
Abstract
Agroforestry plays a pivotal role in mitigating climate change and supporting rural livelihoods. Especially in coastal regions, it aids soil conservation, provides biophysical protection, and diversifies income sources. Through conventional approaches, mapping the arecanut-based agroforests is difficult. This study utilised machine learning models to identify arecanut based traditional agroforestry systems using Sentinel-2 satellite data in Goa, India. A total of 374 non-agroforestry and 70 agroforestry locations were collected for model training and testing. Random Forest (RF), Support Vector Machine (SVM), and Gradient Boosting Machine (GBM) were employed. The Boruta algorithm was applied for feature selection and to improve the model accuracy. The findings showed that the GBM model had significantly higher overall accuracy (0.86) and kappa (0.83) scores than other models during validation. The Boruta analysis revealed NDWI2, B3, and SLAVI as important variables indicating the importance of water indices and vegetation parameters in mapping agroforestry. The GBM model achieved high accuracy in identifying arecanut based agroforestry region amounting to 58.64 km2 followed by the RF with 53.36 km2 and the SVM with 23.21 km2. Using the average of three models, the estimated area under arecanut based agroforestry in Goa was 45.1 km2. The area of applicability (AOA) analysis based on GBM revealed that 97.32% of the total geographic area of Goa was inside AOA indicating better distribution of collected ground truth data. This paper demonstrated efficiency of machine learning algorithms for accurate mapping of agroforestry systems to support land use planning, resource conservation and management in coastal environments. Subsequent studies utilizing hyperspectral sensors can improve the efficiency of machine learning-based agroforestry mapping methods.
Similar content being viewed by others
Introduction
Agroforestry is a sustainable land management system that intentionally combines woody perennials with agricultural crops and/or livestock on the same unit of land to create integrated and productive ecosystems1,2. By efficiently combining multiple species, agroforestry optimizes resource use such light, space, water and nutrient while delivering critical ecological services3,4. Agroforestry also stands as a pivotal strategy in the battle against climate change and the preservation of rural livelihoods. Its multifaceted benefits extend from strengthening climate resilience to enhancing carbon sequestration, biodiversity conservation, soil fertility, and water regulation1,5,6,7,8. Furthermore, agroforestry creates a range of employment opportunities and contributes to food security in rural environments6,9,10,11. Agroforestry is important in coastal areas such as India because of the environmental and socio-economic characteristics of the area. Coastal areas are diverse systems that support important economic and ecological functions. Nevertheless, these areas experience a number of challenges such as climate change, urbanization, pollution, deforestation, unregulated tourism and coastal erosion. Coastal agroforestry has been found to provide a multipurpose intervention that can address these problems through improving soil conservation, coastal protection, biological diversity, and income diversification12,13,14. Combining agroforestry with aquaculture, fisheries, and non-timber forest products provide prospects for prosperity of coastal societies and ensure ecosystem stability and climate change mitigation.
Arecanut (Areca catechu L.) based agroforestry systems are traditional homestead gardening practices commonly found along the west coast of India, particularly in the Konkan region. Locally known as “Kulagar”, this traditional system is inherited from their ancestors where arecanut is the primary crop, and the spaces between the arecanut trees are used to grow various fruit crops, spice crops, tuber crops, timber and vegetables15. This system is a muti-strata design characterized by irregular planting patterns than formal geometric arrangements16. The arecanut-based agroforestry system is the most common form of intercropping along the west coast of India16,17. This traditional developed agroforestry system prioritizes functional diversity and opportunistic space utilization over standard density protocol highlighting the adaptive utilization of available resources. Behera et al18. found that, this system is very important for enhancing the livelihood of small and marginal farmers of coastal region. Despite its importance, mapping agroforestry systems, especially traditional ones like arecanut based agroforestry in Goa, remains challenging. Conventional mapping methods are often manual, labour, and cost-intensive, making them ill-suited for large-scale mapping19,20,21. While remote sensing offers several advantages viz., rapid data collection over large area and inaccessible regions and cost effective22. This technology provides near real-time information, allowing for quicker analysis and more timely decisions. High resolution multispectral remote sensing data and object based image analysis was used to map Populus deltoides based agroforestry system23 and agroforestry area in western Himalayas of India24. Previous studies have also stated that agroforestry systems are complicated to map using remote sensing due to multi-strata, high agrobiodiversity and topographic conditions25,26. Conventional remote sensing methods such as pixel based classification or vegetation index thresholding (NDVI) fails to capture the agroforestry complexity and intricacies. This is where machine learning models with high-resolution remote sensing emerge as game-changers. Machine learning models are objective, fast, and accurate alternatives to traditional methods for mapping agroforestry systems because they automate feature extraction, capture complex patterns in high-resolution imagery, and allow for scalable mapping27,28,29,30. So, the utilization of machine learning models in remote sensing investigations has experienced substantial growth across multiple domains like mapping of land-use and land cover, landslides, floods and gully erosion31,32,33,34,35,36,37,38.
Technological advances in remote sensing and machine learning have contributed significantly in identifying, assessing and monitoring land use and land cover (LULC) dynamics. Geographic Information System (GIS)-supported multi-criteria evaluation (MCE) methods have been widely applied to assess agroforestry suitability. For example, Nath et al.39 applied MCE in the eastern Indian Himalayas to assess the potential of agroforestry. Ahmad et al. (2019) used GIS along with FAO guidelines to evaluate the agroforestry suitability taking into consideration the nutrient availability of soil, climate and topography. Similarly, Ahmad and Goparaju40 used remote sensing and GIS to map nutrient availability, and agroforestry suitability. Machine learning models, such as Random Forest (RF), have proven effective in creating accurate suitability maps41,42. Recent studies used RF, Support Vector Machine (SVM), and Artificial Neural Network (ANN) for above ground biomass estimation43,44,45. Machine models such as RF46,47, SVM48 and Gradient Boosting (GB)45,49 have been used with satellite data for tree species classification. Despite the extensive use of machine learning algorithms in the different domains (LULC mapping, biomass estimation, species classification) of remote sensing-based studies, their specific application for mapping traditional, multi-strata agroforestry systems, particularly mapping traditional arecanut based agroforestry system remains unexplored. This represents a critical knowledge gaps as existing techniques lack precision and scalability needed for effective decision making and conservation planning for these traditional systems. Based on these identified research gaps, this study hypothesizes that machine learning models with high-resolution remote sensing imageries can accurately map arecanut based traditional agroforestry systems in the coastal region of Goa, by effectively capturing their spectral and structural complexity. Based on this background, this study aims to compare various machine learning models for mapping arecanut based agroforestry systems in the coastal region of Goa, India, and to identify important remote sensing-derived variables capturing the spatial patterns of these systems.
Materials and methods
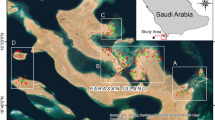
The study was carried out in the state of Goa, which lies in the central Western Ghats of India within the latitudes of 14°53ʹ N to 15°40ʹ N and longitudes of 73°40ʹ E to 74°21ʹ E, bordering the Arabian Sea (Fig. 1). The total reported area of Goa in this study is 3625.7 square kilometers. The research location is characterized by a subtropical climate. The annual mean minimum and maximum temperatures are 22.6 ℃ and 33.2 ℃, correspondingly with an annual mean precipitation of 3405 mm as recorded at ICAR-CCARI, Goa. Goa comprises two distinct physiographic regions: the Western Ghats and the coastal lowlands. The hilly areas have shallow, gravelly soils with slight to moderate acidity, while the coastal plains feature very deep, moderately to strongly acidic soils. These are classified as phosphorus- and aluminium-rich Inceptisols and sandy loam to sandy Entisols50. Goa’s predominant land uses include cashew (Anacardium occidentale) cultivation (55,732 ha), rice (Oryza sativa) fields (47,104 ha), coconut (Cocos nucifera) plantations (25,686 ha), pulses (7,890 ha), and areca nut (Areca catechu) groves (1,600 ha)16.

Study area map depicting different land use classes in Goa, India.
This study used Sentinel-2 satellite data with 10 different spectral bands (B2, B3, B4, B5, B6, B7, B8A, B8, B11, B12) at a spatial resolution of 20 m. The individual spectral bands were utilized to calculate 28 spectral indices (Supplementary Table 1), which were selected based on field investigations and literature surveys. The median values of Sentinel-2 level 2 products available between October and December 2022, coinciding with ground truth collection having cloud cover of less than 10%, were downloaded using Google Earth Engine.
On the other hand, 70 agroforestry locations were identified as the dependent variable based on GPS-based field surveys (Supplementary Fig. 1) and secondary data (FSI). A total of 374 non-agroforestry locations (agriculture, bare area, forest, building, water bodies) were also identified through the field survey and high-resolution Google Earth images to train the model. The classification of agroforestry and non-agroforestry areas using machine learning models was performed using a 70:30 ratio for training (315) and testing (135) datasets, respectively (Fig. 1). The ‘createDataPartition()’ function from the caret package in R Software (Version: 7.0–1; URL link: https://cran.r-project.org/web/packages/caret/index.html) was used to split data into training and testing sets in a stratified way. This function ensures that the distribution of the response variable is maintained in both the training and testing splits especially for classification tasks.
Boruta algorithm
The selection of features (covariates) for the modelling process was conducted using the Boruta algorithm. The Boruta approach automates feature selection, especially in datasets with many potentially significant characteristics. Focusing on the most important variables reduces dimensionality and improves model interpretability and predictive performance. The methodology can be outlined as follows: (i) creating duplicate instances for all independent variables and introducing additional features to remove correlations with the output variable (referred as shadow features). (ii) Training the machine learning (ML) algorithm using the expanded dataset and computation of Z scores. (iii) Identifying variables whose Z-scores are greater than the maximum Z-score among the shadow attributes (MZSA)51,52.
Machine learning models
In the present study, three popular machine learning (ML) models, viz., RF, SVM, and GBM were utilized for agroforestry area mapping. RF is a widely utilized ensemble learning technique employed machine learning for both classification and regression applications53,54,55. It is classified as an ensemble approach as it utilizes many decision trees to construct a more robust and precise model. In the current study, RF was used to classify arecanut-based agroforestry with other land use classes using remote sensing-derived spectral bands and indices as predictors. The outputs from individual decision trees are combined by majority voting. The RF approach requires two user-defined parameters: mtry, which specifies the number of parameters selected at every split, and ntree, which specifies the number of trees.
The SVM is a supervised learning technique that operates on the premise of an optimum separation hyperplane56. SVM exhibit exceptional efficacy in high-dimensional spaces and possess great adaptability in managing several forms of data. The datasets are partitioned into distinct classes by this hyperplane. The present work utilized the radial basis function as a kernel function to convert the dataset33. GBM is a widely used machine learning algorithm that is useful for classification and regression problems. It constructs an ensemble of weak learners, usually decision trees, in a step-by-step fashion, with each subsequent learner rectifying the errors committed by its predecessor57. GBM is known for its high predictive accuracy and robustness in handling noisy data. ML model hyperparameters were optimized using 10-fold cross-validation with the RStoolbox package in R 4.0.2. The methodology is shown in Fig. 2.
To improve the performance, reliability and efficiency of the ML models the strategy of hyperparameter tuning is of great importance. The values of the hyperparameters in the models, namely, RF, SVM and GBM were tuned to improve the models’ performance. This tuning process was performed to get the best prediction of each model for the given dataset. The optimum hyperparmeter for RF were mtry = 38, splitrule = gini and mini.node.size = 1. For SVM optimum value of sigma was 0.0954 and ‘C’ was 1. For GBM model, the optimal number of trees was 150, interaction.depth was 3, shrinkage was 0.1 and n.minobsinnode was 10.

Flow chart indicating procedure followed to prepare agroforestry maps.
Validation of the models
Statistical indices like accuracy and kappa were utilized in the current investigation to evaluate the implemented models. In machine learning, accuracy is a prevalent metric used to assess the efficacy of a classification model. It depicts the proportion of correctly predicted instances with the total number of instances within the dataset58.
Kappa is a statistical measure that assesses the level of agreement between the predictions made by a model and the outcomes that would occur by random chance. Higher Kappa values indicate better-than-chance agreement. Several scholars have emphasized the significance of the Kappa index in model validation55,59,60.
Where xij = number of counts in the ijth cell of the confusion matrix, N = total number of counts in the confusion matrix, xi + = marginal total of row i, and x + i = marginal total of column i.
User’s and producer’s accuracy
User’s accuracy, is determined by dividing the number of correctly classified pixels in a category by the total number of pixels assigned to that category (row total)61. This measure represents commission error and indicates the likelihood that a pixel classified into a specific category truly corresponds to that category in reality. Producer’s accuracy is calculated by dividing the correctly classified pixels for a category (from the main diagonal) by the total test pixels in that category (column total). This metric reflects how effectively the model classifies test pixels of a particular land cover type.
Variable importance
Variable importance plots (VIP) are crucial tools in machine learning as they provide valuable insights into the importance of various features in accurately predicting the target variable. These plots facilitate the identification of the most influential features on model predictions and can assist in feature selection, model interpretation, and gaining domain-specific insights. The variable importance for every model was calculated using ‘varImp’ function of ‘caret’ package in R Software (Version: 7.0–1; URL link: https://cran.r-project.org/web/packages/caret/index.html).
Results
Boruta algorithm
The feature selection process is an essential phase that eliminates completely irrelevant or redundant variables. The Boruta method did not find any of the variables to be redundant with all the 38 variables were confirmed as important (Fig. 3; Supplementary Table 2). Twenty variables had near equal importance (mean of importance between 5 and 10), seventeen variables between 10 and 15, and one variable had mean importance more than 15 (NDWI2 = 18.10). The NDWI2, B3, SLAVI, MCARI, and MNDWI were identified as 5 most important variables.

Feature importance scores from the Boruta algorithm and their selection for modelling (shadow variables—mean, max, and min are shown in blue).
Comparison and validation of machine learning models
The present work utilized three widely-used machine learning methods, namely random forest (RF), support vector machine (SVM), and gradient boosting machine (GBM), to conduct agroforestry mapping. The cross-validation and validation performance metrics for three distinct machine-learning models are presented in Table 1. The GBM model demonstrated the highest accuracy and kappa values for both the cross-validation and validation datasets, indicating its better performance than other models. The GBM model had strong predictive performance as evidenced by its validation accuracy of 0.86 and kappa of 0.83. Although the RF model performed lower than the GBM model, it still obtained a validation accuracy of 0.84 and kappa of 0.81, indicating its strong capacity to generalize unseen data and retain predictive performance effectively. On the other hand, the accuracy of the SVM model was 0.82, and the kappa coefficient was 0.78, which did not surpass the results of the RF and GBM models.

User’s and producer’s accuracy of machine learning model in agroforestry (AF) classification.
The three models performance in classifying agroforestry (AF) was assessed using user’s and producer’s accuracy (Fig. 4). The GBM model demonstrated a high user’s accuracy of 0.94 with only one sample of bare soil were inappropriately included in agroforestry. The Producer’s Accuracy for the AF class was 0.71, indicating that 71% of the actual AF instances were correctly identified by the model. However, five samples of forest and one sample of agriculture that should have been classified as agroforestry were omitted giving a moderate producer’s accuracy. In RF model, only one sample of forest was included in agroforestry demonstrating a higher user’s accuracy of 0.94. While in producer’s accuracy four samples of forest and one sample of agriculture were omitted from agroforestry class and a moderate accuracy of 0.76 was achieved.
In SVM model two sample of forest was wrongly included as agroforestry and with a user’s accuracy of 0.85. While ten samples of forest were inappropriately included in agroforestry leading to a low producer’s accuracy of 0.52. GBM and RF showed higher user’s accuracy (94%) indicating the models reliability in predicting AF. Confusion between AF and forest was the most prominent error across all the models, suggesting overlapping feature characteristics between these classes.
Variable importance plot
The predictor B4 was the most influential in RF, attaining a VIP score of 100 (Fig. 5). This indicated that band 4, which corresponds to near-infrared wavelengths, is an essential factor for mapping arecanut based agroforestry. It is well-established that near-infrared bands contain vital data regarding vegetation density and health, making them indispensable for remote sensing applications. Additional features, including NDWI2 (87.15), B5 (81.73), NBRI (71.55), and SLAVI (68.06) demonstrated considerable importance, thereby signifying their substantial contributions to the process of prediction. These characteristics probably encompass crucial elements such as vegetation, soil moisture content, and land cover, which are vital for mapping agroforestry.
In GBM, the most relevant predictor was NDWI2, with a VIP score of 100. This showed that water-related spectral indices affect the target variable. Following NDWI2, features such as NBRI (62.44), SLAVI (51.89), SATVI (47.66), and MNDWI (47.25) exhibited considerable importance, further emphasizing the influence of leaf area index and spectral characteristics on the prediction. The dominance of water-related indices such as NDWI2 indicates the significance of leaf water content in agroforestry. Vegetation indices like NBRI, SLAVI, and SATVI emphasized the importance of vegetation health or density in predicting the target variable, suggesting possible connections with agricultural productivity or ecosystem dynamics. In SVM, features such as NDWI2 (98.95), CLRE (98.84), NDREI2 (98.84), NDREI1 (98.60), and SLAVI (98.49) stand out as highly important predictors.

Variable importance plot for GBM, RF, and SVM.
Agroforestry map and post-validation
The area under different land use categories in Goa, as analysed using three machine learning algorithms is presented in Table 2. The findings of this research demonstrated that the GBM model can generate a highly accurate probabilistic (0.86) agroforestry map (Table 1). Land use land cover map including Arecanut based agroforestry of Goa generated using the three ML model are displayed in Fig. 6. According to the GBM model the total area of arecanut based agroforestry systems are 58.6 km2. The second-best model was RF (0.84) that estimated an area of 53.4 km2 while the lowest area was estimated by SVM (23.2 km2). The average of these three machine learning models provides an estimated area of 45.1 km² under arecanut-based agroforestry in Goa. Using the best performing model i.e., GBM, area of applicability (AOA) analysis was performed. AOA is defined as the domain within which the model was developed based on acquired relationships, and where we presume that the assessed cross-validation performance is applicable62. The AOA is delineated based on dissimilarity index (DI) which evaluates the distance to the nearest training data point in the multidimensional predictor space for each prediction location.
The AOA is determined through a threshold applied to the calculated DI values to find pixels that differ significantly from reference samples. The threshold for the current study was 0.22. The results of AOA analysis revealed that the only 2.68% of the total geographic area of Goa was outside AOA where the predictions should be used cautiously or excluded due to significant differences in spatial predictor variables from training data (Fig. 7).

Land use land cover map including arecanut based agroforestry map of Goa using (a) RF, (b) SVM, (c) GBM.

Area of applicability (AOA) for LULC mapping including Arecanut based agroforestry map of Goa using GBM.
Discussion
This study emphasized the significant role of machine learning techniques in agroforestry mapping. Machine learning techniques are used in this research due to their effectiveness in performing better than conventional methods63. The feature selection process is an important step in improving the robustness and interpretability of machine learning models. As noted by Hong et al. (2018)64, feature selection enhances model training, reduces complexity and leads to more accurate predictions. In this study, Boruta method identified all the variables as key features, emphasizing each features distinct contribution to the dataset. Notably, NDWI2, B3, SLAVI, MCARI, and MNDWI were identified as significant contributors. These indices help in understanding the vegetation water content, condition of the soil moisture and the surface water in details which are highly significant for monitoring crop status, drought conditions and forest fire risk assessment65,66. This demonstrates the importance of using diverse variables in machine learning models for agroforestry mapping and the effectiveness of advanced feature selection techniques.
Machine learning model testing is another critical step in the process of implementing these models as it offers a sound platform for enhancing performance in a specific domain of use55,59. The superior performance of the Gradient Boosting Machine (GBM) model can be attributed to its ability to capture complex, non-linear relationships through a tree-based boosting approach. This makes it ideal for use in agroforestry mapping because the method can identify interdependencies within data, which is generally diverse and complex45,49. The superior performance of GBM over RF for the classification of land covers is in line with Abera et al., (2022)67. Gradient Boosting Machines (GBMs) employ an iterative ensemble approach, utilizing decision trees as weak learners to enhance predictive accuracy57. Unlike parallel ensemble methods, GBMs sequentially add decision trees, with each new model specifically trained to minimize residuals from the previous iteration’s errors. This progressive correction mechanism allows GBMs to gradually improve overall prediction quality through additive model refinement67. This approach might help GBM in better mapping of agroforestry system compared to other models. The second-best model, RF was also useful in the mapping of agroforestry68. Singh et al. (2022) also used RF for site-specific agroforestry suitability mapping42. Moreover, Hayat et al. (2024) found that accuracy of RF is greater than that of SVM in predicting the suitability of land for agroforestry systems69. Earlier studies have reported that, RF models can effectively handle complex, non-linear patterns while maintaining robustness against noisy training data70,71 and has capability to discriminate spectrally identical categories72.
In the variable importance plot, NDWI2, which reflects vegetation water content73, emerged as one of the most critical features across all three models, highlighting the importance of water content indices in agroforestry mapping. Jiang et al. (2009) stated that NDWI is directly correlated with vegetation water content and serves as a predictor of canopy water content74. The index has been shown to correlate strongly with vegetation water content (VWC), facilitating the monitoring of water availability in diverse agricultural settings75. The arecanut-based agroforestry system requires consistent moisture for optimal growth which is ensured through regular irrigation in the study area. This steady water supply sets arecanut crops apart from other land uses that may not receive the same level of irrigation. Healthier plants exhibit distinct spectral signatures, which are effectively captured by water indices like NDWI2. Other significant features included vegetation-related indices (e.g., NBRI, SLAVI, MCARI, and MTCI) and spectral reflectance bands (e.g., B4 and B5), with minor variations observed among the models. These results suggested that a combination of water content indices, vegetation health parameters, and spectral reflectance characteristics is crucial for precise agroforestry mapping using machine learning algorithms76. Understanding the significance of these features can aid in the selection of input variables, enhancing the accuracy and interpretability of agroforestry mapping models, and promoting sustainable land management and environmental conservation.
The findings also showed that there were differences when the three classification techniques were used to estimate the extent of area under agroforestry. The estimated area under agroforestry by RF and GBM models was much higher than SVM. Classification is problematic with regard to agroforestry, which integrates aspects of both agriculture and forestry. RF and GBM are likely better at capturing this heterogeneity, reducing overfitting and capturing complex relationships77 which results in higher estimates of the area. SVM, on the other hand, is well suited to work with high-dimensional data78 but may have difficulties with the spectral and spatial features of agroforestry, which give rise to a lower accuracy of area computation. Model averaging or ensemble modelling is well recognized for enhancing the predictive accuracy and certainty as compared to individual models79,80,81. This method reduces the individual error of each model, combines their strengths and offsets their weaknesses thereby improving the accuracy of prediction82. Extensions of the present classification models based on hyperspectral remote sensing data can enhance the model performance and, thus may provide better understanding of agroforestry mapping.
Limitations
While the Boruta approach and subsequent machine learning model comparison offers valuable insights into agroforestry mapping, limitations exist. Uncertainties associated with land cover classifications arising from sensor variations and atmospheric conditions could bias the results. However, the findings may not have generalizability, as the context in which they are trained is specific to Goa and in their temporal scope. All three models struggled to effectively distinguish between AF and forest classes, suggesting it is difficult to define clear decision boundaries when classifying land cover types (tree-based systems) with similar spectral or spatial properties. The reliability and applicability of agroforestry mapping efforts should be improved by addressing these limitations. In future, leave location out cross-validation and forward feature selection methods can be tested to better results.
Conclusion
This work highlighted the potential of machine learning models for agroforestry mapping. Using the Boruta method for feature selection, NDWI2, B3, SLAVI, MCARI and MNDWI were found to be key indicators. These findings underscore the importance of integrating diverse remote sensing indices to improve the accuracy and interpretability for agroforestry mapping. Among the tested models, Gradient Boosting Machine (GBM) emerged as the most effective, demonstrating superior accuracy and robustness in capturing agroforestry’s inherent complexity. Random Forest (RF) also performed well, though less effective than GBM, while Support Vector Machine (SVM) faced challenges with spectral and spatial complexities, resulting in lower classification accuracy. Differences in area estimates among the models reflect the need for more advanced algorithms to address agroforestry’s heterogeneous characteristics. The outcomes of this study demonstrate that machine learning models, when properly tuned and combined with high-resolution remote sensing data, can serve as reliable tools for large-scale, accurate agroforestry mapping. Future work should investigate hyperspectral data along with ensemble methods in order to further refine model performance. This study makes an important contribution to the development of accurate agroforestry mapping techniques, which are needed for sustainable land management and environmental conservation promoting sustainable agriculture in coastal and ecologically sensitive regions.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Fahad, S. et al. Agroforestry systems for soil health improvement and maintenance. Sustainability 14, 14877 (2022).
Nair, P. K. R., Kumar, B. M. & Nair, V. D. Definition and Concepts of Agroforestry. In An Introduction to Agroforestry 21–28 (Springer International Publishing, 2021). https://doi.org/10.1007/978-3-030-75358-0_2.
Chavan, S. B. et al. Optimizing tree shade gradients in emblica officinalis-based agroforestry systems: impacts on soybean physio-biochemical traits and yield under degraded soils. Agrofor. Syst. 99, 21 (2025).
Jinger, D. et al. Nature-based solutions for enhancing CO2 sequestration and rehabilitating degraded lands through silvo-aromatic system and soil moisture conservation techniques. J. Environ. Manage. 380, 124904 (2025).
van Noordwijk, M. et al. Sustainable agroforestry landscape management: changing the game. Land 9, 243 (2020).
Plieninger, T., Muñoz-Rojas, J., Buck, L. E. & Scherr, S. J. Agroforestry for sustainable landscape management. Sustain. Sci. 15, 1255–1266 (2020).
Gassner, A. & Dobie, P. Agroforestry: A Primer (CIFOR-ICRAF, 2022).
Uthappa, A. R. et al. Comparative analysis of soil quality indexing techniques for various tree based land use systems in semi-arid India. Front. Glob Chang. 6, 1322660 (2024).
Udawatta, R. P., Gantzer, C. J. & Jose, S. Agroforestry practices and soil ecosystem services. In Soil health and intensification of agroecosytems, 305–333 (Elsevier, 2017).
Goparaju, L., Ahmad, F., Uddin, M. & Rizvi, J. Agroforestry: an effective multi-dimensional mechanism for achieving sustainable development goals. Ecol. Quest. 31, 63–71 (2020).
Sollen-Norrlin, M., Ghaley, B. B. & Rintoul, N. L. J. Agroforestry benefits and challenges for adoption in Europe and beyond. Sustainability 12, 7001 (2020).
Scialabba, N. Integrated Coastal Area Management and agriculture, Forestry and Fisheries (Food & Agriculture Org, 1998).
Craig, R. K. & Ruhl, J. B. Governing for sustainable coasts: Complexity, climate change, and coastal ecosystem protection. Sustainability 2, 1361–1388 (2010).
Kumar, P. et al. Achieving biodiversity conservation, livelihood security and sustainable development goals through agroforestry in coastal and island regions of India and Southeast Asia. In Agroforestry for sustainable intensification of agriculture in Asia and Africa 429–486 (Springer, 2023).
Maneesha, S. R., Devi, S. P. & Singh, N. P. Kulagar’-A potential system to conserve the crop diversity. Indian J. Plant. Genet. Resour. 32, 135–140 (2019).
Paramesh, V., Arunachalam, V. & Nath, A. J. Enhancing ecosystem services and energy use efficiency under organic and conventional nutrient management system to a sustainable Arecanut based cropping system. Energy 187, 115902 (2019).
Sujatha, S. & Bhat, R. Resource use and benefits of mixed farming approach in Arecanut ecosystem in India. Agric. Syst. 141, 126–137 (2015).
Behera, U. K., Paramesha, V. & Kumar, A. Comparative economics of Indigenous Kulagar and integrated farming systems under coastal agro-ecosystem of Goa. Indian J. Agric. Sci. 90, 1555–1562 (2020).
Adam, E., Mutanga, O. & Rugege, D. Multispectral and hyperspectral remote sensing for identification and mapping of wetland vegetation: a review. Wetl Ecol. Manag. 18, 281–296 (2010).
Maxwell, A. E., Warner, T. A. & Strager, M. P. Predicting palustrine wetland probability using random forest machine learning and digital elevation data-derived terrain variables. Photogramm Eng. Remote Sens. 82, 437–447 (2016).
Mahdavi, S. et al. Remote sensing for wetland classification: A comprehensive review. GIScience Remote Sens. 55, 623–658 (2018).
Chaitanya, T., Neelima, T. L., Ramanjaneyulu, A. V. & Krishna, A. Agroforestry area mapping using medium resolution satellite data and object-based image analysis. Agric. Sci. Dig. Res. J. https://doi.org/10.18805/ag.D-6099 (2024).
Rizvi, R. H. et al. Spatial analysis of area and carbon stocks under Populus deltoides based agroforestry systems in Punjab and Haryana States of Indo-Gangetic plains. Agrofor. Syst. 94, 2185–2197 (2020).
Rizvi, R. H. et al. Mapping of agroforestry systems and Salix species in Western himalaya agroclimatic zone of India. Curr. Sci. 121, 1347 (2021).
Escobar-López, A., Castillo-Santiago, M. Á., Mas, J. F., Hernández-Stefanoni, J. L. & López-Martínez, J. O. Identification of coffee agroforestry systems using remote sensing data: a review of methods and sensor data. Geocarto Int 39 (2024).
de Jesus, J. B. & Kuplich, T. M. Applications of SAR data to estimate forest biophysical variables in Brazil. CERNE 26, 88–97 (2020).
Ahmad, F., Uddin, M. M. & Goparaju, L. Assessment of remote sensing and GIS application in identification of land suitability for agroforestry: A case study of Samastipur, Bihar, India. Contemp. Trends Geosci. 7, 214–227 (2018).
Chlingaryan, A., Sukkarieh, S. & Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status Estimation in precision agriculture: A review. Comput. Electron. Agric. 151, 61–69 (2018).
Luo, H. et al. Comparison of machine learning algorithms for mapping Mango plantations based on Gaofen-1 imagery. J. Integr. Agric. 19, 2815–2828 (2020).
Sharma, R., Kamble, S. S., Gunasekaran, A., Kumar, V. & Kumar A. A systematic literature review on machine learning applications for sustainable agriculture supply chain performance. Comput. Oper. Res. 119, 104926 (2020).
Tien Bui, D., Pradhan, B., Lofman, O. & Revhaug, I. Landslide susceptibility assessment in vietnam using support vector machines, decision tree, and Naive Bayes Models. Math. Probl. Eng. 2012 (2012).
Tehrany, M. S., Pradhan, B. & Jebur, M. N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 512, 332–343 (2014).
Hong, H. et al. Comparison of four kernel functions used in support vector machines for landslide susceptibility mapping: a case study at Suichuan area (China). Geomatics Nat. Hazards Risk. 8, 544–569 (2017).
Termeh, S. V. R., Kornejady, A., Pourghasemi, H. R. & Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 615, 438–451 (2018).
Abdi, A. M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data. GIScience Remote Sens. 57, 1–20 (2020).
Eskandari, S., Pourghasemi, H. R. & Tiefenbacher, J. P. Relations of land cover, topography, and climate to fire occurrence in natural regions of iran: applying new data mining techniques for modeling and mapping fire danger. Ecol. Manage. 473, 118338 (2020).
Abdo, H. G., Almohamad, H., Al Dughairi, A. A. & Al-Mutiry, M. GIS-Based frequency ratio and analytic hierarchy process for forest fire susceptibility mapping in the Western region of Syria. Sustain 14 (2022).
Prasad, P., Loveson, V. J., Chandra, P. & Kotha, M. Evaluation and comparison of the Earth observing sensors in land cover/land use studies using machine learning algorithms. Ecol. Inf. 68, 101522 (2022).
Nath, A.J., Kumar, R., Devi, N.B., Rocky, P., Giri, K., Sahoo, U.K., Bajpai, R.K., Sahu, N. & Pandey, R. Agroforestry land suitability analysis in the Eastern Indian Himalayan region. Environ. Challenges, 4, 100199 (2021)
Ahmad, F., Uddin, M. M. & Goparaju, L. Agroforestry suitability mapping of india: Geospatial approach based on FAO guidelines. Agrofor. Syst. 93, 1319–1336 (2019).
Ahmad, F. & Goparaju, L. Geospatial approach for agroforestry suitability mapping: to enhance livelihood and reduce poverty, FAO based documented procedure (case study of Dumka district, Jharkhand, India). Biosci. Biotechnol. Res. Asia. 14, 651–665 (2017).
Singh, R. K. et al. Agroforestry suitability for planning site-specific interventions using machine learning approaches. Sustainability 14, 5189 (2022).
Thapa, B., Lovell, S. & Wilson, J. Remote sensing and machine learning applications for aboveground biomass Estimation in agroforestry systems: a review. Agrofor. Syst. 97, 1097–1111 (2023).
Singh, R. K. et al. Optimising carbon fixation through agroforestry: Estimation of aboveground biomass using multi-sensor data synergy and machine learning. Ecol. Inf. 79, 102408 (2024).
Usman, M. et al. A comparison of machine learning models for mapping tree species using WorldView-2 imagery in the agroforestry landscape of West Africa. ISPRS Int. J. Geo-Information. 12, 142 (2023).
Sabat-Tomala, A., Raczko, E. & Zagajewski, B. Comparison of support vector machine and random forest algorithms for invasive and expansive species classification using airborne hyperspectral data. Remote Sens. 12, 516 (2020).
Raczko, E. & Zagajewski, B. Comparison of support vector machine, random forest and neural network classifiers for tree species classification on airborne hyperspectral APEX images. Eur. J. Remote Sens. 50, 144–154 (2017).
Li, D., Ke, Y., Gong, H. & Li, X. Object-Based urban tree species classification using Bi-Temporal WorldView-2 and WorldView-3 images. Remote Sens. 7, 16917–16937 (2015).
Mäyrä, J. et al. Tree species classification from airborne hyperspectral and lidar data using 3D convolutional neural networks. Remote Sens. Environ. 256, 112322 (2021).
Singh, S. K. et al. Soil nutrient mapping using geoinformatics for input based land use planning–A case study of West Bengal. (2018).
Kursa, M. B. & Rudnicki, W. R. Feature selection with the Boruta package. J. Stat. Softw. 36, 1–13 (2010).
Ge, X. et al. Updated soil salinity with fine Spatial resolution and high accuracy: the synergy of Sentinel-2 MSI, environmental covariates and hybrid machine learning approaches. Catena 212, 106054 (2022).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Naghibi, S. A. & Pourghasemi, H. R. A comparative assessment between three machine learning models and their performance comparison by bivariate and multivariate statistical methods in groundwater potential mapping. Water Resour. Manag. 29, 5217–5236 (2015).
Prasad, P., Loveson, V. J. & Kotha, M. Probabilistic coastal wetland mapping with integration of optical, SAR and hydro-geomorphic data through stacking ensemble machine learning model. Ecol. Inf. 77, 102273 (2023).
Naghibi, S. A., Pourghasemi, H. R. & Abbaspour, K. A comparison between ten advanced and soft computing models for groundwater Qanat potential assessment in Iran using R and GIS. Theor. Appl. Climatol. 131, 967–984 (2018).
Friedman, J. H. Greedy function approximation: a gradient boosting machine. Ann. Stat., 1189–1232 (2001).
Lillesand, T., Olsen, T., Gage, J. & McENANEY, P. New Paradigm, new approaches: restructuring Geospatial information education and training in a traditional research university setting. Int. Arch. Photogramm Remote Sens. 33, 203–210 (2000).
Tien Bui, D. et al. New ensemble models for shallow landslide susceptibility modeling in a semi-arid watershed. Forests 10, 743 (2019).
Nikhil, S. et al. Application of GIS and AHP method in forest fire risk zone mapping: a study of the parambikulam tiger Reserve, Kerala, India. J. Geovisualization Spat. Anal. 5, 14 (2021).
Lillesand, T., Kiefer, R. W. & Chipman, J. Remote Sensing and Image Interpretation (Wiley, 2015).
Meyer, H. & Pebesma, E. Predicting into unknown space? Estimating the area of applicability of Spatial prediction models. Methods Ecol. Evol. 12, 1620–1633 (2021).
Ngolo, A. M. E. & Watanabe, T. Integrating geographical information systems, remote sensing, and machine learning techniques to monitor urban expansion: an application to Luanda, Angola. Geo-Spatial Inf. Sci. 26, 446–464 (2023).
Hong, H. et al. Landslide susceptibility mapping using J48 decision tree with AdaBoost, bagging and rotation forest ensembles in the Guangchang area (China). Catena 163, 399–413 (2018).
Adab, H., Morbidelli, R., Saltalippi, C., Moradian, M. & Ghalhari, G. A. F. Machine learning to estimate surface soil moisture from remote sensing data. Water 12, 3223 (2020).
Adab, H., Kanniah, K. D. & Solaimani, K. Modeling forest fire risk in the Northeast of Iran using remote sensing and GIS techniques. Nat. Hazards. 65, 1723–1743 (2013).
Abera, T. A., Vuorinne, I., Munyao, M., Pellikka, P. K. E. & Heiskanen, J. Land cover map for multifunctional landscapes of Taita Taveta County, Kenya, based on Sentinel-1 radar, Sentinel-2 optical, and topoclimatic data. Data 7, 36 (2022).
Kasahun, M. & Legesse, A. Machine learning for urban land use/cover mapping: Comparison of artificial neural network, random forest and support vector machine, a case study of Dilla town. Heliyon 10 (2024).
Hayat, A., Iqbal, J., Ashworth, A. J. & Owens, P. R. Assessing soil and land suitability of an olive–maize agroforestry system using machine learning algorithms. Crops 4, 308–323 (2024).
Mascaro, J. et al. A Tale of two forests: random forest machine learning aids tropical forest carbon mapping. PLoS One. 9, e85993 (2014).
Safari, A., Sohrabi, H., Powell, S. & Shataee, S. A comparative assessment of multi-temporal Landsat 8 and machine learning algorithms for estimating aboveground carbon stock in coppice oak forests. Int. J. Remote Sens. 38, 6407–6432 (2017).
Immitzer, M., Atzberger, C. & Koukal, T. Tree species classification with random forest using very high Spatial resolution 8-Band WorldView-2 satellite data. Remote Sens. 4, 2661–2693 (2012).
Bouslihim, Y. et al. The effect of covariates on soil organic matter and pH variability: A digital soil mapping approach using random forest model. Ann. GIS. 30, 215–232 (2024).
Jiang, Z., Li, L. & Ustin, S. L. Estimation of canopy water content with MODIS spectral Index. In Remote sensing and modeling of ecosystems for sustainability VI 7454 179–189 (SPIE, 2009).
Cosh, M. H., Tao, J., Jackson, T. J., McKee, L. & O’Neill, P. E. Vegetation water content mapping in a diverse agricultural landscape: National airborne field experiment 2006. J. Appl. Remote Sens. 4, 43532 (2010).
Nofrizal, A. Y. & Sonobe, R. Crop Classification Using a Combination of Spectral Indices from Spatiotemporal Multispectral Imagery and Machine Learning. in IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, 5820–5823 (IEEE, 2022).
Zhou, T., Feng, T. & Kemperman, A. Non-linear associations between the built environment and outdoor activity duration: an application of gradient boosting decision trees. Cities 165, 106146 (2025).
Matyukira, C. & Mhangara, P. Advances in vegetation mapping through remote sensing and machine learning techniques: a scientometric review. Eur J. Remote Sens 57 (2024).
Araújo, M. B. & New, M. Ensemble forecasting of species distributions. Trends Ecol. Evol. 22, 42–47 (2007).
Marmion, M., Parviainen, M., Luoto, M., Heikkinen, R. K. & Thuiller, W. Evaluation of consensus methods in predictive species distribution modelling. Divers. Distrib. 15, 59–69 (2009).
Valavi, R., Guillera-Arroita, G., Lahoz‐Monfort, J. J. & Elith, J. Predictive performance of presence‐only species distribution models: a benchmark study with reproducible code. Ecol. Monogr. 92, e01486 (2022).
Dormann, C. F. et al. Model averaging in ecology: A review of Bayesian, information-theoretic, and tactical approaches for predictive inference. Ecol. Monogr. 88, 485–504 (2018).
Acknowledgements
The authors are highly grateful to ICAR-Central Coastal Agricultural Research Institute, Goa, India for providing the permission to carry out this research work. The authors extend their appreciation to the Kansas Agricultural Experiment Station (Contribution Number: 26-067-J), Kansas, USA.
Author information
Authors and Affiliations
Contributions
Writing – original draft: A.R.U., B.D, A.R; Writing – review & editing: A.R.U., B.D, A.R., P.K., P.V., C.S.B., S.D., P.K.J., P.V.V.P; Conceptualization: A.R.U., B.D, A.R.; Data curation: A.R.U., B.D; Formal Analysis: A.R.U., B.D. C.S.B., S.D.; Funding acquisition: A.R.U., P.K.J., P.V.V.P; Investigation: A.R.U., B.D., A.R.; Methodology: A.R.U., B.D.; Software: B.D. P.K.J., P.V.V.P; Supervision: A.R., P.K; Visualization: A.R.U., B.D., P.K. All authors have reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Generative AI in scientific writing
During the preparation of this work the author(s) used ChatGPT only in the writing process to improve the readability and language of the manuscript. After using this tool/service, the author(s) reviewed and edited the content as needed and take(s) full responsibility for the content of the publication.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Uthappa, A.R., Das, B., Chavan, S.B. et al. Comparison of machine learning models for mapping Arecanut based agroforestry system in Goa by enhancing precision and efficiency. Sci Rep 15, 44280 (2025). https://doi.org/10.1038/s41598-025-27845-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-27845-6
