, YOLOv7-tiny, YOLOv8s, YOLOv8n, YOLOv10n50, YOLOv11n51 andYOLOv12n52 with the REG-YOLO model proposed in this paper. All experiments are conducted in the same experimental environment and configuration, and training and testing are completed with the WiderPerson dataset to ensure comparable results. The experimental results are shown in Table 2, and the effect comparison graph is shown in Fig. 11.

Comparison of the effect of each model.
According to the table, the REG-YOLO model proposed in this paper shows significant advantages over the comparison models in several indicators. Compared with Faster R-CNN, REG-YOLO successfully achieves a significant reduction in the number of parameters and computation, Although its mAP@0.5 decreased by 0.22%, significant progress was made in terms of lightweight design and detection efficiency.
Compared with the lightweight YOLO family of models, REG-YOLO excels in the balance of accuracy and efficiency. Al- though YOLOv3-tiny, YOLOv5n, YOLOv7-tiny, YOLOv11n, and YOLOv12n have lower parameter counts and computational effort, REG-YOLO achieves superior feature expressiveness with higher precision and accuracy. Compared with the baseline model YOLOv8n, the improved algorithm achieves improvements of 0.5%, 1.3%, 1.1%, and 0.9% in detection performance (mAP@0.5, mAP@0.5:0.95, Precision, and Recall), respectively. Additionally, it reduces the number of parameters by 29.2% and computational complexity by 26.4%, highlighting the synergistic effects of model compression and performance optimization. Although the mAP@0.5 of YOLOv8s is comparable to that of this paper, but its number of parameters and computation amount are significantly higher than the latter, indicating that REG-YOLO is able to provide corresponding performance with lower resource consumption and is more suitable for resource-constrained scenarios. In addition, comparing with YOLOv10n, REG-YOLO improves mAP@0.5, mAP@0.5:0.95, Precision, and Recall by 1.2%, 2.5%, 1.2%, and 0.9%, respectively, with 1.1% reduction in parameter quantity, and reduces computation by 13.1%, which further demonstrates the advantages of its structural design.
In addition, the 87.8% precision rate and 81.8% recall rate of the improved algorithm in this paper find a good balance in dealing with the misdetection and omission problems in complex scenarios. In summary, REG-YOLO shows stronger competitiveness in the comprehensive optimization of parameter utilization efficiency, computational cost and detection accuracy, which is particularly suitable for real-time detection tasks in resource-constrained environments.
Comparison experiments of different model improvements
In order to verify the effectiveness of the proposed improved module in different YOLO versions, YOLOv8n, YOLOv10n, YOLOv11n and YOLOv12n are selected as the comparison models in this paper and compared with the same dataset and training configurations, and the experimental results are shown in Table 3, and the comparative effect graphs are shown in Fig. 12.

Comparison of the effect of different models after improvement.
From the table, it can be seen that REG-YOLO based on YOLOv8n has the best performance in terms of accuracy index, but its number of parameters and computation amount are significantly higher than other improved models. In contrast, the improved YOLOv11n and YOLOv12n have less than 2 M parameters though,however,their mAP@0.5:0.95 decreased to 61.7% and 61.5%, respectively, indicating that lightweight design significantly limits accuracy.
The deep network structure and multi-scale feature fusion mechanism of YOLOv8n are more suitable for the embedding of complex modules. C2f-RVB enhances the interaction between local and global features, while the long-range dependency modelling capability of the EMA attention mechanism in the C2f-RVE module is fully demonstrated in high-capacity networks, which can effectively capture cross-layer feature correlations in deep networks. C2f-RVB provides sufficient computation power for the multilayer co-optimization of multiple modules. module co-optimization provides sufficient computational resources, the channel compression design of YOLOv10n weakens the global–local feature interaction capability of C2f-RVB, while the EMA attention mechanism is difficult to establish effective long-range dependencies in low-resolution feature maps; YOLOv11n and YOLOv12n, on the other hand, suffer from insufficient feature space dimensions due to extreme parameter counts and computational compression, which makes the high-dimensional feature fusion modules such as C2f-RVB and C2f-RVE degraded to inefficient operations, while channel shuffling of GSConv further exacerbates the information loss of the lightweight model. In addition, there is some conflict between the dynamic architecture optimization of the lightweight model and the design concept of the improvement module, resulting in the accuracy augmentation potential being severely constrained.
Experiments show that REG-YOLO based on YOLOv8n is suitable for high-precision demand scenarios by virtue of its deep network structure and high computational capacity. Despite the high number of REG-YOLO parameters, YOLOv8n’s mature ecological toolchain lowers the threshold of industrial deployment and balances performance and practicality.
Comparative experimental results after large language model data augmentation
In order to verify the effectiveness of the proposed data augmentation method to further improve the model performance, YOLOv8n, YOLOv10n, YOLOv11n, YOLOv12n, and the improved model are selected as the comparison models for experiments. The dataset is an augmented validation dataset. The experimental results are shown in Table 4.The effect comparison graph is shown in Fig. 13.

Comparison of different models after data augmentation.
From the experimental results in Table 4, it can be seen that the performance of each model is generally improved after data augmentation, but REG-YOLO still maintains the accuracy advantage, Its mAP@0.5 and mAP@0.5:0.95 reached 89% and 63.1%, respectively, significantly higher than the baseline model and other lightweight models. Notably, the improved YOLOv11n and YOLOv12n models showed improved performance after data augmentation, with mAP@0.5:0.95 increasing to 64.2% and 63.9%, respectively, further validating the constraints of lightweight design on model performance.Data augmentation mitigates the lack of feature expressiveness of the lightweight model by expanding the sample diversity, but the high-capacity network maintains the performance advantage by making fuller use of the enhanced data due to its deep structure and sufficient computational resources.
The experimental results show that the relative performance relationship between models remains consistent despite the differences in absolute performance values due to different datasets.REG-YOLO, with its high-capacity structure and complex modular design, exhibits excellent performance in both types of datasets, which verifies its ability to efficiently utilize computational resources. Data augmentation can alleviate the problem of insufficient feature expressiveness of the lightweight model by expanding the sample diversity, but the high-capacity network can more fully utilize the augmented data due to its deep structure and sufficient computational resources. Although the performance of the lightweight model improves more after augmentation, it still lags behind REG-YOLO in the combined performance by comparing the before and after experiments, indicating that the constraints of parametric compression on feature expression ability can be compensated to some extent by expanding the diversity of data. In addition, REG-YOLO shows stable generalization performance under different datasets, which verifies the effectiveness of its high-capacity structure and complex module design, and further highlights the greater role of high-capacity models in high-precision scenarios, which provides a reliable data adaptability guarantee for its industrial deployment.
Comparative experiment on test set consistency data augmentation
Using the WiderPerson dataset as the testing benchmark, we validated the optimization effect of data augmentation on model performance through an experimental design that incorporated synthetic pedestrian images generated by large language models into the training set while strictly maintaining the test set unchanged. YOLOv8n, YOLOv10n, YOLOv11n, YOLOv12n, and the improved model were selected as comparison models for experimentation. The experimental results are presented in Table 5. The comparative visualization is shown in Fig. 14.

Comparison of data augmentation methods using different algorithms.
Experimental results indicate that, when compared against different models in comparative experiments, targeted small-scale incremental supplementation of the dataset led to varying degrees of improvement in detection accuracy across all algorithms following data augmentation. Recall and mAP@0.5:0.95 demonstrated relatively pronounced increases. REG-YOLO and YOLOv12n demonstrated particularly pronounced performance advantages under data augmentation, with REG-YOLO extending its lead further. Its mAP@0.5 and mAP@0.5:0.95 reached 90.7% and 65.5% respectively, not only maintaining its accuracy competitiveness from the original dataset experiments but achieving comprehensive superiority over other models. Conversely, lightweight algorithms such as YOLOv8n, YOLOv10n, and YOLOv11n demonstrated comparatively modest performance gains.
This outcome fully validates the pivotal role of data augmentation: on the one hand, by supplementing the original WiderPerson dataset with additional image samples from more complex scenarios, it effectively mitigates the high false negative rates observed in complex environments across models in Table 2. For instance, YOLOv12n’s recall rate improved from 80.8% in Table 2 to 82.7% in Table 5, directly demonstrating data augmentation’s optimization of false negative issues. On the other hand, data augmentation amplified the performance disparities between different model architectures. Specifically, our REG-YOLO model leverages its C2f-RVB module (which supports multi-scale feature fusion) and C2f-RVE module (which enables region-of-interest focusing) to efficiently utilize the augmented data for improved detection performance. Conversely, lightweight models like YOLOv8n and YOLOv11n, which rely on the basic CSPDarknet module, struggle to fully extract information from difficult samples due to their limited feature expression capabilities. Even with data augmentation, they fail to narrow the gap with high-capacity models. This further demonstrates that while data augmentation can improve model generalization, the feature learning capacity of the model architecture remains the key factor determining the performance ceiling. This demonstrates REG-YOLO’s efficient utilization of computational resources under data augmentation scenarios and its strong adaptability to pedestrian detection tasks. It also highlights that high-capacity, well-optimized models can leverage data augmentation more effectively to enhance performance, offering greater advantages in balancing accuracy and efficiency.
Contrasting experiments on complex scene enhancement
To further validate the detection performance of the improved model in complex scenarios, data augmentation was applied to the augmented validation dataset. This augmented dataset was then merged with the original augmented samples to form an enhanced dataset comprising 30% complex scenarios for experimentation. YOLOv8n, YOLOv10n, YOLOv11n, YOLOv12n, and the improved model were selected as comparison models for experimentation. Experimental results are presented in Table 6. Performance comparison diagrams are shown in Fig. 15.

Performance comparison of different algorithms after data augmentation in complex scenarios.
The experimental results indicate that as data augmentation is further enhanced, the impact of complex scenes on model performance intensifies. The disparity in performance under extreme conditions directly reflects the varying degrees of robustness exhibited by the models. Among these, REG-YOLO demonstrated optimal robustness in extreme scenarios. Even when confronted with challenging conditions such as target contour blurring due to strong backlighting, multiple target overlaps and occlusions within dense crowds, and interference from heavy rain or snow, it maintained a high accuracy rate of 91.6% and a recall rate of 81%. mAP@0.5, and mAP@0.5:0.95 achieved 89.6% and 64.7% respectively. This core advantage stems from its C2f-RVB module, which enhances multi-scale feature capture through the RepViTBlock architecture. This enables precise extraction of critical local features in extreme scenarios, such as pedestrian silhouettes in backlighting or limb edges in occlusion scenarios. The EMA attention mechanism within the C2f-RVE module dynamically filters complex background interference, preventing false positives and negatives caused by scene noise. Concurrently, the GSConv module preserves global semantic information while controlling computational complexity, ensuring feature propagation remains unaffected in extreme scenarios. This enables stable, high-precision outputs even as the proportion of complex scene images increases.
In contrast, lightweight models exhibit more pronounced shortcomings in robustness under extreme conditions. Within extreme scenarios featuring multiple targets with significant overlap, the constrained feature channel dimensions of lightweight architectures fail to effectively distinguish the bounding boxes of adjacent targets. This results in recall rates lower than REG-YOLO. Furthermore, in adverse weather conditions, their ability to filter scene interference is weaker, leading to a marked increase in false detection rates. Whilst YOLOv12n achieves a 65% mAP@0.5:0.95and 81.2% recall rate through its BiFPN architecture and spatial attention mechanism, outperforming other lightweight models in extreme scenarios, it still suffers from insufficient deep feature learning capabilities when confronted with more complex extreme conditions.
Overall, as the proportion of complex scene images increases, REG-YOLO leverages its modular collaborative design to achieve efficient feature extraction and interference filtering in extreme scenarios, with its robustness advantage becoming increasingly evident. Whilst lightweight models can mitigate performance issues in conventional complex scenarios through data augmentation, their limited feature representation and interference resistance result in minimal robustness improvement under extreme conditions. This confirms that high-capacity models better withstand scene noise interference in highly complex detection tasks through deep structures and specialized module design, providing critical assurance for high-reliability detection requirements in industrial settings.
Visualisation analysis
In order to be able to observe the detection effect of the models, test images with occlusion and dense features are selected in this paper to demonstrate the specific detection effect of the baseline model and the two models of REG-YOLO. The visualization results on the WiderPerson dataset are shown in Fig. 16:

Visualisation of the baseline model and REG-YOLO: (a) Baseline model. (b) REG-YOLO model. According to the research paper on the WiderPerson dataset, the WiderPerson dataset and its images can be used for non-commercial scientific research. The localised enlargement in a depicts the region missed by the baseline model, while the localised enlargement in b shows the optimised region by the REG-YOLO Model.
By comparing the detection results of the baseline model in Fig. 16a of with the improved REG-YOLO model in Fig. 16b, it is clear that the latter has optimized its performance on the target detection task. Specifically, REG-YOLO demonstrates significant improvements in target localization accuracy as well as detection confidence. The number of detection frames generated by the improved model is reduced, and these frames are more accurately centred around the target individual, which effectively reduces the false detection rate and the redundant overlap of detection frames. In addition, the confidence scores of the improved model generally increased, indicating that the model has a higher reliability for its detection results. Overall, these improvements not only reduced the false detection rate, but also achieved substantial breakthroughs in enhancing the detection accuracy and improving the confidence of the model, proving the effectiveness of the REG-YOLO model and its potential in practical applications.
Conclusions
In this paper, an enhanced REG-YOLO model is proposed based on the YOLO model framework, which is optimized for the pedestrian recognition problem in complex scenes. In order to reduce missed detections and false positives of traditional target detection algorithms in dealing with pedestrians occluding each other or scenes with complex scenarios, a series of improvement measures are proposed from the perspectives of improving the model accuracy and lightweighting the model, and at the same time, data augmentation is carried out on the dataset by using the large-model image generation technique to fill the sample gaps of the WiderPerson dataset in the complex environments. In the first stage of the study, compared with the baseline model, the improved model proposed in this paper achieves mAP@0.5, mAP@0.5:0.95, Precision, and Recall of 90.0%, 64.4%, 87.8%, and 81.8%, respectively, on the WiderPerson dataset, which is an improvement of 0.5%, 1.3%, 1.1% and 0.9%, while the number of parameters of the model and the amount of computations were reduced by 29.2% and 26.4%, respectively. Meanwhile, in the second stage of the YOLO series of model improvement experiments and data augmentation validation experiments for large language models, it shows more comprehensive advantages and generalization ability, which verifies that the improved method has different degrees of optimization effects on both YOLO series models. Overall, the REG-YOLO model proposed in this study achieves three key contributions: first, it improves pedestrian detection accuracy while maintaining a lightweight design; second, it enhances the model’s robustness in complex scenarios, the false negative rate and false positive rate were reduced by 0.9% and 1.1% respectively, compared to the baseline model’s 80.9% and 86.7%; third, it demonstrates strong generalization ability through large language model-based data augmentation, validating its adaptability to diverse complex environments. The experimental results show that the model is suitable for deployment on resource-constrained devices and has the potential to cope with pedestrian target detection in complex scenarios. Future research will continue to concentrate on model optimization to further improve its performance, allowing it to adapt to more complex practical application scenarios. At the same time, multimodal reasoning capabilities will be incorporated, taking advantage of the cross-modal comprehension capabilities of large language models in text and image processing. By analyzing textual descriptions of complex scenarios through large language models, dynamic detection parameters tailored to each scenario will be generated, enabling the model to adaptively adjust to extreme environments. An adaptive prompt generation system will be developed to overcome the limitations of current fixed templates. This system will enable large language models to automatically refine prompt descriptions based on detection performance feedback from historically generated samples. This enhancement will improve the alignment between synthetic data and real-world complex scenarios, thereby expanding the application boundaries of REG-YOLO.
Data availability
The dataset supporting the findings is provided in the article. For further inquiry, please contact the relevant author.
References
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 580–587, https://doi.org/10.1109/CVPR.2014.81 (2014).
Ren, S., He, K., Girshick, R. & Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intel. 39, 1137–1149. https://doi.org/10.48550/arxiv.1506.01497 (2016).
Liu, W. et al. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11—14, 2016, Proceedings, PartI 14, 21–37, https://doi.org/10.1007/978-3-319-46448-0_2 (Springer International Publishing, 2016).
Jiang, P., Ergu, D., Liu, F., Cai, Y. & Ma, B. A review of yolo algorithm developments. Procedia Comput. Sci. 199, 1066–1073. https://doi.org/10.1016/j.procs.2022.01.135 (2022).
Lin, T. Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, 2980–2988, https://doi.org/10.1109/ICCV.2017.324 (IEEE, 2017).
Zhang, H. et al. A controllable generative model for generating pavement crack images in complex scenes. Comput. Aided Civ. Infrastruct. Eng. 39, 1795–1810. https://doi.org/10.1111/mice.13171 (2024).
Tahir, N. U. A. et al. Object detection in autonomous vehicles under adverse weather: A review of traditional and deep learning approaches. Algorithms 17, 103. https://doi.org/10.3390/a17030103 (2024).
Fang, Y. & Pang, H. An improved pedestrian detection model based on yolov8 for dense scenes. Symmetry 16, 716. https://doi.org/10.3390/sym16060716 (2024).
Su, J., An, Y., Wu, J. & Zhang, K. Pedestrian detection based on feature enhancement in complex scenes. Algorithms 17, 39. https://doi.org/10.3390/a17010039 (2024).
Ke, X., Lin, X. & Qin, L. Lightweight convolutional neural network-based pedestrian detection and re-identification in multiple scenarios. Mach. Vis. Appl. 32, 1–23. https://doi.org/10.1007/s00138-021-01169-7 (2021).
Shen, J., Liu, N., Sun, H., Li, D. & Zhang, Y. An instrument indication acquisition algorithm based on lightweight deep convolutional neural network and hybrid attention fine-grained features. IEEE Trans. Instrum. Meas. 73, 1–16. https://doi.org/10.1109/TIM.2023.3346488 (2024).
Shen, J. et al. Finger vein recognition algorithm based on lightweight deep convolutional neural network. IEEE Trans. Instrum. Meas. 71, 1–13. https://doi.org/10.1109/TIM.2021.3132332 (2021).
Xiao, X. & Feng, X. Multi-object pedestrian tracking using improved yolov8 and OC-sort. Sensors 23, 8439. https://doi.org/10.3390/s23208439 (2023).
Shen, J. et al. An algorithm based on lightweight semantic features for ancient mural element object detection. NPJ Herit. Sci. 13, 70. https://doi.org/10.1038/s40494-025-01565-6 (2025).
Shen, J. et al. An anchor-free lightweight deep convolutional network for vehicle detection in aerial images. IEEE Trans. Intell. Transp. Syst. 23, 24330–24342. https://doi.org/10.1109/TITS.2022.3203715 (2022).
Tang, J. et al. Pfel-net: A lightweight network to enhance feature for multi-scale pedestrian detection. J. King Saud Univ. Inf. Sci. 36, 102198. https://doi.org/10.1016/j.jksuci.2024.102198 (2024).
Son, T., Kang, J., Kim, N., Cho, S. & Kwak, S. Urie: Universal image enhancement for visual recognition in the wild. In Computer Vision-ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16, 749–765, https://doi.org/10.1007/978-3-030-58545-7_43 (Springer International Publishing, 2020).
Gu, K., Tao, D., Qiao, J. F. & Lin, W. Learning a no-reference quality assessment model of enhanced images with big data. IEEE Trans. Neural Netw. Learn. Syst. 29, 1301–1313. https://doi.org/10.1109/TNNLS.2017.2649101 (2017).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 779–788, https://doi.org/10.1109/CVPR.2016.91 (IEEE Computer Society, 2016).
Ningthoujam, R., Pritamdas, K. & Singh, L. S. Edge detective weights initialization on darknet-19 model for yolov2-based facemask detection. Neural Comput. Appl. 36, 22365–22378. https://doi.org/10.1007/s00521-024-10427-4 (2024).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. Preprint at https://arxiv.org/abs/1804.02767 (2018).
Arifuzzaman, M. et al. Innovation in public health surveillance for social distancing during the covid-19 pandemic: A deep learning and object detection based novel approach. PLoS ONE 19, e0308460. https://doi.org/10.1371/journal.pone.0308460 (2024).
Tang, H. et al. A visual defect detection for optics lens based on the yolov5-c3ca-sppf network model. Opt. Express 31, 2628–2643 (2023).
Jocher, G., Chaurasia, A., Stoken, A. et al. Ultralytics/yolov5: v7.0-yolov5 sota realtime instance segmentation. https://doi.org/10.5281/zenodo.3908559 (2022).
Avazov, K. et al. Fire detection and notification method in ship areas using deep learning and computer vision approaches. Sensors 23, 7078. https://doi.org/10.3390/s23167078 (2023).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. Preprint at https://arxiv.org/abs/2207.02696 (2022).
Wang, C. Y. & Liao, H. Y. M. Yolov1 to yolov10: The fastest and most accurate real-time object detection systems. APSIPA Trans. Signal Inf. Process. https://doi.org/10.1561/116.20240058 (2024).
Bie, F. et al. Renaissance: A survey into AI text-to-image generation in the era of large model. IEEE Trans. Pattern Anal. Mach. Intell. https://doi.org/10.1109/TPAMI.2024.3522305 (2024).
Ko, H. K. et al. Large-scale text-to-image generation models for visual artists’ creative works. In Proceedings of the 28th International Conference on Intelligent User Interfaces, 919–933, https://doi.org/10.1145/3581641.3584078 (2023).
Lu, M. Y. et al. A visual-language foundation model for computational pathology. Nat. Med. 30, 863–874. https://doi.org/10.1038/s41591-024-02856-4 (2024).
Dai, F. et al. Improving AI models for rare thyroid cancer subtype by text guided diffusion models. Nat. Commun. 16, 1–16. https://doi.org/10.1038/s41467-025-59478-8 (2025).
Joynt, V. et al. A comparative analysis of text-to-image generative AI models in scientific contexts: A case study on nuclear power. Sci. Rep. 14, 1–23. https://doi.org/10.1038/s41598-024-79705-4 (2024).
Zhou, Y. et al. Semiautomated segmentation of breast tumour on automatic breast ultrasound image using a large-scale model with customized modules. Sci. Rep. 15, 1–11. https://doi.org/10.1038/s41598-025-97098-w (2025).
Huang, Z., Bianchi, F., Yuksekgonul, M., Montine, T. J. & Zou, J. A visual–language foundation model for pathology image analysis using medical twitter. Nat. Med. 29, 2307–2316. https://doi.org/10.1038/s41591-023-02504-3 (2023).
Wu, W. et al. Image augmentation agent for weakly supervised semantic segmentation. Neurocomputing https://doi.org/10.1016/j.neucom.2025.131314 (2025).
Wu, W. et al. Llm-enhanced multimodal fusion for cross-domain sequential recommendation. Preprint at https://arxiv.org/abs/2506.17966 (2025).
Wu, W. et al. Generative prompt controlled diffusion for weakly supervised semantic segmentation. Neurocomputing https://doi.org/10.1016/j.neucom.2025.130103 (2025).
Wang, A., Chen, H., Lin, Z. et al. Repvit-sam: Towards real-time segmenting anything. Preprint at https://arxiv.org/ abs/2312.05760 (2023).
Wang, A., Chen, H., Lin, Z., Han, J. & Ding, G. Repvit: Revisiting mobile CNN from VIT perspective. Preprint at https://arxiv.org/abs/2307.09283 (2023).
Howard, A., Sandler, M., Chu, G. et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 1314–1324, https://doi.org/10.1109/ICCV.2019.00140 (2019).
Ouyang, D., He, S., Zhang, G. et al. Efficient multi-scale attention module with cross-spatial learning. In ICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5, https://doi.org/10.1109/ICASSP49357.2023.10096516 (IEEE, 2023).
Zhang, D. et al. CSART: Channel and spatial attention-guided residual learning for real-time object tracking. Neurocomputing 436, 260–272. https://doi.org/10.1016/j.neucom.2020.11.046 (2021).
Cai, T., Zhang, D., Wang, Y. et al. Learning local-global feature representation for pedestrian detection and re-identification. In 2023 7th Asian Conference on Artificial Intelligence Technology (ACAIT), 756–763, https://doi.org/10.1109/ACAIT60137.2023.10528631 (IEEE, 2023).
Li, H. et al. Slim-neck by GSConv: A lightweight-design for real-time detector architectures. J. Real-Time Image Process. 21, 62. https://doi.org/10.1007/s11554-024-01436-6 (2024).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1251–1258, https://doi.org/10.1109/CVPR.2017.195 (2017).
Zhou, Y., Guo, C., Wang, X., Chang, Y. & Wu, Y. A survey on data augmentation in large model era. Preprint at https://arxiv.org/abs/2401.15422 (2024).
Inc., D. Doubao AI official website. https://www.doubao.com/ (2024).
Cloud, A. Tongyi wanxiang (wanx-v1) official website. https://tongyi.aliyun.com/wanxiang/ (2023).
Zhang, S. et al. Widerperson: A diverse dataset for dense pedestrian detection in the wild. IEEE Trans. Multimed. 22, 380–393. https://doi.org/10.1109/TMM.2019.2929005 (2019).
Hobson, P. J. et al. Target-field design of surface permanent magnets. Phys. Rev. Appl. 22, 034015. https://doi.org/10.1103/PhysRevApplied.22.034015 (2024).
Khanam, R. & Hussain, M. Yolov11: An overview of the key architectural enhancements. Preprint at https://arxiv.org/abs/2410.17725 (2024).
Tian, Y., Ye, Q. & Doermann, D. Yolov12: Attention-centric real-time object detectors. Preprint at https://arxiv.org/abs/2502.12524 (2025).
Funding
This work was supported by the funding for Basic Research Projects in Liaoning Provincial Undergraduate Universities (Grant No. SYLUGXTD07) and the Basic Scientific Research Fund of the Liaoning Provincial Department of Education (Grant No.LJ222510144004).
Author information
Authors and Affiliations
Contributions
Conceptualization, Y.Z.; methodology, Y.Z.; validation, Y.Z.; data curation,Y.Z.; writing—original draft preparation, Y.Z. ; writing—review and editing, Y.Z.and Y.J..; supervision,Y.J.; project administration, Y.J. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Y., Jiang, Y. Research on pedestrian recognition in complex scenarios based on data augmentation using large language models. Sci Rep 15, 45694 (2025). https://doi.org/10.1038/s41598-025-26970-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-26970-6
