
Abstract
The accurate prediction of dissolved oxygen (DO) concentration in rivers is very important for the management of aquatic ecosystems, However, the hybrid model of ' modal decomposition + prediction ' for predicting the nonlinear change of dissolved oxygen in rivers is still insufficient. In this paper, a frequency division prediction framework based on the optimal ensemble of Complementary Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) is proposed. The dissolved oxygen sequence was decomposed into multiple components by CEEMDAN, and the long short-term memory network (LSTM), support vector regression (SVR) and multi-layer perceptron (MLP) models were constructed to predict each component independently. An innovative grid search algorithm with constraints is constructed, and the advantages of each model are complemented by dynamic combination. The optimal ensemble scheme is obtained with the goal of minimizing the mean absolute error ( MAE ) of the training set. The empirical study of monitoring sections A and B in the Ganjiang River Basin shows that : in the prediction task, the prediction of the training set, the MAE of the integrated model is 18.6–35.5% lower than that of the ensemble model, the root mean square error ( RMSE ) is 22.1–22.8% lower, and the determination coefficient ( R2 ) reaches 0.954 and 0.972. In particular, the error accumulation of MAE in the 3-day prediction is 27.2–81.4% lower than that of the mixed model. This framework enables the modes of multi-component dissolved oxygen series prediction to be effectively aliasing, and provides an extensible technical path for the intelligent management of the basin.
Similar content being viewed by others

Introduction
The rapid development of machine learning technology is reshaping the cognition of modern science. Through adaptive feature extraction and nonlinear modeling capabilities, deep neural networks achieve atomic-level accuracy in protein folding prediction (Jumper et al., 2021)1. The machine learning algorithm reduces the positioning error of the key points of the industrial robot trajectory by more than 30% (Bucinskas et al., 2022)2. The deep spatio-temporal graph convolutional network reduces the RMSE of traffic accident prediction error by 0.3439 (Yu et al., 2021)3. The small sample efficient prediction model of machine learning performs well in the application of tungsten mine and tunnel engineering, and the prediction accuracy is 83.33% (Rao et al., 2024)4. In the field of environmental science, the application of machine learning has moved from laboratory to engineering deployment-using additional tree regression (ETR) for high-frequency monitoring of total nitrogen and total phosphorus in Chinese rivers, the accurate classification rates of site water quality standards for TN and TP reached 90.41 + / -6.96% and 92.33 + / -6.41% (Zhang et al., 2024)5. This kind of technology penetration has brought a fundamental change in methodology for river water quality prediction. On the key issue of river water quality prediction, machine learning is gradually replacing traditional mechanism models and becoming a new paradigm for analyzing complex hydrological processes.
Dissolved oxygen ( DO ) is an important water quality parameter, which has a significant impact on aquatic organisms and is a key indicator of water pollution. For a long time, modeling and prediction of river DO index has been a challenging topic(Roushangar et al., 2024)6. Traditional physical and chemical models are difficult to analyze the multi-scale nonlinear characteristics of DO dynamics, and data-driven methods have gradually become a powerful tool to predict dissolved oxygen concentration in aquatic ecosystems (Kim et al., 2021)7. Early studies demonstrated the potential of machine learning in DO prediction through support vector regression (SVR). Liu et al. (2013)8 developed a DO prediction model using SVR algorithm, and proved that it is superior to back propagation (BP) algorithm in prediction accuracy and stability. Zhi et al. (2021)9 constructed a long short-term memory network (LSTM) to predict 236 least disturbed watersheds in the United States. The results show that basins with smaller DO changes have lower RMSE and better performance. Zhang et al. (2023)10 used the maximum information coefficient (MIC) to screen key environmental factors, combined with particle swarm optimization (PSO) to improve SVR parameters, and R2 reached 0.9378 in the 24 H lag prediction of G1 point of Minjiang Shuikou Reservoir. Subsequently, wavelet denoising ( WD ) is added to obtain an optimized WD-MIC-PSO-SVR model for DO prediction, and the prediction accuracy of dissolved oxygen is further improved (Zhang et al., 2025)11. Li et al. (2024)12 used SHapley Additive exPlanations (SHAP) to obtain that the conductivity had the greatest contribution to the DO dynamics of the Tualatin River, revealing the non-temperature-dominated regulation mechanism. Moon et al. (2022)13 found that the predicted R2 value of AdaBoost in Hwanggujicheon was 15.3% higher than that of GB. Garabaghi et al. (2023)14 found that the RF model has a positive impact on the prediction ability of the model in the noise elimination and dimensionality reduction of the data set. Shadkani et al. (2024)15 integrated feedforward neural network (FFNN), clockwork recurrent neural network (CWRNN), long short-term memory network (LSTM) and TPA mechanism. The optimal hybrid model has a coefficient of determination (DC) of 0.993 and 0.965 at ILL and DP sites. Ghanbari-Adivi ( 2024 )16 developed a hierarchical spatio-temporal graph neural network-multilinear regression ( HSTGNN-MLR ) hybrid model ( HM ) for water quality index ( WQI ) prediction. Validated on groundwater data from the Yazd-Adekan Plain ( 1990–2020 ) in Iran, HM achieved higher accuracy ( test MAE = 0.059, R2 = 0.99 ) and lower uncertainty ( PICP = 0.98 ). It performs better than benchmark models ( such as CNN-LSTM, LSTM, MLR ). which proves that the hybrid model has more advantages than the single model.
In order to improve the ability of time series feature extraction, the deep fusion of signal decomposition technology and machine learning has become a new trend. Khani & Rajaee (2017)17 proposed wavelet-artificial neural network (W-ANN). The high-frequency noise of DO sequence is stripped by discrete wavelet decomposition, and the root mean square error (RMSE) is reduced to 0.744. Similarly, Liang et al. (2019)18 coupled empirical mode decomposition (EMD) with SVR to achieve MAPE and MRE of 27% and 1.35%, respectively, in the DO prediction of the Sanchakou section of the Haihe River in China. wang et al. (2024)19 proposed a hybrid prediction model that combines ensemble EEMD with CNN and LSTM. The R2 index of predicting dissolved oxygen in the river of Sanhong Village of Liaohe River at 4 days, 1 day and 2 days reached 0.9438,0.8892 and 0.7859, respectively, which was higher than other models. Although progress has been made, the residual noise of decomposition may still affect the decomposition accuracy. CEEMDAN provides a new path to solve the above problems through adaptive noise injection and integrated averaging strategy. Compared with EEMD, the frequency band overlap of IMF components is greatly reduced (Torres et al., 2011)20. sha et al. (2021)21 used CEEMDAN decomposition to convert DO time series data into two-dimensional gray image input. Compared with the original one-dimensional data, the CE attenuation rate of CEEMDAN input in the sixth step prediction (1 day) is only 4.08%, indicating that its long-term prediction stability is stronger. Pant et al. (2024)22 proposed a hybrid framework based on CEEMDAN, which decomposed the DO time series of the Ganges into 12 intrinsic mode functions (IMFs), divided the high frequency (IMF1-IMF7) and low frequency components (IMF8-residual), and used AdaBoost-BiLSTM and LSTM to model respectively. The proposed CEEMDAN-AdaBoost-BiLSTM-LSTM model is superior to CEEMDAN-AdaBoost-BiLSTM. The RMSE is reduced by 27.491%, 23.280% and 11.567% in the prediction of 1 h, 2 hours and 3 h in advance, which verifies the effectiveness of the modal characteristic adaptation strategy. Although the frequency division prediction framework technology can decompose the original data into simple data for prediction, its error reduction optimization strategy under integration has not been fully explored. Ghanbari-Adivi & Ehteram ( 2025 )23 proposed two hybrid models, namely CEEMDAN-BiLSTM-ANN and CEEMDAN-BiLSTM-SVM, for one-day river flow prediction. The CEEMDAN-BiLSTM-ANN model performs better ( NSE = 0.97, KGE = 0.95 ) and has lower uncertainty, which is better than the model used alone. Xiao et al. (2022)24 used CEEMDAN to decompose the regional water vapor data, and modeled the high-frequency and low-frequency data respectively. The ARIMA model was used for the high-frequency sequence, and the ARIMA-GWO-LSTM integrated model was used for the low-frequency subsequence and residual sequence. In this way, the accuracy evaluation index of the integrated model is more than 20% higher than that of the single model.
Aiming at the multi-component coupling problem in river DO prediction, this study proposes a " frequency division prediction- optimal ensemble " framework, and takes the Ganjiang River Basin as the research object to carry out modeling analysis.Based on the CEEMDAN model, the original DO time series is decomposed into multiple intrinsic mode functions (IMFs), and the LSTM, SVR and MLP models are constructed to independently predict each component. On this basis, A grid search algorithm with constraints is innovatively constructed, and a multi-model adaptation rule based on component time-frequency characteristics is established. The optimal ensemble model is determined by minimizing the mean absolute error ( MAE ) of the ensemble model training set. The experimental design covers different hydrological season scenarios, and systematically evaluates the generalization performance of the ' frequency division prediction-optimal ensemble ' framework in dissolved oxygen prediction and the error propagation law of long-term prediction.
Materials and methods
Study area and data
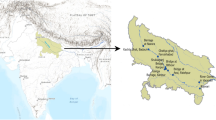
As shown in Figure 1, the study area selected in this paper is the Ganjiang River, the largest river in Jiangxi Province, China, and one of the main tributaries of the Yangtze River.

Ganjiang River Basin Map.
The Ganjiang River Basin flows through many areas of Jiangxi Province from south to north. The north and south span four latitudes, 766 km long, and the basin area is 83,500 square kilometers. The natural drop of the main stream is 937 m. The Ganjiang River Basin belongs to the subtropical humid monsoon climate. The climate is mild and the rainfall is sufficient. The average annual precipitation is 1400–1800 mm. The Ganjiang River Basin has made a significant contribution to the economic development of Jiangxi Province. The Ganzhou River area in the upper reaches of the Ganjiang River is rich in mineral resources. During the mining process, the pollution of the Ganzhou River section of the Ganjiang River is heavy. Up to now, Class IV water quality often occurs in the upper reaches of the Ganjiang River. Therefore, the development of an accurate water quality prediction model for the Ganjiang River Basin is of great significance for the prevention and control of river pollution.
In this study, two monitoring sections of the Ganjiang River Basin are selected as shown in Fig. 1, and the water quality prediction model is established, which are A monitoring section and B monitoring section. The data come from the China Environmental Monitoring Station. From January 1,2021 to December 31,2023, a total of 13,140 data were sampled every four hours. As shown in Fig. 2, this study divided the data set into 80% of the training set ( 5256 data ) and 20% of the test set ( 1314 data ). The DO concentration of A and B monitoring stations in the Ganjiang River Basin showed a significant seasonal cycle. Seasonal fluctuations showed a significant decrease in DO during the wet season ; in the dry season, low temperature increases oxygen solubility, and DO gradually rises, which is in line with the seasonal variation characteristics of river DO.

Dataset division of A Station and B Station.
Frequency division prediction - optimal ensemble modeling framework
Frequency division prediction - the optimal set modeling framework is shown in Fig. 3.
(1) Raw data decomposition. In the application of dissolved oxygen concentration prediction, the CEEMDAN model is used to decompose the original water quality monitoring sequence into several Intrinsic Mode Functions (IMFs). These IMF components show a hierarchical distribution from high-frequency noise fluctuations to low-frequency trend changes based on their differential center frequency characteristics.
(2) Create a dataset, as shown in Material A. From the time series autocorrelation graphs of Station A and Station B, it can be observed that as the time units continuously lag behind, the autocorrelation trend gradually weakens. Additionally, the autocorrelation coefficient at the T-6n time point remains at a high level, indicating that the DO concentration at the current time is significantly influenced by the same time on the previous day. Therefore, in this study, the TensorFlow time series processing API (tf.keras.utils.timeseries_dataset_from_array) was used to construct a sliding window dataset. The step size was set to 1, and the window length parameter was set to 19 time points. The corresponding first 18 time points (i.e., the data of the previous three days) were used as feature values, and the 19th time point was the output value.
(3) Model prediction. Based on the multi-scale intrinsic mode function components obtained by CEEMDAN decomposition, several feature subsets from IMF1 to IMFn are independently imported into three heterogeneous models of long short-term memory network (LSTM), support vector regression (SVR) and multi-layer perceptron (MLP) for parallel training. Each IMF component generates independent prediction results in each of the three models.
(4) Optimal combination. After obtaining the independent prediction results of n IMFs components by LSTM, SVR and MLP, the candidate pool of 3n candidate solution sets (3 models, n IMFs) is first constructed. The constrained grid search algorithm is used to minimize the mean absolute error (MAE) of the training set as the objective function. Finally, the scheme with the smallest MSE is found to determine the optimal combination scheme.
(5) Model evaluation and analysis. In this study, mean absolute error (MAE), mean square error (MSE), root mean square error (RMSE) and determination coefficient (R2) were used, and other indicators were selected to evaluate the accuracy of the model compared with other models.

Frequency division prediction - optimal ensemble modeling framework.
Missing value processing
When collecting dissolved oxygen data in rivers, the failure of automatic monitoring instruments can not be found in time, so there will be data missing in continuous data collection. If the data set with blank values is directly input into the model training, it will cause gradient calculation distortion and prediction offset. so it is particularly important to deal with missing values. In order to ensure the time continuity of the data set, This study abandons the traditional scheme of deleting missing values directly, Instead, the dynamic window mean interpolation method is used to fill the data with the average value of the data at the first three moments of the missing value of the original data, which can avoid the mutation point of the data set and reduce the prediction error of the model.
Model selection
Complementary ensemble empirical mode decomposition with adaptive noise (CEEMDAN)
CEEMDAN is an improvement of Empirical Mode Decomposition (EMD) and its variants, such as Ensemble Empirical Mode Decomposition (EEMD). The EMD method proposed by Huang et al. (1998)25 is prone to mode mixing when dealing with complex signals, resulting in interference and confusion between different modes. In order to alleviate this problem, Wu & Huang (2009)26 proposed the EEMD method, which suppresses modal aliasing by adding Gaussian white noise to the signal multiple times and integrating the decomposition results, but it has the defects of noise residue and low computational efficiency. Torres et al. (2011)20 innovatively proposed a fully adaptive noise ensemble empirical mode decomposition (CEEMDAN) algorithm, which showed better signal decomposition and noise reduction capabilities. The detailed working process is as follows.
(1) A total of N pre-processing sequences \({y_n}(t)\) are constructed by adding N times of Gaussian white noise to the original signal \({y_n}(t)\), where\(n=1,2,...,N\)
(2) EMD decomposition is performed on all preprocessing sequence \({y_n}(t)\) to obtain the first IMF component \(c_{1}^{n}(t)\), and its mean value is taken as the first IMF component \({c_1}(t)\) obtained by CEEMDAN decomposition. At the same time, the first residual sequence \({r_1}(t)\) is obtained, which is shown below.
(3) Similarly, the residual sequence \({r_1}(t)\) is added to the Gaussian white noise to construct N new columns \({r_1}(t)+{\varepsilon _1}{E_1}\left( {{\delta _n}(t)} \right)\). After the EMD decomposition of the N sequences, the mean value is obtained to obtain the second IMF component \({c_2}(t)\), and the difference is obtained \({r_2}(t)\), as shown below.
(4) N times EMD decomposition of \({r_m}(t)+{c_m}{E_m}\left( {{\delta _n}(t)} \right)\), that is, the \(m+1\) IMF sequence after CEEMDAN decomposition is obtained, as follows.
(5) Repeat the above steps until the decomposition stops. Finally, the residual sequence is as follows:
(6) That is, the expression of signal sequence \(y(t)\) after CEEMDAN decomposition is as follows
Long Short-Term memory networks (LSTM)
LSTM was proposed by Hochreiter & Schmidhuber (1997)27 to solve the problem of gradient explosion and gradient disappearance in traditional recurrent neural networks (RNN) (Bengio et al., 1994)28 Its core innovation lies in the introduction of gating mechanism and cell state, and the realization of long-term dependence modeling through selective memory and forgetting (Kawakam, 2008)29.

LSTM structure diagram.
Figure 4.
As shown in Figure 4, The core of LSTM is mainly divided into four parts, forgetting gate, input gate, cell state and output gate. The first step of LSTM is to determine what information to discard from the cell state. This decision is made by the sigmoid layer of the forgetting layer. It is substituted into the calculation by the output of the previous stage \({h_{t - 1}}\) and the input of the current stage \({x_t}\). The next step is to determine what new information we will store in the cell state. This is divided into two parts. First, the sigmoid layer of the input layer determines which values we will update. Next, the tanh layer creates a vector \({\tilde {C}_t}\) of a new candidate value. After that, the two are combined to update the cell state, and the old cell state \({C_{t - 1}}\) is converted to the new cell state \({C_t}\). Finally decide what to output. This output will be based on our cell state. The sigmoid layer of the output layer determines which parts of the cell state we want to output. The specific formula is as follows.
The long-term and short-term memory network ( LSTM ) model constructed in this study is based on the TensorFlow deep learning framework, and improves the prediction performance through systematic hyper-parameter optimization. In the process of grid search, the candidate range of key hyperparameters is set as follows : the number of hidden layer units ( units ) is searched in the integer interval [ 32,64 ] to balance the model capacity and computational efficiency ; the dropout rate is limited to the range of [ 0.3,0.4 ]. Batch size ( batch _ size ) was selected from [ 64,128 ]. The training rounds ( epochs ) were adjusted within the range of [ 20,30 ] and combined with the early stop mechanism to control the training duration. In addition, the activation function is fixed to hyperbolic tangent, and the L2 regularization coefficient ( alpha ) is set to a constant 0.0001 to constrain the weight growth. All parameters were optimized by 3-fold cross validation with negative mean square error ( -MSE ) as the index. The hyperparameter training selection for each IMF component is shown in Table. S1 of Material B.
Support vector regression (SVR)
The core idea of Support Vector Regression (SVR) is based on the structural risk minimization principle of statistical learning theory (Vapnik, 1999)30. The input data is projected into a high-dimensional feature space by nonlinear mapping, and an optimal hyperplane is constructed in this space to minimize the deviation between the predicted value and the true value within the allowable error range (Smola & Schölkopf, 2004)31. Unlike traditional regression methods, SVR penalizes only samples that exceed the error tolerance range \(\varepsilon\) by introducing a \(\varepsilon\)(insensitive loss function), thereby improving the robustness and generalization ability of the model (Drucker et al., 1996)32.
Given the training data set\(\left\{ {\left( {{x_1},{y_1}} \right),\left( {{x_2},{y_2}} \right), \ldots ,\left( {{x_N},{y_N}} \right)} \right\}\), where \({x_i} \in {R^d}\) is the input feature and \({y_i} \in {R^{}}\) is the target value, the goal of SVR is to find a regression function \(f(x)\):
The optimization problem of SVR can be expressed as:
By introducing Lagrange multipliers \(\alpha\) and \({\alpha ^*}\), the dual problem of SVR can be expressed as:
Finally, the regression function of SVR can be expressed as:
In this study, the support vector regression model in the scikit-learn machine learning library is used to optimize the key hyperparameters through the grid search strategy to improve the prediction performance. In the process of parameter tuning, the kernel function is optimized from [ ' linear ‘, ' rbf ' ] to fit the linear and nonlinear features. The regularization coefficient ( C ) is discretely searched in three orders of magnitude [ 0.1,1,10 ] to balance the model complexity and generalization ability. The kernel coefficient ( gamma ) is selected in the range of [ ' scale ‘, ' auto ' ] ; the insensitive loss threshold ( epsilon ) is fixed to 0.1 to control the number of support vectors. All parameter combinations were evaluated by 3-fold cross-validation with negative mean square error ( -MSE ) as an indicator. The hyperparameter training selection for each IMF component is shown in Table. S2 of Material B.
Multilayer perceptron (MLP)
Multilayer Perceptron (MLP), as a classical feedforward neural network, realizes complex pattern recognition and regression prediction through multi-layer nonlinear transformation (Rumelhart et al., 1986)33. Its network architecture consists of an input layer, several hidden layers and an output layer. Each layer of neurons is fully connected by weight \({W^{(l)}}\) and offset \({b^{(l)}}\) (Hornik et al., 1989)34. The number of neurons in the input layer is consistent with the feature dimension. The number of neurons in the hidden layer is usually determined by cross-validation or information criterion optimization to determine that the MLP operation contains two key stages, as shown below:
Forward propagation
Reverse propagation
In this study, the multi-layer perceptron regression model in the scikit-learn machine learning library is used to optimize the network structure and training parameters through the grid search strategy system. In the process of parameter tuning : hidden layer structure ( hidden _ layer _ sizes ) is preferred from four configurations [ ( 10, ), ( 10,10 ), ( 10,10,10 ), 25 ] ; the activation function ( activation ) is compared between [ ' relu ‘, ' tanh ' ] to adapt to the nonlinear characteristics of dissolved oxygen. The L2 regularization strength ( alpha ) is controlled by a discrete search of three orders of magnitude [ 0.0001,0.001,0.01 ] to control the overfitting risk. The learning _ rate strategy is selected from [ ' constant ‘, ' invscaling ‘, ' adaptive ' ] to accelerate convergence. The solver is fixed to ' adam ‘. All parameter combinations were evaluated by 3-fold cross-validation with negative mean square error ( -MSE ) as an indicator. The hyperparameter training selection for each IMF component is shown in Table. S3 of Material B.
Model evaluation
In order to evaluate the prediction performance of each model objectively and comprehensively, four different evaluation indexes are selected: mean absolute error (MAE), mean square error (MSE), root mean square error (RMSE) and coefficient of determination (R2). The specific formulas are as follows. The smaller the MAE, MSE and RMSE are, the more accurate the prediction results are, and the better the model is. The closer the value of R2 is to 1, the better the predictive ability of the model to the regression effect.
Among them, \({y_i}\) is the true value, \({f_i}\) is the predicted value, and \(\bar {y}\) is the average value of the actual value.
Results and discussion
Optimal ensemble
The original sequence is decomposed into the sum of multiple intrinsic mode function ( IMF ) components and residuals ( Res ) by CEEMDAN, and the independent prediction results of each component of LSTM, SVR and MLP are obtained. The optimal ensemble uses a constrained grid search algorithm, which takes the linear sum of all component prediction results ( i.e., IMF1 + IMF2 +… + IMF1 + Res ) as the ensemble framework, and minimizes the MAE on the training set as the optimization objective to find the optimal ensemble scheme to improve the overall performance. The core principle is to make full use of the differences in the ability of different models to capture data features, and to achieve complementary advantages through dynamic weight distribution. When a single model may lead to prediction bias due to overfitting, local optimum or feature sensitivity in complex data, the ensemble method can effectively reduce variance and bias and improve generalization performance.
As shown in Table 1, the optimal integration strategy of each IMF component to the residual term ( Res ) is expressed by the first letter coding of the model (L, S, and M correspond to LSTM, SVR, and MLP, respectively). Among them, the residual term has a small fluctuation range (its variance accounts for less than 0.3% of the total sequence), and the prediction results of the three models are highly consistent, so the LSTM prediction value is uniformly used to improve the calculation efficiency.
It is worth noting that although the single model prediction performance of the C-LSTM model at the A station (R2 = 0.834) and the B station (R2 = 0.957) is weaker than that of the C-SVR and C-MLP models, the ensemble results show that the optimal prediction of most components at the two stations is still contributed by LSTM. In particular, the IMF1 component selects MLP prediction results at both sites, which is not due to the optimal performance of MLP in single-component prediction (its single-component RMSE is 12% -15% higher than SVR), but the combination method reduces the mean square error of the overall integrated prediction by 23.7% (compared to the full LSTM combination). This phenomenon shows that the complementary effects of different models in the feature subspace are significant, and the integration strategy can break through the performance limitations of a single model through the error compensation mechanism between components.
Model comparison
This study systematically evaluates the performance improvement effect of the optimal integration method on the time series prediction model. By comparing the three basic models of LSTM, SVR and MLP and the hybrid model combined with CEEMDAN, the effectiveness of the optimal integration strategy is revealed. In the experiment, the hydrological data of A and B observation stations were selected, and four types of evaluation indexes (MAE, MSE, RMSE, R2) were used for quantitative analysis. The specific research conclusions and improvements are as follows:
The optimal ensemble strategy parameters determined by grid search, the constructed ensemble model shows the best prediction performance. As shown in Table 2, the quantitative results show that in the training set of station A, the integrated model MAE = 0.210, MSE = 0.084, RMSE = 0.290, R2 = 0.954. in the test set of station B, the corresponding indicators are MAE = 0.158, MSE = 0.059, RMSE = 0.243, R2 = 0.972. Compared with all other models, the R2 of the integrated model increased by 0.1% -14.2% and 0.2% -6% at stations A and B, respectively. The R2 of the SE-Cubist ensemble model proposed by Singha et al. (2024)35 is 4.8% higher than that of the optimal single model XGB. It can be concluded that the integrated model is effective in improving the prediction performance.
As shown in Figure 5, in the original data prediction task, the SVR model shows the best independent prediction performance. In the A station test set, R2 = 0.807 (MAE = 0.259, MSE = 0.124, RMSE = 0.353), B station test set R2 = 0.936 (MAE = 0.198, MSE = 0.109, RMSE = 0.331). The prediction accuracy is significantly higher than that of LSTM (Feng et al., 2024)36 (A station R2 = 0.735, B station R2 = 0.668) and MLP (A station R2 = 0.929, B station R2 = 0.933), which is consistent with the theoretical advantage of support vector machine in small sample nonlinear problems (Smola & Schölkopf, 2004)31. The prediction results after CEEMDAN decomposition show that the performance of each model has been substantially improved (song & yao, 2022)37. Among them, the R2 of MLP at station A has the largest increase ( ΔR2 = 0.227 ), which verifies that the signal decomposition technology can effectively extract the multi-scale features of time series data.

Comparison of evaluation indexes of training set and test set of each model.
Through the combination of prediction performance visualization and quantitative indicators, the prediction efficiency of each model in the test set of station A and station B is comprehensively evaluated. Figure 6 systematically shows the prediction trajectory comparison of C-LSTM, C-SVR, C-MLP and the optimal integrated model in the test set, in which (Figure 6 (b, c, e, f)), especially the local amplification analysis of the intermediate stage and the end of the test data. The visualization results show that in the middle data segment (Fig. 6 (b)), the predicted trajectories of the single model all show different degrees of deviation (the average absolute error MAE of the MLP prediction results of station A reaches 0.354), while the prediction curve of the optimal ensemble model and the observed value The coefficient of determination R2 is 0.898, and its mean absolute error (MAE), mean square error (MSE) and root mean square error (RMSE) are 28.1%, 47.5% and 27.4% lower than the optimal single model. The integrated model shows excellent performance in water quality prediction. Compared with the single model, the adaptability and accuracy of the model are significantly improved (Wang et al., 2024)38. At the end of the sequence (Figure 6 (e)), the integrated model successfully captures the inflection point feature of dissolved oxygen mutation. The CEEMDAN method effectively reduces the number of iterations, improves the accuracy of model reconstruction, and verifies the analytical ability of the integrated strategy for complex patterns.

Comparison diagram of test set prediction performance of each model.
Further, the interval prediction characteristics of the predicted values are revealed by scatter regression analysis (Figs. 7 and 8). Figure 7 (a) shows that the LSTM predicted value in the interval (6 mg / L-8 mg / L) presents a part of the predicted points below the observed value, while the MLP in the interval (7 mg / L-9 mg / L) can see most of the over-predicted discrete away from the regression line, and the prediction after the integration of CEEMDAN also has the same problem. In contrast, the predicted values of the optimal integrated model are evenly distributed along the regression line (Figure 7 (g)), and the determination coefficient R2 reaches 0.898, which has stable prediction accuracy in different dissolved oxygen concentration ranges. In Figure 8, it can be seen that the LSTM, SVR and MLP models have too high predicted discrete values in the interval (5 mg / L-7 mg / L), resulting in the optimal ensemble model derived from these models. It also inherits the high predictive value of the interval, but the optimal ensemble model in the interval (9 mg / L-11 mg / L) shows excellent ability R2 reaches 0.973, indicating that the ensemble strategy has error correction ability in the extreme value interval (high concentration) (Zhang & Yang.2020)39.

Scatter point regression diagram of the predicted value of each model of A Station compared with the observed value.

Scatter point regression diagram of the predicted values of each model in B Station compared with the observed values.
Future forecast
In this study, by comparing the performance of C-LSTM, C-SVR, C-MLP and Optimal set in the prediction of dissolved oxygen in the next 1–3 days at A and B stations, the superiority of the optimal integration strategy in future prediction is systematically revealed. The experimental data show that the optimal ensemble model is superior to other models in terms of prediction accuracy and stability, and its performance advantage increases with the gap between the prediction time and other models.
As shown in Table 3, in the short-term prediction (1 day) of station A, although the MAE (0.355), MSE (0.171) and RMSE (0.413) of Optimal set are higher than those of the optimal mixed model C-MLP, it achieves a rebound in the second day prediction, and the advantage is further expanded in the third day prediction : MAE (0.571) is 13.9% lower than C-MLP, MSE (0.459) is 24.0% lower, and RMSE (0.678) is 13.0% lower. The performance of B station is more significant. The MAE (0.069) and MSE (0.006) of Optimal set in 1-day prediction are 39.5% and 66.7% higher than C-MLP, respectively, and its RMSE (0.075) is only 19.1% of C-LSTM.
As shown in Figure 9, with the increase of prediction time, the error of the hybrid model shows an exponential growth trend : the 3-day RMSE (1.519) of C-LSTM at Station A is 0.315 higher than that of 1 day, while the Optimal set only increases by 0.265 (0.413 → 0.678), and the growth rate decreases by 15.9%. The data of station B is more convincing. The 3-day RMSE (0.244) of Optimal set is 21.8% lower than that of C-MLP (0.312), and is better than the 1-day prediction results of all single models (C-MLP 1-day RMSE = 0.135).

Trend chart of evaluation index of model in A Station and B Station in the next 3 days.
Conclusion
Aiming at the problem of nonlinear prediction of dissolved oxygen ( DO ) concentration in rivers, this study proposes a frequency-divided prediction framework based on CEEMDAN decomposition and dynamic optimal integration. The results show that the frequency-divided prediction-optimal integration framework can be applied to the prediction of dissolved oxygen ( DO ) concentration in rivers with significant periodic laws. The empirical study of A and B monitoring sections in the Ganjiang River Basin verifies its effectiveness. The determination coefficient R2 of the optimal integrated model of station A and B was 0.898 and 0.973, respectively. The mean absolute error ( MAE ), mean square error ( MSE ) and root mean square error ( RMSE ) of the optimal integrated model were 28.1% -34.3%, 47.5% -57.7% and 27.4% -35.3% lower than those of the optimal single model. In addition, the optimal integrated model is tested in long-term prediction. The results show that the error accumulation of MAE in the 3-day prediction is 27.2–81.4% lower than that of the mixed model., and the daily average RMSE increase is controlled at 0.195, indicating that the dynamic weight distribution effectively suppresses the error propagation. In addition, this study reveals the component adaptation rule of the optimal ensemble strategy. Although the prediction accuracy of LSTM after CEEMDAN frequency division is lower than that of SVR and MLP, most of the components of the optimal ensemble strategy are contributed by LSTM. The high-frequency noise ( such as IMF1 ) is preferably modeled by MLP, and the low-frequency components ( such as IMF3 and IMF4 ) are commonly predicted by SVR. However, the diversity of models is still limited, and advanced architectures such as Transformer ( self-attention mechanism ) and TCN ( temporal convolutional network ) are not included, which may omit better modeling capabilities for long-term cycle dependence. In addition, the training data of the model in this study is based on the time rolling window, and the historical data of DO in the first three days is used to predict the DO concentration at t + 1 time. However, the current feature engineering only considers the lag effect of the historical DO concentration sequence, and has not yet included the key environmental driving factors such as water temperature, flow rate and pH value. For example, the instantaneous attenuation of DO caused by non-point source pollutants carried by storm runoff can not capture such sudden disturbances only by DO historical sequence.
Data availability
The data can be obtained from the author according to reasonable requirements. Email : [6720230063@mail.jxust.edu.cn]
References
Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold[J]. Nature 596 (7873), 583–589 (2021).
Bucinskas, V. et al. Improving industrial robot positioning accuracy to the microscale using machine learning method[J]. Machines 10 (10), 940 (2022).
Yu, L. et al. Deep spatio-temporal graph convolutional network for traffic accident prediction[J]. Neurocomputing 423, 135–147 (2021).
Rao, G. et al. Long-term prediction modeling of shallow rockburst with small dataset based on machine learning[J]. Sci. Rep. 14 (1), 16131 (2024).
Zhang, Y. et al. Universal high-frequency monitoring methods of river water quality in China based on machine learning[J]. Sci. Total Environ. 947, 174641 (2024).
Roushangar, K., Davoudi, S. & Shahnazi, S. Temporal prediction of dissolved oxygen based on CEEMDAN and multi-strategy LSTM hybrid model[J]. Environ. Earth Sci. 83 (6), 158 (2024).
Kim, Y. W. et al. Forecasting abrupt depletion of dissolved oxygen in urban streams using discontinuously measured hourly time-series data. Water Resources Research 57 (4), e2020WR029188 (2021).
Liu, S. et al. Prediction of dissolved oxygen content in river crab culture based on least squares support vector regression optimized by improved particle swarm optimization[J]. Comput. Electron. Agric. 95, 82–91 (2013).
Zhi, W. et al. From Hydrometeorology To River Water Quality: Can a Deep Learning Model Predict Dissolved Oxygen at the Continental scale?[J] Vol. 55, 2357–2368 (Environmental science & technology, 2021). 4.
Zhang, P. et al. Forecasting DO of the river-type reservoirs using input variable selection and machine learning techniques-taking Shuikou reservoir in the Minjiang river as an example[J]. Ecol. Ind. 155, 110995 (2023).
Zhang, P. et al. Optimized SVR model for predicting dissolved oxygen levels using wavelet denoising and variable reduction: taking the Minjiang river estuary as an example[J]. Ecol. Inf. 86, 103007 (2025).
Li, S. et al. Explainable Machine Learning Models for Estimating Daily Dissolved Oxygen Concentration of the Tualatin River[J] Vol. 18, 2304094 (Engineering Applications of Computational Fluid Mechanics, 2024). 1.
Moon, J. et al. Urban river dissolved oxygen prediction model using machine learning[J]. Water 14 (12), 1899 (2022).
Garabaghi, F. H., Benzer, S. & Benzer, R. Modeling dissolved oxygen concentration using machine learning techniques with dimensionality reduction approach[J]. Environ. Monit. Assess. 195 (7), 879 (2023).
Shadkani, S. et al. Enhanced predictive modeling of dissolved oxygen concentrations in riverine systems using novel hybrid Temporal pattern attention deep neural networks[J]. Environ. Res. 263, 120015 (2024).
Ghanbari-Adivi, E. A new machine learning model for predicting the water quality index[J]. Model. Earth Syst. Environ. 10 (4), 5635–5667 (2024).
Khani, S. & Rajaee, T. Modeling of dissolved oxygen concentration and its hysteresis behavior in rivers using wavelet transform-based hybrid models. CLEAN–Soil, Air, Water, 45 (2), (2017).
Liang, N., Zou, Z. & Wei, Y. Regression models (SVR, EMD and FastICA) in forecasting water quality of the Haihe river of China[J]. Desalination Water Treat. 154, 147–159 (2019).
Wang, Z. et al. Research on water environmental indicators prediction method based on EEMD decomposition with CNN-BiLSTM[J]. Sci. Rep. 14 (1), 1676 (2024).
Torres, M. E. et al. A complete ensemble empirical mode decomposition with adaptive noise. 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP) 4144–4147 (IEEE, 2011).
Sha, J. et al. Comparison of forecasting models for real-time monitoring of water quality parameters based on hybrid deep learning neural networks[J]. Water 13 (11), 1547 (2021).
Pant, N., Toshniwal, D. & Gurjar, B. R. Multi-step forecasting of dissolved oxygen in river Ganga based on CEEMDAN-AdaBoost-BiLSTM-LSTM model[J]. Sci. Rep. 14 (1), 11199 (2024).
Ghanbari-Adivi, E., Ehteram, M. & CEEMDAN-BILSTM-ANN and SVM models: two robust predictive models for predicting river flow[J]. Water Resour. Manage 39, 3235-3271(2025).
Xiao, X. et al. Prediction of Cors water vapor values based on the Ceemdan and arima-lstm combination model[J]. Atmosphere 13 (9), 1453 (2022).
Huang, N. E. et al. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis[J]. Proceedings of the Royal Society of London. Series A: mathematical, physical and engineering sciences 454 (1971), 903–995 (1998).
Wu, Z. & Huang, N. E. Ensemble empirical mode decomposition: a noise-assisted data analysis method[J]. Adv. Adapt. Data Anal. 1 (01), 1–41 (2009).
Hochreiter, S. & Schmidhuber, J. Long short-term memory[J]. Neural Comput. 9 (8), 1735–1780 (1997).
Bengio, Y., Simard, P. & Frasconi, P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE Trans. Neural Networks. 5 (2), 157–166 (1994).
Kawakami, K. Supervised sequence labelling with recurrent neural networks[D]. Ph. D. thesis, (2008).
Vapnik, V. N. An overview of statistical learning theory[J]. IEEE Trans. Neural Networks. 10 (5), 988–999 (1999).
Smola, A. J. & Schölkopf, B. A tutorial on support vector regression[J]. Stat. Comput. 14, 199–222 (2004).
Drucker, H. et al. Support vector regression machines[J]. Adv. Neural. Inf. Process. Syst. 9, 155-161(1996).
Rumelhart, D. E., Hinton, G. E. & Williams, R. J. Learning representations by back-propagating errors[J]. Nature 323 (6088), 533–536 (1986).
Hornik, K., Stinchcombe, M. & White, H. Multilayer feedforward networks are universal approximators[J]. Neural Netw. 2 (5), 359–366 (1989).
Singha, C. et al. Prediction of urban surface water quality scenarios using hybrid stacking ensembles machine learning model in Howrah municipal Corporation, West Bengal[J]. J. Environ. Manage. 370, 122721 (2024).
Feng, D. et al. An ensembled method for predicting dissolved oxygen level in aquaculture environment[J]. Ecol. Inf. 80, 102501 (2024).
Song, C. & Yao, L. A hybrid model for water quality parameter prediction based on CEEMDAN-IALO-LSTM ensemble learning[J]. Environ. Earth Sci. 81 (9), 262 (2022).
Wang, K. et al. Hybrid deep learning based prediction for water quality of plain watershed[J]. Environ. Res. 262, 119911 (2024).
Zhang, X. & Yang, Y. Suspended sediment concentration forecast based on CEEMDAN-GRU model[J]. Water Supply. 20 (5), 1787–1798 (2020).
Acknowledgements
The authors gratefully acknowledge the support provided by the National Natural Science Foundation of China (No. 51964014).
Author information
Authors and Affiliations
Contributions
YangJun Xie: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Resources, Software, Writing – original draft, Validation. Yunzhang Rao: Conceptualization, Funding acquisition, Supervision, Validation. Jiazheng Wan: Software, Validation, Visualization, Writing – original draft. Qiang Huang: Project administration, Software, Validation, Visualization, Writing – original draft. Qiande Lai: Data curation, Software, Validation, Visualization, Writing – original draft. Xiaochun Lu: Visualization, Writing – original draft, Writing – review and editing. Jinkun Liu: Visualization, Writing – original draft, Writing – review and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xie, Y., Rao, Y., Wan, J. et al. Decomposition prediction and optimal ensemble strategy improve river dissolved oxygen prediction accuracy. Sci Rep 15, 43084 (2025). https://doi.org/10.1038/s41598-025-27163-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-27163-x
