
Abstract
Text-to-image (T2I) artificial intelligence models are being increasingly explored in medical education, yet their utility in ophthalmology remains unclear. Slit-lamp anterior segment photography, as a cornerstone of ophthalmic training, provides an ideal context for evaluation. We assessed 40 cases of anterior segment disease. The text descriptions were generated using GPT-4o, and the corresponding images were synthesized via Sora Turbo. Readability was analysed with the Flesch Reading Ease (FRE), Flesch‒Kincaid Grade Level (FKGL), and Gunning Fog Scale (GFS). Twenty ophthalmologists (10 juniors, 10 seniors) rated image-text pairs across five dimensions—text accuracy, image reliability, recognizability, educational value, and generation stability—using a 5-point Likert scale. Entities with distinct morphological features, such as cataracts and subconjunctival haemorrhages, received the highest total scores, whereas those with entropion and corneal foreign bodies scored the lowest. Readability analysis indicated advanced text complexity. Senior ophthalmologists consistently provided lower ratings than junior clinicians did, highlighting expertise-related differences in perceived educational value. Sora Turbo can generate clinically useful anterior segment images for educational purposes, particularly for pathologies with prominent morphological features. This first systematic evaluation in ophthalmology demonstrates the promise of AI-generated atlases as scalable teaching resources for early-stage trainees while emphasizing the need for expert validation and ethical oversight before integration into formal curricula.
Similar content being viewed by others

Introduction
The recent rise of text-to-image (T2I) generative artificial intelligence (AI) models has sparked widespread excitement1. These T2I tools translate textual descriptions into corresponding visual outputs. They typically employ deep neural networks, such as diffusion models or generative adversarial networks (GANs), trained on vast image-text datasets, which first encode the text into a semantic representation and then iteratively decode it into a novel image2. As the capabilities of T2I tools continue to be explored, they hold significant in the medical domain, such as in the areas of popularization, promotion, and diagnosis2,3,4. Recently, interest in applying T2I generative AI to medical education has increased5,6.
Several T2I models (such as Midjourney, DALL-E, Stable Diffusion and Gemini) are currently available and demonstrate utility in medical education5; however, a lack of anatomical precision and fidelity prevents these systems from satisfying the requirements of medical education5. For example, an evaluation of DALL-E 3 depictions of congenital heart disease revealed a high prevalence of anatomical inaccuracies (81%), incorrect annotations (85%), and content unusable for educational purposes (78%)7. Sora Turbo, an advanced text-to-video model developed by OpenAI, has recently expanded its capabilities to include T2I generation8. Unlike traditional T2I tools such as DALL-E, Sora Turbo generates images by leveraging its video frame generation approach, resulting in photorealistic visuals, naturalistic details, and high spatial fidelity. Therefore, Sora’s T2I capability may hold distinct potential for medical education.
Ophthalmic education needs to provide learners with more visual cues to enrich their clinical experience. Compared with other multimodal ophthalmic imaging modalities, slit-lamp anterior segment photography serves as the foundational cornerstone and represents the initial and primary focus for physicians in clinical diagnosis and management. Mastering the features of anterior segment photography in ocular diseases is an essential milestone in the professional development of every ophthalmologist. However, existing learning resources such as textbooks, journal articles, direct clinical observation, and online materials suffer from limitations, including restricted access, fragmented availability, inconsistent quality, and copyright or privacy constraints9,10,11. T2I generative AI models may offer solutions to address these challenges.
In this study, Sora Turbo was used to generate slit-lamp anterior-segment images across common entities, and their quality and educational applicability were evaluated.
Materials and methods
Given that this study did not involve human subjects, human participants, protected health information (PHI), or patient data and relied exclusively on publicly accessible artificial intelligence tools for image generation, informed consent was not needed, and institutional ethics committee review and approval were not applicable (Fig. 1).

Flow chart.
Generation of the anterior segment atlas
Two senior ophthalmologists independently compiled lists of common ocular diseases or lesions of the anterior segment on the basis of their clinical experience. In parallel, a list of common diseases or lesions was generated using the GPT-4o (OpenAI, Inc., San Francisco, California, United States, July 14, 2025), guided by the prompts “Please help list common ocular diseases or lesions of the anterior segment”. Finally, the research team consolidated all three lists into the final, standardized version after a group discussion. The final inclusion criteria focused on three main factors: teaching importance (high frequency or exam relevance), anatomical coverage (ensuring that all major categories, such as the cornea, iris, and lens, were included), and graded difficulty (ranging from obvious, high-contrast signs to subtle findings).
For each anterior-segment disease or lesion, GPT-4o produced text descriptions conditioned on a structured prompt schema; a representative template was “Give me a description of an ocular anterior segment photograph of XX”. The Sora T2I model (OpenAI, Inc., San Francisco, California, United States, July 16, 2025) generated four high-resolution images per disease or lesion according to standard prompt specifications (“Please generate an ocular anterior segment photograph of ‘XX’ for ophthalmic education. The characteristic features are ‘XX’.”). All the images were generated in default mode (no preset), and per image was output at 1536 × 1024 pixels (PNG, aspect ratio 3:2). No manual retouching or postprocessing was performed. Four ocular anterior segment images paired with their corresponding textual descriptions for each disease or lesion collectively constitute the Anterior-Segment Atlas.
Readability analysis
The Readability Analyzer (https://datayze.com/readability-analyzer) was used to assess the readability of the descriptive texts. For each descriptive text, the Flesch Reading Ease (FRE), Flesch‒Kincaid Grade Level (FKGL) and the Gunning Fog scale (GFS) were calculated. FRE is an algorithm that calculates text accessibility on the basis of average sentence length and syllable count per word12. FRE quantifies text simplicity on a 0–100 scale, where higher scores indicate easier comprehension12. Both the FKGL and the GFS are used to measure the years of education required for text comprehension13,14. Technically, FKGL and FRE share computational variables, whereas GFS differentially weights complex words in its readability assessment13.
Anterior-segment photograph evaluation
An expert panel comprising junior (work experience < 10 years) and senior ophthalmologists (work experience ≥ 10 years) was convened to evaluate the anterior-segment atlas across five dimensions: (1) text accuracy (whether the accompanying textual descriptions used accurate medical terminology, were clearly expressed, logically structured, and objectively reflected the pathological features depicted in the images); (2) image reliability (whether the anterior-segment images presented clinically realistic representations, meeting standards sufficient for teaching use); (3) recognizability (whether the disease or pathological features could be reliably identified from the images alone, without reliance on supplemental information); (4) educational value (whether the combination of images and text provided practical value in ophthalmology teaching or self-study, enhancing disease recognition capabilities and deepening clinical understanding); and (5) generation stability (whether the four generated images per case demonstrated uniform, stable, and high-quality characteristics). All dimensions were evaluated using a 5-point Likert scale, where a score of 1 indicated the poorest evaluation and a score of 5 indicated the highest evaluation.
Statistical analysis
The statistical analyses were conducted with SPSS software (IBM SPSS Statistics for Windows, Version 25.0.0; IBM, Armonk, New York, USA). Normality was assessed with the Shapiro–Wilk test; owing to nonnormality, continuous variables are summarized as medians (Q1–Q3), and categorical variables are summarized as frequencies (%). For between-group comparisons (junior vs. senior), scores were first aggregated at the entity level (within-group median per entity and dimension) and then compared using two-sided Mann–Whitney U tests with Benjamini–Hochberg false discovery rate (FDR) adjustment across the five dimensions; effect sizes (Cliff’s δ) were reported. Interrater agreement was quantified using Kendall’s W with tie correction, computed for the overall panel (n = 20) and within each seniority subgroup (n = 10); significance was evaluated via the χ2 approximation. A two-sided p < 0.05 was considered to indicate statistical significance.
Results
The atlas incorporates 40 categories of anterior segment conditions, including normal images along with various pathologies, the latter of which covers 6 conjunctival diseases/pathologies, 8 lacrimal apparatus and eyelid diseases/pathologies, 8 corneal diseases/pathologies, 4 lens diseases/pathologies, 4 iris diseases/pathologies, and 9 unclassified diseases/pathologies. (Supplement Table 1).
Readability analysis revealed FRE scores ranging from 7.74 (band keratopathy) to 51 (a history of radial keratotomy), with FKGL values between 9.07 (chalazion) and 16.26 (hypopyon) and GFS scores ranging from 11.81 (posterior synechia) to 20.92 (hypopyon) (Table 1). Collectively, the readability metrics suggest that the textual descriptions are pitched at an advanced reading level appropriate for professional audiences.
Anonymized information on the evaluators is provided in Supplement Table 2. Across all the raters, agreement was statistically significant for all five dimensions, indicating low-to-moderate agreement overall. In the junior and senior subgroups, agreement remained significant with a similar pattern: image-related dimensions showed relatively higher agreement than text accuracy did. (Table 2).
Ten junior ophthalmologists and ten senior ophthalmologists were asked to assess the quality of the anterior-segment atlas. Table 3 presents the aggregated dimension-specific and composite scores for each image in the anterior segment atlas, which are based on assessments from all 20 ophthalmologists. All the images achieved relatively high text accuracy scores and generation stability scores (scores ≥ 3). However, lower scores (scores < 3) were observed for image reliability (entropion, corneal foreign body, hyphema, iridodialysis, a history of laser peripheral iridotomy), recognizability (entropion), and educational value (entropion, corneal foreign body). With respect to overall quality, only entropion and corneal foreign bodies exhibited poor image quality (total score ≤ 15), with entropion images receiving the lowest total score of 12.5 points. Five images (corneal neovascularization, cataract, subconjunctival haemorrhage, ptosis and normal anterior segment) achieved a maximum of 25/25 (Fig. 2).

Examples of AI-generated anterior segment images. (A) One of the images with the highest total score (subconjunctival haemorrhage), (B) one of the images with the lowest total score (entropion).
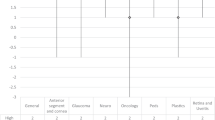
We also evaluated differences in anterior segment image quality scores across the evaluator subgroups. Two-sided Mann–Whitney U tests with BH–FDR adjustment across the five dimensions revealed that all five dimensions remained significant after FDR correction (p < 0.001), with junior raters assigning higher scores than senior raters did. Effect sizes (Cliff’s δ) were large (approximately 0.80–0.88), indicating a robust and consistent difference in rating tendencies (Fig. 3 and Table 4). These findings indicate that senior clinicians apply stricter quality thresholds, whereas junior evaluators are more accepting of the synthetic atlas, suggesting particular value for early-stage training.

Distribution of the evaluation scores between the two groups of clinicians. (A) Text accuracy, (B) image reliability, (C) recognizability, (D) educational value, (E) generation stability, (F) total score.
Discussion
The rapid advancement of T2I generative models has opened new avenues for medical education, particularly in visually oriented specialties such as ophthalmology. Previous studies have explored the utility of T2I tools such as DALL-E and Midjourney in generating medical imagery, although they often highlight limitations in terms of anatomical accuracy and educational suitability4,15. In contrast, Sora Turbo, with its video-based image generation framework, offers enhanced photorealism and spatial fidelity, suggesting potential advantages for medical applications. This study represents the first systematic evaluation in ophthalmology of Sora Turbo’s capability to generate slit-lamp anterior segment images and assess their quality and educational value through expert review.
Our results reveal notable variations in image quality across different anterior segment entities. Conditions with well-defined and gross morphological features, such as cataracts, subconjunctival haemorrhage and ptosis, received consistently high scores across all dimensions. This finding indicates that Sora Turbo excels in rendering visually distinct and clinically recognizable pathologies. In contrast, entities requiring fine anatomical detail or dynamic contextual understanding—such as entropion, corneal foreign body, hyphema and iridodialysis—scored lower for reliability, recognizability and educational value. Our results are consistent with those of the study by Temsah et al., which evaluated DALL-E 3 to illustrate congenital heart disease (CHD)7. They reported a high prevalence of anatomical inaccuracies (80.8% of the images were rated as incorrect or fabricated), particularly for complex cardiac anomalies. Moreover, a comparative analysis of existing T2I models, such as Midjourney, Stable Diffusion, and DALL-E 3, in generating anatomy illustrations similarly highlighted significant limitations, such as inaccurate anatomical details and incomplete understanding of complex structures5,16. These findings suggest that while T2I models are highly capable of generating photorealistic images, their performance may be constrained by the complexity and subtlety of specific ophthalmic structures.
To further contextualize these findings, we compared our results to the performance of T2I models in other visually driven medical fields, specifically dermatology and radiology. Similar to our observations in ophthalmology, studies in dermatology have revealed significant concerns regarding the diagnostic accuracy and ethical readiness of AI-generated content. An evaluation of T2I models for common dermatological conditions revealed that the majority of the generated images severely underrepresented skin of colour (89.8% depicted light skin) and demonstrated poor overall diagnostic accuracy (maximum 22.5% across platforms)17. Moreover, expert scrutiny of skin cancer images confirmed that although DALL-E could capture some features, models such as Midjourney and BlueWillow often generated exaggerated, fictionalized elements deemed unsuitable for formal clinical education. In radiology, the discussion focuses on the potential for AI to generate highly realistic synthetic cardiac CT images, which can aid in creating diverse teaching cases and overcoming data privacy concerns18. However, this capacity simultaneously underscores ethical risk, challenging the integrity and trustworthiness of the data used for both research and education. Collectively, this cross-specialty comparison emphasizes that the successful integration of T2I technology into medical curricula requires a concerted effort to address pervasive issues of anatomical accuracy, algorithmic bias, and ethical oversight, regardless of the medical subspecialty.
With respect to readability assessment, quantitative readability metrics were incorporated into the evaluation system of this study, thereby establishing a relationship between visual content quality and textual cognitive load for better alignment with clinical applications. According to the U.S. Department of Health and Human Services (USDHHS), online information should be written at a 7th to 8th grade reading level, which aligns with the average American reading ability19. Our results indicate that a lower FRE score, together with higher FKGL and GFS, suggests that the generated ophthalmic atlases are more suitable for professionals, such as clinicians or medical trainees, than for public health education.
Senior ophthalmologists consistently assigned significantly lower scores across multiple evaluation dimensions than junior clinicians did. This discrepancy likely stems from the senior evaluators’ greater clinical experience and more rigorous diagnostic criteria, particularly regarding anatomical precision. These findings align with those of medical imaging studies, which have demonstrated that expertise is associated with more efficient visual search patterns and prolonged fixations on critical diagnostic regions, allowing experts to more readily identify subtle inaccuracies that may elude novices20. In contrast, junior clinicians who are still acquiring and developing ophthalmic diagnostic competencies may view AI-generated images as sufficiently accurate and pedagogically valuable for supplementary learning. These findings underscore the need to adapt educational materials to the trainee’s level of expertise, thereby positioning AI-generated atlases as particularly valuable for early-stage ophthalmology training, whereas advanced learners may require higher-fidelity or clinically validated images.
In this study, interrater agreement among 20 experts for five dimensions across 40 entities was evaluated using Kendall’s W. Agreement was statistically significant across all dimensions and subgroups (junior/senior) but exhibited a low-to-moderate magnitude. This magnitude is plausible because of three factors: (1) the inherent subjectivity of text accuracy (which requires heterogeneous internal thresholds for lexical precision and implied factual consistency), (2) the attenuating effect of frequent ties generated by the 5-point Likert scale on the W coefficient, and (3) heterogeneity in rater background and training21. Crucially, agreement was consistently greater for image-related dimensions. From an educational perspective, this low-to-moderate agreement does not undermine utility, as final metrics rely on aggregated scores (mean/median). The stable, significant agreement in image-related dimensions supports their use as alignable instructional objectives and reliable assessment indicators, while lower-agreement dimensions (text accuracy) can be improved through the implementation of standardized scoring rubrics and prerating calibration exercises22.
Beyond addressing the current need for high-quality static ophthalmic images, the generated atlas holds significant potential to enhance future educational modalities, particularly in clinical simulations and remote learning23,24. As T2I technology advances, these synthetic atlases can evolve from static images to dynamic, AI-augmented learning environments25. This evolution would enable trainees to interact with simulated virtual patients, where the AI model rapidly generates variations in disease presentations on the basis of user-defined parameters (e.g., severity, patient demographics, and comorbidities). Such dynamic simulation is critical for developing clinical decision-making skills and diagnostic flexibility. Furthermore, for remote learning and geographically disparate educational programs, these AI-enhanced atlases offer an equitable solution by providing unlimited, standardized, and high-quality simulated clinical cases, effectively reducing the disparities in learning resources across different institutions26.
Despite the promise of AI-generated content, integrating T2I models such as Sora Turbo mandates considering ethical risks, specifically training bias and Deepfake misuse27. Generative AI models are trained on vast, unfiltered internet datasets, inevitably encoding societal biases. In ophthalmology, this limitation translates to the potential for the atlas to propagate diagnostic biases related to demographics or underrepresented lesion presentations27. Such bias could subtly distort visual features, potentially affecting diagnostic pattern recognition when trainees encounter real-world diversity. Furthermore, the model’s capacity to generate highly photorealistic images presents the ethical challenge of deepfakes28,29. The ease of synthesizing convincing medical images necessitates strict governance to prevent their misinterpretation as real patient data. The required rigorous validation by clinical experts and ongoing supervision by interdisciplinary ethics committees, as emphasized in our conclusion, remains essential to vet content for clinical accuracy and the absence of harmful bias30.
Several limitations should be considered. First, the expert panel included 20 ophthalmologists from a limited set of institutions, which may introduce selection bias and constrain generalizability. Moreover, agreement was estimated on ordinal 5-point ratings where ties attenuate W; subgroup precision is limited by a fixed number of raters. We prioritized Kendall’s W (agreement in rankings) over the ICC given the scale and study aim. Future multicentre work with larger rater pools and standardized rubrics may yield higher agreement and narrower uncertainty. Finally, the evaluation was restricted to curated, static images; dynamic light or tear phenomena, depth cues, and three-dimensional relationships were not assessed, nor were the effects of calibration.
Conclusion
In this study, Sora Turbo-generated slit-lamp images of the anterior segment were evaluated. Although the model produced realistic images for gross pathologies, it struggled with fine anatomical structures. Senior ophthalmologists rated images more critically than junior ophthalmologists did, reflecting the influence of clinical expertise on evaluation. AI-generated image atlases show particular promise for early-stage ophthalmology training. Future implementation must include expert validation and ethical oversight to ensure educational safety and accuracy.
Data availability
The data that support the findings of this study are available from the corresponding author, Xuanqiao Lin, upon reasonable request.
References
Currie, G., Hewis, J., Hawk, E., Kiat, H. & Rohren, E. Fitness for purpose of text-to-image generative artificial intelligence image creation in medical imaging. J. Nucl. Med. Technol. 53(1), 63–67. https://doi.org/10.2967/jnmt.124.268402 (2025).
Currie, G. M. Generative artificial intelligence in nuclear medicine education. J. Nucl. Med. Technol. 53(1), 72–79. https://doi.org/10.2967/jnmt.124.268323 (2025).
Waisberg, E. et al. Text-to-image artificial intelligence to aid clinicians in perceiving unique neuro-ophthalmic visual phenomena. Ir. J. Med. Sci. 192(6), 3139–3142. https://doi.org/10.1007/s11845-023-03315-8 (2023).
Balas, M., Micieli, J. A., Wulc, A. & Ing, E. B. Text-to-image artificial intelligence models for preoperative counselling in oculoplastics. Can. J. Ophthalmol. J. Can. D’ophtalmol. 59(1), e75–e76. https://doi.org/10.1016/j.jcjo.2023.09.006 (2024).
Haider, S. A. et al. A validity analysis of text-to-image generative artificial intelligence models for craniofacial anatomy illustration. J. Clin. Med. https://doi.org/10.3390/jcm14072136 (2025).
Muhr, P. et al. Evaluating text-to-image generated photorealistic images of human anatomy. Cureus 16(11), e74193. https://doi.org/10.7759/cureus.74193 (2024).
Temsah, M. H. et al. Art or artifact: evaluating the accuracy, appeal, and educational value of AI-generated imagery in DALL·E 3 for illustrating congenital heart diseases. J. Med. Syst. 48(1), 54. https://doi.org/10.1007/s10916-024-02072-0 (2024).
Temsah, M. H. et al. OpenAI’s Sora and Google’s Veo 2 in action: A narrative review of artificial intelligence-driven video generation models transforming healthcare. Cureus 17(1), e77593. https://doi.org/10.7759/cureus.77593 (2025).
Mahjoub, H., Vasavda, C., Bertram, A., Davison, A. & Sozio, S. The perceived impact of the COVID-19 pandemic on medical students’ future careers. F1000Research 10, 1211. https://doi.org/10.12688/f1000research.73249.2 (2023).
Ting, D. S. W. et al. Artificial intelligence and deep learning in ophthalmology. Br. J. Ophthalmol. 103(2), 167–175. https://doi.org/10.1136/bjophthalmol-2018-313173 (2019).
Buffenn, A. N. The impact of strabismus on psychosocial health and quality of life: a systematic review. Surv. Ophthalmol. 66(6), 1051–1064. https://doi.org/10.1016/j.survophthal.2021.03.005 (2021).
Doğan, L., Özçakmakcı, G. B. & Yılmaz, ĬE. The performance of chatbots and the AAPOS website as a tool for amblyopia education. J. Pediatr. Ophthalmol. Strabismus 61(5), 325–331. https://doi.org/10.3928/01913913-20240409-01 (2024).
Eltorai, A. E., Sharma, P., Wang, J. & Daniels, A. H. Most American Academy of Orthopaedic Surgeons’ online patient education material exceeds average patient reading level. Clin. Orthop. Relat. Res. 473(4), 1181–1186. https://doi.org/10.1007/s11999-014-4071-2 (2015).
Wang, L. W., Miller, M. J., Schmitt, M. R. & Wen, F. K. Assessing readability formula differences with written health information materials: application, results, and recommendations. Res. Soc. Adm. Pharm. RSAP. 9(5), 503–516. https://doi.org/10.1016/j.sapharm.2012.05.009 (2013).
Eldesoqui, M. et al. Assessing the anatomical accuracy of AI-generated medical illustrations: A comparative study of text-to-image generator tools in anatomy education. Clin. Anat. 38(6), 712–717. https://doi.org/10.1002/ca.70002 (2025).
Bae, J. S., Kim, G. Y., Kim, H. J., Han, S. H. & Youn, K. H. Comparison of anatomy image generation capability in AI image generation models. J. Vis. Commun. Med. 48(2), 44–51. https://doi.org/10.1080/17453054.2025.2504491 (2025).
Joerg, L. et al. AI-generated dermatologic images show deficient skin tone diversity and poor diagnostic accuracy: An experimental study. J. Eur. Acad. Dermatol. Venereol. https://doi.org/10.1111/jdv.20849(2025).
Hofmeijer, E. I. S. et al. Artificial CT images can enhance variation of case images in diagnostic radiology skills training. Insights Imag. 14(1), 186. https://doi.org/10.1186/s13244-023-01508-4 (2023).
Edmunds, M. R., Barry, R. J. & Denniston, A. K. Readability assessment of online ophthalmic patient information. JAMA Ophthalmol. 131(12), 1610–1616. https://doi.org/10.1001/jamaophthalmol.2013.5521 (2013).
Brunyé, T. T. et al. Eye tracking reveals expertise-related differences in the time-course of medical image inspection and diagnosis. J. Med. Imag. (Bellingham) 7(5), 051203. https://doi.org/10.1117/1.Jmi.7.5.051203 (2020).
Legendre, P. Species associations: the Kendall coefficient of concordance revisited. J. Agric. Biol. Environ. Stat. 10, 226–245 (2005).
Vergis, A., Leung, C. & Roberston, R. Rater training in medical education: A scoping review. Cureus 12(11), 11363. https://doi.org/10.7759/cureus.11363 (2020).
Koetzier, L. R. et al. Generating synthetic data for medical imaging. Radiology 312(3), e232471. https://doi.org/10.1148/radiol.232471 (2024).
Gichoya, J. W. et al. AI pitfalls and what not to do: mitigating bias in AI. Br J Radiol. 96(1150), 20230023. https://doi.org/10.1259/bjr.20230023 (2023).
Sriram, A., Ramachandran, K. & Krishnamoorthy, S. Artificial intelligence in medical education: transforming learning and practice. Cureus 17(3), e80852. https://doi.org/10.7759/cureus.80852 (2025).
Maleki Varnosfaderani, S. & Forouzanfar, M. The role of AI in hospitals and clinics: transforming healthcare in the 21st century. Bioengineering (Basel) https://doi.org/10.3390/bioengineering11040337 (2024).
Friedrich, F. et al. Auditing and instructing text-to-image generation models on fairness. AI Ethics. 5(3), 2103–2123. https://doi.org/10.1007/s43681-024-00531-5 (2025).
Kashoub, M. et al. Artificial Intelligence in Medicine: A double-edged sword or a Pandora’s box?. Oman Med. J. 38(5), e542. https://doi.org/10.5001/omj.2023.129 (2023).
Morrison K, Mathur A, Bradshaw A, et al. A Human-centered approach to identifying promises, risks, & challenges of text-to-image generative AI in radiology. ArXiv. 2025;abs/2507.16207.
Jin, W., Sinha, A., Abhishek, K. & Hamarneh, G. Ethical medical image synthesis. ArXiv. 2025;abs/2508.09293.
Acknowledgements
The authors would like to express their sincere gratitude to Professor Jin Yang for his invaluable support and assistance throughout the course of this research.
Funding
None.
Author information
Authors and Affiliations
Contributions
Lifang Bai and Yizhou Yang: Data curation, Formal analysis, Visualization and Writing—original draft. Yuecheng Ren: Data curation, Investigation and Writing—review and editing. Xuanqiao, Lin: Conceptualization, Supervision and Writing—review and editing.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
This study involved no human participants or patient data and used publicly accessible AI tools. The institutional review board determined that ethics review and informed consent were not required.
Consent for publication
All the authors have read and approved the final version of this manuscript to be published. We affirm that the content of this manuscript has not been published elsewhere and is not under consideration for publication elsewhere.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, Y., Bai, L., Ren, Y. et al. Assessing the quality and educational applicability of AI-generated anterior segment images in ophthalmology. Sci Rep 15, 42778 (2025). https://doi.org/10.1038/s41598-025-27020-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-27020-x
