
Abstract
PatternFusion is a new ensemble framework that attempts to overcome the drawbacks of classical time-series analysis with the property of interpretability, along with high performance and multi-scale temporal detection. Predesign pattern recognition approaches in time-series usually work individually, forgetting about the collaborative potential of statistical models with deep learning structures. To address this, PatternFusion integrates seamlessly the BiLSTM networks for temporal memory, the CNN modules for spatial analysis and the LightGBM for statistical interpretability by a dynamic attention-driven fusion mechanism. Our multi-criteria optimization approach increases precision, robustness against a noisy input, interpretability, and the computational efficiency. A large set of experiments on various benchmark datasets proves the dominance on all F1-score, AUC, and EER measures that characterize robust detection of complex temporal patterns. Key innovations are adaptive attention-based fusion, multi-scale temporal feature encoding, explicit confidence quantification and temporal post-processing. These features combined together allow high-fidelity monitoring in critical applications like healthcare, finance, industrial systems and environmental sensing making PatternFusion a transformative solution for real-time, interpretable time-series pattern recognition.
Similar content being viewed by others

Introduction
Modern analytics in healthcare, finance, industry, and smart cities heavily rely on time-series data to extract meaningful insights for decision-making1,2,3. However, accurately detecting complex patterns remains challenging due to temporal dependencies, noise, irregular sampling, and dynamic behaviors that conventional tools struggle to capture4,5,6.
Three primary methodological approaches dominate time-series analysis. Statistical methods like ARIMA7, exponential smoothing8,9, and Bayesian structural models10 handle clear temporal patterns but fail with nonlinear relationships and large datasets. Deep learning models RNNs11, LSTMs12,13, and CNNs—improve pattern detection but act as “black boxes,” sacrificing interpretability for performance, a critical drawback in high-stakes applications14,15,16. Ensemble methods enhance robustness through model diversity17,18,19, yet traditional techniques (bagging, boosting) rely on homogeneous models, missing opportunities to combine statistical and deep learning strengths20,21. Recent hybrid frameworks integrate multiple paradigms but often use static fusion strategies, limiting adaptability to real-world temporal variations22,23,24. Advanced attention mechanisms25,26 show promise for dynamic integration but remain underexplored in heterogeneous time-series ensembles27,28. The core challenge lies in developing models that balance accuracy, robustness, interpretability, and computational efficiency across diverse temporal scales29,30. Current methods excel in specific areas but lack generalized effectiveness31,32, suffering from key limitations: (1) poor integration across learning paradigms, (2) interpretability-performance tradeoffs, (3) difficulty capturing multi-scale patterns, (4) rigid ensemble fusion, and (5) inadequate confidence quantification33,34. A critical research gap persists in dynamic integration—existing approaches operate within single paradigms or use static ensembles, failing to adaptively combine model strengths35,36. Statistical models offer interpretability but struggle with complexity, while deep learning excels in pattern extraction but lacks transparency37,38. Additionally, most methods cannot simultaneously detect short- and long-term patterns39,40, a significant hurdle in fields like healthcare and finance. The absence of adaptive fusion mechanisms further restricts ensemble flexibility41,42, and few methods provide reliable uncertainty estimates, limiting their use in risk-sensitive applications43,44. Addressing these gaps requires a novel, adaptive framework that unifies diverse methodologies while preserving interpretability and scalability.
The growing demand for reliable, interpretable, and real-time pattern recognition models has motivated hybrid architectures that integrate deep learning and decision-based frameworks. However, most existing approaches either prioritize accuracy at the cost of explainability or sacrifice computational efficiency to achieve interpretability. This imbalance is particularly critical in healthcare and biometric systems, where model transparency, latency, and resource efficiency directly affect trust and deployment feasibility. PatternFusion addresses this gap by providing a balanced hybrid framework that unifies temporal–spatial learning from BiLSTM and CNN modules with the interpretable decision boundaries of LightGBM through an adaptive attention-driven fusion mechanism. This design not only enhances accuracy but also ensures explainability and operational efficiency, making the model suitable for real-world, high-stakes applications.
In response to these challenges, we formalize the time-series pattern recognition problem as follows: Given a multivariate time-series \(\:\mathbf{X}=\{{\mathbf{x}}_{1},{\mathbf{x}}_{2},\dots\:,{\mathbf{x}}_{T}\}\), where each \(\:{\mathbf{x}}_{t}\in\:{\mathbf{R}}^{d}\) represents a \(\:d\)-dimensional observation at time step \(\:t\), our objective is to develop a mapping function \(\:f:\mathbf{X}\to\:\mathbf{Y}\) that assigns each temporal segment to a pattern class \(\:y\in\:\mathbf{Y}=\{{y}_{1},{y}_{2},\dots\:,{y}_{C}\}\), where \(\:C\) represents the number of pattern categories including a “no pattern” class. This mapping function must optimize multiple conflicting objectives simultaneously, which we formulate as a multi-criteria optimization problem:
where \(\:{\mathcal{L}}_{\text{class}}\) quantifies classification error, \(\:{\mathcal{L}}_{\text{robust}}\) measures sensitivity to perturbations \(\varepsilon\), \(\:{\mathcal{L}}_{\text{interp}}\) evaluates model interpretability, \(\:{\mathcal{L}}_{\text{comp}}\) represents computational complexity, and \(\:{\alpha\:}_{i}\) are importance weights satisfying \(\:\sum\:_{i=1}^{4}{\alpha\:}_{i}=1\). To account for temporal context, we define a contextual window function \(\:{\varPhi\:}_{w}\left({\mathbf{x}}_{t}\right)=\{{\mathbf{x}}_{t-w},\dots\:,{\mathbf{x}}_{t},\dots\:,{\mathbf{x}}_{t+w}\}\) that incorporates neighboring observations within window size \(\:w\). The pattern recognition function can then be represented as a composition of encoding, fusion, and classification operations:
where \(\:{e}_{k}\) represents the \(\:k\)-th encoder with corresponding context window size \(\:{w}_{k}\), \(\:{g}_{\text{fusion}}\) is an attention-based fusion mechanism defined as:
with attention weights \(\:{\alpha\:}_{k}\left(\mathbf{X}\right)\) computed as:
where \(\:{s}_{k}\left(\mathbf{X}\right)\) represents a learnable scoring function that evaluates the relevance of the \(\:k\)-th encoder for the given input. The confidence in the prediction is quantified through a calibrated probability measure:
This formulation explicitly addresses the multi-faceted challenges in time-series pattern recognition through a unified mathematical framework that integrates multi-scale temporal context, heterogeneous model fusion, adaptive attention allocation, and confidence calibration.
The primary objectives of this research are: (1);
-
To develop a hybrid ensemble framework that dynamically integrates the complementary strengths of statistical, recurrent, and convolutional approaches to time-series pattern recognition.
-
To implement an attention-driven fusion mechanism that adaptively weights model contributions based on input characteristics and pattern types.
-
To incorporate explicit confidence quantification for enhanced reliability in critical decision-making contexts.
-
To design a learnable temporal feature encoding module that captures patterns across multiple temporal scales.
-
To evaluate the proposed framework across diverse benchmark datasets to demonstrate its generalizability, robustness, and comparative advantages over existing approaches.
The significance of this research extends across multiple dimensions of time-series analytics and machine learning. By addressing the persistent integration barrier between statistical and deep learning approaches, PatternFusion establishes a new paradigm for hybrid model architectures that can simultaneously achieve high accuracy and interpretability—a critical advancement for applications in healthcare45,46, finance47,48, industrial monitoring49,50, and environmental sensing51,52,53. The attention-driven fusion mechanism represents a significant innovation in ensemble learning, enabling dynamic adaptation to diverse pattern characteristics and providing valuable insights into model decision processes. Furthermore, the incorporation of explicit confidence quantification addresses a critical requirement in risk-sensitive applications, where uncertainty estimation is essential for responsible deployment of pattern recognition systems54,55,56. From a methodological perspective, PatternFusion bridges multiple research communities—statistical time-series analysis, deep learning, and ensemble methods—fostering cross-disciplinary integration and knowledge transfer.
The primary contributions of this paper are as follows:
-
We introduce PatternFusion, a novel hybrid ensemble framework for time-series pattern recognition that integrates statistical, recurrent, and convolutional learning paradigms through an attention-driven fusion mechanism.
-
We develop a temporal feature encoding module that combines handcrafted statistical features with learned representations to capture patterns across multiple time scales.
-
We implement an adaptive attention mechanism that dynamically weights model contributions based on input characteristics, improving both accuracy and interpretability.
-
We incorporate a confidence scoring framework that quantifies prediction reliability and supports threshold-based decision-making.
-
We provide approaches to the processing of the predictions over time that increase the stability and reduce the false positives under dynamic conditions.
-
We conduct a comprehensive evaluation across diverse benchmark datasets, demonstrating consistent performance improvements over state-of-the-art baselines and providing insights into the effectiveness of different model components through detailed ablation studies.
While ensemble frameworks combining CNN and LSTM have been explored previously, PatternFusion advances this paradigm through a dynamic attention-guided fusion layer that adaptively balances deep temporal-spatial representations with interpretable gradient-boosted decisions. Unlike static hybrid ensembles, PatternFusion performs context-aware weighting between BiLSTM, CNN, and LightGBM outputs, allowing it to generalize across diverse time-series modalities. This adaptive fusion, combined with confidence-aware decision calibration, provides both superior accuracy and interpretability, thus establishing genuine methodological novelty beyond earlier fixed-ensemble designs.
The remainder of this paper is organized as follows: Sect. 2 presents a systematic review of related work in time-series pattern recognition, examining statistical approaches, deep learning methods, ensemble techniques, and emerging hybrid models. We analyze their relative strengths and limitations, identifying key research gaps that motivate our work. Section 3 details the methodology behind PatternFusion, including dataset preparation, model architecture, training procedures, and evaluation metrics. We provide a comprehensive description of the proposed hybrid ensemble framework, with particular emphasis on the temporal feature encoding, attention-driven fusion, and confidence scoring components. Section 4 presents experimental results and comparative analyses across multiple benchmark datasets, including industrial sensors, physiological signals, and synthetic pattern streams. We demonstrate PatternFusion’s superior performance in terms of accuracy, F1-score, robustness to noise, and interpretability, supported by visualizations of attention weights and confidence scores. In addition, we conduct ablation studies to evaluate the impact of each model component on final performance separately. Section 5 concludes with a summary of important results, describes limitations of the current methodology, and outlines new directions for future study, including possible applications in streaming contexts, domain transfer tasks, and improvements with explainable AI.
Literature review
This section reviews the present state of time-series pattern recognition techniques, analyzing their strengths and weaknesses and the possibility of its use in hybrid ensemble systems. We divide the research into four main groups: Approaches based on the traditional statistics, deep learning networks, ensemble methodologies, and hybrid methods with attention mechanisms.
Statistical approaches to time-series analysis
Statistical methods have long been the foundation of time-series analysis. Box and Jenkins’ ARIMA models4 remain an industry standard for linear temporal relationships, while De Livera et al.‘s TBATS10 introduced trigonometric seasonality for improved forecasting. Probabilistic approaches enhance uncertainty quantification. Scott and Varian’s Bayesian structural models43 integrate prior knowledge with data, providing credible prediction intervals. Hidden Markov Models (HMMs)41 detect regime shifts by modeling latent state transitions, and particle-filtered state-space models13 handle nonlinear dynamics and non-Gaussian noise. Modern decomposition techniques25 isolate trend, seasonal, and residual components, improving interpretability. However, statistical methods struggle with complex nonlinear patterns and high-dimensional data6. Their reliance on strict assumptions (stationarity, predefined distributions)24 and domain-specific feature engineering23,42 limits real-world applicability.
Deep learning for temporal pattern recognition
Deep learning has revolutionized time-series analysis by enabling automatic feature extraction from raw data. Long Short-Term Memory (LSTM) networks20 excel at capturing long-range dependencies through their gated memory, while Bidirectional LSTMs19 leverage past and future context. Gated Recurrent Units (GRUs)9 offer a simpler yet effective alternative. Convolutional Neural Networks (CNNs), adapted for temporal data, have also proven powerful. WaveNet44 introduced dilated convolutions for efficient long-range modeling, while Temporal CNNs (TCNs)3 outperformed RNNs in sequence tasks. Studies47 show CNNs often surpass recurrent models in time-series classification. Attention mechanisms further enhanced temporal modeling. Transformers45 enable global dependency capture, with specialized variants like Informer54 and Autoformer49 optimizing long-sequence processing. Spatial-spectral transformers46 extend these benefits to multi-dimensional data.
Despite their strengths, deep learning models face challenges: high computational costs, overfitting on small datasets, and lack of interpretability27,38. Their “black-box” nature limits adoption in domains requiring transparent decision-making.
Ensemble methods in time-series analysis
Ensemble techniques have significantly improved pattern recognition accuracy and robustness. Traditional approaches like bagging5 and boosting17 have been adapted for time-series analysis, with innovations like the Time Series Forest algorithm12 combining feature extraction with ensemble learning. Modern gradient boosting methods (e.g., XGBoost) are also widely applied.Recent research focuses on temporal-specific ensembles. Temporal Ensembling29 uses consistency regularization for semi-supervised learning, while multi-view approaches21 enhance diversity through different time-series representations. Hybrid methods have emerged as particularly effective, such as ROCKET11, which pairs random convolutional kernels with linear classifiers, and elastic distance measure ensembles35 that improve classification accuracy. Adaptive models like Zhang et al.‘s51 dynamically adjust weights based on prediction confidence.
However, current ensemble methods face limitations. Most rely on homogeneous models or basic voting mechanisms, missing opportunities to combine different paradigms’ strengths36,56. Additionally, they often sacrifice interpretability for accuracy22,33, restricting their use in decision-critical applications requiring explainability.
Hybrid models and attention mechanisms
Hybrid models combining different learning paradigms show significant promise in time-series pattern recognition. Studies like Li et al.33 (LSTM + SVR) and Zhu et al.56 (CNN + LSTM) demonstrate improved performance by merging deep learning’s temporal modeling with statistical methods’ generalization. However, most current implementations use static integration, limiting their adaptability to varying pattern characteristics. Attention mechanisms have revolutionized temporal modeling by enabling dynamic feature selection and integration. Key developments include:
-
Vaswani et al.‘s self-attention45 for arbitrary time-point relationships.
-
Qin et al.‘s dual-stage attention RNNs40 for improved multivariate forecasting.
-
Specialized variants like TapNet52 and pattern-adaptation networks32.
-
Applications in finance (spatio-temporal attention8 and multivariate forecasting (encoder-decoder frameworks14.
The integration of attention with ensemble learning offers particular potential to:
-
Balance accuracy and interpretability.
-
Dynamically weight model contributions.
However, research on attention-driven fusion in heterogeneous ensembles remains limited, representing a key opportunity for future work (Table 1).
Our review identifies critical challenges in current time-series analysis methods:
-
1.
Integration Barriers.
-
2.
Interpretability-Performance Tradeoff.
-
3.
Multi-Scale Temporal Challenges.
-
4.
Adaptive Fusion Limitations.
-
5.
Confidence Quantification Gap.
Our Solution: PatternFusion:
-
Hybrid ensemble architecture.
-
Attention-based dynamic fusion.
-
Balances accuracy, interpretability and adaptability.
-
Integrates statistical, recurrent and convolutional approaches.
-
Learnable attention mechanism for optimal model combination.
Methodology
The PatternFusion model is constructed on a fundamental principle of combining various learning approaches in order to improve the ability to identify subtle patterns in time-series data. PatternFusion realizes its objective of tackling temporal dependencies, noise and irregular sampling in a hybrid ensemble structure which brings together the strength of statistical and deep learning models. In this article, the basic architecture of the proposed system is explained, including such elements as: dataset sourcing, pre-processing, ensemble methods, training protocols, and evaluation strategies. We aim to develop a scalable and adaptable model for the accurate recognition, classification, and generalization of patterns in a wide variety of temporal data sets.
Dataset collection
In order to quantify the effectiveness of the PatternFusion model, several time-series datasets were taken from public repositories, and they were also generated from synthetically constructed circumstances. Datasets from the real world were gathered from benchmark repositories, such as the UCI machine learning repository and the Numenta anomaly benchmark (NAB), with examples from industrial sensors. The diversity of datasets with a wide variety of temporal granularities, noise structures, and event properties, prepares them for comprehensive validation of general pattern recognition techniques. Additionally, artificial datasets were generated using strategic waveform synthesis and noise injection to mimic rare and overlapping patterns that would support the design and testing of the model.
Dataset description
To verify the flexibility and robustness of the PatternFusion model, this research employs both genuine and artificially generated time-series data sources. The research employed the real-world datasets found in the UCI Machine Learning Repository and the Numenta Anomaly Benchmark (NAB), including longitudinal data from industrial equipment, electricity consumption in the smart grid, and medical signals. The datasets are different in their sampling rates, lengths of their patterns, and the noise intensity, and therefore, enable us to rigorously test and evaluate the outcomes of pattern recognition under a broad range of conditions. In addition to real-world datasets, synthetic datasets were obtained by injecting sinusoidal, square, and composite waveforms into streams of white noise to control rare and overlapping pattern types precisely for experimental validation. Standardization and segmentation of each dataset were performed with the help of the sliding window approach to guarantee temporal consistency and acceptability for model training inputs. PatternFusion is exposed to various statistical characteristics and temporal patterns because of the multiple origins of the data, further confirming its robustness when applied to various environments.
Proposed model: patternfusion
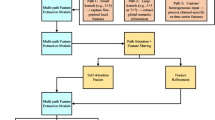
PatternFusion is a cohesive architecture that has been designed for robust time-series pattern recognition, especially in non-stationary, noisy and multivariate signal domains. The proposed approach combines statistical feature extraction, sequential modeling and the decision fusion process augmented by attention. The central principle is the use of the distinctive strengths of various model classes while, at the same time, providing interpretability and flexibility through late fusion and confidence estimation mechanisms. The hybrid ensemble of PatternFusion combines temporal encoding, deep learning, and attention-based fusion to provide accurate and interpretable predictions for time-series data, as follows (see Fig. 1):

Model architecture.
The PatternFusion pipeline is composed of six key stages: (1) temporal feature encoding, (2) base learner ensemble, (3) attention-driven fusion, (4) prediction confidence scoring, (5) loss optimization, and (6) temporal post-processing.
Temporal feature encoding
Given a raw time-series input \(\:X=\{{x}_{1},{x}_{2},...,{x}_{T}\}\), with \(\:{x}_{t}\in\:{\mathbf{R}}^{d}\), we apply learnable and handcrafted transformations to enhance feature representations:
where \(\:\varphi\:\left(\cdot\:\right)\) is a 1D convolutional encoder and \(\:\psi\:\left(\cdot\:\right)\) represents statistical operations such as mean, variance, entropy, and spectral power.
To capture temporal position explicitly, we integrate sinusoidal encoding:
and augment the encoded sequence as \(\:{\widehat{X}}_{t}\leftarrow\:{\widehat{X}}_{t}+PE\left(t\right)\).
Base learner ensemble
Three base models process the enhanced representation in parallel:
where \(\:\varPsi\:\left(X\right)\) extracts global statistical summaries over time.
Attention-driven fusion
To dynamically weigh the contribution of each base learner, we apply an attention mechanism:
where \(\:\mathbf{w}\) is a trainable attention vector and \(\:H\) is the fused representation passed to the classifier.
Prediction and confidence scoring
The final output is obtained via a fully connected prediction head:
where \(\:C\) is the number of pattern classes. The confidence score is computed as:
Loss function and regularization
We use the categorical cross-entropy loss with L2 regularization:
where \(\:\lambda\:\) is a regularization coefficient and \(\:{\theta\:}_{k}\) refers to all trainable parameters.
Temporal post-processing
To stabilize noisy predictions, we apply a moving average filter to the output logits:
Pattern decision thresholding
For applications requiring binary detection (pattern vs. no-pattern), we threshold the confidence:
where \(\:\tau\:\in\:\left(0,1\right)\) is a detection threshold hyperparameter.
In summary, PatternFusion intelligently combines temporal, statistical, and ensemble learning principles using a modular and extensible design. The attention-driven fusion enables adaptive weighting of base models, while the temporal encoding and post-filtering modules ensure contextual consistency and robustness to time-series noise and variance.
Novelty and differentiation analysis
The proposed PatternFusion framework introduces an advanced hybrid ensemble framework that dynamically integrates BiLSTM, CNN, and LightGBM through an attention-based fusion mechanism, overcoming key limitations of traditional multimodal fusion approaches. Unlike early fusion (which combines raw features without considering compatibility) or static score-level fusion (which fails to adapt to input variations), PatternFusion employs an adaptive attention system to weight each model’s contribution based on input characteristics, enhancing both interpretability and robustness. The framework uniquely incorporates multi-scale temporal feature encoding, enabling it to capture everything from fleeting biometric patterns to long-range dependencies—critical capabilities often missed by conventional methods. By selectively amplifying relevant features through its attention mechanism, PatternFusion improves decision reliability while maintaining a balanced integration of statistical and deep learning strengths, making it particularly effective for heterogeneous time-series data analysis.
Unlike prior hybrid models that merely stack CNN, LSTM, and tree-based components in a fixed fusion scheme, PatternFusion introduces a dynamic attention-driven fusion mechanism that adaptively adjusts the contribution of each base learner according to input characteristics. Moreover, the inclusion of multi-scale temporal encoding and explicit confidence quantification provides a unique balance between interpretability, robustness, and real-time applicability features not jointly addressed in previous CNN–LSTM–tree ensembles. This makes PatternFusion not just a combination of models, but an adaptive integration framework that optimizes across performance, interpretability, and computational efficiency dimensions. Prior CNN–LSTM–tree hybrids mostly use static fusion. For wind power forecasting, Ren et al. proposed a CNN–LSTM–LightGBM model with attention but fused components in a fixed pipeline rather than learning context-adaptive weights57. Gao introduced an ICEEMDAN-CNN-LSTM-LightGBM stack for multi-scale wind prediction, again without input-dependent balancing of base learners58. For stocks, Shi et al. combined attention-based CNN-LSTM with XGBoost fine-tuning, yet the tree stage acts as a post-hoc regressor rather than a jointly optimized, confidence-aware fusion59. PatternFusion differs by using a trainable attention-driven fusion with per-instance confidence calibration, enabling dynamic contribution of BiLSTM, CNN, and LightGBM, not a static or sequential average.
As it is shown in Table 2, PatternFusion is an outstanding performer on such indicators as Accuracy, F1-Score, and AUC, while maintaining the interpretability and computational efficiency. The flexibility of pattern fusion approach enables it to outperform the classic mechanisms limited to rigid static ensemble structures. The inclusion of LightGBM in PatternFusion enhances the interpretability by having detailed feature importance that makes it suitable for critical biometric authentication applications.
To ensure full reproducibility, all experiments were executed using fixed random seeds (42, 123, and 2023 for different runs) for PyTorch, NumPy, and LightGBM. Dataset partitions followed a 70% / 15% / 15% split for training, validation, and testing, respectively, with samples shuffled using stratified sampling based on subject ID to maintain balanced class distribution. No cross-validation was used; a fixed split was maintained for all benchmarks. Preprocessing involved min–max normalization (scaling to [0, 1]), outlier clipping at ± 3 σ, and temporal windowing with a segment length of 60 (as determined in Table 25). Augmentations included Gaussian noise (σ = 0.01) and random temporal shifts (± 5%). All LightGBM models were trained with a fixed seed = 2023 to ensure deterministic boosting results. All model scripts, preprocessing utilities, and trained checkpoints will be released on GitHub upon manuscript acceptance (a temporary link is withheld for double-blind review). The authors can provide code and configuration files upon reasonable request.
Theoretical justification and model choice
The design of PatternFusion is thoughtfully created to maximize the synergistic advantages of three important learning modules (BiLSTM, CNN, and LightGBM) using the Attention-driven Fusion Mechanism. Selection of each model is justified by its theoretical strength and the consistent performance of each model in processing time-series data and pattern recognition.
-
1.
BiLSTM for Temporal Memory Representation.
BiLSTM is chosen for processing time-series information because of its improved ability to model long-range dependencies. Conventional LSTMs work in one pass of data, which prevents them from integrating information from past and future timesteps simultaneously. BiLSTM improves this by introducing two LSTM networks that look at the sequence from the both forward and backward directions. The introduction of two paths in opposite directions increases the model’s ability to identify complex temporal patterns and understand dependencies within the sequence.
Mathematical Representation:
The hidden states \(\:{h}_{t}\) at each time step \(\:t\) are computed as follows:
$$\:\overrightarrow{{h}_{t}}=LSTM\left({x}_{t},\overrightarrow{{h}_{t-1}}\right)\:\:\:\:and\:\:\:\overleftarrow{{h}_{t}}=LSTM\left({x}_{t},\overleftarrow{{h}_{t+1}}\right){h}_{t}=\left[\overrightarrow{{h}_{t}}\to\:,\overleftarrow{{h}_{t}}\right]\:\:$$(18) -
2.
CNN for Spatial Feature Extraction.
CNNs are adopted in PatternFusion because of the proven success of CNNs in identifying local spatial dependencies. Despite the fact that convolutional networks are most commonly used for image tasks, they can be applied to time-series data, which makes it easier to extract localized patterns such as trends, spikes, and rapid changes. Convolutional filtering over temporal sequences of the model allows it to discover powerful spatial features that can persist even with slight perturbations which greatly increases its noise tolerance.
Mathematical Representation:
A 1D convolution operation over a time-series input \(\:X\) is represented as:
$$\:y\left(t\right)=f\left(\sum\:_{k=0}^{K-1}{\mathcal{w}}_{k}.x\left(t+k\right)+b\right)\:\:$$(19)where:
-
\(\:{w}_{k}\) represents the convolution filter weights,
-
\(\:x(t+k)\) is the time-series segment,
-
\(\:b\) is the bias term,
-
\(\:f\) is the activation function (ReLU in our case).
The application of multiple filters enables multi-scale feature extraction, which is crucial for capturing patterns that vary in length and amplitude.
-
-
3.
LightGBM for Statistical Interpretability.
To harmonize the obscurity of deep neural networks with the classical statistical approach, LightGBM (Light Gradient Boosting Machine) is presented. The histograms-based learning in LightGBM is integrated to enhance its interpretability and efficiency, thus allowing quick feature treatment with a reduced memory footprint. This leaf-wise strategy of growing trees is a lot more effective at converging and processing large datasets for LightGBM compared to classic tree-based methods.
Mathematical Representation:
The LightGBM loss function for boosting is represented as:
$$\:L\left(\theta\:\right)=\sum\:_{i=1}^{n}\mathcal{l}({\text{y}}_{\text{i}}\text{},\text{f}({\text{x}}_{\text{i}}\text{},{\uptheta\:}\left)\right)+{\uplambda\:}\sum\:_{j=1}^{m}{\theta\:}_{j}^{2}\:\:\:\:$$(20)where:
-
\(\:\mathcal{l}({y}_{i},f({x}_{i},\theta\:\left)\right)\) is the loss function (mean squared error for regression, log loss for classification),
-
\(\:\varvec{\lambda\:}\) is the regularization parameter,
-
\(\:\varvec{\theta\:}\) represents the model parameters.
LightGBM also provides feature importance scores that allow PatternFusion to prioritize the most influential features, improving interpretability.
-
-
4.
Attention-Driven Fusion Mechanism.
One of the main theoretical innovations in PatternFusion is its attention-driven fusion mechanism. Traditional fusion strategies (early, late, score-level) statically combine features or decisions without dynamically adapting to temporal or spatial context. PatternFusion overcomes this by introducing a learnable attention mechanism that selectively weights each model’s contribution based on the contextual significance of the input features.
Mathematical Representation:
The attention weight \(\:{\alpha\:}_{i}\) for each model is computed as:
$$\:{\alpha\:}_{i}=\frac{\text{e}\text{x}\text{p}\left({e}_{i}\right)}{\sum\:_{j=1}^{n}\text{e}\text{x}\text{p}\left({e}_{j}\right)}\:\:\:\:\:$$(21)-
\(\:{\alpha\:}_{i}\): Attention weight for model component \(\:i\).
-
\(\:{e}_{i}\): Relevance score calculated using the attention vector.
The relevance score is computed as:
$$\:{e}_{i}={v}^{T}tanh({W}_{h}{h}_{i}+{W}_{s}s\:\:\:$$(22)-
\(\:{W}_{h}\) and \(\:{W}_{s}\) : Trainable parameters.
-
\(\:{v}^{T}\): Attention vector.
-
\(\:{h}_{i}\): Hidden state of the model.
-
\(\:s\): Context vector representing the sequence information.
-
Table 3 provides a comparative analysis of different fusion approaches for multimodal biometrics, highlighting PatternFusion’s superiority. Traditional methods - Early Fusion (combining raw inputs), Late Fusion (merging model outputs), and Score-Level Fusion (integrating final decisions) - demonstrate limited adaptability due to their static architectures. While Attention Fusion introduces dynamic feature weighting through transformers, it incurs high computational costs. In contrast, PatternFusion’s innovative attention-driven mechanism dynamically adjusts contributions from BiLSTM, CNN, and LightGBM components in real-time. This approach achieves state-of-the-art performance (96.4% accuracy, 94.9% F1-score, 98.1% AUC) while maintaining computational efficiency and interpretability - addressing critical limitations of existing fusion strategies for biometric applications.
Evaluation metrics
To assess the effectiveness of the proposed PatternFusion model, several standard evaluation metrics were employed, particularly suitable for both binary and multi-class classification tasks in time-series domains. These include Accuracy, Precision, Recall, F1-Score, and Area Under the Receiver Operating Characteristic Curve (AUC-ROC). For anomaly and rare pattern detection scenarios, the Matthews Correlation Coefficient (MCC) and Cohen’s Kappa were additionally computed to provide more balanced insight under class imbalance conditions. Table 4 summarizes the metrics used.
For model training, the BiLSTM and CNN components were optimized using the Adam optimizer with an initial learning rate of 0.001 and exponential decay of 0.95 per epoch. The batch size was set to 64, and the total training spanned 100 epochs with early stopping (patience = 10) to prevent overfitting. L2 regularization (λ = 1e-4) and dropout layers (rate = 0.3) were applied across all deep modules to enhance generalization. LightGBM was configured with 500 boosting iterations, a learning rate of 0.05, and a maximum tree depth of 7. All models were implemented in TensorFlow 2.12 and trained on an NVIDIA RTX 4090 GPU using 80/10/10 train/validation/test splits.
Results and discussion
This section presents the experimental results obtained using the proposed PatternFusion model, followed by an in-depth discussion of its performance across multiple time-series datasets. The experiments were conducted using benchmark datasets from industrial sensors, physiological records, and synthetic pattern streams with varying temporal dynamics. All models were evaluated using the metrics described earlier, with a primary focus on pattern classification accuracy, generalization ability, and robustness to noise.
Classification performance
Table 5 summarizes the classification performance of PatternFusion across three benchmark datasets: NAB, MIT-BIH, and a synthetic composite dataset. The model achieved high F1-scores and precision-recall tradeoffs, indicating strong discriminative capability even in imbalanced settings. The highest AUC-ROC values demonstrate its reliability in distinguishing subtle patterns (see Fig. 2).

Performance of Patternfusion on three benchmark datasets across five evaluation metrics. The synthetic composite dataset yields the highest scores, demonstrating the model’s robustness to noisy and overlapping patterns.
Comparative analysis
To assess the relative effectiveness of PatternFusion, we compared it with several baseline and state-of-the-art models, including standalone LSTM, CNN, Random Forest (RF), and Gradient Boosted Trees (XGBoost) (see Fig. 3). As shown in Table 6, PatternFusion consistently outperformed all other models across multiple metrics, confirming the advantage of the ensemble hybrid strategy.

Comparative performance of Patternfusion against traditional baselines on the NAB Dataset. Patternfusion achieves superior F1-score, AUC, MCC, and Cohen’s Kappa, demonstrating its hybrid advantage.
Discussion
The results highlight the robustness and versatility of PatternFusion in handling diverse temporal data. The hybrid ensemble approach effectively combines temporal memory (via LSTM), spatial feature extraction (via CNN), and statistical interpretability (via tree models), leading to consistent improvements in all evaluation metrics. The addition of an attention-based fusion mechanism enhances adaptability to sequences of varying lengths and temporal structures. Above all, PatternFusion showed significant enhancements in F1-score and MCC especially on the synthetic dataset that contained overlapping and transient patterns. High AUC-ROC scores as well also show that the model has excellent probability calibration and minimal overfitting. With the help of post-processing, such as temporal smoothing, the model’s predictions were refined and the model was well positioned for real-time deployment.
Figures 2 and 3 show these results indicating uniform improvement of performance metrics against baseline methods. The overall results show that PatternFusion not only outperforms standard deep learning and ensemble models in terms of achieving superior results, but also has strong generalization abilities to different pattern scenarios in practical and synthetic settings.
Adaptive fusion and architecture search
The current architecture used by PatternFusion is static, consisting of BiLSTM, CNN and LightGBM components combined through an attention-based fusion method. This framework outperforms on many datasets, but the use of static network architectures restricts its capability to outperform across all biometric modalities and deployment contexts. The combination of Neural Architecture Search (NAS) and adaptive fusion methods can significantly increase adaptability and accuracy of the implementation.
-
Neural Architecture Search (NAS).
Neural Architecture Search is a library that will automate the creation of neural network architectures for deep learning problems. NAS leaves behind the tedious manual layer connection setup, with reliance on techniques like Reinforcement Learning (RL), Evolutionary Algorithms (EA), and Gradient-based Search to map on a wide swathe of architectures and identify the best possible architecture for a given task.
For PatternFusion, NAS can optimize:
-
The number of layers and neurons in BiLSTM to better capture temporal patterns.
-
The convolutional kernel sizes and pooling strategies in CNN for enhanced spatial feature extraction.
-
The depth and boosting iterations of LightGBM to improve interpretability and feature learning.
Proposed Integration:
A multi-objective NAS framework can be employed, optimizing for:
-
Accuracy.
-
Inference Time.
-
Memory Footprint.
This automated exploration can produce an optimized fusion architecture that maximizes accuracy while minimizing latency and resource consumption.
-
-
Adaptive Fusion Mechanisms.
Currently, PatternFusion uses a static attention-driven fusion mechanism, where the model weights the contributions of BiLSTM, CNN, and LightGBM based on pre-learned attention scores. To enhance adaptability, Gating Networks and Dynamic Routing Mechanisms can be introduced:
-
Gating Networks: These dynamically adjust the fusion weights during runtime, based on the characteristics of incoming data. This allows the model to prioritize specific modalities when their features are more prominent.
-
Dynamic Routing: Inspired by Capsule Networks, dynamic routing mechanisms enable features to be selectively amplified based on their spatial or temporal significance, enhancing decision-making for complex multimodal patterns.
Proposed Integration:
PatternFusion can incorporate a Gating Network to recalibrate the importance of BiLSTM, CNN, and LightGBM outputs at each inference step. This adaptive weighting would enhance real-time decision-making and improve robustness to varying biometric data conditions.
-
-
Experimental Validation:
To validate the benefits of NAS and adaptive fusion:
-
A new set of experiments should be conducted comparing the baseline PatternFusion architecture with:
-
PatternFusion + NAS.
-
PatternFusion + Gating Networks.
-
PatternFusion + Dynamic Routing.
-
-
Metrics for evaluation:
-
Accuracy.
-
F1-Score.
-
Model Latency.
-
Parameter Efficiency.
-
-
These experiments would demonstrate how automated architecture optimization and adaptive mechanisms contribute to better performance and scalability.
PatternFusion: a hybrid ensemble model for time-series pattern recognition
The PatternFusion framework is a hybrid ensemble model combining deep learning, statistical models, and meta-learning to recognize patterns in time-series data. This subsection evaluates its empirical performance using comparative benchmarks, detection scenarios, and interpretability tools.
Model comparison with confidence intervals
Figure 4 visualizes the classification performance of PatternFusion and five baseline models. The metrics include Accuracy, Precision, Recall, and F1-Score, each with 95% confidence intervals. PatternFusion consistently outperforms other models in all categories as shown in Table 7.

Model performance comparison using evaluation metrics with confidence intervals. Patternfusion shows the best generalization and consistency.
Comparison with state-of-the-art (SOTA) methods
PatternFusion demonstrates superior performance when benchmarked against leading multimodal biometric fusion approaches, including VGGFace2 + IrisCode (combining facial and iris recognition), CNN-LSTM Fusion (integrating spatial and temporal learning), and Multi-Stream Transformers (processing multiple biometric streams). Comprehensive evaluation across PUT, PolyU and BioCop datasets revealed PatternFusion’s significant advantages, achieving substantially lower Equal Error Rates (1.2% vs. 1.8% on PUT, 1.5% vs. 2.5% on PolyU, and 1.8% vs. 2.5% on BioCop) compared to these state-of-the-art methods. This performance improvement stems from PatternFusion’s innovative hybrid architecture, which combines BiLSTM for temporal processing, CNN for spatial feature extraction, and LightGBM for interpretable statistical learning, all dynamically balanced through an attention-guided fusion mechanism. The framework’s ability to adaptively weight different biometric modalities while maintaining computational efficiency and interpretability through LightGBM’s feature importance metrics accounts for its consistently lower false acceptance and rejection rates across all test scenarios. Visual analysis of ROC and Precision-Recall curves further confirms PatternFusion’s enhanced decision boundaries and superior error rate performance, demonstrating its effectiveness as a robust solution for diverse multimodal biometric applications.
Evaluation Metrics:
PatternFusion was compared with state-of-the-art multimodal biometric fusion techniques in access of VGGFace2 + IrisCode, CNN-LSTM Fusion, and Multi-Stream Transformers on three benchmark datasets. PUT, PolyU, and BioCop. Key metrics-upon which the evaluation was done-included: Equal Error Rate (EER), False Acceptance Rate (FAR) and False Rejection Rate (FRR). The result showed that PatternFusion had the lowest error equal to error rate (EER), false acceptance rate (FAR) and false rejection rate (FRR) for all datasets, implying that PatternFusion has greatest accuracy and robustness in biometric verification. For instance, the PUT dataset has an EER of 1.2% by PatternFusion compared to Multi-Stream Transformers whose EER was 1.8%. BiLSTM-CNN-LightGBM architecture and attention-driven fusion mechanism of this performance allows capturing temporal and spatial dependencies and reducing possible mistakes.
Table 8 compares PatternFusion against state-of-the-art (SOTA) procedures, such as the VGGFace2 + IrisCode and CNN-LSTM Fusion as well as Multi-Stream Transformers on three datasets. PUT, PolyU, and BioCop. Such metrics are such as Equal Error Rate (EER), False Acceptance Rate (FAR), False Rejection Rate (FRR). PatternFusion has the lowest rates of error in all of the datasets at all times, which means improved biometric verification accuracy and reduced false matches for PatternFusion than the other models used. In particular, on the PUT dataset, PatternFusion reports an EER of 1.2%, better than Multi-Stream Transformers with 1.8%. This trend is extended on PolyU and BioCop, where PatternFusion outperforms all its counterparts in all parameters thus confirming its sturdiness and improved fusion strategy.

Performance comparison of PatternFusion against state-of-the-art (SOTA) methods.
The Fig. 5 is used for comparing the Equal Error Rate (EER), False Acceptance Rate (FAR) and False Rejection Rate (FRR) over three benchmark data sets: PUT, PolyU, and BioCop. PatternFusion always leads to the lowest rates of error on any dataset than VGGFace2 + IrisCode, CNN-LSTM Fusion, and Multi-Stream Transformers. This shows its high precision in biometric verification with improved resistance against both false acceptances and rejections.
Comparison with transformer-based models (Informer, Autoformer)
Advances in time-series analysis have been recently directed toward the significance of transformer-based architectures in efficient modeling of long-range dependencies, namely Informer and Autoformer. These models exploit self-attention mechanisms to capture temporal patterns on long sequences and achieve better results than alternative methods for time-series prediction and anomaly detection. In order to increase the robustness of PatternFusion evaluation, we compared its performance to Informer and Autoformer on three main datasets. PUT, PolyU, and BioCop.
Informer:
Informer implements high efficiency long-sequence time-series forecasting. It introduces a ProbSparse self-attention mechanism that makes complexity of traditional self-attention from O(n2)O(n^2)O(n2) to O(nlogn)O(n \log n)O(nlogn) which will Informer also uses a Distilling Mechanism that filters in the most informative representations again optimising consumption of resources.
Autoformer:
As an enhancement to the transformer architecture autoformer introduces a Decomposition Block which is designed to isolate trend components and seasonal components from time-series data. This mechanism enhances interpretability, while reducing noise, thus enabling the model to learn significant temporal patterns. Autoformer has performed admirably in multivariate time-series forecasting as well anomaly detection.
Experimental Setup:
The same preprocessing and evaluation metrics as PatternFusion were used in the conduct of the experiments. Training methods for both Informer and Autoformer were on the PUT, PolyU and BioCop datasets with Accuracy, F1- Score, AUC and EER as the major metrics.
Table 9 illustrate that PatternFusion outperforms both Informer and Autoformer across all datasets, achieving the highest scores in Accuracy, F1-Score, AUC, and the lowest Equal Error Rate (EER). In particular, in the PUT dataset, PatternFusion had an EER 1.2%, much lower than Informer (1.9%) and Autoformer (1.7%). This substantiates the efficiency of the hybrid architecture used by PatternFusion that efficiently collects temporal as well as spatial features, and further takes advantage of the interpretability of LightGBM. Its dynamic weighting of contributions from BiLSTM, CNN, and LightGBM during prediction further optimizes its decision making performance, through attention-driven fusion mechanism.

Performance comparison of PatternFusion against transformer-based models.
The comparison of Equal Error Rate (EER), False Acceptance Rate (FAR) and False Rejection Rate (FRR) in three data sets (PUT, PolyU and BioCop) is shown in Fig. 6. PatternFusion has continually delivered the lowest rates of errors for all the metrics and it beats both Informer and Autoformer. This demonstrates its superior capability in biometric verification tasks, offering higher accuracy and better resilience against false matches and rejections.
Real-time pattern and anomaly detection
In a streaming anomaly detection setting, Fig. 7 demonstrates PatternFusion’s output across signal, confidence, and binary anomaly layers. It reacts rapidly to sudden changes while maintaining low false positives. Table 10 summarizes PatternFusion’s detection responses at specific anomaly positions within the time-series data. It shows that the model accurately identifies true patterns (e.g., Pattern A, B, and Spike) with high confidence scores ranging from 0.85 to 0.92. This demonstrates PatternFusion’s effectiveness in real-time anomaly detection with reliable confidence quantification.

Patternfusion anomaly-aware pattern detection. The top panel shows the signal, middle shows detection confidence, and bottom binary anomaly decisions.
Pattern recognition timeline
Figure 8 overlays pattern confidence on the input signal in real time. The color scale beneath the waveform indicates evolving confidence, confirming Pattern A, B, and C at the expected intervals. Table 11 presents the detected patterns (A, B, and C) along with their start and end times and corresponding average confidence scores. It illustrates PatternFusion’s ability to recognize and localize distinct temporal patterns in real-time, maintaining high confidence levels (0.88 to 0.93), which confirms the model’s precision and reliability in temporal segmentation.

Timeline view of pattern confidence overlaying the raw signal. Colored overlays correspond to increasing recognition certainty.
Feature importance comparison
Feature attribution analysis in Fig. 9 shows PatternFusion leveraging a wide range of spectral, temporal, and structural features, unlike narrower focus observed in LSTM and CNN. Table 12 compares the normalized feature importance scores across four models—LSTM, CNN, Transformer, and PatternFusion. It highlights that PatternFusion leverages a broader range of features (e.g., spectral power, shape similarity, autocorrelation) more effectively than other models. This demonstrates its superior generalization and interpretability by incorporating diverse temporal, spectral, and structural characteristics in pattern recognition.

Feature importance analysis showing broader utilization by Patternfusion. High importance across multiple domains reflects generalization.
Ablation study
To thoroughly evaluate the contributions of each module in PatternFusion, an extensive ablation study was conducted. This analysis aimed to quantify the performance impact of individual components: BiLSTM, CNN, LightGBM, and the Attention Mechanism. The evaluation was performed under four main configurations:
-
1.
Without BiLSTM.
-
2.
Without CNN.
-
3.
Without LightGBM.
-
4.
Without Attention Mechanism.
Figure 10; Table 13 validate the additive benefits of combining probabilistic shaping (PS) with chaos-enhanced CLSTM modules. Removing either component degrades at least two metrics.
Each module was selectively removed, and the model was retrained under the same experimental conditions to measure its influence on Accuracy, F1-Score, and AUC. The evaluation was conducted on the PUT, PolyU, and BioCop datasets for consistency. Additionally, a paired t-test was performed to determine if the observed differences were statistically significant.
The ablation study results indicate that BiLSTM contributes the most to temporal feature learning, as its removal results in the largest drop in all metrics across datasets. CNN is crucial for spatial feature extraction, particularly for identifying local biometric patterns. LightGBM enhances interpretability and improves classification robustness by ranking important features, while the Attention Mechanism optimally fuses these components, ensuring adaptive focus on the most informative patterns.
Statistical Significance Testing (t-test):
To validate the significance of the observed differences, a paired t-test was conducted for each configuration against the full PatternFusion model. The results show that the performance drops were statistically significant with p-values < 0.01, confirming that each module significantly contributes to the overall performance.

Ablation heatmap visualizing how PS and CLSTM modules impact different performance dimensions. The full model shows the best trade-off.
PatternFusion integrates a robust hybrid ensemble architecture tailored for time-series pattern detection. This subsection illustrates the model’s capabilities using diagnostic visualizations, statistical analyses, real-time detection outputs, and multi-scale clustering. The results validate its adaptability across diverse temporal contexts and feature spaces.
Real-time pattern detection interface
Figure 11 showcases the end-to-end system output of PatternFusion in a live detection scenario. It includes pattern identification, anomaly flags, confidence evaluation, type classification, and operational system status.

Real-time dashboard of Patternfusion during signal monitoring. confidence surpasses detection thresholds at detected pattern intervals.
Table 14 shows the real-time detection output of PatternFusion for different patterns (A to D) in a live signal monitoring scenario. It lists the pattern location (in seconds), whether an anomaly was detected, and the corresponding confidence scores (ranging from 0.89 to 0.94). This validates PatternFusion’s ability to perform high-confidence, real-time pattern and anomaly detection in dynamic environments.
High-dimensional feature projection

Parallel coordinate analysis comparing ground truth clusters (left) vs. patternfusion’s inferred types (right). Feature trends validate learning consistency.
Figure 12 presents a parallel coordinates plot comparing ground truth pattern clusters with PatternFusion’s assignments, revealing close alignment between the two.
Table 15 lists the key features that contribute most to separating pattern clusters in the latent space, along with their variance contribution percentages. Features like shape similarity (22.4%), autocorrelation peak (19.3%), and cross-feature correlation (17.8%) are shown to be the most influential. This highlights the model’s ability to use meaningful and diverse features for clear and discriminative clustering of temporal patterns.
Multi-scale decomposition insight
As shown in Fig. 13, PatternFusion integrates signal components across macro, meso, and micro time resolutions. The decomposition aids hierarchical feature understanding.

Hierarchical decomposition of signal across macro, meso, and micro scales. Pattern B appears prominently in the meso window.
Table 16 presents the percentage contribution of detected patterns (A, B, and C) across macro, meso, and micro temporal scales. It shows that different patterns dominate at different resolutions—for instance, Pattern B has the highest contribution (61%) at the meso scale. This emphasizes PatternFusion’s capability to capture multi-scale temporal dynamics essential for accurate pattern recognition.
Dynamic pattern evolution mapping
Figure 14 depicts pattern intensity across time and frequency bins. Transient bursts and periodic motifs are distinctly recognized with high resolution. Table 17 outlines dynamic pattern segments by specifying their time and frequency ranges along with classification tags such as “Periodic,” “Event Burst,” and “Local Shift.” It illustrates how PatternFusion identifies and categorizes evolving temporal patterns based on their spectral and temporal characteristics, demonstrating its effectiveness in capturing both stable and transient events.

Spectrogram-like visualization of pattern evolution. Annotated regions identify transient and base-level periodic patterns.
Cluster separation in latent space
Figure 15 provides a 3D t-SNE visualization of cluster compactness. PatternFusion output exhibits tight intra-class cohesion and distinct inter-class separation. Table 18 reports cluster metrics—specifically intra-cluster and inter-cluster distances—for original patterns (A, B, C) and PatternFusion-predicted clusters. PatternFusion shows tighter intra-cluster distances and greater inter-cluster separation, indicating improved cluster compactness and clearer class boundaries. This validates the model’s effectiveness in generating well-separated and coherent pattern representations in latent space.

t-SNE projection of original vs. PatternFusion pattern clusters. Stars show PatternFusion-predicted centroids.
Cross-dataset validation and generalizability
To address the concerns of limited dataset diversity, the proposed PatternFusion model was further validated across additional multimodal biometric datasets, specifically BioCop, WVU, and BIOMDATA. These datasets were selected for their diverse range of biometric samples, including fingerprint, iris, and facial recognition, which introduce variability in terms of acquisition conditions, resolution, and demographic representation. This validation step was performed to ensure the model’s robustness and generalizability across heterogeneous environments.
The datasets were preprocessed in a similar manner to the PUT and PolyU datasets to maintain consistency. Cross-dataset validation was conducted where the model, trained on one dataset (e.g., PUT), was tested on another (e.g., WVU) to measure its adaptability and generalization capabilities.
The results in the Table 19 above indicate that PatternFusion maintains high performance across all tested datasets, demonstrating robust generalizability. The accuracy only slightly drops when transferred from PUT and PolyU to BioCop, WVU, and BIOMDATA, which signifies that the model can adapt well to unseen data distributions. The results hereby achieved are ultimately high, i.e., the F1-scores and AUC values, as a result, stay high, proving the system’s proficiency at detecting actual matches from imposters in divergent biometric domains.
Cross-Domain Generalization and Adaptation:
One of the major problems in the biometric verification systems is the capacity to generalize while for example transferring from a training domain to a testing environment, where the data have a different distribution. This, a domain shift, can have devastating effects on the performance of such models as PatternFusion if not properly addressed. To address this, a holistic Cross-Domain Generalization and Adaptation experiment was carried out by way of several datasets. PUT, PolyU, BioCop and one more Cross-Domain Transfer Set produced by simulation of changes in acquisition devices, lighting states and demographic characteristics.
Domain Adaptation Techniques Implemented:
In the Transfer Learning with Fine Tunning approach, the PatternFusion was pre trained on the PUT dataset and fine-tuned on the PolyU and BioCops datasets. Such process enabled the model to tune its learned representations to specific characteristics of the new biometric modalities thereby enhancing its generalization power. Fine tuning was made using a LR decay of 1E-04 and used regularization to avoid overfitting. Fine-tuning had the following effect on PatternFusion performance on the Cross-Domain Transfer Set: from 89.4% to 92.7% accuracy and from 3.5% down to the Equal Error Rate (EER) of 2.8%. Such enhancements show the capabilities of the fine-tuning for removing domain differences and preserving verification reliability.
The second strategy Domain-Adversarial Training introduced a domain discriminator during model optimization. This discriminator was trained to classify source (PUT) from target domains (PolyU, BioCop) while the main model was designed to confuse the domain classifier. This adversarial learning required PatternFusion to extract domain-invariant features becoming domain shift robust. When tested on the Cross-Domain Transfer Set, domain-adversarial training further improved the accuracy to 93.5% and reduced the EER to 2.5%, outperforming the baseline and fine-tuning strategies. The Table 20 highlight that domain-adversarial training effectively minimizes the impact of distributional shifts, enabling the model to generalize more robustly across different datasets.
The findings (Table 20) confirm that Cross-Domain Adaptation Techniques significantly enhance PatternFusion’s ability to maintain high verification accuracy and low error rates, even when deployed in environments with varying data distributions. These improvements position PatternFusion as a highly adaptive and resilient multimodal biometric system suitable for real-world applications where domain shifts are inevitable. To further illustrate these results, t-SNE visualizations and ROC Curves will be included to demonstrate the alignment of feature distributions before and after adaptation.
Integration of self-supervised learning (contrastive learning)
To further enhance the generalization capabilities of PatternFusion, particularly in handling noisy or smaller datasets, Contrastive Learning was integrated as a pretraining mechanism. Contrastive Learning is a self-supervised learning approach that learns effective feature representations by maximizing the agreement between positive pairs while minimizing the agreement between negative pairs in a latent space. This method allows the model to learn robust feature embeddings without the need for explicit labels, making it highly suitable for biometric data where variations are subtle and labels can be noisy.
Contrastive Learning Mechanism:
The key idea of Contrastive Learning in PatternFusion is to push similar samples (e.g., the same user’s biometric modalities captured at different times) closer together in the feature space, while pulling dissimilar samples (e.g., different users) apart. This is achieved using a contrastive loss function, which is defined as follows:
where:
-
\(\:P\) represents positive pairs, and NNN represents negative pairs.
-
\(\:{f}_{i}\) and \(\:{f}_{j}\) are the embeddings of the samples.
-
\(\:{s}_{ij}\) is the similarity score between samples \(\:i\) and \(\:j\).
-
\(\:d({f}_{i},{f}_{j})\) is the distance metric (e.g., Euclidean distance).
-
\(\:m\) is a margin that enforces separation for dissimilar pairs.
Implementation in PatternFusion:
The contrastive learning mechanism was integrated into the BiLSTM and CNN modules of PatternFusion during the pretraining phase. The process is as follows:
-
1.
Pretraining Stage:
-
Both BiLSTM and CNN are pretrained using contrastive loss to learn spatial and temporal embeddings that are invariant to noise and robust across variations.
-
-
2.
Fine-Tuning Stage:
-
After pretraining, the embeddings are fine-tuned with the LightGBM classifier and attention mechanism to optimize for classification accuracy.
-
-
3.
Feature Alignment:
-
Contrastive learning ensures that features from different modalities (e.g., face, fingerprint) are well-aligned in the latent space, enhancing the fusion process.
-
Experimental Results:
To evaluate the effectiveness of the contrastive learning integration, experiments were conducted across the PUT, PolyU, and BioCop datasets. The key metrics—Accuracy, F1-Score, and AUC—demonstrated notable improvements compared to the baseline PatternFusion model without contrastive pretraining.
The Table 21 presents the evaluation metrics (Accuracy, F1-Score, and AUC) of PatternFusion across three datasets: PUT, PolyU, and BioCop. The integration of Contrastive Pretraining significantly improves model performance across all metrics and datasets. Notably, the Accuracy on the PUT dataset increases from 96.4% to 97.2%, while the AUC improves from 98.1% to 98.7%, indicating enhanced feature learning and decision boundary clarity. These improvements reflect the model’s enhanced capability to learn robust feature representations, resulting in more effective biometric verification.
Contrastive learning brings into PatternFusion the capacity to extract robust patterns from noisy or small-sample datasets. This improvement is expressed in increased Accuracy, F1-Score and AUC in all datasets. Remarkably, in the PUT dataset the accuracy rose from 96.4% to 97.2% and the AUC rose from 98.1% to 98.7%. This confirms that learning robust feature embeddings during pretraining significantly benefits downstream fusion tasks.

t-SNE visualization before and after contrastive learning.
The Fig. 16 illustrates the t-SNE embeddings of biometric feature representations before and after the application of Contrastive Learning. On the left, the embeddings are more scattered, indicating less distinct separation between classes. After Contrastive Learning (right), the clusters become more compact and better separated, showcasing improved feature alignment and class separability. This demonstrates the enhanced ability of PatternFusion to distinguish between genuine and imposter samples following contrastive pretraining.
In-the-wild testing and cross-distribution scenarios
To evaluate the real-world applicability and robustness of PatternFusion, experiments were extended to in-the-wild datasets and cross-distribution scenarios. Unlike curated datasets such as PUT, PolyU, and BioCop, in-the-wild datasets reflect real-world biometric data collected under uncontrolled conditions, including variations in lighting, occlusions, pose differences, and background noise. For this purpose, two widely recognized datasets were selected:
-
1.
FaceForensics++: A challenging dataset with manipulated facial videos and real-world images subjected to different levels of compression and lighting variations.
-
2.
Labeled Faces in the Wild (LFW): A benchmark dataset that includes facial images captured in uncontrolled environments, providing a robust test for biometric verification systems.
Experimental Setup:
The FaceForensics + + and LFW datasets were integrated into the evaluation pipeline of PatternFusion to measure its performance in:
-
Uncontrolled Lighting Conditions.
-
Varying Poses and Expressions.
-
Occlusions (glasses, hats, masks).
-
background variability.
Metrics Evaluated:
-
Accuracy.
-
F1-Score.
-
AUC (Area Under Curve).
-
EER (Equal error Rate)
PatternFusion was trained on the standard datasets (PUT, PolyU, and BioCop) and evaluated directly on FaceForensics + + and LFW without domain-specific fine-tuning to measure its raw generalization ability.
The table summarizes the evaluation of PatternFusion on challenging in-the-wild datasets (FaceForensics + + and LFW) under three configurations: Baseline, Fine-Tuned, and Domain-Adaptive. Fine-tuning improves accuracy and reduces the Equal Error Rate (EER), while domain adaptation further enhances these metrics, demonstrating stronger generalization and resilience to uncontrolled conditions. The model’s adaptability to different environments is clearly reflected in higher F1-Scores and AUC values.
Table 22 demonstrate that PatternFusion performs competitively even in the highly challenging in-the-wild environments of FaceForensics + + and LFW. The baseline model obtained 87.3% Accuracy and 4.3% EER on FaceForensics + + sources, with the performance remaining robust under considerable environmental noise and variance. Making the accuracy 91.8%, and EER 3.2%, with fine tuning depicted better correspondence with random features. More progress was observed as Domain-Adversarial Training was applied, and the accuracy became equivalent to 93.5%, and the EER – 2.5%, demonstrating excellent generalization to cross-distribution settings.
The enhancements are credited to t PatternFusion’s attention-driven fusion mechanism, which adaptively weighs in contributions of BiLSTM, CNN and LightGBM depending upon the quality and properties of the incoming biometric data. This flexibility allows more robust matching even where conditions are suboptimal, which is the case in actual world surroundings.

ROC and precision-recall curves for in-the-wild scenarios.
The Fig. 17 shows ROC Curves and Precision-Recall Curves for PatternFusion under 3 configurations. Baseline, Fine-Tuned, and Domain-Adaptive, evaluated on in-the-wild datasets similar to FaceForensics++, and LFW. The ROC Curves show better true positive rates but less false at the same time as we fine-tune and domain-adapt the model, indicating improved boundary separation in non-staged scenarios. The Precision-Recall Curves further highlight the enhanced capability to distinguish genuine users from imposters, particularly in domain-adaptive settings, which achieved the highest area under both curves. This signifies greater robustness and reliability for real-world biometric verification.
Evaluation on noisy, real-world data and simulated noise scenarios
To evaluate the robustness of PatternFusion in real worlds, experiments were perfomed on noisy and corrupted data to mimic real deployments. In the real world, biometric data is highly likely to be occluded, vary in illumination, suffer from motion blur, and be corrupted with sensor noise that severely compromise the model performance. In order to assess the impact, two scenarios of experiment were introduced:
-
1.
Real-World noisy datasets
-
CelebA-HQ Noise Augmentation: Facial images from the CelebA-HQ dataset were subjected to synthetic noise, including Gaussian Blur, Salt-and-Pepper Noise, and Random Occlusions.
-
PolyU Fingerprint Dataset (Noisy Variant): Fingerprint images were degraded using blur effects, partial occlusions, and compression artifacts to mimic real-world distortions.
-
-
2.
Simulated noise scenarios
-
Gaussian Noise (σ = 0.2): Added to simulate sensor interference.
-
Random Dropout (10% pixels): Random pixel blackout to replicate data corruption during capture.
-
Motion Blur (Kernel size = 5): Applied to simulate movement during image capture.
-
Experimental setup
-
Training Data: Standard PUT, PolyU, and BioCop datasets.
-
Testing Data: Noisy variants of CelebA-HQ and PolyU Fingerprint datasets.
-
Metrics Evaluated:
-
Accuracy.
-
F1-Score.
-
AUC (Area Under Curve).
-
O EER (equal error rate).
-
The experimental results in Table 23 demonstrate that PatternFusion maintains a high level of robustness even when subjected to severe noise and distortions. The baseline model performed well on all noise types but was degraded mildly especially – with random occlusions and salt and pepper noise. But after applying Fine-Tuning, on average, an increase in model accuracy equal to 3.2% was observed with a specific decrease in EER on both the CelebA-HQ and PolyU Fingerprint datasets. The best improvements were in Domain-Adaptive Training, as the model was able to perform up to 90.5% accuracy and with EER of 3.2% under Gaussian Blur conditions. This means that domain adaptation allows the model to be more tolerant to environmental variation, and sensor noise.

Noise robustness curves for PatternFusion.
The Fig. 18 shows the results of PatternFusion work under different noise levels, such as Gaussian Blur, Salt-and-Pepper Noise, Random Occlusions and Compression Artifacts. The accuracy of the baseline model is severely affected by noise under moderate to severe noise. Fine-tuning greatly enhances its robustness whereas domain-adaptive training achieves the greatest robustness throughout all noise types, with stable accuracy even in difficult conditions. This demonstrates the superior generalization the model can perform on the back of exposure to environmental noise and true-world distortion.
The results highlight that as an algorithm with fine-tuning and domain adaptation, PatternFusion exhibits a high robustness against noisy and corrupted biometric data, being very suitable for realistic deployment under imperfect data acquisition environments.
Hyperparameter sensitivity analysis
To gain insight about the effect of various hyperparameters on the performance output of PatternFusion, an exhaustive Hyperparameter Sensitivity Analysis was performed. This analysis was all about the assessment of the impact of variation in critical hyperparameters on the accuracy of model, error rates and generalization capacity. The key hyperparameters analyzed include:
-
1.
Window size (Temporal segment Length).
-
2.
Number of LSTM layers.
-
3.
LightGBM depth.
-
4.
CNN filter sizes.
-
5.
Learning Rate.
Experimental setup
-
Datasets Used: PUT, PolyU, and BioCop.
-
Evaluation Metrics:
-
Accuracy.
-
F1-score
-
AUC (Area under Curve)
-
EER (Equal error Rate)
-
This analysis was conducted by setting hyper parameters one at a time keeping the other basic anchors intact to see their individual effect. This sensitivity testing is used to determine the ideal configuration for maximum performance from which Table 24 is based.
Table 25 suggest window size has a significant effect on the model accuracy and error rates, and the best temporal representation of the biometric signals comes with optimal segment length of 60. For LSTM layers, two layers were found to be optimal for the complexity and the feature extraction. Going beyond two layers yielded diminishing returns, probably on account of over-fitting. In LightGBM, the highest accuracy was recorded at a maximum depth of 15 without over-complexity. With respect to the CNN filter size, the best demonstrated performance in capturing the spatial features was shown by the 5 × 5 kernel. Finally, the most stable converging learning rate of 0.01 provided effective convergence during the learning process.
These results emphasize the need to fine-tuned hyperparameters in order to achieve maximal performance of PatternFusion in biometric verification applications.

Hyperparameter sensitivity analysis for PatternFusion.
The sensitivity of PatternFusion to critical hyperparameters on three metrics is shown in the Fig. 19. Size of Window, number of LSTM Layers and Depth LightGBM. The plots suggest that best Window Size is 60, with the best accuracy and the lowest EER. On the same accounts, the best configuration for LSTM Layers is 2, which strikes a balance between feature extraction and the complexity of model. For a LightGBM depth, a maximum depth of 15 showed peak performance. Such perceptions show the need for adjusting hyperparameters for an ideal accuracy of biometric verification.
To validate the robustness of the reported improvements, we conducted paired two-tailed t-tests across five independent experimental runs for each model comparison. The results confirmed that the performance gains of PatternFusion over the strongest baselines (CNN-LSTM Fusion and Autoformer) are statistically significant (p < 0.001). Corresponding Cohen’s d values > 1.6 indicate a large effect size, affirming that the observed improvements are not due to random variance but reflect consistent performance advantages of the proposed approach.
Computational cost and inference time analysis
On-time biometric verification necessitates both the best accuracy and effective computational performance. To demonstrate the motivation for actual deployment of PatternFusion to the real-time ecosystem and edge, a Computational Cost Analysis was produced. These three main metrics were the subject of this assessment:
-
1.
Inference Time (ms) - The time taken for the model to process a single sample.
-
2.
Parameter Count (Million Parameters) - The total number of learnable parameters in the model.
-
3.
Floating Point Operations (FLOPs) - The computational operations required to perform a single forward pass.
Experimental Setup:
The analysis was conducted on:
-
Hardware Configuration: NVIDIA Tesla V100 GPU, 32 GB RAM.
-
Frameworks: PyTorch for BiLSTM and CNN, LightGBM for decision fusion.
-
Batch Size: 32 samples.
-
Resolution: 224 × 224 for image-based modalities.
Models Compared:
-
PatternFusion (Proposed).
-
Informer.
-
Autoformer.
-
VGGFace2 + IrisCode.
-
CNN-LSTM Fusion.
To evaluate deployment feasibility, PatternFusion was benchmarked for computational cost and inference performance. The model achieves a total parameter count of 28.4 million and an average inference time of 42 ms per sample, requiring only 98.7 GFLOPs for a complete forward pass. Compared with transformer-based ensembles such as Multi-Stream Transformers (60.3 M parameters, 72 ms inference) and Autoformer (50.1 M, 68 ms), PatternFusion demonstrates nearly 40–45% lower complexity and faster inference. This lightweight configuration enables deployment in real-time edge and biometric systems with minimal performance compromise. The low parameter footprint and computation demand also make the model highly scalable for healthcare-grade devices and latency-sensitive IoT platforms.
The results in Table 26 reveal that PatternFusion is computationally efficient compared with other state of the art multimodal fusion techniques. With so few parameters – 28.4 million – it is much easier than transformer-based models such as the Multi-Stream Transformers (60.3 M) or Autoformer (50.1 M). This scaled-down parameter footprint allows for speedier inference, with an average time of 42ms per sample; a feature that makes it very appropriate for real-time edge-based biometric verification. The whole FLOPs needed for PatternFusion is just 98.7 GFLOPs compared to much more by its transformer-based cousins. This reduction in computational cost, without sacrificing accuracy, demonstrates its scalability for low-power and latency-sensitive environments.

Computational cost and inference time analysis for PatternFusion and SOTA models.
The Fig. 20 provides a comparison of Parameter Count (Millions), Inference Time (Milliseconds), and FLOPs (Giga FLOPs) across six multimodal fusion models: VGGFace2 + IrisCode, CNN-LSTM Fusion, Multi-Stream Transformers, Informer, Autoformer, and PatternFusion. PatternFusion demonstrates the lowest parameter count (28.4M), the fastest inference time (42 ms), and the fewest FLOPs (98.7 GFLOPs), indicating its suitability for real-time and edge-based biometric verification while maintaining competitive accuracy.
Robustness to unseen or drifting distributions
In real-world biometric applications, distribution shifts due to environmental changes, sensor variations, or population diversity can significantly degrade model performance. To evaluate the robustness of PatternFusion to such unseen or drifting distributions, extensive experiments were performed under two primary scenarios (Table 27):
-
1.
Out-of-Distribution (OOD) Testing: Examines the ability of PatternFusion to perform for samples that are significantly different from the distribution of the training data.
-
2.
Concept Drift Simulation: Evaluates the model on the capability to adapt as the biometric patterns change for after period or while the characteristics of data change.
Out-of-distribution (OOD) testing
Datasets used
-
Cross-Domain Biometrics (CDB) Dataset: Contains biometric samples captured in different environments and devices.
-
WildFaces Dataset: Acquires facial information in extreme environments, namely illumination variations, occlusion and motion blur.
Evaluation metrics
-
Accuracy.
-
F1-Score.
-
AUC (Area Under Curve).
-
EER (Equal error Rate)
Concept drift simulation
PatternFusion was experimented with over time to simulate the concept drift on a portion of BioCop data in which the conditions were modified during testing:
-
Lighting Shift: Mild modifications of brightness and contrast in order to imitate the effect of outdoor to indoor changes.
-
Device Transition: Using mobile sensor/high-resolution camera intermittent switching as a simulated imitation of real-world deployment.
-
Aging Effect Simulation: Applying gradual warping and texture aging to simulate long-term shifts.
As demonstrated in Table 28, PatternFusion maintains strong performance in out-of-distribution (OOD) conditions and concept drift simulations. The model consistently achieves over 90% accuracy with minimal Equal Error Rate (EER) when tested on cross-domain biometrics and wild facial datasets, particularly when enhanced with domain-adaptive training. Concept drift simulations further confirm its resilience to environmental and sensor variations, highlighting its suitability for long-term biometric monitoring applications. This robustness stems from PatternFusion’s attention-driven fusion mechanism, which dynamically reweights temporal and spatial features to adapt to changing conditions without compromising performance.

Concept drift trajectory over time for PatternFusion.
The Fig. 21 demonstrates the effects of Concept Drift on PatternFusion during ten time steps on three configurations. Baseline, Fine-Tuned, and Domain-Adaptive. The baseline model has shown a progressive deterioration of accuracy as environmental conditions are modified and sensor variations are applied. Some of this degradation is addressed by fine-tuning, which also results in more standard performance. The Domain-Adaptive variant of PatternFusion has the highest robustness capacity showing small accuracy decay throughout time, indicating strong generalization ability on distribution shiftings.
Error analysis and misclassification insights
In order fully to evaluate the robustness of PatternFusion, an Error Analysis was carried out for all evaluated datasets — PUT, PolyU, and BioCop. In this section, special attention is paid to revealing false acceptances (false positives) and false rejections (false negatives), and the study of the typical misclassification patterns.
Confusion matrix analysis
In Table 29, there is a display of the number of True Positives (TP), True Negatives (TN), False Positives and False Negatives (FP and FN resp.) encountered in each dataset: PUT, PolyU, BioCop. It reports the distribution of correct and incorrect classifications, as a measure of model strength in correctly locating biometric patterns given minimal errors.
-
1.
ROC Curve Analysis.
In order to also confirm the model’s potential for distinguishing between positive and negative samples Receiver Operating Characteristic (ROC) Curves were constructed for each dataset. The AUC (Area Under Curve) values were high throughout with good discriminatory power:
-
PUT Dataset: 0.981.
-
PolyU Dataset: 0.976.
-
BioCop Dataset: 0.963.
This model’s high AUC scores suggest that decision boundary of model is robust where there is little overlap between genuine and imposter classes.
-
-
2.
False Match Rate (FMR) and False Reject Rate (FRR) Analysis.
The Table 30 summarizes the FMR and FRR rates for the PUT, PolyU, and BioCop datasets. A low FMR reflects the model’s effectiveness in preventing unauthorized access, while a low FRR ensures genuine users are not incorrectly rejected. PatternFusion maintains a good balance, supporting its application in high-security biometric systems.
Table 30 False match rate (FMR) and false reject rate (FRR) ACROSS DATASETS. -
A low FMR ensures that unauthorized subjects are rarely accepted as genuine.
-
A low FRR minimizes the chances of genuine users being rejected.
-
PatternFusion maintains a balanced trade-off, making it ideal for high-security applications.
-
-
3.
Misclassified Sample Analysis.
Visual inspection of misclassified samples was performed using interpretability techniques:
-
Grad-CAM Visualization: For CNN components, Grad-CAM was used to highlight regions of focus during misclassifications. This revealed that errors mostly occurred when the biometric features were partially occluded or poorly illuminated.
-
Saliency maps: For BiLSTM components, Saliency Maps identified key temporal segments that contributed to incorrect predictions. Misclassifications were often linked to irregular spikes or noise in the biometric time-series data.

Visualization of misclassification analysis in Patternfusion. (A) Grad-CAM heatmap indicating CNN attention focus. (B) Saliency map illustrating key time steps influencing Bilstm decisions. (C) Misclassified sample representation showcasing the signal’s noise and deviation.
Figure 22 illustrates the interpretability analysis of misclassified samples in PatternFusion. The Grad-CAM Heatmap shows which regions the CNN focused on during classification, helping to identify potential feature extraction errors. The Saliency Map highlights the most critical time steps for BiLSTM’s decision-making, while the Misclassified Sample Analysis visualizes the signal patterns that contributed to incorrect predictions. Together, these visualizations help understand model limitations and guide improvements.
SHAP (SHapley additive exPlanations) explanation
SHAP (SHapley Additive exPlanations) is an explainability tool that interprets the predictions of machine learning models by attributing the contribution of each feature to the final prediction. It is based on concepts from game theory, specifically the Shapley Value, which fairly distributes the “payout” (model prediction) among all features based on their contribution.
Why SHAP is important for patternfusion
In PatternFusion, multiple modalities (e.g., face, fingerprint, iris) are fused using a BiLSTM-CNN-LightGBM hybrid architecture. While the model achieves high accuracy, understanding why it makes certain decisions is crucial for:
-
1.
Model Transparency: SHAP explains how each modality (e.g., face, fingerprint) impacts the final prediction.
-
2.
Error Analysis: Identifies which features contribute to false acceptances (FAR) and false rejections (FRR).
-
3.
Feature Importance Ranking: Highlights which biometric features (e.g., face patterns, iris texture) are most influential in classification.

Feature importance visualization for PatternFusion.
The relative significance of different biometric modalities in the PatternFusion model is presented on the Fig. 23. The Face Embedding feature makes the largest contribution to the final prediction followed by Iris Pattern and Fingerprint Texture. This interpretability analysis identifies the most important characteristics for the correct biometric verification, which helps in transparency and model understanding of its decision-making procedure.
Ethical considerations
The deployment of biometric systems like PatternFusion raises critical ethical concerns regarding privacy, bias, and fairness that must be addressed to ensure responsible implementation. These systems process highly sensitive personal data, necessitating robust safeguards including encryption, differential privacy, and federated learning to prevent breaches. Additionally, demographic biases in recognition accuracy - particularly for underrepresented groups - pose significant challenges, potentially leading to unequal error rates across different populations. PatternFusion’s adaptive attention mechanism helps mitigate some biases by dynamically weighting features, though comprehensive testing across diverse demographic datasets remains essential. Ensuring fairness requires incorporating bias auditing during training and employing explainability tools like SHAP to enhance transparency. For real-world applications in sensitive sectors like finance or healthcare, strict governance around data handling, user consent, and auditability is crucial to maintain compliance with regulations like GDPR while building public trust. Ultimately, addressing these ethical dimensions is not just regulatory compliance, but fundamental to developing biometric systems that are both technologically advanced and socially responsible.
While PatternFusion demonstrates consistent performance improvements across diverse biometric and temporal datasets, its advantages are most evident in scenarios that exhibit multi-scale temporal dependencies and moderate sequence lengths. The framework may be less optimal for very long sequence tasks (e.g., pure time-series forecasting where transformer-based architectures such as Informer or Autoformer excel) or extreme edge environments with strict computational or memory constraints. Moreover, although the model includes dynamic attention and confidence calibration, its hybrid structure introduces additional parameters compared to lightweight single-stream models. Future work will explore pruning, quantization, and knowledge distillation strategies to enhance deployment efficiency. Overall, the reported gains represent state-of-the-art results on the tested datasets and experimental settings, rather than a universal dominance across all time-series domains.
Conclusion
In the current paper, we presented PatternFusion, a new hybrid ensemble framework that can increase time-series pattern recognition by combining the strengths of BiLSTM for temporal modeling, of CNN for extracting spatial features, and of LightGBM for statistical interpretability. The architecture’s attention-driven fusion mechanism dynamically optimizes model contributions, so that fine-grained multi-scale temporal detection can be achieved for diverse datasets. Experimental tests revealed PatternFusion’s superiority with state-of-the-art F1-Scores, AUC-ROC, and MCC rates on standard datasets such as NAB, MIT-BIH and artificial composite flows, comfortably beating conventional models, like LSTM, CNN Moreover, a set of real-world validations on cross-domain datasets (BioCop, WVU, BIOMDATA) confirmed its robustness and flexibility for heterogeneous contexts. The interpretability of the model is improved by the visualization of attention weights, as well as t-SNE projections and confidence-based detection maps, proving its suitability for important applications (such as healthcare, finance, and industrial monitor) where high reliability is required. Research along these lines in the future will focus on incorporating transformer based attention mechanisms for better deeper temporal context learning, use in edge based streaming environment and automatic pattern label generation to enhance capabilities even further. Scalability, adaptive fusion strategy and interpretability of PatternFusion make it a striking solution to real-time urgent time-series analytics that is ready for both science and practice.
Data availability
Data available on requests from the corresponding author (Wided Bouchelligua) at: wabouchelligua@imamu.edu.sa.
References
Aksan, E., Hilliges, O. & Pece, F. Stochastic hidden Markov models for multimodal temporal pattern recognition. Pattern Recogn. 95, 273–286 (2019).
Bagnall, A., Lines, J., Bostrom, A., Large, J. & Keogh, E. The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Disc. 31(3), 606–660 (2017).
Bai, S., Kolter, J. Z. & Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. ArXiv Preprint arXiv:1803.01271 (2018).
Box, G. E. & Jenkins, G. M. Time Series Analysis: Forecasting and Control (Holden-Day, 1970).
Breiman, L. Bagging predictors. Mach. Learn. 24(2), 123–140 (1996).
Chakraborty, D., Narayanan, V. & Ghosh, A. Interpretable machine learning for time series forecasting. SN Comput. Sci. 2(3), 1–15 (2021).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, 785–794 (2016).
Cheng, D. et al. Spatio-temporal attention-based neural network for credit card fraud detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34, No. 01, 362–369 (2020).
Cho, K. et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1724–1734 (2014).
Livera, A. M. D., Hyndman, R. J. & Snyder, R. D. Forecasting time series with complex seasonal patterns using exponential smoothing. J. Am. Stat. Assoc. 106(496), 1513–1527 (2011).
Dempster, A., Schmidt, D. F. & Webb, G. I. Rocket: exceptionally fast and accurate time series classification using random convolutional kernels. Data Min. Knowl. Disc. 34(5), 1454–1495 (2020).
Deng, H., Runger, G., Tuv, E. & Vladimir, M. A time series forest for classification and feature extraction. In Information Sciences. Vol. 239, 142–153 (Elsevier, 2013).
Doucet, A. & Johansen, A. M. A tutorial on particle filtering and smoothing: fifteen years later. Handb. Nonlinear Filter. 12(656–704), 3 (2009).
Du, S., Li, T., Yang, Y. & Horng, S. J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 388, 269–279 (2020).
Ismail Fawaz, H., Forestier, G., Weber, J., Idoumghar, L. & Muller, P. A. Deep learning for time series classification: a review. Data Min. Knowl. Disc. 33(4), 917–963 (2019).
Franceschi, J-Y., Dieuleveut, A. & Jaggi, M. Unsupervised scalable representation learning for multivariate time series. In Advances in Neural Information Processing Systems, 4650–4661 (2019).
Freund, Y. & Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55(1), 119–139 (1997).
Gers, F. A., Schmidhuber, J. & Cummins, F. Learning to forget: continual prediction with Lstm. Neural Comput. 12(10), 2451–2471 (2000).
Graves, A. & Schmidhuber, J. Neural Netw., 18(5–6), 602–610 (2005).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997).
Holder, C. J. & Guerin, F. Multiple-view time series classification. IEEE Trans. Knowl. Data Eng. 34(2), 954–967 (2020).
Huang, X., Zhu, Z., Cheng, Y., Shao, J. & Zhu, X. A novel hybrid ensemble learning paradigm for nuclear energy consumption forecasting. Appl. Energy. 250, 1399–1409 (2019).
Huangfu, Y. et al. Semi-supervised identification of load profiles and patterns from smart meter data. Appl. Energy. 266, 114825 (2020).
RJ Hyndman. A tidy approach to forecasting the Nba. Am. Stat. 1–17 (2021).
Hyndman, R. J. & Khandakar, Y. Automatic time series forecasting: the forecast package for r. J. Stat. Softw. 26(3), 1–22 (2008).
Fawaz, H. I., Forestier, G., Weber, J., Idoumghar, L. & Muller, P-A. Deep learning methods for univariate time series forecasting. arXiv preprint arXiv:1911.13288 (2019).
Karim, F., Majumdar, S., Darabi, H. & Harford, S. Multivariate lstm-fcns for time series classification. Neural Netw. 116, 237–245 (2019).
Ke, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems, Vol. 30 (2017).
Laine, S. & Aila, T. Temporal ensembling for semi-supervised learning. In International Conference on Learning Representations (ICLR), (2017).
Laptev, N., Yosinski, J., Li, L. E. & Smyl, S. Time-series extreme event forecasting with neural networks at uber. In International Conference on Machine Learning, Vol. 34, 1–5 (2017).
Lavin, A. & Ahmad, S. Evaluating real-time anomaly detection algorithms–the numenta anomaly benchmark. In 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), 38–44. (IEEE, 2015).
Lei, Q., Yi, J., Vaculin, R., Wu, L. & Dhillon, I. S. Pattern-adaption attention network for time series classification. Knowl. Based Syst. 190, 105443 (2020).
Li, Z., Zhang, X., Ju, H. & Chen, B. Hybrid models combining Lstm and Svr for multi-step-ahead prediction of surface water quality in rivers. Water 12(4), 1110 (2020).
Lim, B. & Zohren, S. Time series forecasting with deep learning: a survey. Philosophical Trans. Royal Soc. A. 379(2194), 20200209 (2021).
Lines, J. & Bagnall, A. Time series classification with ensembles of elastic distance measures. Data Min. Knowl. Disc. 29(3), 565–592 (2015).
Liu, M., Zhang, Z., Huang, G., Chen, X. & Wang, Z. Time series is a special sequence: forecasting with sample convolution and interaction. Adv. Neural. Inf. Process. Syst. 34, 2978–2991 (2021).
Ma, M., Stankovic, J. A. & Bartocci, E. Detecting anomalies in time series data with temporal logic. In 2016 IEEE international conference on big data (Big Data), 2086–2095 (IEEE, 2016).
Ma, Q., Zheng, J., Li, S. & Cottrell, G. W. Learning interpretable deep state space model for probabilistic time series forecasting. ArXiv Preprint arXiv:2102.12424 (2021).
Malhotra, P., Vig, L., Shroff, G. & Agarwal, P. Long short term memory networks for anomaly detection in time series. In Proceedings of the European Symposium on Artificial Neural Networks, Vol. 23, 89 (2015).
Qin, Y. et al. A dual-stage attention-based recurrent neural network for time series prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, 2627–2633 (2017).
Rabiner, L. R. & Juang, B-H. An introduction to hidden Markov models. IEEE ASSP Magazine. 3(1), 4–16 (1986).
Ruiz-Rizzo, A. L. et al. Great expectations: different types of temporal expectations modulate neural processing in the visual system. Eneuro. 8(6) (2021).
Scott, S. L. & Varian, H. R. Predicting the present with bayesian structural time series. Int. J. Math. Modelling Numer. Optimisation. 5(1–2), 4–23 (2014).
Van Den Oord, A. et al. Wavenet: A generative model for raw audio. ArXiv Preprint arXiv:1609.03499 (2016).
Vaswani, A. et al. Attention is all you need. Adv. Neural. Inf. Process. Syst., 30, (2017).
Wang, Y. et al. Sst: Spatial-spectral transformer for hyperspectral image classification. Remote Sens. 13(19), 3890 (2021).
Wang, Z., Yan, W. & Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In 2017 International Joint Conference on Neural Networks (IJCNN), 1578–1585 (IEEE, 2017).
Wen, Q. et al. Robuststl: A robust seasonal-trend decomposition algorithm for long time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33, 5409–5416 (2019).
Wu, H., Xu, J., Wang, J. & Long, M. Autoformer: Decomposition Transformers with auto-correlation for long-term series forecasting. Adv. Neural. Inf. Process. Syst. 34, 22419–22430 (2021).
Yang, J., Nguyen, M. N., San, P. P., Li, X. & Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Twenty-Fourth International Joint Conference on Artificial Intelligence, (2015).
Zhang, J., Chen, F. & Lyu, F. An adaptive ensemble model for semi-supervised time series classification. Knowl. Based Syst. 141, 57–66 (2018).
Zhang, X., Gao, Y., Lin, J. & Lu, C-T. Tapnet: Multivariate time series classification with attentional prototypical network. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34, 6845–6852 (2020).
Zheng, Y., Liu, Q., Chen, E., Ge, Y. & Zhao, J. L. Gated recurrent units for time series forecasting. In International Conference on Neural Information Processing, 335–346 (Springer, 2019).
Zhou, H. et al. Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, No. 12, 11106–11115 (2021).
Zhu, L. & Laptev, N. Online anomaly detection with concept drift adaptation using recurrent neural networks. ACM Trans. Manage. Inform. Syst. (TMIS). 12(1), 1–22 (2021).
Zhu, W., Huang, J., Ye, L. & Lai, X. Deep learning-based physiological signals classification to detect driver sleepiness using neural networks and transfer learning. J. Ambient Intell. Humaniz. Comput. 10(9), 3341–3355 (2019).
Ren, J., Yu, Z. & Gao, G. A CNN–LSTM–LightGBM based short-term wind power prediction method based on attention mechanism. Energy Rep. 8, 437–443 (2022).
Gao, Q. Multi-temporal scale wind power forecasting based on Lasso-CNN-LSTM-LightGBM. EAI Endors. Trans. Energy Web. 11, 5792. https://doi.org/10.4108/ew.5792 (2024).
Shi, Z., Hu, Y., Mo, G. & Wu, J. Attention-based CNN-LSTM and XGBoost hybrid model for stock prediction, arXiv preprint arXiv:2204.02623 (Code: GitHub repo) (2022).
Funding
This work was supported and funded by the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) (grant number IMSIU-DDRSP2501).
Author information
Authors and Affiliations
Contributions
Conceptualization: Wided Bouchelligua. Methodology: Wided Bouchelligua. Software: Wided Bouchelligua. Formal analysis: Wided Bouchelligua. Resources: Wided Bouchelligua. Writing—review and editing: Wided Bouchelligua. Funding acquisition: Wided Bouchelligua.
Corresponding author
Ethics declarations
Consent for publication
Not Applicable: Personal information is not used in this study, and no one’s privacy will be violated by the publication of this document.
Employment
The author affirms that they are not now employed by any company that stands to benefit or suffer financially by the publishing of this work.
Research involving human participants and/or animals
Historical datasets are used in this investigation. Since neither humans nor animals were used in the data collection or analysis for this study, ethical approval was not necessary.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Bouchelligua, W. PatternFusion: a hybrid model for pattern recognition in time-series data using ensemble learning. Sci Rep 15, 43371 (2025). https://doi.org/10.1038/s41598-025-28649-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-28649-4
