
Abstract
The Garden classification, based on X-ray interpretation and established over 50 years ago, remains the standard clinical classification system for femoral neck fractures (FNFs). Yet, this classification has a high interobserver variability of 70%. We sought to develop a deep-learning algorithm capable of accurately predicting FNF types, using only X-ray images, with performance comparable to that of computed tomography (CT). We retrospectively collected data from 1,588 patients who underwent X-ray and 3D-CT scans and were diagnosed with femoral neck fractures at Asan Medical Center. The input X-ray dataset consisted of paired X-ray images of the hip, with anteroposterior (AP) and lateral views. Using 3D-CT as the reference standard, patients were labeled as Garden types I (n = 378, 23.8%), II (n = 68, 4.3%), III (n = 477, 30.0%), and IV (n = 665, 41.9%). Our algorithm consisted of hip-joint detection followed by Garden classification, for which 12 different deep-learning architectures were evaluated. Algorithm performance was externally validated in 100 patients. Our algorithms showed a 90.6% overall accuracy and 88.6% Dice similarity coefficient, indicating excellent FNF type discernment. Our algorithms could serve as a valuable tool for diagnosing FNF based on X-ray data only, with accuracy comparable to that of CT.
Similar content being viewed by others
Introduction
Femoral neck fractures (FNFs) represent a significant orthopedic emergency, particularly among older individuals, and their accurate and timely diagnosis is critical for optimal patient outcomes. Typically, in cases of recent hip fracture, surgery is the consensus treatment1,2. Two mainstream treatment options are: osteosynthesis and arthroplasty, and these are further divided based on the type of fracture.
Usually in an emergency setting, clinicians face the challenge of promptly identifying and classifying hip fractures in a demanding and high-stress environment. A review study from the USA reported that misdiagnosis rates for hip fractures range from 2% to 10%3, emphasizing the need for reliable screening tools.
Despite being in use for over 60 years, the Garden classification system remains the most widely utilized method globally for classifying FNFs in a clinical setting. The Garden classification system is advantageous due to its simplicity and intuitive nature. However, it has clear limitations, primarily because it defines fracture types solely on anteroposterior (AP) radiographs. However, most FNFs require evaluation using radiographs in multiple planes or even with advanced imaging. Advances in computed tomography (CT) have shown that many FNFs that are classified as type I on plain radiographs may potentially be Garden types III or IV displaced fractures4. Moreover, the Garden classification based on AP radiographs alone has been reported to have an interobserver kappa value in the range of only 0.03–0.56, indicating low reliability4,5. Intraobserver reliability has also been reported to be relatively low, with a kappa value of approximately 0.7594,6. Nevertheless, advanced imaging tools, such as CT, which may provide more reliable categorization, are unfortunately not available in all clinical settings.
The potential of artificial intelligence (AI) as a transformative tool in medical diagnosis and fracture classification has garnered attention. By automating the classification process, AI has the capacity to reduce the time and effort required by medical staff in various tasks, and can demonstrate accuracy beyond human capabilities, even with limited information7. Moreover, AI-driven diagnostics offer the promise of improving diagnostic accuracy and consistency, thereby enhancing patient outcomes, and reducing the risk of misdiagnosis.
We sought to facilitate screening of fracture types without incurring the medical costs and radiation harm associated with CT scans. To this end, we developed an AI-based screening algorithm for FNF classification that can accurately predict CT-based diagnoses using only X-ray images. We also proposed a method to identify patient groups with high predictive accuracy using confidence, defined as the prediction probabilities of deep learning models.
Methods
This study was approved by the Ethics Committee of Institutional Review Board of Asan Medical Center, Seoul, Republic of Korea (IRB No. 2023 − 0517), which waived the need to obtain informed consent due to the retrospective nature of the study and the use of anonymous clinical data in the analysis. Data collection was performed in accordance with the relevant guidelines and regulations of the committee.
Research participants and data collection
We retrospectively reviewed the consecutive clinical data of patients who were diagnosed with FNF at the Asan Medical Center between January 2003 to April 2023. We included the data of the patients who had hip X-rays of both the AP and lateral (LA) views, and who underwent preoperative 3D-CT scans. All X-rays and CT scans used in the study were taken on the same day or within one day of the patient’s hospital admission for FNF. We excluded pediatric cases where the growth plates had not closed, and cases where the quality of the X-rays was inadequate or where the CT scans were taken at a lower resolution at an outside hospital. We did not exclude patients who had vascular calcification or a Foley catheter on X-ray, and we also did not consider the position of the hip joint on the X-ray as an exclusion criterion affecting the quality assessment of the hip simple radiograph, as these were regarded as normal variations in real-world data. After applying these inclusion and exclusion criteria, the data of 1,588 patients were finally included in the internal dataset. The demographics of internal dataset including patient age, sex, fracture type are shown in Table 1.
Data labeling: X-ray and 3D-CT imaging
The deep-learning approaches in this study consisted of two stages: detection of the femoral neck in X-ray images and classification of the Garden type using the detected areas (Fig. 1a). For the first stage of detection, the hip joint was labeled using a bounding box (Fig. 1b). A circle was created with its center at the middle of the femoral neck and its radius extending to the farthest point of the femoral head, with a margin of 50 pixels. A square that encompasses this circle was set as the ground truth. This method was applied consistently to both the AP and LA views, resulting in three labels for each patient: two for the AP view (one each for the fracture site and the unaffected side) and one for the LA view.

(a) Bounding box labeling for hip-joint detection. (b) Schematic diagram of deep-learning networks for hip-joint detection and femoral neck fracture classification. (c) Definition of evaluation metrics for hip-joint detection and examples. AP, anteroposterior; LA, lateral.

Representative examples of detection and classification models for femoral neck fracture: (a1–a4) Correct detections and classifications; (b1, b2) Cases with left hip-joint undetected in the anteroposterior (AP) view; (c1, c2) cases with hip-joint undetected in the lateral (LA) view. Detected bounding boxes and corresponding intersection over union (IoU) values are indicated in red. GT, ground truth.
For the second stage of the Garden classification, 3D-CT was used to determine the ground truth, with a single label assigned per patient referring to the more severely affected hip joints. For example, when Garden type II was observed on the left side and Garden type III on the right side, Garden type III was assigned as the final label. Two experienced orthopedists independently classified each case on 3D-CT and when labels were discrepant, they determined the final label by discussion to agreement. Accordingly, internal dataset was composed of Garden types I (n = 378, 23.8%), II (n = 68, 4.3%), III (n = 477, 30.0%), and IV (n = 665, 41.9%).
Deep-Learning networks
For the first stage of deep-learning detection, a Faster R-convoluted neural network (CNN) was used to identify the hip joint in X-ray images (Fig. 1b)8. Original X-ray images varied in format (1070–3520 × 1430–4280 pixels) depending on the patient and imaging device. These images were resized with the longer dimension fixed at 800 pixels, followed by min/max normalization. The images were then zero-padded to create 800 × 800-pixel dimensions to be used as network inputs (Fig. 1b). Separate networks were configured for detection in the AP and LA views, and three areas were ultimately output in the detection stage.
In the second stage of deep-learning classification, the images corresponding to the three areas acquired in the detection stage were used as input. If the image was not square, it was expanded in the short-axis direction by using information from the original X-ray image. Input images, resized as 256 × 256, were normalized by using min/max normalization. Images were used to train a separate network and were combined in the final three fully convolutional layers to determine the final output. The initial weight was adopted from ImageNet for transfer learning. Weighted binary cross-entropy loss was applied as the loss function, defined as:
where w is the weight for the positive class, y is the ground truth label, and p is the predicted probability. The weight w was determined based on the inverse frequency of each class to compensate for class imbalance.
Training setup
The deep-learning models for detection and classification were trained for a maximum of 100 and 200 epochs, respectively, with an initial learning rate of 10− 3. The AdamW optimizer was applied with β1 = 0.9 and β2 = 0.999. The mini-batch size was adjusted to produce better outcomes (8 for detection and 32 for classification). For classification, only horizontal flip was applied in the data augmentation process. Further details of the training setup can be found in Supplementary Table 1. The deep-learning networks were implemented using PyTorch in Python and were trained on a workstation with an Intel Core i9-10920X processor and four NVIDIA GeForce RTX 2080 Ti graphics processing units.
To compare the performance of deep-learning models, five-fold cross-validation was applied, ensuring equal distribution of images from each Garden type across all folds. In the cross-validation, the fold-proportion of training, validation, and test sets was 3:1:1, and the fold-composition was changed in sequence under cyclic permutation.
Performance evaluation
Detection performance was evaluated using precision, recall, intersection over union (IoU), and mean average precision (mAP). Precision was defined as \(\:Pr\:=\:TP/\left(TP+FP\right)\) and recall as \(\:Re\:=\:TP/\left(TP+FN\right)\), where TP is true-positive, FP is false-positive, and FN is false-negative. When IoU was greater than a threshold of 0.5 in this study (Fig. 1c), the prediction was considered TP. mAP was calculated by averaging the area under the precision-recall curve (AUC) across all object classes.
For classification, 12 networks were evaluated. For further improvement of the classification performance, ensemble learning with hard voting was performed using the three best-performing models based on the Dice similarity coefficient (DSC). DSC, also known as the F1-score in machine learning, was defined as:
To address the data imbalance issue, we first classified the fractures as undisplaced (Garden types I and II) versus displaced (Garden types III and IV) fractures, according to the simplified Garden classification9,10, and then performed additional classification into Garden types III and IV for cases predicted as displaced (Fig. 1b). The flow from ground truth to prediction outcomes was visualized with Sankey diagrams.
To evaluate whether the information from the LA view could improve classification performance, we compared the prediction outcomes to those using information of only the AP view. Finally, we proposed a method for identifying patient groups with high predictive accuracy using confidence (prediction probabilities). The evaluation metrics for classification were accuracy, precision, recall, and DSC.
External validation
For external validation, anonymized data from 100 patients with FNFs, treated between January 2019 and April 2022, were obtained from Chungbuk National University Hospital. Data labeling was initially performed by an orthopedic professor with expertise in FNFs at Chungbuk National University Hospital (E. J. Lim) and was validated by an orthopedist at Asan Medical Center (C. H. Kim). The external dataset was evaluated using five algorithm sets, each trained on different fold-combinations from the internal dataset during cross-validation, as described earlier, and the average performance was reported. Otherwise, the external dataset was evaluated in the same manner as was the internal dataset. No additional training was performed using the external data. Using 3D-CT as the reference standard, patients were labeled as Garden types I (n = 24, 24%), II (n = 10, 10%), III (n = 22, 22%), and IV (n = 44, 44%) in external dataset.
Code Availability
All custom code used in this study is openly available under Apache License 2.0 at https://github.com/AMC-CBN/FNF_OPEN_REPO. The repository provides environment files with pinned dependencies and step-by-step instructions in the README to reproduce data preprocessing, model training, and inference. Complete training and inference scripts, model architectures, and hyperparameters are included to enable faithful re-training once appropriate data access is obtained through the controlled process described above. Trained model weights derived from protected clinical data are not publicly distributed due to privacy and institutional restrictions.
Results
Cross-Validation in the internal dataset
Detection of the hip joint
The hip joint was accurately detected by the algorithms, with precision and recall ranging from 98.5% to 100% (Table 2; Fig. 2a1–2a4). In the AP view, only two images had the left hip joint categorized as undetected (Fig. 2b1, b2). Even in these cases, the FNF was still included in the predicted area. The average IoUs for the left and right hip joints were 86.1%. In the LA view, low contrast around the femoral neck led to 24 of 1,588 images being categorized as undetected, of which Garden type I accounted for 4 cases, type III for 8 cases, and type IV for 12 cases (Fig. 2c1, c2). However, of these, fracture site capture failed in only seven images (0.4%).
Classification of undisplaced (Garden type I & II) versus displaced (Garden type III & IV) fractures
When using both the AP and LA views for prediction, the classification performance achievable with a single deep-learning network ranged from 87.2% to 89.6% for accuracy and from 84.1% to 87.3% for DSC (Table 3). The performance was relatively better for the displaced (Garden type III and IV) fractures, which included more cases, with maximum precision and recall values of 94.8% and 91.9%, respectively. Based on the DSC, MobileNetV3 showed the best performance (AUC = 0.93), followed by EfficientNetB4, and ResNet18. When the ensemble approach was applied, the DSC reached 88.6% (AUC = 0.95), showing improvement of 1.3% over the best-performing single network (Fig. 3). For the 24 cases classified as undetected in the LA view, the four models (MobileNet, ResNeXt50, RexNet100, and RexNet130) correctly predicted 22 cases, and in the remaining cases, they achieved correct predictions in 23 cases. The accuracy, AUC, and DSC for each fold are summarized in Supplementary Table 2.

Receiver operating characteristic curves for femoral neck fracture classification using deep-learning models: undisplaced (Garden types I and II) versus displaced (Garden types III and IV). The ensemble result was obtained by combining outputs from MobileNetV3, EfficientNetB4, and ResNet18. DSC, Dice Similarity Coefficient; AUC, area under curve.
Compared to using the AP view information alone, adding LA view information could increase the accuracy of deep-learning prediction by up to 2.8% and the DSC by up to 3.7%. As illustrated in the case examples (Fig. 4), models trained with AP views alone tended to misclassify posterior tilt fractures as undisplaced, whereas incorporating LA view information enabled correct prediction as displaced fractures. However, for EfficientNetB0 and ReXNet150 models, the accuracy was decreased slightly.

Case examples illustrating prediction differences between AP and AP + LA models visualized with LayerCAM (MobileNetV3). In these posterior tilt fracture cases, the AP model predicted the fractures as undisplaced, whereas the inclusion of lateral views as input enabled correct prediction as displaced fractures. AP, anteroposterior; LA, lateral.
Figure 5 shows the distribution of prediction results according to confidence, defined as predicted probability. Most cases in this study were placed within the high confidence region ≥ 95%. The cases with high confidence (versus total patients) demonstrated improved accuracy of 3.2–5.4% and enhanced DSC of 3.3–5.9% (Table 4). MobileNetV3, the best-performing model in this study, achieved a diagnostic accuracy of 93.1% for 87.8% of all patients. Applying ensemble methods increased the diagnostic accuracy to over 95.4%, but 22.6% of patients fell into the gray zone, with confidence < 95%.

Distribution of patients according to confidence. Confidence indicates the predicted probability output by the deep-learning model. On the X-axis, confidence for displaced fractures (Garden types III and IV) increases to the right, while confidence for undisplaced fractures (Garden types I and II) increases to the left.
Classification of garden type III versus IV
The deep-learning models for classifying Garden type III and IV fractures showed a lower predictive capability than that of the previous stage of undisplaced versus displaced classification. Among single networks, EfficientNetB4 demonstrated the highest accuracy of 68.6%. The maximum DSC achievable using an ensemble of the top 3 models (ResNet101, EfficientNetB4, and ResNet50, in order of higher DSC) was 67.6% (Table 5). When limited to cases with confidence ≥ 95%, the DSC of individual networks could be improved to 70.6%, but this approach risked missing 37.7% of patients (Table 6). The outcome of the 5-fold cross-validation conducted exclusively on cases labeled as Garden type III and IV fractures is found in Supplementary Table 3.
Sankey diagram
A Sankey diagram was used to visualize how each Garden type FNF was classified by the deep-learning models (Fig. 6). In the stage of distinguishing between undisplaced and displaced fractures, the risk was frequently underestimated by classifying displaced fractures as undisplaced fractures. Instances of misclassifying Garden type IV as undisplaced were exceedingly rare (Supplementary Fig. 1). In the differentiation between Garden types III and IV, a high proportion of incomplete displaced fractures (Garden type III) were erroneously identified as complete displaced fractures (Garden IV).

Sankey diagrams showing the flow from ground truth to prediction outcomes. The flows on the left side indicate deep-learning classification between undisplaced (Garden types I and II) and displaced (Garden types III and IV) fractures. The flows on the right side indicate the subsequent classification between Garden types III and IV fractures.
External validation
Precision and recall were greater than 99.2% for the left and right hip joints in the AP view, respectively, while decreasing by 14.5% in the LA view as compared to the internal cross-validation (Table 2). The LA view exhibited higher numbers of undetected images (1 vs. 16 on average, from cross-validation), with an average of 2.6 cases where the FNFs were outside the predicted bounding box.
The deep-learning networks achieved classification accuracy of 85.0–87.8% (Table 7). Based on the classification accuracy, EfficientNetB2 exhibited the least decrease (−0.6%) on external validation, while ReXNet130 showed the largest decrease (−3.4%). Similar to the internal validation results, displaced fractures (Garden type III and IV) were better classified than undisplaced fractures (Garden type I and II). Ensemble approaches improved the accuracy to 88.4%. The accuracy, AUC, and DSC of the five models are summarized in Supplementary Table 4.
Discussion
In the current study, we developed an AI model capable of accurately detecting fracture sites from simple hip X-rays. We also developed a model that performs excellently in classifying FNFs into undisplaced and displaced types. Furthermore, within the displaced fracture type, we developed a model capable of screening for Garden types III or IV fractures, with acceptable performance. This suggests that, by utilizing deep-learning techniques, it is possible to achieve fracture classification accuracy comparable to that of CT scans, even in situations where obtaining appropriate data through CT imaging is not feasible.
Generally, surgical intervention is now established as the consensus primary approach for treating FNFs11. Surgical treatment can be categorized into two main options: osteosynthesis and arthroplasty. The femoral head receives its blood supply from three sets of vessels: the superior, inferior, and anterior retinacular arteries12. The extent of vascular damage is closely linked to the fracture displacement, which in turn affects the likelihood of femoral head osteonecrosis13. Therefore, the most important factor in choosing the appropriate surgical option between osteosynthesis and arthroplasty is the fracture pattern, specifically whether it is an undisplaced (Garden types I and II) or displaced type (Garden types III and IV). Undisplaced types are typically treated with osteosynthesis, while displaced types are treated with arthroplasty. Thus, fracture classification is crucial in determining the treatment direction. The screening tool developed in this study can significantly aid in determining the treatment direction, based on X-rays only.
The Garden classification has a long history of use and remains one of the most widely used classification systems for FNFs in clinical practice, due to its convenience. Introduced by British orthopedic surgeon Robert Symon Garden in 1961, this classification system divides FNFs into four groups based on fracture displacement, completeness, and the relationship of bony trabeculae in the femoral head and neck4. However, the very low interobserver reliability of the Garden classification is a significant drawback. The interobserver kappa value ranges between 0.03 and 0.56, indicating poor reliability4, particularly in terms of accurately reflecting posterior tilt. Therefore, caution must be exercised when planning osteosynthesis solely based on the appearance of nondisplaced fractures resembling Garden types I or II on simple hip AP X-ray images.
With the advancement of AI in medical imaging, several studies have applied AI techniques to perform Garden classification. Krogue et al.14 developed a deep learning model to classify hip fractures into six categories, including normal and previous arthroplasty, based on X-ray images from 1,118 patients. FNF types were categorized only as displaced or undisplaced, without individual Garden type classification. Undisplaced fractures were often misclassified as no fracture, resulting in a low sensitivity of 51.2%. Mutasa et al.15 applied data augmentation techniques involving a generative adversarial network and a digitally reconstructed radiograph (DRR) to build an FNF classification model, which improved the AUC for fracture versus no fracture classification from 0.80 to 0.92. Similarly, femoral neck fractures were categorized as displaced or undisplaced, and the sensitivity of undisplaced fractures was 54% in the three-class classification including no fracture. Unlike our study, their ground truth labels for X-ray images were not established using 3D CT imaging, except for approximately 6% of cases used for DRR generation. Sato et al.16 developed a CAD system using a deep learning model for binary classification of hip fractures, achieving an accuracy of 96.1% and an AUC of 0.99. The CAD system helped mitigate discrepancies in diagnostic performance due to varying levels of clinical experience. Although Garden types in hip fractures were identified based on X-ray images, Garden type classification was not included in the model. Recently, González et al.17 developed segmentation and classification models utilizing YOLOv8 to analyze femoral fractures. The models categorized fractures into neck, pertrochanteric, and subtrochanteric regions, with FNF further divided into displaced and undisplaced types. They achieved a Dice similarity of 77% for segmentation and an accuracy of 86.2% for classification. Given the single-center design and the relatively small test set (105 subjects), the generalizability of the results may be limited.
Relatively lightweight models were employed in this study to ensure computational efficiency for timely inference and to reflect the practical constraints of clinical environments, where computing resources may be limited (Supplementary Table 5). Lightweight models minimize inference time, allowing rapid deployment even in emergency settings. Moreover, they facilitate integration with picture archiving and communication systems (PACS). In addition, we aimed to reduce the risk of overfitting, which commonly arises in binary classification tasks with limited dataset size. The availability of larger datasets would enable the deployment of large-scale architectures, such as Vision Transformers, which may achieve further performance improvements. Transfer learning has been widely validated as a more efficient strategy in most cases, even though training from scratch on large-scale datasets may achieve comparable performance. We also applied transfer learning using ImageNet and COCO pre-trained weights, considering both model performance and training efficiency. For data augmentation, we employed horizontal flipping only. In ablation testing, additional augmentations such as rotation, translation, and brightness adjustment did not produce a statistically significant improvement in performance. Nonetheless, incorporating more diverse augmentation strategies, such as elastic deformation technique or the use of synthetic data, may help enhance the generalizability of deep-learning models. These strategies may help address the limited availability of Garden type II fractures by effectively expanding the training data. Techniques such as cost-sensitive learning and oversampling such as SMOTE may further contribute to performance improvement in future work.
Recent studies have highlighted the concept of posterior tilt (posterior angulation) observed on lateral X-ray views. According to the study findings of Palm et al., a posterior tilt of ≥ 20° was the only predictor of the need for reoperation18. In other words, fractures that appeared undisplaced on AP X-ray views could ultimately be identified as actually being displaced. This explains why, in this study, the predictions using both AP and lateral views as input data were superior to those using only the AP view.
In South Korea, insurance reimbursement criteria established by the government are based on the Garden FNF type, leading to disputes, due to the low reliability of the X-ray-based Garden classification. With our algorithms, a classification accuracy similar to that of CT can be achieved by using only X-ray data, thereby reducing costs Furthermore, the proposed algorithm makes it possible to achieve effective treatment when using only X-ray images, even in nations where 3D-CT is not widely used for diagnosing FNFs, thereby significantly reducing social healthcare costs. This approach can also benefit patient health by reducing unnecessary radiation exposure from routine CT scans.
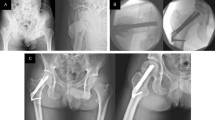
The limitations of this study include the following. The ability of the deep-learning algorithm to distinguish between undisplaced fracture types (Garden types I and II) was not evaluated, mainly due to the limited number of Garden type II (n = 68). However, this is not clinically significant as the treatment for Garden types I and II fractures does not differ greatly. The accuracy in distinguishing between Garden types III and IV remains around 70%. While this accuracy level demonstrates value for screening purposes, the performance is insufficient to replace CT-based diagnosis. For example, as shown in Fig. 7, our ensemble model classified an FNF as Garden type IV based on X-ray views, whereas expert interpretation based on CT data identified it as Garden type III. This discrepancy highlights the model’s current limitations in terms of the ability to discern subtle posterior tilt or incomplete displacement when using only X-ray images. Notably, the Sankey diagram further emphasized that Garden type III fractures present significant classification challenges, warranting careful consideration of additional CT scans when such fractures are suspected. In clinical practice, the decision between osteosynthesis and arthroplasty in unstable fractures is primarily based on factors such as patient age, bone quality, and overall fracture stability, rather than the specific distinction between Garden type III and IV19. Furthermore, according to the NICE guidelines, Garden type I and II fractures, which account for approximately 5–15% of all femoral neck fractures, are recommended to be treated with osteosynthesis, while unstable fractures are generally managed with total hip replacement or hemiarthroplasty. Although Garden types III and IV are both classified as unstable fractures with only minimal differences in treatment strategies, improvements in classification accuracy are necessary to ensure sufficient reliability to replace CT-based diagnosis.

Example for misclassification of femoral neck fractures in X-ray images. Images of a 69-year-old female patient are presented: (a) X-ray anteroposterior (AP) view, (b) X-ray lateral (LA) view, and (c) axial computed tomography (CT) scan. The ensemble model classified the fracture as Garden type IV based on X-ray images of the AP and LA views. However, CT scan evaluation showed the fracture to be Garden type III due to posterior angulation.
To enhance the generalizability and robustness of the proposed algorithm, further validation using multi-center datasets encompassing diverse patient populations, imaging equipment, and clinical practices is necessary. Moreover, prospective clinical studies are necessary to evaluate the prognostic value and real-world feasibility of the AI-based Garden type classification. Ultimately, cost-effectiveness analyses that take into account the clinical environments, healthcare infrastructure, and reimbursement systems of each country will be essential to assess the general applicability of our approach.
Despite these limitations in identifying each category of Garden classification, our deep-learning algorithm based on X-ray images demonstrated the potential to replace CT-based diagnosis. In addition, the confidence-based categorization in our approach may help identify patients who require CT-based diagnosis, allowing for more efficient allocation of imaging resources in clinical settings. For instance, CT evaluation may be recommended for patients with low confidence (< 95%) to assess fracture alignment, including posterior tilt (≥ 20°), which is a known high-risk predictor for re-operation. Furthermore, the proposed model could potentially be integrated with hospital PACS as a decision-support tool for emergency physicians, automatically flagging high-risk cases in real time. Further investigation across diverse patient populations, imaging equipment, and operators could expand the role of X-ray-based diagnosis for FNFs, offering a more cost-effective and convenient alternative for clinical settings.
Data availability
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to conditions of the ethics committee of our university.
References
Kim, C. H., Kim, K. P. & Kim, J. W. Comparison of surgical outcomes for hip fracture between older patients with and without cancer: a propensity score matching analysis. Sci. Rep. 14 (1), 5406 (2024).
Palm, H. Hip Fracture: The Choice of Surgery. In: Falaschi P, Marsh D, editors. Orthogeriatrics: The Management of Older Patients with Fragility Fractures. 2nd ed. Cham (CH)2021. pp. 125 – 41.
Cannon, J., Silvestri, S. & Munro, M. Imaging choices in occult hip fracture. J. Emerg. Med. 37 (2), 144–152 (2009).
Kazley, J. M., Banerjee, S., Abousayed, M. M. & Rosenbaum, A. J. Classifications in brief: garden classification of femoral neck fractures. Clin. Orthop. Relat. Res. 476 (2), 441–445 (2018).
Zlowodzki, M., Bhandari, M., Keel, M., Hanson, B. P. & Schemitsch, E. Perception of garden’s classification for femoral neck fractures: an international survey of 298 orthopaedic trauma surgeons. Arch. Orthop. Trauma. Surg. 125 (7), 503–505 (2005).
Turgut, A. et al. Is surgeons’ experience important on intra- and inter-observer reliability of classifications used for adult femoral neck fracture? Acta Orthop. Traumatol. Turc. 50 (6), 601–605 (2016).
Cha, Y. et al. Artificial intelligence and machine learning on diagnosis and classification of hip fracture: systematic review. J. Orthop. Surg. Res. 17 (1), 520 (2022).
Ren, S. Q., He, K. M., Girshick, R., Sun, J. & Faster, R-C-N-N. Towards Real-Time object detection with region proposal networks. Adv. Neur in ;28. (2015).
Beimers, L. et al. Subcapital hip fractures: the garden classification should be replaced, not collapsed. Can. J. Surg. 45 (6), 411–414 (2002).
Parker, M. J. Garden grading of intracapsular fractures: meaningful or misleading? Injury 24 (4), 241–242 (1993).
Handoll, H. H. & Parker, M. J. Conservative versus operative treatment for hip fractures in adults. Cochrane Database Syst. Rev. 2008(3):CD000337 .
Zhao, D. et al. The significance of evaluating the femoral head blood supply after femoral neck fracture: A new classification for femoral neck fractures. Orthop. Surg. 14 (4), 742–749 (2022).
Kumar, J., Symonds, T., Quinn, J., Walsh, T. & Platt, S. What is the best method of fixation for minimally displaced subcapital neck of femur fractures? A systematic review. J. Orthop. 45, 54–60 (2023).
Krogue, J. D. et al. Automatic hip fracture identification and functional subclassification with deep learning. Radiol. Artif. Intell. 2 (2), e190023 (2020).
Mutasa, S., Varada, S., Goel, A., Wong, T. T. & Rasiej, M. J. Advanced deep learning techniques applied to automated femoral neck fracture detection and classification. J. Digit. Imaging. 33 (5), 1209–1217 (2020).
Sato, Y. et al. Artificial intelligence improves the accuracy of residents in the diagnosis of hip fractures: a multicenter study. BMC Musculoskelet. Disord. 22 (1), 407 (2021).
Gonzalez, G. et al. Classification and segmentation of hip fractures in x-rays: highlighting fracture regions for interpretable diagnosis. Insights Imaging. 16 (1), 86 (2025).
Palm, H., Gosvig, K., Krasheninnikoff, M., Jacobsen, S. & Gebuhr, P. A new measurement for posterior Tilt predicts reoperation in undisplaced femoral neck fractures: 113 consecutive patients treated by internal fixation and followed for 1 year. Acta Orthop. 80 (3), 303–307 (2009).
Kim, C. H. & Kim, J. W. A recent update on the fixation techniques for femoral neck fractures: A narrative review. J. Clin. Orthop. Trauma. 54, 102497 (2024).
Acknowledgements
None.
Funding
This study was supported by a grant (2024IE0010-1) from the Asan Institute for Life Sciences, Asan Medical Center, Seoul, Korea.
This project (AOTAP24-44) was partially supported by AO Trauma Asia Pacific of the AO Foundation.
Author information
Authors and Affiliations
Contributions
J.Y.: performed the experiments, analyzed the data, and prepared the manuscriptJ.P.: data collection, prepared the manuscriptK.P.: prepared the manuscriptE.J.L.: data collection, validated the dataJ.W.K.: data collection, validated the dataJ.K.: performed the experiments, interpreted the data, prepared and revised the manuscriptC.-H.K.: designed the study, interpreted the data, prepared and revised the manuscript.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Consent for publication
All authors agreed to publish this manuscript.
Ethical approval and Informed Consent.
This study complies with the Declaration of Helsinki and research approval was granted by the Institutional Review Board of Asan Medical Center, Seoul, Republic of Korea (IRB No. 2023-0517), the requirement of informed consent from the patients was waived due to the retrospective nature of the study, and the analysis used anonymous clinical data. Data collection was performed in accordance with the relevant guidelines and regulations of the committee.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, J., Park, J., Park, K. et al. Garden classification of femoral neck fracture using deep-learning algorithm. Sci Rep 15, 43926 (2025). https://doi.org/10.1038/s41598-025-27766-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-27766-4
